
Abstract
Language translation is essential to bring the world closer and plays a significant part in building a community among people of different linguistic backgrounds. Machine translation dramatically helps in removing the language barrier and allows easier communication among linguistically diverse communities. Due to the unavailability of resources, major languages of the world are accounted as low-resource languages. This leads to a challenging task of automating translation among various such languages to benefit indigenous speakers. This article investigates neural machine translation for the English–Assamese resource-poor language pair by tackling insufficient data and out-of-vocabulary problems. We have also proposed an approach of data augmentation-based NMT, which exploits synthetic parallel data and shows significantly improved translation accuracy for English-to-Assamese and Assamese-to-English translation and obtained state-of-the-art results.
Introduction
A natural language can be categorized into high-resource, medium-resource, and low-resource language based on the availability of resource. The resource includes works of several native speakers, online data resources, and computational data resources. The low-resource language category fits on a language that has few online resources [1, 2] or computational data [3]. However, a low-resource language scenario can be considered in terms of minimal data required for training the machine translation (MT) model [4]. The exact definition of low-resource language pair is a research question itself. The languages that contain highly inflected words further complicate to define the term “low-resource” due to the presence of sparsity problems with different styles of inflected words. This demands more bitext data to achieve equivalent results against the languages with less inflected words [5]. Defining low-resource in the context of parallel sentence pairs is itself a topic of computational analysis. Conventionally, if the train data contains less than 1 million parallel data, then the language pairs can be considered low-resource [6]. Most of the world languages fall under the category of low-resource, based on the availability of resources. The English-Assamese (En-As) pair can be categorized under low-resource based on the availability of insufficient resources. The Assamese language is the official language of the Indian state of Assam. The native speakers of the Assamese language, also known as Assamese or Axomiya people, are about 1,301,0478 1 speakers [7]. It falls under the Indo-Aryan language family, and its script originated from the Gupta script [8]. The script and word order of English and Assamese languages are very different from each other. The word order of Assamese is subject-object-verb (SOV) whereas English follows subject-verb-object (SVO) as shown in Fig. 1. Unlike English, Assamese is a morphologically rich language [9].
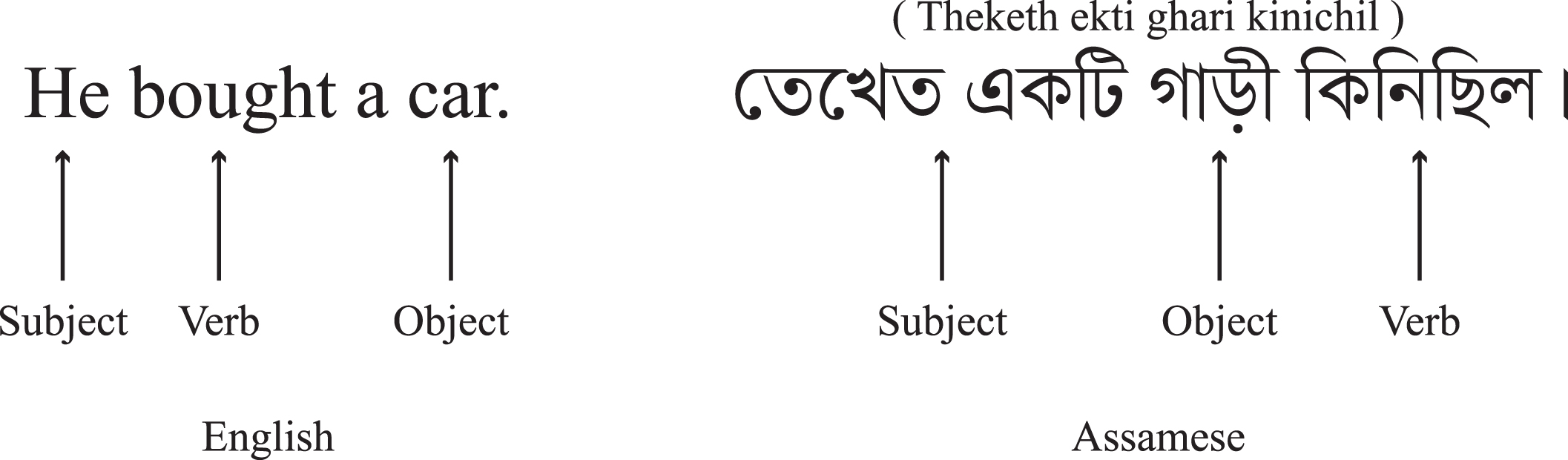
Word order example of Assamese with English translation and transliteration.
