
Abstract
The paper describes the excellent method to get first-rate accuracy and performance in the discipline of Tamil character recognition in a handwritten mode. However, the subject is still at a nascent stage and grossly lacks adequate accuracy in the Tamil language, even though several studies have been conducted within the discipline of handwritten character recognition. This paper draws the attention to the offline handwritten recognition for the Tamil language using the Inception-v3 based transfer learning method. The proposed work is conducted on the readily available HP Tamil handwritten character offline dataset (Hewlett-Packard Lab: hpl-tamil-iso-char-offline-1.0.). It reveals that with the suitable arrangement of transfer learning approach with Inception-v3, the pre-trained model can achieve the recognition accuracy of 93.1%, overtaking the former deep learning designs. The achieved accuracy is due to the use of a pre-trained version with transfer learning that regularly hastens the method of the training process on a new task. Overall, this results in higher accuracy and a more capable version.
Introduction
Understanding the handwritten characters or typed files is straightforward for human beings because we have the potential to learn. An equal potential may be precipitated to the machines additionally, by using the procedure of Artificial Intelligence, Neural Network, Machine Learning, and deep learning algorithms. The discipline which offers this technology is referred to as OCR, which stands for “Optical Character Recognition (OCR).” The OCR is the method of changing the image into an editable digital character [1]. There are various applications for categorizing handwritten characters. It can be utilized to digitize the ancient records in healing centers or workplaces. Moreover, it can be considered in the post office for sorting letters for different regions. The application of OCR can reduce the time utilized in entering the information and the storing space capacity required by the reports. In other words, it can be recovered quickly.
By using the OCR in the field of banking, law, and so on, numerous critical and important archives can be prepared promptly without human mediation. The OCR is categorized into two types, (a) handwritten character recognition and (b) printed character recognition. Further, based on acquiring the input documents, handwritten OCR is categorized into Offline and Online recognition systems [2]. The offline mode deals with recognizing the pre-written report obtained through diverse input methods. But in the online recognizing order, the writing is diagnosed the moment it is written. The device used for the online machine is an Electric pen where it is used for writing the letters or words on the tool, known as the digitizer, based on the pen movement. The handwritten recognition tool needs high identification ability than the online and printed recognition due to the various writing styles of the people. Many a time, even the handwriting of the same men or women does not match at different points in time.
In the deep learning process, the “Convolutional Neural Network (CNN)” has topped in giving the best results in some of the unique complications such as detection and prediction among numerous fields such as pattern recognition, character recognition, additionally object detection also [3]. By using some of the recent deep learning models like VGG, ResNet, and Inception, the classification and prediction task was accomplished with high accuracy. Due to the deep and complex structure of these models, it is tough to train, and need images in bulk to train without over-fitting. Some researchers have introduced substantial data augmentation [4] also to save the model from over-fitting for small dataset problems. By using a novel approach, called transfer learning with high complex model [5], it became possible to enhance the performance of the classifier on the small dataset. Presently, it is the best known standard approach in deep learning. Using this approach, one can utilize the pre-trained models of the first task as the opening point for the same model on the second task. Transfer learning permits us to use learned knowledge of the first task and puts them on to newer and any related second task. It means low-level features and some of the high-level features are being shared across the tasks, which will permit knowledge transfer between tasks. The proposed method in this research is the retraining process of the Inception-v3, using transfer learning method for “Tamil Handwritten Character Recognition (THCR),” as shown in Fig. 1.
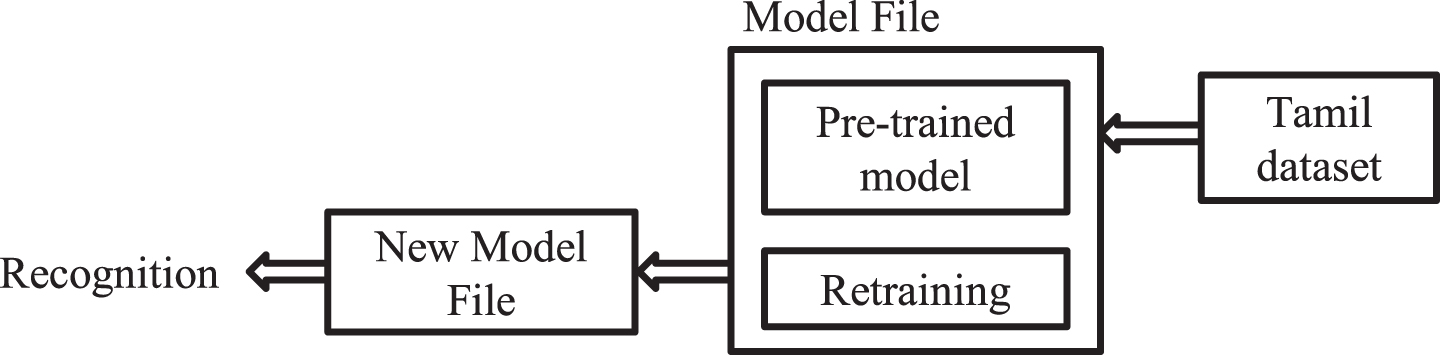
Transfer learning approach for Tamil Handwritten Character Recognition.
