
Abstract
Hate speech on social media post is running now a days. Social media like YouTube, Twitter, and Facebook etc. are responsible for hated speech. Hated speech spreads through digital media, causing individuals to get confused and adopt prejudiced viewpoints. To limit the negative effects of disinformation on the digital platform, it is critical to detect it. Now a days, lots of digital platforms are available. Hate speech detection in dataset is very difficult. As a result, the Twitter dataset is of the size of 25296 is presented in this work. Many deep learning techniques are applied on Twitter dataset. The Google Colab tool is used to scrape dataset material. Different deep learning approaches are utilized to boost the accuracy of the hated speech dataset. For training and validation accuracy and loss some models are used on Twitter dataset like Bi-directional Long Short Term Memory with Glove, Bi-LSTM, and Embedding from Language Model (Elmo) with deep learning, Convolutional Neural Network (CNN), Long Short Term Memory with Glove and LSTM. The performance of the proposed tweet dataset is evaluated using a variety of deep learning classifiers on text dataset. The planned deep learning techniques produced good results on tweet dataset. LSTM with Glove gave the highest accuracy 0.89 and minimum loss 0.19 on tweet dataset. So when compare our model on same dataset that was used earlier then we get highest accuracy and minimum loss.
Introduction
In today’s scenario transmission of messages for communication are done by Social Media Networks (SMNs). Nowadays, SMNs are the principal medium for spreading hate speech. As a result, misfeasance has increased crucially in recent scenario. More studies are being carried out to combat the rise in hate speech on Social Media (SM). SMN services such as Facebook, WhatsApp, We Chat, Twitter, and Instagram are simple to use and a popular venue for people to engage [3]. The availability of information in a multitude of media, such as audio, video, and photos, is one of the reasons for these platforms’ success [3]. On these platforms, individuals discuss current events and express their opinions, which they share with their virtual family and friends via SMN [5].
Deep learning (DL) technologies are useful for producing more accurate and less subjective results [8]. Text classification operations should be automated [33]. For hate speech identification, significant advances in deep learning algorithms have been made, including classical deep learning, ensemble learning, and deep learning (DL). Several deep learning algorithms have attained superior results as a result of the extraordinary breakthrough in NLP.
To amplify the categorization of social media texts as hatred speech or non-hatred speech, academics and practitioners need to keep up with rapidly expanding deep learning approaches. On SM, a lot of time and work has gone into developing new and useful tools that better catch hate speech. In the SM world, slangs and new vocabulary are continuously developing [1]. Because of the growing use of social media, hate speech has become commonplace. Hate speeches, according to studies, can negatively alter the narrative and the political discourse [1].
Abusive social media interactions are a complex phenomenon with several modalities and motivations. Abusive languages have two instances like cyberbullying and hate speech that have drawn the attention of academics in recent decades as a result of their negative implications in our society [29]. On social media several experiments automatically identify these unwanted communications.
By using deep learning methodologies automatic hate speech detection is still very new. During this research, there were few recent and related survey publications accessible on hate speech identification systems. Deep learning methods beneficial for hate speech identification and content analyze from social media. In the last several decades, offensive statements like hated speech and online bullying have been the most investigated subjects in Natural language processing [32].
The identification and classification are the inappropriate remarks in terms of social media data analysis. Deep learning algorithms have proved quite helpful [4]. Advances in deep learning algorithms research have had a significant influence in a variety of fields, resulting in some keys and approaches for surveying extensive amounts of data in natural-world situations.

National News Picture on 12 Nov. 2021.
In this examined a brief evaluation of six hate speech detection classifiers like Bi-LSTM with Glove, Bi-LSTM, CNN, and Elmo with deep learning, LSTM and LSTM with Glove. In natural language processing detection of automated hate speech provided a concise and critical review.
The utmost contribution of this paper are: Introducing a deep learning models on Twitter dataset that consist the 25296 tweets to make a more accurate outcomes. In this paper utilizing the global vector embedding for hate speech detection. Obtain the training and validation accuracy and loss by using Bi-LSTM with tweet dataset, Bi-LSTM with Glove tweet dataset, CNN tweet dataset, Elmo with deep learning tweet dataset, LSTM with tweet and LSTM with Glove with tweet dataset. Analyzing the tuning parameter setting for better classification. For tuning parameters, batch size, activation function, epochs, dropout rate, loss function and optimizer has been used. Our proposed technique LSTM with Glove give 0.89 accuracy that is highest and lowest loss 0.19 from among all the deep learning classifiers that I have used. Our proposed technique give high precision, recall and f1-score values from previous used model that is Logistic Regression (LR) with L2 regularization by T. Davidson [42].
Further we will discuss
In this section the research used the domain-specific embedding and focused on hate speech detection. There has been a significant amount of study with regards to detecting hate speech, but not much effort specifically identifying hate speech.
Hate speech has no broadly accepted definition. There is no unanimity on an individual definition [13]. Hate speech can help annotators work more efficiently. As a result, the annotators’ agreement rate will rise [4]. It might be difficult to tell the difference in certain nations. Hate speech will be defined in a precise and universal way. It is increasingly challenging and complicated. Any speech that contributes to a criminal conduct, on the other hand, is penalized as a hate crime. Other harmful online behaviors, such as cyberbullying, should be addressed in addition to hate speech. Hate speech differs from cyberbullying in that it impacts a larger group of people and has societal implications. Humans and computers have failed to comprehend hate speech because it is a complex and incomprehensible notion. [20].
Y. Zhou et al. [8] introduced three types of deep learning classification methods like Elmo, BERT and CNN on hate speech detection to achieve the accuracy 70.2%, 70.1%, 73.2% and F1 score 63.6%, 62.3% and 69.8% respectively. In this author focus on the fusion approach on original English datasets that consist of 9000 tweets for training and 3000 for testing to get the higher accuracy. Optimized Support Vector Machine with character n-gram recorded the best true positive rate of 89.4% for hate speech with overall accuracy 64.6%, while it recorded very low true positive rate of 6.9% for offensive speech. Novel word dense embedding’s will also be developed by O. Oriola et al. [4]. Acheampong, F. A. et al. [38] has been suggested to use text-based ED. The paper defines text-based ED, discusses emotion models, and lists several significant datasets that are accessible for text-based ED research. The three basic methods used to create text-based ED systems. Mehta, H et al. [39] told about the datasets that underwent exploratory data analysis to reveal numerous trends and insights, and several explainable models were trained on both datasets to produce practical, comprehensible findings. Y. Zhou et al. [40] concentrate on a number of well-known machine learning techniques for text tagging, such as Convolutional Neural Networks (CNNs), Bidirectional Encoder Representation from Transformers (BERT), and Embedding’s from Language Models (Elmo) use these techniques with the SemEval 2019 Task 5 data sets and demonstrate that the classification’s accuracy and F1-score have significantly improved. P. K. Roy et al. [41] developed an automated system with the help of Deep Convolutional Neural Network (DCNN). The new DCNN model outperformed the current models and achieved the best accuracy, recall, and F1-score values of 0.97, 0.88, and 0.92, respectively, using the tweet text and Glove embedding vector to capture the semantics of the tweets.
Dataset and methodology
The following is a description of the methods employed in this study. IEEE Explore, ACM, Science Direct, Scopus, were mostly used to find the needed publications for this research effort.
These databases were chosen because of their reputation. Some of the search keywords utilized in the retrieval include hate speech observation, disrespectful remarks, hostile comments, online bullying, vulgarity, and harmful comments on social media [21].
Dataset description
Twitter dataset that consist the 25296 tweets [42]. This dataset is also publicly available on Kaggle. In this classify the data on the basis of three classes that is class 0 for hate speech, class 1 is for offensive and class 2 is for neither. This is link of dataset that provide on Kaggle.
https://www.kaggle.com/datasets/mrmorj/hate-speech-and-offensive-language-dataset
Deep learning
Standard deep learning cannot successfully analyses some text datasets since they are large and not linearly separable. It is difficult to portray on the Tuning plane. The DL approach [8] was developed to address the problem of anticipating significant trends in non-separable data that is linearly non-separable. DL [8] is simply an extension of the ML approach called an article neural network (ANN). The complexity of the problem determines the depth. Image processing, for example, frequently needs more layers than social media text prediction. Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN) have garnered the interest of academics because they better capture phrase meaning. In contents analysis the semantics and syntax of words are captured by CNN.
Deep learning classifiers
Hate speech via social media has been detected using several deep learning classifiers like Bi-LSTM, Bi-LSTM with Glove, CNN, and Elmo with deep learning, LSTM with Glove and LSTM. The researchers also tested the technique provided by, LSTM (Glove) produced highest accuracy and lowest loss when training and validation done.
LSTM
For solving prediction problems we can use long short-term memory that incorporate under Deep Learning or Recurrent Neural Networks (RNNs) [3] [17].
LSTM is a kind of Recurrent Neural Network. Long-term dependency is an issue that LSTMs were created to address. All recurrent neural networks are made up of a series of repeated neural network modules [2]. When chain like structure is consider in LSTMs then repeating modules are different. One node’s output to other nodes’ inputs represented by a complete vector in Fig. 2. Point-wise operations like vector addition is represented by circles, whereas layers of trained neural networks are represented by boxes. When lines merge then concatenation happens and when a line’s content is duplicated then forking happens and delivered too many locations [2].
