
Abstract
With the rapid growth of social network users, the social network has accumulated massive social network topics. However, due to the randomness of content, it becomes sparse and noisy, accompanied by many daily chats and meaningless topics, which brings challenges to bursty topics discovery. To deal with these problems, this paper proposes the spatial-temporal topic model with sparse prior and recurrent neural networks (RNN) prior for bursty topic discovering (ST-SRTM). The semantic relationship of words is learned through RNN to alleviate the sparsity. The spatial-temporal areas information is introduced to focus on bursty topics for further weakening the semantic sparsity of social network context. Besides, we introduced the “Spike and Slab” prior to decouple the sparseness and smoothness. Simultaneously, we realized the automatic discovery of social network bursts by introducing the burstiness of words as the prior and binary switching variables. We constructed multiple sets of comparative experiments to verify the performance of ST-SRTM by leveraging different evaluation indicators on real Sina Weibo data sets. The experimental results confirm the superiority of our ST-SRTM.
Introduction
With the rapid development of social media, microblog has become a popular communication platform and an essential public information dissemination tool. Twitter, Sina Weibo, and other platforms spread various topics every day, such as daily life, chat, conversation, entertainment information, news events, business activities, and so on. Some topics will attract more people to forward and discuss quickly, such as the “Global COVID-19” and “Tianjin Bombing”, which are hotly discussed on Sina Weibo. We call the above topics as bursty topics. The discovery of bursty topics is significant to many applications, such as news bursty topic collection, topic fast and accurate topic search, intelligent recommendation, and topic knowledge graph construction in social networks. Besides, timely discovery of bursty topics is also crucial for relevant departments to conduct public opinion monitoring and emergency response. Social networks also contain more daily chat, personal sharing, and other topics that change little with time and meaningless content, called ordinary or common topics. Bursty topics and common topics are mixed together, which brings great difficulties to discovering bursty topics.
Bursty topic is a kind of particular topic, that is, its content is short, noisy, and accompanied by sudden in social network. Traditional topic learning methods usually learn topics by modeling extended text corpus and combining them with the unsupervised method. When applied to social network data, it is faced with the semantic sparsity problem of context. Therefore, it is difficult to learn high-quality bursty topics in social network. To deal with the sparsity problem of context, a simple method is to use related words to expand the short text for enriching word co-occurrence information. Zuo et al. [1] constructed the word network association structure using the word co-occurrence relationship between different words. They expanded each word according to the constructed word network to enrich the term co-occurrence information. Biterm topic model (BTM) [2] assumes that word pairs in microblogs share the same topic and improve semantic space density by extracting word pair features to model semantic information. Shi et al. [3] introduced the word embedding feature to learn the semantic relationship of words, which improved the semantic representation quality of the short text. However, these methods only consider the context semantic sparsity. When applied to social network topic discovery, post-processing processes such as clustering and classification are needed, and the results of topic discovery may still not be ideal.
Besides, the bursty topics are scattered, accompanied by many meaningless topics and noise information in social network. These bursty topics are usually stimulated by some events or activities or popular discussions, which attract many people’s attention quickly. However, the traditional methods typically cluster the burst words or burst features to realize the bursty topic discovery and do not consider the temporal characteristics of the topic. Therefore, it is difficult to automatically distinguish and discover the burst topic and the general topic. Comito et al. [4] clustered the tweet streams gradually and aggregated the tweets to the cluster center by maintaining many text and time features. Fedorysza et al. [5] model topics as a series of trend entities that change over time and cluster millions of entities through modular design to discover the new events. Li et al. [6] calculate the burst strength of the features of words, and cluster the burst strength of features through the feature clustering, and then realized the discovery of bursty topics. However, it is challenging to discover the bursty topics with less attention in the case of more noisy data.
Our goal is to automatically discover bursty topics in social networks stream divided by certain time slices based on topic distributions. The key idea of our ST-SRTM is to exploit the burstiness of word pairs, RNN and “Spike and Slab” as prior knowledge to incorporate into topic model for bursty topic automatically discovering. In addition, ST-SRTM construct the spatial-temporal areas to alleviate semantic sparsity. Compared with previous methods, ST-SRTM has two significant advantages. First, it effectively alleviates semantic sparsity problems in topic modeling over social networks, as compared with those methods based on traditional methods. Second, it can well obtain the bursty topics in a principled and efficient way without any additional processing and steps.
Specifically, to overcome the above problems and effectively discover the bursty topics, this paper proposes a spatial-temporal topic model with sparse prior and RNN prior for bursty topic discovery (ST-SRTM) in social networks. ST-SRTM enhances word co-occurrence information by modeling word pair information. Based on spatial-temporal information characteristics, aggregates document information by constructing spatial-temporal areas to deal with the sparsity problem of context. We use RNN and IDF to learn the association relevance of word pairs and use the burstiness of words as a prior. We introduce a Bernoulli prior to determining the source of topic discovery and combine the “Spike and Slab” prior to decoupling the smoothness of the bursty topic distribution. We constructed multiple sets of comparative experiments to verify the performance of our proposed ST-SRTM. Experimental results demonstrate that the ST-SRTM is significantly better than other comparison methods on multiple evaluation indicators.
The contributions of our work are listed as follows: This paper proposes a spatial-temporal topic model with sparse prior and RNN prior. Based on this model, we can realize the automatic discovery of bursty topics and alleviate the semantic sparsity of context and the topic dispersion problem. Based on the “Spike and Slab” prior and RNN prior, we construct spatial-temporal area information and word pair information, which can enhance word co-occurrence and aggregate topics. As far as we know, ST-SRTM is the first bursty topic discovery method that simultaneously introduces “Spike and Slab” prior, RNN prior, spatial-temporal information, Word pair co-occurrence, and burst modeling based on Bernoulli prior. We constructed multiple sets of experiments with different evaluation indicators to verify the performance of the proposed ST-SRTM method. The experimental results show that the ST-SRTM is significantly better than other comparison methods.
The remaining part of this paper is arranged as follows:
In section 2, we review related work and research progress from three perspectives: topic model methods, multi-attribute modeling methods and clustering methods. Section 3 mainly introduces the proposed ST-SRTM and workflow. Section 4 mainly presents the experimental results of the comparison between ST-SRTM and other methods. In section 5, we mainly conclude the research in this paper and indicate the focus of the next step.
Related work
At present, social networks have become an essential platform for users to post topics and relevant authoritative media to release news and announcements. Every day, a large number of users release information through social network platforms, making social networks gather a large number of topics. Besides, most officials usually publish for some emergencies and topics first through social networks every day to ensure the topic’s timeliness and facilitate users’ sharing and reading. However, social networks have a large number of topics generated every day. It is challenging for users or related organizations to get a bursty topic from a large number of topics. We need a method that can quickly and automatically discover bursty topics. Current research on bursty topic discovery in social networks is mainly summarized into three categories [7, 8]: topic model method, clustering method, and multi-attribute modeling methods. The summarization of typical method bursty topic discovering in Table 1. Next, we will introduce the current research progress of emergent topic discovery from the above three categories.
