
Abstract
Clear images are generally desirable in high-level computer vision algorithms which are mostly deployed outdoors. However, affected by the changeable weather in the real world, images are inevitably contaminated by rain streaks. Deep convolutional neural networks (CNNs) have shown significant potential in rain streaks removal. The performance of most existing CNN-based deraining methods is often enhanced by stacking vanilla convolutional layers and some other methods use dilated convolution which can only model local pixel relations to provide the necessary but limited receptive field. Therefore, long-range contextual information is rarely considered for this specific task, thus, deraining a single image remains challenging problem. To address the above problem, an effective residual deep attention network (RDANet) for single image rain removal is proposed. Specifically, we design a strong basic unit that contains dilated convolution, spatial and channel attention module (SCAM) simultaneously. As contextual information is very important for rain removal, the proposed basic unit can capture global long-distance dependencies among pixels in feature maps and model feature relations across channels. Compared with a single dilated convolution, the spatial and channel attention enhance the feature expression ability of the network. Moreover, some previous works have proven that the no-rain information in a rain image will be missing during deraining. To enrich the detailed information in the clean images, we present a residual feature processing group (RFPG) that contains several source skip connections to inject rainy shallow source information into each basic unit. In summary, our model can effectively handle complicated long rain streaks in spatial and the outputs of the network can retain most of the details of the original rain images. Experiments demonstrate the superiority of our RDANet over state-of-the-art methods in terms of both quantitative metrics and visual quality on both synthetic and real rainy images.
Keywords
Introduction
High-level computer vision tasks such as image segmentation [1], image classification [2], and object detection [3] have witnessed significant progress. Clear and transparent images are often a necessary condition for such outdoor vision-based tasks. However, images will inevitably be polluted in real life. For example, images taken on rainy days often cause noticeable visual quality degradation due to rain streaks. Single image deraining can remove rain and restore clean backgrounds from rain images and has drawn considerable recent research attention. Researchers usually denote a background image as
In recent years, the powerful capabilities of feature representation and end-to-end training of CNNs have been actively explored [7, 8]. Unprecedented success has been achieved in CNNs for some low-level tasks [9, 10]. Various deep network structures based on CNNs are designed to solve the image deraining problem. In 2017, Fu et al. [11, 12] pioneered this technology to remove rain streaks task. They separated the high-frequency and low-frequency information of rainy images and exploited a 3-layer network to remove rain streaks for high-frequency parts. Yang et al. [13] proposed a joint rain streak detection and removal framework by using a recurrent dilated convolution network. Subsequently, other novel techniques have also been proposed to solve this problem. In 2018, Zhang et al. [14] introduced a density-aware multistream dense CNN to automatically determine rain-density information. Li et al. [15] proposed a recurrent neural network architecture that combined squeeze-and-excitation blocks for image de-raining. Ren et al. [16] proposed a simple baseline deraining network that unfolds a shallow ResNet repeatedly with progressive recurrent operations. In 2020, Ren et al. introduced a bilateral LSTM framework on the basis of this network [17] to achieve better rain removal performance. In DRD-Net [18], the authors employed a two-stage context aggregation network architecture to remove rain streaks and restore details. In DCSFN [19], Wang et al. downsampled the initial extracted features and constructed their cross-scale relationships to avoid information drop-out. In addition, to improve the computational efficiency of the models and adapt to the needs of mobile devices, the Laplacian pyramid framework is chosen to design lightweight networks, but the rain removal effect of the network under this framework is unsatisfactory. Moreover, adversarial learning [20], unsupervised learning [21] and semi-supervised learning [22] have been introduced to realize single image rain removal recently.
Although numerous existing deep networks based on convolutional neural networks have made noticeable progress in single image rain removal, existing deep networks still have several drawbacks. For example, due to the neglect of long-distance spatial context modeling, they are incompetent to eliminate rain drops and fill in precise content while detecting heavy rain streaks. To achieve a greater receptive field and alleviate the adverse effects of this drawback, several networks were proposed based on dilated convolution. The dilated convolution is usually composed of three distinct scale convolution layers. Although the performance of these methods using dilated convolution is acceptable, the dilated convolution cannot provide global interdependencies between pixels in the spatial domain. The convolution operation is an essential process of local weighted summation and dilated convolution is only an enlarged version of the local operation. To accurately estimate rain streaks on a larger scale, Li et al. [23] designed a non-locally enhanced encoder-decoder network to capture long-distance dependencies between pixel-level pairs in the spatial domain. The nonlocal network proposed by Wang et al. [24] is easy to integrate and not restricted by the constraint of adjacent pixels. On the one hand, single image rain removal networks based on CNNs with non-local blocks will considerably increase the computational complexity. The portability of models between devices is poor, and it is time- and memory-consuming to train. On the other hand, these methods focus on propagating spatial information without considering the correlation between channels. For single image deraining, the aspect of fully reasoning global spatial coherence and channel correlation has rarely been noticed.
