
Abstract
Facial expression recognition has long been an area of great interest across a wide range of fields. Deep learning is commonly employed in facial expression recognition and demonstrates excellent performance in large-sample classification tasks. However, deep learning models often encounter challenges when confronted with small-sample expression classification problems, as they struggle to extract sufficient relevant features from limited data, resulting in subpar performance. This paper presents a novel approach called the Multi-CNN Logical Reasoning System, which is based on local area recognition and logical reasoning. It initiates the process by partitioning facial expression images into two distinct components: eye action and mouth action. Subsequently, it utilizes logical reasoning based on the inherent relationship between local actions and global expressions to facilitate facial expression recognition. Throughout the reasoning process, it not only incorporates manually curated knowledge but also acquires hidden knowledge from the raw data. Experimental results conducted on two small-sample datasets derived from the KDEF and RaFD datasets demonstrate that the proposed approach exhibits faster convergence and higher prediction accuracy when compared to classical deep learning-based algorithms.
Introduction
Facial expressions serve as a direct and powerful means for humans to convey their internal emotions and intentions [1–3]. With the advancements in computer technology, expression recognition has emerged as a novel approach for human-computer interaction, facilitating computers’ understanding of human emotions and also enabling humans to comprehend artificial intelligence. The complexity and diversity of human facial expressions, encompassing both psychological and physiological aspects, present significant challenges for facial expression recognition technology, leading to slower progress compared to other biometric recognition technologies [4–6]. Nevertheless, facial expression recognition technology finds widespread applications in intelligent driving, smart security, healthcare, virtual reality, judicial interrogation, and online education [7]. Consequently, research in facial expression recognition holds immense practical significance.
American psychologists Ekman and Friesen embarked on a pioneering study on expression recognition, marking a significant milestone in the field in 1971 [8]. Their extensive cross-cultural research culminated in the identification of six universally recognized basic facial expressions: anger, disgust, fear, sadness, happiness, and surprise. In 1978, they further refined their work by introducing the Facial Action Coding System (FACS), which establishes the correlation between distinct facial muscle movements and specific facial expressions [9]. Subsequent research in facial expression recognition expanded upon the original six universal basic emotions by including a “neutral” expression, which lacks any particular emotional inclination. Consequently, studies on facial expression recognition predominantly focus on these seven universal basic expressions, as depicted in Fig. 1.

Samples of the KDEF dataset [10].
Based on different feature extraction approaches, current facial expression recognition techniques can be categorized into two main groups: traditional techniques and deep learning-based techniques [7]. Traditional techniques primarily rely on pixel-wise transformations to extract features, to capture abstract and high-level information such as color, spatial structure, and shape from facial images. This category includes four representative methods: geometric feature extraction [11], statistical feature extraction [12], frequency domain feature extraction [13], and motion feature extraction [14]. Deep learning-based techniques employ deep learning models to extract features from facial images. In comparison to traditional approaches, deep learning-based facial expression recognition techniques demonstrate higher recognition accuracy and greater adaptability to complex environments. As a result, the most advanced facial expression recognition algorithms now typically rely on deep convolutional neural networks with additional enhancements. This paper constructs datasets for facial expression local action recognition, designs an expression recognition logic knowledge base. Most importantly, an algorithm called the Multi-CNN Logical Reasoning System (MCNN-LRS) that connects deep learning with logical reasoning through dynamic interaction has been proposed. In MCNN-LRS, the deep learning module is responsible for extracting perceptual information from the data, and the logical reasoning module is responsible for using logical knowledge to assist in deep learning for recognition. Through logical reasoning, this method to some extent compensates for the shortcomings of low accuracy and overfitting of deep learning models on small-sample datasets. Compared with traditional expression recognition algorithms, MCNN-LRS adopts a deep learning model in the perception part, which has stronger robustness and better generalization ability. Meanwhile, due to the integration of logical reasoning, compared with deep learning based models, MCNN-LRS can achieve higher prediction accuracy that deep learning models cannot achieve with minimal training data.In summary, MCNN-LRS fills the gap in existing methods in FER when dealing with small-sample datasets. The content of the study will be introduced in the following order. Firstly, in section 2, some research content in the field of facial expression recognition will be introduced, mainly based on deep learning; Secondly, a detailed introduction to the method proposed in this article will be provided in section 3, which includes logical reasoning methods in facial expression recognition, abductive learning, and a detailed introduction to MCNN-LRS. In section 4, experimental results on two small-sample datasets were presented. Finally, section 5 summarizes the conclusions drawn from this study and proposes future research directions.
Mollahosseini et al. [15] proposed a deep neural network architecture to tackle facial expression recognition challenges across multiple widely recognized facial expression datasets. Their approach exhibited superior performance compared to traditional convolutional neural networks in terms of accuracy and training time. Minaee et al. [16] introduced a deep learning method based on attentional convolutional neural networks, which allows for enhanced focus on crucial aspects of facial expressions. Moreover, they utilized a visualization technique to identify significant regions within facial expressions. Theoretical explanations were provided to illustrate the varying levels of sensitivity to different emotions in distinct facial regions. Kim et al. [17] introduced a facial expression recognition method employing a hierarchical deep learning approach. This method utilized two networks: one focusing on appearance features and the other on geometric features. The appearance-based network extracted comprehensive facial features using preprocessed LBP images, while the geometric-based network learned to coordinate variations in facial action units. The final recognition result was obtained by combining the outputs of both networks. In a similar vein, Georgescu et al. [18] proposed a method that integrates automatically learned features from convolutional neural networks with manually calculated features using visual word bags. Support vector machines were employed as classifiers for facial expression recognition. Nwosu et al. [19] developed a facial expression recognition system based on a deep convolutional neural network that leveraged facial regions. The system employed a dual-channel convolutional neural network, where facial regions were utilized as input for the first convolutional layer. Specifically, the eye region was fed into the first channel, while the mouth region was inputted into the second channel. The information from both channels was combined and passed through a fully connected layer for classification. Wadhawan et al. [20] introduced a part-based ensemble transfer learning network that emulates how humans associate spatial patterns of facial features with specific expressions for expression recognition. Meng et al. [21] proposed a novel identity-aware convolutional neural network (IAANN) that mitigates variations caused by personal attributes and achieves superior expression recognition performance. Fu et al. [22] not only considered the prediction accuracy of sample points but also the smoothness of their domains, leading to a novel method for reducing semantic disturbance. Shahid et al. [23] presented the SqueezExpNet architecture, which utilizes both local and global facial information to construct a facial expression recognition system with high accuracy, capable of handling environmental variations. The system employed geometric attention to extract local salient features and utilized spatial texture for extracting higher-level global features. Sadeghi et al. [24] introduced a deep histogram metric learning approach integrated within a convolutional neural network for facial expression recognition. This approach incorporated histogram computation layers to provide statistical descriptions of feature maps obtained from convolutional layers. Indeed, deep learning-based facial expression recognition algorithms have demonstrated remarkable performance. However, these algorithms impose substantial requirements on datasets, and their performance is heavily contingent upon the quantity and quality of the training data [25]. Generally, a considerable volume of accurately labeled facial expression data is necessary for training to attain satisfactory outcomes, but acquiring a substantial amount of high-quality labeled data is often associated with significant costs in real-world scenarios. Furthermore, humans have already amassed a comprehensive understanding of facial expressions in the fields of psychology and physiology [9]. However, applying this knowledge directly to deep facial expression recognition techniques has proven challenging due to the disparities in feature representation between deep learning and logical reasoning, as well as the absence of explicit logical relationships in individual facial expression images. To address these challenges, MCNN-LRS which combines logical reasoning with deep learning-based FER algorithms is proposed. MCNN-LRS capitalizes on the logical relationship between local facial actions and global facial expressions. It harnesses existing knowledge in the field of facial expression recognition and incorporates abductive reasoning to uncover latent knowledge from the raw data. By dynamically integrating logical reasoning into the training and predicting process of deep learning models, MCNN-LRS accelerates convergence speed and enhances prediction accuracy.
Approach
Logical reasoning approach for FER
As depicted in Fig. 2, empirical observations indicate that in specific contexts, analyzing an individual’s eye movements can yield a remarkably accurate prediction of their global facial expression.

Three examples of inferring global facial expression through eyes movements.
