
Abstract
Connecting objects have increasingly become popular in recent years, leading to the connection of more than 50 billion objects by the end of 2020. This large number of objects will generate a huge amount of data that is currently being processed and stored in the cloud. Fog Computing presents a promising solution to the problems of high latency and huge network traffic encountered in the cloud. As Fog’s infrastructures are dense, heterogeneous and geo-distributed, managing the data in order to satisfy users demand in such context is very complicated. In this work, we propose a data management strategy called ‘RMS-HaFC’ in which we consider the characteristics of Fog Computing environment. To do so, we proposed a hierarchical multi-layer model, on which we designed a migration and replication strategy based on data popularity. These strategies duplicate files dynamically and store them in different locations to improve the response time of users requests and minimize the system energy consumption without loading network usage. The strategy was evaluated using the iFogSim simulator and the experimental results obtained are very promising.
Introduction
The Internet of Things (IoT) is the infrastructure that interconnects a wide range of daily life equipment. It enables the monitoring of the physical characteristics of the environment (e.g. temperature, humidity, presence, etc.) via sensors, as well as the control of the environment via actuators [1]. In recent years, the number of connected objects has risen steadily. Indeed, Cisco forecasts that there will be more than 50 billion objects connected by 2020 [2]. This high number of objects will generate a massive amount of data.
Currently, IoT data is generally processed and stored in the cloud. This meets the majority of IoT application requirements in terms of ubiquitous access, availability and scalability of processing performance and storage capacity [3]. However, the Cloud being a centralized paradigm in few data centers. Indeed, the increase in the number of connected objects will produce a huge amount of data, and sending all the data to the Cloud will generate bottlenecks. This produces high and unpredictable latencies and, consequently, a degraded quality of service (QoS) [4]. In addition, there are many IoT applications, such as the Internet of Vehicles, telemedicine and industry 4.0, that require mobility support, geo-distributed deployment, localization awareness and real response time that cloud computing cannot effectively provide. These problems have led to the emergence of a new paradigm, Fog computing [5, 11].
The Fog uses the resources available in network equipment located between end users and the cloud to be reinforced [6]. Fog Computing is characterized by its proximity to clients, the heterogeneity of its equipment, its dense geographical distribution and its support for mobility [11].
The specificities of Fog Computing lead to the reconsideration of many issues already addressed in other traditional contexts. For example, since data localization is a fundamental parameter for processing, it is important to study how data should be organized in such an infrastructure in order to reduce latencies in the system and increase service availability. This is why we are seeking to achieve, in this work, a data management solution by which users are able to access data from any location, with the shortest possible access time, reduced energy consumption and without overloading the network usage.
Many studies in the literature have addressed the topic of data management in a fog computing environment. For example, Naas et al. in [7] have studied the problem of placing a single copy of data, while Huang et al. [8] and Aral et al. [9] have tackled the placement of multiple replicas. Their objective was to reduce the overall latency of the system. To the best of our knowledge, we find that there is no global and universal data management strategy that can solve latency, network-load and energy consumption problems at the same time and in all situations.
In this paper, we propose a data management strategy in a Fog Computing environment, which we call ‘RMS-HaFC’ (i.e. A Replication and Migration Strategy on the Hierarchical architecture in the Fog Computing environment). The goal of RMS-HaFC is to improve performance such as power consumption and response time in the system. The contributions proposed in this work cover the specification, design and implementation of the hierarchical architecture as well as the approach of data replication and migration. These contributions can be summarized as follows:
We propose in the first place a hierarchical architecture of Cloud and Fog typology. This architecture respects two constraints of such environment. First, the high geographical distribution, we sub-divide the Fog layer horizontally where we group the Fog nodes into regions, and secondly, the heterogeneity of the components of the Fog layer in terms of performance. We then subdivide the Fog layer vertically into three levels. Each level has nodes with different functionalities. For example, we refer to a node that has more powerful capabilities as a data location catalogue in each region. This choice is crucial because such a node is frequently requested in order to search for the requested data. Then, we propose an algorithm for executing the user request. This algorithm is used to route the request to the nearest node hosting the data requested by a user, eventually a connected object. Finally, we propose a data replication and migration strategy to keep data close to the users. In a synthetic way, our strategy is based on the analysis of data access history. It is composed of two fundamental phases: the replication and migration phase, it allows the identification of the data that should be replicated or migrated in the system. In addition, it allows identifying the regions that are concerned with the replication as well as the number of replicas. The replica placement phase enables data replicas to be placed within a region in the best locations. An algorithm is applied in each phase and is based on proposed formulas including the value of a file, the weight of a region and the server index. We implemented our solution in the Fog and IoT environment simulator iFogSim. Indeed, the experimental study showed that the results obtained are globally very encouraging.
