
Abstract
The estimation of gangue content is the main basis for intelligent top coal caving mining by computer vision, and the automatic segmentation of gangue is crucial to computer vision analysis. However, it is still a great challenge due to the degradation of images and the limitation of computing resources. In this paper, a hybrid connected attentional lightweight network (HALNet) with high speed, few parameters and high accuracy is proposed for gangue intelligent segmentation on the conveyor in the top-coal caving face. Firstly, we propose a deep separable dilation convolution block (DSDC) combining deep separable convolution and dilation convolution, which can provide a larger receptive field to learn more information and reduce the size and computational cost of the model. Secondly, a bridging residual learning framework is designed as the basic unit of encoder and decoder to minimize the loss of semantic information in the process of feature extraction. An attention fusion block (AFB) with skip pathway is introduced to capture more representative and distinctive features through the fusion of high-level and low-level features. Finally, the proposed network is trained through the expanded dataset, and the gangue image segmentation results are obtained by pixel-by-pixel classification method. The experimental results show that the proposed HALNet reduces about 57 percentage parameters compared with U-Net, and achieves state-of-the art performance on dataset.
Keywords
Introduction
The top-coal caving mining method that causes the top coal to collapse under the action of gravity is a high efficiency and high yield method for mining thick coal seams [1, 2]. In order to balance the quality and output of coal, it is inevitable that a large amount of gangue is mixed into the raw coal in the process of top coal caving mining. The latest research found that when the mixed gangue rate is 10% 15%, the coal recovery rate reaches the maximum [3]. At present, workers usually control the hydraulic support by identifying the gangue content on the scraper conveyor to realize the decision of “discharge” or “stop discharge” [4]. With the rapid development of artificial intelligence technology, the intelligent top coal caving mining technology [5] can effectively solve the problems of “under discharge” and “over discharge” in manual top coal caving mining, improve the coal recovery rate and reduce the cost of gangue washing. Therefore, the automatic identification of gangue content is the key technology to realize intellectualization of top coal caving mining process.
As a frontier problem in the field of top coal caving mining, many coal gangue recognition technologies have been widely studied in the early stage. At present, the popular methods mainly include infrared detection [6–8], vibration signal [2, 9–11] and dielectric characteristics [12, 13]. These methods use different feature vectors of coal and gangue (such as sound pressure signal and capacitance value) and classification model to identify coal and gangue. However, these methods can only distinguish the two stages of “coal discharge” and “gangue discharge”, but cannot identify the gangue content information. At present, the top coal caving process completely depends on the visual experience of workers to identify the content of gangue [2, 14]. Therefore, computer vision instead of human vision has self-evident advantages in automatic detection of gangue content in complex environment.
So far, a number of literatures are related to the research of coal gangue image recognition. However, the related research mainly focuses on the coal and gangue image classification of the washing plant (i.e. detecting whether there is gangue or coal in the image) and the coal rock interface recognition of the coal mining face (i.e. locating the spatial position of coal seam and rock stratum in the image). The results of these studies cannot provide the content information of gangue in the image. Image segmentation can provide the location and regional characteristics of the object of interest, which is an important task in the field of computer vision. It is mainly divided into traditional segmentation methods [15–19] and deep learning methods [20–23]. Compared with traditional segmentation technology, deep learning can automatically learn feature representation from images without introducing manual coding rules or human domain knowledge [24]. Because of its strong adaptability and accuracy, it has become one of the most popular scientific research trends [25]. Although these methods reported in relevant literature have obtained acceptable recognition accuracy in sparse gangue images, they have some limitations in the application of complex gangue images randomly stacked on scraper in fully mechanized top coal caving face with low illumination, high noise and uneven dust concentration distribution. Considering the fuzzy boundary and complex gradient of gangue image, more high-resolution information is needed for accurate segmentation. In addition, its structure and semantic information are relatively simple, and low-resolution information is helpful for recognition. Therefore, a deep learning framework that can integrate low-resolution information and high-resolution information is preferred.
U-shaped full convolution neural network (U-Net) has achieved great success in the field of small sample medical image segmentation [26] and coal gangue image segmentation [22]. However, the simple feature fusion of U-Net will lead to poor feature extraction ability. In addition, the large-scale and slow reasoning speed limit its application in practice. Therefore, it is an urgent problem to design a small-scale, fast and efficient gangue segmentation network. The potential of lightweight network in practical application stimulate our exploration of segmenting gangue image of top coal caving face through deep learning algorithm. As far as we know, this is the first time to consider intelligent gangue segmentation through network learning in the process of top coal caving mining. In order to obtain higher accuracy of gangue segmentation with limited hardware resources, a hybrid connected attentional lightweight network (HALNet) was proposed for gangue intelligent segmentation on the conveyor of top-coal caving face. Depthwise separable dilation convolution (DSDC) factorizes a standard dilation convolution into two parts to expand the receptive field and reduce computational cost and model size [27]. The design of bridging residual learning framework can minimize the loss of semantic information in the process of feature extraction. The attention fusion block (AFB) can highlight the gangue features of the scraper area and suppress irrelevant areas in the image with little computational cost. The redesigned skip path further reduces the semantic gap between feature mapping and more comprehensive segmentation of gangue. The results of the present research indicated that the proposed method can effectively segment the coal gangue on the scraper in the top coal caving face, which provides a theoretical basis for the intelligent top coal caving mining technology.
