
Abstract
The squash function in capsule networks (CapsNets) dynamic routing is less capable of performing discrimination of non-informative capsules which leads to abnormal activation value distribution of capsules. In this paper, we propose vertical squash (VSquash) to improve the original squash by preventing the activation values of capsules in the primary capsule layer to shrink non-informative capsules, promote discriminative capsules and avoid high information sensitivity. Furthermore, a new neural network, (i) skip-connected convolutional capsule (S-CCCapsule), (ii) Integrated skip-connected convolutional capsules (ISCC) and (iii) Ensemble skip-connected convolutional capsules (ESCC) based on CapsNets are presented where the VSquash is applied in the dynamic routing. In order to achieve uniform distribution of coupling coefficient of probabilities between capsules, we use the Sigmoid function rather than Softmax function. Experiments on Guangzhou Women and Children’s Medical Center (GWCMC), Radiological Society of North America (RSNA) and Mendeley CXR Pneumonia datasets were performed to validate the effectiveness of our proposed methods. We found that our proposed methods produce better accuracy compared to other methods based on model evaluation metrics such as confusion matrix, sensitivity, specificity and Area under the curve (AUC). Our method for pneumonia detection performs better than practicing radiologists. It minimizes human error and reduces diagnosis time.
Keywords
Introduction
Pneumonia has increased significantly in global mortality and morbidity in these recent years. In United States, emergency departments [1] accounted for over 500,000 visits and more than 50,000 deaths during the year 2015; which put the diseases among the top 10 causes of the death in the country [2]. Detecting pneumonia early can reduce morbidity and mortality rate and increase the life span of patients. Research conducted by WHO, 2001, revealed Chest X-Rays (CXR) as the current appropriate approach for the diagnosing and detection of pneumonia infection, which in addition plays a crucial part in clinical care and study of epidemiology [3, 4]. However, the detection and diagnosing pneumonia using Chest X-Rays is a challenging task that relies heavily on expert radiologists. The use of human experts for pneumonia detection can be expensive, error-prone and time-consuming. Novice radiologists - especially those working at the rural areas where the quality of healthcare is relatively low - find it hard to diagnose medical imaging. On the other hand, experienced radiologists find it tedious to read hundreds of radiology images per day, as it takes a large chunk of their working time. Overall, both expert and inexperienced radiologists put in a lot of effort to diagnose CXR images. This has motivated the adoption of computer-aided system (CAS) to improve and produce efficient results in pneumonia detection in particular and medical imaging in general. Deep learning (DL) models have achieved impressive performance in recent studies such as method for software maintainability metric prediction [5], assessment of code smell for predicting class change proneness using machine learning [6] and detecting malware using recurrent neural network [7]. Furthermore, DL has recently played an important role in improving the automatic analysis and clinical diagnosis of medical images. Convolutional neural networks (CNNs) methods have been successfully used to perform classification of diseases on medical images. The progress in CNNs have benefited several trials in medical image analysis, such as disease classification [1, 8–10], image annotation [15, 16], lesion segmentation or detection [14–18], regression [19], noise induction [20], registration [21] and decision making model based on neutrosophic set for heart disease diagnosis [22]. Rajpurkar et al. [17] developed a CNN model for thorax disease classification. The model inputs CXR images and outputs 14 pathological probabilities, which include the prediction of pneumonia. Although, the model achieved good results on some chest diseases in general, pneumonia in particular achieved low classification performance. Sedai et al. [23] proposed a model that consisted of weak supervised learning and CNN to locate the region of diseases in the CXR images. Their method used disease category labels to avoid the difficulty of obtaining pixel level annotation. However, this approach achieved an unsatisfactory detection accuracy that needs further improvement. Several works on pneumonia classification typically employ CNNs. For instance, Wang et al. [15] evaluated four CNN architectures, such as, AlexNet [24, 25], VGGNet [26], GoogLeNet [27] and ResNet [28], which show the existence of multiple pathologies with global CXR images. To view the CXR detection and classification as a multi-label recognition problem, Yao et al. [29] explored the correlation among the 14 pathological labels using the global images based on the ChestX-ray14 [15]. Using a variant of the DenseNet [30] as an image encoder, the study adopted Long-short Term Memory Networks (LSTM) [31] to capture the dependencies. Kumar et al. [10] investigated the loss function which is more suitable for training CNNs from scratch and presented a boosted cascaded CNN method for global image classification. The recently developed method consists in CheXNet [17]. The method fine-tunes a 121-layer DenseNet on the global CXR images and has a modified fully connected layer. CNNs have greatly achieved promising results in the medical imaging diagnosis. However, CNNs have several issues that reduce accuracy during training. Firstly, CNNs require large amounts of datasets for accurate training and prediction, which in medical imaging are relatively small. Secondly, the pooling layer in CNNs increasingly reduce the resolution of feature maps, thereby causing low accuracy of the network. To account for these issues, Sabour et. al, 2017 proposed dynamic routing between capsules (CapsNet) [29]. They have successfully replaced the pooling layer with a ’dynamic routing agreement’, in which size, color and pose parameters are maintained to improve the network performance. For the CapsNet, the existence of an entity in an image can be depicted by the activity instantiation vector from a collection of neurons. Furthermore, CapsNets can accommodate small datasets for training, which is a great tool for medical imaging especially pneumonia CXR imaging. However, the transformation of the logits by the CapsNet Softmax function into a set of concentrative values may mistakenly transfer the background information from the lower layer to the next layer above, which can lead to wrong summation of the prediction vector with larger values and affect the classification result [32]. The issues with pneumonia diagnosis and CNNs mentioned above motivated us in this study to present a method for detecting whether a patient has pneumonia in CXR images using the prowess of CapsNet algorithm. First, we implemented a CapsNet model, which consists of several skip connected convolution blocks and two primary capsules named skip-connected convolutional capsules (S-CCC) and instead of Softmax for coupling coefficient, we adopted sigmoid function. The intuition for skip connection is to improve the network accuracy, where the input is concatenated with each output of the higher-level convolutions. Second, we implemented integrated skip convolutions with capsules (ISCC), and an ensemble skip connected capsules (ESCC) model with its variant by combining several layer blocks of dense convolutions with CapsNet. Due to constant decreasing of resolutions by the pooling layer, which could cause lower accuracy, the skip connection (performing a dot product with the input layer to each output of the higher level convolutions) was done to account for the loss of information during down-sampling of the pooling.
The contributions of this paper are summarized as follows, We implemented three architectures: skip-connected convolutional capsule (S-CCCapsule), integrated skip-connected convolutional capsules (ISCC), and ensemble skip-connected convolutional capsules (ESCC), for the pneumonia detection task. The skip-connected property combines the input feature vectors to the higher output convolutions to maintain important information to improve the detection of pneumonia. ISCC and ESCC, and its variants combine the traditional dense max-pool convolution with capsules. Inspired by [29], we proposed a new routing algorithm. Instead of the conventional squash function, we used vertical squash (VSquash) function. we found that the coupling coefficients based on Softmax function were mainly distributed within smaller interval, which is not well distributed compared to the Sigmoid function. We used the Sigmoid function to assign larger coupling coefficients to real features, while assigning smaller coupling coefficients to the fallacious ones. We performed extensive experiments on three publicly used datasets, i.e. Guangzhou Women and Children’s Medical Center (GWCMC), RSNA and Mendeley CXR. The experiment results show that the effectiveness of our proposed methods achieve promising performance and significantly outperformed the other baseline methods.
The rest of this paper is organized as follows: Section 2 presents the related works. Section 3 describes problem formulation, background for CNNs, our proposed architecture and CapsNet, followed by experimental details in Section 4, result and discussion in Section 5, Finally, Section 6 concludes the paper.
Related works
The goal of Wang et. al. [12] was to initiate future efforts by promoting public databases. The work presented a “machine-human annotated” CXR database that gives a real clinical and methodological challenge of handling tens of thousands of patients. As part of this, they also conducted extensive experiments on the quantitative performance bench marking on eight common thoracic pathology classification and weakly-supervised localization based ChestX-ray 8 database. They implemented multi-labeled CNN architecture with the Caffe framework [25]. The ImageNet pre-trained models, such as AlexNet [24], GoogLeNet [27], VGGNet-16 [26] and ResNet-50 [34] were used from the Caffe model zoo. The integrated DCNN, used weights from the models, transition layers and prediction layers were trained from scratch. Rajpurkar et al. [11] proposed an algorithm that detects pneumonia from frontal-view CXR images at a level to exceed the performance of radiologist. They trained their algorithm using ChestX-ray14 on Dense Convolutional Network (DenseNet) consisting 121-layer [30]. Based on the ability of DenseNets to improve flow of information gradient in the network and make optimization of very deep networks to be tractable, they replaced the final fully connected layer with a layer that has single output and applied sigmoid nonlinearity. Yao et al. [29] presented and evaluated a partial solution to the constraints in adopting LSTMs to overcome interdependency with target labels in predicting 14 pathologic patterns from chest x-rays. They considered the medical issues at hand and proposed a model based on DenseNets [26]. In the first stage, their model inputs were of much higher resolutions. They noted that lower resolution, typically 256 × 256, is enough when solving problems related to natural images, photos and videos while higher resolution is often important to represent regions within images that are small and localized. The size of their presented model was smaller in network depth. Kumar et al. [10] implemented a cascaded network to improve the performance of deep learning model. The method was performed along with modeling label dependencies which is based on the possibility of training Deep Convolutional Neural Network (DCNN) for Computer Aided Diagnosis systems (CADs). In their work, they experimented on a set of deep learning models and proposed a cascaded deep neural network that can diagnose all 14 pathologies better than the baseline and other related published methods. DenseNet161 [3] was used as a baseline neural network architecture, because of its known performance on a variety of datasets. Their work was fully motivated by the modeling DenseNet architecture with few numbers of trainable parameters and was able to reduce over-fitting while benefiting from deep architecture. The cascaded network was designed in a way where every succeeding level in the network can receive prediction from all the prior levels as an input. Qingji et al. [35] presented an attention guided convolutional neural network (AG-CNN) to classify thorax disease. The network consisted of two major branches, known as the global and local branch and included a fusion branch. The global and the local branches were implemented as classification networks to predict the existence of pathologies in the x-ray images. Given an x-ray, the global branch was fine-tuned using a global image. Due to the region of interest to train the local branch, they performed cropping on an attended region of the global image which was used to train for classification on the local branch. Deniz et al. [36] proposed a deep learning structure for a classification task. The network was trained with modified CXR images, using multiple steps during the preprocessing. The classification method used CNNs and residual network (ResNet) architecture to predict whether pneumonia was present or not in the CXR images. A new approach based on weighted classifiers were presented in [37], which combine weighted predictions from state-of-the-art deep learning structures such as ResNet18, Xception, InceptionV3, DenseNet121, and MobileNetV3 for pneumonia prediction. Ansh et al., 2020 [38], explore convolutions and utilized the advantage of dynamic routing procedure in CapsNet for pneumonia CXR detection.
In this study, we present a method for classifying pneumonia based on x-ray image. According to the literature, the CNNs used require large amounts of data; however, the data available in medical imaging are few. In addition, the CNNs do not consider the spatial orientation of the input image which decrease the performance of the networks. We therefore highlight capsule network (CapsNets) for the pneumonia classification task. The introduction of a new routing algorithm with a new squashing method, which we named vertical squash (VSquash) and Sigmoid function for effective coupling coefficient distribution can improve the classification of the networks. We note that our method outperforms previous works.
Methods
Detecting pneumonia is a binary classification task where inputs are the frontal-view of CXR, which we denote as X and the corresponding outputs are binary label y ∈ 0, 1 that indicates the presence or absence of pneumonia respectively. Given a training sample, the weighted binary cross [57] entropy loss can be optimized using the Equation 1.
Generally, CNNs consist of three properties: Firstly, neurons in higher layer receive inputs from the lower layers which are localized in a closest neighborhood. In this way, layers such as first layer extracts edges, textures and corners while the upper layers extract high dimensional complex features. These extracted features are combined in the next layer which detect higher complex features. Secondly, the concept of shared weight is an important property of CNNs, which indicates that similar feature detector can be applied to the entire input image. Finally, CNNs usually implement sub-sampling techniques in the layers to reduce the size of the input. We can compute the convolution with the discrete operator ∗ by using translation-invariant. The translation-invariant linear operator from
CNNs are accepted to provide useful results in many research fields due to the beneficial feature and characteristic it carries. In this work, we noted that the convolution layers do not consider the precise location of the features as beneficial. This makes the approach harmful, because there are variations of information for different instances. Furthermore, several drawbacks of the CNNs are listed as follows: CNNs requires large amounts of dataset for accurate training and prediction. Regards to this characteristic, the network performs poorly when train with small datasets, which is the case with most medical image datasets such as brain MRIs and CXR images [41, 44]. CNNs given a small amount of translational invariance can lose the actual location of the most active feature detectors [39, 40]. Hence, CNNs progressively reduce the resolution of feature maps through down-sampling. Such loss of resolution limits the classification accuracy of the network [46]. When multi-layer perceptron is used i.e. if all layers are fully connected, the CNNs find it difficult to compute, due to the high dimension of the input image.
