
Abstract
Graph data storage has a promising prospect due to the surge of graph-structure data. Especially in social networks, it is widely used because hot public opinions trigger some network structures consisting of massively associated entities. However, the current storage model suffers from slow processing speed in this dense association graph data. Thus, we propose a new storage model for dense graph data in social networks to improve data processing efficiency. First, we identify the public opinion network formed by hot topics or events. Second, we design the germ elements and public opinion bunching mapping relationship based on equivalence partition. Finally, the Public Opinion Bunching Storage(POBS) model is constructed to implement dense graph data storage effectively. Extensive experiments on Twitter datasets demonstrate that the proposed POBS performs favorably against the state-of-the-art graph data models for storage and processing.
Introduction
Graph data storage [1-3] is a prominent technical support for tasks such as social network analysis [4], aiming at efficient management of relationship intensive graph data. These highly connected data are formed by hot topics [5, 6] that trigger related discussions. Therefore, the dense network contains generous repeated data from the same public opinion [7]. However, traditional graph storage models face several challenges in the storage and operation of social networks data. Since the hotspot data is mentioned frequently, it will be refreshed in memory repeatedly. The generation of redundant data and the high probability of repeated use result in a serious waste of space and a slow operation speed.
To tackle the above problems, in this paper, we propose a storage model for social networks graph data to improve storage space utilization and response time. The social networks public opinion is formed by frequent interactions, i.e. attention, forwarding, reply, likes, etc [8]. They reveal the different density redundant data around the hot topic. Therefore, segmenting topics [9, 10] and extracting reused data for independent storage can increase the mapping association between data. It can reduce the repeated storage and reading speed of data. Most existing graph data models do not store differentially these data, such as the property graph model [11], the hypergraph model [12], and the triple stores i.e., RDF storage [13]. Due to the structures being formed after data emerges [14], the graph model usually stores all data equally. Therefore, we optimize the property graph model by developing a public opinion bunching mapping structure that deals with social networks graph data to eliminate redundancy and speed up query operations.
Concretely, we first identify the public opinion network of hot topics by checking the size and the energy value of data. Then, we select the representative elements and map all data lossless to shared storage and association. The most active and intensive data is separated from the original property set and processed to form a public opinion bunching structure based on the equivalence partition in the overall data space. We obtain multiple topic nodes and design the public opinion bunching storage model to realize the dense graph storage of social networks. The experimental results show that the POBS model outperforms the state-of-the-art graph models in terms of processing speed about the data loading, query, and clustering.
The main contributions of our work are summarized as follows: We design a graph data storage model aiming at the hot public opinions in social networks. We extract representative data and make them as a new node to construct graph structure. They compress the shared content and create a public opinion bunching mapping relationship. We define the public opinion bunching storage model based on equivalent partition. It obtains better storage space occupancy and I/O efficiency. We conduct experiments in Twitter to verify the performance of POBS by comparing it with the baseline graph models.
Related work
Graph data storage models
The graph data model refers to the graph database abstracting and managing the data in the form of graphs [15, 16]. The widely used graph data model includes the following three types. From the perspective of the underlying storage structure, both hypergraph and property graph are a native graph, while a triple store is a kind of resource description framework. The hypergraph describes the relationship between multiple nodes, while a property graph focuses more on describing the unidirectional relationship between two nodes. The detailed introduction is as follows.
The triple store [13] is a subject-predicate-object triple data structure. It solves the problem of search efficiency utilizing the six-fold index, but it incurs six times space overhead and costs a lot of updating and maintenance. Since its storage engine is not optimized for storing property graphs, it is not a native graph database. In the case of correlated data-intensive scenarios, self-join operations impose a considerable load and their performance is limited by the the data scale.
The hypergraph model [12] is proposed as an extension of graphs that allows the relationship to connect any number of nodes. The property graph model allows only one association. However, the hypergraph model provides an association for contacting any number of nodes on either end. The model is suitable for many-to-many relationships that dominate the field [17]. In social networks, it is used to construct the network structure and achieve the expert-finding technique by hyper-paths. Although it can effectively conduct queries, graph partition, and reduce the number of relationships, hypergraphs cannot process the redundant data and are only applicable to the field of many-to-many relationships.