The contributions of our work are as follows: A DSDC module combining deep separable convolution and dilation convolution with different dilation rates is proposed, which can effectively obtain receptive field information of different sizes and extract features more efficiently while reducing the amount of model calculation. A bridging residual learning framework is designed to improve the feature extraction ability of deep network and obtain more representative features. An AFB module with skip path connection is introduced to model semantic dependencies between channels and emphasize the gangue regions, which contributes to localization and semantic segmentation of gangue on the scraper conveyor.
This paper is organized as follows. In Section 2, we review state-of-the-art research of related work. The proposed method for gangue segmentation will be detailed in section 3. The detailed experimental results and analysis are presented in Section 4. Finally, Section 5 provides some conclusion and future exploration work.
Related works
The detection of gangue content on scraper conveyor is a key step in the intellectualization of top coal caving mining process. In recent years, researchers have studied methods for coal gangue identification, such as γ-ray detection, radar detection, cutting force response, infrared detection, vibration signal, dielectric characteristics and image detection [4]. At present, the research of top coal caving face mostly focuses on the application of vibration signal to identify coal gangue. This method only realizes the strategy of “stop discharging in case of gangue”, and cannot judge the mixed gangue rate [3]. So far, automatic coal caving still needs to control the coal caving process in combination with workers’ visual observation of the content of gangue in the released mixture [28]. As a non-contact detection technology, computer vision instead of human vision has been widely used in driverless vehicles, medical diagnosis, mineral processing and many other fields.
Wang et al. [29] proposed a gangue image recognition method combining traditional spatial processing with wavelet transformation, and the recognition rate reached 95.12%. In order to further improve the recognition accuracy, some typical deep learning networks are introduced to recognize coal and gangue. Pu et al. [23] established a self-defined convolutional neural network (CNN) model to distinguish coal and gangue by introducing the idea of transfer learning. Li et al. [21] and Liu et al. [20] respectively applied the improved yolov3 and yolov4 algorithms for intelligent and high-precision identification of coal and coal gangue. These studies mainly focus on the classification of coal and gangue, which cannot obtain the gangue content information in the image, and the image segmentation technology can effectively solve this problem.
Sun et al. [15] proposed a single target super-pixel segmentation algorithm of coal and gangue based on color, spatial position and texture fusion. Wang et al. [30] combined the edge detection method of star algorithm with morphological method to complete the fine segmentation of multi-objective coal gangue image with simple background and sparse distribution. Li et al. [18] developed a positioning and recognition system for segmenting coal gangue under solid color background. These traditional image segmentation methods are effective for simple background image or single target image segmentation. In order to improve the segmentation performance of multi-target image in complex background, Gao et al. [22] used U-Net model to segment coal gangue from raw coal images collected under complex conditions, and the segmentation accuracy reached 0.93. However, the simple feature fusion of U-Net leads to the poor feature extraction ability of gangues randomly stacked and buried in the degradation scene of fully mechanized top coal caving face. In addition, large-scale redundant parameters and slow reasoning speed limit its deployment in hardware equipment and practical application. So far, there is no relevant literature report that can process the coal gangue image on the conveyor in this complex environment.
In order to improve the feature learning ability of U-Net, the residual block [31] replaces the convolution block to overcome the degradation problem of deeper network feature extraction. The segmentation accuracy has been significantly improved. However, the direct data fusion brings in a large number of redundant parameters, which increases the computational intensity and complexity. In addition, the attention module helps the network focus on key areas by imitating human attention mechanism. Guo et al. [32] and Zhang et al. [33] embedded the channel attention module into U-Net and residual U-Net respectively, which improved the segmentation performance of retinal vessels and brain tumors. This method only focuses on the local important feature mapping, which is easy to produce semantic gap. Without reducing the resolution of feature mapping, Ma et al. [34] used dilation convolution to increase the receptive field to obtain rich multi-scale information of remote sensing images and improve the feature representation ability of the U-Net.
