
Abstract
Recognizing human activity is the process of using sensors and algorithms to identify and classify human actions based on the data collected. Human activity recognition in visible images can be challenging due to several factors of the lighting conditions can affect the quality of images and, consequently, the accuracy of activity recognition. Low lighting, for example, can make it difficult to distinguish between different activities. Thermal cameras have been utilized in earlier investigations to identify this issue. To solve this issue, we propose a novel deep learning (DL) technique for predicting and classifying human actions. In this paper, initially, to remove the noise from the given input thermal images using the mean filter method and then normalize the images using with min-max normalization method. After that, utilizing Deep Recurrent Convolutional Neural Network (DRCNN) technique to segment the human from thermal images and then retrieve the features from the segmented image So, here we choose a fully connected layer of DRCNN as the segmentation layer is utilized for segmentation, and then the multi-scale convolutional neural network layer of DRCNN is used to extract the features from segmented images to detect human actions. To recognize human actions in thermal pictures, the DenseNet-169 approach is utilized. Finally, the CapsNet technique is used to classify the human action types with Elephant Herding Optimization (EHO) algorithm for better classification. In this experiment, we select two thermal datasets the LTIR dataset and IITR-IAR dataset for good performance with accuracy, precision, recall, and f1-score parameters. The proposed approach outperforms “state-of-the-art” methods for action detection on thermal images and categorizes the items.
Keywords
Introduction
Human action recognition (HAR), also known as action classification or action detection, is a field of computer vision that focuses on automatically identifying and categorizing human actions or activities in videos or image sequences. It involves developing algorithms and techniques to analyze and interpret the motion patterns, spatial configurations, and temporal dynamics of human movements. The goal of HAR is to enable machines, such as computers or robots to understand and interpret human actions in a similar way to how humans perceive and comprehend them. Although action recognition can be utilized in a variety of applications, including animation, gaming, robotics, automated surveillance, home automation systems, and human-machine interfaces, it is a heavily debated topic in the area of computer vision. The growth of nuclear families and the aging the population has motivated the invention of supportive technologies for safe and secure living [1–3]. As a result, research on activity analysis has increased in fields including patient health monitoring and care for the elderly. Human action recognition (HAR) has grown significantly in prominence amongst computer vision in recent years. Recent years have seen an increase in the number of older persons living alone, making it necessary to afford them help [4, 5]. Medical specialists consider it necessary to examine daily activities and monitor for changes in a person’s behavior to detect mental and physical health issues before they get out of hand. The development of automatic surveillance systems for identifying older people’s everyday activities is anticipated because it is challenging for caregivers or families to continuously monitor older adults [6]. Identifying any unusual behaviors, such as falling, is also necessary in an elderely people who lives alone.
The increasing appearance of recent articles in the last several years indicates that HAR based on infrared imaging is becoming increasingly popular. Applications for recognizing human activity in the real world include customer qualities, shopping behavior analysis, and intelligent video surveillance. Because of varying viewpoints, occlusions, crowded backgrounds, etc., accurate activity recognition is a challenging process [7–10]. Most of the current methods assume specific things about the conditions in where the video was captured (for example viewpoint changes, and tiny size). These assumptions, seldom necessarily are the case in the real world. Because the choice of characteristics is so problem-dependent, it is uncommon to know which features are crucial for the task. Different activity classes may appear significantly different in terms of their shapes and movement patterns, especially for recognizing human actions.
Using low-level features as building blocks, DL algorithms are a class of computers that can understand a hierarchy of features [11, 12]. Such learning systems can be trained in either unsupervised or supervised ways, and the resulting systems have been demonstrated to perform competitively in tasks such as denoising, segmentation, brain-computer interaction, audio classification, natural language processing, visual object recognition, and the recognition of human actions. Heavy sunlight and seasonal changes make the thermal image invisible [13–15]. Human action recognition in thermal images refers to the process of detecting and classifying human activities or actions using thermal infrared images as input. Thermal imaging captures the thermal radiation emitted by objects, including humans, and represents them as grayscale images where warmer regions appear brighter.
The challenges in human action recognition from thermal images include the lack of color information and the need to capture subtle differences in thermal patterns caused by human movements. However, thermal imaging has several advantages, such as being less affected by lighting conditions and being able to detect humans in complete darkness or low-light environments. Human action recognition remains an active research area, and researchers are constantly exploring new techniques and approaches to improve the accuracy and robustness of action recognition systems. In recent days, some of the authors work on human action recognition but their studies are having problems in recognizing action accurately. The issues in recent studies are the action detection obtained low classification accuracy along with less computation time. And they recognized few actions only. To solve the issue of identifying people in thermal images, we propose a method for classification human actions. In this paper, we propose a DL technique of CapsNet for classifying human actions. We follow five steps to classify the actions. Initially, to remove the noise using the Mean filter method in given input thermal pictures and then normalize the pictures. After that, utilizing deep recurrent convolutional neural network technique to segment the human from thermal images and then extract the features from the segmented image. So here we choose the segmentation layer of DRCNN is utilized to segment the human and then the Multi-scale CNN layer of DRCNN is used to extract the attributes from segmented pictures to detect human actions. To recognize human actions in thermal pictures, the DenseNet-169 approach is utilized. Finally, the CapsNet technique is used to categorize the human action types with the Elephant Herding Optimization technique for better categorization.
The key contributions of the paper are, To overcome the issues of human actions in thermal images, we propose a deep learning technique with two thermal datasets. Initially, utilizing the Mean filter to remove the noise from the input thermal image and then normalize the pictures utilizing the min-max normalization technique. Then the deep recurrent convolutional neural technique (DRCNN) utilizing to segment and then feature extraction purposes. First, the segmentation layer is to segment the human in thermal images, and then the multi-scale convolutional neural network layer of DRCNN is to extract the features of the human. To recognize human actions in thermal pictures, we propose the DenseNet-169 approach. It recognizes humans and their actions using extracted attributes. The CapsNet approach is employed for classifying human actions into their types with the Elephant Herding Optimization technique for better classification. Here, we perform on two thermal datasets as LTIR dataset and the IITR-IAR dataset.
The other sections of the article are organized as follows. The paper’s relevant literature is shown in Section 2. In Section 3, the proposed method is described. The outcome is presented in Section 4. Finally, the conclusions are stated in Section 5.
Literature survey
Human action or activity recognition contains many types of techniques and methods to recognize and classify. So, we analyzed some papers related to human actions recognition and thermal images. Using the magnetometer, gyroscope, accelerometer, and Google Fit activity monitoring module of integrated smartphone sensors, Javed et al. [16] suggested a model for HAR. The DRNN used in the suggested framework is applied to a sizable training dataset. Utilizing a DRNN, the latter uses 12 people who represent five activity classes. Five activity classes from a group of 12 people are employed in a sizable training dataset.
A lightweight framework for activity recognition supported by deep learning was suggested by Ullah et al. [17] to address these issues in real-time monitoring. Using an efficient CNN model that has been trained on two monitoring datasets, they first identify a human in the video surveillance frame. Through the use of a very quick object tracker known as the minimum output sum of squared error (MOSSE), the recognized person is followed throughout the video stream. The effective LiteFlowNet CNN is then used to collect pyramidal convolutional features for each monitored person from two consecutive frames. The final step is to train a deep skip connection gated recurrent unit (DS-GRU) to recognize activity by learning the temporal variations in the sequence of frames.
A multi-branch CNN-BiLSTM approach for HAR has been suggested by Challa et al. [18] that effectively operates on unprocessed original data obtained from wearable sensors. By utilizing the benefits of BiLSTMs and CNNs, this model can capture both short- and long-term dependencies in time series information. The suggested structure uses a variety of convolutional filter sizes to improve the retrieval of features by taking different local dependencies. It is capable of recognizing both simple activities like jogging, sitting, and walking but also more complex ones like ironing, vacuuming, Nordic walking, and other similar activities with a fair amount of accuracy.
Nadeem et al. [19] developed an A-HPE technique that uses saliency silhouette recognition, a human body structure followed by an entropy Markov method to intelligently identify human activities. To create a solid silhouette, noises were first removed from the images during pre-processing. To support the creation of multidimensional cubes, these important body parts are further optimized. These signals, which help in the identification of actions, including optical flow, energy, and characteristic values. They are supplied into the quadratic discriminant analysis. Finally, a maximum entropy Markov method recognizer engine based on transitions and emissions probability values.
Syed et al. [20] presented a method for detecting falls that considers activity recognition as well as fall direction and severity. Relabeling and windowing are the first steps in data pre-processing. After that, data augmentation is done for classes that don’t have enough need more samples. Finally, feature extraction and classification are carried out. To provide a “fuller” identification system for application in cyber-physical models, this research approaches activity and fall identification as a holistic challenge, by considering various types of falls and activities. Additionally, a CNN-XGB combination is suggested with this objective in mind. For the planned network, two experiments have been performed, one in which each ADL is considered separately, and the other in which each ADL is considered as a single class.
Using raw color (RGB) information, Basly et al. [21] suggested a DTR-HAR by fusing two deep learning architectures: To extract relevant visual residual spatial features that are communicated to a person’s appearances, a feed-forward neural network with end-to-end structure-based residual CNN structure is used. An LSTM network was utilized to record the long-term temporal evolution of activities in surveillance videos.
Thakur et al. [22] suggested a technique to recognize the human actions. Data was initially gathered using an Android smartphone made by Samsung, the Galaxy On-Max. Noise can be found in the raw data gathered by the smartphone’s built-in sensors. Using a low-pass elliptic filter with a 20 Hz cutoff frequency followed by a high-pass elliptic filter, the gravitational acceleration and high-frequency noise were removed from the data. They have retrieved 17 time-frequency domain attributes from the self-collected data. Following extracting features, the dimension of the data is reduced for cost reduction utilizing the feature selection algorithm GRRF. They utilized four different shallow ML algorithms, including NB, DT, SVM, and RF, to create a HAR model with the benefits of statistical attribute retrieval methods and the GRRF feature chosen approach. Table 1 shows the comparative analysis of literature researches.