The rest of this paper is organized as follows. In Section 2, we present some related works existing in the literature. Then, we detail our contributions in Section 3. Section 4 shows the different results of the experimentations, and we will conclude in Section 5.
Literature review
In this paper, we focus on the issue of data management in a Fog and Cloud infrastructure. The objective is to minimize the response time of user requests without encumbering the network and without incurring energy consequences. As the problem we are seeking to solve is recent, we begin this section by presenting the main existing works that use the Fog Computing paradigm; the online placement of IoT data in a Fog-like infrastructure; the placement of IoT service instances in Fog infrastructures. Indeed, these works are close to our problematic in terms of the working context (i.e. Fog computing and IoT), and the objectives (e.g. reduction of response time and system latency) or even the simulation environments used (e.g.: iFogSim, CloudSim).
Naas et al. [7] have proposed an extension of iFogSim, a simulator of Fog and IoT environments. The objective of this extension is to produce a platform dedicated to implementing and testing data placement strategies in a Fog and IoT environment. The authors added three initial components. The first to formulate and compute data placement based on linear programing method to reduce overall system latency. The second to subdivide the infrastructure based on graph theory to reduce the data placement compute time. Indeed, they tested five predefined data placement strategies with a third component which generates different data flow distributions in a generic ‘smart city’ scenario. However, single data placement strategies may lead to high system latencies.
By completing the previous work [7] that addresses the issue of placing a single copy of data, Huang et al. [8] have addressed the placement of several replicas of data in a Fog Computing infrastructure with a multi replicas model called ‘iFogStorM’ strategy. They take into account the two problems of data replication: The number and location of replicas. In addition, given the complexity of the placement of multiple replicas in a large scale infrastructure, the authors proposed a heuristic approach that they called ‘MultiCopyStorage’. The proposed approach uses a greedy algorithm to reduce the searching space for solving the target model. The results of the experiments show that compared to proposed strategies in [7], ‘MultiCopyStorage’ offers good solutions for real-time data storage with minimal overall latencies in the Fog environment. In spite of that, a such strategy may be enhanced by taking in account more in the problem formulation more factors instead of considering the storage capacity as the only limiting factor.
In [9], the authors proposed a distributed data placement algorithm based on the dynamic creation, replacement and deletion of replicas guided by continuous monitoring of data requests from peripheral nodes in the network. In this algorithm, the storage nodes that host the replicas analyze the demand observed on the replicas and act as local optimizers. The authors modelled this problem as a combinatorial optimization problem based on FLP (Facility Location Problem). In this algorithm, and in order to maximize the objective function of the problem, the nodes estimate the cost of storing replicas as well as the latency expected to make a decision to migrate or replicate to one of the neighbors. They may also decide to delete a local replica. The algorithm also allows the user to control the balance between cost optimization and latency optimization. In addition, the authors have added a replica discovery method where concerned nodes are notified of nearby replicas. Experimental results show that this distributed replica placement algorithm offers significant advantages in terms of cost, and latency compared to non-replicated and client side caching approaches.
Vales et al. [13] proposed a fog storage system with hierarchical hybrid architecture. The proposed file system centralized the meta data and policies management and enables the data storage and dissemination in a distributed way. Additionally, the authors design a replication strategy that replicates data to edge devices based on node localization defined by distance from consumers to the data and the node battery level, and spatio-temporal data popularity based on data access frequency. The evaluation results evidence that this proposal enhances network’s lifetime, offers data to consumers with low latency, reduces core traffic and enables a fair energy consumption among battery-powered nodes.