In order to reduce the computational efficiency and the amount of parameters of the network, the lightweight network named MobileNet [27] introduced depthwise separable convolution instead of the traditional convolution to reduce the model size and computational cost. Due to the degradation of image and the limitation of computing resources, these works cannot achieve better segmentation performance for gangue image in top coal caving face. Therefore, in order to meet the demand of obtaining higher coal gangue segmentation accuracy under limited hardware resources, the HALNet is proposed for gangue intelligent segmentation on the conveyor of top-coal caving face.
Materials and methods
Materials
Data collection
The sample images were randomly captured at a resolution of 1280×720 pixels from a video taken by an explosion-proof cameras (IPG-85HE20PY-S) in 8105 working faces of the Zhuxianzhuang Coal Mine, Huaibei Mining Group. These included 200 training images and 25 verification images, and all gangues on the scraper in these randomly captured images are labeled. The data collection and the captured image are shown in Fig. 1. The images captured by the camera were transmitted to the computer through Gigabit Ethernet protocol for display and storage. In order to ensure the diversity of sample images, there are 9200 training images and 75 verification images are generated via data augmentation operations (the specific description can be seen in section 3.1.3), eventually.

Data collection and the captured image: (a) Data collection system; (b) The representative images captured randomly; (c) The ground truth of (b).
Due to the high dust concentration in the top coal caving face, the collected image has low contrast, high haze and serious noise. It is difficult to label and identify gangue without preprocessing. Here, the Retinex-based [35] image enhancement method is used to remove dust and enhance image contrast. A visual comparison of dusty image and enhanced image is shown in Fig. 2. It can be clearly seen that the enhanced images (Fig. 2b) provide richer, more detail information and have a better visual effect than the dusty image with a gray layer (Fig. 2a). Considering the speed of model training, the image size is reset to 512×512 pixels during training.

Example of image preprocessing. (a) Original image. (b) Enhanced image.
In order to imitate the strong recognition capabilities of human vision for gangue and teach the HALNet to distinguish the gangue on the scraper from the interferents, we mark the image as gangue or background through pixel level annotation tool. Due to the serious degradation of image quality and the time-consuming of labeling, the ground truth was not perfect, which is also in line with human visual perception. In the experiment, 225 pairs of original images and ground truth images were utilized to train and test the proposed HALNet.
It is time-consuming and laborious to manually label gangue images of the top coal caving face. In order to increase the diversity of data, reduce the over-fitting in model training and improve the generalization ability of the model, data augmentation is an optimization strategy. Therefore, we performed data enhancement operations on the training data. It includes basic geometric transformation (such as rotation, flip, movement and scale transformation) and scene migration [36]. Scene migration enhances the robustness of the algorithm in changeable environments and improved the generalization ability of the model by exchanging the low-frequency spectrum of training images and different scene images. Figure 3 shows the data augmentation results under scene migration.

Data augmentation under scene migration. (a) Original image. (b) Image of scene A. (c) Image of scene B. (d) Augmented image in scene A style. (e) Augmented image in scene B style
The proposed HALNet model is trained using captured images and the corresponding ground truth. Our network experiment is implemented in Pycharm software environment using Keras library and TensorFlow backend of Ubuntu 16.04. The Adam optimizer (learning rate = 0.001, exponential decay rates = 1e-6) is used to minimize the binary cross-entropy loss. The batch size of the training is set to 4 and the training epochs is 50. All experiments are performed on the hardware platform of Intel(R)Core(TM) i7-5960x CPU@3.00 GHz, 2TB memory, and the NVIDIA GeForce GTX1080(X2) GPU. Data augmentation is performed to increase the diversity of samples, contributing to improving network performance.
Proposed methods
Due to the degradation of data and the limitation of computing resources, the application of deep learning model in intelligent mining of coal mine is very difficult, especially in top coal caving face. Therefore, the HALNet was proposed to segment the gangue on the scraper in the top coal caving face and obtain the gangue content information indirectly. The encoder-decoder architecture of the HALNet is presented in Fig. 4. The deep convolution neural network with residual learning framework [37] can extract the deep features of the image and effectively prevent the gradient disappearance/explosion and accuracy degradation during network training. Therefore, in order to reduce the computational cost, the lightweight residual block composed of depthwise separable dilation convolution designed as bridging residual structure is used to replace the ordinary convolution in the original U-net network, so as to improve the learning ability of the network, as shown in Fig. 4(b).