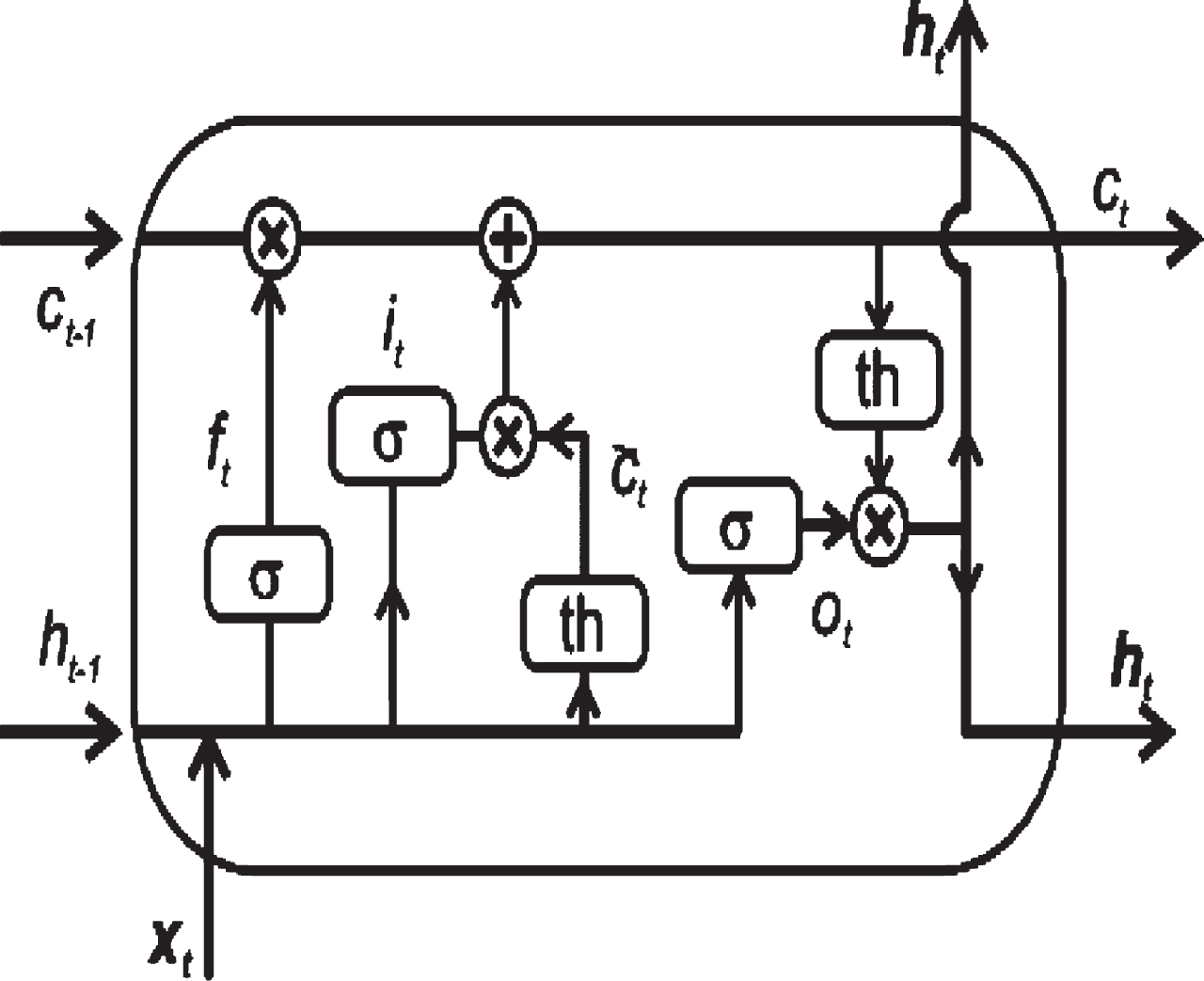
LSTM Architecture.
In this we use architecture of LSTM in Fig. 2. The cell is a type of a conveyor belt. Minor linear changes done by whole chain. Unchanged data can be easily passed. In this LSTM architecture information can be added or deleted by using cell state, which is known as gates. By using gates we can pass the information. These gates are made up of a sigmoid layer and this generates the numbers between 0 and 1. If the value is 0 that mean nothing to pass and if the value is 1 that mean everything is allow to pass.
This technique will allow to store the information in backward or forward in both directions. This technique distinguish it from LSTM when we compare our input with LSTM technique. In LSTM we can flow our input only in one direction either backwards or forwards. While with Bi-LSTM we can flow our input in both direction.
Bidirectional long-short term memory (Bi-LSTM) is the technique of allowing any neural network to store sequence information in both backwards (future to past) and forwards (present to future) orientations (past to future). Bidirectional LSTMs vary from conventional LSTMs in that their input flows in both directions [3].
Emotion detection is one of the most popular study subjects these days. Emotion detection technologies can help machines and people communicate more effectively. It will also aid in the improvement of decision-making. To identify emotions from text, many Deep learning Models have been developed. However, the Bidirectional LSTM Model is the center of this paper [20].
CNN
Deep neural networks are extensively utilized and have resulted in a number of advancements in NLP. Convolutional Neural Networks (CNNs) are a type of deep, feed-forward artificial neural network that employs a multi-layer perceptron with little preprocessing [8].
In a Deep Learning system a Convolutional Neural Network [8] take an input picture, assign relevance to various aspects and objects in the image, and distinguish between them.
ELMO
Elmo is a deep contextualized word representation that represents both intricate features of word use and how these properties vary across language settings [8]. Elmo distinguishes between semantic (meaning-related) and syntactic (grammar-related) links. It outperforms existing word embedding’s like Word2Vec [8] in tackling the problem of polynomial words.
Figure 3 shows the proposed framework. For calculating training & validation accuracy and loss results we applied different classifiers on Twitter dataset.
Proposed framework.
In a nutshell, the properties of Bi-LSTM, CNN, LSTM and Elmo, are as follows. Word embedding is the emphasis of Bi-LSTM, LSTM and Elmo while neural network processing is the center of CNN. All of these techniques have a long history in NLP and each has its own set of advantages [8].
Text classification on hated speech has been intensively explored and employed in numerous real-world applications during the last few decades. Hate speech classification using deep learning may be divided into different steps, as shown in Fig. 4.
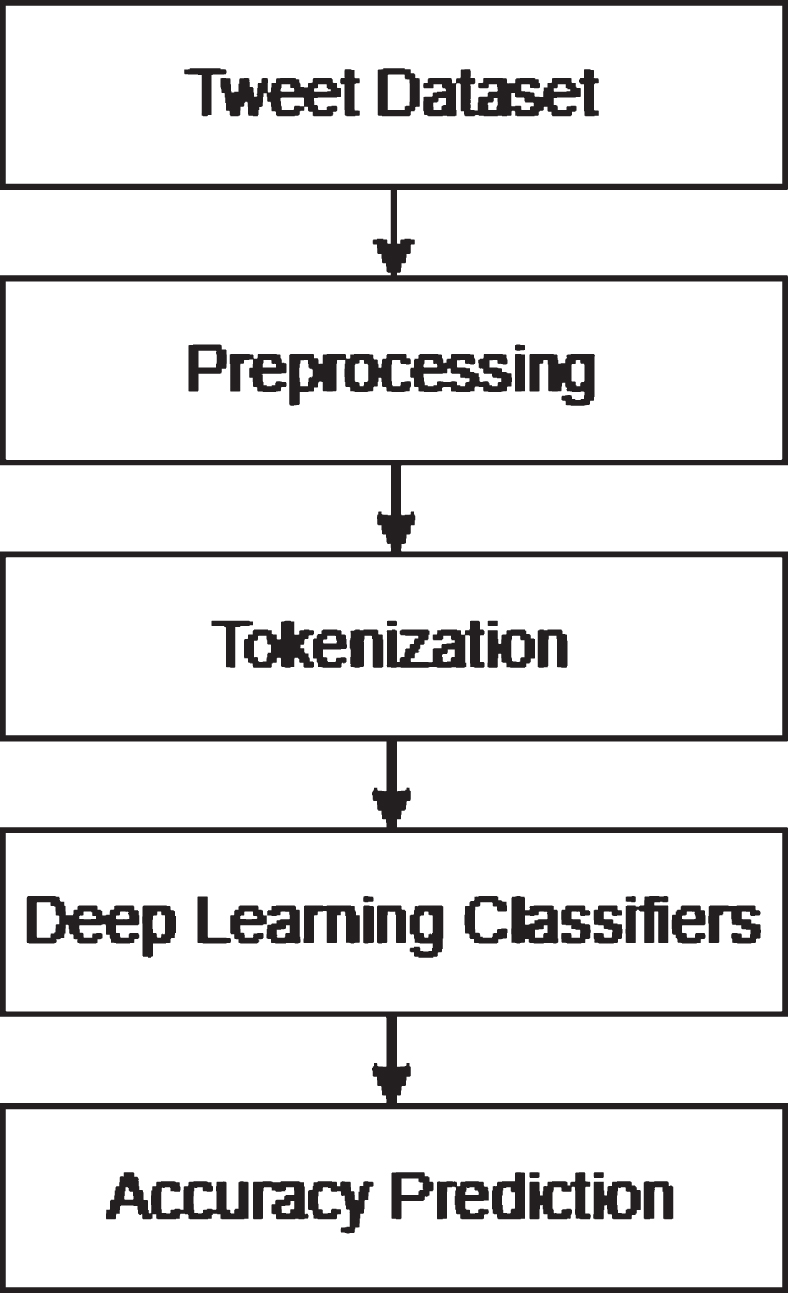
Process flow of our work.
In this work we select the tweet dataset of the size of 25296. On this dataset we perform the preprocessing. After that apply the tokenization like global embedding. After that we apply the different deep learning classifiers like Bi-directional Long Short Term Memory (Bi-LSTM), Bi-LSTM with Global Vector (Glove), Convolutional Neural Network (CNN), and Embedding from Language Model (Elmo) with deep learning, Long Short Term Memory (LSTM) with Glove and LSTM. On basis of this process we predict the accuracy.
Data Collection: We used 25296 tweet datasets for our research to calculate training and validation accuracy and loss. In this scenario, we must choose the tweet dataset. Preprocessing: In this we prepare the data according to our requirement. And remove the stop words like is, an, the etc. or unnecessary details. For converting the words into its root words stemming is applied. For final implementation text and labels are taken. Tokenization: Unstructured data is common in texts. In deep learning approaches mathematical modelling is a core component. The text input from unstructured character converted into a structured character [10]. Unwanted things like non-English words, phrases and unnecessary numbers must be eliminated. Vector techniques can be used to turn the dataset into a vector space once it has been cleaned. Deep Learning Classifier: Hate speech is frequently modelled as a text categorization assignment. Hate speech may be classified using a variety of different classifiers. Most important thing is how we choose the best classifier for hate speech detection. This research focuses on the improvements made in these tactics thus far. In this we use deep learning classifiers like Bi-directional Long Short Term Memory (Bi-LSTM), Bi-LSTM with Global Vector (Glove), Convolutional Neural Network (CNN), and Embedding from Language Model (Elmo) with deep learning, Long Short Term Memory (LSTM) with Glove and LSTM. Accuracy Prediction: Table 1 contain the classifiers that we used for our research and predict the accuracy and loss when applying different classifiers on Twitter dataset.
Measure accuracy and loss based on classifier
Table 1 shows the accuracy and loss based on classifiers.
Accuracy can be calculated in terms of positives and negatives as follows:
Where TP = True Positives, TN = True Negatives, FP = False Positives, FN = False Negatives
We used LSTM with Glove embedding for highest accuracy and minimum loss that is 0.89 and 0.19 respectively on tweet dataset. Because Glove embedding focuses on word co-occurrences throughout the corpus and its embedding’s are related to the chances of two words appearing together. It is easy to parallelize the implementation, which allows for more data to be trained on. That’s why we improved the accuracy by using LSTM with Glove embedding.
From Fig. 5 we got highest accuracy 0.89 and lowest loss 0.19 when LSTM (Glove) applied.
