
Abstract
Prediction of malicious attacks and monitoring of network behaviour is significant for providing security and mitigating the loss of credential information. In order to monitor network traffic and identify different types of attacks in the network, numerous existing algorithms have been provided for classifying unauthorized access from the authorized access. However, the traditional techniques have faced complications in satisfying the accuracy while making predictions of malicious activities. Detection accuracy have been addressed as a drawback which hinders in making appropriate identification of threats. In order to overcome such challenges, the proposed work is designed with effective IDS mechanism for detecting and classifying the attacks taken from the UNSW-NB15 and NSL-KDD dataset. IDS (Intrusion Detection System) implementation is accomplished with three stages such as pre-processing is the initial phase in which scaling re-sizing of all images to similar width and height. Process of checking missing values reduces the computational complexities and enhances accuracy. Second stage is the novel feature-selection process accomplished by E-GSS (Enhanced Genetic Sine Swarm Intelligence) for selecting significant and optimal features. Finally, classification is the final phase in which intrusion is classified using novel DMH-ANN (Deep Meta-Heuristics Artificial Neural Network) which is internally being compared to three classifiers such as RF (Random Forest), NB (Naïve Bayes) and XG-Boost (Extreme Gradient). Experimental evaluation is carried out with the performance metrics such as accuracy, precision and recall and compared with existing algorithms for exhibiting the effectiveness of the proposed model. The research outcome reveals its efficiency in detecting and classifying attacks with greater accuracy.
Keywords
Introduction
Global Internet Statistics Report notified that the growth of the internet in recent days has reached 4.66 billion active users and thus higher than 2 quintillion bytes of data have been generated daily. It shows that the rate of data access has progressed from different sources is extremely fast and the development of methodologies and hacking tools also growing very fast. Hence, there is a requirement for data security and privacy for protecting the data from different intrusions or malicious attacks. Because of the greater volume and greater data speed, the conventional intrusion detection system has not detected the attacks or intrusions in an efficient and faster manner. However certain computational approaches are difficult to handle such kinds of data and required advanced intelligent approaches and powerful technologies. In detecting the attacks, the Intrusion detection system-IDS plays a significant role. IDS system will monitor the traffic in the network to identify threats, attacks or suspicious activities. When such kind of activity is identified, it may issue an alert to the corresponding admin. To handle the intrusion effectively, various ML (Machine Learning) techniques employed handled and classified the intrusion or attacks efficiently [1–3].
For higher than two decades, the IDS system has been generally used to improvise the security in the network and information systems, it has been termed an important tool [4]. Under smart IoT devices protection, IDS is utilized and it has addressed various attacks while evaluating and monitoring the suspicious traffic in the networking environment [5]. Because of the specific protocol stacks, standards, and architectural constraints, the traditional IDS method execution on IoT has been termed a trial. Attack types were not be able to protect the different attack types and thus new methods are essential which include physical hardware application utilizing network probe that transmitted secure data to a remote server and performed malicious detection. However, it required in-depth resources [6]. The IDS plays important role in resisting hacker intrusion and developing effective IDS which is termed a major challenge. For detection of suspicious attacks, ML techniques have been used. For the actual detection process, ML algorithms have been trained and applied to undetected input. In a network, there exist various classification algorithms like ML used for detection of attacks. Feature reduction algorithms have been used to improvise the detection time and classifiers performance [7]. In 1980, the first intrusion detection has been established, and after that several mature IDS, products have been raised. But, several IDSs are still suffering from a greater false alarm rate which generates many alerts to lower non-threatening situations, which in the case raises the security analysts since serious malicious attacks have been ignored in some cases. Therefore, several researchers focus on developing IDSs with minimized false alarm rates and greater detection rates. Another issue with the existing IDS which have been addressed has been the inability in detecting unknown attacks. Since the network environments rapidly change, the new attacks and their associated variants emerge frequently. The unknown attacks detected by IDS, has been found to be essential. ML methods have been considered by the researchers in construction of IDS. Artificial intelligence has categorized as an ML approach that has identified beneficial information from huge datasets. When satisfactory training data has obtained, then IDSs based on ML has attained reasonable detection levels and thus attained adequate generalizability in detection of the unknown attacks and their variants. Moreover, IDS based on ML is not fully dependent on technical knowledge and thus it is easy to construct and design [8].
Detection of intrusions performs the process of identifying malicious activities in network through analysis on traffic behaviour in network. Anomalies have been detected with data mining methodologies. Moreover, dimensionality reduction also has been used in IDS but detection methodology has been observed to be a time consuming strategy. Suggested model [9] focused on feature selection algorithm since it has influenced the speed of analysis to a greater extent. In order to achieve effective detection performance, considered method has deployed filter and wrapper based technique with firefly algorithm has been used for selecting features. Obtained features have been classified using Bayesian network based classification and has retrieved promising outcomes on intrusion detection.
Though Existing studies have provided various techniques for prediction of attacks and classification of normal and abnormal data, the accuracy in prediction still needs improvement. Moreover, existing algorithms have faced challenges with the IDS based on architectural restrictions, protocol stacks, and standards. Above all, accuracy parameter has also required an enhancement. Therefore, major objective of the proposed research is to address the challenges of existing studies while identifying intrusions and other malicious threats such as resource and computational constraints. Motivated by this, the hybridisation of meta-heuristic algorithm with E-GSS for feature selection which aids in identifying the significant and optimal features and DMH-ANN is used for classification, which is a combination of DL and meta heuristic algorithm, it helps in improving the performance of the network and generalization capabilities by fine tuning its parameters which enhances the rate of accuracy. Based on the analysis made from various approaches and its challenges, the contribution of the present research is framed as follows To perform pre-processing with the UNSW-NB15 and NSL-KDD dataset for reducing computational complexities and improving accuracy of the model. To accomplish the task of feature selection with the E-GSS (Enhanced Genetic Sine Swarm) algorithm for selecting best features among better fitness values to perform accurate intrusion detection. To execute the task of classification with DMH-ANN (Deep Meta Heuristic-Artificial Neural Network) classifier for classifying the malicious and non-malicious threats. To evaluate the system with the performance metrics such as accuracy, precision, recall and F1-score for exhibiting the accuracy efficiency of proposed model.
Some of the key contributions of implementing effective IDS mechanism includes, enhanced detection and classification of attacks. It results in higher accuracy in identifying the unauthorized access. In pre-processing stage, proposed model reduces the computational complexities. This helps in enhancing the accuracy through standardized data. In feature selection, E-GSS has been implemented as it aids in selecting the significant and optimal features, by doing so relevant information can be obtained. After feature selection, classification is implemented. Deep meta-heuristic and ANN algorithm was compared with RF, NB and XG-Boost algorithms as it helps in classifying the features effectively and efficiently. Once the process are over, performance metrics are used to assess the effectiveness of the model. The overall contribution of the proposed model is to efficiently detect and classify the malicious attacks in the network and aids in improving the accuracy and precision of the proposed model for finding the efficiency.
Paper organisation
The rest of the paper is organized as section II which discussed the related works of IDS and various ML method implementations addressing different attacks. Further, the proposed IDS model is elaborated briefly in section III. Moreover in section IV, the results and discussion is exhibited and illustrated. Finally, in section V, the paper is concluded with future works.
Related works
The following section discusses the various existing literatures and methodologies utilized in the field of IDS for monitoring traffic and identification of intrusions. For all ML processes, only an individual approach has been used for pre-processing the data. Random forest classifier has taken more time even though it has given better performance [10]. Another ensemble learning-based support vector machine, auto-encoder, and random forest have been used on UNSW-NB15 and NSL-KDD dataset and network log in campus comprised with 300M daily records. The results of this model have been related to other conventional studies that revealed that the ensemble learning model restricted the false negative and false positive predictions [11]. IDS-CNN based on Convolutional Neural Network exhibited different open sources tools like tensor flow, traffic analysis, and packet capture interface. The tensor flow was the ML interface focused on neural network training and testing, intrusion response, and pre-processing. Precision results have shown better values compared with existing approaches [12]. Better detection rates were obtained for IDS-based CNN which has been related to other IDS classifier systems performed on the KDD cup dataset and has suggested the minimization of false alarm rate as a drawback [13]. To overcome that, alarm filtering has been concentrated to increase the accuracy of the detection rate. The higher detection rate of intrusion attained using hybrid ant colony optimization to unsupervised clustering resulted in false alarm rate minimization and also K-means clustering has been used for convergence of ant colony optimization algorithm [14]. Similarly, established with RNN-IDS referred to Recurrent Neural Networks related to other ML models have been analyzed and performance evaluated on the NSL-KDD dataset. Accuracy has improvised but the time taken for training shown more and it has to be considered [15]. By using the support vector machine and extreme learning in multilevel-based hybrid IDS, the unknown attacks detection rates have been enhanced. Using the modified K-means algorithm the IDS performance and overall training time reduced which shown greater accuracy [16].
For detecting malicious behavior in data transmission networks, two ML approaches feed-forward neural networks and Boosted Decision tree has been established. Satisfactory performance and sensitivity values were obtained. The obtained values has been analyzed and related to existing studies have proved its effectiveness [17]. For assuring standard security issues addressed like authenticity, trust, and privacy, effective deep learning-based model has been developed [18]. Further, suggested model [19] used the hybrid data optimization technique comprised of feature selection and data sampling. Outliers have been eliminated by isolation and the sampling ratio has been optimized by genetic algorithm- GA, optimal training dataset obtained by random forest classifier performing on UNSW-NB15 dataset. Rare anomaly behaviors have been detected from this model. For data optimization, more time cost has been required and online procedure support has considered as a limitation. This model has applied to other anomaly detection areas like fraud detection. Searching approaches have been optimized since it has taken more time for classifier training. In [20], the developed model has been inserted into the cloud environment, permitting to capture the incoming network traffic to the physical layers’ router of the edge network. On every cloud router, network traffic captured pre-processing time-based sliding window technique. Using the Naïve Bayes classifier, it further passed through the malicious detection framework. MapReduce and Hadoop commodity server nodes, which has been available in every malicious detection framework in usage observed an increase in network congestion.
Ensemble learning classifiers utilized for the random forest achieved multi-class classification performance for every attack type identification. Further in [21], the IDS- intrusion detection system to MLP- Multilayer perceptron network, fuzzy clustering, and ABC- artificial bee colony have been designed. MLP detected the abnormal and normal network traffic packets in which the ABC algorithm performed the MLP training through linkage biases and weights optimization. For the verification NSL-KDD dataset and clouds simulator has been used. The performance metrics considered were RMSE, kappa statistic, and mean absolute error. The better performance resulted has been compared with existing methods. Moreover in [22], SVM- support vector machine and FCM- fuzzy c means clustering have been utilized for accuracy enhancement for malicious detection in the cloud environment. NSLKDD dataset used for verification of the hybrid context have shown that the proposed model detected malicious activities with lesser false alarm rates and higher accuracy compared with state of art algorithms. In [23], the CS-PSO algorithm developed for IDS has been used in user activities prevented over the cloud environment. Along with that, CS-PSO performed a major role using the NSL-KDD dataset. From a higher dimensional dataset, feature selection has been considered a better technique based on memory storage, and training time have shown the efficiency improvement in IDS. Similarly, in [24], an effective malicious detection model has been developed based on the cloud environment. For intrusion detection and profile training, SVM has been used. The better feature set technique-based optimized NSL-KDD dataset developed to information gain ratio obtained lesser false alarm rate and 96.24% accuracy. SVM approach shown major benefits for IDS evolution in an inspiring difficult environments.