THCR is defined as the capability of recognizing the exact character from digitized print and handwritten Tamil documents with a high degree of recognition accuracy for a variety of Tamil digital inputs. Tamil is the longest- surviving and the oldest language, one of the Dravidian languages primarily vocalized by the Tamil people of India, Sri Lanka, Singapore, and Malaysia. The Tamil alphabets consist of 12 vowels, one Aayudham, 18 consonants, and 216 compound characters. Hence Tamil has a total of 247 characters. About 6 Grantham characters are also present in the Tamil language [6]. THCR is more difficult than the printed Tamil character recognition due to curves in character, sliding characters, and its various strokes and holes. However, many of the researchers take these as a challenging task, and consequently, reasonable accuracy, speed, and performance have not been obtained. So the idea behind this work is to identify and analyze a Tamil handwritten document image, using the Inception-v3 model with the transfer learning approach. This work is carried on in the HP lab Offline THCR Dataset, which includes 156 classes. A sample of print and handwritten images of Tamil language characters are shown in Fig. 2.

Sample image of Tamil language: (a) Printed Tamil Character and (b) Handwritten Tamil Character.
Recognition and classification are significant problems in deep learning. Many of the deep learning researchers gave some new signature models for recognition and classification. Many scientists have studied many machine learning methods such as “Support Vector Machine (SVM)”, ANN, HMM [7], HLP, and deep learning model algorithms like CNN [8]. The researchers used these methods to solve the OCR problems for many languages like Japanese, Chinese, English, Tamil, Devanagari, Telugu, Gujarati, and so on [9]. Similarly, hybrid models by combining deep learning with machine learning were also introduced, like CNN-SVM [10].
Ning Bi and others [11] identified the Chinese handwritten character with the help of GoogLeNet, which is one of the successful deep models in CNN. This work is carried on the database CASIA-HWDB and HCL2000. This experiment exhibited that the GoogLeNet can provide superior results for the Handwritten Chinese symbol identification than the previous deep models. In this research, GoogLeNet model uses numerous inception stages to construct an efficient deep network, which will find the optimal local construction. Saeeda Naz [12] and others introduced a new hybrid model, which was the combination of CNN and “Recursive Neural Network (RNN)” for Urdu Nastaliq recognition. In this hybrid model, low-end features like edges and shapes are extracted by the CNN then forwarded to the RNN architecture to recognize the character. This work is verified on the openly existing “Urdu Printed Text-line (UPTI)” dataset by using the proposed hybrid grouping of the CNN and the RNN for 44-classes, which achieved the superior results on the UPTI dataset.
Adnan Taufique and others [13] recognized the Bangla character by using CNN with the inception module. The dataset includes 85,000 images used for training and 3000 images used for testing. The planned method showed competitive performance with the existing methods based on the test set accuracy for the dataset. The accuracy of this work is better than other models. Many investigators clearly explain the inception models for their studies. In the next stage of an advanced concept, transfer learning is catching the attention to record the progress of the performance of traditional architectures by different researchers.
Le Zhang and others [14] uses the transfer learning technique to identify the numeral digits with the help of multi-layer perceptron and CNN systems. The authors select the five scripts such as Tibetan, Telugu, Arabic, Devanagari, and Bangala. The researchers presented that the transfer learning model is the best model based on less training time, but this model somewhat decreases the accuracy rate. Mohammed Aarif and others [15] select the transfer learning approach with AlexNet and GoogleNet deep learning models to identify the Urdu characters. This research work also especially concentrated on the different fonts and size characters also. AlexNet and GoogleNet generate the recognition rate as 96.3% and 94.7%, respectively. Satyasangram Sahoo and others [16] suggested transfer learning technique with CNN architecture to get the outstanding performance for Telugu and Kannada letters. Usually, Telugu and Kannada letters are almost in similar shape.
Chunmian Lin and others [5] have introduced a new model for traffic sign identification and classification based on transfer learning, which is useful for road infrastructure and driver assistant systems. Using the Inception-v3 model significantly reduced the training data size and computation expense. In this project, Belgium Traffic Sign Dataset was chosen and was augmented through the data pre-processing technique. In this model, the features from different layers using convolution and pooling processes were compared and analysed. As a result, the transfer learning-based inception model cyclically retrained numerous times with fine-tuning parameters at different learning rates. Excellent reliability and repeatability were also observed based on statistical analysis. The result of this work showed that the transfer learning model could achieve the best recognition performance in traffic sign recognition. Jyotsna Bankar and others [17] proposed the system based on the Inception-v3 design of TensorFlow platform, in which they used the transfer learning technology to train the animal classification model on a mammal’s dataset. The classification accuracy rate of the model is approximately 95% on a given dataset, which is higher than the other methods available for classification. Nagender Aneja and others [18] used the same transfer learning with the Inception-v3 technique to recognize Devanagari handwritten character. Results of this work depicted that the proposed model can perform better in terms of accuracy per average epoch time.
Much research was undertaken for the Tamil language also. Kavitha and Srimathi C. [19] used the CNN model to recognize handwritten Tamil characters in the offline mode. They used HP Labs India dataset to understand the character. They trained the model from scratch, which produced the state-of-art result in Tamil character recognition. S. Kowsalya and P. S. Periasamy [20] introduced a new model called the Neural Network with Elephant Herding Optimization to recognize the handwritten Tamil character. Shanthi and Duraiswamy [21] described a model for identifying handwritten Tamil characters by SVM, offline. They used their dataset to recognize the character. Various pre-processing operations were performed on the scanned image. The features were extracted for 64 different zones, and those extracted features trained the SVM. This model achieved good recognition accuracy on the Tamil symbol database.
THCR recognition by inception V3 with transfer learning
From the above literature, it can be concluded that still, THCR is in its very early stage. So THCR has suggested a novel Inception-v3 model with transfer learning technique to enhance the recognition rate. The general architecture of the proposed THCR is shown in Fig. 3. Before entry into the architecture model, dataset loading, preparing dataset, and encoding dataset class labels into numeric values are essential. The HP lab THCR dataset is loaded with some underlying dependencies such as resizing, binarisation and noise removal into the model. Data augmentation step is added by the Image Data Generator framework of Keras, to reduce the over-fitting problem. The dataset images get altered by this data augmentation step with some of the image renovation processes such as shearing, rotation, zooming, and translation. Due to these random transformations, the model does not get the same images each time. Then the HP lab THCR dataset is passed through the dataset split module, where the dataset images are split into training, validation, and testing of the set images. The planned technique in this study consisted of three phases, namely, pre-trained model, retraining process with transfer learning technique, and modified recognition portion.
