
Abstract
As intelligence in smart homes increasingly get sophisticated, it has become necessary adopting ontological reasoning in these domains. However, ontologies presently lack a standardised representation for uncertainty in knowledge. A key challenge therefore lies in developing ontology-based decision-making models that can integrate domain uncertainty. In this paper, a decision network extension to OWL ontology using only a subset of domain concepts relevant for probabilistic modelling is proposed. This relevant set of concepts in ontology can be generated on the fly using an algorithm, OWLMB, introduced in this paper. Given an ontology and a class as inputs to OWLMB, Markov boundary of the class is returned as this minimum relevant set. Also, representations for decision and utility nodes are proposed as an extension of valid decision situation to ontology. Validation of this approach in a smart home scenario shows its feasibility in a real application domain.
Introduction
Research into representing and decision-making under uncertainty in smart homes (SHs) is very much alive even though advances in current research prove SHs to be very beneficial [9,10]. Because of the intrinsic complexity of SH domains, any suitable choice of knowledge representation framework must taxonomically capture domain concepts with high expressiveness. Additionally, any decision-making model in these domains must integrate knowledge representation schema with domain uncertainty.
With the growing complexity of SHs, ontological intelligence has become apparent in these systems [4,19,29,31]. However, ontologies presently lack a built-in support for representing and reasoning under uncertainty [23,28]. But uncertainty cannot be avoided, especially in smart environments where low-level contexts required to deduce high-level implicit knowledge are uncertain. Using this uncertain low-level context in knowledge discovery can lead to high-level contexts which are uncertain too. For example, a fire agent may give false alerts due to noisy sensor information. This inconvenience is better than the real danger of a fire outbreak without notification. Therefore, full realisation of SH benefits depends on the derivation of a common model of uncertainty that can be used by all entities in the environment. This can be achieved with ontology-based models only when it is possible to represent and reason under uncertainty using ontology.
In addressing uncertainty reasoning in ontology, probabilistic approaches [7,13,14,25,29], and particularly Bayesian networks (BNs) [11] have been proposed. Even though BNs remain a powerful tool in uncertainty reasoning, they are unsuitable for decision-making under uncertainty in large-scale ontologies for two reasons. First, the BN structure in its classical form does not support requirements of a valid decision situation. Second, encoding information about the world can be tedious if not impossible, and potentially leads to high complexity models with redundant variables. For time critical domains like SHs, overly complex models are not ideal due to the high computational cost involved.
This paper proposes an approach that integrates OWL ontology [3], Markov boundary (MB) [27], and decision networks (DN) [15] to form a novel bridge among these three different entities in knowledge representation. Key component of this approach lies in the annotation of DN in ontology using relevant minimal set of concepts. This presents the simplest efficient uncertainty decision-making model in ontology, which can be depicted by the metrics of BN complexity.
Efficient uncertainty decision-making in large-scale ontologies can be achieved using a subset of concepts that prove conjunctively useful for probabilistic modelling. A principled way of obtaining this set is to determine MB of a target class in ontology. An algorithm, OWLMB, is introduced to determine MB from ontology. The algorithm takes an ontology and a given class as inputs, and gives MB of the class as the output representing the minimum relevant set.
A DN is a directed acyclic graph (DAG) representing the alternative, information, and preference requirements of a valid decision situation. On the assumption of faithfulness condition, the underlying probability distribution of MB can be represented by a DN. Two challenges are addressed here: translation of MB into a DN; and encoding DN in ontology. In the first case, the structural translation approach of [13] is extended to OWL properties with multiple domains and ranges. Second, since only the information requirement for random variables of DNs exists in the literature [13,14,29], representations of decision and utility nodes as an extension of OWL are proposed. This extension gives OWL more expressive power for sequential decision-making in ontology.
By validating this approach in a SH scenario, the results of experiments conducted show the feasibility in a real application domain. The rest of the paper is organised as follows: the problem description and background are given in Section 2; details of the approach are presented next in Section 3, which is followed by validation in Section 4; finally, related work and conclusions are respectively presented in Sections 5 and 6.
Problem description and preliminaries
Decision-making under uncertainty in SHs presents a challenge of integrating context-based knowledge models with domain uncertainty. The underlying idea is that efficient reasoning in these complex domains can be achieved using ontology-based models that encode dependency properties of graphical models through compact modelling. Compact modelling in this regard therefore requires proper feature selection techniques that provide equivalence preserving model performance without high computational cost.
At the time of decision, both contexts and action outcomes cannot be known a priori. This phenomenon introduces uncertainty into the decision-making process, and efficient reasoning can be guaranteed through the incorporation of uncertainty into decision-making models. Specifically, when relations are represented by probability to encode uncertainty and preferences of actions are represented by utility in ontology, recommendations on best decisions can be made by maximising utilities.
Formally, the degree of uncertainty between any two concepts in ontology can be expressed by
Decision networks
A DN is defined as a tuple
If
For a given DN, the total conditional probability distribution can be computed by:
The solution of a DN is a policy π, which indicates the best action to take. π is a function
Markov boundary
An OWL ontology consists of classes, properties and individuals to taxonomically represent a domain. Properties in ontology specify both class relations and features. Class inheritance as enshrined in OWL semantics, allows taxonomies for both classes and properties to be specified. From this viewpoint, classes and their properties in an ontology can be considered as variables in an equivalent DN of an OWL ontology.
Based on the d-separation criterion [11] of random variables, a DN satisfies the faithfulness condition. In this regard, Markov blanket [30] can be defined as:
(Markov blanket).
A Markov blanket
Where
(Markov boundary).
If
Being a minimal set, the MB of a response variable can be expanded to include arbitrarily variables of interest since such additions have negligible effect on model performance.