Similarly, as illustrated in Fig. 3, facial expressions can be inferred to some extent by observing the movements of the mouth. According to reference [26], the significance of cues from the eyes and the mouth region may vary during the process of predicting different expressions. For example, when identifying sadness, cues from eye movements significantly contribute, whereas cues from the movements of the mouth are more prominent in recognizing happiness. The theoretical framework presented in reference [16] also suggests that different facial expressions elicit varying levels of sensitivity to movements across distinct facial regions. For example, psychological research suggests that mouth movements play a greater role in identifying non negative emotions such as surprise and happiness, while eye movements play a greater role in identifying negative emotions such as sadness and anger [26]. Therefore, when the overall expression recognized by the deep learning model is unclear, these local actions can be used to assist in prediction.
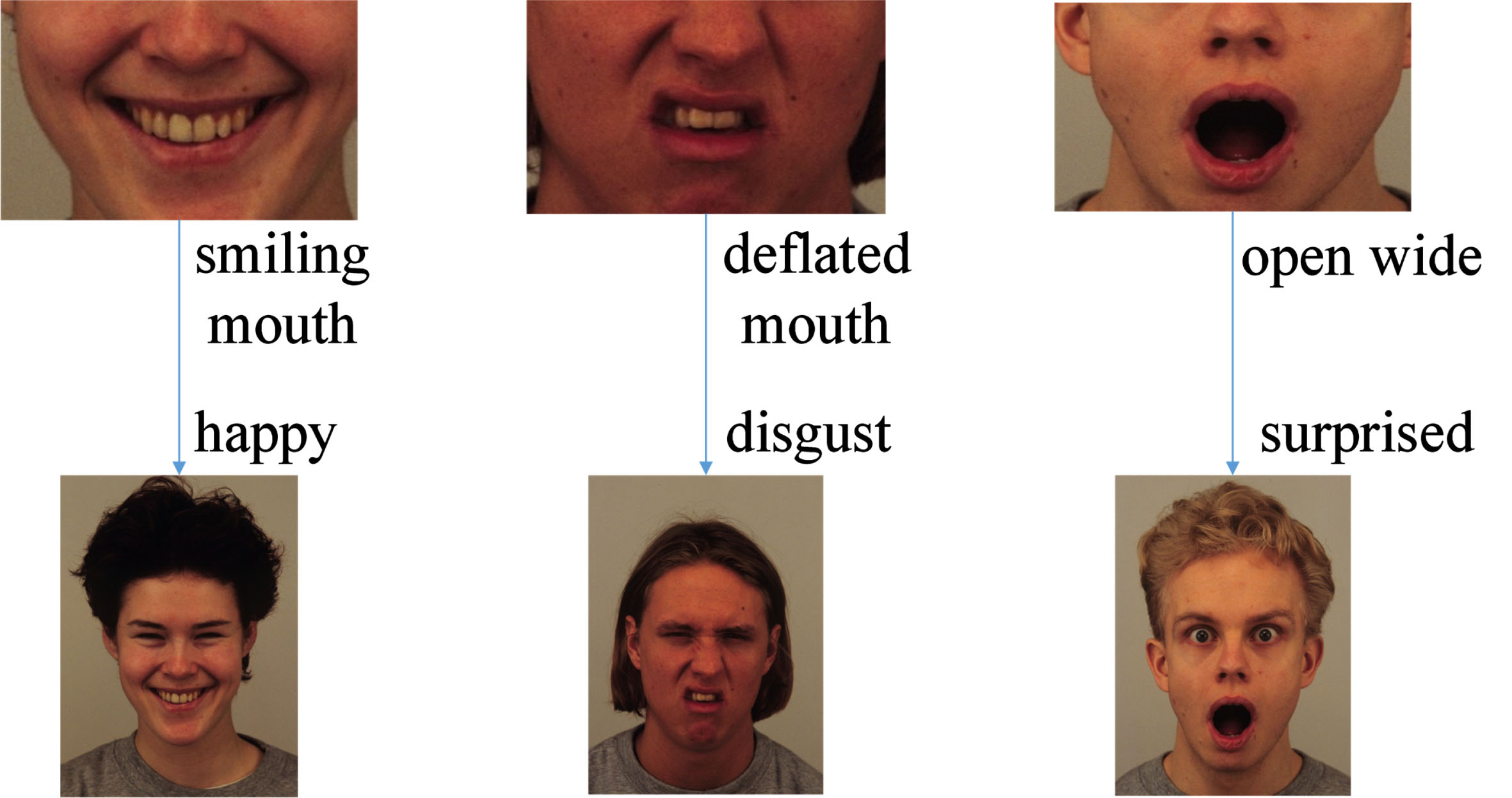
Three examples of inferring global facial expression through mouth movements.
However, for reasoning systems in computer technology, a single facial expression image does not contain explicit logical relationships, making it challenging to directly incorporate logical reasoning into deep learning-based FER algorithms. To address this issue, the proposed MCNN-LRS divides the facial image into two parts: the eye movement and the mouth movement. Three simple and reliable deep learning models are then utilized to recognize these local actions, as well as the global facial expression. Subsequently, the identified local actions and facial expressions are converted into first-order predicates, and by leveraging the logical programming language Prolog, these predicates undergo logical reasoning based on pre-existing knowledge in the field of facial expressions. Finally, the results from logical reasoning and the deep learning model are integrated to obtain the final prediction. Facial expressions are divided into two parts in MCNN-LRS: the Eye Movement (EM) and the Mouth Movement (MM). By leveraging the logical relationship between these local actions and global Facial Expressions (FE), integrated FER with logical reasoning can be achieved. The segmentation strategy employed in MCNN-LRS, as depicted in Fig. 4, assumes that the positions of the left and right eyes in the facial expression are denoted as points e1 and e2, respectively, while the position of the nose tip is represented by point n. The specific segmentation strategy involves calculating the midpoint m (p, t) between e (the midpoint of two eyes) and n. Subsequently, a line y = t is drawn in a Cartesian coordinate system to partition the facial region into two parts: the eye movement image and the mouth movement image.
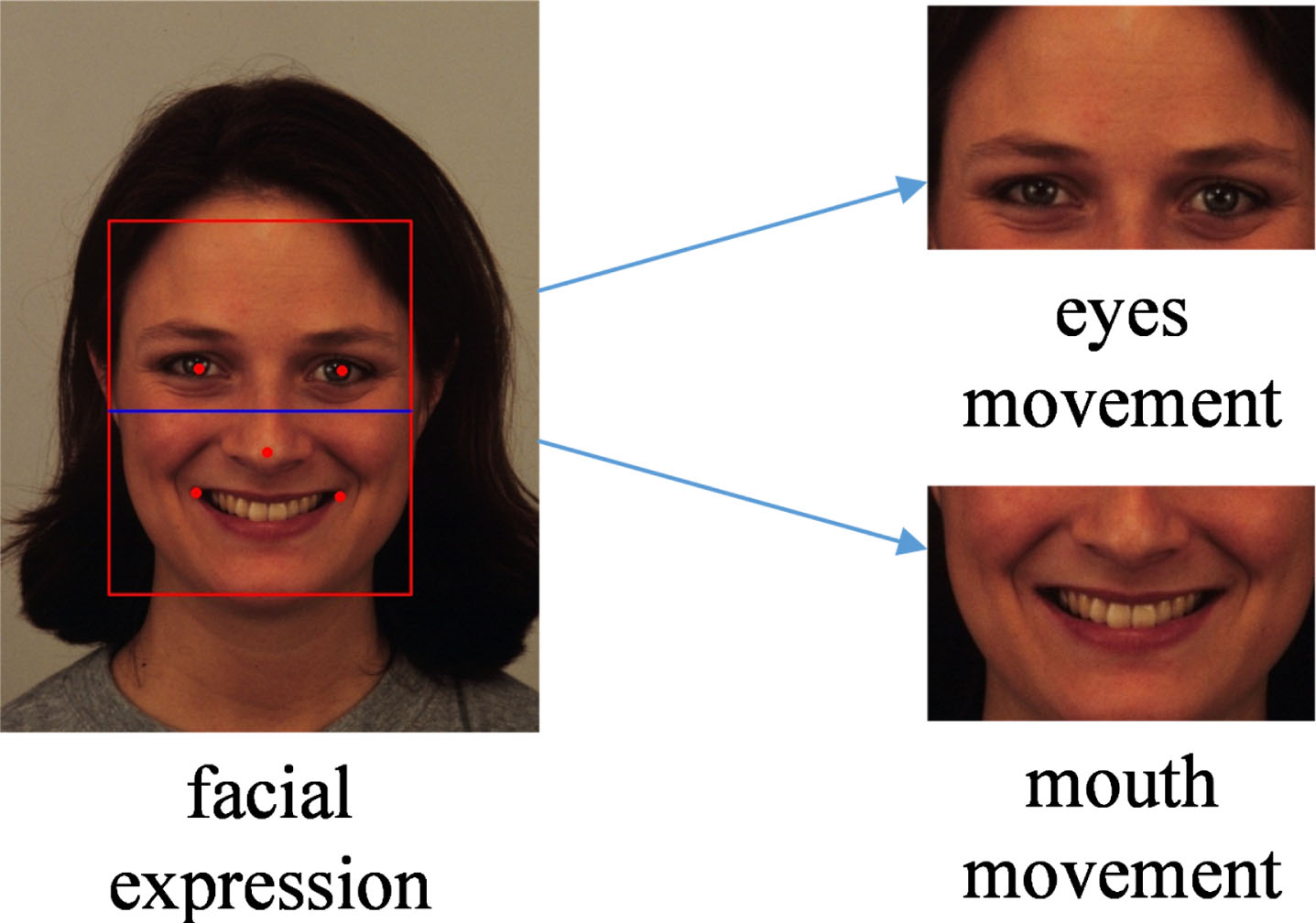
The segmentation strategy in MCNN-LRS.