The summarization of typical method bursty topic discovering in social networks
The summarization of typical method bursty topic discovering in social networks
In social network research, traditional text modeling methods [9] directly model text as document topic distribution, which is challenging to overcome the sparsity of context. Therefore, the first solution is the sparsity problem for social network bursty topic discovery. Many researchers focus on weakening the sparsity of social networks to improve the performance of bursty topic discovery. A typical method is to change the prior form of the topic model [10, 11]. He et al. [12] improved short text modeling performance based on the metropolis Hastings and alias method instead of Gibbs sampling in original BTM. Huang et al. [13] mined the co-occurrence patterns of words from the short text corpus and combined them with the generalized Polya-urn (GPU) to model the semantic information of the short text. Kou et al. [14] introduced spatial-temporal information into the topic model to model the social network context. Zhao et al. [15] integrated the word vector representation and entity vector representation into the variational automatic encoder framework, which effectively alleviated the sparsity for short texts. The above methods improve the performance of short text semantic modeling by introducing a variety of different priors. It ignores the co-occurrence aggregation relationship within short text words, prone to overfitting, and depends on specific data or application scenarios.
In addition, some researchers direct modeling of word co-occurrence information to improve short text sparsity in social networks [16, 17]. Lin et al. [18] proposed a pseudo-document-based topic n-grams model, which is sensitive to word order and alleviates the data sparsity. Qiang et al. [19] constructed a sparse graph to extend each short text using adjacent words. It solved the sparsity problem of short text. Blair et al. [20] calculate the similarity between topics leveraging cosine similarity and Jensen Shannon divergence to aggregate the short text. The above method can alleviate context sparsity to a certain extent by mining the internal relationship of short text. However, the above techniques ignore the comprehensive influence of various information such as time and location in the social network on short text modeling and require a complex post-processing process. There is still much room for improvement.
Multi-attribute modeling methods
The discovery of bursty topics mainly uses direct modeling of bursty topics or through bursty words and bursty feature clustering methods in social networks. In the method of directly modeling bursty topics, Dai et al. [21] introduced binary switch variables into the topic model to realize the automatic discovery of emergent topics, and enhanced contextual word co-occurrence by establishing spatial-temporal area information. Shi et al. [22] introduced word burstiness and RNN as a prior to learn the semantic representation of emergent topics, and combined with the sparse prior process to discover the bursty topics in social networks. Zhu et al. [23] modeled emergent topics by calculating the acceleration of emergent words for real-time discovering the emergent topics in social networks. Choi et al. [24] proposed an emergent topic detection method based on high-efficiency pattern mining, which simultaneously considered topic frequency and utility and obtained better detection results on the Twitter dataset. Shi et al. [25] first used neural network to learn the association relationship of words and then used binary switch variables to guide the discovery of bursty topics. Yan et al. [26] realized the automatic discovery of emergent topics using the suddenness of words prior mixing into the topic model. However, because social network data contains many different characteristics, most of the above methods incorporate a single factor and do not consider the internal semantic relationship between words.
Clustering methods
In the cluster-based bursty topic discovery research, Dhiman et al. [27] used a weighted graph model to capture the relationship between Twitter data. They discovered emergent topics through a graph clustering model. Wei et al. [28] proposed an enhanced model for weakly supervised topic perception. This model achieves content classification by alternately optimizing the detection network and policy network. Li et al. [29] used Bayesian generative models to mine the relationship between word features and link features for improving the burst prediction performance. Xu et al. [30] aggregated the posts of the same period or the same user into pseudo-documents to weaken the context sparseness and obtained real emergent topics through the established emotional perception model of emergent topics. Gao et al. [31] used a coding-only transformation language model to quantify the relationship between words. Then use semantic relevance to discover meaningful topics and topic relevance. However, when faced with massive amounts of data, the bursty topics obtained from sudden words or emergent feature cluster will be mixed with a large amount of noise data, which bring significant impact on the accuracy of topic discovery. Moreover, it is difficult to deal with the sparse context of social networks.
To the best of our knowledge, all existing methods do not jointly consider the multiple attributes, i.e., spatial-temporal information, sparse prior and rnn prior in the context of streams of social networks. Inspired by [14, 22], our ST-SRTM method utilizes multiple attributes of social networks to model social network topics jointly. It combines a variety of priors to automatically discover bursty topics without a related post-processing process. Compared with other existing models, the proposed ST-SRTM can not only effectively alleviate the semantics sparsity in social networks, but also realize the automatic discovery of bursty topics. Therefore, our ST-SRTM is much more suitable to model social network short text with multiple attributes for bursty topic discovery.
ST-SRTM method
This paper proposes a spatial-temporal topic model with sparse priors and RNN priors (ST-SRTM). The overall framework of the ST-SRTM is shown in Fig. 1. It includes four sub-processes: word relation learning, word pair construction, spatial-temporal topic model construction based on sparse prior and RNN prior, and social network burst topic discovery.
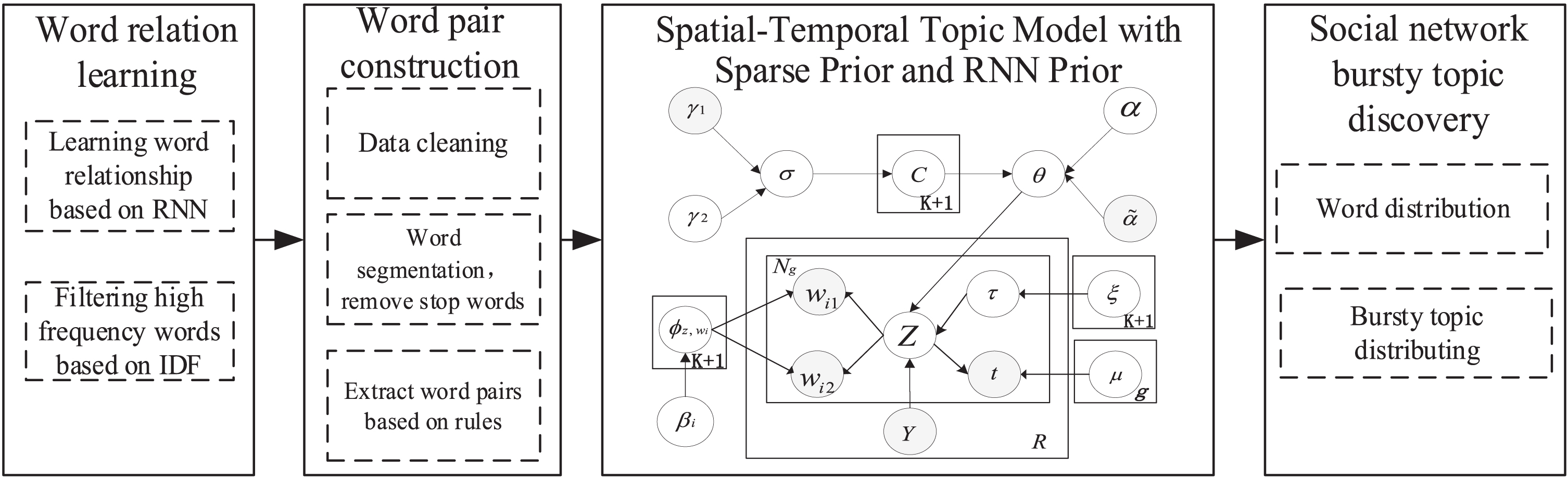
The overall framework of the ST-SRTM.
