
Abstract
Transliteration is phonetically translating a language’s words into an international or non-native screenplay. The machine translation process now plays an essential role in scholarly research. The most crucial complement criterion of the English translation system is preserving the phonetic qualities of the language specification after English translation in the chosen language. However, a suitable bilingual text corpus is necessary for statistical models to attain improved transliteration accuracy. Marathi-to-English direct machine translation is done through a cross-language information retrieval system using the CNN classifier model in this proposed research. The proposed method considers a sequence labelling issue brought on by the split transliteration units used in the process. All half-consonant clusters in the Devanagari script are effectively mapped as half-consonant “a” s and labelled using the Modified Intermediate Phonetic Code (MIPC). After generating the phonetic units for each feature in the base and aim languages, the weight is assigned to a phonetic unit in both languages, and individual phonetic unit probabilities are computed. If the probability is zero, then segments are established and recalculated for each segment based on the target phonetic unit location in the word. Therefore, the proposed approach classifies the required phonetic unit with a high accuracy rate.
Introduction
Information retrieval (IR) is a sector that allows customers to find relevant data within large word databases. The topic has grown in importance with the introduction of the World Wide Web (WWW) since the volume of online content has increased fast, making IR increasingly tricky [1]. It enables users to discover information in a broader range of circumstances. People not only passively seek knowledge from the web’s helpful scholarly resources but also actively produce, share, and tag multidimensional material on social media platforms such as Facebook, Twitter., etc. [2]. The linguistic information in various social media differs in size, format, and character from traditional formal text content. It incorporates a lot of personal rambling, slang, the use of numerals, a combination of different scripts, multiple languages despite utilizing a single script, and so on. Furthermore, such informal language is frequently brief, individualized, obscure, localized, temporal, opinionated, and prejudiced [3]. The words written in a native language but using a non-native plot generally do not follow conventional English grammar but instead use the script’s orthography depending on word sound.
These days, Indian literature must be digitalized to become a reality. An efficient substitute for translating whole literary works into Indian regional languages can be provided by translating search queries into the language where literature is available in prose and poetry. Prose literature is simple, with no ambiguous information. The information is in a sentence or a series of sentences organized as paragraphs. In poetry literature, processing the poetic inquiry is integral in returning the proper match to the user. Poetry literature is allocated for artistically expressing something. Writing norms are not observed, such as starting a new phrase with a capital letter and using punctuation. The lines in a poem stanza might be very long or small, like a one or two-letter word. The poetry form is more expressive or glistening with instances, analogies with rhymes and rhythms, and phrases grouped in stanzas that stress specific moral messages and ideals. The right match in cross-lingual retrieval for source-to-target language transliteration must be implemented, and vice versa.
For cross-lingual information retrieval, also known as CLIR, which is used to retrieve natural substances across language groups, it is necessary to be able to bridge linguistic gaps [4, 5]. Single Languags need not include an extensive vocabulary; therefore, traditional IR techniques concentrating on sparse text representations are inappropriate for CLIR. In monolingual IR, they cannot cross the lexical gap due to their inability to generalize semantically [6]. Using organized genuine semantic features, such as document embedding, is one approach [7, 8]; these representations allow for generalization across the vocabularies found in labelled data, giving extra recovery proof while addressing the universal issue of information sparseness. Their usefulness for monolingual [9] and cross-lingual ad-hoc IR models [10] was already demonstrated.
Transliteration is the phonetic translation of a language’s words into an international or non-native screenplay. Its use is ubiquitous in scientific and journalistic publications when referring to specified entities or occurrences in a language other than the one used to create these pieces. In recent years, there has been significant growth in the amount of Indian linguistic literature accessible on the internet, both through local broadcast websites and data sources like Wikipedia pages in the primary Indian languages like Hindi, Tamil, Telugu and Marathi. This phenomenon is ascribed to growing Web usage in rural regions and the creation of regionally relevant papers for these populations, who find acquiring information in their language easier. If these multilingual websites could be archived and retrieved using Standard English searches, their visibility on the internet would increase globally. As a result, with important English papers, the user can view required paperwork in languages such as Tamil, Hindi, and so on. In certain circumstances, regional languages may have more critical material than English. The system must search the necessary language databases and translate the search into additional languages for transliteration.
The document is written in a native language but using a non-native screenplay usually does not follow conventional English grammar. Instead, it uses the script’s alphabetic system depending on the word noise. The translation process is the phonetic translation of a language’s words into an international or non-native screenplay. The translation process, particularly of the Roman script, is becoming increasingly common on the internet for content and user queries attempting to locate these materials. Before using additional natural language processing (NLP) approaches, this data must be pre-processed. Transliteration is mainly employed in machine translation (MT) and cross-linguistic information retrieval (CLIR). Finch et al. [11] directed a critical study of programmed transliteration in an MT scheme. They proved a transliteration system could improve MT quality when converting unfamiliar terms. Others, such as Zhao et al. [12] and El-Kahky et al. [13], have confirmed this conclusion. There’s been a significant amount of curiosity in machine transliteration recently. Machine transliteration creates the phonetic equivalent of a source phrase in the target language for Out Of Vocabulary (OOV) terms. OOV words are mostly made up of named things and technical terminology. Backward transliteration is the opposite of forwarding Transliteration.
While translating questions from native to foreign languages, many fascinating challenges exist to overcome. Bilingual lexicons might be used to translate requests across languages. However, one of the significant drawbacks of this technique is the lack of coverage of such lexicons. According to [14], out-of-lexicon words account for 83 percent of the prevalent question phrases. The authors in [15] discovered that around half of the out-of-vocabulary terms were entitled objects. The results of [16] reveal that when named entities are not adequately transliterated, the middling exactness scores of a CLIR system are lowered by 50%. As a result, translating Poetry words into the target language is an intriguing problem.
The proposed system seeks to research and develop a model for transliterating online retrieval queries for poetic forms of literature. Four fundamental models can be used: graphene-based, phonetic-based, hybrid, and context-based. This research offers a method for transliterating poetry entities from Marathi to English.
The main contribution of the proposed approach is represented in the upcoming points; A transliteration model based on deep learning is employed to construct a cross-language information retrieval system for poetic forms. Pre-processing is performed in the proposed approach to convert the input text data into a system-acceptable format. To develop a phonetic pattern table for Marathi to English transliteration using a whole consonant technique in conjunction with regional linguistic structure. Design a Convolution Neural Network (CNN) classifier model for effectively categorizing phonetic units, and N-grams are used to train the parallel corpora. All the half-consonant clusters are mapped and labelled effectively using the Modified Intermediate Phonetic Code (MIPC).
The remainder of this article is organized as follows: Section 2 is the background, Section 3 is the proposed methodology, Section 4 is the result and discussion, and Section 5 is the proposed approach’s ending.
Background
Before delving into transliteration approaches, we review some fundamental domain ideas and terminology.
Phoneme: The study of human speech is known as phonetics. [] is used to express the phonetic representation of a sound. A phoneme is the simplest form of a lecture that changes the significance of a word; it is symbolized by the symbol / /. For instance, replacing the acoustic [m] in the word ‘mock’ with [c] results in the word’ cock,’ where /m/ is a phoneme.
Grapheme: A grapheme is a fundamental element of a writing system that consists of alphabetic letters, digits, punctuation marks, and signs. In phonemic orthography, a grapheme relates to one phoneme. In non-phonemic spelling processes, numerous graphemes can symbolize a single morpheme. A digraph is one in which there are two different graphemes for each distinct phoneme; a tri-graph is one in which there are three graphemes; and so on. The word “fish” comprises four graphemes (f, i, s, and h) but only three phonemes since the letter “sh” is a digraph.