We have chosen English with Assamese because English is a high resource and a widely accepted language worldwide. To establish good communication at an international and national level, it is very much essential for the automatic translation of English-Assamese pair. Although Google covers automatic translation of 109 languages
2
worldwide, Assamese language is yet to be introduced. Due to the limitation of the suitable dataset, the English-Assamese MT system is in the outset stage [7, 11]. Therefore, there are research scopes in the English-Assamese MT system. In this work, we investigate: How can effectively improve the neural machine translation (NMT) model in both directions of translations for the low-resource English-Assamese pair? The contributions of this article are as follows: Proposed an approach based on data augmentation and handled problems like insufficient data and out-of-vocabulary to enhance the performance of NMT for low-resource En-As pair. Explored different NMT models and obtained state-of-the-art MT performance for both En-to-As and As-to-En directions.
The rest of the paper is organized as follows: Section 2 briefly discuss the background of machine translation and related work. The dataset description and baseline system are presented in Section 3. Section 4 and 5 describe about tackling the issues of insufficient data and out-of-vocabulary. Section 6 and 7 present the proposed approach and experimental setup. The result and analysis are presented in Section 8. Lastly, Section 9 concludes the paper with future work.
In this section, we briefly discuss the fundamental concept of MT models and review the existing works related to our work.
Machine translation
MT covers language ungraspable issues via automatic translation among natural languages. In MT, there are two broad categories of approaches: the rule-based or knowledge-based approach, which depends on a set of rules, and the corpus-based approach that depends on data, also known as the data-driven approach. MT system switched from a rule-based to a corpus-based approach, which eliminated the need for linguistic experts or language otherness in the case of interlingual MT [12]. Statistical machine translation (SMT) and NMT approaches are two popular categories of corpus-based MT system. The SMT has a variety of techniques that include word-based, syntax-based, phrase-based, and hierarchical phrase-based. Before NMT, phrase-based SMT is the state-of-the-art technique in MT [13]. In this work, we have used phrase-based SMT to extract phrase pairs and that will be used to expand the parallel train corpus. The disadvantages of SMT are the long term dependency problem, inefficient context analysing ability and system complexity that shifts the attention towards NMT [14]. For the feed-forward neural network-based NMT system, the phrase pairs score is calculated by assuming the fixed length of the phrases. However, in real-time scenarios, the source and target phrase length of the translation are not fixed. To deal with variable-length phrases, a recurrent neural network (RNN) based NMT system is introduced [15, 16], where sequence learning is achievable through an end-to-end approach. To learn long-term features, RNN adopts long short term memory (LSTM) for encoding and decoding. However, the encoder fails to encode all the necessary information when the sentence is too long. To mitigate this issue, an attention mechanism is proposed [17]. The attention mechanism permits the decoder to focus on various segments of the source sequences at various decoding steps. In [18], the attention mechanism is improved through a combination of global steps by associating all the source words and local-only focus on the part of the source words. The encoder takes s1, s2 … s
n
has input sequence and converts it into a vector X. The decoder generates the output t1, t2 … t
m
via calculation of condition probability, as shown in Eq. (1).
