
Abstract
Forest fires can pose a serious threat to the survival of living organisms, and wildfire detection technology can effectively reduce the occurrence of large forest fires and detect them faster. However, the unpredictable and diverse appearance of smoke and fire, as well as interference from objects that resemble smoke and fire, can lead to the overlooking of small objects and detection of false positives that resemble the objects in the detection results. In this work, we propose UAV-FDN, a forest fire detection network based on the perspective of an unmanned aerial vehicle (UAV). It performs real-time wildfire detection of various forest fire scenarios from the perspective of UAVs. The main concepts of the framework are as follows: 1) The framework proposes an efficient attention module that combines channel and spatial dimension information to improve the accuracy and efficiency of model detection under complex backgrounds. 2) It also introduces an improved multi-scale fusion module that enhances the network’s ability to learn objects details and semantic features, thus reducing the chances of small objects being false negative during inspection and false positive issues. 3) Finally, the framework incorporates a multi-head structure and a new loss function, which aid in boosting the network’s updating speed and convergence, enabling better adaptation to different objects scales. Experimental results demonstrate that the UAV-FDN achieves high performance in terms of average precision (AP), precision, recall, and mean average precision (mAP).
Keywords
Abbreviations
The following abbreviations are used in this manuscript:
Unmanned Aerial Vehicle
Efficient Channel and Spatial Attention
Feature Enhancement Block
Multi-Scale Prediction Block
Introduction
With the worsening of global climate change and the trend towards extreme weather, the frequency and extent of forest fires are increasing [1], causing enormous damage to the natural environment and human society.
In recent years, the development and application of unmanned aerial vehicle (UAV) technology has led to the widespread use of UAVs in forest fire monitoring and response. With their strong maneuverability [2], wide aerial perspective, and flexible equipment carry, UAVs have become an important tool for forest fire monitoring [3]. Forest fire detection is one of the critical measures for preventing and responding to forest fires. By combining UAVs with forest fire detection, early detection and intervention of fire sources can be achieved, playing a vital role in protecting human safety and ecological diversity. In the field of forest fire detection, the main solutions can be classified into three categories: 1) traditional artificial forest fire detection methods, 2) traditional machine learning forest fire detection methods, and 3) deep learning-based forest fire detection methods.
Traditional forest fire detection methods often rely on manual inspection and monitoring, which are inefficient and easily limited by environmental and human factors. These conventional methods are gradually becoming supplementary means, and many forest fire detection tasks currently employ deep learning-based detection methods. However, existing methods have limitations in solving these challenges and achieving high-performance UAV object detection. For example: 1) wildfire features are complex and difficult to extract well, 2) interfering objects (such as clouds, water, sunlight, street lamps, haze, etc.) significantly interfere with the effect of wildfire identification, resulting in a high false positive rate, 3) the shape of wildfires has great variability influenced by the environment, resulting in a high false negative rate. Therefore, we propose a UAV-based forest fire detection network called UAV-FDN in this paper. We draw inspiration from the concept of the YOLO (You Only Look Once) series of single-stage algorithms (such as YOLOv1 [4], YOLOv2 [5], YOLOv4 [6], YOLOX [7], and others [8, 9]) and consider the unique features of forest fire scenes under UAV perspective. We integrate the efficient channel and spatial attention (ECSA) module, feature enhancement block (FE-Block), and multi-scale prediction block (MSP-Block) into the framework to achieve real-time wildfire detection in various forest fire scenarios. Our contributions can be summarized in the following four aspects: In complex scenes, we have observed that the network struggles to rapidly focus on the objects, resulting in low accuracy and false negatives. This motivated us to propose the ECSA module. Moreover, we have introduced the FE-Block to address the limited capacity of previous networks to learn detailed and semantic features of the objects, which can lead to issues such as misclassification (false positives and false negatives). To overcome the challenges of precisely detecting and classifying objects due to the large variations in objects size from the perspective of UAVs, we have designed the MSP-Block to better cater to UAVs. We have gathered and generated forest fire detection datasets with manual labeling information, comprising 14,974 samples captured from the perspective of a UAV and classified into two categories: ’fire’ and ’smog’. It encompasses forest fire images captured under varying scenes, weather, lighting, and resolutions, thereby resolving the issue of inadequate datasets with manual labeling information for forest fire detection tasks. This dataset holds immense significance for studying forest fire detection tasks in practical scenarios.
In conclusion, our forest fire detection framework has demonstrated to be effective in detecting forest fires. The proposed model has achieved high performance on multiple evaluation metrics, including average precision (AP), precision, recall, F1, and mean average precision (mAP). Our research has contributed to the existing body of knowledge by providing insights into the use of attention mechanisms, multi-scale feature fusion, and multi-scale prediction in this context. Additional analysis reveals that our proposed model outperforms the baseline model by 3.74% on mAP, which is considered the primary evaluation indicator for forest fire detection tasks. We believe that our findings will contribute to the development of better forest fire detection methods and will benefit other related fields that require accurate object detection.
The rest of the work is organized as follows. Section II presents different solutions in forest fire detection tasks. Section III presents the main idea of this paper. The fourth section introduces the implementation details of the experiment and the discussion of the results. The last part is the work summary and future work outlook.
Related works
In the domain of forest fire detection, the main approaches can be classified into three categories: 1) traditional artificial methods for forest fire detection, 2) conventional machine learning methods for forest fire detection, and 3) deep learning-based methods for forest fire detection. These traditional methods are gradually being replaced by more advanced techniques, and presently, many forest fire detection tasks rely on deep learning-based detection methods.
