
Abstract
In this paper, we introduce a retrieval framework designed for e-commerce applications, which employs a multi-modal approach to represent items of interest. This approach incorporates both textual descriptions and images of products, alongside a locality-sensitive hashing (LSH) indexing scheme for rapid retrieval of potentially relevant products. Our focus is on a data-independent methodology, where the indexing mechanism remains unaffected by the specific dataset, while the multi-modal representation is learned beforehand. Specifically, we utilize a multi-modal architecture, CLIP, to learn a latent representation of items by combining text and images in a contrastive manner. The resulting item embeddings encapsulate both the visual and textual information of the products, which are then subjected to various types of LSH for balancing between result quality and retrieval speed. We present the findings of our experiments conducted on two real-world datasets sourced from e-commerce platforms, comprising both product images and textual descriptions. Promising results have been achieved, demonstrating favorable retrieval time and average precision. These results were obtained through testing the approach with a specifically selected set of queries and with synthetic queries generated using a Large Language Model.
Introduction
The description of products in e-commerce applications is increasingly using multi-modal specifications, where textual description of the products and pictures showing images of the products are the main relevant modalities. To this end, one promising avenue in e-commerce applications involves leveraging these different modalities during item searches, where textual descriptions and product images play the most important role. This approach not only offers enhanced flexibility in user-system interactions, but also presents a potential solution to the data sparsity challenge commonly encountered in the development of product recommendation strategies and during deployment in e-commerce applications [1]. However, as different modalities often entail a substantial volume of data, typically of high dimensionality, multi-modal retrieval demands extensive storage space and prolonged retrieval times. Consequently, efficient retrieval techniques based on hashing are commonly employed [2].
In this paper, we expand upon the work presented in [3] and introduce a retrieval framework tailored for e-commerce applications. This framework relies on a multi-modal representation of the items of interest, encompassing textual descriptions and product images, combined with a Locality-Sensitive Hashing (LSH) indexing scheme [4] to expedite product retrieval. The objective is to facilitate the specification of desired products through both images and text, enabling efficient retrieval of similar products. While cross-modal retrieval has been extensively explored in the literature [5], our approach makes a novel contribution by addressing two key aspects:
the exploitation of multi-modal retrieval in the context of e-commerce applications concerning the recommendation of products through both product pictures and textual descriptions; the choice and the analysis of a suitable indexing strategy (LSH) directly working on the joint embedded representation of the product information (textual description and pictures) in an efficient way.
We focus our idea on a data-independent approach [6], where no training data is used to learn the indexing function, and the multi-modal representation is learned upstream. Specifically, in this paper, we utilize the Contrastive Language-Image Pre-Training architecture (CLIP) [7], a widely used deep multi-modal framework that learns a joint embedding of images and textual descriptions in a contrastive manner. In the context of e-commerce, this approach enables the exploitation of a unified representation for both item descriptions and images, facilitating the search for the most suitable products while considering multi-modal input. Subsequently, the unified embedding space can be explored using an appropriate indexing scheme. We propose adopting LSH to balance the precision of results against retrieval time.
A main direction we aim to investigate pertains to the significance of the retrieved results and the response time of the architecture, which are influenced by various factors, including the type and quantity of resources utilized. These factors encompass the type of LSH method employed, the number of hash tables utilized, the quantity of LSH functions employed, and the type of visual encoder utilized. Overall, investigating these issues is essential for optimizing the performance of the retrieval architecture, ensuring that it delivers relevant results promptly, while efficiently using computational resources.
In our experiments, we considered two real-world datasets, one in a technical domain (photo related products) and one in the fashion domain (clothing apparels e-commerce applications). The indexing scheme provided by LSH is a parametric one, relying on different hyper-parameters such as the actual hashing functions, the number of such hashing functions and the number of hash tables to be used. Because of that, we tested different settings of different LSH schemes, and we extended some of the analyses presented in [3] by incorporating a series of synthetic queries. These queries were generated by a Large Language Model using specific prompts, designed to emulate the queries made by a typical user of an e-commerce platform. This addition is of particular significance as it enhances the evaluation of the approach by enabling the processing of queries akin to those typically made by customers on the e-commerce platform, thereby augmenting the relevance of the assessment.
The outline of the rest of the paper is the following: Section 2 discusses related works, Section 3 presents the architecture for generating multi-modal embeddings, Section 4 describes the retrieval strategy based on LSH, Section 5 concerns the description of the experimental framework and of the results, finally conclusions are reported in Section 6.
Related works
The growing interest in the field of multi-modal retrieval aims to bridge the semantic gap between different modalities such as images and text. This may be really important in several domain and application tasks, as well as in the choose of the pertinent technique and approach dealing with such multi-modal information. Several works concerning product search focus on image retrieval only [8], text to image retrieval [9], cross-view image retrieval [10] or image retrieval augmented with text modification input [11, 12]. Feature combination or composition between text and images has also been extensively studied for VQA (Visual Question Answering) [13], which is again a form of text to image retrieval.
Recently, specific techniques for cross-modal retrieval between images and text modalities have received a lot of attention. The objective is to create suitable representations from diverse modalities (text and images in this instance) within a shared space. This enables the application of newly generated features in computing distance metrics [14, 15]. However, when aiming to establish a versatile text-to-image or image-to-text retrieval framework, challenges arise regarding generalizability. This entails ensuring system functionality even in cases of weak correlation between text and image [16], or addressing issues related to local alignment between text and images. This involves leveraging spatial relationships among objects depicted in the image [17, 18].
In our application, we can assume a strong correlation between text and images, since the text is a simple (usually compact) description of a product represented in the image; moreover, local alignment is also a minor problem, since the targeted pictures are representing specific items or products whose global characteristics are usually described in the corresponding text. In addition, the impact of spatial relationships among the objects in the image is very limited in the application we address, making unnecessary the introduction of complex architectures as those proposed in [17], where a stacked series of attention layers has to be properly devised, or in [18], where an additional graph structure is needed to capture spatial relationships after the generation of the multi-modal embedding.
Regarding indexing techniques, methods of cross-modal hashing aim to condense multi-modal data into compact and concise binary codes, while preserving the “semantic similarity” across different modalities [19, 20, 21]. However, differently from our approach, in such works the emphasis is on learning (either in a supervised or unsupervised fashion) the hash coding function, usually through deep learning models. None of them focus on the exploitation of a pre-defined indexing/hashing strategy working on the combined multi-modal embedding of the target objects. An exception is represented by the work in [22], where however, the text and the image representations are used in a rather independent way, since retrieval is based on a first step where text descriptions are compared with a set of keywords, and then the result is further filtered by considering image features. Moreover, image features are manually extracted using visual mappings for color, texture and shape. The only common aspect with our work is the use of an LSH strategy in order to retrieve most similar images from the query.
