
Abstract
Traditional graph convolutional neural networks (GCN) utilizing linear feature combination methods have limited capacity to capture the interaction between complex features. While current research has extensively investigated various syntactic dependency tree structures, the optimization of GCN algorithms has often been overlooked, leading to suboptimal efficiency in practical applications. To address this issue, this paper proposes a cross-feature method that utilizes feature vector multiplication to construct non-linear combinations of GCN features and enhance the model’s capability to extract complex feature correlations. Experimental results demonstrate the superiority of the proposed method, with our models outperforming state-of-the-art methods and achieving significant improvements on three standard benchmark datasets. These results suggest that the cross-feature method can effectively extract potential connections between features, highlighting its potential for improving the performance of GCN-based models in real-world applications.
Keywords
Introduction
Aspect-based Sentiment Analysis (ABSA) is a fine-grained Sentiment classification task that usually consists of two sub-tasks: Aspect word extraction (AE) and Aspect-level Sentiment classification (ALSC). This paper only focuses on ATSC, and its research object corresponds to a specific word or word group in the sentence, also known as the aspect term. For instance, given the sentence "The food was well prepared, but the service is abysmal", the aspect terms are "food" and "service", respectively. Our task is to classify the sentiment polarity of the aspect term as "negative", "neutral", or "positive". This method has been widely used in e-commerce word-of-mouth analysis, public opinion monitoring, content marketing, and other scenarios, providing particular references and creating high commercial value.
ALSC focuses on analyzing the context semantic environment of the aspect terms. So, effectively capturing the sentiment information related to the aspect terms is key to the task. Previously, it used Long-Short Term Memory networks (LSTM) and Gate Recurrent Units (GRU) to extract context sequence information from the sentence [1–5]. They utilize gating units to control the flow of information and achieve remarkable results with the assistance of attention mechanisms [6–8]. However, sequence models can only model context details but cannot extract syntactic relations between aspect terms and context words. Therefore, the task introduces Graph Convolutional Networks(GCN)[9–11] of joint syntactic dependency trees to model the syntactic information between words. For instance, Sun et al. [12] combine the LSTM model with the GCN model to jointly learn a sentence’s context and syntactic information. Zhang et al. [13] use syntactic trees to generate aspect term representations and design gate mechanisms to constrain context representation. Lu et al. [14] devise attention mechanisms to obtain the correlation between the syntactic information of a sentence and the aspect terms.
Further, a range of models based on GCN variants primarily endeavor to exploit the rich structural feature of the syntactic tree. Velickovic et al. [15] proposed graph attention networks (GAT) to compute the coupling factors between nodes. Wang et al. [16] consider connected edges in syntactic trees to enrich node features. Phan et al. [17] consider the syntactic distance between nodes and distinguish the degree of contribution between other nodes in the tree to the current node. Chen et al. [18] combine brain cognitive principles with GCN networks to extract semantic information based on brain understanding. Alternatively, some researchers argue that the syntactic trees generated by syntactic tools such as Stanford [19] or Spacy [20] do not cover all the nodes. They alter the original syntactic trees and construct new ways of connecting the nodes. For instance, Zhang et al. [21] used word co-occurrence probabilities to create word co-occurrence matrices to compensate for the incomplete structure of the syntactic tree. Chen et al. [22] use various attention mechanisms to construct potential graph structures that enrich the information representation of the syntactic tree.
In summary, almost all existing research on syntactic tree-based GCN models either focuses on utilizing the structural properties of syntactic trees, such as node information, edge information, and modifier attributes, or addressing the structural deficiencies of syntactic trees, such as constructing a global node information matrix. Although these methods have achieved promising experimental results, they all overlook a fundamental problem, which is the limitation of the GCN model algorithm itself, i.e., the linear feature combination cannot fully extract the correlations between features, thereby limiting the performance of GCN models in practical applications.
Because the multi-layer convolutional structure of the GCN is similar to a Multi-layer perceptron(MLP) [23], using hidden layers to transform the inputs into a high-level dimensional space. Nevertheless, this linear feature combination approach of weighted summation between elements is a weak representation of feature interaction and cannot express the underlying connections between features. Given a sentiment ambiguous sentence: "How can hope to stay in business with service like this", the aspect term is "service", and the corresponding sentiment polarity is "negative". The attention mechanism and GCN model will give too much attention to ’stay’ or ’hope’, which often have positive sentiment connotations and lead to incorrect classification results. This paper believes that aspect-level sentiment classification should rely on co-occurrence relationships between words. In the absence of indicative sentiment words, multiple words rather than individual words jointly determine the sentiment tendency of the aspect term. Notably, the GCN’s algorithmic structure is insufficient to efficiently string together multiple features, limiting the model’s generalization ability.
This paper designs a novel graph convolutional neural network based on cross-feature [24–27] to solve this problem. Firstly, the model uses LSTM to learn the context information of sentences. Secondly, to ensure that the GCN model can effectively identify the co-occurrence environment of words, this paper modifies the feature transformation algorithm of the GCN. It employs a non-linear feature combination strategy based on feature product instead of a linear feature combination method based on feature-weighted summation, which can improve the ability of the GCN to model feature interactions. The contribution of this paper is as follows:
•This paper considers the feature transformation structure of the GCN as equivalent to a multilayer perceptron and shows the detailed reasoning process in the second section of the article. This method of learning feature interactions through weighted summation is less effective than the product of features in extracting correlations between aspect terms and information about their surroundings.