Comparative analysis of the literature survey
Comparative analysis of the literature survey
From the above survey, they have some issues are found. They must study more typical daily activities from a larger sample size of persons across a range of ages. They require enhanced methods to identify unusual activity in monitoring, such as accidents, actions that harm the property or violate the law, and criminal behavior like fighting, robbery, etc. As a result, it is challenging to analyze feature points and derive an accurate edge of the human body from them. Additionally, variables like a person’s movement and the distance between the human body and the sensor will readily impact the pixel values. During the detection stage, visible images shows some issues like lighting and noise problems. So we choose thermal images to detect human actions. Thermal imaging is a appraoch that captures the infrared radiation emitted by objects, including human faces. This allows for the detection of temperature differences on the surface of the face, which can provide information about facial expressions and emotional states. Thermal imaging has some advantages over traditional visual analysis of facial expressions.
Proposed methodology
Human action recognition is a growing topic nowadays. The human actions in thermal images are providing some issues like lightening and climate change. To overcome all of these problems, we propose a new deep-learning technique. In this paper, we propose a DL technique of CapsNet for classifying human actions. They had five steps to classifying the actions. Initially, remove the noise using the mean filter method from given input thermal pictures and then normalize the pictures utilizing the min-max normalization method. After that, utilizing Deep Recurrent Convolutional Neural Network (DRCNN) technique to segment the human from thermal images and then retrieve the features from the segmented output. So, we select the fully connected layer of DRCNN as the segmentation layer is utilized to segment the human in thermal mages and then the multi-scale convolutional neural network layer of DRCNN is employed for extracting the attributes such as shape, size, and presence of human from segmented pictures to detect the human actions.
To recognize human actions in thermal pictures, the DenseNet-169 approach is utilized. Finally, the CapsNet technique is used to classify the human action types with Elephant Herding Optimization (EHO) technique for better classification. All of these things are demonstrated in Fig. 1 above.
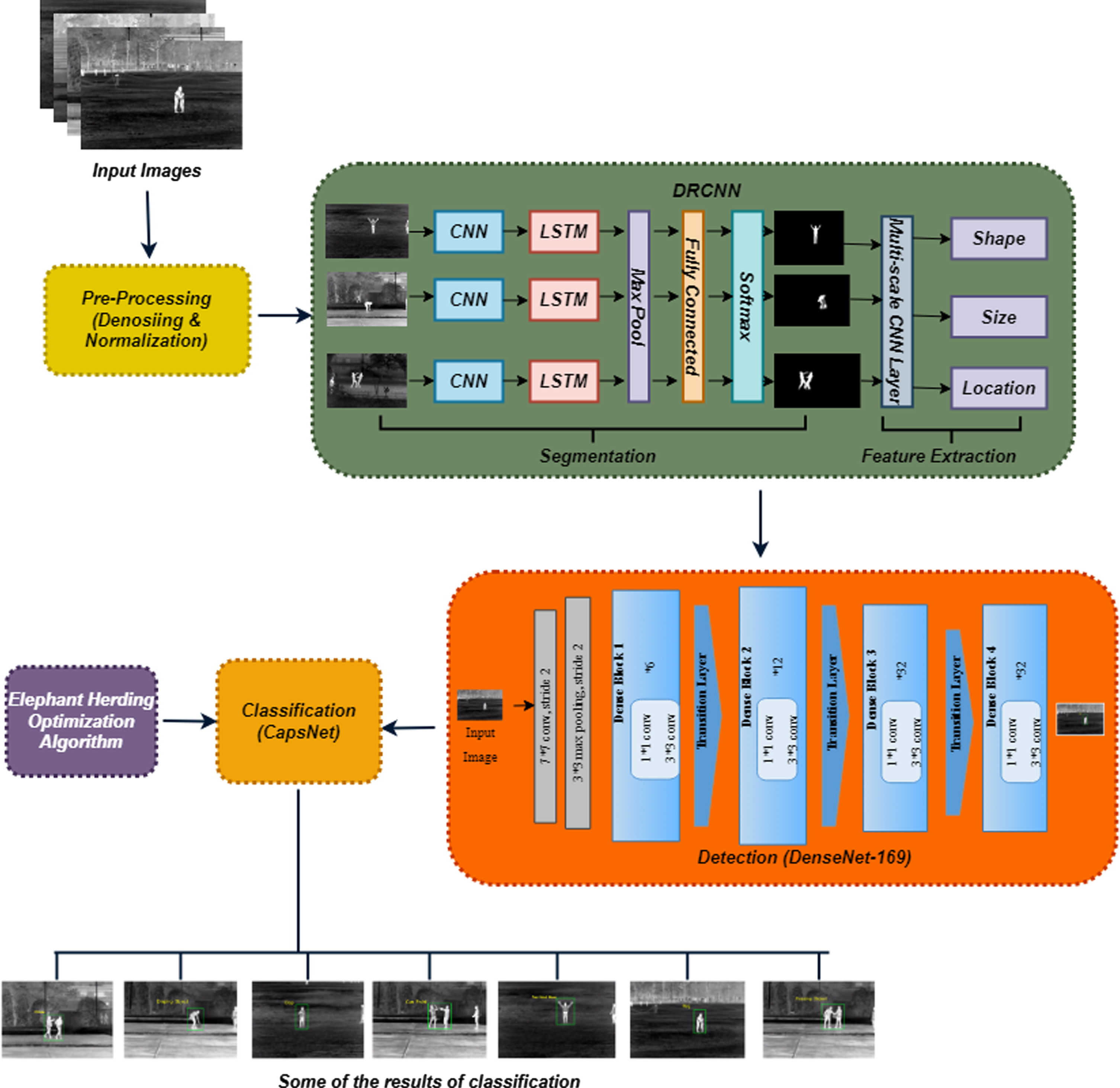
The proposed architecture of human action recognition.
In a pre-processing step, we doing the noise and normalize the images. Here, the mean filtering is initially used to reduce the noise from input images. Using different image smoothing templates for image convolution processing to reduce or eliminate noise is a traditional method of image de-noising in the spatial domain. Mean filtering’s fundamental premise is to replace a pixel’s single grey value with the combined grey values of multiple adjacent pixels. The image after smoothing and mean filtering is g(x, y), and the g(x, y) is determined for a pixel point (x, y) in a given image with f (x, y), its neighborhood S comprises M pixels by the below formula:
An image can be thought of as a two-dimensional function, f(x,y), with x and y being spatial (plane) coordinates, and the amplitude of ‘f’ at any given pair of coordinates, (x,y), is referred to as the intensity or grey level of the image at that location. In a mean filter, f(x,y) refers to the value of the pixel at location (x,y) in the image being filtered. The purpose of a mean filter is to replace the value of each pixel in the image with the average value of the pixels in its neighborhood. Where f(x,y) is the original image.
Then, we normalize the image and then remove noises from input images to better detection of human actions. The Min-Max normalization approach is selected to standardize the original data, hasten model convergence, and boost model accuracy, and is denoted as
Thermal images are aligned and encapsulated to a detailed anatomic template as part of the normalization process. Normalization is required because diverse human acts necessitate distinct outputs. Normalization frequently entails using a template and a source picture to translate discrete subject-space data to a reference space.
After the process of pre-processing, the thermal human image is sent to the segmentation process. The DRCNN model is used to accurately segment the abnormal area. The CNN and an RNN built on an LSTM network are combined to create the DRCNN model. Four different kinds of layers compensate for the DRCNN’s structure [22]. There are the deep BiLSTM network layer, the embedding layer, the multi-scale convolutional neural network, and the final fully connected layer, also known as the segmentation layer. In thermal images, it segments the human. After that, a combined vector of the global maximum and global average characteristics of the thermal human image is created by integrating mean-pooling and max-pooling algorithms into the multiscale CNN.
Segmentation layer
A fully connected layer implementation is used for this layer. An activation function called the sigmoid has been used. The output of the image’s pre-processing is passed into this layer. We used the BCE loss, which is derived as follows, to forecast the likelihood of each image. We assigned the threshold value to 0.2.
Where y
b
is the appropriate goal value,
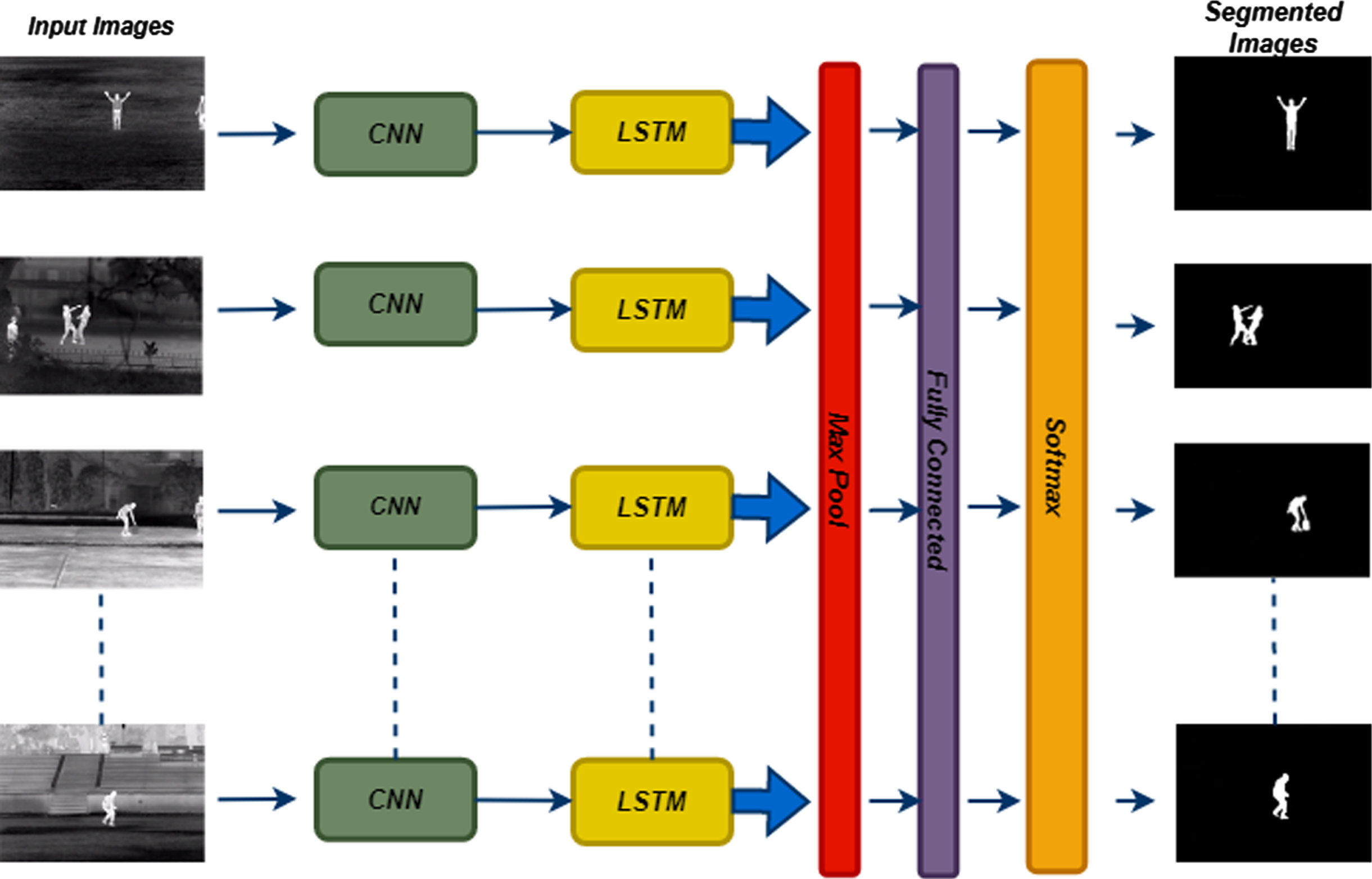
Structure diagram of the DRCNN model.