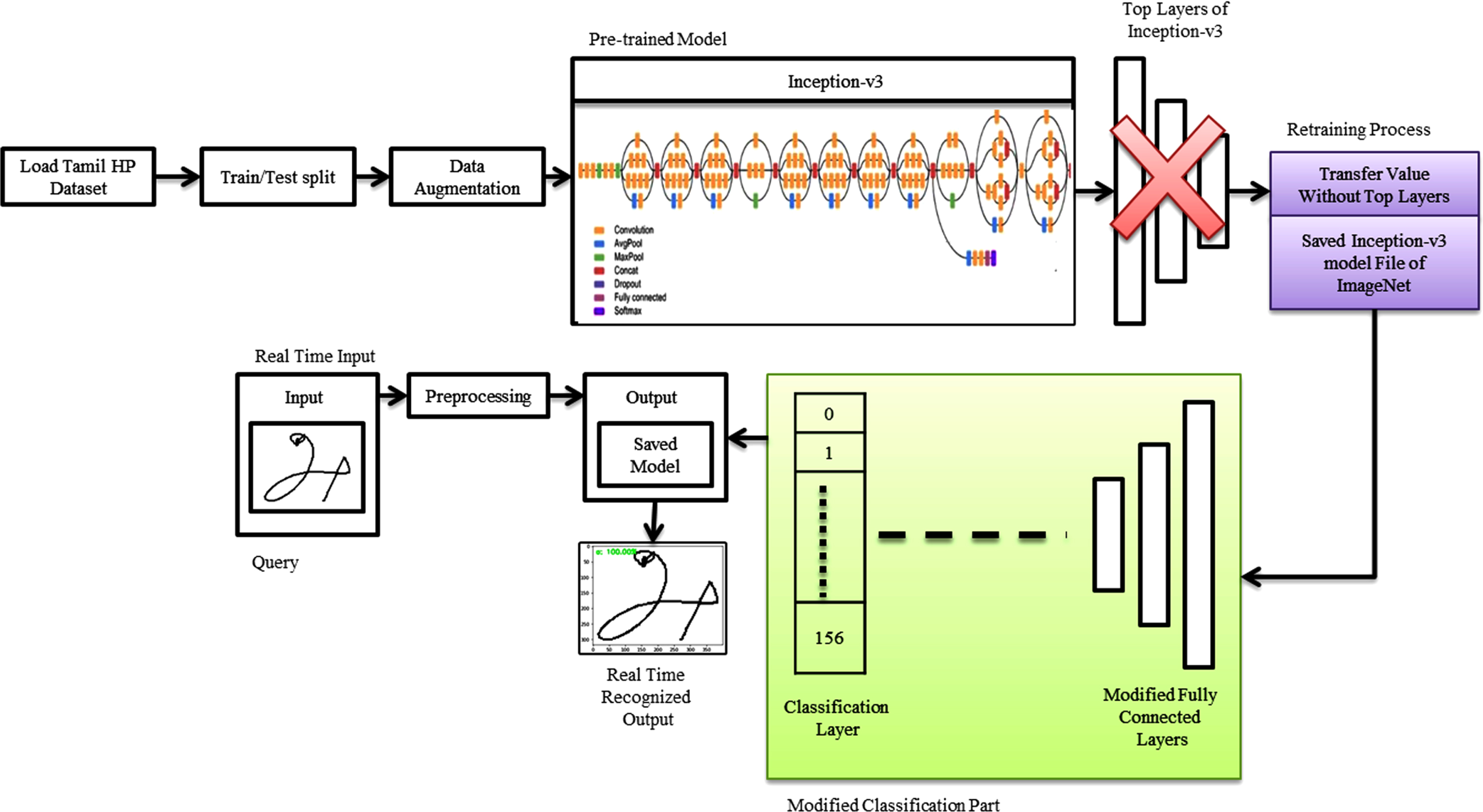
General architecture of THCR using Inception-V3.
A pre-trained model is a saved architecture, which was previously trained on a massive dataset. Pre-trained models are a brilliant source of researchers to learn an algorithm or try out an existing framework for future problems. Due to time boundaries or computational limits, it is not always possible to build a model from scratch. Pre-trained representations are introduced to resolve these issues. Pre-trained model is a standard model to either develop the performance of the existing model or test the new model against it. The perception behind the pre-trained model for classification problem is that if a model was trained on a massive and universal dataset, this model would be successfully considered as a standard model of the optical world. In general, for classification applications, specific standard models like VGG, ResNet-50, XCeption and Inception-v3 models are presented, which were trained on standard ImageNet dataset. Hence, it would be beneficial for researchers to use these models. The ImageNet dataset covered 14 million images of 1000 groups. The THCR is proposed based on the Inception-v3 model as a pre-trained model, which is trained on ImageNet weight. The Inception-v3 is an extensively used image classification model that has been developed by concluding many ideas of multiple researchers over the centuries.
This is established from the original research paper [22] by Szegedy and others. This model is the third version of the series made by Google Deep Learning Convolutional Architectures. The Inception-v3 got the first runner up on ImageNet Large Visual Recognition Challenge, which attained 21.2% top-1 and 5.6% top-5 error rate. Visualization of the Inception-v3model architecture is presented in Fig. 4. The model is made up of many building blocks, including convolutions, average pooling, max pooling, concatenation, dropouts, and fully-connected layers. Batch normalization is used comprehensively, all over the model, and applied to activation inputs. The image label is computed by the probability value, which is calculated by the Softmax classifier.