To practically overcome the above limitations, we propose a residual deep attention network (RDANet) to explore and utilize information from multiple dimensions for the tough image deraining. The purpose of our network design is to obtain the training ability of a deep network but simultaneously learn more useful channel- and spatial-wise features. Specifically, we design a novel basic unit with the function of capturing global spatial relationships between pixels and exploring full interdependencies across feature map channels. Such special treatment of spatial and channel features makes our network more focused on informative features. It is worth noting that the images will inevitably lose some details in the process of removing rain streaks, which makes the visual effect of reconstructed images unsatisfactory. In our framework, we introduce a novel source skip connection (SSC) that encourages the lost details to return to clean images. Roughly speaking, a standard 3×3 convolution kernel is employed to perform preliminary feature extraction on a rainy image and we denote the output as F0. Then, the output is injected into each basic unit through source skip connections. In this way, the model we proposed can effectively remove long rain streaks while retaining image details to the greatest extent. The source skip connections can also be regarded as a kind of residual connection, which reduces the training difficulty of the model. As shown below, our method achieves better visual results and recovers more image details than other state-of-the-art single image deraining methods.
Based on the improvements mentioned above, we present a powerful CNN-based model for high-quality image deraining. The main contributions of this paper are summarized as follows: We build a novel residual deep attention network for single image rain streaks removal. More specifically, a basic unit that consists of dilated convolution, spatial and channel attention is proposed. Different convolution modules enlarge the receptive field and model local and global dependencies in the feature maps. Regardless of the extent of the rain streaks, our model can completely capture and eliminate them. We propose a residual feature processing group that incorporates several source skip connections (SSCs) with basic units. The RFPG can not only preserve more image details while removing rain streaks, but also alleviate the training pressure caused by the complexity of the model simultaneously. Experimental results on both synthetic and real-world datasets demonstrate that our structure achieves superior performance compared with the state-of-the-art methods.
Related works
Since this topic was proposed, it has attracted the participation of many researchers, and numerous methods have been proposed for single image deraining. Over the past decade, methods based on artificial intelligence techniques have been widely used in many fields [25–27] and have made considerable progress. Recently, CNN-based deraining methods have sprung up and we mainly introduce the methods based on them in this section.
CNN-based single image deraining methods
CNN-based methods have been extensively studied in image deraining tasks due to their strong nonlinear representational capabilities. In 2017, Fu et al. first introduced deep learning methods to the deraining task and proposed DerainNet [11]. The DerainNet decomposed rain images into low- and high-frequency parts. The high- and low-frequency information processed separately by the network are fused to obtain a clean image. To make the training process easier, the authors [12] further proposed DDN to remove rain content. Yang et al. [13] proposed a deep recurrent dilated network with multi-task processing for joint rain streaks detection and removal. Li et al. [15] introduced squeeze-and-excitation (SE) into a recurrent neural network structure for rain removal. Zhang et al. [14] proposed a density-aware multistream densely connected CNN for jointly estimating rain density and removing rain streaks. Ren et al. [16] proposed a simple baseline deraining network by repeatedly unfolding a shallow ResNet. Furthermore, they introduced recurrent layers into shallow ResNet to form a progressive recurrent network. To enrich the details of rain removal images, Deng et al. [18] designed a two-stream network that can remove rain and preserve details simultaneously. Besides, several works have attempted to design a lightweight deraining model by using cascaded scheme or Laplacian pyramid framework. However, these methods often come at the cost of loss of model performance. To achieve better visual quality, Jiang et al. [28] recently explored the relationship between multi-resolution of a rainy image and fused multi-scale features to achieve image de-raining. The models trained on synthesized paired rain images are commonly unable to cope with the real-world, and other approaches, such as adversarial learning [20], unsupervised learning [21] and semi-supervised learning [22] are also adopted to train de-raining networks. Very recently, Fu et al. [29] combined graph convolution attention with an encoder-decoder architecture to achieve clean images. Similarly, Zamir et al. [30] proposed a multi-stage progressive image restoration network based on the encoder-decoder subnetwork and supervised attention module. All in all, although a variety of model architectures and training strategies for image deraining have been proposed, these deep networks failed to consider the long-range dependencies of pixels in the spatial domain and relationships between channels, thus, these networks cannot achieve satisfactory results. In this paper, we aim to develop a network to learn the relationships between different features and improve the performance of single image deraining in terms of both visual effects and evaluation metrics.
Attention mechanism
The attention mechanism in neural networks originated from the study of the human brain physiological perception of the external environment. Due to the bottleneck of information processing, humans will selectively focus on part of all information while ignoring other visible information. Wang et al. [24] proposed a non-local neural network to capture the feature relationships in the spatial domain of an image. Hu et al. proposed SENet [31], which can adaptively assign different weights to each channel through the global loss function. Driven by its success in high-level tasks such as image classification [32] and object detection [33], attention modules have been widely used in low-level tasks in recent years. Directly implementing non-local operation requires a huge memory cost and several single image deraining methods such as RESCAN [15] and DRD-Net [18], deploy SENet to further enhance performance. However, a few recent works combine these two types of attention mechanisms and use them in image rain removal tasks. There is high-frequency and low-frequency information in an image. The combination of two attention mechanisms can better distinguish and utilize image information. In addition, the combination with dilated convolution can explore and eliminate rain streaks of multi-scale, making the network generate better task-specific feature representations.
