
Abstract
Word vector is an important tool for natural language processing (NLP) tasks such as text classification. However, existing static language models such as Word2vec cannot solve the polysemy problem, leading to a decline in text classification performance. To solve this problem, this paper proposes a method for making Chinese word vector dynamic (MCWVD). The part of speech (POS) is used to solve the ambiguity problem caused by different POS. The POS structure graph is constructed and the syntactic structure information of POS features is extracted by GCN (Graph Convolutional Network). POS vector and word vector are concatenated into PW (POS-Word) vector. Parametric matrix is added to improve the fusion effect of POS and word features. Multilayer attention is used to distinguish the importance of different features and further update the vector expression of word vectors about the current context. Experiments on Chinese datasets THUCNews and SogouNews show that MCWVD effectively improves the accuracy of text classification and achieves better performance than CoVe (Context Vectors) and ELMo (Embeddings from Language Models). MCWVD also achieves similar performance to BERT and GPT-1 (Generative Pre-Training), but with a much lower computational cost and only 4% of BERT parameters.
Introduction
Text classification [1] is a basic task in NLP, which is widely used in spam detection, news topic classification, speech emotion analysis and other fields. How to improve the accuracy of text classification task has been the focus of research. The semantic accuracy of word vector also directly determines the performance of text classification task. Existing language models, such as Word2vec [2], generate a static word vector [3], which cannot solve the problem of word ambiguity. In recent years, large-scale language models like BERT (Bidirectional Encoder Representations from Transformers) [4] have achieved a dynamic word vector representation, but their extensive model size and computational cost have restricted their widespread use in practical applications. To address these issues, this study proposes a dynamic word vector method based on POS and multi-layer attention mechanisms. The purpose of this paper is to dynamically update static word vectors with minimal computational cost in order to improve the accuracy of text classification tasks.
Word2vec is a word embedding language model in the NLP field. It has the advantages of fast speed, high universality, and does not rely on large-scale corpus. Although large-scale pre-training models such as BERT and GPT [5] have emerged in recent years, Word2vec still has some application advantages when there are few pre-training corpora, poor server deployment performance, and simple tasks. Word2vec is based on the prediction idea of CBOW [6] (continuous bag of words) and Skip gram [7]. CBOW predicts the central word based on context, while Skip gram predicts the context based on the central word. Therefore, the word vector trained by Word2vec has contextual semantic information, and the similarity between words and languages is comparable. However, due to the one-to-one relationship between vector and words, words with polysemy will be represented by the same word vector in different contexts, which obviously does not conform to Chinese semantics. In order to make the static word vector generated by Word2vec have dynamic semantic representation, this paper combines text words with POS to obtain PW (POS, Word) vector with dynamic semantics.
A graph is a data structure that represents the spatial structure information of features. GCN [8] is a network model based on graph. GCN combines the topological structure of the graph with the convolutional idea of CNN (Convolutional Neural Network), and has a strong spatial structure feature extraction ability. GCN has been widely used in social networks [9], traffic routes, node classification and other tasks, and has achieved good results. The POS vector can also be constructed as a graph structure. Different parts of speech have strict grammatical space structure. Using GCN combined with POS grammatical structure, we can extract the deep level grammatical features of POS.
Attention mechanism is a powerful feature selection method. In text classification tasks, the most common attention methods are additive attention [10] and point multiplication attention [11]. When the query and key length are inconsistent, the additive attention function is often used, and when the query and key length are consistent, the point multiplication attention function is often used. The general way to calculate text feature attention is to calculate the word attention score to distinguish important words. When the word is not the only feature, the use of multi-level attention calculation can assign weight information to the feature from all aspects, so that the model’s attention is focused on the important parts of the text feature. In this paper, we pay attention to the word sequence level, POS and word feature level, and make a deep selection of PW vector features.
In summary, MCWVD leverages the advantages of POS, GCN, and hierarchical attention mechanism to achieve dynamic word vector representation. The contributions of MCWVD are as follows. Previous research, such as BERT and GPT, has explored dynamic word vector representation, but no universal solution for updating word vectors has been proposed. The unique contribution of MCWVD is providing a universal solution for dynamic word vector representation. While large language models such as BERT have achieved dynamic word vector representation, they also come with significant computational costs. In contrast, MCWVD achieves excellent dynamic word vector representation with minimal computational cost. In contrast to existing research, we introduce POS and attention to achieve the dynamic representation of word embeddings. On this basis, we combine GCN to obtain deeper syntactic information about POS, which is a new approach. Moreover, hierarchical multi-head attention mechanism is used to differentiate the importance of various features and further endow word embeddings with contextual semantic representations.
Literature review
POS
In recent years, scholars have gradually paid attention to the study of POS features in NLP. Cheng et al. [12] proposed an attention mechanism based on POS, which used POS to capture emotional words in sentences and gave emotional words a higher weight. Chen et al. [13] proposed an attention method combined with POS. In this study, sentiment scores are put into feature selection to improve sentiment recognition. Qin et al. [14] combined POS to filter and remove noise words, and combined synonyms to reduce redundant features of text sequences, which improved the accuracy of text classification tasks. In literature [15], POS tags and words were used to form POS-word pairs. Word2vec was trained to obtain vector representation of POS-word pairs. Then, the POS-word pairs were spliced with the original words to obtain the vector representation of PT-WT (part of speech-word, word), which improved the accuracy of text classification of the model. This paper is based on literature [15]. The above work proved that POS can improve the accuracy of text classification tasks.
Attention
For hierarchical attention, Yang et al. [16] used additive attention to calculate attention at word level and sentence level, which improved the accuracy of text classification. Zhang et al. [17] proposed a multi-layer attention mechanism for emotional analysis, which can obtain more information about emotional features in text. Huang et al. [18] proposed a feature selection method based on multi-layer additive attention. The first level calculated the attention of the word-sentence. The second level calculated the attention of the sentence-document. She et al. [19] proposed a multi-layer attention for text classification, using multi-layer attention to calculate the importance of output vectors of different models. The above work has fully demonstrated the effectiveness of hierarchical attention.
Dynamic word vector
Due to the traditional static word vectors cannot express polysemy, researchers began to focus on dynamic word vectors. McCann et al. [20] proposed a dynamic word vector representation based on LSTM [21] (Long Short-Term Memory) and attention. After the training of the machine translation task was completed, the parameters of the encoder were retained. Then, the text is spliced directly with GloVe to CoVe via the encoder layer. Matthew et al. [22] proposed the ELMo (Word Embeddings from Language Models), which realized context extraction based on BiLSTM (Bidirectional Long Short-Term Memory), and finally obtained a new vector representation by splicing forward LSTM output and reverse LSTM output. Google [4] has proposed a bidirectional encoder pre-training language model based on Transformer [23] architecture, called BERT. BERT has achieved excellent performance by pre-training multi-layer transformers and fine-tuning downstream tasks. OpenAI [5] proposed a pre-training language model based on multi-layer transformers, called GPT-1. The GPT-1 also uses multi-layer transformers, but the transformer is unidirectional. After analyzing the above literature, the existing research basically realizes the dynamic of word vector through the attention mechanism.