To achieve the recognition of EM and MM, separate datasets based on the KDEF dataset and the RaFD dataset [27] were created. By analyzing the data in these datasets and utilizing the results of image clustering algorithms [28], EM was categorized into three classes: frown, neutral e , and open _ wide e . Similarly, MM was categorized into six classes: open _ wide m , open _ slightly, neutral m , corners _ rise, corners _ down, and bare _ teeth. Using these classification results, two distinct datasets were annotated for EM classification and MM classification, each comprising 1000 samples, and neural network models were then trained on these respective datasets. Samples of these two datasets are depicted in Fig. 5 and Fig. 6.
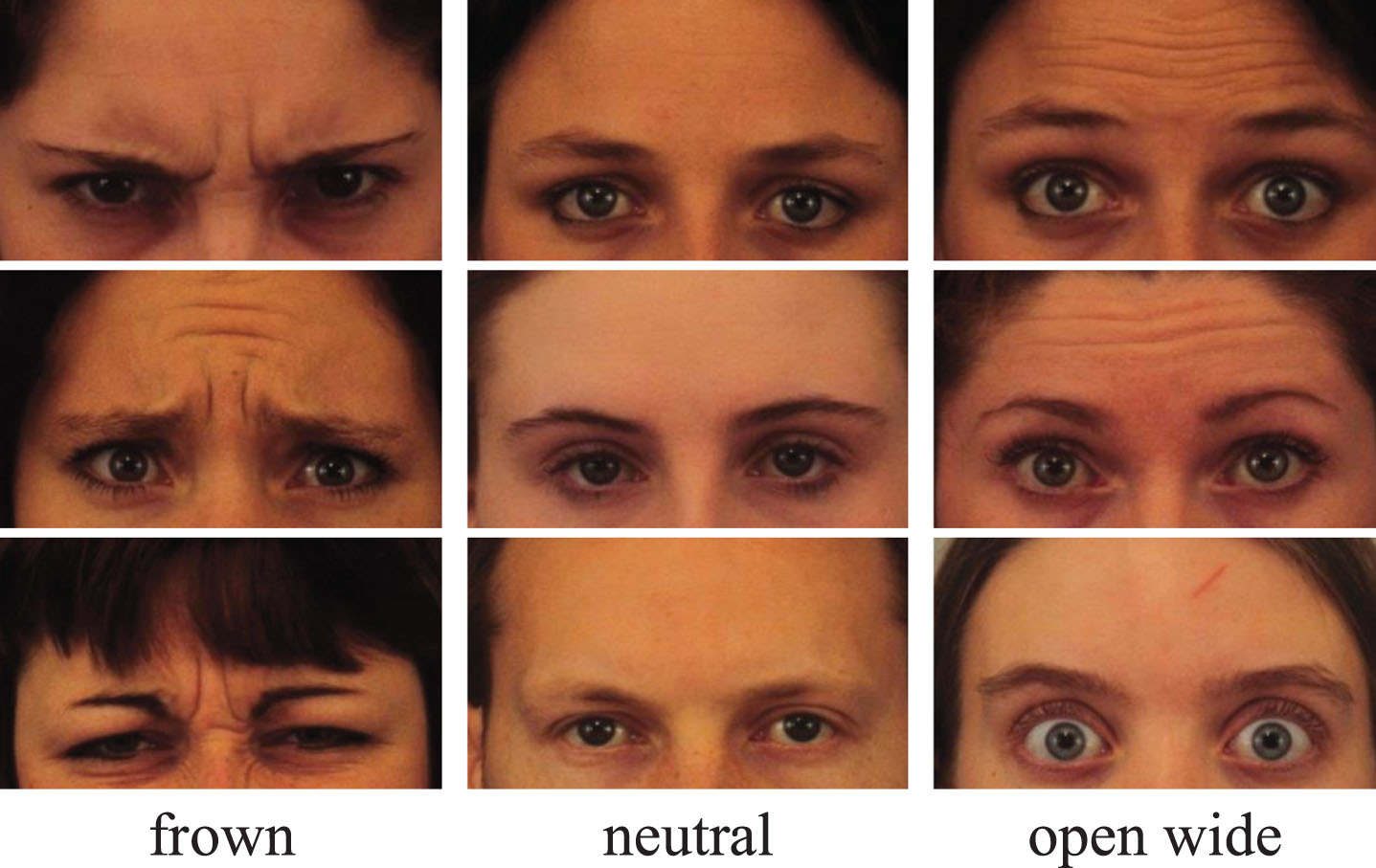
Samples of the EM dataset.

Samples of the MM dataset.
Based on the aforementioned theory, this paper proposes a data organization format for logical reasoning in MCNN-LRS, known as Facial Expression Logical Relationship Triplet (FELRT) t = (FE, EM, MM). Each facial expression image is recognized and transformed into a FELRT after passing through the deep learning model. For example, when a facial expression instance e is recognized by three deep learning models, the triplet t e = (surprised, open _ wide e , neutral m ) is obtained. The triplet can be further converted into three first-order logic predicates: emotion (surprised), eye (open _ wide e ), and mouth (neutral m ). These predicates indicate that the current expression is “surprised”, the EM is “opening wide”, and the MM is “neutral”. During the prediction process of MCNN-LRS, the logical correctness of the corresponding first-order logic predicates is evaluated to reason, assess, and potentially refine the prediction made by the deep learning algorithm based on its perception.
Table 1 provides some examples for FELRTs evaluation. Suppose that a FELRT perceived by deep learning models is e = (neutral, neutral e , open _ wide m ), which represents a neutral facial expression, neutral eye movement, and an open wide mouth. Translating it into first-order predicates, they will be emotion (neutral), eye (neutral e ), and mouth (open _ wide m ). The Reasoning rule emotion (neutral) ∧ mouth (open _ wide m ) →False reveals a conflict between emotion (neutral) and mouth (open _ wide m ), indicating their inability to occur simultaneously. On the contrary, rule emotion (neutral) ∧ eye (neutral e ) → True suggests that the predicates representing emotion and mouth can coexist without conflict. Lastly, the conjunction of False and True results in False. Therefore, based on the knowledge in the knowledge base, the FELRT (neutral, neutral e , open _ wide m ) is logically incorrect and needs to be corrected.
When the confidence level of the facial expression predicted by deep learning models falls below a predefined threshold, logical reasoning can be utilized to predict the facial expression using only EM or MM. As presented in Table 2, suppose a FELRT labeled as (none, neutral e , corners _ rise) is obtained, which indicates that the confidence level of the deep learning model for expression recognition in this prediction is below the threshold so it is none about facial expression. As a result, logical reasoning is employed to predict the facial expression. Rule neutral e ∧ corners _ rise → happy represents the conjunction of predicates eye (neutral e ) and mouth (corners _ rise) inferring the predicate emotion (happy), which means “happiness” is the most probable facial expression now. Moreover, when one of deep learning models for EM and MM recognition fail to meet the confidence requirements in a given prediction, logical reasoning can still be employed to predict the facial expression using only one local action information, as illustrated in the last two entries of Table 2. The entire process of logical reasoning for evaluation and prediction is illustrated in Fig. 7 (a) and Fig. 7 (b), respectively. By integrating the aforementioned theories, it is evident that using facial local movements is a rational and feasible approach to validate the recognition results of deep learning models and predict facial expressions.
