Vertex classification is an important graph mining technique and has important applications in fields such as social recommendation and e-Commerce recommendation. Existing classification methods fail to make full use of the graph topology to improve the classification performance. To alleviate it, we propose a Dual Graph Wavelet neural Network composed of two identical graph wavelet neural networks sharing network parameters. These two networks are integrated with a semi-supervised loss function and carry out supervised learning and unsupervised learning on two matrixes representing the graph topology extracted from the same graph dataset, respectively. One matrix embeds the local consistency information and the other the global consistency information. To reduce the computational complexity of the convolution operation of the graph wavelet neural network, we design an approximate scheme based on the first type Chebyshev polynomial. Experimental results show that the proposed network significantly outperforms the state-of-the-art approaches for vertex classification on all three benchmark datasets and the proposed approximation scheme is validated for datasets with low vertex average degree when the approximation order is small.
With the rapid popularity of social networks such as Facebook, Twitter, Weibo, and WeChat, a large amount of structured and semi-structured data are continuously being produced [1]. These data have huge commercial value and thus attract more and more researchers’ attention to graph mining [2]. As a representative of graph mining, the vertex classification problem studies how to infer labels of unlabeled vertices in a given graph with a small number of vertices labeled. Solutions to this problem have many applications in fields such as social network recommendation, e-Commerce recommendation, and sociological study of communities [3].
However, it is difficult, if not possible, to make high-quality predictions because the number of labeled samples in the dataset to be classified is much smaller than that of unlabeled ones [1]. There are many reasons. First, labeling data samples often requires human support and thus is expensive. For instance, item recommendation in e-Commerce often relies on users to score the product they bought, but no one want do this without reward [4]. Second, labeling data samples may threaten user’s privacy. For example, political affiliation prediction in a social network depends on users’ political views, but most are reluctant to share this sensitive information. Traditional supervised classification techniques such as the support vector machine [5] and k-nearest neighborhood [6] often rely on a large number of labeled samples to train and thus can not be applied to solve this problem.
Recently, researchers have proposed graph-based semi-supervised learning techniques by making use of graph topology information to improve the classification performance based on two essential assumptions. One is the local consistency that adjacent vertices are likely to have similar labels; the other one is the global consistency that vertices with the same context may have similar labels [7]. Existing graph-based semi-supervised learning methods can be classified into two categories: (1) graph-based regularization ones such as LP (Label propagation) [7]; and (2) graph embedding ones such as DeepWalk [8], LINE [9], and node2vector [10]. Deep Learning (DL) is a subset of Machine Learning that uses numerous layers of algorithms similarly to the way neurons are used in the human brain [11]. As DL techniques such as CNN and RNN have made breakthroughs in image recognition [12], video processing [13], and natural language processing [14], some researchers are trying to transplant them to irregular graphs. For example, Gori et al. [15] pioneered the research of graph neural networks and proposed the recursive graph neural network Gori GNN (Graph Neural Network) based on message passing and then various types of graph neural networks sprang up like bamboo shoot. The ones closely related to our work can be classified into two kinds: (1) spatial-based graph convolutional network such as GraphSage [16]; and (2) spectral-based graph convolutional networks such as Spectral GCN (Graph Convolutional Network) [17], ChebyNet [18], GCN [19], GWNN (Graph Wavelet Neural Network) [20], and DGCN (Dual Graph Convolutional Network) [1]. All these graph neural networks [1, 15–20] extract vertex feature representations by stacking multiple hidden layers and fed them into the output layer to obtain the prediction results.
In summary, traditional supervised learning methods [5, 6] are not suitable to solve the vertex classification problem because the number of labeled vertices is limited; graph-based semi-supervised learning methods [7, 10] have multi-step pipelines and thus are hard to optimize; graph neural networks [15–19] have poor classification accuracies as they do not make full use of unlabeled vertices; graph neural networks [1, 20] improve classification accuracies by introducing regularization terms that reflect sample distributions to objective functions of their output layers. Inspired by [1, 20], we propose a Dual Graph Wavelet Neural Network (DGWN) for the vertex classification problem. DGWN consists of two identical graph wavelet neural networks with shared network parameters. These two networks are integrated by a semi-supervised loss function and conduct supervised learning and unsupervised learning on two matrixes, respectively. These matrixes are extracted from the same graph dataset with different levels of consistency information embedded. Experimental results show that our proposed network outperforms state-of-the-art classification methods on all three benchmark datasets. The main contributions of this work are as follows:
We propose a dual graph wavelet neural network composed of two identical graph wavelet neural network sharing network parameters. This design combines the advantages of supervised learning and unsupervised learning to improve the classification accuracy.
We design an algorithm to construct the Positive Pointwise Mutual Information (PPMI) matrix from the raw graph dataset based on the random walk and random sampling. The PPMI matrix embeds the global consistency information of the graph.
We define the graph convolutional operation by using the graph wavelet transform. The sparsity of graph wavelets makes it much more computational efficient; the locality of graph wavelets makes the proposed DGWN have a good classification performance.
We present an approximate scheme to calculate the bases of the graph wavelet transform and its inverse based on the Chebyshev polynomial. It can significantly reduce the complexity of the proposed network with tolerable performance degradation.
