
Abstract
With the advent of the digital economy era, business systems such as web advertising and recommendation system have put forward the demand for predicting the click through rate (CTR) of items. However, the current CTR prediction research is not enough to mine user behavior, resulting in the lack of accuracy of user interest representation. In this paper, we propose a CTR prediction model, called MLIM, which can deep mine the evolution law of user interest. Specifically, we first use BiGRU to obtain the low-level user interest representation in the interest extraction layer, and then continue to use attention mechanism, BiGRU and sliding time window multi-components collaborative modeling in the interest evolution layer to obtain multi-level user interest representation with richer information, which can improve the accuracy of CTR prediction to a certain extent. Comprehensive experiments on two real datasets show that the proposed model achieves better performance than the mainstream baselines integrating user behavior analysis.
Keywords
Introduction
As a prominent representative of the digital economy, e-commerce is growing at an alarming rate and has become an important driving force for the innovative development of China’s economy and society. E-commerce provides a platform for the vigorous development of online advertising. Online advertising is a kind of advertising placed on online media, and is also an advertising information dissemination activity among advertiser, e-commerce media and user by means of the Internet. In this activity, brand image, goods and services and other advertising related information are spread to the target audience through the Web.
The CTR prediction value is the key reference index for online advertising putting. CTR prediction refers to predicting the probability of a user clicking on an advertisement (item) in a specific context [1], and is usually regarded as a binary classification problem: Given information about the user, the advertisement, and the context, it is required to predict the probability of the current user clicking on the advertisement event.
At present, researchers in academia and industry generally use machine learning methods to learn the patterns behind users’ clicking advertisement event from historical data. Among the traditional methods, logistic regression and factorization machine are widely used [2–6]. As deep learning has worked well in the fields of graphics and images, speech recognition and natural language processing, some researchers have also applied it to CTR prediction. In 2016, FNN [7], SNN [7] and other models appeared, and then researchers continued to research and improve, resulting in more complex CTR models such as PNN [8], ONN [9], NFM [10]. These methods used multiple neural network components to learn the deep cross features in data in the form of single channel structure. Since these methods could not fully learn the multi-level cross features in advertising data, some researchers continued to propose Wide & Deep Learning[11], DeepFM [12], Deep & Cross Network [13], xDeepFM [14] and other CTR models with dual channel structure. Most of the above methods focused on extracting cross features from different levels, and paied little attention to user behavior analysis and user interest preferences. Therefore, some researchers proposed CTR models including user behavior modeling, such as DIN [15], DIEN [16], DSIN [17]. However, these methods still had some problems, such as insufficient exploration of the evolution law of user interest, lack of future foresight and guidance to users.
In view of this, this study proposes a novel CTR prediction model, named MLIM (Multi-Level Interest Modeling), which is based on the large-scale user behavior data in the recommendation scenario and can fully mine the potential user preferences. Specifically, we design an interest extraction layer, which use a BiGRU [18] network to model the front and back dependencies in the behavior sequence, so as to obtain the low-level user interest representation. On the basis of low-level user interest representation, we also design an interest evolution layer, which continues to extract user interest via using attention mechanism, BiGRU network and sliding time window [19] to obtain multi-level user interest representation reflecting the evolution law. This study cannot only enhance the user experience, but also bring more traffic and economic benefits to online media. At the same time, it will provide valuable theoretical basis and application ideas for digital marketing.
The main contributions of this paper are summarized as follows:
∙ We propose a novel CTR prediction model describing the evolution law of user interest. The model adopts a two-stage structure to model user behavior, focusing on describing the evolution law of interest, and obtain the interest representation containing rich information, which are helpful to improve the accuracy of CTR prediction.
∙ In order to effectively capture the interest evolution law from user behaviors, we design a special interest evolution layer. On the one hand, we use attention mechanism to model the correlation between each user interest point and the current target item, and obtain the long-term user interest representation with diversity. On the other hand, we continue to use BiGRU to model the potential correlation between each interest point to obtain the user interest representation with relevance. At the same time, we also use sliding time window to model the user interest in different time stages, and obtain the short-term user interest representation with concentration and periodicity, forming some future foresight and guidance to users.
∙ We have conduct comprehensive experiments on real datasets, and the results show that the proposed model achieves better results than current advanced and mainstream CTR models incorporating user behavior analysis. In addition, in order to verify the effectiveness of the proposed model, we also conduct extensive and deep studies on the influence of key parameters and model structure on the performance.
The rest of this paper is organized as follows. In Section 2, the related work is introduced. In Section 3, MLIM model and its architecture are described in detail. In Section 4, the comprehensive experiments are conducted to verify the performance of the proposed model. In Section 5, the study work is summarized and the future work is prospected.
Related work
Due to its good nonlinear characteristics and multi-layer nature, deep neural network can realize automatic feature combination and theoretically has the expression ability of infinite approximation to the nature of data. Some researchers have used it for CTR prediction and recommendation [7–17,20–34].