Proposed method
Figure 1 illustrates the overall pipeline of our proposed residual deep attention network (RDANet) for single image de-raining. In this section, we propose a CNN-based model for single image deraining via residual deep attention. To present our network more precisely, in the following we describe the network design, loss function and other key implementation details of our method.
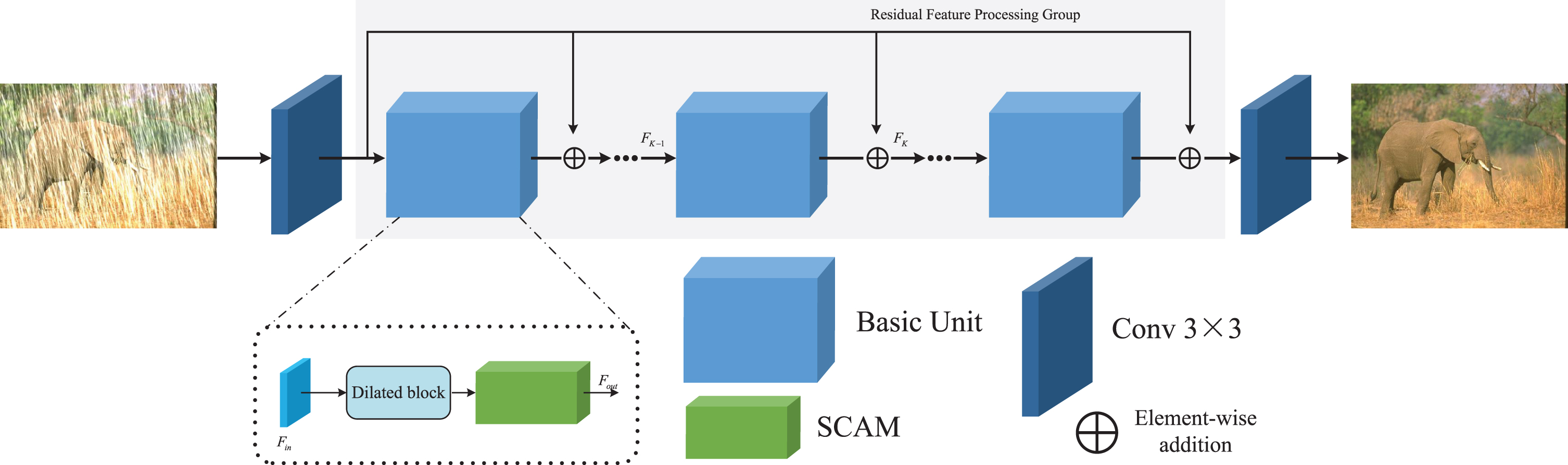
The overall architecture of our proposed RDANet for single image de-raining. Each basic unit contains one dilated convolution and one spatial and channel attention module.
Our network architecture consists of three major processing steps: (1) initial feature maps extraction on the input rain image I
rain
, (2) residual full-dimensional extraction and exploration of initial feature maps, and (3) reconstruction of a clean image. Given a rainy input image I
rain
(H × W), as investigated in some prior works [34], a 3 × 3 convolution layer is first deployed to extract shallow features
We now provide more details about our proposed residual feature processing group (RFPG) (see Fig. 1). The basic unit aims to exploit abundant local spatial patterns and global contextual information. Various previous works have demonstrated that it is feasible to use this serial block structure as an image deraining model skeleton. However, they seldom consider preserving raw images features. At the same time, image deraining networks also suffer from training difficulties or performance bottlenecks due to the depth of CNNs. By deploying source skip connections, our model is able to effectively eliminate rain marks from multiple dimensions. A large amount of low-frequency information from rainy images can flow smoothly thus the reconstructed image is faithful to the raw image details. The K-th basic unit in the group can be represented as
Dilated convolution module
Generally speaking, repeated unfolding of vanilla convolutional layers with a kernel size of 3 × 3 can gradually increase the receptive field. However, in real-world scenarios, the scale of rain streaks is commonly varied due to the influence of weather conditions. For example, rain streaks in heavy rain are spatially long and almost invisible in light rain. When capturing the long-range dependence, stacking convolutional layers for better receptive fields is not efficient enough. Therefore, we utilize the dilated convolution operations to rapidly increase receptive fields while reducing the number of parameters and retaining resolution. The features obtained by dilated convolution are represented as
As shown in Fig. 2, three paths are designed in each dilated module to process the features. The three paths have different divisions of labor. One path with standard convolution to capture small-scale spatial streaks, while the others are mainly for increasing the receptive fields. These three features are then fused by one 1 × 1 convolution layer and used as the output of this module. In this way, the output feature contains information of different receptive fields, i.e., 3 × 3, 7 × 7, 23 × 23. This allows the dilated module to extract multi-scale local spatial features effectively. Although this module can obtain multi-scale local spatial representations, the information contained in the fused features is still from a local spatial region. Therefore, we further propose the spatial and channel attention module to learn representations of global spatial coherence and channel correlation.