The rest of this work is organized as follows: Section 2 formulates the vertex classification problem; Section 3 introduces the detailed design of the proposed DGWN; Section 4 analyzes the parameter complexity of the proposed network and presents an approximate scheme for calculating the bases of the graph wavelet transform and its inverse; Section 5 validates the performance of the proposed network through a series of experiments; Section 6 reviews the related work on the vertex classification problem; Section 7 concludes this work.
Graph-based Semi-supervised Classification Problem
Graph data modeling
Data generated from social network platforms can naturally be represented as graphs. They can be weighted or unweighted, directed or undirected, connected or disconnected. In this work, we assume that the graph is weighted and undirected and denote it as =(V, E, A), where V = {v1, v2, . . . , vn} and E ={eij|vi, vj∈ V } are the set of vertices and edges, respectively; and A is the adjacent matrix with element aij representing the weight of edge eij. Each vertex vi ∈ V has d attributes and all attributes of all vertices form the vertex feature matrix X ∈ Rn×d. Every column vector x = {x1, x2, . . . , xd}∈Rd of X is a graph signal with xi denoting the values of the ith attribute of all vertices. In addition, a small number of vertices in the graph have labels. We denote the labeled and unlabeled vertex sets as VL and VU, respectively, where VL ∪ VU = V, VL∩ VU = Ø, and |VL| ⪡ |VU|. ∀v ∈ VL, we denote its label as y ∈ { 0, 1 } |C| with C be the set of all possible labels.
Problem formulation
Given an undirected weighted graph with a small subset VL of labeled vertices, the vertex classification problem is to infer the label y ∈ { 0, 1 } |C| of each unlabeled vertex v ∈ VU. Note that some researchers assume that labels of labeled vertices are changeable during the inference process and then the goal is to predict labels of all vertices. We do not make this assumption in this work. The above problem can be modeled as a graph-based semi-supervised learning problem, the key to which is the consistency assumption. Often there are two consistency assumptions. One is the local consistency assumption that adjacent vertices may have the same label and the other one is the global consistency assumption that the vertices with the same context may have the same label. Assume that the loss functions of semi-supervised, supervised, and unsupervised learning are denoted as , and , respectively, then we have:
where α∈ (0, 1) is a dynamic weighting factor; the design of and are closely related to the specific classifier. They will be discussed in Section 3.5.
Traditional classification method
We introduce the fundamental of the spectral-based GCN, which lays foundations for our proposed DGWN presented in Section 3. The core operation of the spectral-based GCN is the spectral graph convolution. It is defined in the Fourier domain through computing the eigendecomposition of the graph Laplacian matrix [21]. For a graph signal x ∈ Rn defined on graph , the graph Fourier transform and its inverse of this signal are defined as and , respectively, where U = (u1, u2, …, un) are the eigenvectors of the graph Laplacian matrix. Then we can define the graph convolutional operation *G as:
where ⊙ is the Hadamard product and g (Λ) is a diagonal matrix with Λ = {λ1, λ2, …, λn} being the corresponding eigenvalues of U. Often a spectral-based GCN learns embedding representations of vertices by stacking multiple graph convolutional layers and feeds them into the output layer to predict their labels.
Evaluation metrics
We establish a set of evaluation metrics including accuracy ac, precision pr, recall rate rc, and F1 score, to evaluate the performance of classifiers. Assume that (1) the graph dataset ) for testing has |Ctest| labels; and (2) the ratio of the number of vertices with label ci (ci ∈ Ctest) to the number of all vertices is denoted as γi ∈ (0, 1), which satisfies ∑ci∈ctest
γi = 1. Regarding each category as positive and the rest as negative, we can define the above four evaluation metrics as follows: (1) accuracy ac measures how many observations are correctly classified. It can be computed as , where TPi, TNi, FPi, FNi represent the number of true positives, true negatives, false positives, and false negatives, respectively. (2) precision pr measures how many observations predicted as positive are actually positive. It can be computed as . (3) recall rate rc measures how many observations out of all positive observations have we classified as positive. . (4) F1 score is the harmonic mean between precision and recall and can be calculated as .
