
Abstract
Credit scoring is widely used by financial institutions for default prediction, however, a significant portion of online credit loan customers have inadequate or unverifiable credit histories, making it difficult for financial institutions to make effective credit decisions. Since the widespread use of smartphones and the popularity of mobile applications, it is worth investigating whether mobile application usage behaviors (App behaviors) of customers can effectively predict online loan defaults. This paper proposes a combined algorithm of CNN and LightGBM, and establishes credit scoring models with App behaviors to evaluate the default risk of online credit loans based on logistic regression, LightGBM, CNN and the combined algorithm, respectively. The experimental results suggest that App behaviors have an obvious effect on the default prediction of customers applying for online credit loans, and the combined model outperforms the other models in terms of the area under the curve (AUC). Furthermore, integrated credit scoring models are developed by combining App behaviors with traditional scoring features. A comparison of the integrated models and the traditional scoring model indicates that the integrated models have achieved a significant improvement in classification performance and App behaviors can be a powerful complement to the traditional credit scoring model.
Keywords
Introduction
In recent years, with the change of people’s consumption concept and the development of internet finance, not only internet financial platforms are promoting online lending business, but many traditional financial institutions are also shifting their lending business to online. As an efficiently reachable and unsecured retail financial product, the online credit loan has attracted a large number of customers due to its convenience and low cost, but it has also brought new challenges to the traditional scoring system. Traditionally, financial institutions use the basic information of customers and the data of the Credit Management Bureau as input features to establish credit scoring models [1–4]. After years of practical experience, the credit data has proven to be very effective in predicting the credit defaults of customers. However, a considerable number of online credit loan customers’ credit information is insufficient, which makes it difficult for financial institutions to assess customers’ credit risk. In 2017, Demirguc-Kunt et al. [5] revealed that the number of adults without financial accounts is estimated to be 1.7 billion. Data-driven methods for decision making and the use of non-traditional data become future research directions for credit scoring [6]. Some researchers have attempted to explore non-traditional features to establish default prediction models, especially for the peer-to-peer lending platform. For instance, account transactional data [7–9], online operation behavior data [10], social network information [11] and social media data [12] are new data sources for alternative features on credit scoring. Djeundje et al. [13] found that credit scoring models based on email usage, psychometric data, and demographic data can achieve better performance than models that only use demographic data. Liang and He [14] used loan-related semantic features extracted from textual information as input features to develop a credit evaluation model to evaluate the default risk of borrowers. They found that the semantic features related to loans greatly improved the predictive ability of credit evaluation models, especially for first-time loan applicants. Based on Facebook data, Cnudde et al. [15] developed a well-performing credit scoring model with an automatic scoring function for microfinance and the model can also be applied to other financial scenarios. More recently, the use of mobile phone data as non-traditional features for credit scoring has aroused the interest of researchers. There have been some credit scoring articles exploring the correlation between mobile phone usage data and default. For example, Óskarsdóttir et al. [16] extracted detailed call records from the customer’s mobile phone and established the customer’s calling network with the information obtained from the mobile operators. Roa et al. [17] tested the validity of customer data extracted from a mobile supper application for default prediction.
The proportion of population with mobile phones in the world has exceeded 95% and the number is still growing [18]. People’s lifestyle has changed by the popularity of smartphones and applications: People are used to going out without cash and credit cards, using mobile payment instead; The number of phone calls is reduced and young people prefer to communicate directly through WeChat or online videos; Most of the entertainment activities such as watching videos, listening to music, playing games and reading news are carried out on cell phones; Life behaviors such as paying bills, course learning, socializing and blog sharing are done through mobile apps. The same goes for financial activities, where the vast majority of online loans are applied by customers on mobile phones. People applying for online credit loans may not have rich credit histories or proof of stable income, but they commonly have extensive mobile app usage behavior data. However, to our knowledge, there are no studies exploring the relationship between App behaviors and online loan defaults. In this paper, we explore the feasibility of App behaviors as alternative data for credit score modeling through empirical analysis. The experimental results show that behavioral data such as installation, browsing time, usage locations and push messages of apps are available for customer behavior profiling, and that App behaviors can enable financial institutions to effectively evaluate the default risk of online loans as well as provide personalized and convenient credit services to customers who lack credit history.
With the application of non-traditional data on credit scoring, the data volume is increasing and the data forms display pluralism simultaneously, which requires the algorithms for training scoring models to handle more feature data and mine deeper information. Over the past decades, a great deal of research has been performed on individual credit scoring, and the early credit scoring models were constructed by statistical methods such as linear discriminant analysis [19], logistic regression [20] and Naive Bayes [21, 22]. Logistic regression is of epoch-making significance, and nowadays, the credit scoring model based on logistic regression is still widely used by financial institutions and academics because of its explanatory power and stability [23, 24]. However, with the popularization of big data, it is difficult for traditional statistical methods to mine high-dimensional and nonlinear information, so machine learning algorithms are widely applied in credit scoring models, for instance, support vector machine [25–27] and neural networks [28, 29]. Furthermore, many ensemble learning algorithms have been used to enhance the performance of scoring models, like random forest [30], adaptive boost [31], and extreme gradient boosting (XGBoost) [32]. Experimental results revealed that the performance of ensemble learning classification approaches is better than individual learners [33, 34]. Recently, as deep learning has become a research hotspot in artificial intelligence for its superior performance, many scholars also established credit scoring models using deep learning algorithms such as CNN [7], long short-term memory [35] and deep belief networks [36], which have achieved desirable prediction results.
