
Abstract
Recently, the e-learners are drastically increased from the last two decades. Everything is learnt through internet without help of the tutor as well. For this purpose, the e-learners are required more e-learning applications that are able to supply optimal and satisfied data based on their capability. No content recommendation system is available for recommending suitable contents to the learners. For this purpose, this paper proposes a new semantic and fuzzy aware content recommendation system for retrieving the suitable content for the users. In this content recommendation system, we propose two content pre-processing algorithms namely Target Keyword based Data Pre-processing Algorithm (TKDPA) and Intelligent Anova-T Residual Algorithm (IAATRA) for selecting the more relevant features from the document. Moreover, a new Fuzzy rule based Similarity Matching algorithm (FRSMA) is proposed and used in this system for finding the similarity between the two terms and also rank them by using the newly proposed Similarity and Temporal aware Weighted Document Ranking Algorithm (STWDRA). In addition, a content clustering process is also incorporated for gathering relevant content. Finally, a new Fuzzy, Target Keyword and Similarity Score based Content Recommendation Algorithm (FTKSCRA) is also proposed for recommending the more relevant content to the learners accurately. The experiments have been conducted for evaluating the proposed content recommendation system and proved as better than the existing recommendation systems in terms of precision, recall, f-measure and prediction accuracy.
Keywords
Introduction
Today, the enormous data availability in internet is facing the serious issues including data overloading. The availability of huge volume of data is leading to a developing issue in the process of Information Retrieval (IR) process through IR systems for retrieving and handling the data for the user effectively. The IR is used to store the large volume of contents as documents electronically and also assisting the user’s for navigating, tracing and arranging the available web documents effectively [1]. The IR is also useful for retrieving the relevant data and irrelevant data by using an organizational method that is used to help the internet user for searching the relevant data and retrieve the document. Usually, the search engines are presenting the retrieved relevant and irrelevant documents based on the relevancy ranking of web contents. The web contents are arranged based on the relevancy of the internet user’s needs that are expressed through request. Here, the highest ranked web contents are to be considered as most relevant content and the next document slightly less likely and so on. All the available search engines are working as above in nature. The internet user can examine the web contents from top to bottom in the list and following at a time.
In the recent years, many IR systems have been introduced by various researchers as alternative each of them. These all IR systems are normally related each other according to the visualization and the presentation. The internet is a famous information resource including text, metadata, audio and video. The large volume of information over the internet has enlarged to thousands of times since its origin [2, 3]. Many new search engines that are available in the market are facing the enormous amount of task of returning the more relevant contents as results according to the user request.
Feature selection process is necessary for retrieving the relevant content due to the availability of large volume of data in internet. The document similarity is also mapped with each other based on the keywords relevancy and the result of feature selection procedure. Specifically, the semantic analysis is very useful for extracting the relevant content from internet source by applying the clustering approaches that are adopted various kinds of methodology to perform clustering. Since the web documents that convey the similar meaning of the term and it have same kind of terms on them, they are grouped automatically in similar group in majority of the cases. The various kinds of mechanisms including data mining techniques, decision trees, rule based approaches, inductive logic programming, genetic algorithms and neural networks etc. that are used greatly for performing the document clustering process. All the available approaches are widely applied in various research directions including machine learning, information retrieval, natural language processing, database and artificial intelligence. Moreover, the various web users for tagging any one of the web site with short form of text and also for collecting the large number of keywords daily.
In this work, a new fuzzy logic based content recommendation system is proposed for retrieving the suitable content for the users. Here, we propose a new sentiment analysis based data pre-processing algorithm for identifying the useful and contributing contents in online document. Moreover, a new similarity score based content ranking algorithm has been proposed for identifying the priority of the contents of web documents. In addition, a new document fuzzy clustering algorithm is also proposed for grouping the relevant contents and web documents. Finally, the relevant and recommended content is retrieved by applying the newly proposed data retrieval algorithm. The rest of this paper is organized as below: Section 2 describes in detail about the relevant works in the direction of semantic analysis, fuzzy logic, clustering and content recommendation system, Section 3 explains the overall architecture of the proposed content recommendation system. The proposed content recommendation system is explained with all the algorithms in section 4. The experimental results and the explanation about the significance in the performance are presented in section 5. This paper is concluded by highlighting the achievements and the future directions in section 6.
Literature survey
Many research works have been carried out by enormous researchers in the recent years in the direction of information retrieval, pre-processing [4], document clustering and recommendation system [5]. Among them, Konstantina and Maria [6] developed a new fuzzy based knowledge definer which is able to evaluate the web oriented educational method and it provides the domain instruction individually. Their system is useful for identifying the student’s knowledge level dynamically according to their domain. They also used fuzzy cognitive maps for representing the dependencies among the various domains.
Juan Yang et al. [7] developed a pattern recognition based learning style prediction model. The major advantages are including that it is a new form of middleware tutoring systems and it is able to process the topic based information for making the predictions and also updating the learning style profiles in a recursive manner. Their experimental results were demonstrated that the effectiveness of the prediction model.
Sannasi et al. [4] analysed the various feature selection and classification algorithms that uses the intelligent agents. They also proposed new intelligent agent based feature selection and intelligent rule based classification algorithms. Sai Ramesh et al. [8] proposed new prediction system for predicting the user’s interests by analysing the user’s feedback and ranking algorithm. Sankar et al. [9] proposed a new fuzzy logic based family tree and similarity based recommendation system for recommending the relevant content to the e-learners.
Ahmet et al. [10] developed a new ranking method that works based on the visual similarity score among huge volume of web pages by applying structure and the vision oriented features. The main objective of the work is for understanding and also representing the visual structure of the relevant web pages. Moreover, they have mapped between the visual layout and the respective web pages and also compared, removed the visual segmentation and also generated the web page layout signatures. They also have prepared a questionnaire for conducting a survey that covers 312 subjects.
Laith et al. [11] proposed a hybrid algorithm for solving the document clustering issue. In their work, the initial solutions of their algorithm were derived from the standard K-Means clustering and the decisions made by combining two of their objectives. In their work, they have used nine benchmark datasets for evaluating the performance of their algorithms. Finally, they have proved their algorithm by comparing with other existing clustering algorithms. Qing Zhao et al. [12] proposed a graph oriented semantic search technique by explaining the ambiguity and the complexity of the medical terminology in queries and the clinical text to enhance the process of medical data retrieval.
Fabio et al. [13] developed a new knowledge oriented method which is used for calculating the inter-document similarity score according to the context based semantic similarity. They have developed various special techniques based on the particular knowledge base. Their method relies over a generic knowledge for extracting the content from semantic context. Finally, they have proved that their information retrieval process that outperforms than other techniques result that are developed based on semantic analysis.