Representing decision network in OWL ontology
An OWL ontology and a DN can represent the same domain because they have structural similarities. In this view, a DN can be visualised as a DAG where nodes denote OWL: Classes and arcs represent OWL:Properties. By assuming the d-separation criterion, characteristics of individuals of a class depend only on the characteristics of the class. This, thus, satisfies the definition of an ontology as a structured form of knowledge representation, which encodes conditional independence using class properties.
Markov boundary in OWL
To translate an OWL ontology into a DN, overly complex models can be avoided by using a subset of concepts relevant for probabilistic modelling. One feasible approach that is adopted in this paper is to determine the MB of a class in ontology as a minimal set of concepts that prove conjunctively feasible for probabilistic modelling.
In ontology, class memberships and relations can be used to describe conditional independence assumptions. For instance, two disjoint OWL classes Light and Temperature are related by axiom rdfs:subClassOf Sensors. Since Light and Temperature are disjoint, they exist as independent entities without the class Sensors. This illustrates the d-separation criterion of DNs, and an OWL graph as such satisfies the faithfulness condition. Thus, for a given class in OWL ontology, any subset of classes rendering all other classes independent of same defines its Markov blanket. Consequently, MB of a class in the ontology can be derived using Definition 2.
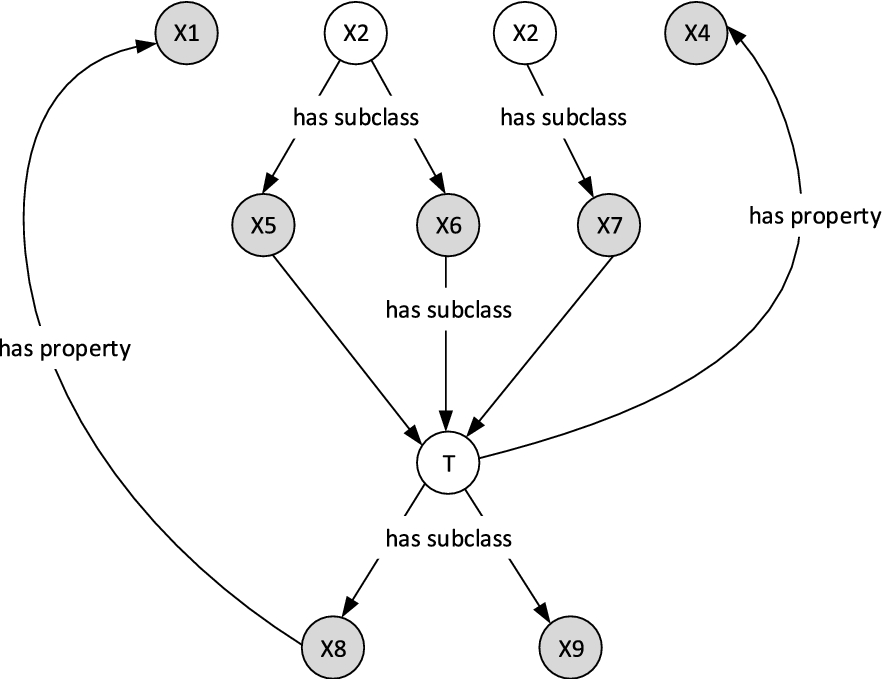
An example of OWL ontology. The gray-filled nodes are the Markov boundary of class T.
An example of MB of class T is given as the gray-filled nodes in Fig. 1. From this graph, all other nodes except
To facilitate automatic generation of concepts and properties for efficient ontological probabilistic modelling, an OWL-Markov boundary (OWLMB) algorithm is introduced in this paper. OWLMB is structured into two phases, and takes an OWL ontology and a target class(s) as inputs, and returns a set of classes and properties as the MB.
In phase 1, as shown on line 4, MB is initialized to T. With this initialization, T is excluded from the search space C as line 5 indicates. Next, the algorithm looks up all spouses, parents and children of T in C, and updates MB whenever true (lines 5–18). Execution is transferred to phase 2 when C is exhausted.