Where the parameter matrices
The NMT based MT approaches achieve state-of-the-art methods in both high and low-resource pair translations because of its ability to handle long-term dependency problems and contextual analysis [23–26]. Nevertheless, it requires sufficient parallel corpus for training, which is a challenging issue in a low-resource scenario. In this work, RNN and transformer based NMT models are used for En-As pair translation.
The common challenges in low-resource NMT include insufficient data, out-of-vocabulary, and rare-word problems [27, 28]. In respect of MT work on En-As, very limited MT works have been performed on En-As pair [7, 11]. In [7, 10], SMT based system is developed with a very limited dataset. However [11], proposed a corpus and implemented two baseline systems using phrase-based SMT and RNN based NMT. In this work, we have utilized the En-As corpus of [11] and attempt to improve the NMT by tackling insufficient data and out-of-vocabulary problems in both En-to-As and As-to-En directions.
Dataset description and baseline system
The English-Assamese corpus, EnAsCorp1.0 3 is developed in [11], and the same has been used in this work. It comprises both parallel and monolingual data. In EnAsCorp1.0, different possible online sources were explored to prepare parallel data that included Bible, multilingual online dictionary (Glosbe, Xobdo), SEBA multilingual question paper, PMIndia, and Learn-Assamese website. Also, monolingual Assamese data was prepared by collecting data from the various webpages, blogs, Holy books (Bible, Gita, Quran), and Assamese data from the parallel corpus were added to increase the size of monolingual data. The data statistics are presented in Table 1. Moreover, they utilized English monolingual data of about 3 million sentences from WMT16 to develop baseline systems for both En-to-As and As-to-En translations [11]. For English–Assamese baseline systems [11], two models were implemented, phrase-based SMT (baseline-1) and RNN-based NMT (baseline-2) and results of bilingual evaluation under study (BLEU) [29] scores are shown in Table 2. In this work, we have attempted to improve the translational performance of the existing work [11]. For comparative analysis, we have collected the predicted output of [11] and evaluated with other evaluation metrics, namely, translation error rate (TER) [30], rank-based intuitive bilingual evaluation score (RIBES) [31], metric for evaluation of translation with explicit ordering (METEOR) [32], and F-measure scores, as shown in Tables 3, 4.
Data statistics of EnAsCorp1.0
Data statistics of EnAsCorp1.0
BLEU scores of baseline systems [11]
TER and RIBES scores of baseline systems
METEOR and F-measure scores of baseline systems
Without modifying the NMT model architecture, we have tackled insufficient data issue in two-ways: injecting phrase-pairs and utilizing synthetic parallel data.
Train data statistics after phrase pairs injection
Train data statistics after phrase pairs injection
Table 5 shows four types of train data that we investigate using different NMT models to examine the performance, which are reported in Section 8. “original parallel corpus”: Only original parallel train data is considered in the NMT training models. “original parallel corpus”+ Setp≥0.5: The original parallel train data along with phrase pairs having translation probability p ≥ 0.5 are considered in the NMT training models. “original parallel corpus”+Setp=1: The original parallel train data along with phrase pairs having translation probability p = 1 are considered in the NMT training models. “original parallel corpus”+Set
all
: The original parallel train data along with all phrase pairs are considered in the NMT training models.
[33] combine the extracted phrase-pairs with the original parallel train data. They maintain a fair ratio using Eq. (9) to tackle the trained models from biased towards sequence length.
However, by the inclusion of identical source-target sentences, corpus quality degrades. It can lower the performance of NMT [36, 37]. In this work, we have augmented phrase pairs with the original train data without considering a ratio unlike [33]. To examine the performance of NMT models with phrase pairs and whether the trained NMT models are biased towards sequence length or not, we have performed a comparison in Section 8.
