
Abstract
Changes in plateau body lake water are an important indicator of global ecosystem changes, and a timely and accurate grasp of this change information can provide a scientific reference for the formulation of relevant policies. The traditional fuzzy C-means clustering (FCM) algorithm takes into account the ambiguity of the classification of the ground object pixels but does not consider the rich spectral information of the neighboring pixels and is very sensitive to the background noise” of the remote sensing image, resulting in low water extraction accuracy. Aiming to compensate for the shortcomings of the traditional FCM algorithm, this paper proposes an improved FCM algorithm. This algorithm replaces the Euclidean distance of the traditional FCM algorithm with a combination of the Mahalanobis distance and spectral angle matching (SAM) to fully take into account the spectral information of neighboring pixels and improve the clustering accuracy. The study selected Sentinel-2 images of the Fuxian Lake and Xingyun Lake basins during normal, wet, and dry periods as the data source. Under the same conditions, the clustering accuracy was compared with the traditional FCM algorithm, improved FCM algorithm, K-means clustering method and iterative self-organizing data analysis (ISODATA) clustering method. The experimental results show that the improved FCM algorithm has a higher water extraction accuracy than the traditional FCM algorithm, K-means clustering method and ISODATA clustering method. The kappa coefficient and overall accuracy (OA) of the improved FCM algorithm can be increased by 5.56%–9.45% and 2.66%–5.32%, respectively, and the omission error and commission error can be reduced by 1.72%–4.55% and 12.14%–22.10%, respectively. When the improved FCM algorithm is used, the extraction accuracy is higher for plateau deep lakes than for plateau shallow lakes, and the extraction effect for lakes with poor water environments is more significant than that of other methods. The improved FCM algorithm better maintains the integrity of the water boundary and overcomes the influence of a certain number of mountain shadows and urban building pixels on the clustering results.
Introduction
As the connection point of interaction between atmosphere, hydrosphere, lithosphere and biosphere [1], the lakes are constantly changing under the influence of the natural environment and human development [2]. Their changes not only reflect changes in lake water volume but also affect coastal beaches. Area and wetland ecosystem declines serve an important indicator function [3]. The functions of lakes such as flood control and water storage, tourism and recreation, and climate regulation are important drivers of sustainable development [4, 5]. In the past 30 years, the ecological service functions of the nine plateau lakes in Yunnan Province have declined, and the imbalance between the supply and demand of water resources has been prominent [6]. The high frequency of human development has degraded the carrying capacity of the plateau lake ecosystem, which has had a massive impact on lake ecological environment protection and residents’ production and lives [7]. The nine plateau lakes are the areas with the highest degree of economic and social development in Yunnan Province. Fuxian Lake and Xingyun Lake are typical lakes among the nine plateau lakes and play an irreplaceable role in the regional ecological-economic system. Therefore, quickly and accurately extracting the range of plateau lake water bodies and grasping its change over time has important practical significance for the effective development of the lakeside zone and the formulation of ecological environmental protection policies.
Traditional lake water extraction methods mainly use ordinary measurement methods and photogrammetry methods. Traditional measurement methods are inefficient, costly, and greatly affected by the geographical environment. Especially in some areas with harsh environments, measurement work is not possible [8]. Remote sensing monitoring technology has the advantages of wide coverage, strong timeliness, and a large amount of information and is not affected by the geographical environment, which makes it play an important role in the monitoring of lake changes and the spatiotemporal transformation of water resources.
In recent years, domestic and foreign scholars have used different methods to segment and extract water bodies from various remote sensing data. The main extraction methods are threshold segmentation [9–11], edge detection [12, 13], object oriented method [14–16], active contouring [17, 18], support vector machines (SVM) [19], and deep learning [20, 21]. However, in practical applications, lake water includes a variety of water types, such as pure water, water mixed with vegetation, water mixed with suspended organic matter, water mixed with sediment, especially in shallow water areas at the edges of lakes. When mixed with a substantial amount of sediment, the spectral curve of this type of water is quite different from that of pure water [22]. If a unified pure water body extraction method is used to extract information from these types of water bodies, the extraction accuracy will not be ideal, and it cannot adapt to the fuzzy boundary condition of water bodies mixed with other substances. There is no strict definition between water bodies and non-water bodies, and their pixel relationship is essentially vague. There is an intermediary between their shapes and categories, and they have the characteristics of “both this and that". Therefore, water bodies and non-water bodies are suitable for softening classification, and fuzzy clustering can be used to solve this kind of pixel blur problem and improve the classification accuracy of lake water bodies [23].
Clustering is an analysis problem of classifying a given sample into several “classes” or “clusters” according to their feature similarity or distance [24]. The traditional fuzzy c-means (FCM) clustering algorithm is currently the most representative clustering algorithm. Among the clustering algorithms based on objective functions, the FCM-type algorithm theory is the most complete and the most widely used. It has been applied to medical image classification, optimization problem solving, pattern recognition, remote sensing image classification, data mining and other fields. However, the traditional FCM algorithm considers only image grayscale features when clustering and does not consider the rich spatial neighborhood information of the image, which results in the algorithm being very sensitive to background noise and insufficient edge information, seriously affecting the image segmentation effect and precision [25].
In response to the above problems, many scholars have improved the traditional FCM algorithm, which can be mainly divided in two categories. (1) Multiple algorithms or parameters are combined to improve the objective function. Xiao et al. [26] combined domain information and introduced control parameters and proposed an FCM algorithm based on spatial correlation. The algorithm has a good noise suppression effect and clear image segmentation boundaries, However, some parameter settings of the algorithm are subjective and empirical, and the universality needs to be optimized. Tian et al. [27] used spatial information and spatial patterns combined with traditional FCM algorithms, reducing the number of misclassifications and the impact of noise. Zhang et al. [28] used a nonlinear filtering process to retain important edge structures while reducing the influence of noise in the segmentation experiment. However, the algorithm still needs to combine the spatial characteristics of the pixels to further improve the accuracy of image segmentation. Liu et al. [29] used the neighborhood characteristics of the sample itself and proposed the nearest neighbor sample density weighted FCM (NSD-WFCM), neighbor sample membership weighted FCM (NSM-WFCM), and neighbor sample density and membership weighted FCM (NSDM-WFCM) algorithms. To a certain extent, it overcomes the shortcomings of the FCM algorithm, improves the unsupervised classification ability of remote sensing images, and has a certain universality. (2) The other type of method is postclustering processing. Hao et al. [30] used threshold weighting and inverse distance weighting to process clustering results; the accuracy of the classification results was higher than that of the maximum membership method, and the number of noise pixels was reduced.
By combining the existing studies, the robustness of the water extraction method is mainly limited by the water spectrum and spatial diversity and the heterogeneity of adjacent surfaces in different regions. At present, most studies focus on a single method, while the importance of neighborhood spectral heterogeneity to boundary preservation is analyzed less often. Based on the above analysis. This paper selects Sentinel-2 images in normal, dry, and wet periods, and uses the improved FCM algorithm proposed in this paper and the traditional FCM algorithm, K-means clustering algorithm, and ISODATA clustering algorithm to analyze the water bodies of Fuxian Lake and Xingyun Lake. Extraction, and use kappa coefficient, OA coefficient, omission error, commission error and other indicators to evaluate the accuracy of the water body extraction results.
Materials and methods
Overview of the study area
Fuxian Lake and Xingyun Lake are geologically connected and adjacent to each other (Fig. 1). Originally, they were two connect lakes. Later, the two lakes separated after the outflow diversion project was implemented. Fuxian Lake, located at the junction of Chengjiang, Jiangchuan and Huaning counties in Yuxi city, is the plateau deep-water freshwater lake with the best water quality and the largest storage capacity among inland freshwater lakes in China. The average depth of the lake is 95.2 m, and the deepest depth is 158.9 m. At present, it has Class I water quality, and it is the first great lake at the source of the Pearl River. Fuxian Lake is a gourd-shaped north-south rifted dissolution lake with an area of 216.6 km2 and a lake capacity of 20.62 billion m3. It accounts for 72.8% of the total water storage capacity of the nine plateau lakes in Yunnan and 9.16% of the water storage capacity of freshwater lakes in the country. Xingyun Lake is located in Jiangchuan County, Yuxi city. It belongs to the Pearl River Basin and is the source lake of Fuxian Lake. It is connected to Fuxian Lake by a 2.2 km river. The depth of the lake is shallower than that of Fuxian Lake, with an average water depth of 7 m and a maximum depth of 10 m. The current water quality is poor, with Class IV water quality. The ecological system of Xingyun Lake is fragile. The towns and villages around the lake are densely distributed. Industry and agriculture are developed. In particular, flue-cured tobacco, vegetables and other industries account for a large proportion of the local economic activities. The water quality of Xingyun Lake is declining year by year, and the degree of eutrophication of the water body is increasing [31].