Several computer vision tasks have been completed using Convolutional Neural Networks, which is a type of frequently utilized neural network design. CNNs have recently been employed in some NLP activities, such as image segmentation, detection, and categorization. Kernels are used by the previous Convolutional Neural Network methods to automatically derive image features from the original information. This is a major disadvantage for such image segmentation, which calls for the extraction of visual features to improve detection. Multi-scale learning was determined to be a good method for dealing with this issue because it retrieves several scale segmentation information.
To retrieve semantic characteristics from the segmentation, we utilized a multi-scale Convolutional Neural Network architecture. The results of all Convolutional Neural Networks are pooled for each identified image to create the final feature matrix or
The multi-scale CNN’s feature matrices are denoted by the symbol
Feature extraction identifies the most suitable shape information. With a methodical approach, it is easy to categorize tasks using these characteristics. So they can be understood by robots, and characteristics may vary in appearance to humans and machines. Nearly every feature is used to describe a specific component of an image, such as its size, position, or the presence of a certain object.
Propose a method to identify the human to the category of action types after feature extraction. We use the DenseNet-169 approach for the human detection stage in this case. The DenseNet-169 method’s structure and its role in detection are therefore covered in this stage. Deep Convolutional Networks, which comprise unusual varieties of pooling and convolutional layers, are the most effective frameworks for image recognition. The gradient or input data that was present in the topmost layer by the time the bottommost layer was reached, however, vanishes as the network becomes deeper. DenseNet circumvents the gradient diminishing issue by directly connecting all of the layers with equivalent feature sizes. The feature extraction procedure was carried out using the pre-trained DenseNet-169 convolutional neural network, which has 169 layers. The large ImageNet dataset, which is openly available, was used to build this approach. Four dense blocks, three transition layers, and a pooling and convolution layer at the beginning compose the DenseNet-169 design. A maximum pooling of 3x3 and 7x7 convolutions with stride 2 are utilized after the first convolutional layer [23]. The network then consists of three sets, each of which has a dense block at its center and a transition layer before it. Direct connections are made accessible to the network from any layer to any other layer to create the dense connectivity proposed for DenseNet. Concatenating the feature maps of the preceding layers are required to achieve this. The DenseNet structure is divided into several dense blocks that are tightly connected before since convolutional neural networks are generally utilized to downsample the feature-maps size. A flowchart of how this approach was applied is shown in Fig. 3.
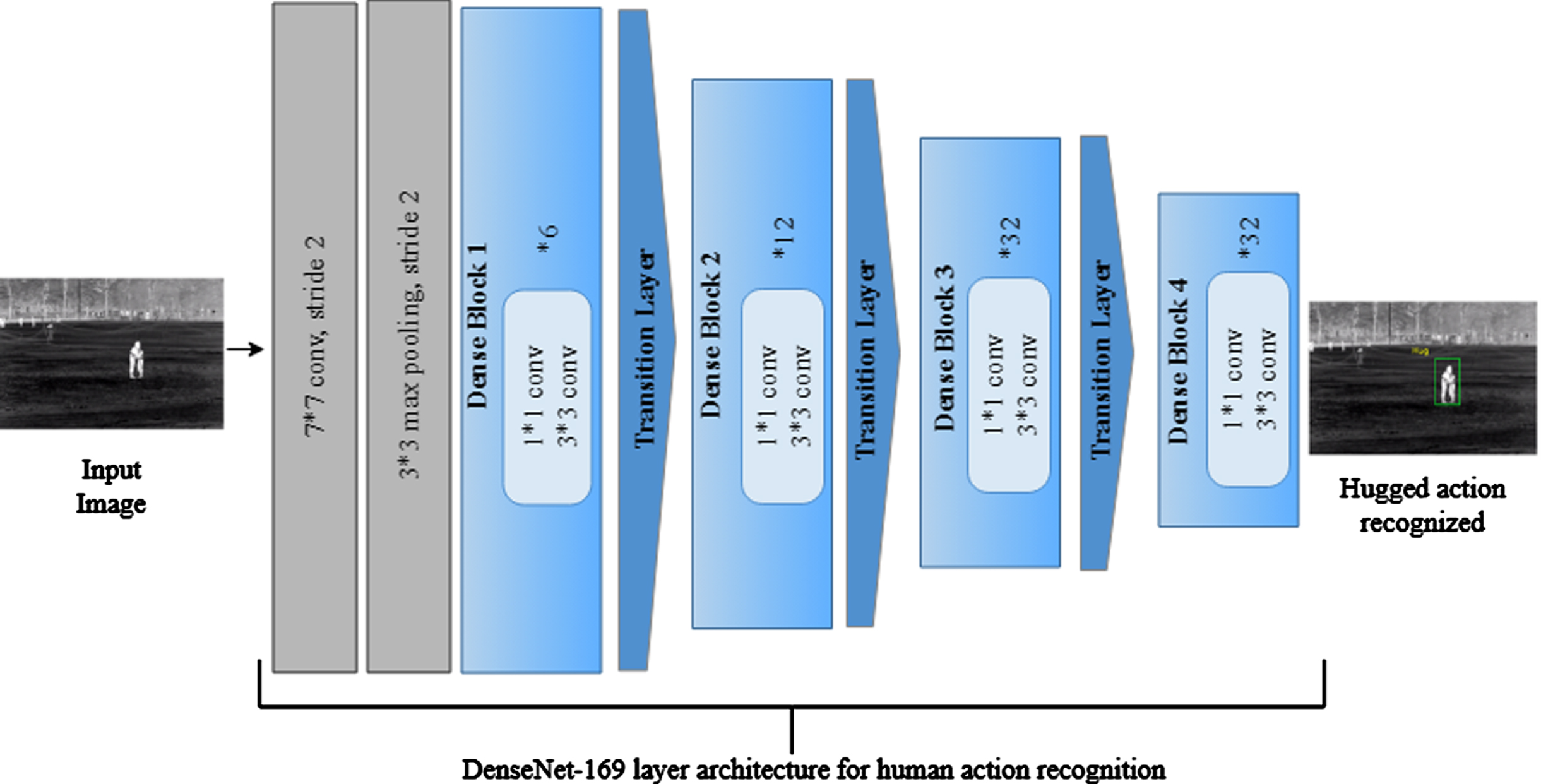
Represents a flowchart showing how our methodology was used.
Layers referred to as transition layers are used to divide these substantial blocks. A batch normalization layer, a 2x2 average pooling layer, a 1x1 convolutional layer, and a stride of two contribute to each transition layer in the network. Four large blocks with two convolution layers together contribute to the structure. The sizes of the first and second layers are 1x1 and 3x3, respectively. The DenseNet-169 architecture features four dense blocks with respective sizes of 6, 12, 32, and 32. This layer is followed by a completely connected layer that conducts global average pooling of 7x7 and a final fully connected layer that uses “softmax” as the activation. The DenseNet approach’s structure is shown in Table 2.
Structure of DenseNet
After detecting the humans and their actions in given input thermal images, we propose a Capsule Network (CapsNet) to classify the human actions. The activation vector is composed of capsules, which are a gathering of neurons whose outcomes are interpreted as various aspects of the same entity. A primary capsule layer (the outcome of the final convolutional layer that has been reshaped and compressed) and ActionCaps layers compensate for our proposed design [24]. Each capsule predicts the output of the parent capsule, and if the predicted output matches the actual output of the parent capsule, the coupling coefficient between these 2 capsules increases. If the output capsule is identified as u
i
, its prediction for the parent capsule is established according to Equation (5).
Where W
ij
is the weight matrix that needs to be known during the backward pass and
If capsule I and capsule j should be connected starting with the agreement process at the beginning of the routing, set b
ij
, which indicates the log-likelihood, to 0. To compute the parent capsule input vector j, use Equation (7).
To normalize the outcome capsule vectors by preventing them from exceeding 1, a non-linear squashing function is applied in the last step. Thus, its length can be viewed as the likelihood that a capsule will find a specific characteristic. The initial vector value of each capsule, as displayed in Equation (8), determines the end output of each capsule.