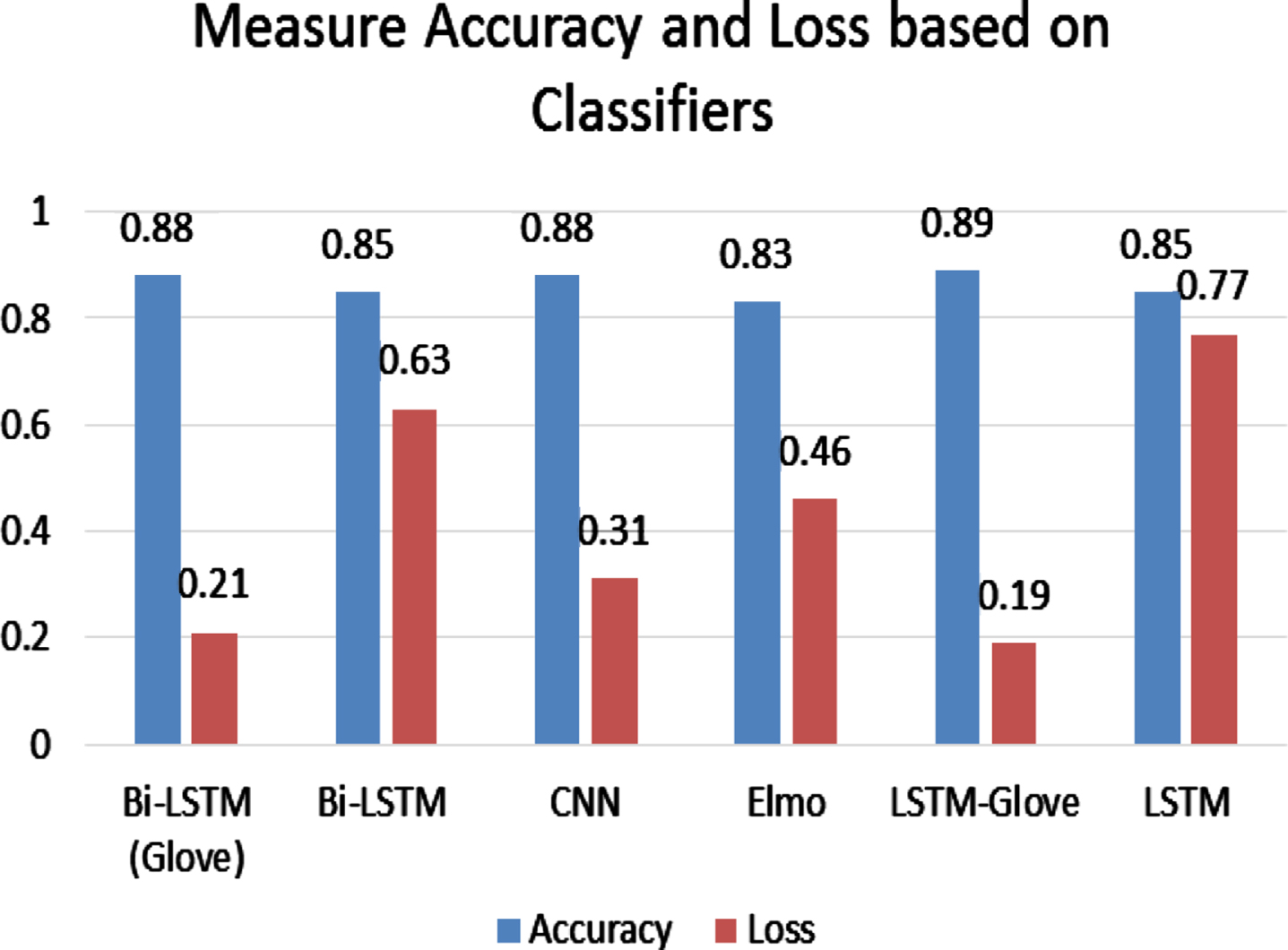
Measure accuracy and loss based on classifiers.
We also used a number of deep-learning models like Bi-LSTM with tweet dataset, Bi-LSTM with Glove tweet dataset, CNN tweet dataset, Elmo with deep learning tweet dataset, LSTM with tweet and LSTM with Glove with tweet dataset in this research. A deep learning model may automatically pick up new features for obtaining the training and validation accuracy and loss by using these deep learning classifiers.
Bi-LSTM with tweet dataset
In Table 2 we find the total parameters 5,161,403, trainable parameters 5,161,403 and non- trainable parameters 0. Found the accuracy 0.85 and loss 0.63.
Layered architecture of Bi-LSTM
Layered architecture of Bi-LSTM
Total parameters: 5,161,403; Trainable parameters: 5,161,403; Non-trainable parameters: 0.
In Table 3 set the parameters according to our requirements.
Tuning-parameter settings of Bi-LSTM
Figure 6(a) (b) shows the training and validation accuracy and loss by using Bi-LSTM with tweet dataset. Figure 6(a) represents that with the increased value of epochs training accuracy improves while validation accuracy decrease. Figure 6(b) represents the training loss decrease and when epochs increase then validation loss slightly increases.
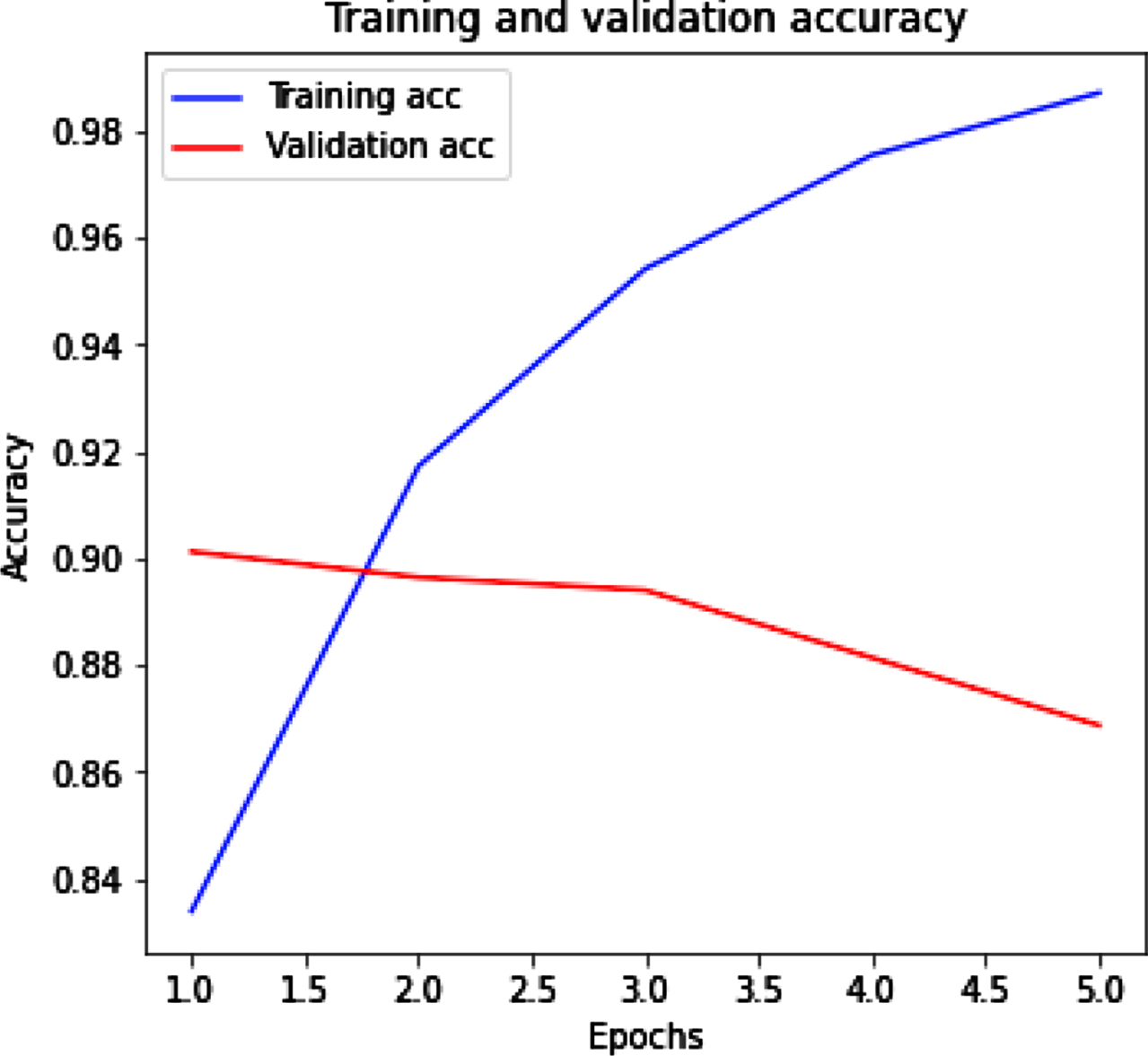
Bi-LSTM with training and validation accuracy.
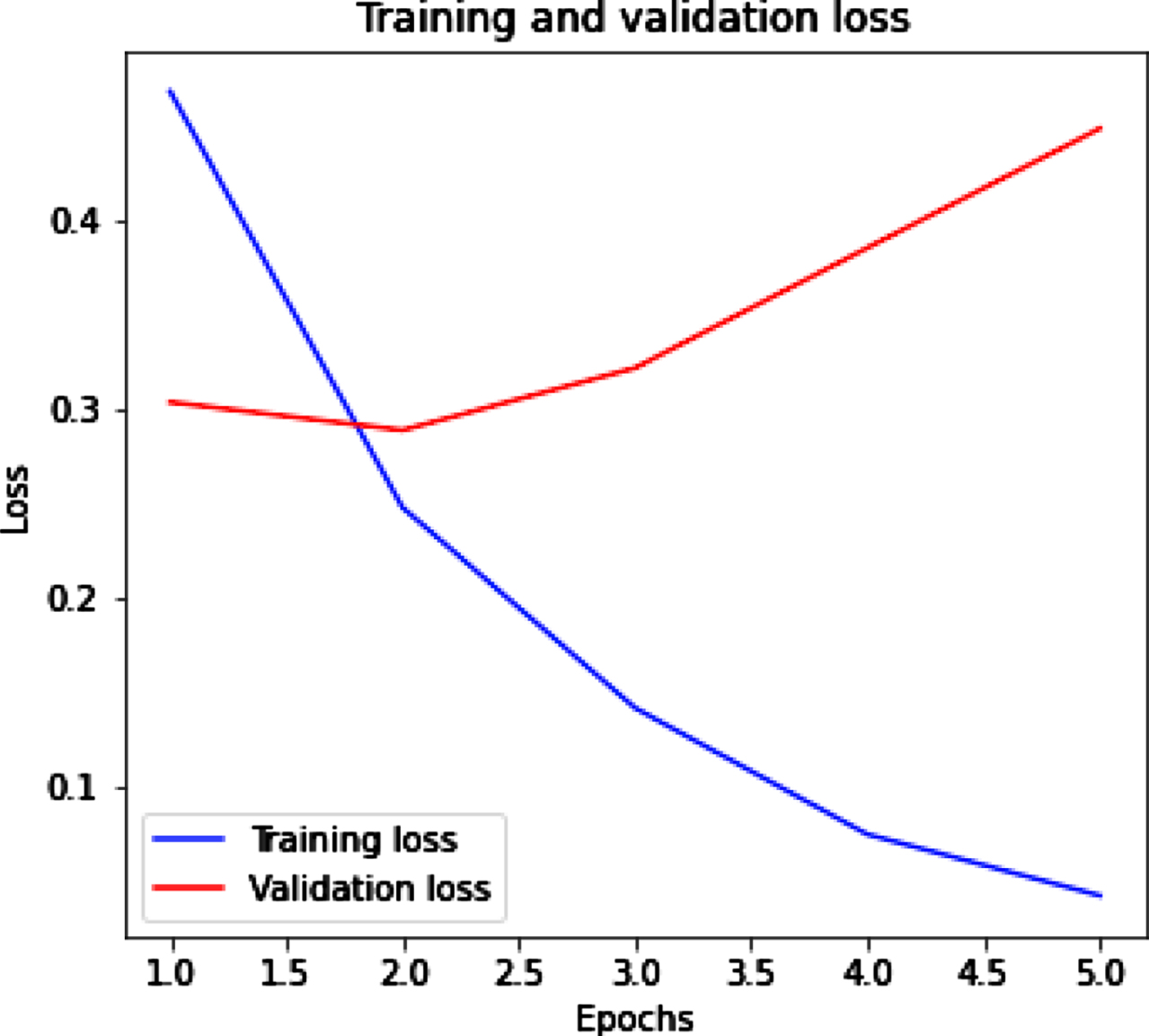
Bi-LSTM with training and validation loss.
