
Abstract
In recent years, face detection has emerged as a prominent research field within Computer Vision (CV) and Deep Learning. Detecting faces in images and video sequences remains a challenging task due to various factors such as pose variation, varying illumination, occlusion, and scale differences. Despite the development of numerous face detection algorithms in deep learning, the Viola-Jones algorithm, with its simple yet effective approach, continues to be widely used in real-time camera applications. The conventional Viola-Jones algorithm employs AdaBoost for classifying faces in images and videos. The challenge lies in working with cluttered real-time facial images. AdaBoost needs to search through all possible thresholds for all samples to find the minimum training error when receiving features from Haar-like detectors. Therefore, this exhaustive search consumes significant time to discover the best threshold values and optimize feature selection to build an efficient classifier for face detection. In this paper, we propose enhancing the conventional Viola-Jones algorithm by incorporating Particle Swarm Optimization (PSO) to improve its predictive accuracy, particularly in complex face images. We leverage PSO in two key areas within the Viola-Jones framework. Firstly, PSO is employed to dynamically select optimal threshold values for feature selection, thereby improving computational efficiency. Secondly, we adapt the feature selection process using AdaBoost within the Viola-Jones algorithm, integrating PSO to identify the most discriminative features for constructing a robust classifier. Our approach significantly reduces the feature selection process time and search complexity compared to the traditional algorithm, particularly in challenging environments. We evaluated our proposed method on a comprehensive face detection benchmark dataset, achieving impressive results, including an average true positive rate of 98.73% and a 2.1% higher average prediction accuracy when compared against both the conventional Viola-Jones approach and contemporary state-of-the-art methods.
Introduction
Face detection and tracking play pivotal roles in a multitude of computer vision applications, encompassing human-computer interaction (HCI), human-robot interaction (HRI), computer surveillance systems, biometrics, facial recognition, facial expression recognition (FER), and various authentication solutions [22]. Yet, it remains an intricate challenge within the realms of computer vision, image processing, and pattern recognition. Face detection involves the identification of faces in digital images or videos, encompassing tasks such as determining their precise locations, recognizing facial landmarks, and even discerning emotional expressions [15]. Furthermore, achieving high detection accuracy in complex backgrounds holds paramount importance in real-time scenarios, where factors such as pose variations, varying illumination, occlusions, and scale variations pose significant hurdles [28].
In recent years, researchers have introduced various techniques to address the challenges associated with face detection. These techniques leverage different types of prior knowledge about faces and can be broadly categorized into four distinct approaches: (i) Knowledge-Based Approach: This approach, as outlined in [16], relies on predefined rules based on human understanding of facial geometry. These rules dictate the relative distances and positions of facial features. By applying these rules, faces are detected and recognized. A subsequent verification process is often employed to eliminate incorrect detections. (ii) Template Matching Method: The template matching method, as described in [20], involves using a predefined face template or a parameterized face model to identify faces within input images. This technique entails analyzing the pixels within an image window using a predefined pattern to determine the presence of a human face. After initial detection, a verification step is typically applied to refine the results. The edge detection method is employed to detect specific facial features such as eyes, nose, and mouth within a face model. This method is utilized both for face detection and facial feature localization. (iii) Feature-Invariant Approach: The feature-invariant approach, as discussed in [9], focuses on extracting structural features of the face. Initially, these features are utilized for classifier algorithms that distinguish between faces and non-faces in images or videos. Such features may include skin tone, facial contours, and specific facial elements like eyes, nose, and mouth. (iv) Appearance-Based Approach: In the appearance-based approach, detailed in [29, 32], a collection of representative training face images is used to create a face model. This model encapsulates pixel intensities, effectively representing the human face. Machine learning techniques are often employed to identify relevant facial image characteristics.
The Viola-Jones algorithm yields significant results in real-time scenarios. It was introduced by Paul Viola and Michael Jones in 2001 [21]. This algorithm is a general-purpose tool for object detection when trained with datasets of other objects. It comprises four key components: Haar-like features with thresholds, integral images, AdaBoost, and a cascade classifier. Haar features are used to extract a vast number of features for identifying faces in images. These features are designed as black-and-white rectangular regions where the difference in pixel intensities is calculated. If the feature values fall below a threshold, the detection window is classified as positive (indicating a face); otherwise, it’s classified as negative (non-face). Integral images expedite the Haar-like Feature extraction process. AdaBoost, a machine-learning algorithm, selects Haar-like features and combines them to build a strong classifier by iteratively selecting the weak features [7]. However, constructing a classifier with a low error rate often requires a significant number of rounds for identifying optimal features. When using a decision stump as a weak classifier, AdaBoost may require more time to identify optimal features. This often leads to a higher false-positive rate, particularly in dynamic environments [31]. Furthermore, AdaBoost must search among over 180,000 possible features, involving a staggering 2.16 × 1013 feature evaluation combinations. The cascade classifier efficiently dismisses non-faced regions in images or video frames. Besides, the algorithm is sensitive to face rotation, potentially leading to missed detections if faces are not upright. Scale variations are another challenge, impacting accuracy for extremely small or large faces. The algorithm’s computational complexity during training time is one of its shortcomings, as it necessitates a large number of features due to the exhaustive search mechanism used in the AdaBoost algorithm. Moreover, faces that are partially obscured or hidden by occlusions might not be accurately detected. These challenges stem from the selection of numerous features in AdaBoost and the time required to determine the optimal threshold values for identifying strong features while detecting faces in the search window. However, several studies [5–7, 9] have suggested exploring more homogeneous feature types to enhance detector performance. Nevertheless, expanding the number of features inevitably leads to a larger feature set and increased storage memory requirements. As the feature space grows significantly, it becomes evident that the exhaustive search mechanism employed in the standard AdaBoost algorithm is inadequate for efficiently managing the search process. Consequently, this prolongs the training time, which constitutes one of the primary factors discouraging many approaches from exploring alternative feature types.
