
Abstract
Multitask learning (MTL) is a machine learning paradigm where a single model is trained to perform several tasks simultaneously. Despite the considerable amount of research on MTL, the majority of it has been centered around English language, while other language such as Arabic have not received as much attention. Most existing Arabic NLP techniques concentrate on single or multitask learning, sharing just a limited number of tasks, between two or three tasks. To address this gap, we present ArMT-TNN, an Arabic Multi-Task Learning using Transformer Neural Network, designed for Arabic natural language understanding (ANLU) tasks. Our approach involves sharing learned information between eight ANLU tasks, allowing for a single model to solve all of them. We achieve this by fine-tuning all tasks simultaneously and using multiple pre-trained Bidirectional Transformer language models, like BERT, that are specifically designed for Arabic language processing. Additionally, we explore the effectiveness of various Arabic language models (LMs) that have been pre-trained on different types of Arabic text, such as Modern Standard Arabic (MSA) and Arabic dialects. Our approach demonstrated outstanding performance compared to all current models on four test sets within the ALUE benchmark, namely MQ2Q, OOLD, SVREG, and SEC, by margins of 3.9%, 3.8%, 10.1%, and 3.7%, respectively. Nonetheless, our approach did not perform as well on the remaining tasks due to the negative transfer of knowledge. This finding highlights the importance of carefully selecting tasks when constructing a benchmark. Our experiments also show that LMs which were pretrained on text types that differ from the text type used for finetuned tasks can still perform well.
Keywords
Introduction
In recent years, significant progress has been made in the field of artificial intelligence (AI), particularly in Natural Language Processing (NLP), thanks to advancements in deep learning. Deep neural networks aim to optimize millions of parameters gradually to solve complex problems. Transfer learning has emerged as a leading approach in modern AI, involving learning to solve a general problem first and then transferring that knowledge to solve a specific task. In NLP, pre-trained language models that optimize general language tasks, such as Masked Language Model (MLM) and Next Sentence Prediction (NSP), are used to achieve this goal by training them on large amounts of unlabeled data.
The popularity of language models has grown in recent years, particularly with the introduction of Bidirectional Encoder Representations from Transformers (BERT) by Jacob Devlin et al. [1]. BERT has set the state-of-the-art in most NLP problems, owing to its ability to capture contextualized meaning and richer representations. It is a pre-trained language model that utilizes transfer learning and has been trained on vast amounts of unlabeled data to optimize MLM and NSP objectives. BERT can be used for feature extraction or fine-tuning, where feature extraction involves using the pre-trained BERT parameters without updating them, while fine-tuning involves fine-tuning any number of layers or parameters for a specific task using labeled data.
Traditional machine learning models focus on performing a single task, ignoring the fact that humans learn tasks by building upon related tasks. In NLP, many language tasks may share some degree of relatedness [2]. Multi-task learning (MTL) is a machine learning approach that involves learning multiple tasks simultaneously with the goal of improving generalization across all tasks by utilizing helpful information shared across related tasks [3]. In the context of language models, the general MTL architecture involves sharing layers/parameters, either fully or partially, of the language model across multiple tasks. This enables millions of parameters to receive signals during training, allowing them to learn about each task. The parameters can be shared through either hard parameter sharing or soft parameter sharing [4]. Hard parameter sharing involves sharing a single model’s weights across multiple tasks, with each task having its own task-specific layer/classifier, and the objective is to optimize multiple loss functions. Soft parameter sharing, on the other hand, refers to each task having its own model, but the distance between the models’ parameters are regularized.
Despite the many advantages of MTL, it remains an active area of research in NLP. Because MTL involves training multiple tasks simultaneously, it is possible to have some tasks that have conflicting knowledge, which can lead to negative transfer. This problem occurs when reducing the loss of one task increases the loss of another task. Various methods have been proposed to mitigate the impact of negative transfer, such as loss weighting, which involves balancing multiple loss functions into a scalar [5]. Another method is task scheduling, which aims to identify which tasks should be trained together at each training step [6]. Other methods include task relationship and knowledge distillation. For more details, readers can refer to [3]. However, dealing with negative transfer is a broad topic beyond the scope of this work.