In some cases, intrusion detection is challenging due to the resource constraints and computational complexity exhibited. Lightweight access control protocols established by K-NN and SVM to save computational resources and system lifetime in IoT devices [25]. The accuracy rate has not been satisfactory in certain cases using the data mining approaches and thus new IDS-based linear correlation co-efficient for feature selection with conditional random field and CNN for classification has been employed. Greater accuracy has been attained. More efficiency has been yielded based on optimized standard approaches [26]. Using conventional IDS-based advanced attacks detection have shown lesser efficiency. Deep learning models have also been used to address the issue and however, it has been concentrated on Denial of Service- DoS attacks. For evaluation, the KDD cup-99 dataset has used contains probing attacks, DoS attacks, user to root U2 R attacks, and remote to local attacks. Compared with RNN, CNN have shown better efficiency in intrusion detection. Multi-class classification has not been focused on yet [27]. Different ML and deep learning approaches have been considered for DoS attack detection which resulted in better accuracy [28]. Different IoT malware detection method considered to perform rapidly and precisely in the IoT field. Different behaviors have been recognized using the malware detection dynamic evaluation-based neural network, which was extracted to a system call, memory, and virtual process system. Further, it has been transformed into malware images and by analysis damages in such behavior images have been minimized [29]. U2 R, probing attacks, and R2 L attacks have been focused on automated IDS systems and computational overhead has resulted in detecting other attacks from NSL-KDD datasets. However, stability and potentiality has also been recorded [30]. Extreme learning ELM-based neural network has been executed for handling dimensionality reduction. Both IDS execution and detection efficiency were enhanced on the NSL-KDD dataset. Better performance has been observed [31]. PSO (Particle Swarm Optimization) has selected feature-subsets and hyper-parameters in single process [32]. Optimized features and parameters have been selected automatically in pre-training stage and outcomes have shown significant improvement in detection of intrusions. GA(Genetic Algorithm) based feature selection and hybridized classification with DT (Decision Tree) and LR (Logistic Regression) have achieved better rate of detection [33]. Meta-heuristic algorithms applied in feature selection approaches have solved complex problems significantly in intrusion identification [34]. Meta-heuristic optimization technique in [35] based on hierarchical IDS have identified different attacks. It has optimized the hyper-parameters of extreme-learning machine with the construction of various binary models in the detection of attacks. Suggested model [36] has presented feature selection strategy through boosting up the performance of GTO (Gorilla Troops Optimizer) depending on the methodology of BSA (Bird Swarm Algorithm). Integrated GTO-BSA has obtained feasible solutions and improved convergence considerably. Performance validation on UNSW-NB15 and NSL-KDD has achieved better prediction level of intrusions. Similarly, suggested study has implemented a meta-heuristic algorithm called Ebola Optimization Search Algorithm (EOSA). This algorithm was based on the propagation mechanism of the Ebola virus disease. from the experimental outcome, it was addressed that recommended model delivered better results for complex problems such as attacks and malicious threats [37]. Correspondingly, another meta -heuristic optimizer, called Reptile Search Algorithm (RSA), motivated by the hunting behaviour of Crocodiles. The 2 main steps involved are behaviour of the crocodile which includes encircling which was performed by high waling or belly walking or hunting. Performance of the RSA was evaluated using different classical test functions and the performance of the suggested model was further compared with different models and from the experimental outcome it was identified that, suggested model performed better than the existing ones [38]. Likewise, recommended paper implemented AO (Aquila Optimizer), it was inspired by behaviour of Aquila in nature during the process of catching the prey. 4 different methods were employed in the suggested model. The performance of the suggested model was evaluated using different performance metrics and from the results it was identified that, recommended model performed better than the existing ones [39].
From the existing studies, it was identified that accuracy of the existing models were less when compared to the proposed models, this leads to ineffective and inefficient model for detecting the malicious attacks in the network. And the existing studies found difficulty in handling the higher speed in evolving attacks.
Proposed methodology
In the proposed model, two datasets are employed. Initially, the dataset is pre-processed using data pre-processing techniques. Data pre-processing techniques are used to remove the unwanted and noisy data from the dataset using scaling techniques and by checking missing values. Once data pre-processing is over, feature selection is employed. Feature selection is used to make the process more accurate and precise. It also helps in increasing the prediction power of the algorithms by selecting the most critical variables and eradicating the redundant and extraneous ones. Therefore, proposed method implemented E-GSS (Enhanced Genetic Sine Swarm Intelligence) for feature selection as it combines genetic algorithms and sine swarm intelligence algorithm to identify the significant and optimal features. In E-GSS, genetic algorithm and sine swarm intelligence algorithm are combined to perform feature selection. Since, the algorithms aims to identify the most relevant and significant features from the dataset which contribute the most classification or ID tasks as E-GSS reduces the dimensionality of the input data and eradicate the irrelevant or redundant features, by selecting the most informative features.
Once, the features are selected, these features are trained and tested accordingly and automatically enters into process of classification. In classification, Deep Meta Heuristic- ANN is used, as it automatically selects a minimal subset of features that produces greater accuracy for classification. DMH-ANN improve the performance of the network and generalization capabilities by fine tuning its parameters. Before evaluating the performance of the proposed model, K-fold cross validation is employed, which helps in avoiding the over fitting process. Finally, the performance of the model is evaluated using different performance metrics which includes accuracy, recall, F1 score and accuracy. The overall flow of the proposed model is given in Fig. 1.
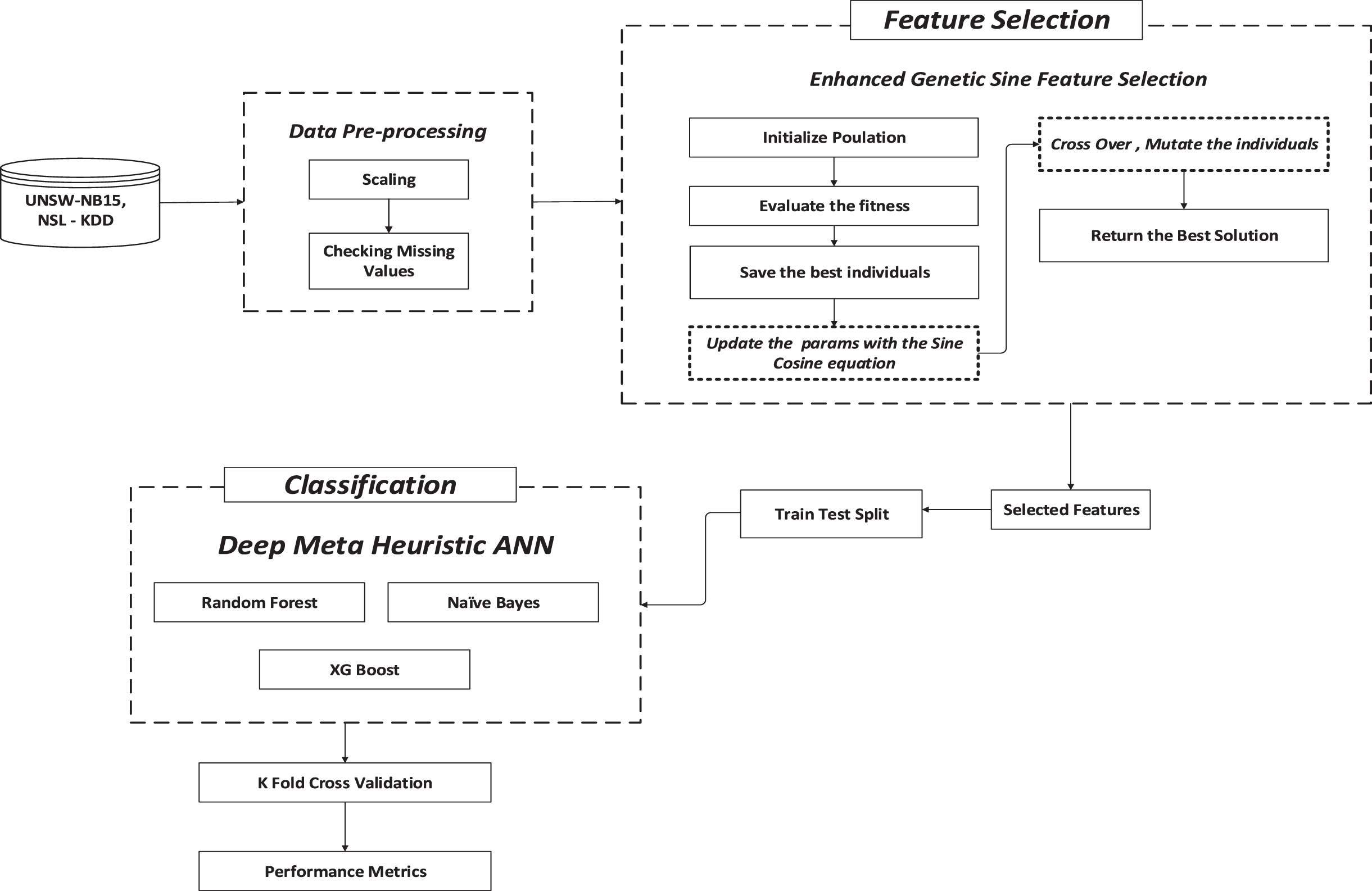
Proposed flow.
Initially, the UNSW-NB15 dataset is loaded as mentioned in Fig. 1, and pre-processing such as scaling and missing values checking are performed. Further to enhance the accuracy of detection, the feature selection process is performed using the Enhanced Genetic Sine Swarm algorithm, which selected only the significant features. Finally, the classification of the anomalies is performed using the Deep Meta-Heuristic ANN classifier. In the prediction phase, it detects all attack types. Finally, the proposed Enhanced Genetic Sine Swarm algorithm (E-GSS) based Deep Meta-Heuristic ANN classifier (DMH-ANN) model was evaluated in terms of different performance metrics and compared with various existing models to prove its efficiency.
The feature selection process is performed on the selected UNSW-NB15 dataset and NSL-KDD dataset using the proposed E-GSS algorithm. The hybridisation of GA (Genetic Algorithm) with SCA (Sine Cosine Algorithm) is being used as the proposed feature selection strategy.
Genetic algorithm
The enhanced genetic algorithm here solves the decrease in accuracy issue while identifying the fitness value issue and initializing the population from lesser pairing sets and improving the population again and again by providing new pairings from the remaining search space using improved customize genetic operators. At first, the Genetic algorithm’s initial population ini_pop is performed and the further main loop performed contains selection, crossover and mutation, and other operators imposed in sequential order.
Selection:
The selection operator is imposed for chromosome selection which in turn to be parents for child chromosomes reproduction. A binary tournament selection operator is assumed in the proposed GA in which two sets of two chromosomes, everyone is formed randomly. Among these sets, the parents with the best fitness value are transferred to the crossover stage.
Crossover:
The transition stage is referred to as the crossover stage in which the parent chromosome’s genetic information is transferred to the following generation as same as new child chromosomes reproduction. The following crossover operators are discussed:
Crossover 1- The probabilities depend on the fitness of parents in deciding the genes which are transferred to the child’s chromosome.
Crossover 2- To increase the convergence rate, greediness is integrated into reproduction operators corresponding to domain knowledge. The known part of the child chromosome generates zero solution build-up by randomly selected pairings or from parent chromosomes columns. The procedure is shown above in Algorithm 1. By repeating the procedures, the crossover operators changed to constitute two-child chromosomes from two-parent chromosomes.
Mutation:
The mutation operator is imposed on the resulting child chromosomes after the crossover part. Premature convergence is prevented by the mutation part. Getting stuck at local optima is avoided by changing child chromosomes genes with the help of some probability. Compare the two mutation operators in the current work such as mutation 1 (bit-flip mutation operator) and mutation 2 (mutation operator based on population’s fitness solution density). In mutation 1, if ith gene selected for mutation, followed by bv1i flipped from 0 to 1 or 1 to 0. However in mutation 2, if the ith gene is selected for mutation, followed by bv1i is mutated from 0 to 1with 1 s in fittest individual percentage probability and similarly for 1 to 0.
Feasibility Heuristic:
The feasibility of resulting child chromosomes is not definite and in other words, it may or may not covers all values. The feasibility heuristic is needed to carry out the feasibility in child chromosomes. Simultaneously the child’s chromosome fitness should be maintained. The feasibility heuristic is changed in which a repeated pairing removal is involved at the end. The minimum quality index pairing was selected for every uncovered value. The repeated pairing removal step included the heuristic which identifies and deletes the same values exhibited by those pairings shown in algorithm 1.