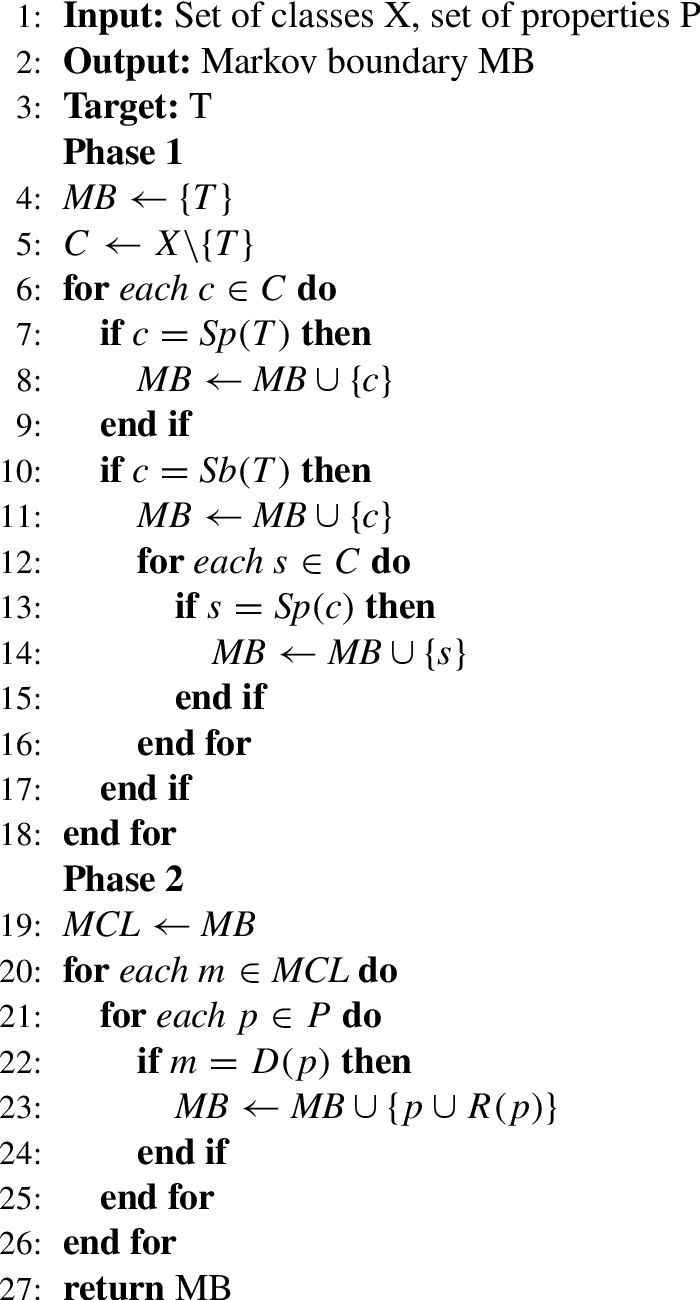
OWLMB
Next in Phase 2, the algorithm finds all properties associated with the elements of the MB obtained in Phase 1. Line 19 presents a new search space MCL as clone of the MB determined in phase 1. Then from lines 20–26, a property gets to be valid if it has a domain class in MCL, and MB is updated with this property and its range. The output after this phase gives the complete MB of T.
In a DN, the information, alternative and preference requirements model respectively the probability, decision and utility components. Thus, random, decision and utility nodes must be defined in MB before the encoding process. To simplify the presentation here, all nodes are considered binary in the encoding process.
Let A, B, denote random classes, C a decision class, and U a utility class in ontology. The probability that an individual belongs to class A can be represented by a prior probability
The definition of probability in ontology provided in this paper is inspired by the approaches of [13,14]. Two mandatory OWL classes: PriorPClass; and CondPClass; representing prior and conditional probabilities respectively are defined. PriorPClass will have instances of the form

Prior probability annotation.

Conditional probability annotation involving more than one parent.
To represent a decision variable in ontology, a mandatory class DecClass is required. Also required are hasCVariable, hasParent, and hasDecision as properties of this class. hasDecision specifies possible decision outcomes for actions in the domain. An instance of DecClass must have at least one decision specified. No value is specified in the representation of DecClass because its value is the expected utility computed whenever beliefs are updated. An illustration of encoding decision node in ontology is given by Listing 3. This example encodes a decision variable that is influenced by two other nodes, and specifies actions for turning on or turning off an air-conditioner.

An example of how to express decision information in OWL ontology.
For the representation of a utility node in ontology, a mandatory class UtilClass with properties hasUtility, hasParent and hasUValue is defined in ontology. This can specify a utility function using a property hasUtility, and the predetermined value of the utility given by another property hasUValue. Just like the annotation of conditional probability, utility values are also tabulated. An example of encoding a utility table in ontology is shown in Listing 4.

An example of how to express a utility function in OWL ontology.
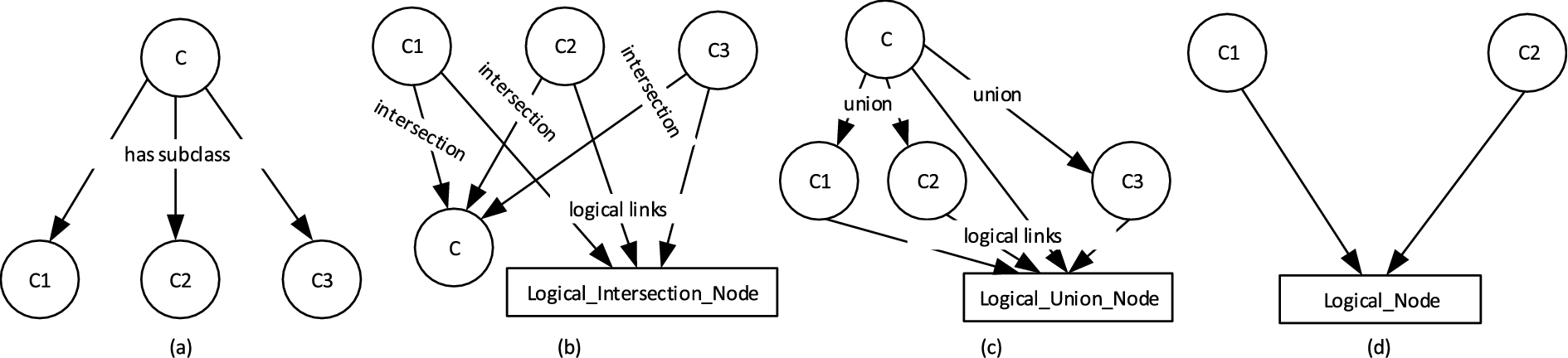
Subnets of axioms based on our translation rules.