Recently, there has been a shift in research towards MTL in English language understanding, thanks to the development of the General Language Understanding Evaluation (GLUE) benchmark [7]. However, MTL in other languages, such as Arabic, has been slow to progress due to the absence of well-developed benchmarks. To bridge this gap, a new Arabic Natural Language Understanding (NLU) benchmark called the ALUE has been introduced [8].1
Leaderboard
Our paper focuses on utilizing a BERT-based architecture with hard parameter sharing across multiple Arabic NLU tasks. We evaluate MTL performance only on the tasks offered in the ALUE benchmark and investigate the capabilities of different pre-trained Arabic LLMs when fine-tuned on specific tasks with varying text types. The objectives of the research are presented below:
To examine the effectiveness of hard parameters sharing strategy in enhancing Arabic NLU tasks performance in various tasks. To explore the applicability of different pretrained Arabic LMs, including those trained on text types different from the finetuned tasks. To demonstrate the impact of positive and negative transfer learning on the ALUE benchmark tasks.
The main research contributions can be outlined as follows:
To the best of our knowledge, this is the first attempt to study MTL on a larger scale of Arabic NLU tasks, compared to prior work. Enhancing the performance of various Arabic NLU tasks in the ALUE benchmark. Conducting a thorough analysis of the results and offering recommendations and suggestions for future research.
The paper is organized as follows. In Section 2, we review related work on multitask learning in both English and Arabic. In Section 3, we provide details on the resources used in this study, including the Arabic language models and benchmark datasets. Section 4 presents our proposed ArMT-TNN, a multitask learning framework with hard parameter sharing for NLU tasks. In Section 5, we provide experimental setup and implementation details of this work, including training procedure and hyperparameters. Section 6 reports the results of the ALUE benchmark tasks and provides a detailed discussion on the obtained results, including the analysis of positive and negative transfer of knowledge. Finally, we conclude our study in Section 7, where we summarize the main contributions of this work and outline directions for future research.
This section discusses various studies and research works that have explored the benefits of using MTL for various English and Arabic NLP tasks. The section highlights the advantages of using MTL for tasks such as detecting hate speech and offensive language, sarcasm and sentiment analysis, cross-lingual abstractive summarization, Modern Standard Arabic (MSA) and dialect identification, fake news detection, and named entity recognition. The studies discussed in this section have shown promising results in using MTL for these tasks compared to other traditional approaches.
MTL in english NLP
In this section, we review the related work on MTL in NLP, specifically the research that employs Language Models (LM) based on the Transformer architecture [9] in both English and Arabic.
One of the earliest works that utilized BERT as a shared text encoder layer in MTL was presented in [10]. The lower layers of this MTL architecture are shared across all tasks, while the top layers are specific to each task. This method achieved state-of-the-art performance on eight out of nine GLUE tasks. In a similar vein, [11] investigated various fine-tuning strategies for text classification tasks, including the MTL paradigm, and concluded that MTL was helpful in some cases.
To improve the knowledge transfer in MTL, Liu et al. [12] and Clark et al. [13] utilized knowledge distillation. This technique aims to distill knowledge from a set of single-task models (teachers) into a single multitask model. Both works showed improvements over traditional MTL.
Recently, Aghajanyan et al. [14] and Aribandi et al. [15] proposed a new strategy to better exploit the benefits of MTL, called massive MTL. This approach involves extensively prefinetuning the model’s parameters on a large-scale dataset, including a massive amount of labeled data on a wide range of tasks. Both works reported noticeable improvements over the vanilla MTL approach across several tasks.