From Table 4 we find the total parameters 3,684,283, trainable parameters 83,483 and non- trainable parameters 3,600,800. Found the accuracy 0.88 and loss 0.21.
Layered architecture of Bi-LSTM (Glove)
Layered architecture of Bi-LSTM (Glove)
Total parameters: 36,84,283; Trainable parameters: 83,483; Non-trainable parameters: 3,600,800.
In Table 5 set the standards according to required tuning parameters.
Tuning-parameter settings of Bi-LSTM (Glove)
Figure 7(a) (b) shows the training and validation accuracy and loss by using Bi-LSTM with Glove tweet dataset. Figure 7(a) represents that with the increased value of epochs training accuracy improves while validation accuracy slightly increase. Figure 7(b) represents the training loss decrease and when epochs increase then validation loss remain constant.
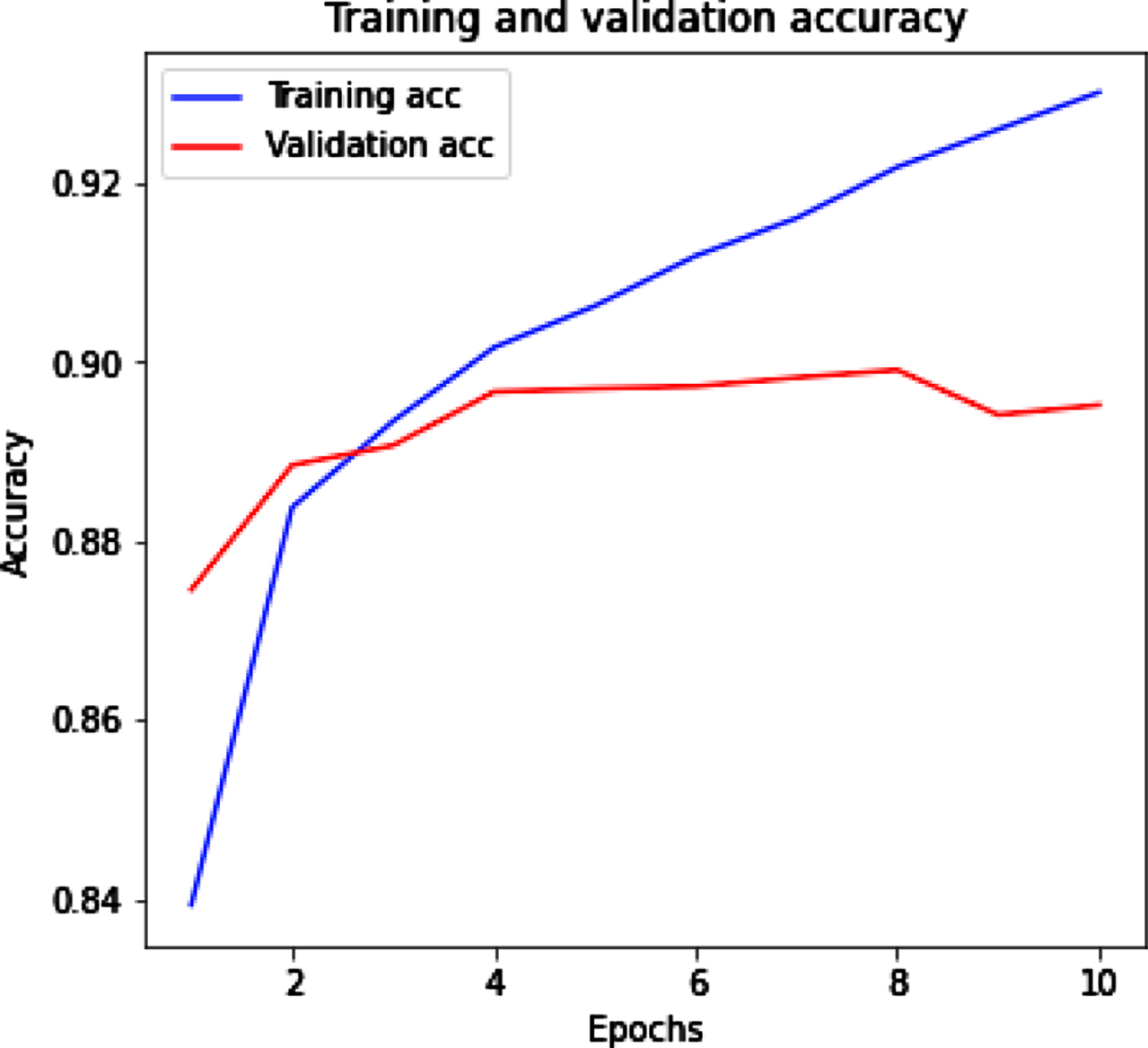
Bi-LSTM with Glove training and validation accuracy.
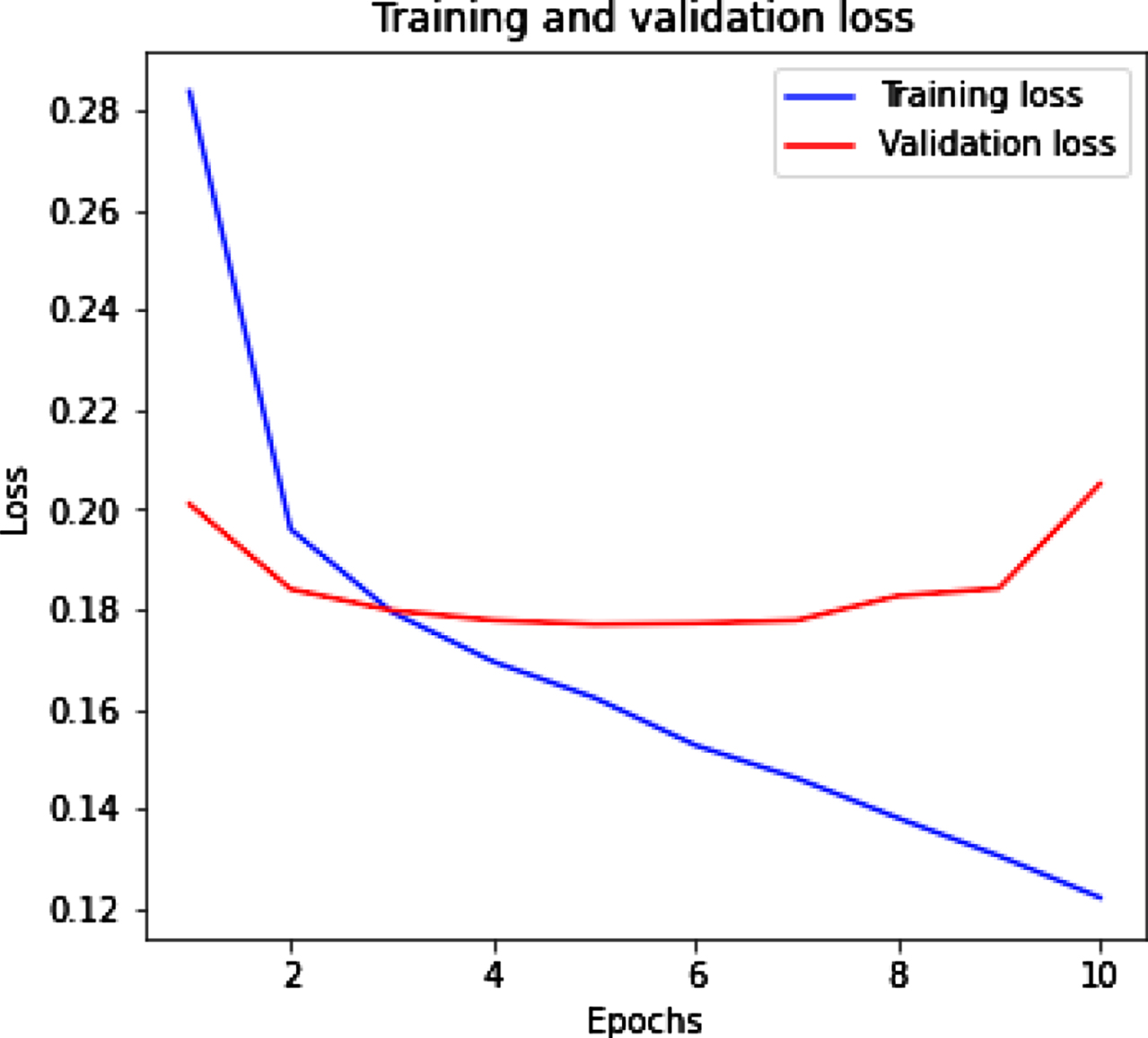
Bi-LSTM with Glove training and validation loss.
In Table 6 we find the total parameters 1,101,253, trainable parameters 1,101,253 and non- trainable parameters 0. Found the accuracy 0.88 and loss 0.31.
Layered architecture of CNN
Layered architecture of CNN
Total parameters: 1,101,253; Trainable parameters: 1,101,253; Non-trainable parameters: 0.