In order to sufficiently validate the default prediction effect of App behaviors, the paper proposes an innovative algorithm combining CNN and LightGBM, and applies App behaviors to establish scoring models to predict the default of online credit loans based on logistic regression, LightGBM, CNN and the combined algorithm, respectively. The performance of scoring models based on App behaviors are compared by means of the receiver operating characteristic (ROC) curve, the area under the curve (AUC) and the population stability index (PSI). Moreover, App behaviors are combined with traditional scoring features to establish integrated credit scoring models, which are used to verify the complementary effect of App behaviors on the traditional scoring model. To the best of our knowledge, we are the first to employ the customers’ various App behaviors to establish credit scoring models.
The structure of this paper is organized as follows. Section 2 describes the dataset used in this paper and how it is processed. Section 3 introduces the methods and evaluation measures for credit scoring models. Section 4 analyses the experimental results and compares the performance of the scoring models. Section 5 draws the conclusion, and section 6 discusses regulatory implications and future recommendations.
Data
Dataset description
The research on default prediction is in cooperation with a medium-sized commercial bank in China. The data for establishing credit scoring models is derived from the information of customers who got online credit loans from the bank between July 1, 2018 and September 30, 2019. Customers who were overdue for more than 90 days within 12 months after loan issuance are defined as default samples. The normal samples refer to customers who have not been overdue within 12 months after loans were issued. The dataset includes 19,225 default samples defined in this way. Because the number of normal samples is much more than that of default samples, the undersampling method is used to extract normal samples to alleviate the class imbalance problem. According to the normal to default samples ratio of 8:2, a corresponding proportion of normal samples are randomly selected from the monthly dataset to ensure the balance of the sample data.
The paper innovatively takes customers’ mobile application usage behaviors as input features for credit scoring models. The customers’ information used in our models is encrypted and App behaviors are processed into statistical feature series. The technical requirements and conditions for gathering data are very strict, requiring customers to authorize the bank to collect information from the lending app when they apply for credit loans. The collected information includes the types and quantity of apps, installation and uninstallation, usage frequency and duration, apps push information, geographic location change on GPS and the concentration of usage time, which are shown in Table 1.
The feature series of mobile apps
The feature series of mobile apps
Apart from the features mentioned in Table 1, traditional scoring features (including basic customer information, credit records, repayment ability, loan information, account information and real estate) are also used to train models. Table 2 describes the detailed traditional features of the credit scoring model. Further, traditional features and App behaviors are combined to build scoring models for comparative analysis.
The traditional features of credit scoring
To ensure the quality of the training data and the accuracy of the scoring model, data cleaning is performed on the features and samples. If the features contain too many nulls or zero values, or if the samples contain outliers, it will lead to deviation in the model results. Table 3 displays the changes in the quantity of modeling data after removing the anomalous features and samples.
The result of data cleaning
The result of data cleaning
To test the classification ability of the models, the dataset is divided into a training set and a test set, as shown in Table 4. The customers who applied for online credit loans from July 1, 2018 to June 30, 2019 are considered as training samples. From July 1, 2019 to September 30, 2019, customers who applied for online credit loans are regarded as test samples. At the same time, it is ensured that there is no duplication of customers in the training and test sets, so they are simultaneously independent of each other in terms of time and sample. Further, this paper adopts a 10-fold cross-validation method to randomly sample 90% of the training set for model training and 10% of it for validation, and the average of ten model validation results is taken as the final model result.
Training samples and test samples
Training samples and test samples
As the quality of features affects the training effect of the algorithms, feature pre-processing is a crucial step in the model establishment. Credit scoring models in the research are trained by logistic regression, LightGBM and CNN. It is necessary for different algorithms to implement corresponding feature preprocessing, which usually includes feature selection and feature encoding.
Logistic regression is a generalized linear regression model for classification prediction, so the size of input feature values has a great influence on the result of the model. Therefore, to achieve dimensionality uniformity, it is essential to encode the input features using the transformation methods like the weight of evidence (WoE) [37]. Moreover, since the model based on logistic regression shouldn’t contain too many features, it is necessary to screen features through methods such as information value (IV) [38] and correlation test.
The weight of evidence (WoE) is a popular method to encode the original features. WoE encoding starts with grouping the original features. After grouping, the calculation formula of WoE for the group i is as follows:
Information value (IV) is also known as information concentration. It can measure the overall predictive power of each feature with the calculation formula as follows:
When IV is less than 0.02, it means that the feature has barely any predictive ability to the target variable and should be removed. If IV is between 0.02 and 0.1, the feature has a weak relevance to the target variable. When IV is from 0.1 to 0.3, there is a moderate correlation between the feature and the target variable. Once IV is equal to or greater than 0.3, the feature has a strong predictive ability for the target variable.