Overview
To facilitate an intuitive understanding of the research focus of the relevant work, we have provided a summary table, which is shown in Table 1.
Related work overview
Related work overview
From Table 1, we can see that POS is mainly used as a tool for data filtering and data augmentation. The key advantage of these approaches is that they enable the model to focus more on words related to POS, which is useful for sentiment analysis. However, the limitation lies in overlooking the role of POS in implementing dynamic word embeddings. As for attention mechanisms, they are limited to using hierarchical but single-head networks, which results in weaker feature selection capabilities. Regarding the research on dynamic word embeddings, most of them achieve dynamic representation based on attention mechanisms. The limitation of these approaches is that they consume excessive computational resources.
Making Chinese word vector dynamic
The Chinese text is full of many ambiguous words, such as “show” in “Let me show you something” and “This is my show”. The former sentence indicates the “show” of verbs, and the latter sentence indicates the “show” of nouns. To distinguish different meanings of the same word, this paper combines the POS of the word with the word itself to form a PW vector, such as (v, show), which can be well distinguished from (n, show). Due to the universality and simplicity of Word2vec, this paper selects Word2vec as the word embedding model. In fact, MCWVD’s word embedding model can be replaced by any static language model.
The vector representation of PT-WT (POS Item, Word Item-Word Item) is proposed in literature [15], as shown in Fig. 1.
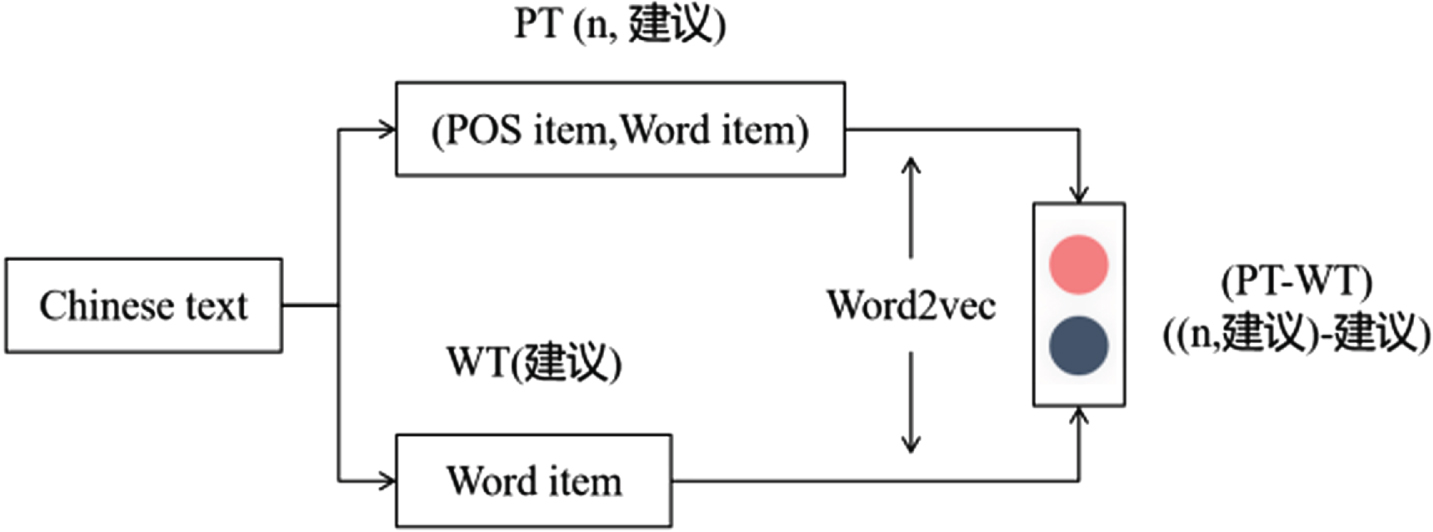
PT-WT vector in literature [15].
In Fig. 1, the PT vector as a whole is trained by Word2vec. The POS embeddings is bound by specific words, and cannot be used to learn pure POS grammatical semantics. Therefore, we believe that using Word2vec directly to train the POS feature can obtain pure syntactic semantics of POS, as shown in Fig. 2.
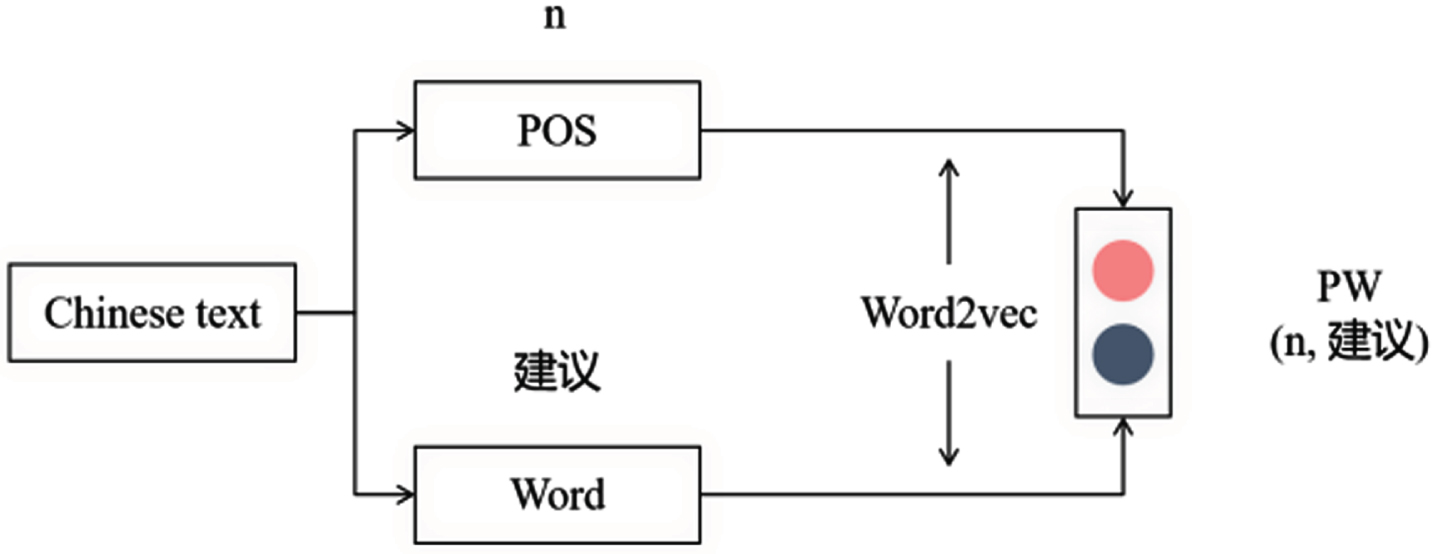
PW vector in MCWVD.