Graph-based Semi-supervised Classification Problem
An overview of the DGWN
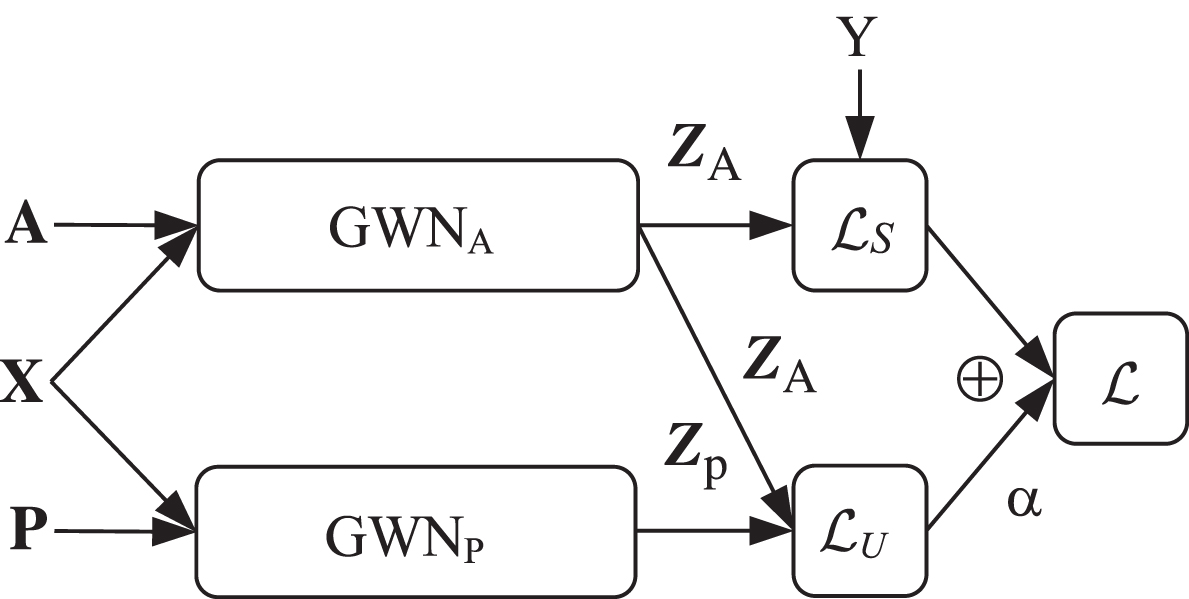
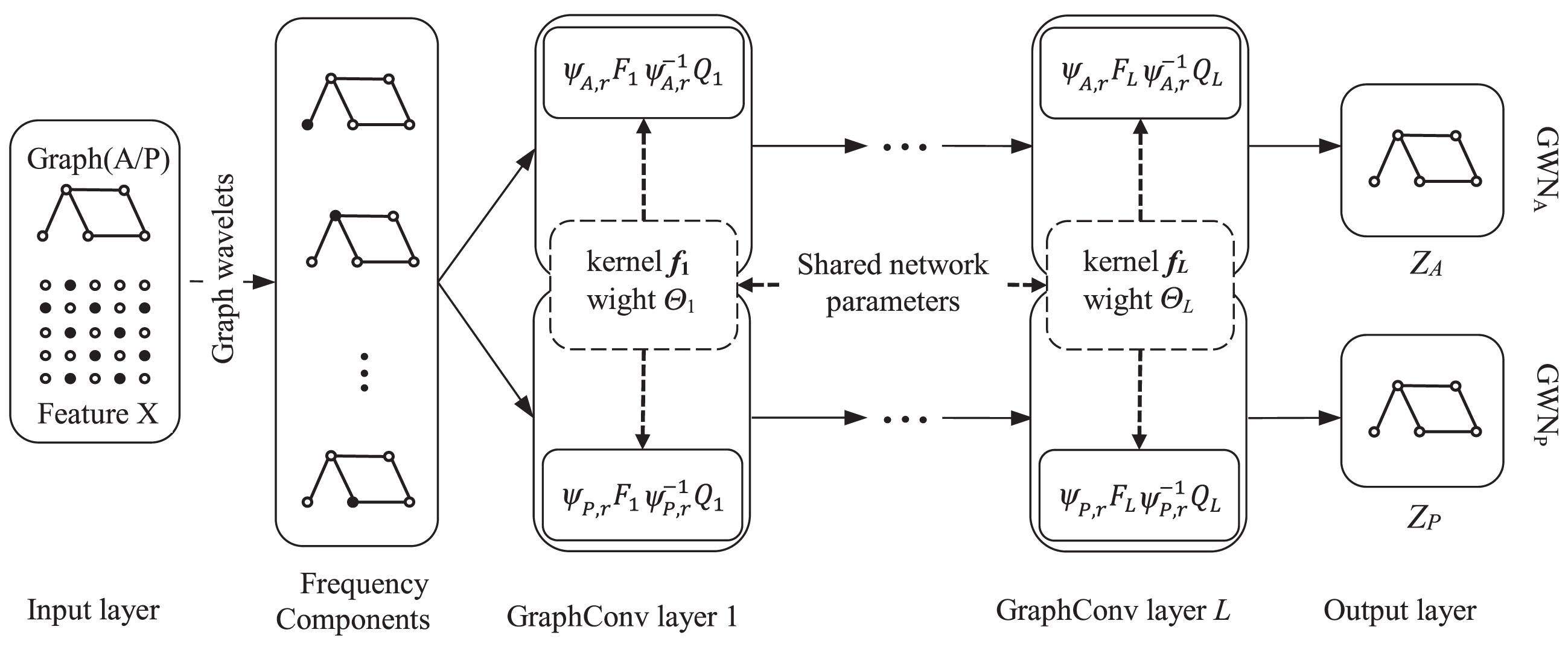
We can see from Figs. 12 that the proposed DGWN is composed of two identical graph wavelet neural networks GWNA and GWNP sharing network parameters. Each GWN is composed of an input layer, L graph convolutional layers, and an output layer, the principle of which will be presented in Section 3.2, 3.3, and 3.4, respectively. For GWNA, it takes as input the adjacency matrix A embedding the local consistency information of the graph, the vertex feature matrix X, and label matrix Y to conduct supervised learning and output the label prediction matrix ZA. For GWNP, it takes as input the PPMI matrix P embedding the global consistency information of the graph and X to conduct unsupervised learning and output the label prediction matrix ZP. The semi-supervised loss function that integrates these two networks is a weighted sum of the supervised learning loss and unsupervised learning loss, the definitions of which will be introduced in Section 3.5.
An overview of the architecture of the proposed DGWN.