In the literature, several studies addressed the issue of the placement of IoT service instances in the Fog. This was done with objectives such as: Minimizing latency, reducing energy consumption or improving service quality. For example, Taneja et al. [12] proposed and algorithm that enable the placement of modules of an IoT application in the nodes of a Fog-Clod infrastructure. This algorithm sort the nodes and modules based on their capacities in increasing order. Then the algorithm iterates from Fog nodes to Cloud nodes and places the modules on eligible nodes. Benamer et al. in [10], defined a model based on linear integer programming to optimize the placement of modules (or service instances) in a Fog infrastructure. It is an exact solution but it is exponentially complex. The authors defined another heuristic solution that aims to find the best placement for each module by taking into account the inter-node latency, the overall latency of the system, as well as the capacities of the Fog nodes in terms of CPU and RAM. The evaluations show a significant reduction in latency compared to the two placement methods in iFogSim (Cloud and Edge Ward).
Positioning our strategy regarding some related work
Positioning our strategy regarding some related work
We tried in Table 1 to position our approach regarding to the existing related works cited in this section. We made a comparative study of our strategy which is based on several criteria such as the response time Energy consumption and the different techniques used.
The main objective of this work is to create a data management solution adapted to a Fog environment. The aim is to reduce the response times while minimizing the overall energy consumption of the system.
Indeed, our proposal is structured in three main phases. First, the configuration phase, where we will propose a hierarchical architecture that respects the geographical dispersion of a Fog infrastructure. This architecture is used to subdivide the Fog layer into several regions and to select nodes with particular functionalities. We detail this architecture in the following section. In addition, we build the logical elements that will be deployed in the infrastructure.
