
Abstract
The rise of decision processes in various sectors has led to the adoption of decision support systems (DSSs) to support human decision-makers but the lack of transparency and interpretability of these systems has led to concerns about their reliability, accountability and fairness. Explainable Decision Support Systems (XDSS) have emerged as a promising solution to address these issues by providing explanatory meaning and interpretation to users about their decisions. These XDSSs play an important role in increasing transparency and confidence in automated decision-making. However, the increasing complexity of data processing and decision models presents computational challenges that need to be investigated. This review, therefore, focuses on exploring the computational complexity challenges associated with implementing explainable AI models in decision support systems. The motivations behind explainable AI were discussed, explanation methods and their computational complexities were analyzed, and trade-offs between complexity and interpretability were highlighted. This review provides insights into the current state-of-the-art computational complexity within explainable decision support systems and future research directions.
Keywords
Introduction
The need to support automated decision-making processes in industries such as law, healthcare, finance, transport and others has led to the adoption of Decision Support Systems (DSS) to support human decision-makers [1]. DSS is often used in situations where complex problems need to be solved and traditional analytical methods may be inadequate [2]. DSS utilizes data, analytical models, and user inputs to help decision-makers evaluate and choose among alternative courses of action. The main goal of a DSS is to provide support to the decision-making process by providing timely, accurate, and relevant information to decision-makers.
The use of DSS in critical domains has raised concerns about trust, accountability and reliability and potential biases [3]. These systems rely on Artificial Intelligence (AI) and machine learning (ML) algorithms for the decision-making process. Therefore, inheriting their black-box nature and inherent challenges. Explainable Decision Support System (XDSS) has emerged as a promising solution to address these concerns by providing a logical and transparent explanation for those decisions [4]. XDSS is powered by Explainable Artificial Intelligence (XAI).
Explainable Decision Support Systems (XDSS) represent an innovative stride in the field of artificial intelligence and decision science, envisaged to bridge the gap between complex computational decision-making and human interpretability. These systems are designed to provide not only robust decision support but also a coherent explanation of their decision-making processes, catering to the increasing demand for transparency and accountability in automated decision systems [5].
Due to the continued growing importance of transparent and interpretable decision-making processes, explainable decision-support systems have received more attention in recent years [6]. XDSS provides insight into the decision-making process by describing the logic behind complex decision-making models or algorithms. When insights are provided, users understanding and confidence in the decision-making process increases and this also helps in facilitating compliance with legal and ethical requirements [7]. The introduction of explainability into decision support systems, although important, introduces the challenge of computational complexity.
Computational complexity, a concept rooted in theoretical computer science, refers to the quantification of the computational resources required to solve a given problem or execute a given algorithm [8]. In the context of XDSS, it encompasses the resources required not only to generate decisions but also to explain them in a humanly understandable manner. This added complexity could potentially impede the real-time performance and scalability of XDSS, which are crucial in many time-sensitive and data-intensive applications [9]. In addition, the need to minimize computational complexity should not compromise the quality of explanations provided, which is a critical balance to strike.
Furthermore, the increasing complexity of data processing in decision models introduces significant computational complexity to XDSS. As the scope and size of datasets increase, so does the complexity of the decision models used and the computational requirements for processing and interpretation. In order to successfully implement and use XDSS, there is a need to address the computational challenges, since the extent of computational requirements can limit system performance, hinder real-time decision-making and lead to high computational costs [10].
This review provides the following contributions: Provide an overview to a better understanding of the computational aspects of XDSS. Highlight the role and challenges of computational complexity in explainable decision support systems. Provide actionable insights for different stakeholders to tackle challenges and optimize system performance.
The remainder of the paper is organized as follows: Section 2 presents an overview of XDSS with respect to DSS, the importance of explanations and their challenges. Section 3 presents computational complexity issues within XAI. In Section 4, the challenges pertinent to Computational Complexity in XDSS is presented. Section 5 discusses the explanation methods employed in DSS, and Section 6 provides some of the strategies for optimizing computational complexity in XDSS. Section 7 discusses some case studies and real-world applications of explainable decision support systems and Section 8 presents the gaps and future directions. Section 9 concludes the review.
DSS is designed to aid informed decision-making by providing relevant information and analysis [11]. Traditionally, DSS would rely on rule-based systems or statistical models to generate recommendations based on the input data. However, with the growing integration of AI and ML techniques in decision-making processes, the need for explainability has become increasingly important [12]. This section presents an overview of DSS, discusses the significance of explainability in the context of DSS, and highlights the challenges associated with building explainable decision support systems.
Overview of decision support system
Data analysis, modeling, and visualization are used in facilitating decision-making processes in DSS. These systems enable understanding complex problems by checking for alternatives and evaluating outcomes [2]. Traditionally, the basic types of DSS include but are not limited to manual, data, knowledge, document, communication, knowledge, intelligent and hybrid DSS.
In recent times, AI and ML technologies have transformed DSS, incorporating advanced data processing, recognition of patterns, and predictive modeling. These modern DSS leverages AI models, like ensemble methods and deep neural networks to provide accurate and context-aware recommendations. The AI-based DSS can provide better performance, but they operate as black-box models, making it challenging for users to comprehend the reasoning behind their decisions.