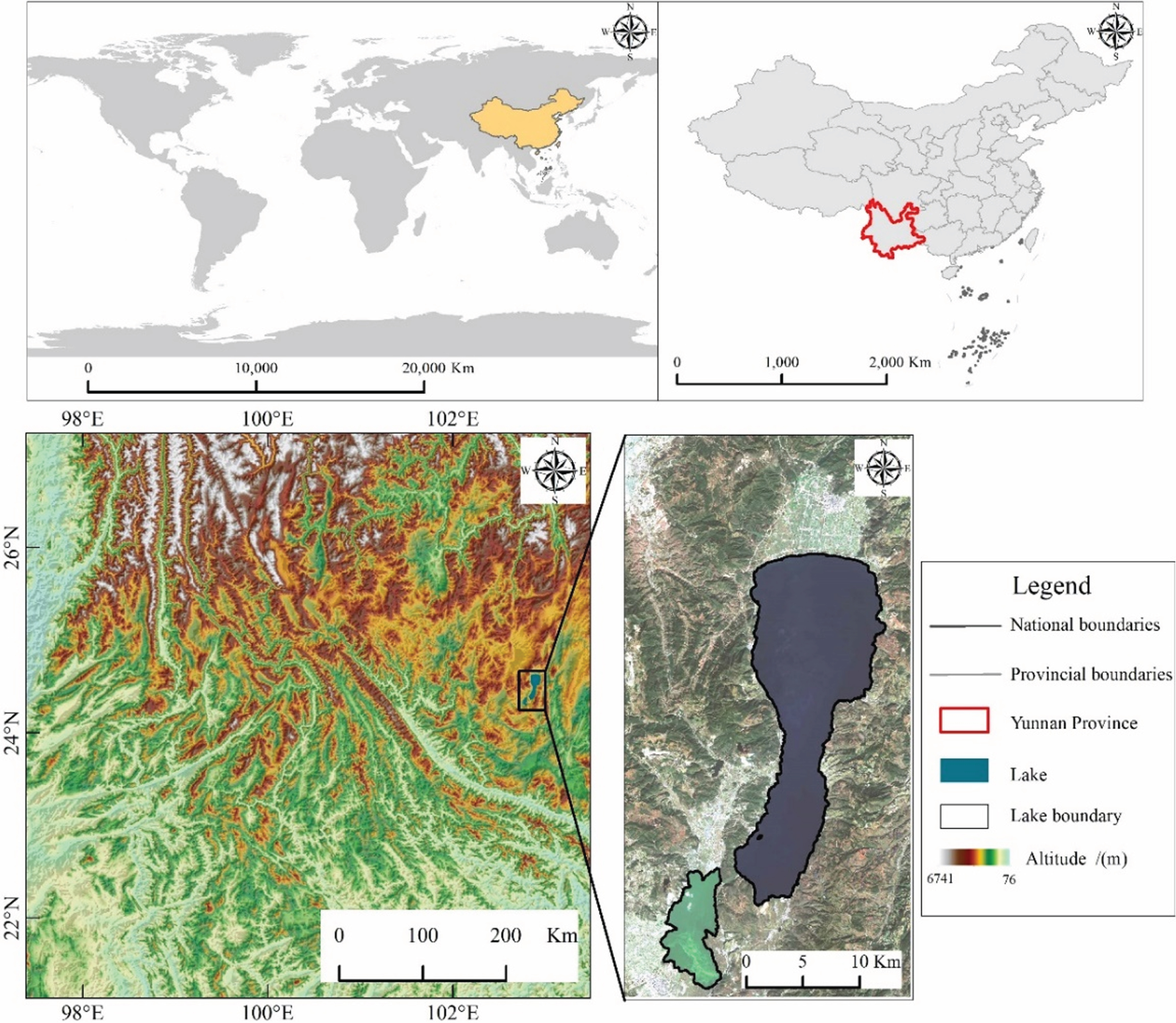
Schematic diagram of the relative position of the study area.
Remote sensing image data
Images of Fuxian Lake and Xingyun Lake in a normal-water period (February to April), wet season (May to September) and dry season (October to January of the next year) were used to the extract water bodies and analyze the accuracy. The remote sensing data come from Sentinel-2 image data of the US Geological Survey (https://www.usgs.gov/). Based on the ENVI 5.3 version platform, basic preprocessing such as geometric registration, resampling, radiometric calibration, and atmospheric correction are performed on the multispectral and panchromatic bands [32]. Histogram equalization is used to increase the contrast of the image and enhance the clarity of the details. The Lee filter is used to smooth the noise pixels closely related to the image and the additional or multiplied noise [33]. While suppressing the noise, the Lee filter retains the sharpening information and details of the image [34]. The filtered pixels will be replaced by the surrounding pixels. After applying histogram equalization and Lee filtering, it can create conditions for the subsequent image clustering to obtain a better degree of membership. The list of remote sensing images is as follows (Table 1):
Image data list
Image data list
Image comparison before and after pretreatment (Fig. 2)

Comparison of effects before and after pretreatment.
Using corrected water level data measured on the ground (the date of acquisition of the water level data used for accuracy verification is consistent with the production date of the image), data such as the water level line derived from a digital elevation model (DEM) with a grid spacing of 2 m, using the kappa coefficient and OA, leakage accuracy evaluation is performed for the omission error and commission error. The specific flow chart of the experiment is shown in Fig. 3:
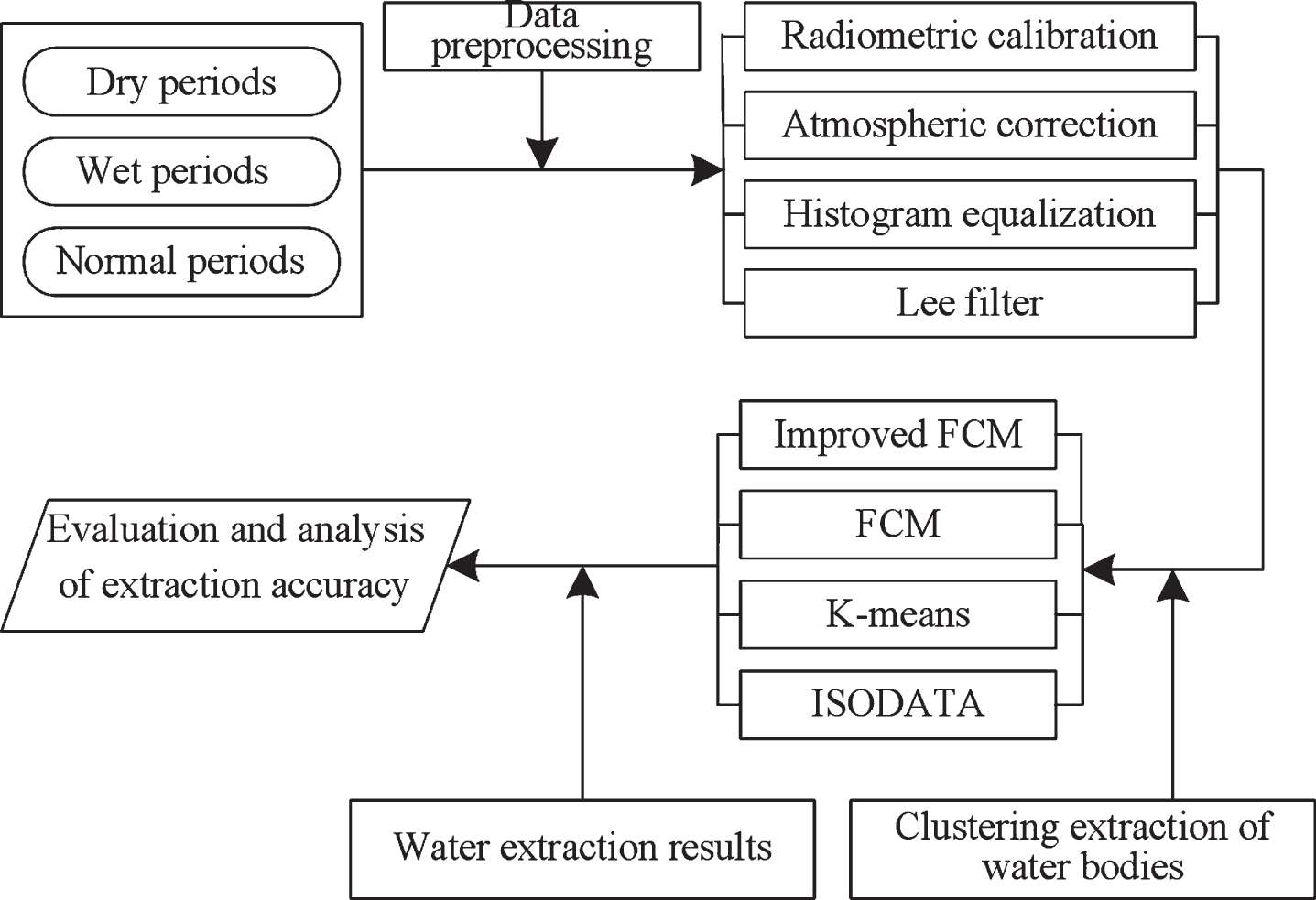
Experimental flow chart.