In addition, we also used GCN to further improve the semantic accuracy of the POS feature vector. The vector representation of PW vector relative to context is further learned by combining the attention mechanism. MCWVD consists of five parts, including pre-processing, word embedding, POS feature extraction, feature fusion and attention distribution, as shown in Fig. 3. In the following sections, we will expand and explain each part of MCWVD.
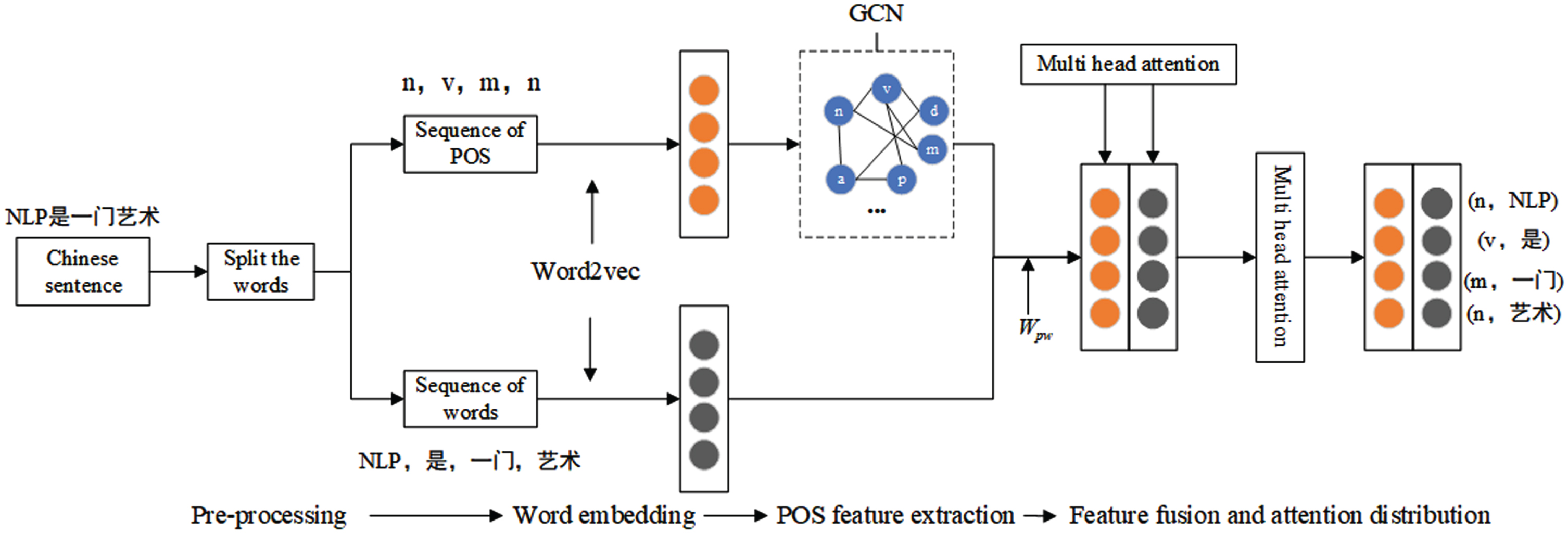
PW vector in MCWVD.
THUCNews and SogouNews are extensive Chinese text classification datasets containing numerous Chinese and English punctuation marks that do not contribute to the classification process. To address this, we employed relevant Python functions to eliminate punctuation from each document. Furthermore, we removed insignificant stop words from every document based on the list compiled by the Harbin Institute of Technology. Since Chinese sentences do not use symbols to differentiate words, Chinese NLP tasks often require sentence segmentation. In this study, we utilized the Language Technology Platform (LTP) [26] to perform word segmentation and POS tagging for each document. LTP offers a comprehensive suite of Chinese natural language processing tools, encompassing Chinese text segmentation, POS tagging, syntactic analysis, and more. After applying LTP for word segmentation and POS tagging, POS and words are mapped in a one-to-one correspondence.
Word embedding
MCWVD aims at dynamic transformation of static word vectors. Therefore, the word embedding model in MCWVD can be replaced by any static language model. Due to the Word2vec is the most classical static language model, we chose Word2vec as the vector tool for words and POS to carry out a series of experiments. In order to reduce the computation of the model, this paper used CBOW algorithm to train word vectors. The objective function of CBOW algorithm is shown in Equation (1).
In order to further capture the spatial structure information between different POS features, to further improve the semantic accuracy of the POS vector. We proposed constructing the POS structure graph and using GCN to extract POS feature information. Word sequences can be constructed into graphs depending on the relationship between words, and the same POS sequences can also be constructed into graphs. If the Chinese sentence is (NLP, is, an, art), the corresponding POS sequence is (n,v,m,n), the POS sequence can be constructed as shown in Fig. 4.
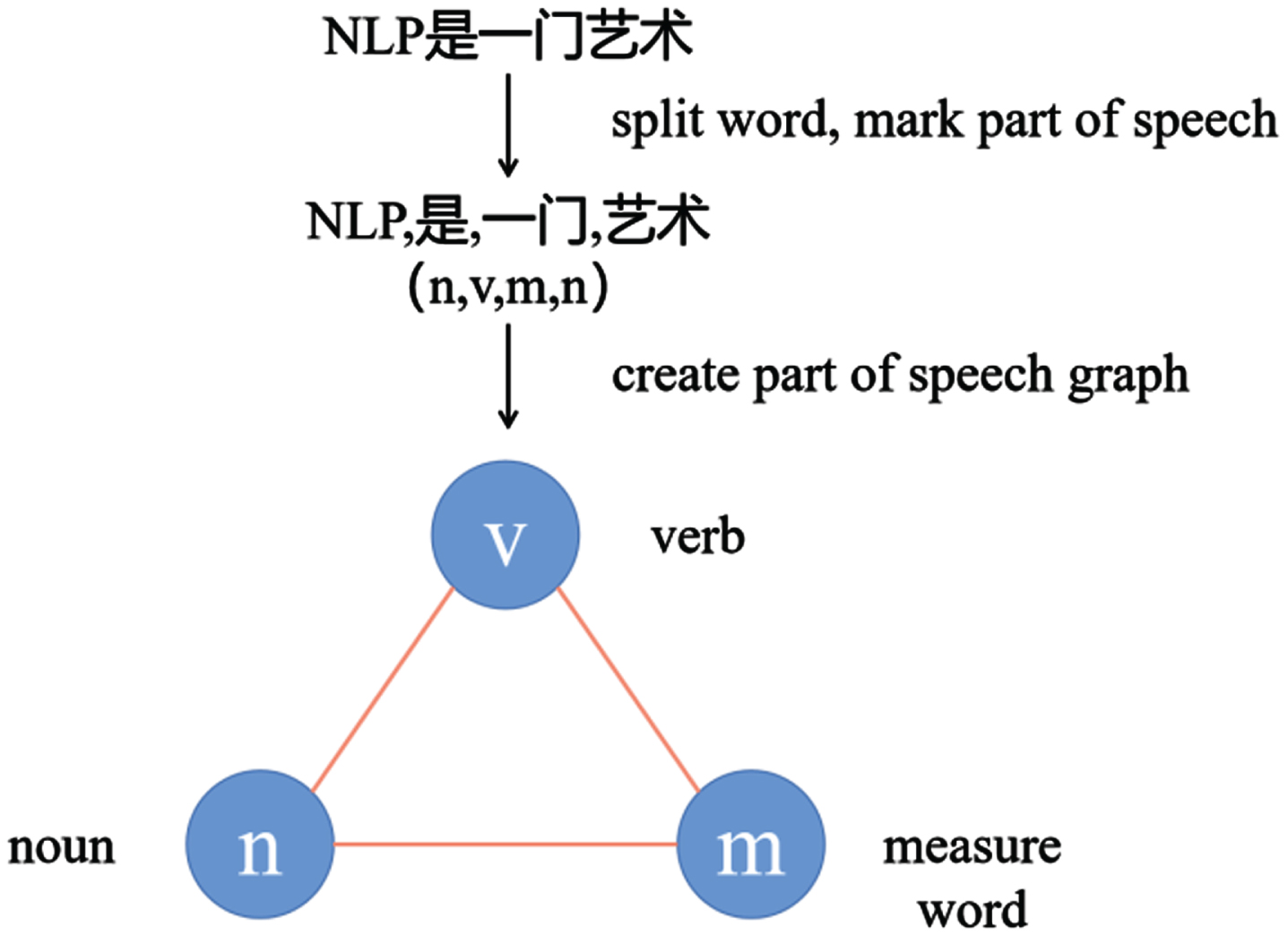
POS spatial graph.