LightGBM is an ensemble learning algorithm with a boosting framework based on decision tree classifiers. The size of the input feature values does not affect the model result because of the characteristics of the decision tree algorithm. Therefore, the key preprocessing operation is to select features that have a significant impact on the model through feature importance screening. The feature importance screening refers to evaluating the predictive power of features based on the times of a feature used in decision trees classifiers and the information gain from the feature during the training process of the ensemble algorithm.
CNN is a typical feedforward neural network which requires scaling input features, as different feature dimensions can affect the results of neural network. To eliminate the dimensional influence of features, the max-min normalization method is performed to transform the original data into [0,1] through the following formula:
Besides, deep learning networks can automatically extract features, which means that no additional feature selection process is required.
This section will introduce three algorithms including CNN, LightGBM and the combination of CNN and LightGBM. Since logistic regression is a commonly used method in scoring models, it will not be described in detail, but only for modeling and performance comparison. Then the evaluation measures used to assess the classification performance and stability of the scoring models are presented, which are the ROC curve, the AUC and the PSI.
LightGBM
Light gradient boosting machine (LightGBM) is a novel gradient boosting decision tree (GBDT) algorithm proposed by Microsoft in 2017 [39]. As a member of the GBDT family, LightGBM achieves higher processing efficiency and lower memory usage than other boosting algorithms without compromising accuracy. LightGBM innovatively adopts the histogram algorithm instead of the pre-sorted algorithm to improve computational efficiency. In addition, Gradient-based One Side Sampling (GOSS) and Exclusive Feature Bundling (EFB) are put forward in LightGBM for more efficient processing of data with large samples and features.
GOSS is a sampling optimization method that significantly improves the training speed of the model by reducing the number of data samples while ensuring the accuracy of the model. It removes samples with smaller absolute values of gradients by random sampling, and only utilizes the remaining data to calculate information gain [40]. When calculating information gain, since samples with larger gradients have a greater impact on the information gain and samples with smaller gradients are given corresponding larger weight coefficients for compensation, GOSS can obtain fairly accurate results on the remaining samples. Meanwhile, sampling will increase the diversity of the base learners, which potentially helps to improve the generalization performance.
EFB is used to solve the problem of the high time complexity of the histogram algorithm for sparse data. The core role of the EFB algorithm is to extract features of sparse data by binding mutually exclusive features that will not simultaneously be zero to reduce the number of features effectively [41]. It is an NP-Hard problem to get the best bundling mutually exclusive features, so the greedy algorithm is used to obtain a proper approximation ratio, which can reduce the number of features without greatly affecting the determination of the segmentation point.
LightGBM has also optimized the growth strategy of the base tree classifier by using Leaf-wise tree growth that is a more efficient method than Level-wise tree growth for the same number of splits. Leaf-wise can reduce more errors and get better accuracy because the leaf with the largest splitting gain can be found from all the current leaves to split each time. Since Leaf-wise may generate a deeper decision tree, LightGBM limits the depth of the tree by setting super parameters of max_depth to prevent overfitting [42].
CNN
Convolutional Neural Network (CNN) is a popular deep learning network, which has achieved excellent performance for large-scale image processing and has great success in the field of image recognition, image segmentation and pattern recognition. It was also applied to build scoring models and the experimental result showed that it could effectively predict mortgage default [7]. The principle of CNN and the network structure of our scoring model are described as follows. The input feature data in the paper is App behaviors, which are different from the picture with three dimensions, having only a one-dimensional series of 396 features. Fig. 1 is the 1-D convolutional neural network structure.
