
Abstract
BACKGROUND:
For a traditional vision-based static sign language recognition (SLR) system, arm segmentation is a major factor restricting the accuracy of SLR.
OBJECTIVE:
To achieve accurate arm segmentation for different bent arm shapes, we designed a segmentation method for a static SLR system based on image processing and combined it with morphological reconstruction.
METHODS:
First, skin segmentation was performed using YCbCr color space to extract the skin-like region from a complex background. Then, the area operator and the location of the mass center were used to remove skin-like regions and obtain the valid hand-arm region. Subsequently, the transverse distance was calculated to distinguish different bent arm shapes. The proposed segmentation method then extracted the hand region from different types of hand-arm images. Finally, the geometric features of the spatial domain were extracted and the sign language image was identified using a support vector machine (SVM) model. Experiments were conducted to determine the feasibility of the method and compare its performance with that of neural network and Euclidean distance matching methods.
RESULTS:
The results demonstrate that the proposed method can effectively segment skin-like regions from complex backgrounds as well as different bent arm shapes, thereby improving the recognition rate of the SLR system.
Keywords
Introduction
Sign language involves communication through hand gestures and body language, which can convey the same degree of information as the spoken or written word. Sign language recognition (SLR) provides a simple and natural mode of human-computer interaction that has gradually developed various applications, such as motion sensing games, [1] robotic control, [2] and intelligent buildings [3]. Moreover, for people with hearing impairments, sign language is their predominant method of communication.
Currently, SLR methods can be categorized based on the method of data acquisition into sensor-based or vision-based approaches. Sensor-based approaches directly capture accurate spatial information of the hands, wrists, fingers, and other body parts using sensors such as power gloves, [4] surface electromyogram signal sensor, [5] cyber gloves, [6] and data gloves [7]. For example, previous studies using various types of sensor data have achieved high gesture recognition rates of over 90% [8, 9]. However, the sensor devices used in sensor-based approaches can restrict the movements of the signer and may require complicated and costly setup.
Conversely, vision-based approaches only require a camera to identify sign language gestures, which has the advantage of being more user friendly. Vision-based approaches typically comprise hand region acquisition, hand-arm segmentation, classification, and recognition. Currently, the typical methods of hand region acquisition are background subtraction [10] and methods based on a color space such as RGB [11]. For example, Zhang et al. achieved robust hand detection by precisely extracting features using background subtraction with a recognition rate of up to 92.5% [12]. Lee et al. also applied background subtraction to extract moving gestures using the difference between the foreground and the background [13]. Lim et al. proposed a background detection method based on a combination of median and template filters [14]. To obtain the foreground object, the absolute difference between the image and the current background were calculated; then, the absolute difference between two subsequent frames was obtained to segment the hand motion region14. For the background subtraction method, it is vital to determine the difference between the foreground and background in order to avoid substantial errors.
Due to the unique color of human skin, methods based on a color space are commonly used for hand detection. Rautaray and Agrawal implemented an effective hand tracking approach based on the
The process of arm segmentation removes the arm from the image and eliminates all redundant information. For example, Liu et al. used a method that detected the spindle of the minimum enclosing rectangle of the hand in order to determine the wrist line; however, this method does not work when the hand is rotated and it is not applicable to the case of a bare elbow or a bent arm [19]. Zare et al. proposed a wrist cropping algorithm based on the longest horizontal line of the hand to the hand-arm segment that requires the arm direction to be adjusted prior to the calculation [20]. Gao et al. used the narrow boundary width to determine the location of the horizontal wrist line and remove the area below this line [21]. However, these methods require geometric correction to adjust the image when the arm is tilted. Therefore, it is difficult to segment bare or bent arms using existing SLR systems. As such, signers must ensure that their arms are covered to avoid complex segmentation of the hand-arm region. Moreover, existing methods are only suitable for forearm segmentation and not for segmentation of the upper arm when displaying different bent arm shapes.
In this study, a segmentation method is proposed for different bent arm shapes based on image processing. Morphological reconstruction is then employed to design a static SLR system based on the proposed segmentation method. After skin segmentation and denoising, the hand-arm region is obtained based on both the area operator and the location of the mass center. For different bent arm shapes, the transverse distance is calculated to distinguish the arm shape. Then, images containing a hand plus small bent arm are segmented using the vertical cutting line and images containing a hand plus large bent arm or a hand plus long arm are segmented based on the Euclidean distance and the cutting line. Finally, the geometric features of the spatial domain are extracted and the gesture is identified using the support vector machine (SVM) model. In contrast to existing segmentation methods, the proposed method can resolve the problem of multiple skin and skin-like regions in an image, effectively segment different bent arm shapes, and accurately recognize all 26 individual English letters. Furthermore, this method has wide applicability as it is effective regardless of how the arm is rotated, the size of the hand, or the color of the skin.
The remainder of this paper is arranged as follows. Section 2 describes the proposed SLR system including acquisition of the hand-arm region, hand-arm segmentation, classification, and recognition. The experimental results are presented and discussed in Section 3. Finally, the conclusions are presented in Section 4.
SLR system design
A static SLR system was designed to extract the hand region from a complex background and identify the sign language image. After skin segmentation and image denoising, the image containing the hand-arm region was obtained by hand-arm localization. However, different types of hand-arm regions may exist in the image; therefore, if the image is segmented with the same method, the quality of the segmented image will be affected. As a result, different segmentation algorithms were designed to obtain the hand region for different hand-arm images. A vertical cut line was employed to segment hands plus slightly bent arms and both the Euclidean distance and a cutting line were employed to segment hands plus highly bent arms or hands plus long arms. The geometric features of the spatial domain were then extracted. Consequently, the sign language image was identified with a SVM model. The detailed algorithm is shown in Fig. 1.