Second, the processing phase: This step consists of executing several instances of a generic IoT application model (See Fig. 2). This model follows the DDF model (i.e. Distributed Data Flows), in which an application is modeled as a Directed acyclic graph (DAG). The vertices of the graph represent the instances of the modules (i.e., Virtual Machine “VM”) that perform incoming data processing and the edges indicate the data dependencies between these modules.
Finally, and after analyzing the results of the previous phase, we apply the proposed strategy to minimize response time and energy consumption. Our strategy uses replication and data migration techniques while investigating the following issues: Which data needs to be replicated or migrated? Which regions need replicas? How much should we replicate in each region? And what is the location of replicas in each region?
Proposed architecture.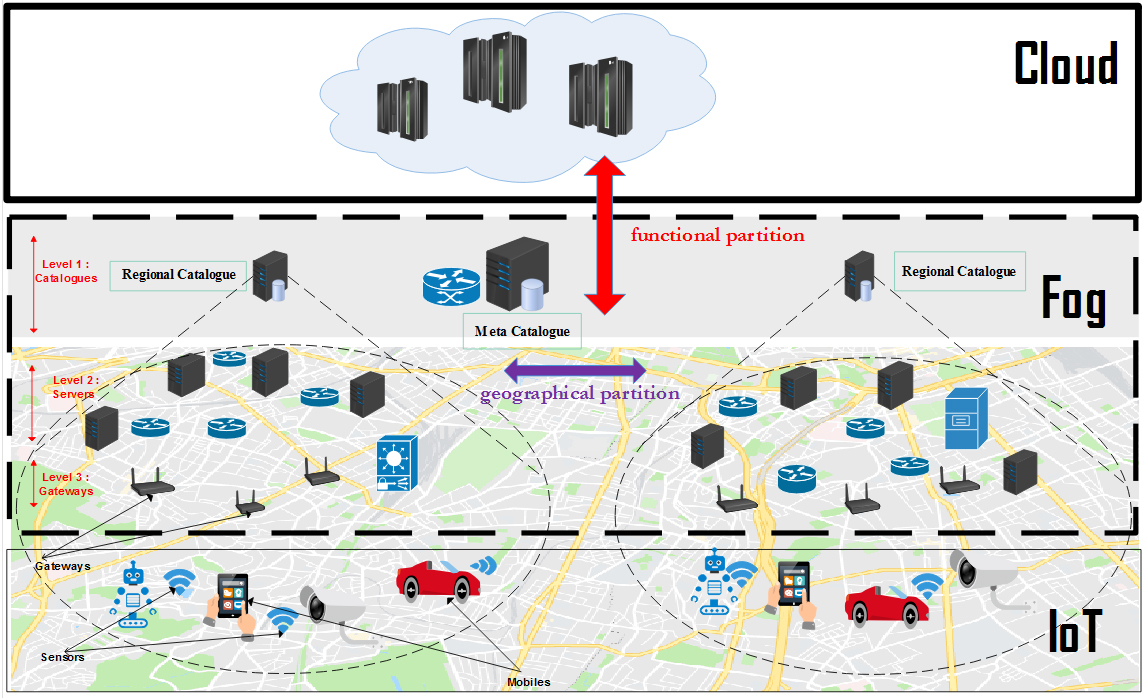
In this section we discuss the need of organizing the nodes of the Fog environment. Since the Fog has a dense and widespread geographical infrastructure [11], and in order to respect these characteristics, we have therefore subdivided the Fog layer horizontally where Fog nodes are clustered into regions. In addition, and by the nature of Fog equipment that is heterogeneous in terms of performance, we have subdivided the Fog layer into three vertical levels. The first is the catalogues level in which we design an entity called ‘meta-catalogue’ that act as a root of the Fog layer and that have a global vision without details on all the regions (hosted data, workload …). Also we design a regional data catalogue as a root in each region. The second level we find the servers with a limited storage and computing capacities. The third level we find gateways that are closer to users, Fig. 1 illustrate this architecture. We believe that such infrastructure organization is very helpful to meet user requirements in term of system latency as well as the services providers.
