
Abstract
Currently, breast cancer is one of the most common cancers among women. To aid clinicians in diagnosis, lesion regions in mammography pictures can be segmented using an artificial intelligence system. This has significant clinical implications. Clustering algorithms, as unsupervised models, are widely used in medical image segmentation. However, due to the different sizes and shapes of lesions in mammography images and the low contrast between lesion areas and the surrounding pixels, it is difficult to use traditional unsupervised clustering methods for image segmentation. In this study, we try to apply the semisupervised fuzzy clustering algorithm to lesion segmentation in mammography molybdenum target images and propose semisupervised fuzzy clustering based on the cluster centres of labelled samples (called SFCM_V, where V stands for cluster centre). The algorithm refers to the cluster centre of the labelled sample dataset during the clustering process and uses the information of the labelled samples to guide the unlabelled samples during clustering to improve the clustering performance. We compare the SFCM_V algorithm with the current popular semisupervised clustering algorithm and an unsupervised clustering algorithm and perform experiments on real patient mammogram images using DICE and IoU as evaluation metrics; SFCM_V has the highest evaluation metric coefficient. Experiments demonstrate that SFCM_V has higher segmentation accuracy not only for larger lesion regions, such as tumours, but also for smaller lesion regions, such as calcified spots, compared with existing clustering algorithms.
Introduction
One of the most prevalent malignancies in women, breast cancer, is a malignant tumour with a high morbidity and mortality rate. Breast cancer is one of the illnesses that gravely endangers the lives of women, and its prevalence in the world’s population has been rising in recent years. Therefore, the best strategy to lower mortality and increase patient cure rates is early identification of breast cancer. One of the most popular early detection techniques for breast cancer is medical imaging, and mammography is frequently employed in this regard. Lesion segmentation in mammography, however, still relies on the clinical expertise of medical professionals to make decisions. Due to their various sizes and shapes, some breast lesions are difficult to see on mammography images. For radiologists, who must perform extensive daily reading and diagnoses, this presents a problem. As a result, the use of computer-aided diagnosis, which uses artificial intelligence algorithms to segment lesion areas in mammography pictures to help doctors make a diagnosis, significantly lessens the workload of doctors and can increase the accuracy of their judgement.
Whether a computer can correctly segment a lesion area in a mammary molybdenum target image is of great importance to breast cancer screening. It is also a key technical issue. Currently, medical image segmentation is a popular field with numerous technical approaches. They are generally classified into the following categories: graphical-based methods, mathematical morphology-based methods, classification methods, deep learning methods, and clustering algorithms. Graphics-based methods, such as the gradient operator or edge detection, are commonly used for texture segmentation, and threshold segmentation is based on the grey difference. Nalini [1] et al. helped radiologists detect early-stage breast cancer by using the segmentation thresholding algorithm through the convex and nonconvex border of image optimization and delineating the edges and boundaries in mammograms. Wu et al. [2] used improved texture segmentation technology to segment synthetic vascular images. Based on mathematical morphology, watershed, level set and region growth algorithms are usually used for image segmentation. Chattaraj et al. [3] improved the existing watershed algorithm. He developed a novel marker-controlled watershed algorithm for mammogram segmentation that highlights suspicious regions more clearly. For example, Qiao et al. [4] used the improved region growing method to segment the liver. It used the centroid of the largest connected region as the seed point location for region growth and used the dual-threshold regional growth method to segment the image, which made the segmentation result more accurate. Classification methods usually use tagged segmented images to extract features and train segmentation models. For example, Ramudu et al. [5] used a hybrid method to obtain a smooth medical image and a support vector machine (SVM) to identify and segment tumours in brain images. Alpaslan et al. used kNN (K-nearest neighbour) to segment breast molybdenum target images. Deep learning methods require large numbers of labelled samples for training and a better hardware configuration. Arora and Raman [6] proposed a deep neural CNN model with CRF for breast mass segmentation in mammogram images. Zhang et al. [7] proposed a new ROI method for mammary molybdenum target images and improved the AlexNet convolution neural network for pattern recognition of mammary gland calcification images. Tagged samples are difficult to obtain for medical images, but the emergence of the U-Net model [8] enables better image segmentation on smaller datasets. Many researchers have improved the U-Net model and applied it to breast image segmentation [9, 10]. Li et al. [9] used the improved U-Net architecture to segment breast masses by combining a densely connected U-Net model with attention gates (AGs). In addition, in the past decade, clustering-based methods have been widely used in medical image segmentation. The problem of medical image segmentation can be seen as dividing different pixels in an image into the same area. This process can be thought of as a clustering problem. For example, Rahman [11] used a filter to extract new texture features from an image and used these features to segment the image using a nonparametric Bayesian clustering method. Saleck et al. [12, 13] proposed extracting texture features using the fuzzy C-means clustering algorithm and greyscale co-occurrence matrix (GLCM) to ultimately achieve breast cancer detection on molybdenum target images. Lbachir et al. [14] combined a global threshold and K-means algorithm to extract the lesion area in a molybdenum target image. Ramadijanti [15] also applied a hierarchical K-means clustering algorithm for breast mass segmentation.
However, in the absence of a large number of high-quality label datasets, some of the above methods that require segmentation model training are not suitable for breast image segmentation. Clustering is one of the most popular techniques in medical image segmentation. It is an unsupervised learning technique and deserves to be studied. Most of the clustering algorithms mentioned above focus on larger lesion areas, such as tumours. Other small lesions, such as calcification points, cannot be successfully segmented. Because these calcification spots are so small and some of them only appear in a few pixels in an image, segmentation becomes more challenging. In fact, these clusters of calcified dots are an important basis for determining whether a woman has breast cancer. Whether the calcification can be correctly segmented is of clinical importance and is the key to image segmentation. Because the traditional clustering FCM [16] and MEC [17] algorithms are unsupervised, the proportion of lesion area samples in the total sample set is small, and their pixel values do not differ much from those of other areas, lesion area samples can easily be classified into other cluster categories. Therefore, the traditional unsupervised fuzzy clustering algorithm is not suitable for segmenting small lesions. To ensure that our algorithm can accurately segment small lesions and large lesions, such as tumours, we try to solve this problem by applying semisupervised fuzzy clustering to image segmentation. Some previous researchers have tried to use semisupervised fuzzy clustering algorithms for medical image segmentation, such as Al-Dmour et al. [18] and Ai et al. [19], who used semisupervised fuzzy C-means to segment brain MR images, and Santos et al. [20], who used seeded fuzzy C-means (Sfc-Means) for segmentation and achieved good results on leukaemia, skin cancer, cervical cancer, and glaucoma images.