Input: graph adjacent matrix A ∈ Rn×n; path length u; window size s; number of walks per vertex m;
Output: vertex co-occurrence count matrix O
1: VCC()1
2: { Oij ← 0, i, j ∈ [1, n] //Initialize O with zeros
3: Ω← Ø;
4: foreach vertexvi ∈ Vdo
5: { foriter in rangedo
6: { πi← RandomWalk (A, vi, u) ; //obtain a path with vi as the path root according to Equation (6)
7: Ω← uniform_pair_sampling (πi, s);
8: for each pair (vj, vk) ∈ Ωdo
9: Ojk ← Ojk + b, Okj ← Okj + b;
10: }
11: }
12: }
13: }
Graph wavelet transform and graph convolution
In this section, we introduce the graph convolutional operation based on the graph wavelet transform. As GWNA and GWNP have the same structure, unless stated otherwise, we do not distinguish them in the rest of this section. Assume that Ψr={ψr1, ψr2, … , ψrn } is a basis of the graph wavelet transform. ψri represents an energy signal diffusing from vertex vi. It describes the local neighborhood structure of vi with r being a scaling factor. Ψr can be computed as Ψr = UGrUT, where U is the graph Fourier transform basis and ) is a scaling matrix with g (rλi)=e
λir. Using the graph Fourier transform introduced in Section 2.3 for reference, we can define the graph wavelet transform and its inverse of a graph signal x as and , respectively, where =UG-rUT and G-r is obtained by replacing rλi with-rλi. Then the graph convolutional operation *G based on the graph wavelet transform can be obtained by substituting the graph wavelet transform basis Ψr for the graph Fourier transform basis U in Equation (2):
where gθ (Λ) is computed by diagonalizing the spectral graph wavelet-kernel . To reduce the network parameter complexity, we break down the graph convolutional operation of the lth layer (1≤l≤L) into two parts, feature transformation and graph convolution [20]. They are defined as:
where Θl is the feature transformation matrix of the lth layer; Hl and Hl+1 are the input and output of the lth graph convolution layer; Fl is the diagonal matrix obtained by diagonalizing the spectral graph wavelet-kernel fl = (fl1, fl2, …, fln) of the lth layer.
Construction of graph topology representation matrix
The most commonly used graph topology representation matrix is the adjacency matrix A ∈ Rn ×n. It encodes the local consistency information of the graph, that is, the labels of two adjacent vertices may be the same. For the global consistency information, we use the positive pointwise mutual information matrix P ∈ Rn×n to embed it. The row vector pi,: is the embedded representation of the vertex vi; the column vector p :,j is the embedded representation of the context ctj ; pij represents the probability that the vertex vi appears in the context ctj. The matrix P can be obtained by random walk on the graph. Assume that the context ctj of the vertex vj is represented as a path πj with vj being the root node and a length of u, we can calculate pij as the frequency at which the vertex vi appears on the path πj. Suppose that the vertex index where a random walker locates at time τ is denoted as x (τ) and x (τ) = vi, then the probability tij of the random walker walking to its neighbor vertex vj at time τ + 1 is:
Performing random walk of length u on each vertex of the graph according to Equation (6) generates the path π representing the context of the vertex. Then vertex-context co-occurrence matrix O can be obtained by calculating the number of co-occurrences of any two vertices on each path by using the random sampling. ∀oij ∈ O, it represents the number of times that the vertex vi appears in the context ctj and can be used to calculate pij. Algorithm 1 gives a pseudo-code of obtaining the vertex-context co-occurrence matrix.
Theorem 1.The time complexity of Algorithm 1 is O (nmu2).
Proof. Algorithm 1 includes triple nested for-loops, which requires n, m, and u2 iterations, respectively. Thus, the time complexity of Algorithm 1 is O (nmu2). Proofed.
Based on the vertex co-occurrence matrix O, we can calculate the co-occurrence probability of the vertex and the context and the corresponding marginal probabilities. Assume that these three probabilities are denoted as pr (vi, ctj) , pr (vi) and pr (ctj), then we have:
According to Equation (7), the value of pij of the positive point-by-point mutual information matrix P can be obtained by the following equation:
Algorithm 2 DGWN)
Input: vertex feature matrix X ∈ Rn×d; graph topology matrix A ∈ Rn×n and P ∈ Rn×n; the indices of training data
for masking YL; dynamic weight function α (t); the number of graph convolution layer L;
Output: the trained model including feature transformation matrix Θl; spectral attention weights fl
5: { for each graph convolution layer l in range [0, L] do
6: { ;//Calculate output of layer l according to Equations (4) and (5)
7: ; //Calculate output of layer l according to Equations (4) and (5)
8: }
9: ;
10: ;
11: Λ ← Λs + αΛU;
12: Θl, Wl, fl← Adam_updating(Λ, Θl, Wl, fl);
13: ifconvergedthen
14: break;
15: }
16: }
The vertex classification layer
We select the softmax function to define the output layer of the GWN. The function takes as input the output of the Lth graph convolution layer and outputs the predicted label of each unlabeled vertex:
where and Z is an n * |C| dimensional matrix representing the prediction result with each column vector Zj denoting the probability of all vertices having label cj (cj∈C). Because the difference between ZA of GWNA and ZP of GWNP is negligible at the end of neural network training, we may as well take ZA as the output of the entire neural network.
