
Abstract
The lack of training data in new domain is a typical problem for named entity recognition (NER). Currently, researchers have introduced “entity trigger” to improve the cost-effectiveness of the model. However, it still required the annotator to attach additional trigger label, which increases the workload of the annotator. Moreover, this trigger applies only to English text and lacks research into other languages. Based on this problem, we have proposed a more cost-effective trigger tagging method and matching network. The approach not only automatic tagging entity triggers based on the characteristics of Chinese text, but also adds mogrifier LSTM to the matching network to reduce context-free representation of input tokens. Experiments on two public datasets show that our automatic trigger is effective. And it achieves better performances with automatic trigger than other state-of-the-art methods (The F1-scores increased by 1∼4).
Introduction
Named entity recognition (NER) is a basic information extraction task. It focuses on extracting entities in an unstructured text and classifying them based on predefined entities (such as person, location, organization names) [1]. The latest progress of NER focuses on neural network-based models, such as BiLSTM-CRF [2], Lattice_LSTM [3] and so on. When the label set is fixed and has enough training data, most of the NER neural network models performed well [4–9]. However, with the popularization and application of NER technology, such as task-oriented systems, it is challenged by the application domains of diversity and rapid changes [4]. As we all know, NER model training requires a lot of manual annotation data. In the face of many new domains, if we comply the previous model training methods, we need to annotate a large number of new training data, which is not economical. Therefore, how to use less labeled data to train the neural network model has become a significant research task in NER research.
In order to solve the problem, Lin et al., based on the characteristics of the English text, proposed the concept of entity trigger and the trigger matching network (TMN) framework [5]. And using the trigger-enhanced training data and manual entity annotations, this method uses 20% of the labeled data to achieve the experimental result of the traditional method using 70% of the training data. The data enhancement method (Zeng et al.,) using entity contextual content matching [6] is also an excellent work for this question and has a guiding role for future related research.
However, different language texts have different characteristics. Lin et al. only conducted related experiments in the field of English text. Whether it is equally effective in other language fields (such as Chinese) requires further experiments. Moreover, the trigger tagging work still needs to be done manually, this could pose a question: in a sentence, different annotators have a strong subjectivity about whether a word is a trigger or not, and these data may affect the results of the experiment. In order to solve this question and improve the efficiency of trigger annotation, can we adopt a fixed format and equally effective trigger tagging method based on the grammatical characteristics of the language text?
Therefore, we have made the following improvements: Based on our study of Chinese grammar and NER causality model [6], we assume that the entity triggers Chinese text can be simply considered as the context nearby entity, without requiring annotators to spend extra effort to analyze sentence triggers. For example, in the sentence “” “” “” and “”