Importance of explainability in decision support systems
Due to the concern raised on the lack of transparency and interpretability in AI models especially in critical domains like autonomous vehicles, finance and healthcare [13]. In these domains, decision-making processes may have significant real-world consequences and understanding the reasons behind AI-based recommendations is important.
Explainable Decision Support Systems are meant to address this challenge by providing human-interpretable explanations for the decisions made by AI models [14]. Explainability is vital for so many factors: fosters accountability, enhances user trust and enables users to validate the model’s predictions. In the case of complex decision-making scenarios, the understanding of the underlying factors contributing to a recommendation is crucial, as it allows users to identify potential biases, uncover hidden patterns, and make informed decisions.
Challenges in explainable decision support systems
The development of XDSS is presented with some challenges. One basic issue is in finding a balance between model complexity and interpretability. It is difficult to obtain comprehensible explanations due to the complexity of AI models [15, 16]. Explanation methods need to be carefully designed to provide meaningful insights with high accuracy.
Another issue is in evaluating the quality and effectiveness of explanations [17, 18]. Explanation evaluation metrics are not as well-established as traditional performance metrics used for model evaluation. It is important that the provided explanations are robust representations of the model’s decision process and relevant to the context of use.
The scalability of explanation methods is another challenge [19]. This scalability issue emanates from computational overheads present in some explanation techniques, causing them to be impractical for real-time decision support systems or large-scale datasets. For adoption of these systems in real world scenario to happen, the design of computationally efficient methods that deliver high-quality explanations is essential.
Then the issue of proprietary model architectures where organizations or companies may not disclose the complete workings of their proprietary AI models [20]. Therefore, limiting the transparency of explanations. Though, addressing the trade-off between explanation transparency and proprietary model architectures is an ongoing challenge.
The stated issues can be overcomed by interdisciplinary collaborations and research involving DSS experts, AI researchers, ethicists, and domain specialists are required. These collaborations can achieve better accountability, transparency, and trustworthiness in AI-based decision-making processes.
Computational complexity in XAI
XAI aims to provide comprehensible explanations for the decisions made by AI models. However, achieving explainability without compromising the performance of AI models is a challenging task. This is because XAI techniques would operate on complex ML models with several parameters and intricate structures, such as deep neural networks. Hence providing explanations of the inner workings of these models requires additional computations, as the explanations need to analyze and interpret the complex relationships and patterns learned by the model. This section highlights the concept of computational complexity in the context of XAI, emphasizing its significance, and exploring the trade-offs between complexity and interpretability.
Computational complexity and AI models
Computational complexity fundamentally denotes the amount of computational resources, such as time and space, required to execute an algorithm or solve a problem [8], thereby the efficiency of algorithms and models in terms of the resources required for their execution. In the context of AI, computational complexity plays a vital role in determining the time and resources needed for training, inference, and generating explanations from complex models [21]. The computational complexity of AI models varies depending on parameters such as model architecture, parameter count, depth, and the amount of input data.
Deep learning models, such as deep neural networks, often have many layers and parameters, resulting in high computational complexity. For such models to be trained especially on large datasets, it can be time-consuming and computationally intensive [22]. In addition, generating explanations from these complex models can also pose challenges [9], as it may involve analyzing numerous model components and their interactions.
In the context of Explainable Decision Support Systems (XDSS), computational complexity extends beyond mere algorithm execution to encompass the resources necessary for generating, maintaining, and communicating explanations in a human-understandable manner [5]. The inherent complexity of XDSS arises from the intricate interplay between decision-making algorithms and explainability mechanisms, each with its computational demands. A nuanced understanding of computational complexity is imperative for the design, evaluation, and optimization of XDSS.
Importance of managing computational complexity in XDSS
Managing computational complexity in XDSS is important for several reasons. It has a direct impact on system performance, scalability, and usability. High computational complexity can lead to prohibitive execution times, rendering the system impractical in real-time or large-scale scenarios [9].
The computational complexity of explainable AI models directly impacts their practical applicability [10]. In real-world decision support systems, especially those requiring real-time or near-real-time responses, the efficiency of the underlying AI models becomes critical. If the explanation generation process takes a substantial amount of time, it may impede the decision-making process and hinder user adoption.
Considering computational complexity is also crucial when deploying explainable AI models on resource-constrained devices, such as smartphones or edge devices [23]. These devices may have limited processing power, memory, and energy, making it essential to design efficient explanation methods that do not overly burden the hardware.
Moreover, in interactive decision support systems, users often anticipate quick and interpretable responses [24]. High computational complexity might cause delays in providing explanations, leading to user frustration and reduced trust in the system’s reliability.
Measures and metrics of computational complexity
Computational complexity in Explainable Decision Support Systems (XDSS) is a critical aspect that influences their efficiency, scalability, and overall effectiveness. The measure of computational complexity in XDSS can be articulated through various metrics, each illuminating different facets of complexity. Common measures include:
Time Complexity: The amount of computational time taken by an algorithm to complete its execution, often expressed as a function of the size of the input represented using Big O notation, which describes how the execution time increases with the size of the input data [25]. In XDSS, time complexity not only pertains to decision-making algorithms but also to the generation and rendering of explanations, invariably it is the amount of time a system takes to reach a decision or provide an explanation. Time complexity is crucial in real-time decision-making scenarios.