Word relationship learning is used to learn the relationship between words in social network documents. We use RNN to learn and record the relationship between the current word and the previous words, based on the inverse document frequency (IDF) to reduce the impact of common high-frequency words on the entire learning process. Synthesize the word relationship learned by RNN and the result of IDF. We construct the weight prior β mixed into our ST-SRTM model.
The word pairs construction is mainly based on preprocessing and word segmentation of social network documents. The word pairs are extracted and constructed through preset word pair extraction rules. In addition, we introduce the results of word relationship learning, which can carry the relationship between words.
The topic model with RNN and sparse prior is used to model bursty topics. It learns more word co-occurrence information by constructing spatial-temporal areas and extracting the generation of word pairs to solve the context sparsity. The suddenness of words is introduced as a prior, combined with binary switch variables to determine the origin of topic discovery. The weak smoothing prior in the “Spike and Slab” prior is introduced to decouple the sparseness and smoothness of the discovered topics so that the discovered bursty topics are more focused and coherent.
The bursty topic discovery in social networks mainly uses the bursty topic distribution and word distributions obtained by ST-SRTM to automatically discover bursty topics from social network data.
In our ST-SRTM, for social network information, each content M includes time information, text information, and location information of the text. The spatial-temporal region describes a specific region from two dimensions of space and time. Words that appear simultaneously in the same time range and the same space area are called words belonging to the same spatial-temporal area. By adjusting the time scale or spatial scale, the scale of spatial-temporal region can be changed. We introduce t represents the temporal characteristics of social network information, and Y represents the spatial-temporal area of the message. Y describes the typical features from space and time dimensions. Here, the spatial granularity is set to “province” and the temporal granularity to “day”. Besides, ST-SRTM involves the bursty topics distribution θ, the bursty words distribution φ, the common words distribution φ g (representing common topics) and the time distribution μ. where the bursty topics distribution θ, bursty words distribution φ and common words distribution φ g is Multinomial distribution, and time distribution μ is the Beta distribution. Y denotes the number of spatial areas, and K denotes the number of bursty topics.
In the “spike and slab” sparse prior, given the social network text dataset D ={ d1, d2, . . . , d
N
d
}, we use Bernoulli distribution to define the topic selector C
Z
as a binary switch variable. It is used to indicate whether the selected topic is consistent with the burst topic. We define the smoothing prior α as Dirichlet hyperparameter, which is used to determine whether the smoothing topic is selected by the selector. On the contrary, we define weak smoothing prior
Word relation learning
We use the classic Elman RNN to learn and record the association relationship of words in social networks [32, 33]. The IDF is used to judge all the words to reduce the impact of common words. We integrate the results of RNN and IDF learning to establish a weight prior for learning the relationship between words. The framework of word relationship learning is shown in Fig. 2.
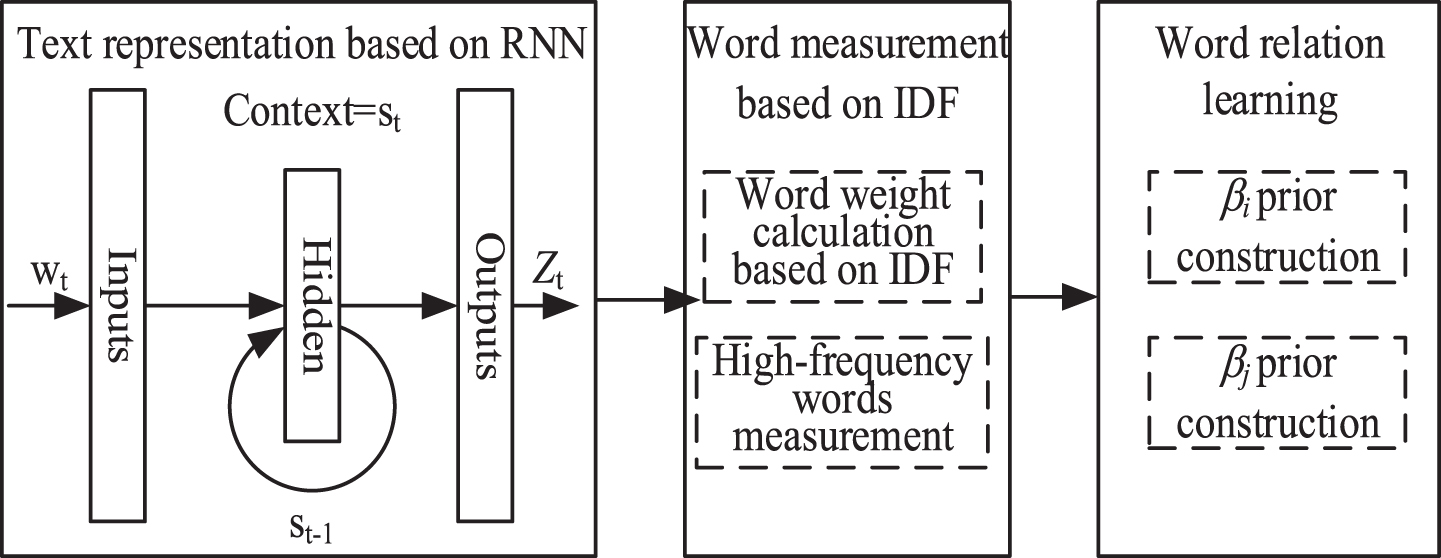
The framework of word relationship learning.
In Fig. 2,
where
In the output result, z
i
represents the relationship between word pairs wm,1 and wm,1, as shown in Equation (3):
where z l (m) denotes the probability of occurrence of wm,1, given the wm,2. Since the hidden parts S t and St-1 can record all the previously learned words, the relationship between the previous word and the current word can be learn by the RNN.
Besides, the IDF is used to measure each word. The calculation of IDF is shown in Equation (4):
where |d ∈ D : wm ∈ d| represents the number of words w appearing in the document. We combine the output of the RNN and the calculation result of IDF to build the weight prior β. The specific calculations are shown in Equations (6) respectively:
where ρ is a relatively small positive number, which is used to alleviate the prior β is too small.
We use Equations (6) to get the weight prior to replace the hyperparameters in the original topic model. This parameter replacement can make the model learn more consistent topic semantic representation.