Fitness function Evaluation:
The objective function of the problem is the fitness function and it evaluates the chromosome’s fitness value. The important objective is to reduce the total pairing cost and also cover all values at once and the unique fitness function exhibited. The performance is measured by the fitness value assigned to the chromosome. Once the population generation is completed, the fitness value of each chromosome is measured. the fitness value is higher based on better chromosomes. Thus the chromosomes of individuals corresponding to greater fitness value show a better chance of survival.
The final step of the genetic algorithm is the population updations step in which the parent and child chromosome’s survival population is selected and it becomes the parent population for the following genetic algorithm sequence refer as a generation. A generational and steady-state approach is followed usually for population updations. In this work, the generational approach is chosen and the best n chromosomes among the n parent and n child are chosen which are transferred to the following generation.
Further, the computational time of the standard genetic algorithm is reduced by, Minimize the individuals staying in Minimize the fitness of individual computational time Prevent frequent fitness evaluations
The solution to minimizing the number of individuals is to maintain smaller population size. In this case, the system converges to the local optimum rapidly. Initially, the size of the population is set to be greater and minimized over time to address these issues, hence initially the system can discover the search space, and further certain optimal solutions get converged. Frequent fitness evaluations are prevented through memory storage of individual fitness. To calculate every longer fitness, this approach is required. However, if so many individuals are presented in memory, the memory may be too long in identifying the particular individual. Hence fixed memory size is used to store the individuals and the lower fitness individuals are deleted further.
Enhanced-Genetic sine algorithm implemented in the proposed study possess various advantages which includes exploration and exploitation. E-GSS algorithm strikes a balance between exploration of the search space and exploitation of the promising solutions. This characteristics allows them to avoid getting trapped in local optima and maximize the chances of finding globally optimal or near optimal solutions. Similarly, E-GSS can adapt and evolve the population of the candidate solutions which enable them to handle changing problem landscapes or dynamic environment. This adaptability provide various advantages, where the optimal feature subset may change over time or vary across different datasets. Correspondingly, E-GSS can be easily parallelized as the competency of parallel processing accelerates the search process and permits scalability predominantly in large scale feature selection problem. In addition, it also maintain a diverse population of candidate solutions throughout the search process as this diversity improves the exploration capability of the algorithm and minimizing the chance of discovering a wide-range of high quality feature subsets. They are often robust to noise or incomplete information in the problem domain. They can tolerate the uncertainties and imperfect fitness evaluations by making then suitable for feature selection.
Due to these advantages of E-GSS algorithm, it is implemented in the proposed model. Therefore, proposed E-GSS leverages the concept of sine functions to capture periodic patterns in the data. This can be particularly helpful in domains where the features exhibit cyclic behavior or possess inherent temporal dependencies. By explicitly incorporating the sine functions, E-GSS algorithm can effectively detect as well as select the features which contribute to capture such periodic patterns. Leading to more improved accuracy as well as interpretability. Similarly, E-GSS aids in capturing the non-linear dependencies among the features by permitting the selection of pertinent feature combinations which might be unexploited by linear or non-linear based algorithms. E-GSS algorithm employs an automatic feature representation approach by encoding features using sine functions. This automatic feature representation minimizes the burden on the users to manually engineer feature representations and can lead to more efficient and accurate feature selection. Similarly, by using the sine functions in the algorithms feature representation can contribute to interpretability. The periodic nature of sine functions allows for intuitive understanding of the selected features and their impact on the target variable. GSS inherently possess the capability to balance exploration and exploitation. The balance between exploration and exploitation enable the algorithm to efficiently search for optimal or near optima feature subsets without getting trapped in suboptimal solutions.
Sine cosine algorithm-SCA
The sine cosine algorithm- SCA is considered a new stochastic optimization technique for updating the sine and cosine operations. The algorithm is population-oriented and starts with the random search agents or set of solutions placed in the optimization problem’s search space randomly and search agents are directed towards an optimal solution through the fitness function. It further assesses every search agentt ahm’s every iteration. Sine cosine algorithm keeps m search agents population and through n-dimension, every agent is described as Xi (i = 1, 2, … , sa) variable vector in which population search agent i is Xi. The proposed algorithm maintains the position of a better solution attained through all the search agents in every iteration population. The basic SCA algorithm mathematical model is expressed as,
Where itn is referred as the iteration number and r2 and r3 are random numbers and cp1 is referred as the control parameters that balances the exploration and exploitation phases of the algorithm.
From Equation (1), the current iteration number is itn, and the control parameter is cpi which stable the exploitation and exploration phases. At every iteration, the constant value is reduced by a to for Equation (2). The random numbers are cpi, cp2, cp3, ands. This system shows a circular search pattern showin which the desired destination point or a better solution is obtained and a search agent is placed nearby. The circular search region is further categorized as representing the Xi exploration region. cpicontrols the move of Xi, it moves to Pos if cpi>1, exploitation step or else from Pos it moves away, referred as exploration step. In balancing the exploitation and exploration, cpi is used and its random value controls the movement. According to Equation (1), parameters switched randomly among the sine and cosine operations.
The hybridisation approach is mainly designed to extract the significant intrusional features from the dataset which assist in better level of classification. It integrates the exploration capability oSCA and exploitation ability of GA in order to avoid earlier convergence. It considerably activates the seekinoperation and makes the rate of convergence faster. Through, effective outcomes are achieved in a reasonable time. Integration of two different algorithms provides advantages. Since GA has the potential of tracking possiblsolutions aist in converging to a global optima in a diversified population and hence helps SCA accelerates towards optimal solution. The following algorithm 2 expressed the developed E-GSS algorithm namely Enhanced Genetic Sine swarm optimization for feature selection,
From Algorithm 2, it is clear that from the group of feature subsets such as f1, f2, . . . , fm in which population is initialized and individual fitness function is being calculated using the genetic operation. Initially, it starts with the exploration of the search space and fitness values obtained are stored in memory which is in fixed size. Individuals with lower fitness values are removed from memory when it is full and the algorithm is automatically terminated when the population contains single individual. newFit (i) updates the new solution and oldFit (i) is the oldest fitness which is being removed and curPopSize determines the total individuals in the memory and P is the new individual stored in memory.
Classification using Deep Meta-Heuristic ANN (DMH-ANN) algorithm
The classification of selected optimal features is classified using the proposed Deep Meta-Heuristic ANN (DMH-ANN) algorithm evaluated with Random forest, Naïve Bayes, and XGBoost approaches. Further, it undergoes k-fold cross-validation for different performance metrics to evaluate the proposed methodology. ANN- Artificial Neural Network is considered a ML framework, similar to a human brain model with no. artificial neurons among them. ANN neurons show fewer connections and the architecture of ANN is shown in Fig. 2.
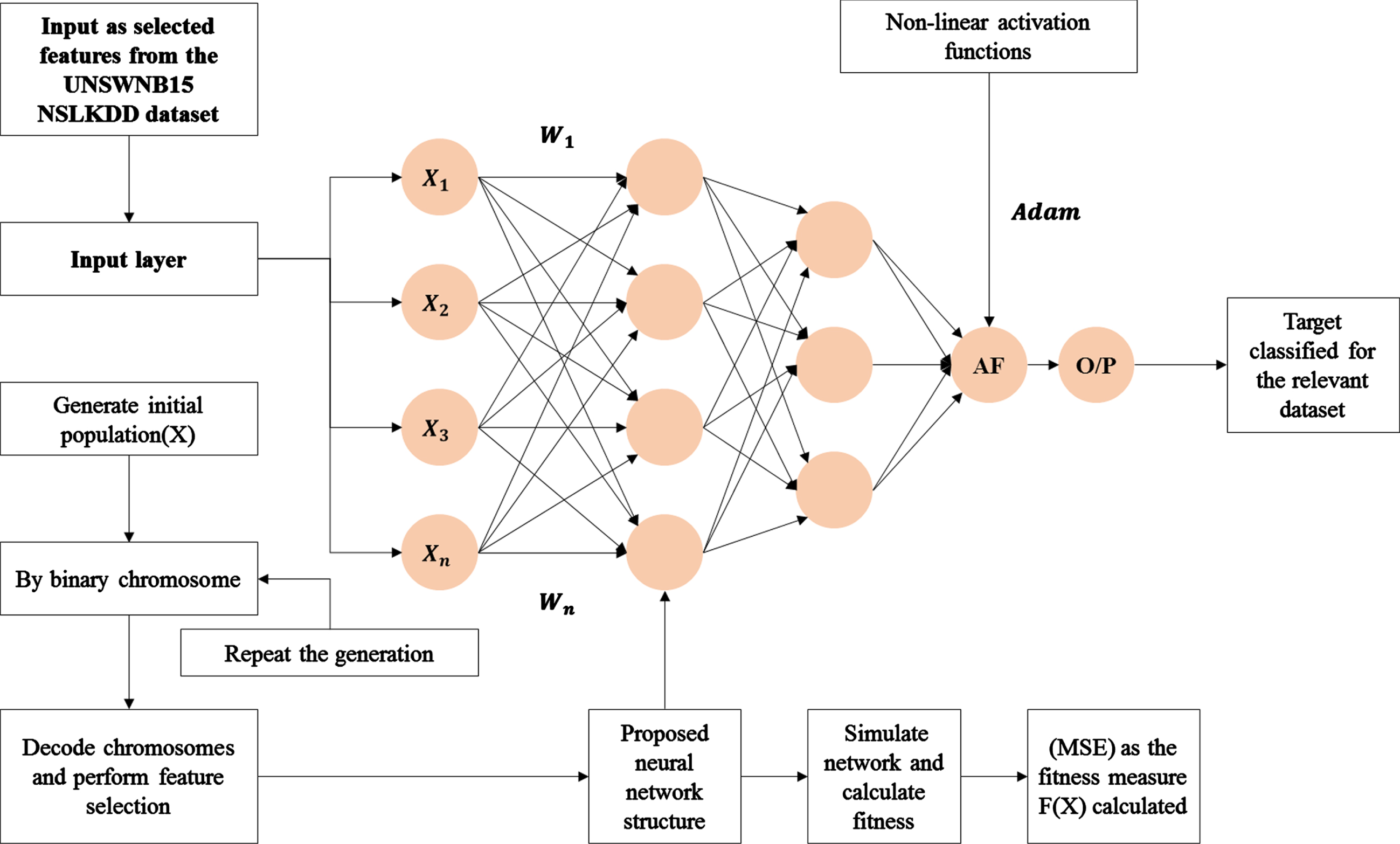
Deep Meta-Heuristic ANN (DMH-ANN).
The advantage of ANN as depicted in Fig. 2 indicates that the perceptron structure intakes the weighted sum of inputs and sends the output. If the sum is greater than threshold value, it is referred as activation function and the following algorithm exhibited the steps followed in the proposed classifier Deep Meta Heuristics ANN,
Algorithm initially begins with the data preparation and population determination. A binary code genetic algorithm is used to characterize the chromosome. The chromosome is categorized into two parts. The length of chromosome is determined by X dimension and population size is determined by Y dimension. The first part comprised of N bits represented as N no. of dataset features value as 0 or 1 shows either feature at the specifically selected location or not. At ANN hidden layer, the part of the second chromosome indicates M no. of nodes. The chromosome’s second part length is set automatically and thus the similar decimal value is not smaller. It needs only smaller code even when the size of the network is greater. The fitness function is measured for MSE-Mean square error of validation dataset shown in Equation (3), in which no. of output nod, no. of examples are ne, for jth pattern,
The chromosome with lesser MSE shows a better option which is to be selected as a parent and for the next generation, it has survived. This has been attained through the selection process in which the ranking conversion of MSE value is performed. if the ranking value is greater then a better chromosome is obtained. Based on ranking value, ith chromosome fitness has been measured. defined in Equation (4),
From Table 1, the fitness value for every chromosome resulted from Equation (2). Followed by roulette wheel selection process has been applied to select chromosomes for performing crossover and parent functions. These processes yield two children which inherit their parent’s genetic details. The replacement procedure is the followed step in which the newly born offspring replaces the final two poor chromosomes. For the next generation, the best-fit chromosome will survive and the poor chromosome will expire. Further, the mutation function performs. Typical single-point mutation and crossover functions are used. For every generation, the parents are moving towards the crossover function procedure. A random crossover location is generated in the initial step during the crossover process. After that swapped location all bits among the parents are yields two offsprings. In case of the mutation operation, every chromosome bit will turnover from 0 to 1 or 1 to 0 to the probability of mutation.