Space Complexity: The amount of memory used by an algorithm, also often expressed as a function of the input size [25]. Like time complexity, space complexity can be expressed in Big O notation. Space complexity in XDSS encompasses the memory requirements for both decision-making and explanation generation. This is particularly relevant for systems handling large datasets.
Algorithmic Efficiency: It combines both time and space complexity. It evaluates how well an algorithm performs in terms of speed and memory usage, which is crucial for real-time decision-making scenarios [10]. Efficient algorithms are especially important in XDSS where timely and accurate decisions are paramount. Therefore, assessing how well the system performs with respect to resource utilization.
Interpretability-Complexity Trade-off: This measure assesses the balance between the complexity of a model and its interpretability. Generally, more complex models like deep neural networks offer higher accuracy but lower interpretability, whereas simpler models like decision trees provide higher interpretability but may lack accuracy [26].
Scalability: Scalability metrics evaluate how well an XDSS can adapt to increasing data sizes or complexity without a significant loss in performance. This is essential for systems deployed in dynamic environments with growing data requirements [27].
Fidelity: Model fidelity is a measure of how accurately the explanations or decisions of an XDSS reflect the true model’s behavior. Higher fidelity indicates that the explanations are more reliable and trustworthy [28]. Given that the fidelity of explanations is influenced by various factors, such as the internal workings of the predictive model, the mechanisms of the employed explainable method, and the complexity of both the model and the data [29], it can be accounted for as a measure pertaining to computational complexity.
Challenges of computational complexity in XDSS
Increasing complexity of datasets and decision models
The onset of big data has witnessed a substantial increase in the size and complexity of datasets utilized in various domains. In Explainable Decision Support Systems (XDSS), the intricacies of data and decision models pose a significant challenge. The computational complexity of explaining decisions grows with the complexity of data and models, thus intensifying the challenge of fostering explainability while managing computational demands [30]. The many features and the high-dimensionality characteristic of modern datasets further increase the computational burden, making real-time explanation generation a daunting task.
Impact of computational complexity on performance and interpretability
The computational demands of XDSS have a consequential impact on both system performance and interpretability. High computational complexity often translates to prolonged processing times, thereby hindering real-time decision support, which is crucial in many application domains like healthcare and finance. The bid to reduce computational complexity can, however, compromise the quality of explanations, undermining the primary goal of explainability in XDSS [31]. The balance between interpretability and computational efficiency is a delicate one, requiring nuanced approaches to maintain an acceptable level of both.
Trade-offs between complexity reduction and decision accuracy
Reducing complexity is a possible approach to enhance system performance. However, this often comes at the cost of decision accuracy. Simplifying models to lessen computational demands might lead to less accurate or overly generalized decisions. The other is that some models generate improved accuracy but compromises the interpretability of the model. This issue impacts the purpose of utilizing these models to facilitate user analysis and comprehension, as the model’s transparency diminishes with increasing complexity [32]. Therefore, it is crucial to strike an effective balance between accuracy and transparency [33, 34].
Trade-offs between complexity and interpretability
One prominent trade-off in Explainable AI is between the complexity of AI models and their interpretability [35]. Complex AI models, such as deep neural networks, can achieve high accuracy in predictions but tend to be less interpretable. Conversely, simpler models, like linear regression or decision trees, offer better interpretability but may sacrifice predictive performance for certain complex tasks [36].
The need to explore explanation techniques that would adequately interpret insights without compromising the predictive performance of AI models cannot be overemphasized. To achieve the right balance between model interpretability and decision accuracy, evaluation of the trade-offs between complexity presented by the model and interpretability is crucial in identifying the most suitable explanation methods for specific decision support systems and application domains.
Scalability in diverse and dynamic environments
As decision support systems are increasingly deployed in various dynamic environments, scalability becomes a critical challenge [27]. The ability of an XDSS to efficiently scale its computational resources to handle varying sizes of datasets, adapt to new types of data, and maintain performance under different operational conditions is crucial [19]. This includes challenges in processing speed, memory management, and the adaptability of algorithms to new or evolving data types without compromising on the accuracy or interpretability of the system.
Explanation methods in DSS
One important aspect of AI-based system is explainability or interpretability. Various explanation methods categorized into local vs. global interpretability methods, post-hoc vs. ante-hoc methods, and model-specific vs. model-agnostic methods are used in DSS to provide users with interpretable insights into the decision-making process of AI models and they are presented in this section. Figure 1 depicts these explanation methods and their possible relationship.