Based on the above-mentioned shortcomings, a new architecture called CapsNet was introduced to mitigate the problems and enhance performance of the network. The CapsNet is robust to translation and rotation compared to the CNNs. This network is reviewed in Section 3.3.
Skip-connected convolutional capsule (S-CCCapsule)
The proposed model introduces feature-level augmentations through skip connections that combines deep, coarse and fine, appearance cues from mid-layers. Further, our model performs 2-dimensional (2D) convolutions with capsules modules, which does a coarse-level feature fusion in a structured manner, as depicted in Fig. 1. The residual feature flows alleviate vanishing gradient of deep networks by moving important information from lower layer to the layers above. Even though the shortcut seems like a summation to the traditional CNN connection, it mitigates training and minimize the number parameters [34, 47].
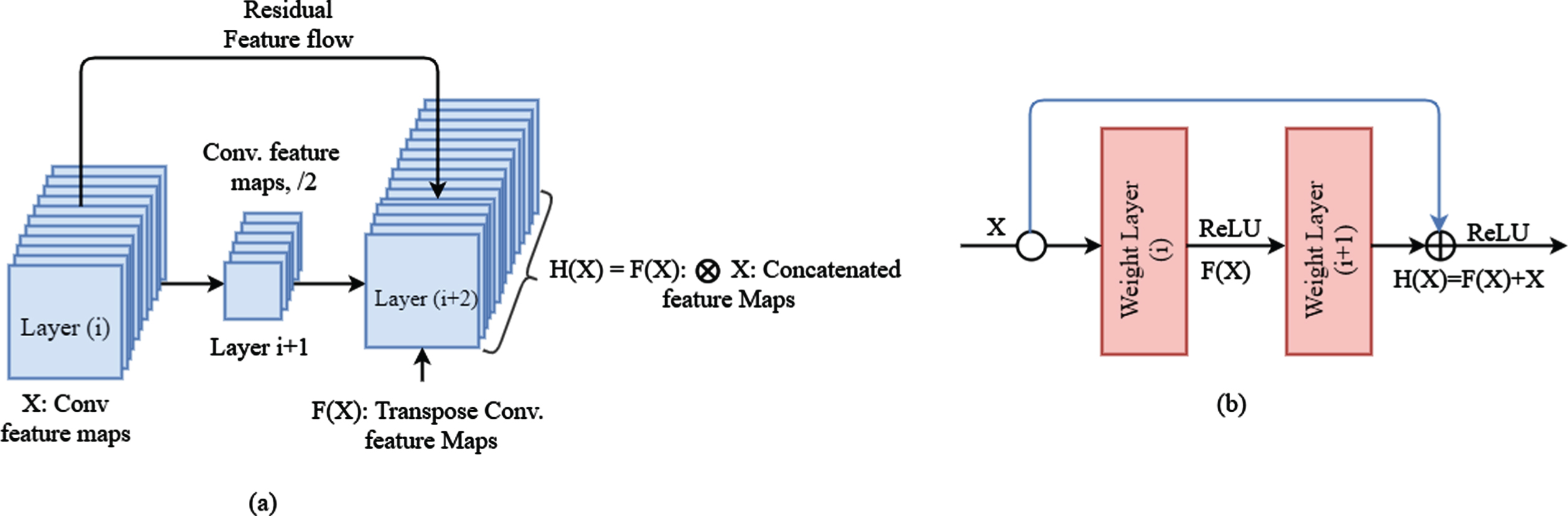
Convolutional feature flow: (a) residual concatenated feature mapping of our proposed models (b) ResNet flow.
An illustration for ResNet connection is shown in Fig. 1(b), where X is an input feature, H (X) is a transformation, and F (X) is a residual mapping. In [35, 47], the operator for feature fusion H (X) = F (X) + X is performed by a short concatenation and element-wise addition. Despite that, our model stacks the features depth-wise as H (X) = F (X) ⊗ X, like in Fig. 1(a), where ⊗ denotes coarse-level feature concatenation. The feature map output of the previous convolution layer and scale are combined using concatenation. That is output of a convolution used on the same-scale feature from the previous convolution layer [43] and output of a strided convolution used on the fine-scale feature vector from the previous convolutional layer computed by concatenating their results. It is favorable to have a smaller number of filters in conv layers resulting less computation.
Figure 2 shows our proposed S-CCCapsule model. The size of the kernel k, stride s, and dimension of the output are described in the following order and in enclosed braces (k, s) [H × W × D] in each layer. Where the H, W and D represent height, width and dimension of the input and feature maps respectively. The entire structure has 9 layers with 8.3M trainable parameters that compose three major components: encoder, decoder and classifier. The encoder is composed of Convolutional layers, primary capsule (PrimaryCaps) layers and disease capsule (DiseaseCaps) layer. In the encoder, we initialized filter size of 96, 64, 32, 32, respectively in the preceding four conv layers where we maintained kernel size, k = 1×1 and stride, s = 1. In contrast, we set the kernel and stride size to 3 and 2 in the two (2) primary capsule layers which produced 21×21 feature maps. The intuition of setting the kernel and stride size to 1 is to achieve high activation map to produce better accuracy. The dynamic routing given in Algorithm 2 is performed between the PrimaryCaps and DiseaseCaps, which this work introduced a vertical squash function (VSquash) to better shrink long vectors to vector slightly close to 1 and short vectors to 0. Instead of Softmax function for distribution of the coupling coefficient, we adopted Sigmoid function which gave better distribution of coupling coefficient. Moreover, the spatial dimension of the feature maps is maintained without striding in the encoding stage except the primary capsule layer where striding the kernel at a rate of 2 are performed. Thus, the PrimaryCaps layer of the encoder generates feature maps that have spatial dimension of 21×21 which is then forward to the last encoder layer called DiseaseCaps. We introduced batch normalization (BN) after conv layers to alleviate over-fitting. To achieve the precise decoded feature maps, there are three fully connected layers which are sequentially connected. The final layer of the decoder network provided output feature maps with same spatial dimension as the input. The fully connected layers consist of dropout rate of 0.2 and 0.5 and finally the last classifier layer consist of sigmoid function as a classifier. For the sake of clarity, we elaborate the concept of capsule network with dynamic routing algorithm which exists between the PrimaryCaps and DiseaseCaps in Section 3.3, Algorithm 2 and Fig. 7.
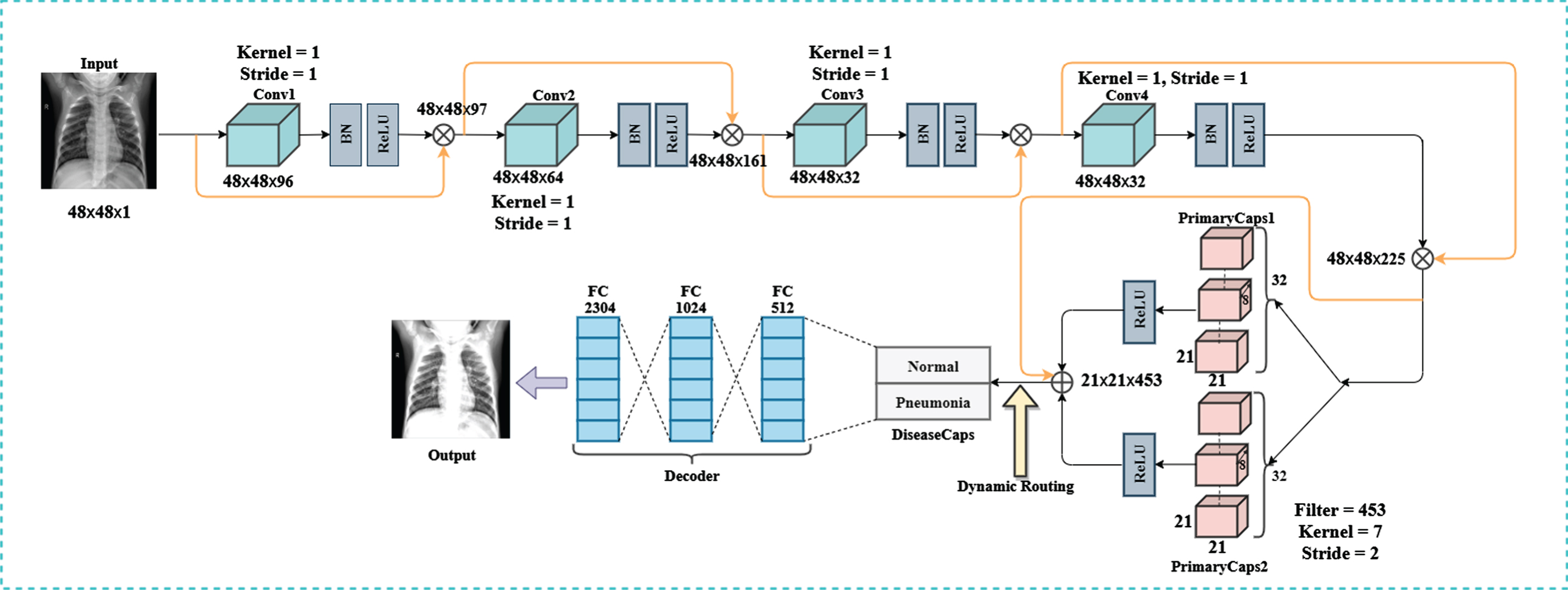
Proposed S-CCCapsules architecture.
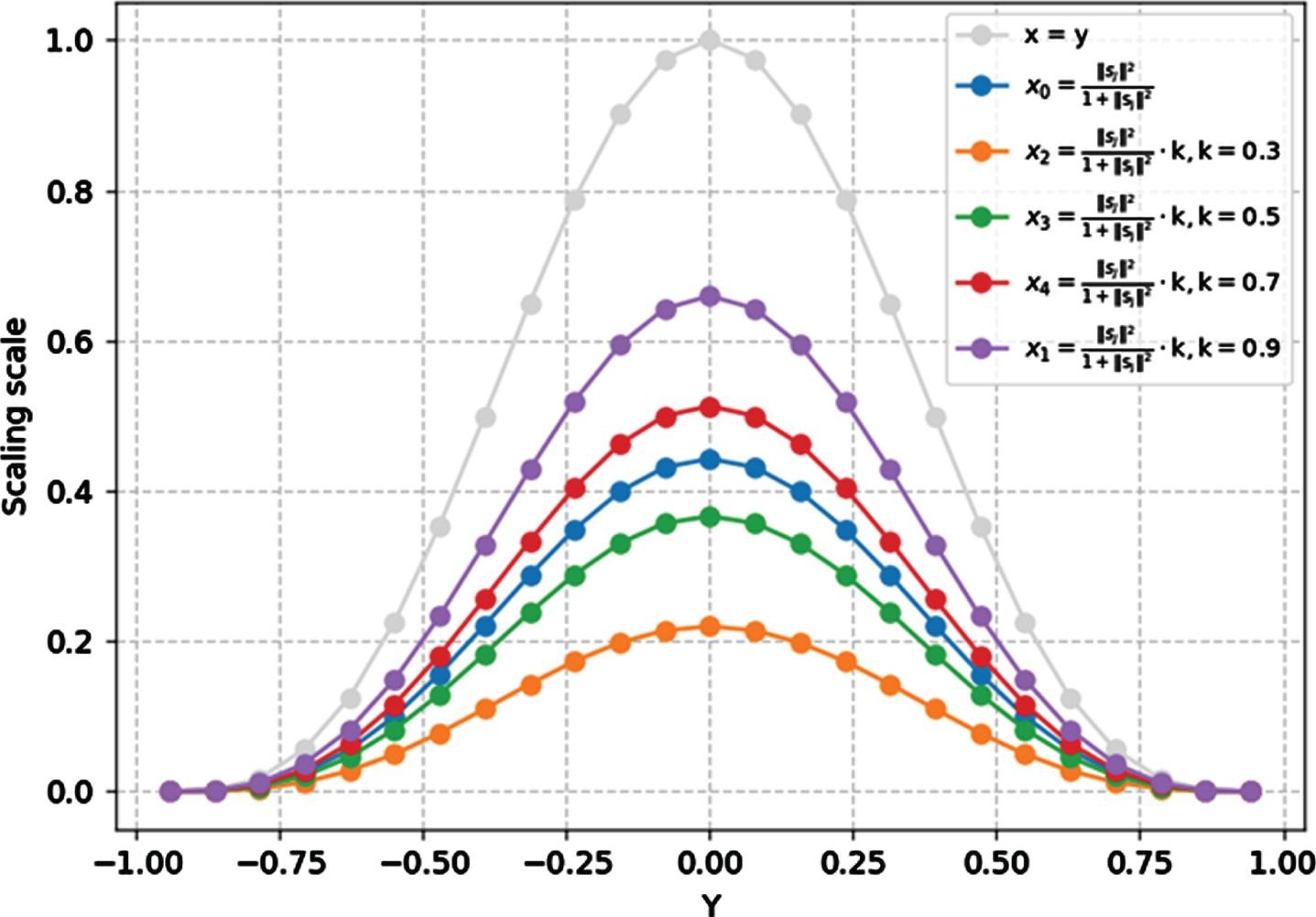
Comparison of different squashing functions.