Syllable: A word or phrase is a unit of pronunciation. It has a high syllable point, generally a vowel, in addition to selectable beginning and ending earnings, which are usually consonants. A monosyllabic word has just one syllable (for example, dog). Similarly, terms with two words are called di-syllabic, while conditions with three syllables are called tri-syllabic. A phrase with more than three syllables or any phrase with only one syllable is called a polysyllable.
Writing System: A text scheme is a method of representing expressible components or sentences in languages. Each note-taking system needs a collection of specific symbols known as personalities or graphemes and guidelines and conferences that give the graphemes meaning.
Challenges in machine transliteration
Karimi et al. [17] identified five common issues encountered by device translation systems as a whole script requirement, absent noises, translation differences, the linguistics of the source, and deciding whether to translate or transliterate an identity.
Script Specifications: A screenplay characterizes one or many writing materials with symbols depicting a message with a shared characteristic. A single screenplay can be employed to write in numerous languages. Some written languages, on the other hand, necessitate the use of numerous scripts. To manage such a wide range of language screenplays computationally, one must be familiar with various feature compression algorithms for the signs. One more aspect of the linguistic storyline is the writing path, which can be either left-to-right (LTR) or right-to-left (RTL) (RTL). For example, Arabic, Persian, Hebrew, and Taana scripts use RTL, while regional dialects using Devanagari or Roman alphabets use LTR. Translation processes that change word characters must handle two opposing orientations correctly.
Missing Sounds: Every dialect has its acoustic framework, represented in the linguistic storyline by signs. Solitary noises are depicted by digraphs and trigraphs when a language’s letters lack sound. For example, the new digraph for ‘sh’ corresponds to the sound [s], whereas ‘h’ does not. Translation processes are required to understand the norms for composing absent noises in both the source and destination languages and the norms for transferring noises from one language to the other.
Transliteration Variations: Because of translation, numerous versions of a primary phrase can legitimately depend on the views of dissimilar humanoid translators who speak different languages. Obtaining all potential variations for all words in a single corpus is impossible for succeeding causes. Not most linguistic talkers will be able to participate in the review procedure. Other than norms evolved among ideas, no specific criteria exist for such a comparison.
Furthermore, developing new company, product, and person names makes conventional transliteration problematic. As a result, evaluating transliteration systems becomes difficult, wildly when contrasting the effectiveness of various processes.
Transliterate or Not: MT systems struggle with determining if transliteration is necessary for a name. Named Entities are non-dictionary terms that may require both translation and transliteration. When an entity like “Congress Parliamentary Committee” occurs in a document, the first word, “Congress,” must be transliterated. The following two words, which indicate an incomplete transliteration, must be understood. Every word in this name must be transliterated.
Machine transliteration techniques
⇛ Grapheme-Based Models: In this method, the grapheme arrangement of the original linguistic is mapped to the grapheme sequence of the target language, with no consideration given to phonemes. Graphemes are the smallest units of written form in every language. The translation is an orthographic method by grapheme-based designs, which converts original linguistic personalities to their destination linguistic variants.
1. Approach based on rules: This strategy is based on verbal and lingual data about the available origin and destination languages. Linguistic information may be gathered using lexicons, which are collections of grammatical structures manually developed to separate the named entities, making named entity identification easier. This strategy necessitates a thorough understanding of the syntax and rules of the language in question.
2. Statistical Method: This approach employs mathematical tools, such as the assumption that every destination linguistic translation from the basic linguistic has about probability. The most significant change has the most likelihood. A likelihood density function is used to translate each document. The key issues with this approach are evaluating the likelihood of translation and systematically determining the sentence with the most significant and excellent probability. Sentences are transliterated based on their probability. This approach aims to generate target transliterations based on probabilities from the source-target language parallel corpus.
3. The Finite State Transducer (FST): This technique depends on transducers with the intrinsic ability to transliterate from origin to destination linguistics. A transmitter switches from one position to the next to produce output in a particular target dialect. An FST is more valuable as a translator over a specific set of strings. A sequence of letters is fed into the FST during the morphological parsing process, and the FST outputs a string of morphemes. It is useful in pattern recognition applications.
4. Approach Using the Hidden Markov Model: This method is usually used in temporal pattern classification and related fields like writing style, way of speaking, gesticulation identification, musical score following grammatical tagging, and computational biology. Given a sentence s=(s1, s2,..., sn) in the original dialect, the person wants to try to translate. The user wishes to predict which is the most likely target sentence will be t=(t1, t2,..., tm) will be in the objective linguistic to which the client wishes to translate.
⇛ Phoneme Based Models
Phoneme-based designs use phonetic data rather than orthographic details during the translation procedure. Labelled objects are translated based on their pronunciation. The final results of phoneme-based designs are produced in two steps:
1. Source Grapheme-to-Source Phoneme Transfiguration: This entails mapping an original language term (grapheme) to its phonetic equivalent.
2. Source Phoneme-to-Target Grapheme Transfiguration: The origin phoneme is mapped to the target language word (grapheme).
Thus, the first process in this technique is to extract the origin language’s phonetics. The second stage is to convert that pronunciation lecture to the grapheme of the chosen linguistic.
⇛ Hybrid Approaches
We need to integrate both methodologies for greater accuracy and efficiency. It can be a mix of grapheme and phoneme-based approaches, or it can be any grapheme-based model. These designs are effective at reducing bugs in transliteration systems. The output of a hybrid model is just the interpolation of the probability of grapheme and phoneme-based processes. Among the hybrid models’ techniques are:
1. Multi-Engine Approach: This hybrid machine translation and transliteration technique requires simultaneously running multiple translation systems’ output. The last and final output is formed by combining the outputs of all translation systems used. In most cases, these arrangements employ statistical or rule-based transliteration approaches.
2. Statistical Rule Generation: This method uses statistical data and information to develop lexical and syntactic rules. Like a rule-based translator, the input data in the language specification is filtered using lexical regulations.
3. Multi-pass: The most common approach in a multi-pass system is to analyze the user input using a rule-based scheme and then transmit the results to a data model, generating the best result.
Related works
Transliteration is forwarding or reverse transliteration based on the direction of transliteration. Forward transliteration converts a native language’s script into a foreign or non-native language’s script. The method of translating a translated script back into its native language script is known as back transliteration.
A hybrid (statistical+rules) approach-based transliteration system for human names was built by Deep et al. [18]. The suggested system derives its English (Roman Script) transcription from a Punjabi name (Gurumukhi Script). This proposed model uses tokenization and 41 transliteration rules for transliteration. The proposed approach gives an accuracy of 90 and 91.4% for the dictionary comparison rules and direct mapping, respectively.
C. Sunitha et al. [19] proposed a Phoneme-based transliteration method for English-Malayalam translation that depends on speech and outperformed the Grapheme-based model. A pronunciation dictionary is used in this model. However, it suffers from the OOV problem when a term is not found in a dictionary. Kunchukuttan et al. [20] presented the Brahmi-Net to provide a complete transliteration and script conversion solution for all Indian sub-continental languages. According to Dasgupta et al. [21], an English-Bangla translation was created from a collection of papers by transliterating Romanized English-written Bangla texts into their original characters. As a result, the authors devised several methods for creating a parallel translated English-Bangla vocabulary of over 100,000 words. Using the specified lexicon of transliterated English-Bangla paired associations, two unique computational algorithms are developed to identify, recognize, retrieve, and discover transliteration units (TUs). However, the system needs two different models, increasing complexity.