On the other hand, the advancement of deep learning approaches, such as YOLO [40, 41], SSD [44], Fast-RCNN [47], and CNN-based face detection [43], offers significant performance in a real-time environment. These algorithms are general object detection methods designed for real-time processing speed but may not be as specialized for face detection. They could encounter challenges, especially in scenarios with crowded faces, impacting optimal face detection performance. Similarly, Faster R-CNN achieves high accuracy in complex scenarios in images and video sequences but demands a substantial amount of training data and computational resources. This makes it less suitable for simple applications. Notwithstanding, these algorithms require a large amount of data for training and significant computational resources [46] for implementation on small devices such as mobile cameras.
In this paper, we proposed a Particle Swarm Optimization (PSO) algorithm that integrates into the AdaBoost framework and replaces the exhaustive search used in the original AdaBoost for efficient feature selection and finding the optimal threshold values in the decision stump. PSO is used in a wide range of feature screening optimization and computer vision tasks and has given promising results so far [8, 11]. The proposed approach aims to expedite the training process time, minimize the training error, and develop a robust classifier for face detection by selecting discriminative features. The essential contributions of this paper are as follows: We have optimized the extraneous feature selection process in AdaBoost with the PSO algorithm, Threshold values of the AdaBoost selection process are optimized using PSO, The proposed method has reduced the computational time during the feature selection process, and, The performance of the proposed method has been compared with the conventional method using related metrics of the face detection algorithm.
This paper is organized into five sections. Section 2 presents related works regarding face detection using evolutionary and heuristic approaches and challenges. Section 3 summarizes background information on conventional methods. Section 4 discusses the proposed Viola-Jones algorithm utilizing PSO. Section 5 presents the experimental results and comparison of other state-of-the-art algorithms. Finally, Section 6 concludes the overall works, findings, and results summary.
Related work
Selection criteria
This section presents existing works in the face detection approach, focusing on efforts to reduce computational time and optimize the feature selection using evolutionary and heuristic approaches like PSO. To gather related works for this analysis, we conducted searches across various databases, including Scopus, Web of Science, IEEE, and Science Direct. We used specific keywords such as “Face Detection”, “PSO”, “Viola-Jones algorithm”, and “Object Detection and PSO” to refine the search. While many keywords were available, we limited our search to find papers related to Viola-Jones and evolutionary algorithms. Fig. 1 illustrates the PRISMA (Preferred Reporting Items for Systematic Review and Meta-Analysis Protocols) flow diagram, depicting the paper selection process and the exclusion criteria applied to carry out this research work. Additionally, this paper [2, 27] provides insights into existing face detection methods and highlights current challenges that occur still in the real-time face detection process.
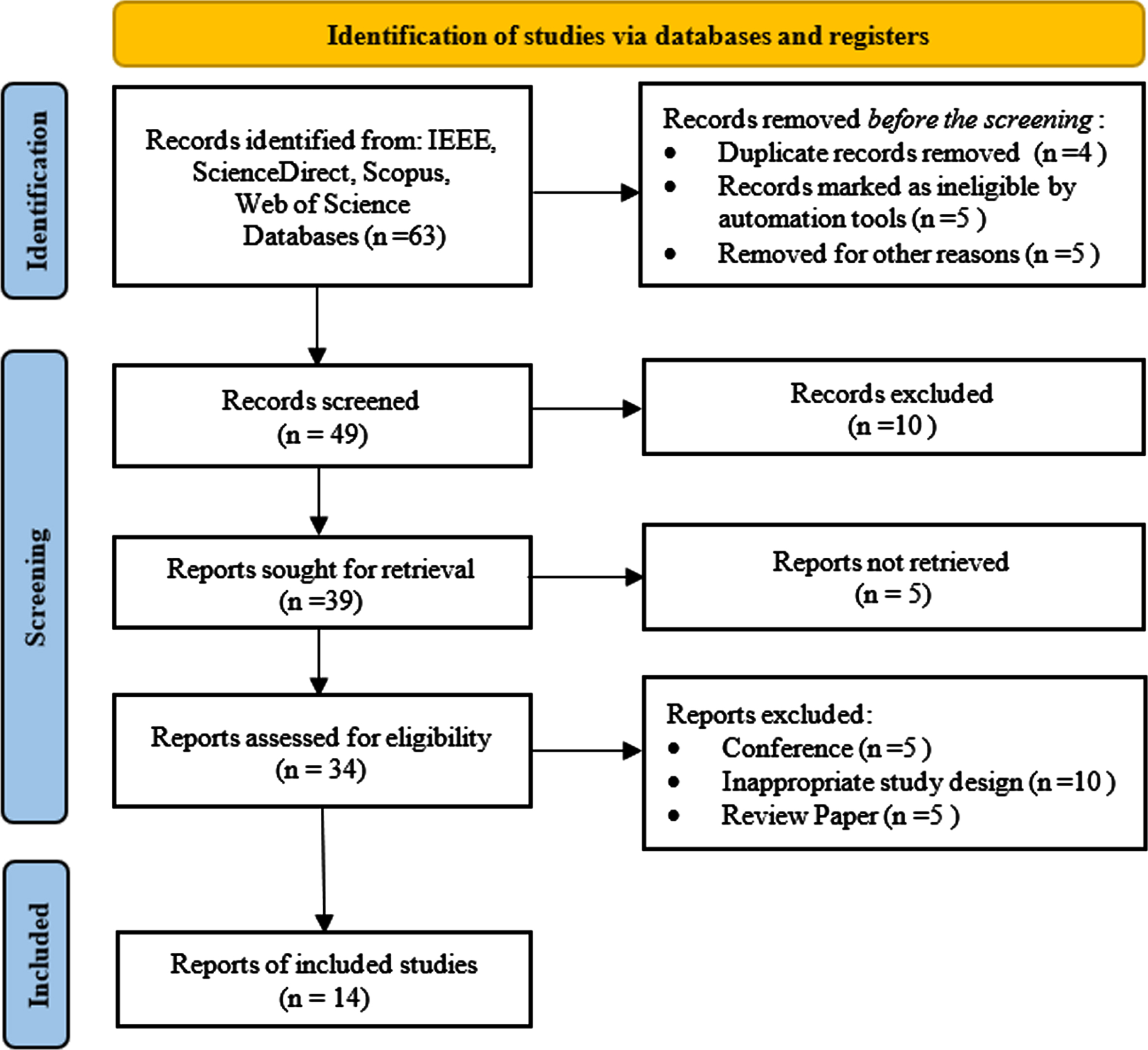
Prisma flow diagram for paper selection for this study.