Therefore, in this study, we made a bold and innovative attempt to use semisupervised fuzzy clustering to segment mammography target images. However, several current semisupervised FCM algorithms do not make full use of the knowledge of labelled samples in the clustering process, so it is not possible to accurately separate the lesion areas in mammography images. Therefore, in this paper, we improve the conventional semisupervised FCM method. We propose a semisupervised fuzzy clustering approach based on the cluster centres of labelled samples (called SFCM_V, where V stands for cluster centre). Because the cluster centre may effectively represent a class of data, the proposed SFCM_V model can fully mine the information from existing labelled samples. By fully referencing the cluster centre of the labelled sample dataset during the clustering process, the labelled samples can guide the unlabelled samples during clustering and enhance the clustering performance. The experiment demonstrates that our algorithm outperforms the currently used clustering algorithm in segmentation accuracy. SFCM_V can be used to segment both larger areas of breast lesions, such as tumours, and smaller lesions, such as breast calcification.
The innovations in this algorithm are as follows: 1) The semisupervised method solves the problem that the proportion of lesion area samples is small, and its pixel values differ little from those of other areas and are difficult to cluster. 2) A semisupervised fuzzy clustering algorithm is used for breast image segmentation for the first time. 3) Labelled samples can be used to guide the clustering of unlabelled samples by highly abstracting and fully referencing the clustering centres of labelled sample datasets.
The rest of this article is organized as follows: Section 2 reviews concepts related to FCM and semisupervised FCM algorithms. Section 3 describes the improvement ideas and introduces the new algorithm steps. Section 4 compares the unsupervised clustering algorithm with the existing semisupervised fuzzy clustering algorithm and our proposed algorithm on real-world mammary molybdenum target images. Our algorithm has better performance in mammography segmentation. The last section gives the experimental results.
Related work
Fuzzy C-means (FCM) clustering
The fuzzy C-means clustering algorithm (FCM [16]) is a common fuzzy clustering algorithm. In fuzzy set theory, the samples do not belong to only one category; that is, they can be divided into multiple cluster classes. By calculating the membership of the samples at each cluster centre, the final cluster into which the samples are divided is determined. Assume that X ={ x1, x2, …, x
N
} is the data sample set and N is the total number of samples. C denotes the number of clusters, and we provide an expression for the objective function of the FCM:
Because
The FCM algorithm has more stable performance and better universality [21] and is widely used in medical image segmentation. However, since FCM is based on pixel grey values, it not only has weak noise resistance but also poor segmentation performance when the region of interest (ROI) has low contrast with the surrounding pixels. As a result, obtaining a good segmentation result on some mammographic lesions is difficult. To solve the problem of noise, L. Xiao et al. [22] proposed a fuzzy C-means clustering algorithm (ENDFCM) based on energy noise detection for breast cancer image segmentation, and it has a good anti-noise ability. To solve the low contrast problem in the area of interest, M. Mohan et al. [23] used some image enhancement techniques to increase the contrast and then used the FCM algorithm for segmentation. To address the issue of poor grey contrast, A. Chattaraj and A. Das [24] suggested a new kernel-based fuzzy C-means clustering algorithm that leverages the entropy and intensity of the kernel as the fuzzification feature.
“Category label information” and “constraint information” make up the two categories of supervisory information in clustering tasks [25]. The term “category label information” refers to the label of a small number of samples obtained through prior knowledge before the clustering algorithm is applied. These labels are often determined using the knowledge of relevant industry experts. “Constraint information” refers to whether two samples can be divided into the same cluster according to certain rules and constraints. In 2000, Wagstaff proposed using “must-link” and “cannot-link” to describe this constraint relationship [26].
Semisupervised fuzzy clustering (SFCM) was introduced in 1985 by Pedrycz [27], and it was called partial supervision [27, 28]. Pedrycz’s partially supervised fuzzy clustering algorithm is based on an objective function. It introduces the supervised part with labelled samples into the objective function of the FCM algorithm and constitutes a partially supervised FCM algorithm (semisupervised FCM, SFCM). The purpose is to guide the whole clustering algorithm to obtain better clustering performance through a small number of labelled samples. In the semisupervised FCM algorithm, due to the need to input labelled samples, it can also be seen from the algorithm loss function that the must-link and cannot-link restrictions are transformed into labelled samples for processing [29] in the clustering process, so the whole algorithm supervisory information belongs to the category label information class.
Based on Pedrycz’s [27, 28] description, the loss function expression of semisupervised fuzzy clustering (SFCM) can be expressed as:
The labelled samples’ membership is considered known information, and the matrix F = [f ij ], where f ij represents the membership of labelled x i to the jth cluster centre, which can be calculated a priori and is known before the algorithm starts, is used. Here, α represents a scaling factor whose role is to balance the supervised and unsupervised parts of the function optimization process. α is proportional to the ratio of the total number of samples N to the number of labelled samples M.
Using standard Lagrange multiplier techniques, the optimization problem is converted to unconstrained minimization. The Lagrange equation is constructed as:
We fix parameter V and only consider parameter U. To minimize parameter U, we set the partial derivative of U to zero:
Due to the constraint condition
To obtain cluster centre V, the iterative formula of the FCM algorithm cluster centre is applied [28].
SFCM increases α through labelled supervision and unlabelled supervision with FCM according to Li’s [29] analysis of the SFCM objective function Equation (4), where
Because of the low contrast between the region of interest (ROI) and surrounding pixels, the traditional unsupervised clustering algorithm cannot correctly segment the lesions in a mammary molybdenum target image, so we consider that prior knowledge given by experts can be used to guide the whole clustering process, i.e., a semisupervised clustering algorithm. After trying out the semisupervised fuzzy clustering algorithm, it was found that because the area of the displayed lesion, such as tumours, masses, and other large areas, is uncertain, it is easy to segment. However, calcified point lesions appear smaller in an image, and some are only a few pixels in size, which makes them difficult to segment. This is due to insufficient supervisory information (see Section 4 for the details of the experiment). Cluster calcification is one of the important criteria for judging whether breast cancer is present in practice. This shows that the traditional semisupervised clustering algorithm is not only ineffective but also difficult to apply in clinical practice. Therefore, we improve the traditional semisupervised FCM algorithm by fully referencing the clustering centre of the labelled sample dataset in the clustering process and designing semisupervised fuzzy clustering based on the cluster centres of labelled samples (called SFCM_V, where V stands for cluster centre), which has higher accuracy than the traditional clustering algorithm in the segmentation of larger lesions, such as tumours, and can correctly segment smaller lesions.
Learning model based on the cluster centres of labelled samples
Clustering centres have a high degree of data abstraction and can well represent a cluster and all associated samples in a cluster [31]. In the division-based fuzzy clustering algorithm, the class centre V can reflect the distribution of the data to some extent and is potentially available information [32]. Therefore, the clustering centre of a labelled sample dataset can reflect the data distribution of the labelled samples and its division into cluster classes. The model is trained by using cluster centres with labelled samples as knowledge. In the clustering process, by fully referencing the cluster centre of the labelled sample dataset, we can learn the sample partition of the labelled samples and guide the existing fuzzy clustering algorithm to complete the cluster partitioning task.