Pradeepika and Hari [14] introduced a new extraction method to summarize the multi-document which covered three relevant and most important features such as coverage, non-redundancy and relevancy. Moreover, they have considered the branch coverage and the non-redundancy features are designed for generating a single document from the various documents. Finally, they proved that their method is an effective for performing the multi-document summarization.
Kanimozhi et al. [15] introduced a new prediction system for predicting the cancer diseases by applying effective fuzzy rules. Sankar et al. [16] proposed an intelligent fuzzy rule based e-learning recommendation system for predicting the user’s interests. Minh-Tien et al. [17] presented a new design for capturing the usual relationships between the two sentences of a document and between the tweets for performing document summarization. Their matrix co-factorization algorithm calculates the score of each sentence of a document and the user post and extracts the top ranked document sentences and comments (or tweets) as a summary.
Antonio et al. [18] developed a semantic method for classifying the documents using visual and textual detection method by applying the deep neural classifier and knowledge graph. They have considered the semantic aware multimedia data that exploits and also conducted many experiments for proving the efficiency of their method. Antony Rosewelt and Arockia Renjit [19] developed a new content recommendation system that is the combination of new embedded feature selection algorithm and the new Fuzzy Temporal Logic based Decision Tree incorporated CNN for recommending the suitable contents to the e-learners. They have proved their recommendation system is better than the existing content recommender systems.
Perumal et al. [20] proposed a new Fuzzy logic incorporated Recommendation system by applying Ant Clustering method which uses the newly generated fuzzy rules and the existing ant clustering method for recommending the suitable contents. They have proved the efficiency of their system by conducting various experiments. Mingsong et al. [21] developed an e-commerce product recommendation system by performing content analysis effectively and achieved better accuracy. All the existing systems are achieved better prediction accuracy based on their aspects and compared with limited methods. But the existing content recommendation systems are lacking to fulfil the users’ expectations in terms of providing relevant content which is meaningful and useful. In this work, we introduce a new recommendation system for recommending the more relevant content to the learner’s short time span.
System architecture
The overall system architecture is shown in Fig. 1 and it contains seven major modules namely internet user, user interface module, decision manager, Fuzzy Recommendation System, repository/database, rule base and fuzzy rule manager.
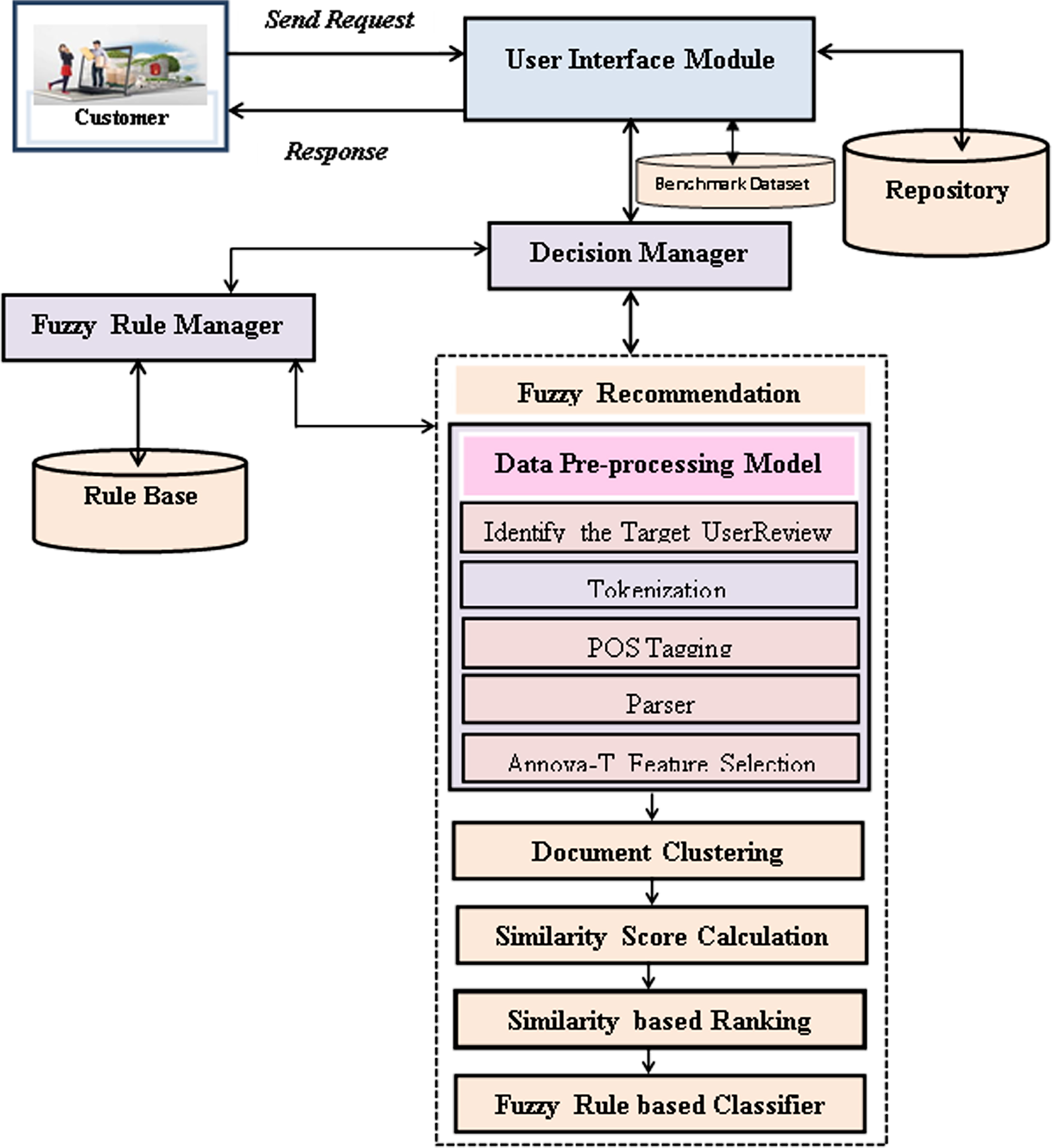
System Architecture.
The internet users send the requests to the recommendation system for recommending the relevant content. The user interface module checks the relevant contents are in local repository or database. If it is available then it will be considered for further process and it forward to the recommendation system for performing semantic analysis, feature selection, similarity score computation, clustering and classification. The recommendation system consists of six major sub components such as data pre-processing, similarity score calculation, document clustering, similarity based ranking and classification. The data pre-processing is used the proposed data pre-processing algorithm called target user based data pre-processing algorithm for performing the processes of Tokenization, parser and the POS tagging. The proposed algorithm uses NLP for performing the basic pre-processing and it also identify the relevant and target customer or user. Moreover, a new feature selection algorithm is applied for selecting the relevant features that are useful for categorizing the content according to the relevancy.