Examples of FELRTs Evaluation
Examples of FELRTs Prediction
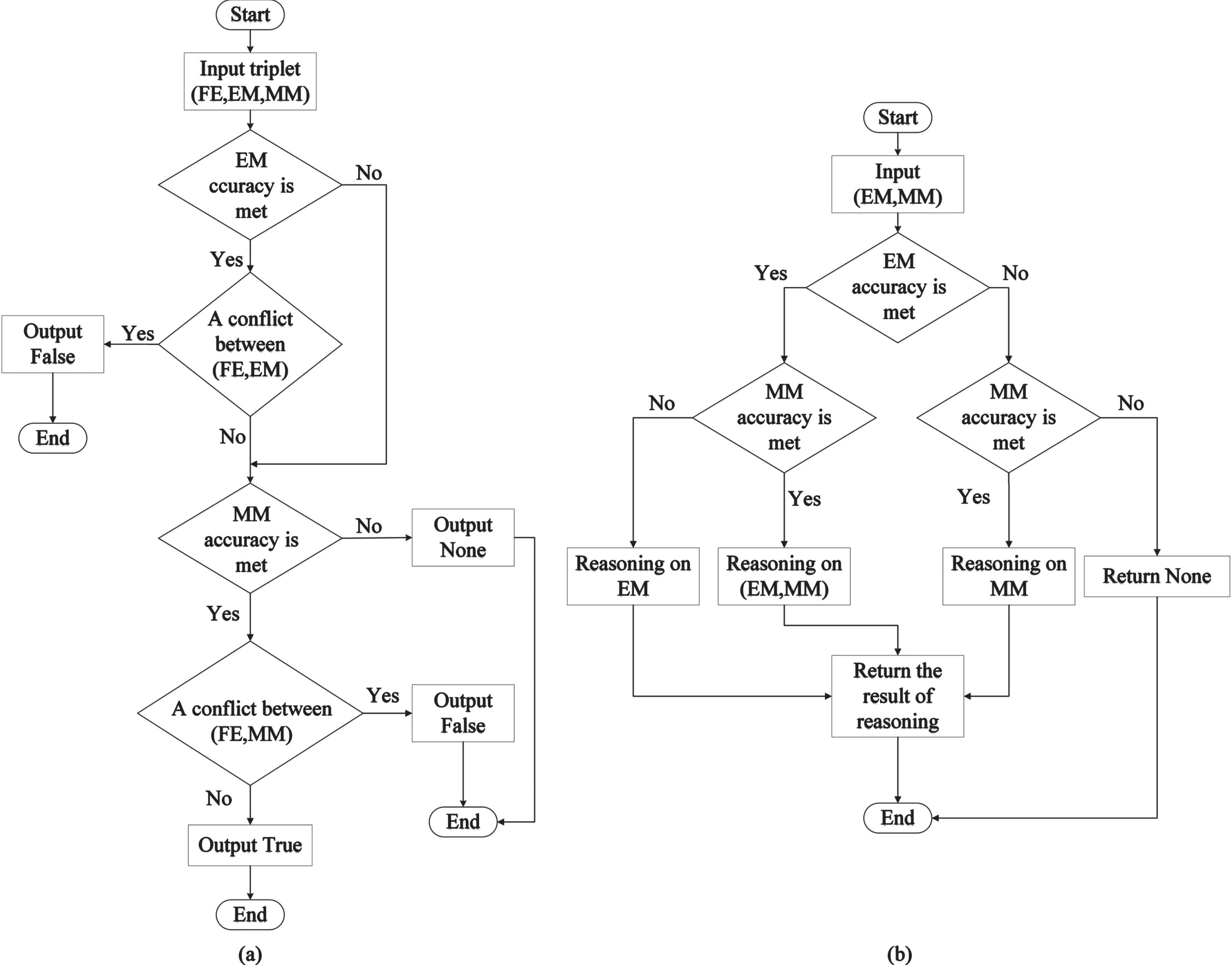
(a) Evaluation flow chart; (b) prediction flow chart.
Abductive learning is a novel machine-learning framework that uses dynamic interaction to integrate machine learning and logical reasoning [29–31]. In the abductive learning framework, the machine learning module is responsible for obtaining perceptual information from the raw data and the logical reasoning module is responsible for correcting the perceptual errors of the machine learning module and improving the machine learning model using symbolic knowledge [32]. Traditional supervised learning aims to obtain an objective function f : X ↦ Y by fitting a large amount of labeled data X = {x1, x2, . . . . . . , x
n
} to its label Y = {y1, y2, . . . . . . , y
n
}. In abductive learning, unlabeled data can be utilized to substitute for some labeled data, alongside a domain knowledge base KB and an initial classifier C for the given problem. The task of the abductive learning is also to fit the objective function f, based on which the logical facts perceived by the machine learning module conform to the constraints of the knowledge base KB [33]. In the case where there is less labeled data and the accuracy of the initial classifier is low, the abductive learning model corrects the illogical parts of the machine learning model predictions by minimizing the inconsistencies based on the knowledge base KB and uses the corrected results to retrain the classifier [34]. The process is described as follows:
Fig. 8 illustrates the structure of MCNN-LRS, which consists of three key components: the deep learning module, the Pyswip communication module, and the logical reasoning module. The deep learning module acts as the “eyes” of the whole algorithm, responsible for perceiving image data and extracting perceptual information. The logical reasoning module extracts valuable logical knowledge from the information perceived by the neural network and aids the neural network in making the final prediction. Last but not least, the Pyswip communication module is responsible for the communication between the deep learning module and the logical reasoning module.
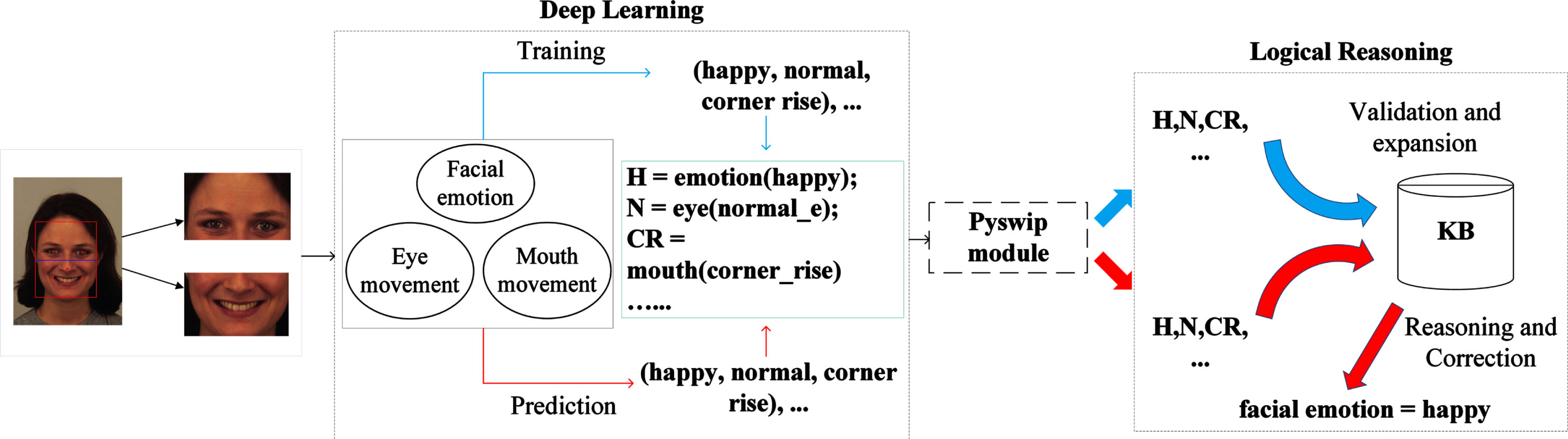
The structure of the MCNN-LRS (blue arrows indicate the training process; red arrows indicate the prediction process).