Perez and Vallejos [7] proposed using PSO to optimize template-based face detection on frontal faces. This approach yielded significant results, relying on face size and line integral values. Lu and Ming [35] introduced a composite feature-based face detection algorithm to enhance the detection rate of rigid objects on faces. They conducted an experiment using the FDDB benchmark dataset and achieved considerable results compared to conventional approaches. Huang et al. [34] improved the Viola-Jones algorithm by upgrading it with HoloLens and enhancing face detection using Haar-like rectangle features. This approach resulted in a 12% increase in average detection accuracy compared to existing face detection methods. Mohemmed et al. [5] proposed optimizing the AdaBoost feature selection process using the PSO evolutionary algorithm. This method selects the best features and optimizes the threshold values within the search space. Experiments were conducted with a “Wisconsin Breast Cancer” image dataset, achieving an average classification rate of 0.97% and a false-negative rate of 0.02%. Similarly, Zakaria and Suandi [38] combined a neural network with AdaBoost methods for face detection, improving detection performance and creating a robust AdaBoost classifier. However, the method was too complex for rapid face detection. An AdaBoost neural network, developed by Zakaria et al. [39], is hierarchical, with the skin module roughly identifying faces, the AdaBoost filtering non-face regions, and the neural network serving as the primary face recognition tool. Li et al. [19] created a Gaussian model for skin color distribution, identified regions with different shades, and detected skin color areas using a cascade classifier. Additionally, the work of Lee et al. [33] attempted to incorporate a weight adjustment factor into a normalized support vector machine (SVM) as the base learner for AdaBoost.
In addition, Zhang and Ye [14] modified AdaBoost by incorporating two features: used PSO to determine the threshold values corresponding to the optimal solution of these two features, and they formed a strong classifier by combining weak classifiers based on these dual features. Zhang and Fan [12] employed Q-statistic correlation determination in training weak classifiers to reduce commonality among them and eliminate similar rectangular functionalities. In a study conducted by Yang et al. [36], they utilized a neural network and AdaBoost to develop an efficient pedestrian detection algorithm. Krishnan et al. [46] designed face detection for thermal and visible image registration using a saliency map strategy integrated with PSO techniques. The author achieved an average improvement of 16.93% similarity index score and 7.02% image quality index score. Subsequently, Besnassi et al. [47] introduced a dispersed Haar filter and optimized it with PSO, differential evolution, and genetic algorithm. The author achieved significant results when using Haar-differential evolution on frontal face detection on various state-of-the-art face detection datasets. Babu et al. [50] presented a facial expression recognition system based on a Deep belief network and PSO used for feature extraction with PCA. Taherkhania et al. [4] developed a CNN based on AdaBoost to reduce the computational processing time required for component prediction over large training datasets. These approaches either reduce training time or enhance detection rates, but none of them completely address the shortcomings of the Viola-Jones-based face detection algorithm. Similarly, Deep learning-based approaches like the paper [45] have presented a modified version of U-NET for significant face detection and recognition accuracy of face images captured by AI cameras with filters. This study attained reasonable detection and recognition accuracy on AI face images. Ranjan et al. [42] introduced a deep pyramid single-shot face detector method for face verification and identification. However, this study does not focus on face-detection challenging images.