Structure of the proposed sign language recognition system.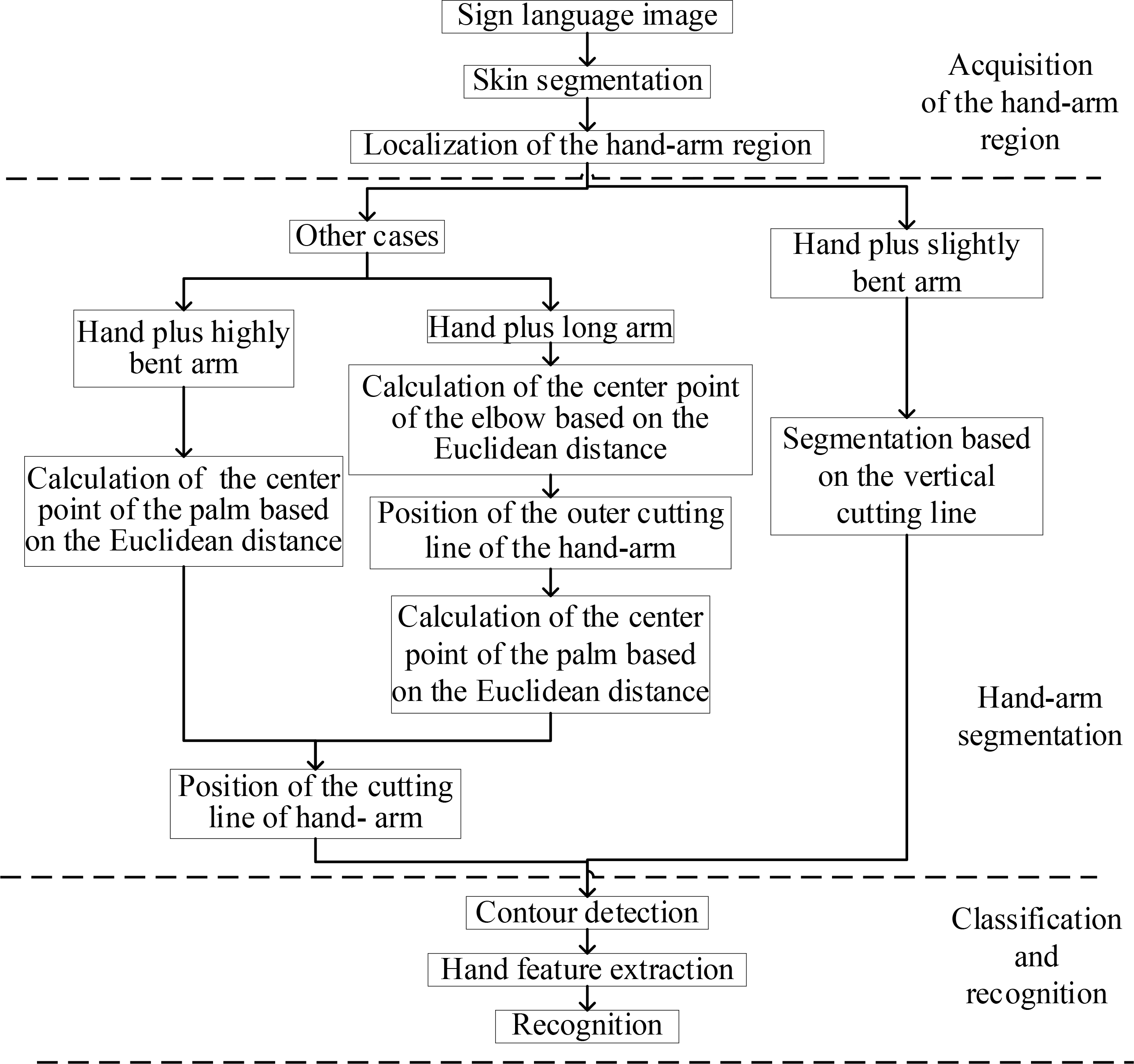
Skin segmentation
Because luminance and chrominance are separate in YCbCr color space, it was employed in this study to extract skin regions. An example sign language image from the dataset used in the experiment is shown in Fig. 2a, in which the signer is wearing a skin-like color and has a bare arm. Furthermore, the color of the background is similar to that of the signer’s clothing. 100 sign language images were randomly selected from this dataset. The ranges of Cb and Cr values with variable brightness (Y) are shown in Fig. 2b for YCbCr color space, which were used to set the Y, Cb, and Cr value ranges for the experiments; i.e.:
According to Eq. (2.1.1), the skin regions in the sign language image were detected in YCbCr color space, as shown in Fig. 2c, which shows three skin or skin-like regions after skin segmentation. However, there is also noise in the image, which will influence the accuracy of subsequent hand-arm recognition.