The property graph model uses native graph storage and processing to manage the graph data [11]. It consists of nodes, relationships, properties, and labels. The nodes are connected by links to form a graph with index-free adjacency [18]. The nodes and relationships as containers can store properties, and the property value exists in the form of any key-value pair. At the same time, the nodes can be labeled with one or more tags, which can organize the nodes together and indicate their role in this dataset. In addition, the relationships make the nodes more semantic by direction and name. Since the graph model is convenient for the management of the system [19], the graph structure contains much available potential information. With the prevalence of social networks, the need to convert robust relational data into graph models has emerged significantly. Neo4j and Titan are excellent implementations of the property graph model. Inspired by the advantages of the property graph, we optimize the data model to achieve the compression storage in the social networks graph.
Graph data storage and optimization methods
Existing techniques for graph data storage and optimization [20, 21] can be broadly categorized into the compression storage of general graph and query-friendly graph compression [22, 23].
General graph compression storage has been studied for ample graphs scenario [24]. The idea is to encode a graph or its transitive closure into compact data structures via node ordering determined by, e.g., document similarity, hosts, and linkage similarity [24]. These methods preserve the information of the entire graph and highly depend on the graph type, coding mechanism, and application domains. Besides, they need decompression before querying. Therefore, there is an unsatisfactory efficiency for the methods of general graph compression.
Query-friendly storage models aim at optimization specific of queries, which include neighborhood [25] and reachability queries [26], etc. Nelson et al. propose the query-able compression based on exploits Eulerian paths and multi-position linearization. The existing methods only preserves information for a particular query instead of all types of queries. They have to modify the query evaluation algorithms on original graphs to answer queries in their compact structures.
Our work differs from the current compression methods in the following: In addition to the structure of nodes and edges in the original graph, we also consider the role of the property in graph storage. The storage techniques we designed is developed for all types of queries while preserving the information of the entire graph. We query directly in the compressed graph data structure without decompressing.
Preliminaries
In this section, we briefly present some important preliminary contents involved in our design POBS graph model.
The property graph model
Property graph denotes as G = (V, E, A). V (G), E (G), and A (G) denote the collection of nodes, edges, and properties. The node and edge usually contain multiple property fields. A (G) is made up of a fixed-size record and referenced by a node and a relational record. The record contains a pointer to the inline value or the dynamic store record. When the size of the property value is less than the recording capacity, it is stored in the inline value. Otherwise, the property value adopts dynamic storage in the index file.
Hot public opinion in social networks
Public opinions are content that has caused widespread discussion after a hot topic or event occurred in social networks [3, 27]. It spreads from network platforms such as social networks and gains enough attention. In public opinion, there are abundant mutual forwarding relationships among all information posted on Twitter. It consists of different topics, which can inspire multiple dense network structures. These public opinion data contain discussions on the same topic, resulting in quantity of duplicate nodes being stored and frequently read. The existing methods [3-7] for identifying hot topics mainly rely on technology such as comparing the similarity of message content and clustering high-frequency hot words.
Equivalence relation
Let Q be a binary relation on a non-empty set B. If Q is reflexive, symmetric, and transitive, then Q to be an equivalence relation on B.
Based on equivalence relation, B can be divided into different equivalence classes, that is, the equivalence classes of Q constitute the partition of B. The equivalence class refers to the collection of all elements associated with b ∈ B. The set of all equivalence classes is called quotient set, [b] Q |b ∈ B = B/Q. The purpose of introducing the equivalence relation [28] is to classify the social networks data into multiple network clusters, each of which is a collection of topic. The representative topic elements are selected within each set to common management of the repetitive content, so that reduce the computational complexity and storage utilization.
The proposed POBS model
In this section, we propose a novel graph data storage model. Since the native graph storage can increase the independence of the graph data model, it ensures the separation of graph structure (nodes, edges) and graph data (property). In the light of the native node storage and relationship storage in the property graph model, we design POBS by integrating topic nodes and the public opinion bunching relationships. The difference of graph data storage between the property graph model and POBS is shown in Fig. 1. It demonstrates the node type and interaction relationship of the storage files in the property graph model and POBS, respectively.