Traditional fuzzy c-means clustering algorithm
The traditional FCM algorithm is a kind of unsupervised classification learning algorithm. FCM clustering maximizes the within-class similarity class and minimizes the between-class similarity. The membership degree is used to measure the probability that different pixels belong to a certain class. This clustering feature is more in line with the actual situation of a fuzzy boundary between water and land. The FCM algorithm divides N samples into k sets and iteratively updates each cluster center to cluster the images according to the principle of maximum membership. The objective function is as follows:
In the formula, U represents the ambiguity of all the pixels; v
i
represents the set of clustering centers;
The FCM algorithm is an iterative convergence process that minimizes the objective function. The Lagrange function optimization method is used to solve the problem:
The cluster center and membership matrix are obtained by iterative updating until the iterative change is less than the threshold, and the algorithm ends.
Mahalanobis distance
When the traditional FCM algorithm uses the Euclidean distance to minimize the objective function, it does not have a good effect on nonspherical clusters and clusters with different dimensions and different densities. The Euclidean distance does not take into account the impact of the importance of each feature on the clustering results. When processing some data with highly correlated attributes, it tends to increase the commission error. To solve this problem, we use the Mahalanobis distance combined with spectral information instead of the Euclidean distance to fit and minimize the objective function. The Mahalanobis distance represents the covariance distance of the data, which is an effective method to calculate the similarity of two unknown sample sets. It can consider the relationship between each feature [35].
Let the sample be (x
i
, y
i
) ∈ R
n
× R1 (i = 1, 2, ... m). There are m samples, x
i
is the n-dimensional feature vector, and y
i
∈ [-1, 1] represents the class label of x
i
. Let X represent the input matrix of m × n, where each row is a sample. Then, the sample’s mean, autocorrelation matrix and covariance matrix can be expressed as matrices:
In the formula,
The Mahalanobis distance has three properties, namely, translation invariance, rotation invariance and affine invariance, and it can also eliminate the interference of correlation between variables.
Spectral angle matching (SAM) is an image classification method based on the included angle. According to the spectral principle of remote sensing, the reflectance spectral information of ground objects will greatly affect the classification results of ground objects, so the SAM classification method is developed. In this method, the spectral information of each pixel in the image is regarded as a vector, the unknown spectrum is compared with the reference spectrum, and the angle between the two vectors is calculated to determine the similarity between them. The smaller the angle of the vector, the greater the similarity between them, otherwise, the smaller the similarity. Then, the similarity calculation formula between unknown spectrum t and reference spectrum r is as follows [36]:
In the formula,
The average spectrum of known points is directly extracted from the existing spectral library or image as the reference spectrum, and the angle α between the spectral vector of each pixel and the reference spectral vector is calculated. In practical applications, the average spectrum is selected as the sample center from the known region of the image, the angle between each pixel in the remote sensing image and each cluster center vector is calculated, and the pixel is then classified into the category with the smallest angle.
The improved FCM algorithm uses the Mahalanobis distance and SAM to replace the Euclidean distance. This calculation method comprehensively considers the spectral information and direction of the vector, and considers the influence of different correlations on the clustering results. The specific distance calculation formula is as follows:
The improved FCM algorithm proposed in this paper is based on the traditional FCM algorithm. The traditional FCM algorithm mostly considers the information of the pixel itself but cannot take into account the rich spectral information in the neighborhood. Therefore, based on the traditional FCM algorithm, the Mahalanobis distance is used instead of the Euclidean distance, and the image is clustered by combining the spectral information of pixels to achieve more accurate extraction of water information. The improved objective function is as follows:
In the formula,
Set the number of clusters 2 ⩽ C ⩽ Cnum-max, m > 1, the conditions for algorithm termination ɛ, and the maximum number of iterations max _ iter; Initialize each cluster center c
i
; Calculate the values of the spectral similarity SAM and Mahalanobis distances; Use the current cluster center c
i
and calculate the membership function When the termination condition ɛ and the maximum number of iterations max _ iter are met, the algorithm converges and the iteration ends; otherwise, return to step (3) to continue the calculation.
After the calculation is completed, the clustering center of each cluster and the membership degree of each pixel are obtained, the ASCII code data of the clustering result is output, and the specific clustering result is obtained after spatial display. The detailed calculation flow chart of the improved FCM algorithm is shown in Fig. 4:
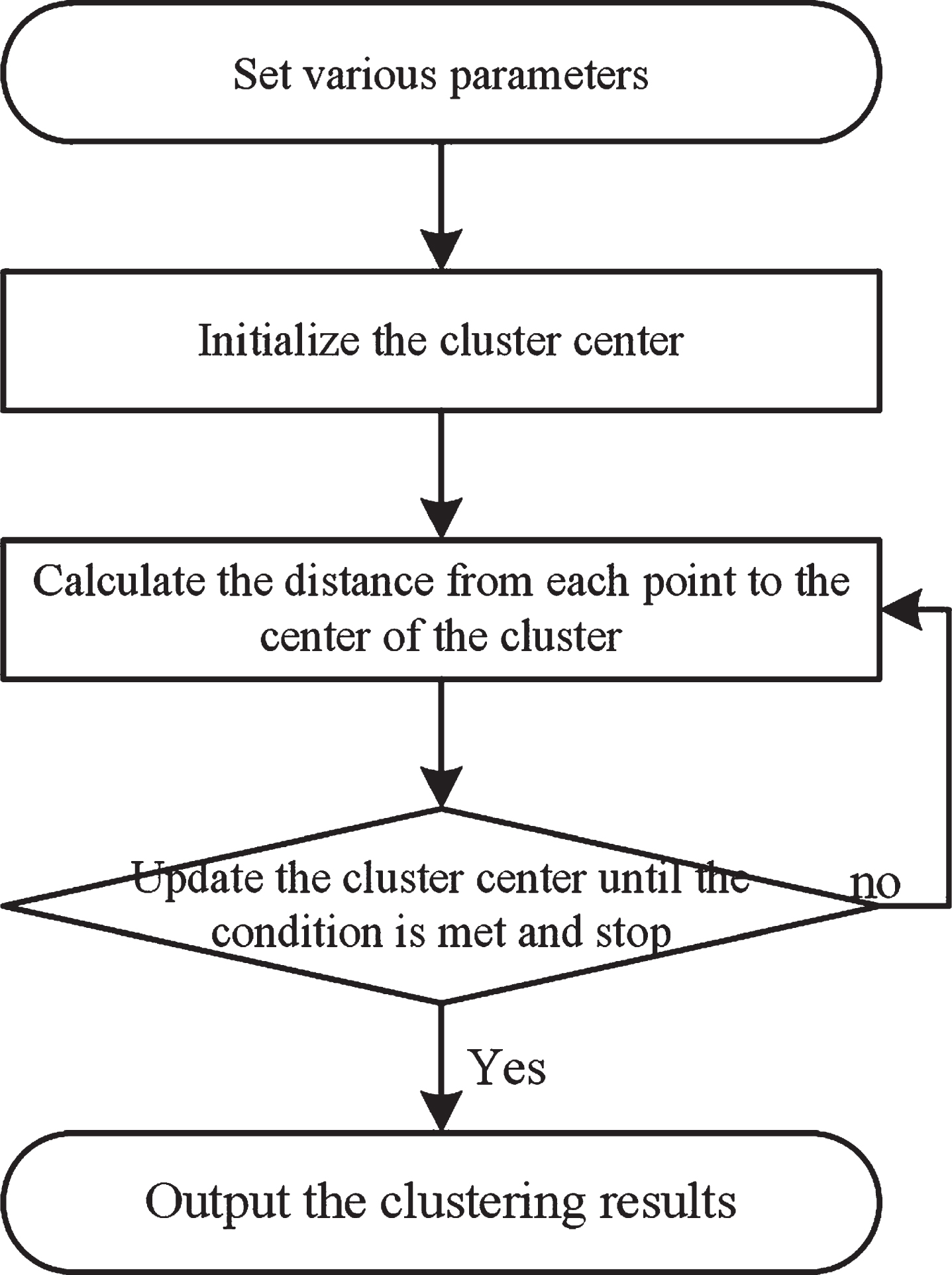
Improve FCM algorithm specific calculation flow chart.