Owing to the natural semantic sparsity, the context lacks word co-occurrence information in social networks. We can effectively enrich the co-occurrence information of context words by extracting two words in the same social network context to construct word pairs. Two different words in the word pair share the same topic. Specifically, we get the social network document data for the experiment after data cleaning and processing. Then the word pairs are extracted by traversing all the words in the document. The formal expression of word pair extraction is shown in Equation (7):
It is worth noting that other methods, such as BTM [2], also introduce word pairs to enhance word co-occurrence patterns in context. Our ST-SRTM is essentially different from the BTM. Our ST-SRTM introduces prior knowledge based on RNN and IDF in extracting and constructing word pairs. Prior information is introduced in each traversal process to learn and record the association between word pairs effectively.
As mentioned above, the function of our proposed ST-SRTM is to discover bursty topics based on topic model. Therefore, a natural guess is that the resulting topics may be mixed when we get a small number of documents. To deal with this problem, we introduce a mathematically classic “Spike and slab” sparse prior to the model topic distribution. “Spike and slab” is a mathematically complete parameter selection method based on Bayes rule. It can effectively decouple the smoothness and sparsity of related distributions by introducing the Bernoulli distribution in the sparse prior to indicate the “on” and “off” states of specific variables. Therefore, the introduction of this prior can enable our method to automatically determine whether a variable works. In our ST-SRTM, we use the switch variables in the “Spike and Slab” prior to determine whether the discovered topic is coherent with the bursty topic, that is, whether the discovered topic defined below is the central topic.
However, the “Spike and slab” prior has a typical ill-conditioned distribution problem. For example, when the state of all random variables in the model is determined to be “off”, this distribution is not true. A typical solution [34] is to introduce an intermediate variable and set the state of the variable to always be “on”. However, this method increases the complexity of the model, making it difficult to infer the model. The core idea of another solution [35] is that when a variable is closed, we give it a very weak prior. Conversely, when the variable is in the “on” state, we give it a normal prior. This method effectively solves the problem of ill-conditioned distribution by not wholly closing a variable and does not increase the difficulty of model inference. In our ST-ETM, we choose the second method to deal with the problem of ill-conditioned distribution. The weak smoothing prior is directly introduced in ST-SRTM to avoid the ambiguity of the probability distribution and ensure the stability of the model.
ST-SRTM introduction
In social networks, we all know that the suddenness of words is directly related to the suddenness of topics. The suddenness of words can be used to understand the suddenness of topics. Because a word in the social network can be a normal word that is used normally, or it may be a sudden word accompanying the bursty topic. Therefore, our ST-SRTM models the topic through the suddenness of words and guides the discovery of bursty topics. The probability graph model of ST-SRTM is shown in Fig. 3. The shaded parts represent variables that can be observed.
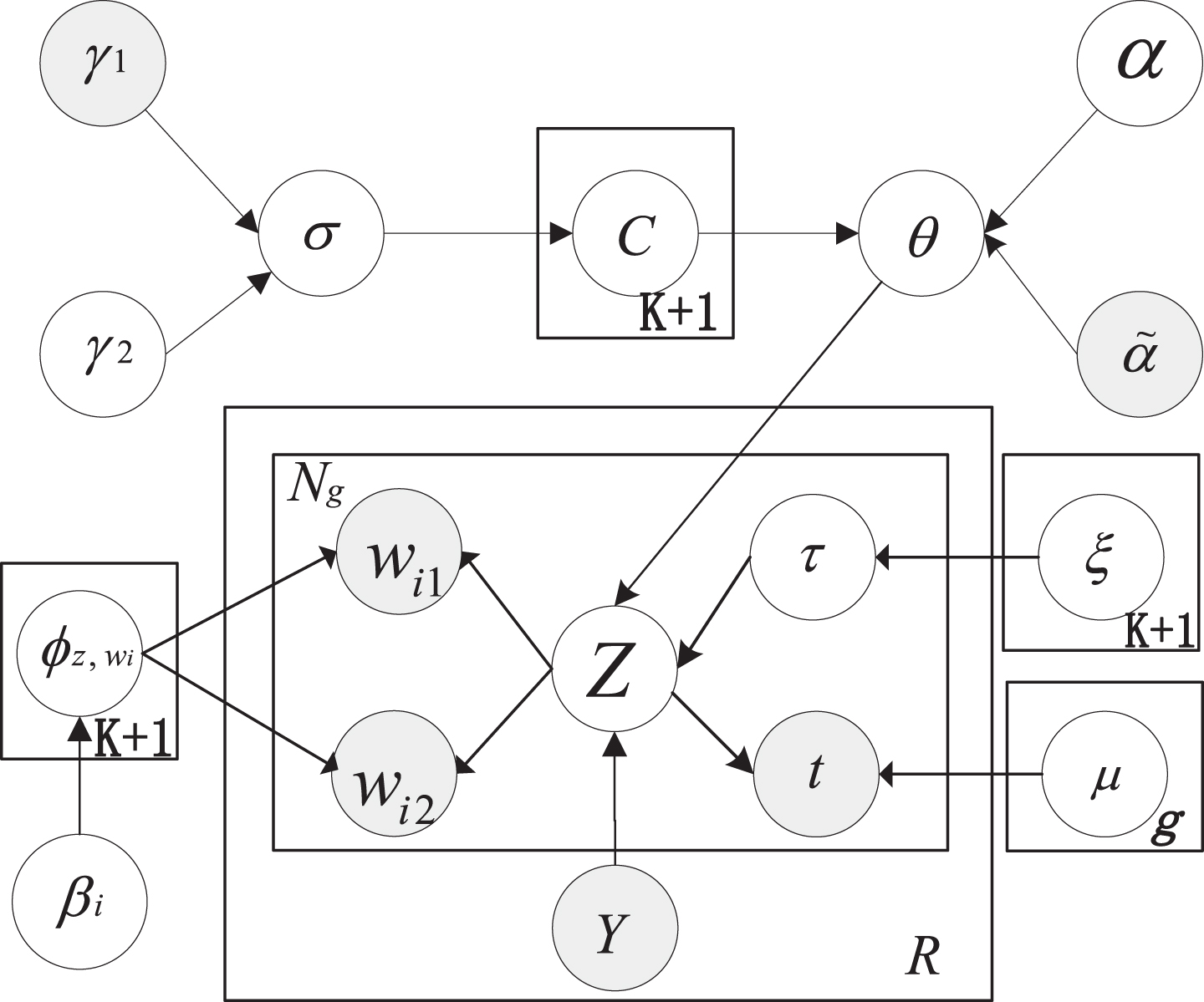
The probability graph model of ST-SRTM.
In ST-SRTM, we map text information, spatial temporal information to a unified topic semantic space, and narrow the semantic space by modeling different temporal and spatial area information, thereby enhancing word co-occurrence information. In addition, through the learning of word relations and the extraction of word pairs, the semantic sparsity of social networks is further alleviated. Combined with binary switch variable, the automatic discovery of social network burst topic is realized.