•This paper introduces the idea of cross-feature modeling to the aspect-level sentiment analysis task and designs a novel graph convolutional neural network model based on cross-features. The model takes advantage of GCN iteratively updating node information and using a non-linear feature combination based on the product of features to replace the original linear feature combination, enhancing the GCN model’s ability to extract potential connections between components.
•Experimental results on multiple publicly available datasets show that the ACC and F1 indicators of the model have improved in different datasets, which further proves the effectiveness of the cross feature.
Graph convolutional neural networks with multi-layer perceptron
Graph convolutional neural networks
The traditional GCN uses the syntactic dependency tree to capture the adjacent node information of the target node and obtains the embedded representation of the target node through the summation operation. We take the initial layer as an example to introduce the convolution process of GCN in detail. The formulation is:
Then, GCN utilizes a feedforward neural network to transform the updated target node embedding representation into a higher-level nonlinear feature representation, the formulation is:
Equation (1) represents the process of GCN aggregation of adjacent node information by the GCN, which enriches the embedding representation of the target node by collecting adjacent node features. Equation (2) represents the process of GCN feature transformation, which uses a weighted summation method to map the target node to a higher-level feature space. The combination of Equation (1) and Equation (2) represents the complete single-layer convolution operation of the GCN.
In order to mine the deeper adequate node information, GCN often use multiple convolutional layers, which makes the feature transformation process of GCN evolve from a single-layer neural network to a Multi-layer Perceptron. The formulation is:
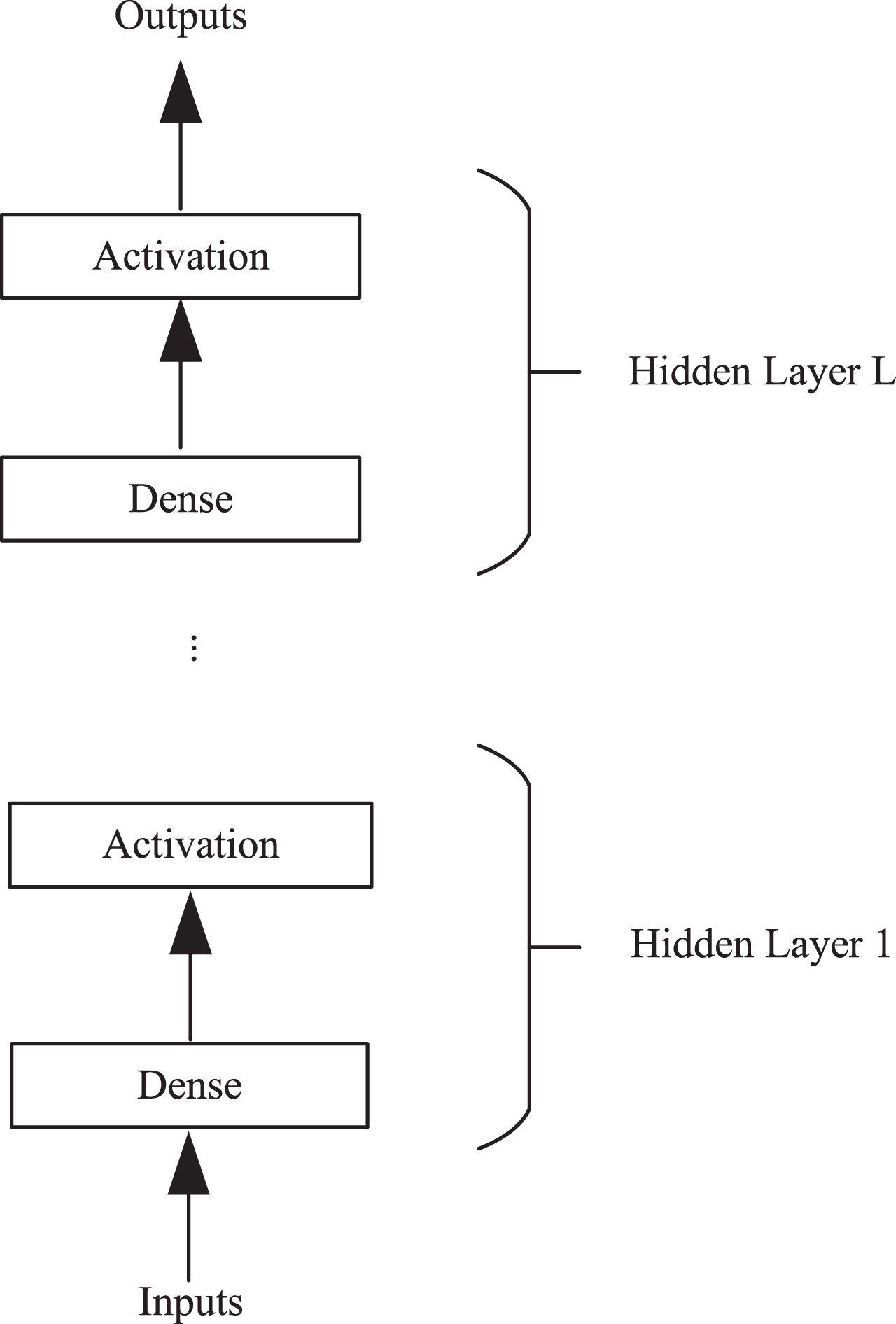
Multi-layer perceptron construction.