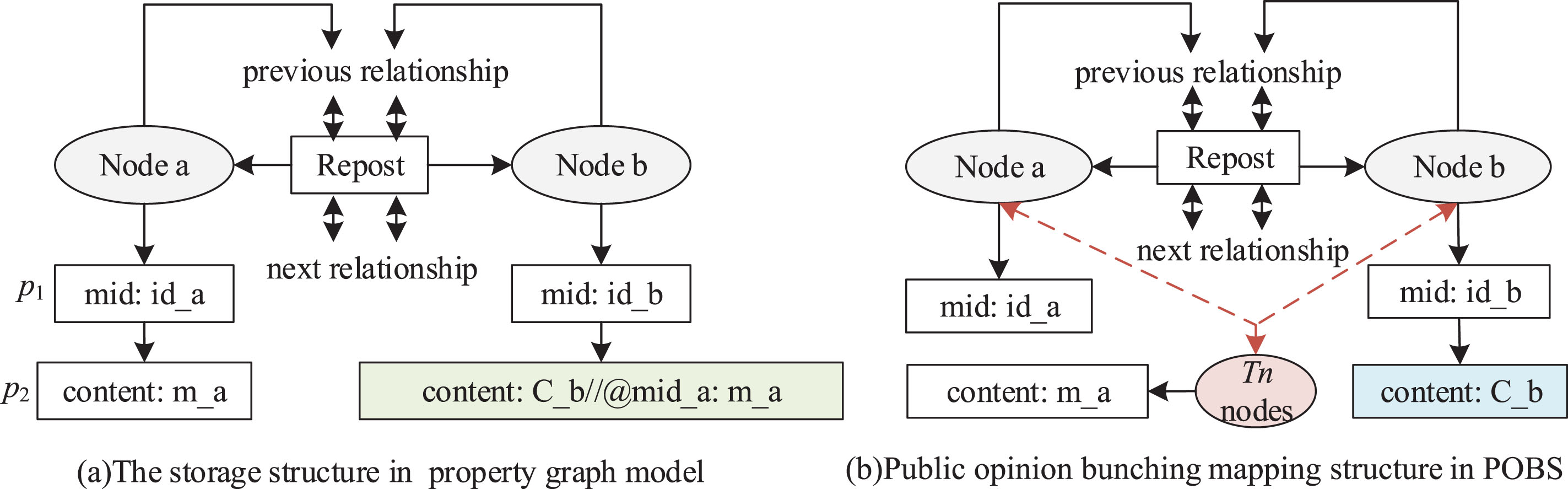
The difference between the property graph and POBS in data storage.
In the native graph storage of the property graph model, the interaction of each storage file on the disk is shown in Fig. 1 (a), where the relationship is a doubly-linked list structure, and the property is a one-way linked list structure. Node a, b is the message nodes. T n is the topic nodes in different topic clusters. p1, p2 denote the property fields. Each entity node has a pointer to the property, which stores the tweet id, the tweet content, forwarding volume, number of comments or likes, etc. Depending on the size of the property value, the property is stored as an inline value, or as a new record in the dynamic storage file. Each node points to a specific property p i (such as mid and content), which forms a one-to-one mapping.
Public opinion bunching storage relationship is a two-way linked list structure in the proposed POBS model, while the property is a one-way linked list structure shown as in Fig. 1 (b). The dotted line indicates the many entities discussing the same topic point to the one dynamic storage file across the common topic nodes Tn. POBS dramatically reduces the number of copies of property records of entities, e.g. tweet content property of node b. Through the transformation of inline values and pointers, the dynamic stored records of common property records of the original entity nodes are shared. Hence, POBS achieves the compression of storage space and accelerates the operation of relevant data.
POBS denotes as G T = (V, E t , A), where V is divided into message node M and topic node Tn, M∩ Tn = ∅ and M ∪ Tn = V. A includes the shared property, which are the duplicate data stored in dynamic storage records T∼ and reminder property A t , A t ∩ T∼ = ∅ and A t ∪ T∼ = A. The node set M points to the property set A t . The property domain corresponding to Tn is T∼. Thus, the node set is |V| = |M| + |Tn|, which is all sample nodes in the dataset. |Tn| is usually the number of hot topics in the dataset. The graph is a public opinion bunching mapping structure formed by multiple nodes with duplicate data pointing to one topic node Tn i ∈ Tn. The duplicate content is stored by Tn i and shared by other corresponding associated nodes.
Identifying network structure of hot public opinion
Hot public opinion consists of different topics, which can inspire multiple dense network structures. Since the topic that can cause clustered dense networks are diverse, we need to measure the heat of data comprehensively. The purpose is to find the data in A (G) which can be constructed into T∼.
We construct a directed graph by forwarding operation, which is a simple graph without self-looping and parallel edges. The nodes represent messages. The edge is the forwarding between messages. The nodes in the identical cluster are densely connected and discuss the same topic. We define and recognize the network structure of hot public opinion that can lead to high aggregation and a large amount of content redundancy.