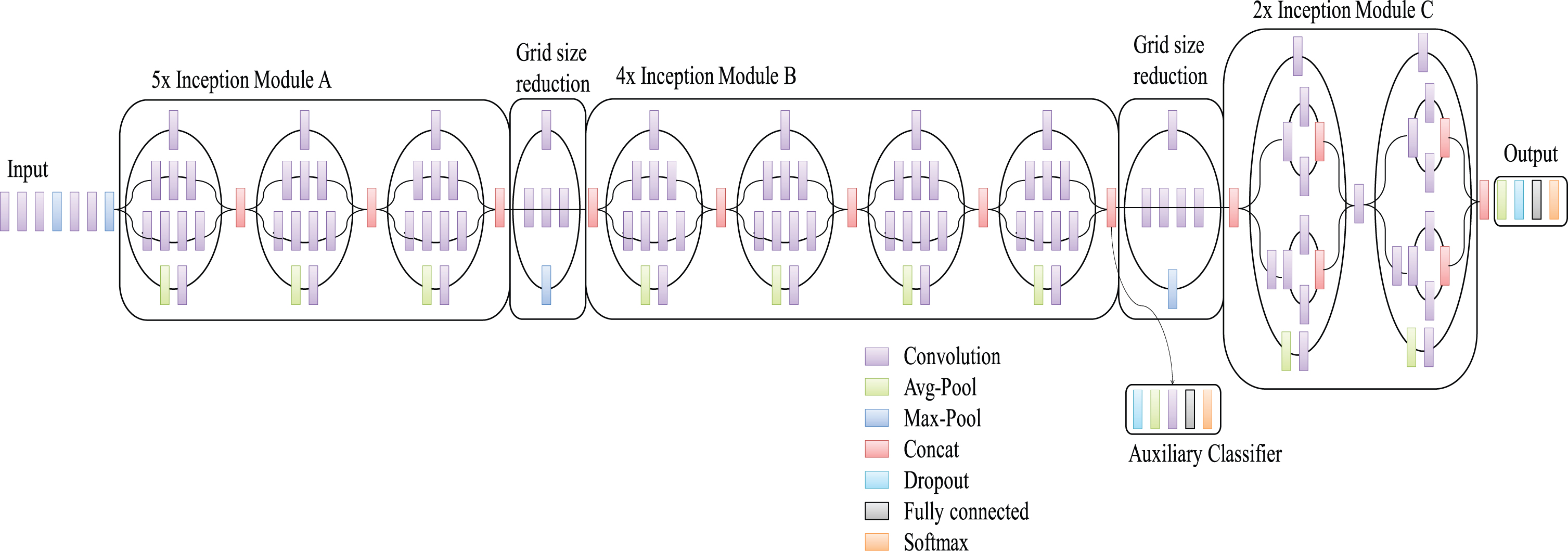
Inception-v3 model for classification.
The corresponding teams have publically shared a lot of their great deep learning designs. Millions of parameters, feature maps, and weights of these designs were saved as customers to help new users. That publically shared model is called a pre-trained model, which is processed on a particular problem in a stable mode. Due to deep learning believes in sharing, by using these learned feature maps, millions of parameters and weights can train large models on the big dataset without having to start from scratch, which is defined as transfer learning. Keras is the famous deep learning Python library, which offers an interface to use and download these pre-trained models. But one essential requirement of transfer learning is the presented pre-trained design, which has been proven to be a well-performing model on the source tasks. Transfer learning model with Inception-v3 architecture for THCR is displayed in Fig. 5. In this work, the Imagenet classification with Inception-v3 model is considered as the source task, and THCR is the target task. The trained features of the source task are transferred to the new THCR task. The target HP Tamil dataset is small and similar to the source task, Imagenet dataset. If the entire feature map-files of Imagenet are transferred to the new THCR model, over-fitting will occur. To avoid this problem, train only the classification part. Due to the requirements of only the high-level range features, freeze all the Inception-v3 layers and remove the classification layers of the source task. After removing the old classification layers, add the new classification layers on top of the model depending on the target task. Now the model trains only the newly added classifier layers. By using this model, processing time also gets reduced, which is one of the most top advantages.