The Integrated skip convolutional capsules (ISCC) shown in Fig. 3 was built for the pneumonia detecting task. The model shows a combination of traditional dense convolutions with capsule layers. The bottom of the model shows a simple capsule block where dynamic routing between PrimaryCaps and PneumoniaCaps are performed. The ISCC network has two main substructures namely, the dense skip convolutional substructure (dSCS) and capsule dynamic routing substructure (CDRS). The substructure dSCS in the ISCC architecture consist of two maxpool layers found in the third and sixth convolution layers. Reference [48] showed that, late down-sampling achieves high activation map, which produce good accuracy. This motivated the introduction of 1×1 kernel size in the dSCS block. In the Conv1 ReLU layer, 32 filter size was used which produced 48×48×32 feature vectors. The Conv2 ReLU layer has 64 filter size that utilizes 48×48×64 and repeated in the Conv3 ReLU followed by maxpool2d_1 with 2×2 kernel size producing 24×24×64 feature vectors. The 4th, 5th, 6th convolutions have the 24×24×128, 24×24×256 and 24×24×512 feature vectors respectively and followed by Maxpool2d_2 of 12×12×512 feature vectors. The bottom layer block CDRS consist of simple capsule model. The Conv7 ReLU of the CDRS gives a dimension of 12×12 feature vectors. The resulting feature vectors from Conv7 ReLU is mapped to the PrimaryCaps layers which has 16 channels of 8-Dimensional capsules. Here every primary capsule produces 8 units, with 3×3 kernels and 2 strides. Each primary capsule is provided with 128×128 from the Conv7 ReLU layer. Hence, the PrimaryCaps produce 5×5×16 feature vectors as output. The capsule 5×5 feature map shares their weight for equivariance with the high-level capsule with the high agreement.
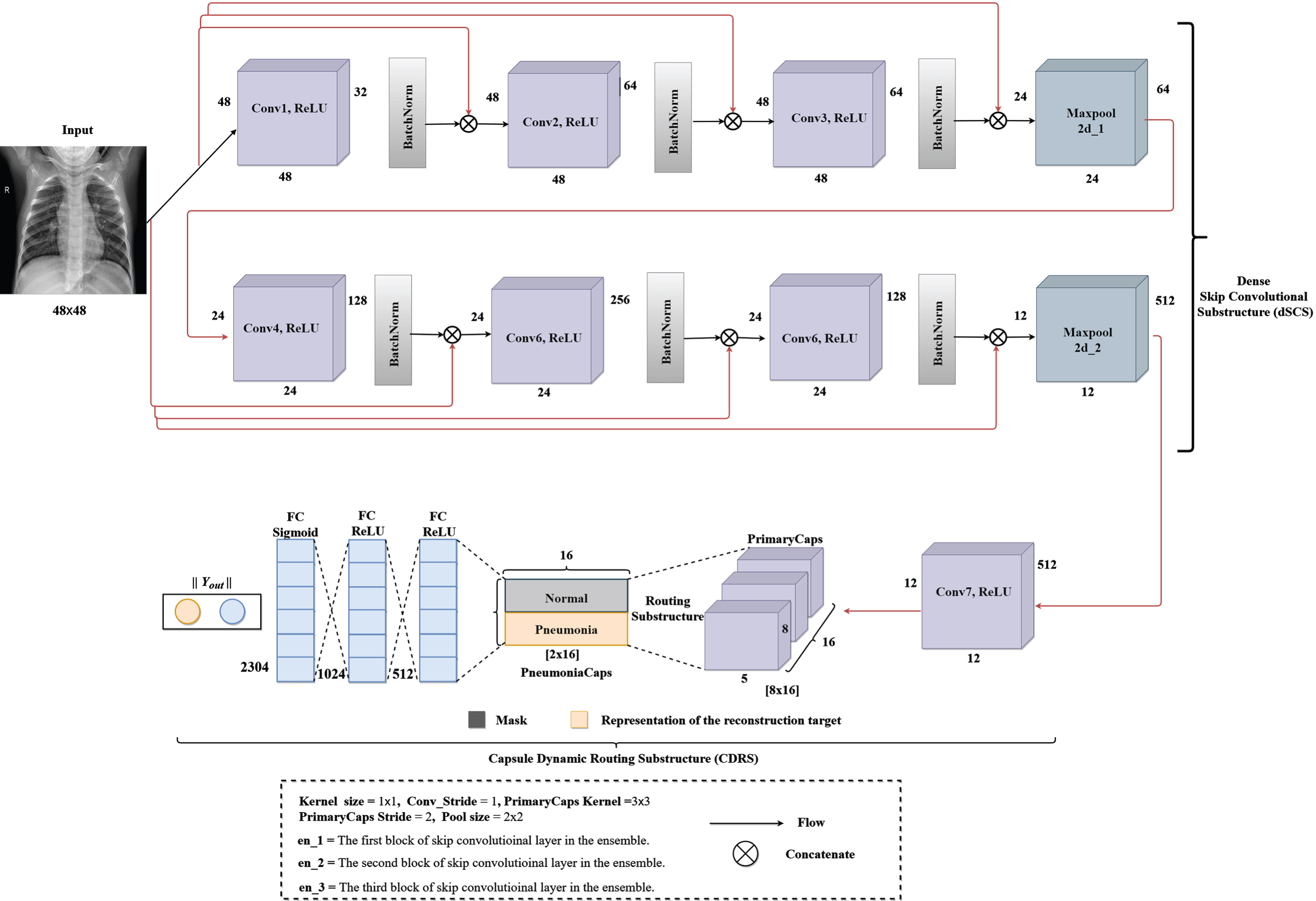
An integrated skip convolution with capsules which we named integrated skip convolutional capsules (ISCC).
We implemented the CDRS substructure with the configuration of the capsule layer (i.e. routing, margin loss etc.). Lastly, Y_out was used to determine the probability “Normal” or “Pneumonia” existing in the CXR image.
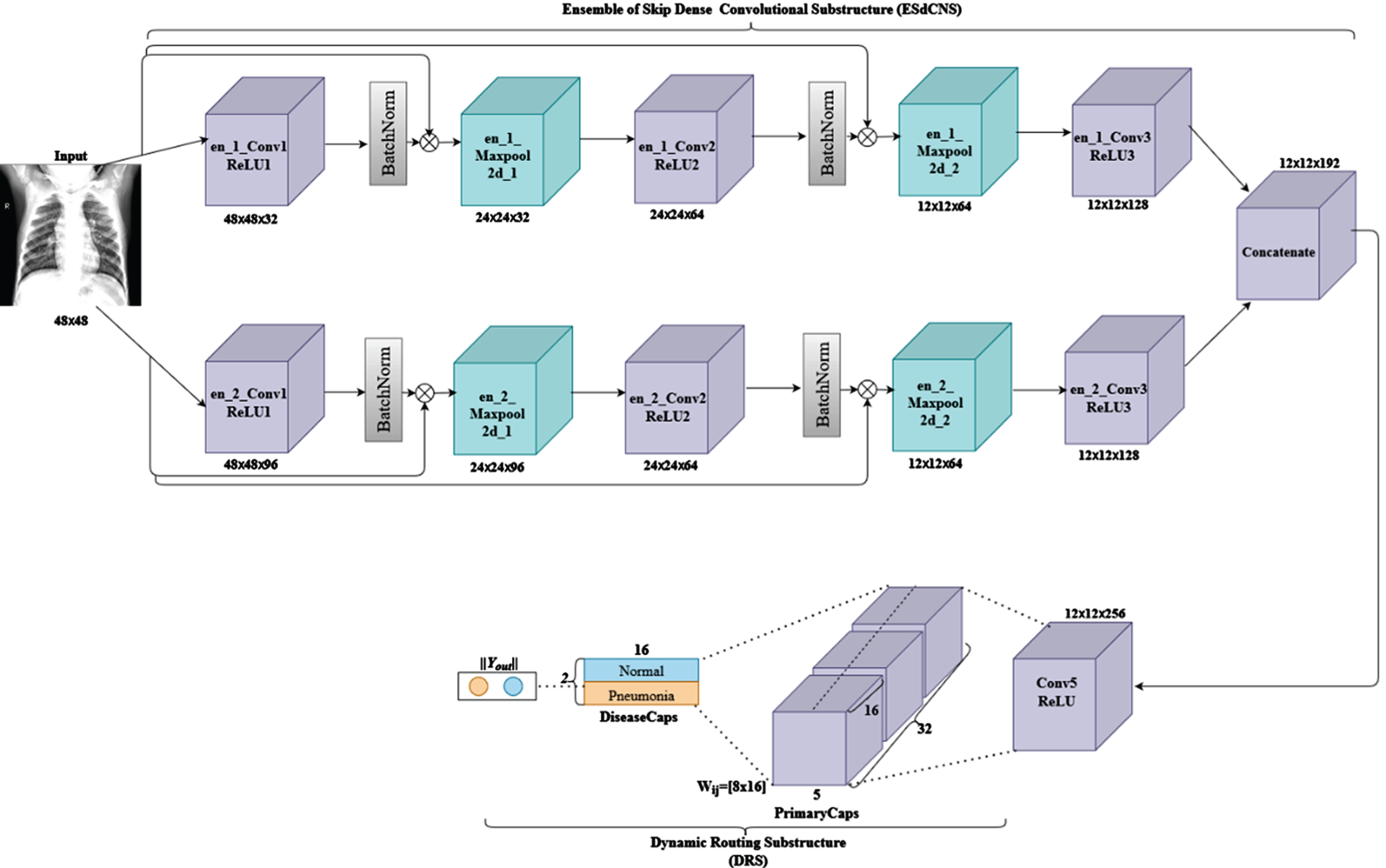
This model named Ensemble of skipped convolutional capsule (ESCC) presented in Fig. 4 consists of an ensemble of skip convolutions. In addition, the network has substructures namely ensemble skip dense convolution substructure (ESdCNS) and dynamic routing substructure (CDRS). The ESdCNS model consists of 6 convolutions with 4 maxpool layers corresponding to the two divided ensemble convolutions with 2 maxpooling each. The convolutions adopt configuration from the ISCC structure which is kernel size, pool size and nonlinearity function. The en_1_Conv1 layers as the first convolutional layer has 32 feature maps and has 48×48 feature vectors from the input images where maxpooling application is performed to achieve 24×24 feature vectors. BatchNormalization (en_1_Bn_1) is applied after the layers in order to minimize overfitting (as described in the Section 3.2.2). The layers above en_1_Conv consist of 32, 64 and 128 feature maps respectively. The model combines these layers into a single block layer as depicted in ISCC model. We constantly repeated the process through Convolutional layers with ReLU and Max_pool2d layers (i.e. en_1_Conv2, en_1_ReLU2, en_1_Bn2, en_1_Max_pool2d_2, en_1_Conv3, en_1_ReLU3, en_1_Bn3) to produce vector feature maps of 24×24×32 and 12×12×64 in the 2nd block layer and finally, 12×12×128 feature vectors for en_1_Conv3. The second blocks of convolutions with en_2_Conv1 layer has 96 feature maps producing 48×48×96 feature vectors from the input. This is followed by maxpooling layer to get 24×24 feature vectors and dropout (en_2_dropout_1). As shown in Fig. 4, the convolutional with ReLU, maxpooling and dropout are combined to obtain vector feature maps of 24×24×96 and 12×12×64 (i.e. the 2nd block of convolution, maxpool and dropout), finally the last block of convolution en_2_Conv3 produced 12×12×128 feature vectors. The output from en_1_Conv3 and en_2_Conv3 is concatenated, and output feed to the capsule block.
