
Abstract
In this manuscript, we introduce a multi-criteria decision-making (MCDM) method under T-spherical fuzzy set environment. Firstly, we propose a method to use the correlation coefficient and standard deviation (CCSD) method to determine the attribute weight under T-spherical fuzzy environment, when the attribute weight information is completely unknown or partially unknown. Secondly, we introduce a T-spherical fuzzy complex proportional assessment (COPRAS) method. Finally, a numerical example is given to illustrate the application of the T-spherical fuzzy COPRAS method, and some comparative analysis is carried out to verify the feasibility and effectiveness of the proposed method.
Keywords
Introduction
Multi-attribute decision-making is a process of ranking alternatives according to the attribute values of different alternatives under different attributes. It is an important field of modern decision science. With the development of modern society, there are many uncertainties in real life, and many situations are difficult to express with precise numbers. The fuzzy set (FS) was proposed to solve this kind of problem by Zadeh [1], which is characterized by a membership degree α. On this basis, Atanassov [2, 3] proposed the intuitionistic fuzzy set (IFS) characterized by a membership degree (α ∈ [0, 1]), a non-membership degree (β ∈ [0, 1]). But when a person gives such a value, the sum of the degree of membership and the degree of non-membership exceeds 1, then IFS can’t handle it. To deal with this situation, Yager [4] proposed the Pythagorean fuzzy set (PyFS), the sum of the squares of its membership degree and non-membership degree does not exceed 1. Later, Yager [5] further proposed q-rung orthopair (q-ROFS) on this basis, and the sum of the q-powers of its membership degree and non-membership degree does not exceed 1.
Once the PyFS was put forward, it caused many scholars to study and discuss it. In the core database of web of science, the subject is set to the Pythagorean fuzzy set and the period time is set to 2013–2020, and bibliometric analysis is performed on the retrieved literature. From Fig. 1. we can see that during 2013–2017, the number of related papers was relatively small, but it was also increasing year by year. During 2017–2020, the number of related papers reached a high level, with more than 150 papers published each year. It represents that in recent years, more and more scholars have conducted research and discussion in this field. Figure 2. is a Sankey diagram of author country, author, and keywords. On the left is the country distribution of authors, in the middle are some authors with a high number of publications, and on the right are some related keywords. From Fig. 2. we can see that there are many Chinese scholars in this field, accounting for a very high proportion of all the authors’ countries, followed by Pakistan, Turkey, and other countries. From Fig. 2. also get to know some well-known researchers in this field. The main research contents in this field are multi-attribute decision-making, aggregation operators, group decision-making problems, similarity measurement, and so on. There is also a combination with some methods, such as TOPSIS and so on. Figure 3. is the Co-occurrence Network, from this we can see some research hotspots in this field, as well as some extensions of topics in this field? The research on Pythagorean fuzzy set in the past two years is mainly to propose some new aggregation operators, score functions, distance functions, and combinations with some multi-attribute decision-making methods. For example, Huang and Lin, etc. [6] proposed two novel distance measures and a novel score function for PyFS, and combined PyFS with the MULTIMOORA method. The MULTIMOORA method has great advantages over some existing multi-attribute decision-making methods. Figure 4 is the main path analysis of the PyFS related literature from 2013 to 2020. From Fig. 4, we can know some important nodes in the development process of the PyFS.