In summary, our work has the following contributions: We propose a cost-efficient entity trigger tagging method for Chinese text data. This method eliminates manual tagging, improves efficiency, and avoids the subjectivity of manual tagging. Based on the above trigger annotation method, we propose a m-TMN model that strengthened semantic matching and generalization. Experiments on two public Chinese NER datasets show that on the same trigger-enhanced training data, our model performs better than the TMN model.
The question we consider is how to quickly label entity triggers and verify their effectiveness. Then enhancement the original model according to the characteristics of the trigger.
In this section, we will introduce basic concepts and symbols, describe the traditional NER data annotation process and its way to annotate English entity triggers. On this basis, we propose an annotation method for the Chinese entity trigger. Finally, we present a task of training a Chinese NER model based on Chinese trigger-enhanced data.
In traditional neural network supervised learning, c = [c(1) ; c(2) ; … ; c(n)] denoted a sentence in the data set D
L
. Each tagged sentence corresponds to a NER tag sequence s = [s(1) ; s(2) ; … ; s(n)]. And
For the English data set, according to the manual tagging method of Lin et al., [5],
We show the trigger tagging method for English text and Chinese text. (a) “I had” and “at” are the triggers of the entity “Dongbei Restaurant”, which need to be manual tagging. (b) “” and “”
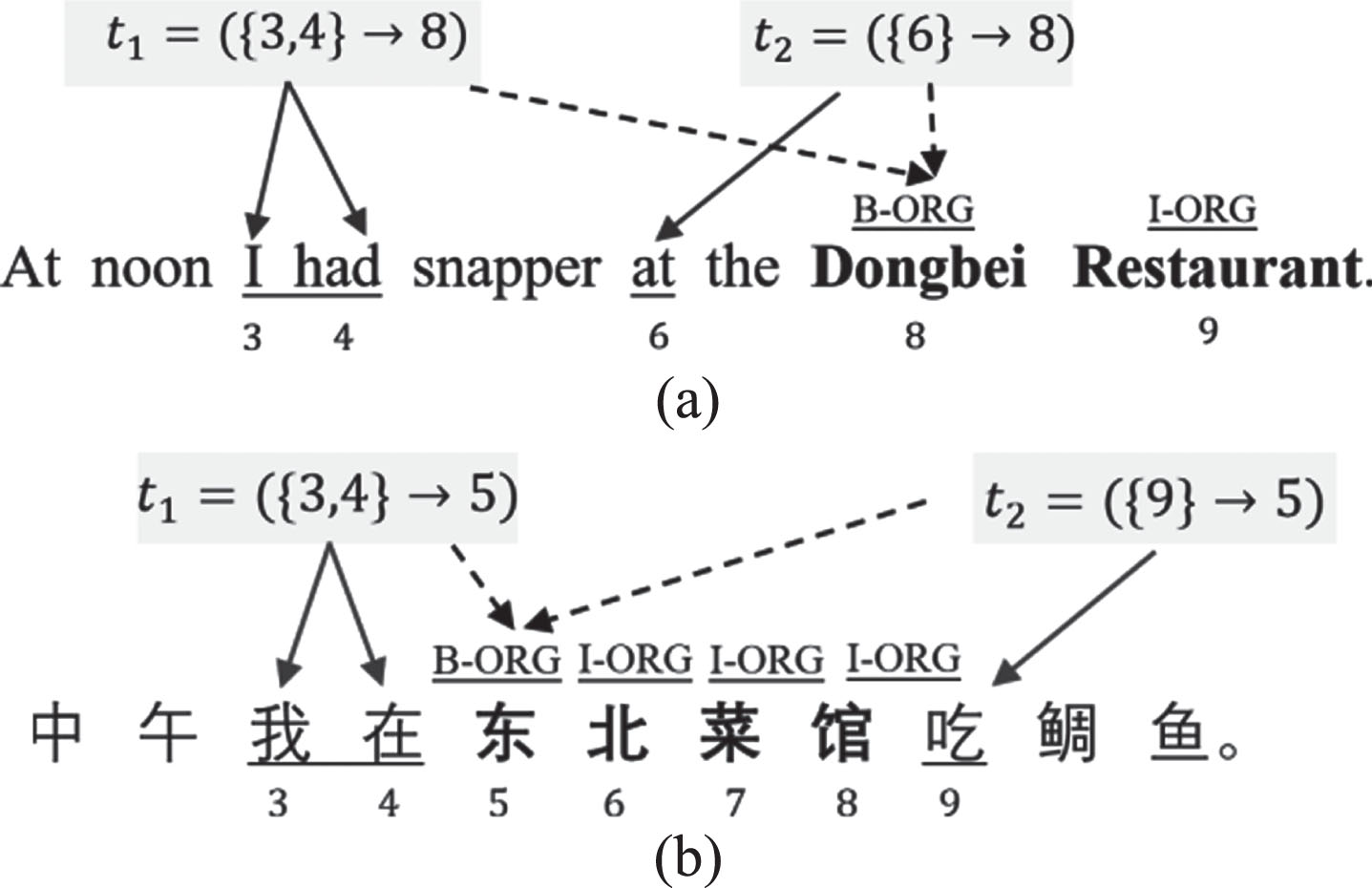
“”
For the Chinese data set, inspired by Chinese text expression and recent NER data enhancement work [6], we use the index of the first character of the entity as the entity index and the two characters around the entity as the trigger of the entity. The concrete tagging method is as follows: for entities located in the middle of the sentence, we choose two characters on each side of the entity as entity triggers; for entities located at the beginning or end of a sentence, only two characters on one side of the sentence are selected as entity triggers; If there are fewer than two characters on one side of the entity, only one character is selected as the entity trigger.
In the example shown in Fig. 1(b), “” “”
Add triggers according to the above method to create a new data format as
In this section, we first introduce the latest Mogrifier LSTM structure, and then propose m-TMN, which is mainly composed of Trigger Encoder, Semantic Matching Module and Sequence Tagging. Finally, we simple introduce the classical model BiLSTM-CRF [9].
Mogrifier LSTM
Mogrifier LSTM is an improvement of LSTM. The standard LSTM update [21] is as follows, Input and state are represented by m and n respectively
At each time step t (t ∈ [1, …, m]), the standard LSTM calculates a current hidden vector h(t) based on a memory cell c(t). In particular, a set of input gate i(t), output gate o(t) and forget gate f(t) are calculated as follows:
Where [W k ; b k ] are weight matrices and biases. σ denotes the logistic sigmoid function; ⊙ denotes elementwise multiplication.
Mogrifier LSTM is based on LSTM, equip the gates that scale the columns of all its weight matrices W** in a context-dependent manner. Therefore, its two inputs x and h
prev
are mutually modulated in an alternating manner before the LSTM calculation takes place (see Fig. 2). That is to say,
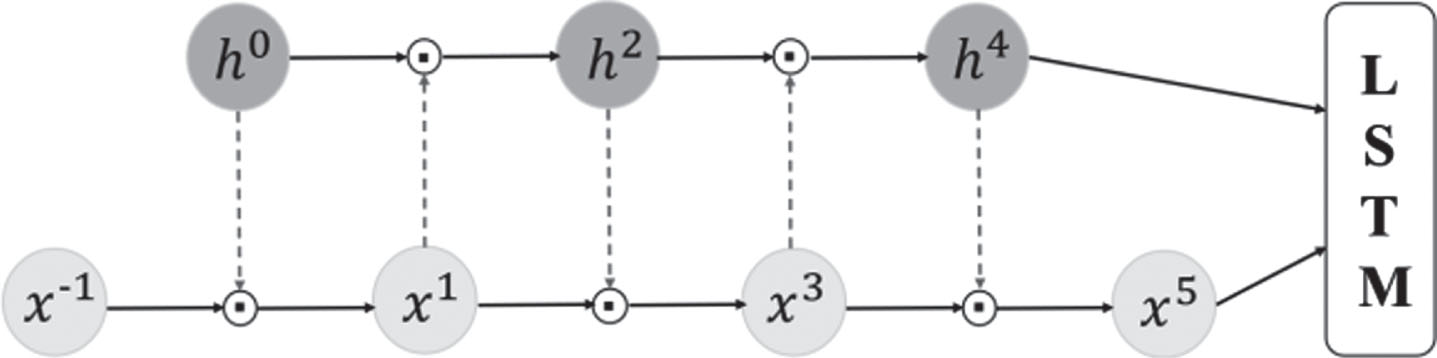
Mogrifier has 5 rounds of updates. The previous state h0 = h prev fed through a sigmoid and gates x-1 = x in an elementwise manner producing x1. Then, x1 gates h0 produces h2. After several repetitions of this mutual gating cycle, the final values of the h* and x* sequences are fed to the LSTM cell.