Indeed, we have implemented a generic IoT application model (see Fig. 2). In this scenario, the sensor sends data to the mobile phone to which it is connected. Afterwards, the mobile sends a request to the gateway. This request requires a specific data file to be executed (usually a service). To do this, Algorithm 1 is designed to redirect the request to the nearest location of the data requested by a user.
A generic application model.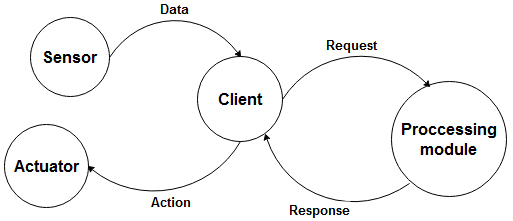
Sequence diagram to depict a use case scenario of data search algorithm.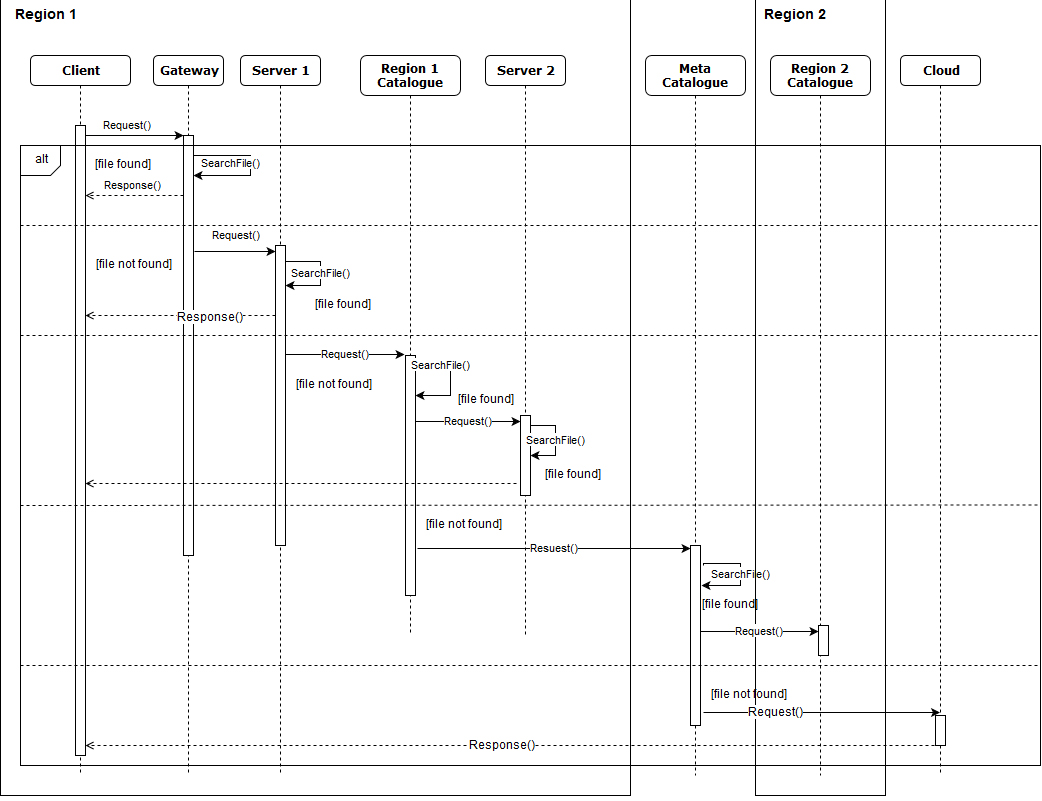
This distributed algorithm imperatively reduces the response time. In a nutshell, it works as follows:
When a request arrives, the node initially tests if it does not require any data (file). If so, the request is executed (2 and 3 lines). Otherwise, the node starts a search algorithm to find the requested data. In this alternative, three (03) cases may arise: first, if the data is found locally, the query is executed (line 5–12). The node sends the request to the child having the data (line 13–26) if he finds the data in the catalogue. And finally, if the data is not available locally nor in the catalogue, he sends the request to the parent (line 27–30).
Noting that this algorithm records the path taken by the request in a LIFO list (by saving the path trace), this list is used to redirect the response to the client that sent the request.
Moreover, we have implemented a Round Robin request scheduler that assigns tasks in an equitable manner for load balancing purposes. The usefulness of this scheduler occurs when we have a large scale system with a large number of files and queries respectively. Hence a catalogue will find the searched data in several children. Indeed, the latter stores all the children who have the requested file
Activity diagram of principal phases of our proposed approach.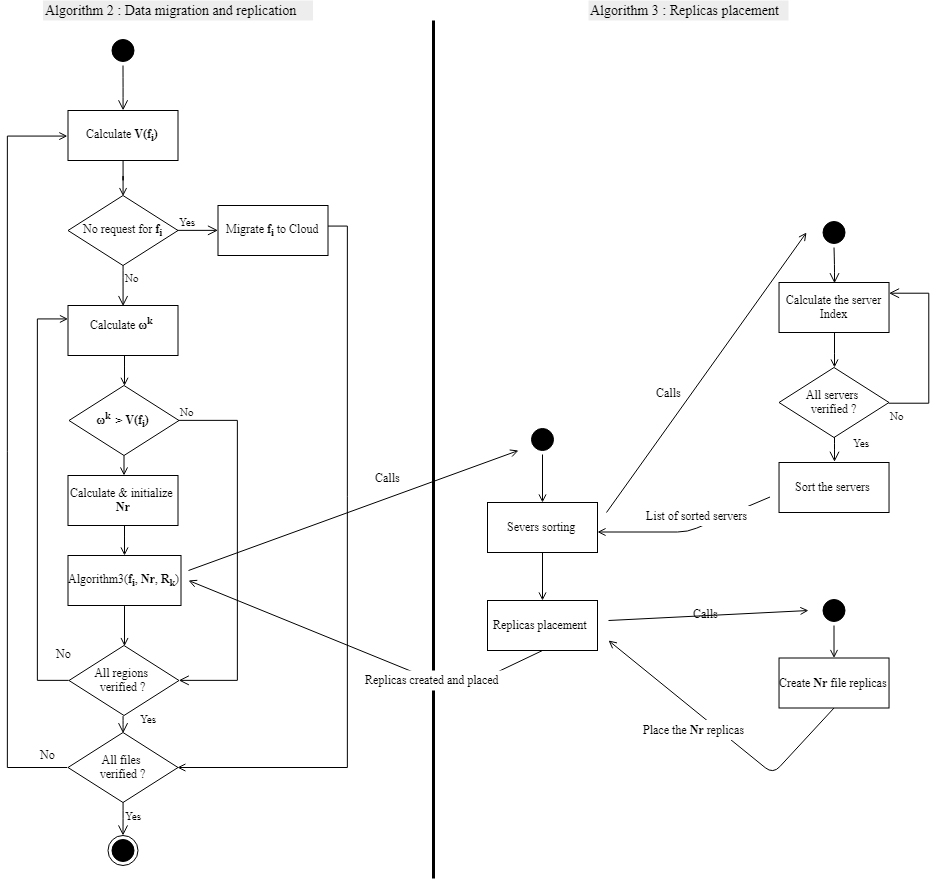
To better understand this process, we have modeled the handling of a request in a concrete example of our architecture, where it contains two regions. We used a sequence diagram as shown in Fig. 3. A sequence diagram is a graphical representation of the interactions between the different system actors in a chronological order. According to Fig. 3, we can see that the Cloud is solicited only in the worst cases. This shows the usefulness of Algorithm 1.