MTL has also been shown to improve the performance of various NLP applications. For instance, Kim et al. [16] and Li et al. [17] utilized MTL for knowledge graph completion and linkage between entities. MTL is an effective method to leverage knowledge in the semantic network. Additionally, Morio et al. [18] proposed an MTL framework for spoken language understanding, where the input is speech, and the MTL system produces several NLP tasks such as question answering, intents, and named entity recognition. Other NLP applications, such as argument mining [18], biomedical text mining [19], and peer assessments [20], multimodal aspect sentiment analysis [21], and emotion intensity for detecting suicidal tendencies [22] have shown that MTL produces better representations of knowledge and is robust to errors.
In recent years, there has been a growing interest in incorporating prompt-based learning approach into MTL paradigm. A few recent studies have demonstrated that prompt-based learning can facilitate the transfer of knowledge in language models with zero-shot and few-shot learning [23, 24, 25, 26, 27]. This is achieved through extensive multitask learning across a wide range of tasks utilizing prompt learning.
Based on the related work discussed above, it can be concluded that MTL has shown promising results in various English NLP tasks such as detecting hate speech and offensive language, sarcasm and sentiment analysis, cross-lingual abstractive summarization, MSA and dialect identification, fake news detection, and named entity recognition. The studies discussed in this section have utilized Language Models (LM) based on the Transformer architecture and have explored various MTL architectures and approaches such as knowledge distillation, massive MTL and prompt learning.
MTL in Arabic NLP
Recently, there has been a growing interest in utilizing MTL for various Arabic NLP tasks. For instance, Farha and Magdy [28] investigated the effectiveness of different approaches such as BiLSTM, CNN, CNN-BiLSTM, and BERT MTL for detecting hate speech and offensive language. Other works, such as [29, 30, 31], also explored the advantages of using MTL in this area. Additionally, sarcasm and sentiment analysis have also shown improvements with MTL. Mahdaouy et al. [32] proposed an attention interaction layer on top of a BERT task-specific dense layer, which achieved promising results in both tasks. Similarly, Alharbi and Lee [33] introduced a method that incorporates three models: word embeddings, contextualized embeddings, and MTL, which achieved the best performance in sarcasm detection.
Another application of MTL in NLP is cross-lingual abstractive summarization, where Takase and Okazaki [34] proposed a MTL framework called Transum, which utilizes translation pairs and monolingual sentence summaries. This method achieved top ROUGE scores in both Chinese-English and Arabic-English abstractive summarization. Additionally, applied El Mekki et al. [35] applied MTL for MSA and dialect identification at both country and province levels, and the results showed that MTL outperformed the task model. Moreover, MTL approaches have outperformed other methods in fake news detection [36] and named entity recognition [37].
The above Arabic MTL studies have shown promising results in various NLP tasks, such as detecting hate speech and offensive language, sarcasm and sentiment analysis, cross-lingual abstractive summarization, MSA and dialect identification, fake news detection, and named entity recognition.
However, there are still some gaps and challenges in the existing studies. For example, there is a lack of large-scale labeled datasets in Arabic NLP, which limits the application of MTL in Arabic NLP. Additionally, most of the existing studies focus on a limited number of tasks, and there is a need for more comprehensive studies that cover a wide range of Arabic NLP tasks. Moreover, some studies do not compare their MTL approach with other traditional approaches, making it difficult to evaluate the effectiveness of MTL.
Arabic language resources
This section describes the Arabic language resources used in our study, including pretrained language models and datasets for natural language understanding tasks. Our resources mainly consist of Arabic pretrained language models and a collection of NLU datasets. Several Arabic pretrained language models have been made available for public use in recent years, and we have selected language models that focus on dialectal Arabic. For our NLU datasets, we use the ALUE, a recently proposed benchmark for NLU.
Arabic pretrained language models
This subsection presents an overview of the Arabic pretrained language models utilized in our study, with a focus on models developed for dialectal Arabic. The following Arabic pretrained language models are included in our resources, all of which are based on the BERT architecture and available on the Huggingface library.
Statistics of train, dev, and test sets of tasks in the ALUE benchmark
This subsection presents an overview of the ALUE benchmark, which comprises eight tasks that evaluate NLU performance. The tasks are described in detail below.