Mogrifier Trigger Matching Networks is an improvement of TMN proposed by us. Based on the characteristics of Chinese text and cost-efficient Chinese trigger, it improves the original trigger encoding method and combines the Mogrifier LSTM structure to solve the context-independent representation of the input tag.
Trigger encoder and semantic matching module
Recall the trigger example “” and “” discussed in Section 2 to see that attention-based matching between entity triggers and sentences is necessary. Therefore, learning trigger representation and semantic matching are two inseparable tasks. The trigger vector should capture the semantics in a shared embedding space and token the hidden state. At this stage, the TMN contains a shared embedding space to jointly train the trigger encoder and attention-based trigger matching module.
Specifically, in a sequence s containing multiple entities {e1, e2… }, for each entity e
i
, we assume that there is a set of triggers
For the triggers of the English data set are manually labeled and have a high matching degree, the public TMN uses LSTM to encode the training instances. For Chinese data sets and program tag triggers, there is no such high matching degree, so it is not appropriate to use LSTM encoding. Based on the strengths of the above-mentioned Mogrifier LSTM, we decided to first apply a Mogrifier LSTM on the training instance (c, e, t) to obtain a hidden state sequence. We use H to denote the matrix containing the hidden vectors of all entity tokens, and we use Z to denote the matrix containing the hidden states of all trigger t. Our new model is called m-TMN.
Then, we follow the self-attention method of Lin et al. to learn triggers and sentence representations [23]. As follows:
W1 and W2 are two trainable parameters for computing self-attention score vectors
m-TMN uses the type of entity corresponding to the trigger as supervision to guide its representation. Therefore, the trigger vector g
t
is further fed to the multi-class classifier to predict its corresponding entity e type. The loss of the trigger classification is as follows:
Next, we think that the trigger and its matched sentence have similar vector representations. Therefore, we use contrastive loss [24] to learn match triggers and sentences. The training process of the matching module is as follows: We first randomly mix triggers and sentences, so that we have two training instances (matches and mismatches). Then two training instances are fed to the semantic matching module. The contrastive loss of the matching is defined as follows, if it is a matching instance, then l
matched
is1, otherwise it is 0:
Thus, the joint loss of the first stage is L = L TC + λL SM , where λ is a hyper-parameter. Figure 3 shows this joint training process.
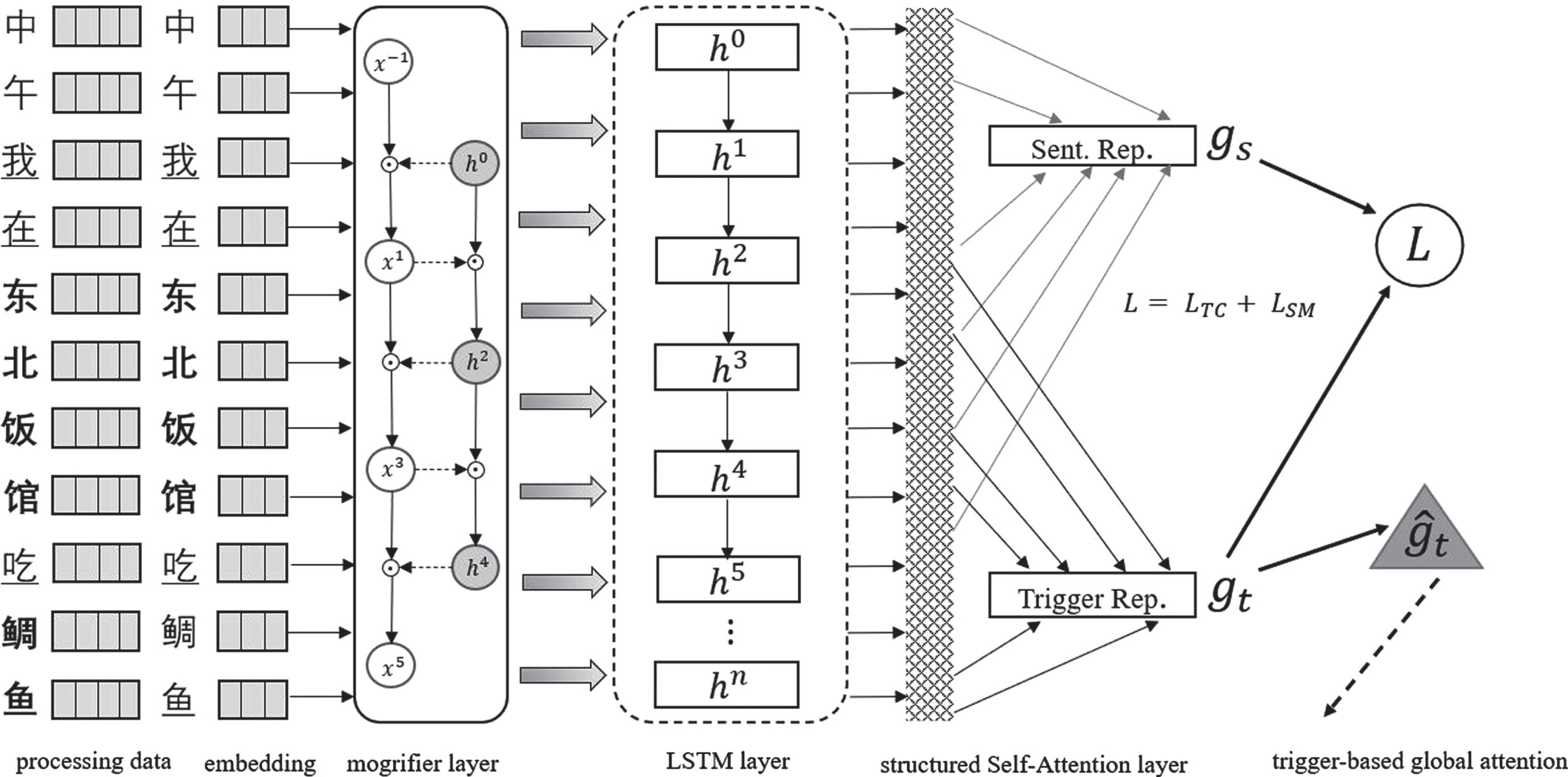
Jointly train the Trigger encoder (via trigger classification) and the semantic matching module (via contrastive loss).
After obtaining the mean of trigger vector
U1, U2 and v are trainable parameters for calculating the trigger enhanced attention scores. Then, we concatenate the original token representation H with the trigger enhancement H0 as the input for the CRF tagger.
When inferring tags on unlabeled sentences, we use trigger matching to calculate the similarity between the sentence and the trigger and finally select the best trigger as the additional input of sequence tagger. Specifically, we obtained a trigger dictionary from the training data, T = {t| (. , . , t) ∈ D
T