(a) Original image, (b) distribution of Cb and Cr with brightness (Y), and (c) image after skin segmentation using the values derived from (b).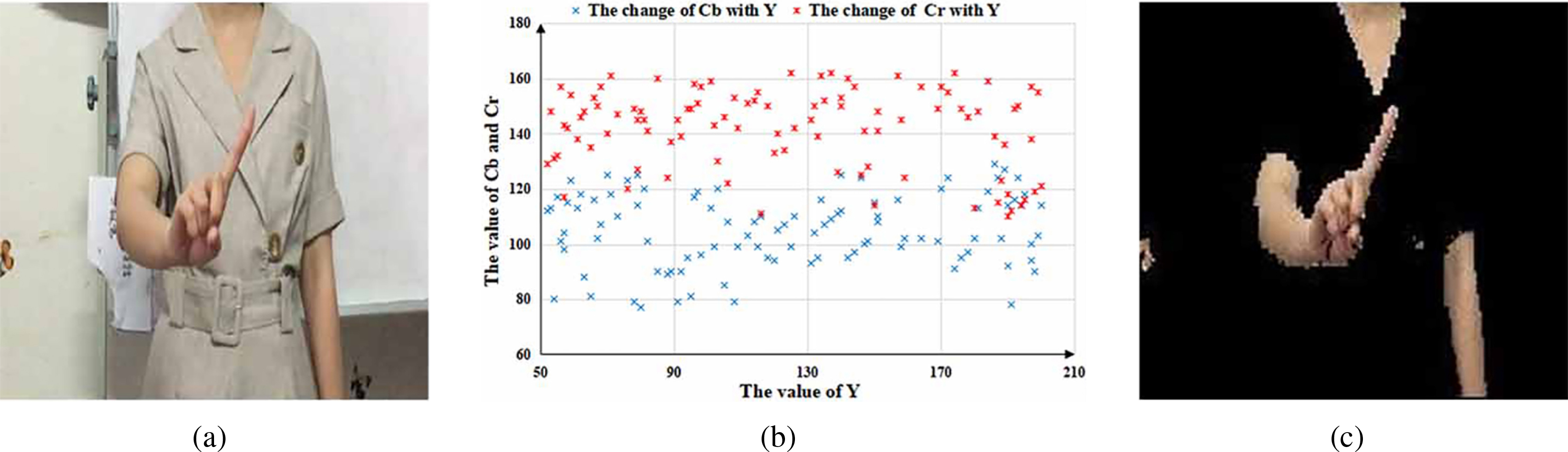
The median filter was used to remove the noise. Performing image denoising before or after skin segmentation results in a difference in image quality, as shown in Fig. 3. The image filtered after skin segmentation is superior to that filtered before skin segmentation. Hence, image denoising was performed after skin segmentation in the experiments.
A hand-arm region image filtered (a) before skin segmentation and (b) after skin segmentation.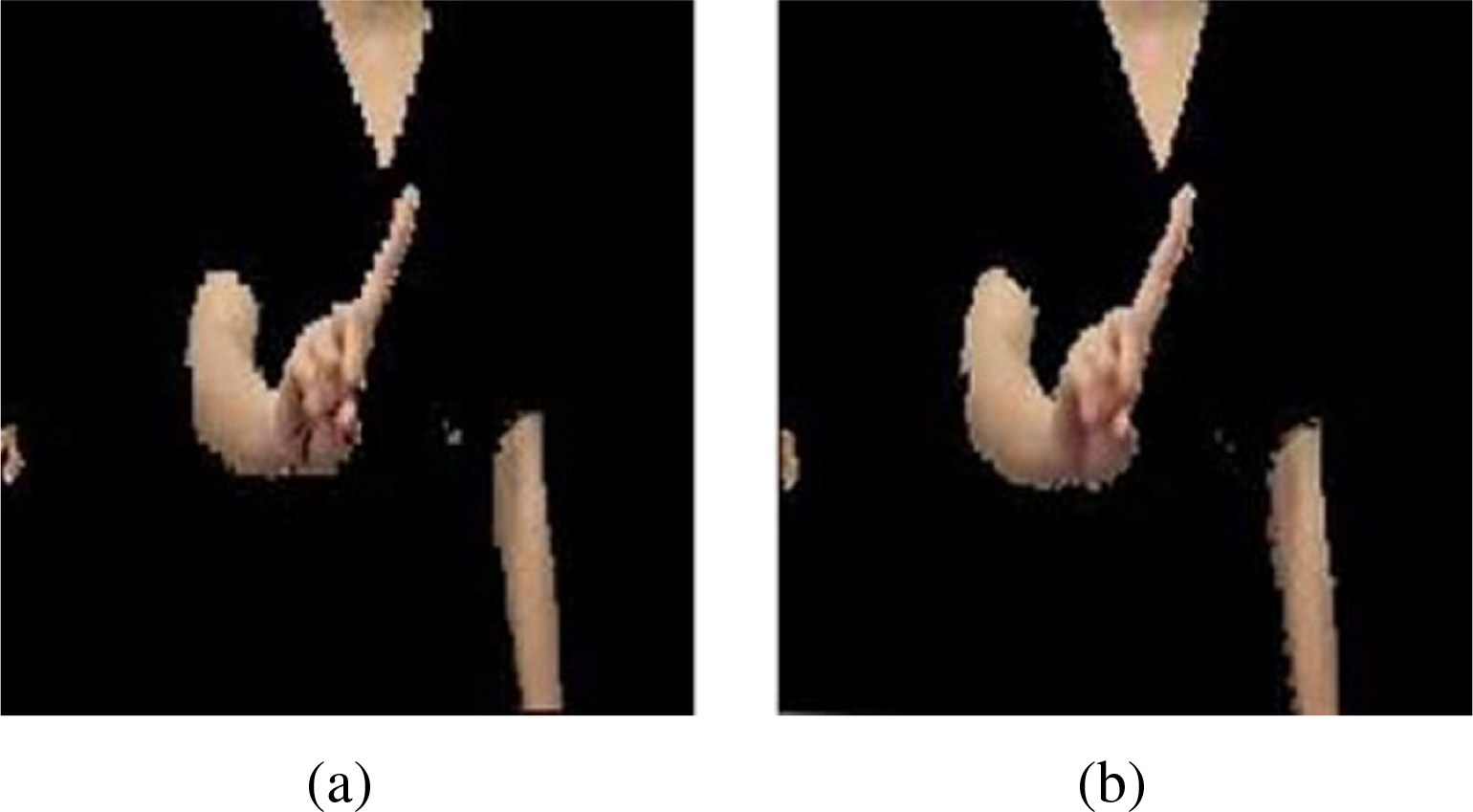
Images of the three types of hand-arm region extracted from the complex background: (a) a hand plus slightly bent arm, (b) a hand plus highly bent arm, and (c) a hand plus long arm. Left-hand images are after binarization and right-hand images are after positioning.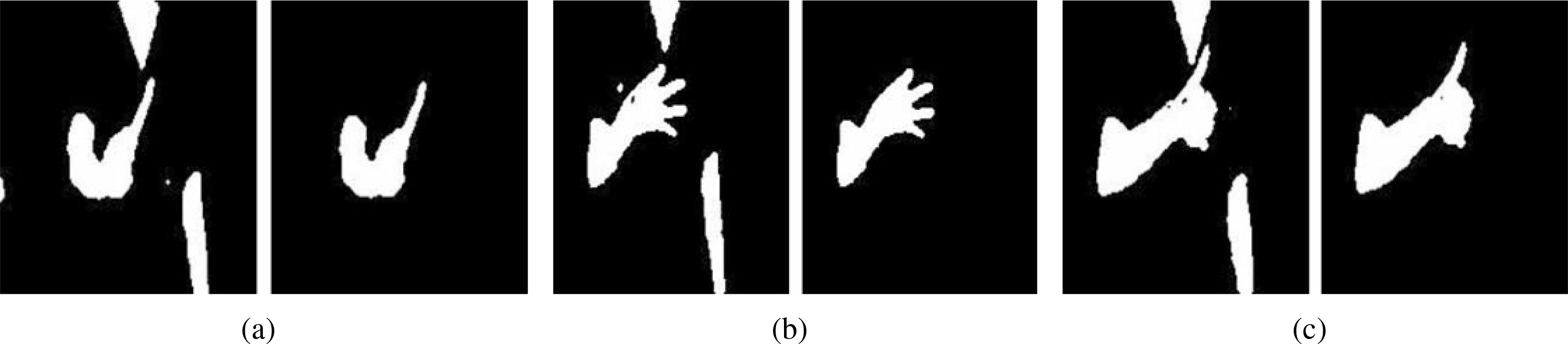
After skin segmentation and image denoising, three skin or skin-like regions are still apparent in the example filtered image (Fig. 3b), which will influence segmentation of the image; thus, all other regions except for the hand-arm region must be