As mentioned before, our goal in this work is to create a data management solution in a Fog environment. The primary aim is to reduce response time and minimize energy consumption while considering the characteristics of such an environment.
In a Fog environment, a server is considered as a small data center that groups several machines. However, in our system, we consider that a server contains only one machine (host). In addition, we assume that a server cannot host more than one copy of a data. Noting that in this work, all the data requested by users exist in the system and the term ‘a data’ means ‘a file’ and vice-versa.
Initially, we create an infrastructure with the proposed hierarchical architecture. Then, the files will be created and placed randomly and equitably in the infrastructure by an entity called Orchestrator. We consider that the Orchestrator has a global vision on the whole infrastructure. After a treatment phase, the Orchestrator applies to our strategy, which is composed of two fundamental phases. As shown in the activity diagram in Fig. 4, the two phases are dependents and each one goes through several steps in a chronological order to achieve the desired objectives. Below, we present the description of the phases processed. Table 2 shows the semantics of the symbols used in this section.
Replication and migration phase
The replication and migration phase allows identifying with precision the files that need to be replicated or migrated in the system. For this purpose, the access history of each data file is examined. The advantage of such a technique is to determine what data are recently requested in such a region that is more probable to be requested again in the near future.
Definition of symbols
Definition of symbols
The value of a file, noted
Such that
And
Our strategy takes account of the geographical partitioning. Hence, the weight of a region
where
Based on the file value, we will determine the minimum number of replicas to be created for a data
As discussed before, we designed an entity named Orchestrator. This entity has a global vision on the entire infrastructure and takes in charge the data management in the entire system. To do this, we have designed several algorithms in the Orchestrator. Algorithm 2 is used to determine the number of replicas in each region. This algorithm invokes another procedure to place replicas within a given
Algorithm 2 is based on the formulas detailed in this section. Noting that two types of migration have been defined, the first is the one represented in the lines (4–6) that is used to migrate the data to the Cloud if the data has not received any requests from the region to which it belongs. The second type is inter-regional migration. This migration is done when this data has the number of replicas equal to one (01) in the region to which it belongs.
After having determined the number of replicas required in each region, the next phase is now underway. In this phase, we place the replicas of the data in an efficient way.
We remind that this step is dependent on the previous phase. Indeed, Algorithm 3 presented below, is invoked by the migration and replication procedure (see Fig. 4).
Algorithm 3 uses as input parameters a
where
The index of servers is used to evaluate the servers in order to decide which is the best server to host the replica? It is based on factors such as the number of files in each server in order to have a distributed storage. The number of
Initially, Algorithm 3 calculates the index of each server in the region with Eq. (7). Then, it sorts the servers in descending order and selects the server Nr with the maximum server index to place the replicas.
In order to emphasize the advantages of our approach, we have implemented our solution in the Fog and IoT environments simulator iFogSim [14]. We will focus on the following metrics: response time, energy consumption and network usage. These metrics are provided by iFogSim’s monitoring service.
Indeed, the iFogSim simulator is an extension of Cloud Computing simulator CloudSim [17, 18]. This simulator is composed of a set of entities that model physical components such as sensors, actuators, and servers, a set of entities that model logical elements, and entities that manage processing resources [14, 7]. Also, we have added a set of entities to apply our proposal, such as the class called simulation which is performed from a graphical interface. The latter allows configuration and display of results and the File class which is used to model the data. Figure 5 shows the UML class diagram of iFogSim [7], the added set and the original classes that we have modified are framed by a solid line. In iFogSim, the physical entities communicate with each other using predefined events, noting that we have added events to handle specific cases such as file liberation and tuple migration.