Equation (9) takes the cluster centre of the labelled sample dataset as a reference to ensure that the current class centre is to some extent consistent with the class centre of the labelled sample when the objective function is optimal. β is the regularization factor. When β → 0, the labelled sample class centre is considered to be less reliable and not worth learning. When β→ + ∞, it is believed that the centre of the labelled sample class has high confidence and should be referred to more. When the influence of supervisory information is small, cluster centres with labelled samples are used as information to guide learning, and existing cluster centres are continuously adjusted to achieve the best clustering effect. This makes up for the lack of supervisory intensity and can improve the performance of clustering.
For the SFCM_V algorithm, after a priori knowledge is provided, at the stage of constructing the labelled sample set, at least one labelled sample is provided for each cluster class when the number of clusters is determined. Therefore, for data with a labelled sample set, its cluster is known. The samples of each class in the labelled sample set are part of the corresponding cluster samples in the whole sample dataset. The dataset X = X L ∪ X U = { x1, x2, …, x N } includes a labelled sample set X L as well as an unlabelled sample set X U . N represents the total number of samples.
Here, X
L
={ Z1, Z2, …, Z
C
} is the labelled sample set. The number of labelled samples is M.C represents the number of clusters. Z
i
, i = 1, 2, …, C represents a collection of known samples of class i. After removing duplicates for set Z
i
, only one sample with the same value is retained, and the result is expressed as set G
i
, i = 1, 2, …, C. The cluster centres of Z
i
, i = 1, 2, …, C are represented by
Based on Equation (10), the cluster centre
From the above analysis, we believe that the reliability of labelled samples is high, so using the cluster centre of a labelled sample set as the initial cluster centre of the SFCM_V algorithm can achieve the optimal clustering effect and prevent falling into a local optimal situation.
The medical image segmentation clustering algorithm generally uses pixels as samples and the grey values of pixels as sample characteristics for clustering. In traditional semisupervised fuzzy clustering, SFCM [28], when the lesion area is very small, the proportion of lesion samples to the total samples is small, resulting in a small proportion of labelled lesion area samples to total samples. The supervision strength of
Based on a physician’s prior knowledge, a set of labelled samples is given, and the sample categories in the set of labelled samples contain all the classifications required for mammography. We then compute the cluster centres for each category in the set of labelled samples, each representing a class of samples. A clustering centre of the labelled sample set may be near the lesion sample area, and hence, is of some reference value. Therefore, referencing the cluster centre of the labelled sample dataset during the clustering process can compensate for the insufficient supervised intensity and improve the accuracy of lesion segmentation in small areas. Based on this improvement, we give the objective function of SFCM_V:
We use Boolean vectors
According to prior knowledge, the membership degree f
ij
of labelled samples is calculated. The matrix F = [f
ij
] is used to represent the membership from the labelled x
i
to the jth cluster centre. N represents the total number of samples, and the number of labelled samples is M. C indicates the number of clusters. U = [u
ij
] N×C denotes the fuzzy membership matrix, and u
ij
denotes the membership of point x
i
belonging to the jth cluster. V = [v1, v2, …, v
c
]
T
denotes the cluster centre matrix, and v
j
denotes the jth cluster centre.
This architecture adds a learning model based on the cluster centre with labelled samples to the traditional SFCM [28] loss function. The third item in Equation (11) is the materialization of Equation (9). Combining Equation (9) with constraints on the membership of the samples makes the known membership of the labelled samples and the membership calculated during the clustering process as close as possible while referencing the cluster centre of the labelled sample set. When β = 0, it degenerates to the traditional SFCM [28] approach, which effectively avoids unreliable cluster centres with marked sample sets. When α = 0 and β = 0, it completely degenerates into an unsupervised FCM [16] algorithm.
For Equation (11), a Lagrange equation is constructed using the Lagrange multiplier method, and the optimization problem is converted to an unconstrained minimization problem:
We fix parameter V, take a partial derivative of parameter U, and set
Because
By substituting Equation (14) into Equation (13), the iteration formula of membership u
ij
can be obtained.
We fix parameter U, take a partial derivative of parameter V, and set
The iteration formula for cluster centre v
j
is obtained as follows:
After obtaining the iteration formulas for membership u ij and cluster centre v j , we provide a detailed description of the SFCM_V algorithm:
Dataset and settings
To verify the superiority of the SFCM_V algorithm proposed by us on different mammary lesions, we performed experiments on mammography images of mammary glands with tumours, benign calcification, and malignant calcification. In this research, 34 mammography images of real patients were provided by the Intelligent Medical Technology Research Center of the First People’s Hospital of Changshu. Among them, 14 images of tumours, 10 images of benign calcification, and 10 images of malignant calcification constitute our sample test set. Specific lesions are delineated by doctors or technicians as “ground truth” to determine the quality of the segmentation.
To prove that the performance of SFCM_V is better than that of an unsupervised fuzzy clustering algorithm, we compare the results with those of FCM [16] and MEC [17], as well as with the two latest clustering algorithms, KGFCM, proposed by Gupta et al. [33], and POCS-based clustering, proposed by Tran et al. [34]. To prove its superiority over other semisupervised fuzzy clustering algorithms, SSFCM proposed by BAI [25] and SFCM proposed by Pedrycz [28] are selected for comparison. Seven clustering algorithms are applied to mammography images of different lesions to compare their performance. The grid search method is used to obtain the best parameters for all six methods. The fuzzy index m in the FCM fuzzy cluster is set in the grid {1.5,2,2.5}. The regularization coefficient γ in the maximum entropy clustering (MEC) algorithm is set in the grid {0.001, 0.0005, 0.0001}. The KGFCM loss function has two parameters: the exponent p of the Euclidean distance and the fuzzy weighted exponent m. By setting appropriate values for p and m in the algorithm, the kernel k-harmonic means (KKHM) or the kernel fuzzy c-means (KFCM) clustering algorithm can be executed. For KKHM, the search parameter interval of p is {2 : 1:10}, and for KFCM, the search parameter interval of m is {2 : 1:10}. For all semisupervised fuzzy clustering algorithms, SFCM_V, SSFCM, and SFCM, where the scaling factor α, which controls the supervised learning weight, is generally proportional to the total number of samples N and the number of labelled samples M, i.e.,
For each image to be segmented, after a priori knowledge is provided by a professional doctor, this experiment constructs a set of labelled samples based on greyscale. We consider that a pixel point with a certain grey value belongs to a specified cluster class, and then all sample points with that same grey value are labelled as the specified cluster class. All three semisupervised fuzzy clustering algorithms cluster on the same labelled samples. The seven clustering segmentation algorithms are applied directly to mammography. Each algorithm has the best parameters, sets the number of cluster categories to 3, and divides the picture into three regions: background, normal breast tissue, and lesion. Finally, we compare the clustered segmented lesion areas with the real lesion areas drawn by the physician using evaluation indices to compare the performance of the seven algorithms.