Results
The accuracies of the improved FCM algorithm, traditional FCM algorithm, K-means clustering method, and iterative self-organizing data analysis technique (ISODATA) clustering method are compared. The kappa coefficient, OA, omission error and commission error were used to perform a quantitative analysis of accuracy, and visual judgment was used to perform a qualitative analysis of the extraction effect for local small water bodies. According to the accuracy evaluation results (Figs. 5, 6, 7 and 8), it can be clearly seen that the kappa coefficient and OA coefficient in Fuxian Lake area are more accurate than that in Xingyun Lake area. The leakage rate in Xingyun Lake area is higher than that in Fuxian Lake area. The leakage rate in Fuxian Lake area is lower under different water quantity periods and different classification methods. The kappa coefficient in different water volume periods is the highest in the normal-water period, followed by the wet periods, and the lowest in dry periods, while the OA in different water periods for Fuxian Lake is the highest in normal-water periods, followed by wet periods and lowest in dry periods. The kappa coefficient and OA for Xingyun Lake fluctuate little during the normal period. Among them, the time period with the highest omission error was concentrated during the dry season for Xingyun Lake, and the time period with the highest commission error was concentrated during the wet season for Xingyun Lake. According to the statistical results of the accuracy extracted by the different classification methods in the different water periods (Figs. 9 and 10), the classification accuracy of the improved FCM algorithm proposed in this paper is better than that of the traditional FCM algorithm, ISODATA clustering method and K-means clustering method in the Fuxian Lake and Xingyun Lake areas, and the omission error and commission error are lower than those of the other classification algorithms. In the Fuxian Lake area, the kappa coefficient and OA of the improved