Our goal in the present paper is to exploit a standard hashing methods, such as LSH, for approximating a similarity-based retrieval, without the need of building a specific architecture for learning the hashing code. In addition, we want to exploit the power of deep learning methods for multi-modal embeddings (such as the CLIP-based architecture), in such a way that the representation of the target objects can keep all the similarity information from both text and image modalities.
Indeed, when handling data presented in various modalities, such as in e-commerce applications, it is crucial to leverage the information from each modality comprehensively and consistently. Comprehensive utilization ensures that no part of the information is overlooked, while consistency ensures that different formats of the same information are fused in a coherent way. Integration of deep learning and hashing methods for multi-modal retrieval can significantly enhance the efficiency of the retrieval step. Features extracted from deep models contain richer semantic information and are more adept at expressing the original data.
Two distinct primary approaches are available for consideration: data-dependent and data-independent [6]. The data-dependent category concerns approaches that learn both a representation and an indexing scheme from the original multi-modal data, frequently through supervised learning methodologies. Methods like Deep Cross Modal Hashing (DCMH) [23] and Pairwise Relationship Deep Hashing (PRDH) [24] integrate feature and hash learning directly, considering modal similarity and preserving it in hash code generation. Adversarial strategies like Self-Supervised Adversarial Hashing (SSAH) [25] and Attention-aware Deep Adversarial Hashing (ADAH) [26] further refine this idea by incorporating discriminators and attention mechanisms.
Our proposal focuses on the data-independent approach. Rather than training a deep model to simultaneously obtain multi-modal representation and hashing, we separately tackle learning latent representation and employing appropriate data-independent indexing method for retrieval. Through this architecture, we demonstrate the feasibility of constructing a multi-modal retrieval system that adopts LSH to achieve rapid retrieval times and high-quality retrieved items. While the number of hash functions and tables may depend on the data, we point out that with a relatively small number of such resources excellent results, measured by mean Average Precision, (mAP), can be achieved in reasonable time. The only data-dependent aspect is the number of probes used, which dynamically adjusts based on the required retrieval precision. Experimental results reveal that employing high-quality embeddings, specifically tailored to accurately represent cosine similarity among inputs, yields favorable outcomes across a variety of LSH configurations.
Multi-modal embedding for images and text
Given the multi-modal nature of e-commerce data and the need for a general architecture usable in different contexts without any modifications, the first task to address is the generation of specific multi-modal embeddings. To this end, we propose the use of CLIP, a model trained on a diverse range of images and texts without being specialized for any specific task (task-agnostic model).
The approach consists in training the model in a contrastive manner [27], such that it predicts, from a batch of
Contrastive pre-training in CLIP (from [7]).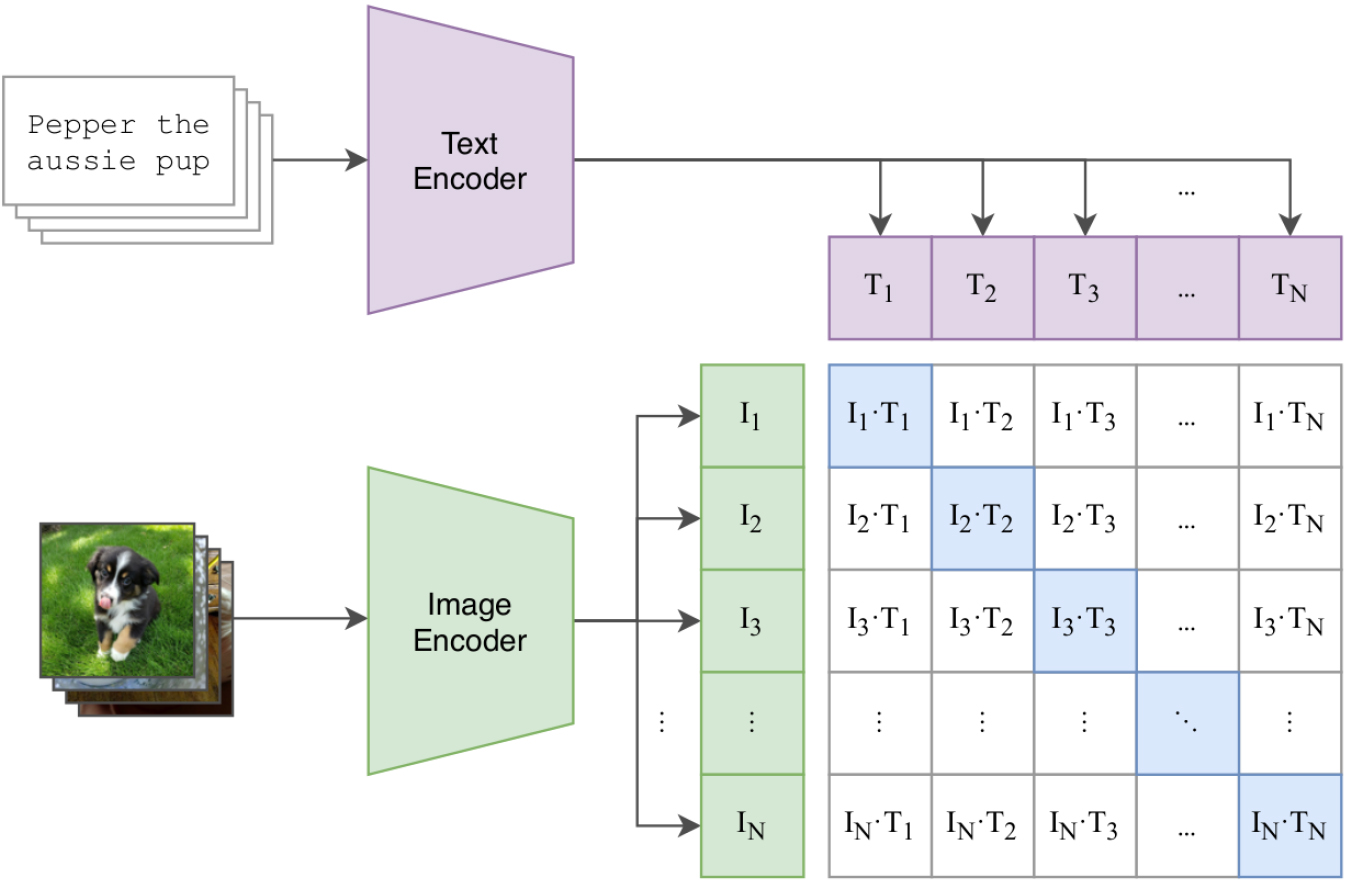
We examined various pre-trained versions of CLIP and ultimately opted for the following: RN50 and ViT-L/14. These options primarily differ in the image encoder utilized: RN50 employs ResNet50 [28], while ViT-L/14 utilizes a Vision Transformer (ViT) [29]. The selected CLIP architectures represent a compromise between the time taken to produce an embedding and its size. Specifically, RN50 generated embeddings are larger but require less time compared to those generated by the ViT-L/14 version.