To reasonably evaluate the effect of segmenting lesions, we chose the DICE coefficients and intersection over union (IoU) [35], which are the two most commonly used indices in the field of medical image segmentation.
The DICE coefficient is the ratio of the area where two objects A and B intersect to the total area. The range is [0, 1]. A larger DICE coefficient means better performance. The value is 1 when the split is perfect.
The intersection over union (IoU) ratio represents the area where two objects A and B intersect divided by the union area. The range is [0, 1]. The larger the IoU is, the higher the coincidence and similarity between the two objects. When the value is 1, it means that A and B are exactly the same size and located at the same position. These two evaluation indices can indicate how many pixels in the object are correctly segmented and how many pixels outside the object are correctly excluded.
The experimental environment in this study is an Intel Core i7-9750 h 4.5 GHz CPU and 8 G RAM, Windows 10, and Pycharm2018.
First, the seven clustering algorithms are applied to the tumour lesions of mammary molybdenum target images, and the DICE and IoU results of each algorithm are displayed in Table 1. To facilitate observation, we plot the results as a line graph in Fig. 1.
DICE and IoU performance of all comparison algorithms on mammogram images containing tumours
DICE and IoU performance of all comparison algorithms on mammogram images containing tumours
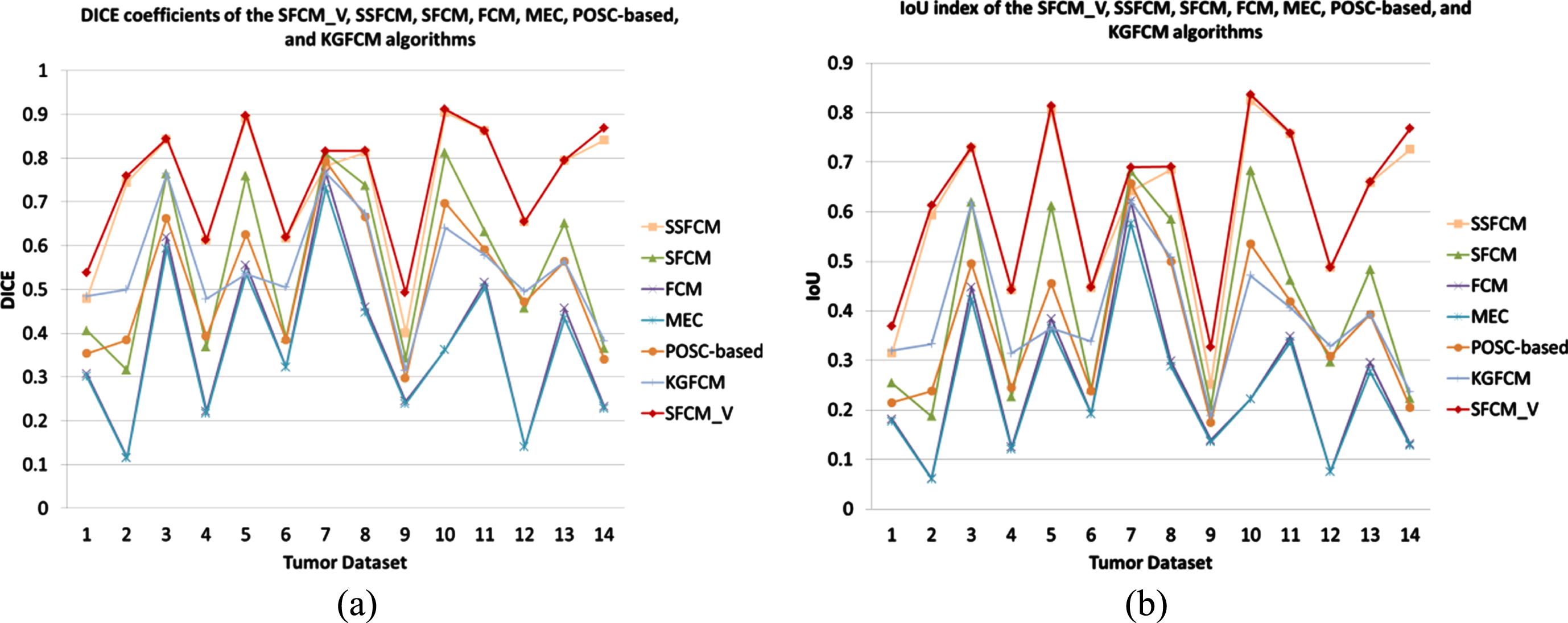
Line graphs of the DICE and IoU values for all algorithms on the tumour dataset: (a) DICE; (b) IoU.
From the table and polyline graph, we can see that the semisupervised clustering algorithm is significantly better than the unsupervised clustering algorithm. Among the four unsupervised algorithms, the DICE and IoU values of KGFCM are the highest, but they are still lower than those of the SFCM_V algorithm we proposed. Among the three semisupervised fuzzy clustering algorithms, the DICE and IoU values of SFCM_V are higher than those of the other two algorithms. This shows that our algorithm has higher accuracy in the segmentation of larger lesions, such as tumours. As an example, we consider the tenth mammography image. The segmentation results of the algorithms on the 10th mammary molybdenum target tumour are shown in Fig. 2.