According to the order of development, these traditional methods of artificial forest fire detection can be divided into five categories: ground patrol, observation station detection, sensor detection, aerial patrol and satellite remote [10–13]. Forest fire detection method using traditional machine learning [14–18] have strong interpretability, but its precision is not as good as the deep learning algorithm. If the forest fire detection task depends on ground patrol, observation station detection, and sensor detection, it will be largely restricted by environmental factors. Then, monitoring forest fires through air patrols or satellite remote sensing is not an optimal solution, either because of the limited equipment effect or the high cost, so the above solution is not the best choice. Traditional forest fire detection methods are becoming auxiliary methods due to their environmental limitations or cost.
Nowadays, with the development of computer vision, forest fire detection methods based on deep learning have become a research hotspot in recent years. [19] proposed a vision-based approach for forest fire detection using color and motion-based analysis, which is specifically designed for UAV-based firefighting applications. [20] introduced a novel approach for fuzzy smoke detection based on machine learning techniques. The proposed methodology incorporates a fuzzy logic-based smoke detection and segmentation scheme, along with an extended Kalman filter-based intelligent regulation rule to realize smoke detection. The proposed UAV-FFD [21] utilizes a large-scale YOLOv3 network to process images received from the UAV, enabling accurate and efficient detection of forest fires. It emphasizes the speed advantages of the algorithm, but also notes the need for further improvement in the reliability of forest fire detection. As such, the algorithm currently faces significant challenges in terms of false positive and false negative rates.
In response to the drone’s tight computing resources, [22] proposed a lightweight hierarchical artificial intelligence (AI) framework that adapts switches between a simple machine learning-based model and an advanced deep learning-based convolution neural network (CNN) [23] model. However, it may be computationally hard for a large dimension of decision criteria. [24] focuses on addressing the problem of UAV wildfire classification and segmentation using deep learning models. To this end, the authors proposed a novel ensemble learning method that combines EfficientNet-B5 [25] and DenseNet-201 [26] models to detect and classify wildfires. [27] developed an early wildfire smoke detection and notification system using an improved YOLOv5m model and a wildfire image dataset. However, this method has been found to have a high number of false positives in challenging scenarios, and nighttime detection of wildfires is another potential issue that needs to be addressed.
On the other hand, there are some related studies. [28] identifies fire candidate regions through the Faster R-CNN [29–31] network, and proposes a fire detection method that analyzes multidimensional textures of images. SAN-SD[32] proposed a smoke detection algorithm that utilizes a self-attention network. The system was deployed on a high tower to monitor straw burning. The approach enhances performance by incorporating the transformer attention mechanism and optimizing the feature extraction network structure. However, the system’s use of a tower-mounted camera may not be feasible in remote or complex terrain, and the limited coverage area could result in monitoring blind spots. Aiming at the problem that the model cannot learn effective information due to the small size of forest fire objects in remote image capture. [33] developed a new smoke roots search algorithm based on a multi-feature fusion dynamic extraction strategy, this algorithm can increase the detection rate and signifcantly reduce false positive rate. FCDM [34] uses CNN to automatically extract multi-dimensional features of forest fire images, and the improved model can identify different types of forest fires. [35] proposes a forest fire small object detection model combining convolutional attention module CBAM [36] and BiFPN [37] of feature pyramid network. [38] proposes a forest fire smoke detection method based on a fuzzy entropy optimization threshold fusion convolutional neural network. They introduced spatial transformer network (STN) in the CNN layer and added entropy function threshold operation in the softmax layer, and finally improved the detection precision.
In contrast, when compared to traditional algorithms, deep learning-based forest fire detection methods can extract more comprehensive and abstract feature information. The aforementioned studies demonstrate that the network architecture can be tailored to the specific characteristics of the object in the task scenario to enhance the performance of the CNN.
Forest-fire detection network for unmanned aerial vehicle
Due to the rapid development of digital camera technology and image processing technology, UAV forest fire detection methods based on deep learning have gradually replaced the dominant status of traditional forest fire detection methods. UAVs have strong mobility, convenience, and a wide range of work. It can achieve high-definition hovering shooting, real-time image transmission, perspective change shooting, and other functions. It is an innovative measure that combines traditional methods with intelligent patrol technology. It has the advantages of low price, wide application range, and simple operation. Therefore, the UAV equipped with visual cameras is particularly well-suited for detecting forest fires.
The existing researches mainly divide into two types of detection methods, one type is a forest fire detection method based on the flame, and the other type is based on the smoke. They all have unique advantages in detection, such as improved precision due to single detection tasks, but the defects are also apparent. For example, when flames are obstructed by trees and only smoke is visible in the image, forest fire detection methods based on flames cannot identify the occurrence of disasters. For another example, there will be clear flames and very slight smoke in night scenes, especially the black smoke generated by incomplete combustion. The smoke-based fire detection methods are difficult to detect the existence of danger. The aforementioned phenomenon is extremely dangerous, and any delay in the activation of fire alarms could result in severe consequences. In addition, existing methods have limitations in addressing these challenges and achieving high-performance UAV object detection, including a high rate of false positives and false negatives.
Therefore, UAV-FDN comes into being. It is capable of detecting both smoke and flames simultaneously, allowing for real-time forest fire detection and preventing the spread of forest fires due to false negatives in the aforementioned scenarios. Existing methods demonstrate limitations in addressing these challenges and achieving high performance in UAV object detection, such as intense variability in objects scale, background clutter, image degradation, and extreme susceptibility to confusion by similar objects. UAV-FDN is proposed to solve the challenge of forest fire detection from the UAV perspective. Its primary objective is to detect the existence of smoke and flames in forests quickly, accurately, and comprehensively. UAV-FDN achieves early detection and intervention of fire sources by integrating UAV, which plays a crucial role in safeguarding the natural environment and human society. The overall framework of UAV-FDN is illustrated in Fig. 1. Under the guidance of a one-stage object detection algorithm and considering the characteristics of forest fire scenarios from the perspective of UAVs, we have designed a dedicated network. The main idea of our work will be presented in three parts.