The Out-of-Vocabulary (OOV) problem arises due to the named-entities, compounds, technical terms and misspelled words [40]. There are two types OOV: Completely Out-of-Vocabulary (COOV) and Sense Out-of-Vocabulary (SOOV). If the words are absent in the training data then it is called as COOV, whereas SOOV represents those words which are present in the training data with different sense or usage from the test data words. NMT produces <unk> (unknown) tokens against OOV words. Moreover, NMT shows weakness in case of rare word translation since fixed-size vocabulary, which forces producing <unk> [16, 41]. Have pointed out that the sentences having rare words produces poor translation than sentences having frequents words. We have tackled the OOV issue for the English–Assamese pair by augmenting parallel nouns in the train data and using Algorithm-1 in the translation process. We have compared Algorithm-1 with the existing technique of word segmentation, byte pair encoding (BPE) [42], reported in Section 8. BPE is used to handle the OOV issue. For BPE, we have used 32k merge operations. Algorithm-1 consists of two main components: bilingual dictionary and transliteration module.
Proposed approach
Our proposed approach utilizes phrase pairs as discussed in Section 4 to augment with “original parallel corpus.” The experiments are carried out in three different phases. Initially, for the first phase, we have trained different NMT models with only “original parallel corpus + phrase pairs” to select the best type of phrase pairs (as given in Table 5) and best-trained model, as reported in Section 8. It is observed that the transformer model achieves the best translational performance from As-to-En and higher than the reverse direction of translation, i.e., En-to-As translation. Then, parallel noun phrases (as discussed in Section 5) are augmented with “original parallel corpus + phrase pairs.” and trained the NMT model (transformer) to obtain the better model, as reported in Section 8. Therefore, we have chosen the best trained NMT model (transformer) of As-to-En to generate synthetic En sentences using the monolingual sentence of As in the second phase. For simplicity, we have considered maximum sentences (Assamese) with a length of 20 words only during the generation of synthetic English sentences. Moreover, Algorithm-1 is applied during the translation process to tackle the OOV problems. We have removed blank lines, single word sentences from the synthetic En as well as corresponding As sentences. Then, in the third phase, we have trained the NMT model (transformer) on the augmented dataset of original and pseudo parallel data. However, due to the presence of noise in the synthetic data, the translational model performance with augmented data is lower than the “original parallel corpus + phrase pairs + noun phrases.” Therefore, to leverage synthetic parallel data in the training model, we have pre-trained the model with synthetic data and “original parallel corpus + phrase pairs + noun phrases” and then fine-tune it using only the “original parallel corpus + phrase pairs + noun phrases” following the technique of [39]. Hence, the final model initializes the parameters from the pre-trained model that enhances the training performance when the “original parallel corpus + phrase pairs + noun phrases” was used. Lastly, OOV problems are handled using Algorithm-1 during the translation process. Moreover, by utilizing monolingual data with Glove [44], we have leveraged the pre-trained word vectors in NMT models. The proposed approach is as illustrated in Fig. 2. The Algorithm-2 depicts step by step working of the proposed approach. In Section 8, we have reported results and analysis by considering various data combinations, and it shows our system yields better translational performance than the baseline system in En-As low-resource language pair translation.