Omar et al. [22] developed an automated Somali-to-English transliteration method that employs translation policy provisions on the orthographic mapping of original language creatures to target language features. The authors also presented an alignment method that maps Somali personalities to provide appropriate translation in English if no corresponding direct personality occurs. Aadil et al. [23] provide a hybrid strategy for developing an English-to-Kashmiri transliteration system based mainly on Phonemes. In addition to direct mapping (word-to-transliteration), phonemes are retrieved from accessible phonetic dictionaries, and rules are created to transliterate the phonemes. An English word’s grapheme is used to extract its phonemes. In addition, character-to-character transliteration is employed for words whose transliteration is not achieved until the last step of transliteration. However, the approach is inaccurate because of many mappings of the same phoneme and a lack of a competent word processor for Kashmiri that can be used to de-syllabify the tokenized transliteration word.
Dhindsa et al. [24] developed a system for transliterating named things from English into Hindi. The suggested method comprises two modules that use a phoneme-based approach to transliterate named things. Module-I uses the Pronouncing lexicon for transliteration, which has a collection of 133270 words with their pronunciation. ModuleII is used if the word to be transliterated is not found in the CMU Pronouncing lexicon. ModuleII is based on the 5-gram model, which uses a maximum of five letters to construct the transliterated target letter. Ameur et al. [25] proposed an attention-based encoder-decoder scheme for Arabic-English Machine Translation. Devi et al. [26] offered a syllabification-based machine transliteration technique. The machine transliteration was done from English to Manipuri. Grundkiewicz et al. [27] presented Named Entity Transliteration Using Neural Machine Translation Techniques. The authors use well-established NMT techniques such as dropout regularization, model ensembling, rescoring using right-to-left models, and back-translation to develop a powerful transliteration system. Islam et al. [28] created an English-to-Bodo machine transliteration system to improve the translation results of the English-to-Bodo Statistical Machine Translation (SMT) system. The MTn system was created utilizing a hybrid technique with multi-domain English-Bodo parallel words or concepts. The correctness of the SMT system’s translation result has been tested using an automated evaluation approach.
Ahmadi et al. [29] present a regulation procedure for translating Sorani Kurdish’s two frequently used orthographies. It recognizes a word’s character by eliminating potential uncertainties and charting it into the objective orthography, describing distinct issues in Kurdish text mining and proposing fresh approaches for the Sorani Kurdish transliteration assignment. Wergor, this transliteration system, achieves an overall accuracy of 82.79 percent and a detection rate of more than 99 percent for double-usage letters. The authors also give a manually transliterated Kurdish corpus. Singh et al. [30] created the GRT system based on the grapheme technique, which immediately transliterates text from Gurmukhi to Roman characters. This process utilizes handcrafted rules and the character mapping (CM) methodology for translation among the local dialects. The CM for the Gurmukhi script and its Roman counterpart is finished. It translates Punjabi messages into English. It performed 99.27 percent correctly on 65,130 Punjabi words.
Lakshmi et al. [31] described the transliteration of Romanized Kannada words into Kannada script. This method uses a bilingual corpus of approximately 3 lakh words, consisting of pairs of Romanized Kannada words with their equivalent Kannada script words and orthographic and phonetic metadata. Romanized Kannada words are divided into phonemes based on predetermined criteria. These phonetic symbols are statistically translated into the Kannada script based on likelihood. The paradigm used 3000 Romanized Kannada test phrases and attained a precision of 85.4%. He et al. [32] explored the effect of integrating phonetic characteristics for English-to-Chinese transliteration in the context of multi-task learning (MTL), where authors establish a phonetic auxiliary task to improve the simplification presentation of the primary transliteration task. In addition to the current approach, the authors present a new English-to-Chinese dataset and offer a unique evaluation measure considering several alternative transliterations given a source name. Shakeel et al. [33] proposed an algorithm that successfully solves transliteration problems. The system works by converting encoded roman words into Urdu script words and matching them with the dictionary. The text editor will show the word if a match is detected. The terms with the max frequency are displayed if more than a match is in the dictionary. If no single occurrence of the match is found, demonstrate the first encoded and transformed example as the default, and then adapt the provided ambiguous word to their desired location based on their context.
However, much study has been done to transliterate nouns and named entities from one language to another. However, there is relatively little study on transliterating poetry literature in internet searches. As a result, there is a need to build a new model to transliterate Marathi to English and versa.
Machine Transliteration of Marathi To English Using CNN
The World Wide Web (WWW) search is the most basic approach to getting knowledge and obtaining information. Throughout the world, information retrieval is done in the regional language, and literature is available in regional and foreign languages. The existing models discovered that lexical transliteration from the source to the target language was challenging without considering the original script’s context leading to imprecise transliteration. The challenge that transliteration systems must address is the potential of differing scripts between the source and destination languages. The Devanagari script is used in Marathi, whereas the Roman script is used in English. The proposal aims to transliterate specified entities from Marathi to English and back transliterate. The literature form of poetry is normalized by pre-processing the input data, which is converted into a system-acceptable format. Since the proposed methodology uses the phoneme of the source input as a feature, raw input in Devanagari must be represented using the source language’s syllabic format and the work flow of the proposed Machine Transliteration of Marathi to English is illustrated in Fig. 1.
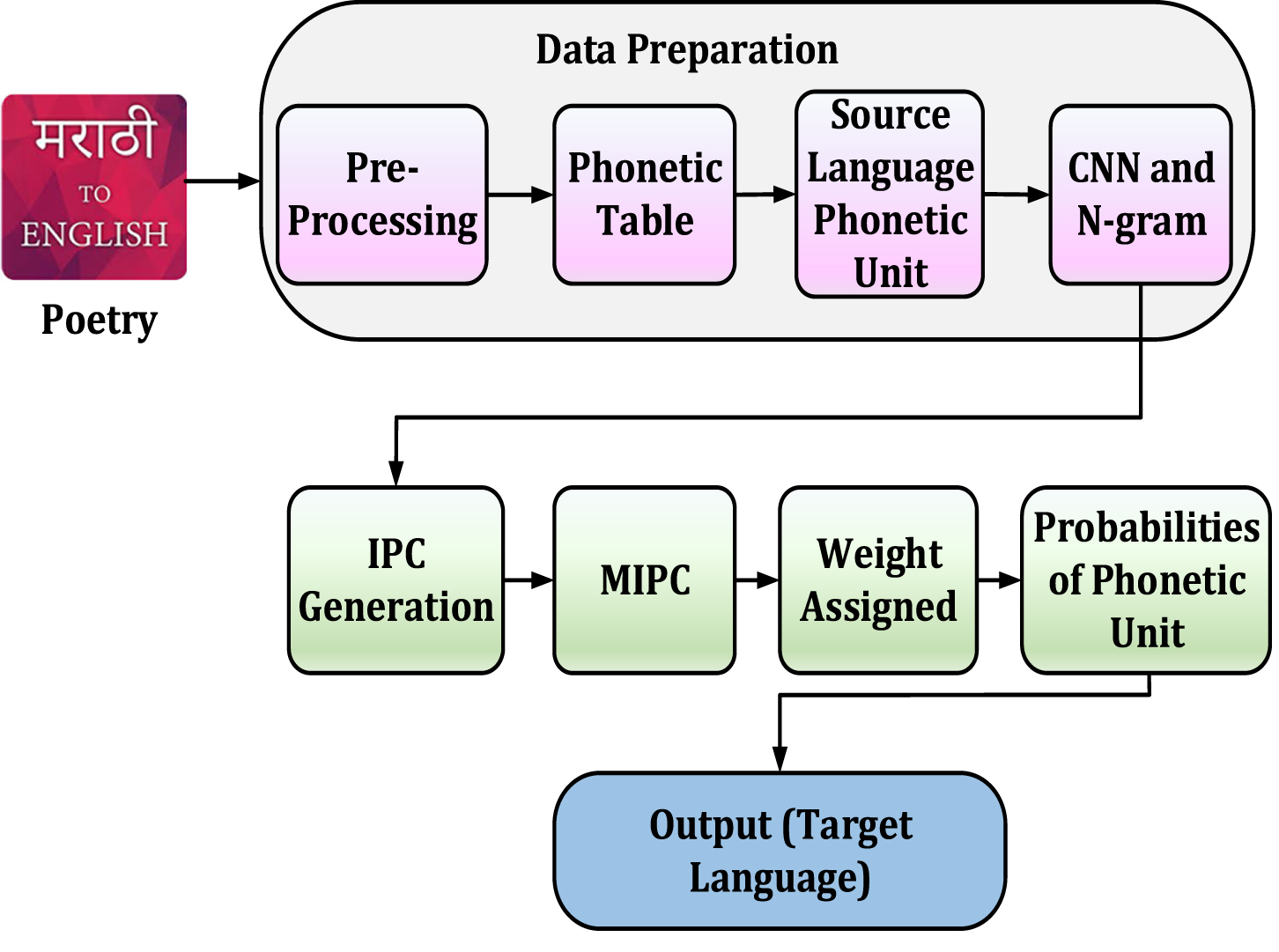
Workflow of proposed approach.