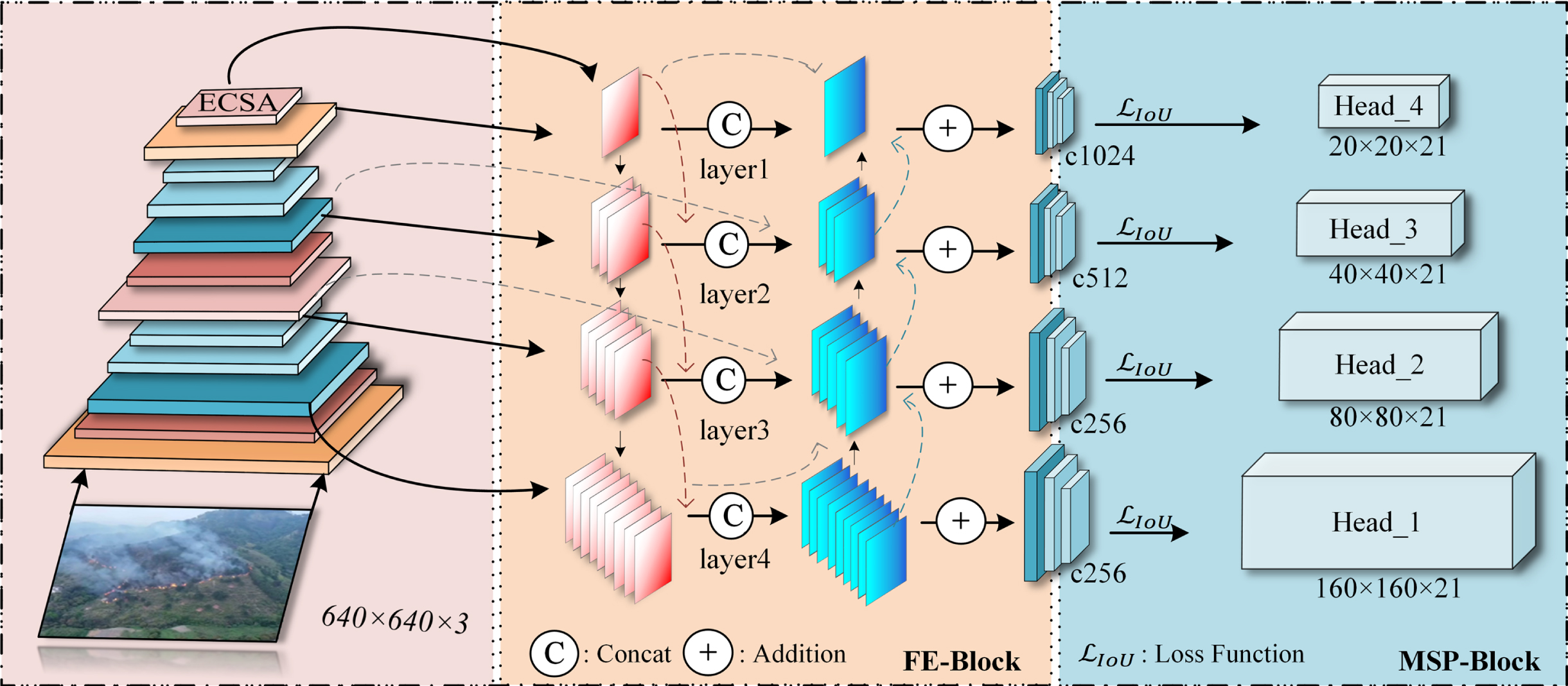
Overall framework of UAV-FDN. The input image is first fed into the backbone network and then the extracted features undergo processing using the ECSA module. The module applies an attention mechanism in both the spatial and channel dimensions. This enhances the network’s non-linear representation ability while also reducing the parameter count. Then the features from multiple levels of the backbone network as well as the features processed by the attention mechanism are combined and inputted into the FE-Block. This block completes information fusion and communication for multi-scale features, thereby enhancing the network’s ability to learn objects details and semantic features. Finally, the enhanced features are fed into the MSP-Block, which employs its loss function and four detection heads to ultimately regress and predict the bounding boxes for objects. The proposed UAV-FDN achieves high performance in terms of average precision (AP), precision, recall, and mean average precision (mAP).
In the field of object detection, the attention mechanism is often introduced into the deep learning network structure. The core of the attention mechanism is to enable the network to focus more adaptively on the relevant areas, thereby facilitating better extraction of essential information
Among them, channel attention aims to explicitly construct the correlation between different channels, and automatically learn the importance of each channel through the network. It involves calculating corresponding weights for each feature channel and enhancing important features or suppressing unimportant ones based on the calculated weights [39, 40]. Spatial attention aims to enhance the feature representation of key regions in the image. By transforming the spatial domain features of the original image, the corresponding weights are calculated for each spatial feature, and the target area is enhanced and the background area is weakened according to the calculated weights [41–45]. It is worth noting that the experimental results from previous studies have shown that CBAM has been integrated into various models [46], and has improved their performance to varying degrees, even on diverse datasets. These findings further substantiate the efficacy of incorporating spatial and channel attention.
In this paper, the ECSA module is proposed by using the advantages of channel attention, and spatial attention, and integrating the characteristics information of spatial dimension and channel dimension. As illustrated in Fig. 3, this module initially applies the attention mechanism in the channel dimension to enhance its nonlinear capabilities through 1D convolution of the input feature maps, effectively reducing the computational cost of the network. The weight information learned by the network is leveraged to weight the original input feature maps and obtain the channel attention feature maps F
c
. The configuration of 1D convolution is simple and compact, enabling real-time and low-cost hardware implementation. The ECA has demonstrated that convolution has a strong ability to extract cross-channel information [40]. Then, the spatial attention feature maps F
s
are obtained by three sets of 3*3 convolution, pooling and activation, using F
c
as input. The specific calculation formula is as follows Eq. 1, 2, 3:
Through experiments, it has found that the ECSA module can enhance the nonlinear representation ability of the network in the spatial dimension and simplify the parameter numbers of the channel dimension, and improve the detection performance and operational efficiency of the network. In an experimental setup aimed at validating ideas using models and data, the number of network parameters was reduced from 7,258,680 to 7,235,421, GPU memory usage during training was reduced from 3.95G to 1.99G, and accuracy was improved from 78.2 to 79.0. The specific experimental details of this framework have been described in section 4.