Class diagram of iFogSim simulator.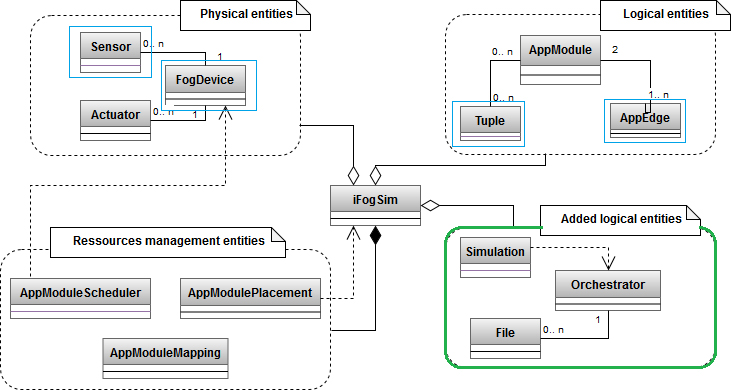
To investigate the behaviour of our proposal and analyse its results obtained by simulation, we will compare it to three approaches:
Traditional centralized approach where all files and services exist only in the Cloud Computing. The second is a decentralized approach where 90% of the files are deployed in Fog’s infrastructure. The rest (10%) are in the Cloud Computing. And the third is ‘3-Replicas’ approach a static replication strategy used in modern and current distributed storage systems. For example, data storage systems such as Amazon S3, Google file system, Windows Azure and Hadoop distributed file system all adopt a default data replication strategy [15, 16], i.e. they store 3 copies of each data at a time (3 replicas).
To conduct the various experiments, we used a machine with an Intel(R) Core(TM) i5-3320M CPU processor, a speed of 2.60 Ghz and a memory capacity of 8 GB.
General configuration parameter
The test scenario used in this study is a generic IoT application which is described in the Section 3.1 and illustrated in Fig. 2. We test this scenario in an architecture with 4 regions with 5 servers in each region (see Fig. 3). For each approach we repeat the simulation five time intervals by varying the number of requests (i.e. application service instance). Table 3 defines a set of parameters used in the simulation that are the same for all of the experiments presented.
The First experience for the response time which is represented in Fig. 6 by the Y axis and which is measured in MS, and the X axis represents the variation in the number of requests.
We found that the response time for the centralized approach is effectively high because the files are stored in the cloud which is located away from the users. On the other hand, decentralized, 3-replicas strategies and the proposed “RMS-HaFC” strategy bring replicas closer to the user, which improves response time.
Average response time with a variation on the number of requests.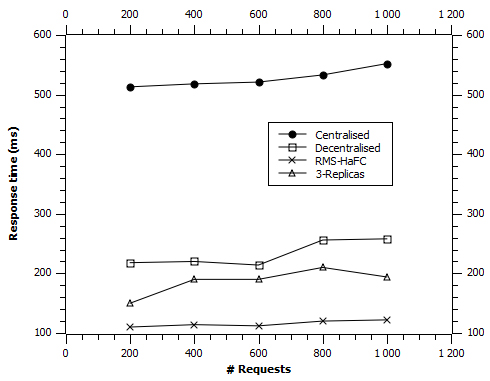
By replicating only, the popular files that will probably be used in the future, while taking into account the geographical placement, we have found that our strategy gives a better response time. On the other hand, our strategy determines the minimum number of replicas that must be added to the system to ensure a reduced response time, while the 3-Replicas approach defines a static number of replicas for all files, thus leading to static storage resource usage, which can sometimes be penalizing, especially when requests are very dynamic.
We note that our approach was able to improve response time with a system gain equivalent to 76.43% compared to the centralized approach, a gain of 47.85% compared to the decentralized approach and 33.61% compared to the 3-Replicas strategy.
Figure 7 illustrates the second experience for energy consumption that is measured in Watt. We note that our “RMS-HaFC” strategy is much better compared to the other approaches where we obtained a gain of more than 20% compared to the centralized approach and the decentralized approach; And more than 24% compared to the approach of the 3-Replicas. Following this reduced energy consumption, we can qualify it by an ecological strategy.