The RN50 architecture is derived from ResNet50 with a modification known as ResNet-D [30]. This tweak involves altering the downsampling block of ResNet50 by adjusting the convolution stride in path A to prevent information loss and adding average pooling on path B before convolution (refer to Fig. 2b for details).
Model tweak on ResNet50 [30].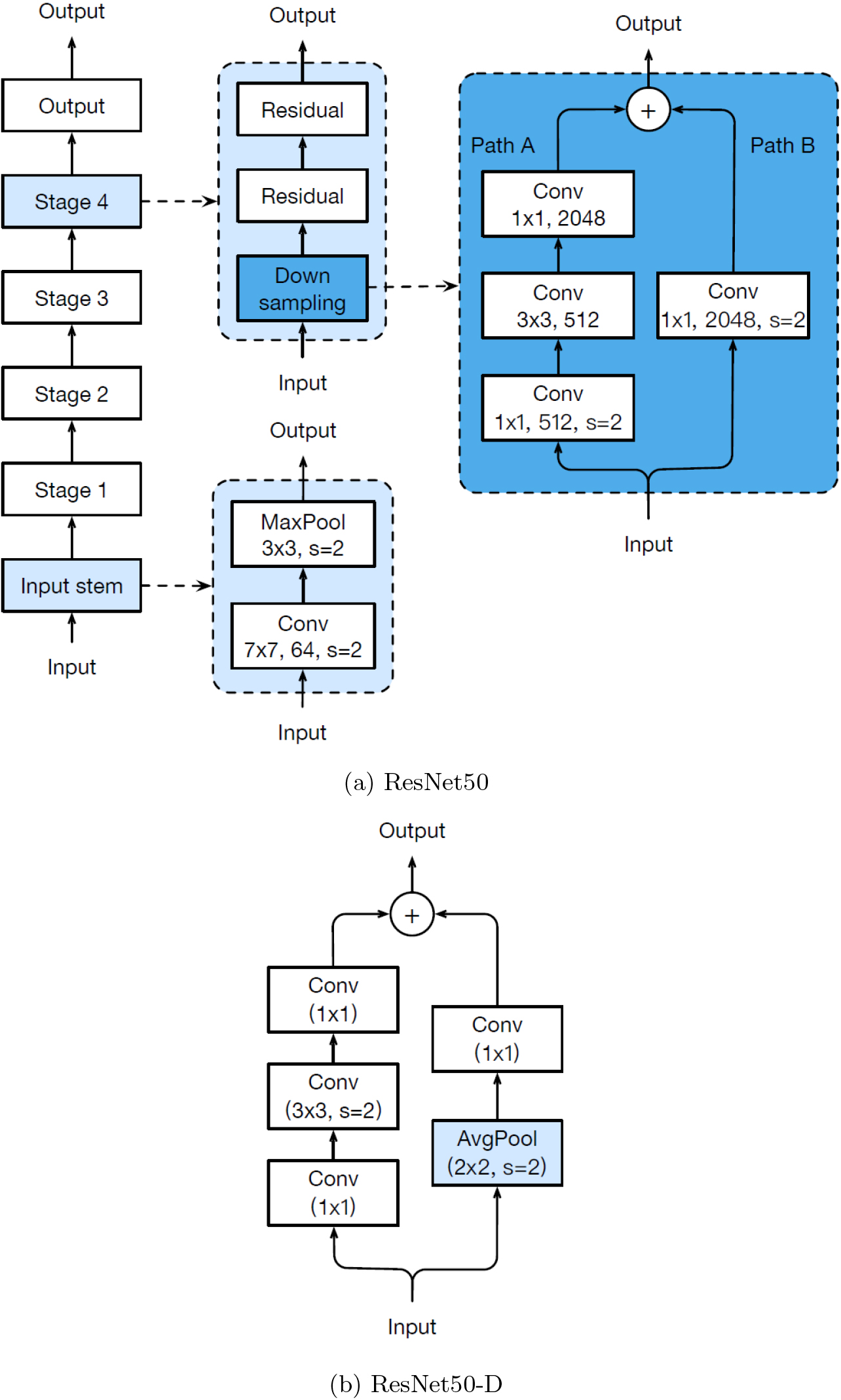
Additionally, we incorporated low-pass filtering to anti-alias for maintaining shift-invariance [31]. Furthermore, we replaced the global average pooling layer with attention pooling, implemented using a single attention layer akin to the transformer architecture. Finally, a scaling strategy inspired by the methodology outlined in [32] was adopted to achieve a better balance among depth, width, and resolution of the image encoder.
For the transformer-based architecture ViT-L/14, we implemented the version described in [29], which includes the following parameters: a 14
Once the multi-modal embeddings are generated, as described in the preceding section, a retrieval mechanism needs to be established to identify the embeddings most similar to a given query. This task can be tackled by exploiting some form of hashing to index the embeddings for search and retrieval. In this study, we adopt Locality-Sensitive Hashing or LSH [4] as the indexing scheme, as it offers a balance between the precision (and recall) of retrieved results and time needed to retrieve them. This balance is crucial in our context, as we aim to construct an architecture that provides the flexibility to prioritize either precision or retrieval speed based on the configuration used. LSH is a technique where similar data points are hashed into the same “buckets” with high probability. This enables the implementation of (approximate) nearest-neighbor queries by means of the detection of collisions in a given set of hash tables properly devised for the task [34]. The main idea is to build a hash table by concatenating a suitable number
LSH is a parametric indexing methods and relies on two primary hyper-parameters: the number
For implementation, we opted for Falconn: FAst Lookups of Cosine and Other Nearest Neighbors [36], a well-tested and efficient library that implements LSH-based algorithms. Falconn supports two primary hash families: hyperplane LSH [37] and cross-polytope LSH [38]. Both families offer theoretical guarantees for cosine similarity, which is particularly relevant in our case since CLIP generates multi-modal embeddings that maximize input’s cosine similarity. Multi-probe is employed in both LSH families to minimize memory usage.