In summary, the ECSA module improves the feature extraction ability and cross-channel information acquisition ability of the backbone network, thus solving the problems of precision and efficiency under complex backgrounds, and effectively reducing the problem of false negative detection for small objects.
Due to the diversity of objects scales in forest fire detection tasks, [47, 48] point out that it is necessary to make full use of characteristic information under different resolutions to better detect smoke and flame. In order to solve the problems of small objects and fine-grained information loss caused by flight altitude, a feature enhancement module FE-Block is proposed. FE-Block is designed under the inspiration of the idea of a multi-scale fusion network. For example, FPN introduces a top-down channel to fuse features, PANet adds a bottom-up channel on the basis of FPN, NAS-FPN uses the irregular topological structure found by searching, BiFPN achieves simple and fast multi-scale feature fusion through a weighted bidirectional feature pyramid network. FE-Block enhances the learning and representation capabilities of different levels of features through the information exchange between features at different levels of the network. It integrates depth features of multiple levels by improving the feature pyramid network and introduces spatial-to-depth convolution [49] to learn richer fine-grained information, thus alleviating the problem of feature loss caused by conventional convolution operations. It consists of a spatial-to-depth layer and a non-strided convolutional layer and can be applied to many CNN architectures. Thus, the precision rate and recall rate of the model can be improved.
The convolutional neural network extracts the features of the objects through layer-by-layer abstraction, and one of the crucial concepts is the receptive field [50, 51]. Higher-level features have relatively larger receptive fields and stronger semantic representation, but the feature map has low resolution and lacks spatial geometric feature details, so the ability to represent geometric information is weak. The receptive field of low-level networks is relatively small, and the representation ability of semantic information is weak. Lower-level features have relatively smaller receptive fields and weaker semantic information representation capabilities, but feature maps have higher resolution and stronger geometric representation capabilities. Among them, the high-level semantic information can help us accurately detect the objects, and the low-level geometric information can accurately contain the location information of the objects.