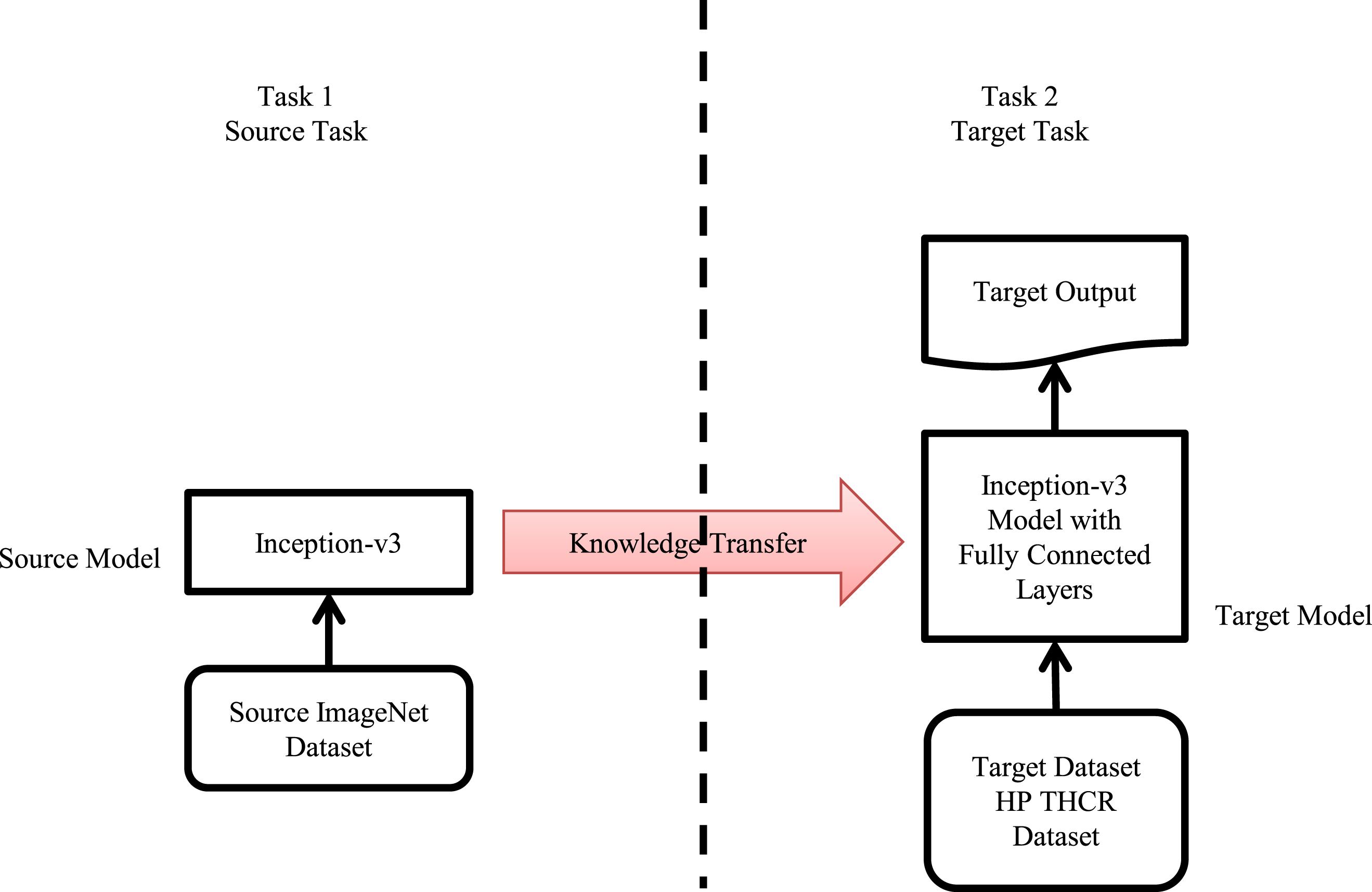
Transfer learning approach with Inception-v3 for THCR.
In this proposed work the Inception-v3 is used as a feature extractor by freezing all inception blocks for THCR. Freezing of the inception blocks is proper because, in transfer learning model, there is no need for weight updating in base layers during model training [18]. The Inception-v3 pre-trained model learned a definite hierarchy of features from Imagenet dataset. Therefore, the learned model with a good representation of features from a million images in 1,000 different categories can perform as a suitable feature extractor to input image of new target classification problems. Even though the target images might not even exist in the ImageNet dataset or might be of entirely different categories, the model can extract relevant features. During transfer learning, there is no necessity for fully-connected layers, since the proposed model uses their fully-connected dense layers to classify Tamil characters. Thus the Inception-v3 model is improved by adding fully-connected and modified layers. The trained feature extracted layers of the Inception-v3 from Imagenet dataset, get flattened, and serve the dense layer of the fully-connected modified deep classifier. The dense layer is one of the actual network layers, where all outcomes of the previous layer are feeds to the following layer in that model. The dropout of 0.3 is added, to enable regularization. Fundamentally, dropout is a dominant technique of regularising in deep neural nets [23]. The modified version of the fully-connected layer of THCR is shown in Fig. 6.
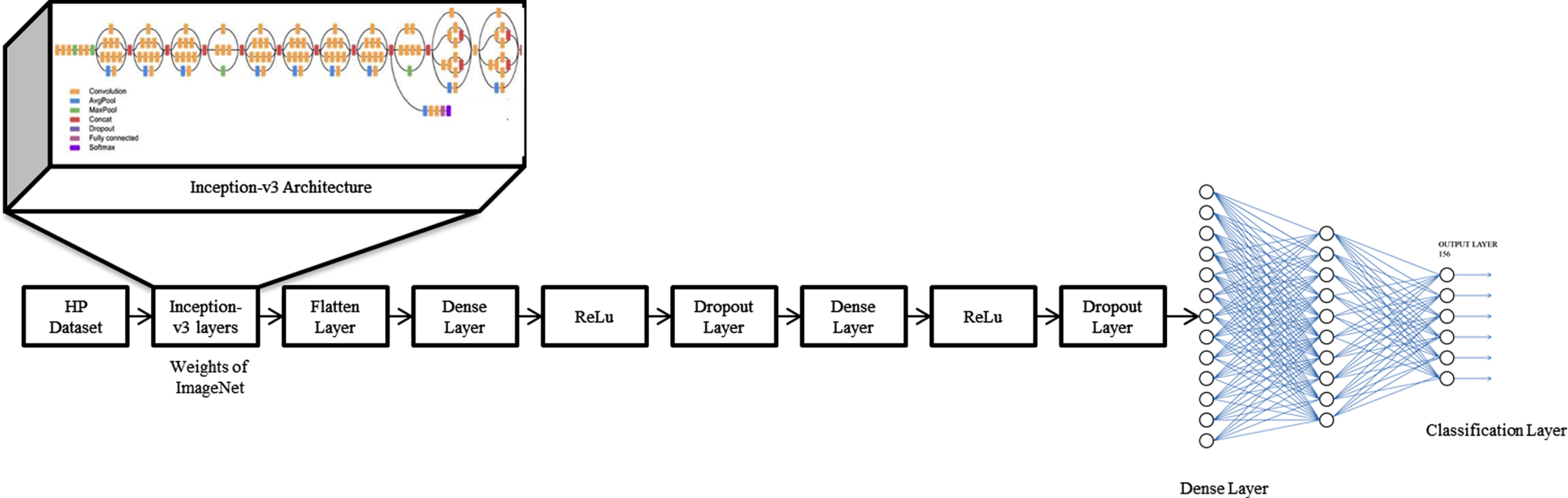
Modified version of the fully-connected layer of THCR.