Here, steps are provided to facilitate construction of an equivalent DN of an annotated ontology with decision and utility nodes. In this representation, OWL properties can have multiple domains and ranges. Taking guidance from the structural translation rules of [13], extensions are provided to their approach to include properties with multiple domains and ranges. Axioms of OWL underline the basic idea of this augmentation, and a multiple domain/range property defines an intersection semantics using the axiom owl:unionOf. The following rules are therefore proposed to achieve this augmentation:
rdfs:subClassOf axiom is modelled as a directed arc from the superclass node to the subclass node in the translated graph. The subnet of this translation for classes A class C defined by the axiom owl:intersectionOf of the classes A concept class C defined using the axiom owl:unionOf of the classes For two classes Every property P is mapped to a class node P_Class in the translated DN. For a single domain D and range R, P_Class must be a parent of R, and child of D. For a multi-domain property, a class node LD_Class is mapped to union of the domain classes. LD_Class is then the parent of P_Class in the translated DN. The subnet shown in Fig. 3 is an example of a translated network of a multi-domain property. A property with a multiple range maps a class node LR_Class to union of the range classes. P_Class then has the child LR_Class.
For a given ontology annotated with DN information, these rules clearly show the translated DN consists of logical and concept nodes. Therefore, for conditional probability distributions, CPTs for both types of nodes are required and can be constructed based on the semantics provided in this paper.
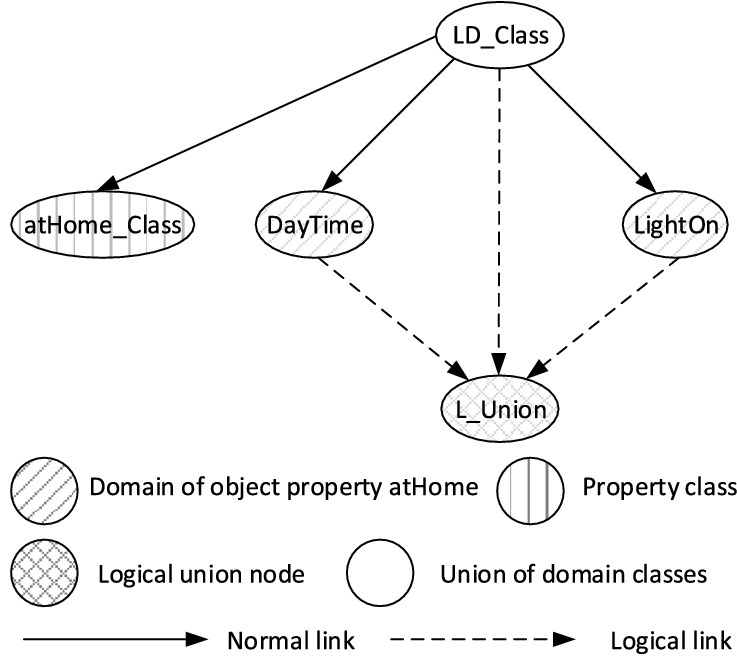
Subnet of a property with two domains.
In ontological reasoning, high-level contexts deduced from low-level uncertain contexts are uncertain too. Selecting a best action outcome using these high-level contexts as evidence is therefore an optimal decision-making problem, which holds uncertainty management as a tuning factor.
Within the framework of DNs, best action outcomes always correspond to optimal policies. The optimal policy can be computed using the principle of maximal expected utility (MEU). For example, it may be required to either turn on or turn off a home’s air conditioner depending on the prevailing condition of the home. This clearly smacks of uncertainty in respect of future contexts that may occur in the environment and the corresponding action to take. Thus, a non-deterministic action A can have several outcomes
Suppose a binary decision node has k binary parents,
As shown in Algorithm 2, the underlying idea of computing the optimal policy of a DN using VE is to first find an optimal decision for each value of the parents of the last decision. This produces a factor of maximum values, which results into a new DN that can be solved recursively.

VE for DNs
As can be seen, this algorithm takes a DN as an input, and computes the expected utility of an optimal decision (line 1 and 2). After initialising the set of decision functions
In a multiple decision situation, the sensitivity of expected utility
In this section, the feasibility of this approach is demonstrated in a SH scenario. Additionally, performance evaluations of Algorithm 1 and MB in context reasoning are discussed.
Smart home scenario
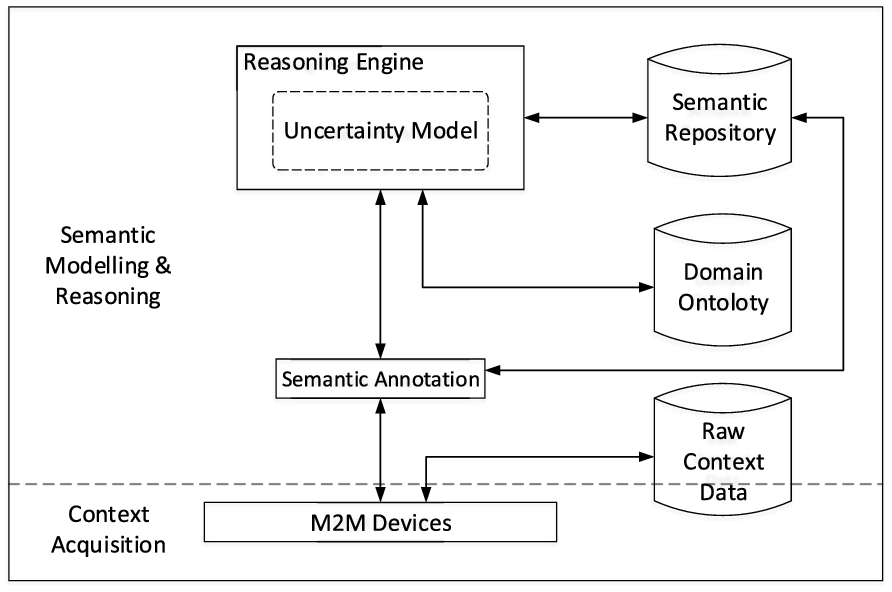
Ontology-based semantic reasoning model.