Combining the display picture and the result picture into one, as shown in Fig. 2, it not only more intuitively shows the characteristics and challenges of forest fire detection tasks under the UAV perspective, but also displays the results of UAV-FDN in the picture as a reference. Fig. 4 shows the general structure of FE-Block, whose overall design idea is to use residual structure and Space-to-depth convolution to enhance the feature extraction capability of the network [52–54]. In order to ensure that the network can extract enough context information and details of the objects, the cross-level information is added to the multi-scale information fusion block to share learning. The advantages of low-level features and high-level features are combined to complete information interaction operations in the processing of the same level and across levels.

It shows forest fire scenes captured from the perspective of a drone, providing an intuitive demonstration of the characteristics and challenges of forest fire detection tasks from a drone’s point of view. All examples are taken from the dataset constructed in this paper, which comprises various environments, flight altitudes, lighting, and seasonal conditions from real-life scenarios. Nevertheless, label occlusion and objects overlap may occur due to the relatively small size of image samples and objects, and the large volume of class and probability information output by the network. In order to present the data examples more clearly, we have decided to retain only the predicted bounding boxes output by the network, which are differentiated by different colors to represent distinct objects categories.
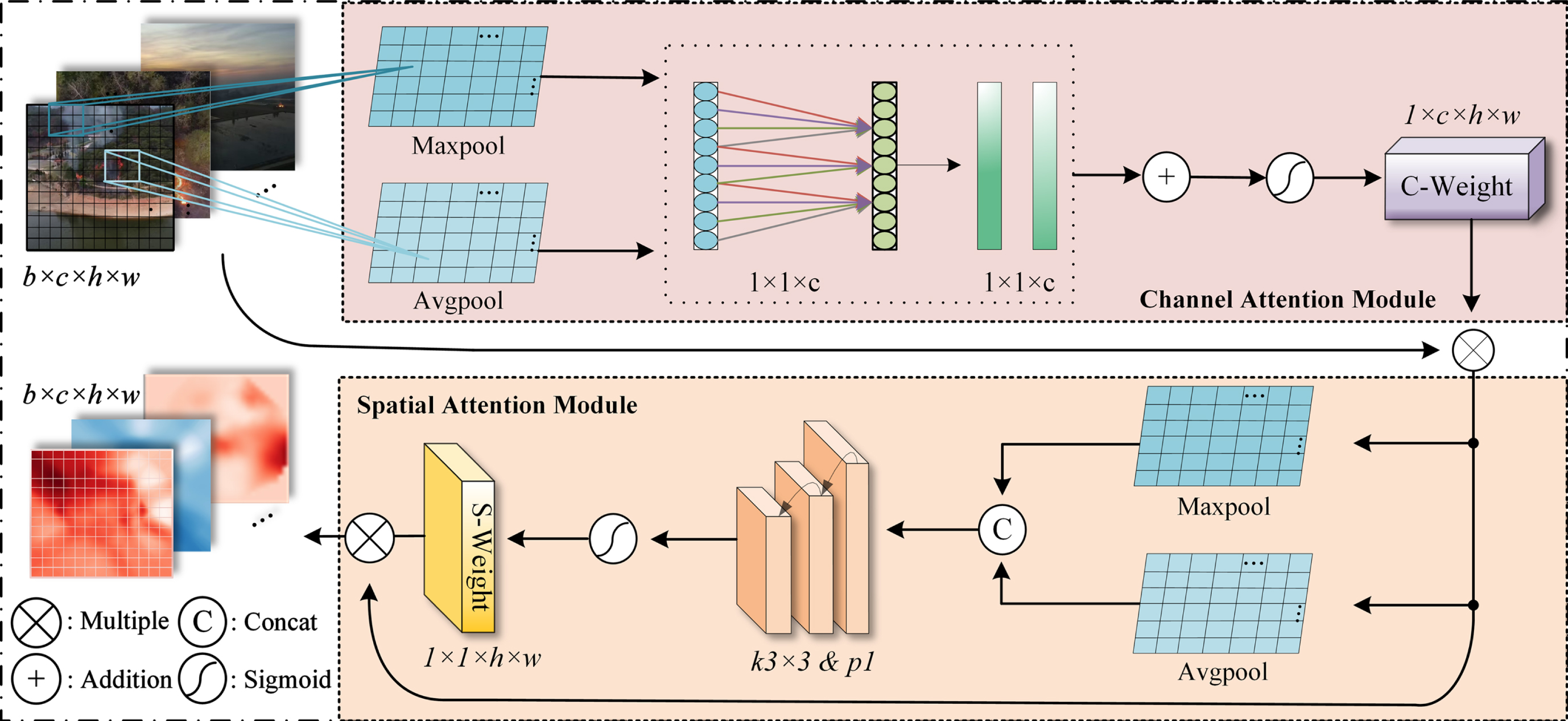
It illustrates the Efficient Channel and Spatial Attention (ECSA) module proposed in our UAV-FDN framework. By leveraging the advantages of channel attention and spatial attention, the ECSA module combines feature information from both spatial and channel dimensions, thereby enhancing the network’s feature extraction and cross-channel information collection capabilities. By enhancing the nonlinear representation ability of the network in the spatial dimension and reducing the parameter space in the channel dimension, the ECSA module can improve the network’s efficiency and performance, thereby addressing the accuracy and efficiency issues in complex background scenarios.
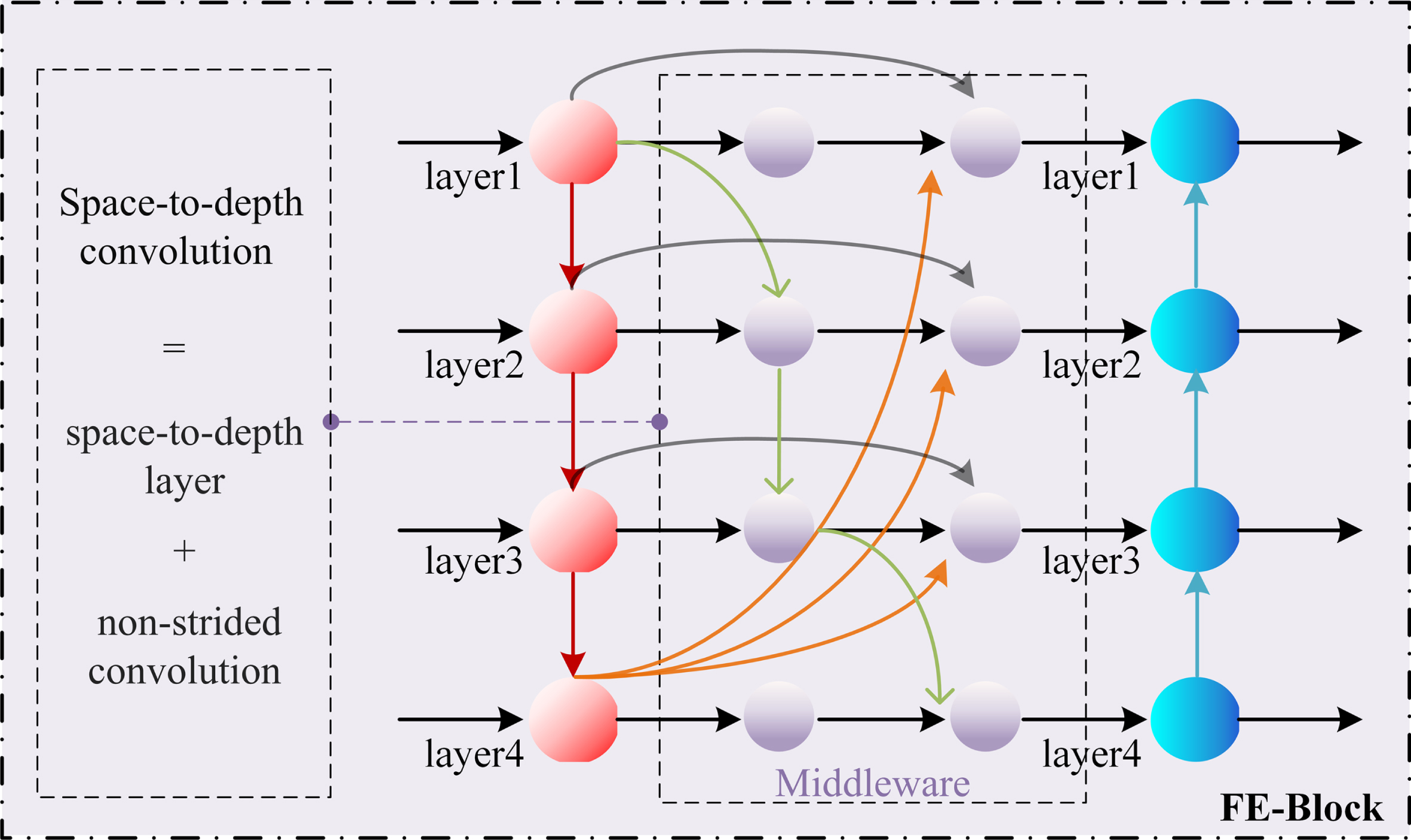
It illustrates the Feature Enhancement Block (FE-Block) of our proposed UAV-FDN framework. The main function of the FE-Block is to facilitate information exchange among different hierarchical network features. The "middleware" component in the FE-Block conducts spatial-to-depth processing and no-stride convolutional operations on image features during the information exchange process, thereby extracting richer contextual information and objects features.