We present a variant of ESCC model which is named Ensemble skip n-convolutional capsule (ESnCCs) shown in Figs. 6. The figures are composed of ensemble skip convolutions like ESCC except for the number of convolutions and primary capsules in the substructure used in these models. These networks have two substructures: the ensemble skip n-dense convolutional substructure (ESnDCS) and dynamic routing substructure (DRS). The number of convolutions is initialized as n, where n ∈ {3, 4, 5, 6, 8}. In the variant ensemble network implemented, the image size used was downscaled from the original size to 48. We present a variant of ESCC model which is named Ensemble skip n-convolutional capsule (ESnCCs) shown in Figs. 6. The figures are composed of ensemble skip convolutions like ESCC except for the number of convolutions and primary capsules in the substructure used in these models. These networks have two substructurescolon the ensemble skip n-dense convolutional substructure (ESnDCS) and dynamic routing substructure (DRS). The number of convolutions is initialized as n, where n ∈ {3, 4, 5, 6, 8}. In the variant ensemble network implemented, the image size used was downscaled from the original size to 48×48 to reduce the number of features and train parameters. The E3SCC model in Fig. 5 is a variant of the ESCC model, which consist of 12 convolutions with 6 maxpooling layers. The 6 maxpooling layers are divided among the ensemble of 3-layer convolutions. The first convolution en_1_Conv1_ReLU layer has 32 feature maps that with 48×48 feature vectors. The feature vector is subjected to a maxpooling to get 24 × 24 feature vectors. In this sub-block, the process is repeated through convolution ReLU layers and Maxpooling layers to get feature maps of vectors 24 × 24 × 67, 12 × 12 × 67, 12 × 12 × 131 (through en_2_Conv2_ReLU, en_1_Maxpoo2d_2, en_3_Conv3_ReLU) and finally, 12×12×131 through en_1_Conv4_ReLU. In the second substructure, the en_2_Conv_ReLU has 64 feature maps that uses 48 × 48 × 64 feature vectors from the input image. The feature vectors are subjected to maxpooling to obtain 24 × 24 × 64 feature vectors. The process is repeated through en_2_Conv2_ReLU, en_2_Maxpool_2d_2, en_2_Conv3_ReLU and finally, en_2_Conv4_ReLU to obtain 24 × 24 × 67, 12 × 12 × 67, 12 × 12 × 131, and 12 × 12 × 131 feature vectors. The third substructure (en_3) operates similarly to the 2nd substructure. In order to regularize the models and minimize overfitting, batch normalization was used after convolutions. Regularization methods and activation functions used are explained in Appendix A and B, respectively.
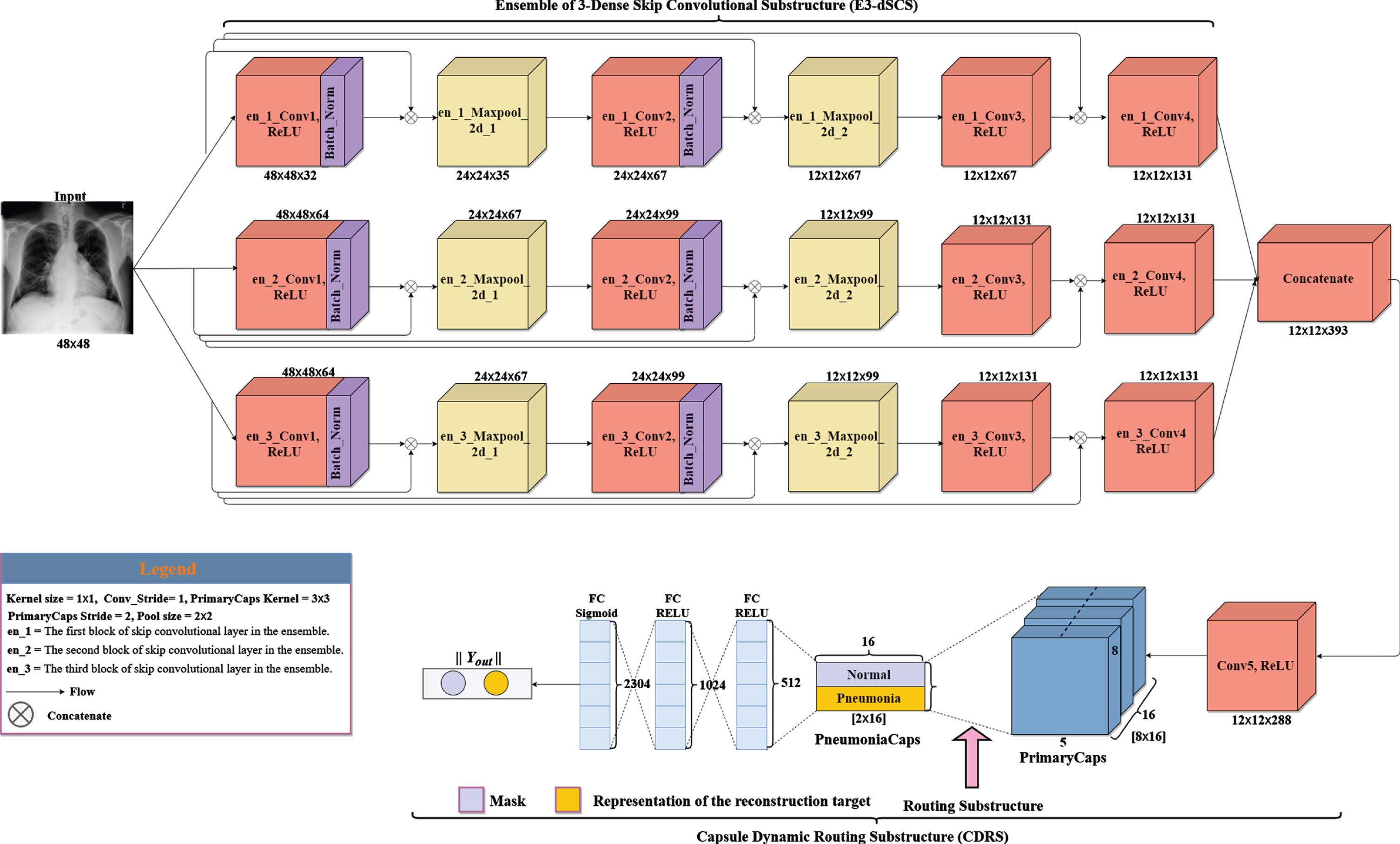
Ensemble of 3-skip convolutions with capsules (E3SCC).
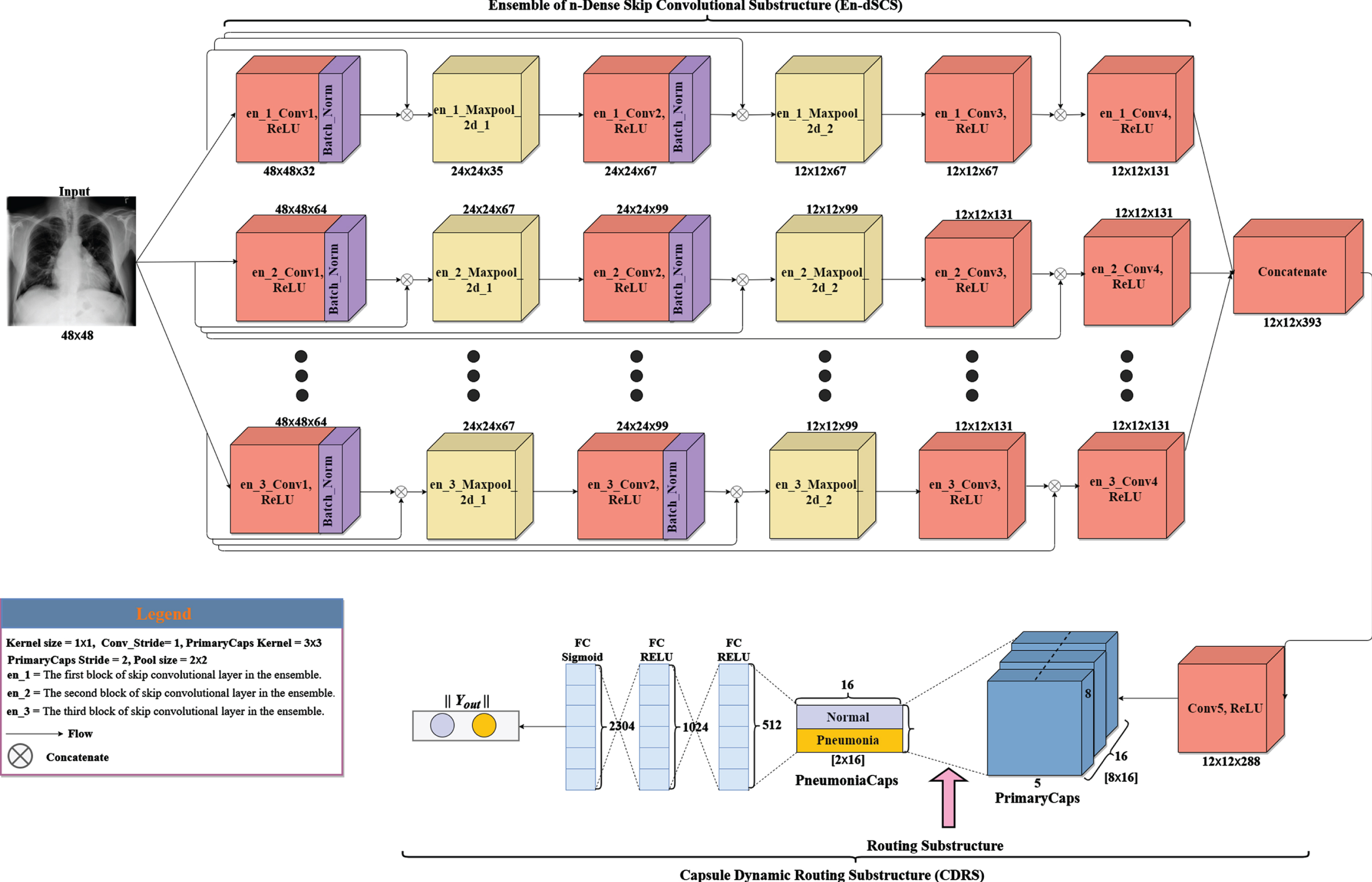
An Ensemble of n-skip convolutions with capsules (EnSCC) architecture with a decoder layer as a variant of EnSCC.
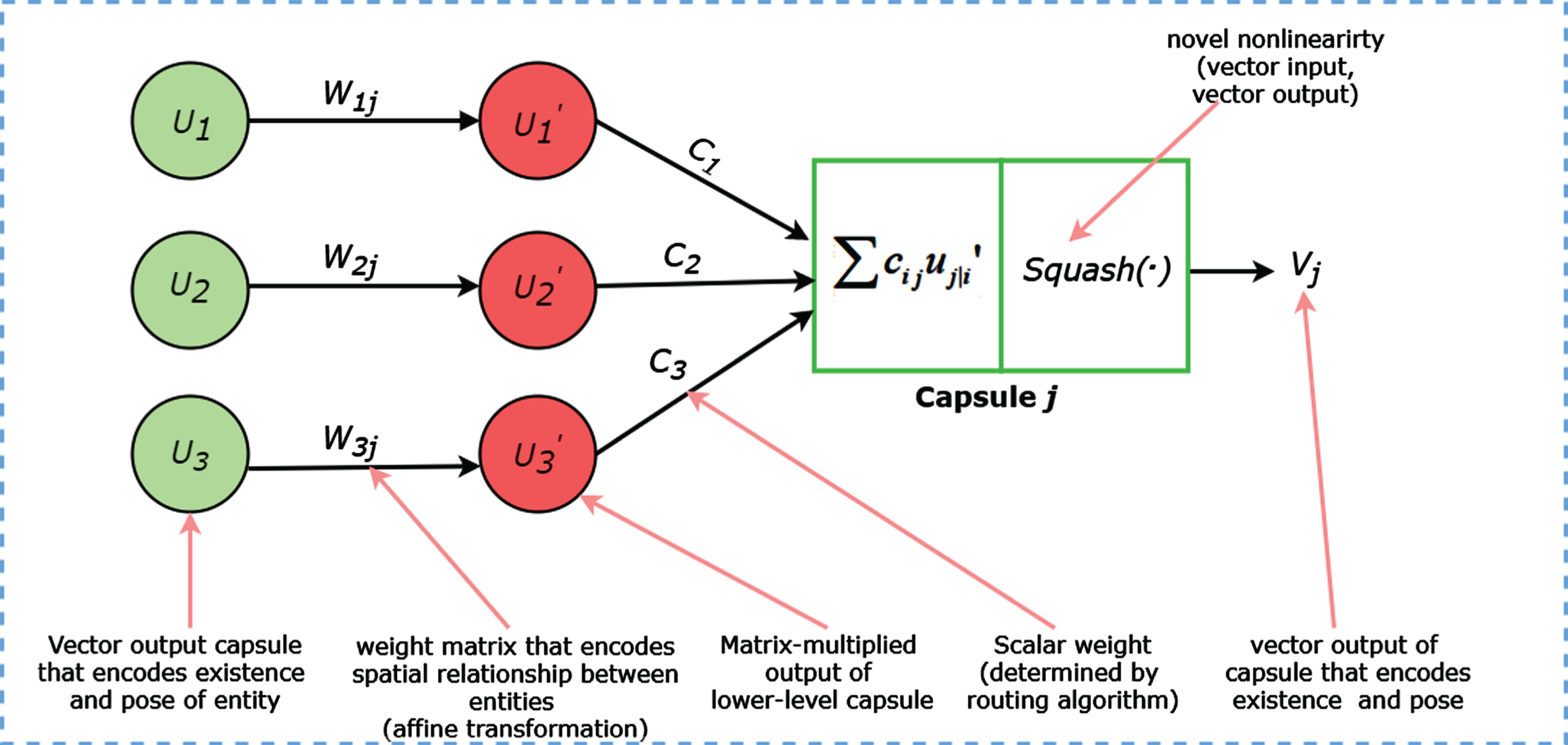
The concept of capsule proposed by [42] is defined as the collective neurons indicating activity vectors of the neurons which represent the existing pose parameter. The length of the various vector shows the probability existence of a specific entity. The pooling layer in CNNs mostly pose a challenge to the structure by reducing resolution [49]. With this as a result, CapsNet has successfully substitute pooling layer with routing by agreement method. The “routing by agreement” by CapsNet has shown appropriate replacement of the pooling layer. Based on these criteria, outputs from the lower layer are forward to each parent capsules within the high layers; however, each of their coupling coefficients tend to be different. Every Capsule in the lower layer predicts the output of the parent capsules. When the predictions match with output of the parent capsule, the coupling coefficient for these two capsules are increased. Let q
i
be the output of capsule i, its prediction for parent capsule j is computed as
Finally, at this stage, non-linearity squashing function is applied to ensure the output vectors of capsules do not exceed 1 and forms the output of every capsule based on the given value of the initial vector defined in above equation
The log probabilities are updated in the routing process based on the agreement between v
j
and using the fact that if the two vectors agree, their inner product will be large. Therefore, agreement for updating log probabilities and the coupling coefficients can be computed as
Each capsule n in the last layer is a match to the loss function l
n
, which puts high loss on capsules that have long output instantiation parameters when entity does not exist. The loss function l
n
is calculated as
In this paper, instead of Softmax function (Equation 5) for coupling coefficient in Algorithm 1, we adopted Sigmoid function (Equation 11) to scale the transforming space and calculated the coefficient to enhance the capsule.