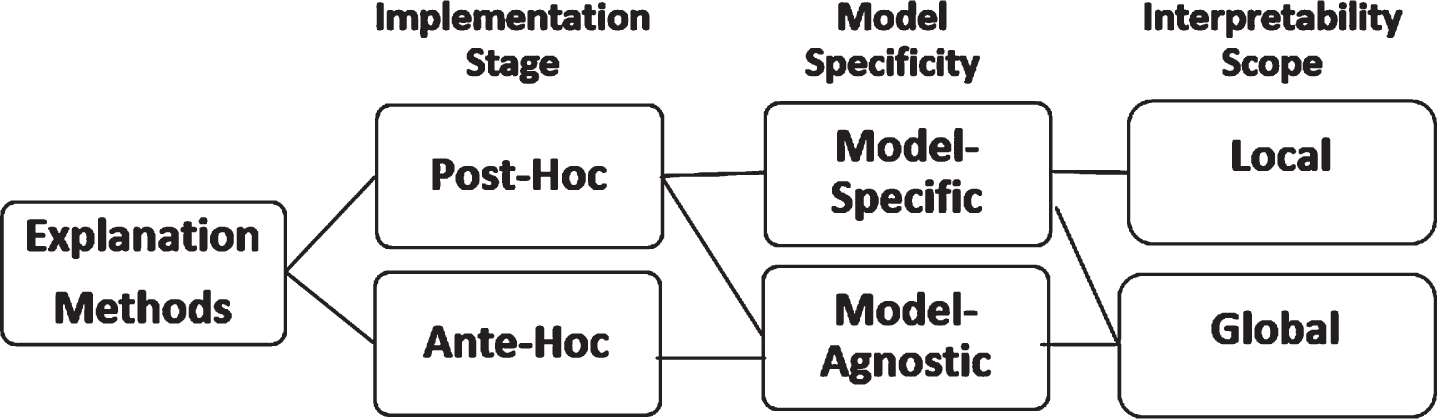
Explanation methods and their relationship.
Local interpretability methods focus on explaining individual predictions made by AI models. These methods zoom in on a particular instance or data point to assess the behavior of the model with the aim of providing users with insights into why a specific decision was reached. LIME (Local Interpretable Model-agnostic Explanations) is an example of one of the commonly used local interpretability method. LIME offers explanations for individual predictions regardless of the underlying model by perturbing input data and observing changes in predictions [37]. Anchors, Counterfactual Explanations and SHAP (SHapley Additive exPlanations) are some of the other examples of this method. Though SHAP can be used for both local and global explanations.
Global interpretability methods are used to provide a holistic view of an AI model’s behavior across the entire dataset [38]. These methods are aimed at explaining the decision rules and feature importance learned by the model such as weights, structures, and other parameters. Some of the examples of globalmodel interpretability are feature importance [39], which evaluates the influence of each input feature on the model’s predictions, SHAP, PDP(partial dependency plots) and Rule-based Explanations.
Model-specific methods vs model-agnostic methods
Model specific methods are designed on the details of the specific structure of the machine learning or deep learning model which is applied [40]. This method is explicitly used for a specific model architecture and leverages on the characteristics. For example, in a convolutional network model such as CNN, this approach uses reverse engineering in generating explanations of specifics used by ML algorithm is providing the relevant decision.
Model-agnostic methods can be applied to any type of XDSS model. They do not rely on the specifics of the model’s architecture. This is considered a benefit as it is flexibility. Especially when applied to complex models like neural networks. Explanations are obtained when perturbation and mutation has been applied on the input data and the understanding of both the performance of these mutated data and the original data [40]. These provide insights into the input which is providing accurate insight. Some of popular model agnostic techniques are SHAPley values, and LIME.
Post-hoc methods vs ante-hoc methods
Post-hoc explanation methods are used in generating explanations after the model has made its predictions [41]. For this method, there is no need to modify the underlying model. It counts for versatility and can be applied to any XDSS model. Post-hoc explanation methods can provide both global explanation of the black-box model known as global surrogate as well as local explanation for a given example known as local surrogate. Some of the best-known post-hoc methods are model-agnostic, meaning they can work for any type of underlying black-box model. Examples of these methods include LIME, SHAP, and feature importance analysis.
Ante-hoc methods are intrinsic since they are designed to provide explanations during prediction. These methods are integrated into the model’s architecture and explainability are embedded in the model from onset [4]. Examples include rule-based models, decision trees, and certain neural network architectures like attention mechanisms.
Complexity analysis of explanation methods
The focus of this review is on computational complexity therefore the complexity of explanation methods in DSS is analyzed. The computational complexity of explanation methods can significantly impact the overall performance and usability of the DSS [42]. The computational complexity of explanation methods in decision support systems varies based on the nature of the method and the underlying model. While simpler, more interpretable models and methods require less computational effort, they may offer limited insights compared to more complex approaches that provide deeper, though computationally expensive. Table 1 showcases the explanation methods/models and the possible level of computational complexity.
Computational complexity analysis of explanation methods
Computational complexity analysis of explanation methods
Local interpretability methods like LIME and SHAP typically entail generating a new interpretable model for each instance of interest, which can be computationally intensive. The complexity of these methods can also depend on the complexity of the AI model being explained and on the size of the data. For both large datasets and complex models, the computational cost of generating explanations for all instances can be substantial. They often require creating separate models or calculations for each instance, increasing computational load with the complexity and size of the dataset [37, 43]. When it comes to global interpretability methods, such as feature importance analysis or PDPs, they are generally less computationally demanding. These methods often require analyzing the AI model’s learned parameters or conducting simple feature importance calculations. These methods are computationally efficient and scalable, making them suitable for larger datasets. However, the simplification inherent in isolating feature importance can sometimes lead to a loss of accuracy in the explanations provided.
Post-hoc methods analyze the model’s predictions after they are made. Techniques like SHAP require evaluating model predictions for all possible feature subsets, leading to an exponential increase in computational complexity as the number of features grows [43]. Ante-hoc Methods, being part of the model, can have varying computational complexities. Some can be more computationally efficient due to their inherent transparency while others are not. Decision trees have relatively low complexity due to their hierarchical structure. However, methods like attention mechanisms in neural networks can be computationally intensive due to complex weight computations [44].