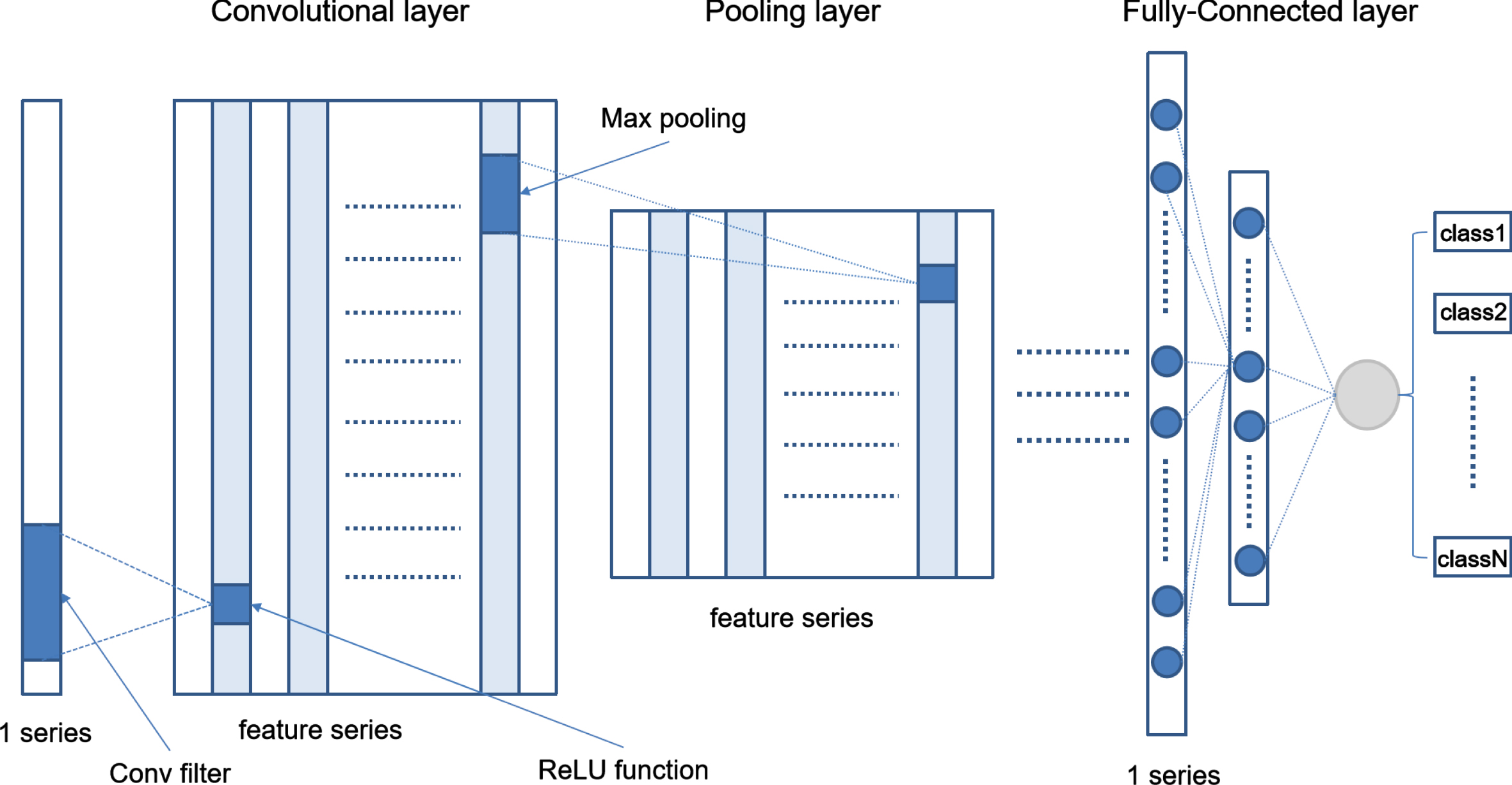
The 1-D convolutional neural network structure.
Convolutional layer: The purpose of convolutional layers is to extract different features from input data. A convolutional layer contains multiple filters, and each element of the filter corresponds to a weight coefficient and a bias term. Weight sharing of the filters provides an effective way to reduce the number of parameters and shorten the training time of models. The network structure of our model contains two convolutional layers. The first layer is composed of 64 filters with the size of 11, and the second layer consists of 128 filters with the size of 9.
An activation function follows a convolutional layer to enhance the nonlinear expression ability of networks. The activation function used in the paper is the ReLU function which has numerous advantages. Firstly, the gradient can be avoided to disappear during the backpropagation. Secondly, it can reduce the interdependence of parameters and alleviate the overfitting problem. Thirdly, the computation of the backpropagation is relatively smaller than other activation functions. For feature X, the ReLU activation function implements a nonlinear transformation of its value x by the formula max (0, x).
Pooling layer: The pooling layer can simplify the complexity of the network by compressing features to remove redundant information from high-dimensional features and reduce computation, while preserving the key features and some shift invariance of the input features to prevent overfitting and improve generalization ability. The paper uses the max-pooling layer with the size of 4 after each convolutional layer to replace four features with their maximum one. After two pooling layers, the dimension of features is reduced to 1/16 of the original.
Fully connected layer: CNN applies fully connected layers for classification prediction. It can realize the dimensional transformation of data from high to low dimension while retaining valuable information. The flattened features are obtained by combining local features, and then fully connected layers perform a weighted summation of the features with matrix parameters. Subsequently, it applies a nonlinear activation function to forecast classification results. Two fully connected layers are used in our network. The first layer contains the input of 3200 features and the output of 64 features, and the second layer outputs binary classification results through the input of 64 features and the Softmax activation function.
The dropout method is used in each convolutional layer and fully connected layer, which randomly assigns zero weights to neurons in the network. Since we choose a keeping ratio of 0.7, the thirty percent of neurons will be zero weight. Through this regularization method, the network’s response to small changes in data is less sensitive. Therefore, it can prevent overfitting and improve the robustness of the model.
The CNN structure of our credit scoring model is shown in Fig. 2. It is composed of one input layer, two convolutional layers, two pooling layers, two fully connected layers and one output layer. The number of layers and hyperparameters of our model have been adjusted and optimized after extensive experiments.

The CNN structure of our credit scoring model.