In Table 7 set the standards of CNN according to required parameters.
Tuning-parameter settings of CNN
From Fig. 8(a) (b) we get the training and validation accuracy and loss for tweet dataset by using CNN. Figure 8(a) represents that with the increased value of epochs training accuracy increased while validation accuracy decrease. Figure 8(b) represents the training loss decrease and when epochs increase then validation loss slightly increases.
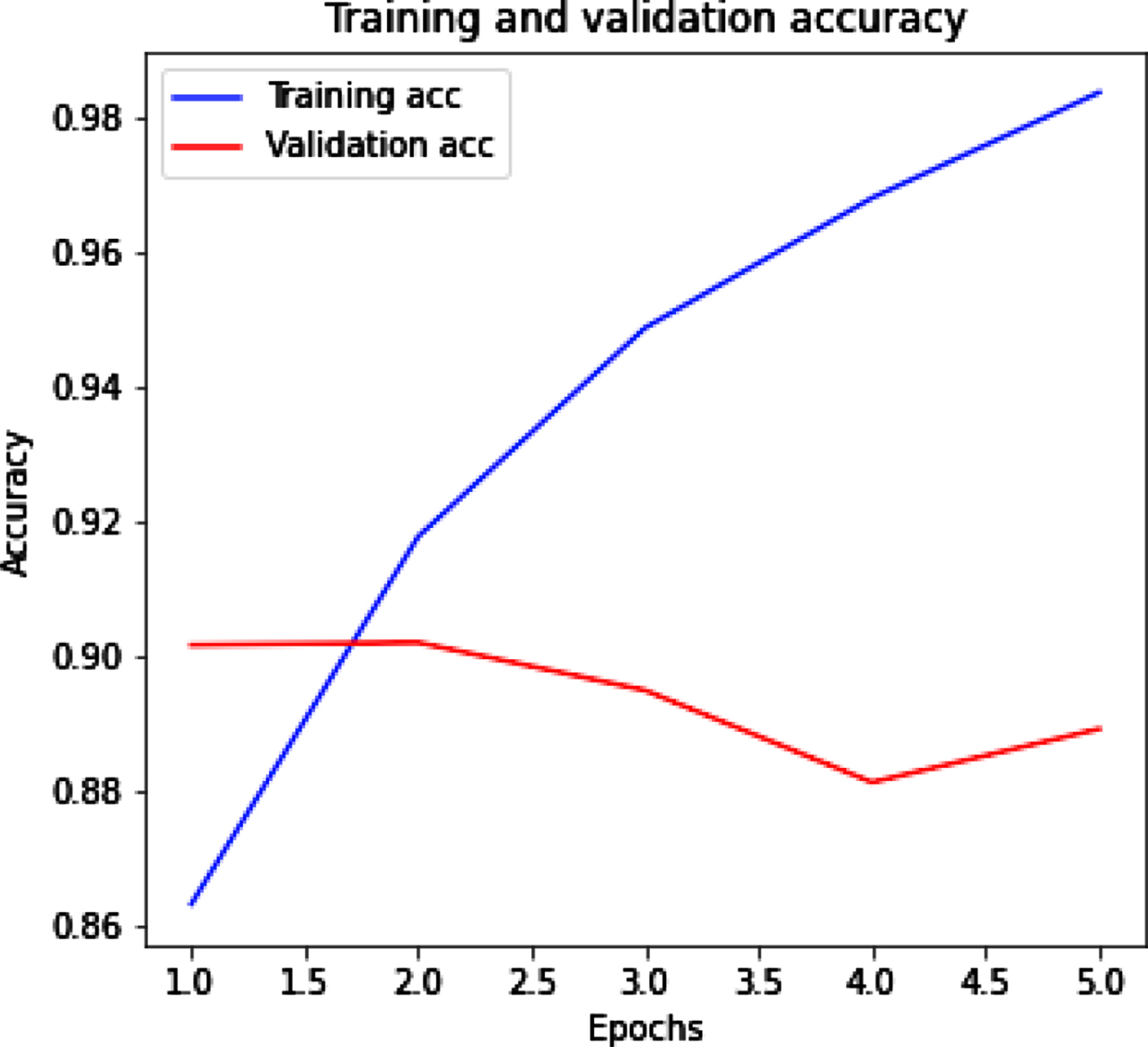
CNN with training and validation accuracy.
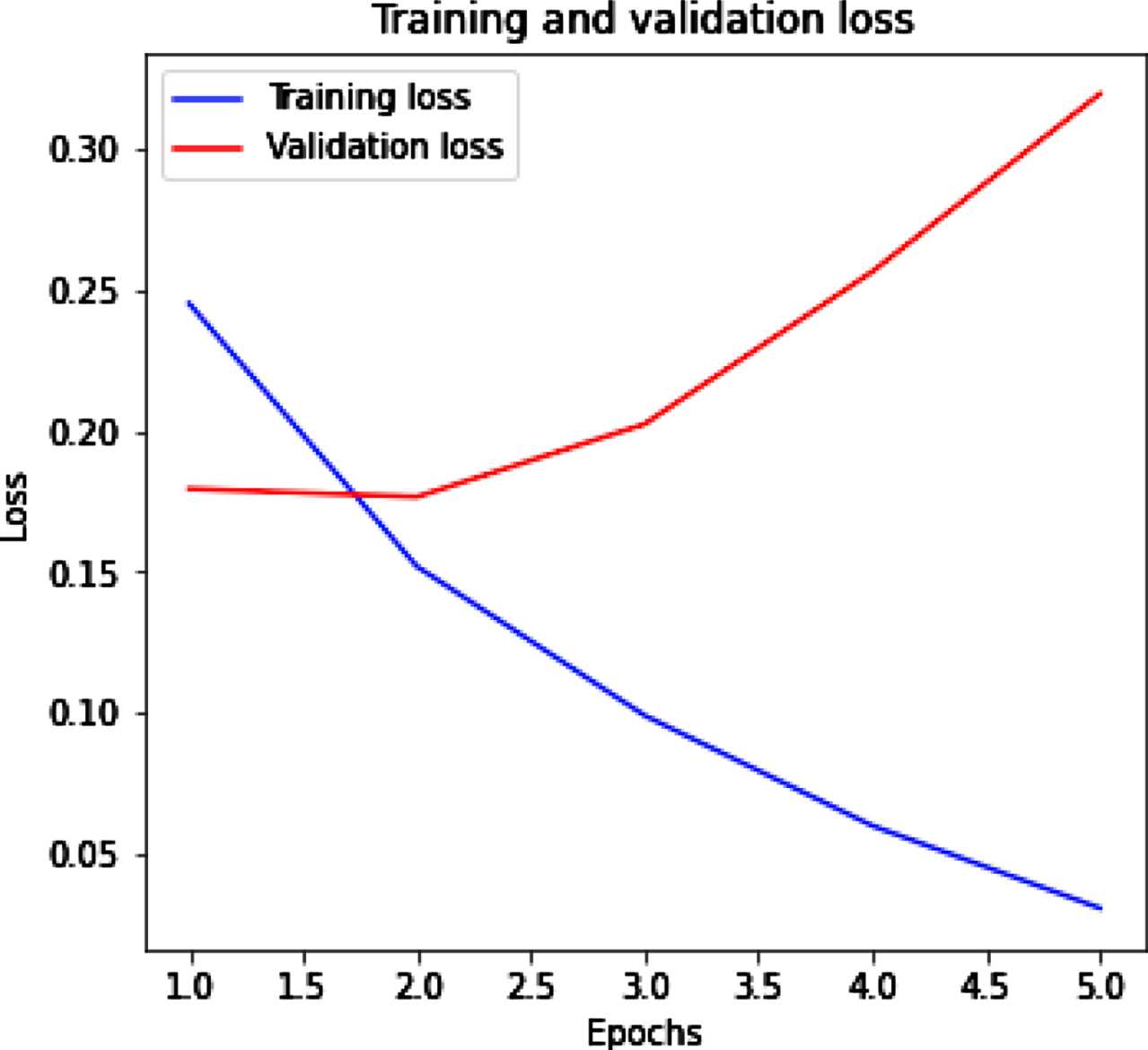
CNN with training and validation loss.
In Table 8 we find the total parameters 17,966,595, trainable parameters 17,966,595 and non-trainable parameters 0. Found the accuracy 0.83 and loss 0.46.
Layered architecture of Elmo
Layered architecture of Elmo
Total parameters: 17,966,595; Trainable parameters: 17,966,595; Non-trainable parameters: 0.
In Table 9 set the standards of Elmo according to tuning parameters.
Tuning-parameter settings of Elmo
Figure 9(a) (b) shows the training and validation accuracy and loss for tweet dataset by using Elmo. Figure 9(a) represents that with the increased value of epochs training accuracy improves while validation accuracy remains almost constant. Figure 9(b) represents the training loss decrease and when epochs increase then validation loss remains almost constant.