Table 1 presents the statistics of the train, development, and test sets of tasks in the ALUE benchmark. There are eight tasks listed in the table, namely SEC, MDD, FID, MQ2Q, XNLI, OHSD, SVREG, and OOLD. The text type involved in the tasks is either MSA or Arabic dialects (DIAL), and each task is described in terms of the inputs and associated labels. The number of training, development, and test samples are shown for each task, along with the task type, which could be either single-sentence classification with 2 or 11 labels, sentence-pair classification with 2 or 3 labels, or single-sentence regression with scores between 0 and 1.
This section describes the architecture and functionality of the ArMT-TNN system. It is designed as a Multitask Deep Neural Network System that enables the simultaneous learning of multiple tasks with the aim of positively transferring knowledge among related tasks. The proposed approach is a straightforward implementation of MTL that shares all parameters across all tasks using the Bidirectional Encoder Representation from Transformers (BERT) pretrained language model. Fine-tuning BERT on downstream tasks has been shown to result in significant improvements for many NLP applications. The ArMT-TNN system’s architecture is illustrated in Fig. 1.
Architecture of the proposed ArMT-TNN system.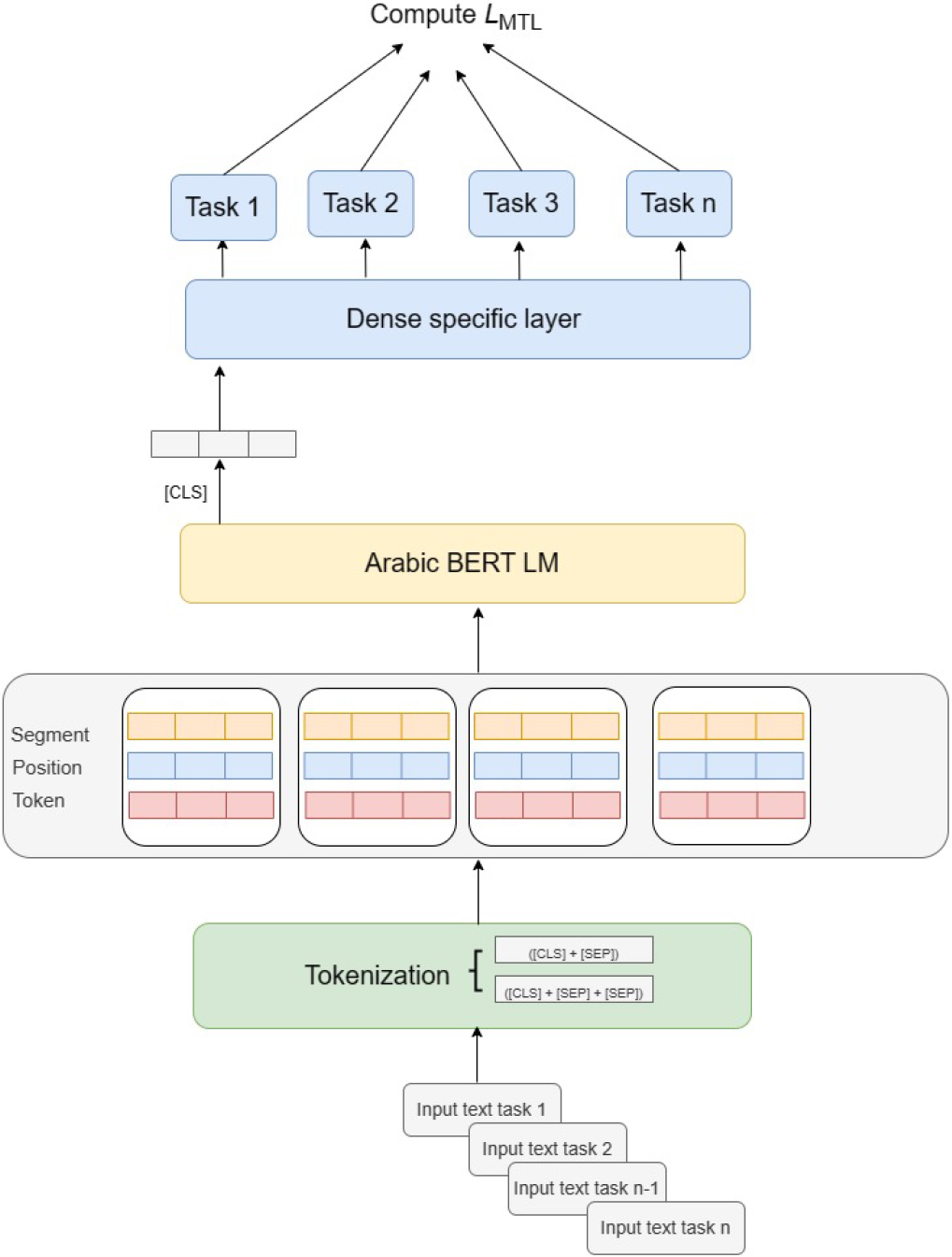
We use Arabic BERT as our input encoder, and the output of the encoder is passed into a classification head based on the corresponding task. Each task has its own classification head. The input sequence of wordpieces
The ArMT-TNN training algorithm initializes its model parameters using a pretrained Arabic LM and sets specific hyper-parameters. For each task, the dataset is divided into mini-batches, which are then combined into a single batch B. During training, for each epoch, the algorithm iterates over each mini-batch in B, calculating the loss based on the task type (classification, binary classification, or regression). After summing all individual losses, the total loss is computed, its gradient is determined, and the model parameters are updated accordingly.
For each learned task, we use a dedicated classifier. For single sentence classification tasks, such as OOLD for binary classification, SEC for multi-label classification, or SVREG for regression, the model calculates the probability of class