This technique considers one source language syllabic unit a single phonetic unit. Pre-processing is accomplished by breaking down the work into sub-modules in which the source and target language entities are segmented into source and target language translation Units, equivalent to the phonetic unit of the origin or destination linguistic. Various Marathi language terms such as Akshara, Swara, Vyanjana, Jodaakshar, Syllable, and Schwa are utilized in our work. To translate Marathi to English, we first create a phonetic map list using a whole glottal technique with a regional linguistic framework. Following that, we must create the Marathi Phonetic Units, for which Unicode use the complete consonant method, which considers the Marathi consonant phoneme and vowel phoneme as independent units. The CNN is used to categorize phonetic units, and the N-grams are used to train the parallel corpora.
Next, to generate the Intermediate Phonetic Code (IPC), the Devanagari phonetic units to similar phonetic units have been mapped using a phonetic map, with each word separated into syllables. Even though the IPC was created, due to Unicode’s complete consonant nature, every Devanagari vowel matra in IPC shape has an inherent ’a accompanied by consonant phoneme via mapping. The inherent ‘a’ formed by any vowel matra for Devanagari phonetic components should be removed. One of the problems with Devanagari to English translation is the transition of conjugates. As a result, all half consonant clusters in the Devanagari script mapped as half consonants ’a” have been deleted and labelled as Modified Intermediate Phonetic Code (MIPC). After generating the phonetic units for every feature in the origin and destination linguistics, the weight is assigned to a phonetic unit in both languages, and individual phonetic units’ probabilities are computed. If the probability is zero, segments are established and recalculated for each segment based on the target phonetic unit location in the word. For transliteration, the basic linguistic is Marathi, and the aim linguistic is English. As an outcome, the proposed machine transliteration model gives a very accurate result compared to other transliteration methods.
The proposed approach considers the data preparation stage by collecting, combining, organizing and structuring required data to enhance the classification performance. This phase consists of a pre-processing, phonetic table, source language phonetic unit and CNN classifier to categorize the phonetic units and N-grams to train the parallel corpora.
Pre-processing
The proposed approach [34] fed the input data into the pre-processing stage for transforming the raw input data into an acceptable form of system. In the system, raw inputs are considered a set of strings or words which the system cannot easily process. Therefore, these poetry words are normalized as an appropriate form to process by the system. In the proposed approach, the phoneme of source inputs is used as a specific feature to represent the raw input of Devanagari, which is processed using the syllabic format of the source language. One source language syllabic unit is considered one phonetic unit in this proposed research work. In the proposed approach, pre-processing is done by categorizing the task into two sub-modules are mentioned below; Syllabification Alignment using Phonetic mapping
⇛ Syllabification: The segmentation process of the origin and the destination linguistic NEs into the source and target language Translation Unit (TU) is called syllabification. The syllabic unit or phonetic unit of the source or target language is equivalent to the translation unit. A phonetic unit is a sound that differentiates one word from another in a specific language. The phoneme is used as an essential feature in the implementation process because each input corresponds to a phonetic unit. The input is tagged with the target language TU, considered Marathi’s phonetic equivalent in English. The source language Tus are formed by Marathi Entity, while the target language Tus is formed by English phonetic units. The Marathi Entity can be syllabified using the following algorithm shown in Table 1 into their equivalent TUs.
Algorithm for Syllabification
Algorithm for Syllabification
Using the above algorithm, Marathi words are syllabified into appropriate phonetic units. Some of the examples of Marathi to English syllabified words are represented in Fig. 2 and Table 2; they are;

Examples of syllabification.
Devanagari Script for Marathi to English phonetic table




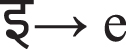
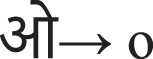

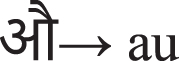

Devanagari Script
Devanagari represents Deva, “Deity”, and Nagari”, the script of the city”, also called the nigari script, used to write Marathi, Nepal, Hindi, Prakrit and Sanskrit languages. The Devanagari script evolved from the north Indian momentous script known as Gupta and later from the Brahmi letters, upon which all modern Indian writing processes have been derived.
The proposed approach utilizes Convolution Neural Network (CNN) for categorizing phonetic units, and the N-grams used to train the parallel corpora. CNN is the most important and widely used neural network proposed for visualizing data like videos and images. CNN also plays a significant role in non-image data like NLP, text classification, etc. CNN, also called Vanilla Neural Network (Multilayer Perceptron), follows forwarding and back warding propagation [35].
The neural network’s architecture, which we created specifically for the transliteration task, is depicted in Fig. 3. The basic transliteration blocks for the Marathi to English transliteration are segmented substrings sent directly into the input layer as separated letter strings. The letters are merely created as one-time vectors. All the data is combined into one value by adding a convolution over the transliteration units.