A demonstration of this approach in a SH scenario for a home’s comfortability is presented. In this demonstration, a virtual SH environment incorporating modules for SH server, context generator and a client node based on the semantic model shown in Fig. 4 is designed. The two main layers of this semantic model are context acquisition and semantic modelling and reasoning. The context acquisition module acquires contexts from M2M [33] devices in the environment, and works to change sensed information into situational context according to a user’s activity and the home’s condition through semantic annotation. Basically, annotation of context is adding semantic markups that add meaning to contextual information. Two levels of storage are provided to keep history of both the raw and annotated contexts.
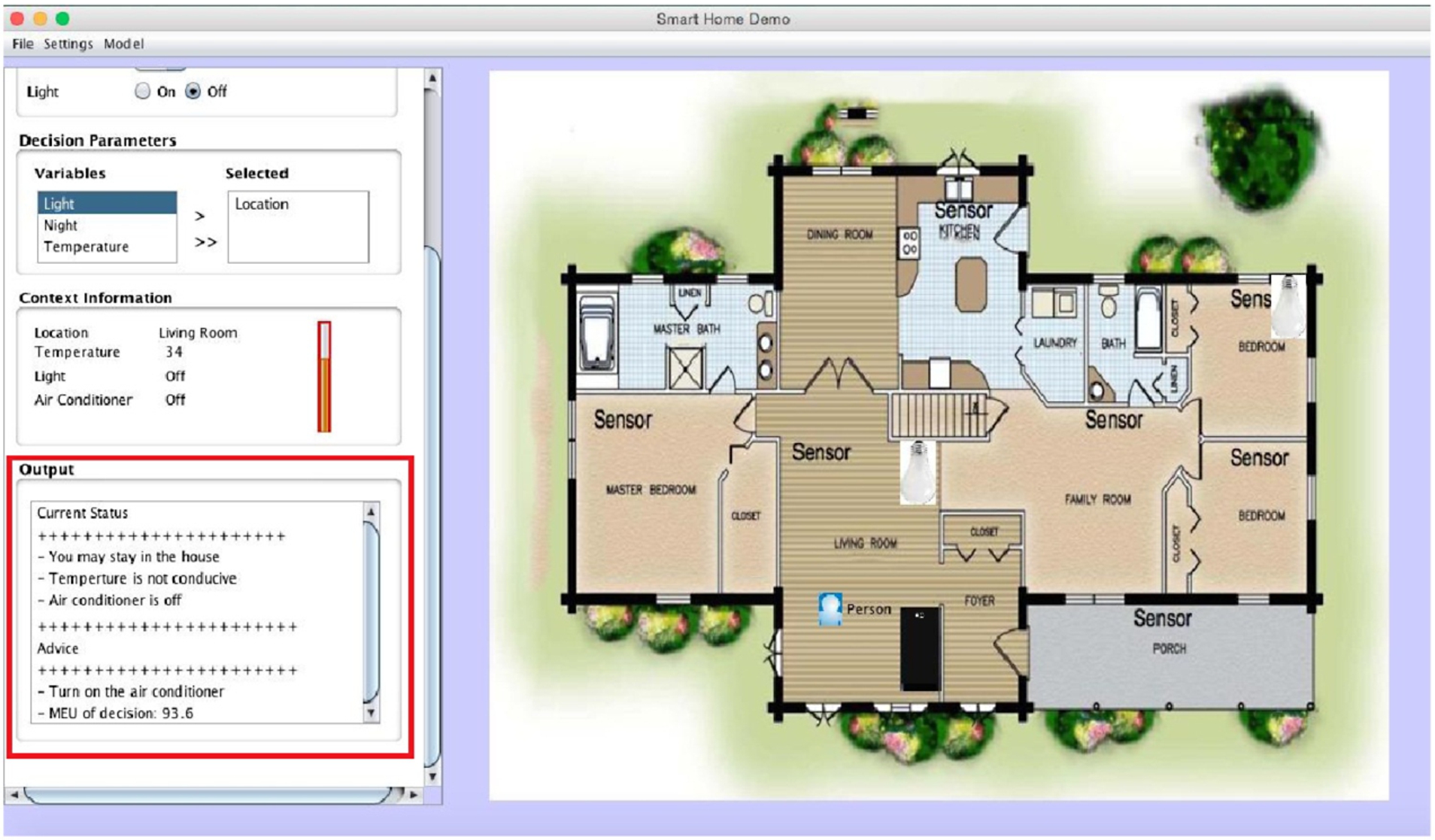
Interface of a SH scenario. This includes modules for SH server, context management and client node.
By making use of context-awareness, the SH server can pro-actively alert the user on the home’s condition through the client node. In this particular case, the context-awareness is provided by a reasoning engine implemented in the SH server. The reasoner is an MB-based DN of a context ontology in which domain knowledge merges with annotated information. Implicit knowledge pertaining to decisions on the home’s comfort can therefore be made using contextual information from the environment as evidence.
The context information considered in this scenario corresponds to the home’s temperature, user location, state of light, and state of air conditioner. When a context event occurs, domain uncertainty is handled by updating beliefs in the DN, and expected utilities are recomputed for all possible decisions. The decision that produces the MEU then becomes the user’s alert, and such notifications are sent through the client node. Essentially, this design can achieve increased computing capabilities since it compactly represents the home environment, decision models and other operational settings as shown in Fig. 5. This means the model is suitable for generic designs in which user friendliness is key, and independent collaborative models can be leveraged for complex reasoning tasks in SHs.
To evaluate the performance of OWLMB, the mean algorithmic run-times of three different scenarios are measured in seconds. Three output sizes 3, 5, and 9 were used to represent these scenarios, and their mean run-times for 100 tries were measured. In each case, the size of the ontology was varied from 40 to 130 concepts. Mean run-times of the scenarios for ten different input sizes are shown in Fig. 6.