Model-specific methods leverage specific model characteristics can have varying complexities. For instance, decision tree-based methods like CART have complexity proportional to the dataset size and tree depth [45]. These methods tend to be more interpretable but may struggle with capturing complex relationships. Model-agnostic methods like LIME and SHAP aim to explain any model. Their complexity depends on the number of perturbed samples generated for LIME or the number of potential coalitions of features in SHAP. These methods are generally more computationally demanding due to their generality [46]. Model-agnostic methods have higher computational complexity due to their ability to explain any model. The trade-off is between the computational resources required and the flexibility to work with diverse models.
The trade-offs between local and global interpretability, post-hoc and ante-hoc methods, model-specific and model-agnostic methods extend to their level of detail and granularity and the fact that they are presented with distinct complexities. The Local interpretability methods provide instance-specific explanations, offering detailed insights for individual predictions but may not capture the model’s overall behavior. While the Global interpretability methods, provides an overview of feature importance but may lack the granularity needed to explain individual predictions comprehensively.
To choose the most appropriate explanation method in XDSS, a careful assessment of the trade-offs between these explanation methods, interpretability and their computational complexity must be done. These assessments for selection of explanation methods will include the specific requirements of the DSS, the complexity of the underlying AI model, and the desired level of interpretability. By understanding the complexity of explanation methods, researchers and practitioners can design efficient and effective DSS that empower users to make informed decisions based on transparent AI models.
The exploration of how to optimize computational complexity of the underlying AI models and algorithms is vital for efficiency and practical deployment of XDSS to be possible. This section discusses various strategies for optimizing computational complexity in XDSS.
Complexity-optimized model architectures
The design of model architectures that balances accuracy and simplicity would aid in reducing computational complexity in XDSS. AI models such as deep neural networks are complex and can achieve high accuracy but often come with significant computational overhead. Conversely, models like linear models or even decision trees are defined to be simple but are computationally more efficient but may sacrifice accuracy.
In terms of XDSS, the use of hybrid models that combine the strengths of both simple and complex models has been explored. An example is an AI model can consist of an interpretable decision tree that serves as the primary decision-maker, while a smaller neural network refines the decision boundaries and handles more complex patterns. Such hybrid models can achieve a good trade-off between complexity and accuracy, providing reasonably accurate predictions with reduced computational burden [47]. Though it may still weigh on the computational complexity due to the integration of models.
Another approach to optimize the computational XDSS within the context of complexity-optimized model architectures is through approximation. Approximations or simplifications are used in order to make explanations more understandable by explanation methods that are designed for complex AI models [33]. These approximations help in improving model interpretability but may not accurately represent the underlying decision process of the complex model.
Algorithmic optimization techniques
Algorithmic optimization techniques can help in improving the efficiency of XDSS. To reduce computational complexity and maintain the model’s interpretability in this context, various algorithms can be optimized.
Pruning in decision tree-based models has been used as an optimization technique. When decision trees can grow to be excessively large, causing an increase of the inference time and complexity [48]. Pruning is used to remove redundant branches and nodes from the tree, simplifying the decision-making process without significantly affecting accuracy.
In addition, approximation algorithms to accelerate explanation generation have also been explored [10]. One instance is the use model-agnostic interpretability approach where the role played by each feature is analyzed at both global and local scale. Thereby providing important scores through perturbations of the data based on quantiles of the empirical distribution of each feature [49]. This approach can reduce the number of instances requiring explanation significantly, leading to a lowered computational complexity while maintaining reasonable interpretability.
Complexity-aware feature selection and extraction
The choice of input features has a significant effect on the computational complexity of AI models [50]. In XDSS, the selection of relevant features in combination to considering their computational cost is essential. Efficient representative sampling can be used instead of the entire dataset can mitigate computational burden.
Feature selection techniques are used to identify a subset of the most important, relevant, and informative features that can lead to accurate predictions. The idea within feature selection techniques is that by reducing the number of input features, then there will be a reduction in the computational overhead and model’s complexity, while still maintaining satisfactory performance. Techniques like Recursive Feature Elimination (RFE) and feature importance analysis can assist in identifying the most relevant features for the DSS [51].
With Feature extraction methods, the original features are transformed into a lower-dimensional space. This is also related to dimension reduction. This dimensionality reduction is meant to simplify the model and accelerate computation without significant loss of information.
By incorporating complexity-aware feature selection and extraction techniques, XDSS can streamline the decision-making process, reduce resource consumption, and improve overall system performance.
Case studies and applications
In this section, the discussion of a few case studies and applications of XDSS in different domains. The presented cases are examples of decision-critical domains where automated decisions need to be explainable and well-understood which would aid the acceptance of these AI-powered applications. Therefore, highlights of the practical implications and benefits of incorporating explainability into decision-making processes are presented to buttress the need to ensure that these systems are computational efficient to encourage practical deployment.