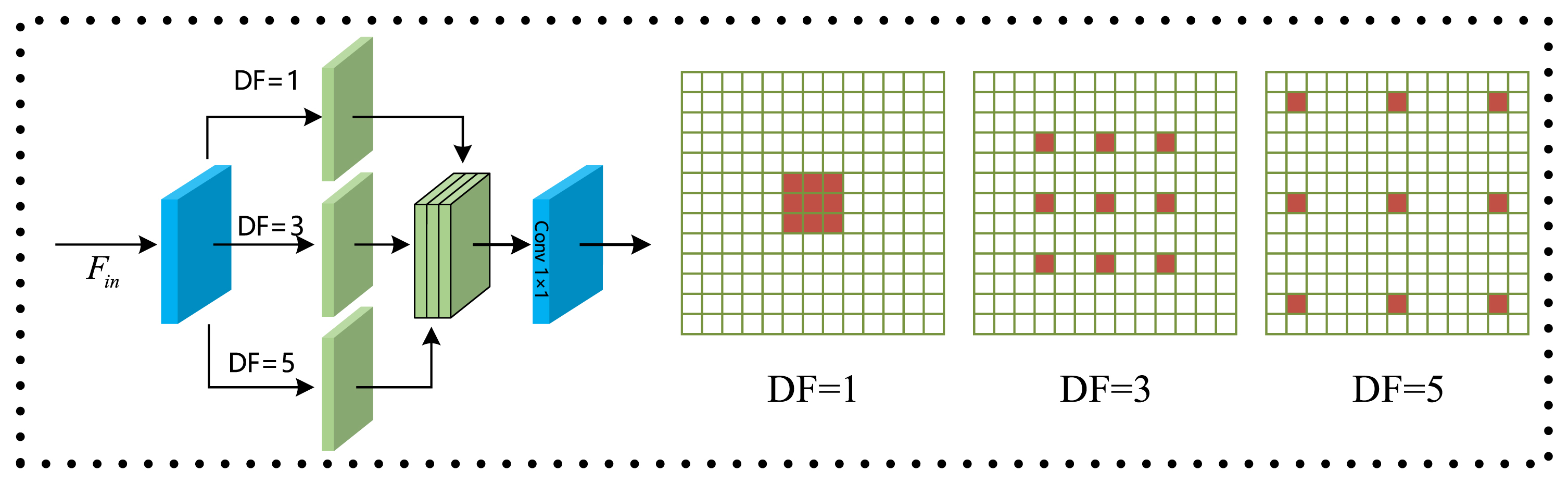
The structure of our dilated convolution module. F in is the input features and DF represents the dilation factor.
Some researchers have proposed their own methods for single image de-raining. Rain streaks removal is an acknowledged thorny problem since the scale and density of rain streaks are distinct. Preliminary studies have shown the effectiveness of the channel attention mechanism. The features between channels can be recalibrated by explicitly modeling interdependencies. In the spatial domain of an image, although the dilated convolution is utilized to obtain a receptive field, the information contained in generated features is still from a local spatial region. Few works take into account the large-range information relationships between features. In this paper, inspired by the success of spatial and channel attention mechanisms in single image super resolution [35], we combine spatial and channel attention with residual dense blocks to explore global spatial domain coherence and channel correlation between features.
As shown in Figs. 1 3, the feature maps F of size C × H × W produced by the dilated convolution module need to go through three stages next: (a) global attention pooling for context modeling, (b) bottleneck transformation to capture channel-wise dependencies, and (c) broadcast element-wise addition for feature fusion. We formulate N
p
(N
p
= H × W) as the number of positions in each feature map, and Z denotes the output of this attention block. The feature maps F are processed by a 1 × 1 convolution operation to reduce dimensionality first. The output of size 1 × H × W is then reshaped and normalized in turn. Thus we further obtain a feature map P whose size is HW × 1 ×1. The feature maps F are also reshaped to a size of C × HW, and we define it as Q. Then P is matrix multiplied with Q to calculate and assign different attention to features in the spatial domain. The output of stage (a) and the input of stage (b) are denoted as T, with C feature maps of size 1 × 1. The transform procedure for distributing different weights to each channel is similar to [31]. We sequentially put T through one 1 × 1 conv layer, one LayerNorm (LN) and ReLU, and one 1 × 1 conv layer to compute the importance for each channel. Layer normalization inside the bottleneck transform (before ReLU) is performed to ease optimization, and to act as a regularizer that can benefit generalization. We add the output of transform and F
i
to obtain the final attention feature map. The whole process can be formulated as
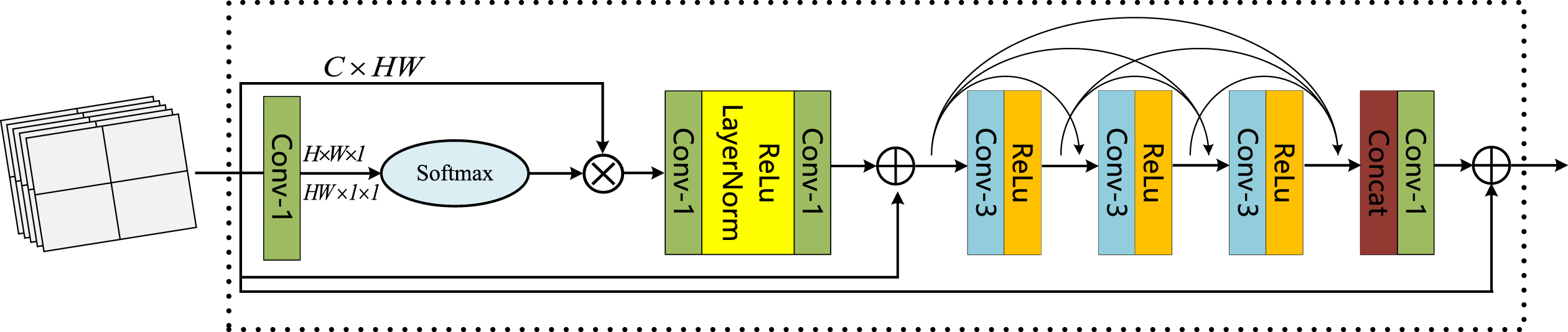
The structure of spatial and channel attention module.