Where v
j
is the output and s
j
represents the entire input into capsule j. based on the consensus between v
j
and
By using a dynamic routing technique, the routing co-efficient will be raised to a j-parent capsule by a factor of
The proposed CapsNet model for categorizing human behaviors is shown in Fig. 4 below.
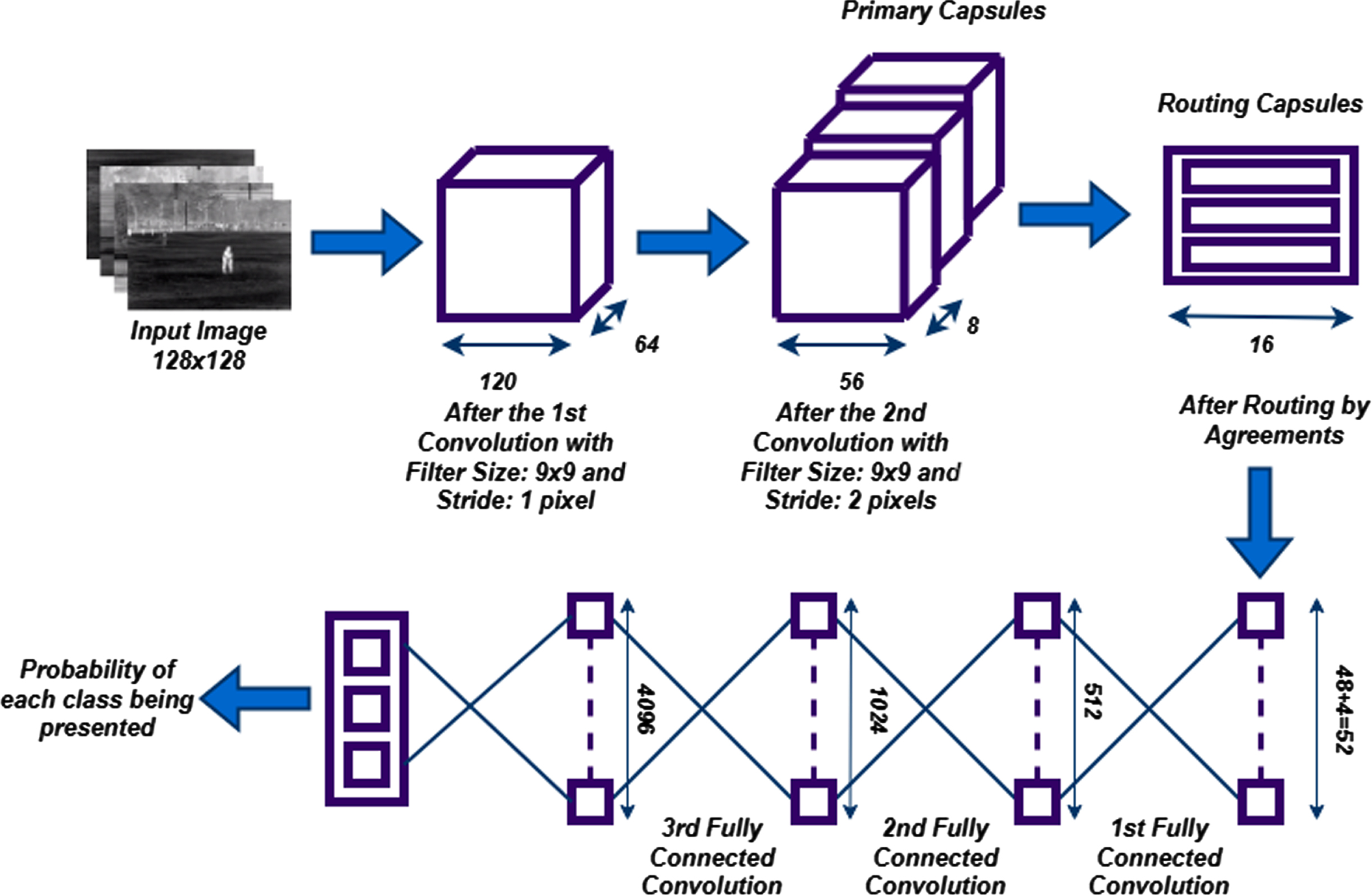
CapsNet structure is used for classifying thermal images of human actions.
Several convolutional layers could be used before the first capsule layer, if necessary. The max-pool layers, which were CNN’s primary flaw, are not present in CapsNet. CNN was losing certain important details and the spatial relations from the image as a result of the max-pool layer. To reduce the dimensionality, CapsNet employs convolution with strides bigger than 1. This classification technique classifies human actions into their categories. For better classification outcomes, the Elephant Herding Optimization (EHO) technique is utilized.
Elephants have complex social structures with both calves and females. They also exhibit social behavior. A matriarch and her calves or other related females serve as the group’s leaders. An elephant herd is made up of several clans [25]. A woman establishes a clan. EHO is concerned with the following hypotheses. The elephant family is divided into their clans, and every clan consists of a particular type of elephant. A certain percentage of male elephants (ME) leave their group to live on their own. A matriarch is the head of each clan.
The elephant herd’s matriarchal group preserves the ideal resolution. There are j clans that compose the total population of elephants. Each elephant’s new position is influenced by the matriarch, c
i
. In Clan c
i
, the elephant j can be computed by using
Where elephant j’s new location in the clan is c
i
is denoted by xnew,ci,j and the old position is indicated by x
c
i,j
. The matriarch c
i
, or the best elephant, is represented by the expression xbest,c
j
. A scaling factor, r ∈ [0, 1] is shown by a ∈ [0, 1]. Each clan’s best elephant is determined using
Here, β ∈ [0, 1] the second parameter controlling the effect of the xcenter,ci,d defined in
The center of the clan ci (xcenter,ci,d) can be updated Equation (12), 1 ⩽ d ⩽ D, and n
ci
represents the number of elephants in the clan. xci,j,d is the d
th
dimension of each elephant. When dealing with optimization problems, the dividing process could be modeled as a dividing operator. The least valuable elephants in each tribe are relocated to the position indicated by
Here, x min and x max respectively, denote the lowest and higher bands of the search space. The random value chosen from the uniform distribution is denoted by rand ∈ [0, 1].
The EHO algorithm performed better when tested against multiple benchmark set functions and in the region of activity detection. The EHO method is used in this work to optimize the CapsNet parameters. The CapsNet model’s output is based on the weights and biases of the network’s earlier layers. The key attributes of EHO are its high convergence rate and minimal localization mistakes with short execution times. Directly tackling non-convex ML issues is possible with the approach. This method aids in obtaining a greater level of classification accuracy for our paper.
The first half of this section compares our methodology to “state-of-the-art” approaches by categorizing human actions using our dataset’s evaluation and our method for obtaining human action feature attributes. Provide the assessment findings based on experimental data to evaluate our methodologies in the following subsections.
Dataset description
Here, we utilized two different thermal image datasets to better predict and classify.
LTIR dataset
Visual object tracking (VOT) problems and LTIR datasets are combined. Each sequence in the collection was recorded by one or more temperature sensors. The collection includes both outdoor and indoor videos that were recorded under various climatic conditions. Each row contains the x and y coordinates of the corners of the bounding box. These data are used to evaluate the annotations quantitatively.
IITR Infrared Action Recognition (IITR-IAR) Dataset
The 21 action categories in the IITR-IAR dataset can be broadly split into 3 groups. (1) Individual actions include waving with two hands (wave2), and one hand (wave1), walking, jogging, jumping, clapping (clapping), and squatting. (2) Person-object interactions include throwing an object, taking a selfie, filming a movie, picking up an object, holding or pointing a gun, and dropping an object. (3) Person-person interactions include punching, pushing, passing an object, fighting, hugging, kicking, chasing (chase), and handshaking. 70 videos involving 35 different people ranging in age from 8 to 37 have been compiled for each action class. A total of 44 videos were acquired, with 9 videos merely containing ADL and 35 videos including a fall in addition to the usual ADL. The collection contains some empty frames or situations in which there is no human. Videos of people attempting to enter from the right and left are also included.
Quantitative metrics
Human action recognition in thermal images is a widely interesting domain, here we propose a novel technique to recognize humans in thermal images and then classify them into their categories. It has five steps to classifying the actions. In preprocessing step, utilizing the mean filter to remove the noise and then normalize the image using the min-max normalization technique. Then, segment the human area using the segmentation layer of deep recurrent convolutional neural network (DRCNN), and after segmentation is done, using the multi-scale convolutional neural network layer of DRCNN to retrieve the attributes such as shape, size, and presence of a human. Then, utilizing the DenseNet-169 approach to identify human actions in thermal images. Finally, the CapsNet technique is used to classify the human action types with Elephant Herding Optimization (EHO) technique for better classification. We collect images from two thermal image datasets for experiments.
Figure 5 demonstrates the proposed method performance outcomes and they are placed in their category type.

The evaluation performance of the proposed methodology.
The proposed method’s Precision (P), Accuracy (A), Recall, and F1-score (F) were examined as performance indicators (R). These measurements show:
Accuracy
To determine whether the classification of bamboo species is accurate, the accuracy measure is calculated.
Precision is defined as the ratio of positively predicted results to all correctly predicted positive observations. Precision is the capacity to perform the following tasks.
Sensitivity and True Positive Rate (TPR) are the terms for the recall. The recall score illustrates the ability of the classifier to find all positive samples. It is the sum, including FN, divided by TP. As an example, consider the following:
The harmonic mean of recall and precision is calculated using F-Measure.
In the performance of methods, several human actions are performed in IITR Infrared Action Recognition (IITR-IAR) Dataset. The performance values of the proposed method on the IITR-IAR dataset are measured without optimization techniques and with optimization techniques are shown in Table 3. Using with Elephant Herding Optimization technique provides higher precision, accuracy, f1-score, and recall values compare to CapsNet percentages.
Multi-class categorization of the proposed method on the IITR Infrared Action Recognition (IITR-IAR) Dataset
Multi-class categorization of the proposed method on the IITR Infrared Action Recognition (IITR-IAR) Dataset
The performance of the proposed methodology in the IITR-IAR dataset is demonstrated in Fig. 6 below.