The semi-supervised loss function
The two graph wavelet neural networks GWNA and GWNP are integrated by a semi-supervised loss function, which is defined as the dynamic weighted sum of supervised learning loss of GWNA and unsupervised learning loss of GWNP. For , we define it according to the cross-entropy as:
For , we define it as follows to ensure GWNA and GWNP output consistent prediction results by minimizing the difference between ZA and ZP as much as possible:
The cross-entropy-based unsupervised loss function defined in Equation (11) can be regarded as training ZP and ZA by interpreting ZA as a posterior distribution over |C| labels when GWNA is trained. Then we can obtain the loss function of DGWN by combining Equations (1), (10), and (11):
where α (τ) is a temporal function of training step τ for. dynamically adjusting the relative importance of supervised and unsupervised learning at different stages. In the beginning, is dominated by the supervised learning loss. As the training process proceeds, increasing α (τ) along with τ will force the proposed DGWN to consider the knowledge learned by GWNA on unlabeled samples.
DGWN training algorithm
The proposed DGWN is composed of two graph wavelet neural networks. They are in fact feed-forward neural networks and thus can be trained by using gradient descent methods such as the Batch Gradient Descent (BGD) and Stochastic Gradient Descent (SGD). As BGD has good convergence, we design an algorithm based on it to train our proposed network. Algorithm 2 presents the pseudo-code of our proposed training algorithm.
Theoretical analysis and optimization
Network complexity analysis
Theorem 2.The parameter complexity of the lth graph convolution layer of the DGWN is O (n + pl × pl+1).
Proof. Based on the definition of DGWN in Section 3, the lth (1 ≤ l ≤ L) graph convolution layer of each GWN contains n + pl × pl+1 parameters, where n is the total number of vertices of and pl is the number of features of each graph vertex has on the lth layers. As GWNA and GWNP share network parameters, parameter complexity of the lth layer of DGWN is O (n + pl × pl+1).
Approximation scheme for the graph wavelet transform
Calculating the bases of the graph wavelet transform and its inverse involve costly matrix eigendecomposition, the time overhead of which is unbearable for big graphs. To alleviate it, Hammond et al. [22] approximated ψr and by using the first type Chebyshev polynomial. Its specific process is as follows:
The first type Chebyshev polynomial is defined as a set of orthogonal polynomials: Tk (x) =2xTk−1 (x) − Tk−2 (x), where T0 = 1 and T1 = x. ∀x ∈ [–1, 1] , Tk (x) = cos (karccos (x)) and Tk (x) ∈ [–1, 1]. For each real-valued function h in a square-integrable Hilbert space ), we can construct a uniformly convergent Chebyshev series with Chebyshev coefficients . ∀x ∈ [0, λmax], the Chebyshev polynomials can be transformed to with the help of domain shifting by using the transformation x = a(y + 1), where and [–1,1]. Then we can approximate g (rx) as , where x ∈ [0, λmax] and . Truncating this Chebyshev expansion to K terms can obtain the approximation of the graph wavelet transform of graph signal x ∈ Rn:
where can be efficiently computed according to without matrix eigendecomposition.
Evaluation results
Experiment setup
(1) Dataset. The Citeseer dataset contains 3327 scientific publications and 4732 citation links between them. Publications and their citations form a citation network, where publications are divided into six categories and each of them is encoded by using the one-hot encoding scheme. The Cora dataset contains 2708 scientific publications and 5429 citation links between them. In its citation network, all the publications are divided into three categories and every publication is also encoded by using the one-hot encoding scheme. The Pubmed dataset contains 19,717 scientific publications and 44,338 citation links between them. In its citation network, all the publications are divided into three categories and every publication is encoded by a Term Frequency-Inverse Document Frequency (TF-IDF) vector derived from a dictionary consisting of 500 terms. Their detailed information is summarized in Table 1, where the label rate represents the proportion of labeled vertices for training.
Graph Datasets Summary
Dataset
#Vertices
#Features
#Edges
Average vertex degree
#Classes
Label rate
Citeseer
3327
3703
4732
2.84
6
0.036
Cora
2708
1433
5429
4.01
7
0.052
Pubmed
19717
500
44338
4.50
3
0.003
(2) Baselines. To validate the performance of our proposed network, we select several state-of-the-art baselines with public source codes for comparisons. Their brief introductions are as follows:
DeepWalk regards a path generated by random walk on a graph as a “sentence” and applies the word sequence modeling technology in natural language processing to the path to obtain the vertex embedding. The source code of DeepWalk is publicly available
1
. LP [7] regards the vertex classification as the propagation of labels from labeled vertices to unlabeled ones on a graph. It is simple and easy to implement. Planetoid. Inspired by the Skip-Gram model [23],
PLANETOID [24] embeds graph topology and label information by using the positive and negative samplings. The source code of PLANETOID is publicly available
2
. Spectral CNN [17] defines the graph convolutional operation based on the graph Fourier transform to obtain embeddings of all vertices. ChebyNet [18] defines the graph convolutional operation by using K-order polynomial to obtain the embeddings of all vertices. The source code of ChebyNet is publicly available
3
. GCN [19] simplifies the ChebyNet network by using a first-order polynomial to define the graph convolutional operation. The source code of GCN is publicly available
4
. GWNN [20] defines graph convolutional operation by using the graph wavelet transform to obtain the embeddings of all vertices. The source code of GWCN is publicly available
5
. DGCN [1] consists of two GCNs sharing parameters. The source code of DGCN is publicly available
6
.