As depicted in Fig. 4, each POS is represented as a node within the graph, with edges between distinct POS nodes established based on their contextual relationships. In this study, we treated the connections between various POS nodes equally, resulting in the construction of an undirected and unweighted graph. Every sentence within the dataset underwent the aforementioned processing. The POS graph generated using the THUCNews dataset is illustrated in Fig. 5, while the one created with the SogouNews dataset is presented in Fig. 6. In both Figs. 6, the weight assigned to each edge is 1. Each node symbolizes a POS, and the respective POS node values were obtained through Word2vec training.
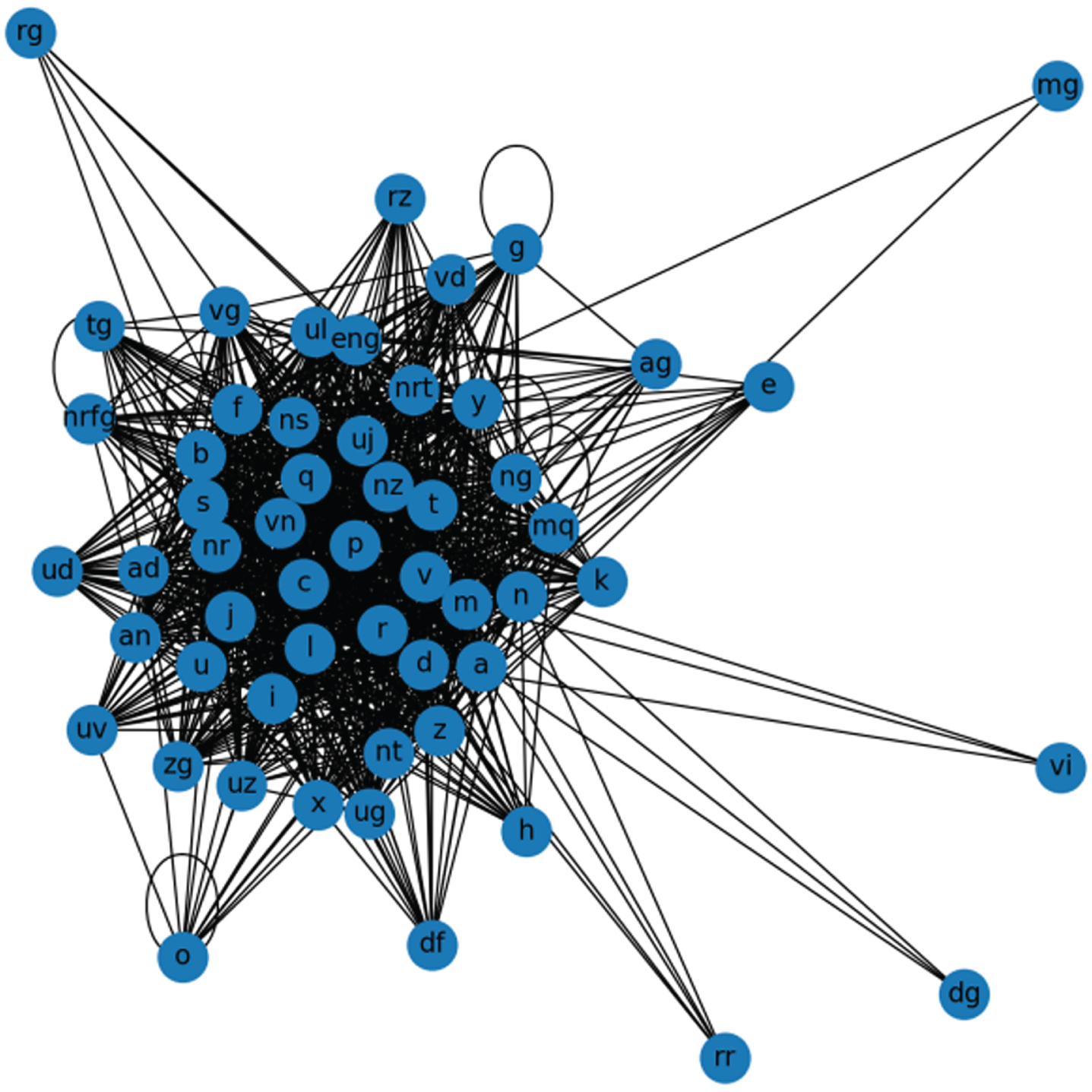
The POS spatial graph of THUCNews.