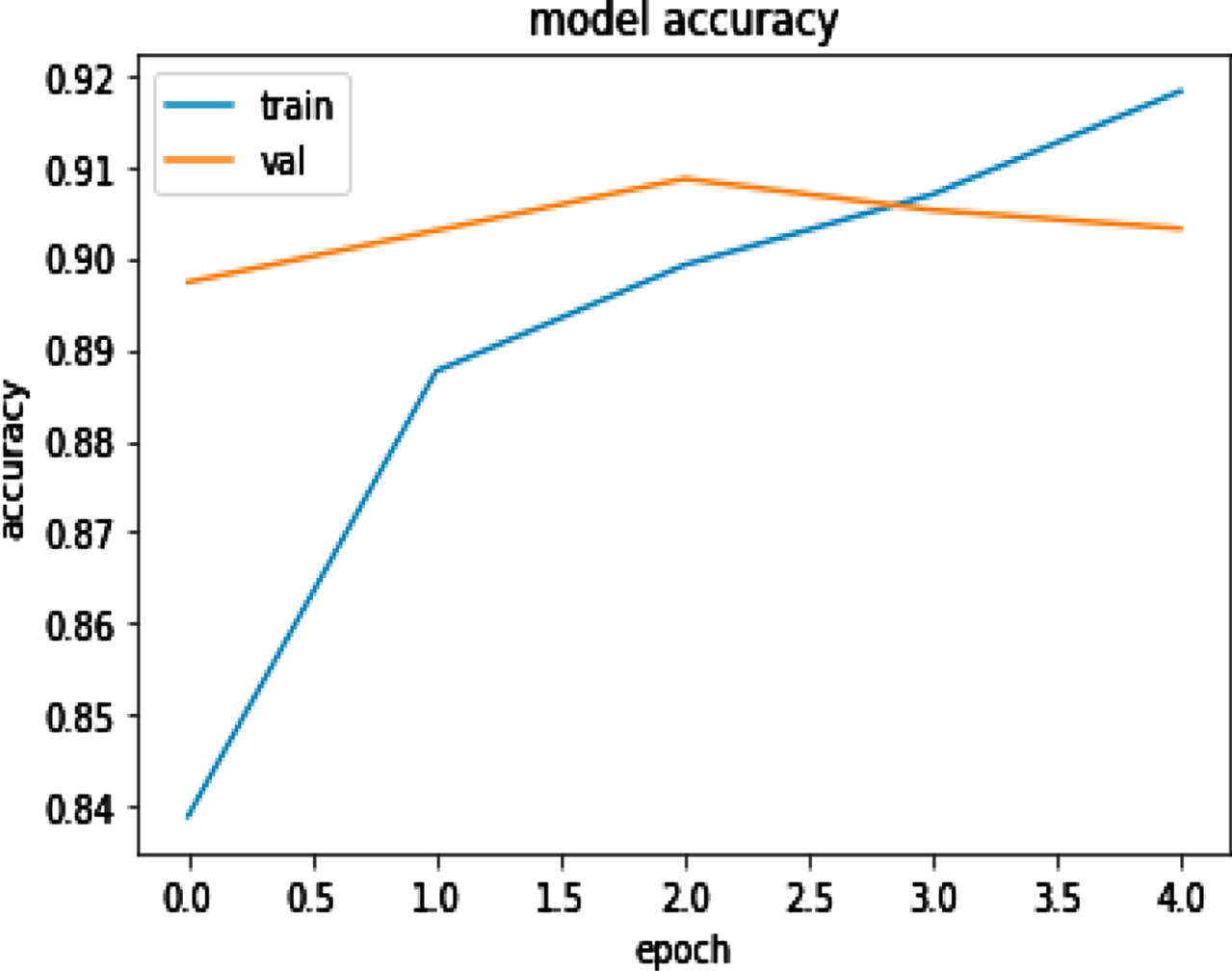
Elmo with deep learning training and validation accuracy.
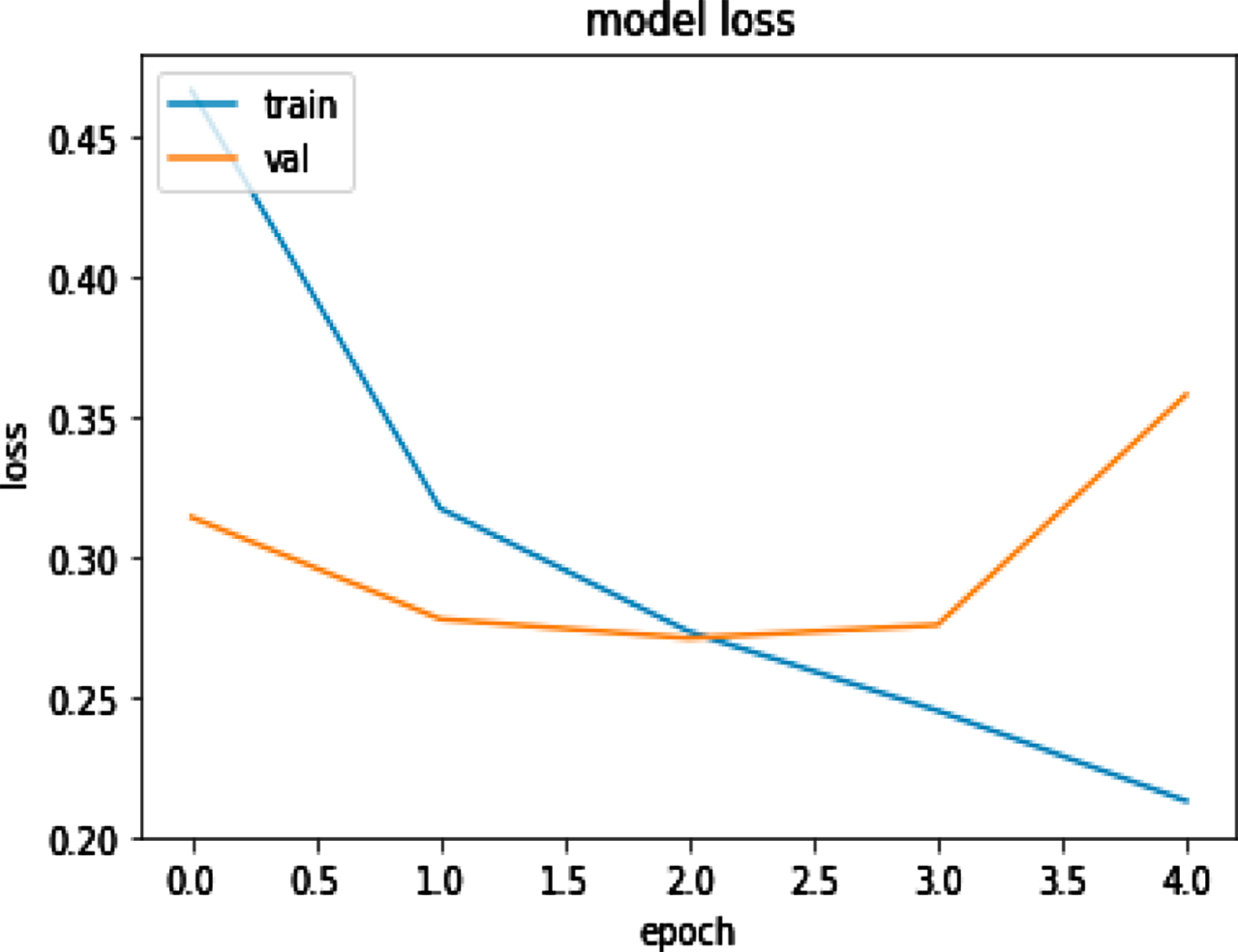
Elmo with deep learning training and validation loss.
In Table 10 we find the total parameters 3,642,643, trainable parameters 41,843 and non- trainable parameters 3,600,800. Found the accuracy 0.89 and loss 0.19.
Layered architecture of LSTM (Glove)
Layered architecture of LSTM (Glove)
Total parameters: 3,642,643; Trainable parameters: 41,843; Non-trainable parameters: 3,600,800.
In Table 11 set the standards according to requirements.
Tuning-parameter settings of LSTM (Glove)
Figure 10(a) (b) shows the training and validation accuracy and loss for LSTM with Glove tweet dataset. Figure 10(a) represents that with the increased value of epochs training accuracy improves while validation accuracy slightly increased. Figure 10(b) represents the training loss decrease and when epochs increase then validation loss remains almost same.
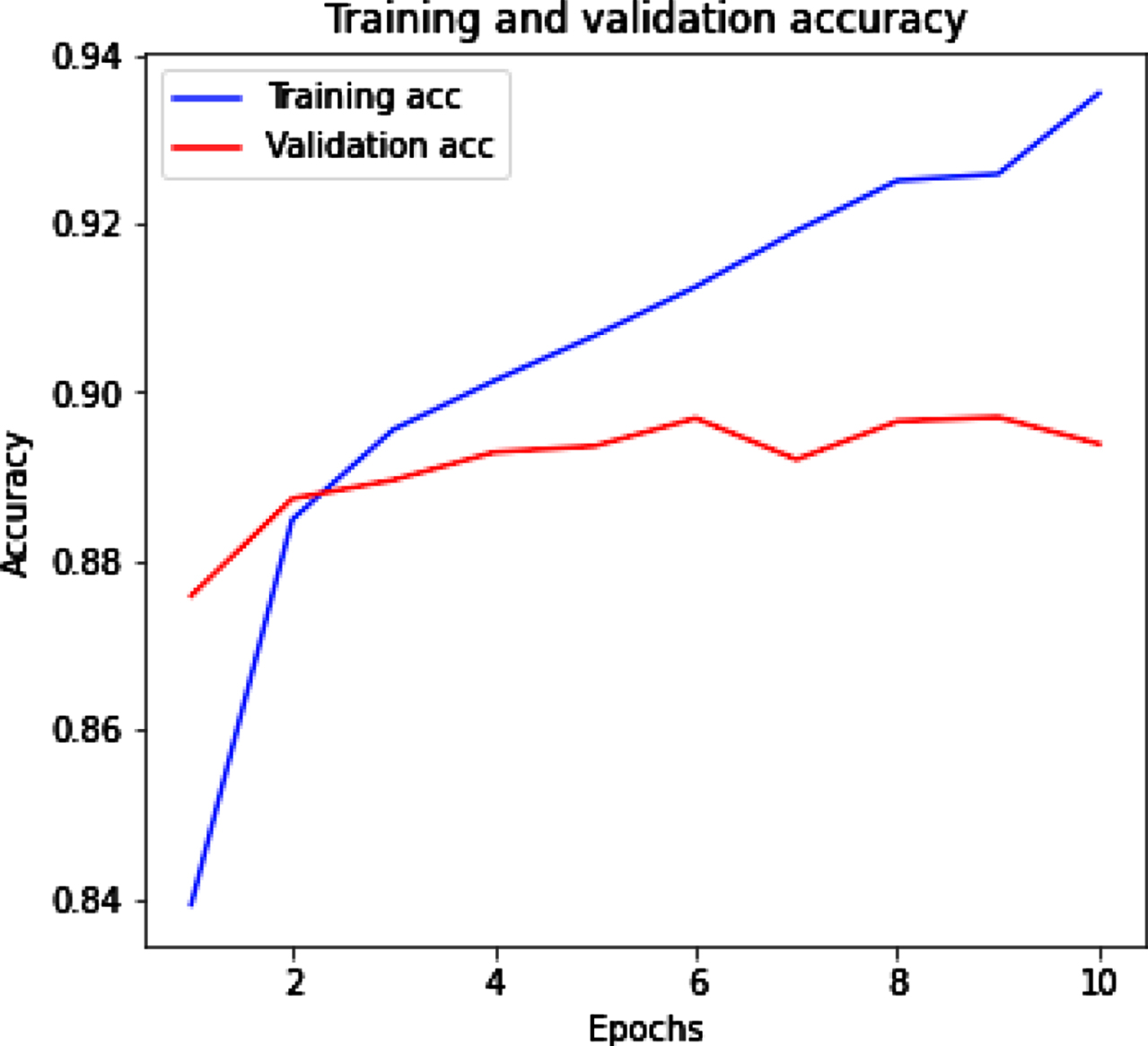
LSTM with Glove training and validation accuracy.