Indexing architecture for multi-modal retrieval.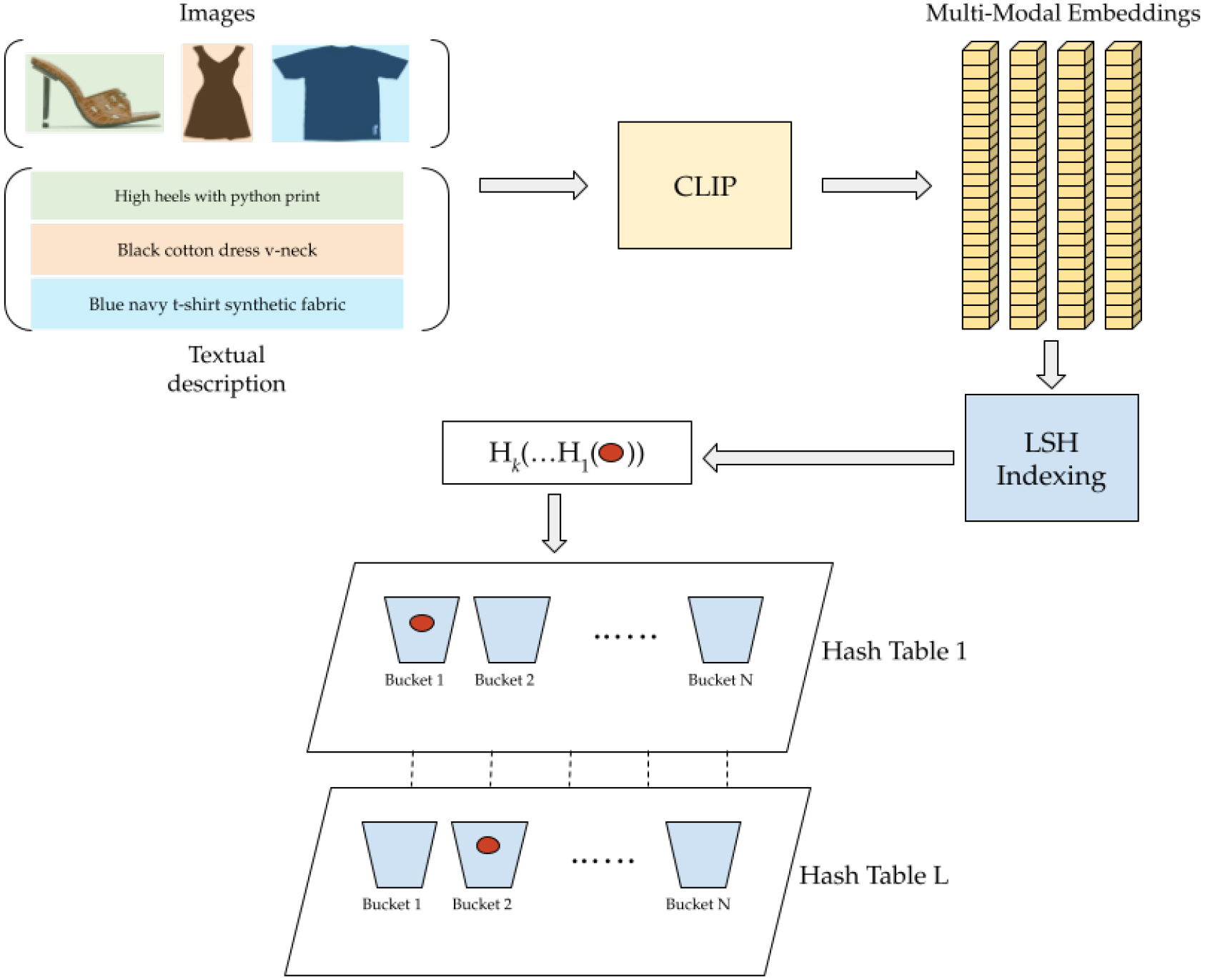
Figure 3 shows the final architecture we propose, highlighting the role of the joint embeddings provided by CLIP, and the final hashing determined by LSH.
We conducted an experimental analysis using two different datasets:
FC: this dataset comprises photographic products from a medium-sized Italian e-commerce site managed by Inferendo. We utilized product images and names for this dataset. However, some items lacked associated images, so embeddings were generated solely based on text. We processed 11.500 images and 342.000 names. AC: this dataset consists of approximately 190.000 Amazon fashion products, including images, reviews and item metadata. Similarly, we considered only the item image and product name. As many products had multiple images associated with them, we totally processed over 280.000 images.
As previously outlined, our proposed architecture is based on a deep neural network pretrained with a contrastive language-image approach (CLIP), coupled with an LSH indexing scheme to expedite retrieval of the generated multi-modal embeddings.
We evaluated the architecture using the aforementioned datasets in three phases:
Embedding Generation. Utilizing CLIP, we generated embeddings using two underlying visual encoder architectures: RN50 and ViT-L/14. LSH Indexing. We indexed the embeddings using LSH, considering various parameters: the LSH algorithm (random hyperplane or cross polytope), the number of hash functions ( Evaluation. We assessed a set of multi-modal queries on the selected configurations.
For each dataset, we examined 16 distinct experimental configurations, encompassing different combinations of LSH algorithm (hyperplane or cross polytope), number of tables (30 or 50), number of hash functions (16 or 17), and the image encoder network (RN50 or ViT-L/14). These configurations were carefully selected as the most representative after testing several other combinations.
We set up two different querying frameworks, one with a set of specifically selected queries, and one by exploiting a Large Language Model (LLM) for the query generation. For each query, given the number
A linear scan of the item embeddings is used to get the items that are relevant for a query. We select the
Finally, the Mean Average Precision (mAP) is calculated over all the
where
Specifically selected queries
Regarding the initial phase of the experimentation, we configured
a set of queries corresponding to actual items within the considered dataset; a set of textual queries from item textual descriptions; a set of visual (image-based) queries sourced from the world wide web.
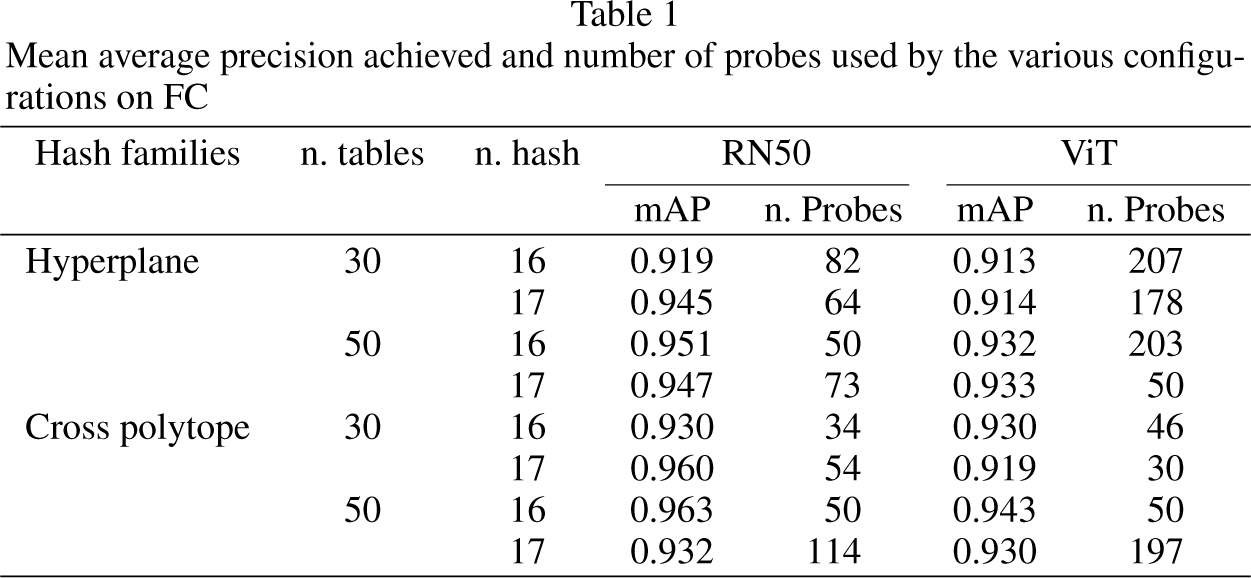
The task we focused on is the recommendation of the top-5 most relevant items, where relevance is characterized by the similarity of the item with respect to the query. Table 1 presents the results for dataset FC, while Table 3 displays the results for dataset AF.