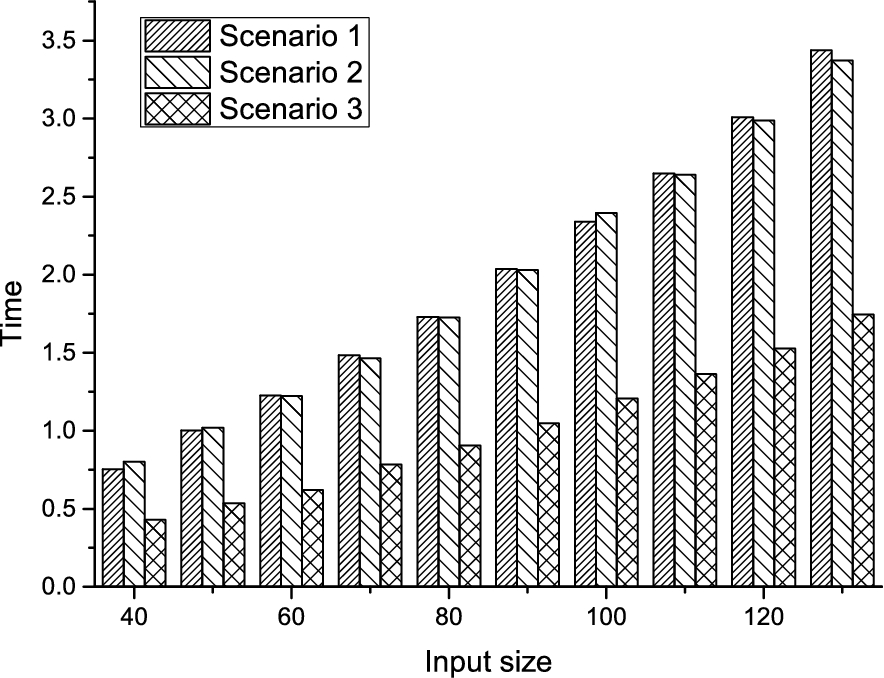
Run time of OWLMB for three different output sizes.
Pruning redundant nodes in the DN generated using MB set and other arbitrary domain concepts. Redundant nodes are shown in red. We used the Bayes net software by AISpace.org.
Analysing each input separately reveals that lowest mean execution times are for Scenario 3, and followed marginally by Scenario 2. There are a few cases, however, that the mean times for Scenario 2 are slightly higher than those of Scenario 1. This, perhaps, is the case of variance in the measurements that was ignored in the experiment. But interestingly, even though mean times for Scenario 1 and Scenario 2 seem overlapping, there is a wide gap between them and Scenario 3. It can be seen also that between input sizes 100 and 130, the performance of Scenario 3 is approximately twice the performances of the other two. This gives an indication that this algorithm’s performance can scale well with large output given a large input.
By examining the increasing mean run-times with input size in each scenario, a trend of traditional order of growth of run-time of an algorithm is observed. This depicts a power rule’s pattern, and the graph’s order can be approximated using the ratio of the logarithm of the quotient of two successive times to the logarithm of the quotient of corresponding inputs. For Scenario 3, when the input size gets larger (
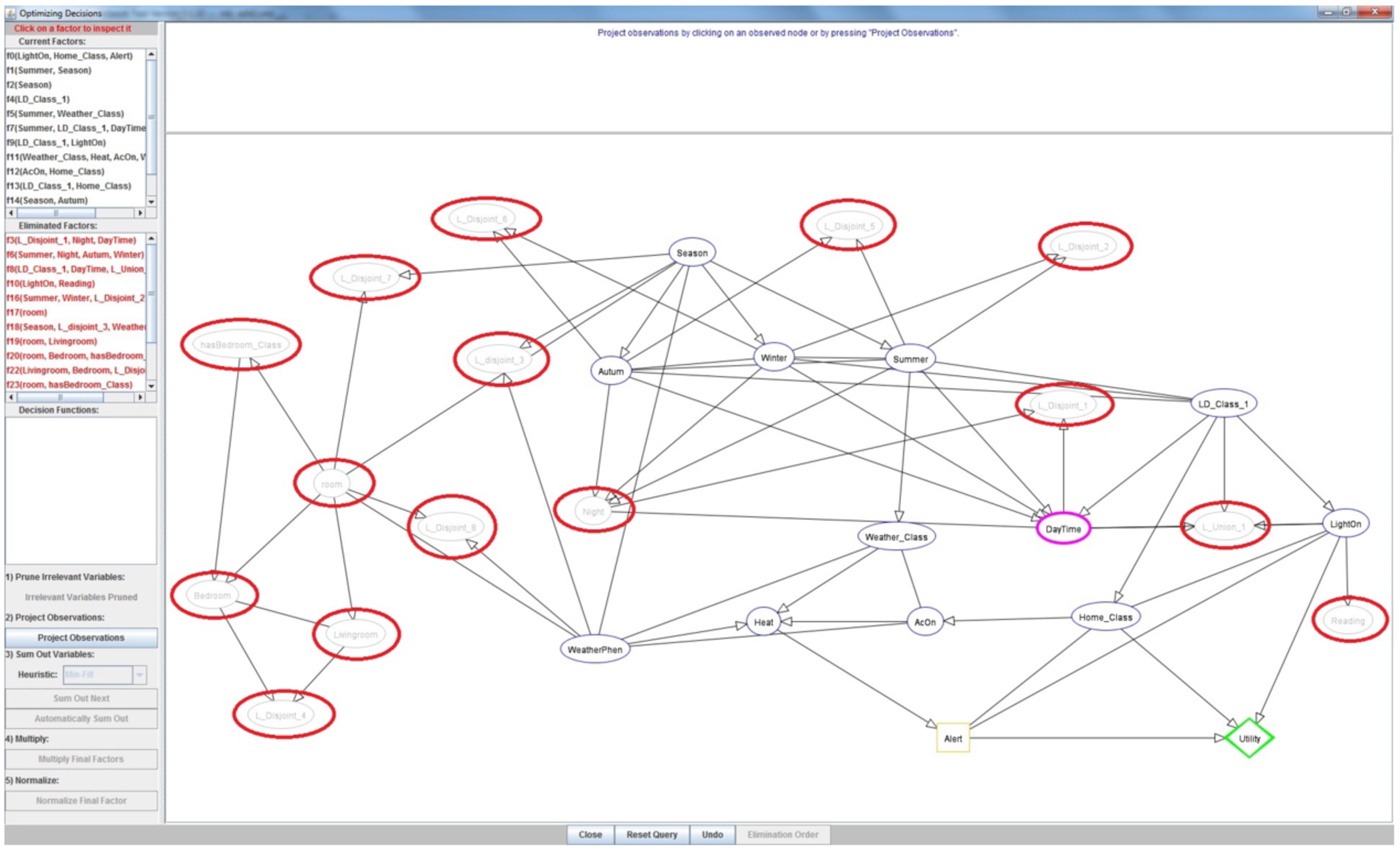
The suitability of MB-based uncertainty modelling in ontology was evaluated in two phases. In the first case, the quality of feature selection based the MB approach to prove irrelevance of some concepts for probabilistic modelling in ontology was investigated. Figure 7 shows the output of a decision process during the experiments. As can be seen indicated by the red circles in this figure, all concepts not in the MB set were automatically pruned in optimizing decisions. The only node in the MB set that was also pruned is Night, and this explains the