}. When inferring an unlabeled sentence, we first train and calculate its self-attended vector g
s
and
The BiLSTM model [9] is one of the classic models in the NER task. This model consists of embedding, BiLSTM layer, tanh layer and CRF layer, etc. First, through the embedding layer, the sentence is represented as a sequence text of vector S = (s1, …, s
t
, …, s
n
). In the BiLSTM layer, the forward LSTM calculates the representation
Experiments
In this section, we first discuss how to collect the triggers in the Chinese text data set, and then verify the effect of the triggers annotated with this method and the strength of our new framework m-TMN.
Tagging of trigger
For the Chinese text field of NER, we use two public data sets for research. They are Resume NER [10] in the field of resume and Weibo NER [11] in the field of social media. Table 1 shows the statistics of these two data sets. These two data sets have been well researched and popularized in NER models such as BiLSTM-CRF.
Statistics of datasets
Statistics of datasets
In order to collect the triggers of Chinese data sets efficiently, we have studied the Chinese text expression and done a lot of experiments. Finally, we decided to programmatically label two characters around the entity as its trigger. (other numbers of characters experiments performed poorly). The details are introduced in section 2. In the field of Chinese text NER, our trigger tagging method can be completed by programs instead of manual labor, eliminating the labor costs. The effectiveness of this new trigger is demonstrated in the following experiments.
Trigger efficiency verification. We need a basic model to compare with the public TMN model to verify whether the triggers that are labeled by our proposed method are effective. We choose BiLSTM-CRF [9] as our basic model because its popularity in neural network and application research. In addition, the hyperparameters of BiLSTM and CRF of the two models are also the same, which can ensure a fair comparison between the base model and the TMN model. We believe that the effective experimental result of the trigger should be that the TMN model can experiment with the experimental results of the traditional model based on less training data. Therefore, during the training process, we divide the data set with different fixed percentages (5% ∼100%) to train two models at the same time.
Performance strengths verification of m-TMN model. We need to compare the performance of our m-TMN model with the standard TMN model under the same number of training sets and triggers. The division of the data set is the same as above. The experimental method and data set division are based on the experimental settings of Lin et al. [5]
NER evaluation
The evaluation index generally used by NER are P(Precision), R(Recall), and F1 value.The precision of the NER is the ratio of the number of completely correct entities predicted by the model to the number of all entities predicted by the model.
The TP is true positive, the FN is false negative, the FP is false positive and the TN is true negative. The recall is the ratio of the number of completely correct entities predicted by the model to the number of real entities in the sample.
It should be emphasized that the NER is label words(characters) and its purpose is to find entities. So instead of calculating the accuracy of the label, it is calculating the precision and recall of the predicted entity. The F1 value is calculated from P(Precision) and R(Recall).