Mean average precision achieved and number of probes used by the various configurations on FC
Mean average precision achieved and number of probes used by the various configurations on FC
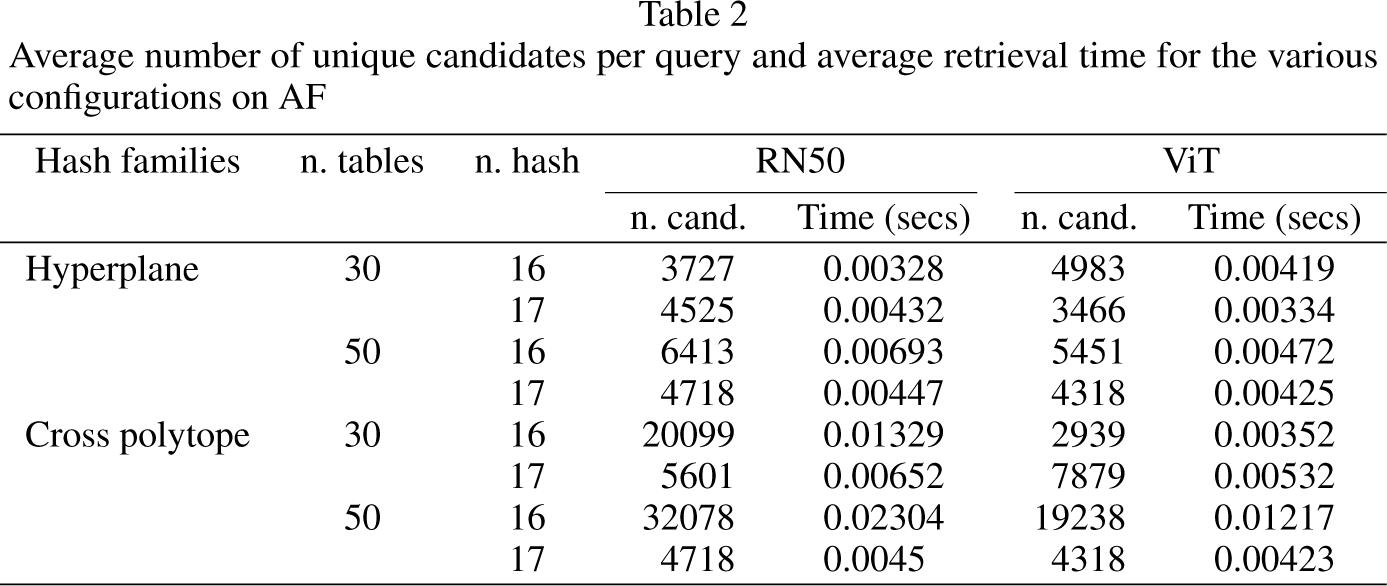
Average number of unique candidates per query and average retrieval time for the various configurations on AF
Mean average precision achieved and number of probes used by the various configurations on AF
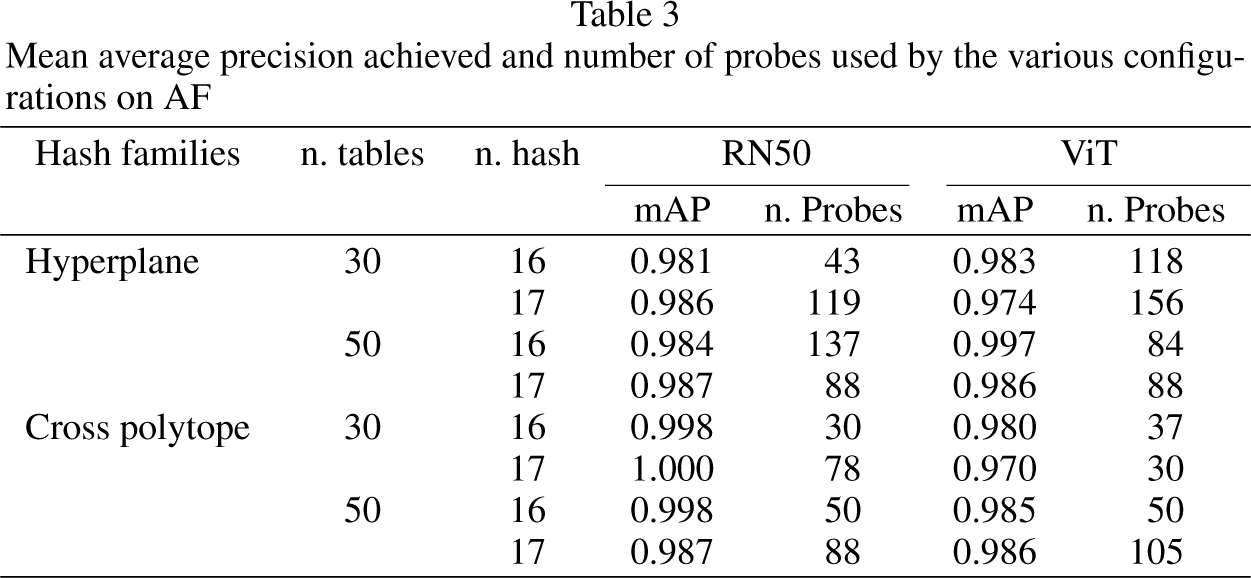
For each configuration, we also provided the dynamically computed number of probes specific to the situation. Across all tested configurations, the performance in terms of mAP of LSH retrieval on the generated multi-modal embeddings proved to be consistently strong, with no clear indication of one configuration being definitively superior to others. The qualitative performance slightly improved for the
Additionally, Table 2 reports the average number of unique candidates which are examined by the retrieval procedure, along with the corresponding response time for queries, specifically for the AF dataset (the largest one). Across various configurations, only a few thousand candidates were selected, and the response was typically delivered within a few milliseconds on average. Notably, the cross polytope version of LSH tended to select a larger number of candidates compared to the hyperplane-based algorithm. However, since qualitative results in terms of mAP were comparable for both approaches, this suggests that employing a simple hyperplane LSH algorithm can be highly effective in the tested scenarios.