(3) Platform. The model of our hardware server is Inspur NF5280M5. It has two Intel Xeon Platinum 8270 processors, 754GB memory, 26TB hard drives, and four NVIDIA Tesla V100 GPUs. Its operating system is CentOS Linux 7.8.2003 and the compiler is GCC 4.8.5-44.
We implement the proposed DGWN by using Theano 1.0.4
7
and use the Xavier parameter initialization method proposed by Glorot and Bengio [25] to initialize network parameters including Θl and fl. We trained and optimized the network by using Algorithm 2. In addition, we adopt the dropout method proposed by Srivastava et al. [26] to avoid over-fitting.
We establish a DGWN composed of two graph convolutional layers and train it on the aforementioned three graph datasets. They are partitioned into a training dataset, a test dataset, and a validation dataset by using the partitioning method proposed by Kipf and Welling [19]. The training process is terminated when the verification loss does not decrease for 50 consecutive epochs.
Experiments and result analysis
Experiment 1 (Classification Accuracy Validation) This experiment is designed to validate classification accuracy of the proposed network on different datasets. Best results are reported and the value of hyper-parameters on different datasets obtaining the best results are shown in Table 2. For comparisons, we implement the aforementioned nine classification methods and record their best results. Experimental results are shown in Table 3.
Optimal values of hyper-parameters on different datasets
Dataset
Citeseer
Cora
Pubmed
Hidden size
128
64
16
Learning rate
0.1
0.8
1
Dropout rate
0.5
0.9
0.1
Scale
0.5
1
2
Comparisons of vertex classification accuracy of different methods
We can see from Table 3 that our proposed DGWN performs the best on all three datasets. DeepWalk and LP perform poorly on all three datasets, which agrees with the view mentioned in Section 1 that “graph-based semi-supervised learning methods have low classification accuracies”. Compared with PLANETOID, Spectral CNN performs better on all three datasets although they use similar sampling strategies to embed both the graph topology and label information. One possible reason is that the sampling strategy used by PLANETOID is too simple to fully embed all the known information. However, Spectral CNN performs worse than ChebyNet and GCN because the graph convolutional operation in Spectral CNN does not well meet the consistency assumption. GWNN improves classification accuracy over GCN by replacing the graph Fourier transform in GCN with the graph wavelet transform. DGCN is the-state-of the-art and achieves the highest classification accuracy on all three datasets by using a dual neural network architecture that integrates two GCNs with a semi-supervised loss function. This design enables DGCN consider the global consistency information for each vertex. Compared with DGCN, our proposed DGWN improves the classification accuracies on three datasets by 2.70%, 0.60%, and 1.20% respectively, by replacing the GCNs in DGCN with GWNs. There may be two reasons: (1) the basis of the graph wavelet transform better meets the locality assumption than that of the graph Fourier transform; and (2) the scaling parameter can adjust diffusion ranges of graph signals to best describe each vertex’s neighborhood or context.
Experiment 2 (Influence of network hyper-parameters on classification accuracy) This experiment is designed to study the influence of network hyper-parameters on classification accuracy. Hyper-parameters considered include the learning rate, the dropout rate, the scale parameter, and the hidden layer size. For each hyper-parameter, we vary it from a list of typical values and record the corresponding classification results on Cora with the other hyper-parameters set to the optimal values shown in Table 2. Experimental results are shown in Table 4.
Influence of network hyper-parameters on the classification accuracy
(a) Hidden size
hiddenSize
Classification Accuracy
16
78.1%
32
81.0%
64
84.1%
128
83.4%
256
82.1%
(b) Dropout rate
DropoutRate
Classification Accuracy
0.10
69.7%
0.20
66.9%
0.30
61.3%
0.40
70.5%
0.50
65.2%
0.60
65.2%
0.70
82.4%
0.80
80.1%
0.90
84.1%
(c) Learning rate
LearningRate
Classification Accuracy
0.10
78.6%
0.20
83.5%
0.30
83.7%
0.40
82.3%
0.50
82.9%
0.60
83.7%
0.70
82.9%
0.80
84.1%
0.90
82.3%
1
82.8%
(d) Scale
Scale
Classification Accuracy
0.10
31.8%
0.20
57.2%
0.30
54.2%
0.40
78.4%
0.50
81.1%
0.60
83.3%
0.70
83.8%
0.80
83.3%
0.90
82.4%
1.00
84.1%
We can see from Table 4 that the scale parameter of the wavelet function has the biggest impact on the accuracy of the network vertex classification, followed by the dropout rate, the hidden layer size, and the learning rate. This is because that the Mean Squared Errors (MSEs) of the classification accuracies of the four hyper-parameters are 0.000211, 0.000788, 0.000148, and 0.001710, respectively. In addition, we find that classification accuracy is not a monotonic function of any hyper-parameter. Taking the hidden layer size hyper-parameter for example, the classification accuracy increases from 78.1%when hidden layer size is 16 to 84.1%when hidden layer size is 64 and then drops rapidly. For the other hyper-parameters, larger values are recommended.
Experiment 3: (Performance of the Chebyshev polynomial approximation scheme) This experiment is designed to validate the time efficiency of the Chebyshev polynomial approximation scheme and to study its influence on classification accuracy. We compare the mean training time per epoch of the original DGWN and DGWN using K-order Chebyshev polynomial as its propagation rule (denoted as DGWN-Cheby-K) over 300 epochs on different datasets and record their best classification accuracies. Experimental results are shown in Tables 56.