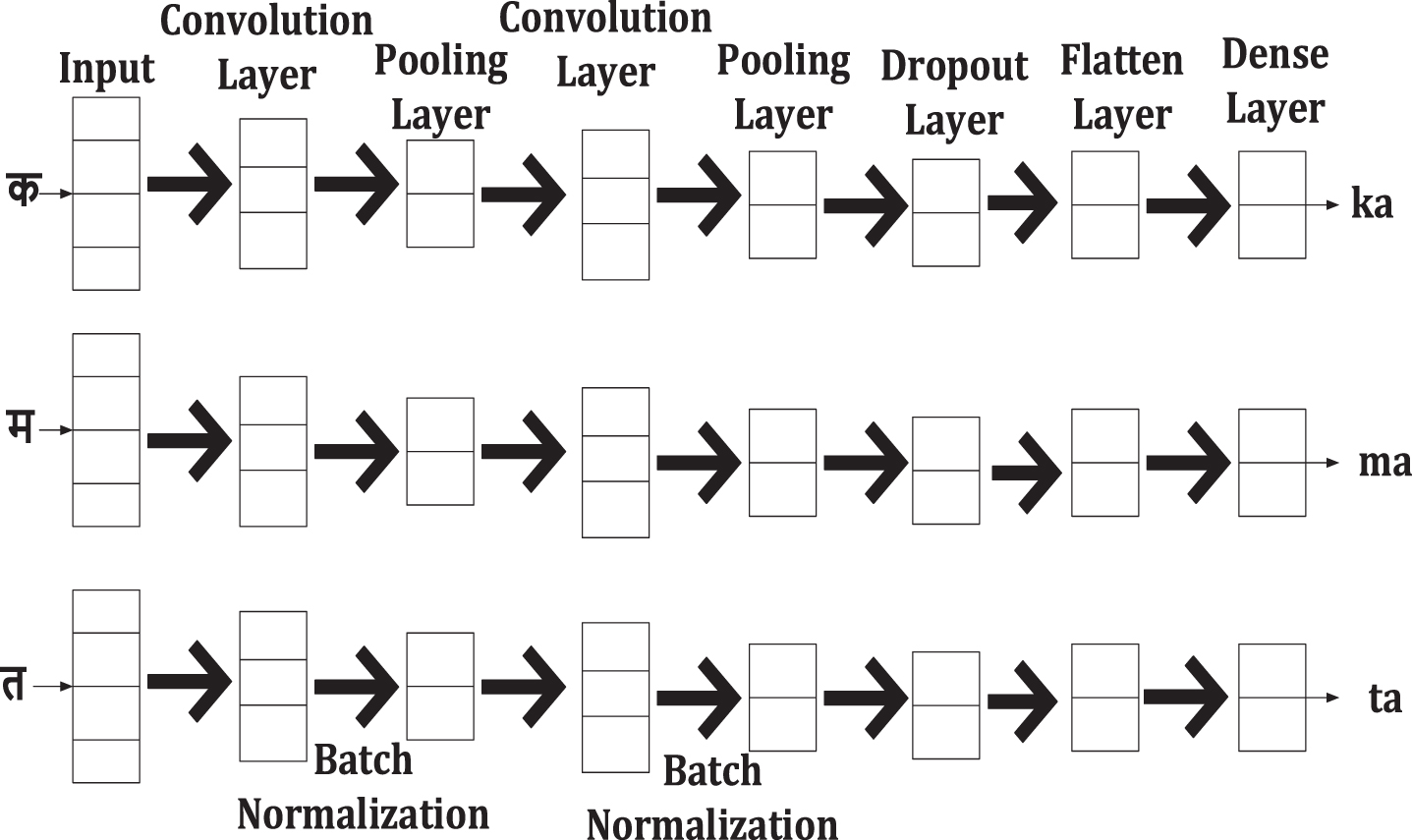
Structure of modified CNN.
In each layer of the modified CNN, convolution is achieved by applying various-sized filters to the inputs. The convolution layer then uses batch normalization by scaling the values to fit between 0 and 1. It can improve the speed of the training process while preventing model overfitting, making deep network model training more accessible and more stable by increasing the model’s resolution. The feature values are scaled using the normalization approach, with a minimum value of 0 and a maximum value of 1. A one-dimensional convolutional layer and a regular pooling layer are added after the input layer. These layers filter out the noise and identify which letters are more critical for transliteration. The output of the pooling layer for complete filters is then passed on to the dropout layer. The system then uses the dropout approach with a dropout value of 0.5 to reduce overfitting. Then, the flatter layer converts the input data as a one-dimensional vector, fed into the dense or fully linked level. Next, the failure parameter optimizes the over-fitting issues during training to flatten the layer.
The output of a flattened layer is provided as a dense layer input, called a densely or fully connected layer. It generates the output results of a classification in the dimension of M × 1. Here M signifies the number of classes. The most commonly used layer operation is represented in the following equation;
Here Out represents the output layer, σ (Sigma)the activation function, and the dot product between the weight vector Wei
D
used in this layer and the input. In the proposed approach, the CNN model is used for classifying phonetic units and the N-grams, which are constructed by an N-dimensional hyperplane to optimize and separate as two partitions. CNN learns the set of inputs with corresponding output values. Let us consider the data set as {X1, X2, X3, … , X
N
}, and its desired class or output label is represented as Y
I
∈ { + 1, - 1 } after that two boundary planes, and hyperplane is attained by using the below equation;
Where 1 ⩽ I ⩽ N the data points must satisfy the above three equations for the appropriate classification. By using the below optimization problem equation, the decision boundary is computed;
Sometimes misclassification also happens when a small amount of error is tolerated. For that reason, slack variables are introduced as control parameters to measure the misclassification rate. The above equation (2) and (3) becomes, after using slack variables are represented in the following equation;
Here the issues are addressed under the constraint
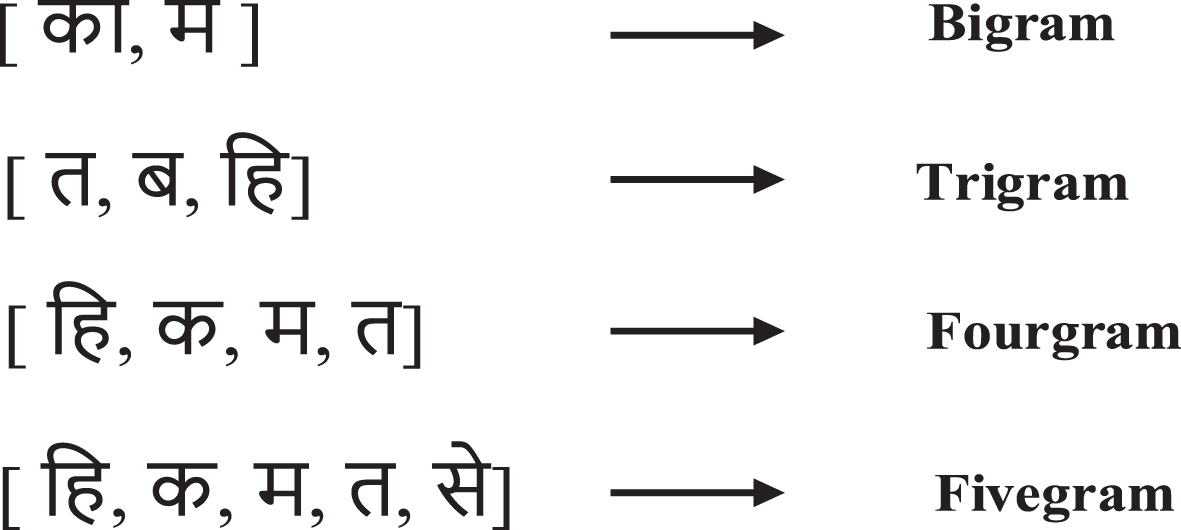
Examples of N-grams categorization.
⇛ Bigram: A bigram feature is a sequence of two adjacent elements taken from strings of tokens, commonly syllables, letters or words. Bigram is initially used to train the parallel corpora in the proposed approach. The bigram features to build the CNN classes by considering the current and next STU. Two Words in Devanagari script, “ ” and “
” and “ ”, are used to describe the formation of classes. After training the above dataset, the CNN classifier model generates eight patterns using the bigram feature. By utilizing the bigram feature, the pattern for poetry words “
”, are used to describe the formation of classes. After training the above dataset, the CNN classifier model generates eight patterns using the bigram feature. By utilizing the bigram feature, the pattern for poetry words “ ” would be [
” would be [ ], and for poetry words “
], and for poetry words “ ” would be [
” would be [ ,
,  ,
,  ,
,  ,
,  ]. In the proposed approach, a few patterns are classified by the CNN model as positive and negative space.