Fitness value for every chromosome attain through MSE validation
Flow features
A random forest algorithm is introduced by Breiman, for the idea of a forest and an election. Every tree in the forest identifies as a voter. The set of percentages and votes is the standard for making the end decision. The bagging method is used for every tree by the RF method for random training dataset generation. By RF, splitting features are selected semi-randomly. A random subset of a particular ratio is provided through the possible feature space splitting. In a random forest, the bagging mechanism enables the algorithm to generate the classifiers for rapid higher-dimensional data. The decision of classification accuracy is attained through voting from ensemble individual classifiers. The general element in all of the steps determined that no. of random vector Si and i tree generated using a bootstrap sample which shows independent of past random vectors with similar distribution, using Si and training set a tree is grown. The corresponding RF algorithm is given below
From Algorithm 4, it is clear that the variable TS denotes the training sample with f is used as the input instance being utilized on every tree. Accuracy obtained through classification in whicnumber of i tree and TSi as the random-vector with the utilization of bootstrap sample generated independently with past vectors but with similar distribution and tree id grown and denoted by attribute Ci. Classification is accomplished effectively using RF methodology.
NB(Naïve Bayes) classifier
When handling continuous data, the standard possibility shows that the continuous values correlating with every distributed class are based on Gaussian distribution. Through standard deviation and mean, training data are split by class. Hence for evaluating the continuous dataset probabilities, the below Equation (5) is used,
From Equation (5), the variable is x, class is c, the standard deviation is θ and ɛ is the mean. NB algorithm is presented below
From Algorithm.5, it is clearly indicated that the TD is the training dataset for the model and predictor variables are denoted as pv1, pv2, pv3, … pvn. Mean and standard deviation for the predictor variable in every class is being measured and the process is being repeated until the probability of variables have been calculated. The likelihood of every class is being formulated and achieves greater likelihood. The characteristics of predictor attributes are needed for classification. Probability of data matched with some characteristics in particular class is assigned to be the probability emerged through multiplication by samples in likelihood and divided by samples attained globally.
XG Boost is defined as a scalable tree boosting model, currently used because of the greater prediction accuracy and excellent efficiency. It is comprised of multiple decision trees which are used in the regression and classification fields. XG Boost performs as Newton Raphson in the operation space, unlike gradient boosting performs as gradient descent in operation space. Normalization is used in the objective function, minimizing the complexity, and over-fitting is prevented. In loss function, 2nd order Taylor approximation is used to make the Newton Raphson method’s connection. The detail of the model is explained below algorithm.
From Algorithm 6, it is clear that XGBoost algorithm achieves greater accuracy than a single DT model which utilizes the intrinsic interpretability of the DT. The path that trees makes in decision is important but following hundreds of path is harder and hence XGBoosting is used which approximates the similar decision function. Classification of intrusion is achieved with better efficiency. Comparison on all three classification algorithms with the performance metrics are performed individually with the features selected from proposed E-GSS approach.
Results and discussion
Dataset description
The proposed Enhanced Genetic Sine Swarm algorithm (E-GSS) based Deep Meta-Heuristic ANN classifier (DMH-ANN) method was used to detect the intrusion on UNSW-NB15 and NSL-KDD dataset in the application of anamoly based IDS for detecting malicious attacks and adapts to new threats. The UNSW-NB15 dataset raw network packets have been generated by UNSW Canberra cyber range lab for synthetic contemporary behavior attack and generating activities of real modern normal. Multiclass imbalance in dataset is being handled through adjusting the cost on data with the calculation of mean values. The proposed hybrid approach handles imbalance issues. Different balanced datasets are created for minority classes and then fed into the DL algorithm that outputs the pool of rules which evolutionary algorithm act as a classifier from the rules. The UNSW-NB15 dataset [40] was generated using the IXIA PerfectStorm tool in the cyber range lab of ACCS- Australian center for cyber security for creating realistic modern normal activities hybridization and from network traffic, synthetic contemporary attack behaviors focused. A tcpdump tool is utilized to record network traffic of 100GB. Bro-IDS and Argus tool were utilized and for extracting features 12 models have been developed using Tables 1–5 [41].
Standard features
Standard features
Content features
Time features
Additional features
Table 6, explains the generation of the training and testing set from the selected dataset UNSW-NB15 dataset, originally obtained from https://research.unsw.edu.au/projects/unsw-nb15-dataset. A part of the dataset observed and records have been divided with a 60 : 40 percent ratio approximately as a training and testing set. In attaining the IDS evaluation authenticity, no redundant records between the training and testing set are recorded. Further, the basic NSL-KDD dataset is explored below obtained from https://www.unb.ca/cic/datasets/nsl.html and https://www.kaggle.com/code/timgoodfellow/nsl-kdd-explorations/.
Dataset distribution
The following Fig. 3 illustrates the correlation matrix of the selected UNSW-NB15 dataset, here the most correlated features identified are
Confusion Matrix for UNSW-NB_15.
spkts, sbytes, sloss dpkts, dbytes, dloss sinpkt, is _ sm _ ips _ ports swin, dwin tcprtt, synack ct _ srv _ src, ct _ srv _ dst, ct _ dst _ src _ ltm, ct _ src _ dport _ ltm, ct _ dst _ sport _ ltm is _ ftp _ loginct _ ftp _ cmd
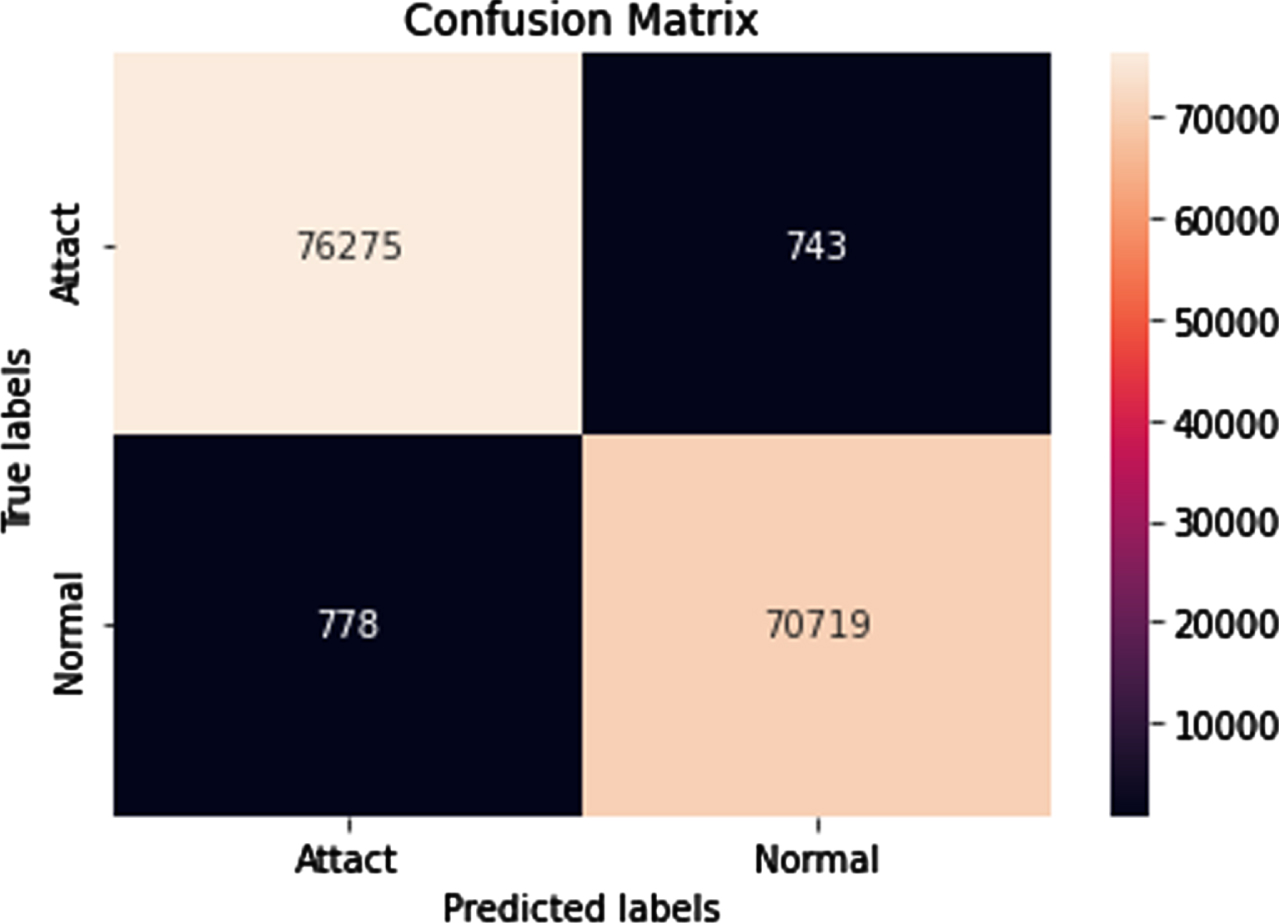
The experimentation with the proposed algorithm for the prediction of intrusion is being evaluated with confusion matrix for NSL-KDD dataset and given as follows
The combination of actual and predicted values are illustrated in Fig. 3. From the positive and negative classes, the number of actual prediction is found to be high which shows the better accuracy of the system. Similarly for NSL-KDD is also given in below Fig. 4.
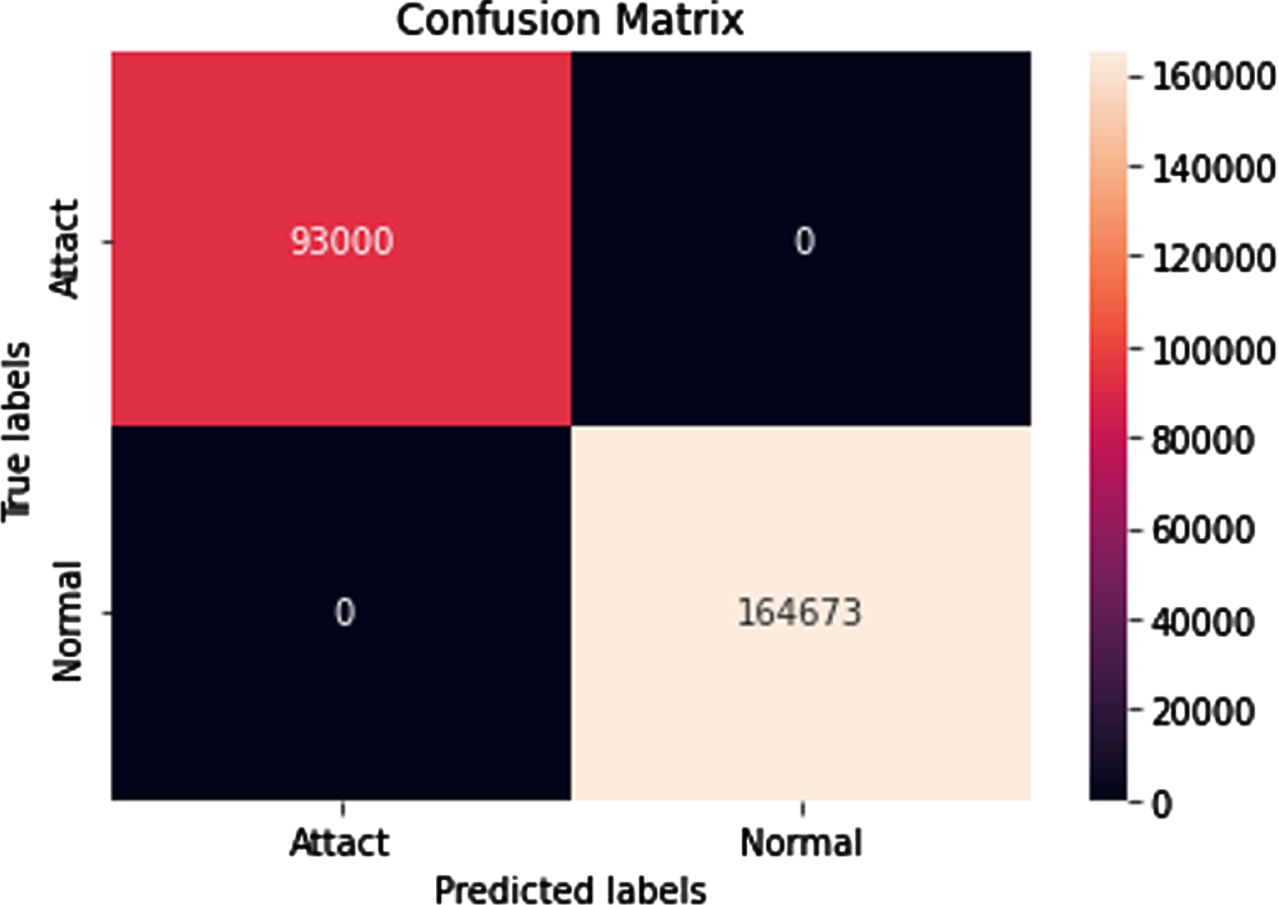
NSL-KDD Confusion Matrix.