eliminated prior to segmentation. Therefore, a positioning method based on both the area operator and the location of the mass center was employed to obtain the hand-arm region. First, the coordinates of the mass centers of each region were calculated based on the zero moment and first moment, as shown in Eqs (2.1.3) and (3). Two regions had mass center coordinates that were smaller in the
Here,
Illustrations of the 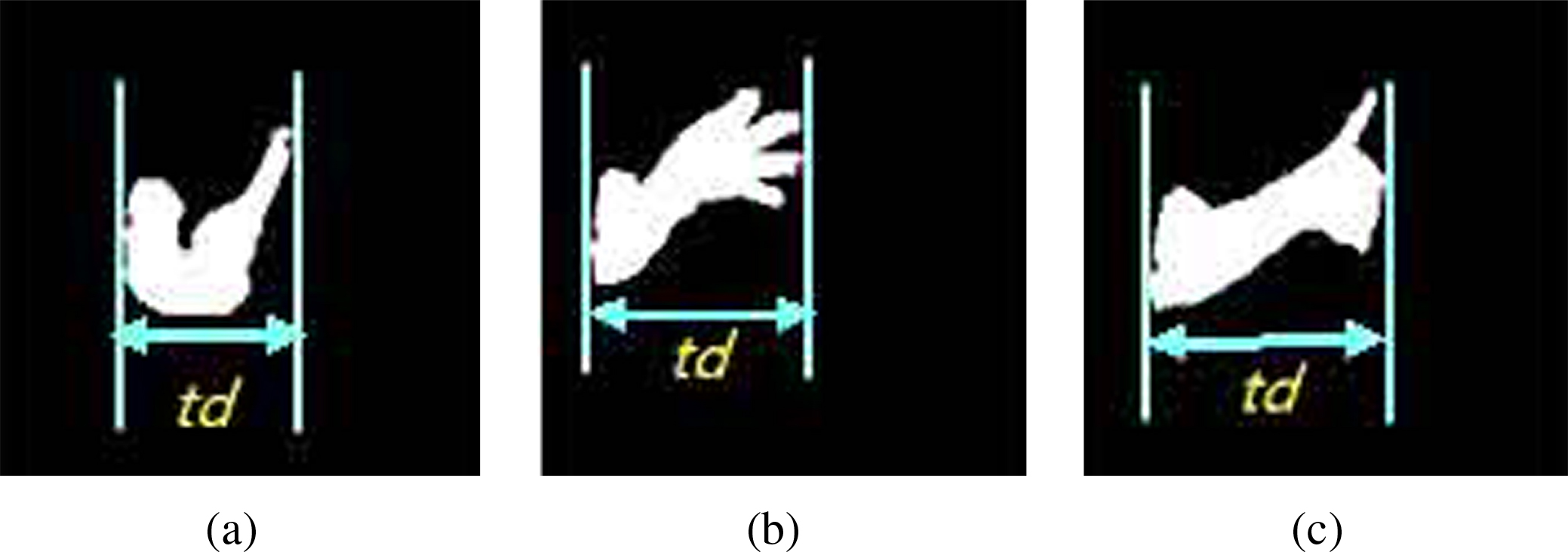
Images of a hand plus slightly bent arm (a) before segmentation and (b) after segmentation.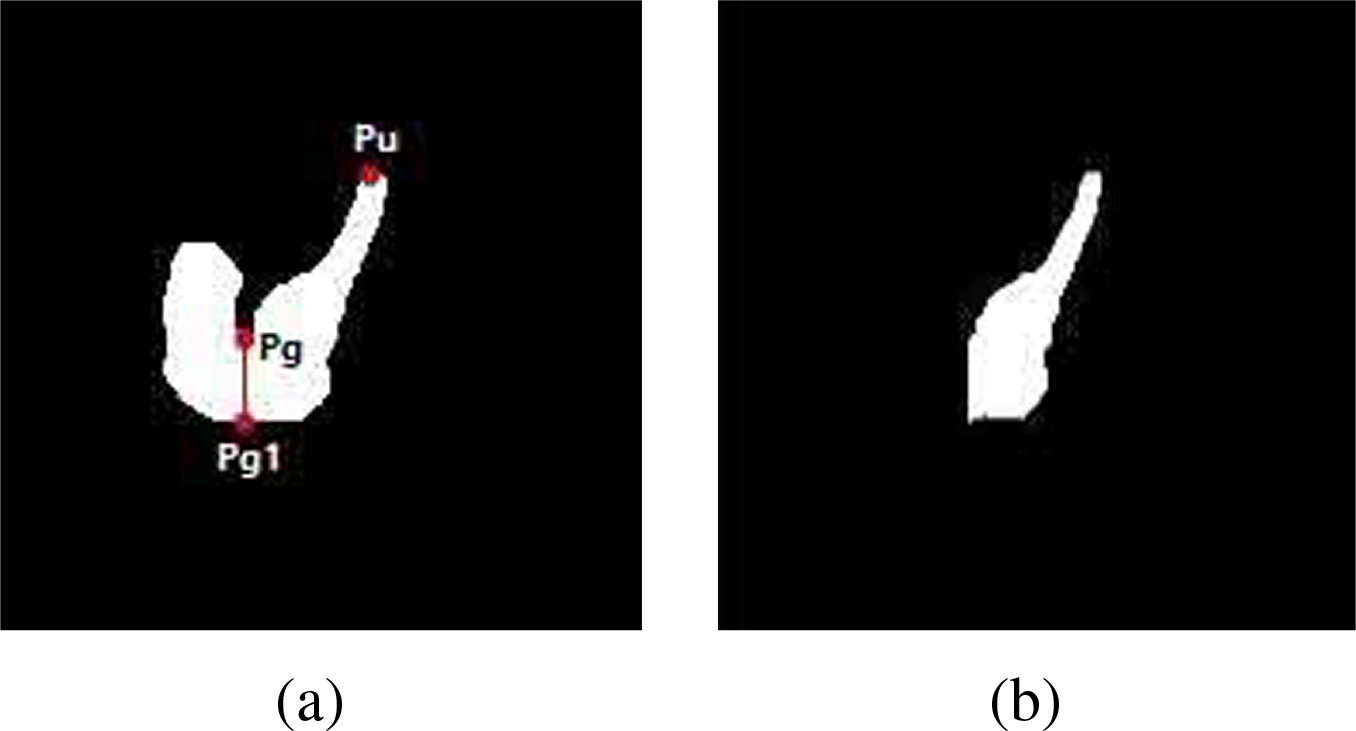
For traditional vision-based SLR, the signers typically wear long-sleeved clothes to avoid complex segmentation of the arm. However, bare arms are inevitable in natural interactions. To address this problem, different segmentation algorithms were designed for different bent arm shapes. First, the hand-arm contour was obtained using a chain code tracking algorithm. The leftmost point and the rightmost point of the contour were selected, respectively, and the abscissa difference between them was defined as the transverse distance and denoted as
Segmentation of a hand with a slightly bent arm