Next, the attention enhanced feature is fed to three consecutive convolutional layers that are densely connected. As illustrated in Fig. 3, the input of each convolutional layer is the concatenation of all outputs of its previous layers. The input of layer l can be formulated as:
Generally, the structural similarity index (SSIM) or Mean Square Error (MSE) [36] is the most commonly used loss function for constructing a single image deraining network. Compared with MSE, SSIM is more sensitive to local image characteristics, such as edge and luminance changes, and is closer to the human visual system. Rain streaks are local characteristics contained in the image, and SSIM is more appropriate to construct the deraining network. While the deep neural network gradually converges, the loss should decrease. To maximize the effectiveness of our model, we adopt the negative SSIM [16] as our loss function. Given a training set with n rainy images and their corresponding ground-truth images denoted by
Our RDANet is implemented using PyTorch [37], and trained with the Adam algorithm [38] on a PC equipped with one NVIDIA GTX 1070 GPU. We connect 10 basic units and source skip connections in the residual feature processing group. The kernel sizes in the fusion operations and spatial and channel attention are all 1 × 1, and the rest are 3 × 3. The reduction ratio r of channel-downscaling and channel-upsampling is set as 16. We randomly crop the training images into 100 × 100 patch pairs with horizontal flipping as the input of the network. The batch size is 16 and we initialize the learning rate to 0.0001. When reaching 80 and 160 epochs, the learning rate is decayed by multiplying 0.5 and terminating training after 240 epochs.
Comparison with prior works
To further demonstrate the innovativeness of this work, in this section, we provide several details about the differences between our network and other relevant representatives.
Experiments
In this section, the network we proposed conducts extensive experiments on three public used datasets. We compare the results generated by RDANet with several state-of-the-art methods: DDN [12] (CVPR2017), RESCAN [15] (ECCV2018), NLEDN [23] (ACM MM2019), JORDER-E [39] (TPAMI2019), PReNet [16] (CVPR2019), SPANet [40] (CVPR2019), BRN [17] (TIP2020), SIRR [22] (CVPR2019), and DCSFN [19] (ACM MM2020).
Datasets and measurements
Synthetic Datasets
We use four public synthetic datasets which are called Rain100H, Rain100L [13], Rain1200 [14] and Rain1400 [12] to train our model. The Rain1200 dataset contains rain streaks in three modes: heavy, light, and medium. We merge them and obtain a total of 12,000 pairs of images for training and 1,200 pairs for testing. Rain100H and Rain100L are all selected from BSD200, and both include 1,800 pairs of images for training and 200 pairs for testing. Rain100L simulates a scene of light rain in the real world and therefore is relatively easy to deal with. In contrast, Rain100H depicts a scene of heavy rain with rain streaks of different sizes, shapes and directions. There are 12,600 and 1,400 pairs of images for training and testing in Rain1400, respectively. Each of the background images in Rain1400 has 14 different types of rainy images corresponding to it. Moreover, all testing images are assured to have different background images with training images.
Real-world Datasets
The evaluation results of real-world rainy images can better illustrate the pros and cons of the model. To demonstrate the generalization ability of our method, we select proper images from the released datasets [40] and download a number of rainy images from the internet to construct this experiment.
Evaluation metrics
For synthetic datasets, the most widely used metrics to evaluate the quality of restored images are the peak signal-to-noise ratio (PSNR) [41] and structure similarity index (SSIM). The two measurements are used to compare the restored result with the corresponding ground-truth. On the contrary, since the no-rain images corresponding to the rainy images captured in the real-world are not obtainable, we evaluate the performance on a real dataset singly based on visual comparison.
Comparison with state-of-the-arts on synthetic datasets
We measure the PSNR and SSIM of the proposed method on the datasets mentioned in Section 4.1.1. The quantitative comparisons of our model and state-of-the-art methods are reported in Table 1, which demonstrate that our RDANet consistently outperforms the compared methods by a significant margin. Compared with the DCSFN proposed in 2020, it is especially worth noting that the proposed method is approximately 0.8 dB better in PSNR and 2% stronger in SSIM on the most challenging Rain100H dataset, respectively. Moreover, to further demonstrate the performance of our model, we show some rain removal visual comparisons on synthetic datasets in Fig. 4. As displayed in Fig. 4, on the one hand, most contrast methods have difficulty recovering tiny details, such as the lines on the ground and railings while our RDANet can perfectly reproduce the original image almost without any artifacts or blur. On the other hand, although BRN is slightly better than our model in quantitative results, our model is even better in terms of visual performance. Since the high- and low-frequency information in the image can be better distinguished and treated by the SCAM, and the source skip connections continuously convey low-frequency detail information, thus the clean images restored by RDANet are richer in detail. We also report some comparison values from the Rain1400 dataset in Table 2 in which RDANet obtains the best result. Although Wei et al. designed a deraining network based on semi-supervised learning, the performance of it is unsatisfactory.