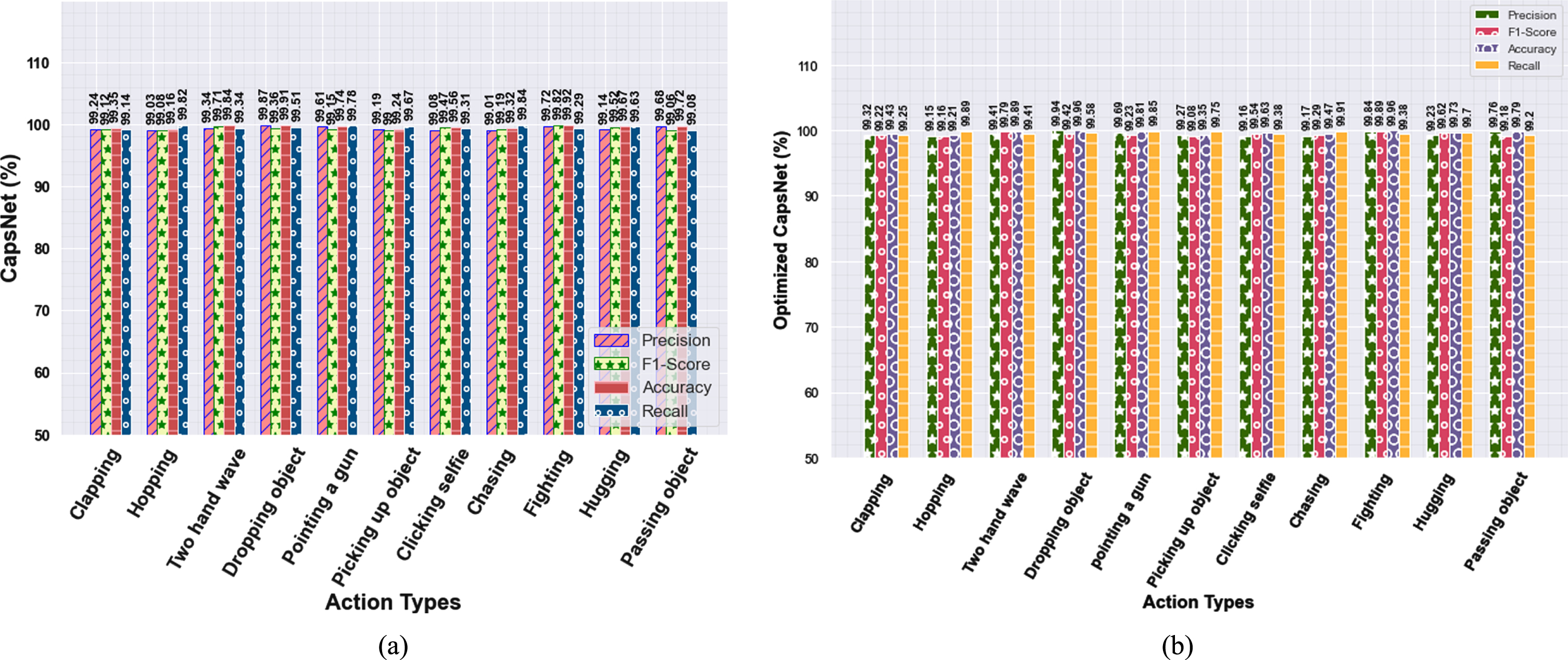
The performance of the proposed methodology in multiple classifications in the IITR-IAR dataset (a) without optimization, (b) with optimization.
In the performance of methods, several human actions are performed in the LTIR dataset. The performance values of the proposed method on the LTIR dataset are measured without optimization techniques and with optimization techniques are shown in Table 4. Using with Elephant Herding Optimization technique provides higher precision, accuracy, f1-score, and recall values compare to CapsNet percentages.
Multi-class categorization of the proposed method on the LTIR dataset
The performance of the proposed methodology in the LTIR dataset is demonstrated in Fig. 7 below.
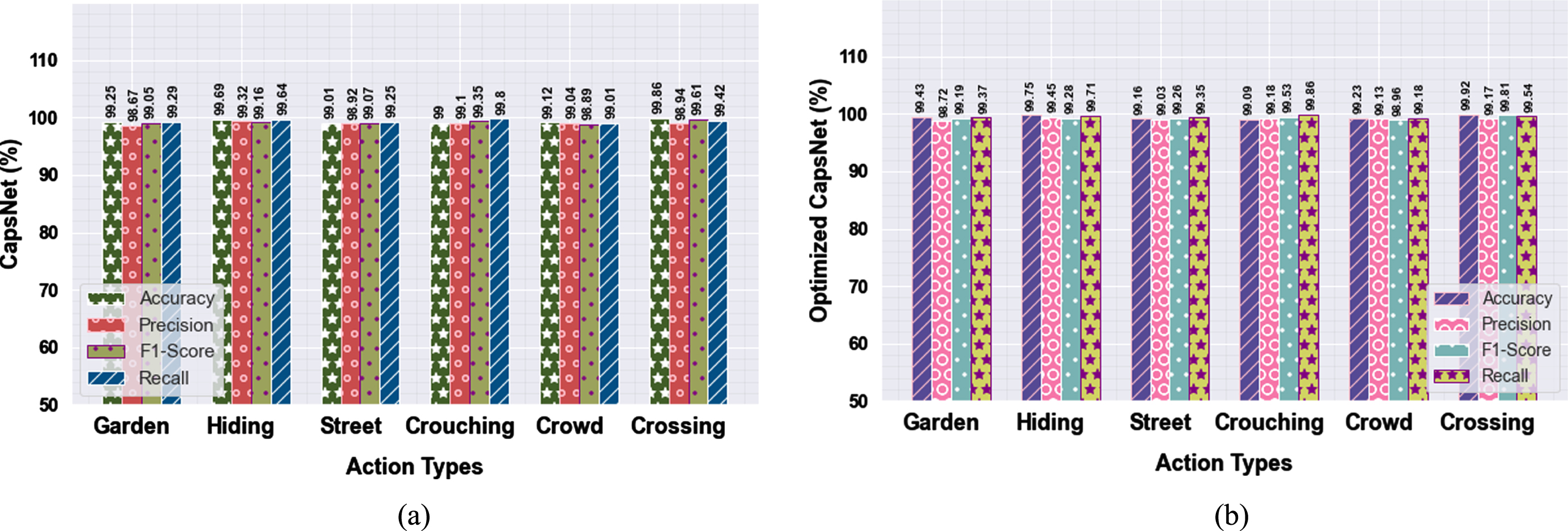
The performance of the proposed methodology in multiple classifications in LTIR dataset (a) without optimization, (b) with optimization.
IITR-IAR and LTIR datasets’ performances can be compared with the previous techniques. The previous techniques like CNN-BiLSTM, YOLOv3, DRA, and GAN are compared with the proposed technique.
From Table 5, the proposed methodology is compared with two other techniques on the IITR-IAR dataset. It obtain 99.57% of accuracy and 96.32% TPR compared to other techniques, and the FPR is lower at 0.75% than others. In the LTIR dataset, the proposed technique got 99.23% of accuracy and 97.55% TPR compared to the other two existing techniques. The FPR rate is lower than other existing techniques.
Comparison of the test result on different techniques
Comparison of the test result on different techniques
On the IITR-IAR dataset, Fig. 8 shows a visual representation of TPR and Accuracy. When the difference can be achieved using the previous methods, our proposed technique achieves better results.
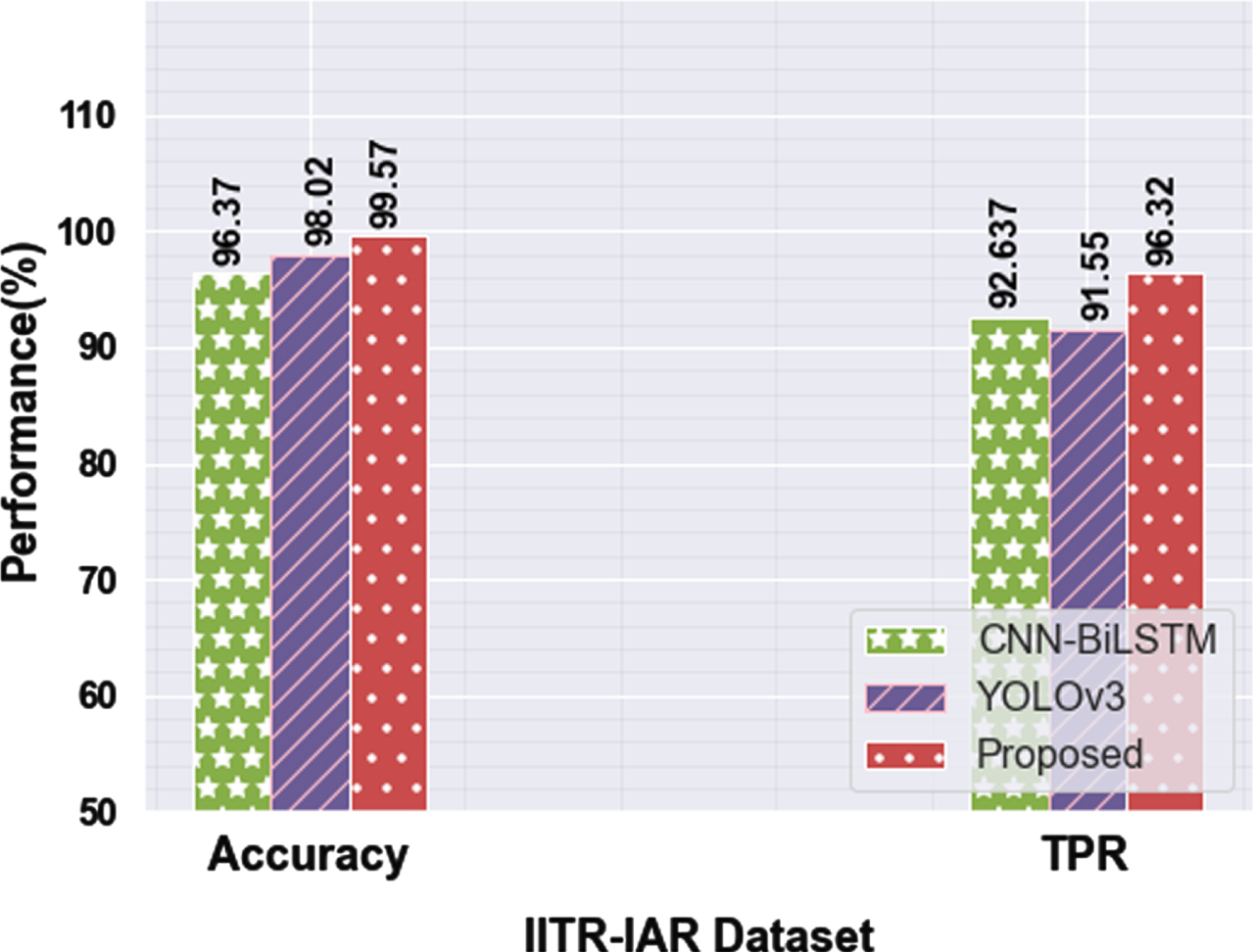
Various performances of the IITR-IAR dataset proposed techniques with previous techniques.