For the hand plus slightly bent arm shape, the point whose ordinate is largest among all points in the upper boundary was selected and denoted as
Segmentation of other hand-arm shapes
For the hand plus highly bent arm or hand plus long arm cases, the minimum distances between each point inside the hand-arm region and the points on the hand-arm contour were calculated based on the Euclidean distance. Then, the set including the minimum distances was built and denoted as
For the hand plus highly bent arm case, the inscribed circle of the palm with a center
Images of hand plus highly bent arm: (a) the inscribed circle, (b) the outer circle, (c) Pmax, (d) the cutting line, and (e) the morphological reconstruction.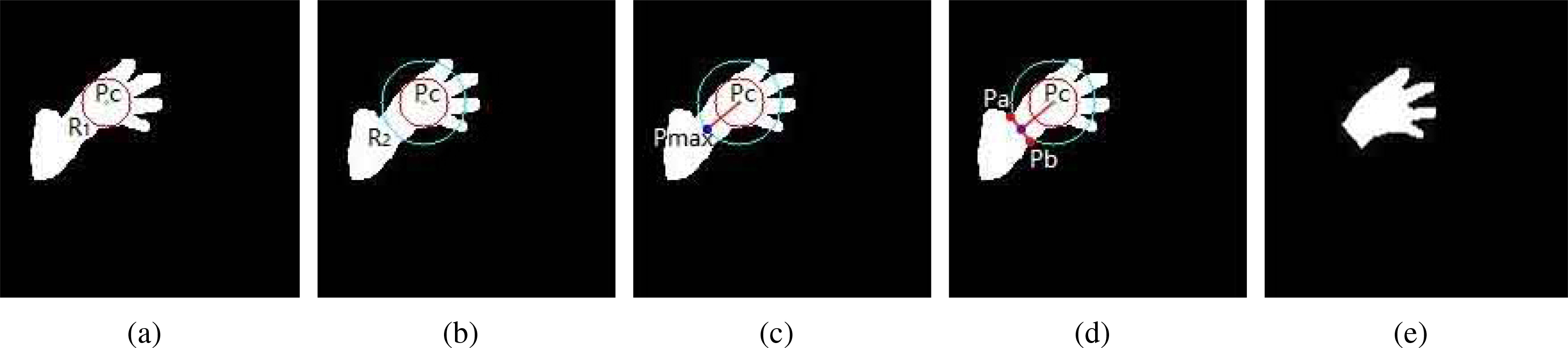
For the hand plus long arm case, the set including the minimum distances was built according to the same method as that for set
Images of a hand plus long arm: (a) the inscribed circle, (b) the outer circle, (c) 
Hand contour detection
Due to their complexity, a chain code tracking algorithm was employed to extract the hand contours. An example of an extracted contour is shown in Fig. 8e. The extracted hand contours were continuous and integrated; thus, they could be used to extract features.