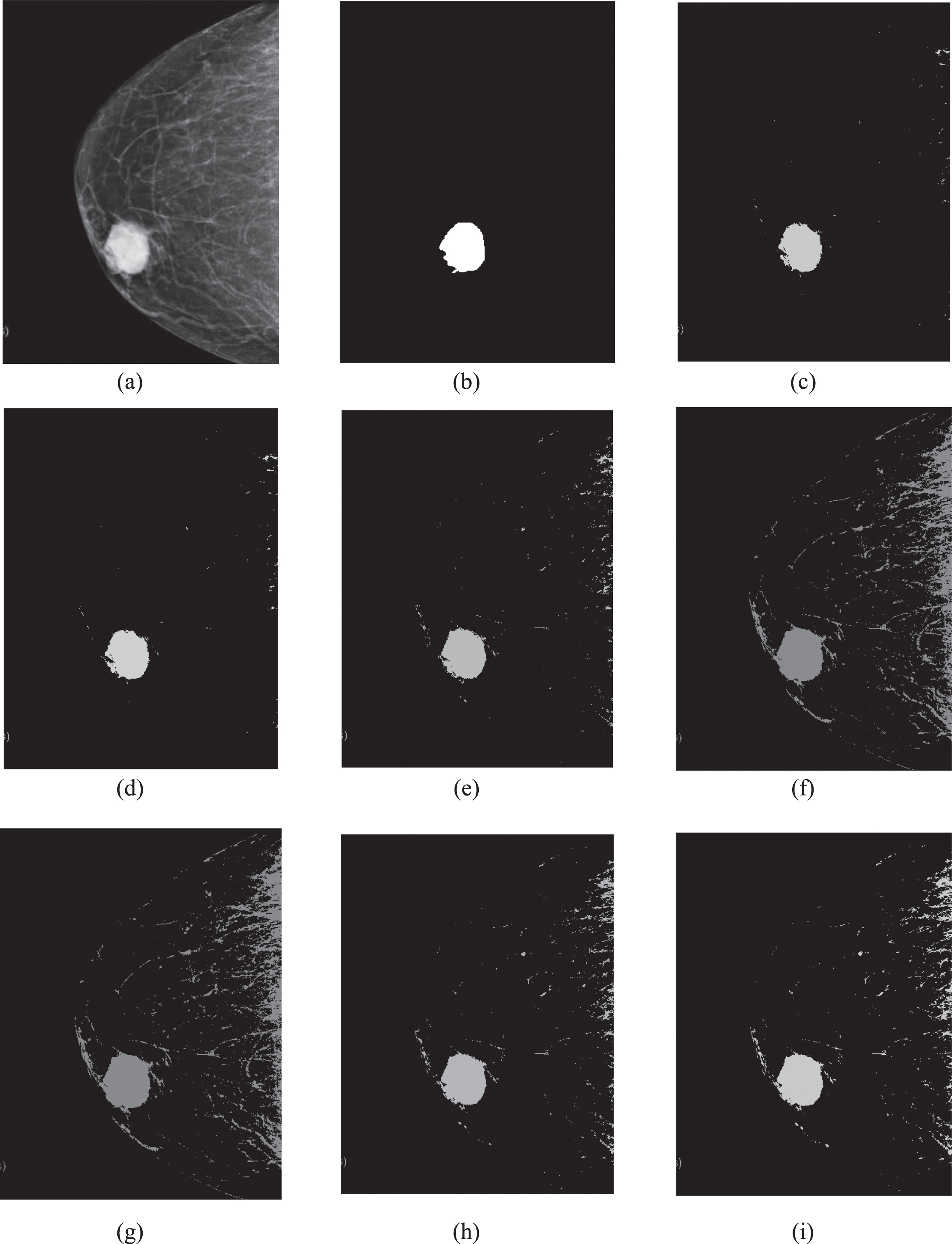
Segmentation results of algorithms on the 10th mammary molybdenum target tumour: (a) The original image of the 10th picture; (b) The ground truth of the 10th picture; (c) The segmentation result of SFCM_V on the 10th picture; (d) The segmentation result of SSFCM on the 10th picture; (e) The segmentation result of SFCM on the 10th picture; (f) The segmentation result of FCM on the 10th picture; (g) The segmentation result of MEC on the 10th picture; (h) The segmentation result of POCS-based clustering on the 10th picture; (i) The segmentation result of KGFCM on the 10th picture.
In Fig. 2, by comparing the results of various algorithms on the 10th mammography target image, it can be seen that after unsupervised segmentation, there are a large number of normal mammary glands and skin tissues in the image, and the lesion area was not successfully segmented. The traditional SFCM algorithm, compared to the unsupervised algorithm, effectively reduces the mammary gland and skin group misclassifications, but the normal mammary gland and skin tissue are still very obvious. According to our analysis in the previous sections, this is caused by the insufficient influence of the supervised information in the SFCM algorithm. The results of the SFCM_V and SSFCM algorithms, which contain only a few gland tissues, successfully segmented the lesion area, while the details of the SFCM_V algorithm are better than those of the SSFCM algorithm. We divide and enlarge the resulting images obtained by these two algorithms. The enlarged images of the SFCM_V and SSFCM segmentation result areas are shown in Fig. 3.
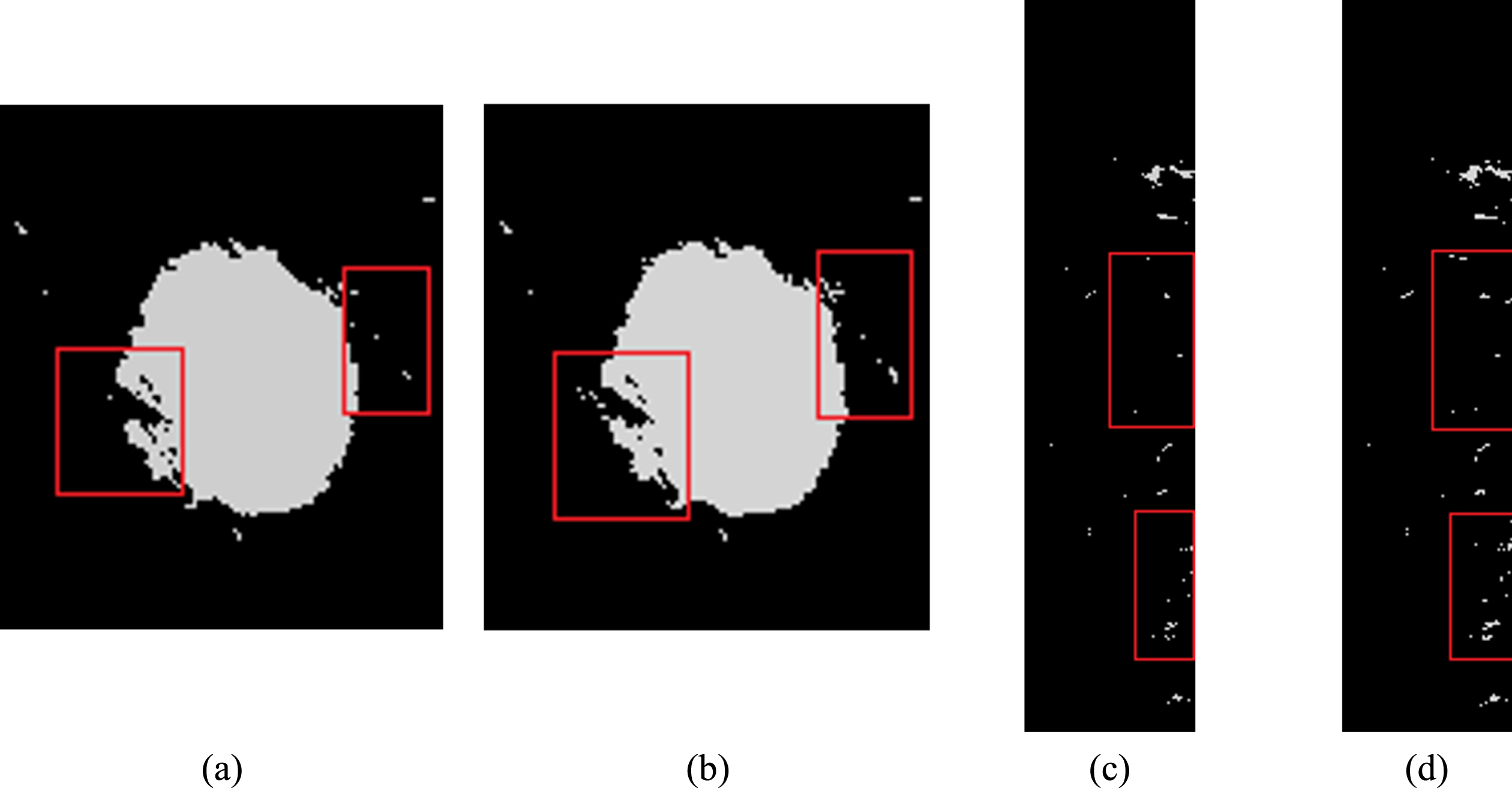
Enlarged images of the SFCM_V and SSFCM segmentation result areas: (a) An enlarged image of the lesion area from the segmentation result of SFCM_V; (b) An enlarged image of the lesion area from the segmentation result of SSFCM; (c) An enlarged image of the background area from the segmentation result of SFCM_V; (d) An enlarged image of the background area from the SSFCM segmentation result. The red-box-labelled areas in the four pictures highlight notable comparison areas.