Healthcare decision support systems
DSS in the healthcare industry plays a critical role in many aspects of healthcare from diagnosis, treatment planning, patient management, to improving patient outcomes, healthcare delivery and optimizing healthcare operations [52]. Invariably, XDSS in healthcare can assist medical professionals in making informed decisions and enhance patient safety especially because these decisions will have direct implication on patients’ well-being. An example is in disease diagnosis, models that provide transparent explanations for their predictions can help doctors understand the reasoning behind the diagnosis and validate the accuracy of the model’s recommendations. This helps in fostering trust between and may lead to acceptance and adoption of AI-based tools in healthcare. Furthermore, XAI can help in personalized treatment by providing recommendations that can help physicians tailor treatments based on patient-specific factors and medical history [53]. The transparency of these models can also assist in identifying possible biases and disparities in treatment plans, ensuring equitable healthcare delivery. In healthcare some of the studied cases have shown that XDSS not only improves diagnostic accuracy but also supports clinical decision-making, resulting in better patient care and outcomes.
In healthcare, XDSS can help in radiology. It can aid radiologists in analyzing and interpreting medical images, such as X-rays and MRIs for diagnosis. However, the complexity of neural networks used for image analysis, combined with high-resolution images, poses computational challenges. XDSS needs to analyze numerous images with precision, requiring extensive processing power and time. Delays in image analysis could hinder timely patient care, emphasizing the need to optimize computational complexity without compromising accuracy.
Optimization of computational complexity in healthcare DSS can aid more accurate and fast prediction and subsequently improving patient outcomes. One case study for optimizing a decision support system for diabetic retinopathy diagnosis employed a hybrid model that combines convolutional neural networks (CNNs) for image classification and a rule-based expert system for providing explanations, achieving accurate predictions while reducing the computational cost of the model [54]. Another optimization of computational complexity explored the use of model distillation in healthcare DSS. Distillation involves training a smaller, more lightweight model to mimic the predictions of a larger and more complex model. This process allows for faster inference times without sacrificing prediction accuracy [55].
Financial decision support systems
DSS is used for risk assessment, investment strategies, fraud detection and many decision-making tasks in the financial sector. Employing XDSS in finance aid in providing insights into the factors influencing predictions, helping financial analysts, investors, and other stakeholders to understand the rationale behind investment recommendations [56]. Interpretable models can provide insights on reasons why a loan application was approved or denied, considering factors such as credit history, income, and debt levels in credit risk assessment [57]. This transparency is in accordance with financial regulations and for promoting fairness in lending practices. XDSS can enhance fraud detection and reduce potential losses by identifying anomalies and suspicious activities in financial transactions [58]. The ability to explain the reasons behind predictions fosters trust among stakeholders and enhances the overall reliability and acceptance of AI-driven financial decision-support systems.
In the business domain, XDSS is important. For instance, the case of fraud detection in financial transactions. A bank may employ XDSS to flag potentially fraudulent transactions. However, due to the high number of transactions and the need for real-time decisions, it may face computational complexity challenges. In virtually all high-frequency trading environments, can be exacerbated due to the demand for instantaneous decisions while maintaining transparency. XDSS must strike a balance between accuracy and computational efficiency to prevent false positives without causing delays that hinder business operations.
In Financial Decision Support Systems, computational complexity arises from the need to process and analyze vast amounts of financial data, perform complex risk calculations, and optimize portfolios in real-time. To effectively manage this complexity is crucial for providing timely, accurate, and actionable insights to financial professionals and investors.
Business decision support systems
Businesses leverage decision support systems to optimize operations, marketing strategies, and customer experiences. XDSS in business settings enables companies to tailor marketing campaigns and product recommendations by offering valuable insights into customer behavior [59]. These models can explain the reason why certain customers are targeted for specific promotions or recommendations, creating a sense of transparency in marketing practices. For instance, XAI can assist in demand forecasting and inventory optimization by providing interpretable explanations for demand fluctuations and inventory allocation decisions in supply chain management [60]. This transparency aids business managers in understanding and validating the system’s recommendations, leading to improved supply chain efficiency. XDSS can help businesses comply with data privacy regulations, as they can provide clear justifications for data processing and usage, ensuring ethical and responsible use of customer data [61]. Case studies in the business domain highlight the value of explainability in fostering customer trust and improving business decision-making processes.
XDSS will benefit both retailers and policymakers in segmenting customers for targeted marketing and policy implementation. To develop accurate models to segment customers based on their preferences and behaviors involves dealing with large datasets and intricate models. The computational complexity challenge arises from the need to process substantial data and complex models to ensure accurate segmentation. If XDSS is computationally intensive, it may lead to delayed decisions, impacting marketing campaigns or policy adjustments.
Computational complexity in Business Decision Support Systems is prevalent in tasks such as predictive analytics for customer segmentation and personalized marketing, financial forecasting, and real-time data processing. By leveraging advanced computing technologies and optimization strategies, organizations can effectively manage this complexity and harness the full potential of Business DSS to drive data-driven decision-making and gain a competitive advantage in the dynamic business landscape.
Other domains
Explainable decision support systems find applications in various other domains, including education, environmental management, and public policy. In education, these systems can provide personalized learning paths for students, explaining the rationale behind suggested learning materials and exercises [62]. This promotes student engagement and self-directed learning. In environmental management, explainable DSS can assist in ecological decision-making, such as biodiversity conservation and habitat restoration [63]. These models elucidate the factors influencing environmental predictions, aiding conservation efforts. In public policy, explainable AI can be used to analyze and interpret data related to social issues, enabling policymakers to make evidence-based decisions and understand the potential impact of policy changes [12]. These examples demonstrate the versatility and wide-ranging applications of explainable DSS across various domains.