The key indication of this project recognizes the handwritten Tamil characters. The weights and biases of the Imagenet dataset-based Inception-v3 model are used as the re-used model for Tamil character recognition training model. In this study, those pre-trained model, act as a feature extraction part of the new model, as mentioned earlier. The inception layers are frozen to update weight, or else the key point of transfer learning cannot be confirmed. The top layers of the proposed model are modified depending on the THCR application. Due to the inception blocks being in the frozen stage, the training process is carried only on modified fully-connected layers.
The experimental setup and system specification for THCR are given in Table 1. The model using the Adam optimizer for modified layer parameter updates. Also, the proposed system planned to use the Categorical cross-entropy loss as the error function. Based on this error function value, the parameter values are modified. To train the model, the THCR system is using the 0.001 value as the learning rate and selects 500 as the Epoch value and 32 as the Batch Size.
Experimental setup and system specification for THCR
Experimental setup and system specification for THCR
From Fig. 7, it can be concluded that the proposed Inception-v3 model is the best model for THCR. The gap between the training and validation accuracy Fig. 7(a) shows the model is the best without over-fitting. The loss graph Fig. 7(b) indicates the system learning with proper parameters. In this investigational arrangement, the Tamil character dataset includes the 155 classes, where all classes have more algorithm controls over the power of adaptive learning rates methods to find individual learning rates for each parameter.
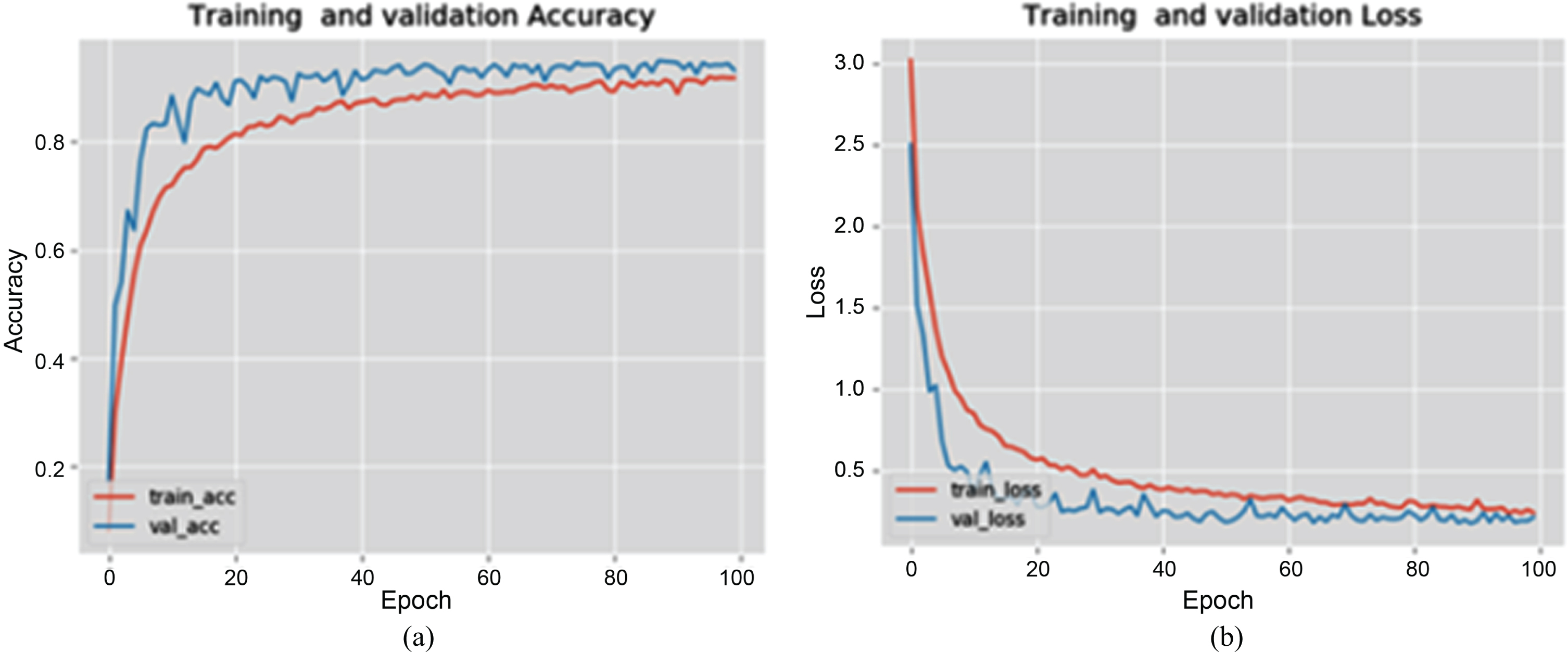
Performance analysis of the THCR using Inception with transfer learning: (a) Accuracy and (b) Loss.