Based on the established “spike and slab” prior, we can focus the bursty topics effectively. Specifically, given a short text data G ={ g1, g2, . . . , g N s }, its associated word pair set is B ={ B1, B2, . . . , B N s }. We introduce the binary switch variable τ of Bernoulli distribution with parameter ς to encode the source of topic generation. Where τ = 0 indicates that the word pair B comes from a normal topic, and τ = 1 indicates that the word pair comes from the bursty topic. Through this kind of probability prior to encode the probability of emergent topics, we can realize automatic discovery of bursty topics.
In ST-SRTM, we assume that word pair B appears
where
In addition, we can use the estimated value
where
After obtaining the
where
Moreover, given a piece of social network information, take social network text information, time information, and spatial-temporal area information as input, the topic distribution can be obtained. ST-SRTM symbols and its descriptions are shown in Table 2.
Variables and notations in ST-SRTM
The generation process of ST-SRTM is as follows: For the social network document M, the auxiliary variables σ ∼ Beta (γ1, γ2) are extracted based on the hyperparameters γ1 and γ2, the topic selector cz ∼ Bernoulli (σ) is extracted using the Bernoulli distribution, and the bursty topic distribution For each bursty topic, extract the beta distribution Beta (ɛ), and use the β
i
and β
j
learned based on RNN and IDF as the hyperparameters to extract the two word distribution φk, 1 ∼ Dir (βi), φk, 2 ∼ Dir (βj) in the word pair, and at the same time, extract the common word distribution φg, 1 ∼ Dir (βi) and φg, 2 ∼ Dir (βj). For each spatial-temporal information r, given its spatial-temporal area r
m
, the associated topic distribution θm can be extracted. For each word pair B
i
∈ B, the binary switching variable τ ∼ Bernoulli (ς) is extracted based on the burst probability of the word obtained by Equation (13).
If τ = 0, we extract words wi,1, wi,2 ∼ Multi (φ g ) separately based on multinomial distribution.
If τ = 1, we extract bursty topics k ∼ Multi (θ) based on multinomial distribution, extract word pairs wi,1, wi,2 ∼ Multi (φ k ), and extract timestamps t ∼ Beta (μ).
Due to the coupling relationship between different parameters, it is difficult to accurately solve these unknown parameters. It needs to adopt mathematical approximate solving methods. The collapsed Gibbs sampling [36] is adopted to derive the unknown parameters. Specifically, we need to derive the values of three unknown variables, namely topic distribution, word distribution, and time distribution. Firstly, we extract the switching variable based on Gibbs sampling. The calculation method is shown in Equations (13), respectively
where
We mainly use σ· as an auxiliary variable to sample topic selector C
z
, and derivation through joint distribution. The calculation method is shown in Equation (14)
The topic selector c z is iteratively sampled based on the joint distribution. We use the Metropolis-Hastings distribution based on symmetric Gaussian distribution for the hyperparameter α. For parameter γ1, the gamma sampling method proposed in reference [37] is used, where I [·] denotes the indicator function. Fz = { z : n k > 0, z ∈ { 1, ⋯ , K }}.
By the generation process and derivation process of ST-SRTM, we can obtain the bursty topic distribution and bursty word distribution in social networks. In the derivation process, we randomly assign topics to each word and word pair. In each iteration of the sampling process, we combine Equations (12), (13) and (14) to sample the variables in ST-SRTM. After convergence, we can get the bursty topic distribution, word distribution and topic-time distribution, as shown in Equations (15), and (17), respectively:
According to Equation (15), the bursty topic distribution can be calculated. Combining Equation (17), we can get the bursty words distribution: φk,w = [φk,w1, φk,w2, …, φk,wn]. where the parameter μ μ can be solved by the moment estimation, t
avg
is the mean for time,
We use the obtained Sina Weibo as experimental data. The ST-ETM, SRTM, RIBS, BBTM, Twevent, and LDA were used as comparison methods. Several evaluation indicators include topic discovery accuracy, topic coherence, and topic discovery quality are adopted. The average of the results is used as the final experimental result.
Dataset
We use more than 1 million Sina Weibo data crawled from Sina Weibo from January 1, 2020 to May 31, 2020 as experimental data. We use random user IDs as seeds to collect Sina Weibo posted by users over a period of time. These data include bursty topics such as “Wuhan COVID-19” and “Chenzhou Big Touwa” on social networks. We process the data as follows: (1) Obtain each Weibo text, user, time and location and hashtags information; (2) Remove duplicate and non-Chinese Weibo; (3) Delete Weibo with less than 10 entries in a period of time or an administrative area; (4) Word segmentation and stop words removal; (5) Words that appear less than 8 times. The processed data contains 400,000 Weibo. The time slice is set in days.
Baseline methods
ST-ETM [21]: By introducing spatial-temporal areas to model social network emergent topics, it realizes the discovery of emergent topics and reduces the sparseness of social network context.
SRTM [22]: A social network bursty topic discovery method based on topic model, which guides the discovery of emergent topics by leveraging the emergent prior of words.
RIBS [10]: A social network modeling and topic discovery method, which learns the association relationship between word pairs by replacing the prior to the weighting of RNN and IDF, thereby alleviating the sparse social context networks.
BBTM [26]: An emergent topic discovery method by the BTM. This method introduces Bernoulli distribution to judge whether the topic is an emergent topic.
Twevent [6]: A typical burst topic discovery method using burst characteristics. It segments social network documents and calculates the suddenness of features based on the segmented segments. Then, cluster the features with strong suddenness to discover emergent topics. Finally, use Wikipedia to filter some general topics.
LDA [9]: A text semantic modeling method, which realizes text modeling by modeling document-topic distribution and topic-word distribution. In the experiment, we use the result of its modeling topic as the result of the topic discovery.
Evaluation indicator
To verify the performance of the proposed ST-SRTM, we use the P@N [38], topic coherence [39], topic discovery quality [40] to establish experiments. The following are the evaluation indicators we use:
P@N
P@N represents the accuracy of the results of the top-N topics discovered. In the experiment, given the value of N, we record the accuracy of the top-N returned bursty topic results.
PMI-Score
The most classic evaluation index for topic coherence is Pointwise Mutual Information (PMI-Score). In the experiment, the higher the PMI-Score, the more relevant the topics discovered. Therefore, if the PMI-score is higher, the topics discovered are more coherent and have better interpretability. Given topic Z, selected the top-L related words w1, w2, …, w
l
, the PMI-Score is calculated. The calculation method is shown in formula (20):
where p (w e , w f ) represents the probability that the word pair w e and w f appear together in the external database, and p (w e ) denotes the marginal probability of the word w e in the external database.
The quality of topic discovery is evaluated by clustering. Purity is a standard evaluation method for evaluating clustering, which is used to express the proportion of topics that are true to clustering in the total topics. Therefore, we use Purity to verify the quality of topic discovery, and the calculation of Purity is shown in Equation (21):
where D represents the total number of topics in E. |e i ∩ fj| denotes the number of topics in the ei ∩ fj intersection.