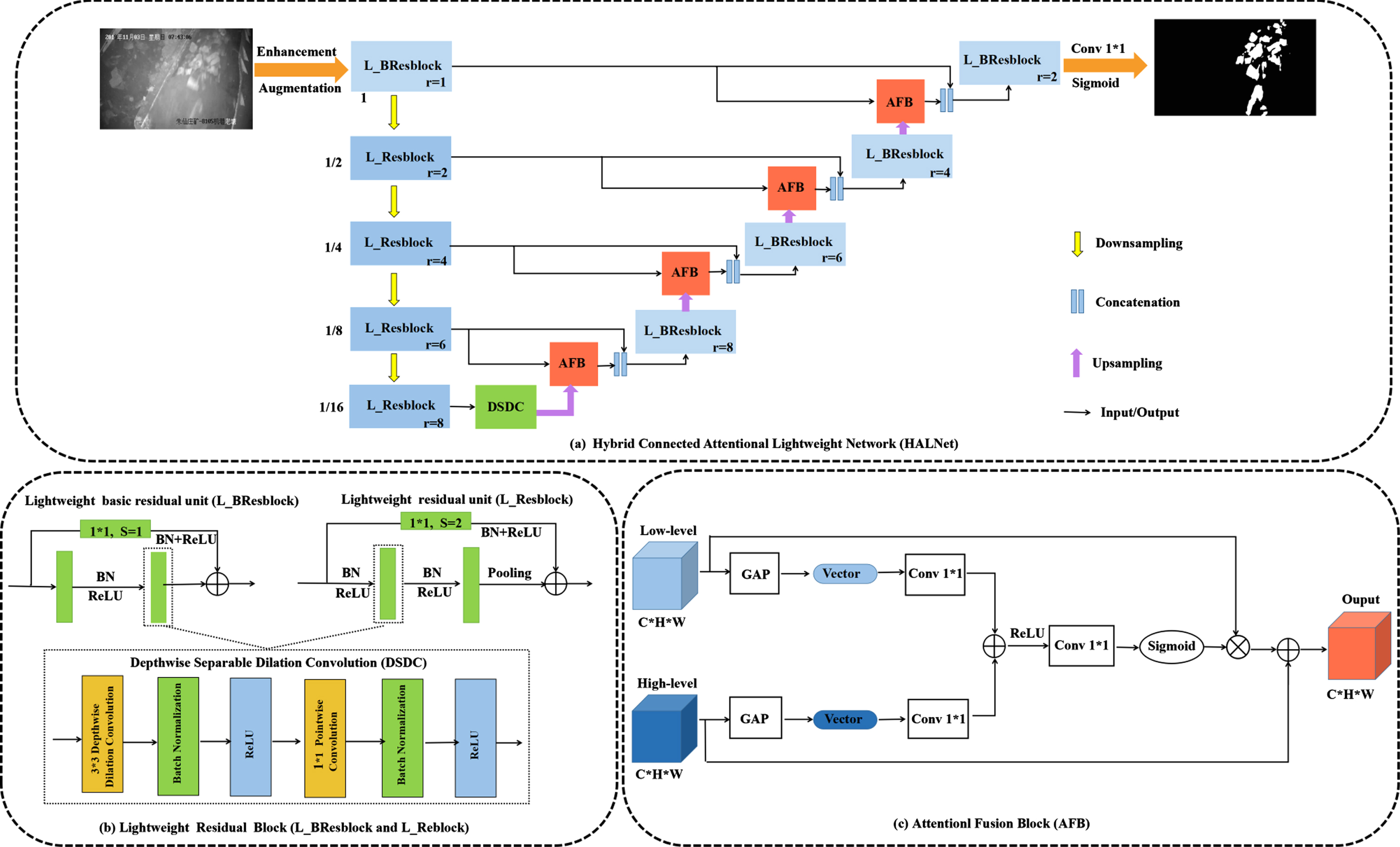
The architecture of proposed hybrid connected attentional lightweight network and its components. (a) Overall architecture. (b) Lightweight residual block (c) Attention fusion block.
The encoder mainly focuses on extracting the semantic features of gangue by gradually reducing the resolution of the image through the down sampling operation. Here, the convolution operation with step size of 2 and the maximum pool operation are combined to reduce the size of feature map, rather than one of them.
The depthwise separable dilation convolution module replaces the ordinary convolution to extract features intensively. Different dilation rates (r = 1, 2, 4, 6 and 8) are set in different convolution layers to expand the receptive field and effectively obtain context information of different scales, as shown in Fig. 4(a). The decoder mainly up-samples the feature image through bilinear interpolation and convolution, and gradually restores the resolution to the level of the original image. The lightweight attention block and the re-designed skip pathways are combined to replace the simple skip connection of the original U-net to obtain richer semantic and spatial information (Fig. 4(a) and (c)). It only needs little computational cost, which is helpful to the deployment of gangue segmentation algorithm. The lightweight residual block and attention fusion block will be introduced in detail next.