Comparison of quantitative experiments in terms of PSNR and SSIM conducted on synthetic datasets. The best and second-best results are denoted in Red and Blue, respectively
Comparison of quantitative experiments in terms of PSNR and SSIM conducted on synthetic datasets. The best and second-best results are denoted in Red and Blue, respectively

Visual comparison of image deraining results generated from RDANet and SOTA on some examples from Rain100H. Our method obtains the best visual quality while recovering more image details than other state-of-the-art SR methods. To zoom in for better visualization.
Quantitative comparison on Rain1400 dataset
The capability of our model and other SOTAs to remove rain streaks from real-world rainy images is clearly illustrated in Figs. 5-6. There is no doubt whether from the overall perspective or the selected enlarged areas of the color frame, our method achieves the best performance among all evaluated methods. As shown in Fig. 5, the drops of different scales and shapes on real-world rain images can be effectively eliminated with our model. Each pixel can emit its original color and brightness without new negative problems occurring such as distorted lines and white oversmoothed patches. Figure 6 shows four visual examples that confirm some previous methods are powerless when dealing with light rain. The rain images processed by BRN and PReNet are polluted by giant black patches which distort the original semantics and gravely affect visual perception. In particular, we note that SPANet is comparable to our model in removing rain streaks. However, some image information that resembles rain stripes in color or shape is also removed, such as watermarks in images and white letters on clothes. This also demonstrates that the network we proposed is more robust in terms of preserving details than other methods in real-world rainy conditions.
Visual comparison of image deraining results generated from RDANet and SOTA on real-world rainy images. Our method consistently obtains the best visual quality while recovering more image details than other state-of-the-art deraining methods.

Visual comparison of some examples from real-world datasets. Our method obtains better visual quality and recovers more image details than other state-of-the-art deraining methods.
In terms of complexity, the number of floating-point operations (FLOPs) and model parameters are two commonly used measurements. The training and reasoning speed of the model is determined by FLOPs. The higher the FLOPs, the slower the training and reasoning of the model. In this section, we evaluate the number of parameters and FLOPs of seven methods. The results are presented in detail in Table 3. It can be clearly observed that the DCSFN FLOPs values and BRN parameters are the highest. Compared with the models proposed in the last two years, our model achieves optimal numerical results while using fewer parameters and FLOPs. In summary, the proposed method obtains a trade-off between performance and complexity.
Complexity quantitative comparisons on FLOPs and numbers of parameters
Complexity quantitative comparisons on FLOPs and numbers of parameters
Performance versus complexity
In this section, we assess the influence of the number of basic units on the network effect. Specifically, we specify the basic unit numbers B ∈ {8, 10, 12}. Based on past experience, one can easily predict that as the number of basic units increases, the representation and nonlinear expression capabilities of the model are further enhanced. We show some visual evaluation results that are generated by networks with different numbers of basic units in Fig. 7.
Visual comparisons of the influence of different numbers of basic units on model performance.
Complexity analysis of networks with different number of basic units
As discussed above, we propose an efficient rain streaks removal basic unit that contains dilated convolution, spatial and channel attention, and three densely connected convolutional layers. Each of them plays a different role in feature extraction and processing. Dilated convolution can explicitly model local feature relationships, and spatial and channel attention is essential for capturing long-distance rain streaks. At the same time, the combination of these two greatly expands the receptive field of the model. To validate the effectiveness and necessity of the internal network design of each of them, we conducted some studies to compare RDANet with its variants trained and tested on the Rain100H dataset. It should be noted that when we observed the experimental process, we found that the learning rate suitable for training RDANet is not suitable for training other variants. Therefore, to ensure the trainability of all models and the fairness of the experiment, we selected the learning rate and other parameters that suit everyone. The specific performance changes in terms of PSNR and SSIM are listed in Table 5.
Investigations of different components of our proposed network
Investigations of different components of our proposed network
We observe the PSNR (dB) values in 1.62 × 105 iterations.