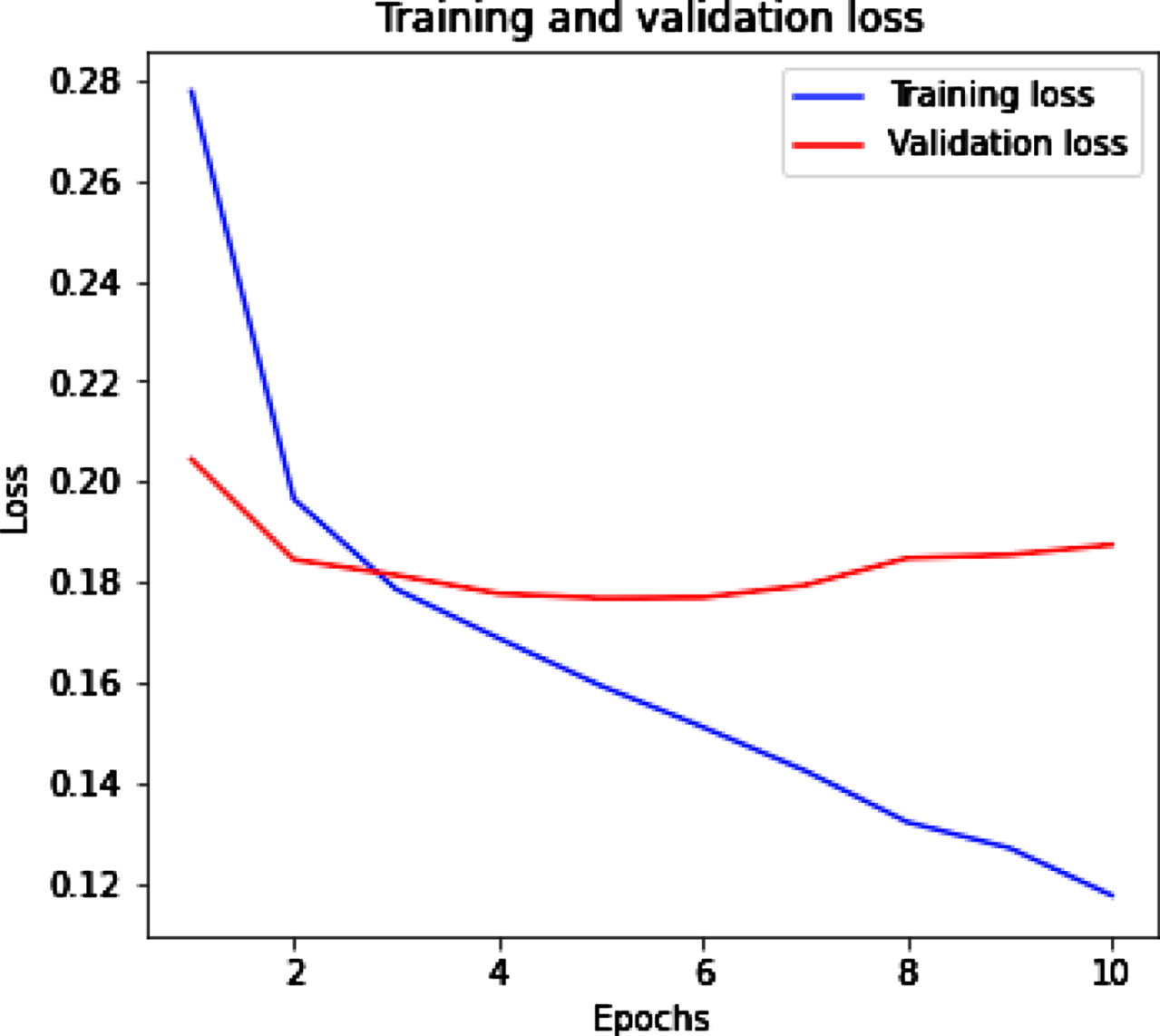
LSTM with Glove training and validation loss.
In Table 12 we find the total parameters 5,080,703, trainable parameters 5,080,703 and non- trainable parameters 0. Found the accuracy 0.85 and loss 0.77.
Layered architecture of LSTM
Layered architecture of LSTM
Total parameters: 5,080,703; Trainable parameters: 5,080,703; Non-trainable parameters: 0.
In Table 13 set the standards for tuning parameters.
Tuning-parameter settings of LSTM
Figure 11(a) (b) shows the training and validation accuracy and loss for tweet dataset by using LSTM. Figure 11(a) represents that with the increased value of epochs training accuracy improves while validation accuracy decrease. Figure 11(b) represents the training loss decrease and when epochs increase then validation loss also increase.
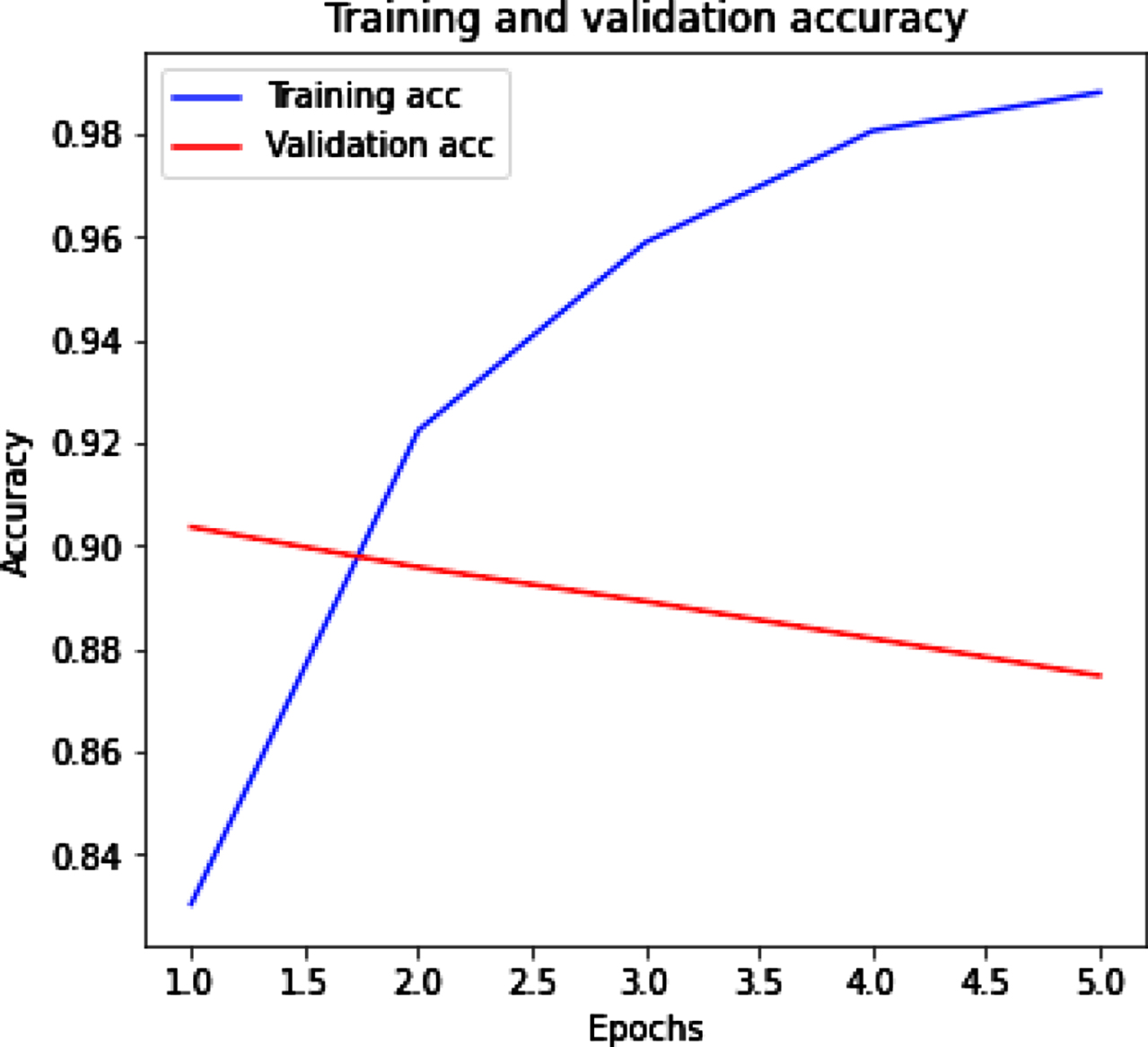
LSTM with training and validation accuracy.
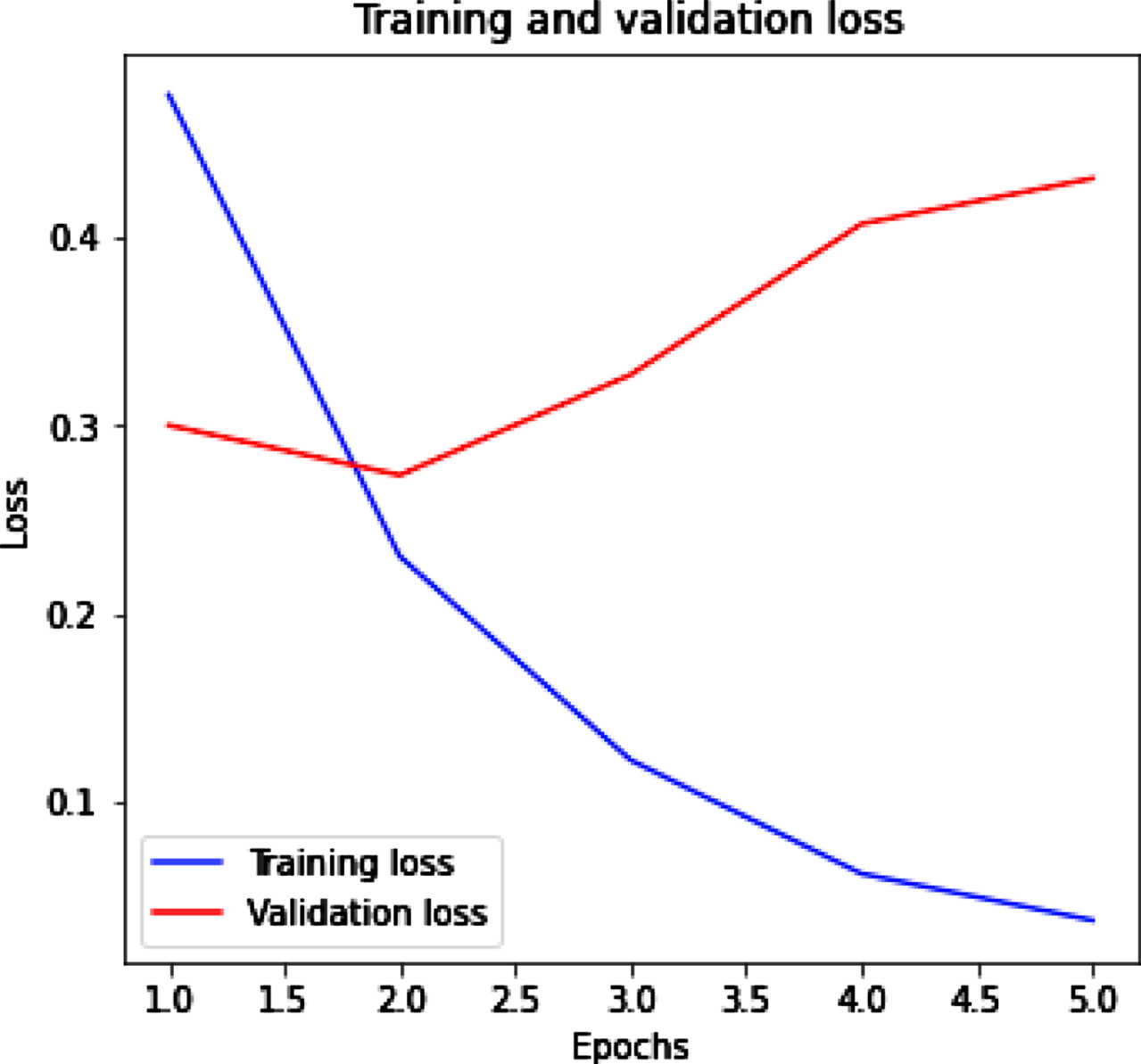
LSTM with training and validation loss.