owl:disjointWith axiom between Night and DayTime, which was the observed node in the experiment. Interestingly, all logical nodes were also pruned. This development is considered a good sign of feasibility of this approach, and also an opportunity for future research into finding alternatives for the logical nodes in the semantics.
Empirically, the irrelevance of some concepts for probabilistic modelling is further explained in terms of sensitivity of expected utility shown in Fig. 8. Observing each column from left to right shows that the sensitivity of expected utility of the MB model grows steadily with increasing context until MEU is attained. Essentially, this figure shows two phenomena of decision-making in which the MB model shows best performance. Where the MB model appears marginally less sensitive, such as when the number of contexts is equal 1 and 2, the action under consideration is not an optimal decision. On the other hand, when the number of context is greater than 2, the action is an optimal decision, and maximal sensitivity of expected utility is obtained for the MB model. Clearly, the sensitivity of expected utility is invariant with increased model complexity, and the MB model as such offers increased computing capabilities with the compact modelling it achieves.
Secondly, the run-time delay as a measure of computational complexity of context decision-making is shown in Fig. 9. The MB-based model has the lowest delay, and as the model complexity increases, the delay grows steadily. Also, looking down each column, as more context information is added, the delay time decreases for the MB model whilst the rest increase significantly. Obviously, the DN-based context reasoning shows improved performance with large context information for the MB model. Therefore, for time critical domains like SHs, this approach is promising since acceptable results can be achieved with best performance.
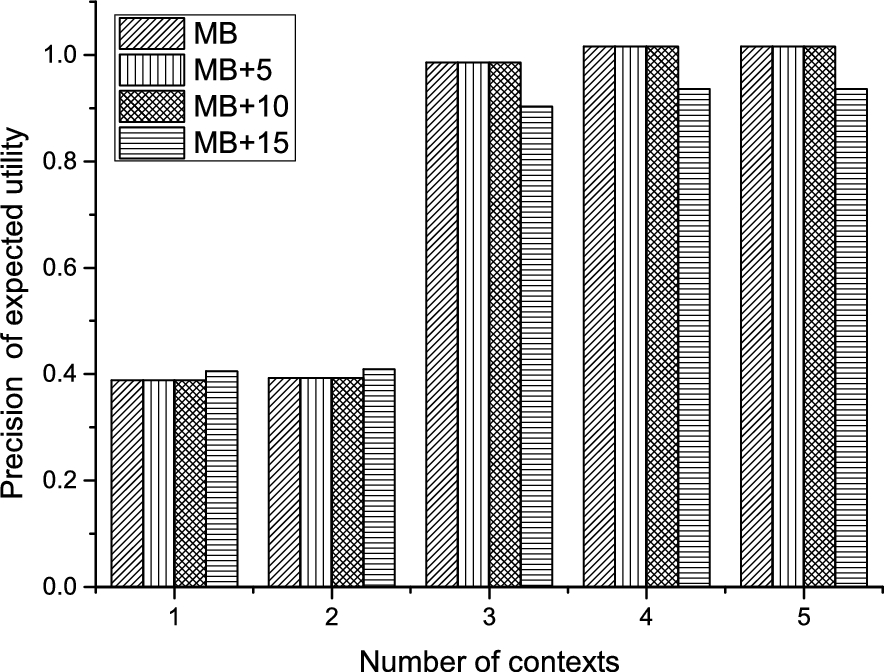
Sensitivity of expected utility of context decision making.