Finally, by way of illustration, Fig. 4 showcases the top-1 results (i.e., the most similar item) obtained for three sample queries from the AF dataset.
Some results on AF dataset.
To further expand the number of experiments to analyze we decided to focus on the largest of the two datasets we have previously considered (AF) and to produce a set of synthetic textual queries generated from the product titles (names) contained in the corresponding catalog. The idea is to automatically produce textual queries similar to those that would be reasonably used by a person when searching fashion products. Since we are not aware of any collection of human queries on the Amazon fashion repository, we decided to exploit the features of a Large Language Model (LLM) to create a synthetic dataset, somewhat similar to a real collection of human generated queries. This approach harnesses the power of LLMs to automatically generate textual queries by just looking at the products titles.
After extensive experiments with models of increasing complexity we decided to consider the Falcon-40b model from TII (Technology Innovation Institute, Abu Dabhi).1
www.tii.ae.
The following is an example of a prompt we used ({product} is a placeholder for each product name in the AF dataset):
Context: To find the following product: “COCOLEGGINGS Adventure Time Print 3/4 Length Strechy Capri Legging L” on amazon.com the following text was used: “Adventure Time leggings”. Request: Given this other product: {product} a text to find it on amazon.com would be: For example if product
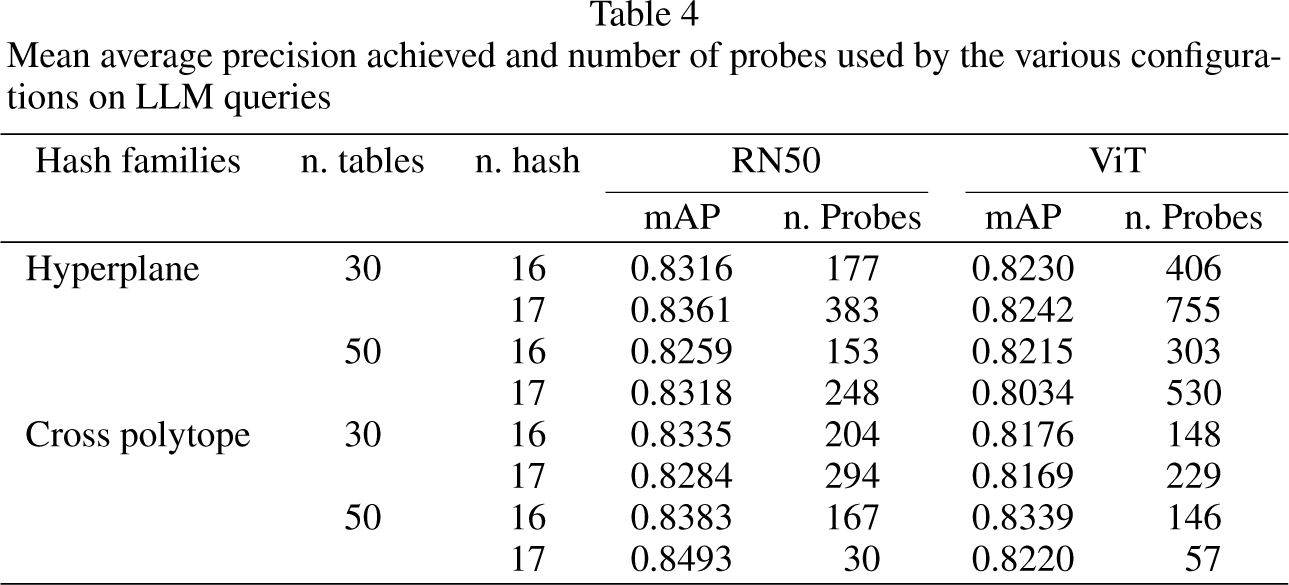
We randomly selected 1000 products from the AF dataset and prompted the LLM model with them; we collected the generated textual descriptions and we submitted each one, complemented with a picture of the product, to the system for evaluation. Table 4 reports the results in terms of mAP and number of probes, while Table 5 shows the average retrieval time together with the number of candidates checked.
Mean average precision achieved and number of probes used by the various configurations on LLM queries
Average number of unique candidates per query and average retrieval time for the various configurations on LLM queries
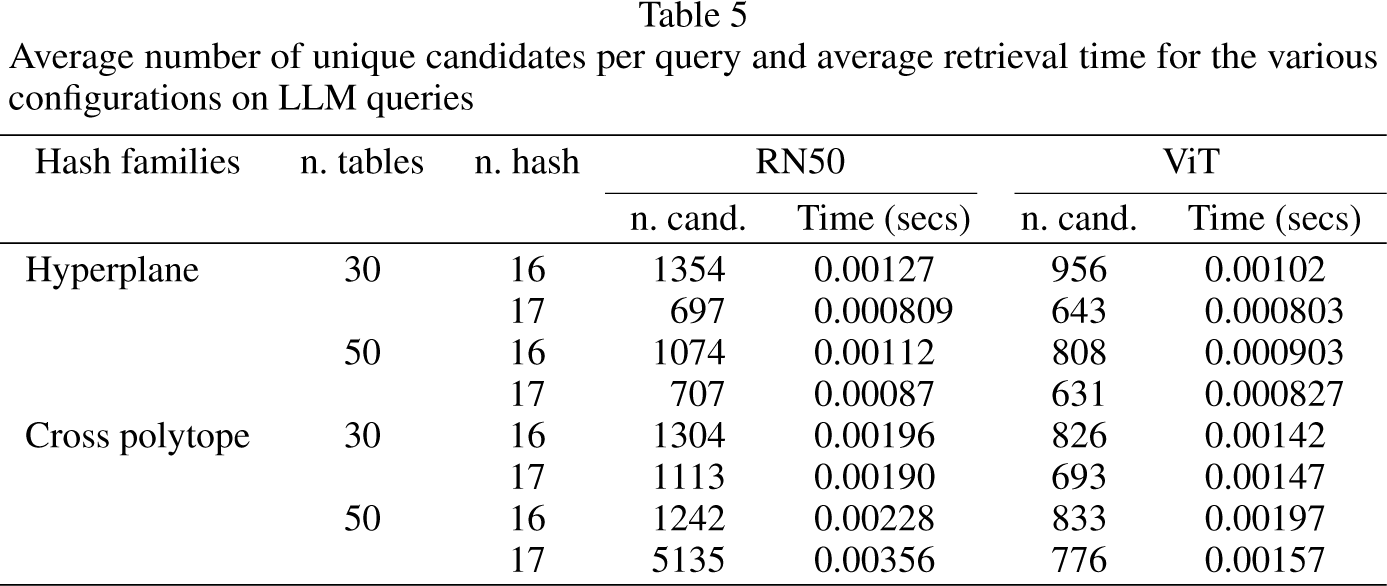
As in the previous case, we remark a good performance in terms of mAP (always above 0.8); the smaller values with respect to the previous set of tests can be explained by the fact that LLM generated queries have a more generic textual description that in the previous case. Also in this situation, there is no clearly prevalent architectural configuration (results in terms of mAP are very similar, independently of the considered configuration). The number of probes is still very limited, and few thousands candidates are always evaluated in a few milliseconds. We can remark that the number of candidates is more contained in case of hyperplane LSH using embeddings generated through RN50, while no clear difference can be noticed, in these terms, when using ViT. We can conclude that in both the tested situations, the average performance in terms of mAP, number of candidates and probes, and retrieval time can be considered really satisfactory. Concerning the choice of a proper LSH method, we can conclude that the use of a hyperplane LSH, which is simpler to tune than polytope LSH (fewer parameters) and faster in setting up the tables, can be regarded as really effective.