From Fig. 4, it is clear that the actual prediction of normal and abnormal data is being calcualted with the metric of confusion matrix in NSL-KDD dataset which exhibits the efficiency of the model and ROC graph analysis is being depicted in Fig. 5.
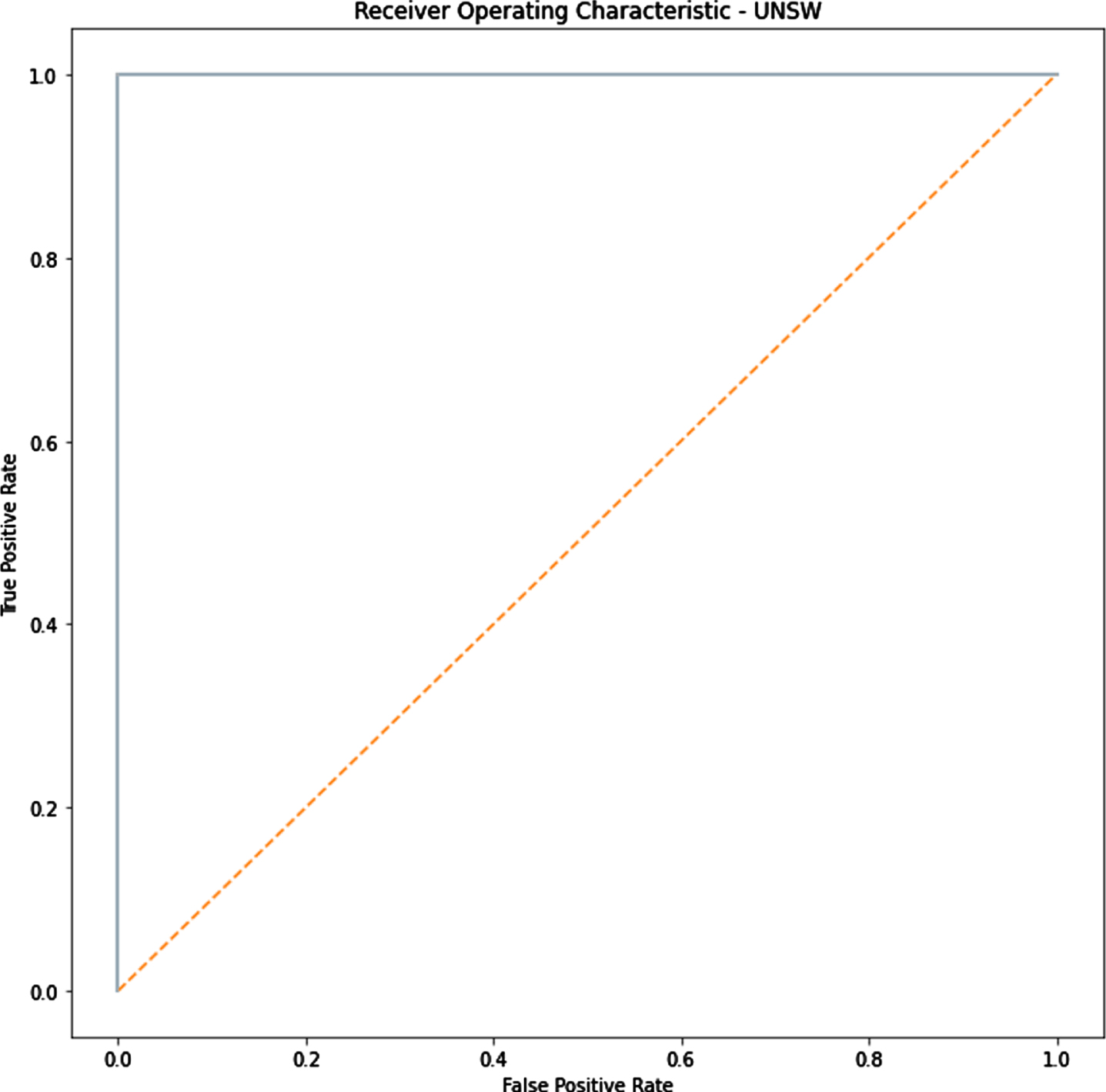
UNSW-NB_15 ROC Curve.
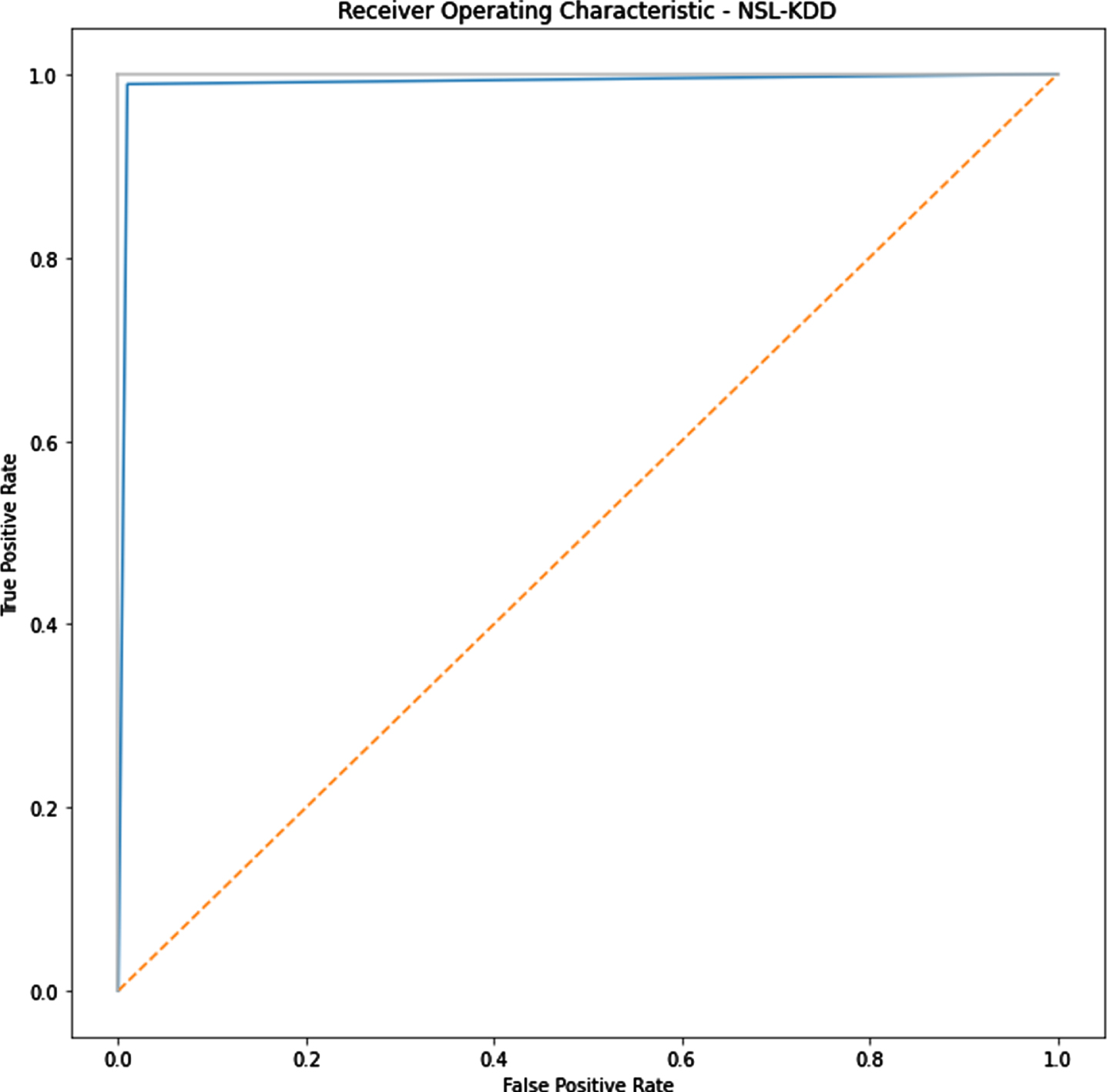
ROC Curve for NSL-KDD.
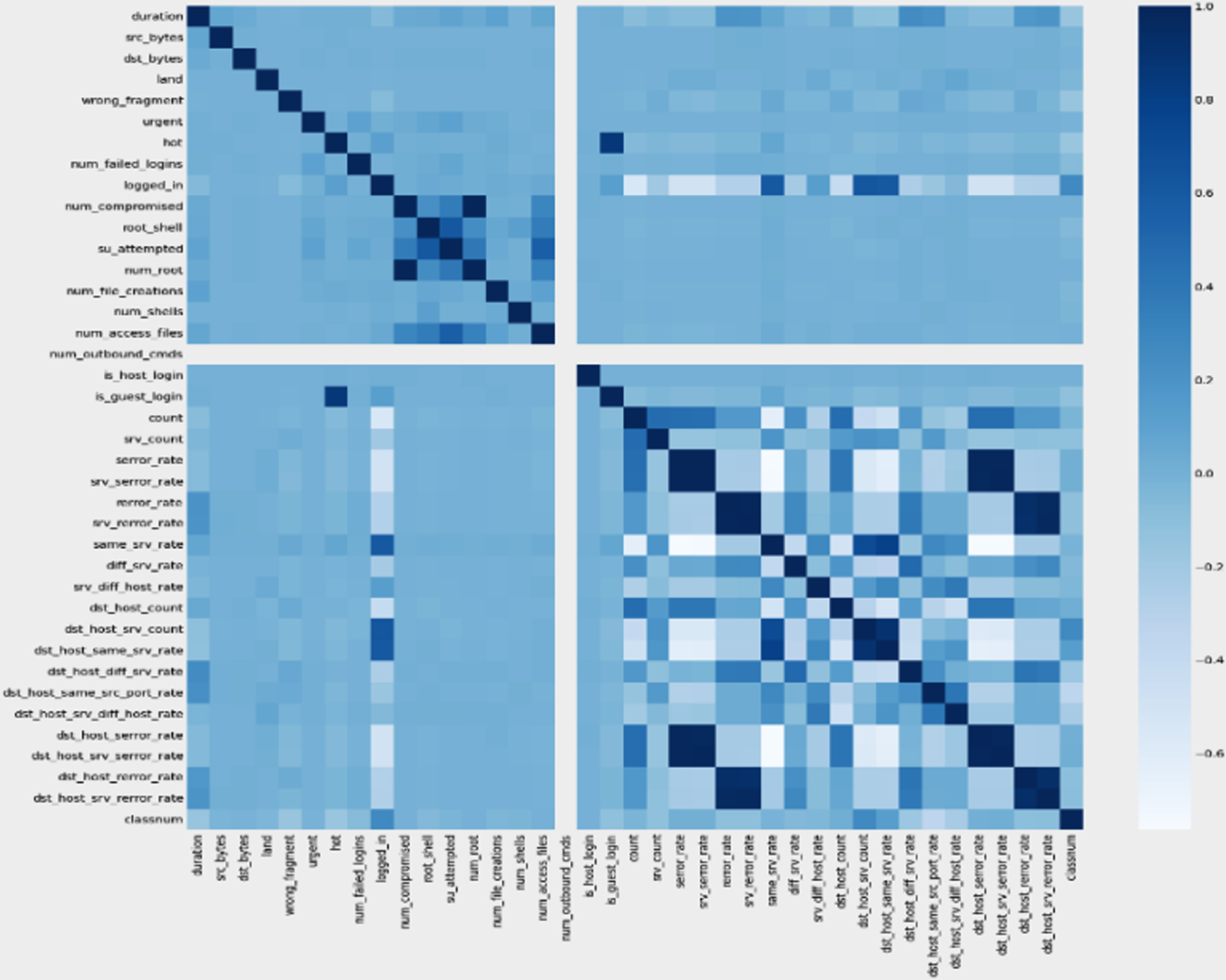
NSL_KDD Correlation Matrix.