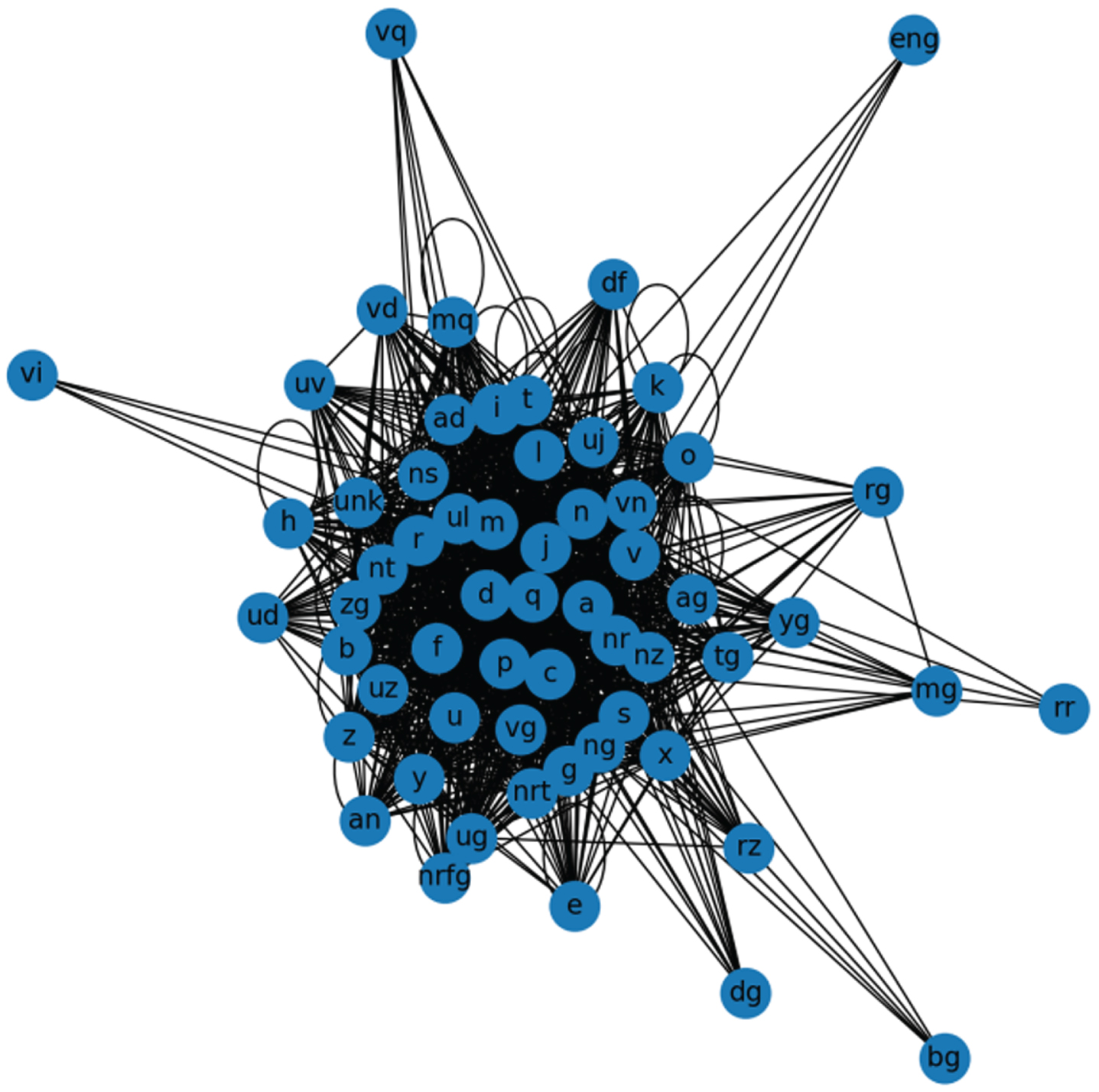
The POS spatial graph of SogouNews.
The POS graph has been constructed. Next, we use GCN to extract structural information from the POS graph. GCN is also a neural network layer, and the propagation formula between layers is shown in Equation (2) [28].
The POS vector updated by GCN will be merged to PW with the word vector for splicing. In order to better integrate the POS feature with the word feature, we add a parameter matrix to adjust the eigenvalues of the PW vector. The formula is shown in Equation (3).
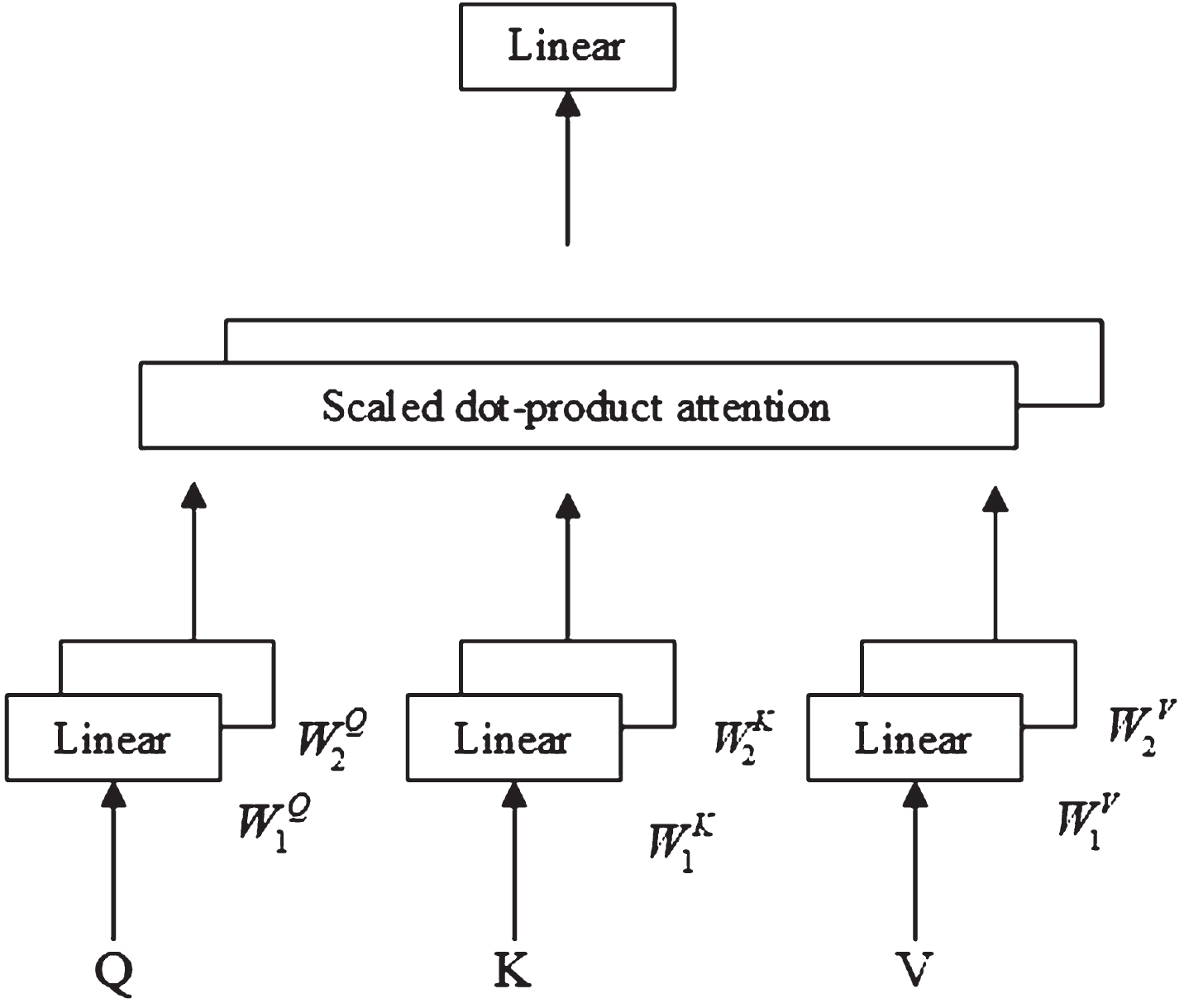
Multi head attention.