Hand feature extraction
The performance of the SLR system can be significantly improved by extracting good quality features. In this study, the geometric features of the spatial domain were used to describe the two-dimensional projections of the hand image. Due to the invariant characteristics of translation, scaling, and rotation, the Hu moment was employed to obtain the image area, center of gravity, symmetry, and other characteristics. Seven invariant moments of the hand contour were extracted:
where
Sign language gestures with similar hand shapes cannot be accurately classified based on the Hu moment. Therefore, two hand descriptors were designed to further distinguish similar gestures. First, the sum of all pixels in the hand contour was calculated (Fig. 9a). The polygon was defined as the convex hull connecting the outermost points of the hand contour and was colored in cyan (Fig. 9b). The sum of all pixels in the convex hull was also calculated. The first descriptor was the ratio of the sum of pixels, as shown in Eq. (6) and the second descriptor was the ratio of the long axis to the short axis of the ellipse, as shown in Eq. (7). The orientation angle was calculated using both the zero moment and the second moment, as shown in Eq. (2.3.2). Here, the ellipse has the same orientation angle as the hand contour and contains all points on the hand contour. The long axis and the short axis of the ellipse were calculated using Eq. (9).
The convex hull of the hand contour.
Here,
Here,
Therefore, the feature vector
The most common techniques used for the classification and recognition of SLR are SVM, the Hidden Markov Model (HMM), neural networks, and Euclidean distance matching. Because SVM boasts simple calculation and rapid operation, we employed it in this study to segment and identify sign language images.
Validation experiments
Dataset and threshold settings
The SLR image dataset was collected under natural light conditions according to the English sign language standard library for all 26 letters. A camera was placed directly in front of the signer’s face for image acquisition. Five signers were used, all of whom were wearing skin-colored clothing. The dataset consisted of 6240 images that included the face, neck, and other skin regions (Fig. 10). All signers used their right hand to make gestures.