The similarity score computation is the next sub module of the fuzzy recommendation system. Here, it calculates the similarity score after completion of the data pre-processing. Based on the similarity score, the content/documents are clustered by applying an existing fuzzy clustering algorithm for grouping the relevant content. The grouped contents are forwarded into the ranking module to rank the grouped relevant contents. According to the clustered document rank, the content is classified with the help of fuzzy rules that are generated according to the similarity score and it store into rule base.
The rule manager is used to manage the rules to extract the necessary rules and also send it to the decision manager for making effective decision over the web content. Finally, the recommendation system recommends the right product to the customer with less time through user interface module to the internet user.
This section describes in detail about the data pre-processing, content pre-processing by applying feature selection, similarity score based content ranking, clustering the document and the content classification.
Content pre-processing
This section explains the content pre-processing activities such as tokenization, Parts of Speech (POS) tagging and Parser. Here, the tokenization is used to split contents in to token, eliminate all the stop words that are available in the input content and the not important content. Afterwards, the POS tagging is performed for identifying the subjective and adjectives terms. Here, the subjective terms are to be removed and it considers the adjectives for further process. Finally, the parser is used to construct a new tree for every content and it is also inherent the relationship between the terms in the content.
Tokenization
Contents are divided into tokens or also called as terms. The sequences of works are grouped together such that it gives useful sematic units for further processing.
POS Tagging
POS provides the information on word how it used in a sentence. Parts of speech like nouns, pro nouns, adjective, verbs are tagged. Adjective plays important role to know the opinion expressed in the comment. POS tagging simply label the word with its appropriate POS tagging, which helps to know the sentiment / opinion available in the sentence/ comments in further processing.
Parser
Parsers are simply a program that provides the grammatical structure of sentence. This model groups the contents together words based on Subject or Object. The steps of the proposed Target User based Data pre-processing Algorithm (TUDPA) are as follows:
Target keyword based data pre-processing algorithm (TKDPA)
Read the contents C {} = {c1, c2, c3. . . .cn} Check whether each words contains the target keyword Begin If the content/document contains the target keyword then Repeat the steps 2 to 5 for all the contents. Begin Apply the tokenization through NLP Identify the stop words such as pull-stop (.) and Comma (,) Remove the identified stop words Apply POS tagging through NLP Identify the POS for each tokens Remove the unwanted / less useful informative token Construct a semantic tree through NLP Parser The useful token information such as adjective, noun, adverb will be considered Construct the semantic tree for the contents. Produce the useful information of each content and store it into the repository or database End Else Ignore the contents End
The proposed TKDPA is applied for performing pre-processing over the relevant contents that are considered from the local repository or internet source database. Here, we have used NLP toolkit for performing the basic pre-processing activities such as tokenization, POS tagging and parser. The proposed algorithm is identified the target user by scanning the contents and check whether the target user detail is present in contents. The major contribution of this proposed data pre-processing algorithm is to identify the target keyword and also to perform the pre-processing by applying the newly proposed Annova-T feature selection algorithm.
In this work, a new algorithm is proposed for data analysis during pre-processing named Intelligent Anova-T Residual Algorithm (IAATRA) by extending the existing algorithm namely Anova-T residual algorithm [22]. Therefore, new User log files are extracted from the web server and they are pre-processed first using natural language processing techniques followed by a pre-processing using document cleaning algorithm and finally using the proposed pre-processing algorithms namely IAATRA. The main advantage of the proposed algorithms is that they help to reduce the error rate in the classification of e-learning contents in order to provide suitable e-learning contents to the learners.
Content Pre-processing using intelligent agent based anova-t residual algorithm
In this work, the proposed Intelligent Agent based Anova-T Residual Algorithm (IAATRA) is used for performing effective pre-processing of the web documents for selecting relevant features and to clean irrelevant features in web documents. For this purpose, statistical features are selected in which the values of mean and variance play a major role as important features. In order to select the most important features, the Intelligent Agent based Anova-T model is proposed in this work by applying rules. In the existing Anova-T model [22], yij is calculated by using the formula which is given in Equation (1).
Where Yij is the Anova T value computed in this work and is also compared with the Anova table values, M represents the Mean of Variables, ai indicates the standard deviation and eij represents the Residual value. After feature selection, rules are applied based on e-learning users, contents and domain of the contents. Moreover, intelligent feature selection is performed after data cleaning and thus reducing the dimensionality of the e-learning documents. The data reduction techniques help to reduce the size of the e-learning documents so that it is possible to identify the most relevant and most useful documents from the document repository. When these selected features are used by the classifier, it increases the classification accuracy and also reduces the classification time. In this research work, intelligent rules and the residual property are embedded into the ANOVA table which is used to perform effective statistical analysis. This intelligent agent based Anova T Residue Classifier is useful to perform feature selection by classifying the features into useful features and ordinary features. The steps of the Intelligent Anova T Residual Algorithm (IATRA) are as below:
Intelligent anova t residual algorithm (IATRA)
Read one paragraph from e-content or web document Perform word counting for each word. Assign variables to each group of words Compute the mean and variance of variables. Find Anova T value for the current paragraph. If Anova T value is > threshold then Add the variable and its statistics to feature list Else Begin Read user registration details Apply rules to find user level End If number of features is increased in current iteration then Go to step 1 Else Stop Run Return the pre-processed content
End of this data pre-processing module, can get retrieve the pre-processed content that are planned to extract the relevant contents. Initially, the semantic analysis has been done by this module and the second phase of this module performs the feature selection process by applying the IAATRA. This entire module is responsible for providing the featured identified content for further process.
In this work, two types of similarity computation techniques namely Jaccard similarity and Cosine similarity are used to effectively calculate the similarity measure. In addition, fuzzy rules are applied so that grouping is possible based on fuzzy rules. Fuzzy membership values are used to form fuzzy rules and hence this work considers triangular membership function to divide the documents into low, medium and high similar documents. For this purpose, a set of fuzzy rules on each topic of the software engineering course are defined specially for e-learning of the course software engineering.
The formula shown in Equation (2) is used in this work for similarity computation which is adapted from the standard formula for measuring the Jaccard’s coefficient.
In this formula, A and B are two documents which discuss about fundamental concepts in software engineering. The probability of A and B is the set of all words which appear in both the documents A and B and are similar. At the same time, P(A U B) indicate the number of words which occur either in document A or B or both and that are similar. The Cosine similarity is calculated by using the formula given in Equation (3).