As shown in Fig. 7, the input Q, K, and V correspond to the query, key, and value, respectively, and their dimensions are usually the same. Q, K, and V are split into multiple heads, and enter the scaling point layer calculation through the parameter matrix. The calculation formula is shown as Equations (4), (5) and (6).
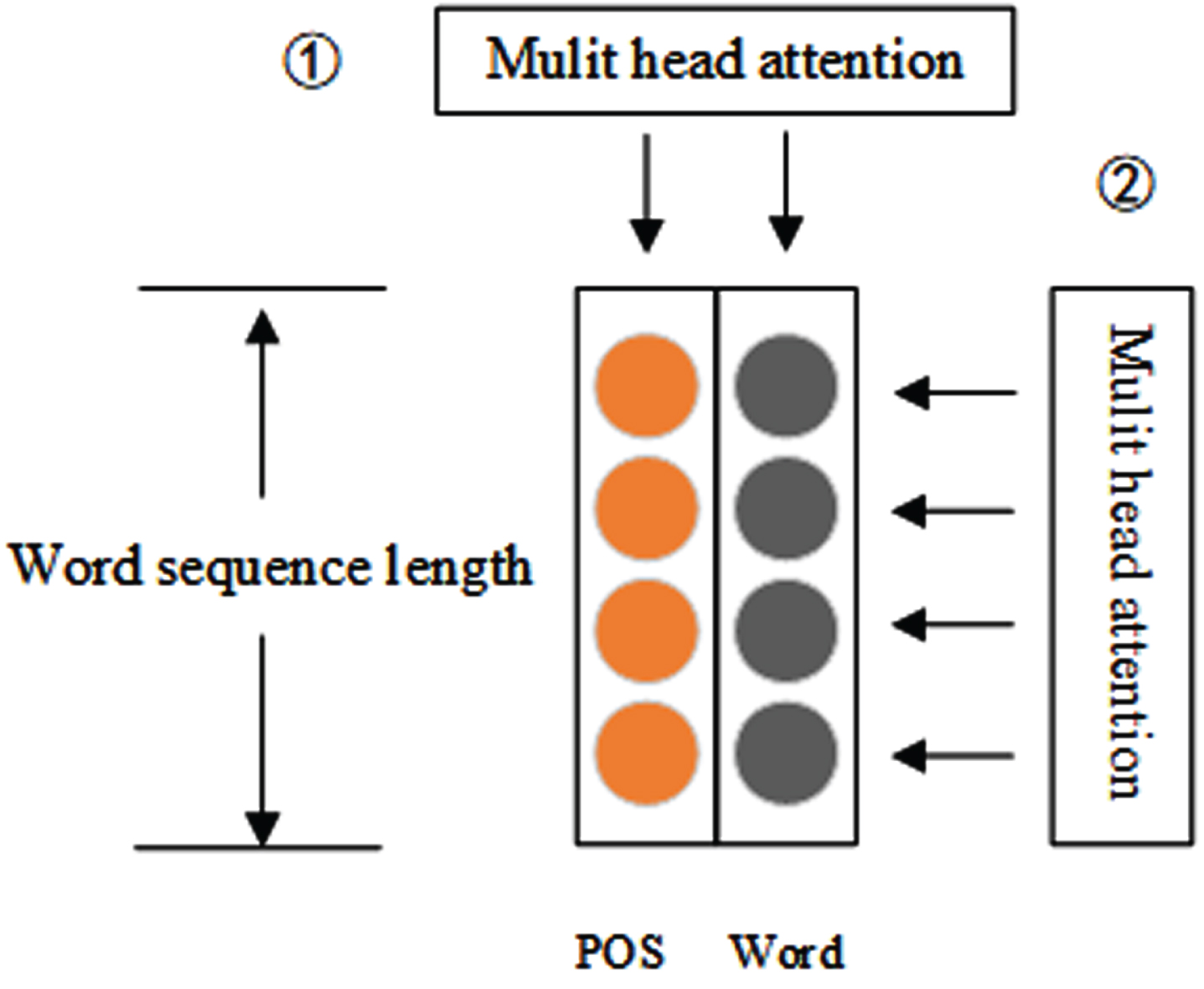
Multi head attention computation for PW vector.
Figure 8 demonstrates the process of calculating attention at both the POS and word feature levels. Subsequently, we computed the word level attention in relation to the sentence context. Through the application of two-layer multi-head attention, we were able to generate a refined PW vector with greater accuracy.
Experimental datasets
This experiment was conducted on Chinese datasets THUCNews [30] and SogouNews [31]. In THUCNews, we randomly selected about 1,300 samples from each category. THUCNews includes sports, entertainment, home furnishing, lottery, real estate, education, fashion, current politics, constellations, games, society and technology. We randomly selected 2,000 samples from each category on SogouNews. SogouNews includes business, travel, automotive, campus, women, health and sports. THUCNews and SogouNews are large Chinese data sets. Therefore, this paper selects some of them as experimental data sets, 80% of which are data sets and 20% are test sets. Relevant data sets are shown in Table 2.
Dataset related information
Dataset related information
To validate the classification performance, we experimented with multiple learning rates and stopped training when the model reached convergence. The optimal performance was recorded for each run. Our analysis determined that in the THUCNews dataset, we trained the model 60 times using a learning rate of 0.001, while in the SogouNews dataset, we trained the model 30 times with the same learning rate. In addition, we set the dimension of the POS vector and word vector to 100, and the number of attention heads to 2. For Word2vec, we used the default parameter with a window size of 5. We trained the model using the ReLU activation function and Adam optimizer.
Experimental evaluation index
The accuracy and F1 score of classification tasks are used as the experimental evaluation indicators. The calculation method is shown in Equations (7), (9) and (10).
To evaluate the effectiveness of the MCWVD method in Chinese text classification tasks, we utilized BiGRU [33] (Bidirectional Gated Recurrent Unit) and CNN [34] as feature extraction layers for downstream tasks. BiGRU is capable of extracting strong global features, while CNN excels in extracting local features [35]. Our method builds upon literature [15], and to demonstrate its effectiveness, we conducted comparative experiments with literature [15] as well as ablation experiments. Further details regarding the experimental methods can be found in Table 3.
Details of experimental methods
Details of experimental methods
The experimental results of this method on THUCNews and SogouNews are shown in Table 4.