In order to compare the application effect of m-TMN and the relationship between pretrained word embedding, we did two sets of experiments, random word embedding and Chinese word embedding. We chose Chinese pre-trained word vector data published by Tencent AI Lab. This data contains 100,000 Chinese words, each of which is represented as a 200-dimensional vector. The word vector data is based on Tencent’s large-scale and multi-source corpus, so that the generated word vector data can cover a variety of domains. And the training algorithm is the Directional Skip-Gram (DSG) algorithm self-developed by Tencent AL Lab. [29] The algorithm is based on Skip-Gram (SG) [28]. Based on the co-occurrence relationship of word pairs, it considers the relative positions of word pairs and improves the accuracy of semantic representation of word vectors.
Result
The experimental results are shown in Tables 2 3.
Results on datasets: Resume and Weibo with random word embedding. “sent.” means the percentage of the sentences (labeled only with entity tags). “trig” means the percentage of the sentences (labeled with both entity tags and trigger tags)
Results on datasets: Resume and Weibo with random word embedding. “sent.” means the percentage of the sentences (labeled only with entity tags). “trig” means the percentage of the sentences (labeled with both entity tags and trigger tags)
Results on datasets: Resume and Weibo with Tencent word embedding. “sent.” means the percentage of the sentences (labeled only with entity tags). “trig” means the percentage of the sentences (labeled with both entity tags and trigger tags)
Tables 2 3 respectively in the random word model training vectors and Tencent pretraining word vector result. TMN is a model proposed by Lin et al. and others for English triggers [5]. We train on the Chinese dataset based on the model combined with the Chinese trigger tagging method of this paper. M-TMN is our improved TMN model based on the characteristics of Chinese data. It is also trained on the Chinese data set based on the Chinese trigger tagging method. After many demonstrations and experiments, we finally selected 5% ∼40% of the training data of the Resume NER dataset and 5% ∼50% of the training data of the Weibo NER dataset to compare and verify the experimental data. From the comparison between the BiLSTM-CRF column and the TMN column, it can be seen that the trigger collected in our method are efficient. Compared with the BiLSTM-CRF model, the TMN model based on this trigger has a great improvement. From the comparison between the TMN column and the m-TMN column, we can see that the m-TMN model we proposed for Chinese NER data and trigger characteristics also obtained ideal results.
Compared with TMN, our m-TMN under the same amount of training data and trigger conditions, the F1 value of the result is increased by about 1∼4. Compared with the traditional model BiLSTM-CRF method, m-TMN model is based on our trigger at the same training data, F1 values are increased 2∼9. Using only 20% of the training data can achieve the effect of the traditional model with 40% of the training data.
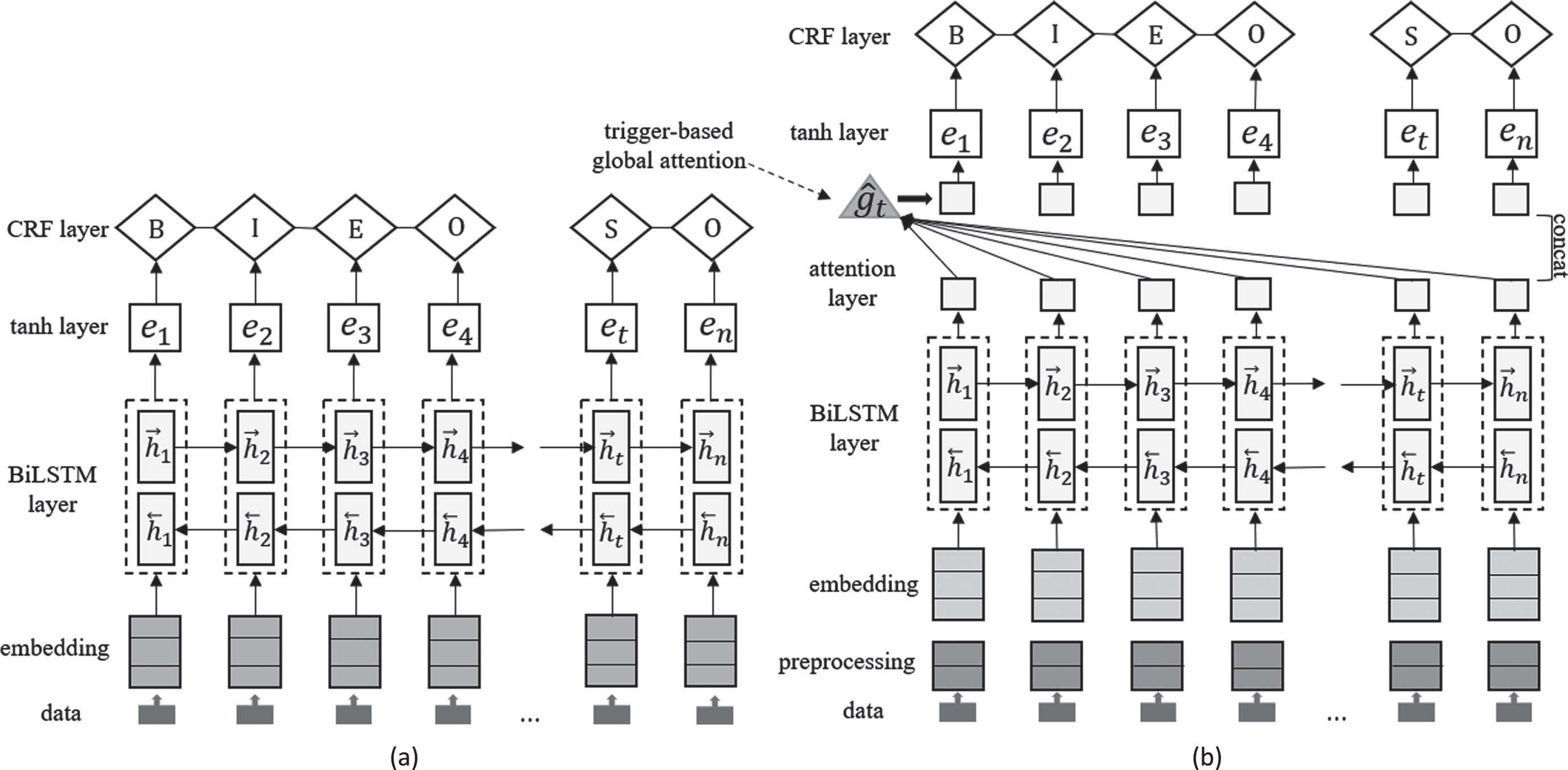
The architectures of BiLSTM-CRF model (a) and our trigger-based global attention BiLSTM-CRF model (b).