CNN can automatically learn multiple features from the training data. The weight sharing of filters and the sparse connectivity between layers can reduce the training parameters and decrease the complexity of the network, so it extracts features more effectively and have stronger adaptability. These advantages of CNN are mainly realized in convolutional layers and pooling layers. The role of full connection layers is to integrate features extracted by the previous layer to predict the classification. However, when the sample size is not large enough, simple nonlinear methods may fall into the local optimum situation, which is difficult to achieve the ideal result. Therefore, LightGBM may be used instead of fully connected layers for classification prediction.
To improve the classification accuracy of the model, a combined algorithm of CNN and LightGBM is proposed to build the credit scoring model. Fig. 3 shows the main procedure of the combined algorithm. In order to enhance the feature extraction performance and generalization ability of the scoring model, we apply the 10-fold cross-validation to establish ten different CNN models and fix their weight parameters. Inspired by the transfer learning and ensemble learning, convolutional layers and pooling layers of the 10 CNNs are used to extract features of App behaviors, and then the features are retrained by LightGBM to predict classification.
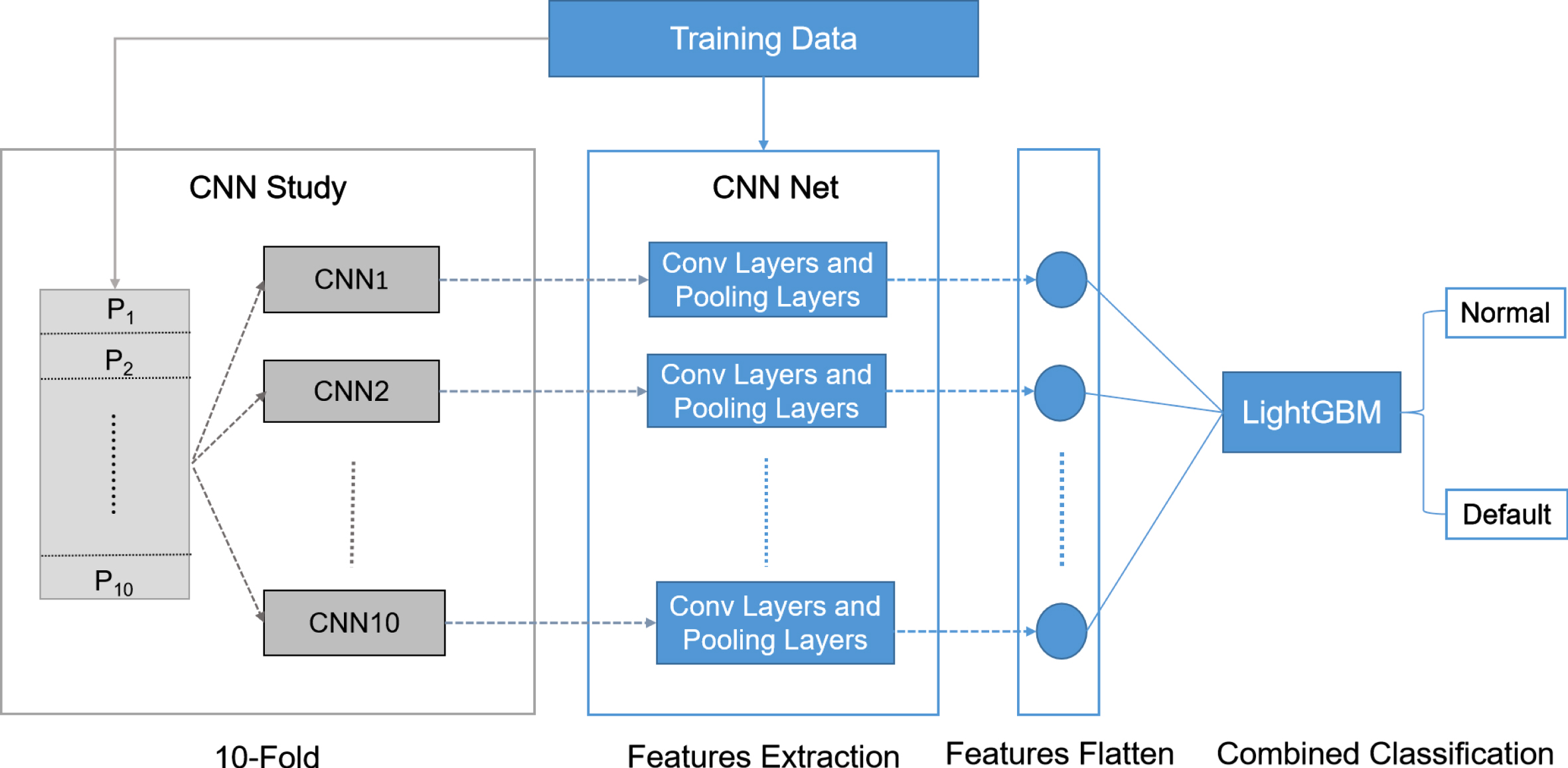
The main procedure of the combined algorithm.
The implementation of our proposed ensemble algorithm is as follows:
Step 1: Construct the convolutional neural networks according to the structure in Section 3.2 and initialize the weights.
Step 2: Divide the training data into 10 equal-sized parts randomly and then combine them into 10 data groups. In the ith group, the part P i is used for validation, while the rest of the parts are applied for training.