The Loss function performs as monitors to the optimizer if it is moving in the right way to reach the global minimum. In the proposed work, categorical cross-entropy is used as a loss function to optimize the parameter values of the projected model. The loss value suggests how a model performs at every end of the iteration of the training process. For comparison purpose, the THCR system using simple CNN, VGG-16, VGG-19, CNN with modified lion optimizer model and CNN with modified sea lion model is shown in Fig. 8.
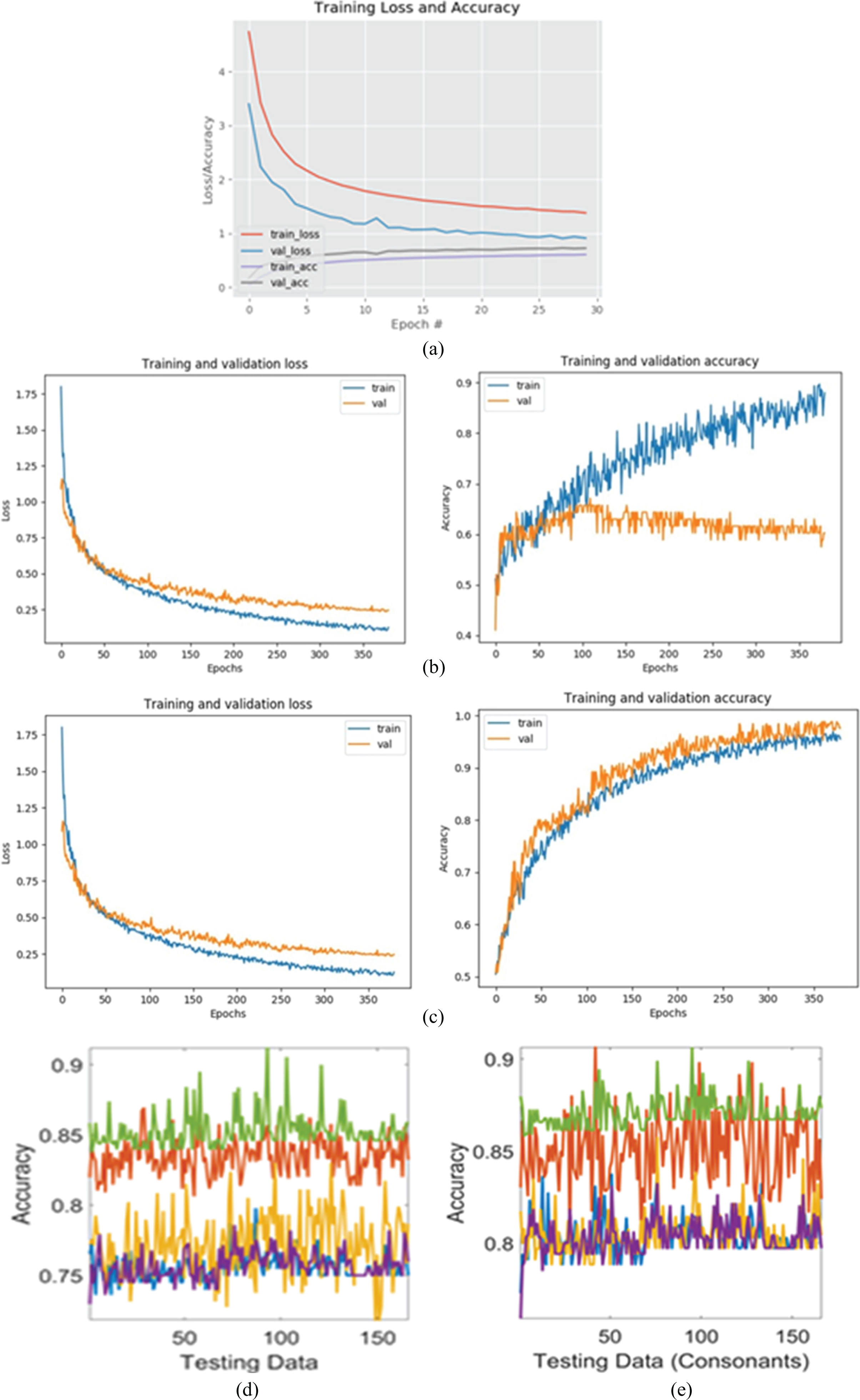
Performance analysis of the THCR (a) simple CNN (b) VGG-16 (c) VGG-19 (d) CNN with modified Lion optimizer (e) CNN with modified sea lion optimizer.
Accuracy is used to find the performance metrics of the proposed algorithm of the THCR model. The training process results for THCR are shown in Figs. 7, 8 and Table 1. The baseline architecture of the proposed model gave 93.1% test accuracy for Tamil handwritten recognition, which produced Training accuracy of 95.45% and 91.82% as validation accuracy. The efficiency is further improved by introducing the fine-tuning methods, where all the inception blocks were not frozen.
Table 2 displays the testing accuracy for 20 individual classes from the 155 classes of HP dataset, and Fig. 9 shows the accuracy comparison between these 20 different classes of Tamil language. From Table 1 and Fig. 9, the accuracy for the dataset increases when increasing the depth of the model architecture, which also increases when introducing transfer learning model with less processing time. Some of the test images recognition is shown in Fig. 10.