Routing using the Sigmoid is same as the Softmax routing procedure in [33], but we rather used Sigmoid function as shown in Equation (11). Here the c ij does not mean the allocation of probabilities toward the final capsules in reference [28], but represents the strength of correlation between the primary capsules and the final capsules. Replacing Softmax function with Sigmoid function for coupling coefficient gives more improvements to the capsule, such as: 1. The important predictor vectors are multiplied by large coupling coefficients, which makes the significant feature more decisive, while unrelated figures get smaller ones. Additionally, it increases the difference between the lengths of the vectors in the final capsule layer, where the correct digit capsule exceeds all the other digit capsules in length. The adoption of the Sigmoid function in our models produced better performance compared to using Softmax routing. In summary, this work modified Algorithm 1 by replacing the Softmax function and squash function with Sigmoid function and VSquash function, respectively, to obtain Algorithm 2. The Algorithm 1 shows the Softmax function with original squash function while our Algorithm 2 shows the Sigmoid function routing with VSquash function procedure.
1:
2: for capsule i in layer l and capsule j in layer (l + 1) : (b ij ← 0)
3:
4: for capsule i in layer l: c ij ← Softmax (b ij ) ⊳ softmax computes Equation 5
5: for capsule j in layer (l + 1) :
6: for capsule j in layer (l + 1) : v j ← Squash (s j ) ⊳ squash computes Equation 7
7: for capsule i in layer l and capsule j in layer (l + 1) :
8:
1:
2: for capsule i in layer l and capsule j in layer (l + 1) : (b ij ← 0)
3:
4: for capsule i in layer l: c ij ← Softmax (b ij ) ⊳ sigmoid computes Equation 11
5: for capsule j in layer (l + 1) :
6: for capsule j in layer (l + 1) : v j ← V Squash (s j ) ⊳ VSquash computes Equation 12
7: for capsule i in layer l and capsule j in layer (l + 1) :
8:
In order to enhance capsule routing, we replace the squash function (Equation 7) with our proposed vertical squash function, which we named VSquash shown in Equation 12. The function is used to restrict the vector h
j
close to 1 as shown in Equation 7. The squash function compresses short vectors to a length close 0 and long vectors slightly close 1. Equation 7 is the original squash function represents the scale with
If 0 < k < 1, the vector of function v j vertically shrunk by multiplying each of the vector h j by constant figure k. 0 < k < 1. The models with VSquash (i.e. k = 0.5) achieved improved accuracy than the squash function in [33]. In Algorithm 2, we show the improved Sigmoid function routing with VSquash function. Figure 7 shows a comparison of squash function in [33] and VSquash function with different k initializations.
The steps in Algorithm 2 and Fig. 8 are shown as follows:
Set all the probability, parameters and let all b equals to 0 to make C distribute evenly using Softmax as a normalize function. Convert all input data using the attitude matrix. Apply dynamic routing to the input weights. Using the formula C
ij
Uj|i, update these parameters to make decision about the mapping between the levels. Where C
ij
indicates the weight and the sum is equal to 1. The weight sum gets the average position of features of the object in the image. The output of the Sigmoid function is non-negative and it’s equal to 1. Use nonlinearity VSquash function as activation in equation 12, where h is united and converted to final vector v, which is the modular length and final output.
Capsule networks routing algorithm.
Dataset
This section introduces the datasets used to train our model. We used three public datasets (i.e. Guangzhou Women and Children’s Medical Center (GWCMC), Mendeley CXR and Radiological Society of North America (RSNA)). For the GWCMC data, there are 5,863 chest x-ray images and are categories into “Pneumonia” and “Normal”. The data was released by a public website, kaggle.com and are organized into 2 folders (train, test) which contains subfolders for each image category (Pneumonia/Normal). The CXR images were chosen from retrospective cohorts of pediatric patients from one to five years old from (GWCMC), Guangzhou. As part of the patient’s routine clinical care, all the CXR imaging was performed. The chest radiographs were screened, and low quality or unreadable scan removed for quality control. We note that the diagnoses of the images were graded by physicians and approved before training on the AI system. Secondly, we used CXR images taken from the Mendeley CXR dataset [51]. The data consist of 5857 CXR images and divided into 2 classes: “Normal” and “Pneumonia”. Our third dataset for the experiment was released by kaggle.com. The data was provided by the RSNA, which specified the identity of an x-ray image and indicate the presence of pneumonia in the x-ray data. The data contains 29,684 x-ray images. We used 26,684 images for training and 3,000 thousand were used for testing. Table 1 presents the distribution (i.e. classes, training, testing, validation set and total data set) of the used datasets. Samples of the x-ray images are shown in Fig. 9, showing the normal chest x-ray (no infection) and pneumonia chest x-ray (infected with bacteria and virus).
Distribution of pneumonia CXR images into training, testing, validation and total set
Distribution of pneumonia CXR images into training, testing, validation and total set
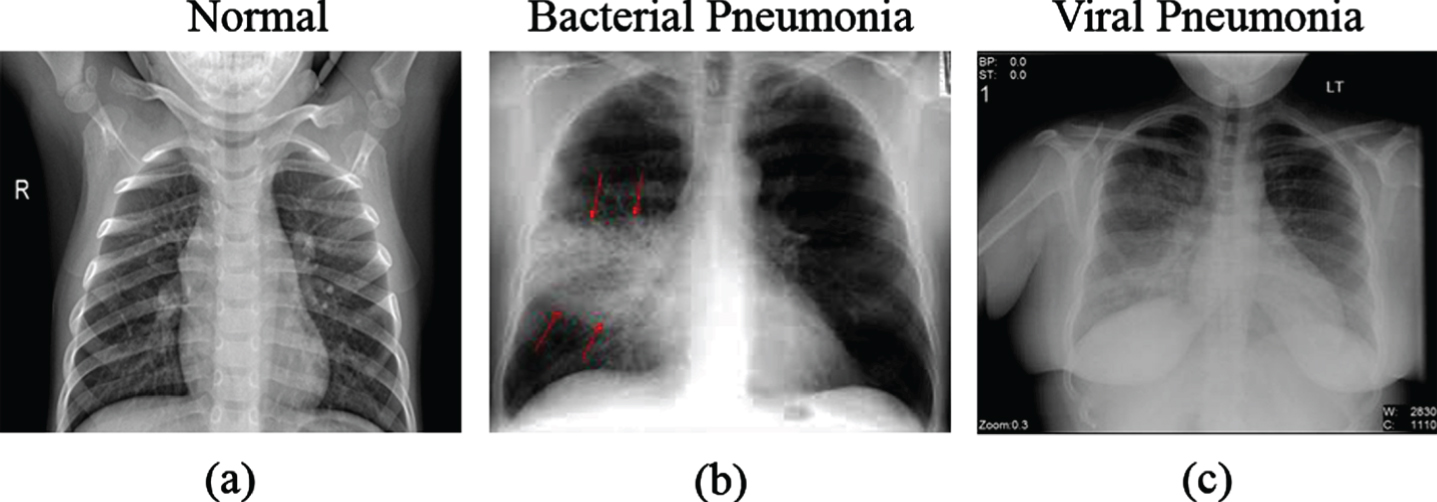
Sample CXR images from patient’s pneumonia diagnosis. (a) shows the normal chest x-ray with clear lungs and without any abnormal opacification within the image. The middle image (b) shows a pneumonia infection by bacterial which is a typical focal lobar consolidation appearing in the right upper lobe with the red arrows. Finally, the last x-ray (c) shows a pneumonia infection by virus manifesting with more diffuse pattern in both lungs.
Our experiments and evaluations were conducted with Keras deep learning libraries with TensorFlow backend. NVIDIA GeForce GTX 1060 6GB GPU system was used for the experiments. Secondly, the original CapsNet architecture [33] was used for better comparison with the our proposed method.
Results and discussion
This section presents the result and discussion of our models experiment. We show the result from our experiments with S-CCCapsule architecture and its three ablation study architectures in Table 2. For our capsule network architecture, we implemented convolutional layers and two (2) capsules in the primary capsule layer. Alongside hyperparameter tuning, we added a dropout layer after every activation to prevent overfitting and sigmoid function at the last FC layer for output. To enable our network with rapid convergence, we used the Adam optimizer which was better than the other optimizers [52]. Binary cross entropy was used as our loss function and sequentially applied dropout rates of 0.4 and 0.6. The dropout function was used randomly to remove a specified number of neurons in the neural network. On the RSNA data, we performed experiments with training epochs of 150 and filter size of 96. Training on the Mendeley CXR pneumonia data, epochs of 300 was used with filter size 96 and batch size set to 32. For the GWCMC data, we trained with filter size of 96. We used batch size of 32, learning rate of 0.0001 and applied ReLU as the transfer function on the three datasets. The use of ReLU transfer provided the network with a good reconstruction compared to the other activation functions.
Comparison S-CCCapsules with three different ablation models. The models are compared on basis of validation accuracy, AUC, Precision and Train Time. The best results are indicated in bold
Comparison S-CCCapsules with three different ablation models. The models are compared on basis of validation accuracy, AUC, Precision and Train Time. The best results are indicated in bold
We evaluated and compared S-CCCapsule with four state-of-art method, which used supervised classification methods using the three publicly available chest x-ray datasets. For fair comparison, we evaluated the S-CCCapsule with a baseline CapsNet model. The results in terms of accuracy for all the datasets are provided in Table 2, where the best produced results are marked in bold.
Ablation study
In [47], an ablation study has shown to be a useful tool for comparative study of models. Therefore, we considered an ablation study for the proposed architecture. Through the study, we resulted in three more architectures namely, CapsNet+Maxpooling, basic simple capsules (BSCapsNet) and long skip capsules (LSCapsNet). To effectively demonstrate the effect of capsule network with dynamic routing, we introduced maxpooling. We conducted experiments on all the datasets with the different ablation architectures. We performed training and testing on the datasets with CapsNet+Maxpooling, BSCapsNet, LSCapsNet and compared the results to our proposed model S-CCCapsule. The ablation results are presented in Table 2, where we can see our proposed architecture outperforms the ablation models in terms of validation accuracy.
The proposed S-CCCapsule architecture has more parameters compared to maxpooling. The intuition is that, maxpooling does not have any parameters to perform feature routing. Whiles in capsules, dynamic routing selects features dynamically and use weights for the features. For any captured important feature, the weight assigned tends to be high. Hence, dynamic routing is better option compared to maxpooling as we gave detail explanation in Section 3.3 above. In Table 2, we can conclude that S-CCCapsule on GWCMC, RSNA and Mendeley CXR images achieves 83.65%, 99.35%and 91.35%, respectively, which are better performances compared to the other three feature extractors in terms of the accuracy. The training accuracy, validation accuracy, loss and confusion matrix of the S - CCCapsule model mentioned in Fig. 2 are given in Fig. 10 as the best training model. For better evaluation of S-CCCapsule, we present the confusion matrix of the three ablation architectures in Fig. 11. We can observe that the Capsule+Maxpooling model Fig. 11(a) produced 7 false negatives (FNs) (1.80%of the “Pneumonia” CXR images) from the CXR validation set 624 images. In diagnosing pneumonia, FNs can be a critical as a patient who has pneumonia may be diagnosed to be healthy and may not be treated. In contrast, the model had 106 false positives (FPs) (45.3%of the “Normal” CXR images), which are normal CXR images diagnosed as pneumonia. The ablation architecture, BSCapsule confusion matrix is given in Fig. 11(b). The model classified 3 instances of the pneumonia as FNs (0.77%of the “Pneumonia” CXR images) and 387 instances positively as pneumonia (99.23%) from the validation set of 624 images. Meanwhile, the model had 120 FPs (51.28%of the “Normal” CXR images), which normal CXR images predicted as pneumonia. The LSCapsule architecture Fig. 11(c) predicted 3 instances of the pneumonia as FNs (0.77%) and 387 instances predicted as true positives (TPs). On the other hand, LSCapsule had 126 FPs (53.85%of the “Normal” CXR image), which is normal patients diagnosed as pneumonia patients. Finally, on the GWCMC images, our proposed architecture S-CCCapsule produced 7 (1.79%) instances of the pneumonia CXR images as FNs and 383 (98.21%) instances of the pneumonia images predicted as actual pneumonia (TPs). The FPs from the S-CCCapsule was 95 instances (50.60%of the “Normal” CXR images). It can be observed from the confusion matrix that, though the number of FNs minimize, but the FPs increased or decreased. The predicted FPs are not harmful compared to FNs, because a person who is not infected by pneumonia, but diagnosed as pneumonia patient would be subjected to treatment. Therefore, the number of FPs is accepted in a certain scope unless the patient is affected by different diseases.