Step 3: Input the data groups obtained by Step 2 into the convolution neural network in Step 1 separately, and update the weights iteratively by backpropagation until the model converges and the loss is lower than the target threshold. As a result, 10 different convolutional neural network models are built.
Step 4: Fix the weights of the 10 CNN models trained in Step 3 and reserve the network modules before the fully connected layers.
Step 5: Input the training data into the reserved convolutional layers and pooling layers to extract feature data, and then flatten feature data into a one-dimensional feature vector.
Step 6: Apply LightGBM instead of the fully connected layer to retrain the flattened feature data for classification prediction.
The ROC curve and the AUC are widely used to evaluate the classification performance of credit scoring models because of their character agnostic to the skew dataset [22]. The ROC curve is a graphical approach to evaluate the sorting ability of scoring models. Its abscissa and the ordinates are true positive rate (TPR) and false positive rate (FPR), respectively. TPR is defined as the proportion of the default samples correctly predicted by the credit scoring model, and FPR is corresponding to the fraction of actual normal samples wrongly predicted as the default category by the credit scoring model. As the score increases, both TPR and FPR will approach 1, forming a curve starting from the coordinate point (0, 0) and ending at the point (1, 1). AUC is the area under the ROC curve with values from 0 to 1. When a model can perfectly identify default customers, the AUC will approach 1. When a classifier just performs random guessing, the AUC will be equal to 0.5.
The PSI is an important indicator to measure the stability of scoring models, which can assess the difference in the distribution of scores between training samples and test samples. Its calculating formula is:
where
Our experiments have two purposes. One is to verify whether App behaviors can effectively evaluate the default risk of online credit loans and whether the combination of App behaviors and traditional scoring features can achieve the desired enhancement effect. The second is to verify whether the combined model of CNN and LightGBM can obtain better performance in the default prediction.
Credit scoring models based solely on App behaviors
The first experiment applies App behaviors to establish credit scoring models with logistic regression, CNN, LightGBM and the combined algorithm of CNN and LightGBM, respectively. Then the ROC curves are employed to compare the performance of models, as displayed in Fig. 4. The classification ability of the models is evaluated by AUC and the stability of the models is evaluated by the value of PSI, which is shown in Table 5. As seen in Table 5, the AUC value of each model is greater than 0.64, which suggests that App behaviors have a certain predictive power. The PSI values of models are much less than 0.1, illustrating that all credit scoring models are stable. The Combined model performs best on the evaluation metric of AUC and hence has a superior default prediction ability. The classification capacity of the models trained by LightGBM and CNN is close to that of the combined model. Although the LR model has the lowest AUC, the AUC values are quite close on the training and test sets and its PSI is the lowest, which indidcates that LR has reliable stability.
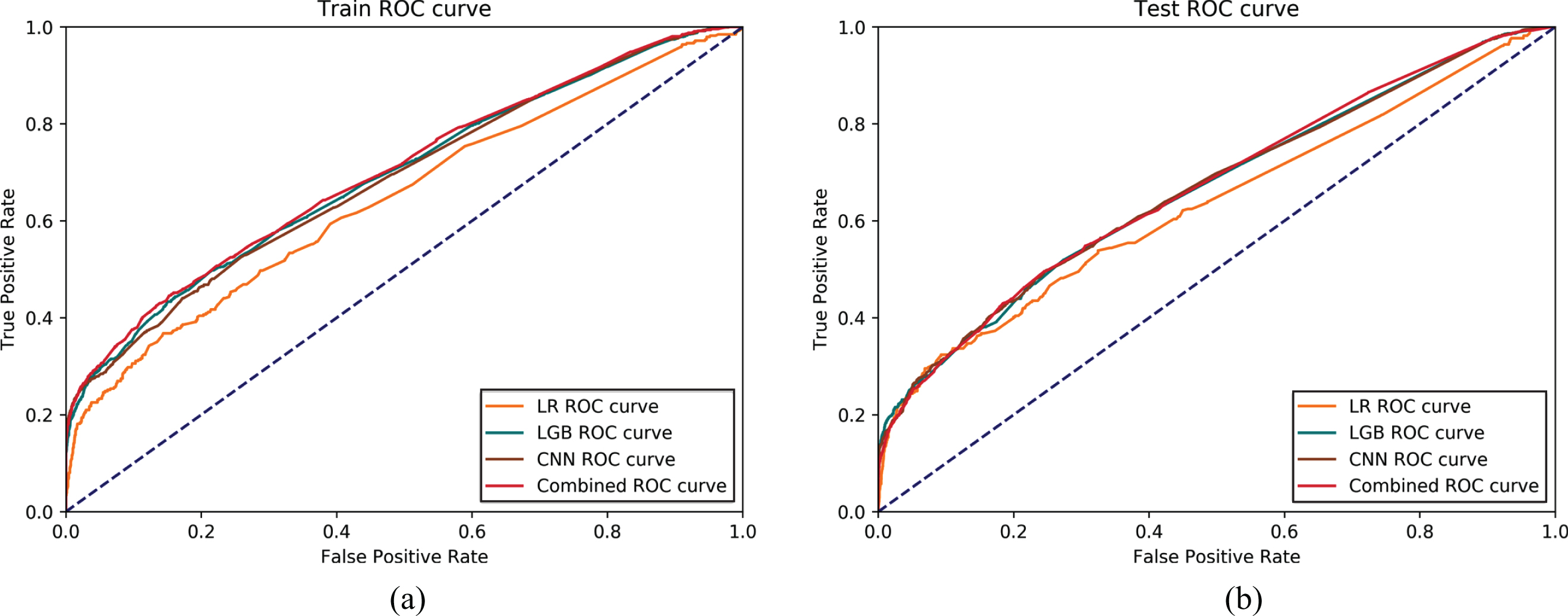
The ROC curves of models based on the App behaviors. (a) is on the training set, (b) is on the test set.