FCM algorithm are 2.70%–4.84% and 1.27%–1.97% higher, respectively, than those of other algorithms, and the omission error and commission error are 0.01% - 0.15% and 10.60%–23.72% lower, respectively, than those of other algorithms. In the Xingyun Lake area, the kappa coefficient and OA of the improved FCM algorithm are 9.06%–14.07% and 4.08%–8.68% higher, respectively, than those of other algorithms, and the omission error and commission error are 3.43%–8.96% and 13.70%–20.48% lower, respectively, than those of other algorithms. Improved FCM algorithm clustering accuracy is more obvious in the Xingyun Lake area, but in the Fuxian Lake area, the commission error is improved significantly. From the visual results (Figs. 11, 12, and 13), it can be concluded that the improved FCM algorithm better maintains the integrity of the lake boundary than the traditional FCM algorithm, ISODATA clustering method, and K-means clustering method. At the same time, it effectively eliminates the influence of part of the mountain shadow and vegetation on the clustering information, and the number of misclassified pixels is greatly reduced. The boundary preservation effect for the Fuxian Lake area is better than that for the Xingyun Lake area. At the same time, the overall extraction accuracy for the Fuxian Lake area is higher than that of the Xingyun Lake area. The water leakage area of the Xingyun Lake area is mainly concentrated in the central and southern regions where pollutants and water bodies in the lake are seriously mixed, while the water leakage area of the Fuxian Lake area is concentrated on the edge of the lake at the boundary of land and water.
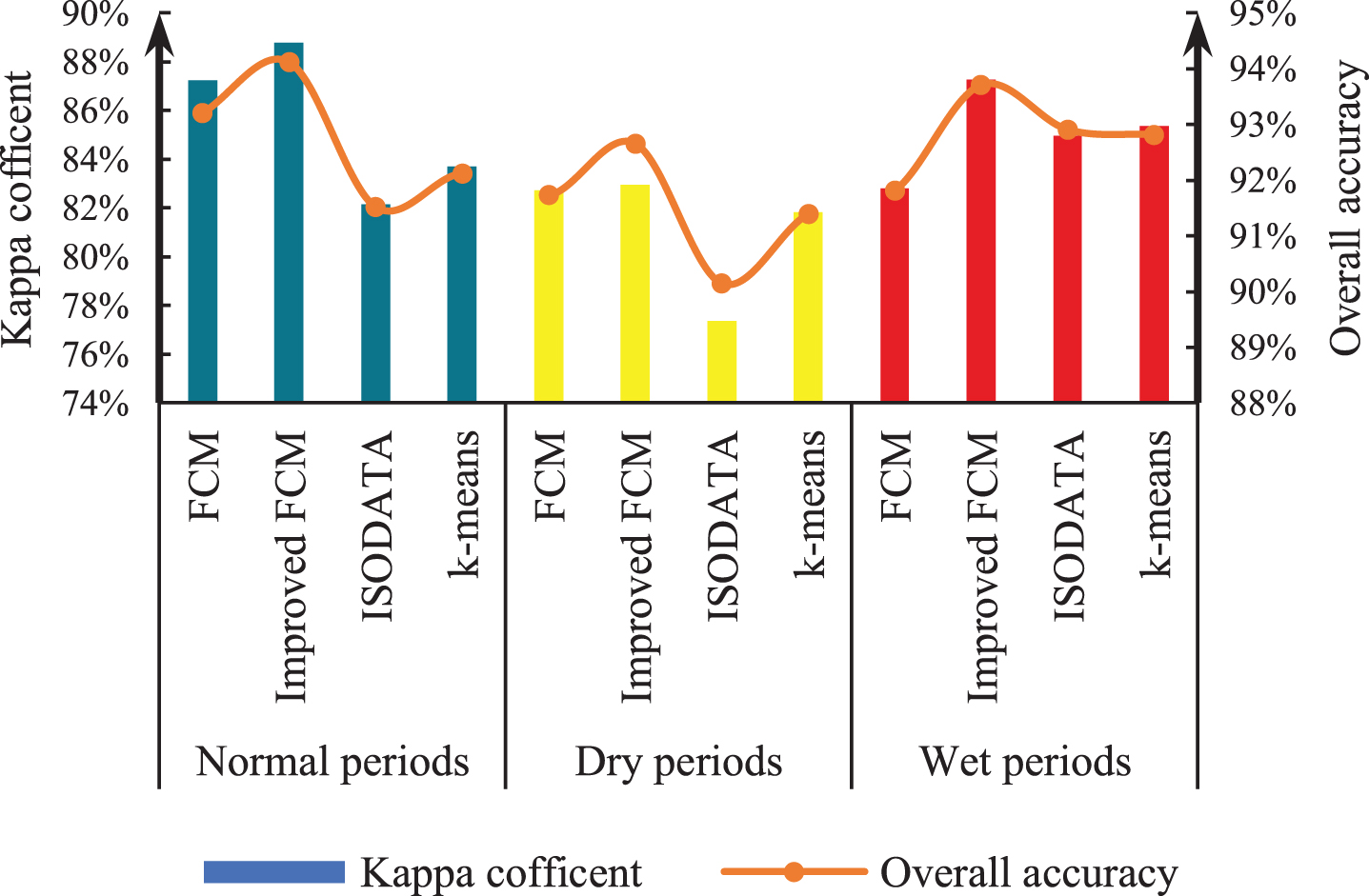
Kappa coefficient and OA for Fuxian Lake
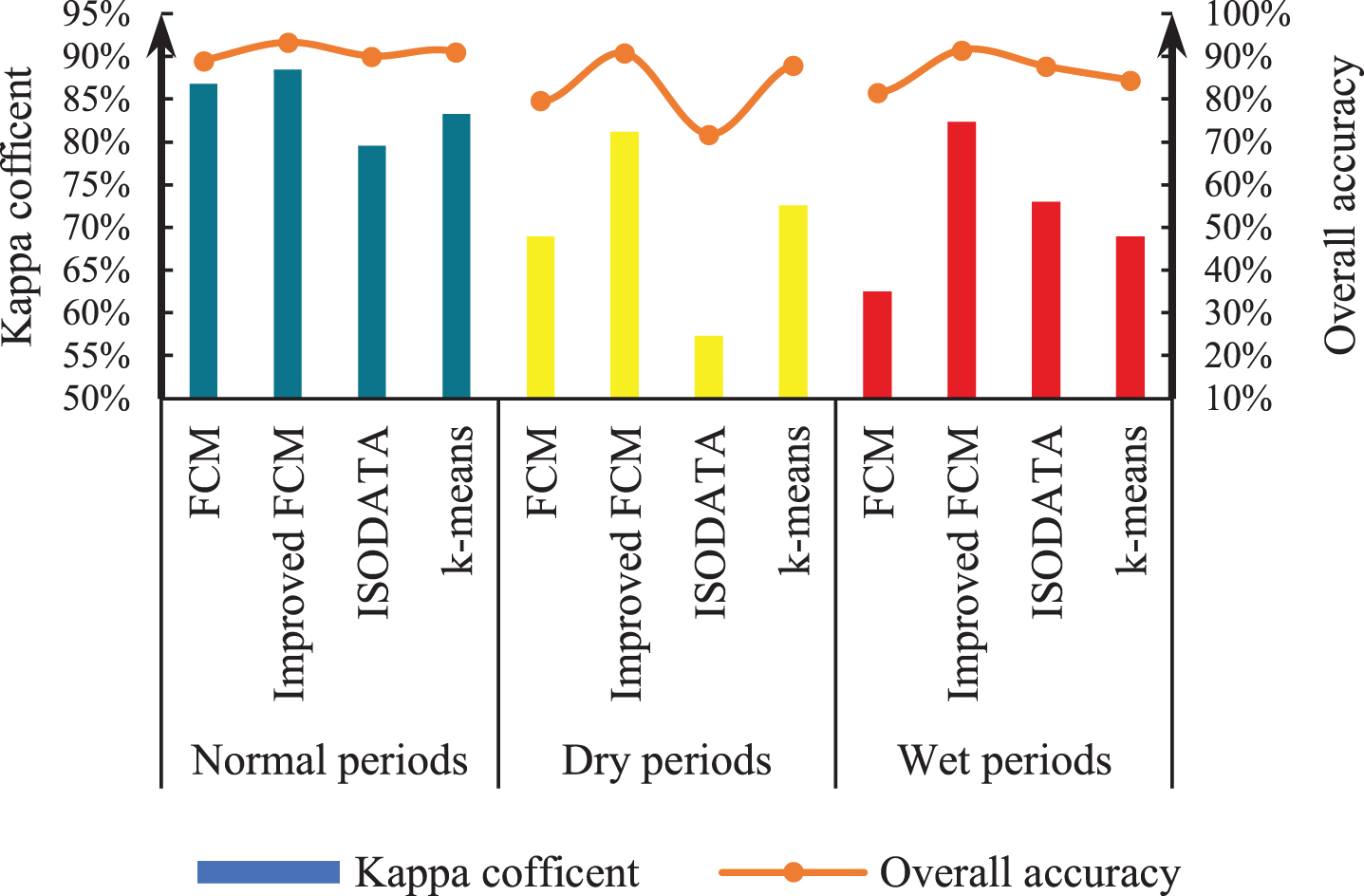
Kappa coefficient and OA for Xingyun Lake.

Omission error of the various algorithms in the different water volume periods.
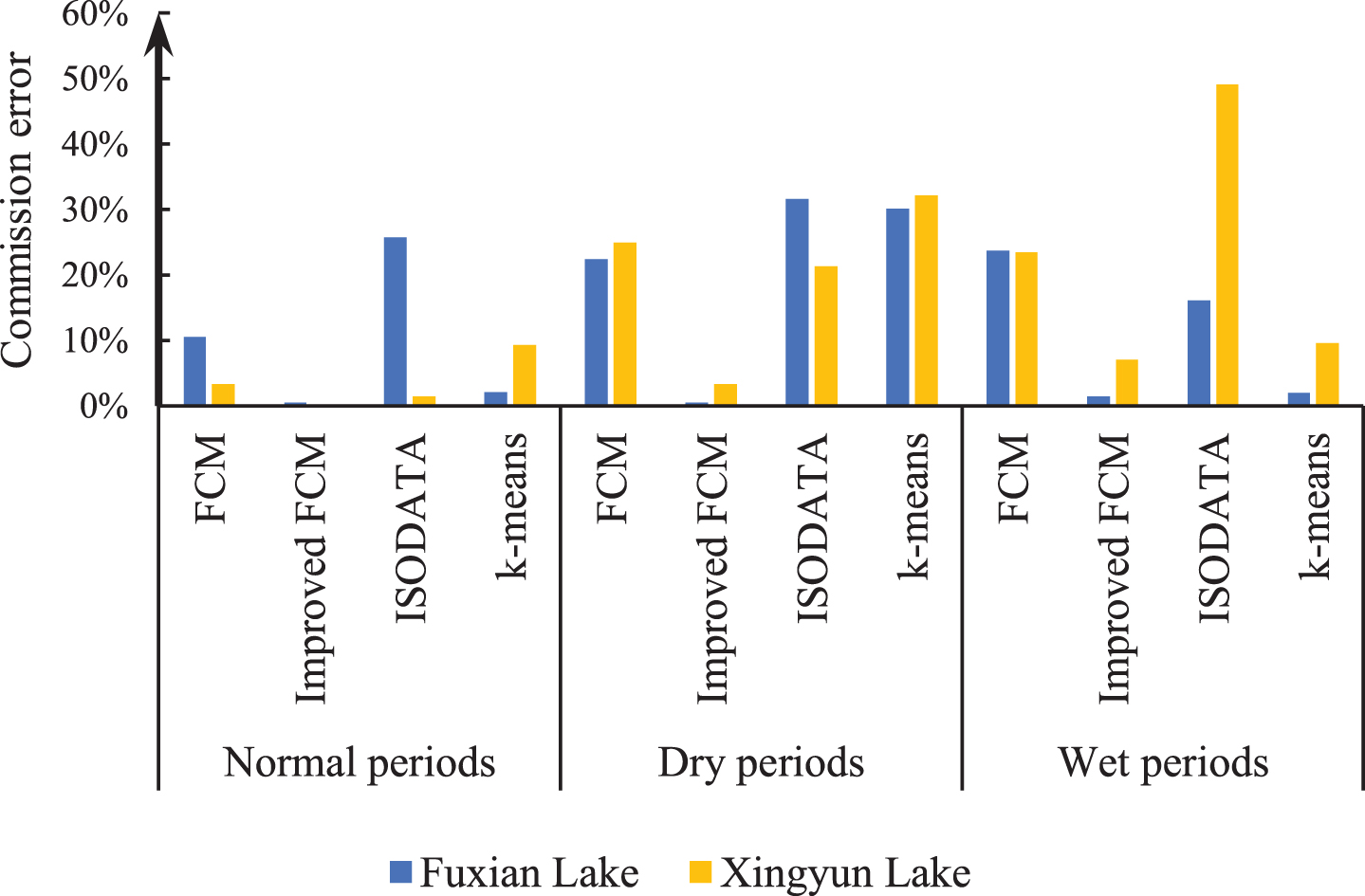
Commission error of the various algorithms in the different water volume periods.