On the LITR dataset, Fig. 9 shows a visual representation of TPR and Accuracy. When the difference can be achieved using the previous methods, our proposed technique achieves better results. The performances of FPR metrics are compared and it is represented in Fig. 10.
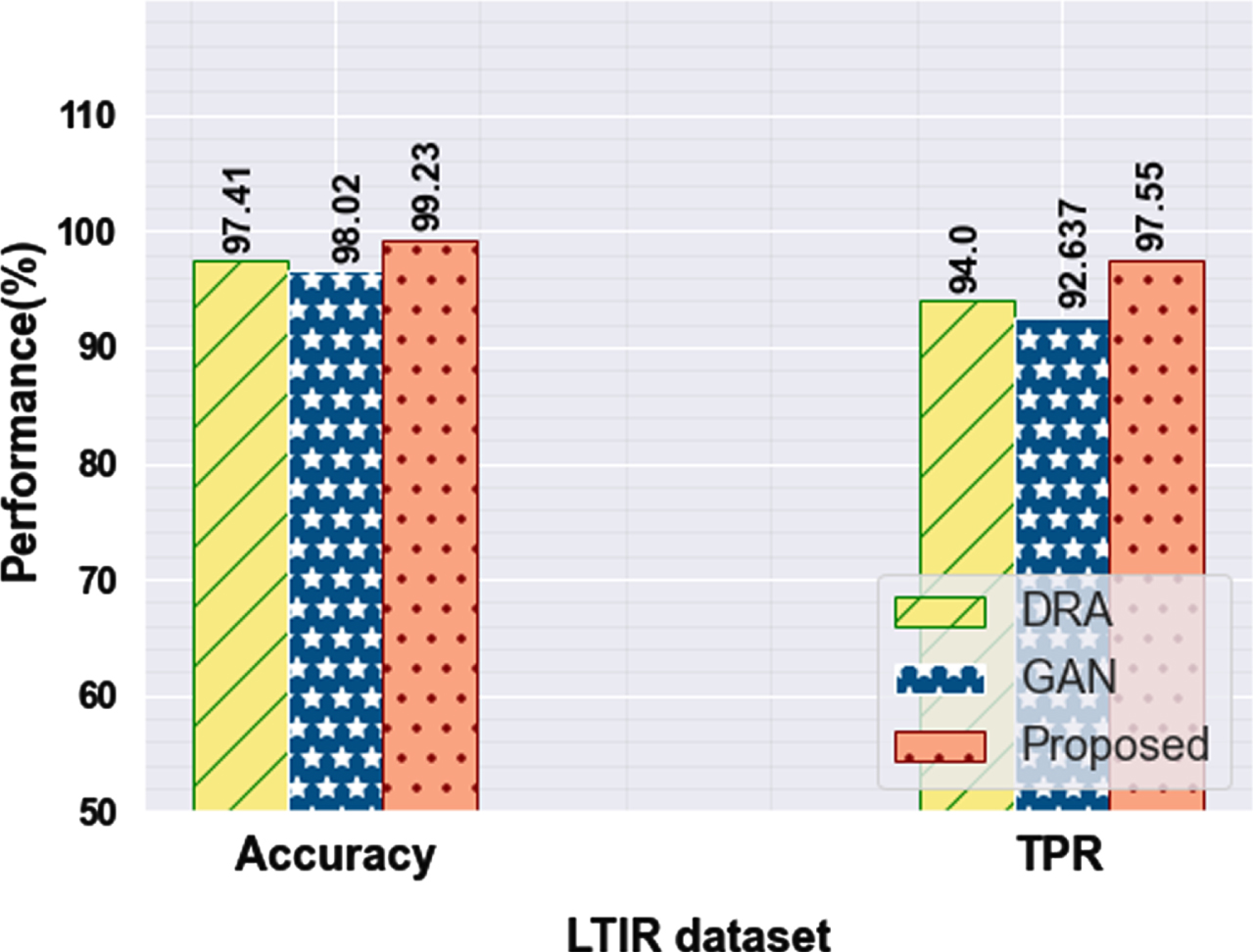
Various performances of the LITR dataset proposed technique with previous approaches.
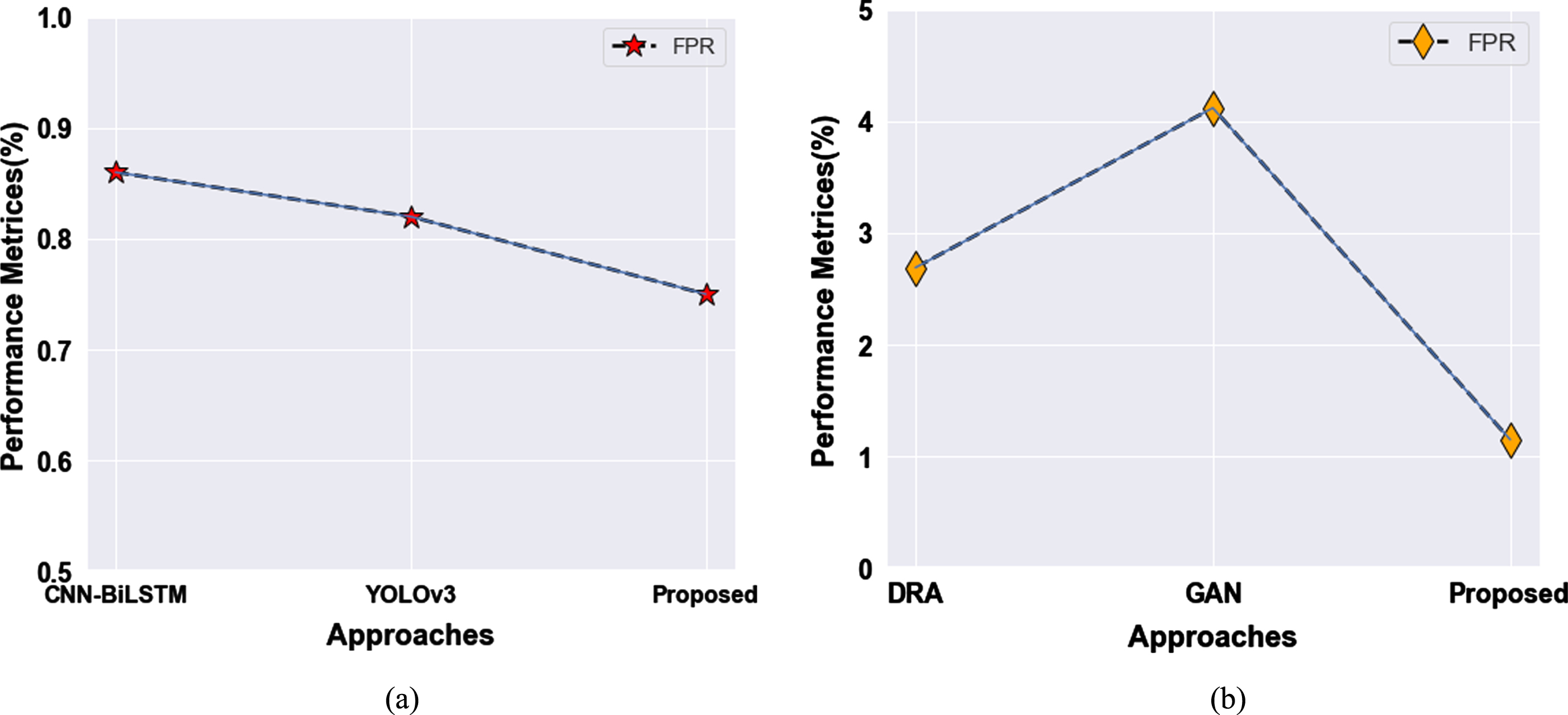
The FPR performance metrics of the proposed methodology with other existing methods (a) IITR-IAR dataset, (b) LITR dataset.
A comparison of the proposed technique with previous techniques is shown in Table 6. It shows the performance evaluation values of accuracy, f1-score, recall, precision, FRP, and FNR.
Overall performance of our proposed methodology compared with previous techniques
Table 5 shows a comparison of the F1-score, Recall, and Precision metrics with previous techniques for the identification of the actions. The proposed model achieved a higher accuracy of 99.65% with the support of an optimization algorithm. The performance of our proposed technique obtains 98.57% of precision, 98.86% of recall, and 99.01% f1-score compared with other action recognition techniques. The outcomes demonstrate that the proposed model efficiently enhances the detection rate in comparison with other approaches.
The compared proposed categorization technique with previous action categorization approaches is obtain higher values, which are represented in Fig. 11 above.