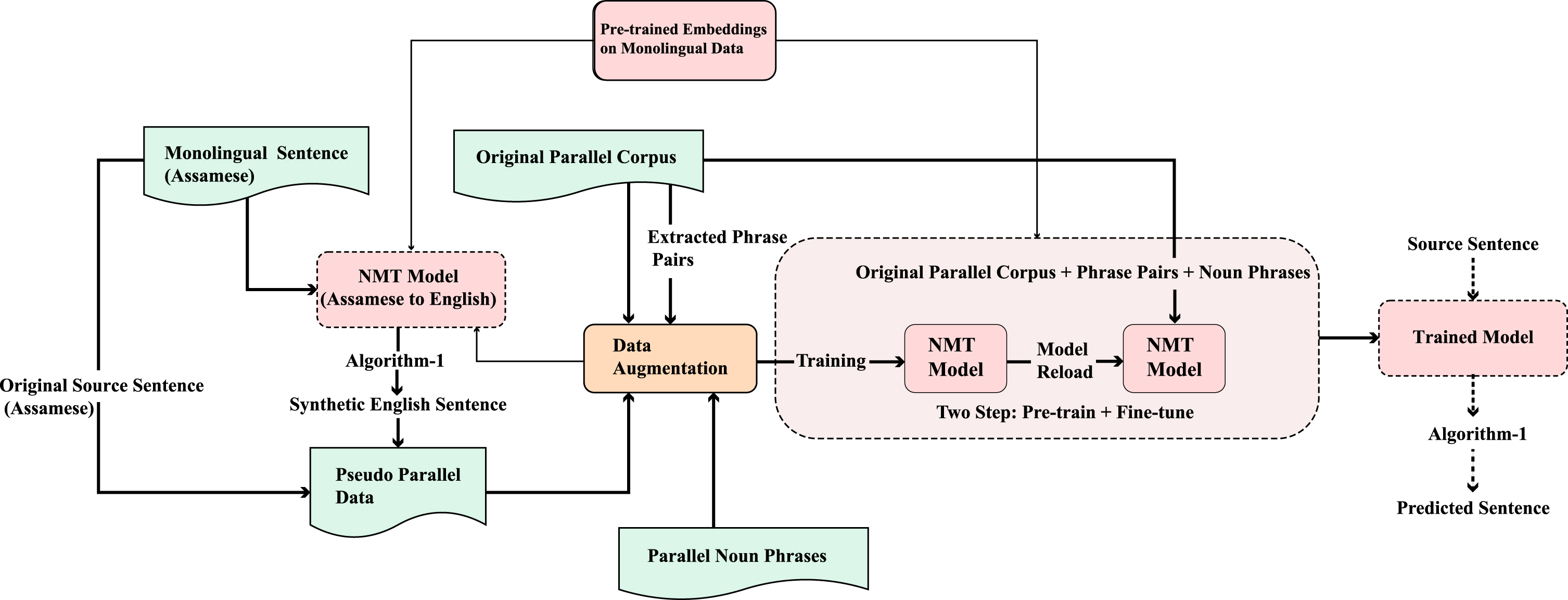
Proposed approach for leveraging synthetic parallel data to train the NMT Model (transformer) and fine-tuned on the “original parallel corpus + phrase pairs + noun phrases.”
We have employed NMT systems with different models, namely, RNN, BRNN, and Transformer models. The models are implemented using the OpenNMT-py 7 toolkit, which is freely available. There are four primary steps in our experiments: unsupervised pretraining, preprocessing, supervised training, and testing. The experiments are carried out separately for En-to-As and As-to-En translation. We have used unsupervised pre-trained word vectors of monolingual data using Glove 8 . The pretraining is performed up to 100 iterations with embedding vector size 200. The primary need for the preprocessing step is the tokenization of the source and target sequences that creates the word vocabularies. It also generates indices sequences while performing indexing on each word in the vocabulary during the training process. The vocabulary dimension of the source-target sentences are taken as 50,000. In the training process, we have used a 2-layer network of LSTM units that contains 512 nodes in each layer for RNN and BRNN. We have used a drop-out value of 0.3 in RNN and BRNN. In case of the transformer model, default 6 layers and 0.1 drop-out are used. Also, Adam optimizer with a default learning rate of 0.001 is used. The models are trained on a single NVIDIA Quadro P2000 GPU up to 200,000 epochs. In the testing step, predicted sentences are generated by utilizing the optimum trained model obtained from the training process on test data. We have used beam search technique with default size 5 to find out the best translations.