mAP vs size of retrieval set: RN50.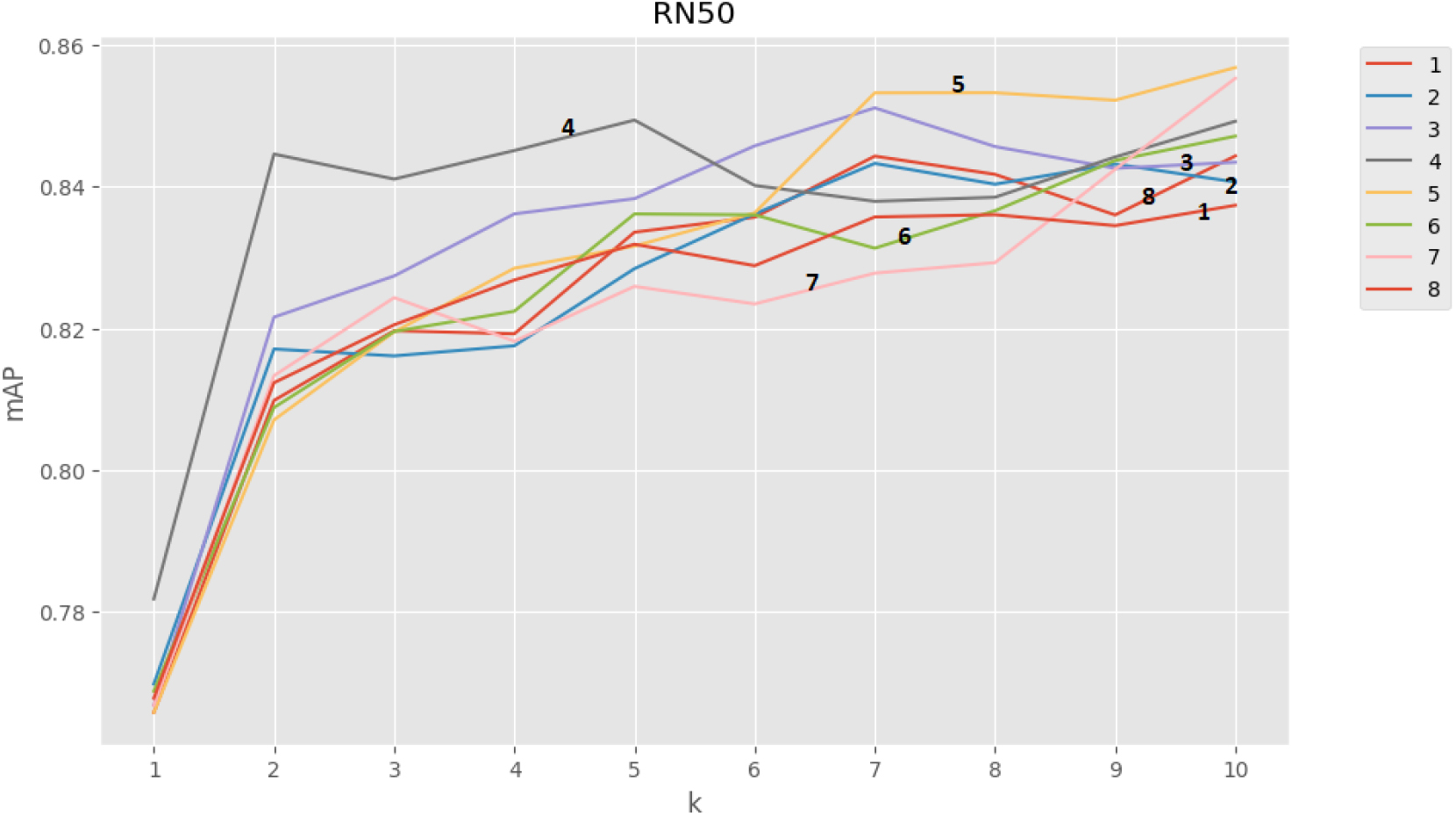
mAP vs size of retrieval set: ViT.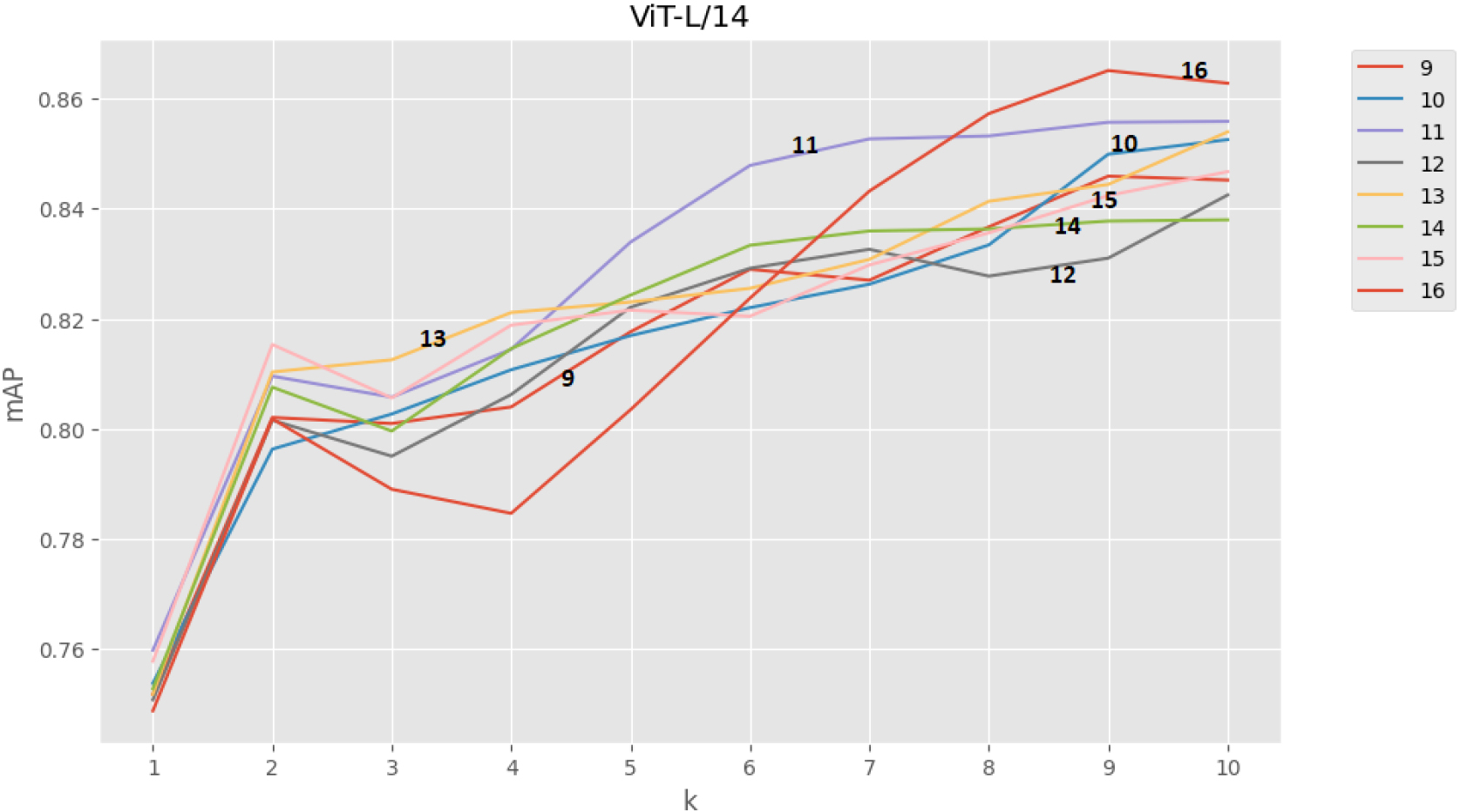
Finally, we also tested the behavior of the different configurations with respect to the size of the retrieval set
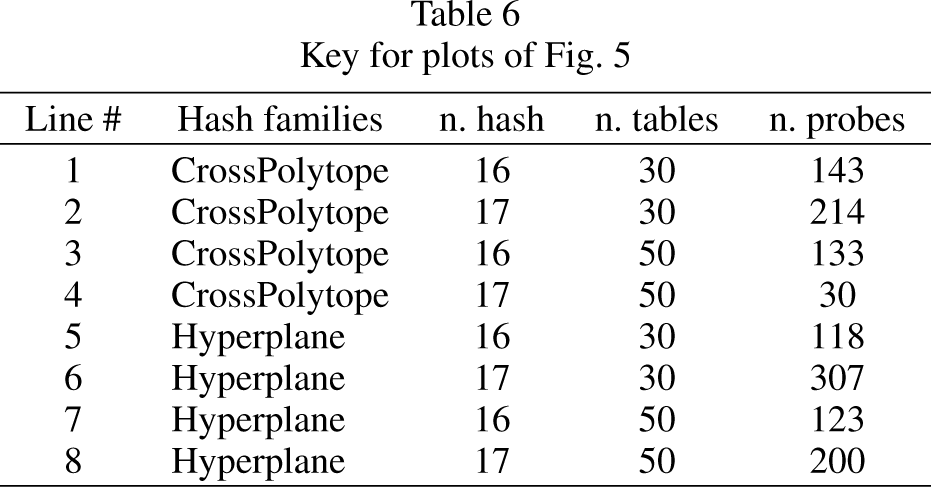
Key for plots of Fig. 5
Key for plots of Fig. 6
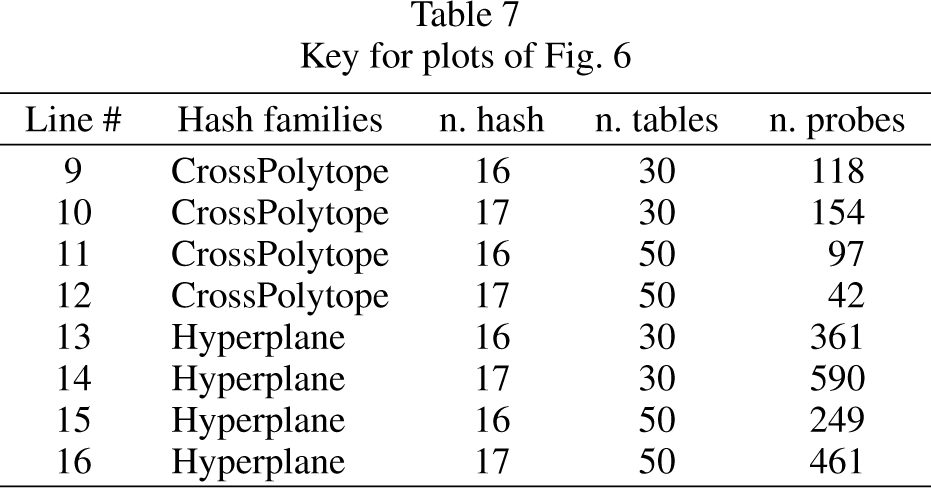
Tables 6 and 7 show the key for reading the different comfigurations in the plots. We notice that there is a significant difference in terms of mAP among the configurations when the number of relevant products is limited (small values of
This paper has presented a retrieval architecture tailored for e-commerce applications, using a multi-modal representation of items of interest (textual descriptions and product images). This architecture is complemented by LSH indexing, which facilitates rapid and efficient retrieval of potential products. This allows the user to specify the desired products both visually (by showing or selecting a picture) and textually (by providing a textual description), in such a way that products similar to what the user is looking for can be retrieved in an efficient way. We have performed an in-depth analysis concerning the possible architectural choices for the embedding generation, as well as the features of the most suitable LSH scheme to be adopted. Promising results have been obtained when testing the architecture on real-world datasets and on synthetic data obtained through the use of an LLM able to mimic user interaction with the system.
In conclusion, a comprehensive exploration of a multi-modal architecture designed for the retrieval of products described through images and text has been presented. Through the described experimentation, we have gathered insights about the effectiveness and promise of our proposed approach. The results underscore the potential of leveraging both textual and visual modalities for product retrieval in e-commerce applications. As future works we devise an extensively testing of the architecture using datasets larger in size. Additionally, efforts will be directed towards evaluating the robustness of the approach when datasets containing data expressed in only one modality are combined with datasets containing data expressed in both textual and visual modalities, in various relative proportions.