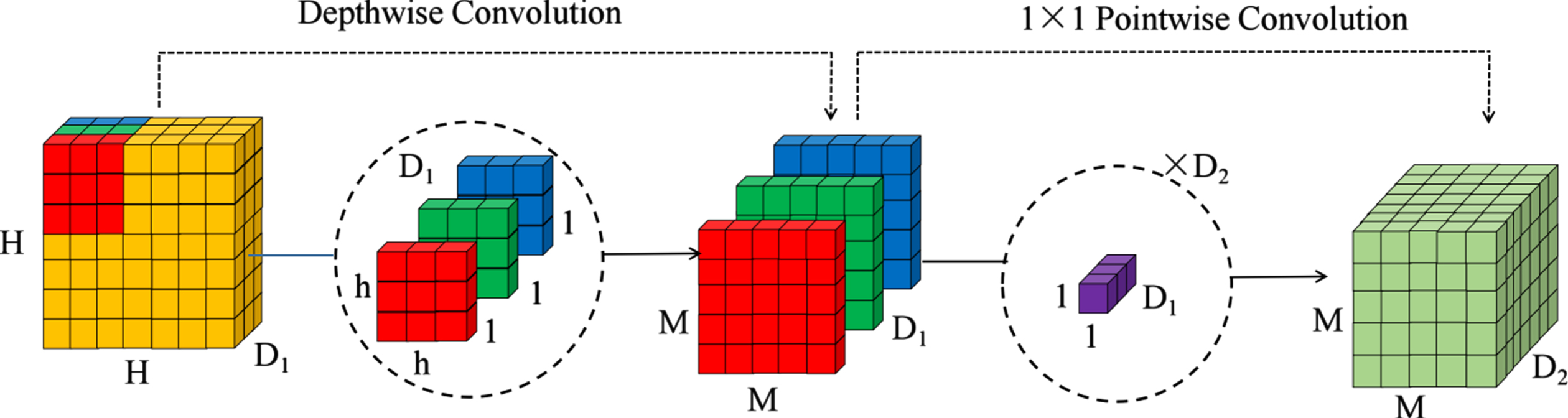
Depthwise separable convolution.
In depth learning, the depth network designed as residual connection structure can better learn abstract features and prevent the disappearance of gradient in the training process [24, 38]. Therefore, feature extraction through the combination of depthwise separable convolution and residual connection is a common method in lightweight networks [39, 40]. The encoder and decoder use the depthwise separable dilation convolution with different residual structure as the basic unit instead of the standard convolution in the proposed HALNet model, as shown in Fig. 4(b). In this structure, the gradient of the upper layer can quickly propagate back to the lower layer. In addition, the down sampling process uses the residual block of the combination of convolution operation with step size of 2 and maximum pool operation to fuse the feature data and extract the features more fully. The depthwise separable convolution decomposes the standard convolution into a depthwise convolution and a pointwise convolution [27], which greatly reduces the parameters and computation in the network, as shown in Fig. 5.
Assuming that the feature map of H × H × D1 is taken as the input, the convolution operation is carried out through the convolution kernel with the size of h × h to generate the feature map of M × M × D2, where D1 and D2 is the number of feature map channels. The number of parameters and computational cost of standard convolution are D1 · h · h · D2 and h · h · D1 · D2 · H · H, respectively. The number of parameters and computational cost of depthwise separable convolution are D1 · h · h + D1 · D2 and h · h · D1 · H · H + D1 · D2 · H · H, respectively. The ratio of the depthwise separable convolution and the standard convolution parameter is shown in Equation (1). When the convolution kernel size h = 3, the parameters and computation of deep separable convolution are reduced by about 9 times compared with standard convolution, which can greatly reduce the number of parameters and improve the operation efficiency.
In addition, the dilation convolution with different dilation rates (r = 1,2,4,6,8) is used instead of depthwise convolution to expand the receptive field, which can effectively fuse multi-scale information without increasing the amount of parameters, as shown in Fig. 4(a) and 4(b).
The decoder of the original U-net network fuses the low-level features with rich spatial information and the high-level features with rich semantic information through the up-sampling and skip connection structure. However, the low-level features of gangue image contain a lot of useless background information, which may interfere with the segmentation of target objects through simple fusion. In order to solve this problem, the AFB module is designed to emphasize the target location details in the low-level feature maps and capture the global context and semantic information in the high-level feature maps, so as to improve the representation of features, as shown in Fig. 4(c). AFB employs global average pooling (GAP) to capture global context and computes an attention vector to guide the feature learning, which helps to emphasize key features and filter background information [41], as described in Equation (2) for the feature map size of W × H × D.
Formally, the high-level features x
h
are firstly performed up-sampling and the features X
h
are generated. Then input low-level features x
l
and the features X
h
through the average-pooling generate G (X
h
) and G (x
l
), respectively. Then a convolutional layer followed by the sigmoid activation function on the concatenated feature descriptor is used to generate the attentive vector, as shown in Equation (3). The output feature map x
s
is generated by Equation (4).