On the one hand, the data cannot be encoded as inline values and occupy the storage space in the property graph data model when the content exceeds 32Byte [11]. Therefore, we distinguish the size of a message to discover the data that may waste storage space. On the other hand, the amount of forwards, comments, and likes decide the heat of the messages. If the volume of interactions reaches a certain threshold set by the empirical values, the message is hot data that influence the throughput of I/O operations [29]. In accordance with the above two conditions, we define the message as a public opinion network(PON) entity, in which the size and the energy value satisfy these requirements. They attract many forwarders to form a public opinion network, which contains massive duplicate data.
Equivalent partition and public opinion bunching mapping
In this section, the topic nodes are extracted from the entities of hot public opinion. T∼ is constructed from A (G) and the public opinion bunching structure is generated.
Equivalence relation on the hot public opinion network
In a public opinion network, each entry is a collection whose elements are the mapping of key-value pairs. The property value of message content is segmented into shared data (i.e., forwarded original messages) and differentiated parts (i.e., opinions on forwarding content) by flags “RT @”.
We first transform each message into a vector in the same order as the property segments. According to the related research on text feature analysis [30], the top-3000 most frequently used words in a dataset can fully represent the semantics of all texts. So, we select the top 3,000 words with the highest frequency in the microblog dataset to compose a feature dictionary. The message is denoted as a vector in the continuous space with each bit corresponding to a word feature of the vocabulary. Thus, the value of each bit is the number of occurrences of the word in the message m. We further split the feature representation of the messages into two components based on “RT @”. The shared contents are represented as a vector
Because the original messages have no different parts, they are represented as
Suppose T is the space of all messages in the neighborhood of the original microblog message, where
According to the equivalence relation, T can be divided into several disjoint subsets. Each subset can be regarded as an equivalent class to represent all elements. Therefore, the elements in T can be replaced by a series of equivalent classes. The segmentation is achieved based on equivalence classes composed of different topics. We extract the common feature in equivalence class so that the class can be distinguished from any other equivalence class in T. We use these features to represent the equivalence classes and define them as germ elements in public opinion network shown in Definition 1.
In the public opinion network space, for any
Law of Reflexivity.
For → So
Law of Symmetric.
For → → So
Law of Transitivity.
For → → Based on the above three equations, we can obtain
To sum up, ∼ is an equivalence relation on T. The germ elements in set T can effectively cover all the data in space T.
The germ elements contain the public part of the equivalence class set. We regard the germ element as a special node in the graph model, which is called the topic node. The topic nodes are constructed by the equivalence reduction to store the repetitive content in their property fields.
The social networks with intensive and massively relational data increase the workload of the graph database and occupy primary system resources when traversing its nodes. So we introduce the public opinion bunching relationships to prune out the redundancy data. In this way, we can segment the large-scale graph data effectively and compress each clustering structure by mapping between the topic nodes T n and the remaining data M. After the extraction of the germ elements in the property record file, we construct the public opinion bunching mapping between the topic nodes and the message nodes. They ensure the data is lossless.
In order to generate public opinion bunching relationships, we need to discover and label the importance of properties. We acquire the node properties in turn by the label and then establish the index on the label property. Based on the PON entry, we obtain the property name and the value of compressed object, which exceed the given threshold. We traverse the node set D
v
connected to the node v and then check its property. If the property value of message content p
c
in a node meets the conditions of the network structure of hot public opinion, an index will be created on the property of this node. The index tree
The public opinion bunching structure is shown in Fig. 2. The nodes id _ a, id _ b, id _ c are the original message nodes, and tid _ a, tid _ b, and tid _ c are the extracted topic nodes. Other nodes are forwarding nodes around the original nodes, and they contain the original message content and comment information. The retweets not only are independent microblogs released by the user but also contain the content of the tweets, which is the original data dumped. So much the same content data is contained in different entity nodes, which causes multiple copies throughout the store file. Therefore, the message content is repeatedly stored in the property of each node, resulting in a waste of data space. We design a public opinion bunching structure to jointly point the cluster data of each topic to a topic node. Common data within a topic is stored by topic nodes and shared by all nodes. The message node only stores the different content of each forwarding. The public opinion bunching structure not only avoids the repeated storage of data but also ensures the integrity of the graph structure.