After improving the network structure, in order to ensure the smooth operation of the network, it is necessary to introduce operations such as upsampling, downsampling, and convolution between the feature layers. In the process of information interaction, the middleware structure is introduced, which uses space-to-depth convolution for the extracted features. The space-to-depth convolution includes the space-to-depth layer and non-step convolution layer, replacing the step convolution and pooling operations. Because the use of step convolution or pooling layer will lead to the loss of fine-grained information and inefficient feature learning.
The middleware structure starts with an intermediate feature graph X with an input size of (S * S * C1). X can be divided proportionally. In other words, each subgraph f0,0 - fscale-1,scale-1 is downsampled with a scaling factor. When scale = 2, we can split out a series of sub-feature maps f0,0, f0,1, f1,0, f1,1, each of shape (S/2, S/2, C1), and downsample X by a factor of 2. Next, these subfeature maps are connected along the channel dimension to obtain a feature map . Among them, the spatial dimension of feature graph is reduced by a scaling factor, and the channel dimension of feature graph is increased by a scaling factor of 2. Thus, space-to-depth is the way to transform the input feature map X (S, S, C1) into an intermediate feature map . Subsequently, non-strided convolutions are used to help FE-Block extract more objects features. In general, a step size larger than 1results in non-discriminatory loss of information, where C2 and further transforms , scale2C1) to X″ (S/sacle,
S/sacle, C2).
Through experiments, it has been found that FE-Block can enhance the fusion ability of multi-level features, improve the accuracy, and reduce misclassification rate of the network in low-resolution image and small objects detection tasks.
In this study, forest fire scenes are examined from the perspective of drones, and it is found that they contain numerous small instances, such as initial smoke and flame. In comparison to forest fire detection tasks based on the tower view, targets in the drone view are generally smaller in scale, and the background is broader and more complex, which tests the model’s robustness and adaptability. Additionally, the objects scale of UAV varies greatly due to different heights during flight tasks, resulting in accuracy attenuation and even false negatives. The framework incorporates a multi-head structure and a new loss function, which aid in boosting the network’s updating speed and convergence, enabling better adaptation to different objects scales.
Some classic algorithms, such as GIoU [55], and CIoU [56]. Among them, GIoU not only focuses on overlapping areas, but also on other non-overlapping areas, which can better reflect the degree of overlap between the two, but GIoU is not sensitive to scale, because the aspect ratio of the anchor frame has not been factored into the calculation. CIoU takes into account the distance, overlap rate, scale and proportion between the target frame and prediction frame, making the target frame regression more stable, but its convergence speed needs to be improved. Different from the previous loss functions, the L IoU loss function reflects the distance between the real box and the target box by making a difference between the square value of the diagonal length of the minimum connected rectangle and the square value of the current long diagonal anchor box, and when the absolute value of the input value of the function is less than 0.98, the function will be more sensitive to the change of the input value, as shown in 1. See Eq. 4, 5, and 6 for the specific formula of our proposed loss function.
Comparative experimental results of the loss function
Comparative experimental results of the loss function
The design motivation of the MSP-Block is to better adapt to the UAV platform. It also focuses on the aspect ratio between the actual frame and the prediction frame, accelerating the network’s convergence speed to address accuracy and misclassification issues caused by the rapid change of objects aspect ratio. These improvements will improve the convergence speed and detection mean AP of the network to varying degrees.
Subsequently, MSP-Block adds a prediction head, use four prediction heads to detect objects. In fact, four prediction heads are used, each of which is responsible for detecting objects at a different scale. By combining the outputs of these four prediction heads, the network is better able to handle objects of varying sizes and scales. The four-head structure can alleviate the challenges posed by rapid changes in target size, this can be particularly useful in scenarios such as UAV object detection, where the objects being detected may be rapidly changing in size and scale as they move through the environment. The prediction head (Head1), whose size is 160 × 160 × 21, is generated from a low-level, high-resolution feature map. Where 21 is 3 × (2 + 5), 3 is the number of anchors, 2 is the two classes of smog and fire, and 5 is (x, y, w, h, conf). It is the coordinates, width, height and confidence of the prediction box. Because it has a smaller downsampling ratio, it has a smaller receptive field, a larger feature map, and is more sensitive to tiny objects and more suitable for predicting tiny objects.
After UAV-FDN adopts the prediction structure with four heads, although the computational and storage costs are increased, the detection performance of tiny objects is greatly improved. Among them, MSP-Block adopts four prediction heads, which is the result of balancing detection performance and calculation cost. The prediction head we add has a smaller downsampling rate, a larger feature map, and a wider receptive field, and it is generated by lower-level feature layers and large-size resolution feature maps, so it is more sensitive to small objects. By using multiple prediction heads to detect objects at different scales, the MSP-Block architecture can improve the accuracy and robustness of the object detection process.
In conclusion, this module introduces a prediction head with a low down-sampling rate and uses the improved loss function L IoU to perform regression and prediction of the target bounding box, replacing the previous loss function. The MSP-Block improves the training speed and reasoning precision of the network and enhances the network’s adaptability to significant changes in the objects scale. Additionally, it reduces the false negative rate while improving the detection precision.
This section presents the implementation details of the experiment and the discussion of the results, including the experimental platform, dataset, model evaluation metrics, network training details, experimental results, and effectiveness of the proposed method.