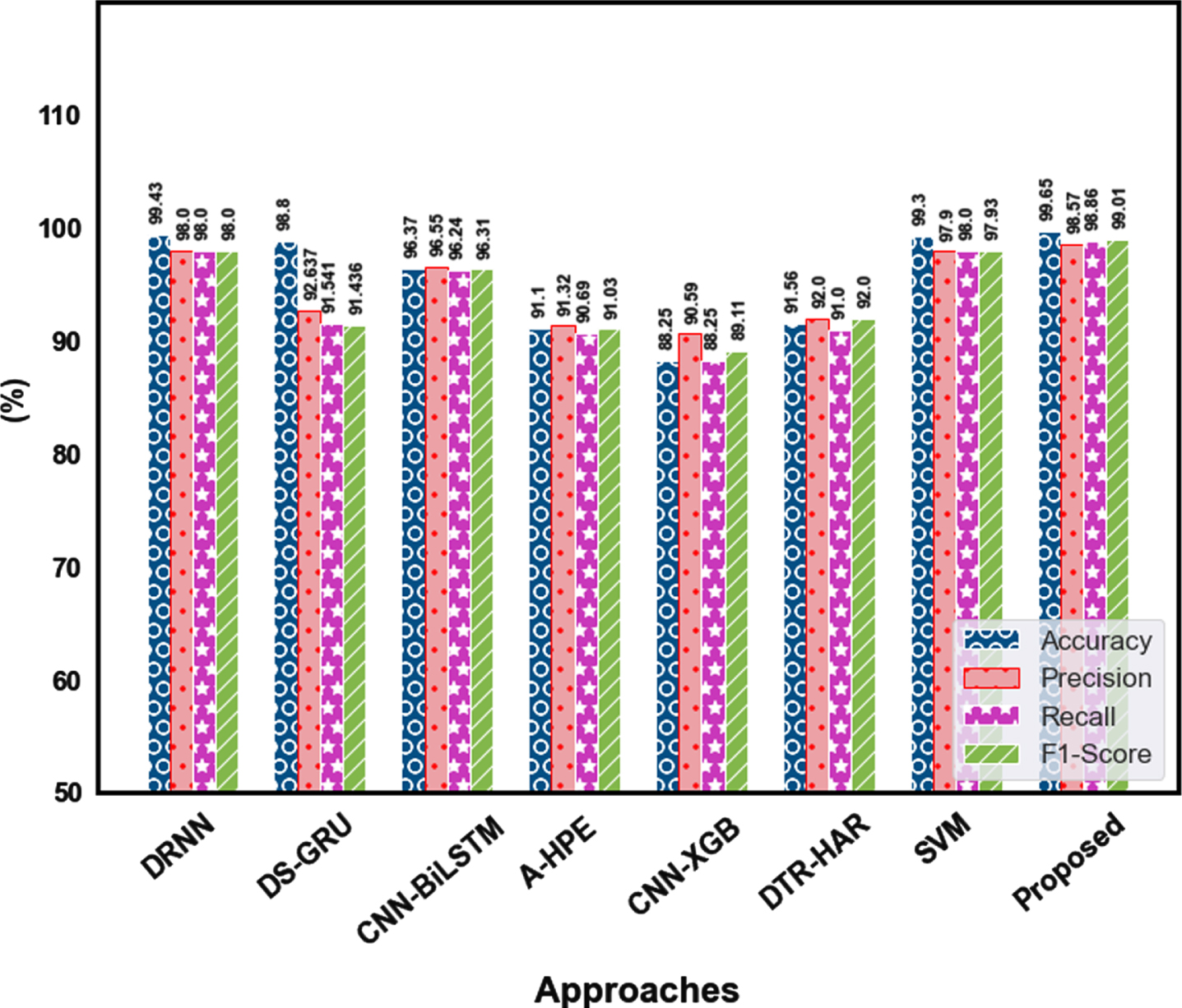
Comparison of the proposed approach categorization Results with previous techniques Precision, accuracy, recall, and f1-score.
Also, the FNR and FPR values of the proposed technique compared with other previous approaches are shown in Fig. 12. Compared to other human action classification techniques, our proposed technique provides better classification accuracy with the help of the EHO optimization algorithm, and their testing and training values are improved than others.
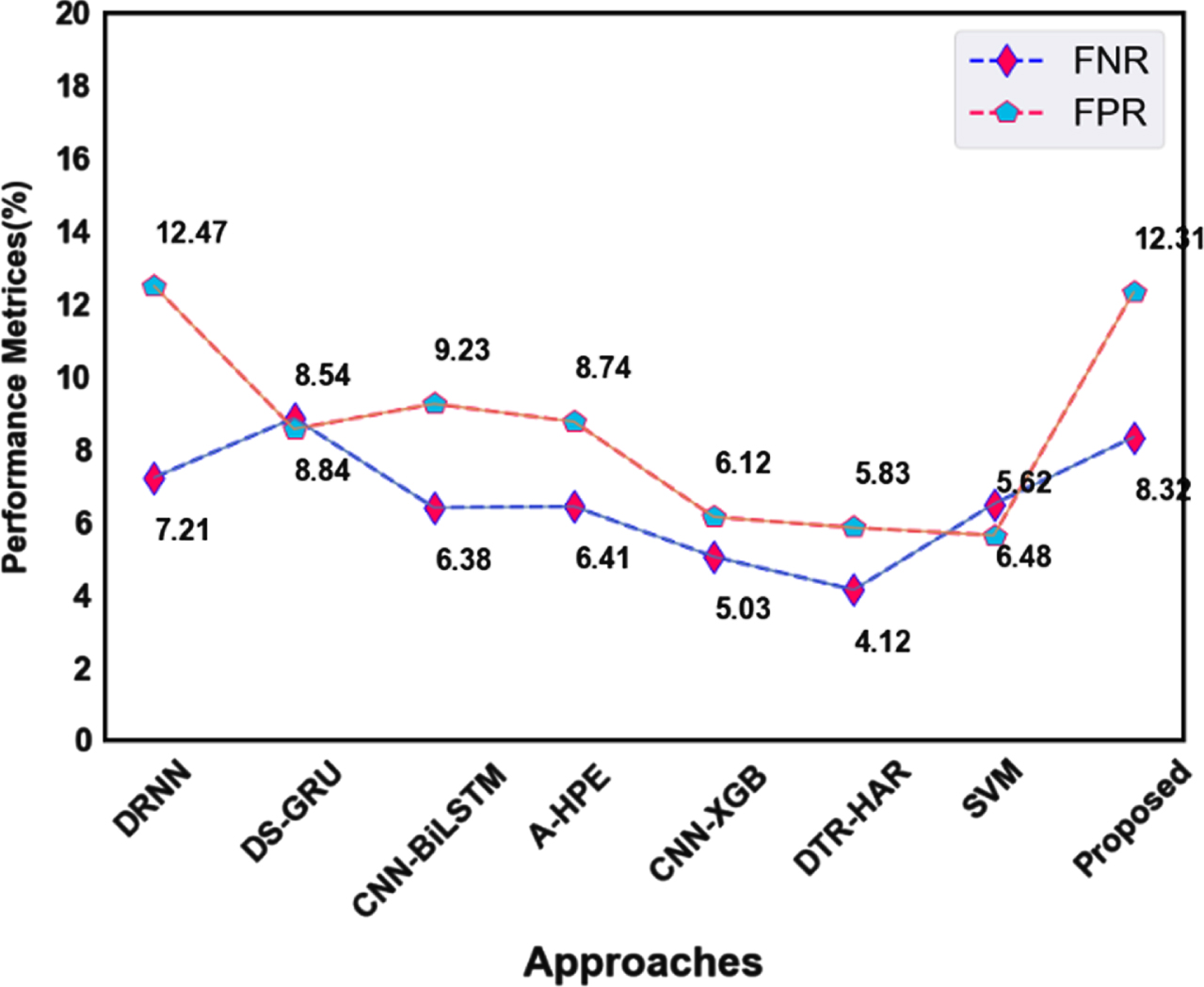
Comparison of the proposed approach categorization results with existing approaches FPR and FNR.
Figure 13 depicts how the classifier’s evaluation criteria for the two datasets are affected by data imbalance. It is noticeable from this graph that the data augmentation technique enhances classifier performance. With the EHO-based imbalance technique, the classifier on the IITR-IAR dataset achieves 99.37% accuracy.