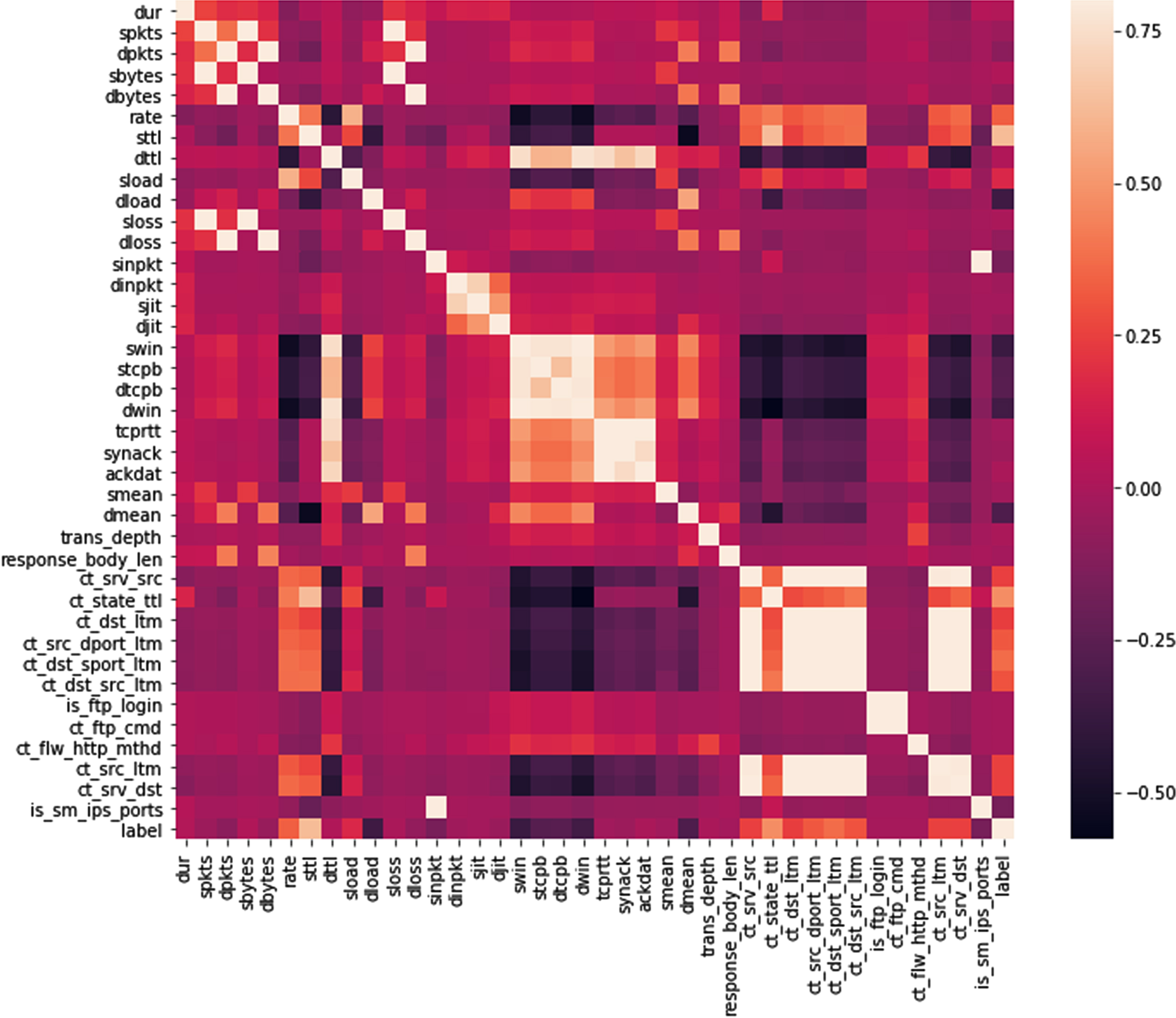
UNSW-NB_15 Correlation Matrix.
The ROC value obtained with the enhanced technique given in Fig. 5 illustrated that area value acquired from the classification framework provides that the system is efficient and it has the ability for predicting the abnormal malicious data accurately and also detects the normal traffic data based on the classification model. ROC curve for NSL-KDD dataset is given as follows
The increasing ROC curve for NSL-KDD explains the effectiveness of the proposed IDS algorithm and Correlation matrix for both datasets are given as follows
The total correlated column to state vs target is depicted in the following in Figs. 9 10 as shown below. Normal and attacks graph is depicted in the feature.
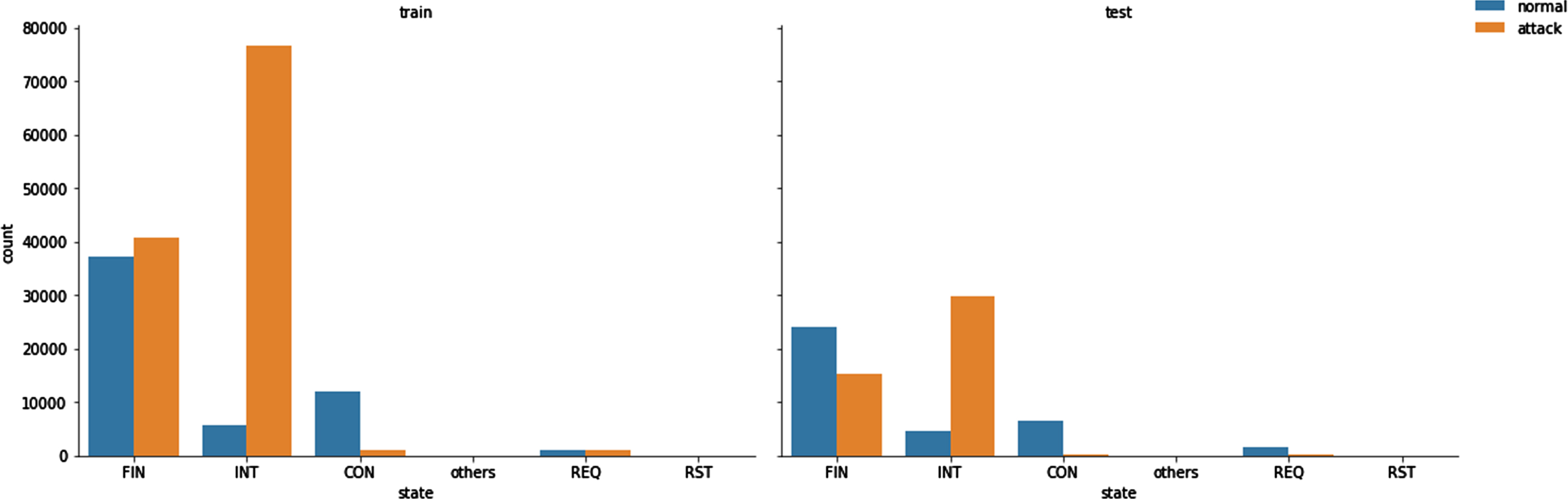
State vs Target.
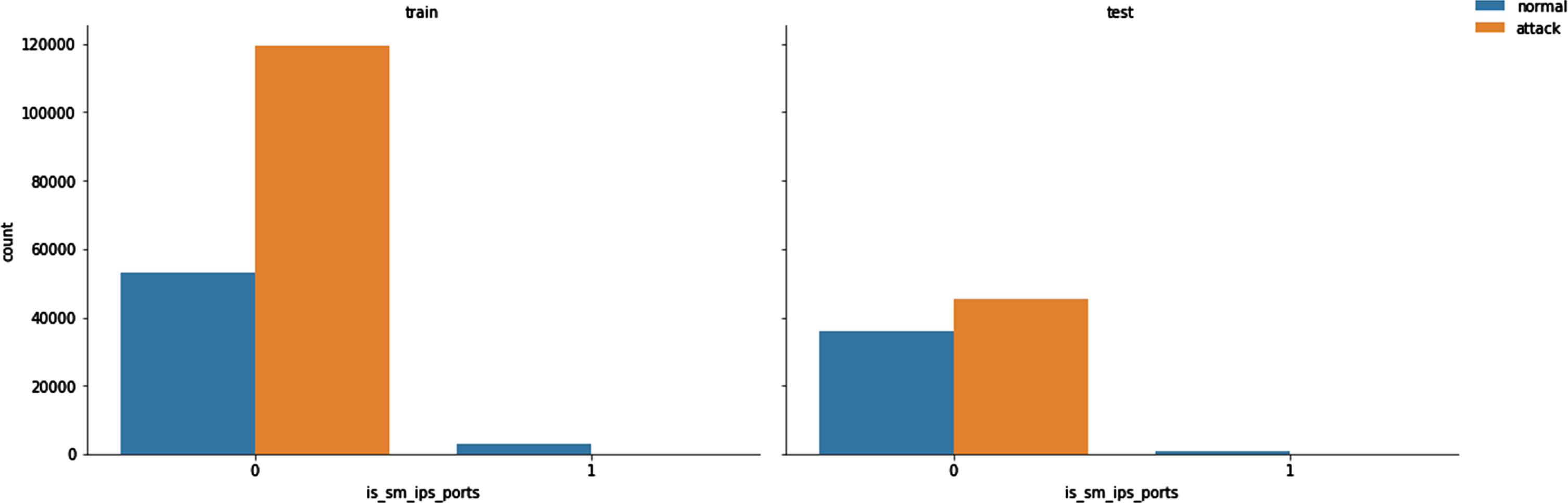
is_sm_ips_ports vs Target.
From Table 7, the performance of the proposed IDS model on the UNSW-NB15 dataset is depicted in the accuracy, precision, recall, and F1 score. By using the Enhanced Genetic Sine Swarm algorithm (E-GSS) feature selection, accuracy, precision, recall, and F1-score obtained as 99.26, 99.14, 99.21, and 98.36 respectively whereas without the feature selection algorithm the accuracy, precision, recall, and F1-score obtained as 94.15, 94.36, 93.14 and 93.25 respectively. Hence the proposed Enhanced Genetic Sine Swarm algorithm (E-GSS) performed well in enhancing the accuracy values of the IDS model.
Performance analysis of proposed IDS model (with/without feature selection)
Table 8, shows the total features identified from the UNSW-NB15 dataset as 43, from that the selected optimal features through proposed feature selection algorithm are 1,2,5,7,8,9,12,15,16,18,31,35,37 and thus the total no. of selected features is 14 which is used for classification.
Total features selected
From Fig. 11, it has been observed that every type of protocol difference. To find a type of traffic, the protocol may be considered helpful, and the flags behave a similar way are shown in Fig. 12. it exhibited the normal and attack-type flags.