Experimental results(%)
Table 4 demonstrates the effectiveness of our proposed method, PW*, which involves the addition of a parameter matrix. A1 and A2 refer to the first and second layers of attention calculation, respectively. Our method achieved the best results on both datasets, surpassing the original word sequence-based approach for text classification. The integration of POS information into word vectors improved semantic accuracy, with the PW method outperforming the PT-WT method by 1.19% in accuracy and 1.49% in F1 value. This suggests that grammatical meaning can be obtained by training part-of-speech sequences alone. The use of GCN with the PW method further improved classification accuracy by 1.29% and F1 value by 1.26%, demonstrating the effectiveness of GCN in extracting grammatical spatial features in the POS graph and improving the accuracy of POS vectors. Comparing PW* with the PW method, the accuracy and F1 value improved by 2.25% and 2.99%, respectively, demonstrating that the use of parameter matrix instead of direct splicing can enhance the coupling between different features. Table 3 shows that using A1 and A2 separately can improve text classification performance, but using them together produces even better results, as the multi-layer attention’s calculation range is more comprehensive. Figures 10 illustrates the relationship between the training accuracy and training time for each method, further confirming the effectiveness and superiority of our proposed approach.
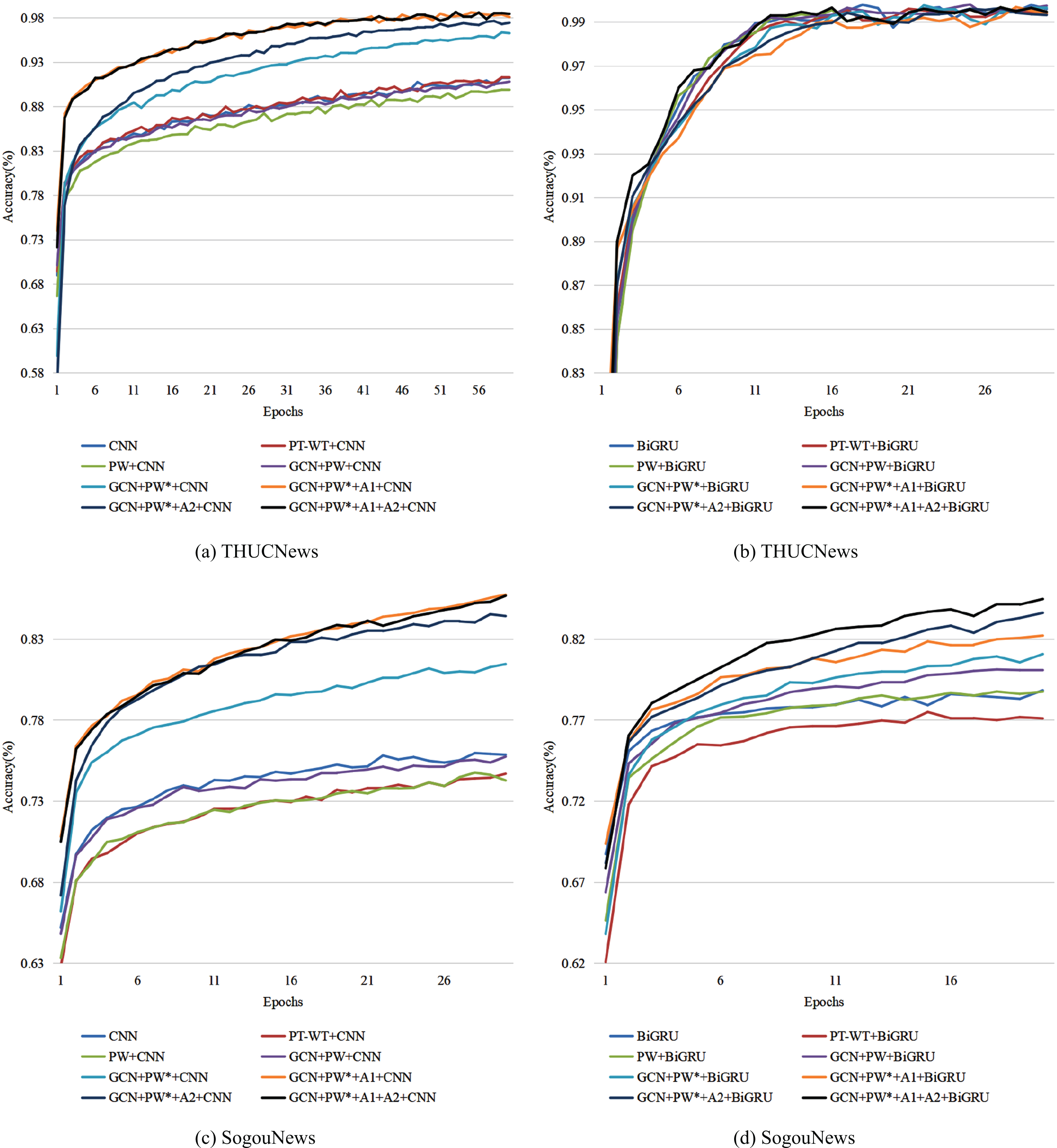
The relationship between accuracy and training times.
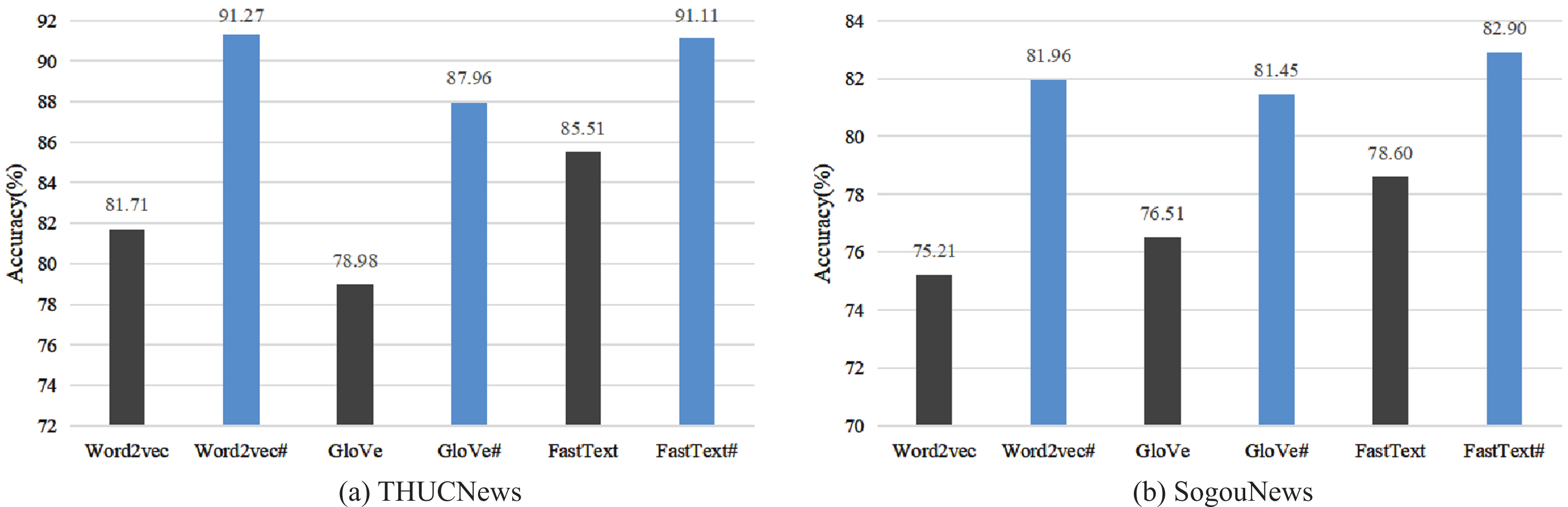
Accuracy of static language model on THUCNews and SogouNews.