]. In the proposed approach, a few patterns are classified by the CNN model as positive and negative space.
⇛ Trigram: A trigram is a sequence of three adjacent letters, considered the second feature to train the parallel corpora. The trigram features generate the CNN classes by recognizing the present and instant next two STUs. The trigram feature patterns for NE are represented as “ ” would be [
” would be [ ,
,  ,
,  ] and for entity “
] and for entity “ ” would be [
” would be [ ,
,  ,
,  ,
,  ,
,  ,
,  ].
].
⇛ Fourgram: A fourgram representing the N-grams includes four items from a sequence, considered the third feature to train the parallel corpora. Here CNN classes are generated by present and instant three STU. The Fourgram feature pattern for the given entity is represented as “ ” would be [
” would be [ ,
,  ,
,  ], and for Entity “
], and for Entity “ ” would be [
” would be [ ,
,  ,
,  ,
,  ,
,  ,
,  ].
].
⇛ Fivegram: A five-gram representing the N-grams includes five items from a sequence, considered the fourth feature to train the parallel corpora. Here the CNN classes are generated based on the present and instant next four STUs. The five-gram feature pattern for Entity “ ” would be [
” would be [ ], and for Entity “
], and for Entity “ ” would be [
” would be [ ].
].
In the proposed approach, the testing phase consists of two files as input. The first is a model file created during the training stage, and the second is a test file. The test file format is similar to the training file and looks for a specific pattern using a separating hyperplane. The distance of a class from a separating hyperplane in a model file is denoted by a score value for each pattern, which can be positive or negative. The appropriate output is generated if the specified Hindi and Marathi input is combined with the patterns. If the pattern is not recognized, it is considered garbage output which means incorrectly transliterated output into English. For example, if the input set is “ ”, then it generates the output in the following format;
”, then it generates the output in the following format;
Based on the Vowel matra “ ”, the phonetic strategy is derived from the complete glottal method. If any additional vowel matra is used with the Devanagari morpheme component, the inherent “a” is updated. Intermediate Phonetic Code refers to the storyline created in English using the pronunciation mapping system for a Devanagari phonetic unit with an inherent “a.” (IPC). Table 3 shows the IPC in English for the Devanagari constant phoneme.
”, the phonetic strategy is derived from the complete glottal method. If any additional vowel matra is used with the Devanagari morpheme component, the inherent “a” is updated. Intermediate Phonetic Code refers to the storyline created in English using the pronunciation mapping system for a Devanagari phonetic unit with an inherent “a.” (IPC). Table 3 shows the IPC in English for the Devanagari constant phoneme.
IPC for Devanagari Consonant
The Devanagari script represents all half-consonant clusters as half-consonant “a” using modified intermediate phonetic code. The probability of each phonetic unit is then determined once weight is applied to it in both languages [36]. By mapping STUs to TTUs, an IPC is produced. STUs are created using Unicode encoding from the Devanagari name. All Devanagari vowel Matras in IPC form has an inherent “a” phoneme followed by a consonant because Unicode is a complete consonant system. It is best to eliminate the inherent “a” produced for Devanagari phonetic unit with any vowel matra. Conjugate transformation is one of the issues with Devanagari to English translation. The letter symbol “a”, which acts among two consonant phonemes, represents the half-consonant cluster in the Devanagari script. In English, it is not customary to represent such a half-consonant. Thus the result after eliminating inherent ‘a and ‘a‘’ is denoted as Modified IPC (MIPC). For example, the word “ ” is converted into IPC to MIPC for Devanagari NE “Srigurucharani” are represented in Table 4.
” is converted into IPC to MIPC for Devanagari NE “Srigurucharani” are represented in Table 4.
IPC to Modified IPC for Devanagari Entity “Srigurucharani”
This section examines the effectiveness of the proposed strategy. In the proposed method, the dataset is created using the collected data, which consists of bhajans from 125 Marathi books such as GuruchechintanNityaNirantar. The proposed model divides the dataset into 80% for training and 20% for testing. For the Marathi-to-English transliteration, the author uses preset numbers of epochs, such as 200.
The tests are run on a standard Intel Core i7 Processor. It takes roughly 170 seconds to transliterate from Marathi to English. Moreover, training the Marathi to English transliteration model necessitates a relatively more extensive memory (at least 4 GB). The test data is processed for final submission using the models of the top 10 most effective epochs.
As with machine translation, we split each word into small units to view the machine transliteration operation.
The source language (Marathi) is transliterated into the target language (English) for transliteration. The proposed approach selects N-gram features like Bigram, Trigram, Fourgram and Fivegram as the window size. By using only forward movement, N-grams are generated, and makefile is a file used to modify based on the requirement of N-gram.
Two parameters are considered essential in the proposed approach during the training process: file location because it is a bilingual corpus written in the training format. The second is the prefix name of the model file. For the Devanagari script, the parsing direction is from the left to the right direction. Here the default setting is chosen for forwarding parsing mode (left to right). In the proposed approach, the make file sets different parameters for bigram, trigram, fourgram and N-gram.
Performance analysis
The Word Error Rate (WAR), which forecasts the accuracy of the transliteration candidate produced by a transliteration system, is used to assess the accuracy of the proposed technique. Let us consider that accuracy = 0 represents the incorrect pattern, and accuracy = 1 represents the correct pattern. The following equation computes the accuracy of transliterating Marathi to English;
Here Acc represents, the accuracy N represents the total number of entities. Therefore, the proposed approach performs better, accurately transliterating the source language (Marathi) to the target language (English). The proposed approach gives very accurate results compared to other existing transliteration methods.
Figure 5 represents the performance of the proposed approach with training and testing accuracy over 30 epochs. Training accuracy represents the identical word which is used for training and testing. In contrast, testing accuracy represents that the trained model detects the independent word not used in the training phase.