Finally, the redesigned skip path fuses the output features x s with low-level features x l to reduce the semantic gap between the feature mapping of encoder and decoder sub networks. The proposed AFB module can suppress the interference of gangue image in non-scraper area and scraper components, highlight more gangue feature information, and is conducive to rapid gangue positioning in scraper area. In addition, the global average pool compresses the global information into a vector, which greatly reduces the computational cost, so the module dose not add too many parameters.
In order to evaluate the performance of our model, we compare the segmentation results with the corresponding ground truth and divide the results of each pixel comparison into true positive (TP), false positive (FP), true negative (TN) and false negative (FN). In gangue image segmentation, the proportion of target and background areas is seriously unbalanced. The Matthews correlation coefficient (MCC) is suitable for the performance measurement of binary classifications for two categories with different sizes [32]. Therefore, the Precision, Dice similarity coefficient (Dice), Matthews Correlation Coefficient (MCC), Accuracy (ACC), Parameters and Frames Per Second (FPS) are used to evaluate the performance of the model. In addition to the parameters, the larger the value of other evaluation indexes, the better the segmentation effect. In the experiment, the mean value of all test pictures was used as the evaluation index. The calculations are shown below.
The precision is described as:
Dice represents the similarity between the segmentation result and the ground truth, which is described as
MCC and ACC are defined as:
FPS represents the algorithm speed, which is defined as follows:
Ablation experiments
In order to prove that each component of the proposed HALNet can improve the performance of gangue segmentation, ablation experiments were performed to validate the effect of each component of HALNet. The same training environments for all models. Table 1 show the segmentation performance of Unet, D-Unet (i.e. Unet+depthwise separable convolution), DR-Unet (i.e. D-Unet+bridging residual structure) DRA-Unet (i.e. DR-Unet+AFB), DRAD-UNet (i.e. DRA-Unet+dilation convolution) and ours (i.e. DRAD-UNet+re-designed skip connections) from top to bottom, respectively.
Detailed performance comparison of each component in our proposed HALNet
Detailed performance comparison of each component in our proposed HALNet
The results show that, (1) although the segmentation accuracy of D-Unet is slightly lower than that of original Unet, the amount of parameters is far lower than that of Unet, which is helpful for timely segmentation on the platform with limited calculation in practical application. (2) DR-Unet has better performance compared with the D-Unet and Unet, although the parameter amount is increased (but still far lower than Unet), which indicates that adding the bridging residual structure can improve the network performance to a certain extent. (3) The DRA-Unet, DRAD-Unet and HALNet (ours) all achieve better segmentation performance than Unet for gangue segmentation, which proves the strategy of the introduction of attention mechanism and dilation convolution are effective. In particular, compared with the original Unet, our HALNet not only reduces the parameters by half, but also the Precision, Dice and MCC are significantly increased by 0.1323, 0.0528 and 0.054, respectively. Therefore, HALNet is a lightweight and effective network for the gangue segmentation task on the scraper in the top coal caving face.
Finally, we compare the performance of HALNet with other state-of-the-art methods currently applied in gangue segmentation task and related frameworks (i.e., Unet [22], Res-Unet [31], ARes-Unet [33] and SA-Unet [32] on our test dataset. The comparison of gangue segmentation results is shown in Fig. 6. As can be seen in every green/red rectangle in Fig. 6, our method makes the segmentation results closer to the ground truth without too many over segmented and under segmented regions, which confirms the advantages of our method in degraded image segmentation. Although the result of Unet segmentation seems to be more comprehensive than other methods, this large-area excessive segmentation seriously interferes with the judgment of the actual gangue content, especially when the low content of coal gangue mixture leads to the exposure of scraper components similar to the gray scale of gangue, such as the second column and third column in Fig. 6. Due to the integration of more semantic information in the global context, the attention of important features and the suppression of unimportant features, the over segmentation phenomenon of Res-Unet, ARes-Unet and SA-Unet is significantly improved compared with that of Unet, but it still exists, and even a large-area undersegmentation phenomenon appears, such as column 4 and column 5 in Fig. 6.