In Fig. 12 we used the total parameters, trainable parameters and non-trainable parameters for different classifiers.
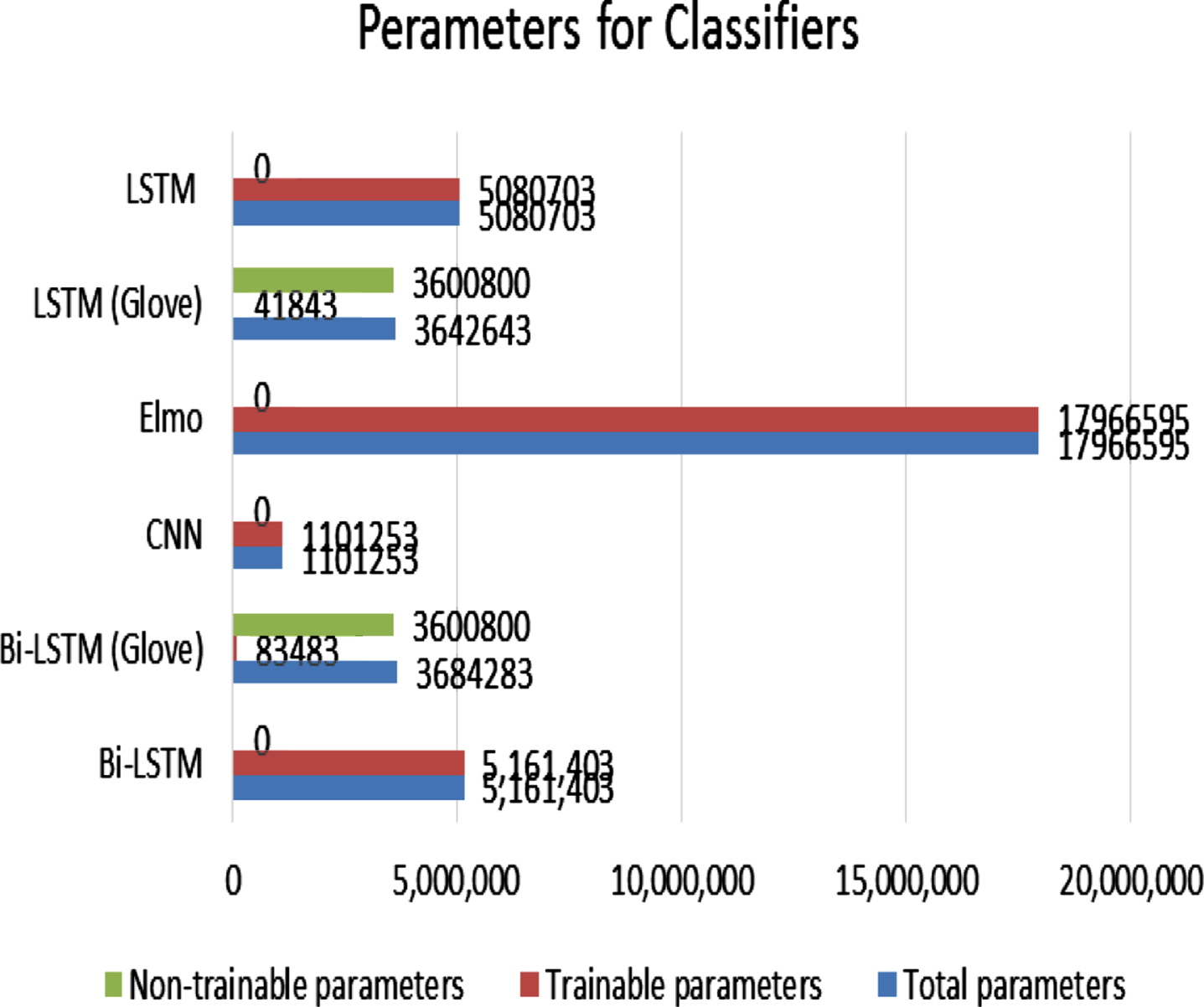
Used parameters for classifiers.
In Table 14 we compare our proposed model i.e. LSTM (Glove) with the previous models. So we can say that our proposed model is best for overall predictions.
Comparison of proposed model LSTM (Glove) with previous models
In Fig. 13 we compare our proposed technique LSTM Glove embedding with previous technique Logistic Regression (LR) with L2 regularization.
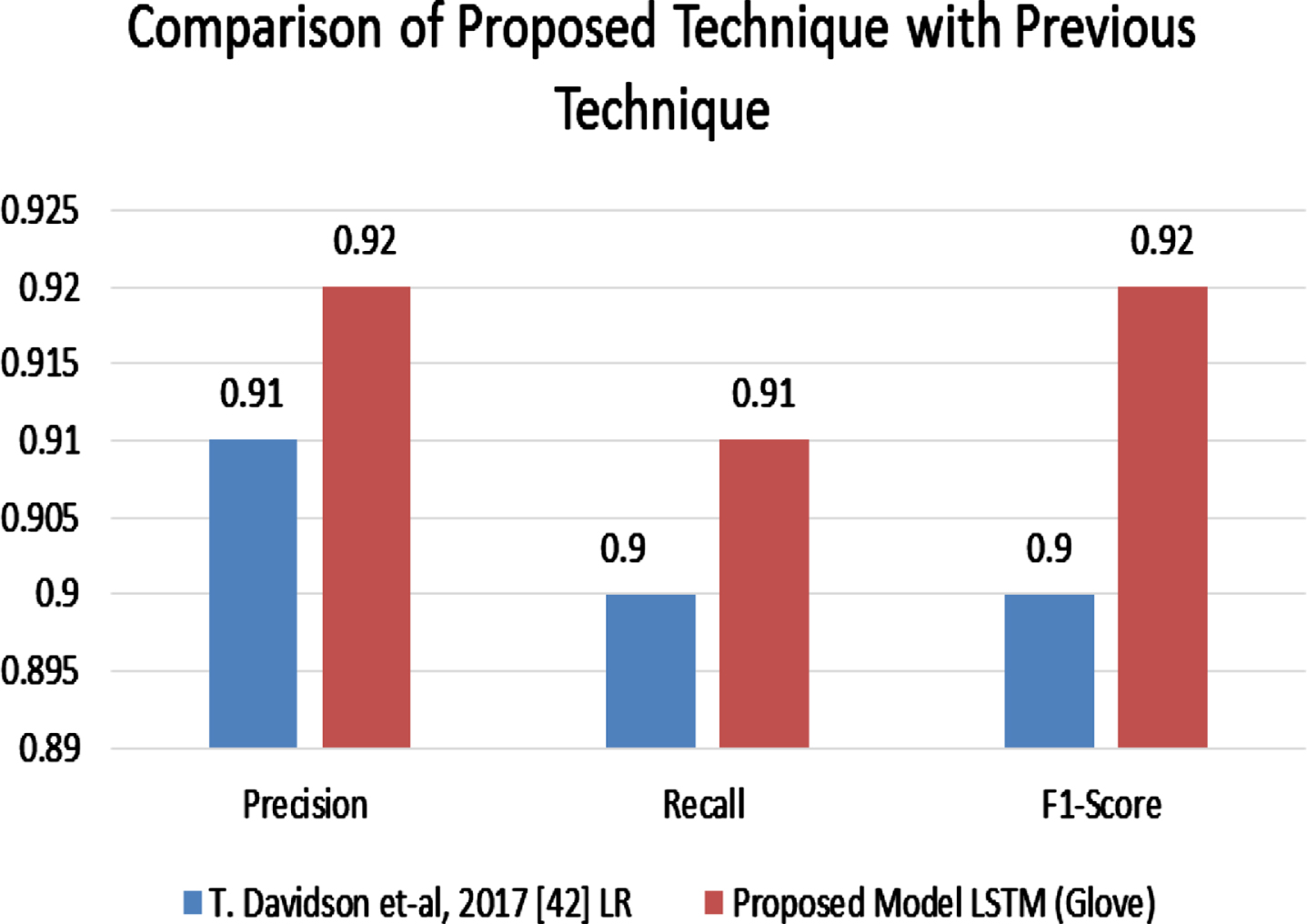
Comparison of proposed technique with previous technique.
There are three matrix for comparison used in our experimental work.
Precision
Precision is the ratio of the retrieved result that is relevant. For instance, in a text query, it displays the proportion of accurate output to total results returned.
Where, TP = True Prediction and FP = False Prediction
Recall
It is the percentage of pertinent documents that are recovered with success. Additionally known as sensitivity.
Where, TP = True Positive and FN = False Negative
F1-Score
The harmonic mean of recall and accuracy is known as the F1-score. It is typically used to gauge how accurate the test dataset is.
Conclusion & future work
This paper presented the concepts of six different types of text categorization techniques and examined the advancements in automated hate speech detection on social media. It is an ancient research field in the field of computers. For that we use Glove embedding and tuning parameter settings for hate speech detection from 2017 to 2022. In this paper we applied different deep learning models like Bi-LSTM, Bi-LSTM with Glove, CNN, Elmo, LSTM with Glove and LSTM with tweet datasets. For that we calculate the accuracy and loss of training and validation by setting the tuning parameters. LSTM with Glove gave the highest accuracy 0.89 and minimum loss 0.19 on tweet dataset. And when we compare our proposed technique LSTM Glove with previous technique Logistic Regression with L2 regularization than it give highest results in terms of precision, recall and f1-score like 0.92, 0.91 and 0.92 respectively.
In future, we identify the linguistic features on tweet dataset by applying different deep learning models and machine learning classifiers. And also we predict the hate speech on audio-video dataset as well as German and Hindi dataset also in our further work.