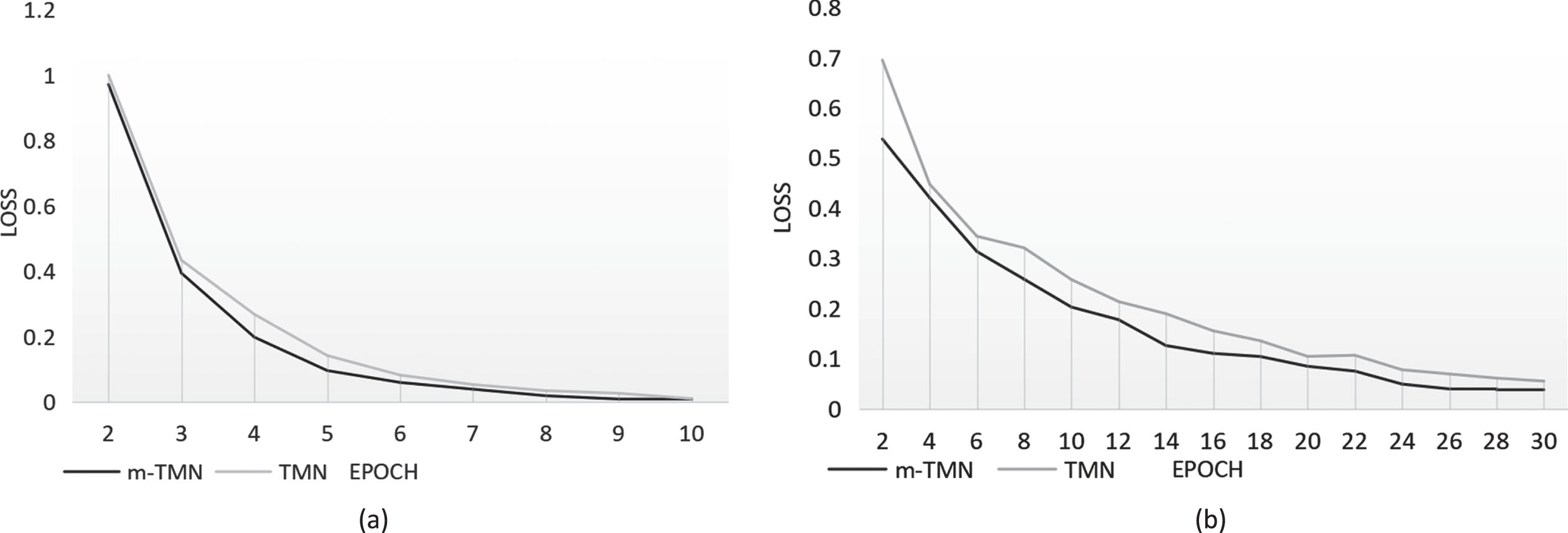
Normalized loss(Y axis) on validation set, trained with 20% labeled data, over different epochs(X axis). (a) is Resume NER dataset, (b) is Weibo NER dataset.
Similarly, for Weibo NER data set, using smaller amount of training data (below 20%), the F1value of our m-TMN model based on cost-efficient trigger training is about 5∼6 higher than that of the traditional BiLSTM-CRF model. It can be seen that based on the same training data, the F1 value of the m-TMN model has increased by 5–8, and the m-TMN model can achieve the effect of 50% of the traditional model with only 20% of the training data.
On the Weibo data set, under the same minor data, the training score of the m-TMN model is 3–9 higher than the BiLSTM-CRF model, and 1–4 higher than the TMN model.