The AUC and PSI results of models with App behaviors
LR is a logistic regression model, LGB is a LightGBM model, CNN is a CNN model as described in section 3.2, and Combined is the model based on the combined algorithm as described in section 3.3. Combined performs best on the evaluation metric of AUC. The performance of the CNN and LGB are close to the Combined model. The AUC value of the LR model is the lowest and so is its PSI.
By analyzing the results of the credit scoring models, we can further study the characteristics of App behaviors in default prediction and find out which kind of App behaviors has a significant effect on default prediction. As observed in Fig. 4, the curves are closer to the upper left corner in the low scoring segments of the scoring models. This indicates that the scoring models have better default prediction ability in the low scoring segments than that in the high scoring segments, and therefore the App behaviors data is more suitable for identifying default behavior of ’bad’ customers.
Furthermore, the feature importance screening results of the LightGBM model and the IV values of the features are applied to determine what kind of App behavior has a significant impact on default prediction and the degree of impact, where the IV values are taken from the IV maximum of the corresponding kinds of App behavior features. Meanwhile, the Spearman correlation test is used to analyze the correlation between App behaviors and default. The main App behavior features used in the model and the correlation results are shown in Table 6.
Mainly used App behavior features and their correlation results
Mainly used App behavior features and their correlation results
From Table 6, it can be seen that the App behaviors of Lending & Borrowing are positively correlated with default, and its IV is the highest, so the degree of influence is the greatest. In general, customers who install many lending apps or often browse lending apps are usually cash-strapped and borrow frequently, making it difficult for one or two financial institutions to meet their financing needs. Therefore, those customers are bound to have a higher default risk than normal customers. Meanwhile, excessive usage of entertainment and gambling apps also signals a higher risk of default. Customers who spend a lot of time on entertainment apps or indulge in illegal gambling apps will have a higher probability of payment difficulties or credit fraud compared to the other customers. Besides, abnormal app usage behavior is positively correlated with default as well. Customers whose geographic locations change frequently, especially those with city positioning changes, and customers who often use mobile phones at night also have a certain risk of default. Conversely, the behavior features of financial management apps and office apps are negatively correlated with default. Customers who often use financial management apps or install more office apps always have a good asset condition or stable white-collar jobs, therefore, they have a higher repayment ability and are less likely to default.
The second experiment is to further verify the superiority of combining App behaviors and traditional scoring features for default prediction. Logistic regression is used to develop six credit scoring models, which differ only in terms of input features. The performance of the models are measured and compared by ROC, AUC and PSI, as shown in Fig. 5 and Table 7. As observed, the AUC value of the model TR using only traditional features is 82.32% on the test set. After integrating traditional features with App behaviors, the classification performance of the integrated models has significantly improved according to the AUC values. Among the five integrated models, the model TR_Com that uses the Combined model result as input feature performs best in classification with the AUC value of 86.01% on the test set. In terms of AUC values and PSI values, the classification ability of TR_CNN, TR_LGB and TR_Com is close and significantly better than that of TR_App and TR_LR. Correspondingly, the stability performance of the latter is better than that of the former.