As shown in Figure 1, the Multi-layer perceptron consists of an input, a dense layer, an activation layer, and an output. A dense layer, also known as a fully connected or linear layer, mainly uses linear functions to fit the relationship between features. However, linear functions cannot solve the XOR problem between features, limiting linear models’ expressiveness. Therefore, the Activation layer uses a nonlinear activation function to convert the output of the dense layer into a nonlinear feature representation, which increases the expressiveness of the model. With enough neurons, a single-layer neural network can approximate any function, but it also increases the risk of dimensionality curse and overfitting. MLP increases the complexity of the model by deepening the number of neural network layers. Compared with expanding the some neurons in a single-layer network, MLP has fewer parameters and more robust expression capabilities.
However, MLP is a neural network based on additive operations, given an input
For example, the output of the m-th neuron is ωm1x1 + ⋯ + ω mn x n + b n , the weighted summation of each feature in the input obtains a linear feature combination and uses the activation function to obtain the hidden layer output, which is the input of the upper network. Finally, the interaction between the features is achieved by iterating layer by layer. However, the weighted summation is not the most efficient way to interact with features. Moreover, Qu et al. [24] mentioned that the relationship between features is more of an “and” relationship, not an “add” relationship. For instance, given two sentences:” Food videos over 10 minutes in length” and “Videos longer than 10 minutes and food videos”, the former feature combination method can better reflect the close relationship between features.
Mathematically, cross-feature is the product of two or more features. The multiplication relationship can be a logical " ∩ " operation, the product of a series of conditions that take effect together. For example, the Youth Internet Health Management Mechanism predicts whether the user type is a teenager. The premise is that teenagers have more behaviors in the game APP during weekends and holidays. Assuming that the time feature "Saturday", the app category "Game", and the behavior feature " Purchase Skin" occur together in one user, it is highly likely that the user category is teenagers. By analogy, a k-order cross-feature calculates as follows:
where, x
i
is the i-th dimensional feature in the input. However, the dimension of features in natural scenes is significant, and it is expensive to construct cross features manually. Therefore, the automatic construction of cross features employing vector products is the key to freeing the workforce. Given a feature vector
By subdividing the formula (8), the e-th dimension feature in the output of the hidden layer is
However, cross-feature will generate new high-dimensional features, such as formula (9), the time complexity of the output vector of the e-th dimension hidden layer is O (n k ), the parameter complexity is O (En k ), and the amount of parameters is the key to improving the performance of the model.
Therefore, our paper adopts the method of Feng et al. [27] to reduce the time complexity and the number of parameters. For ease of understanding, we use the second-order cross-feature as an example for the low-order near-rank derivation of Eq. (9). Given an input
Since
So, the conversion formula for the k-order cross-feature can be expressed as follows:
After low-order near-rank derivation, the original parameter quantity is reduced from E × n k to E × k × n, the time complexity is reduced from O (En k ) to O (Ekn), and the parameter quantity and computational complexity increase linearly with the cross order. As a result, the dimensional explosion problem caused by cross-feature will be reduced to a linear level within the tolerance of the model.
This paper builds a graph convolutional neural network model based on cross features. As shown in Figure 2, CF-GCN is mainly composed of Input, BI-LSTM, GCN, Mask, and Output. Each part of the model will be introduced separately in this section.