There are multiple common parameters for ST-SRTM and the baselines methods. To ensure the fairness of the experiment, we follow the best parameters in the original paper of the comparison method to set. The number of iterations is set to 500. The K is set from 10 to 50. For ST-SRTM, our time slice is set to 1 day, α = 0.1,
The accuracy of bursty topic discovery
Firstly, the accuracy of bursty topic discovery (P@N) is used to verify the performance of ST-SRTM. Since the crawled data has no label information, we manually annotate the data through six volunteers. The detailed judgment rules are as follows: if a bursty topic is only actually occurs in the current time period, and it does not appear in other time periods. Thus, the topic is considered to be bursty topic. If a topic is just daily chatting, the topic will be judged as a common topic. If more than half of the volunteers think the topic is a bursty topic, it will be regarded as a bursty topic. We using the average accuracy of the top-N words P@N as an evaluation index to verify the accuracy of bursty topic discovery. Table 3 lists the P@N for all comparison methods under different N value settings.
The accuracy of bursty Topic discovery
The accuracy of bursty Topic discovery
From the experimental results in Table 3, we can get the following conclusions. The accuracy of the ST-SRTM has always been higher than 0.78 under different settings of N values, which is significantly better than other methods. It indicates that ST-SRTM can discover bursty topics more accurately. In particular, the accuracy of ST-SRTM in N = 50 is 3.6%higher than ST-ETM and 59%higher than LDA. The above experimental results further show that bursty topics can be effectively aggregated by introducing spatial-temporal characteristics and sparse priors, and ST-SRTM can obtain higher accuracy. When N = 10, the accuracy of ST-SRTM is slightly worse. The main reason is that the bursty topics numbers generated are too low, making the topic learning results unable to focus. The accuracy results of SRTM and RIBS are better than BBTM, indicating that different forms of priors can enhance the co-occurrence information of the context words and promote the accuracy of bursty topics.
In addition, we can also observe that the accuracy of BBTM is better than Twevent and LDA. That is because BBTM can realize automatic discovery of social network emergent topics by introducing binary switch variables. In all the comparison methods, LDA always obtains the worst accuracy. The main reason is that LDA requires a lot of post-processing to realize emergent topic discovery, and it cannot weaken the sparsity of context. Therefore, the results obtained may be mixed with a large number of common topics.
To verify the capability of ST-SRTM to model bursty topics, the PMI-Score is selected as the evaluation index. In addition, since PMI-Score needs to use external auxiliary data for calculation, we use the Chinese Wikipedia data downloaded from the official website of Wikipedia as the additional corpus. The L is set to 10, the K is set from 10 to 50, and the step is set to 10. Figure 4 draws the results of the PMI-Score of the bursty topic discovery of all comparison methods.
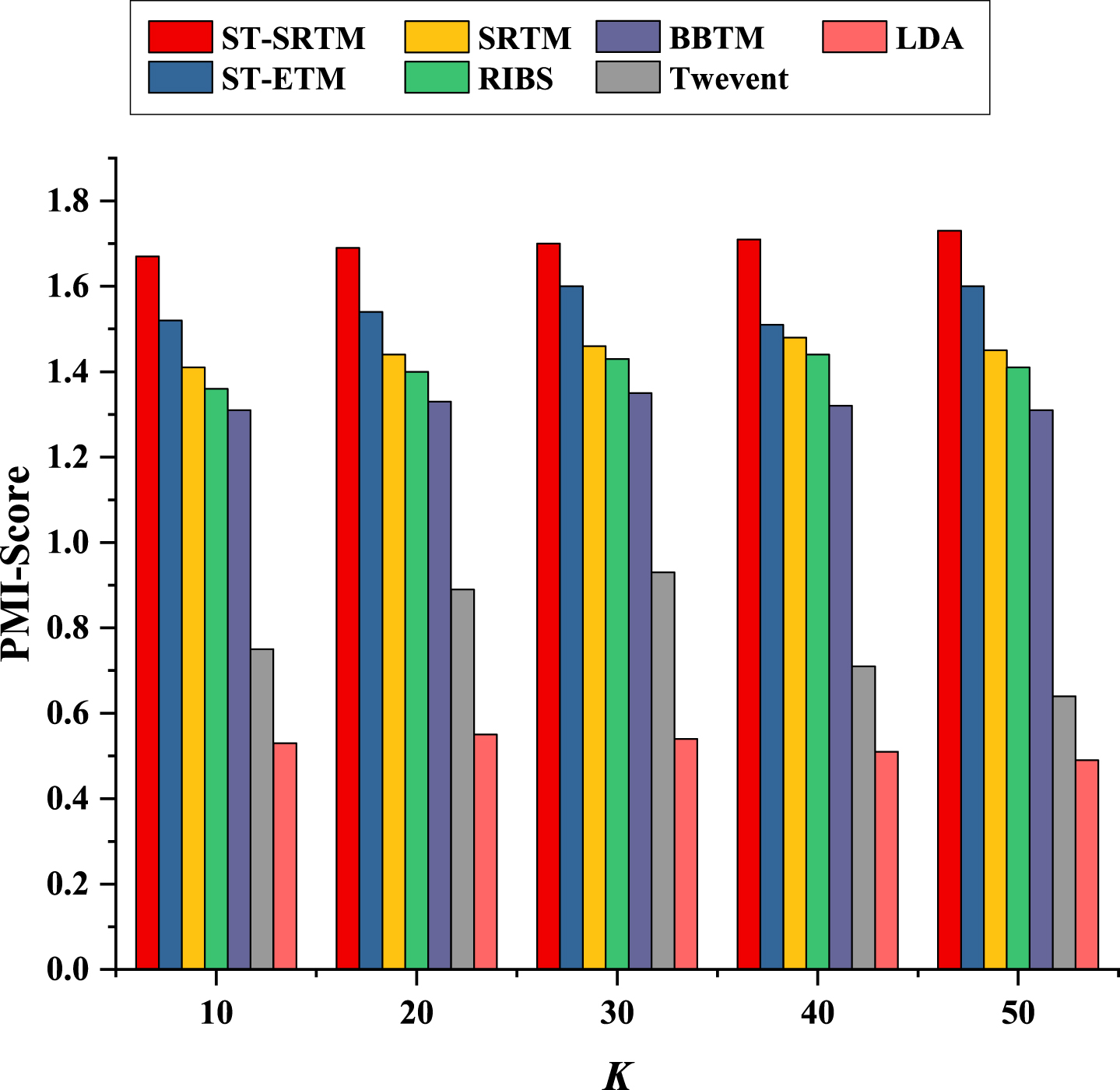
Topic consistency results of bursty topic discovery.
From the results in Fig. 4, we can draw the following conclusions. In all the comparison methods, our proposed ST-SRTM obtains the highest PMI-Score value. This shows that ST-SRTM can get more coherent bursty topics from the context of social networks. ST-ETM and SRTM are better than RIBS, indicating that the introduction of spatial-temporal information and RNN priors enable the model to obtain more coherent emergent topics. BBTM also obtained better PMI-Score results. This is because BBTM able to effectively weaken the sparsity of context. Compared with LDA, Twevent also achieved good topic coherence results, mainly because Twevent can cluster similar emergent topics through burst feature clustering. In all the comparison methods, LDA obtain the worst result. The main reason is that LDA cannot alleviate the sparse semantics of social network context.