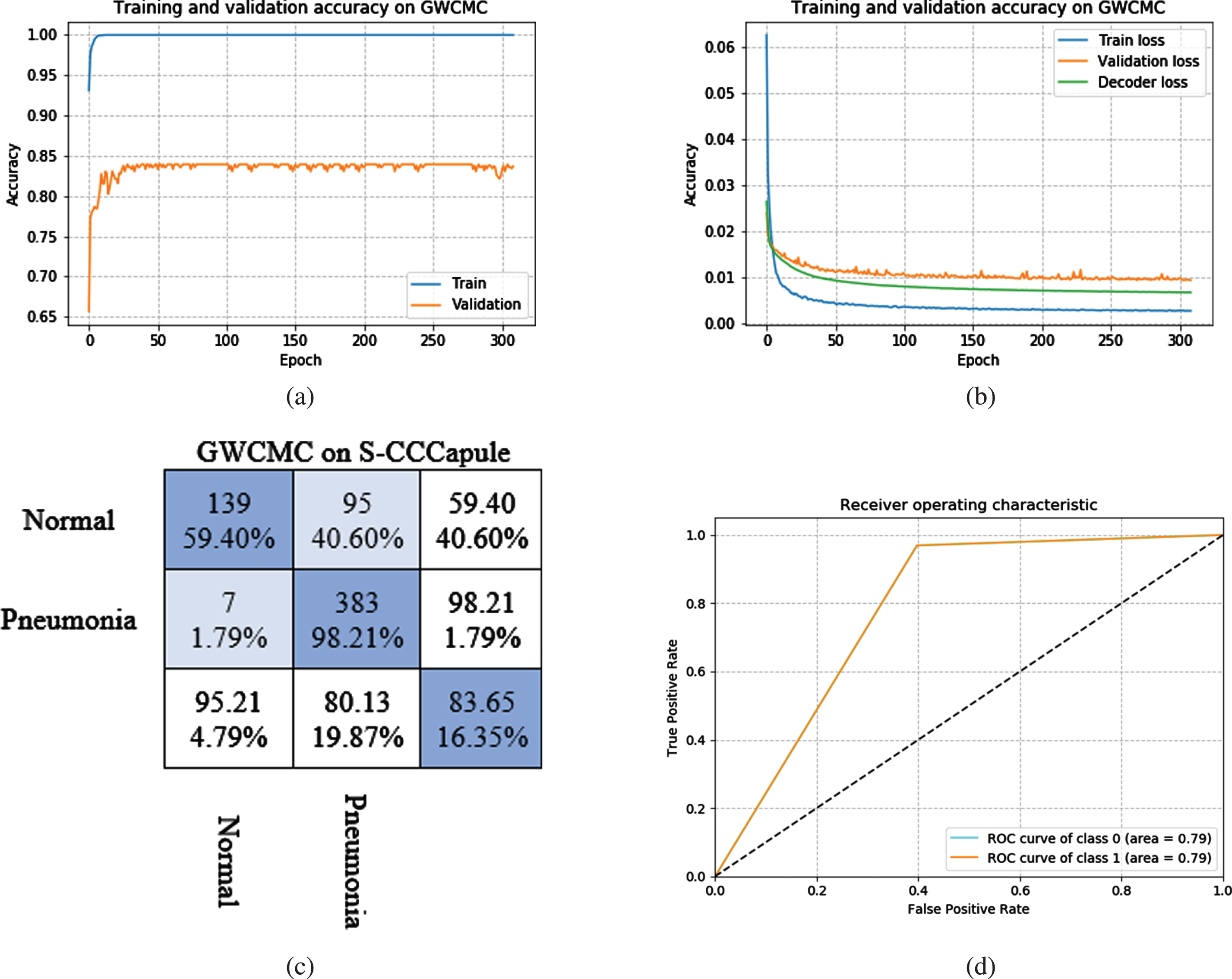
S-CCCapsule training, validation and loss curves on GWCMC images dataset. (a) Training (blue) and Validation (orange color) accuracy curve. (b) Training (blue) and validation (orange color) loss curves, (c) presents the confusion matrix of the 2 classes: “Normal” and “Pneumonia”, and (d) shows the AUC, where S-CCCapsule achieved 0.79.
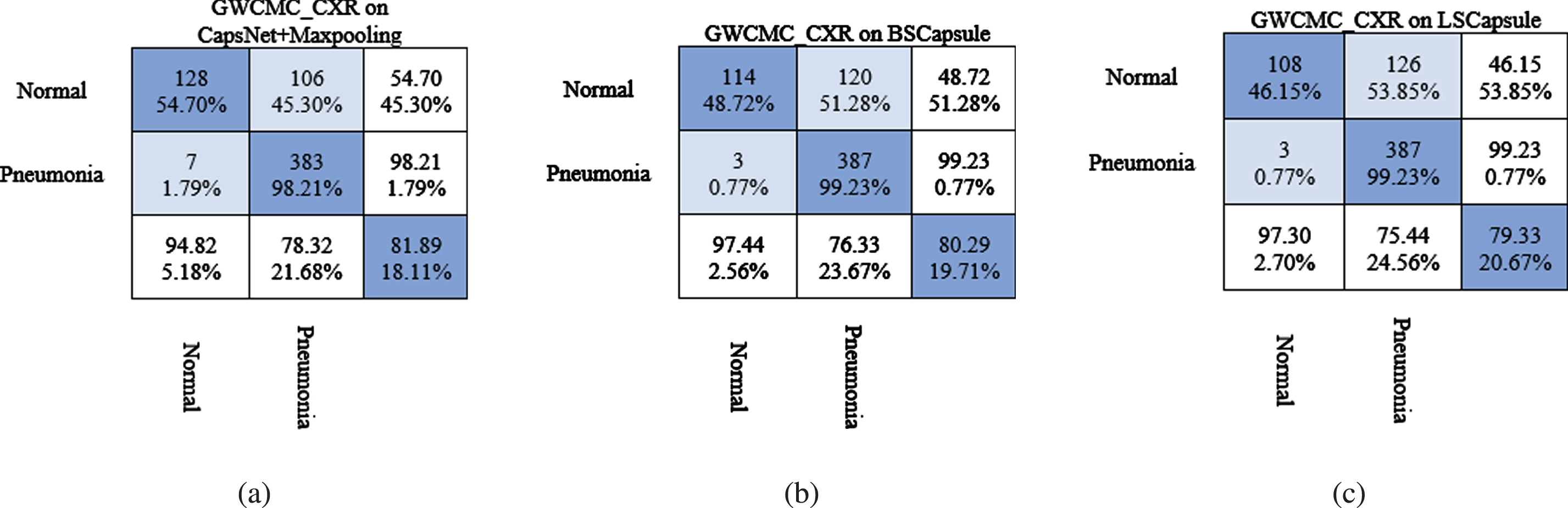
Confusion matrix for Pneumonia detection on GWCMC CXR images using the ablation models. (a) CapsNet+Maxpooling, (b) BSCapsule and (c) LSCapsule.
In Fig. 12, we present the training, validation accuracy (a), train loss, validation loss, decoder loss (b), confusion matrix (c) and area under curve (AUC (d)) of the S-CCCapsule on RSNA CXR images. In training the RSNA CXR images using S-CCCapsule model, we set epoch of 150, meanwhile, the model converged at epoch 64 with 99.35%. The model produced a better probability of discriminating the two class (“Normal” and Pneumonia), with AUC score of 0.96%as presented in Fig. 10(d). In the confusion matrix (Fig. 12(c)), 0 instance was predicted as FNs (0%of the “Pneumonia” CXR images) and 3000 instances (100%) predicted as true pneumonia instances from the CXR validation set 3234 images. On the other hand, 21 instances (8.97%) of the normal images were predicted as pneumonia (FPs) and 213 instances (91.03%) were predicted as true negative (TNs), which is a person with no pneumonia condition predicted to be free from pneumonia. As discussed earlier, the number FPs predicted is not harmful compared to the number FNs, where pneumonia patients are wrongly diagnosed as healthy patients and denied from treatment.
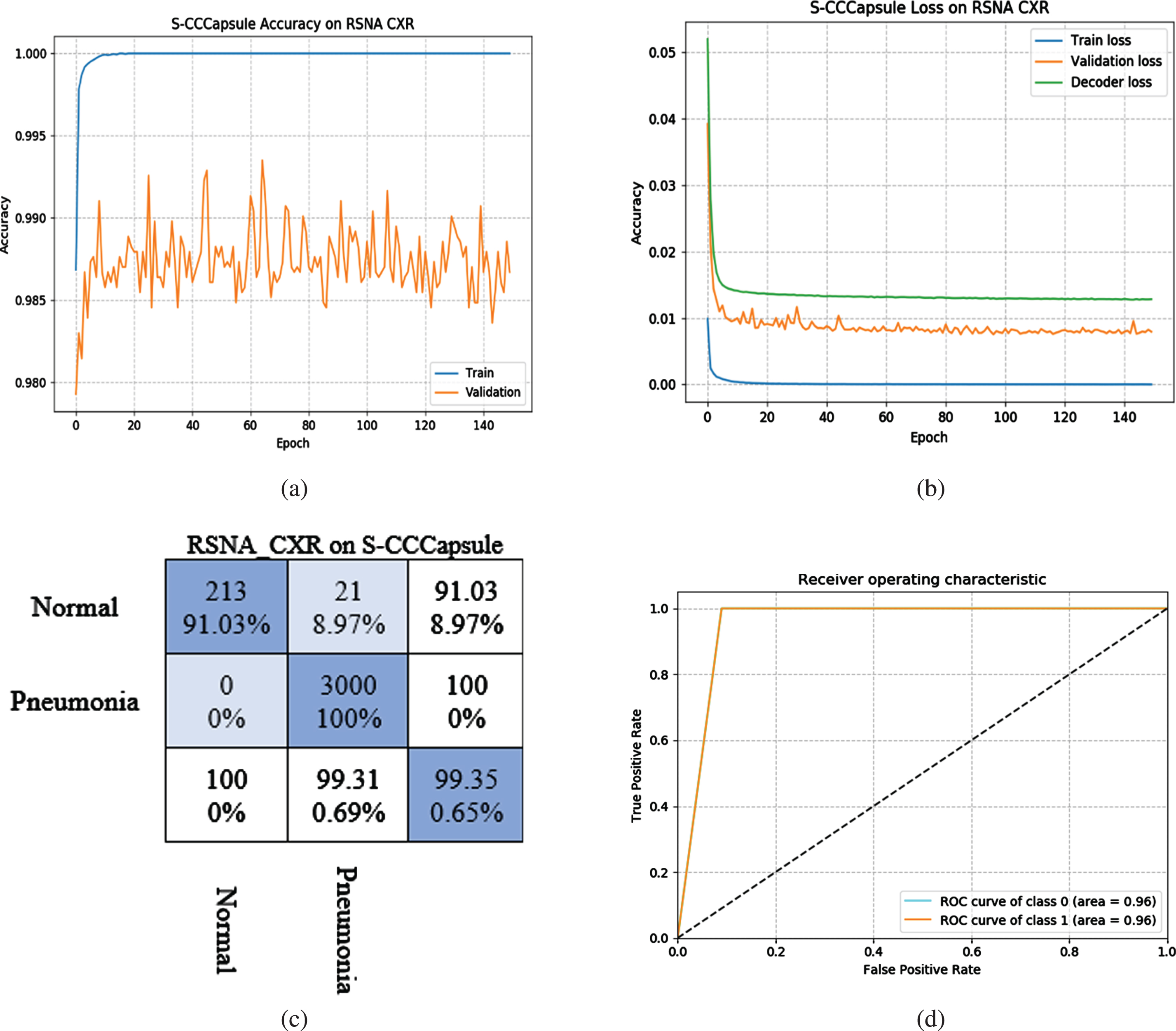
S-CCCapsule training, validation and loss curves on RSNA CXR images dataset. (a) Training (blue) and Validation (orange color) accuracy curve. (b) Training (blue) and validation (orange color) loss curves, (c) presents the confusion matrix of the 2 classes: “Normal” and “Pneumonia”, and (d) shows the AUC, where S-CCCapsule achieved 0.96.