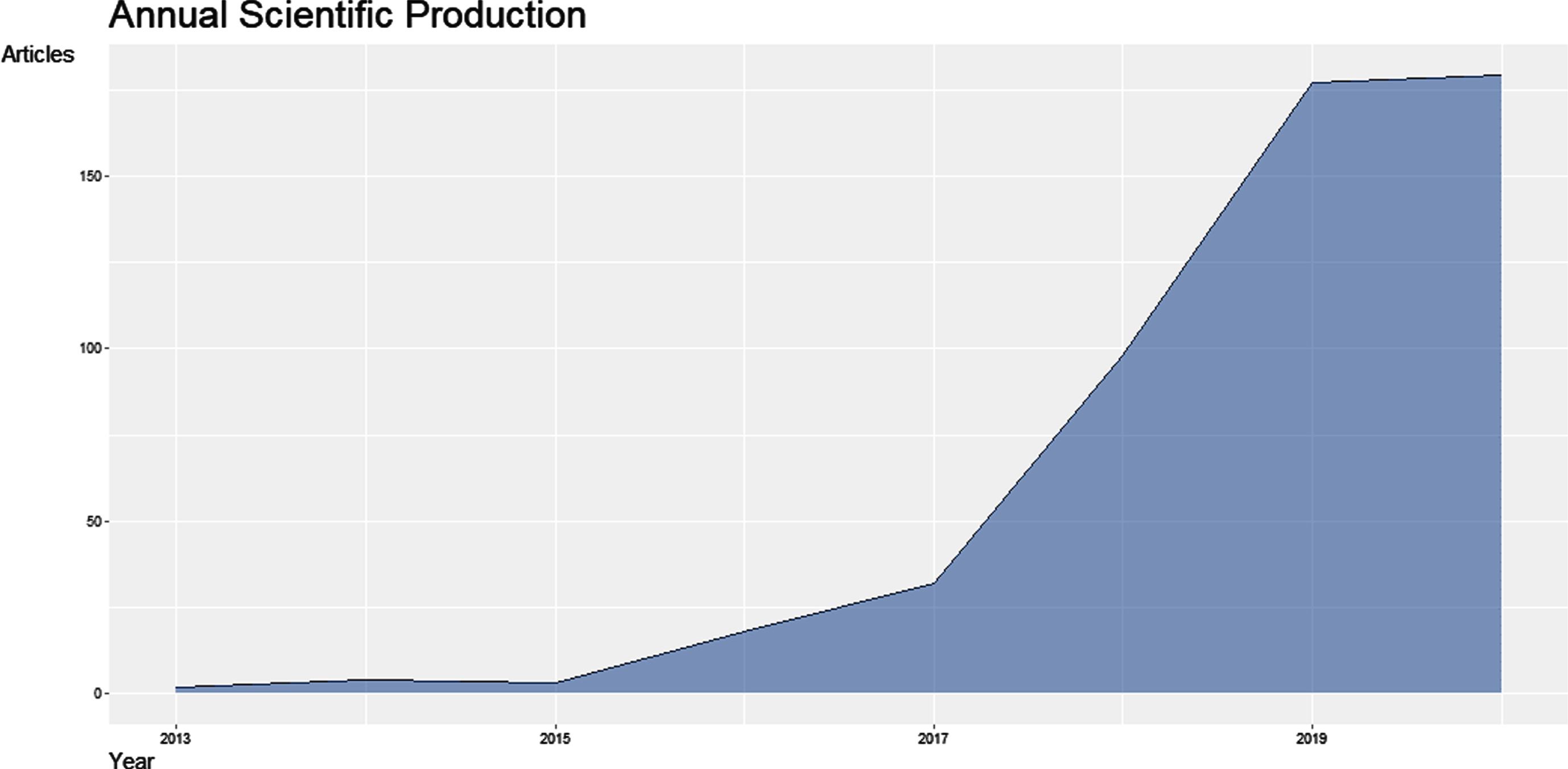
Annual scientific production.
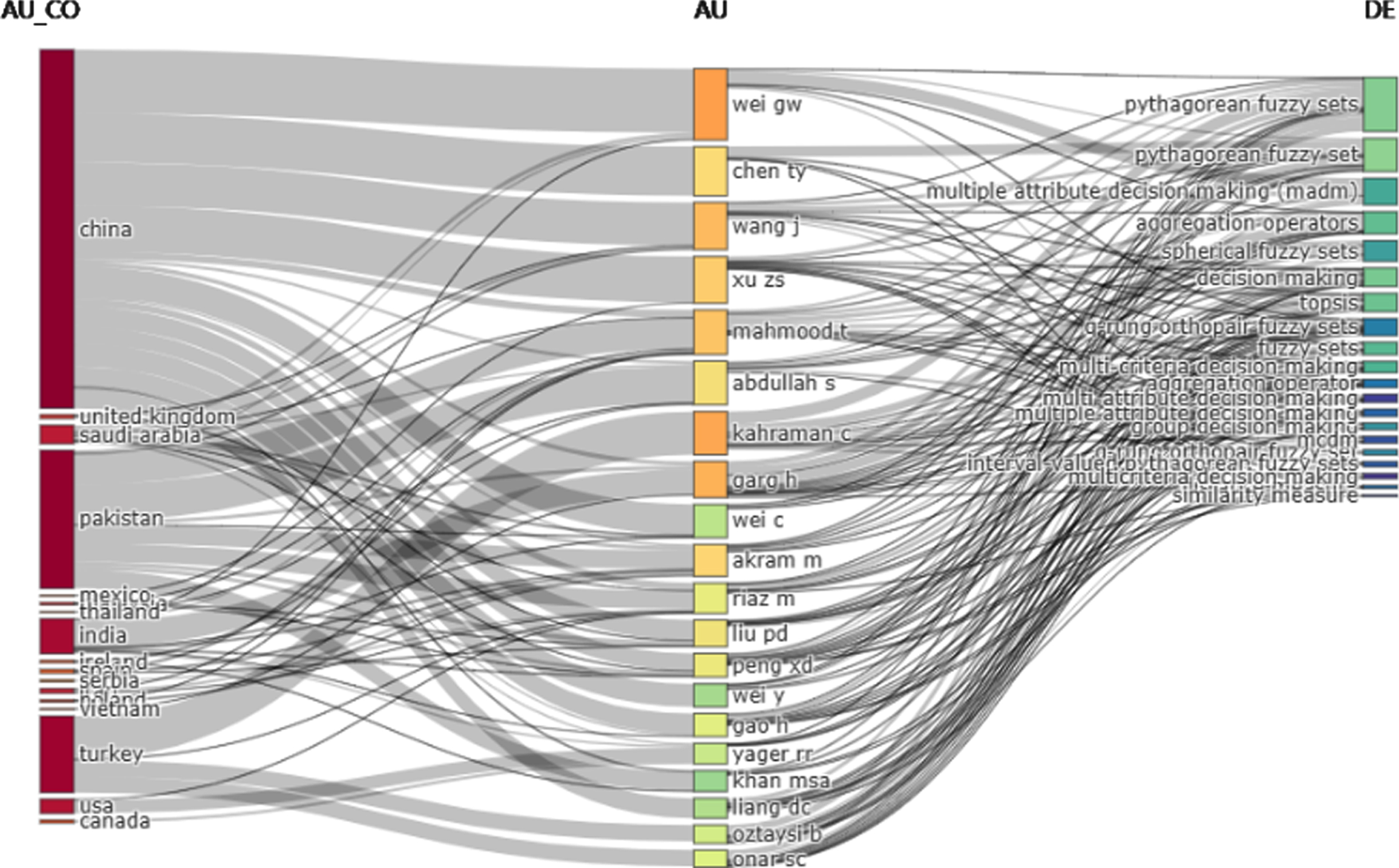
Sankey diagram.
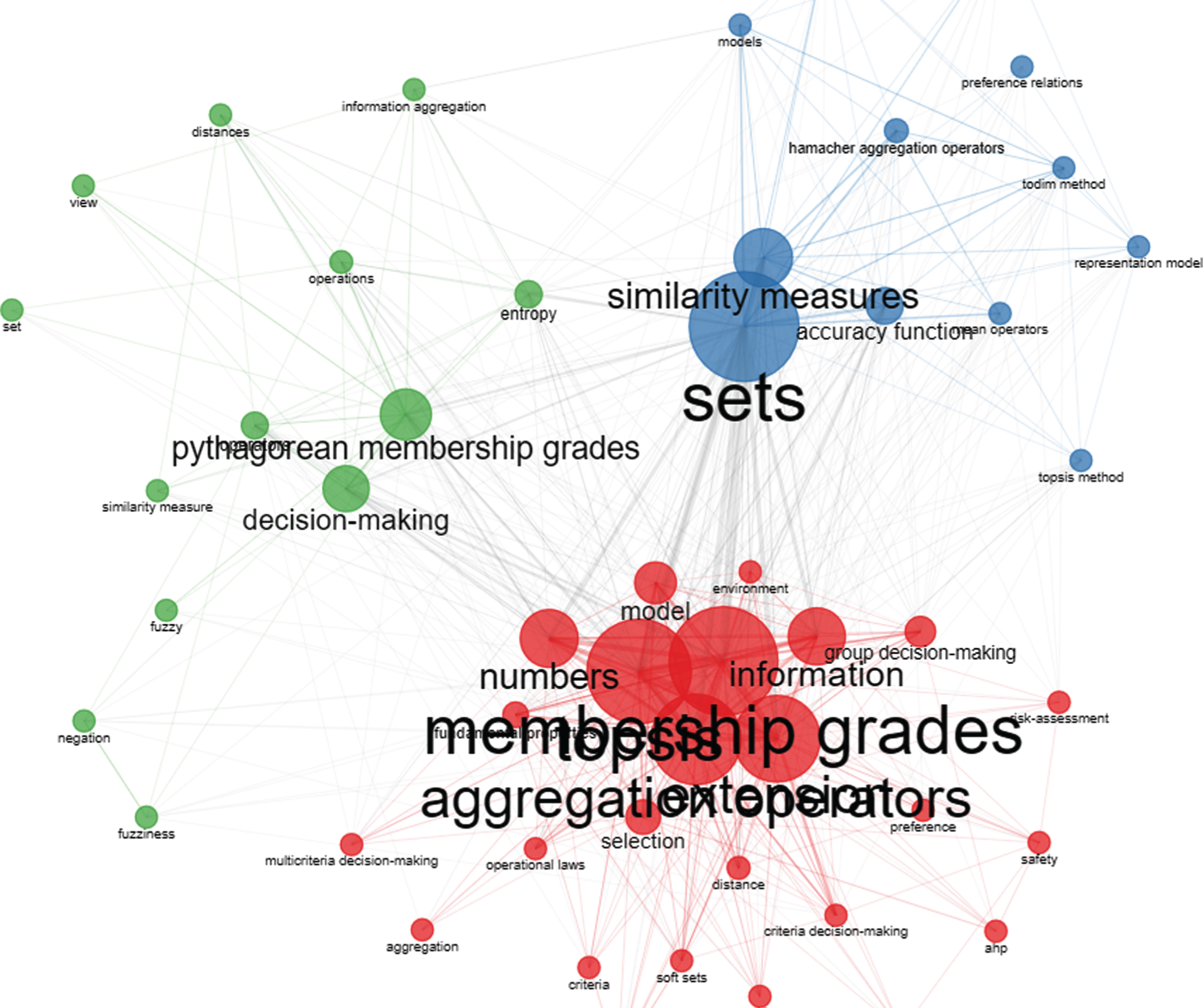
Co-occurrence network.

Main path analysis results.
However, in some cases, human views may involve more types: yes, no, abstain, refusal. For example, voting activities in real life are like this, and there may be four types of voting results: vote for, abstain, vote against, and refuse to vote. To deal with such situations, Cuong and Kreinovich [7, 8] proposed the picture fuzzy set (PFS), which is characterized by a membership degree (α), a neutrality degree (γ), and a non-membership degree (β), and 0 ⩽ α + γ + β ⩽ 1.
Recently, inspired by PyFS and q-ROFS, given that the sum of membership degree, neutrality degree and non-membership degree given by a person is greater than 1, the PFS cannot handle this situation. Mahmood [9] et al. proposed the spherical fuzzy set (SFS) and T-spherical fuzzy set (T-SFS) which is characterized by a membership degree (α), a neutrality degree (γ) and a non-membership degree (β), and respectively have the following restrictions 0 ⩽ α2 + γ2 + β2 ⩽ 1 and 0 ⩽ α q + γ q + β q ⩽ 1. The T-SFS allows decision-makers to have more freedom in the decision-making process without considering the restriction that the sum of membership, neutrality, and non-membership is less than or equal to 1.
The T-SFS can be applied to many aspects, such as pattern recognition [13, 18], evaluation of water reuse [20], evaluation of the performance of search and rescue [17], medical diagnosis [9], the selection of solar cells [12], evaluation of the product quality [52], etc. The T-SFS has very broad application prospects in many aspects.