Environment
Experiment platform
The experimental platform was configured as follows: The system version was Windows 10 Pro 64-bit, the processor was 12th Gen Intel Core i9-12900KF, and the graphics processing unit was NVIDIA GeForce RTX 3090 Ti 24GB. The system relied on python 3.8.15, numpy 1.24.1, opencv-python 4.6.0.66, torchvision 0.13.0+cu116, torch 1.12.0+cu116, and pandas 1.5.3. Due to the large dataset, the batch size was set to 8, and the number of workers was set to 4. For comparison purposes, we selected Faster-RCNN, SSD [57], Retinanet [58], YOLOV3, YOLOV5, and YOLOV7 [59] to evaluate the detection performance of the proposed model.
Experiment dataset
The dataset used in this study consists of forest scene images captured by UAV-equipped image acquisition equipment. The collected materials were further improved in quality using data cleaning and data enhancement techniques. The annotated and reviewed image data resulted in the construction of a forest fire dataset containing 14974 samples of two label classes: ’smog’ and ’fire’. The dataset includes forest fire images under various scenes, weather conditions, lighting conditions, and resolutions, addressing the lack of open datasets with manual labeling information in forest fire detection tasks. This dataset is of significant importance for the study of forest fire detection in real scenarios.
The data was collected from real scenes, including fire scenes under various flight altitude conditions and seasonal conditions, such as spring, summer, autumn, and winter. The dataset also includes various environmental conditions, such as plains, hills, plateaus, villages, urban parks, coastal forests, tropical rainforests, and nature reserves. Additionally, the dataset includes a variety of lighting conditions, such as local overexposure caused by backlighting conditions, lighting conditions in foggy and snowy weather, and fire scenes in the early morning, noon, evening, and night conditions. Table 2 shows some representative data samples. To improve the generalization performance of the network and the portability of the model, we collected many sample images of different resolutions, in addition to high-resolution forest fire images.
The result of comparative experiment
The result of comparative experiment
In this article’s experiment, we used average precision (AP), precision rate (Precision), recall rate (Recall), F1-Score (F1), and mean average precision (mAP) as the main evaluation indicators, which are defined by Eq. 7, 8, 9, 10, 11.
The result of attention experiment
The result of attention experiment
Compared with precision and recall metrics, F1 and mAP metrics can provide a more comprehensive evaluation of classifier performance. precision metric reflects the classifier’s ability to correctly identify positive samples, while recall metric reflects the classifier’s ability to recognize all positive samples. However, these two metrics can only evaluate the accuracy and recall rate of classifiers, respectively, and cannot effectively balance these two abilities. In contrast, the F1 metric integrates information from both precision and recall and can comprehensively evaluate the performance of classifiers at different thresholds. Meanwhile, the mAP metric considers the performance of different categories, and provides an effective performance evaluation for multi-category objects detection tasks.
In practical applications, classifiers are often evaluated using the F1 and mAP metrics, particularly for object detection and imbalanced datasets. Among these, mAP is considered the most important and closely monitored indicator. In this paper, we have chosen to use mAP as the main comprehensive reference index for evaluating the performance of our forest fire detection method. This is because mAP can reflect the model’s performance at different thresholds in forest fire detection scenarios, and it provides a comprehensive evaluation of both precision and recall. Therefore, we have selected mAP as the primary evaluation metric for our models in this study.
The result of ablation experiment
Object detection is an important technology in computer vision. The detection process usually begins with extracting a set of features from the input image. A classifier or locator is then used to identify the target in the feature space. These classifiers or locators are either based on a sliding window style throughout the image or on a subset of the image area [60]. As shown in Table 2, forest fire detection scene from the perspective of the UAV, we conduct horizontal comparison experiments between several classical detection algorithms, including Faster-RCNN, SSD, YOLOv3, Retinanet, YOLOv5, and YOLOv7. To ensure the fair nature of the comparative experimental results, all training is performed on the same platform. To analyze and demonstrate the forest fire detection performance of UAV-FDN, AP, precision, recall, F1, and mAP are used as evaluation indicators.
These metrics can effectively and concisely show the performance difference between different models. Our model was trained on the training set and evaluated on the test set. Compared with some classical detection networks, experiments illustrate that the UAV-FDN can achieves satisfactory results in the forest fire detection task.
From the experimental results, first of all, Faster R-CNN may achieve a higher recall rate 72.25% due to RPN processing, but it takes more time to converge. Secondly, Yolov7 may benefit from the improved MPConv module, which makes the network have a high precision rate of 65.09%, but the larger model requires higher hardware requirements. In Table 2, we can clearly find that the YOLO series detection algorithm has better comprehensive performance. The performance of UAV-FDN stands out among these models, AP are 81.83% and 59.21%, precision are 89.61% and 76.67%, recall are 66.99% and 31.08%, and F1 are 0.77 and 0.44. Among them, as the main reference index mAP, it achieved the best performance 70.52%.
Compared with the baseline, the proposed network showed significant improvement in the "smog" category, with an increase of 5.31% in AP, 2.29% in precision, 6.80% in recall, and an increase of F1 from 0.71 to 0.77. In the "fire" category, the AP increased by 2.16%, precision increased by 8.38%, recall decreased by 6.76%, and F1 decreased from 0.49 to 0.44. Overall, the proposed network showed a comprehensive improvement in the main reference indicator mAP, with an increase of 3.74%. Through comparative experiments, we found that the proposed network had significant improvements in multiple performance indicators compared to the baseline, further validating the effectiveness of our method. However, regarding the issue of decreased recall and F1 indicators in the "fire" category, we believe that this may be due to the relatively small proportion of flame objects compared to smoke objects in the image. The proposed method, such as the FE-Block, introduced too much irrelevant or useless image information during multiscale fusion or space-to-depth convolution, causing the network’s focus to deviate during learning and even learning the wrong features in some cases.
Ablation experiments
To comprehensively evaluate the proposed UAV-FDN network in this paper and better understand the performance of each proposed module, we conducted ablation experiments. These experiments gradually removed each part to judge the impact of the part on the overall effect of the entire model.