Result and analysis
We have used automatic evaluation metrics to evaluate the quantitative results of predicted translations. The automatic evaluation metrics such as BLEU, TER, RIBES, METEOR, and F-measure scores. Tables 6 and 7, present the BLEU score results of various NMT models by considering phrase pairs injection of data types, as shown in Table 5. From the Tables 6 and 7, it is noticed that the transformer model (T2:“original parallel corpus”+Setp≥0.5) with Algorithm-1 outperforms in both En-to-As and As-to-En directions of translation, as bold mark in Tables 6 and 7. Therefore, we have considered only the transformer model(T2:“original parallel corpus”+Setp≥0.5) in Table 8. It is observed that the transformer model without considering the ratio (N), provides better than the transformer model with ratio (N). It is because addition of identical source-target sentences by the consideration of the ratio (N), degrades translational performance. Also, the trained models are not biased towards short sentences since the ratio of number of extracted phrase pairs to the original parallel train sentences already maintain a fair ratio 1:2 in case of, T2:“original parallel corpus”+Setp≥0.5 (1(“original parallel corpus”):2(Setp≥0.5)) as shown in Table 5. We perform a comparison between BPE and Algorithm-1 in Tables 6, 7. The BPE faces issues in disambiguating the words of Assamese. Because it is a morphologically rich language containing various affixes, it is the reason for lower translational performance than word-based Algorithm-1. Furthermore, we have investigated the transformer model performance with parallel noun phrases and the results are reported in Table 9. The trained model of As-to-En translation is used to generate synthetic parallel data. In Table 10 and 11, 1-to-1 ratio (“original parallel corpus”: synthetic parallel) with and without phrase pairs + noun phrases are considered. Here, first pre-train on the augmented data and then fine-tune on the “original parallel corpus + phrase pairs + noun phrases.” It is observed that the transformer model achieves higher BLEU score for As-to-En translation on 1:4 + phrase pairs + noun phrases, as bold marked in Table 10. For En-to-As translation, the transformer model achieves higher BLEU score on 1:5 + phrase pairs + noun phrases, as bold mark in Table 11. Table 12, 13 and 14 present comparison of our system with baseline NMT system (as discussed in Section 3) in terms of BLEU, TER, RIBES, METEOR and F-measure scores. Here, our system consider, 1:4 + phrase pairs + noun phrases for As-to-En and 1:5 + phrase pairs + noun phrases for En-to-As translation. Higher the score value in case BLEU, RIBES, METEOR, and F-measure except for TER indicates better translation accuracy. From Table 12, 13, 14, 2, 3 and 4, it is observed that our system outperforms baseline NMT and phrase-based SMT systems. By handling the OOV problem using Algorithm-1 and data augmentation in train data, reason about better translation performance in our system compared to the baseline systems.
BLEU scores of En-to-As NMT models on four types of data, as given in Table 5
BLEU scores of En-to-As NMT models on four types of data, as given in Table 5
BLEU scores of As-to-En NMT models on four types of data, as given in Table 5
BLEU scores of transformer model (T2:“original parallel corpus”+Setp≥0.5) with Algorithm-1 on three groups of test data. EA:En-to-As and AE:As-to-En. Here, N denotes the ratio of number of extracted phrase pairs to the original parallel train sentences
BLEU scores of transformer model with and without noun phrases (T2: “original parallel corpus” + Setp≥0.5)
BLEU scores of different proportion using As-to-En NMT (Transformer) (PP: phrase pairs, NP: noun phrases)
BLEU scores of different proportion using En-to-As NMT (Transformer) (PP: phrase pairs, NP: noun phrases)
BLEU scores comparison of our system with baseline
TER and RIBES scores comparison of our system with baseline
METEOR and F-measure scores comparison of our system with baseline
This paper explores different NMT models explicitly for the En-As low-resource pair in both directions of translation. We have tackled the insufficient data and OOV issues for such low-resource pair translation. This investigation proposes an augmentation-based NMT approach by incorporating phrase pairs, leveraging large-scale synthetic parallel data, and handling the OOV problem to improve translational performance compared to the baseline system. In the future, we will increase the corpora size and investigate the multilingual-based transfer learning approach to tackle the insufficient data problem for further research.