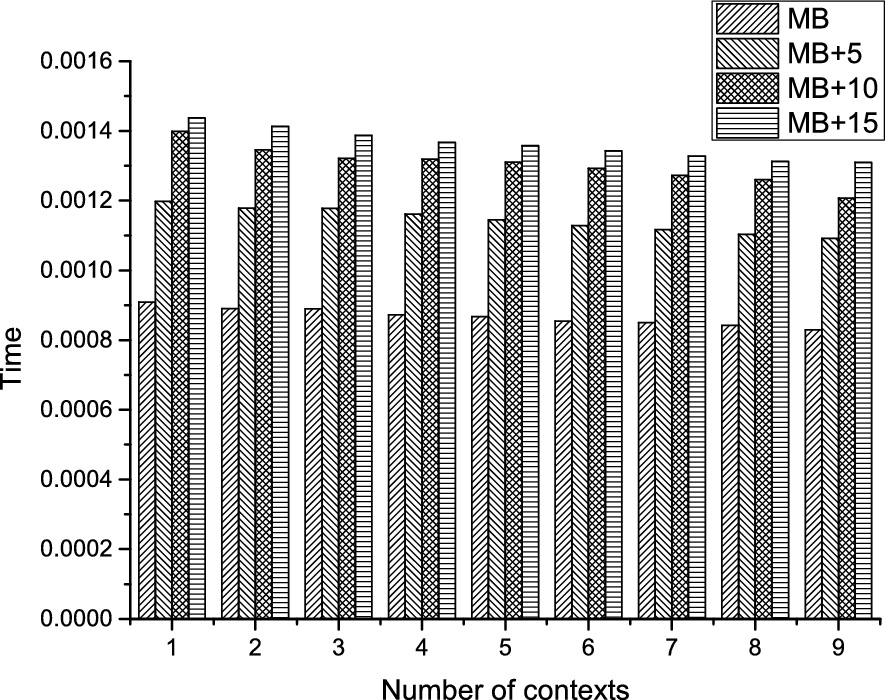
Context decision-making run-time performance of the MB-based model as against growing model complexity.
Knowledge representation and reasoning are a key enabling technology that will ease the design and reasoning requirements of complex systems. Even though other knowledge representation formalisms exists, ontologies are currently the most favoured technology for large-scale knowledge representation. The ability of ontologies to taxonomically represent concepts, properties and interrelationships of the entities of a domain provides a convenient framework for modelling complex domains.
The expressive power of ontologies has promulgated the application of ontological intelligence in many important research domains. In information extraction, an automated learning method that trains and mines an ontology to obtain classification rules has been proposed [17]. With these rules, extensive analysis of current general purpose search engines can be performed. Because semantic integration and interoperability have become effective means of reconstructing and revolutionising traditional industries [22,24], ontology mapping is increasingly being used to define relations between ontologies [20]. Agent-based modelling [12], and query formulation [26] are other important domains that have seen the application of ontologies.
However, the most significant gap in the expressive power of ontology is the lack of standard representation for vague and uncertain information. Uncertainty is unavoidable in real domains, and using certainty-based techniques to model these uncertain domains defeats the very essence of the choice of ontological intelligence. To deal with this limitation, fuzzy ontology approach has been proposed to support adaptive teaching for a large class [21]. A fuzzy domain ontology extraction algorithm underlines this approach, and concept maps can be automatically generated based on messages of online discussion forums. Viewing granularity as a special kind of uncertainty in ontology, Rough Mereology has been applied in conjunction with rough set and fuzzy set theories to compute degree of imprecision of concepts, relationships, and assertions [18]. Avoiding the burden of information overload in word-based searches has also inspired the adoption of fuzzy ontological modelling in information extraction [1]. This approach incorporates fuzzy descriptors into ontological structures so that approximate matches to user queries can be found. But because vagueness, which is handled by fuzzy logic is different from uncertainty [23], this paper takes guidance from the axiomatic notion of probability to deal with uncertainty in ontology.
A probabilistic approach for learning ontologies from a corpus of text documents has been proposed [32]. Without a knowledge of seed ontology, concepts in documents are identified and organised into a subsumption hierarchy. In [5,13], full advantage of BN is taken towards uncertainty reasoning based on probability theory. A variant of BN, termed Layered BNs, are adopted in [2] for probabilistic reasoning in ontology. Also, Multi-Entity BN has been proposed towards addressing uncertainty in ontology [6,16]. Closely related to this paper’s approach is [8], which adopts Markov Logic for ontology-based decision-making under uncertainty. However, none of these approaches make provision for controlled model complexity, which is essential for time critical domains like SH. Also, state-of-the-art has no compatible representation meeting the full requirements of valid decision situation in ontology.
In this paper therefore, an algorithm for identifying a minimum number of concepts relevant for probabilistic modelling in large-scale ontologies is introduced. Further, a representation that explicitly encodes the requirements of valid decision situation in ontology is provided.
Conclusion
A representation for finite sequential decision problems in OWL ontology was proposed. This saw an extension of the current OWL standard to incorporate valid decision situations in ontology. As a way of ensuring demand responsiveness in time-critical domains, this approach has also addressed the problem of probabilistic model complexity for large-scale ontologies. Compact modelling in this regard is achieved using only a subset of domain concepts relevant for probabilistic modelling. This minimal set of concepts in ontology is determined through the application of Markov boundary in ontology, and can be generated on the fly using the proposed algorithm in this paper. Evaluation of this approach in a smart home scenario gave impressive results suggesting its feasibility in real application domain. Though promising, this approach can only handle uncertainty in the domain at this stage. Future work of this research will include vagueness, which is different from the axiomatic notion of probability. Additionally, this approach can be extended to indefinite and infinite domains to be able to capture cyclic relations in knowledge.
Footnotes
Acknowledgements
This research was sponsored by NSFC 61370151 and 61202211, National Science and Technology Major Project of China 2015ZX03003012, Central University Basic Research Funds Foundation of China ZYGX2014J055, and Huawei Technology Foundation YB2013120141 and YB2015070068.