Comparison of the time efficiency of different propagation models
Time (s/epoch)
Citeseer
Cora
Pubmed
DGWN
1.718
2.979
1710.131
DGWN-Cheby-K(K = 2)
2.237
1.906
256.040
DGWN-Cheby-K(K = 3)
3.411
4.626
1013.290
DGWN-Cheby-K(K = 4)
3.264
5.538
3845.382
Classification accuracies of DGWN-Cheby-K
Classification Accuracy
Citeseer
Cora
Pubmed
DGWN-Cheby-K(K = 2)
65.4%
69.1%
68.0%
DGWN-Cheby-K(K = 3)
56.9%
57.1%
61.2%
DGWN-Cheby-K(K = 4)
57.9%
56.5%
61.5%
We can see from Table 5 that the Chebyshev polynomial approximation scheme can effectively accelerate the graph wavelet transform and its inverse on graph datasets with larger vertex average degrees and is counterproductive on graph datasets with smaller vertex average degrees. For example, when K = 2 the mean training time per epoch of DGWN-Cheby-K on Cora and Pubmed decrease 36.0%and 85.0%respectively than that of DGWN. However, the mean training time per epoch of DGWN-Cheby-K on Citeseer increases by 30.2%than that of DGWN. Compared with DGWN, the classification accuracies of DGWN-Cheby-K on all three datasets are still acceptable with a decrease of 9.9%, 15.0%and 13.2%respectively. With the increase of the approximation order, the mean training time per epoch of DGWN-Cheby-K on three datasets increases rapidly and even exceeds that of DGWN and the classification accuracies of DGWN are even worse. This shows that the Chebyshev polynomial approximation scheme is only valid when K is small.
Related work
Our proposed DGWN for vertex classification draws inspiration from graph-based semi-supervised learning and graph neural networks. The research progress in the above two fields is summarized as follows.
Graph-based semi-supervised learning. Graph-based semi-supervised learning methods can be classified into two categories: graph-based regularization ones and graph-based embedding ones. The former employs various graph regularizations to make embeddings of data samples smooth on local neighborhoods by assuming that data samples are located in low-dimensional manifolds. For instance, El Traboulsi et al. [27] propose a Kernel version of the Flexible Manifold Embedding (KFME) for pattern classification. The KFME formulation uses the graph Laplacian smoothness term to smooth the label inference. Recently, graph-based embedding technology has gained more and more attention from researchers due to the great success of the Skip-Gram model [23] in natural language processing. Perozzi et al. [8] propose a DeepWalk algorithm for learning embeddings of graph vertices by applying the Skip-Gram model to the truncated vertex random walk sequence. The LINE algorithm [9] and the node2vec algorithm [10] extend the DeepWalk algorithm by using more complex random walk strategies and by using breadth-first search frameworks, respectively. These methods [8–10] are difficult to optimize because they have multiple steps such as random walk generation and semi-supervised training. To alleviate it, Yang et al. [24] propose a novel graph-based semi-supervised learning algorithm named Planetoid with label information injected in the embedding process.
Graph neural network. Graph neural networks are deep learning frameworks dedicated to graph data. Those closely related to this work are graph convolutional neural networks and graph wavelet neural networks.
(1) Spatial-based graph convolution neural network. It directly defines the graph convolutional operation in the vertex domain for aggregating features of neighbors of a target vertex. Gori GNN [15] uses the contraction mapping function as the propagation rule to iteratively aggregate information among adjacent vertices until vertex representations reach the stable state. However, it has a long-term dependence problem. To solve it, Li et al. [28] introduce a recurrent neural network training algorithm into Gori GNN and propose the GGS-NN (Gated Graph Sequence Neural Network). Hamilton et al. [16] propose a graph neural network named GraphSage. Instead of considering all neighbors of a target vertex, GraphSage randomly samples a fixed number of neighbors of every vertex and aggregates their features with the maximum or mean aggregation functions.
(2) Spectral-based graph convolution neural network. Instead of explicitly using information propagation mechanisms on graphs, this type of graph neural networks defines graph convolutional operation in the spectral domain with the help of the convolution theorem. Bruna et al. [17] pioneer the research of spectral-based graph convolutional neural network and propose the Spectral GCN (Spectral Graph convolutional network). Because the convolutional operation requires the eigendecomposition of the graph Laplacian matrix, this network has the problem of high temporal and spatial complexity. To alleviate it, Defferrard et al. [18] propose the ChebyNet with the k-order Chebyshev polynomial being the propagation rule to aggregate the features of neighbors of a target vertex. To further simplify the ChebyNet, Kipf and Welling [24] propose the GCN by truncating the Chebyshev polynomial to one order. Zhuang and Ma [1] propose the DGCN by combining two parallel GCNs to embed the local and global consistency information of the graph topology, respectively. This network currently reports the highest classification accuracies on three benchmark datasets including Citeseer, Cora, and Pubmed. However, all these spectral-based graph convolutional neural networks [1, 25] have the problem that their graph convolutional operations do not well satisfy locality consistency.
(3) Graph wavelet neural network. Wavelets are being used for analyzing signals, fast algorithm for easy implementation, and time–frequency analysis [29]. Xu et al. [20] propose the Graph Wavelet Neural Network (GWNN) by replacing the graph Fourier transform with the graph wavelet transform in GCN. The sparsity and locality of graph wavelets makes the GWNN have good classification accuracy and time complexity.