Input and Bi-LSTM
Given a sentence S = {w1, w2, ⋯ , w
n
}, where Aspect = {a1, a2, ⋯ , a
m
} is the sequence of aspect terms in the sentence. In addition to word vectors, the input layer also adds position embedding information and part-of-speech embedding information. This paper uses the embedding matrix
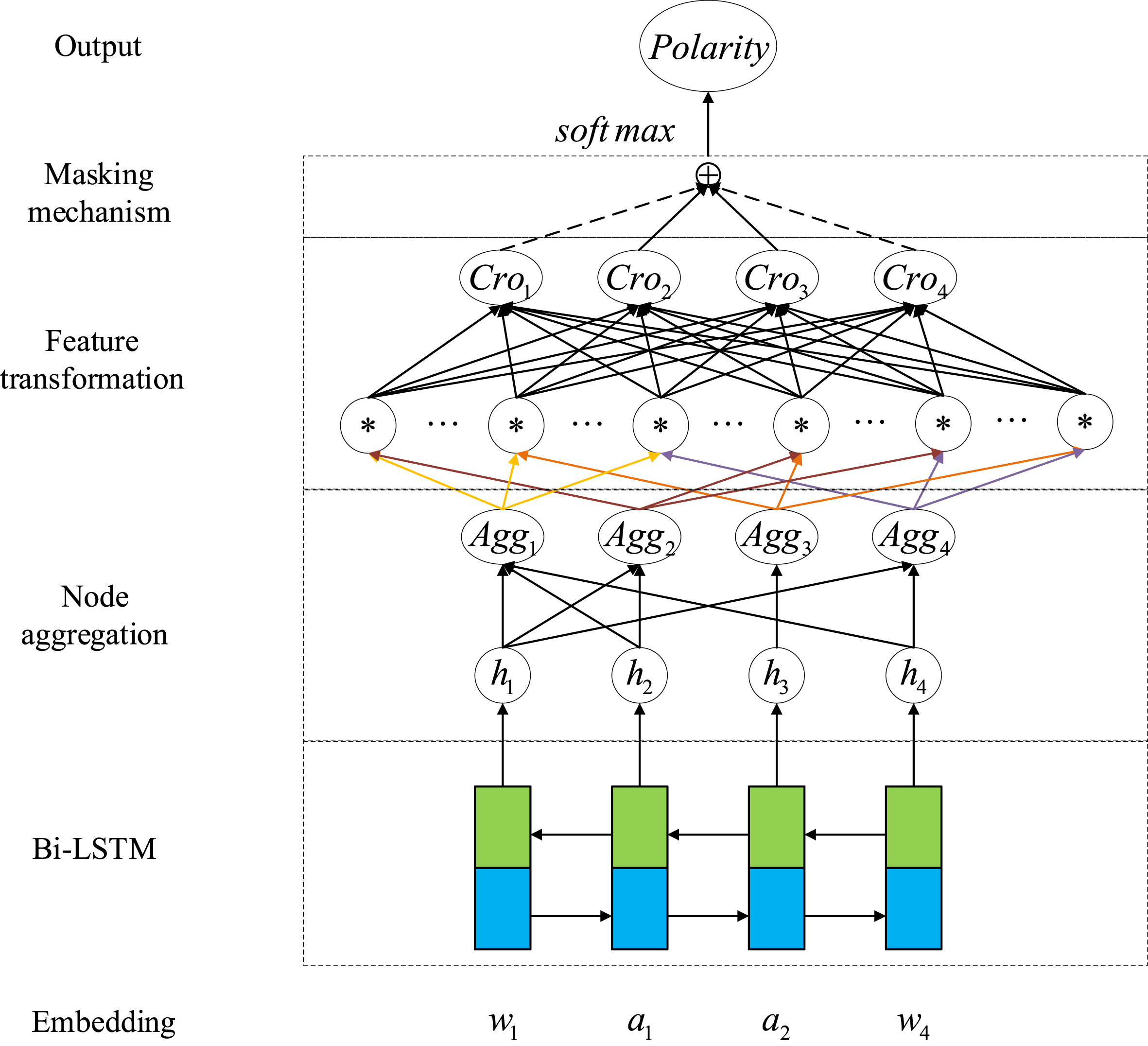
Structure of CF-GCN model based on cross-feature.
Firstly, the hidden state vector of Bi-LSTM is the input of the GCN layer. Then, the model obtains the embedded representation of the target node by aggregating the adjacent node information. The formula is:
Secondly, perform the outer product operation on the target node to generate the order cross-feature, the formula is:
where
where
In this paper, the mask filtering mechanism weakens the interference of irrelevant features on the final output and retain the feature representation of the aspect word itself. The formula is:
where f is the final output. The mask mechanism depends on whether the current word belongs to the aspect term, and the hidden state vector retains if it belongs to the aspect term. Otherwise, it sets to 0.
In this paper, the final output obtained is fed to the fully connected layer and finally classified by softmax as follows:
The model trains with a cross-entropy loss function:
Datasets
ALSC is to determine whether the polarity of an aspect term is positive, negative, or neutral for a given aspect term in a sentence. The experiments are conducted on three widely used benchmarking datasets for ABSA, whose statistics are summarized in Table 1:
•Twitter is a dataset gathered by Dong et al. [29];
•Restaurant and Laptop are downloaded from SemEval 2014 task 4 [30], which contains sentiment reviews for restaurant and laptop domains.
Statistics of datasets
Statistics of datasets
In this paper, a 300-dimensional Glove word vector is used to initialize the word embedding, and all the weight parameters of the model are initialized with a uniform dis-tribution. When the number of GCN convolutional layers is set to 2 and the cross order set to 2, the model performance is optimal. The hyper-parameter setting of the model is shown in Table 2.
Hyper-parameter setting
Hyper-parameter setting
The model performance is compared with a range of benchmark models, briefly described below.
•TD-LSTM [1]: using LSTM to model the correlation between target words and context.
•ATAE-LSTM [2]: based on LSTM sequence modelling, an attention mechanism is designed to calculate the weights of aspect words and different contexts.
•IAN [3]: model the aspect words and contextual features, respectively, and design an interactive attention mechanism to learn feature representations of both.
•CDT [12]: an integrated model based on LSTM and GCN, which jointly learns the context information and syntactic dependency information of sentences.
•ASGCN [13]: an integrated model based on LSTM and GCN, using the aspect term generated by GCN to distinguish the context weight of LSTM output.