The similarity score is calculated and measured based on the values between 0 and 1. The reason for the usage is the application of fuzzified similarity scores. Here, 0 means that “No Similarity between the terms” and 1 means that there is a similarity between the two terms. If the value is between the 0 and 1 then that is a degree of similarity between the two terms.
Fuzzy Rule based similarity matching algorithm (FRSMA)
Input: Set of web documents D
Output: Grouping of documents based on similarity. Read one document Di Convert the document into tokens and perform stemming and stop-word removal Perform morphological analysis on Di and add POS tags. Divide the document Di into sub documents Di = (d1, d2, d3...dn) Compute the term frequency for each word in the document. Read next document Dj Compute the Jaccard’s similarity between documents Di and Dj Compute the Cosine similarity between Di and Dj. Apply fuzzy rules on both Di and Dj Divide the documents into less similar, medium similar and high similar using step 11. If Jaccard’s similarity between Di and Dj < 0.5 then Similarity1 = low Else if Jaccard’s similarity > = 0.5 AND < 0.75 then Similarity1 = Medium Else Similarity1 = High If Cosine similarity between Di and Dj < 0.5 then Similarity2 = low Else if Cosine similarity > = 0.5 AND < 0.75 then Similarity2 = Medium Else Similarity2 = High For each pair of documents If Cosine similarity and Jaccard’s similarity match then Similarity analysis = Accepted Else Repeat Similarity analysis until either Accepted or (Similarity1 –Similarity2) <0.01 Perform grouping using similarity measures. End
In this section, documents are given ranking based on the quality of the content for each sub areas of software engineering or the contents that is extracted from UCI Repository. Contents are ranked based on the citations, in-links and out-links. The rank is computed using the formula which is given in Equation (4).
In this formula, more weightage is given for W1 and W2 and less weightage is given for W3 depending upon the available documents.
The values of the document scores are used to rank the documents by the ranking algorithm. Steps of the ranking algorithm are as follows:
Documents without ranks for each category namely software engineering, software process models, software project management, software analysis, software design and software testing. Ranked documents for each category. Read one document. Perform semantic analysis using place marking Perform semantic analysis using temporal constraints. Perform semantic analysis using the domain. Perform pragmatic analysis. Compute the ranks for documents using the formula given in equation 1. Find the area score using the formula: Area Score = ((W1×Number of words in sub area +W2×Number of words in common area))/((W1×W2)) // In this formula, W1 is given more than 70%weightage and the remaining weightage is given for W2. Rank the documents with respect to main area software engineering and its sub area using the document score and area score.
The results obtained from the proposed ranking algorithm are compared with the existing HITS algorithm for page ranking. From the experiments conducted in this work, it is observed that the proposed algorithm provides more relevant documents than HITS algorithm for learning software engineering through e-learning contents.
Content clustering
In this work, document clustering is performed to group the documents so that it is possible to search them easily. The documents are clustered into k groups using the fuzzy k means clustering algorithm [23]. For each cluster, a location is identified in the storage and the documents are indexed based on titles and are stored together in the storage. A learner can get all the related documents from the same area in the repository and they are arranged based on level of difficulty also. A naïve user is provided with fundamentals in the subject and an advanced user is provided with advanced concepts. In this work, a naïve user is provided with five levels of materials in software engineering. After this, five levels of materials are provided in advanced software engineering in which object oriented software engineering concepts are discussed.
A new e-learner can take a pre-test before e-learning by logging into the system. For this purpose, the user is asked to complete a registration process in which the user must provide his basic personal information followed by his technical knowledge and programming knowledge. Based on this information, along with the score obtained from the pre-test if available are considered for deciding the level of the user in the software engineering course. The learner is asked to appear for the test periodically and then finally on all the topics of fundamentals of software engineering. He can go to the next level in which object oriented software engineering is taught. If a user completes these two modules, specialized modules are provided in requirements engineering and analysis modeling, software design, software project management, software quality management, software metrics, risk management, software configuration management, software testing and software maintenance. The user can choose one topic at a time and learn the advanced concepts. The user is provided with exercises for solving the problems. Based on the problem solving capability, the users will be given grades namely ‘A’, ‘B’, ‘C’, ‘D’, ‘E’ and ‘F’ in which A indicates the score between 90 to 100, B indicates the score between 80–89, C indicates 70–79, D indicates 60–69, E indicates 50–59 and F indicates less than 50 in which case the user must learn once again and reappear for the test to get a better grade. In this way, software engineering is taught to learners and the main contribution of this work is the provision of relevant contents through the proposal of similarity and semantic based rearrangement of clusters so that more relevant documents are easily identified and retrieved by the system.
Fuzzy logic based content recommendation
This section provides the basic information about the fuzzy logic, fuzzy rules and recommendation system.
Fuzzy logic
The fuzzy logic is described in this sub section clearly and how it is applied in this recommendation system. Moreover, it shows the fuzzy rule based on sentiment score. Moreover, one of the standard fuzzy membership functions called trapezoidal fuzzy membership is applied for performing fuzzification process and also identifies the fuzzy interval. This function has four parameters {a, b, c, d} and it also demonstrates in Equation (5).
The trapezoidal is demonstrated in differently in Equation (6).
The fuzzy membership function parameters {a, b, c, d} with a less than b, b less than or equal to c, c is less than d that determines the x coordinate values of the four possible sides of the specific trapezoidal fuzzy membership function.
In addition, fuzzy logic method is used to convert product sentiment score to recommendation level by applying Fuzzy rules to target user. The fuzzy rules are generated in this manner for categorizing the recommendation level based on the similarity score of the contents.
The sample fuzzy rules are listed as below: IF Similarity_Score (e-content/document) <3 AND Similarity_Score(e-content/document) >0 THEN Not Recommended the contents / documents IF Similarity_Score (e-content/document) <5 AND Similarity_Score(e-content/document) >2 THEN Likely to Recommend the Specific e-content/ documents IF Similarity_Score (e-content/document) <8 AND Similarity_Score(e-content/document) >6 THEN Recommend the Specific e-content/ documents IF Similarity_Score (e-content/document) <10 AND Similarity_Score(e-content/document) >7 THEN Highly Recommend the Specific e-content / documents
The listed fuzzy rules were used to make a useful decision on contents of each and every online user’s and their comments. These different fuzzy rules are generated and stored on an ontological database if the situation is arise then these all fuzzy rules will be used for decision making process in recommendation system.
In this section, Recommendation rating for each relevant content or document with associated user category is computed by internet user based product ranking recommendation algorithm. First, read all the contents from local repository and the e-contents. Second, pre-process all the contents for each user’s request by using Target Keyword based Data pre-processing Algorithm (TKDPA). Third, calculate the similarity score by using the Target Keyword and user request. Forth, Identify the content according to the similarity score for the documents and perform the document clustering by using the existing k-means clustering algorithm. Fifth, identify and recommend content by applying fuzzy rules and similarity score. Finally, recommend the content based on the users request.