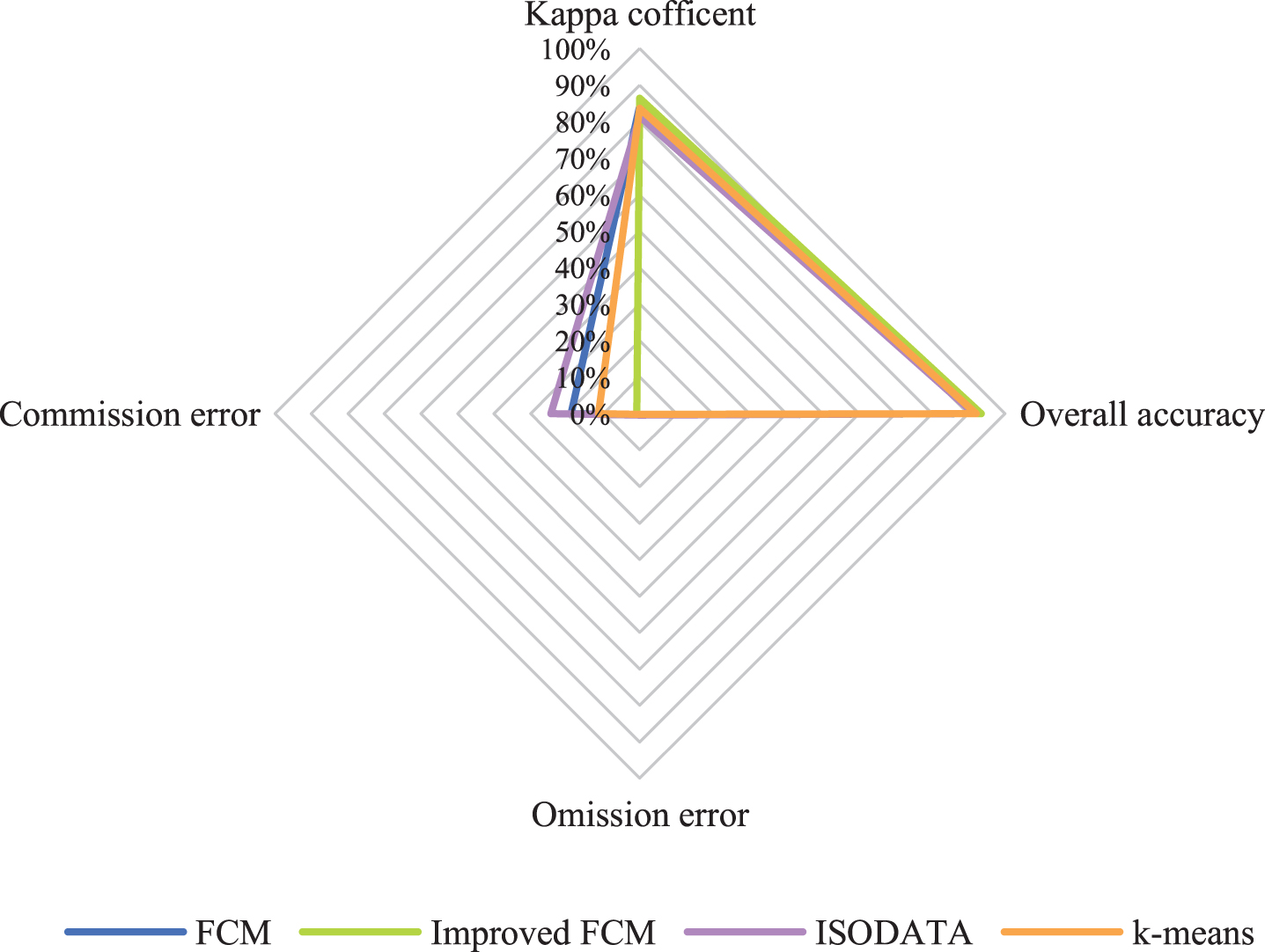
Accuracy comparison for Fuxian Lake.
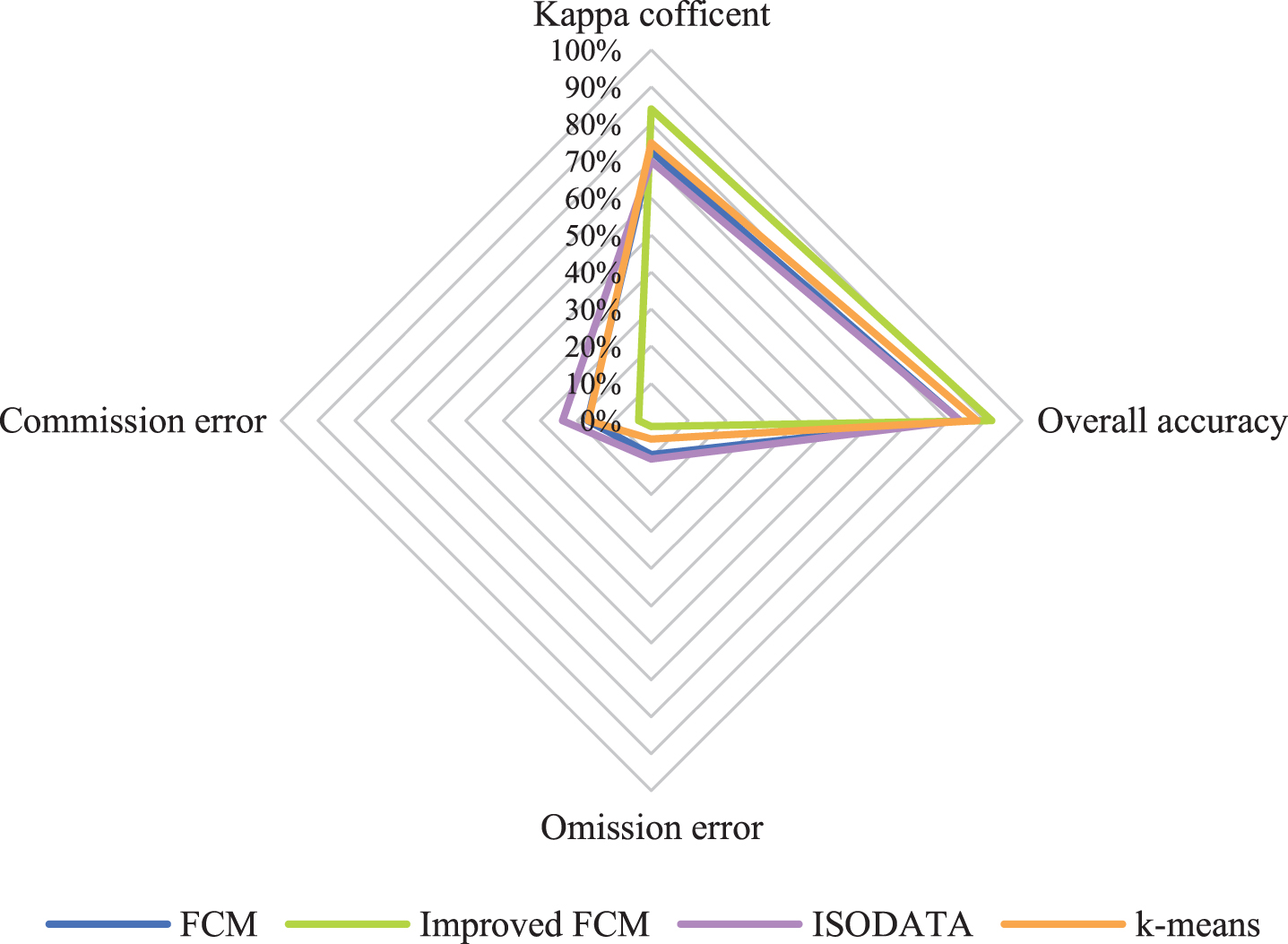
Accuracy comparison for Xingyun Lake.
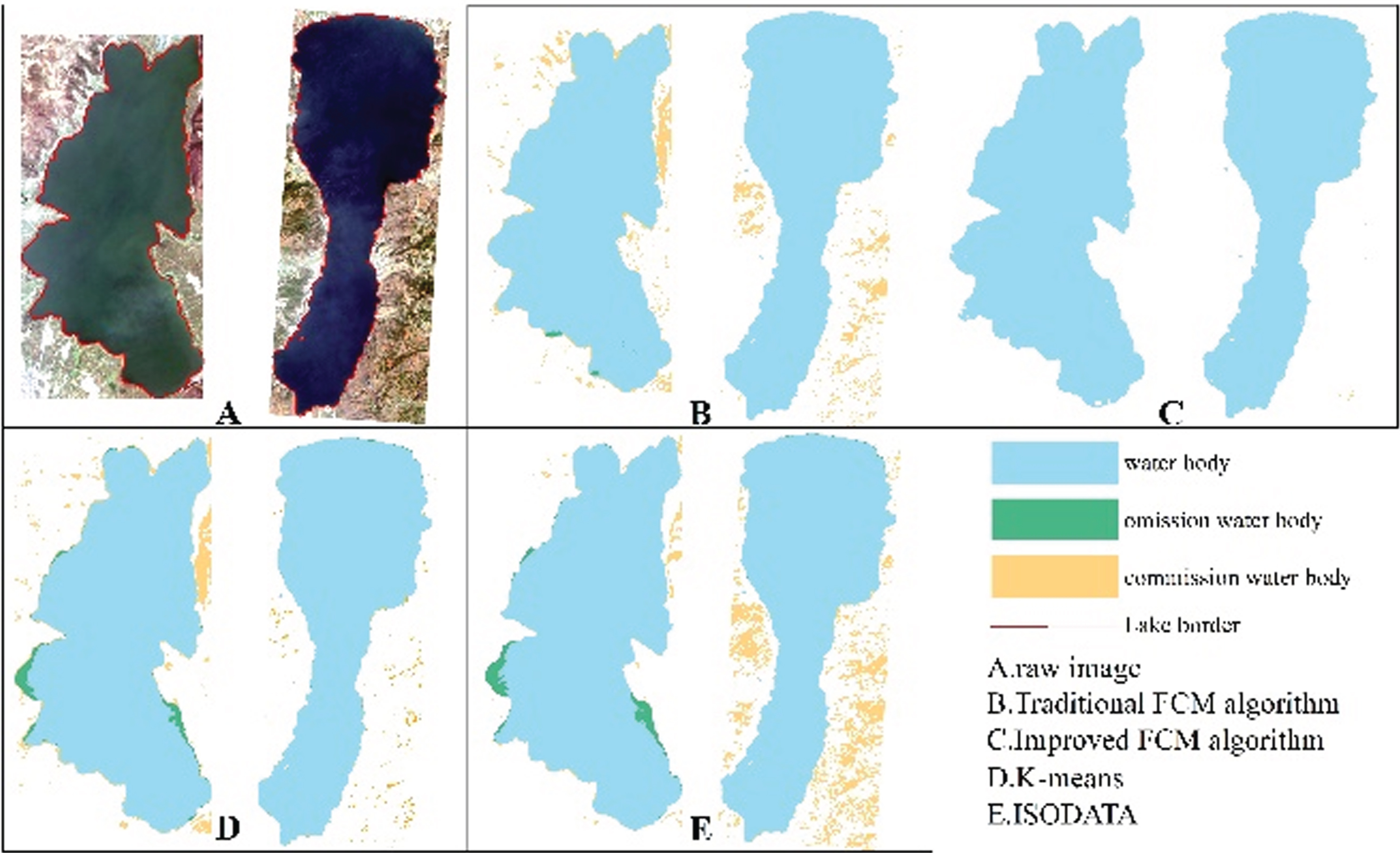
Results of the various classification methods during the normal-water period.