•Bi-GCN [21]: taking the word co-occurrence rate into account in syntactic modelling to compensate for the flaws of text processing tools’ error analysis.
•Kuma-GCN [22]: modifying the syntactic dependency tree to improve the sensitivity of aspect terms to sentiment words.
•RGAT [16]: Pruning and reconstructing of the dependency tree to weaken the interference of invalid features in the syntactic dependency tree.
•BSSCN [18]: Semantic modeling of GCN based on cognitive guidance of the brain.
•AGGCN [14]: using a special aspect gate designed to guide the encoding of aspect-specific information and construct a graph convolution network on the sentence dependency tree.
•Rep-Walk [31]: The RepWalk model leverages the syntactic structure of the sentence to find crucial contextual information and enriches the representation for the classification.
•DGEDT [32]: dual-transformer network model, which jointly considers the flat representations learned from Transformer and graph-based representations learned from the corresponding dependency graph in an iterative interaction manner.
•ABSACap [33]: The ABASCap model improves the multi-head self-attention and proposes a context mask mechanism based on an adjustable context window to effectively obtain the internal association between aspects and context.
Experimental result
Model performance comparison
Model performance comparison
Table 3 presents the performance comparison of each model on the three datasets. Among a series of LSTM-based models, the TD-LSTM model slightly outperformed the ATAE-LSTM model on the Twitter and Laptop datasets, suggesting that the aspect term distinguished the importance of context at different locations. The IAN model argues that aspect terms should be modeled independently and designs interactional attention mechanisms to couple aspect terms with context features, outperforming the TD-LSTM model and ATAE-LSTM model on all three datasets.
The CDT model, which jointly learns contextual and syntactic dependency information, outperforms the IAN model on all three datasets, especially the Laptop dataset, with a 5.14% improvement in Acc and a 5.61% improvement in F1 values. The experimental results demonstrate that syntactic information enhances aspect-level sentiment classification accuracy. The ASGCN model uses a gate mechanism to distinguish the contribution of neighboring nodes to the target node during the convolution process. Compared to the CDT model, its experimental results on the three datasets were reduced by 2% on average. The AGGCN model added aspect terms to the LSTM model to avoid the model missing aspect-related sentiment information. Its experimental results on the Twitter dataset and laptop dataset were reduced by 1% on average compared to the CDT model. The experimental results of ASGCN and AGGCN were slightly lower than those of the CDT model because the CDT model adds position embedding vectors and part of speech embedding vectors to the inputs.
The Bi-GCN model constructs word co-occurrence matrices, and the Kuma-GCN model makes multiple graph structures. Both supplement the syntactic tree structure but are less effective than the CDT model on all three datasets. Significantly the Kuma-GCN model reduces ACC by 2.21% on the Twitter dataset. The experimental results illustrate that the integrated model based on LSTM and GCN is simpler and more efficient. Similarly, the RGAT model reconstructs the syntactic tree and considers both aspectual items and edge information of the syntactic tree. The model achieves outstanding results on the Twitter dataset with an Acc of 75.57%. In contrast, the BSSCN model is based on human cognitive principles and combines GCN with convolutional neural networks to learn semantic information. Compared to the RGAT model, this model improved the accuracy of the Laptop dataset by 0.32%.
CF-GCN model introduces nonlinear factors in the GCN feature conversion process. The accuracy of the Twitter dataset is 75.23%, which is lower than 0.34% of RGAT, and the F1 value is higher than 0.14% of RGAT. On the Laptops dataset, the accuracy is 77.81%, and the F1 value is 74.56%, which are 0.07% and 0.35% higher than BSSCN, respectively. On the Restaurants dataset, the accuracy is 83.36%, and the F1 is 76.18%, compared to RGAT increased by 0.10%, respectively. Experimental results demonstrate that the CF-GCN model is more straightforward and effective than the RGAT and BSSCN models, the introduction of cross-feature in the GCN convolution process optimizes the ability of the GCN model to extract sentiment and that cross-features strong feature interaction significantly outperforms the weak interaction of linear combinations. In addition, this paper compares the CF-GCN model with other models that use different methods, and the CF-GCN model performs well on three datasets. On the Twitter dataset, the accuracy of the CF-GCN model is 2.83% higher than the Rep-Walk model and 2.31% higher than the ABSACap model. On the Laptop dataset, the accuracy of the CF-GCN model is 1.01% higher than the DGEDT model. Experimental results show that the feature combination method of cross-feature has obvious advantages over other feature extraction methods, and it can better extract the correlations between features.
We first performed an ablation analysis for the input layer to verify the rationality of position embedding and part-of-speech embedding merging based on the BI-LSTM model, as shown in Table 4.
Input layer ablation comparison
Input layer ablation comparison
From the analysis in Table 4, we can see that with the inclusion of location information in the BI-LSTM, words close to the location of the aspect term enjoy higher weights. In comparison, words farther away from the location of the aspect term have relatively lower weights. The performance of the w Post model is improved across the three datasets, indicating that the aspect-based location embedding serves to differentiate the importance of context. By introducing part-of-speech information into BI-LSTM, the model performance of the w Pos model was improved on both the Twitters dataset and the Restaurants dataset, demonstrating the positive impact of the inclusion of part-of-speech on the sentiment information of the analyzed aspect term. Finally, both po-sition and part-of-speech information were added to the BI-LSTM model for testing, which performed best on both the Twitter dataset and the Laptops dataset, demonstrating that both contributed positively to the model’s performance.