Fuzzy, target keyword and similarity score based content recommendation algorithm (FTKSCRA)
Input: e-content and users request with keyword
Output: Recommended the content
Begin Read all the contents as documents {D1, D2, D3,. . . .,Dn} Compute Recommendation rating level for each document Begin Repeat Step 3 to Step 6 for all the reviews on each document Implement the pre-processing activities for the given keyword Apply Pre-process for all the e-contents / documents using Target Keyword based Data pre-processing Algorithm (TKDPA) Remove all the less useful information from reviews Implement Sentiment Analysis Apply Sentiment analysis using Target Keyword based Sentiment Analysis Algorithm Compute Sentiment Polarity: Positive, Very positive, Negative, Very negative Find the similarity score of contents with associated target keyword by applying the algorithm Target Keyword based Sentiment Score Computation Algorithm Identify Sentiment score at sentence level Identify Review sentiment score with associated target keyword Identify recommended e-content Sum all the review sentiment and similarity score of the content Apply fuzzy rule for identifying the recom -mendation level End Recommend the content to the user by below order based on user preferred target users. Highly recommended contents Recommended contents Likely recommended contents End The proposed algorithm is recommended that the contents by performing sentiment analysis for the contents with associated target user. The major contribution of this proposed fuzzy logic-based recommendation algorithm is to identify the relevant content that suite for the target user that customer really want to download. Here, fuzzy rules are applied for making effective decision over the sentimental score, similarity score of the contents / documents that are pre-processed, clustered and ranked. This proposed fuzzy recommendation system recommends the content according to the sentimental score as “Not Recommended”, “Likely to “Recommend”, “Recommended” and “High Recommended Products”.
Results and discussion
This section explains the test bed which is used for evaluating the proposed fuzzy logic based content recommendation systems. The proposed fuzzy aware content recommendation system is used to retrieve the relevant contents or the documents from internet resources and the local repositories. Here, the usual evaluation metrics that are used for measuring the performance of proposed model in terms of relevant content or document retrieval. The various experiments carried out by using e-contents or web documents that are containing the specific subject contents or the review comments of the products. Here, the input file will be in two different forms like CSV file which contains the user feedback in amazon dataset and the content of Software Engineering subject.
Benchmark dataset and experimental setup
In this work, the standard benchmark dataset called UCI Repository [24] is used to carry out the different experiments. This benchmark dataset consists of around 500 e-content documents. Here, all the documents that are used to perform training and testing processes. In addition, the WEKA tool is used as software to carry out the experiments. Moreover, the proposed recommendation system has been developed in JAVA (in Intel core i3 with 3GB RAM) for performing the pre-processing, clustering process and classification process in the fuzzy logic based content recommendation system.
Performance evaluation parameters
This sub section is defined the three evaluation parameters such as precision, recall and f-measure that are helpful for evaluating the proposed recommendation system in terms of prediction accuracy on documents. The Equations (7), (8) and (9) are defined the evaluation parameters.
These three evaluation metrics were used for performing the evaluation process over the standard benchmark dataset by conducting various experiments in this work. Here, the evaluation parameters such as precision, recall and f-measure values are calculated for predicting the content relevancy. Finally, it predicts and recommends the content in this work by demonstrating the recommendation score and the prediction accuracy analysis.
Table 1 shows the precision, recall and f-measure value analysis for the proposed fuzzy aware content recommendation system Here, five different experiments have been conducted in this work with various numbers of documents such as 1000, 2000, 3000, 4000 and 5000 documents.
Fuzzification
Fuzzification
From Table 2, it demonstrates that the performance of the proposed fuzzy aware content recommendation system is better in terms of precision value, recall value and f-measure value in all the experiments. Specifically, the precision value is high in all the five experiments than the recall and f-measure values. Even though, all the experiments of precision, recall and f-measure are almost similar. The reason for the performance is the use of Fuzzy rules, Annova-T classifier and fuzzy aware document clustering.
Precision, Recall and F-Measure Analysis
This work is considered with small sentences having tokens which are divided into 8 to 10 words for each topic. Then we have calculated the similarity value of different concepts, properties and the relevancy in each and every report by taking into similarity measurement by Jaccard’s coefficient. Figure 2 shows the document similarity of various documents.
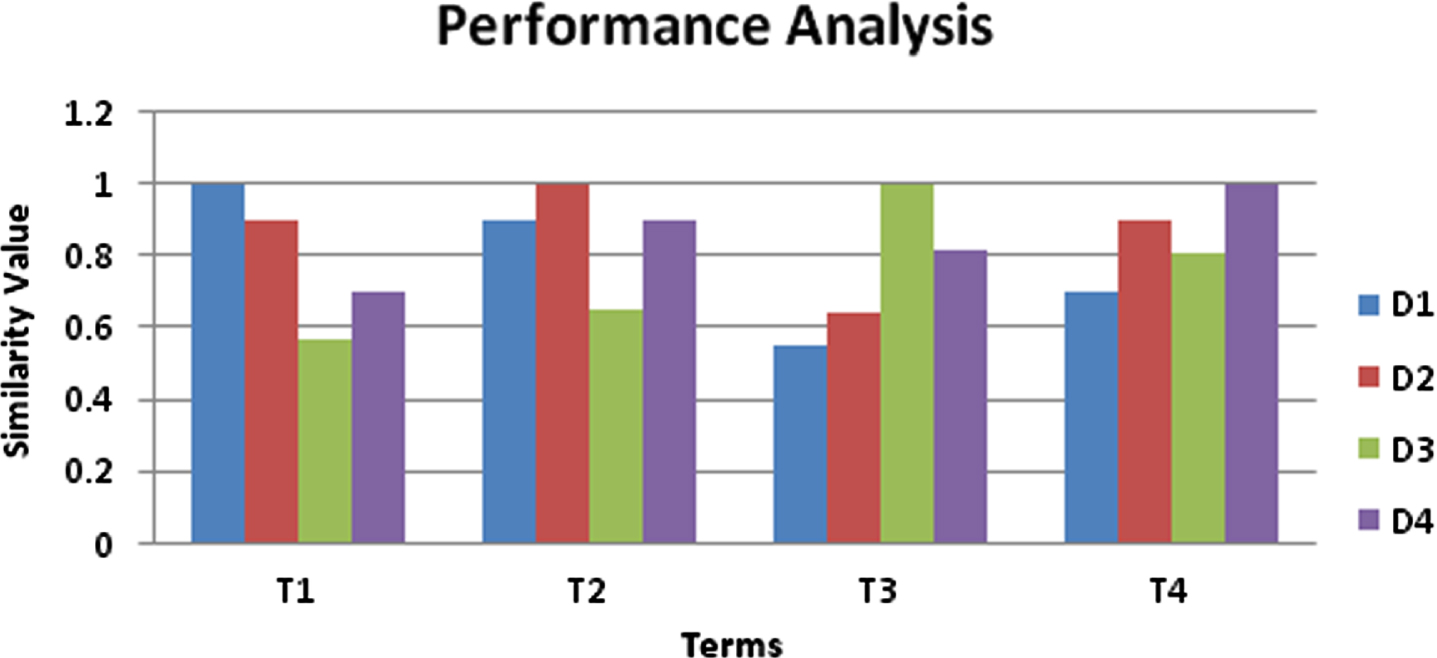
Documents Similarity Chart.