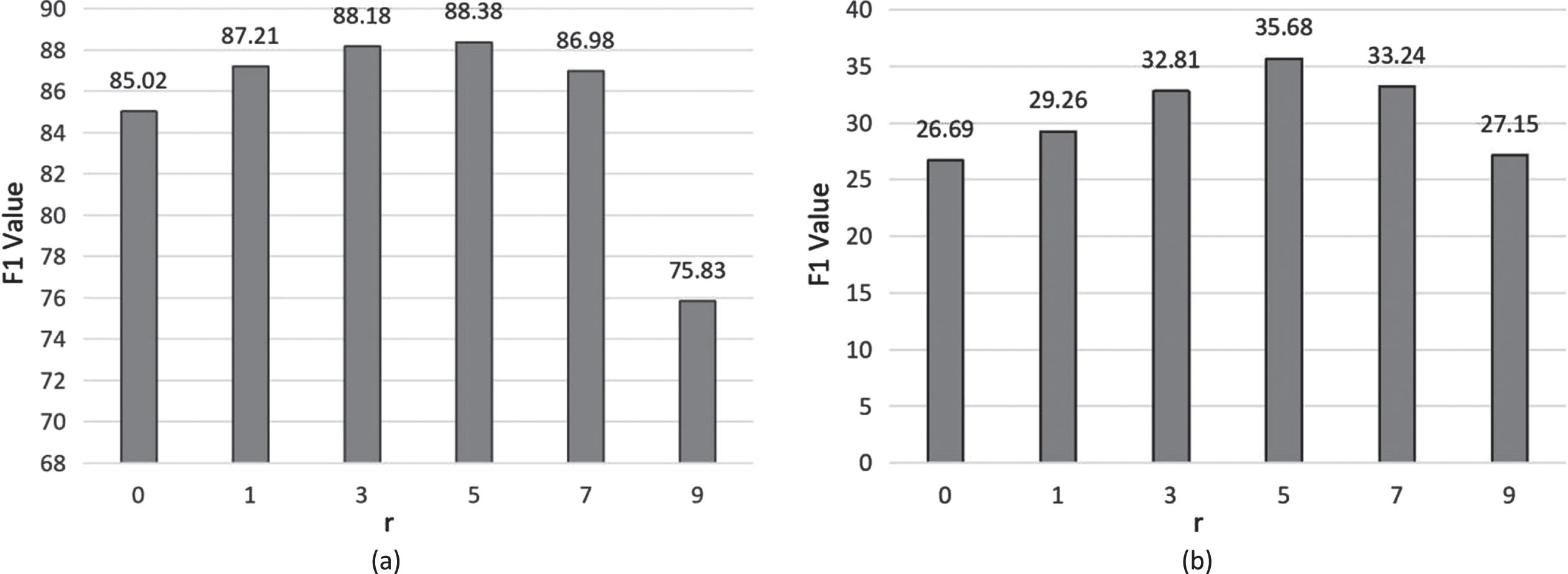
The influence of the number of status updates r on the F1 value of the experimental results. (a) is Resume NER dataset, (b) is Weibo NER dataset.
In order to show that our m-TMN model is superior to the public TMN on Chinese text NER, we plot the loss curve of m-TMN and TMN on the validation set using 20% training data in Fig. 5. As shown in the figure, after training for a few epochs, the loss curve of the m-TMN model drops faster than the TMN model. After training for a few epochs, the loss curve of the m-TMN model drops faster than the TMN model. As the number of training increases, the loss curve of m-TMN also converges earlier and has a smaller value than TMN. This shows that the performance of our m-TMN model in Chinese NER tasks based on our triggers has a greater improvement than TMN. Moreover, the strengths of m-TMN are not only reflected in the F1 evaluation index, but also has a significant effect on shortening training time.
Additionally, as a further test of the impact of the hyperparameter r (number of status updates) in Mogrifier LSTM, we also make a comparison among different values. We set the r value to 1∼9 and did the model performance test respectively. The training data is the 10% Resume NER dataset and 10% Weibo NER dataset. The experimental results are shown in Fig. 6. The results show that the model performs best when the number of status updates is 5 times. Too many status updates will have a negative impact on model performance.
To illustrate that Chinese entities and their around words is much greater than that of other languages, we use the proposed trigger labeling method to annotate entities on English domain datasets and conduct comparative experiments on Chinese datasets. Unlike Chinese text, which is character-based, English text is word-based, so we choose a word around the entity as its trigger.The experimental results are shown in Table 4. Table 4 shows that in the English dataset, using words around entities as its triggers did not improve model performance.The effect of this trigger is lower than the artificial trigger of Lin et al. and even it makes the model perform lower than BiLSTM-CRF. For example, in the CONLL2003 dataset, using the same 20% ratio of training data, our proposed trigger makes the F1 value of the model about 10 lower than that of Lin et al, and about 4 lower than that of BiLSTM-CRF. While in the Resume dataset, our proposed triggers make the F1 value of the model higher than that of BiLSTM-CRF. Thus, Chinese entities and their around words is much greater than that of other languages.
Finally, a note about the cost-effectiveness of the model. Lin et al. consider the extreme case that tagging triggers requires twice the human effort, the TMN is still significantly more labor-efficient in terms of F1 scores [5]. The m-TMN model proposed in this paper realizes the automatic tagging of triggers, eliminating the need for manual tagging of triggers. Although the model complexity will increase, the model training results are significantly improved without increasing manual labor, which makes the m-TMN model more cost-effective.
In this section, we will first review our research results, and then try to answer some questions that deeply understand our work. Then, we put forward some limitations of the methods found so far to guide future research. We hope that these limitations will help readers understand our method more deeply.