Here,
For single sentence multi-class single-label tasks, such as MDD, or pairwise text classification tasks, such as XNLI, we use softmax as:
Our dataset consists of four different types of tasks: multi-class classification, binary classification, multi-label classification, and regression. To train our model for each task, we use different loss functions tailored to each task’s specific requirements.
For multi-class classification tasks, such as XNLI and MDD, we use the cross-entropy loss function:
Here,
For binary and multi-label classification tasks, such as OOLD and SEC, we use the binary cross-entropy loss function:
Here,
For regression tasks, such as SVREG, we use the mean squared error (MSE) loss function:
Here,
To train our model for all tasks, we combine the loss functions for each task using a weighted sum:
Here,
The section describes the methodology used in the experiments, including text preprocessing, data and models used, evaluation metrics, and implementation details such as cloud computing services, batch size, input sequence length, optimizer, and dropout rate.
Text preprocessing
We begin by performing basic Arabic text preprocessing, which includes removing diacritics, English letters, numbers, URLs, and emojis. For Twitter hashtags, we remove the hashtag and underscore symbols and replace them with whitespace. Additionally, we handle repeated characters, which are often used for emphasis or to convey strong emotions. We reduce words to their standard form, keeping at most two consecutive repeated letters.
Data and models
Our training and testing data come from the ALUE benchmark [8], as described in Section 3.2. We include the validation set during training, if available. We use the pretrained language models mentioned in Section 3.1 for fine-tuning, and compare our models with state-of-the-art models listed on the ALUE leaderboard.2
We use four evaluation metrics to assess the performance of our models on the ALUE benchmark. F1-score is used for tasks such as MQ2Q, OOLD, OHSD, FID, and MDD, while Jaccard similarity score is used for SEC and Pearson correlation coefficient is used for SVREG. Accuracy is employed for XNLI.