To more intuitively verify the coherence of the bursty topic discovery of ST-SRTM, we select the top-10 words in the bursty topic results discovered by all comparison methods to qualitatively analyze the coherence of the emergent topic. We chose a hot and bursty topic from the discovered bursty topics: “ Wuhan COVID-19”. This topic began to erupt on January 21, 2020. Table 4 lists the top-10 words close to the topic of “ Wuhan COVID-19” discovered by all comparison methods.
Top-10 words related to the “Wuhan COVID-19” discovered by all methods

From Table 4, as we can see, ST-SRTM are relatively closer to the content of the “Wuhan COVID-19” topic. ST-ETM is also similar to the topic content, only a few noise words such as “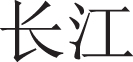 (tourism)” and “
(tourism)” and “ (Yangtze River)” are mixed. The SRTM results include noise words such as “
(Yangtze River)” are mixed. The SRTM results include noise words such as “ (weather)”, “
(weather)”, “ (waters)” and “
(waters)” and “ (contaminated)”. The RIBS include general words such as “
(contaminated)”. The RIBS include general words such as “ (citizen)”, “
(citizen)”, “ (supermarket)”, “
(supermarket)”, “ (weather)” and “
(weather)” and “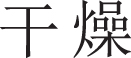 (Bridge)”. The result of BBTM is a mixture of common words such as “
(Bridge)”. The result of BBTM is a mixture of common words such as “ (dry)”, “
(dry)”, “ (Travel)”, and “
(Travel)”, and “ (relatives)”. Twevent contains a lot of irrelevant words, such as “
(relatives)”. Twevent contains a lot of irrelevant words, such as “ (tourism)”, “
(tourism)”, “ (Wechat Moments)” and “
(Wechat Moments)” and “ (hotel)”, which shows that the bursty topic discovery method based on sudden word clustering is more sensitive to noise data. The results of LDA contained many words that were irrelevant to the topic, such as “
(hotel)”, which shows that the bursty topic discovery method based on sudden word clustering is more sensitive to noise data. The results of LDA contained many words that were irrelevant to the topic, such as “ (transit),
(transit), 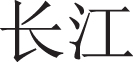 (urban rail lines)”, “
(urban rail lines)”, “ (Yangtze River)”, “
(Yangtze River)”, “ (Nanjing)” and “
(Nanjing)” and “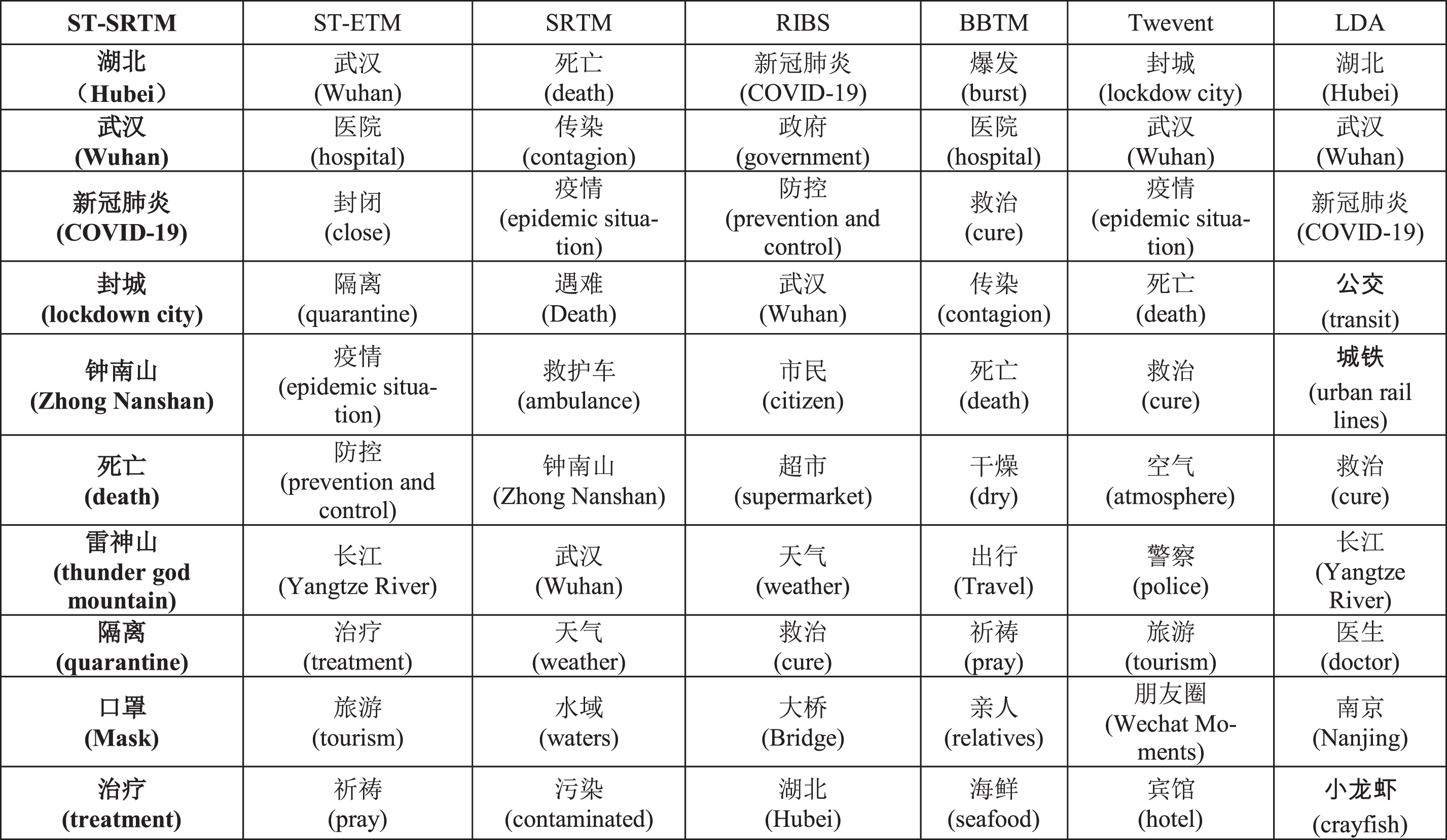 (crayfish)”, etc., and only fewer words were closer to the “Wuhan COVID-19”. The above results further verify that the traditional topic model is difficult to distinguish between ordinary topics and bursty topics, and thus cannot obtain better coherence results.
(crayfish)”, etc., and only fewer words were closer to the “Wuhan COVID-19”. The above results further verify that the traditional topic model is difficult to distinguish between ordinary topics and bursty topics, and thus cannot obtain better coherence results.