Comparison of triggers in different languages: The training dataset selection ratio is 20%
Comparison of triggers in different languages: The training dataset selection ratio is 20%
Our method has made significant improvements on two public data sets, but there are still some problems that haunt us. Q1: Why does the trigger of Chinese text only need to be set as the entity context to get the effect of well, but other languages can’t? Q2: Why does this method perform well on the smaller amount of training data? Q3: After using Mogrifier LSTM to improve the LSTM coding layer for trigger matching, why the experimental results are better?
Answer for Q1: The essence of entity triggers is the context in the text that is strongly related to the entity. According to our research on the written expression and grammar of Chinese texts, the correlation between Chinese entities and their around words is much greater than that of other languages. Therefore, we choose to use the program for trigger tagging. Although this method is less accurate than manual marking, it has the strengths of high efficiency and eliminates the subjectivity of manual marking. The experimental results also proved that this kind of trigger performs well.
Answer for Q2: The method of trigger attention enhancement, its essence is to encode entities and triggers separately, and then perform semantic matching again. The research of Zeng shows that the NER model pays more attention to the entity rather than the context [6]. Agarwal et al. also found that entity representation contributes more to model performance than context representation [12]. Therefore, to certain extent, context representation may have more spurious correlations between the input features and output labels. Through the semantic matching of the entity and the context, the spurious correlation between the context representation and the variant features in the output label is eliminated. Answer for Q3: The triggers that are automatically marked may have a certain mismatch, and these mismatched triggers will affect the performance of the trigger matching model. The design motivation of Mogrifier LSTM is to solve context-free representation of the input token by conditioning the input embedding on the recurrent state some benefit was indeed derived. And this design is more applicable to character-level tasks, and the Chinese NER task is sometimes a character-level task [10]. So, we add the Mogrifier LSTM structure to the semantic matching module. Experiments prove that our design has greatly improved the performance of the model.
Limitations and future work
Although our work has realized the automatic collection of triggers, we have also improved the model based on the characteristics of this trigger. However, the trigger form of automatic tagging is still relatively fixed and currently only applies to Chinese text data. Our future work directions include: 1) Develop a more intelligent trigger annotation method and improve the model for the new method. 2) Further research on trigger automatic tagging methods for low-resource languages.
Related work
When facing smaller amount of training data, the most direct method is data enhancement. That is, high-quality samples are selected to expand the training data. Sample selection is the core module of data-enhanced NER. It selects samples with high confidence and large amount of information to participate in training through certain measurement criteria. A typical idea is Active learning sampling. A typical idea is Active learning sampling. For example, Shen et al., use the “uncertainty” standard d to improve data quality by mining the intrinsic information of the entity [13]. This method focuses on instance sampling and manual annotation, and it requires annotators to first label the most useful instance. However, a recent study believes that manually annotated data is almost not helpful for training new models [14]. NER based on feature transformation is also one of the important methods to solve this problem. This method transfers features to each other or maps the data features of the source and target domains to the agreed feature space [15] to reduce the learning process of differences between domains. Daume et al., preprocess the feature space to achieve the combination of target domain and source domain features [16]. In a task with only two domains, expand the feature space R F to R3F, which corresponds to the domain problem, expand the feature space to R(K+1)F. Qu et al. started with domain and label differences, first trained large-scale source domain data, then measured the correlation between the source domain and target domain entity types, and finally fine-tuned by means of model migration [17]. Another way to solve this problem is NER based on knowledge links. That is, structured resources such as ontologies and knowledge bases are used to heuristically mark data, and the structural relationships of the data are shared objects to help solve the target NER task. It is essentially a learning method based on remote supervision, using external knowledge bases and ontology libraries to supplement annotated entities. Richman et al., used Wikipedia knowledge to design a NER system [18]. This method uses Wikipedia category links to associate phrases with category sets, and then determines the type of phrase. Similarly, Pan et al., used a series of knowledge base mining methods to develop a cross-language name tag and link structure for more than 200 languages [19]. Although these methods greatly reduce the workload of manual annotation, the quality of matching sentences largely depends on the coverage of the dictionary and the quality of the corpus. The learned models tend to have similar entities in the dictionary. There are also some works that focus on redefining NER as a different problem to reduce the need for manually labeled training data. For example, the chain rule (Safranchik et al) is based on votes recognize entities through whether adjacent elements in a sequence belong to the same class [20]. Different from the work aimed at getting rid of training data or manual annotations, Lin er al proposed a new and effective human interpretation agent “entity trigger” to promote the effective learning of NER models [5]. But there are problems such as how to automatically generate triggers, low-resource language migration, and improvement of modeling methods.
Conclusion
In this paper, we propose a cost-efficient trigger tagging method for Chinese text based on the NER model enhanced by triggers. Then, in view of the characteristics of this trigger, we improved the standard TMN framework. Experiments on two public data sets show that this new trigger tagging method is not only economical but also effective. And our improved m-TMN framework also has a better performance improvement than the previous model. Therefore, we believe that our work has great research significance in the Chinese NER task with limited training data. At the same time, this is an exploration of the application of Mogrifier LSTM.
Footnotes
Acknowledgments
This research was supported by National Natural Science Foundation of China (No. 61871234).