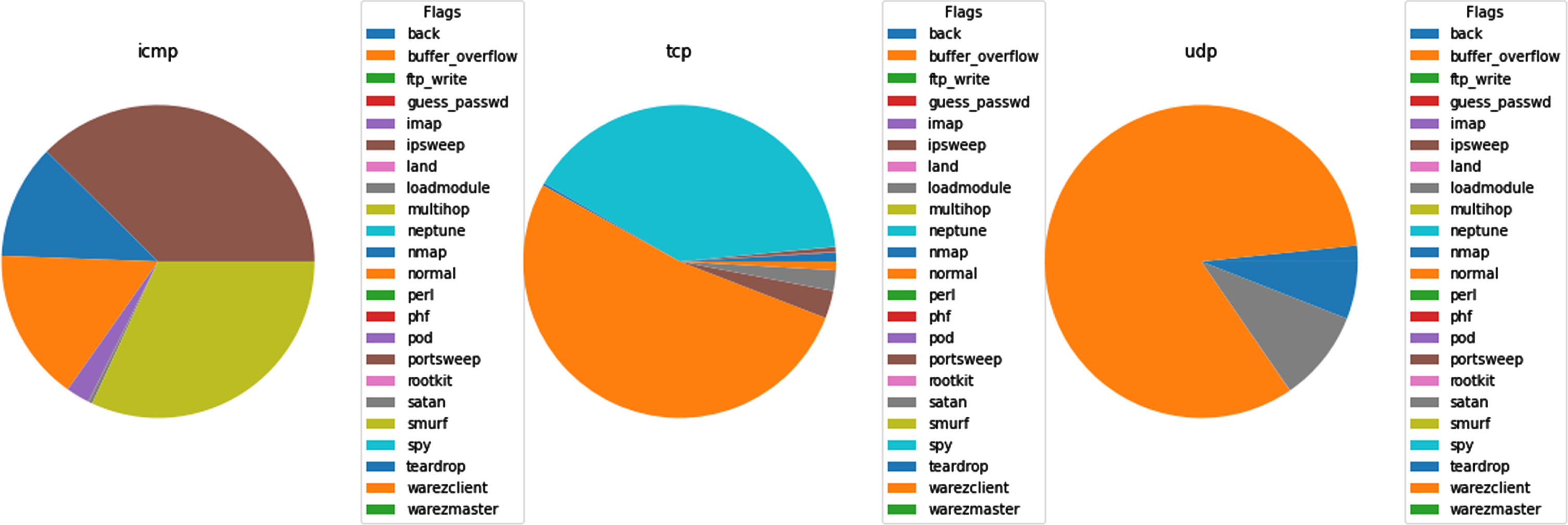
NSL-KDD dataset- every protocol series.
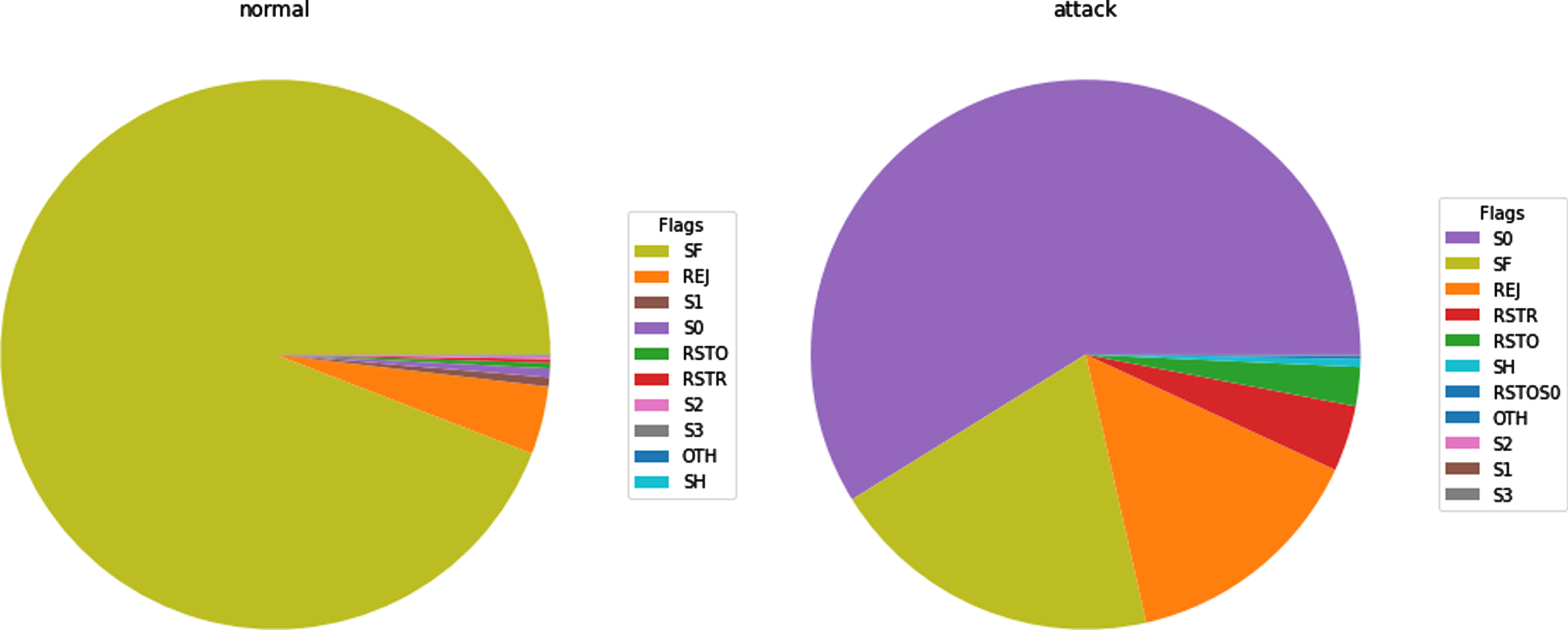
NSL-KDD dataset- Normal and Attack flags.
From Table 9, the performance of the proposed IDS model on the NSL-KDD dataset is depicted in the accuracy, precision, recall, and F1 score. By using the Enhanced Genetic Sine Swarm algorithm (E-GSS) feature selection, accuracy, precision, recall, and F1-score were obtained as 99.12,98.16, 97.82, and 97.36 respectively whereas without the feature selection algorithm the accuracy, precision, recall, and F1-score obtained as 95.36, 95.12, 94.28 and 94.36 respectively. Hence the proposed Enhanced Genetic Sine Swarm algorithm (E-GSS) performed well in enhancing the accuracy values of the IDS model.
Performance analysis of proposed IDS model (with/without feature selection)
From Table 10, it shows the total features identified on NSL-KDD dataset as 43, from that the selected optimal features using proposed algorithm are 1,2,4,5,8,9,10,12,15,16,18,20,21,23,24 and thus the total no. of selected features are 14 which is used for classification.
Total features selected
Table 11, shows the 5-fold cross-validation of the proposed IDS model. Initially, for 1 fold both the UNSW-NB15 and NSL-KDD dataset attains an accuracy of 94.36 and 95.61 respectively. However when the validation extends, and at 5-fold cross-validation, the accuracy in attack detection is exhibited as 99.26% and 99.1% for UNSW-NB15 and NSL-KDD datasets respectively.
K – Fold Cross-Validation of Accuracy value
From Fig. 13, it shows the proposed meta-heuristics ANN classifier value compared with existing methods such as random forest, XG-Boost, and Naïve Bayes algorithms. The proposed classifier shows better values for both UNSW-NB15 and NSL-KDD datasets compared with other existing algorithms.
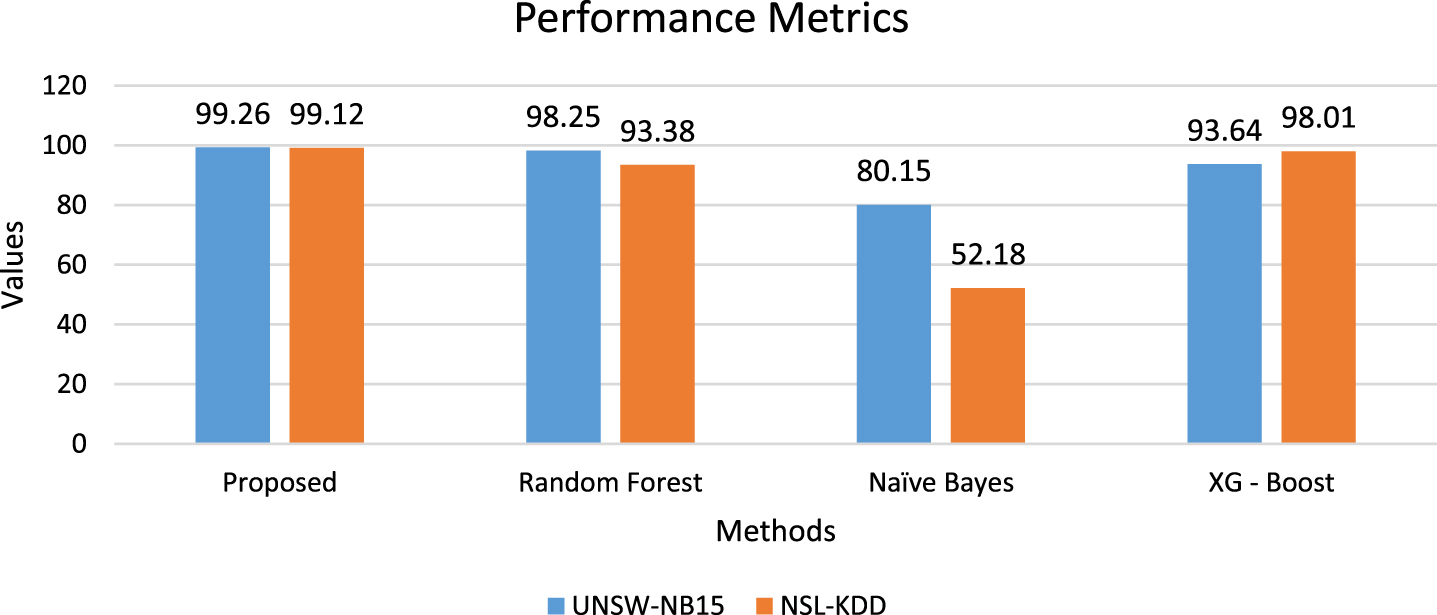
Internal comparison.
Statistical test provides the mechanism for making the quantitative decisions about a process. Statistical test of the proposed dataset is tabulated in Table 12.
Statistical analysis of UNSW-NB15 dataset
Statistical analysis of UNSW-NB15 dataset
The different statistical values are found for UNSW- NB 15 and NSL-KDD. T-statistic value obtained for UNSW-NB15 dataset is 2.89, P value obtained is 0.03, mean difference obtained is -1.74. if the mean difference provides negative value, then the experimental group has a lower mean score than the control group and finally the Standard deviation obtained by the dataset is 3.41. Table 13 depicts the statistical test of NSL-KDD dataset.
Statistical analysis of NSL-KDD dataset
The t-statistic value obtained by the NSK-KDD dataset is 1.45 and p-value attained is 0.01, mean difference obtained is 1.5 and standard deviation obtained is 4.12.
Table 14 depicts the statistical analysis of both the dataset.
Statistical analysis of both UNSW-NB15 and NSL-KDD dataset
The different statistical values are found for UNSW-NB 15 and NSL-KDD. T-statistic value obtained for UNSW-NB15 dataset is 2.89, P value obtained is 0.03, mean difference obtained is –1.74. if the mean difference provides negative value, then the experimental group has a lower mean score than the control group and finally the Standard deviation obtained by the dataset is 3.41. The t-statistic value obtained by the NSK-KDD dataset is 1.45 and p-value attained is 0.01, mean difference obtained is 1.5 and standard deviation obtained is 4.12.
From Fig. 14, it shows the comparison among the proposed and existing methods [42] such as DT, LR, SVM, ANN, and KNN, showing that the proposed Enhanced Genetic Sine Swarm algorithm (E-GSS) based Deep Meta-Heuristic ANN classifier (DMH-ANN) method outperformed all the other existing algorithms in terms of accuracy value on UNSW-NB15 dataset.