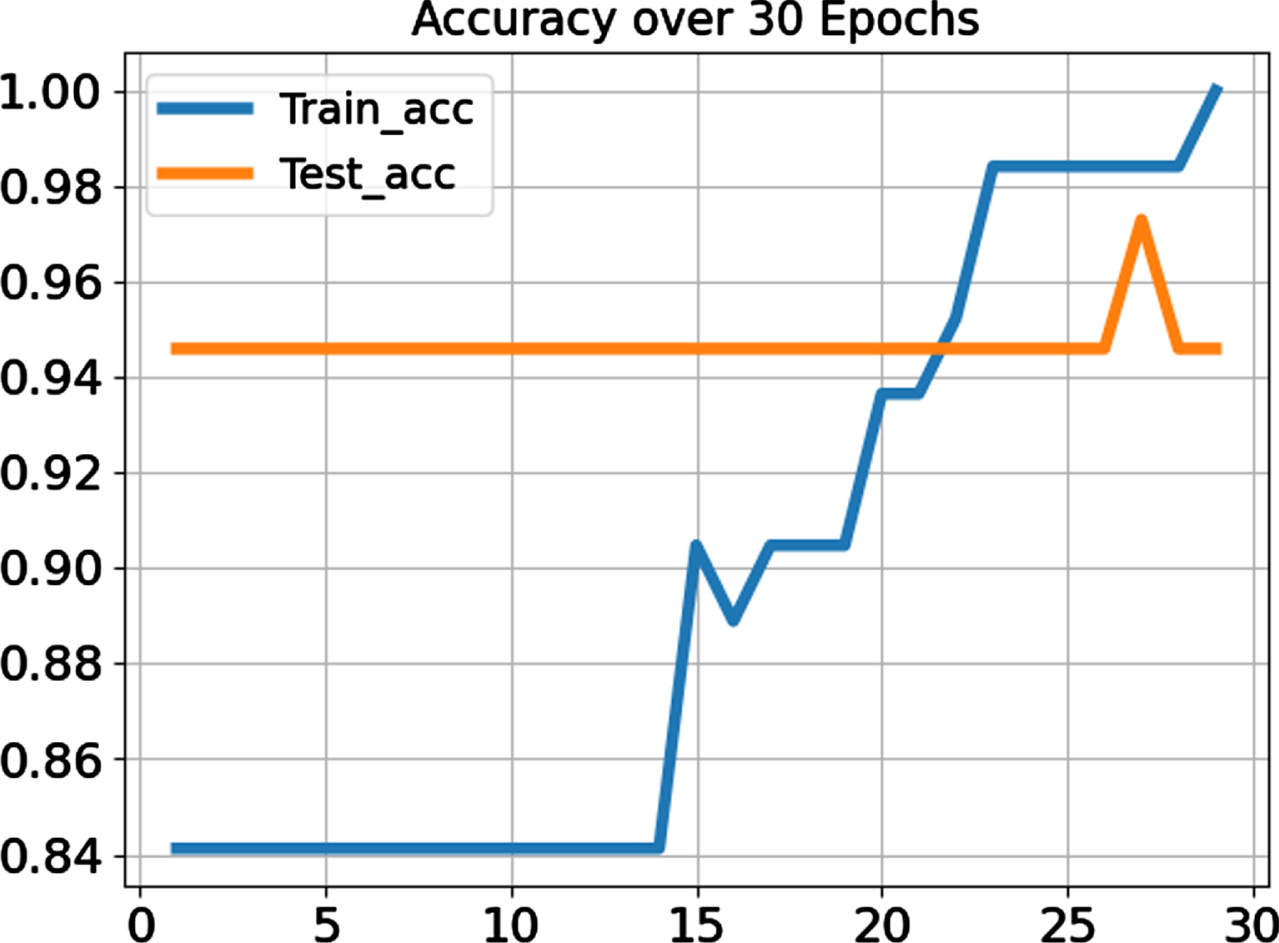
Accuracy over 30 Epochs.
Figure 6 represents the loss of training and testing over 30 epochs. Loss of training and testing represents the number indicating how wrong the CNN classifier model transliterates the Marathi to the English language. If the model prediction is accurate, the loss is zero or else the loss is significantly less.
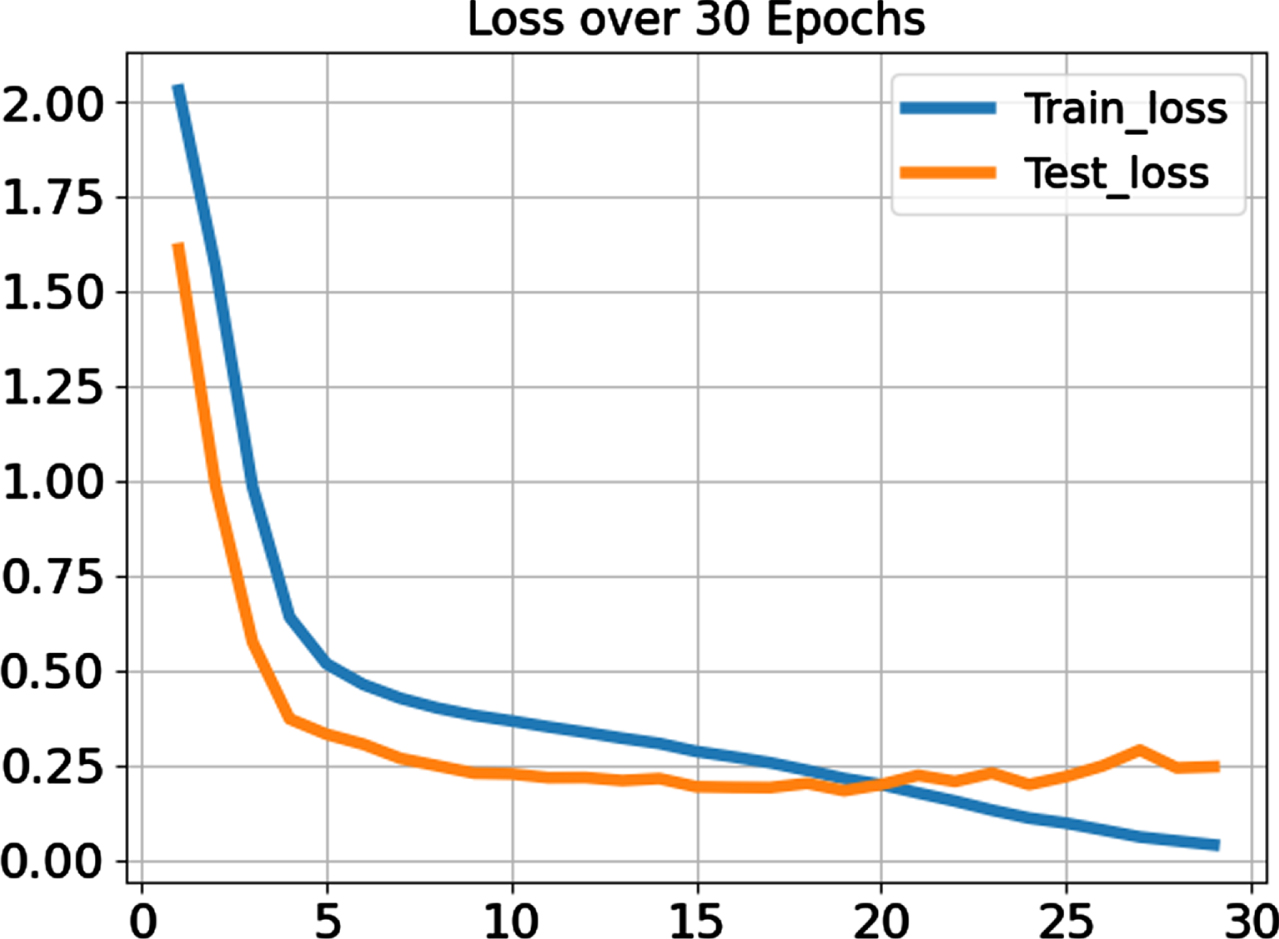
Loss over 30 Epochs.
Figure 7 represents the output of the proposed approach. The input of the Marathi language is transliterated into the target language English efficiently. Therefore, the proposed approach provides a better accurate result in transliterating Marathi to English.