The T-SFS has caused many scholars to study it as soon as it was proposed, and T-SFS is a very hot topic. Garg [10] proposed some new and improved aggregation operators for the T-SFS. Ullah [11] et al. introduced some new similarity measures for the T-SFS such as cosine similarity measures, grey similarity measures and set-theoretic similarity measures and applied them to the pattern recognition. Zeng [12] et al. proposed some new interactive averaging aggregation operators by assigning associate probabilities for the T-SFS and applied them to the selection of solar cells. Wu [13] et al. introduced a new divergence measure for the T-SFS and applied it to pattern recognition. Liu [14] et al. proposed some new aggregation operators for the T-SFS and applied them to the multiple-attribute group decision-making (MAGDM). Zedam [15] et al. proposed an original notion of a T-SFS graph theory. Ullah [16] et al. presented some correlation coefficients for T-SFS and applied them to multi-attribute decision making (MADM) and clustering. Ullah [17] introduced some Hamacher aggregation operators based on the T-SFSNs. Wu [18] et al. proposed cosine similarity measures for the T-SFS and applied them to pattern recognition. Munir [19] defined some improved algebraic operations for T-SFS known as Einstein sum, Einstein product and Einstein scalar multiplication based on Einstein t-norms and t-conorms and applied them to the MADM. Khan [20] proposed some novel operational laws for T-SFSNs based on the Schweizer-Sklar t-norm (SSTN) and the Schweizer-Sklar t-conorm (SSTCN). Munir [21] et al. introduce some associated immediate probability geometric aggregation operators for T-SFS. Liu [22] proposed the normal T-spherical fuzzy numbers (NT-SFNs) which can depict both normal distribution phenomenon and neutral information with a considerably large expression domain, and defined some operational laws, score function, accuracy function, expectation as well as distance measure of NT-SFNs. Mahmood [23] introduced the generalized MULTIMOORA method for T-SFS and proposed some Dombi prioritized weighted aggregation operators. Garg [24] presented the concept of power aggregation operators for T-SFS and applied it to the MADM. Ju [25] et al. introduced a MAGDM-TODIM method for T-SFS.
At present, there are some decision-making methods for MCDM problems, such as VIKOR [26], DEMATEL [27, 31], MOORA [28], MULTIMOORA [6, 31], COPRAS [29], ARAS [30], WASPAS [31], TODIM [32], EDAS [33], TOPSIS [34], etc. These MCDM methods all have their characteristics, among which TOPSIS is based on positive and negative ideal solutions to determine the best solution, and VIKOR uses the concept of compromise solution to determine the best alternative solution. These MCDM methods have been applied in a variety of fuzzy environments. Huang and Lin [6], etc. combined the MULTIMOORA method with the PyFS and applied it to specific applications. Lin, etc. [35] applied the TODIM method to the hesitant fuzzy linguistic term sets (HFLTSs) and used it to solve practical examples. Simic [36] proposed the picture fuzzy WASPAS method for selecting last-mile delivery mode: a case study of Belgrade. Demircan [37] applied the EDAS method in the neutrosophic fuzzy environment and used it to solve the problem of the evaluation of software development suppliers in the banking sector.
Among these MCDM methods, the COPRAS method has its advantages in some aspects. The COPRAS method was developed in 1996 by Vilnius Gediminas Technical University scientists Zavadskas and Kaklauskas. The COPRAS method is used to assess the maximizing and minimizing index values, and the effect of maximizing and minimizing indexes of attributes on the assessment of the results is considered separately. The selection of the best alternative is based on the ideal and anti-ideal solutions. Over the other MCDM methods such as TOPSIS, VIKOR, DEMATEL, COPRAS can more easily be adopted for the majority of the decision problems. Also, decisions provided by COPRAS are shown to be more efficient and less biased than those provided by TOPSIS and Simple Additive Weighting.
The COPRAS is a method of normalizing. This method accommodates the direct and proportional dependence of priority. It is a compensatory method. Recently, more and more scholars have combined the COPRAS method with multi-attribute decision-making. Alipour [38] studied the application of the COPRAS method in the PyFS environment. Krishankumar [39] proposed a COPRAS method under the probabilistic hesitant fuzzy information features. Wei [40] developed the COPRAS model to solve the MAGDM under single-valued neutrosophic 2-tuple linguistic sets (SVN2TLSs). Darko [41] introduced an extended COPRAS method for MAGDM based on dual hesitant fuzzy Maclaurin. Buyukozkan [42] presented a novel approach integrating AHP and COPRAS under PyFS for digital supply chain partner selection. Yucenur [43] introduced a novel method that combined the SWARA method and COPRAS. Yuan [44] proposed an improved Decision-Making Trial and Evaluation Laboratory (DEMTEL)-COPRAS method under probabilistic linguistic environment.