In Fig. 3, among all the segmentation results, there were fewer isolated pixel points obtained by SFCM_V, as shown in the area labelled with the red box, than obtained by SSFCM. It is also shown that SFCM_V reduces the presence of isolated nonlesion pixels and improves segmentation accuracy for larger lesions, such as tumours.
Second, the seven clustering algorithms are applied to benign calcification point lesions in mammary molybdenum target images. The benign calcification point is smaller than the mass in the image, and the greyscale of some lesions is similar to that of other areas. There is some difficulty in segmentation. The DICE and IoU results of each algorithm are shown in Table 2. To facilitate observation, we plot the results as a line graph in Fig. 4.
DICE and IoU performance of all comparison algorithms on mammogram images with benign calcification
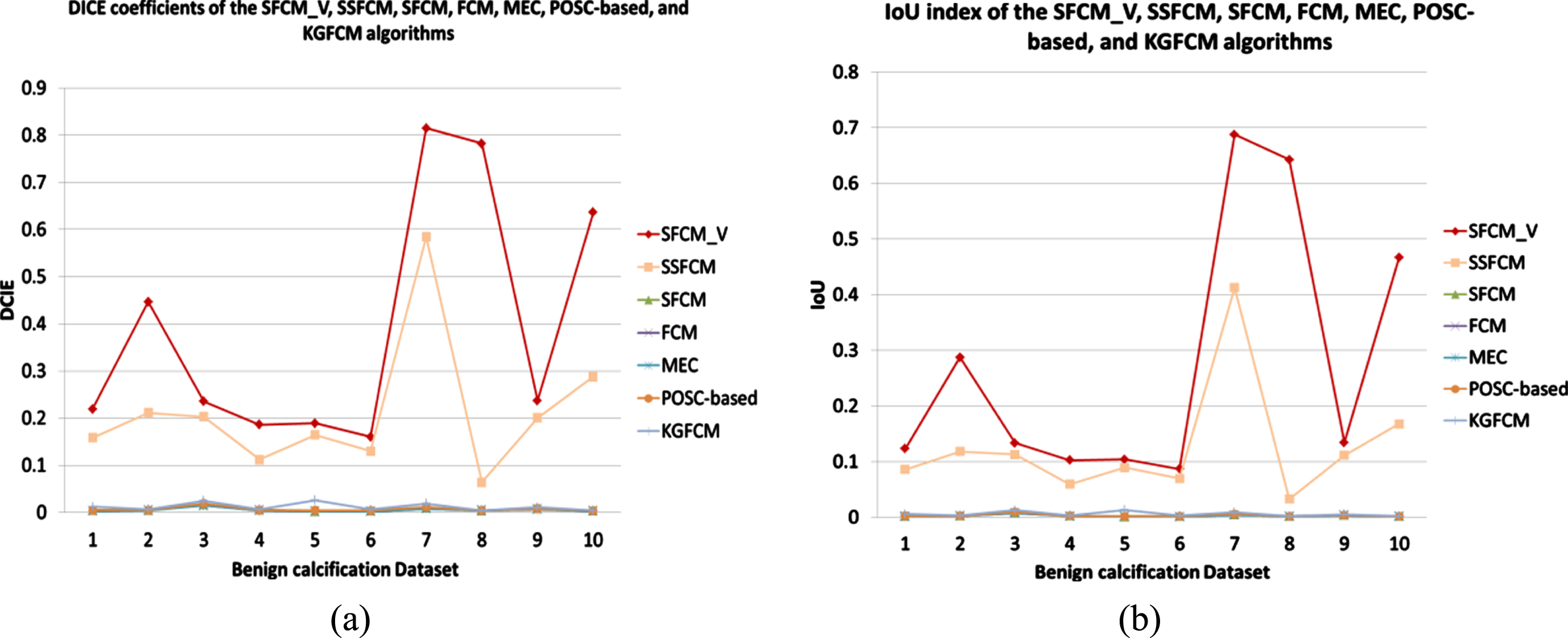
Line graphs of DICE and IoU values for all algorithms on the benign calcification dataset: (a) DICE; (b) IoU.
The table and polyline graph show that the DICE and IoU indices of the SFCM_V algorithm after segmentation are significantly higher than those of the other six algorithms. SSFCM is not as effective as SFCM_V in segmenting lesions, whereas SFCM and the four unsupervised clustering algorithms cannot completely segment lesions. Even the DICE and IoU coefficients of KGFCM and POSC-based clustering, which are unsupervised clustering algorithms, are higher than those of SFCM, a semisupervised clustering algorithm. It shows that SFCM does not fully exploit the prior knowledge. The 7th picture of a benign calcification in breast tissue is taken as an example. The segmentation results of the algorithms on the 7th picture of a benign calcification in breast tissue are shown in Fig. 5.