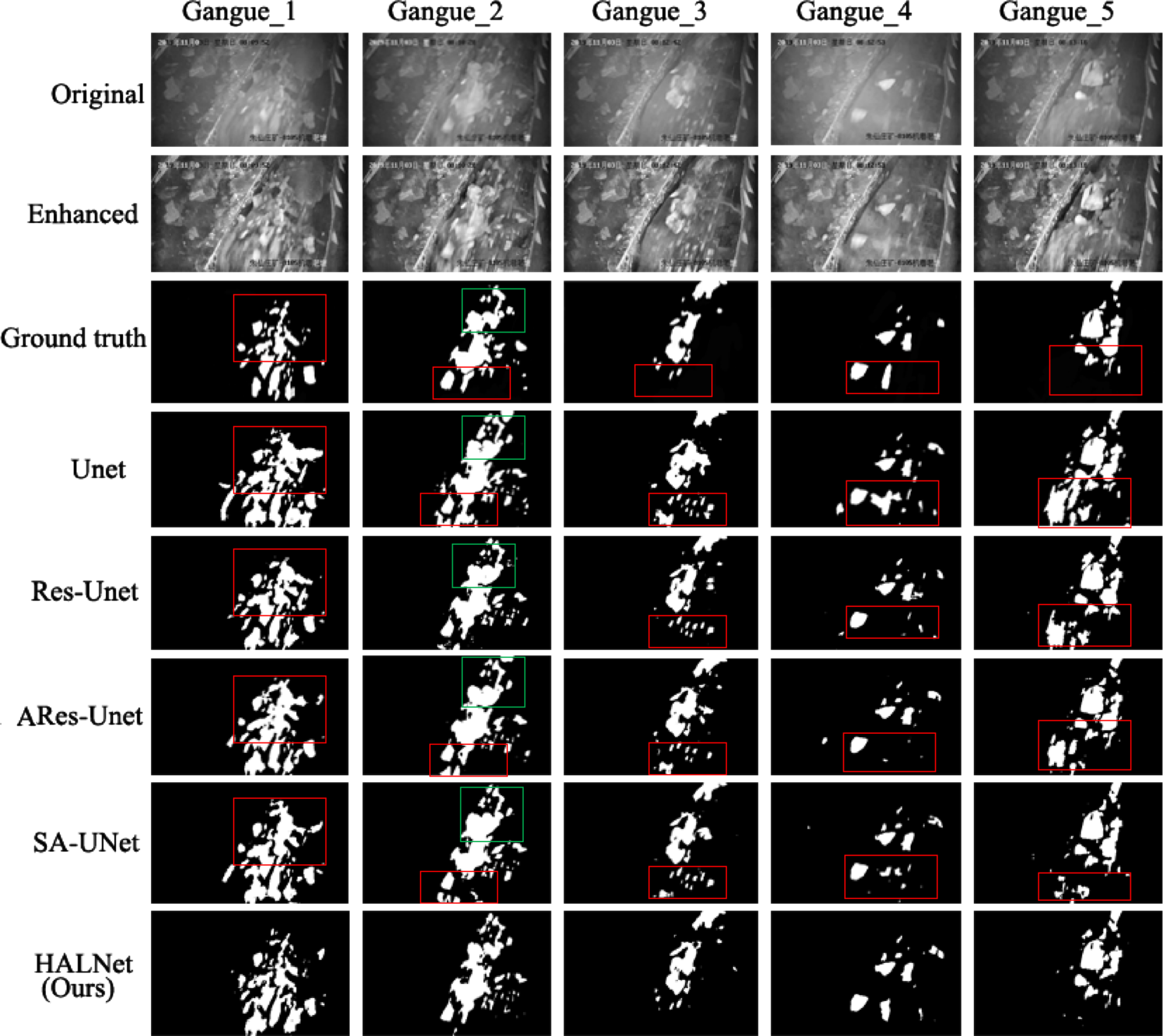
Image segmentation results of different methods.