Face detection challenges
Face detection is the first step of various face-related applications such as face recognition, facial emotions recognition, face tracking, and face analysis. The process of face detection is to identify the location of the face in images or video frames. There are two different types of factors that affect the effectiveness of the face detection algorithm. One is intrinsic factors that affect face appearances through facial hair, sunglasses, age, and cosmetics, and another one is extrinsic factors, which are illumination, pose variation, scale variations, and noise [30]. However, face detection techniques always require an efficient method to detect the face in various challenging conditions [12]. Figure 2 shows examples of typical challenges associated with faces.

Sample Face Detection challenge images [30].
The first one is locating, and detecting the face is not an easy task in motion and when it has a complex environment. The second one is the illumination which affects the image visibility by the magnitude of light intensity as well as patterns of shading and shadows of the visible image. The third one is, pose variations with different rotations of the face orientation. It is one of the serious problems for face identification. However, the face detection system can handle rotation of head movement up to 40° in the Viola-Jones algorithm. It becomes more challenging when it goes to a higher angle if the trained image is with a particular angle. The final one is occlusion, which is a blockage on the face. It is one of the hardest challenges in face detection when the whole face is not available as input images.
Hence, there are several face detection algorithms in deep learning and machine learning. Currently, the Viola-Jones algorithm is still widely used in digital cameras and social networking applications. Many authors have attempted to modify the Viola-Jones algorithm using various techniques for general object detection purposes. However, there is still a gap in identifying problems and exploring new approaches for improvement.
This section briefly explains the fundamental taxonomy of the Viola-Jones and PSO algorithms and their significance in integrating to enhance face detection performance.
Viola-Jones algorithm
Viola and Jones [21] introduced the Viola-Jones algorithm for general object detection, but it was later trained using face images for face detection.
The Pseudocode for the AdaBoost algorithm is as follows:
This system accelerates the detection process by promptly eliminating non-face images upon detection. It employs four fundamental sets of Haar-like features, Integral images, AdaBoost, and Cascade classifier. For identifying facial features, this system utilizes five sets of Haar-wavelet features, which are black-and-white regions subtracted to compute features (refer to Fig. 3(a)). Approximately 1.80 million pixels of features are generated by varying the height, width, and feature position in a 24 × 24 moving window, as depicted in Fig. 3(b). Integral images play a crucial role in rapidly computing these simple features, as defined by Equation (1). To construct a robust classifier, it’s important to note the abundance of rectangle attributes associated with sub-windows [35, 13].
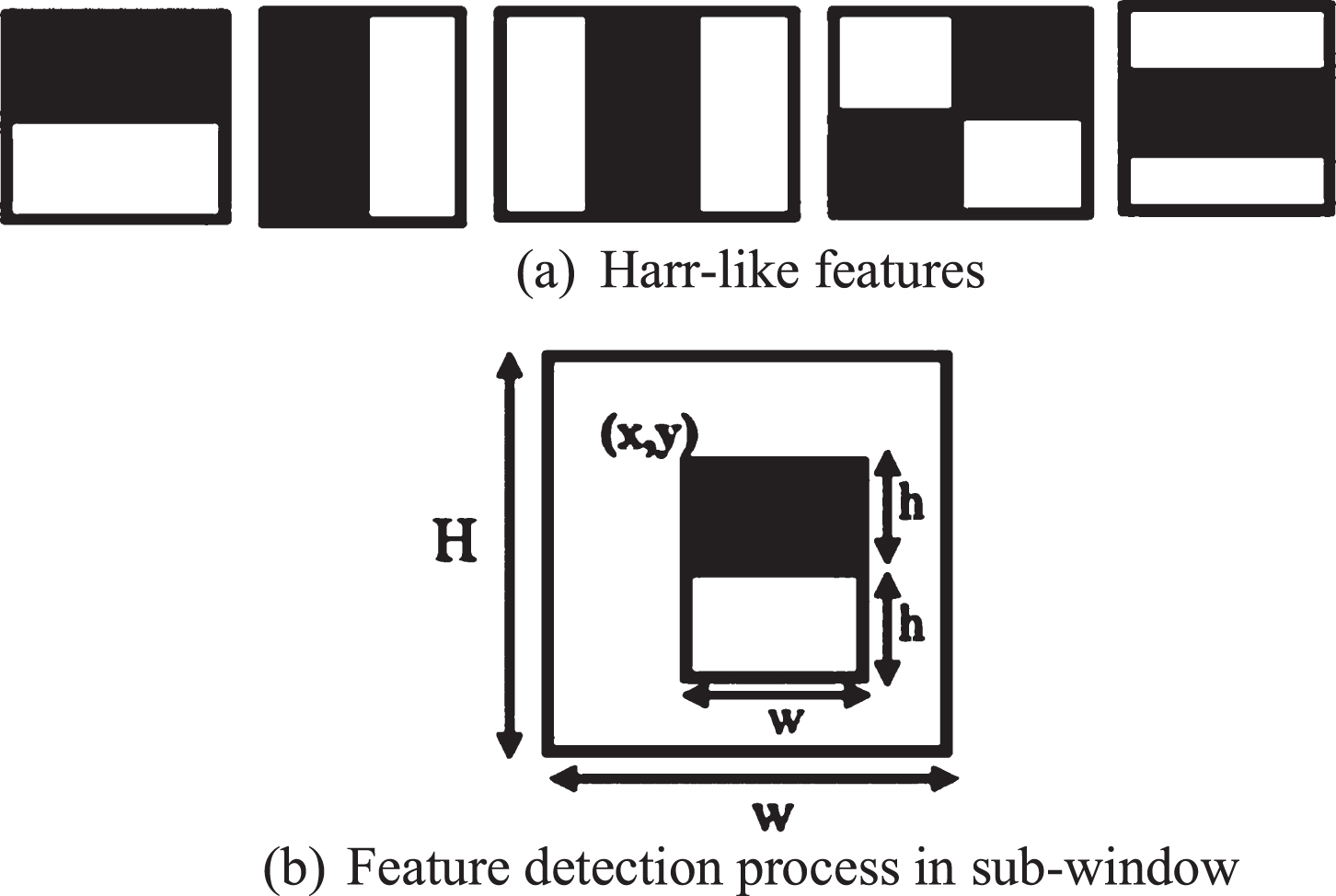
Haar-like Features for feature extraction.