From Fig. 2, it demonstrates the documents similarity value distribution over the four different documents such as D1, D2, D3 and D4 according to the four different terms or keywords. According to the terms or user’s keywords how the different documents are getting similarity value.
Table 3 show that the relevancy score analysis of the proposed fuzzy recommendation system and the existing HITS algorithm [25]. Here, the various number of experiments such as 1000, 2000, 3000, 4000 and 5000.
Relevancy Score Analysis
From Table 3, it is proved that the efficiency of the proposed system in terms of relevancy score is better than the standard algorithm called HITS algorithm. The reason for the improvement of the relevancy accuracy in the proposed system is the use of fuzzy rules, similarity score and sentiment analysis.
Figure 3 shows that the time analysis of the newly developed fuzzy recommendation system and the existing systems such as classical model, Sankar et al. [16], Sai Ramesh et al. [4] and Youcef et al. [26]. Here, we have considered different number of user’s requests such as 2000, 4000, 6000, 8000 and 10000 in the five different experiments E1, E2, E3, E4 and E5.
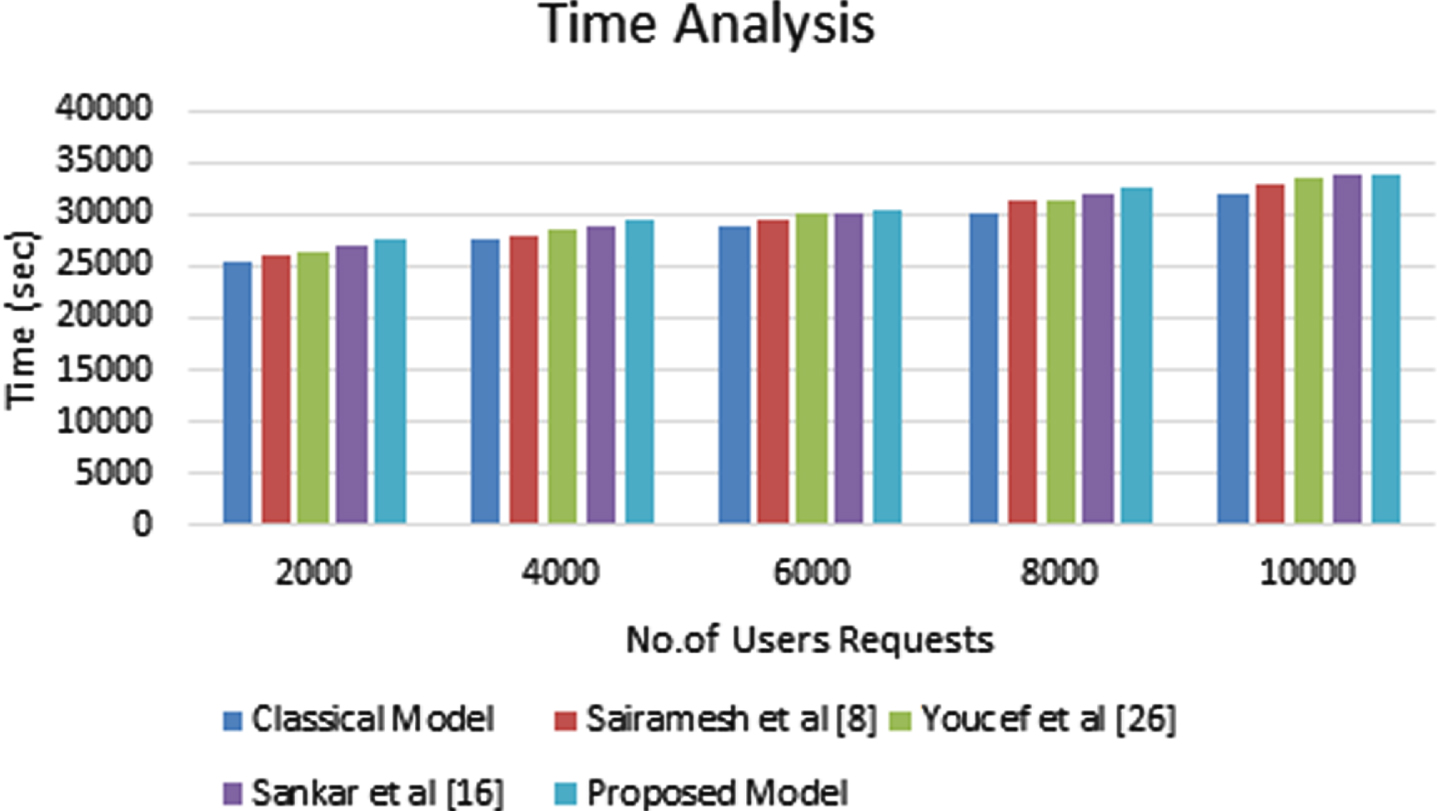
Time Analysis based on Internet User’s Requests.
From Fig. 3, it is demonstrated that the time analysis of the proposed recommendation system and the other existing systems in these directions such as conventional model, Sankar et al. [16], Sai Ramesh et al. [4] and Youcef et al. [26]. Here, the proposed recommendation system consumes less time than the existing systems for execution and processing. The reason for the achievement is to the use of feature selection and fuzzy rules.
Figure 4 shows the performance analysis based on the utilization of number of clusters over the newly proposed fuzzy recommendation system and the same number of clusters are used in the existing fuzzy recommendation systems such as conventional model, Sai Ramesh et al. [8], Youcef et al. [26] and Sankar et al. [16]. Here, the different number of clusters were considered in five different experiments such as E1, E2, E3, E4 and E5 that are contains different number of clusters such as 4, 8, 12, 16 and 20.