Conclusions
In this work, we have proposed the DGWN composed of two identical GWNs sharing network parameters for the problem of vertex classification. This dual-network architecture design enables DGWN to combine the advantage of supervised learning and unsupervised learning to learn good embeddings of graph vertices with local and global consistency knowledge embedded. The sparsity and locality of graph wavelets ensure the impressive performance of DGWN. Experimental results show that the first type Chebyshev polynomial approximation scheme is only validated for graph datasets with low vertex average degree and small K. In future work, we will study more effective approximation schemes.
Footnotes
Acknowledgments
This work was supported by the Key Project of Research & Development Plan by the Science and Technology Department of Shandong Province under grant No. 2019TSLH0201.
References
1.
ZhuangC. and MaQ., Dual graph convolutional networks for graph-based semi-supervised classification. In Proceedings of the 2018 World Wide Web Conference, 2018, pp. 499–508.
2.
WuZ., PanS., ChenF. and Long.G., A comprehensive survey on graph neural networks, IEEE Transactions on Neural Networks and Learning Systems, 2020.
3.
BhagatS., CormodeG. and MuthukrishnanS., Node classification in social networks, Springer, Boston, USA: Social network data analytics, 2011.
4.
YuX., MaH., HsuB-J. and HanJ., On building entity recommender systems using user click log and freebase knowledge. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, 2014, pp. 263–272.
5.
GuentherN. and MatthiasS., Support vector machines, The Stata Journal16(4) (2016), 917–937.
6.
ZhangS., LiX., ZongM., et al., Learning k for kNN classification, ACM Transactions on Intelligent Systems and Technology8(3) (2017), 1–19.
7.
ZhuX., GhahramaniZ. and Lafferty.J., Semi-supervised learning using Gaussian fields and harmonic functions. In Proceedings of the 20th International Conference on International Conference on Machine Learning, (2003), pp. 912–919.
8.
PerozziB., Al-RfouR. and SkienaS., Deepwalk: online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (2014), pp. 701–710.
9.
TangJ., QuM., WangM., et al., Line: large-scale information network embedding. In Proceedings of the Twenty-fourth International Conference on World Wide Web, (2015), pp. 1067–1077.
10.
GroverA. and Leskovec.J., node2vec: scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (2016), pp. 855–864.
11.
AlzubaidiL., ZhangJ., HumaidiA.J., et al., Review of deep learning: concepts, CNN architectures, challenges, applications, future directions, Journal of big Data8(1) (2021), 1–74.
12.
LiJ., JinK., ZhouD., KubotaN., et al., Attention mechanism-based CNN for facial expression recognition, Neurocomputing411 (2020), 340–350.
13.
DavyA., EhretT., MorelJ.M., et al., A non-local CNN for video denoising. In Proceedings of the IEEE International Conference on Image Processing, (2019), pp. 2409–2413.
14.
YinW., KannK., YuM., et al., Comparative study of CNN and RNN for natural language processing. arXiv preprint, 2017, arXiv: 1702.01923.
15.
GoriM., MonfardiniG. and Scarselli.F., A new model for learning in graph domains. In Proceedings of IEEE International Joint Conference on Neural Networks, (2005), pp. 729–734.
16.
HamiltonW., YingW. and LeskovecZ., Inductive representation learning on large graphs. In Proceedings of Advances in Neural Information Processing Systems, (2017), pp. 1024–1034.
17.
BrunaJ., ZarembaW., SzlamA., et al., Spectral networks and locally connected networks on graphs. In Proceedings of International Conference on Learning Representations, (2014), pp. 1312.6203.
18.
DefferrardM., BressonX. and VandergheynstP., Convolutional neural networks on graphs with fast localized spectral filtering, Advances in Neural Information Processing Systems, (2016), pp. 3844–3852.
19.
KipfT.N. and WellingM., Semi-supervised classification with graph convolutional networks. arXiv preprint, 2016, arXiv: 1609.02907.
PratapA., RajaR., AlzabutJ., et al., Finite-time Mittag-Leffler stability of fractional-order quaternion-valued memristive neural networks with impulses, Neural Processing Letters51(2) (2020), 1485–1526.
22.
HammondD.K., VandergheynstP. and GribonvalR., Wavelets on graphs via spectral graph theory, Applied and Computational Harmonic Analysis30(2) (2011), 129–150.
23.
MikolovT., SutskeverI., ChenK., et al., Distributed representations ofwords and phrases and their compositionality, Advances in Neural Information Processing Systems, (2013), pp. 3111–3119.
24.
YangZ., CohenW. and SalakhudinovR., Revisiting semisupervised learning with graph embeddings. In Proceedings of International Conference on Machine Learning, (2016), pp. 40–48.
25.
GlorotX. and BengioY., Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, (2010), pp. 249–256.
26.
SrivastavaN., HintonG., KrizhevskyA., et al., Dropout: a simple way to prevent neural networks from overfitting, The Journal of Machine Learning Research15(1) (2014), 1929–1958.
27.
El TraboulsiY., DornaikaF. and Assoum, A., , Kernel flexible manifold embedding for pattern classification, Neurocomputing167 (2015), 517–527.
ur RehmanM., BaleanuD., AlzabutJ., et al., Green-Haar wavelets method for generalized fractional differential equations, Advances in Difference Equations2020(1) (2020), 1–25.