The settings of the two key thresholds are described here. The first threshold,
Images of (a)–(d) a hand plus slightly bent arm, (e)–(g) a hand plus highly bent arm, and (h)–(j) a hand plus long arm.
In order to verify the validity of our extracted features, we calculated and compared the recognition rate of single letters and the average recognition rate for the entire dataset, derived using Hu, Hu and
Comparison of the recognition rate for (a) the letter A and (b) the entire dataset obtained using Hu, Hu 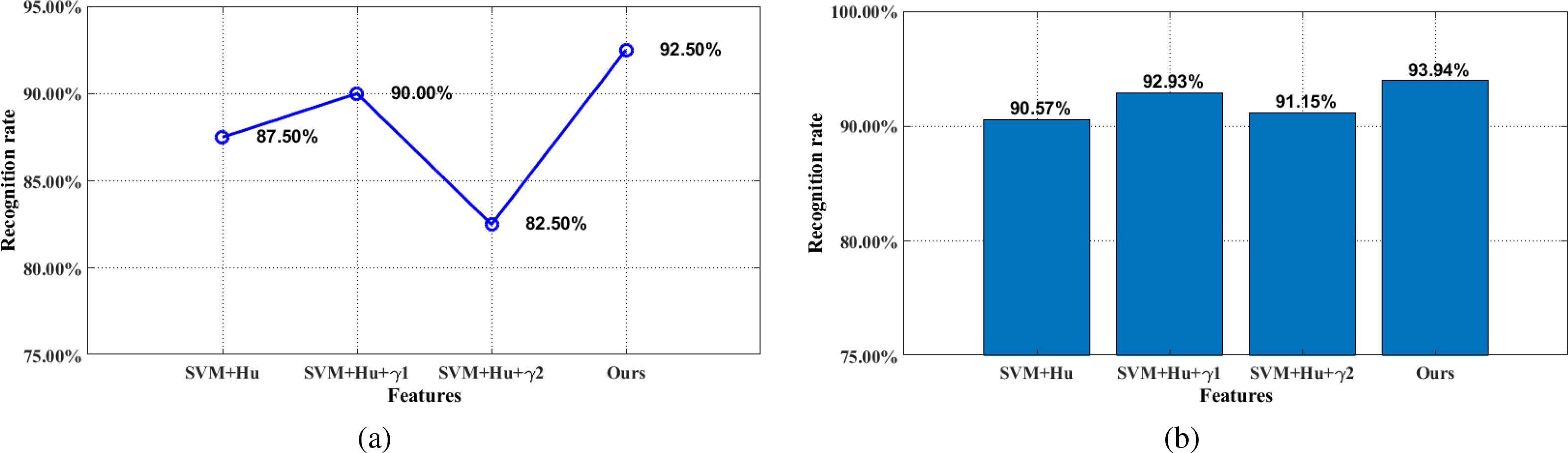
Change in recognition rates with an increasing number of images in the dataset.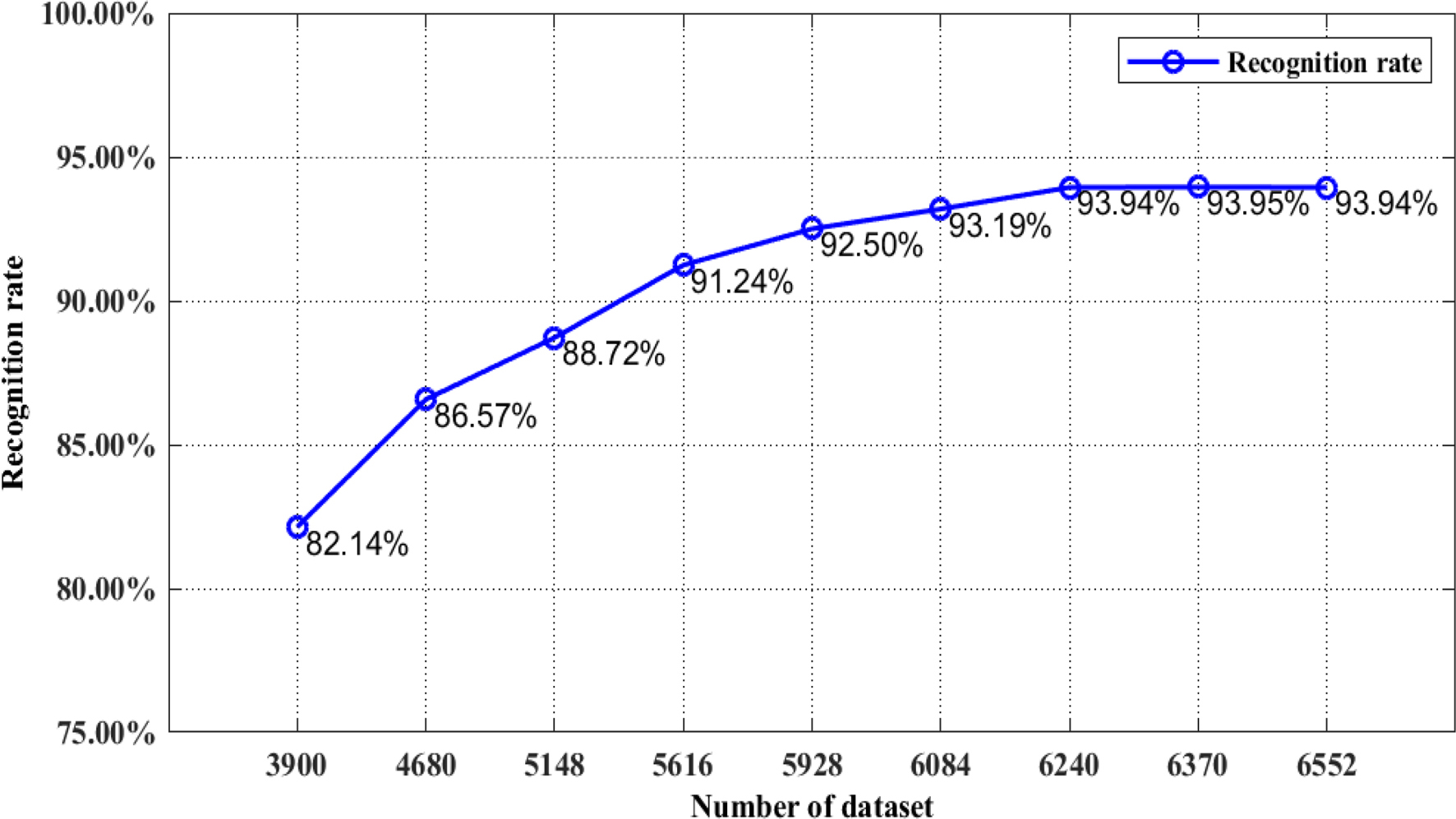
Comparison of recognition rates for the three classification and recognition methods.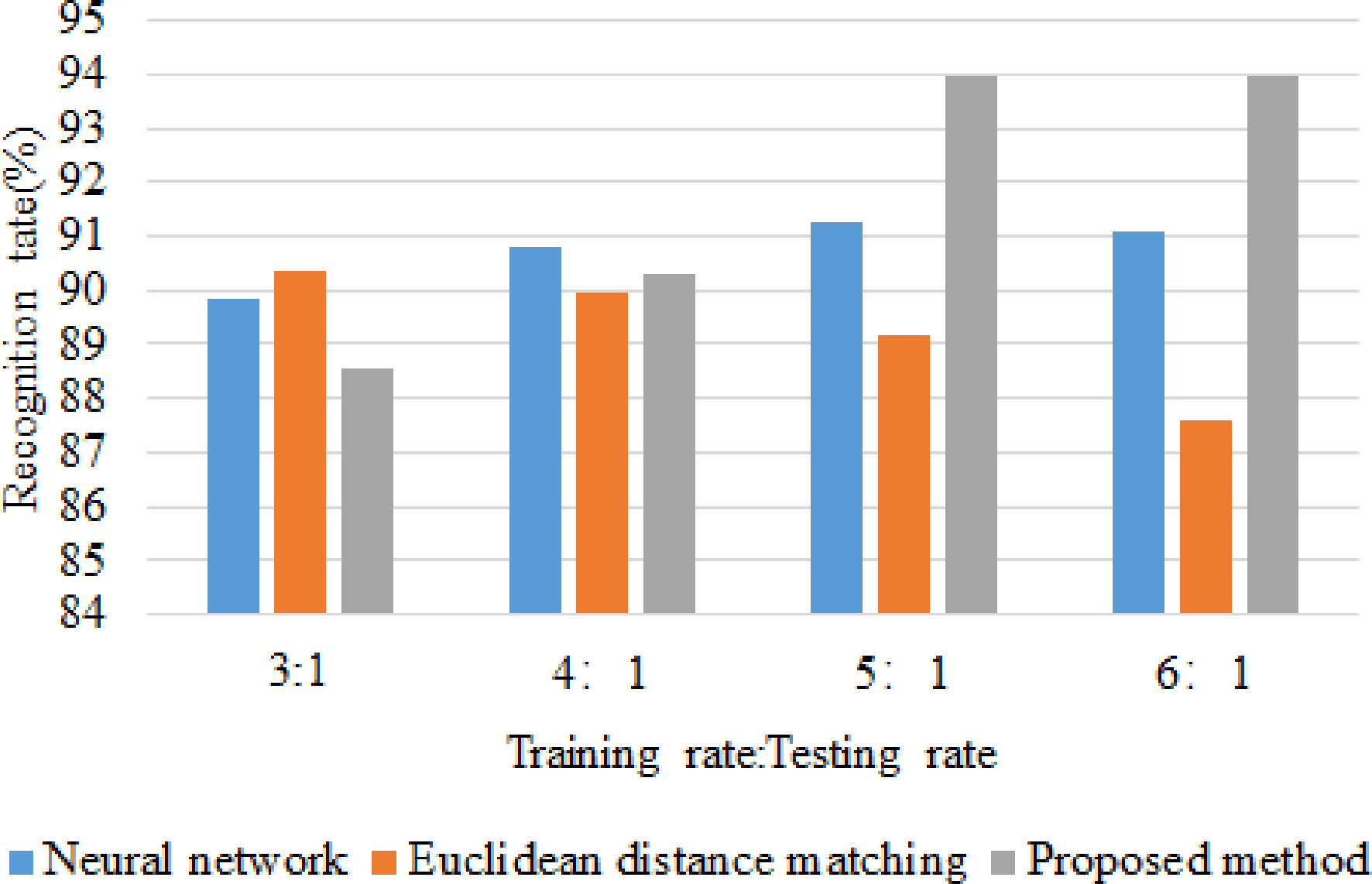
To verify the feasibility and validity of the proposed method, two experiments were conducted. The first experiment was the feasibility test. The sign language recognition rates were calculated for different numbers of images in the dataset (Fig. 12). For the lowest number of images (3900), the recognition rate was only 82.14%, which increased gradually as more images were included in the dataset to 93.94% with 6240 images. The recognition rate did not improve notably with more than 6240 images. Therefore, 6240 images were used in the experiments.
The second experiment was a comparison with other common classification and recognition methods; i.e., the neural network and Euclidean distance matching. All methods were used to classify and identify 26 English sign language letters. First, different ratios between the training set and testing set were analyzed: 3:1, 4:1, 5:1, and 6:1. Then, the recognition rates were obtained using the above methods (Fig. 13). The recognition rate obtained by the neural network did not improve significantly with increasing ratio whereas Euclidean distance matching was effective with only a few training samples but the recognition rate decreased with increasing sample size. Conversely, the recognition rate of the proposed method improved substantially with increasing ratio. Furthermore, the recognition rate obtained by our proposed method was clearly superior to those of the other methods, but only for a ratio between training and testing sets of 5:1. Prior to this ratio, no obvious improvement was observed in the recognition rate with increasing ratio. Therefore, the ratio between training and testing sets was set to 5:1 in the experiments and the recognition rate and computational time were calculated for the above three methods (Table 1).