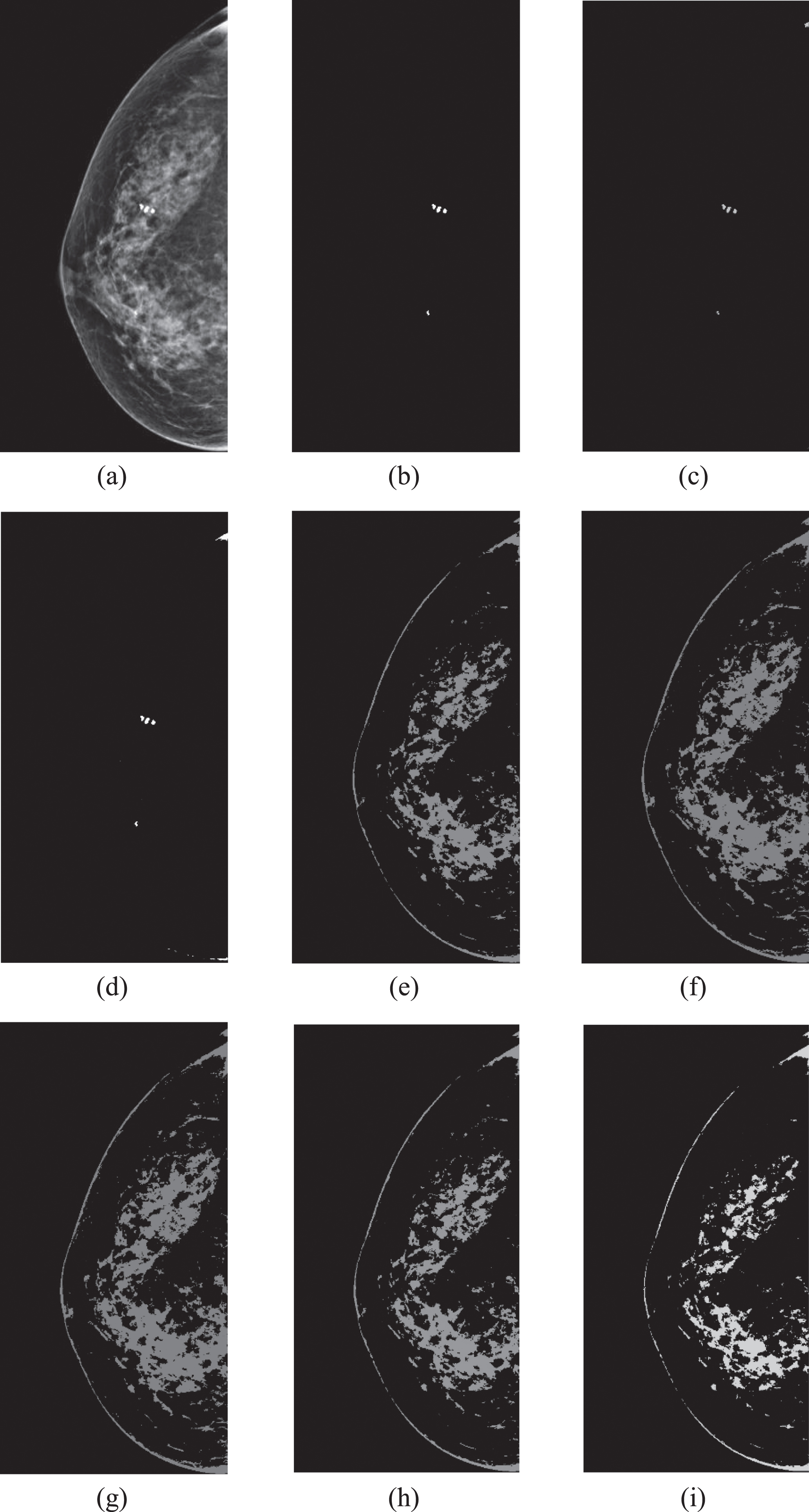
Segmentation results of the algorithms on the 7th picture of a benign calcification in breast tissue: (a) The original image of the 7th picture; (b) The ground truth of the 7th picture; (c) The segmentation result of SFCM_V on the 7th picture; (d) The segmentation result of SSFCM on the 7th picture; (e) The segmentation result of SFCM on the 7th picture; (f) The segmentation result of FCM on the 7th picture; (g) The segmentation result of MEC on the 7th picture. (h) The segmentation result of POCS-based clustering on the 7th picture; (i) The segmentation result of KGFCM on the 7th picture.
Figure 5 shows that SFCM, FCM, MEC, POCS-based and KGFCM all fail during segmentation, and the benign calcification lesion areas are completely invisible. Four benign calcification points were found in the segmentation results of SFCM_V and SSFCM, but there was more breast skin tissue in the SSFCM images and less skin tissue in the SFCM_V images. SFCM_V is more suitable for assisting doctors in making clinical diagnoses. SFCM_V is most effective for benign calcification lesions with small areas.
Finally, the seven clustering algorithms were applied to malignant calcified lesions in mammography, and the DICE and IoU results of each algorithm are displayed in Table 3. To facilitate observation, we plot the results as a line graph, as shown in Fig. 6.
DICE and IoU performance of all comparison algorithms on mammogram images with malignant calcification
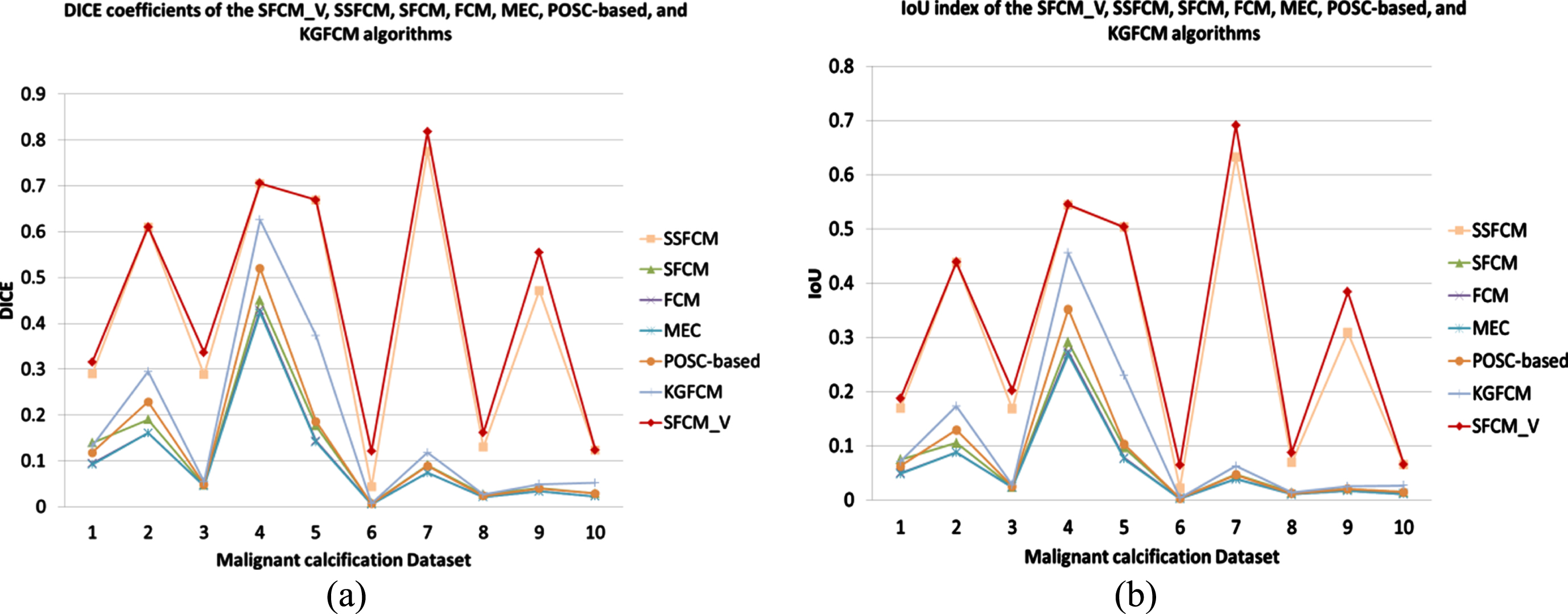
Line graphs of DICE and IoU values for all algorithms on the malignant calcification dataset: (a) DICE; (b) IoU.