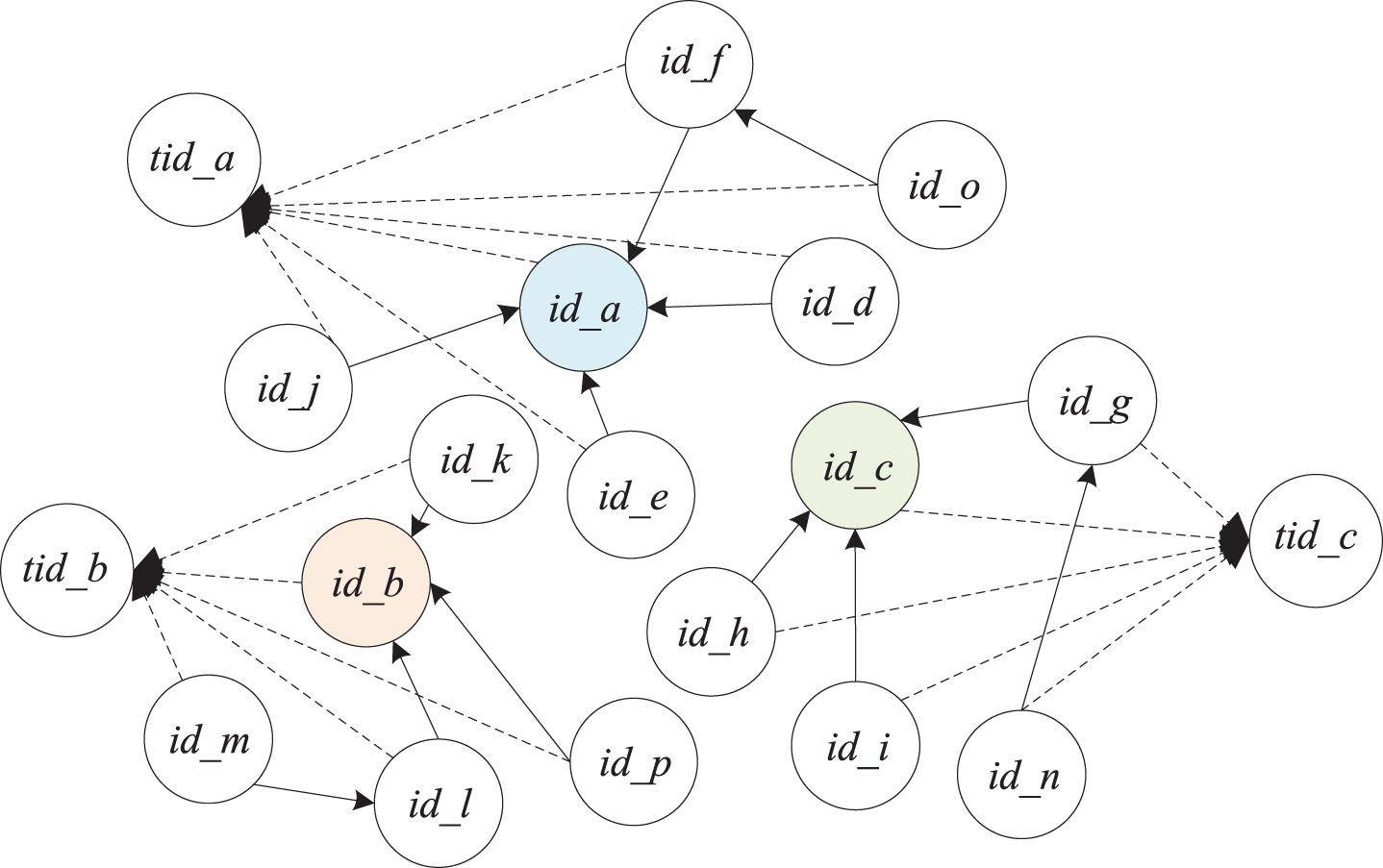
The public opinion bunching mapping structure of POBS.
The data structure composed of the topic nodes and the public opinion bunching mapping relationship is further formally defined as the public opinion bunching storage model to realize the decoupling of network clusters. All topic nodes about equivalence relation form the public opinion bunching set of T. We use T∼ to represent the public opinion bunching set:
In this section, we experimentally evaluate the performance of POBS in terms of storage utilization and operating time on a set of microblog datasets. We adopt the typical graph operation and describe each workload in detail to make a comprehensive comparison. Concretely, we select three benchmark models as a comparison to verify the performance of the POBS in four aspects, including data loading, common queries, random queries, and clustering tests, respectively. The typical models are the triple store model, the hypergraph model, and the property graph model.