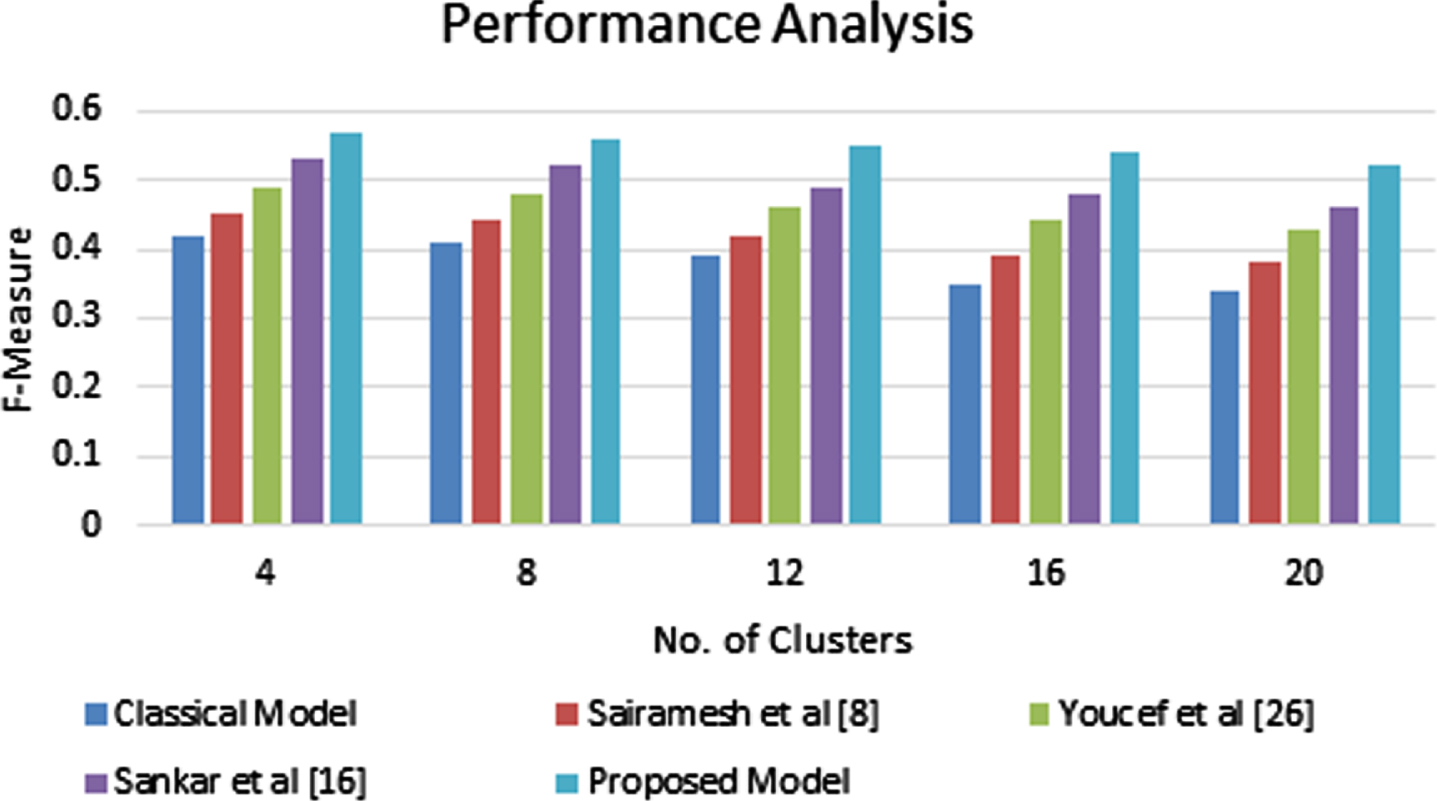
Performance Analysis based on no. of clusters.
From Fig. 4, can understand the efficiency of the proposed recommendation system in terms of F-Measure values of various numbers of clusters used in five different experiments. This is due to the fact that the use of fuzzy rules, semantic analysis and similarity score.
Figure 5 shows the performance of the proposed system and the existing systems. It consists of precision, recall and f-measure values for the proposed system and the existing systems.
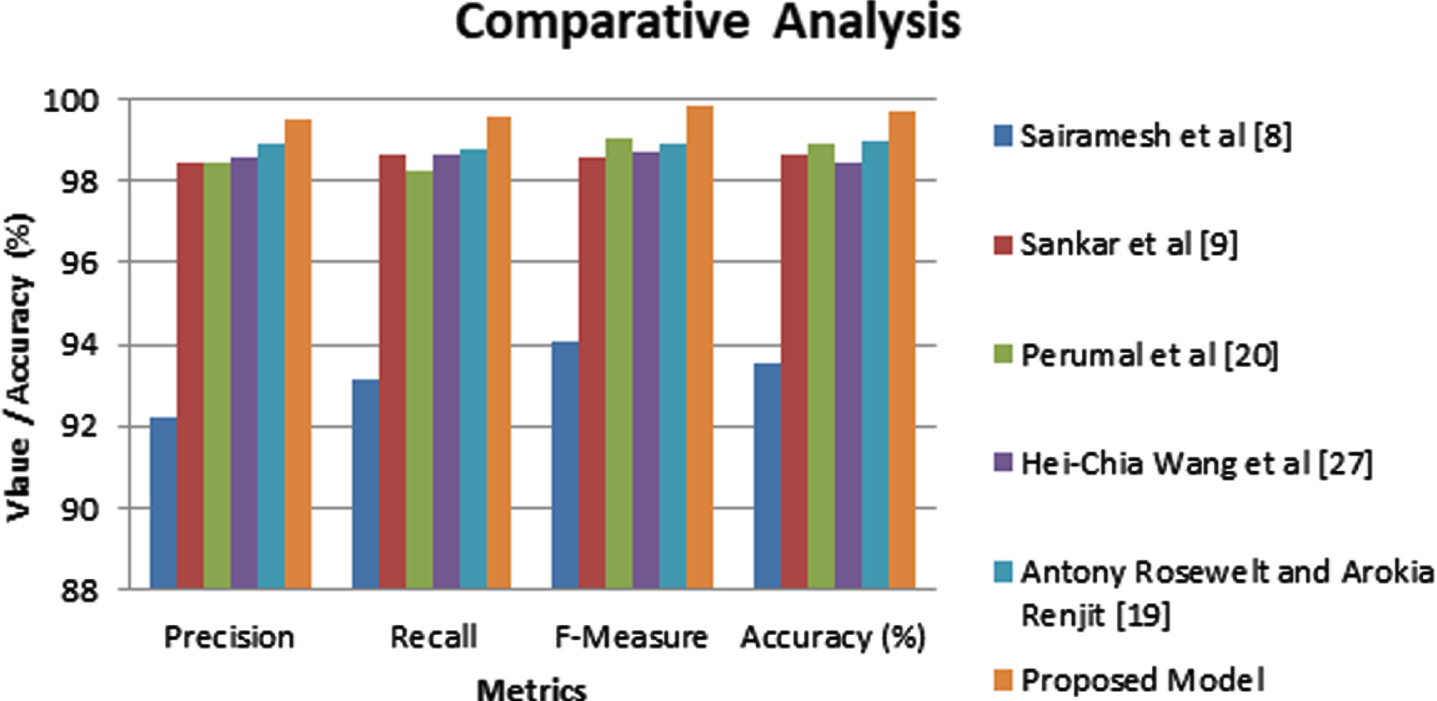
Performance Comparative Analysis.