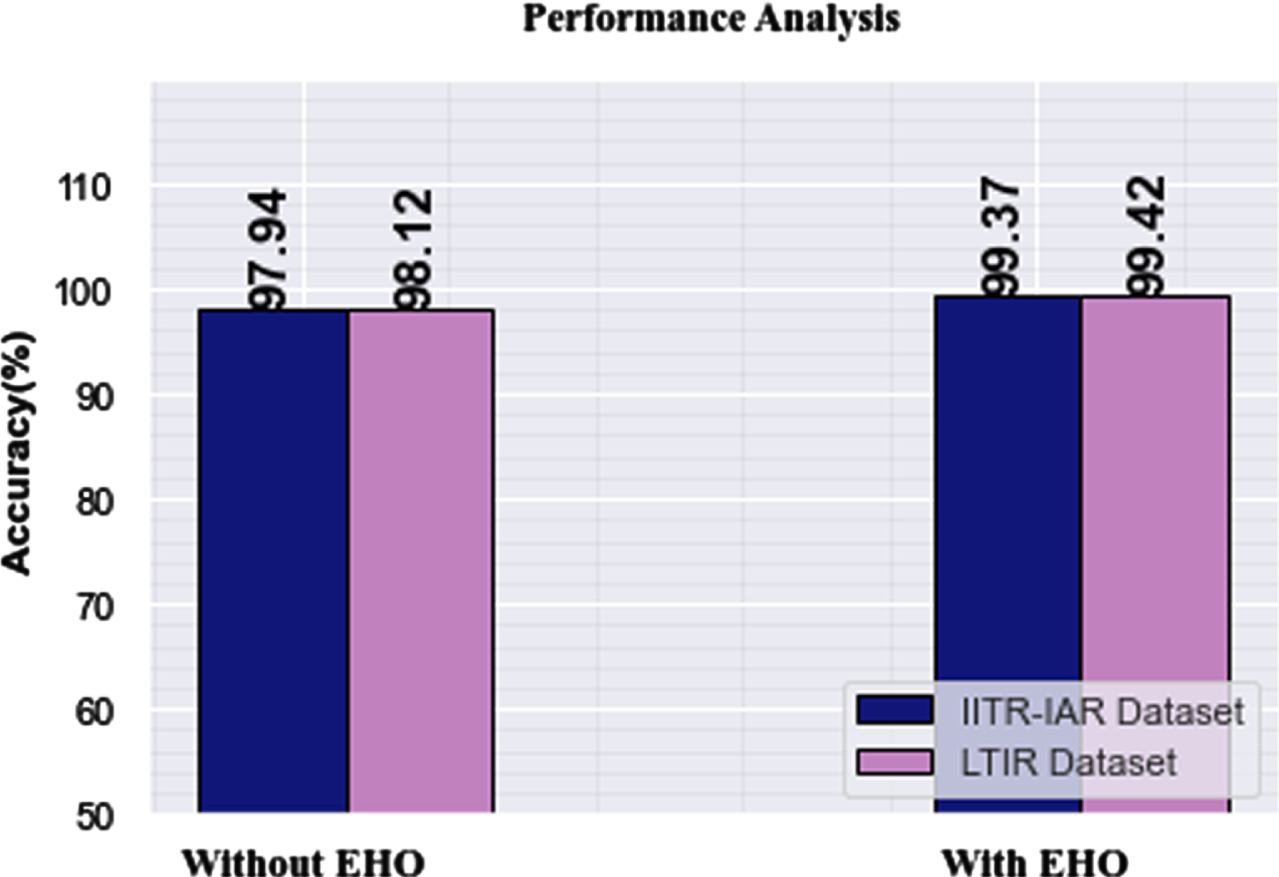
Analysis of Data imbalance technique.
It only performs at 97.94% without EHO. Similar to this, the classifier achieves 99.42% accuracy on the LTIR dataset by employing categorization methods. This method produces a significantly higher amount of training samples than methods that produce training data without data imbalance.
A graph of loss value and classification accuracy as the number of iteration steps increased is shown in Figs. 14 and 15. The graph demonstrates that the method discussed in this study has a positive impact on convergence. The dataset was divided into testing and training phases. A 25% of the testing data and 75% of the training data were produced specifically for this research. The processed training set is used in the training phase to train the proposed methods for 200 iterations. The learning rate is currently at 0.1.
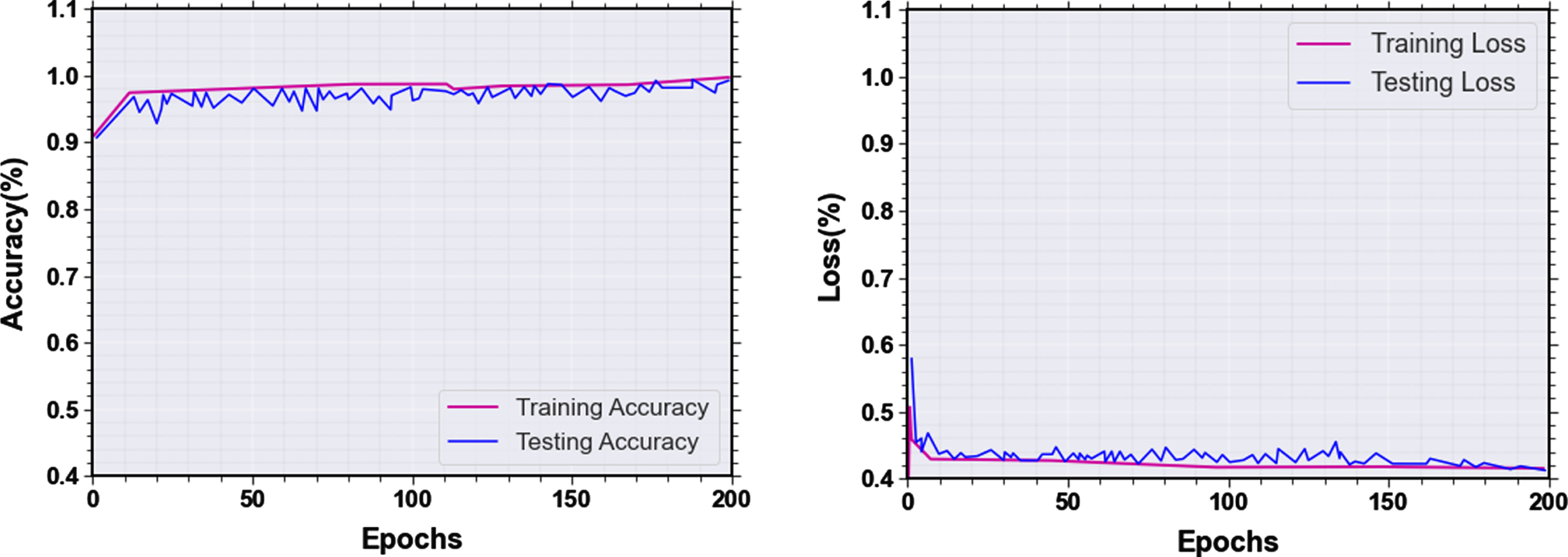
(a) Training and testing accuracy, (b) Training and testing loss for the IITR-IAR dataset.
The training and testing accuracy and also testing and training loss functions for two datasets are represented in Figs. 14 and 15.
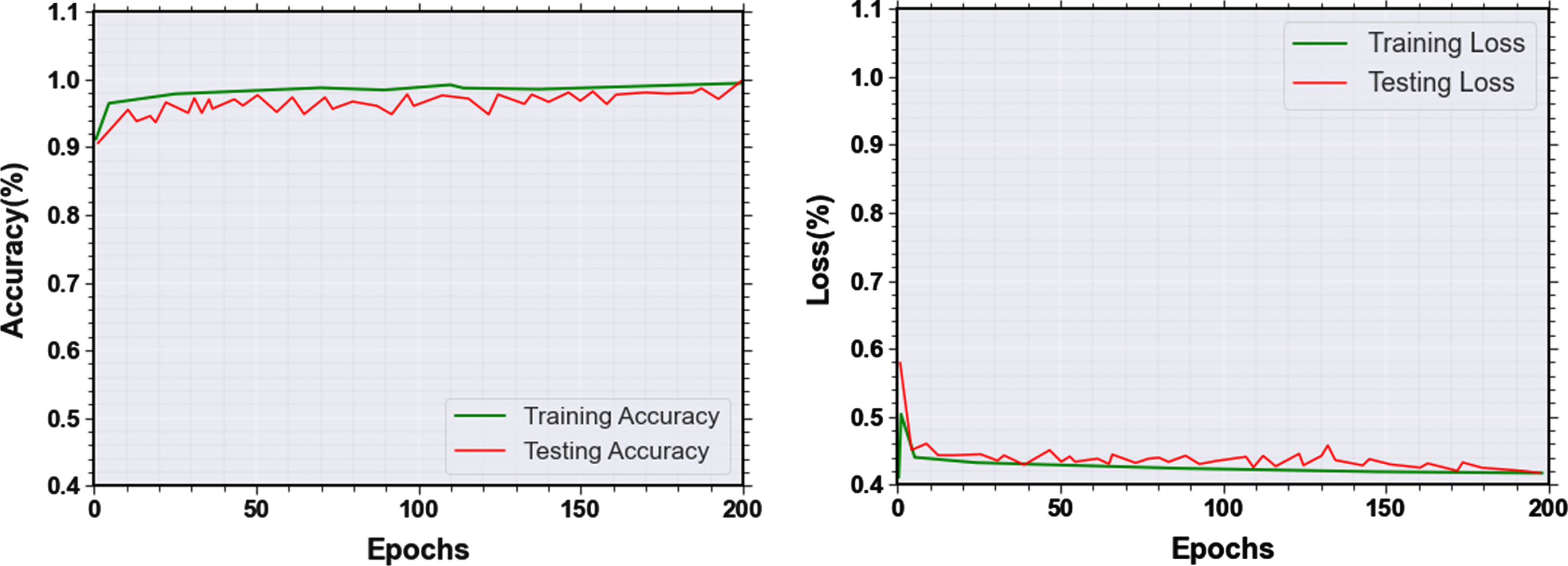
(a) Training and testing accuracy, (b) Training and testing loss for LTIR dataset.
Computers analyze a series of video frames to determine human activities automatically, reducing the need for manual labor. This process is known as human action identification from videos. To solve this issue, we propose a novel deep-learning technique for predicting and classifying human actions. In this paper, initially, to remove the noise from the given input thermal images using the mean filter method and then normalize the images using with min-max normalization method. After that, utilizing Deep Recurrent Convolutional Neural Network (DRCNN) technique to segment the human from thermal images and then extract the features from the segmented image. So, here we choose a fully connected layer of DRCNN as the segmentation layer is utilized for segmentation, and then the multi-scale CNN layer of DRCNN is used to extract the features from segmented images to detect human actions. To recognize human actions in thermal pictures, the DenseNet-169 approach is utilized. Finally, the CapsNet technique is used to classify human action types with Elephant Herding Optimization (EHO) technique for better classification. The outcome of our experiment was given the highest accuracy of 99.65% with the optimization algorithm. The performance of our proposed technique obtained 98.57% of precision, 98.86% of recall, and 99.01% of f1-score. By adding new characteristics to the system, we need to enhance the recognition of essential body parts in the future. We will also broaden our experimental setup to include local clinics, gyms, and kindergartens.
Conflicts of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Footnotes
Acknowledgment
We declare that this manuscript is original, has not been published before, and is not currently being considered for publication elsewhere.
Funding
Not applicable.
Availability of data and material
Data will be made available on request.
Code availability
Not applicable.
Author’s contributions
The author confirms sole responsibility for the following: study conception and design, data collection, analysis and interpretation of results, and manuscript preparation.