Total energy consumption.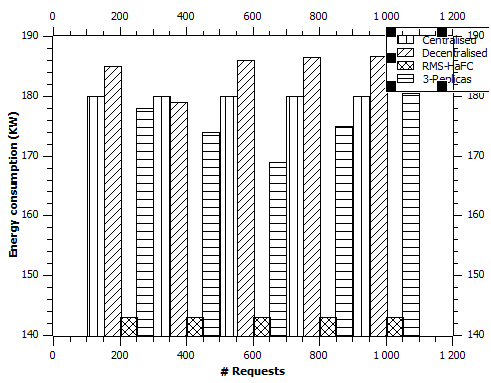
And the third experiment for the use the network where y axis in Fig. 8 represents the amount of data transmitted on the network measured in KB.
Total network usage.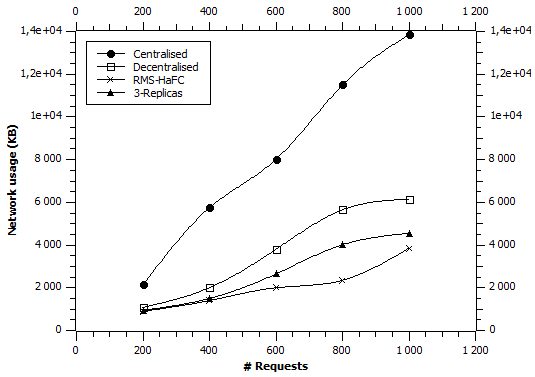
We see an increase in network usage in the three approaches, which translates into the number of hops made by a user request. We have estimated the gain where we have a reduction of 74% compared to the centralized approach and over 44% compared to the decentralized approach, and over 30% compared to the 3 replicas approach.
And to conclude this experimental study, we tried to compare our “RMS-HaFC” proposal by positioning it in relation to the three approaches according to the three metrics (response time, energy consumption and network load), to estimate the gain in “RMS-HaFC” to be obtained by considering these three metrics simultaneously (Fig. 9).
We define a new metric that is based on the three metrics used previously. It is calculated as follows:
where,
We can see that the pace of the RMS-HaFC curve is below the other three approaches. This shows that RMS-HaFC behaves well when considering all 3 metrics simultaneously.
Three metrics synthesis: 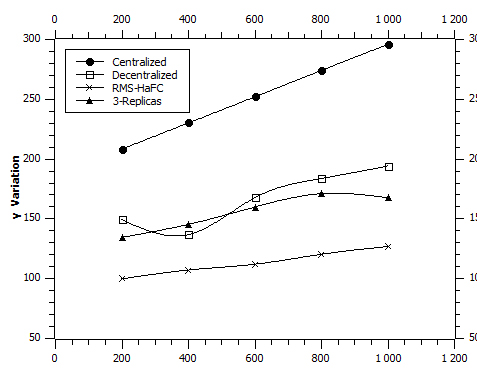
Hence it offers a gain of 55.06% compared to the centralized approach, 31.88% compared to the decentralized approach and 27.23% compared to the 3-Replica approach.
Fog Computing presents a promising solution to the problems of high latency and huge network traffic encountered in the cloud. The dense, heterogeneous and geo-distributed components of Fog’s infrastructures make the management of data that are requested by users a very complicated task. In this paper, RMS-HaFC, A Replication and Migration Strategy on the Hierarchical architecture in the Fog Computing environment is proposed to reduce the average response time for user’s requests and optimize the total energy consumption of the system. This strategy considers the geographical dispersion of the Fog’s infrastructure as well as the popularity of data. It specifies the number and best locations of replicas in each region. We also proposed an algorithm that is used to redirect the request to the nearest node hosting the data requested by a user, eventually a connected object, in a manner that balances the workload. Although our data management solution is functional, where we have evaluated it in the iFogSim simulator and the results obtained are very encouraging. Nevertheless, many elements in our proposal can be improved. For example, architecture can be used to combine this hierarchy with the P2P model, as well as an algorithm for dynamic clusters, produces a fault-tolerant and self-organized system. On the strategic plan, mobility awareness, Fog node resource management and data consistency management are interesting directions for future contributions.
Footnotes
Author’s Bios