MCNN-LRS incorporates a deep learning module that utilizes a deep neural network, along with a logical reasoning module implemented using the logic programming language engine, Swi-prolog. The communication between the machine learning module and the logical reasoning module is facilitated by Pyswip, an open-source bridge tool that connects Python and Swi-prolog. Pyswip offers a comprehensive Swi-prolog interface, enabling convenient prolog queries. Fig. 9 illustrates the specific interaction flow between the deep learning module and the logical reasoning module in MCNN-LRS.

The interaction process between the deep learning module and the logical reasoning module.
The deep learning module serves as the “eyes” of MCNN-LRS, responsible for perceiving information from the training data and transmitting the extracted perceptual information to the logical reasoning module for knowledge summarization and logical reasoning correction. The deep learning module employs classical and efficient deep learning models, including three models specifically designed for EM recognition, MM recognition, and FE recognition. When dealing with small-sample datasets, complex neural networks often face the risk of overfitting. To mitigate this issue, MCNN-LRS adopts the simple yet effective VGG16 neural network model as the core component of the deep learning module. The structure of VGG16 is illustrated in Fig. 10 [35]. When selecting the model, considering that MCNN-LRS mainly processes small-sample datasets, it is not advisable to choose overly complex models, as overfitting may occur. At the same time, it is necessary to ensure the model’s ability to extract features. Finally, after comparing the training performance of multiple classic neural network models on small datasets, VGG16 was selected. Compared to shallow networks, it can explore deeper and more abstract image features [36]. Additionally, compared to deep networks, it can alleviate overfitting issues caused by excessively complex network models. When selecting neural network hyperparameters, MCNN-LRS draws on the methods of using intelligent optimization algorithms to adjust the hyperparameters of deep learning models, such as Grey Wolf optimization and Genetic algorithm [37–40].
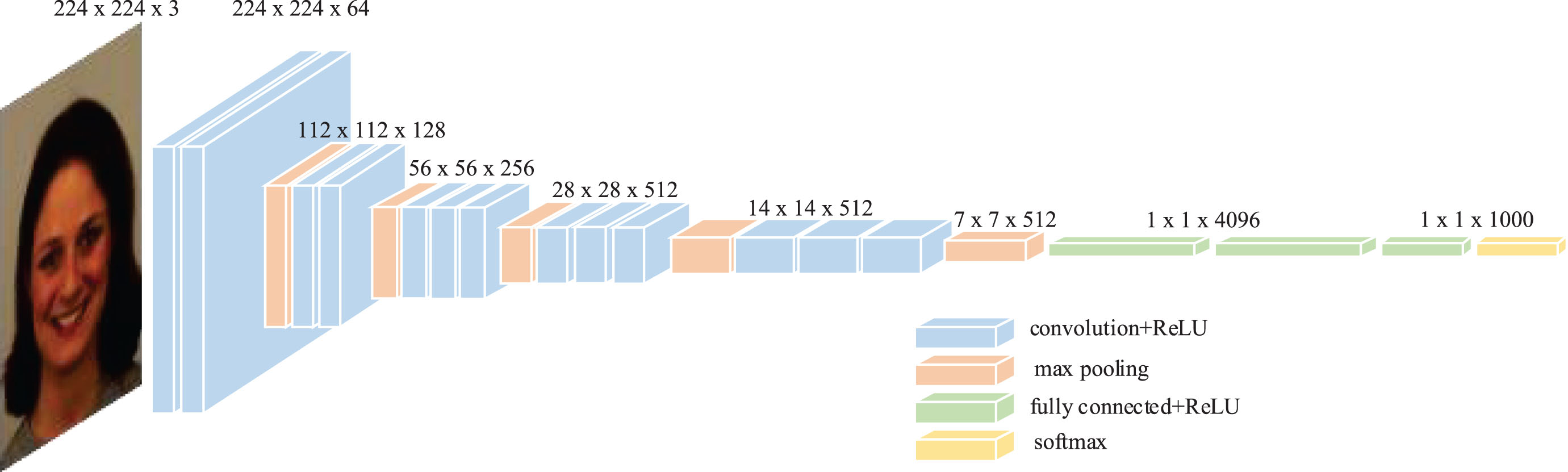
VGG16 architecture.
The logical reasoning module receives the perceptual information sensed by the deep learning module and utilizes logical inference to extract knowledge hidden in the training data, thereby assisting the deep learning module in facial expression recognition. This module is based on the Swi-prolog, a logic programming language engine. Prolog, which stands for “Programming in logic,” is a logic-based programming language rooted in first-order predicate calculus and focused on deductive reasoning. Prolog possesses simple grammar, expressive power, and distinctive attributes as a non-procedural language, making it well-suited for representing human thinking processes and inference rules. SWI-Prolog is a versatile and cross-platform Prolog language engine that incorporates robust multithreading capabilities and extended data types. Its comprehensive low-level C language interface ensures effective integration with high-level languages such as C++, C#, Java, and Python. The Pyswip communication module functions as a bridge for interaction between the deep learning module and the logical reasoning module. It is implemented as a Python library. Furthermore, the Pyswip utility class have been restructured to align with the requirements, facilitating streamlined communication of information between the deep learning module and the logical reasoning module. Once the deep learning model achieves a predefined threshold of accuracy on the training dataset, the logical reasoning module becomes active and converts the perceived facial expression triplets into first-order logic predicates and incorporates them into the knowledge list to be tested. During each subsequent training step, predicates in the list are examined to assess their consistency with the information perceived by deep learning modules. In MCNN-LRS, a knowledge evaluation algorithm is proposed to determine the usefulness of the knowledge acquired by deep learning models. The implementation of this evaluation algorithm is as follows: let K represent the knowledge obtained during a training process, with a score of S
k
. The variables j and k denote the number of matches and conflicts between this logical knowledge and the information perceived by deep learning modules in the epoch-th training process, respectively. The score evaluation result for this logical knowledge is calculated according to Eq. (4).
Algorithm 1 Training of MCNN-LRS
1: preprocess dataset
2: initialize KB;
3: train the deep learning model;
4: if f has reached the threshold accuracy then
5: While KB is incompatible with the deep learning model do
6: use f to obtain perceptual information;
7: obtain first-order predicate knowledge from training dataset;
8: evaluate the predicate knowledge using Eq. 4;
9: add the effective knowledge to KB;
10: continue training deep learning model f;
11: end while
12. else
13: training deep learning model f;
14: end if
15: return f and KB;
The testing datasets used are two small-sample datasets derived from the KDEF and RaFD datasets, comprising frontal face images. The first dataset consists of 140 images for training, 380 images for validation, and 776 images for testing, and the second dataset consists of 70 for training, 300 for validation, and 1000 for testing. The reason why MCNN-LRS use frontal face images is that creating EM and MM classification datasets is relatively straightforward with frontal face images. In contrast, incorporating side faces in these datasets introduces greater challenges in movements classification and annotation. Consequently, the proposed method is initially validated on frontal face images to assess its feasibility. Once the required local action classification datasets are completed, further testing can be conducted on more diverse datasets. In MCNN-LRS, the Adam optimizer is employed during the training process of neural network models to optimize its parameters using the categorical cross-entropy loss function, which is shown in Eq. (5), where y
i
represents the true class label of the i-th instance, and
In the data preprocessing stage, in order to enable MCNN-LRS to cope with expression images with poor lighting conditions, linear transformation was used to enhance the contrast before the image was input into the model. Assuming that the input image is I, the width is W, the height is H, and the output image is O, the definition of linear transformation is shown in Eq. (7).
As shown in Fig. 11, on the RaFD training dataset, the deep learning model reaches the preset threshold accuracy at approximately 40 epochs, and the logical reasoning module starts to intervene, resulting in a widening gap between the two approaches. Compared to the VGG16 model, the initial stage of introducing the logical reasoning module shows an improvement of about 20% in accuracy on the training dataset. As the number of training iterations increases, the accuracy of VGG16 gradually improves, while MCNN-LRS consistently maintains a higher accuracy. When the training progresses to around 70 epochs, the accuracy curve of MCNN-LRS on the training dataset remains relatively stable, and after epoch 75, the final accuracy stabilizes at 100%. On the validation set, compared to VGG16, MCNN-LRS had already stopped the accuracy jitter at approximately 75 epoch, and the overall accuracy curve showed a steady and slow upward trend, reaching stable at the highest accuracy at approximately 125 epoch, with a performance improvement of about 15%. Throughout the comparison with VGG16, there exist some specific instances within each expression category where the deep learning model failed to accurately recognize the expressions. In contrast, MCNN-LRS, utilizing logical knowledge, demonstrated the ability to detect and rectify the perception errors made by deep learning models, thereby accurately predicting the correct expressions. Fig. 12 provides visual examples illustrating the successful correction of predictions through logical reasoning during the experimental process. Fig. 13 showcases the recognition results of the deep learning model for the six examples depicted in Fig. 12.