Recalling a substantial number of features selected from rectangles allows for the construction of an effective classifier. The primary objective is to identify the relevant features. The fundamental AdaBoost algorithm is presented in Algorithm 1. This algorithm iteratively trains a weak classifier over T rounds. During training, the algorithm adjusts the weights for samples that were misclassified, increasing the weight for those misidentified and decreasing it for those correctly identified. Likewise, correctly classified samples are less likely to be included in the next iteration, while misclassified samples are given greater consideration. AdaBoost takes a training sample, denoted as S = (x1, y1) , … (x i , y i ) . . , (x m , y m ) with a size M, as input. In this context, each sample x i represents a vector in the domain space X, and y i represents a label in the label space Y. A weight vector is assigned to each sample and updated during each iteration of the training process (as described in Equation (2)). The error rate for each sample is calculated using Equation (3), as shown AdaBoost algorithm. Based on the weights assigned to the weak classifiers h1, and h2, the final strong classifier, H (x), is determined. Therefore, this algorithm is particularly focused on challenging facial samples that are difficult to detect. This research work focuses on binary classification in which Y = {0, 1}.
This algorithm works based on a population approach to determine optimal function parameters through a naturally inspired optimization method known as particle swarm optimization (PSO) [5, 25]. PSO, a stochastic gradient technique inspired by the collective behavior of a swarm, was initially proposed by James Kennedy in 1995. In the PSO algorithm, each solution is referred to as a particle in the search space. These particles have cost values that are optimized by a cost function, and their velocities define their orientation [26, 3].
The PSO process begins with a random population of particles drawn from the original solution space, and their velocities are initialized at irregular intervals within the problem search area. The motion of all particles is guided by the most promising location in the search space, as well as the best position of each particle. The ideal position for each particle is attained by adjusting the particle’s speed and acceleration [37]. According to the following equation, the velocity and position of each particle ‘i’ are updated at iteration ‘t’:
Here, s1 and s2 represent random values within the range [0,1], while c1 and c2 represent cognitive constants, and P and V denote the position and velocity of the particles, respectively. In each iteration, all particles undergo dynamic modifications based on the aforementioned position and velocity, as defined by the algorithm above. Consequently, in most cases, the velocity quickly attains extremely high values, especially for a population distant from its global optimum. PSO consists of two topologies: the Global Neighborhood Topology, which promotes information sharing among particles, and the Ring Topology, which restricts knowledge transfer and prevents a population from converging to a local best solution [3].
In this paper, we propose two ways of approaches to optimize the Viola-Jones algorithm for enhancing prediction accuracy and minimizing training errors. First, we employ PSO to select the optimal threshold values in the decision stump for choosing the best features. Second, we optimize AdaBoost to select the optimal features, enhancing face detection accuracy and speed on cluttered real-time images.
The proposed algorithm of Viola-Jones using PSO pseudo-code is given below.