The correlation coefficient and standard deviation (CCSD) is the method of determining criteria weight proposed by Wang and Luo [45]. The CCSD method can be used to determine the attribute weight information when the attribute weight information is completely unknown or partially unknown. The CCSD method has a very wide range of application scenarios and has been applied to many multi-attribute decision-making problems. Mir [46] proposed a new framework that integrates two fuzzy group decision-making approaches including TOPSIS and ELECTRE II and used the CCSD method to determine the attribute weight. Dahooie [47] introduced a new combination of Data Envelopment Analysis (DEA) as a powerful objective weighting method and used the CCSD method to determine the attribute weight.
Most of the existing multi-attribute decision-making methods related to T-SFS have complex calculation processes, which may be difficult in specific applications. Moreover, in the decision-making process, the determination of attribute weights is also a very important issue. At present, there are few studies on weight determination for the T-SFS. Therefore, we propose the T-SFS-COPRAS method, which is relatively simple to calculate and can be applied in many situations.
Compared with the existing literature, the main contributions of this paper are as follows: First, we introduced the CCSD method to determine attribute weights for the T-SFS. The CCSD method can deal with the situation where the attribute weight information is completely unknown or partially unknown and has strong flexibility. Second, we proposed the T-SFS-COPRAS method. The method proposed in this paper is relatively simple to calculate and has strong practicability. Compared with some existing methods, the effectiveness and rationality of the method proposed in this paper are verified.
The rest of the paper is organized as follows: Section 2 reviews some important concepts about T-SFS and the CCSD method. In section 3, we propose a T-SFS COPRAS method and use the CCSD method to determine the attribute weight. In section 4, we provide a numerical example to prove the feasibility and effectiveness of the method. In section 5, we have compared some existing methods. In section6, we have made some conclusions and prospects for this article.
Some basic concepts
Here α (x), β (x): X → [0, 1] are the membership and non-membership with the condition 0 ⩽ α (x) + β (x) ⩽1. The r (x) = 1 - (α (x) + β (x)) is the degree of the refusal of x in X.
Here α (x), β (x): X → [0, 1] with a condition that 0 ⩽ α2 (x) + β2 (x) ⩽1. The
Here α (x), γ (x), β (x): X → [0, 1] represents the membership, the neutrality, and the non-membership respectively, with the condition 0 ⩽ α (x) + γ (x) + β (x) ⩽1 and r (x) = 1 - (α (x) + γ (x) + β (x)) are the degree of refusal of x in X. The triplet (α, γ, β) is the picture fuzzy numbers (PFNs).
Here α (x), γ (x), β (x): X → [0, 1] represents the membership degree, neutrality degree, and non-membership degree respectively with the condition 0 ⩽ α2 (x) + γ2 (x) + β2 (x) ⩽1. The
Where α (x), γ (x), β (x): X → [0, 1] represents the membership, the neutrality, and the non-membership respectively, which satisfy the following condition 0 ⩽ α q (x) + γ q (x) + β q (x) ⩽1, q ⩾ 1. The refusal degree of the element x is r (x) = [1 - (α q (x) + γ q (x) + β q (x))] 1 /q. The triplet (α, γ, β) is called T-spherical fuzzy numbers (T-SFNs).
The T-SFS becomes PFS when q = 1. The T-SFS becomes spherical fuzzy set (SFS) when q = 2. The T-SFS becomes q-rung orthopair fuzzy set (q-ROPFS) when γ (x) = 0. The T-SFS becomes Pythagorean fuzzy set (PyPS) when γ (x) = 0, q = 2. The T-SFS becomes intuitionistic fuzzy set (IFS) when γ (x) = 0, q = 1. The T-SFS becomes fuzzy set (FS) when γ (x) = 0, β (x) = 0, q = 1.
If S (a) > S (b), then a > b. If S (a) = S (b), then: If H (a) > H (b), then a > b. If H (a) = H (b), then a ∼ b.
Step 1: Distribute the neutral degree to the membership and non-membership degrees as follows:
Step 2: Calculate the crisp value by:
This method of operation can be extended to T-SFS. When extended to the T-SFS, the r = [1 - (α q + γ q + β q )] 1 /q.
The correlation coefficient and standard deviation (CCSD) method
The CCSD is the method of determining criteria weight proposed by Wang and Luo [32], concerning standard deviation (σ j ) between the criteria and their correlation coefficients (ζ j ) with the global evaluation of alternatives. The CCSD method can be used to determine the attribute weight when the attribute weight information is completely unknown or the weight information is partially unknown.