In this way, the contribution or limitation of the improved modules to the network can be fully evaluated. Table 4 shows the results of the ablation experiments. In an experiment in which each module was used alone, the ECSA module significantly improved the mAP by enhancing the nonlinear representation ability of the network in spatial dimensions and simplifying the number of parameters in channel dimensions, verifying the positive role of the module in network performance and efficiency. The FE-Block achieved the best performance in both recall and AP for small objects by fusing multiscale feature information, verifying its effectiveness in small objects detection tasks. The MSP-Block combined the structure of four prediction heads with an improved loss function, and many performance indicators were improved to varying degrees when the objects scale changed greatly, verifying the effectiveness of the improved method.
In the next experiment, we removed the FE-Block and found that combining the ECSA module with the MSP-Block improved the accuracy and stability of network target recognition. Without introducing the MSP-Block, the ECSA module combined with the FE-Block was able to better detect objects, especially small flames with brighter features. Finally, with the introduction of ECSA, FE-Block, and MSP-Block, the performance of the network was further improved. Although the recall indicator for small objects was reduced accordingly, the overall performance and key indicators of the algorithm were significantly improved, and the mAP achieved optimal performance. These results demonstrate that the proposed method is effective. We also conducted a horizontal experiment of the attention mechanism for forest fire detection tasks from the perspective of the UAV, and the results are shown in Table 3. The experimental results directly reflect the performance of the proposed ECSA module in mAP and other parameters. Although not every indicator of ECSA has reached the optimal level, its overall performance makes it stand out in the end, further demonstrating the effectiveness of ECSA.
In multi-scenario smoke and flame detection, we found that there are still some scenes or situations that are difficult to detect, such as some thin smoke or fire with a similar background color. These objects are challenging to detect in many networks, so we plan to explore new research solutions based on the characteristics of smoke and flame. We hope that the ideas presented in this paper can provide some inspiration or help for future research.
Detection results
In this section, we selected some representative and convincing examples of forest fires in real scenarios and visualized the prediction results of the algorithm using a 6x6 image grid, as shown in Fig. 5. The demonstration effectively showcases the application performance of the algorithm in actual scenarios. It can be seen that the proposed algorithm accurately identifies smoke and flames in various complex backgrounds.

It shows the display results of forest fire scenes captured from the perspective of an unmanned aerial vehicle (UAV). The figure presents a diverse set of representative and challenging samples, providing an intuitive demonstration of typical and high-difficulty scenarios, such as smoke without fire, fire without smoke, small smoke or flames, backlighting, overexposure, nighttime, streetlights, lakes, snow, fog, and bodies of water. These examples demonstrate the robustness and efficacy of our proposed forest fire detection framework under various challenging conditions.
Specifically, images (a) and (b) demonstrate the detection performance of the network in various scenarios, including but not limited to villages, forest areas, mountains, nature reserves, hills, plains, high-rise buildings, and marine vessels, and shows strong adaptability to white, gray, yellow, and black smoke. The network also performs well under interference such as highlight, backlight, and dark night, and is capable of detecting small objects, as shown in images (c) and (d). These samples contain small smoke and small fires, which can be influenced by factors such as distance, flight altitude, and fire stage. Image (e) represents scenes that are easily subject to background interference and can cause objects misdetection, such as street lights, clouds, fog, snow, lake water, and highly exposed rocks. The absence of a detection box in the image indicates that the network does not confuse positive and negative sample characteristics. Image (f) contains some samples that are difficult to identify, but overall, the UAV-FDN shows strong robustness and applicability.
Although unmanned aerial vehicles (UAVs) are convenient and manoeuvrable for forest fire monitoring, they face significant challenges in practical applications due to issues such as objects scale changes, false positives, and false negatives. In this article, we proposed a deep learning framework that integrated the ECSA module, FE-Block, and MSP-Block to effectively mitigate these issues. First, we highlighted the problem of false positives and false negatives in traditional deep learning-based detection models for early forest fire detection in UAV’s field of view. To address this issue, we employed the ECSA module to reduce the number of parameters in the channel dimension of the feature maps and enhance the non-linear representation ability in the spatial dimension, thereby improving the detection efficiency and accuracy of the framework in complex backgrounds. Next, we used the FE-Block to fuse and communicate feature information between multiple layers of the network to tackle the problem of false positives and false negatives detection. We then utilised the loss function and multi-head structure of the MSP-Block to address problems arising from objects aspect ratio or scale changes from the UAV’s perspective. Finally, we conducted extensive experiments on real datasets to demonstrate the feasibility and effectiveness of the UAV-FDN method in forest fire detection with the potential to respond to fires in non-woodland settings. In the future, we plan to perform a rigorous computational complexity analysis of the proposed method to demonstrate its feasibility in providing computational flexibility for resource-constrained UAVs/nodes.
Footnotes
Acknowledge
This work was supported by national natural science foundation of China (No. 62202346), Hubei key research and development program (No.2021BAA042), open project of engineering research center of Hubei province for clothing information (No. 2022HBCI01), Wuhan applied basic frontier research project (No. 2022013988065212), MIIT’s AI Industry Innovation Task unveils flagship projects (Key technologies, equipment, and systems for flexible customized and intelligent manufacturing in the clothing industry), and Hubei science and technology project of safe production special fund (Scene control platform based on proprioception information computing of artificial intelligence).
Author statement
Minghua Jiang (First Author): Conceptualization, Software, Data Curation, Investigation, Writing - Original Draft; Yulin Wang: Methodology, Writing - Original Draft, Formal Analysis, Validation; Feng Yu (Corresponding Author): Conceptualization, Funding Acquisition, Resources, Supervision, Writing - Review & Editing, Project Administration. Tao Peng: Visualization, Investigation, Software; Xinrong Hu: Resources, Supervision.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.