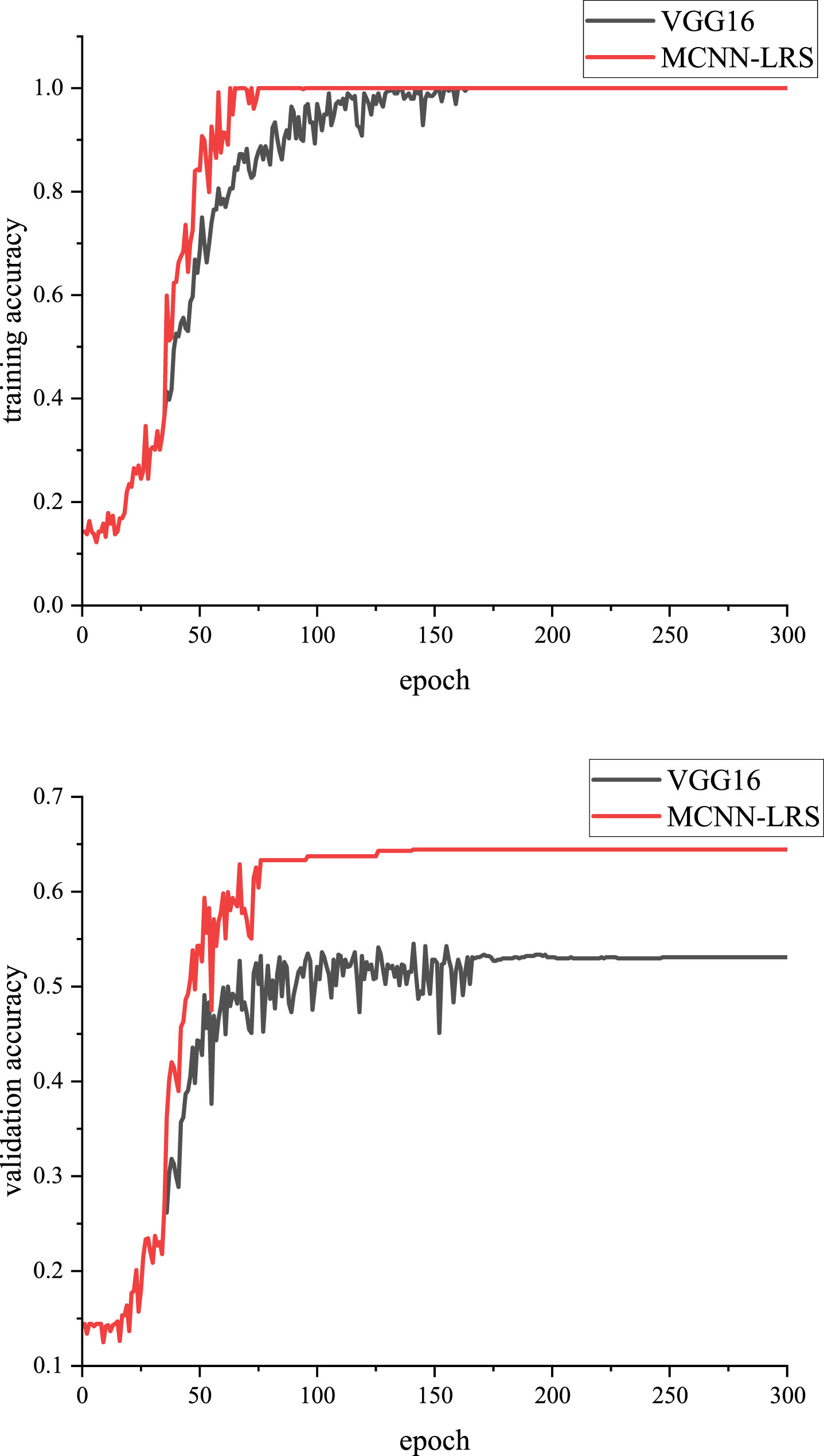
Learning curve of VGG16 and MCNN-LRS on training and testing datasets.

Instances corrected by logical reasoning.
Table 3 represents the facial expression logical triplets for 6 examples in Fig. 12, and Table 4 showcases the logical reasoning process for these examples.
FELRTs of 6 examples in Fig. 12
The logical reasoning process of 6 examples in Fig. 12
From the reasoning process, it can be observed that in MCNN-LRS, the logical reasoning module first utilizes logical knowledge to determine whether there is any conflict between the FE recognized by the deep learning model and EM as well as MM. If there is more than one conflict present, a new expression is derived through the conjunction reasoning of EM and MM. It can be noticed that Fig. 12 (c) and Fig. 12 (d) have the same reasoning process in the first two steps, and their FELRTs are also identical. However, they end up with different reasoning results. The reason for this phenomenon is that the same set of EM and MM can lead to multiple candidate facial expressions through reasoning. After obtaining the candidate expression set, the most likely expression that satisfies both the deep learning model’s result and the constraints of the logic knowledge base can be determined by comparing the confidence levels of the various expressions shown in Fig. 13. In Fig. 13 (c), besides “neutral", the highest confidence is assigned to the angry expression, while in Fig. 13 (d), the candidate expression is sadness. Furthermore, from Fig. 12 and 13, it can be observed that deep learning models often struggle with distinguishing facial expressions that have subtle movements and less pronounced features. These types of expressions are typically classified as “neutral” by the model. However, by incorporating logical reasoning, the recognition of subtle movements can effectively mitigate this phenomenon.
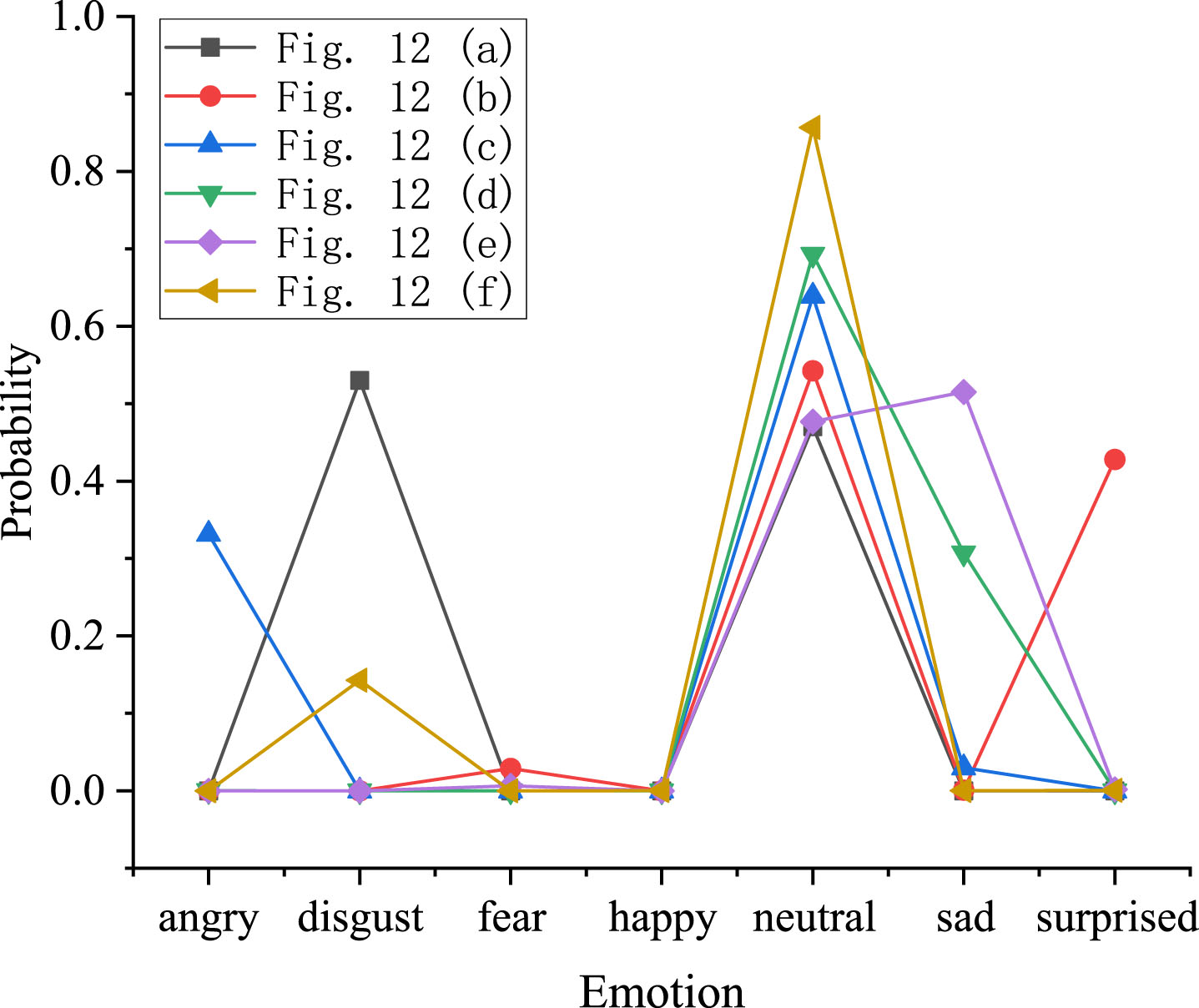
Prediction results of the deep learning model.