Then, we performed an ablation analysis of the model architecture to verify the validity of the incorporation of each part of the model, performing an ablation test based on the CF-GCN model, as shown in Table 5.
Model architecture ablation comparison
From the results in the above table, we see that the effect of CF-GCN is significantly reduced after removing the Mask mechanism, and the accuracy rates in the Twitter and Laptop datasets are reduced by 1.71% and 1.83%, respectively, indicating that the Mask mechanism plays a role in filtering invalid information. Secondly, removing the cross features, the accuracy of the model in the Twitter and Restaurant datasets decreased by 1.0% and 0.77%, respectively, indicating that the linear combination has a weak ability to learn feature interaction and cannot give full play to the advantages of GCN.
Since the depth of information captured by GCN is directly related to the number of GCN convolutional layers, we conducted visualization experiments on the original GCN model. The integrated model of Bi-LSTM and GCN uses the number of GCN convolutional layers as a hyper-parameter to observe the performance of GCN, as shown in Figure 3.
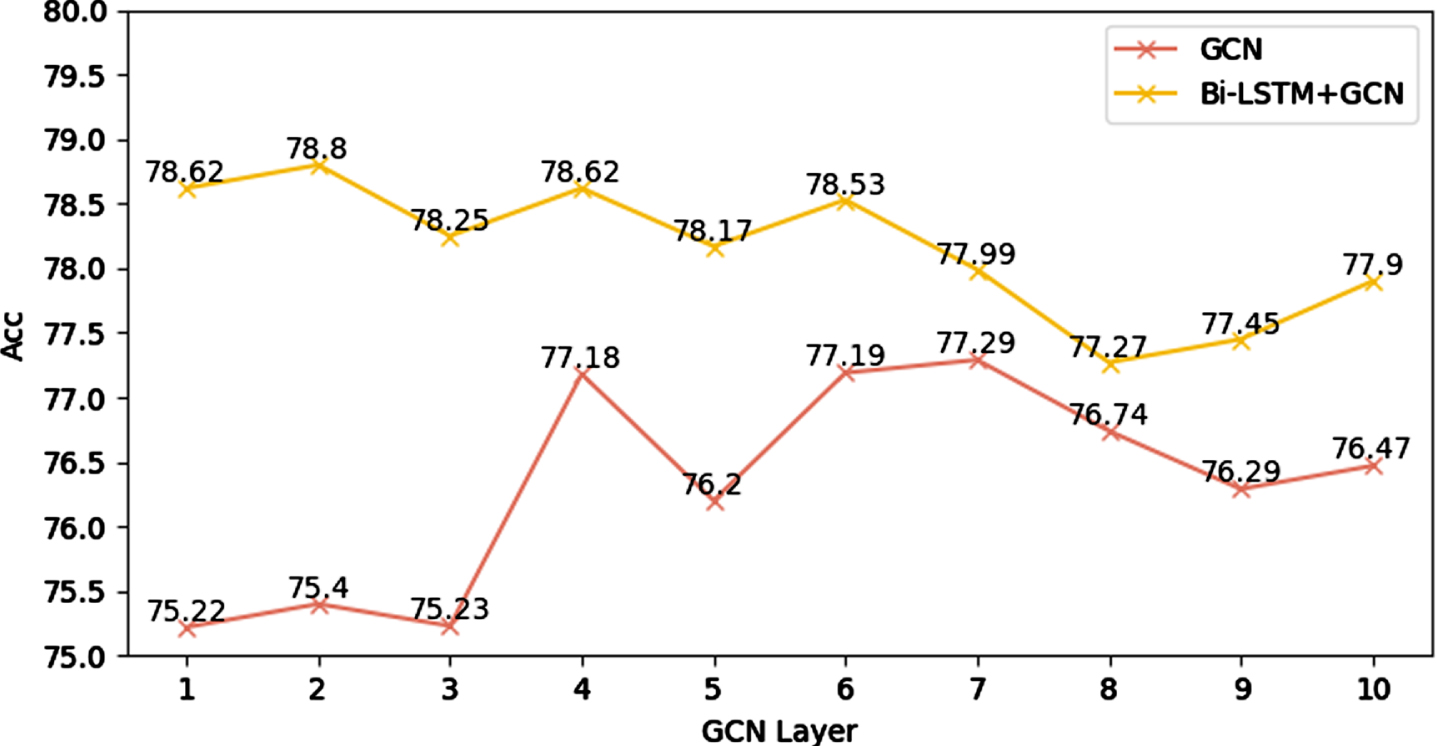
GCN model convolutional layers test.