Implementation details
We conducted the finetuning phase on AWS cloud computing services with 4 NVIDIA Tesla T4 GPUs, totaling 192GB of memory. Our implementation is based on the Huggingface library.3
Evaluation performance of MTL approach and state-of-the-art models on ALUE test set
Performance results of all tasks on test datasets over 10 epochs. The x-axis denotes the number of epochs, while the y-axis represents the performance.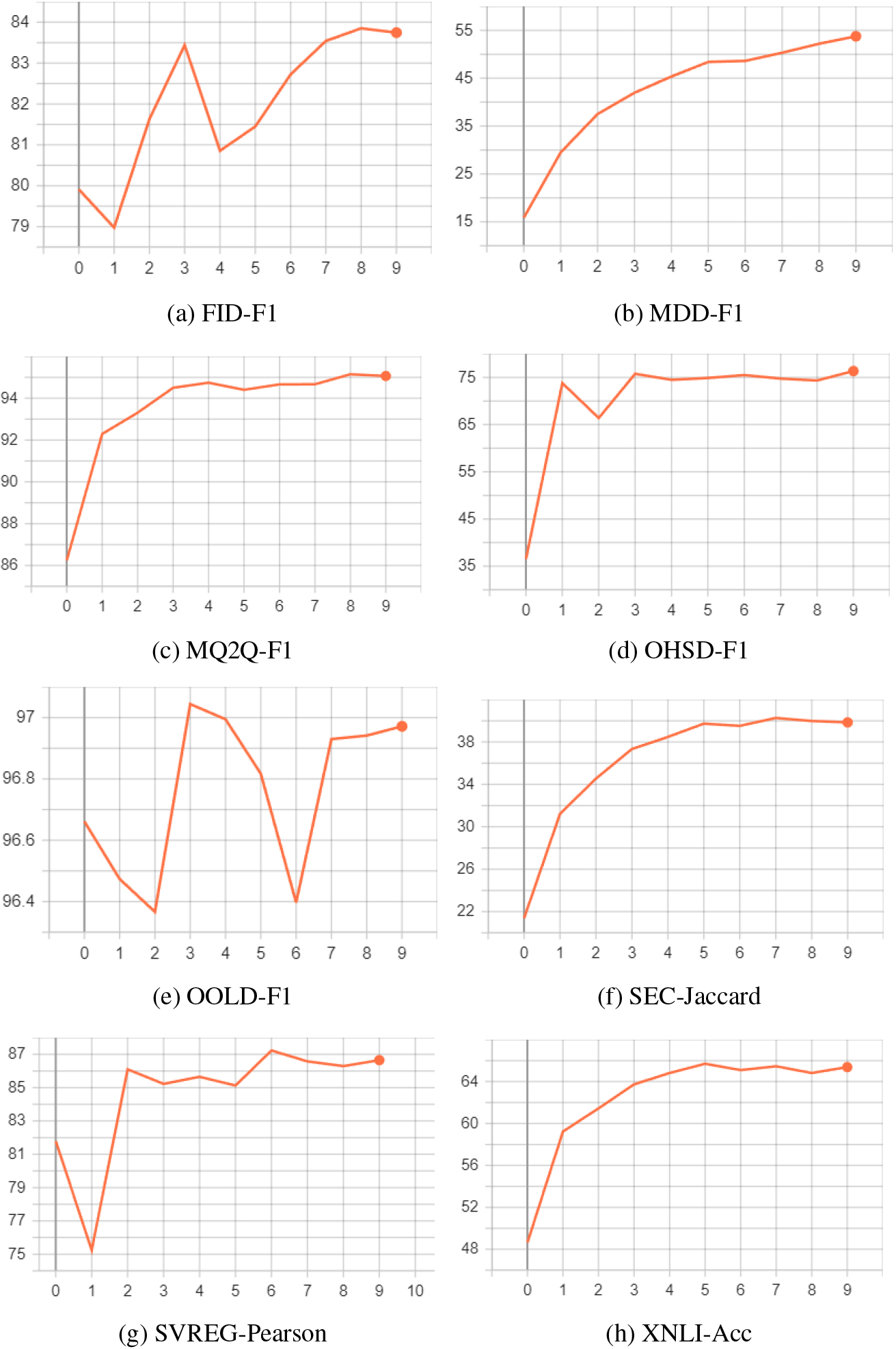
We conducted an evaluation of our MTL approach using three Arabic pre-trained language models (PLM) – AraBERT-v02, ArabicBERT Multi Dialect, and MARBERT – against the state-of-the-art models found on the ALUE leaderboard. Our MTL approach outperformed all existing models on four ALUE tasks test sets, as shown in Table 2. The top part of the Table 2 shows the models found on ALUE leaderboard. Our proposed work is on the bottom part of the table showing three different models. The state-of-the-art results are shown in bold. F1-score metric is used for MQ2Q, OOLD, OHSD, FID, and MDD. Jaccard similarity score and Pearson correlation coefficient are used for SEC, and SVREG respectively, accuracy metric is used for XNLI. The rest of the tasks are using F1-score metric. We have also visualized the performance results of our models on the test datasets of all tasks over 10 epochs, and the corresponding plot is shown in Fig. 2.