R a refers to the result of subtracting the whole SCAM component in each basic unit. We choose it as the most initial baseline, which only includes several source skip connections and dilated convolution modules. The baseline model reaches PSNR=19.65 dB and SSIM=0.74. In R b and R c , we added channel and spatial attention functions to the baseline model R a , respectively. As shown in the table, releasing channel attention achieves an average improvement of 0.46 dB in terms of PSNR and a 2.7% increase in SSIM. Similarly, the spatial attention improves the baseline by 0.33 dB and 1.3% in PSNR and SSIM. The quantitative result R d increases when combining them, resulting in an improvement of 20.90 dB and 6.3%, respectively. As verified by previous work, dense connection enhances the transferability and utilization of features in the model. By deploying dense connections, the number of calculations in the model is reduced, and the occurrence of overfitting is also prevented to some extent. Taking the comparison between R a and R e or between R d and R f as an example, the values of PSNR and SSIM have been improved definitely when adding the dense connection. Moreover, we provide a visual comparison of I rain , R a , R d , R e , R f and its corresponding Ino-rain in Fig. 9. As can be seen, the basic unit with spatial and channel attention module effectively captures and removes most of the long-range rain streaks. These improvements prove the effectiveness and universality of our proposed spatial and channel attention mechanism. The training scatter plots, as demonstrated in Fig. 8, also verify our point of view. It is obvious that when removing the whole SCAM part, the training value is low and extremely flat, not increasing with the increase in training steps. Then, by deploying spatial and channel attention, the training value of the model is greatly improved. This is mainly because the combination of spatial and channel attention is able to explore the rich global contextual representation of information. The integration of spatial attention and dilated convolution also greatly expands the receptive field of the model, and the long-range dependence between pixels can be modeled in the spatial domain. Dense connections enhance the ability of the model to utilize features and improve the availability of features. As discussed above, our model mainly realizes image rain removal by several basic units in series, which consist of SCAM and dilated convolution. In Fig. 8, the red scatter corresponds to our proposed RDANet. The performance improvement is significant and reaches the highest PSNR value, which proves that our proposed method is an effective design.

Visual comparison of deraining results of I rain , R a , R d , R e , R f and Ino-rain.
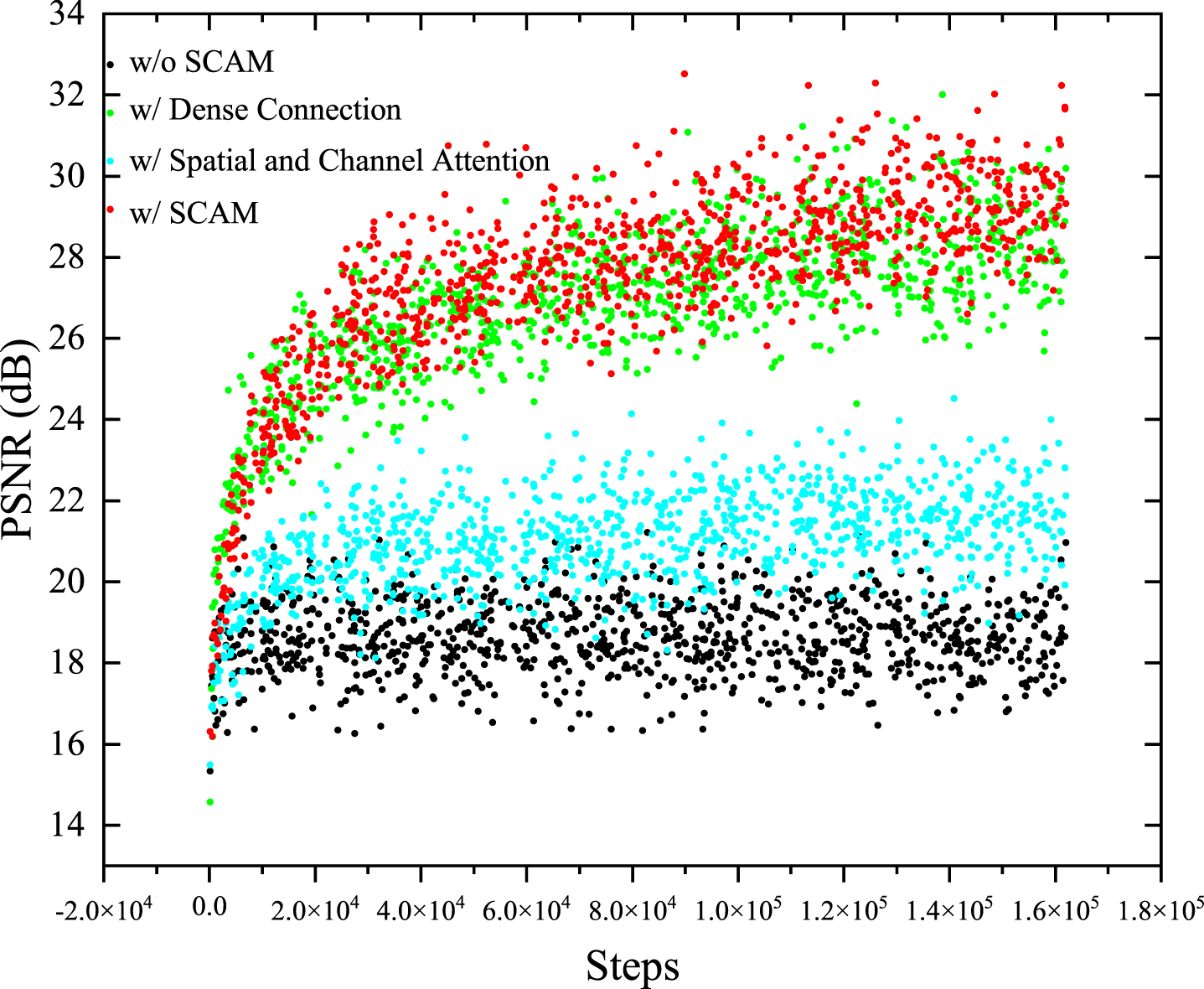
Visual comparison of training plots of R a , R d , R e and R f .