As shown in Table 5, on the test set with a size of 776, MCNN-LRS achieved a prediction accuracy that is 20.62% higher than VGG16. The number of facial instances involved in logical reasoning reached 146, accounting for 18.81% of the total test set. Among them, 133 facial instances had corrected logical reasoning results, accounting for 91.10% of the instances involved in reasoning.
Logical reasoning results on test set
The Confusion matrices of MCNN-LRS on the KDEF and RaFD datasets are shown in Fig. 16. MCNN-LRS achieves varying degrees of improvement in accuracy for each expression category. Except for a slight improvement in anger and disgust, MCNN-LRS shows significant improvements in fear, happy, neutral, sad, and surprised categories, with substantial increases in accuracy.
Besides, a comparative analysis was conducted on the training process and recognition accuracy of 11 deep learning based facial expression classification algorithms. Fig. 14 illustrates the training accuracy curves of six representative algorithms on the small-sample facial expression classification dataset. The experimental findings indicate that the compared algorithms exhibit slower convergence speed during training and lower final accuracy on the validation set compared to MCNN-LRS.
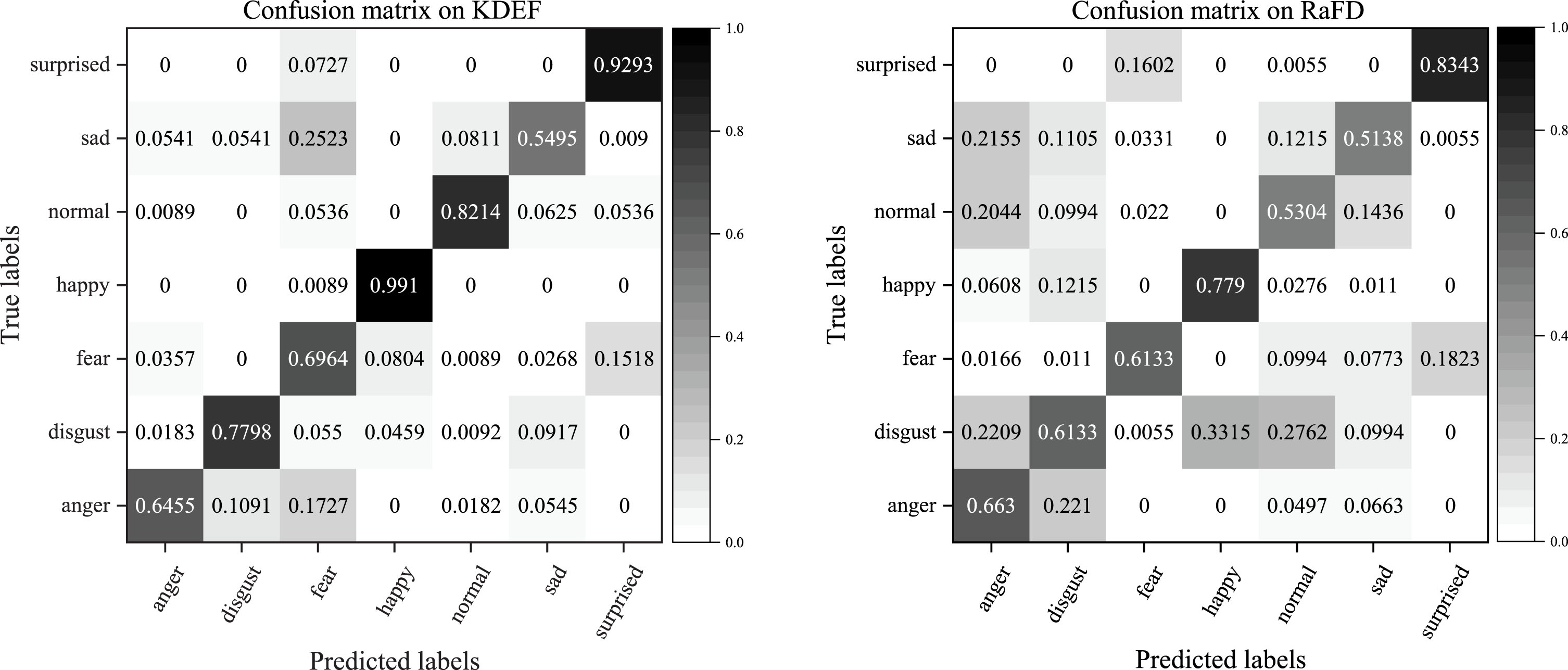
Confusion matrices of MCNN-LRS on the KDEF and RaFD datasets.
As shown in Tables 6, 7, Fig. 14 , and Fig. 15, complex networks like ResNet50 and InceptionV3 tend to overfit when dealing with extremely small training sets. MCNN-LRS achieves a final prediction accuracy of 77.32% on the KDEF test set and 63.74 on the RaFD test set. It also demonstrates significant advantages over other deep learning-based facial expression recognition algorithms. Besides, to test the significance of performance improvement, the wilcoxon rank sum test was used on two datasets. The results of the rank sum test are shown in Table 8, where P represents the calculation results of the Wilcoxon rank sum test, R represents whether there is an improvement in MCNN-LRS compared to the algorithm. + indicates an improvement, - indicates that MCNN-LRS is inferior to the algorithm, and = indicates that the two algorithms are similar. From the test results, it can be seen that MCNN-LRS has a significant performance improvement compared to comparative algorithms.