Datasets
We investigate some hot public opinions and crawl the Twitter data using Twitter API based on the relevant keywords and the area in which the event occurred. The dataset contains 215,276 tweets. Each message consists of five fields, namely Twitter id, tweet content, forwarding volume, number of comments, and likes. We obtain data on three hot public opinion events: “Queensland Floods”, “Rio Olympic Games”, and “Election2016”.
To thoroughly verify the performance of the POBS under different scales and topic sizes, the Twitter data is formed into three datasets. The dataset I is a single topic about “Queensland Floods”. Dataset II merges “Queensland Floods” and “Olympic Games”. Dataset III is a mixture of the above three topics. Since each hot topic can generate several public opinion network structures, the number of PON entries in each dataset determines and reflects the effectiveness of POBS in dealing with redundant data. We preprocess the data by removing the punctuation and special symbols without affecting semantic comprehension. Then, we identify the complex network cluster and calculate the proportion of datasets occupied by PON entities. The statistics of the dataset are shown in Table 1.
Summary of dataset statistics
Summary of dataset statistics
We evaluate the performance of our POBS model after importing data mainly by conducting two types of insert operations, which are single insertion workload, and massive inserted workloads. We compare the proposed POBS with three graph models in the data loading under three datasets. The detailed analysis and discussion are as follows.
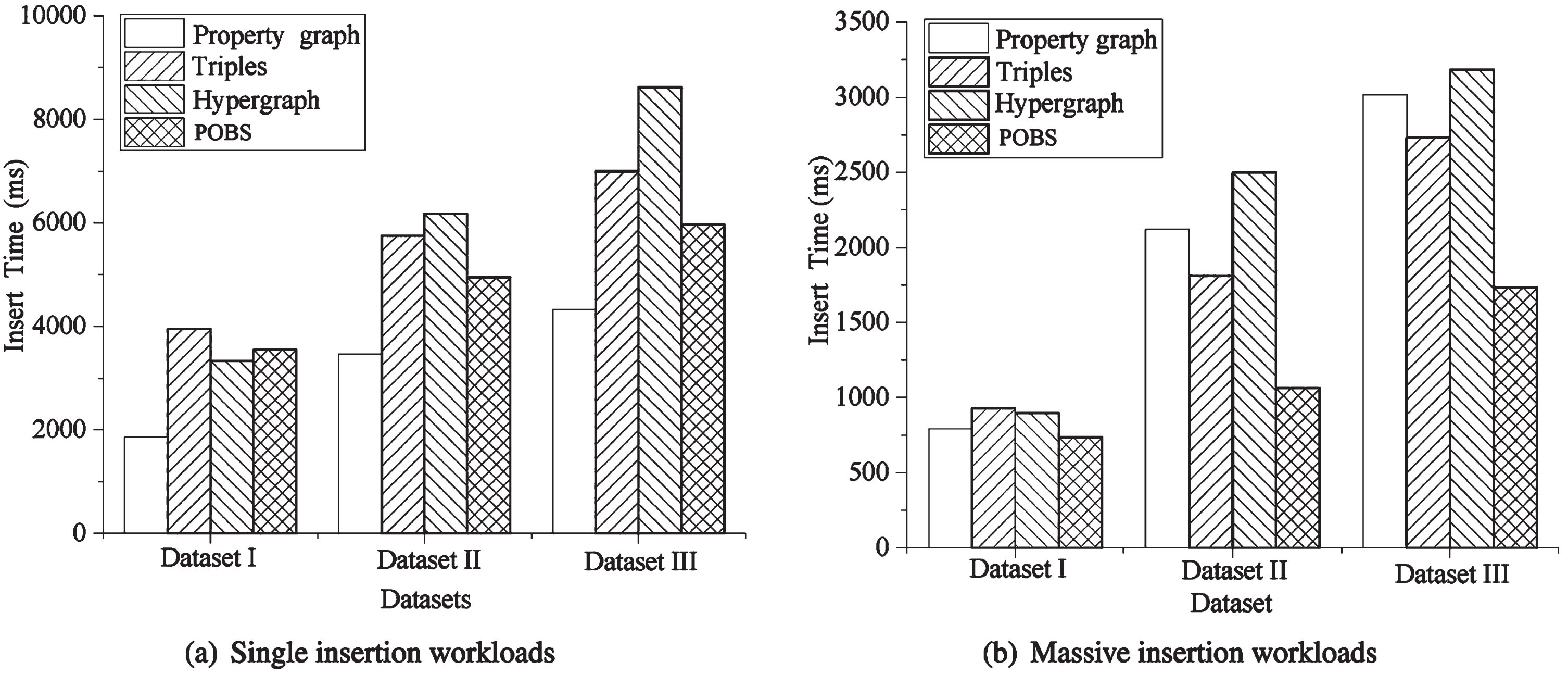
The efficiency of massive insertion workloads.