Selecting threshold value using PSO
In the proposed method, for selection of threshold values, a weak classifier has significantly improved the computational efficiency of the base algorithm by utilizing a decision tree with two leaves, commonly known as a decision stump instead of exhaustively searching for a multitude of features to construct a weak classifier, we employ PSO to pinpoint the optimal decision stump threshold. When decision stumps are employed as weak classifiers on complex datasets, the algorithm must explore all possible thresholds to minimize training error. Consequently, finding the best threshold values can be time-consuming. In such cases, an evolutionary search strategy PSO is invaluable as a proposed approach, accelerating the training of an AdaBoost classifier. Furthermore, each iteration of the PSO approach is dedicated to learning a new weak classifier, and through numerous runs, it may uncover the ideal set of values that collectively form a strong classifier.
In the PSO algorithm, the cost function is utilized to optimize each particle within the entire solution space. Particles employ thresholding values to categorize the solution space into two classes: 1 (representing ’face’) and 0 (representing ‘non-face’). In the initial stage, sample values greater than the threshold are classified as 1, while values below the threshold are classified as 0. This classification is reversed in the subsequent stage during the training of weak classifiers. The training loss is computed for each subgroup, and the weak classifier output with the lowest error is selected. For instance, let S = ((x1, y1) … . (x n , y n )) represent a training set of weak classifiers, where the labels y i ∈ {0, 1}. To calculate each particle, a decision stump requires three parameters: the decision limit (+1 or 0), index characteristics (j), and the optimized threshold value to split the solution space. For input examples x, Equation (6) defines the positive cost function, while Equation (7) defines the negative stump.
The computational cost of the enhanced Viola-Jones algorithm depends on two factors: the population size (S) and the number of iterations (T). Each step in the boosting procedure optimizes the S×T classifiers. PSO is employed to select the best threshold Haar-like features in the AdaBoost.
Enhancing the speed of the face detector without compromising classifier accuracy is a crucial objective. However, the exhaustive feature selection process in AdaBoost often leads to increased complexity. Furthermore, the limited learning capacity of the simple decision stump classifier reduces the efficiency of conventional face detection approach. To address this, we have incorporated the PSO in AdaBoost for the selection of the optimal features for face detection and optimizing the computational processing time. Considering these factors, we propose two improvements to our face detector to reduce the computational burden of feature selection and enhance the selection speed. Firstly, we employ PSO to select optimized threshold values, as discussed in the previous section. Lastly, we combine the PSO technique with the AdaBoost algorithm, enabling rapid exploration of the entire feature space and the selection of the most optimal feature sets, thus expediting the training process and minimise the training error. Algorithm 2 illustrates the proposed Viola-Jones using PSO approach.
In the AdaBoost classifier, exhaustive searches are conducted each time to select relevant features and minimize classification errors. To address the high complexity associated with this exhaustive search, we introduced the use of PSO within the AdaBoost algorithm. PSO is applied to explore potential feature locations, sizes, orientations, and combinations, resulting in the selection of a discriminative feature set. These selected features are then incorporated into AdaBoost to construct an ensemble classifier. The PSO demonstrates efficient search capabilities compared to exhaustive search techniques. In PSO, each particle could explore not only its own space but also the spaces of other particles. Consequently, many particles collectively strive to identify the best possible positions. However, this collaborative approach can lead to a decline in the diversity of selected features as we integrated a random feature selection approach. Specifically, we initially employ PSO to identify the most relevant features at an early stage. As the boosting phase unfolds, our proposed approach transitions to random feature selection to uncover additional discriminative features, thus expanding the pool of candidate features. This adjustment strikes a balance between efficient feature selection and the preservation of feature diversity, enabling us to discover a wider range of optimal features during the boosting process.
Experiments and discussion
This section analyzes the performance of the conventional Viola-Jones algorithm and compares it with an improved approach incorporating PSO optimization. In the conventional Viola-Jones algorithm, AdaBoost employs an exhaustive search to build a weak classifier, while in the proposed approach, AdaBoost utilizes an optimized search to select the best features and threshold values. Furthermore, significantly reduced the false positive rate.
Dataset description
Face images were collected from the Yearbook Dataset of frontal-facing American high-school seniors [23], while non-face images were obtained from the Stanford Background Dataset [24] and ImageNet [10]. These images are used for both training and testing purposes. These databases contain 4,999 different face images and 6,960 non-face images, all with a pixel resolution of 25 × 25. The positive and negative images are randomly divided into two folders. The training folder comprises 1,200 positive and 1,000 negative grayscale images (See Fig. 4). The test set consists of 750 positive and 658 negative images. This experiment was validated using the Wider Face test benchmark dataset, which includes various real-time facial detection challenge images [30]. The dataset comprises 32,203 photographs and labels 393,703 faces, covering a wide range of scales, poses, and occlusions.

The face detection algorithm has two classes: faces and non-faces. The performance of the proposed method is evaluated using Equations (9) and (10). The True Positive Rate (TPR) is used to measure how well the model correctly predicts the positive class. The equation for TPR is given below:
False Positive Rate (FPR) is used to measure the outcome of the model that incorrectly predicted the negative classes. This equation is given below:
To construct the weak classifier for selecting the best threshold value, we examined the particle’s size and maximum iteration using the ImageNet dataset. The results are displayed in Table 1 showing the performance of various particle sizes and their iterations. The selected optimal threshold value is then applied in the feature selection section of AdaBoost to optimize the features and computation time. Besides, the best PSO parameters were chosen according to Table 1 (Particle size 20 and iteration 100).