Finally, Fig. 13 presents the training, validation accuracy (a), train loss, validation loss, decoder loss (b), confusion matrix (c) and area under curve (AUC (d)) of the S-CCCapsule on Mendeley CXR images. On the Mendeley CXR images, S-CCCapsule achieved the best result at epoch 15 with 91.35%superior to the ablation models (i.e. CapsNet+Maxpooling, BSCapsNet and LSCapsNet) with 88.94%, 89.74%and 87.10%, respectively. In the confusion matrix (Fig. 13(c)), 10 instances were predicted as FNs (2.56%of the “Pneumonia” CXR images) and 380 instances (97.44%) predicted as true pneumonia instances from the CXR validation set 624 images. On the other hand, 44 instances (18.80%) of the normal images were predicted as pneumonia (FPs) and 190 instances were predicted as TNs (81.20%of the “Normal” CXR images). As discussed earlier, the number FPs predicted is not harmful compared to the number FNs, where pneumonia patients are wrongly diagnosed as healthy patients and denied from treatment. The AUC 0.89%in Fig. 13(d), shows the probability of the S-CCCapsule to efficiently separate the two classes (“Normal” and Pneumonia). Additionally, the S-CCCapsule had precision score of 0.89, which is higher than the other ablation models. Although, the train time per epoch and step was high compared to that of CapsNet+Maxpooling and BSCapsNet, but gained start-of-the-art accuracy due to efficient distribution of coupling coefficient using Sigmoid, effective vector squashing with the proposed VSquash function in the routing algorithm and finally, important information in the images was well aggregated using the skip connection method.

S-CCCapsule training, validation and loss curves on Mendeley CXR images dataset. (a) Training (blue) and Validation (orange color) accuracy curve. (b) Training (blue) and validation (orange color) loss curves, (c) presents the confusion matrix of the 2 classes: “Normal” and “Pneumonia”, and (d) shows the AUC, where S-CCCapsule achieved 0.89.
Tables 3, 4 and 5 represent the training accuracy on GWCMC, RSNA and Mendeley CXR image datasets using the ISCC and ESCC models describe earlier. The figures presented represent CapsNet accuracy, CapsNet loss, Decoder loss and the total loss (the sum of all loses). We note that the name CapsNet accuracy and all other term mentioned have CapsNet, because the architectures have capsule layers.
Comparison of models for Pneumonia detection from chest X-Ray images on GWCMC dataset. The comparison was performed based on number of epochs, CapsNet accuracy, CapsNet loss, Decoder loss, total loss, Area Under Curve accuracy and Precision Recall accuracy
Comparison of models for Pneumonia detection from chest X-Ray images on GWCMC dataset. The comparison was performed based on number of epochs, CapsNet accuracy, CapsNet loss, Decoder loss, total loss, Area Under Curve accuracy and Precision Recall accuracy
Comparison of models for Pneumonia detection from chest X-Ray images on RSNA dataset. The comparison was performed based on number of epochs, CapsNet accuracy, CapsNet loss, Decoder loss, total loss, Area Under Curve accuracy and Precision Recall accuracy
Comparison of models for Pneumonia detection from chest X-Ray images on Mendeley CXR dataset. The comparison was performed based on number of epochs, CapsNet accuracy, CapsNet loss, Decoder loss, total loss, Area Under Curve accuracy and Precision Recall accuracy
We present the models performance in Table 3 on GWCMC data based on the training, validation accuracy (CPNtrain, CPNval), train loss (CPNLosstrain), validation loss (CPNLossval), decoder loss (DeLosstrain, DeLossval) and total loss (Losstrain, Lossval). Figure 14 shows the confusion matrix of the experimented models and exhibits how the model performs on the given classes. The model was trained with total test set of 624 consisting of 2 classes (i.e. “Normal” and “Pneumonia”) having 390 and 234 samples, respectively. CapsNet model by (Sabour et al., 2017) [33] converged after 90 epochs with 72.85%, which is the low performance in Table 3. The ISCC model converged after 100 epochs and achieved validation accuracy of 81.09%. ESCC had 84.65%validation accuracy after 150 epochs (slightly higher than ISCC model). We can observe from Table 4 that the ensemble networks: E4SCC, E6SCC and E8SCC produced better accuracy of 86.06%, 86.38%and 89.74%, respectively, except E3SCC and E4SCC models. In Fig. 14(c), ESCC predicted 7 instances of TNs (1.80%of the “Pneumonia” CXR images) and 383 instances predicted as TPs (98.20%of the “Pneumonia” CXR images). However, 95 instances (40.60%) of the normal CXR image were predicted as FPs. The ensemble model E3SCC in Fig. 14(d) predicted 4 instances (1.03%) of the pneumonia CXR images as TNs, which improvement of the ESCC model. These models used two substructures of convolutions and dynamic routing substructure. Similarly, E6SCC in Fig. 14(g), predicted 3 instances (0.77%) of the “Pneumonia” CXR images) as TNs and 387 (99.23%) pneumonia instance as TPs. Finally, in Fig. 14(h), E8SCC produced a better performance amongst the other models with 2 instances (0.51%) of the pneumonia CXR predicted as TNs and 388 instances (99.49%) predicted as TPs. Moreover, the E8SCC predicted the least FP of 62 instances (26.50%) of the “Normal” CXR images. From Table 3 and Fig. 14(a-h), we can conclude that, the integration of convolutions and capsule network coupled with softmax and VSquash function produced more important information for generalization of the model.
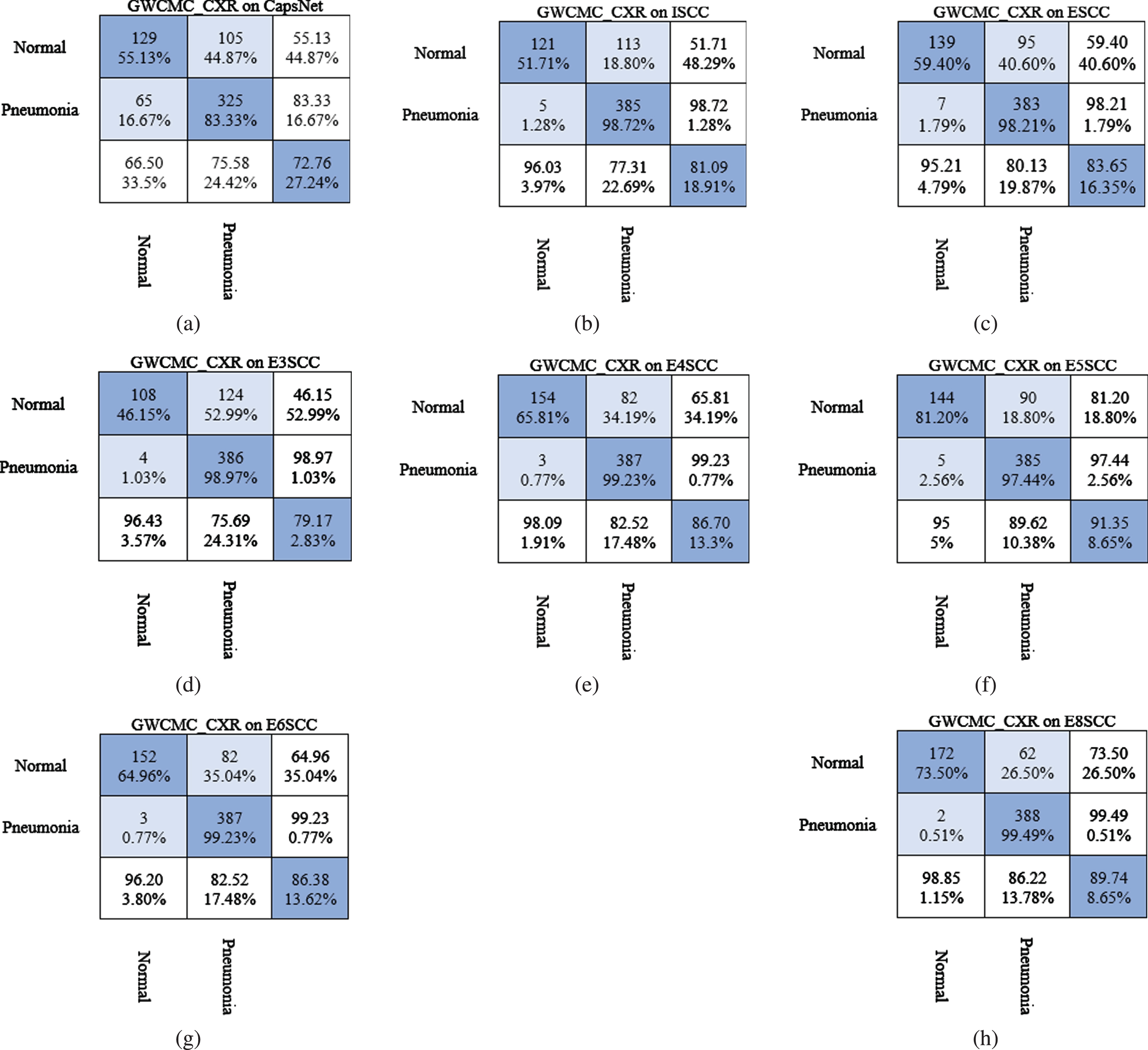
Confusion matrices for Pneumonia detection on GWCMC CXR images using (a) CapsNet, (b) Integrated skip convolutional capsule (ISCC), (c) Ensemble skip convolutional capsule (ESCC), (d) Ensemble of 3 skip convolutional capsule (E3SCC), (e) Ensemble of 4 skip convolutional capsule (E4SCC), (f) Ensemble of 5 skip convolutional capsule (E5SCC), (g) Ensemble of 6 skip convolutional capsule (E6SCC), and (h) Ensemble of 8 skip convolutional capsule (E8SCC).
This section presents the accuracy using the RSNA data. The dataset was trained without any image modifications. The experiment conducted in this stage shows that the performance accuracy of our method is high compared to previous works.
In Table 4, we present the accuracy of the CapsNet, ISCC, ESCC and the variants models, based on the training, validation accuracy, train loss, validation loss, decoder train loss, decoder validation loss, total train loss and total validation loss. We observe that CapsNet converged at epoch 150 with the least score of 93.63%with high training parameters. In contrast, ISCC produced 95.95%with an improvement of 2.32%over the original CapsNet model. As alluded earlier, the integration of capsule network with skip convolution generates improve performance of the network. The ensemble networks (ESCC) and variants proves successful in the afore-mentioned intuition. We can see from Table 4 that the ensemble models constantly improve performance except for ESCC, which had least accuracy of 96.06%. The E6SCC and E8SCC achieved the remarkable accuracy of 98.98%and 999.85%, respectively. The models evaluation metrics (i.e. AUC and Pre_Rec, sensitivity, specificity) increasingly improves, which show how well the model generalized on the two classes (“Normal” and “Pneumonia”).
Mendeley chest X-ray
Table 5 presents the accuracy of the CapsNet, ISCC, ESCC and the variants models, based on the training, validation accuracy, train loss, validation loss, decoder train loss, decoder validation loss, total train loss and total validation loss. We observe that CapsNet converged at epoch 150 with the least score of 83.75%with high training parameters. In Fig. 15(a) of the confusion matrix, 9 instances were predicted as TNs (2.31%of the “Pneumonia” CXR images) and 381 instances (97.69%) predicted as TPs. In contrast, ISCC produced 90.71%with an improvement of 7.06%over the CapsNet model. This clearly explains that, integration of capsule network with skip convolution generates improve performance of the network. The ensemble networks (ESCC) and variants proves the afore-mentioned intuition. We can see from Table 5 that, the ensemble models constantly improve performance except for E3SCC, which had least accuracy of 88.30%. The E6SCC and E8SCC achieved the remarkable accuracy of 98.72%and 98.88%, respectively. The models metrics performance (i.e. AUC and Pre_Rec) increasingly improves, which show how well the model generalized on the two classes (“Normal” and “Pneumonia”). Figure 15 shows the confusion matrices for the models in Table 5, respectively. In Fig. 15(d) of the E3SCC model, the number of FNs predicted was 10 instances (2.56%of the “Pneumonia” CXR images) and 390 instances predicted as TPs (97.44%of the “Pneumonia” CXR images). However, 63 instances were predicted as FPs (26.9%of the “Normal” CXR images), which represent a person with no pneumonia infection hence predicted as pneumonia patients. In comparison to the best ensemble model (E8SCC), the E8SCC in Fig. 15(h) recorded 1 instance of TN (0.26%of the “Pneumonia” CXR images), which is pneumonia patients wrongly predicted as normal patients. This result is critical as a pneumonia patient may be denied of treatment and can result to death. Meanwhile, the model had 389 instances predicted as TPs (99.74%of the “Pneumonia” CXR images), which represent the true prediction of the patients with pneumonia. Furthermore, 6 instances were recorded as FPs (2.56%of the “Normal” CXR images), which is someone predicted to be pneumonia but do not actually have pneumonia. In summary, integration of skip convolutions, ensemble skip convolutions with capsules coupled with the proposed Algorithm 2, provided more importance information in the Mendeley CXR to achieve state-of-the-art performance. Detailed accuracies of the performance metric such as Precison_Recall, sensitivity, specificity, area under the curve (auc) and accuracy are shown in Table 5. It could be seen that the model was well generalized and achieve a good prediction on the test set.