To preliminarily validate that our proposed RDANet is helpful for high-level computer vision tasks that are usually deployed in outdoor environments, we employ the Baidu Cloud Vision API to evaluate a contaminated image and a group of images which are processed by different rain removal methods. One of the results is shown in Fig. 10. As shown in Fig. 10a, the Baidu Cloud API cannot recognize the object in the image due to the shelter of dense rain streaks. Furthermore, according to the confidence score shown in Fig. 10b–d, our results are recognized as “Lynx” with the highest probability, which also proves that our algorithm has the least damage to the raw semantic information of the image and is totally useful for outdoor-based computer vision tasks.
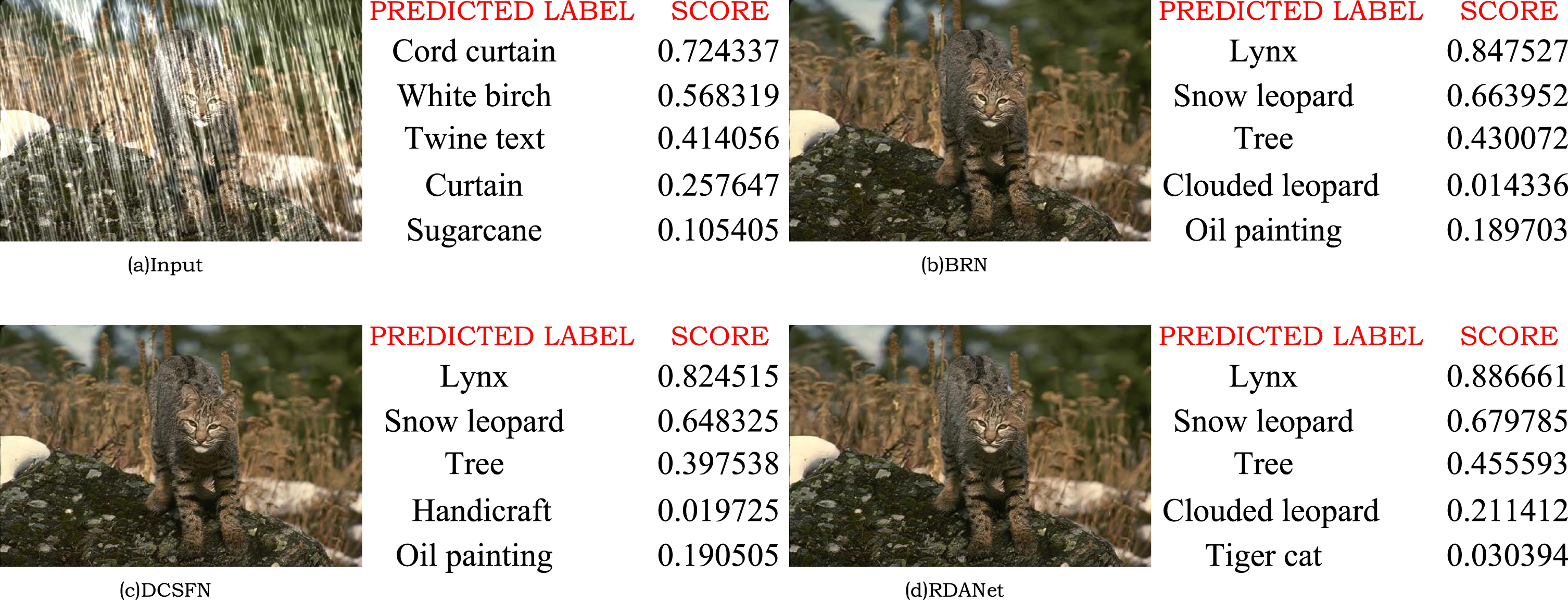
The deraining results are assessed through object recognition on the Baidu Cloud Vision API. From (a)-(c): (a) is recognized as “Cord curtain” with the highest probability. (b)-(d) are recognized as “Lynx” but our result is more accurately with the highest probability.
In this paper, we proposed a novel CNN-based single image deraining framework. Specifically, we designed a residual feature processing group consisting of several basic units and source skip connections. By jointly deploying the attention mechanism and dilated convolution, the basic units are capable of capturing the dependencies between features at multi-scale and exploiting rich feature representations. Multi-scale rain streaks can be completely captured and eliminated due to their giant receptive field. Moreover, the reconstructed images can contain the overall background information of rain images with the help of employing source skip connections. Qualitative and quantitative experiments on standard benchmark datasets demonstrated that our method outperforms the state-of-the-art CNN-based approaches in terms of removing rain streaks and recovering image details.
In the future, our probable research and development work mainly includes three aspects. First, we plan to extend the algorithm proposed in this paper to a wider range of low-level image processing tasks, including image dehazing, image denoising and image moire removal. Second, based on Section 4.6, we will focus on solving the gap between low-level vision and high-level vision, and deeply explore the direct application of our proposed network to high-level computer vision tasks. Third, we intend to further design an effective model that can be applied in the video deraining task.