The quality of topic discovery is a significant indicator for evaluating bursty topic discovery. The Purity is selected as the evaluation indicator to verify the quality of topic discovery for all baseline methods. Purity is a classical clustering quality evaluation measure. The larger its value is, the better the quality of topic discovery is. In addition, because the crawled data do not contain label information, we use the hashtags information of Sina Weibo as the clustering label. The number of bursty topics K is set 10 to 50, and the number of steps to be 10. Figure 5 shows the experimental results of bursty topic discovery quality for all comparison methods under different bursty topic numbers.
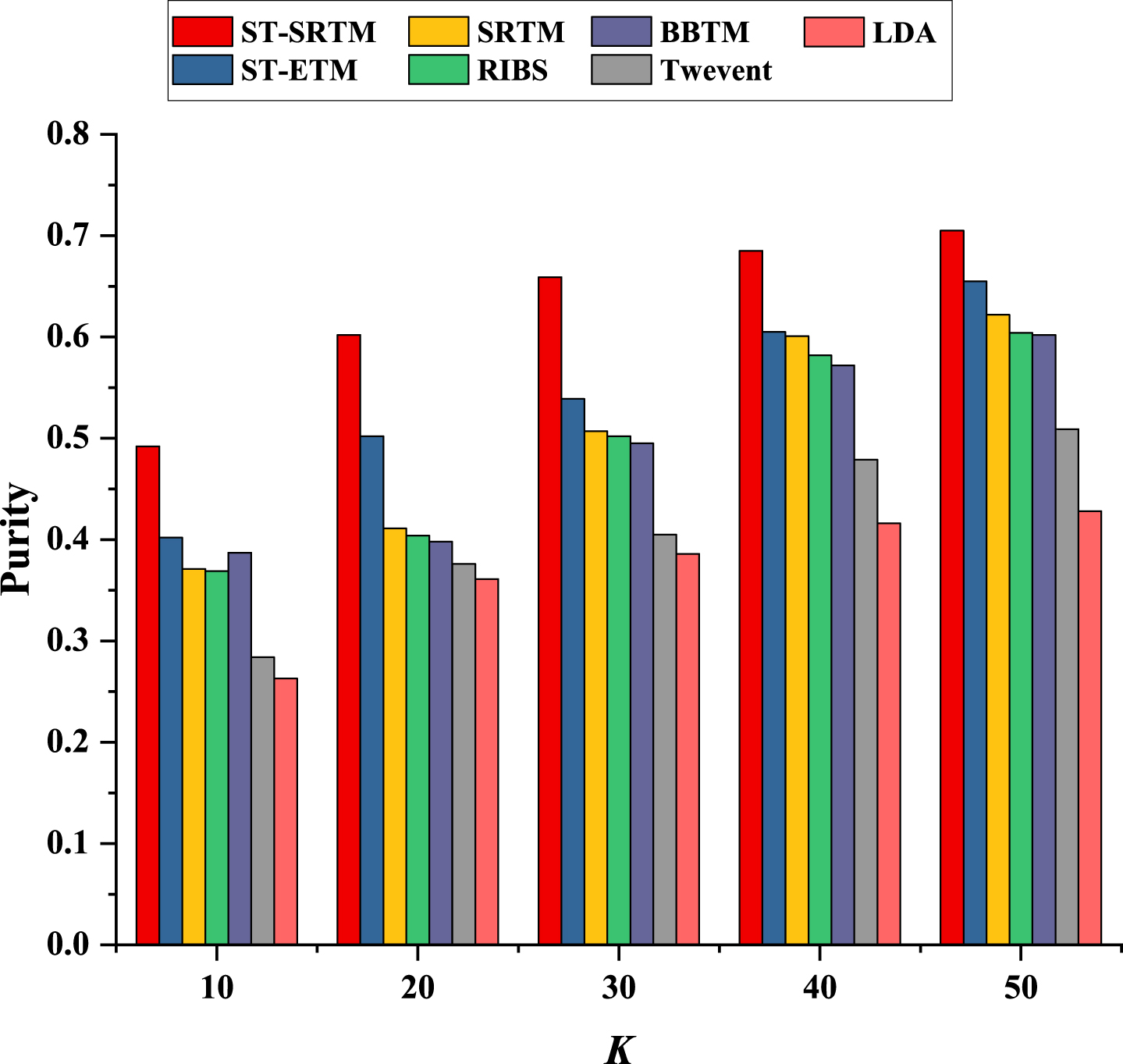
Comparison of clustering purity of bursty topics.
From Fig. 5, we can draw the following conclusions. The proposed ST-SRTM is superior to other comparison methods in Purity. The results show that the proposed ST-SRTM can obtain high-quality bursty topics. ST-ETM and SRTM also obtained better results. However, compared with our proposed ST-SRTM, they still perform slightly worse. The main reason is that the proposed ST-SRTM can effectively enhance the semantic space to generate more word co-occurrence information by modeling spatial-temporal areas and can obtain high-quality topics by introducing sparse prior. RIBS and BBTM also get high-quality bursty topics. The main reason is that RIBS and BBTM can weaken the context sparsity through different means. The performance of Twevent is better than LDA, mainly because Twevent uses burst word information to describe bursty topic, which can improve the quality of bursty topic discovery. In all comparison methods, LDA always performs the worst because LDA only models text semantics from document topic distribution, cannot distinguish common topics from bursty topics, and cannot alleviate context sparsity in social networks.
The social network content is noisy and sparse, accompanied by a large number of meaningless topics and common topics, which brings difficulties and challenges to the bursty topic discovery. To deal with the above problems, the paper proposes a spatial-temporal topic model with sparse prior and RNN prior for bursty topic discovering. Our method learns between words by introducing RNN priors and use spatial-temporal information to construct spatial-temporal area information to enhance word co-occurrence information for alleviating the semantic sparsity. To further deal with the problem of semantic sparsity, we directly model words to learn more word co-occurrence information. Meanwhile, the emergence of words is introduced as a prior, combined with binary switch variables to realize the automatic discovery of bursty topics. In addition, we introduce a sparse prior to decouple the sparseness and smoothness of the topics learned to obtain more coherent bursty topics. Multiple evaluation indicators are used to verify the performance of the proposed ST-SRTM. The experimental results demonstrate that the proposed ST-SRTM can automatically discover bursty topics, and its performance is better than other comparison methods.
In addition, social networks include not only spatial-temporal characteristics but also a lot of user information, hashtags information, social relationship information, cross-media information, and other different attributes and modal information. Our ST-SRTM cannot model the above information. By introducing multiple attributes and modal information of social networks to model the semantic information of social networks, we can reduce the semantic space and alleviate semantic sparsity. Through the mutual supplement of different modal information, the ability and granularity of semantic modeling can be further improved, to provide support for upper layer applications. In future work, we will introduce the above different attributes and modal information to fine-grained model the semantics of social networks for realizing the accurate search of bursty topics, knowledge graph and intelligent recommendations in social networks.