Specifically, it can be observed from Table 2 that using AraBERT-v02 improved MQ2Q by 3.9% compared to SABER, while MARBERT outperformed SABER in OOLD, SVREG, and SEC by 3.8%, 10.1%, and 3.7%, respectively. However, SABER remained the state-of-the-art on the other four tasks, which are OHSD, FID, XNLI, and MDD, outperforming our best model by 10.1%, 3.1%, 4.7%, and 23.7%, respectively.
It is noticeable from our average score compared to Saber’s that although our overall average score is lower, some of our models perform exceptionally well on certain tasks. Specifically, our models show positive transfer and improve performance on MQ2Q, OOLD, SVREG, and SEC, depicted in Fig. 2. However, it appears that OHSD, FID, XNLI, and MDD do not benefit from knowledge sharing, and actually exhibit negative transfer. This may be attributed to the fact that the learning tasks are not uniformly related, with some tasks being dominant over others.
Furthermore, we observed that some tasks such as FID, OOLD, and SVREG experience performance fluctuation during weight updates, with these fluctuating tasks performing particularly well. We attribute this to the fact that their loss functions are smaller, which drowns out the gradients compared to tasks with larger loss functions that become more dominant for optimization. However, this is not always the case, as MQ2Q does not experience fluctuations even though its loss function is small. This may indicate that MQ2Q is highly related to the other tasks.
Interestingly, we also observed that language models pretrained on different data types from the tasks’ data type can still perform well on those tasks, as demonstrated by the success of MARBERT on MQ2Q and XNLI, which are both of the MSA type of Arabic text. MARBERT outperformed Arabic-BERT, mBERT, Jaber, and Saber on MQ2Q, but only outperformed Arabic-BERT and mBERT on XNLi. This suggests that MTL can overcome differences in data types, as long as there is some relatedness between the tasks. However, more tasks based on MSA text types should be added to ALUE for deeper insights.
Overall, our findings demonstrate the potential of our proposed model for improving performance on multiple related tasks, and highlight the importance of careful task selection for effective knowledge sharing.
Conclusion and future work
In conclusion, our study presented ArMT-TNN, a multitask learning framework for Arabic NLU tasks, which allows for knowledge sharing and transfer between tasks. We found that some tasks experienced positive transfer of knowledge, leading to improved performance, while others experienced negative transfer. Our results suggest that careful consideration of task relationships and loss scaling may mitigate the issue of negative transfer in future work. We also demonstrated the potential of using Arabic massive MTL to further improve the performance of our framework.
As for limitations, our study was limited to a set of eight Arabic NLU tasks, and further investigation on other tasks and domains may be needed to confirm our findings. Additionally, our study only utilized hard parameter sharing, and other types of parameter sharing mechanisms may have different impacts on knowledge transfer and performance.
For future work, we plan to further explore the issue of negative transfer and investigate more effective methods for mitigating it, such as dynamic weight allocation and task clustering. We also plan to extend our framework to handle more complex tasks, such as question answering and dialogue generation. Finally, we intend to explore the use of other parameter sharing mechanisms and investigate their effects on multitask learning performance.
Footnotes
Acknowledgments
This project was funded by the Deanship of Scientific Research (DSR), King Abdulaziz University, Jeddah, under grant no. (J: 13-611-1443). The author, therefore, acknowledge with thanks DSR technical and financial support.