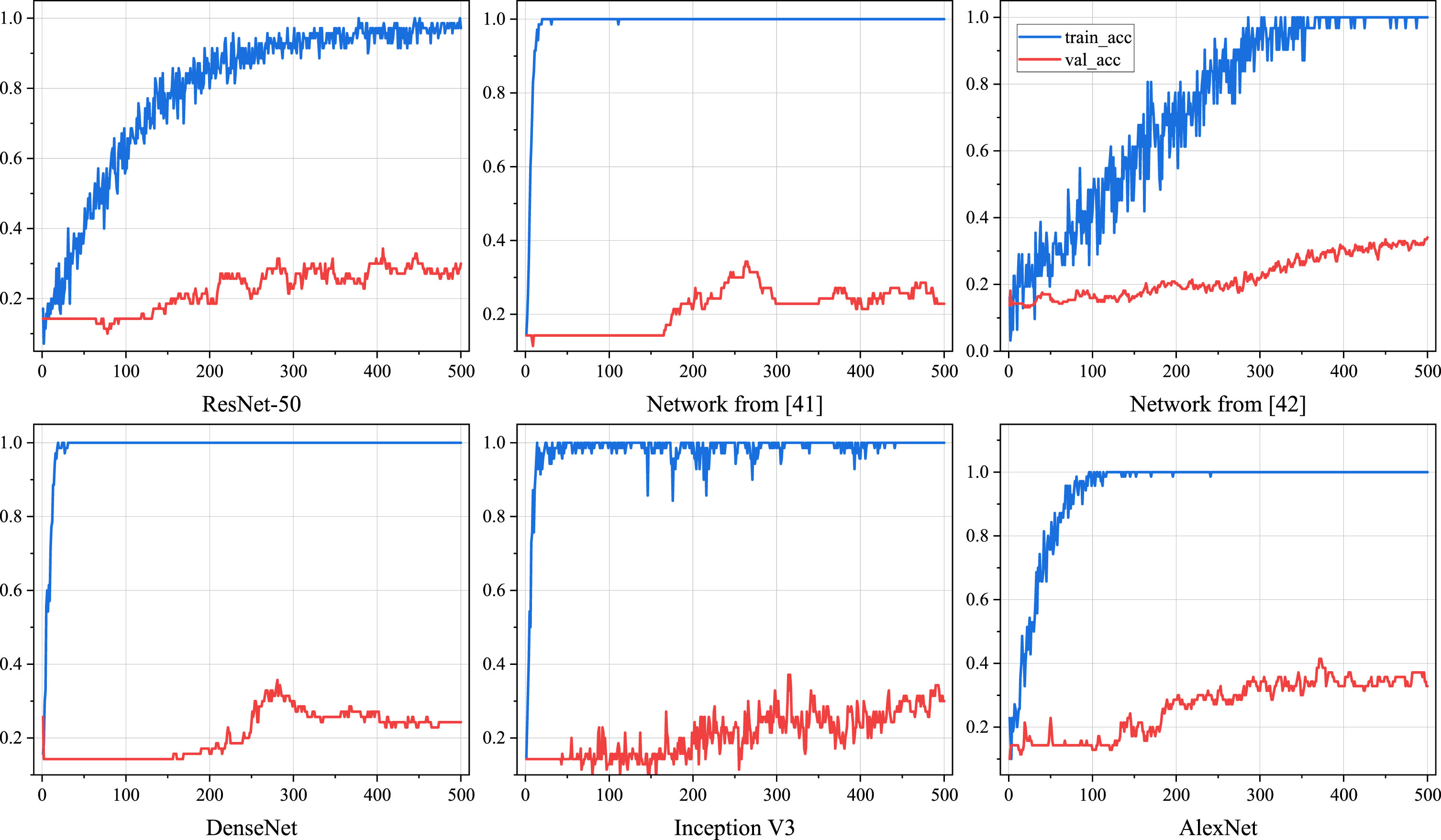
Learning curve of 6 deep learning-based FER algorithms on small-sample datasets.
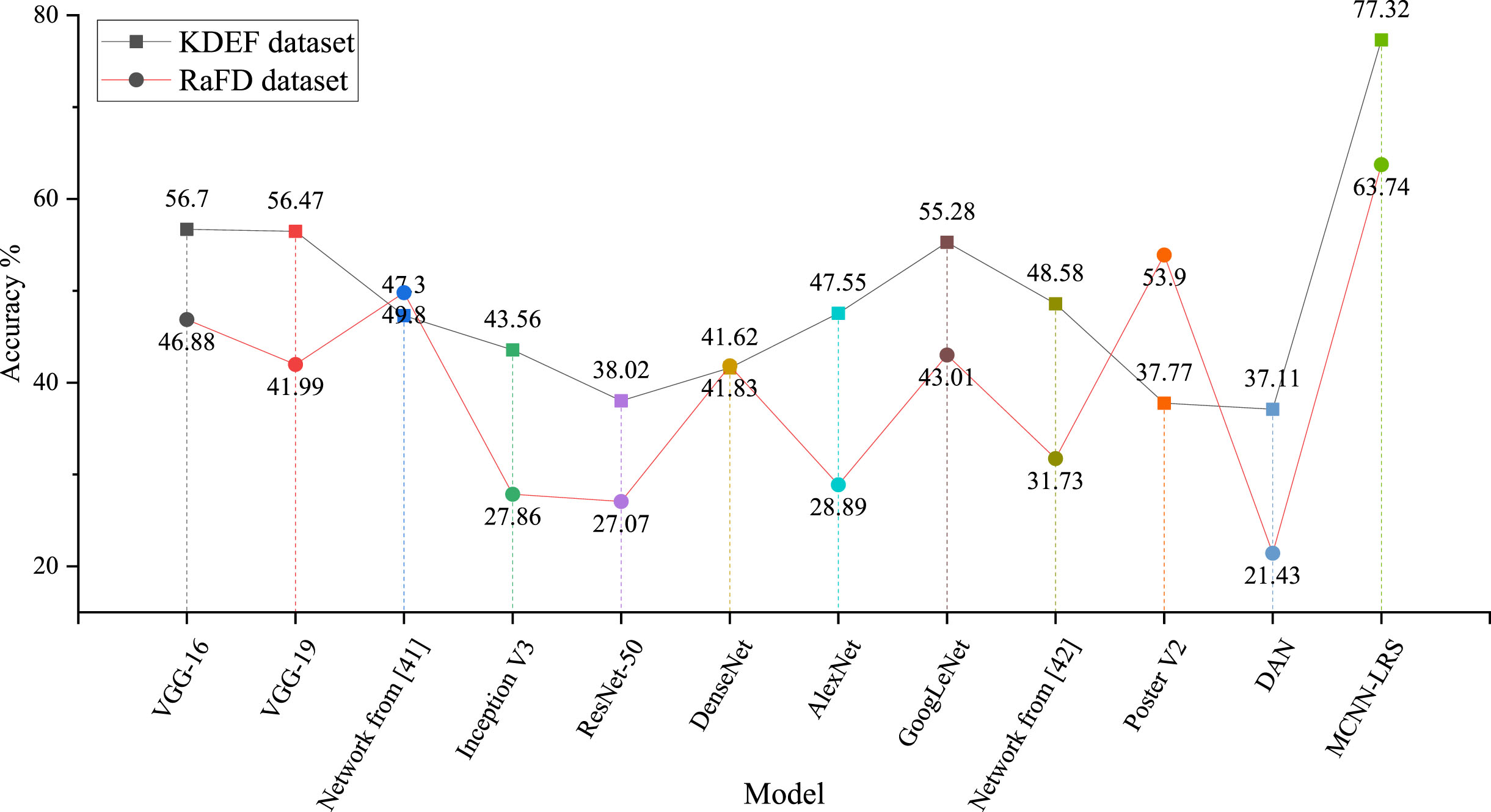
Accuracy line charts of each model on two datasets.
Accuracy (Acc%) of different models on the KDEF dataset
Accuracy (Acc%) of different models on the RaFD dataset
Results of wilcoxon rank sum test
This paper presents and designs a multi-CNN based facial expression recognition algorithm that integrates logical reasoning to address small-sample datasets. The proposed algorithm achieves this by segmenting facial expression images into the eye region and the mouth region, capturing the implicit logical relationships within global facial expressions. Through logical reasoning, it extracts hidden logical knowledge from the raw data and integrates it to assist in the training and prediction of deep learning models. On the small-sample frontal facial expressions dataset, MCNN-LRS outperforms recent traditional deep learning facial expression recognition algorithms in terms of accuracy. Additionally, the algorithm demonstrates advantages in terms of convergence speed during the training process. There is no doubt that MCNN-LRS can be used not only in FER, but also in other areas of computer image processing. For example, in some fine-grained classification tasks, a similar approach to MCNN-LRS can be used for local action recognition to transform the fine-grained problem into a coarse-grained classification problem in order to improve recognition accuracy and reduce recognition difficulty. While the proposed algorithm shows promising results on small-sample frontal facial expression datasets, it is important to note that real-world facial expressions are complex and diverse, influenced by various factors such as lighting conditions, image blurring, facial occlusions, profile views, and other sources of interference. In addition, MCNN-LRS also has some other limitations. Firstly, it contains multiple deep learning components, which reduces its interpretability. Secondly, due to the limitations of the local action dataset, it has not yet been able to adapt well to diverse samples. In future research, the application fields of MCNN-LRS will be more extensive. At present, possible research directions include: (1) improving the local action recognition module, including improving the design of corresponding datasets and optimizing models, to enhance the model’s generalization ability; (2) Optimize the logical reasoning module, including the design of reasoning mechanisms and predicate logic, to improve the accuracy of logical reasoning; (3) Optimize the deep learning model training process, including data preprocessing and model tuning, to adapt to more complex real-world environments.