Suppose that A = {a1, a2, …, a
m
}, m alternatives and C = {c1, c2, …, c
n
}, n criterion. Let w = {w1, w2, …, w
n
} be the weight vector of attributes that satisfies:
The main steps of the CCSD method are as follows:
Step 1: Obtain the decision-making matrix.
Step 2: Normalize the decision matrix according to the following formula.
Step3: Calculate the global evaluation value of each alternative using the simple additive weighting (SAW) method.
Step4: We now remove the attribute c
j
and consider its impact on decision-making. When criteria c
j
is removed, the global evaluation value of each alternative can be redefined as
Then calculate the correlation coefficient between the values of c
j
and the global evaluation value of each alternative.
where
If ζ j is close to 1, then the criteria c j has little effect on global evaluation. Otherwise, the criteria c j should be given an important weight.
Step5: Based on the previous analysis, we can define the attribute weight as:
Where σ
j
is the standard deviation (SD) of the values of c
j
defined by
Step6: Construct a nonlinear programming optimization CCSD model:
This nonlinear optimization model can be solved with Microsoft Excel solver, MATLAB software or LINGO software packages. In addition, this model can also increase the preference information of decision makers and increase the constraint conditions of weight information, such as w i > b, etc.
The T-spherical fuzzy sets COPRAS method.
Suppose that A = {a1, a2, …, a
m
}, m alternatives and C = {c1, c2, …, c
n
}, n criterion. Let w = {w1, w2, …, w
n
} be the weight vector of attributes that satisfies:
The proposed method can be divided into two stages.
First, we need to obtain the T-spherical fuzzy decision matrix R1 = [x ij ] m×n from the experts.
Phase1: Determine attribute weights according to the CCSD method.
Step1: Obtain the crisp decision matrix from the R1 according to Dedinition9.
Step2: Obtain the attribute weight according to the CCSD method.
Phase2: Use the COPRAS method to determine the ranking of alternatives under T-spherical fuzzy sets.
Step1: Calculate the sum of the attribute evaluation values for benefit attribute (P
i
) and cost attribute (Q
i
) respectively for each alternative according to the T-spherical fuzzy decision matrix R1 = [x
ij
] m×n.
The
The
Step2: Determining the minimal value of Smin (Q i ).
Step3: Determine the relative weights of each alternative
This can also be written as
Step4: Rank alternatives according to the relative significance of each alternative. The greater is the significance G i , the higher is the priority of the alternative.
The numerical example
In this section, a numerical example is given to verify the feasibility of the proposed method. A waste disposal company wants to select a clean and green disposal technology for municipal solid waste (MSW). After preliminary screening, there are four processing techniques to choose from: incineration (A1), sorting (A2), composting (A3), landfill (A4). Through communication with relevant experts, qualitative indicators were considered, as follows: environmental protection (c1), social impact (c2), economic benefit (c3), technological advancement (c4). c1, c3, c4 are the benefit criteria and c2is the cost criteria.
Invite a relevant expert to evaluate these four processing technologies in four evaluation criteria. To allow experts to fully express their preference information, evaluation information can be expressed by T-SFNs. Table 1 is the decision matrix given by experts. From Table 1, we can know that q = 2.
T-spherical fuzzy decision matrix R1
T-spherical fuzzy decision matrix R1
The following will use the proposed method to solve this problem, respectively when the attribute weight information is completely unknown and the attribute weight information is partially unknown.
Phase1: Determine attribute weights according to the CCSD method.
Step1: Obtain crisp value decision matrix according to Definiton9 as shown in Table 2.
Crisp decision matrix R2 = [r
ij
] 4×4
Crisp decision matrix R2 = [r ij ] 4×4
Step2: Normalize the decision matrix according to the following formula.
Step3: Here we use Lingo software to solve the following nonlinear programming model.
Phase2: Sort alternatives.
Step1: Calculate the sum of the attribute evaluation values for benefit attribute (P
i
) and cost attribute (Q
i
) respectively for each alternative according to the T-spherical fuzzy decision matrix R1.
Step2: Determine the minimal value of Smin (Q
i
).
Step3: Determining the relative weights of each alternative.
Step4: Ranking alternatives according to the value of G
i
.
From this, we can know the order of alternatives.
Phase1: Determine attribute weights according to the CCSD method.