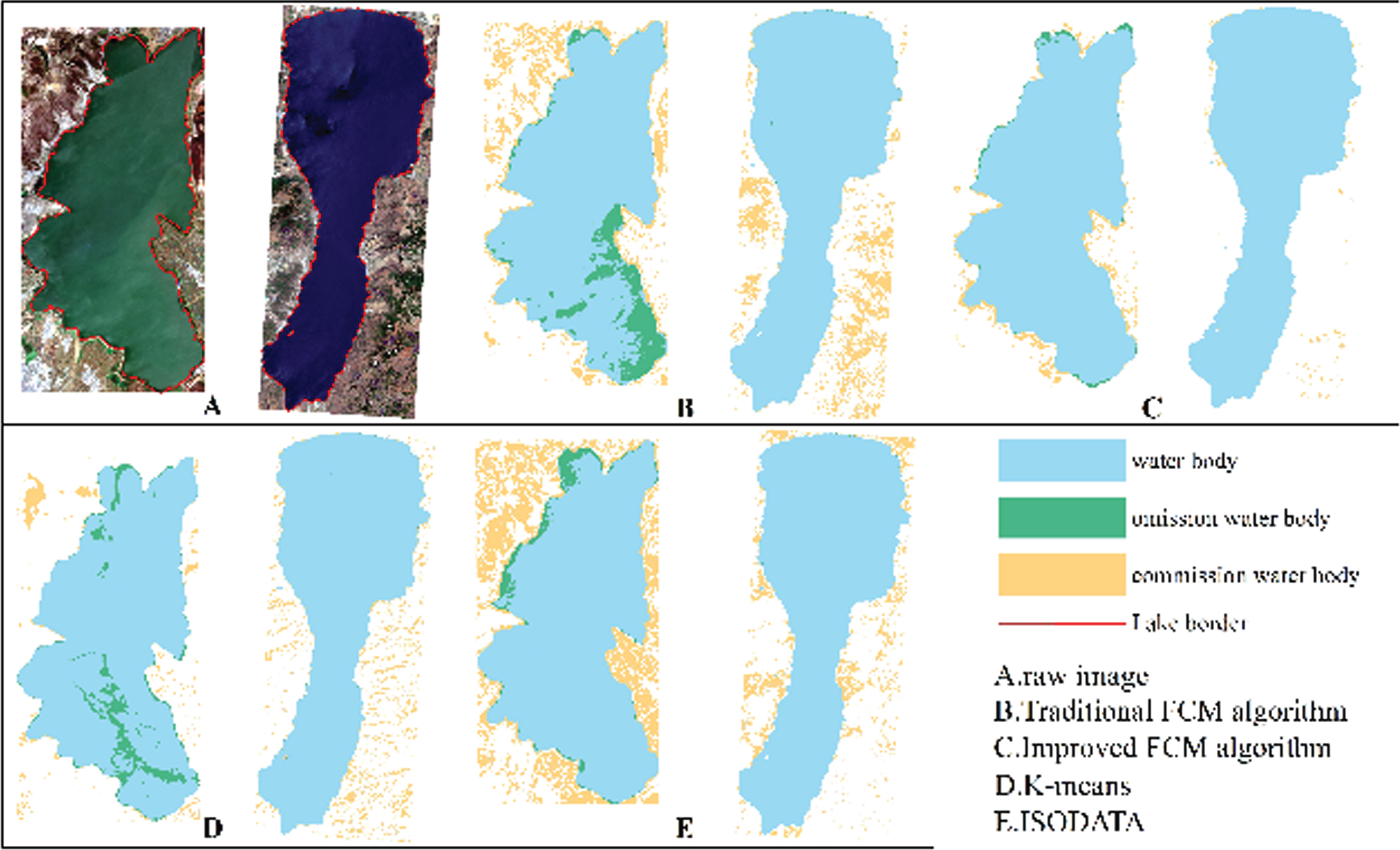
Results of the various classification methods during the wet-water period.
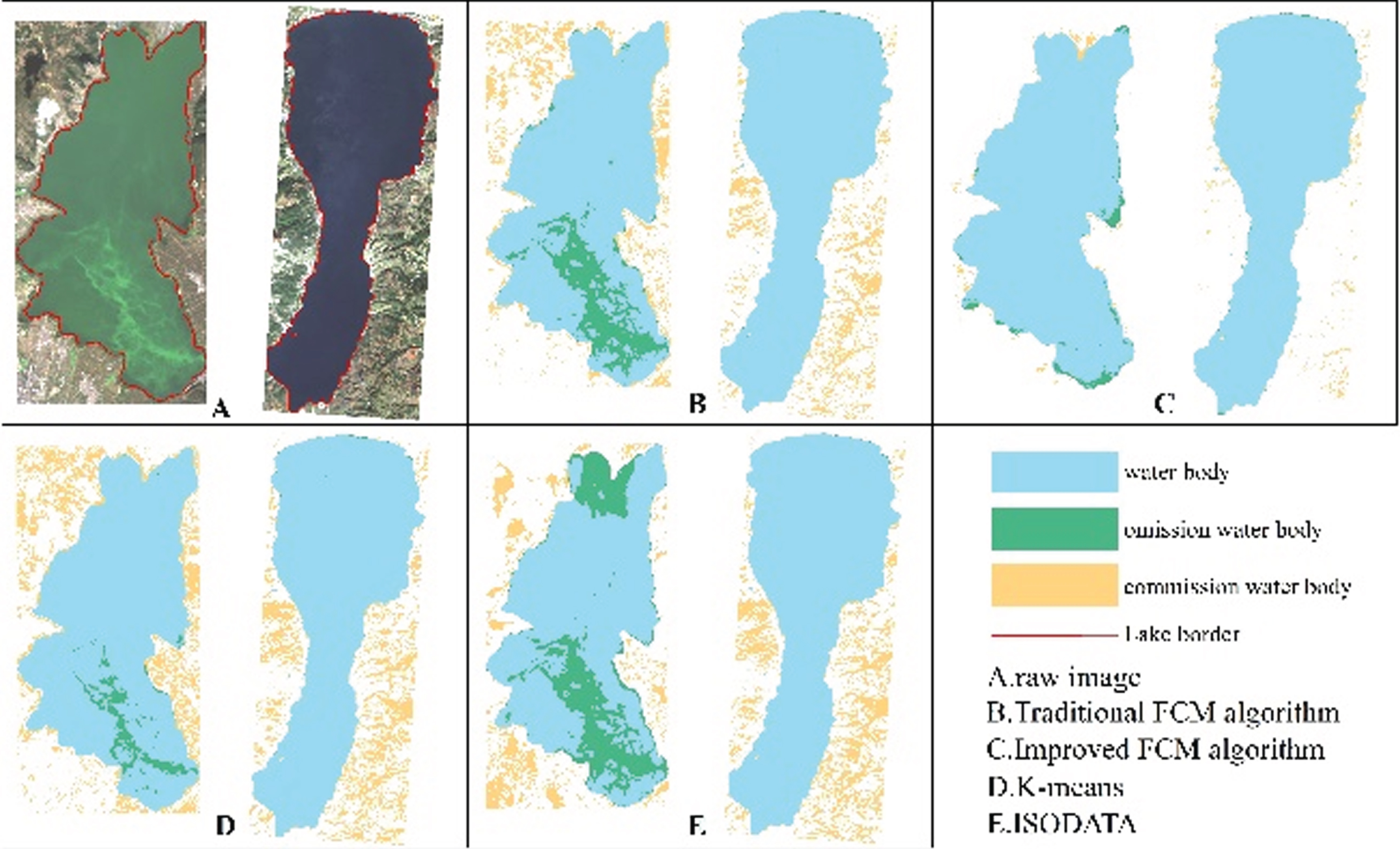
Results of the various classification methods during the dry-water period.