Comparisons of the recognition rate and computational time for the three classification and recognition methods
Comparisons of the recognition rate and computational time for the three classification and recognition methods
The recognition rate obtained using our proposed method was quantitatively superior to that obtained by the neural network. In addition, the computational time was significantly shorter using the proposed method. Compared with Euclidean distance matching, the computational time of the proposed method was slightly longer; however, the recognition rate was substantially higher. These results indicate that our proposed hand-arm classification and recognition method is both feasible and effective.
In order to solve the problems of existing methods related to background interference and arm redundancy, a static sign language recognition system was proposed for different bent arm shapes based on image segmentation and arm removal. The system consists of hand-arm acquisition, hand-arm segmentation, contour detection, hand feature extraction, and recognition. The proposed segmentation algorithm can be adapted to different hand-arm shapes and guarantees the integrity and accuracy of the extracted hand region. The results of the proposed method were compared with existing classification and recognition methods according to the recognition accuracy and computational time. The experimental results proved the efficacy of the proposed method However, the long computational time of the proposed method should be improved through future research.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (51405448).
Qiuhong Tian acknowledges financial support from the doctoral research start-up funding of Zhejiang Sci-Tech University (18032117-Y).
Qiaoli Zhuang acknowledges financial support from the doctoral research start-up funding of Zhejiang Sci-Tech University (19032141-Y).
Zhejiang Sci-Tech University 2019 National University Students Innovation and Entrepreneurship Training Program (201910338012).
Conflict of interest
There are no conflicts of interest to declare.