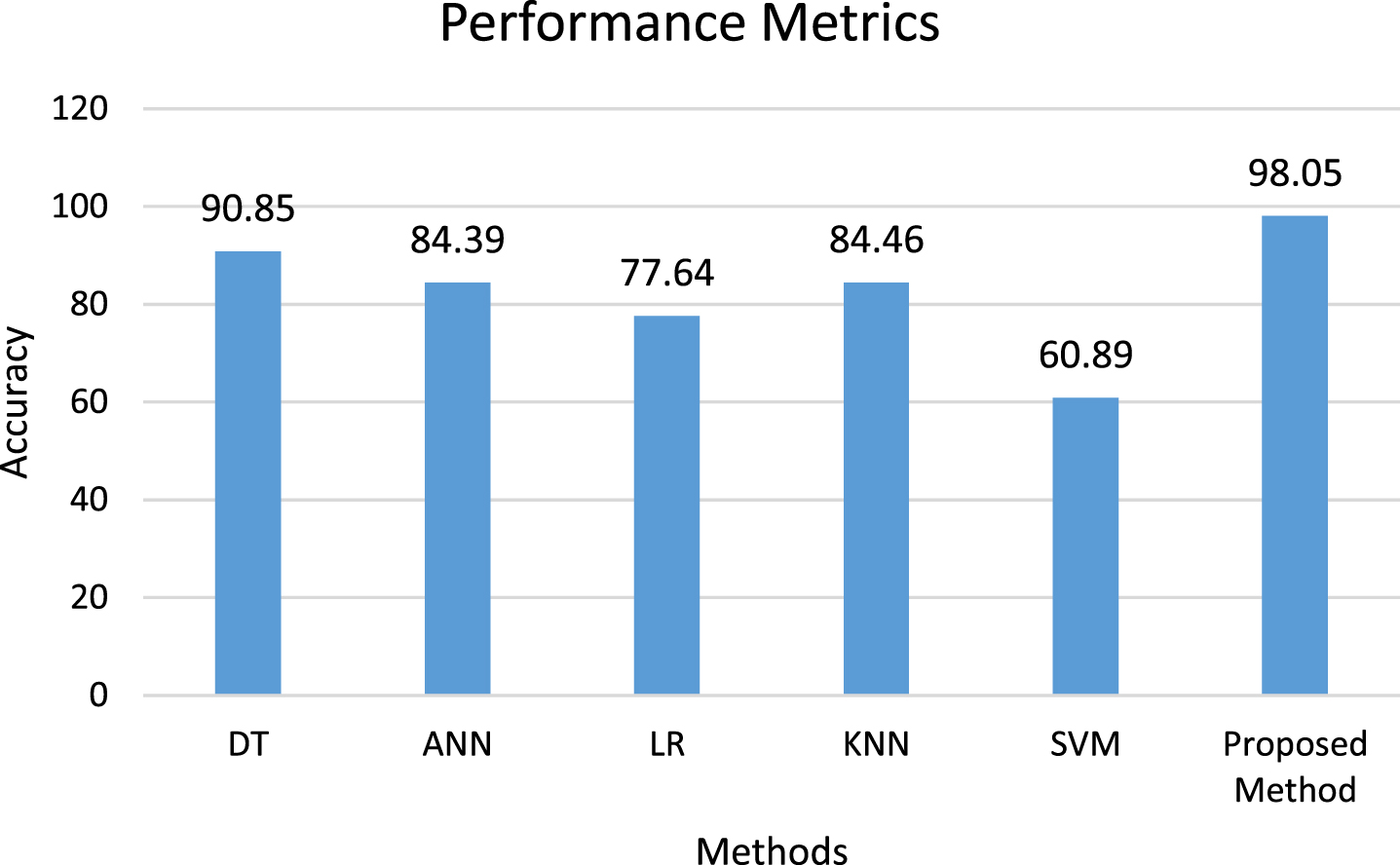
Comparative analysis of proposed and existing methods [42] on the UNSW-NB15 dataset.
From Fig. 15, it shows the comparison among the proposed and existing methods [43] such as CNN CE, CNN SMOTE AND FL-NIDS showing that the proposed Enhanced Genetic Sine Swarm algorithm (E-GSS) based Deep Meta-Heuristic ANN classifier (DMH-ANN) method outperformed all the other existing algorithms in terms of accuracy value on UNSW-NB15 dataset.
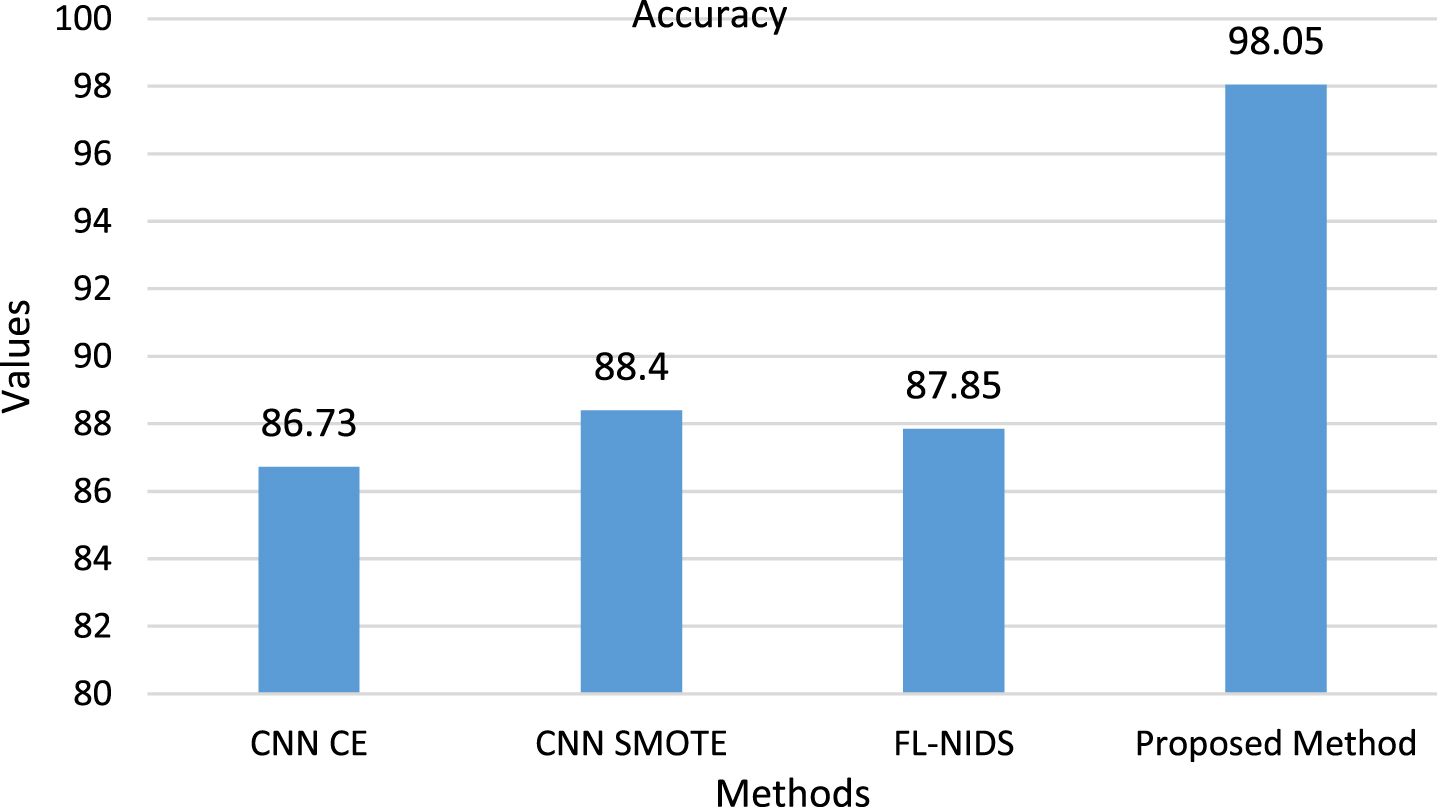
Comparative analysis of proposed and existing methods [43] on the UNSW-NB15 dataset.
From Table 15, the comparison results show the proposed Enhanced Genetic Sine Swarm algorithm (E-GSS) based Deep Meta-Heuristic ANN classifier (DMH-ANN) method on the UNSW-NB15 dataset outperformed the existing OCNN-HMLSTM, CNN, MSCNN, SVM, NN, CONV-LSTM, DNN AND ELM methods [44] in terms of accuracy, precision, recall, and F-measure metrics. Kappa metric value of 0.989 for UNSW-NB15 and NSL-KDD of 0.979 indicates efficiency of model and considered a higher conservative measure of accuracy. It is being identified that proposed IDS achieves greater efficiency. Comparison of classifiers exhibits that proposed classification kappa accuracy is higher which identifies normal and abnormal traffic accurately.
Comparison of proposed and existing algorithms [44] on the UNSW-NB15 dataset
From Table 16, it shows the comparison among the proposed and existing methods [45] such as XG BOOST DNN, LR, SVM, AND NB, shows that the proposed Enhanced Genetic Sine Swarm algorithm (E-GSS) based Deep Meta-Heuristic ANN classifier (DMH-ANN) method outperformed all the other existing algorithms in terms of accuracy, precision, recall and f1-score value on NSL-KDD dataset.
Comparison of proposed and existing methods [45] on the NSL-KDD dataset
From Table 17, it shows the comparison among the proposed and existing methods [46] such as SVM, MLP, Ensemble, NB, c4.5, Bi-LSTM, CNN, CFS+ANN, CNN-Bi-LSTM, and SVM-RBF, showing that the proposed Enhanced Genetic Sine Swarm algorithm (E-GSS) based Deep Meta-Heuristic ANN classifier (DMH-ANN) method outperformed all the other existing algorithms in terms of accuracy, precision, recall and f1-score value on NSL-KDD dataset. Statistical analysis provides essential support to the derived conclusion through analysis made with the comparison of proposed work with existing methodologies. Based on accuracy and execution time considered as a measure of criteria, efficiency of the proposed detection algorithm is evidently measured which exhibits the efficiency of the proposed model.
Comparison of proposed and existing methods [46] on the NSL-KDD dataset
Attacks are becoming common in recent days, due to this it is important to detect these attacks as early as possible for classifying the malicious threats or non-malicious threats and increasing the accuracy of the model. However, the existing studies lacked in delivering better accuracy rate, which can be overcome by implementing E-GSS algorithm for feature selection and DMH-ANN for classifying the malicious and non- malicious threats. The dataset used in the proposed model was UNSW NB15 and NSL-KDD dataset. E-GSS consisted of two algorithms which includes genetic algorithm and sine swarm algorithm. E-GSS was considerably used to identify significant and optimal features. The aim of the E-GSS helped in reducing the dimensionality of the input data and helped in eliminating the irrelevant features, which helped in improving the accuracy and effectiveness of the IDS systems for feature selection. After the process of feature selection, DMH-ANN was used for classifying the malicious and non-malicious threats by combing DL and meta-heuristic optimization algorithm. DMH-ANN algorithm could effectively capture complex patterns and representations in data and improved the performance of the network as well as generalization capabilities by fine-tuning the parameters. Efficiency of the proposed model was further assessed by employing different performance metrics such as accuracy, recall, precision and F1 score, and specificity. The accuracy obtained by UBSW-NB15 dataset was 99.26%, precision obtained was 99.14%, recall obtained was 99.21% and F-measure of 98.36%. Whereas the accuracy obtained by NSL-KDD dataset was 0.9912, precision obtained was 0.9816, recall obtained was 0.9782, F1 score obtained was 0.9736 and specificity obtained was 99.63%. From the experimental outcome, it was identified that, proposed model outperformed the existing models. In future, other meta-heuristic algorithms can be used for classifying the malicious and non-malicious threats, improving the accuracy of the model by using larger dataset and by employing more sophisticated feature selection and classification techniques, make more scalable and secure model by using techniques such as encryption and authentication and by implementing distributed computing techniques.
Footnotes
Acknowledgments
None.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Declaration of competing interest
There is no conflict of interest for any of the participants.
Author contribution statement
All authors have approved the manuscript and agree with its submission.