The training error of the training dataset
To analyse the proposed approach reliability, accuracy and time spend of each sample parameter are used. The proposed approach consists of 200 particles and could run for up to 1,000 iterations for constructing a weak classifier. However, it terminates if there is improvements are observed in the feature selection process within the global solution search space. Initially, the population is randomly defined, with the feature selection parameters (x, y, w, h) in the range of [0, 250] and the feature type in the range of [0, 4]. The social value parameters are set to c1 and c2, both ranging from 100 to -100. Random values are independently sampled from the range [0, 1], and Q1 and Q2 are both set to 3.05. These experiments were conducted with 1,000 iterations, and the results, including the best, worst, and average, are reported in Table 2. These experiments were run on Google Colab with GPU K80.
Number of features needed for detection
Number of features needed for detection
The proposed approach is analyzed in terms of classifier accuracy and execution time. The experiments were repeated ten times for each algorithm, and the best, average, and worst outcomes are presented in Table 2. Additionally, the analysis indicates the number of features required for face detection process on complex face images. The performance of face detection is influenced by both the population size and the number of PSO iterations. The results demonstrate the effectiveness of PSO for optimal feature selection in this problem when compared to the conventional Viola-Jones algorithm.
This experiment reveals that the proposed method utilizes as few features as possible compared to the conventional algorithm. Table 2 shows the number of features generated for a strong classifier during the training process. Viola-Jones with PSO required only 120 features in the best case, 134 in the average case, and 150 features in the worst case for building the weak classifiers, whereas the conventional Viola-Jones algorithm required 340 features in the best case. Therefore, the proposed method constructs superior classifiers using only 120 features in the best case, which is significantly fewer than the conventional Viola-Jones method.
Table 3 summarizes the overall comparison between the conventional Viola-Jones and the proposed method on the ImageNet test dataset. The proposed approach achieved an average classification accuracy rate of 98.73% and a False Positive Rate (FPR) of 1.27% on the face images when testing. In contrast, the conventional Viola-Jones algorithm achieved an average accuracy of 96.63% and a 3.37% FPR on the face images. These results indicate that the proposed method is not only more efficient than the Conventional-VJ algorithm but also more effective in classifying unseen datasets. Furthermore, the proposed method requires less time to test the dataset compared to the conventional algorithm.
Face detection performance
Face detection performance
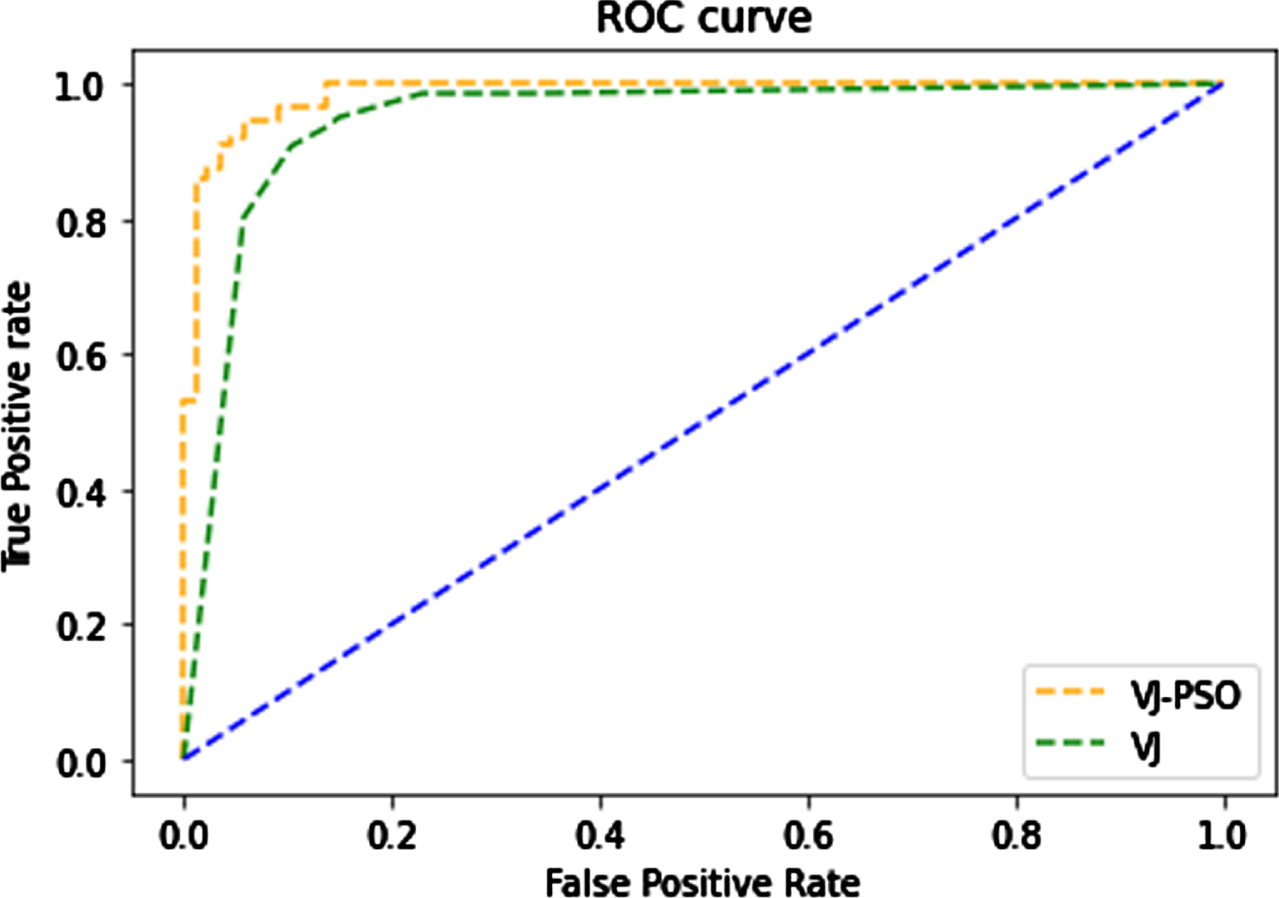
ROC curves of Conventional-VJ and VJ with PSO.