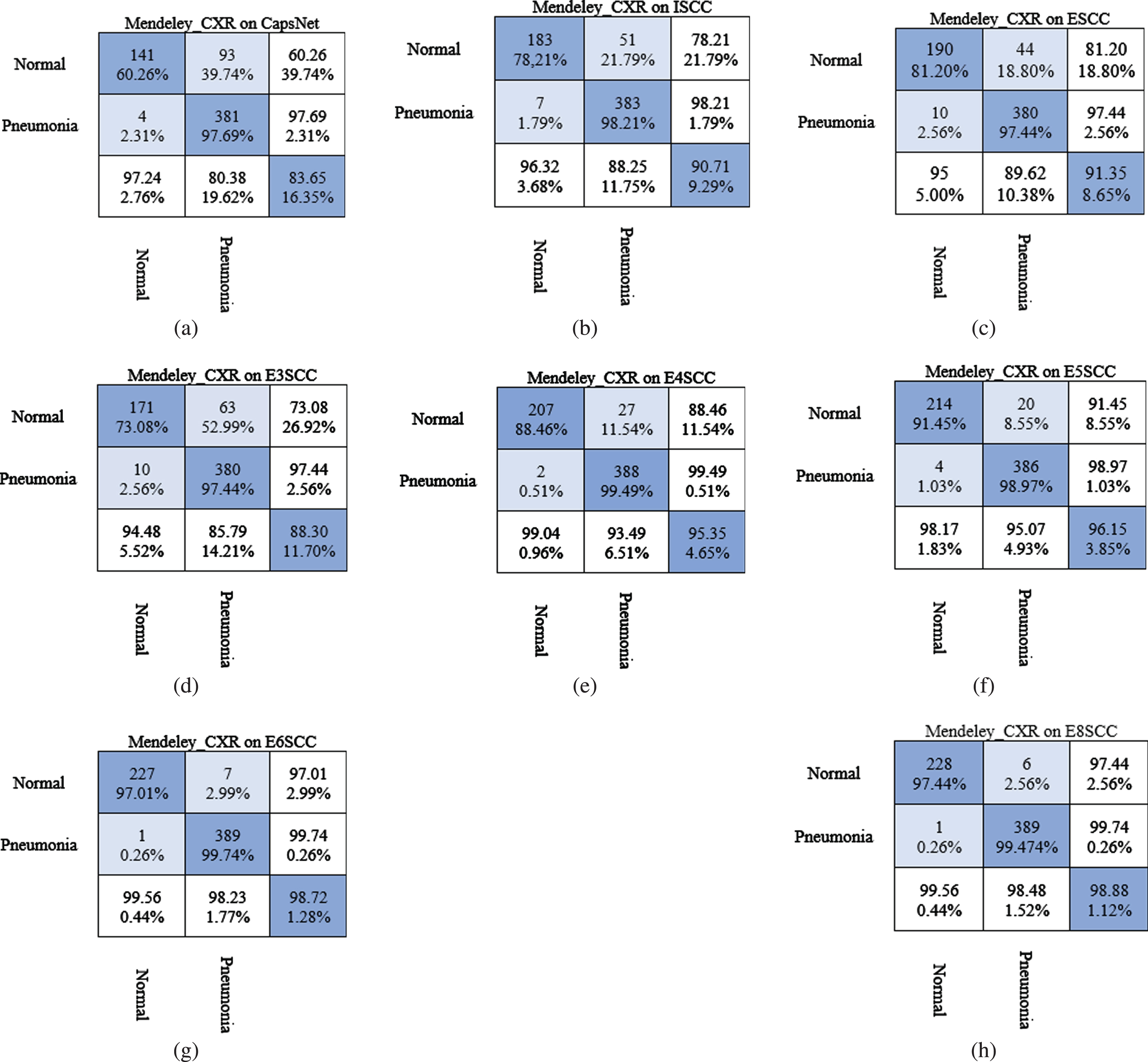
Confusion matrices for Pneumonia detection on Mendeley CXR dataset using (a) CapsNet, (b) Integrated skip convolutional capsule (ISCC), (c) Ensemble skip convolutional capsule (ESCC), (d) Ensemble of 3 skip convolutional capsule (E3SCC), (e) Ensemble of 4 skip convolutional capsule (E4SCC), (f) Ensemble of 5 skip convolutional capsule (E5SCC), (g) Ensemble of 6 skip convolutional capsule (E6SCC), and (h) Ensemble of 8 skip convolutional capsule (E8SCC).
In this section, we performed a test prediction to evaluate the efficiency of the model. In the prediction, capsule with the maximum length of vector is considered the output of the classifier. In order to evaluate the generalizability of the models, a comparison was done with the original image (ground truth). We used sample images from both classes (“Pneumonia” and “Normal”) as input to the predictive model for the prediction probabilities. Figure 16 shows result from the predictions. Figure 16 provides the probability per each class compared to the original image. We can observe that the dynamic routing coupled with the VSquash and our model performed well on the CXR images. Furthermore, the dynamic routing with VSquash produced high likelihood values for the per class prediction probabilities for each image. However, in our method produced 1 misclassification, where a “Normal” image was predicted as “Pneumonia” (see Fig. 16, column 2 row 4). This can be attributed to the similarity of image from the two classes. Overall, the prediction accuracies show that our method can effectively discriminate between the classes.
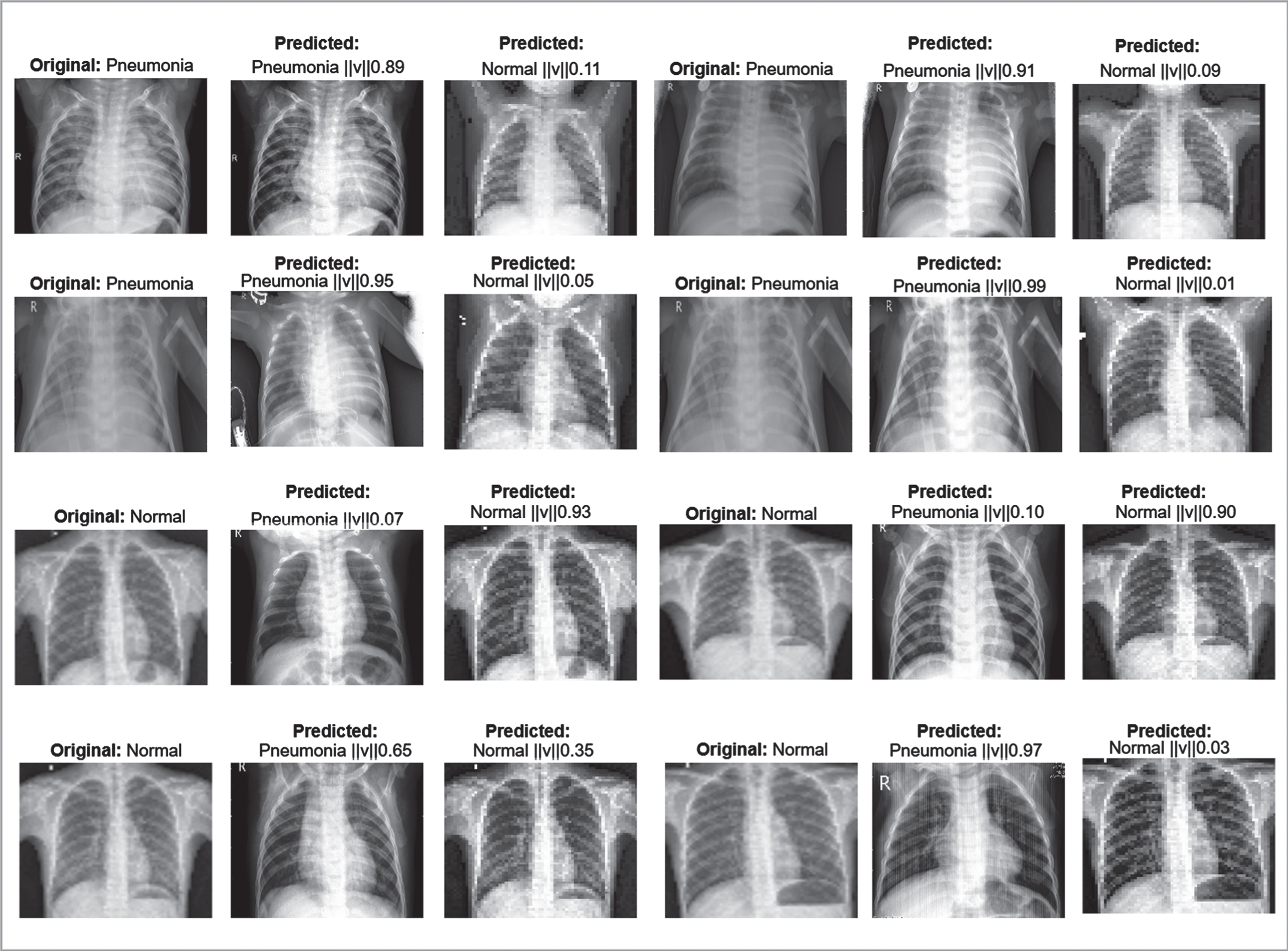
Visualizing prediction probability from our proposed method.
The confusion matrices that summaries the system’s performance for both studies conducted on the three datasets. The X-axis represents the predicted values (i.e. Model prediction) while the Y-axis indicates the true labels (ground truth/Actual). In the confusion matrices, the non-white columns show the actual classes and the non-white rows represent the output classes. Precision, Sensitivity, Specificity, and Accuracy have been calculated as in Equation (13)–(16).
Equation (13) shows the computation of precision, sensitivity, specificity and accuracy on our confusion matrix.
Where,
True Positive (TP) is the total number of predicted cases from the model indicating the patient have the pneumonia diseases.
True Negative (TN) is the total number of predicted cases from the model indicating the patient do not have the pneumonia diseases.
False Negative (FN) is the predicting outcome from the model showing the patient does not have the pneumonia disease; however, the patient does have the disease.
False Positive (FP) is the predicting outcome from the model showing the patient have the pneumonia disease; however, the patient does not have the disease.
In this work, a deep learning model named skip-connected convolutional capsules (S-CCCapsule) based on Capsule Networks architecture for pneumonia detection problem was presented. The skip-connection method transfers the input feature to each output of the high-level convolutional layers to keep more important information for better classification accuracy. Secondly, unlike squash function in [33], we proposed a new squash function called vertical squash (VSquash) to shrink vectors and prevent the activation values of the primary capsule in order to reduce non-informative capsules and promote the discriminative capsules. To obtain uniform distribution of routing coefficient of probabilities between capsules, we adopted Sigmoid function instead of Softmax function used in [33]. Ablation study was conducted on the S-CCCapsule model to see the effect of the CapsNet, which we arrived at three architectures (i.e. CapsNet+Maxpooling, BSCapsNet and LSCapsNet). Furthermore, integrated skip connected (ISCC), Ensemble architecture and its variants were implemented, which combine dense convolutions and capsules. For fair comparison, we implemented the original capsule network (CapsNet) and used as a baseline.
Our experiments were based on three public CXR datasets such as Guangzhou Women and Children’s Medical Center (GWCMC), Mendeley Chest X-Ray pneumonia and Radiological Society of North America (RSNA) images. The experimental result in the ablation study on the GWCMC, RSNA and Mendeley CXR images shows that S-CCCapsule achieves validation accuracy (CPNval) of 83.65%, 99.35%and 91.35%, respectively, compared to the other ablation models. Among the ISCC, ensemble models (ESCC), and its variants introduced in this work, the ISCC, ESCC and its four variants (E4SCC, E5SCC, E6SCC and E8SCC) produces best validation accuracy on the three datasets. We note that the introduction of skip connection, VSquash and Sigmoid enhanced the robustness of the models to overfitting and effectively generalized well on the images. Based on the experiment conducted, we can observe that the proposed method performed better compared to other methods. In addition, our designed architecture has shown to improve the accuracy in Pneumonia detection problem based on the presented confusion matrices.
Acknowledgment
This work was supported by National Natural Science Foundation of China (NSFC Grant No. 61550110248), Sichuan Science and Technology Program (Grant No.2019YFG0190) and Research on Sino-Tibetan multi-source information acquisition, fusion, data mining and its application (Grant No. H04W170186). The authors would like to thank the editor and the reviewers for their helpful suggestions and valuable comments.
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.