It can be seen from Figure 3 that from the perspective of GCN model performance, when the layer is equal to 7, the performance is the best. When the number of convolution layers is less than 4, GCN is not enough to obtain deep node information; when the number of convolution layers is in the range of 8 to 10, as the number of convolutional layers increases, accuracy shows a downward trend, which results in an over-smoothing problem. From the perspective of the integrated model of Bi-LSTM and GCN, the integrated model achieves the best performance when the number of convolutional layers is 2. The advantage of the Bi-LSTM model in modelling global sequence information allows the integrated model to achieve the best performance without relying on too high a convolutional depth. In summary, the integrated model has the advantage of modelling global sequence information. The lowest accuracy value of 77.27% is at the same level as the highest accuracy value of 77.29% for the GCN model. The integrated model is undoubtedly the best choice, and the convolutional layer value of 2 is the best hyper-parameter.
In order to test the influence of the cross feature order on the practical effect, we set the number of convolutional layers of GCN to 2 to test the relationship between the model performance and the cross-order. The effect is shown in Figure 4:
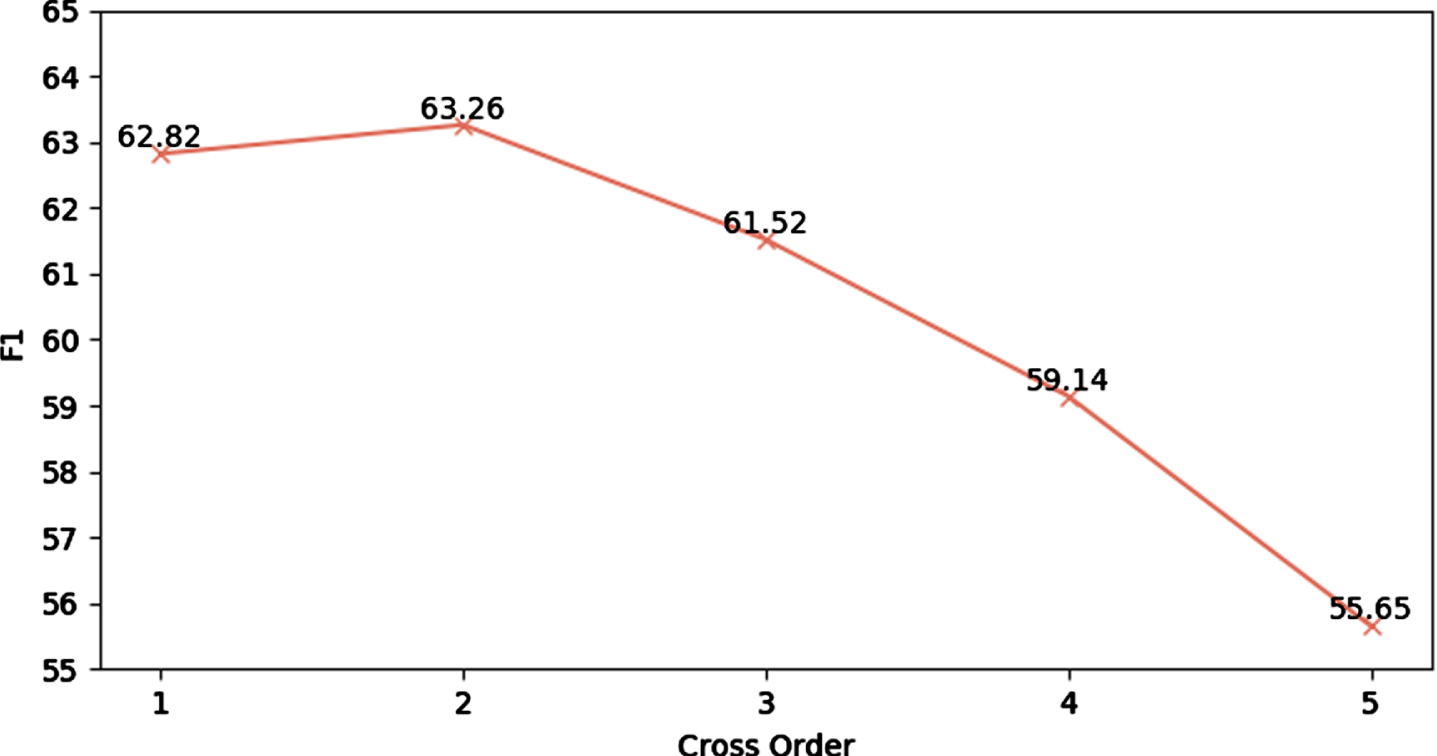
CF-GCN model cross-order test.
As shown in figure 4, the best result is obtained when the cross order is 2. When the cross order is 1, the linear combination between features does not constitute a direct cross effect. When the cross order is greater than 2, as the cross order increases, the noise generated by the cross of invalid features increases, and the accuracy rate decrease precipitously. When the cross order is 5, the F1 value slips by 7.61%, indicating that the noise has seriously affected the model’s performance. Therefore, the hyper-parameter of the cross features is optimal when taken as 2.