Test accuracy for first 20 classes from the dataset
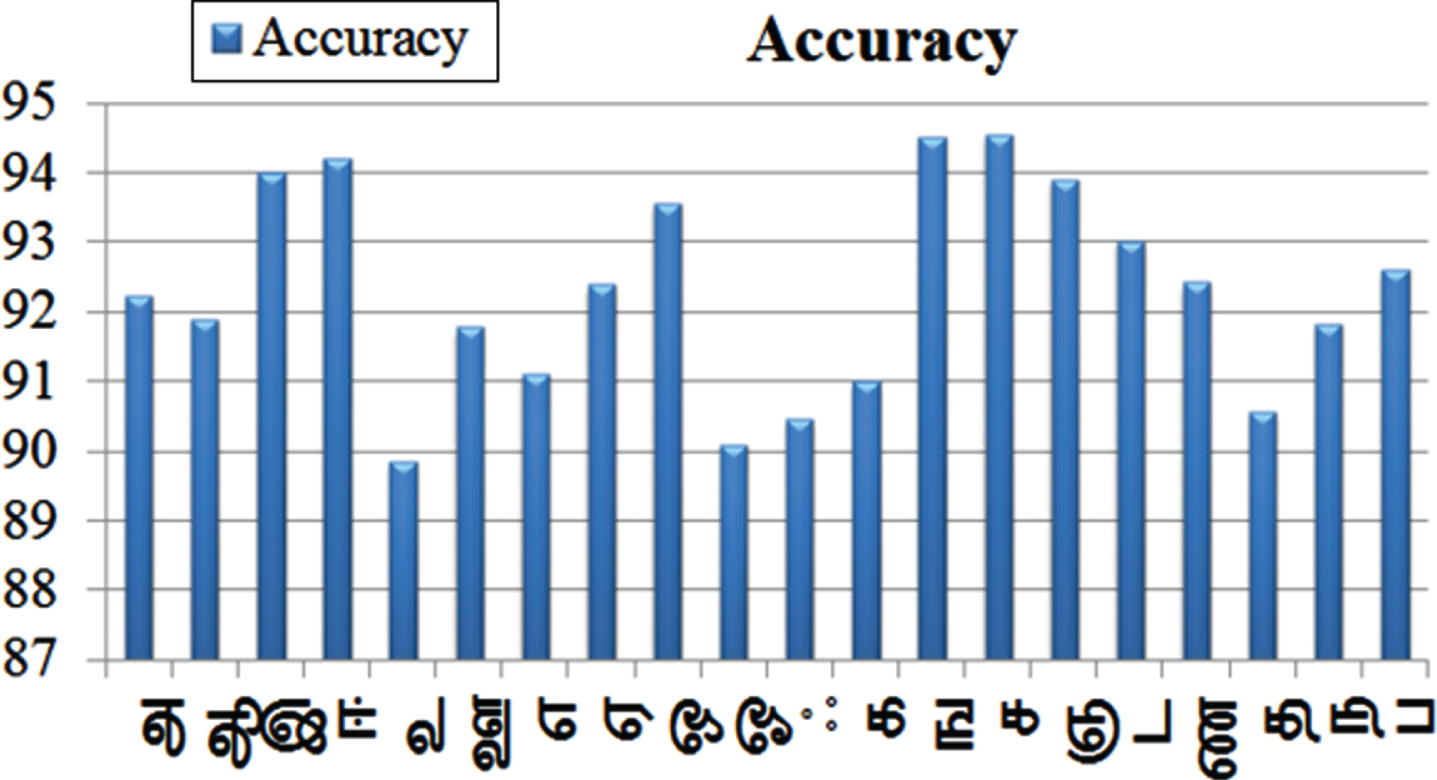
Accuracy comparisons between 20 different classes of Tamil language.

Test image recognition.
The Inception-v3 model trains the planned THCR with modified fully-connected layers by selected hybrid parameters. The trained model file is saved. The real-time input image is considered as a query image, which is passed through the pre-processing process such as resizing, noise removal, slant correction and slope removal. Then the pre-processed query image is given into the saved proposed model file. Based on that saved model file, labels are assigned to the output in the form of the class of the given query image. Some of the real-time output of input queries is shown in Fig. 11.

Query image output (a) Input Image (b) Preprocessed Image (c) Segmented Image (d) Recognized output.
The THCR system is trained with different deep learning architectures based on heuristic-based and meta-heuristic based optimizer. Based on the experiments, the comparison table for Tamil handwritten character recognition is shown in Table 3.
Comparison between different models for THCR system
The best model is based on accuracy and also learning speed. When considering the Inception-v3 model without transfer learning approach, the model takes a long time to train, since the Inception-v3 is a very deep model. Because the simple CNN model without transfer learning techniques takes nearly 2217 s per epoch. When considering 30 epochs, it is a long time process. At the same time the Inception-V3 model with transfer learning technique takes only 774us per epoch, even though it is a very deep model. Based on the speed and accuracy rate, the proposed model is the best model. The comparison work based on the THCR system with different existing work is shown in Table 4. From the Figs. 7, 8, Tables 3 4, it can be concluded that the proposed transfer learning-based THCR system with the Inception-v3 model is the best model in terms of accuracy and less learning period.
Comparison between the various existing works
Transfer learning allows retraining only the top layer of a proposed model, causing a significant reduction in both training time and also the size of the dataset. A prominent model that can be used for transfer learning is the Inception-v3, to recognize the handwritten Tamil characters. As expressed, this model was initially prepared with the assistance of over a million pictures from 1,000 labels on some extremely incredible models. Being able to retrain the final layer signified that the model could maintain the knowledge that it had learned during its original training, and could apply it to a smaller HP Tamil handwritten character dataset. The result is with highly accurate classifications, without the need for extensive training and computational power. The proposed THCR system achieved 93.1% testing accuracy, which is higher than THCR using the CNN model. The main identification errors were due to abnormal writing and ambiguity among similar shaped characters. Future work can include more robust extracting features for the classifier to achieve better discrimination power by performing a fine-tuning process in the Inception layers. The recognition accuracy of the individual characters can be additionally enhanced by combining the hybrid models. And also, the future work will consider the special segmentation technique for the identification of abnormal writing and among similar shaped characters.