From the data in the table, among the 10 pictures, SFCM_V still has the best segmentation effect; its DICE and IoU results are the highest, while the SFCM, FCM, MEC, POSC-based and KGFCM algorithms failed to segment the lesion. The DICE and IoU indices of SFCM_V are slightly higher than those of SSFCM when the picture is well presented and good for clustering. The SFCM_V algorithm is much more effective than SSFCM when the image has a small lesion area and low contrast with the grey values of other regions.
Malignant calcification usually appears as clusters of calcification points. When malignant calcification appears in mammography images, there is high probability that the patient has breast cancer, which is clinically useful. Malignant calcification is characterized by a small area in an image and can even be only a few pixels in size. Its greyscale values are similar to those of the other parts of the breast tissue. This presents a challenge to sample-based greyscale clustering and makes it difficult to segment malignant calcified lesions. This experiment demonstrates that our SFCM_V algorithm performs better in this case than the other four clustering algorithms.The sixth image, which contains a malignant calcified lesion in the breast tissue, as an example, as shown in Fig. 7.

Segmentation results of the algorithms on the 6th picture, which contains malignant calcification in the breast tissue: (a) The original image of the 6th picture; (b) The ground truth of the 6th picture; (c) The segmentation result of SFCM_V on the 6th picture; (d) The segmentation result of SSFCM on the 6th picture; (e) The segmentation result of SFCM on the 6th picture; (f) The segmentation result of FCM on the 6th picture; (g) The segmentation result of MEC on the 6th picture; (h) The segmentation result of POCS-based clustering on the 6th picture; (i) The segmentation result of KGFCM on the 6th picture.
From Fig. 7, on this mammogram, the malignant clusters of calcified spots are small and scattered in the normal mammary glands. Because the the greyscale difference in the surrounding tissue is not obvious, it is difficult for the naked eye to recognize them quickly, which presents a challenge for doctors to diagnose the patient’s condition. The SFCM, FCM, MEC, POSC-based and KGFCM algorithms all fail to segment these lesions, and no malignant calcified lesion areas are found. In the results of SSFCM, malignant calcification points are adhered to normal breast tissue, and the type of lesion cannot be distinguished, so SSFCM also fails. Although SFCM_V does not completely separate the lesions, most of the clustered calcified lesions in the centre of the image are clearly visible, basically showing the lesion area in this image, which is clinically sufficient for a doctor to diagnose.
Seven algorithms are tested on mammography images containing three different lesions. The performance of each clustering algorithm is compared using the DICE and IoU indices. Based on the experimental data, the semisupervised clustering algorithms SFCM_V and SFCM have higher DICE and IoU coefficients for any lesion than the other clustering algorithms. The feasibility of using a semisupervised clustering algorithm to segment mammographic lesions is demonstrated. In the unsupervised clustering algorithm, the POSC-based clustering algorithm uses the parallel projection method of the projection onto a convex set (POCS) to find a suitable cluster prototype in the feature space. The algorithm considers each data point as a convex set and projects the cluster prototype parallel to the member data points. Projections are combined convexly to minimize the objective function used for data clustering purposes. The KGFCM algorithm uses the kernel function technique to map low-dimensional linearly inseparable data to high-dimensional data, which becomes linearly separable. Because both algorithms use different calculation methods than FCM and MEC, they show better performance, but the performance of KGFCM is extremely unstable, and the segmentation effect is either good or bad. On the datasets of benign and malignant calcified lesions, although the unsupervised clustering algorithms, KGFCM and POSC-based clustering, could not segment the lesion regions, they had higher DICE and IoU indices than the semisupervised SFCM algorithm. This indicates that SFCM, as a semisupervised clustering algorithm, does not make full use of the tagged sample information, resulting in poor segmentation results. Among the three semisupervised fuzzy clustering algorithms, the SFCM_V algorithm proposed by us always has the highest DICE coefficients and the highest intersection over union (IoU) values on the three lesion datasets. SFCM_V has excellent performance because it makes full use of the information from the labelled samples, especially when the lesion area is small and the lesion pixels and the surrounding pixels have low greyscale contrast. It can effectively reduce scattered and isolated pixel points in nonlesion areas. It is proven to be more accurate than traditional clustering algorithms at segmenting large lesion areas, such as tumours, and small lesion areas, such as calcification points. It is suitable for segmenting common lesions in various mammography images.
Because we did not preprocess the mammography images or reprocess the segmented images, in some segmented images, the algorithm successfully segmented the lesions; however, some skin tissue remained. In this respect, how to effectively separate muscle from skin tissue and pre- or postprocess mammography images to improve the accuracy of segmentation is a research direction worth exploring.
Conclusions
In this research, we innovatively attempt to use a semisupervised fuzzy clustering algorithm for mammography image segmentation to assist doctors in clinical diagnosis. To improve the traditional semisupervised fuzzy clustering algorithm, insufficient supervisory information leads to the problem of low segmentation accuracy. We propose semisupervised fuzzy clustering based on the cluster centres of labelled samples (SFCM_V). In the experiment, we apply SFCM_V and the existing clustering segmentation algorithm to tumours, benign calcification, and malignant calcification. The experimental data show that the accuracy of the SFCM_V algorithm is the highest for all three lesions. It is suitable for common mammography lesions, especially malignant calcification. It is very helpful for doctors to judge whether patients have breast cancer. However, since SFCM_V is based on the clustering centre of the labelled samples, the quality of the labelled sample set affects the segmentation result of SFCM_V. When the selection of the labelled sample set is not representative, the advantage of SFCM_V is not obvious. In subsequent studies, we will try to determine how to improve the performance of the semisupervised fuzzy clustering algorithm when the labelled sample set is not representative. Future work will extend our algorithm to other medical image segmentation applications. We will extend this framework to various clustering algorithms to obtain satisfactory segmentation results for medical images.
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China under Grant 62171203, in part by the Suzhou Key Supporting Subjects [(Health Informatics(No.SZFCXK202147)], in part by the Changshu Science and Technology Program [No. CS202015, CS202246], in part by the Changshu City Health and Health Committee Science and Technology Program [No. csws201913], and in part by the “333 High level personnel training project of Jiangsu Province”.