This paper analyses the model’s performance using weighted heatmaps to highlight the differences between the GCN based on cross-feature and traditional GCN models. The CDT and ASGCN model share two parts with our CF-GCN model: following the traditional syntactic tree structure; and an integrated model of the joint LSTM and GCN. The difference is that the CDT model uses the original form of the GCN, and the ASGCN model improves the aggregation process of the GCN algorithm by using a gate mechanism to calculate the contribution of neighboring nodes to the target node. The CF-GCN model, on the other hand, improves the feature transformation process of the GCN algorithm by replacing the weighted summation operation with the feature product operation. Therefore, the CDT and ASGCN models were chosen as the baseline models. Since neither CF-GCN nor CDT adopts the attention mechanism, we calculate the impact of the current word change on the final output by masking the word vector representation in the final output. Finally, we use the difference between the final output before and after the change to calculate the word influence score. The higher the obtained score, the greater the importance the model places on the current word. The effect is shown in Figure 5:
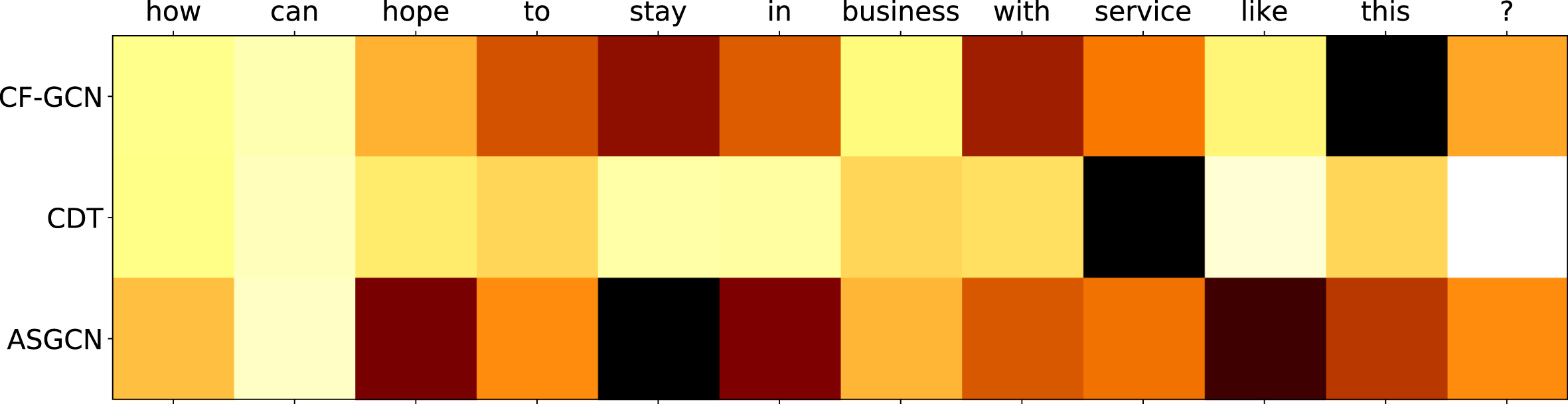
CF-GCN example weight heatmap.
Given the example: "How can hope to stay in business with service like this ?" the aspect term is "service", which corresponds to the " negative " sentiment polarity. First of all, CDT gives the most significant attention to "service". The attention to other words is roughly the same, which means that the model fails to obtain valid information from the sentence environment, leading to the model’s wrong classification results. Secondly, ASGCN pays the closest attention to "stay in" and also focuses on "hope" and "like". However, the object of "hope to stay in" is "business" rather than "service", the polysemous word "like" also confuses sentiment polarity, which leads to the model giving incorrect classification results. Finally, CF-GCN gives the greatest attention to "this". In the case of great attention to "stay", the model accurately identifies the auxiliary role of "with", and the object referred to by "with. . .this" is exactly the aspect of "service". The comparison results show that our model pays more attention to the sentence environment than CDT and ASGCN. It focuses on mining the co-occurrence relationship of words in the context.
The feature transformation process of the traditional GCN model is similar to a Multi-layer perceptron, using a weighted summation approach to generate a linear combination of features. In a semantic environment with ambiguous sentiment information, this way of learning feature interactions is slightly inferior. This paper designs a novel cross-feature graph convolutional neural network model to address this problem. In the convolution process of GCN, the model generates non-linear features in the form of feature multiplication, replacing the original linear combination method. The advantage is that it iteratively generates different cross-feature pairs, constructing a diverse feature co-occurrence scene and improving the GCN model’s ability to learn potential connections between features. A series of experiments demonstrate the validity of the cross-feature.
Undoubtedly, our model also has several limitations: (1) the problem of cross-order, increasing cross-order will not only increase the complexity of the model and lead to the risk of overfitting but also introduce noise, which may reduce the performance of the model. (2) There is a conflict between cross-feature and information pruning methods. The advantage of cross-feature is to extract the correlations between different features and expand the information collection range of the model. In contrast, pruning methods weaken the interference of irrelevant features and focus on a small portion of useful information. Currently, these two methods are not compatible with each other.
In the future, this paper will focus on developing a selectable feature-cross algorithm that strategically interacts with node information that has a positive effect on aspect terms to further improve the accuracy of aspect-based sentiment classification.
Footnotes
Acknowledgments
This work is supported by National Natural Science Foundation of China (No. 62166041) .