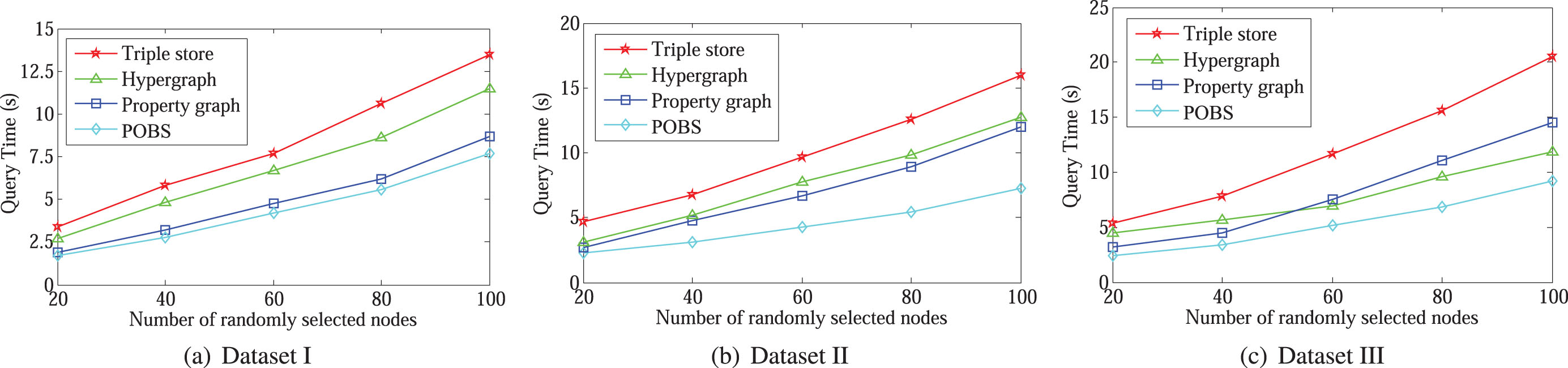
We perform two common graph queries on the four graph data models, which are the finding neighbors (FindNeighbours) and the find shortest path (FindShortestPath). For the FindNeighbours, we can find a user’s friend or follower on the social network. Through the FindShortestPath, we can understand the intimacy of the two users. For social networks, it is crucial whether these queries can be efficiently implemented in the shortest time.
From the results presented in Fig. 4, we can see that the execution time of the POBS model in the different numbers of query nodes is significantly lower than the benchmark models. The efficiency of POBS has been significantly improved with the increase in query data volume and repetition rate. This is because POBS extracts redundant data and compresses the relationship structure, thus obtaining efficient graph query performance.
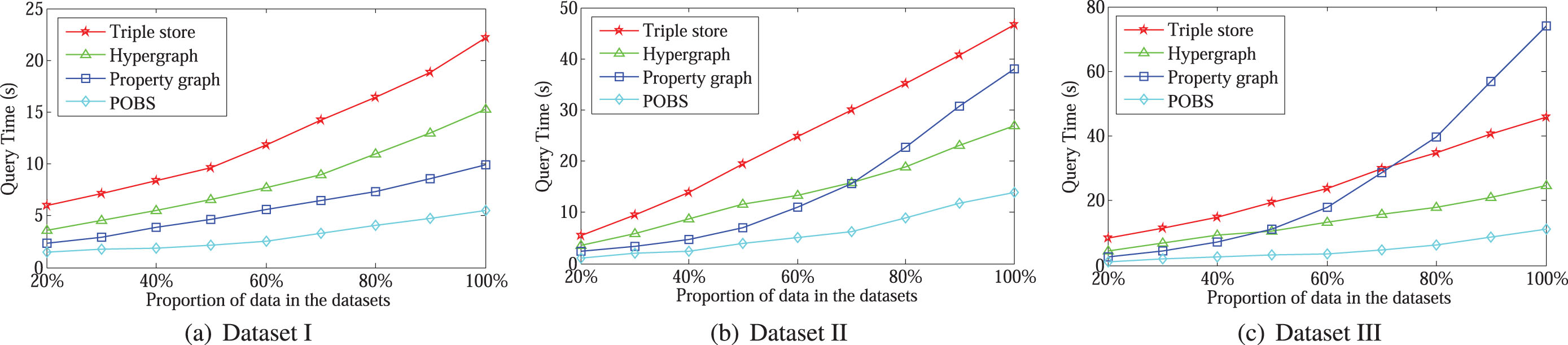
The efficiency of massive insertion workloads.