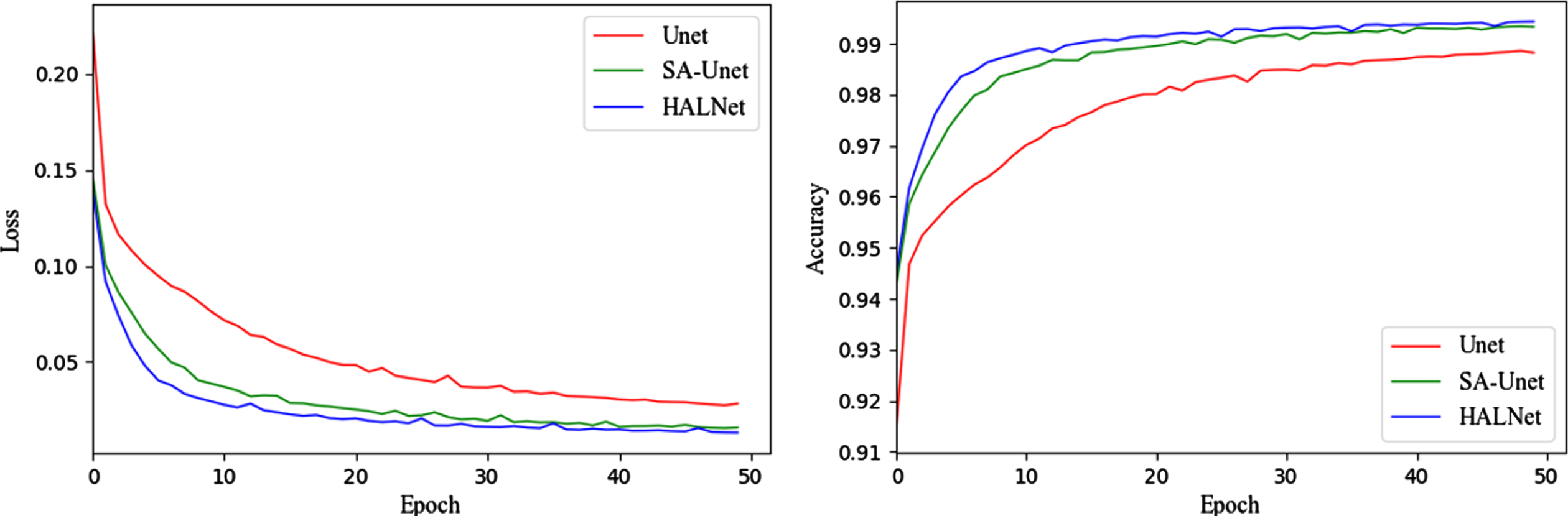
The loss (left) and accuracy (right) curves of different methods during training.
By contrast, our proposed HALNet almost yielded very comparative and even better results than these competitive methods. Although the results also have a small proportion of under segmentation and over segmentation (compared with the ground truth in Fig. 6), it has little impact on the estimation of the proportion of gangue content. This is also in line with the global estimation characteristics of human vision. In addition, we summarize the performance of different methods through six quantitative evaluation indexes in Table 2.
Performance comparison of our method against other state-of-the-art methods
From the results in the table, it can be concluded that HALNet has achieved the best performance. It achieves the highest Precision of 0.8684, the highest Dice of 0.8415, the highest MCC of 0.8291, and the highest ACC of 0.9726. Most notably, the number of parameters is only about 2/5 of Unet and 1/5 of Res-Unet, which greatly improves the operation efficiency and reaches 11FPS. The running speed of scraper in 8105 working faces of the Zhuxianzhuang Coal Mine is 1.6 m/s, and the capture range of the camera is about 1 m. Therefore, there is no need to process each frame image, and the inter frame processing can meet the requirements. Since Res-Unet and ARes-Unet are not satisfied, they are omitted in the following analysis.
To further observe the performance of the proposed HALNet, we compare the training accuracy and training loss curve of our method with other methods, which is shown in Fig. 7. Comparatively speaking, our proposed HALNet almost has achieved the highest accuracy values and the lowest loss values than other methods, and the convergence rate of HALNet is the fastest.
Based on the above analysis, it indicates that our proposed method achieves better gangue segmentation performance in the complex environment of top coal caving face, and meets the real-time segmentation effect under special needs.
In this paper, we propose a hybrid connected attentional lightweight network named HALNet for the intelligent segmentation of gangue in top coal caving face. Gangue image dataset is a typical small sample dataset. Coupled with the serious image degradation in harsh environment, it is difficult to obtain a large number of annotated training samples. Firstly, a set of comprehensive data augmentation is applied to increase the diversity of training samples to prevent over-fitting during training. Then a novel lightweight network structure is proposed and it is trained to segment gangue on the scraper conveyor in the complex environment of top coal caving face. Besides, the trained network is able to real-time segment gangue under special needs with an accuracy of 0.97 while takes very low computational costs and the content information of coal gangue is obtained through the calculation of gangue proportion. Finally, the experiment proves that our strategy of redesigning skip pathways and the introduction of DSDC, bridging residual learning framework and AFB are effective. Compared with other state-of-the-art methods for gangue segmentation, our lightweight HALNet achieves state-of-the-art performance, especially for segmentation of images with extremely similar gray levels between the components exposed by the scraper and the gangue when the content of coal gangue mixture is low. So the proposed algorithm has great potential to realize the gangue intelligent segmentation of top coal caving face in complex environment while takes little computational costs. However, the dataset in this study is mainly based on a series of image data collected from the underground top coal caving face. The training model in this study may not be able to directly obtain similar segmentation results for the test images collected in different scenes. However, the proposed segmentation model can obtain more satisfactory segmentation results by training more different scene data sets, which is also the future work of this research.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant No. U1704242). The authors thank the Coal Industry Engineering Research Center of Top-coal Caving Mining for its help. The authors declare no conflicts of interest.