Real-life application of XDSS in healthcare
In healthcare, the imperative to address computational complexity in XDSS is underscored by the need for both accuracy and usability in clinical settings. A real-life example that vividly illustrates this need is the development and implementation of the IBM Watson for Oncology system.
IBM Watson for Oncology is an advanced DSS that uses artificial intelligence to assist in cancer treatment [64]. It analyzes large volumes of medical data, including clinical trials, medical records, and journal articles, to recommend treatment options to oncologists. The Challenges of Computational Complexity presented in this case are: Data Volume and Variety: The system processes an immense volume of unstructured and structured data. This complexity not only demands substantial computational power but also sophisticated algorithms to parse and interpret varied data types, from text in medical journals to numerical data in patient records [65]. Real-Time Analysis: In a clinical setting, the system is expected to provide rapid insights. Thereby providing updates in real-time [66]. Balancing the computational load to deliver quick responses while sifting through extensive data repositories is a major challenge. Accuracy and Reliability: In healthcare, the stakes are incredibly high. A minor error or oversight due to computational limitations could lead to incorrect treatment recommendations, posing significant risks to patient health [67].
Some efforts in addressing these complexities have also been identified in literature: Optimized Algorithms: Although Watson employs natural language processing and machine learning algorithms. These algorithms needs to be constantly optimized for speed and accuracy as well as to handle the growing data more efficiently. Optimization of the Algorithms involved will led to better diagnosis and treatment measures [64, 68]. Scalable Infrastructure: IBM has invested in scalable cloud infrastructure [65] to manage computational demands and to ensure that the system remains responsive and reliable. Collaboration with Medical Experts: Continuous collaboration with oncologists and health experts helps in fine-tuning the system’s recommendations, ensuring they are clinically relevant, consistent and accurate [69].
This case study exemplifies the critical nature and importance of managing computational complexity in healthcare DSS. Effective complexity management leads to systems that are not only accurate and reliable but also quick and user-friendly, key attributes in a fast-paced clinical environment. Such systems can significantly augment the decision-making capabilities of healthcare professionals, leading to better patient outcomes.
This review has shed light on various aspects of computational complexity in explainable decision support systems, several research gaps and future directions have emerged.
Addressing scalability issues
Scalability is a critical aspect of decision support systems, especially when dealing with large datasets and complex models. As explainable decision support systems (DSS) evolve and become more sophisticated, addressing scalability issues becomes paramount to ensure their practical applicability.
One approach to addressing scalability is to leverage distributed computing and parallel processing [70]. Researchers have explored the use of distributed frameworks to distribute computational tasks across multiple nodes, enabling faster processing and handling larger datasets.
Furthermore, optimizing model architectures for parallelization can significantly improve scalability [71]. Model parallelism techniques, where different parts of a model run on separate processing units, have been explored to reduce computational bottlenecks in explainable DSS.
Apart from distributed computing, model compression techniques have also been explored to address the scalability challenge. Techniques like knowledge distillation and parameter pruning can reduce the model’s size and computational requirements while preserving its interpretability [72].
Evaluating performance-complexity trade-offs
Evaluating the trade-offs between performance and complexity is crucial for decision-makers seeking to deploy explainable DSS in real-world applications. While high-complexity models might provide more accurate predictions, they can also be computationally expensive and challenging to interpret. On the other hand, low-complexity models might sacrifice some predictive accuracy but offer faster inference times and enhanced interpretability.
Researchers have employed various evaluation metrics to assess the performance-complexity trade-offs in explainable DSS. One common approach is to use accuracy-interpretability curves, which visualize the trade-off between model accuracy and interpretability across different complexity levels [73].
Moreover, researchers have introduced complexity-adjusted performance metrics, which consider the model’s complexity when evaluating its overall performance [74]. These metrics are to offer a more comprehensive assessment of model effectiveness, accounting for both predictive accuracy and computational cost.
Ethical and legal implications
Due to the influential increase on the possible use of DSS in various domains, it is now imperative to understand the ethical and legal implications of using XAI models. For DSS to be ethical, principles such as transparency, fairness, and accountability must be considered in the design.
Transparent explanations can lead to user trust in AI-driven decisions [4]. When clear and understandable explanations is provided for the system’s recommendations, it can empower decision-makers to make informed choices.
On the part of fairness, avoiding biases in the decision-making process is essential. Researchers have developed methods to detect and mitigate biases in XDSS has been proposed to promote fair and equitable decision-making [75].
For accountability, XDSS must conform to legal operations [33]. The regulatory landscape surrounding the use of AI in decision-support systems has been proposed. Understanding exactly what the legal frameworks entail and the requirement for compliance is essential to ensure the responsible and lawful deployment of XAI models.
Interdisciplinary collaborations
The design, development, and optimization of XDSS will require collaboration between different disciplines. These interdisciplinary collaborations between computer scientists, domain experts, ethicists, social scientist and policymakers will form a way forward to creating robust and effective systems.