Figure 9 illustrates the correlation between training accuracy and time for each method. Our approach achieves the highest accuracy in a relatively short amount of time when tested on THUCNews and CNN. Moreover, it performs the best on SogouNews and BiGRU. Notably, the curves of each method on SogouNews and CNN are significantly different, with the PW vector curve outperforming the PT-WT vector curve. Addition of GCN resulted in a significant improvement in accuracy, as demonstrated by the parameter matrix. The classification accuracy was further enhanced through two-level multi-head attention calculation, as depicted in Fig. 9, which highlights the effectiveness of our proposed method. Subsequently, we validated the proposed approach on other static language models and obtained experimental results that are presented in Fig. 10.
In Fig. 10, the symbol ’#’ represents the utilization of the word vector processing method proposed in this paper. It can be observed from the figures that Word2vec, GloVe [36], and FastText [37] demonstrated significant improvements in text classification accuracy after applying this method. Specifically, the accuracy of text classification of Word2vec increased by 9.56% and 6.75% respectively, while the accuracy of text classification of GloVe improved by 8.98% and 4.94% respectively. FastText also demonstrated improvement in accuracy, with a 5.6% and 4.3% increase in accuracy of text classification. These experiments successfully demonstrate the effectiveness and versatility of the method proposed in this paper, which can produce favorable results on any static language model.
To verify the accuracy of the method’s dynamic semantic generation, the method was compared to commonly used dynamic language models, and the experimental results are shown in Table 5.
Accuracy of dynamic language model comparison experiment(%)
In Table 5, “Param” and “Speed” respectively represent the number of parameters of the model and the number of samples processed per second. According to Table 5, our classification accuracy surpasses CoVe by 2.63% and 2.79%. In THUCNews, our classification accuracy is 0.63% higher than that of ELMo. We achieved higher classification accuracy than ELMo and CoVe at a lower computational cost. Moreover, our approach delivers comparable performance to BERT and GPT-1 with significantly lower computational cost and a parameter count of only 4% that of BERT. Lastly, we illustrate the impact of combining word vectors with POS and multilayer attention, and present the word vector distribution post MCWVD processing in Fig. 11.
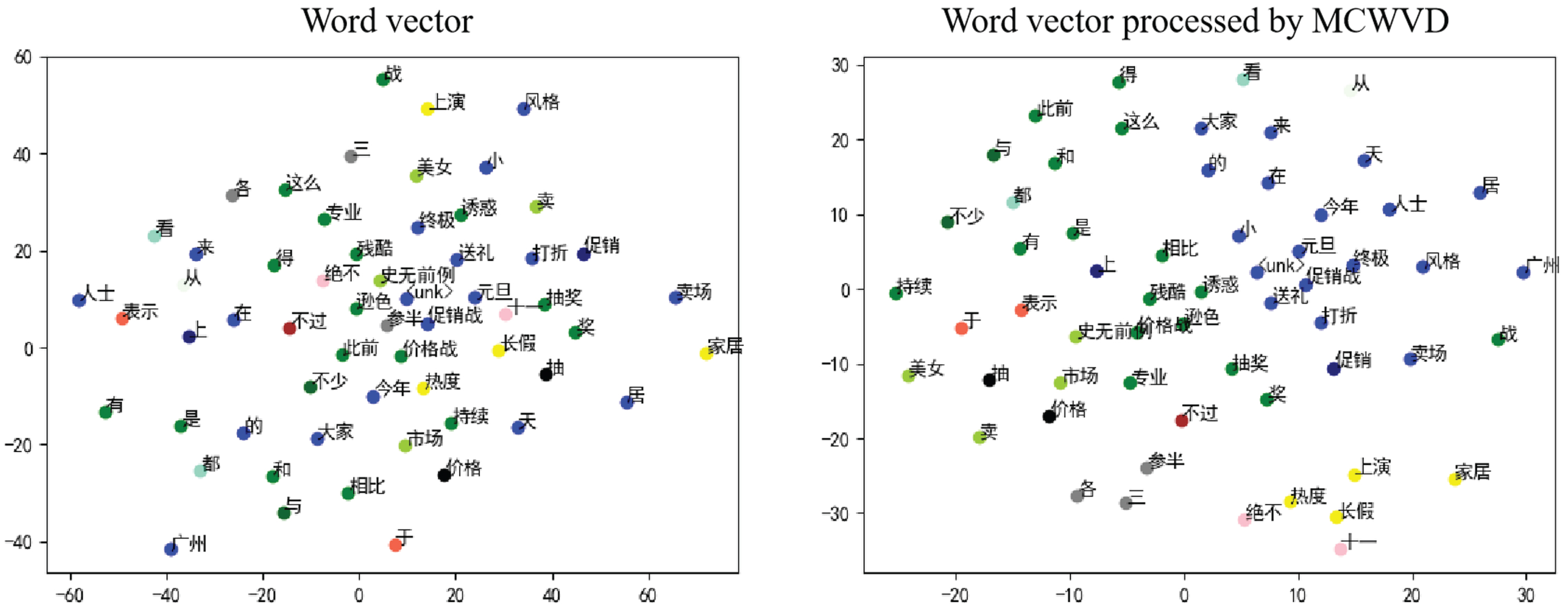
The word vector distribution after MCWVD processing.
Figure 11 displays the word vector distribution of a randomly selected document, where words with identical POS are assigned the same color, with each word represented as a node. The application of MCWVD results in the shortening of distances between word vectors of the same POS, which enables clear differentiation between different senses of a polysemous word. This finding indicates that the integration of POS and multilayer attention can facilitate dynamic word vector modeling, thus enhancing the semantic precision of word vectors.
To address the issue of static word vectors failing to capture word ambiguity, we proposed a dynamic word vector representation method that utilized POS, GCN, and multi-level attention. The dynamic representation of words provided by POS helped to resolve ambiguity caused by differing POS. GCN enhanced the semantic accuracy of the POS vectors, while multi-level attention distinguished the importance of various features and updated the word vectors’ expression with respect to the current context. Experimental results indicated that our approach significantly improved text classification accuracy and enhanced the semantic accuracy of word vectors. Moreover, our method outperformed CoVe and ELMo in terms of classification performance while maintaining a low computational cost. Though our method’s performance was comparable to that of BERT and GPT-1, our computational cost was substantially lower, and our model’s parameter count was only 4% of BERT’s. As our approach was applied after the language model and before the downstream task, it was highly versatile. In some simpler tasks, some static language models such as Word2Vec were still commonly used, making our research highly relevant and valuable.