Differences in the classification results under different water quality environments
This study uses Sentinel-2 images as the data source to compare the extraction accuracy and applicability of the proposed improved FCM algorithm during the normal, wet, and dry periods. The water quality environments of Fuxian Lake and Xingyun Lake are quite different. Fuxian Lake has Class I water quality, while Xingyun Lake has only Class IV water quality. Under different water quality environments, water body transparency, biological content, organic suspended matter, the large difference in the spectral information between pixels will have a greater impact on the clustering results. Therefore, different water quality environments are used to test the robustness and universality of the improved FCM algorithm.
Numerous studies have shown that different water quality environments have a certain impact on the classification of water bodies. Wen et al. [37] studied the black-odor water bodies in Nanjing and found that the remote sensing reflectivity of the black-odor water bodies in the city is low, the spectral reflection peaks and valleys are not prominent, and the spectral slope is the smallest within a certain range, which leads to poor classification effects. YuSuFuJiang et al. [38] compared the spectral characteristics of different water body information and found that the commonly used water body information extraction methods cannot meet the needs of dynamic monitoring of inland lakes, so a new water body information extraction method was proposed. In this study, the water quality environment of the Fuxian Lake area is better than that of the Xingyun Lake area, and the spatial difference in water quality is small, which has little impact on the classification effect. However, the water body of Xingyun Lake is in a state of eutrophication throughout the year [39]. The distribution of eutrophication in the water body is different during different water volume periods, which increases the spatial difference between neighboring pixels and has a massive impact on the classification results. Xingyun Lake has more organic suspended matter and algae than Fuxian Lake, which will produce reflection effects in the near-infrared spectrum, making it more difficult to extract the water body of Xingyun Lake. During the dry period of Xingyun Lake, the water volume of the lake is reduced, and the pollutants in the lake are mixed with the water, resulting in the phenomenon of “the same substances with different spectra, different substances with the same spectrum", which causes massive interference to the extraction of spectral information, resulting in a large number of missing pixels in the clustering results. During the rainy season of Xingyun Lake, the input of the river increased significantly, and the total nitrogen content was at the highest level in the year, which increased the pollution of the lake’s water body, resulting in a higher rate of misclassification.
Influence of mountain shadows on classification results
In the process of water extraction, the similarity between the spectral curve of mountain shadows and the spectral curve of water body makes it difficult to distinguish the two, which often leads to large-scale misclassification. Chen et al. [40] used the SVM algorithm to classify the water body information of Nanjing city. Some shadows were mistakenly classified as water bodies. After adding texture information and a DEM, the classification effect was greatly improved. Yin et al. [41] took Erhai Lake as the main research area, using their strong absorption characteristics, which increases the difference between water body and other ground features, effectively suppresses the interference of environmental noise such as buildings and mountain shadows, to extract the water range more accurately. Liu et al. [42] took two inland lakes as the study area and used the spectral bimodal method to determine the water range. The experimental results showed that the bimodal method can eliminate some shadow pixels between land and water. In this paper, SAM is used to cluster the ground objects through the similarity of the angle between the measured spectrum and the image spectrum. The experimental results show that the influence of a certain number of mountain shadows on the clustering results can be overcome by considering SAM. For images with highly dense buildings, there will be building and water mixing, which leads to misclassification. In view of this situation, in future research, we will consider combining the building index or impervious surface data to eliminate the impact of building on water clustering.
The effect of different classification methods on the water extraction accuracy
When clustering remote sensing images, the traditional FCM algorithm considers only the gray characteristics of the fixed neighborhood image. There is no coupling relationship between the spectral information and the spatial information, and the rich neighborhood information in the image is ignored. Therefore, the traditional FCM algorithm is sensitive to noise points and outliers, and there are a large number of abnormal points and noise points in the real surface image. The clustering results have a great impact, so it is very difficult to use the traditional FCM algorithm to cluster remote sensing images. Therefore, the combination of the Mahalanobis distance and spectral information similarity replace the Euclidean distance in the traditional FCM algorithm for clustering, to fully consider the neighborhood spectral information. The experimental results show that the improved FCM algorithm not only keeps the fuzzy classification characteristics of the traditional FCM algorithm but can also better maintain the boundary of lake water bodies and improve the accuracy of water segmentation.
The classification accuracy of the improved FCM algorithm is generally higher than that of the traditional FCM algorithm, unsupervised classification K-means clustering method and ISODATA clustering method. The K-means clustering method is a process of iteratively aggregating pixels using a uniformly distributed initial mean in space by using the minimum distance technique, calculating the mean of each category in each iteration, and finally using the new mean to cluster the pixels. However, there are two problems with the K-means clustering method: it cannot handle categorical data, and it is vulnerable to outliers [43]. Increasing or decreasing the mean value of the region leads to an increase in the classification error of each category. The ISODATA clustering method adds two operations of “merging” and “splitting” to the clustering results based on the K-means algorithm and sets the clustering algorithm for various control parameters. However, the ISODATA clustering method requires more parameters to be set, and different parameters will affect each other. To obtain good clustering results, it is necessary to have the most optimized initial settings of the parameters. The traditional FCM algorithm classifies each pixel by optimizing the membership degree of each pixel to each cluster center. When clustering remote sensing images with high dimensionality, the nonlinear characteristics of their spectral bands make the traditional FCM algorithm unable to achieve better clustering results. Many scholars have studied the problem that the similarity of the image spectrum leads to an unsatisfactory clustering effect. Hong et al. [44] used the image’s spectral heterogeneity measure and proposed a variable neighborhood area FCM algorithm, which effectively reduces the “salt-and-pepper” phenomenon of the traditional FCM algorithm and is better at suppressing background noise. Zhu et al. [45] constructed a new type of index, the temperature vegetation water index (TVWI), by analyzing the reflectivity and principal component characteristics of water bodies and different ground objects. This index has a high degree of discrimination between water bodies and nonwater bodies and has a high extraction accuracy for different types of lake water bodies. Wang et al. [46] used the minimum variance technique to adjust the gray value of the multispectral band involved in fusion to reduce the color difference, and the transformed image obtained a higher accuracy when the water body was extracted. The improved FCM algorithm proposed in this paper uses SAM to map the measured spectral vector into a series of angle values representing the similarity between the vector and the reference spectral vector, realizing the conversion from the measurement space to the feature space, increasing the separability between each category, and improving the accuracy of the clustering algorithm [36].
The algorithm proposed in this paper still has a problem to be improved: it needs to rely on certain prior knowledge in advance when determining the number of initial clusters, which affects the unsupervised performance of the clustering algorithm and substantially increases the calculation time. In future research, the sliding window algorithm with reference to mean shift clustering will be considered to find the dense area of data points, and finally, the center point and the corresponding grouped data will be obtained to improve the computational efficiency of the algorithm.
Conclusion
The traditional FCM algorithm does not fully consider the spectral information of the neighborhood in the image clustering, which leads to its sensitivity to noise points. First, the Lee filter is used to suppress the shadow and noise of the image, and then the traditional FCM algorithm is improved. To obtain a higher precision of lake water extraction, the improved FCM algorithm first uses remote sensing images as the data source after image enhancement processing, replaces the Euclidean distance of the traditional FCM algorithm with the Mahalanobis distance and SAM, and assigns different weights to the Mahalanobis distance and SAM. The proposed method iteratively calculates the cluster centers and stops when the iterative conditions are met, and finally obtains the water clustering results. Images of Fuxian Lake and Xingyun Lake in different water quantity periods and with water quality environments are selected. The improved FCM algorithm, traditional FCM algorithm, K-means clustering method and ISODATA clustering method are used to carry out relevant experiments and extraction accuracy comparisons. From the experimental results, it can be concluded that the classification accuracy of the improved FCM algorithm proposed in this paper is better than that of the traditional FCM algorithm, ISODATA clustering method and K-means clustering method in the Fuxian Lake and Xingyun Lake areas, and the omission error and commission error are lower than those of the other classification algorithms. The proposed improved FCM algorithm has a higher extraction accuracy in deep lake areas with good water quality than in heavily polluted plateau shallow lakes, while in heavily polluted plateau shallow lake areas, the improved FCM algorithm has a much higher extraction accuracy than the other three categories. The extraction effect is better than that of the other three methods.