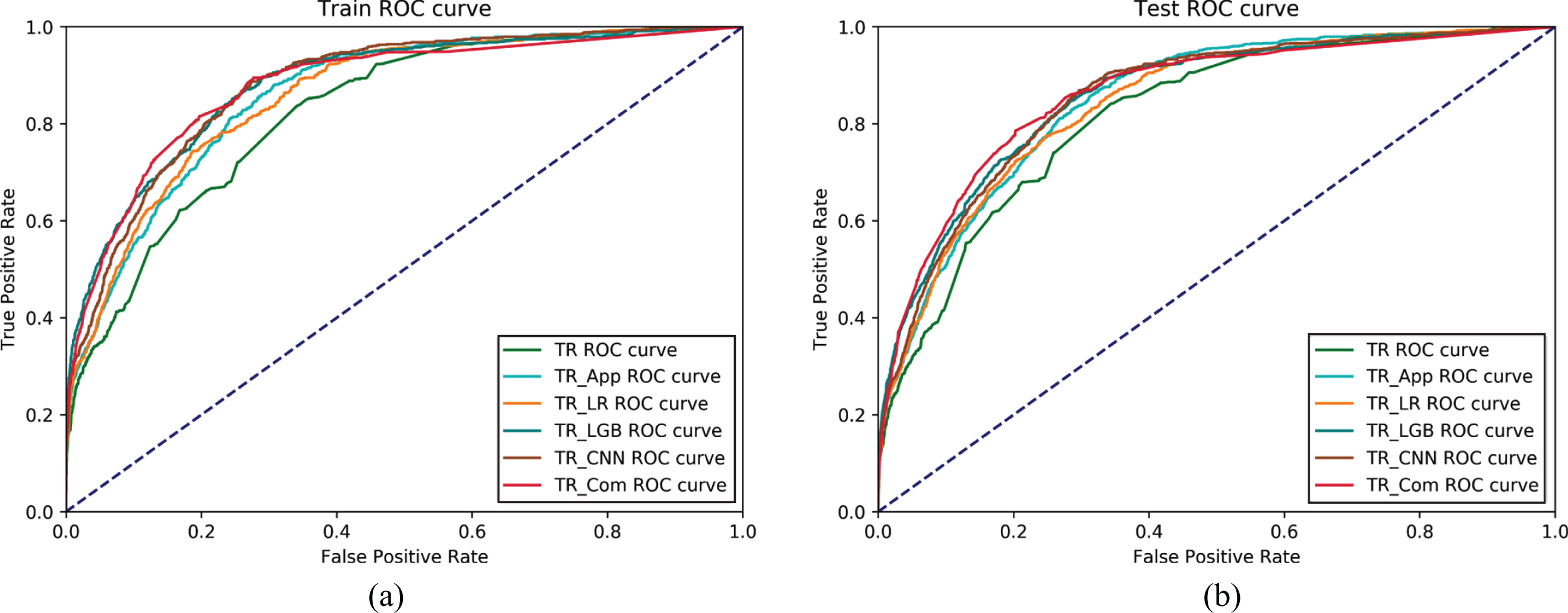
The ROC curves of models based on combined features. (a) is on the training set, (b) is on the test set.
The AUC and PSI results of models based on combined features
The above models are established by the logistic regression algorithm, and the only difference between the six models is the input features. TR represents the model only using traditional features. TR_App represents the model using the combination of traditional features and App behaviors. TR_LR is the model using the combination of traditional features and the LR model result. TR_LGB is the model using the combination of traditional features and the LGB model result. TR_CNN is the model using the combination of traditional features and the CNN model result. TR_Com represents the model using the combination of traditional features and the Combined model result.
In this paper, we explore the role of App behaviors in default prediction and propose a combined scoring model with excellent performance.
Firstly, the credit scoring models are established based on App behaviors using logistic regression, LightGBM, CNN, and the combined algorithm of CNN and LightGBM, respectively. The experimental result shows that App behaviors has a clear default predictive value for online credit loan and the logistic regression algorithm-based scoring model has the highest stability. Meanwhile, the combined algorithm-based model has the best classification ability and the stability of the model is within the acceptable range, hence its overall performance is outstanding.
Secondly, the result of the integrated models trained on App behaviors and traditional scoring features demonstrates that App behaviors significantly improve models’ performance and strengthen the default prediction power of credit scoring models. In particular, the integrated model that used the combined model result as the input feature has the best performance in classification. So both App behavior data and the combined algorithm of CNN and LightGBM are quite valuable for credit scoring models.
Finally, the feature importance screening results and the correlation between App behaviors and default show that App behaviors are indeed highly correlated with the credit risk of customers applying for online loans. As the analysis results of the scoring model shown, the behavior features of lending apps are highly predictive of default, and customers who frequently install and browse many lending apps have a higher risk of default. Likewise, customers who frequently use entertainment apps, gambling apps, and those with abnormal app usage behavior are also subject to a certain risk of default. Conversely, customers who often use financial management apps and office apps usually have assets and stable jobs, and rarely default on their loans. Therefore, it is of great practical significance for financial institutions to use App behaviors for customer profiling and risk identification.
Regulatory implications and recommendations
The collection and application of mobile App behavior data rely on the authorization of customers and the technological capability of financial institutions. In practice, the bank solicits customers to voluntarily authorize it to access application information for credit decisions by providing them with preferential credit policies. Since just part of the customers will agree to authorize financial institutions to collect application information due to their trust in financial institutions, the scoring model based on App behaviors can only be applied to these customers. Therefore, on the premise that customers voluntarily authorize and lending apps collect information based on the principle of minimum necessity, financial institutions apply App behaviors as alternative data for credit scoring modeling, which is in line with regulatory policies and can provide customers with better credit services.
Since the stability of the credit scoring model based on the combined algorithm is poorer than that of the logistic regression-based model, it is necessary for financial institutions to maintain a high frequency of iterative optimization when using the combined model. Furthermore, by observing the ROC curve in Fig. 4, it can be found that the scoring models perform better in the low-scoring segment than the high-scoring segment in terms of classification ability. It suggests that App behaviors are likely to be more suitable for identifying default risks of low-scoring customers. The App behaviors may be applied in the future to develop the fraud prediction model for so-called long-tail customers.