From Fig. 5, it is proved the efficiency of the proposed fuzzy aware content recommendation system in terms of precision value, recall value, F-measure value and the prediction accuracy values. It is better than the existing systems such as Sairamesh et al. [8], Sankar et al. [9], Perumal et al. [20], Hei-Chia Wang et al. [27] and Antony Rosewelt and Arockia Renjith [19]. The reason for the performance enhancement is the use of similarity score, semantic analysis, clustering, ranking process and fuzzy rules.
Figure 6 shows the recommendation accuracy analysis between the proposed fuzzy logic based content recommendation system and the existing models like conventional system, Sai Ramesh et al. [8] and Sankar et al. [16]. Here, this system considered the various documents such as 100, 200, 300, 400 and 500 for experiments.
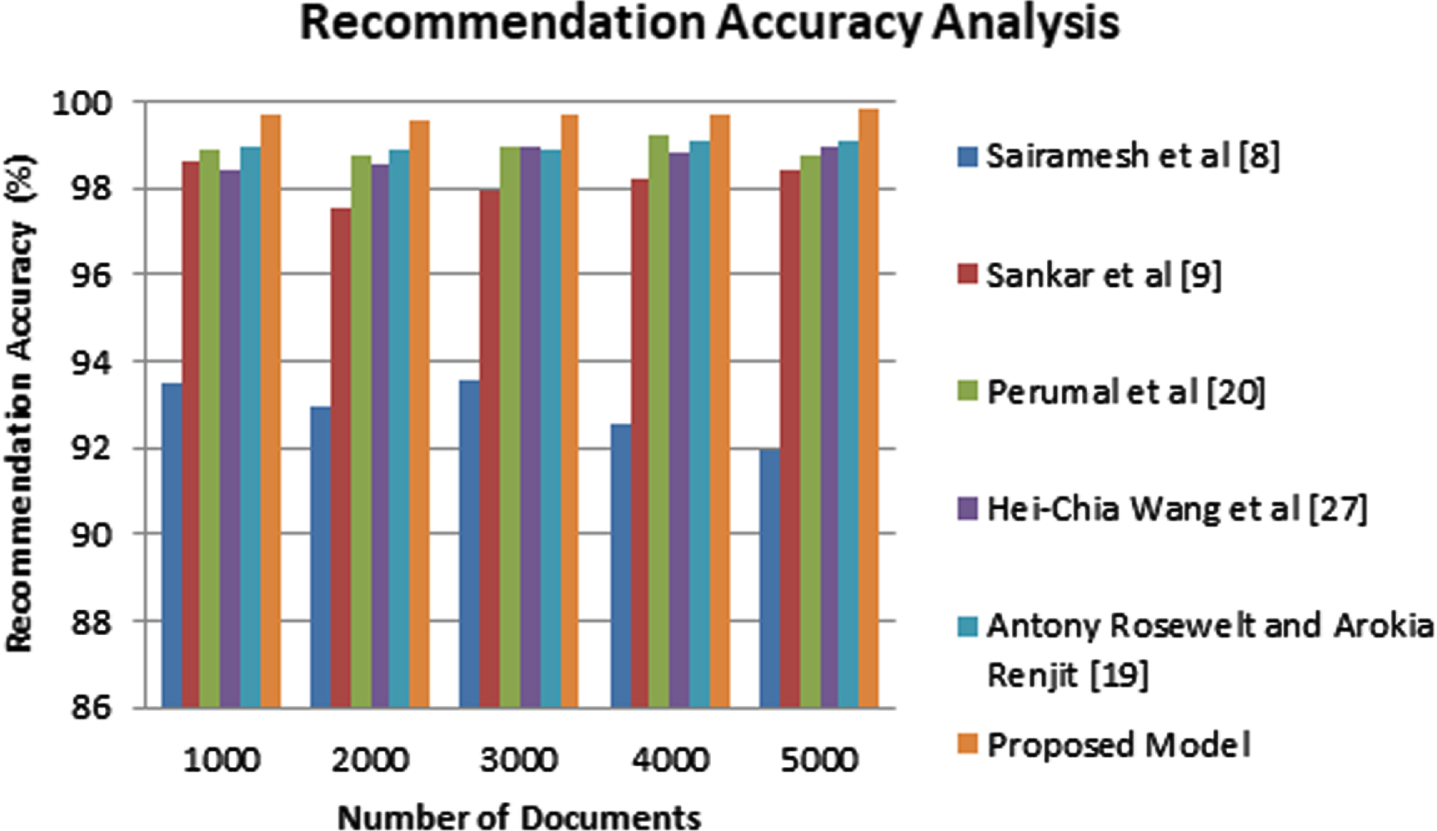
Recommendation Accuracy Analysis.
From Fig. 6, it demonstrated the efficiency of the proposed model which achieves highest recommendation accuracy than the existing content recommendation systems that are proposed by Sairamesh et al. [8], Sankar et al. [9], Perumal et al. [20], Hei-Chia Wang et al. [27] and Antony Rosewelt and Arockia Renjith [19]. The reason for the performance enhancement of the proposed model is the use of similarity score calculation, semantic analysis, Annova-T based feature selection and fuzzy rule, document clustering and content ranking algorithm.
A new fuzzy logic based content recommendation system has been proposed and also implemented for retrieving the relevant and suitable content for the internet users. Here, a new sentiment analysis based data pre-processing algorithm is also proposed and implemented for identifying the useful and contributing contents in internet source or repository. Moreover, a new similarity score based content ranking algorithm has been proposed and implemented for identifying the priority of the contents of web documents. In addition, a new document clustering algorithm is also proposed for grouping the relevant contents and web documents. Finally, the relevant and recommended content is retrieved by applying the newly proposed ranking algorithm and applies the fuzzy rules. The experimental results of the proposed recommendation system are proved that it is better than the existing systems in terms of prediction accuracy of products and target users. This work can be extended by the introduction of new deep neural network along with the pre-processing and clustering for better performance in recommendation.