Here we add some known attribute weight information. The processing of the initial decision matrix has already been done before, so I won’t elaborate on it here, but the previous data should be used. According to the Standardized decision matrix R3 = [r ij ] 4×4 in Table 3, we can directly construct a nonlinear programming model.
Standardized decision matrix R3 = [r
ij
] 4×4
Standardized decision matrix R3 = [r ij ] 4×4
Calculate this nonlinear programming model through Lingo software. We can get the weight vector as: w = [0.2000, 0.1385, 0.4615, 0.2000] T .
Phase2: Sort alternatives.
Step1: Calculate the sum of the attribute evaluation values for benefit attribute (P
i
) and cost attribute (Q
i
) respectively for each alternative according to the T-spherical fuzzy decision matrix R1.
Step2: Determine the minimal value of Smin (Q
i
).
Step3: Determine the relative weights of each alternative.
Step4: Rank alternatives according to the value of G
i
.
From this, we can know the order of alternatives.
In this part, we compare the proposed method with the existing method. There is a multi-attribute decision-making problem, there are four alternatives A = {A1, A2, A3, A4} and four evaluation attributes C = {c1, c2, c3, c4}. Among them, c2 is a cost attribute, and the others are benefit attributes. The weight vector is w = [0.4,0.25,0.19,016]. The T-spherical fuzzy decision matrix is as follows:
According to the decision matrix in Table 4, we use the methods proposed by different authors to rank the alternatives, and the results are shown in Table 5.
T-spherical fuzzy decision matrix
T-spherical fuzzy decision matrix
Comparative results
From the results in Table 5, we can find that the alternatives calculated by different methods are not the same, and there are some discrepancies. As far as this example is concerned, the proposed method, the Ju’s [24] method, the Garg’s [24] method, the Liu’s [22] method, and the Munir’s [19] method can conclude that A1, A1 are hesitant to A3, A4. The results obtained by the Mahmood’s [8] method and Ullah’s [17] method are the same. Through the comparison of the results obtained by these methods, the method proposed in this paper is effective. Also, the method proposed in this article is simple to calculate and has a very wide range of application scenarios.
In this paper, we introduce a T-spherical fuzzy COPRAS method, when the attribute weight information is completely unknown and the attribute weight information is partially unknown.
We extend the CCSD method to the T-spherical fuzzy environment. The CCSD method can be used to determine attribute weight information, whether the attribute weight information is completely unknown or partially unknown. The proposed method is simple in a calculation, has very good feasibility and reliability, and can be applied to many multi-attribute decision-making problems.
In the future, the CCSD method has room for further improvement and application scenarios. After the operation rules of T-SFSN become more abundant, T-SFSN can be directly used to calculate the standard deviation and correlation coefficient, and the information of T-SFSN can be fully utilized. In addition, if there is a more complete T-SFS weighted aggregation operator in the future, the method proposed in this article can be further improved and the accuracy of the method can be improved.
In addition, in the field of decision-making, group decision-making (GDM) is becoming more and more common, and some scholars have studied and discussed it. In future studies, the GDM of T-SFS can also be considered. The difficulty of GDM is how to gather the evaluation information of different experts accurately, objectively, and reliably. At present, for the GDM problem, some scholars propose to build and improve a more suitable consensus model. In GDM problems, decision-makers often give linguistic term evaluations due to the uncertainty of the problem and the vague understanding of alternative solutions. Zhang and Lin [49] proposed a minimum adjustment-based optimization model to test and improve the individual consistency by considering the linguistic preference relation (LPR) and introduced the PIS-based individual consensus-level maximization model and a PIS-based minimum adjustment model for consensus reaching in linguistic GDM by considering the personalized individual semantics (PISs). At last, Zhang also proposed the algorithm for consensus reaching. Considering that experts may show a willingness not to cooperate in the consensus reaching process (CRP), Gao and Zhang [50] proposed a non-cooperative behavior management mechanism that dynamically adjusts the trust degrees in the social network. Considering the asymmetric case of linguistic term sets, Zhang et al. [51] proposed a simplified linguistic computational model to fuse multi-granular unbalanced linguistic terms. Moreover, Zhang et al. developed two optimization models to generate adjustment advice and introduced an algorithm to help decision-makers reach consensus in GDM.
In the future, it also has this important research value for the GDM problem of T-SFS.