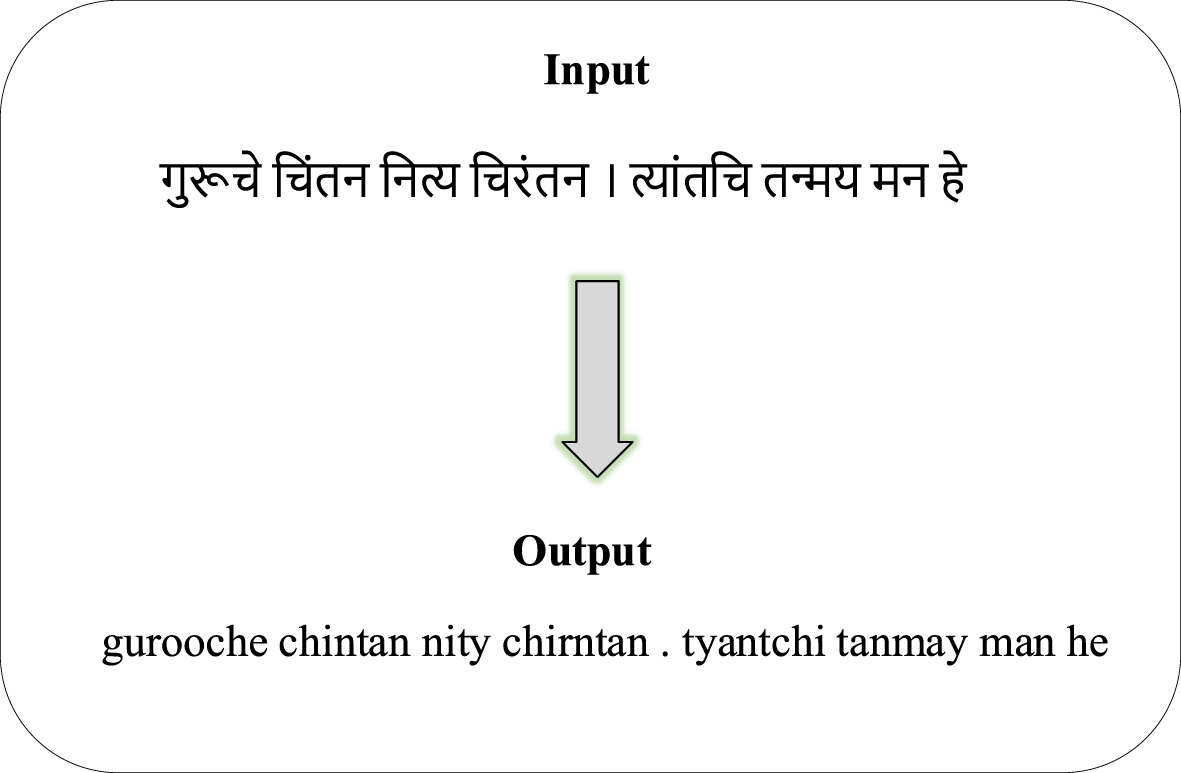
Output of proposed approach.
This section compares the proposed technique of modified CNN with the existing CNN techniques using various parameters such as accuracy. The overall comparison of the proposed techniques with the proposed, existing techniques is shown in Table 5 and Fig. 8.
Comparison of Modified CNN with CNN
Comparison of Modified CNN with CNN
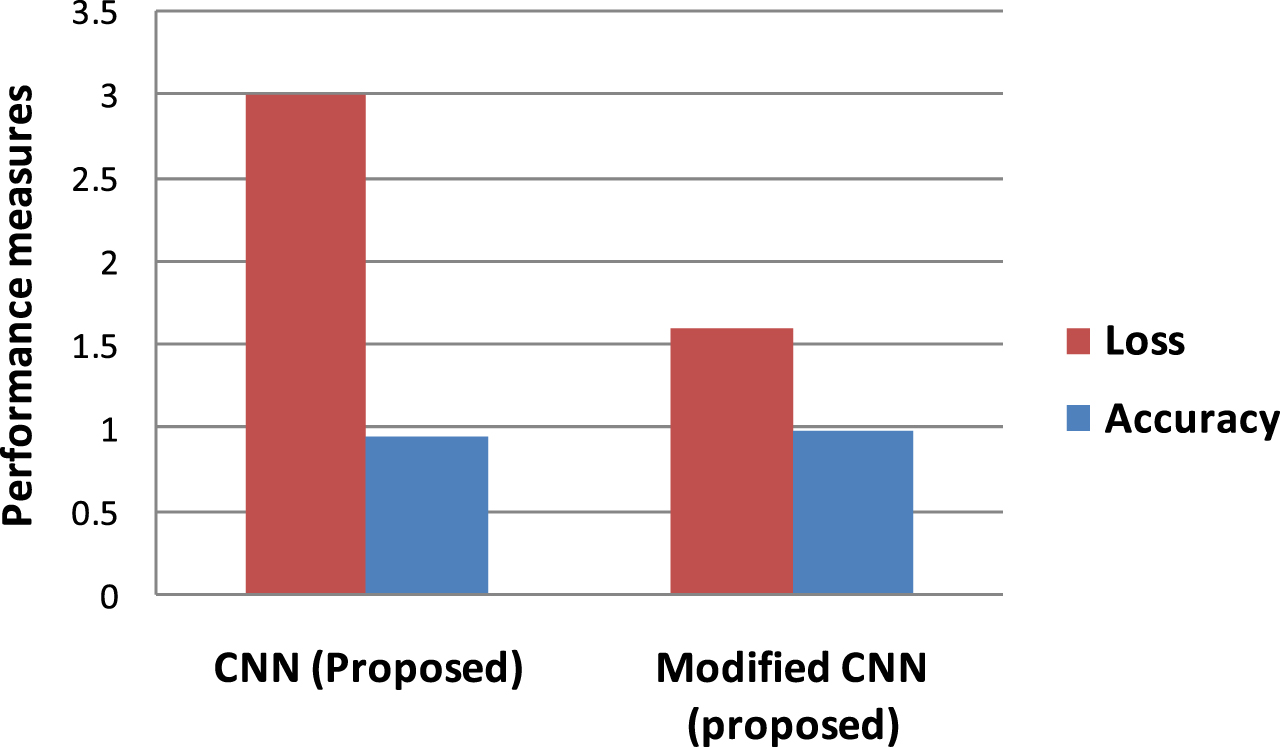
Comparison of modified CNN with CNN.
Comparing the CNN with the modified CNN shows that the modified CNN achieves a high test accuracy value of 97.5 compared with the standard CNN, which has a value of 95. The loss value was also compared in terms of modified CNN and CNN, which results that modified CNN has low test loss values of 1.6 over 30 epochs. It is achieved by adding the batch normalization and dropout layer to the CNN to modify it, which reduces the overfit and increases the layers’ training speed.
In recent days, machine translation has received a great deal of attention. The phonetic equivalent of a source sentence in the target language is produced through machine transliteration. Depending on the transliteration’s orientation, transliteration is either forward or backwards. This work proposes cross-language information retrieval for poetry forms of literature based on machine transliteration using the CNN model. Initially, input data are pre-processed to convert input data into the system-acceptable form. Pre-processing is done by breaking down the work into sub-modules in which the origin and destination linguistic entities are segmented into the origin and destination linguistic translation units. The first phonetic map table is created for transliterating Marathi to English. A variable-sized N-gram is considered the second feature since Devanagari Entities in Marathi comprise two, three, four and five grams. In the proposed approach, the CNN classifier model does classify designs depending on phonemes and changing N-gram dimensions. The CNN model is an efficient classifier for transliteration problems to generate acceptable classes for all accessible patterns. The Devanagari script represents all half-consonant clusters using modified intermediate phonetic code. The probabilities of each phonetic unit are then determined when weight is applied to it in both languages. Therefore, the proposed approach provides a better accurate result in transliterating Marathi to English. Our proposed method faces some limitations: needing a large amount of data for a network to work effectively, leading to a long time to train the data. Hence, future research will focus on a broader range of neural network designs, including an ensemble of bidirectional encoder frameworks, various cell types, such as LSTM, vanilla RNN, and GRU, and detailed parameter estimates.