Emphasis on the importance of involving domain experts throughout the model development stages has been made [76]. Domain experts’ insights can help refine the models, ensuring that they align appropriately with specific requirements and constraints of the application domain.
The role of Ethicists in guiding the ethical considerations of XAI is of paramount importance [77]. Collaborating with ethicists can guide the identification of potential biases and ensure that the models uphold ethical principles.
Policymakers and legal experts can guide in ensuring that the developed decision support systems adhere to legal requirements, compliance and regulations related to AI deployment [78].
These interdisciplinary collaborations will support the studies on how to solve the complexities of building XDSS and ais in the development of reliable, transparent, and ethical AI-driven decision-making tools.
Conclusion
Summary of key findings
The review delved into the role of computational complexity in XDSS and explored the challenges and opportunities associated with implementing XAI models in DSS. The findings of this review can be summed up as follows:
Decision support systems are increasingly used in diverse domains, and the need for explainability is growing with the adoption of AI techniques. XAI models aim to provide interpretable and transparent explanations for their decisions, enabling users to understand the reasoning behind the recommendations.
Computational complexity plays a crucial role in the design and implementation of explainable DSS. Emphasis has been on balancing interpretability and complexity so that accurate predictions can be obtained in addition to maintaining model transparency. Relative to the trade-off between performance and complexity which is crucial in understanding the balance between model accuracy and computational cost.
Explanation methods such as local interpretability methods and global interpretability methods were discussed. The discussion reveals that certain techniques may introduce additional computational overhead, impacting the system’s performance and real-time usability. Therefore, Optimization strategies that can be employed to mitigate the computational burden associated with explainable AI models was reviewed. These optimization techniques are complexity-optimized model architectures, algorithmic techniques, and complexity-aware feature selection,
Highlights on some of the possible benefits of XDSS as well as ideas on improving their decision-making processes in different applications were provided using the case of healthcare, finance, business, and other domains.
The scalability issue was discussed and highlights the importance of addressing it especially as it would impede the practical deployment of XDSS when dealing with large datasets and complex models.
Ethical and legal implications must be carefully considered in the development and deployment of explainable DSS to ensure fairness, transparency, and compliance with regulations.
Insights on Interdisciplinary collaborations involving computer scientists, domain experts, ethicists, and policymakers which is vital for creating robust and responsible explainable decision support systems was also given.
In each of these scenarios, computational complexity directly impacts real-world decision-making. Delays caused by high complexity could lead to missed business opportunities, delayed medical diagnoses, less effective policy implementations, and inefficient emergency response. Therefore, optimizing computational complexity while maintaining accurate and interpretable decisions is crucial for the successful deployment of XDSS across various domains.
Implications for practice
The insights gained from this review have significant implications for the practical implementation of explainable decision support systems:
Designing Transparent and Interpretable Models: Decision support systems should prioritize the development of models that offer clear and understandable explanations for their recommendations. This transparency will build user trust and enhance the system’s usability in real-world applications.
Balancing Complexity and Interpretability: Practitioners should carefully balance the trade-offs between model complexity and interpretability based on the specific application requirements. Complexity-optimized model architectures and algorithmic techniques can aid in achieving this balance.
Selecting Appropriate Explanation Methods: The choice of explanation methods should align with the system’s objectives and the end-users’ needs. Local interpretability methods may be more suitable for individual decision-making, while global interpretability methods provide insights into overall model behavior.
Optimizing Computational Performance: Addressing scalability issues and considering complexity-aware feature selection can enhance the computational performance of explainable DSS, making them more practical for real-time applications.
Ethical Considerations and Fairness: Practitioners must be diligent in evaluating the ethical implications of using AI models in decision support systems. Detecting and mitigating biases in the models will promote fairness and equitable decision-making.
Interdisciplinary Collaborations: Collaborating with domain experts, ethicists, and policymakers will enrich the development process, ensuring that the system’s design aligns with domain-specific requirements and ethical guidelines.
Research gaps and future directions
While this review has shed light on various aspects of computational complexity in explainable decision support systems, several research gaps and future directions have emerged:
Benchmarking and Standardization: Developing standardized benchmarks and evaluation metrics for explainable AI models will facilitate fair comparisons and consistent assessments of model performance and complexity.
Dynamic Complexity Management: Research into adaptive and dynamic complexity management techniques will enable decision support systems to adjust their complexity based on real-time demands and available computational resources.
Human-Centric Explanations: Future research can focus on refining explanation methods to provide human-centric and domain-specific explanations that resonate with end-users and decision-makers.
Scalability in Large-Scale Systems: Further exploration of scalability techniques in large-scale decision support systems will be essential to handle massive datasets and ensure efficient performance.
Hybrid Models and Trade-off Analysis: Investigating the trade-offs between model accuracy, complexity, and interpretability in hybrid models that combine various AI techniques can offer valuable insights for practical deployment.
Long-Term Impact Assessment: Studying the long-term impact of explainable decision support systems on decision-making processes and user trust will provide a better understanding of their real-world effectiveness.
By addressing these research gaps and pursuing these future directions, researchers can advance the field of explainable decision support systems, leading to more robust, efficient, and ethically sound AI-driven decision-making tools.
Footnotes
Acknowledgment
The authors acknowledge the Department of Computer Science and The Centre of Excellence in Mobile e-Services at the University of Zululand.