The efficiency of massive insertion workloads.
To verify the efficiency of an ad-hoc query, we conduct random query workloads on the graph models. We set rand and t to ensure the randomness. rand is used to limit the degree of the relationship. t is used to qualify the number of nodes. Two types of random queries are as follows.
CQL1: profile match graph = (a)-[*0..rand]-(b) return graph limit t;
CQL2: profile match dire graph = (a)-[*0..rand] → (b) return dire graph limit t;
where a and b are the starting node and ending node. The two query statements used for the undirected or directed graph are executed seven times. They query a graph with an arbitrary number of edges and output the first t items. The comparison of random query time is shown in Table 2. From the results, POBS obtains the minimal query times and outperforms the contrast models in all random cases. The comparison of other models is Triple store>Hypergraph>Property graph. The reason is that public opinion bunching mapping of POBS associates large amounts of related data reducing edge traversal in the query. Therefore, the POBS model has better integrity and stability in the query.
Comparisons of the time of random query (ms)
Comparisons of the time of random query (ms)
Clustering is the common operation for data analysis within social networks, such as topic discovery, community mining, etc. The speed of clustering is a critical metric to the performance of the graph storage. We select widely used clustering algorithms, including K-means [31], DBSCAN [32], Spectral Clustering [33] and Hierarchical Clustering [34], to perform clustering operations on four graph data models and compare their execution speed.
Since Dataset III contains the maximum redundant data, which can exclude the interference of other factors to demonstrate the advantages of the POBS fully, we conduct experiments on Dataset III in this section. In all clustering operations, we use the vector space model to quantify the message and convert the similarities to text distance. Based on the number of topics in Dataset III, we set the number of clusters to 26 in all clustering methods that need to specify the number of clusters. We select the corresponding initial cluster centers for K-means. Notably, we use topic nodes as the initial centroids in the POBS model. In DBSCAN, according to the given MinPts and the value of the radius Eps, all the core points are calculated. The mapping of the core point to the point that is less than the radius Eps is set at the core point. Particularly, we know from the nature of DBSCAN that every topic node can serve as the core object. For Spectral Clustering, we use the K-nearest neighbor as the composition method and Ncut as the cut method. When we deal with the data through POBS, we treat multiple nodes connected to each topic node as one node and do not consider the public opinion bunching relationship. We use the cohesion method in hierarchical clustering.
We execute 20 times clustering operations on the above four algorithms in the POBS and baseline graph models, respectively. Table 3 reveals the efficiency of POBS about average running time in the clustering task. We obtain some observations by comparing them with the baseline graph models, POBS makes each clustering algorithm achieve the best execution efficiency, that is, the shortest clustering time. It is due to the doubly linked list structure in the topic node of the public opinion bunching relationship. We can use each topic node to determine which cluster is directly connected by the multiple nodes. In addition, the K-means algorithm has the shortest clustering time among the four clustering algorithms. The reason is that POBS specializes in dealing with redundant data that normally belongs to the same category. In the storage process, POBS initially aggregates the same topic of forwarding relationship and maps it to the same topic node. Thereby, the topic nodes act as the initial centroid of the K-means algorithm, and the number of iterations is greatly reduced. In summary, the POBS reaches superior performance in the clustering as a result of the distinct advantages.
Comparisons of the average running time in clustering task (ms)
Comparisons of the average running time in clustering task (ms)
We propose a graph data storage model for the hot public opinion in social networks. Firstly, we identify the public opinion network and act as the targets for storage management. Secondly, we propose the equivalent partition and germ elements in data space. Finally, we extract the topic node that is shared content and design the public opinion bunching mapping relationship to decouple the data. Experiments indicate that POBS effectively improves the space utilization rate and processing speed. In future work, we will further perform multiple mode representation and compressed storage on multi-modal data of social networks.