The performance of the proposed approach and the conventional Viola-Jones algorithm is depicted using the Receiver Operating Characteristic (ROC) curve (See Fig. 5). The performance of the proposed method is represented in orange color, whereas the conventional Viola-Jones algorithm’s performance is shown in green. According to the ROC curve, the proposed approach achieved a 98.73% accuracy on the face and non-face image dataset, whereas the conventional algorithm achieved 96.63%. After a successful testing process, the proposed approach converted as face detection model also saved as.XML file, allowing it to detect faces in various challenging contexts. Finally, a comparison of the performance of the classic machine learning based face detection algorithm and the proposed technique is presented in Table 4. The Viola-Jones algorithm with PSO performed effectively in various face detection complex real-time face images, including scale variation, illumination, pose variation, and occlusion, compared to the conventional method. Table 5 shows the results of prosed approach detection performance and conventional approach.
Performance comparison of the proposed method with another approach in Face Detection
Performance comparison of proposed and conventional Viola-Jones algorithm on the Wider benchmark dataset [30]
The computational complexity of the optimized Viola-Jones algorithm is determined by two parameters: S, which represents the number of particles, and T, which represents the number of iterations. In contrast, the computational complexity of the AdaBoost algorithm is determined by the parameter N, denoting the number of samples. The time complexity of the proposed algorithm at each stage of the boosting technique is O(S×T), whereas the time complexity in the base model is O(Nˆ2). The basic AdaBoost technique trains a weak classifier in polynomial time, while the improved PSO-based Viola-Jones algorithm’s time complexity scales linearly with S and T.
In this paper, we propose an efficient and enhanced face detection approach using PSO in Viola-Jones to improve prediction accuracy for complex real-time face images. This research work aims to enhance the optimal feature selection process and global threshold determination in AdaBoost and Haar-like features using PSO. The use of PSO enables a reduction in false-positive rates and computational time significantly. The proposed approach constructs a more efficient weak classifier for face detection in complex face images. Instead of an exhaustive feature search, PSO optimizes the selection process, leading to better performance. The proposed method is validated on the Wider face detection benchmark and demonstrated superior results compared to the conventional algorithm. It achieved an impressive average true positive rate of 98.73% with only a 1.27% false positive rate. Additionally, the proposed approach significantly reduced face detection time on the test samples. Although the proposed approach outperformed the conventional algorithm in terms of true positive rate, longer training time on the dataset. The results suggest that the proposed method can be a promising solution for achieving accurate and rapid face detection in various applications.
Acknowledgment
The authors convey sincere thanks to the ISO Certified (ISO/IEC 20000-1:2018) Centre for Machine Learning and Intelligence (CMLI) funded by the Department of Science and Technology (DST-CURIE), India for providing the facility to carry out this research study.
Conflict of interest
The authors declared that no conflict of interest in this work.
Author’s contribution
P. Subashini developed the methodology and design of the manuscript. Diksha Shukla contributed to the text and content of the manuscript, including entire revisions and edits. M. Mohana conducted the experiments, compared the results, created the figures, and drafted the entire manuscript with contributions from the co-authors. All authors were involved in conducting the experiment and analyzing the results. They have reviewed and approved the content of the manuscript and are willing to be held accountable for the work.
Ethics approval and consent to participate
This study was approved by the Avinashilingam Human Ethics Committee, Coimbatore, India. The approval number is AUW/IHEC/CS-21-22/XMT-03.
Data availability
Open-source Wider Face, Yearbook, and ImageNet Datasets.
Fund availability
There is no external funding for this research study.
Declaration of AI and AI-assisted technologies in the writing process
During the preparation of this work, the authors utilize Grammarly assistant tools included in Microsoft Word for grammar checking. After using these tools, the authors reviewed and edited the content as necessary and take full responsibility for the publication’s content.