Jiang et al. proposed a CTR prediction model DBNLR [20], which used deep belief network to learn potential association relationship in data, obtained the high-order feature representation, and then used logistic regression to calculate the click through rate. Zhang et al. proposed two CTR prediction models FNN and SNN [7], both of which used deep neural network to automatically learn effective patterns from categorical features, and the difference lied in the different embedding layer structure for processing input. Qu et al. proposed a novel inner production based CTR prediction model PNN [8]. Compared with the FNN model, the difference was that it added an inner product layer on top of the embedding layer of FNN, and captured rich low-order feature interactions through inner product. On the basis of PNN, Yang et al. proposed the ONN model [9], which used operation-aware embedding to replace the ordinary embedding layer. For each feature field, sufficient coefficients should be trained in the operation-aware embedding layer to generate enough intermediate result vectors for subsequent inner product operations. He et al. proposed a novel CTR prediction model for sparse data, NFM [10], which used a Bi-Interaction layer to calculate the quadratic term in FM after the embedding vector of the categorical data was obtained at the embedding layer. Then, the obtained results were input into the deep neural network to capture the nonlinear relationship between features, and the 1-order terms and offset term of FM were added to the output of the last layer of the deep neural network. Jiang also proposed an intelligent recommendation approach for online advertising [21], which firstly used embedding mapping network to process sparse input data, and then used FM to model low-order feature interactions. On this basis, stacked denoising autoencoder was adopted to learn high-order feature interactions, and finally logistic regression was adopted to calculate the click through rate.
Deep CTR models mostly follow the paradigm similar to embedding & MLP. Based on this basic paradigm, more and more models focus on the feature interactions learning. Cheng et al. proposed a Wide & Deep Learning model [11], in which Wide model was used to model low-order feature interactions to ensure the memory ability of the model, while Deep model was used to model high-order feature interactions to ensure the generalization ability of the model. Since Wide & Deep Learning required manual feature engineering, Guo et al. proposed an end-to-end learning model DeepFM [12], which integrated factorization machine and MLP into a new neural network architecture, in which the Wide and Deep parts shared the same input, and no special feature engineering was required. Wang et al. proposed the Deep & Cross Network model [13], which introduced another cross network to explicitly perform feature crossing in each layer on the basis of retaining the advantages of MLP. On the basis of DeepFM, Lian et al. proposed the xDeepFM model [14], which designed a compressed interaction network structure named CIN for display feature interaction modeling, providing feature combination capability together with MLP. With the success of attention mechanism in the field of natural language processing, some researchers began to introduce attention mechanism into deep recommendation model [23–28].
The above CTR prediction models can effectively fit the complex nonlinear relationship in the data and obtain better prediction effect because they adopt deep structure to learn high-order feature interactions. But they ignore the mining of user behavior information. In recommendation system, in addition to user, items and context information, there are also a large number of user behavior data. Making full use of these behavior data is helpful to accurately understand user’s intent, obtain high-quality user interest representation, and improve the accuracy of recommendations [15–17].
Zhou et al. proposed a deep interest network for CTR prediction, DIN [15], which used the deep network with attention to adaptively learn the user interest representation from the historical behavior related to the target advertisement. Zhou et al. continued to improve DIN and proposed a deep interest evolution network model DIEN [16]. In this model, the interest extraction layer was designed to obtain interest points from historical behavior sequences and the interest evolution layer was designed to capture the interest evolution process related to the target advertisement. Feng et al. proposed a deep session interest network model DSIN [17], which used a self-attention module with bias coding to extract the user’s interest features in each session, and used Bi-LSTM to capture the interaction and evolution of the user’s interest in multiple historical sessions.
Some scholars studied the technology of combining users’ long-term preference and short-term intention [29–31], and achieved good recommendation effect. Bogina et al. introduced resident time and recursive neural network into session-based recommendation [30], taking into account the length of the user’s stay on the item in the session. The longer the resident time stayed, the more interested the user was. Yu et al. proposed an adaptive user personalized recommendation model SLi-Rec based on long-term and short-term preferences [31].
The above CTR models including user preference modeling learn user interest representation from user behavior and inputs it into deep neural network together with user, advertisement, context and other information for CTR prediction, achieving good effect. However, there are still some problems in these methods, such as poor representation of the evolution law of user interest, lack of foresight for the future and guidance for user. In this study, we will fully mine user preferences from a large number of user behaviors and accurately describe the evolution law of user interest such as relevance, diversity, concentration and periodicity, so as to improve the accuracy of CTR prediction.
MLIM model
Interest points of the same user often show diversity, and different interest points have different effects on CTR prediction results. user’s interest will show a certain internal correlation over time, and also reflect the concentration in a short time due to some events. Using the excellent characteristics of attention mechanism, GRU network and sliding time window [19], and referring to the ideas of literatures [11,16], we propose MLIM model, which can fully mine user preferences from behaviors sequences data, obtain user interest representation reflecting relevance, diversity, concentration and periodicity, and improve the accuracy of CTR prediction.
MLIM model architecture
The architecture of MLIM model is shown in Fig. 1.
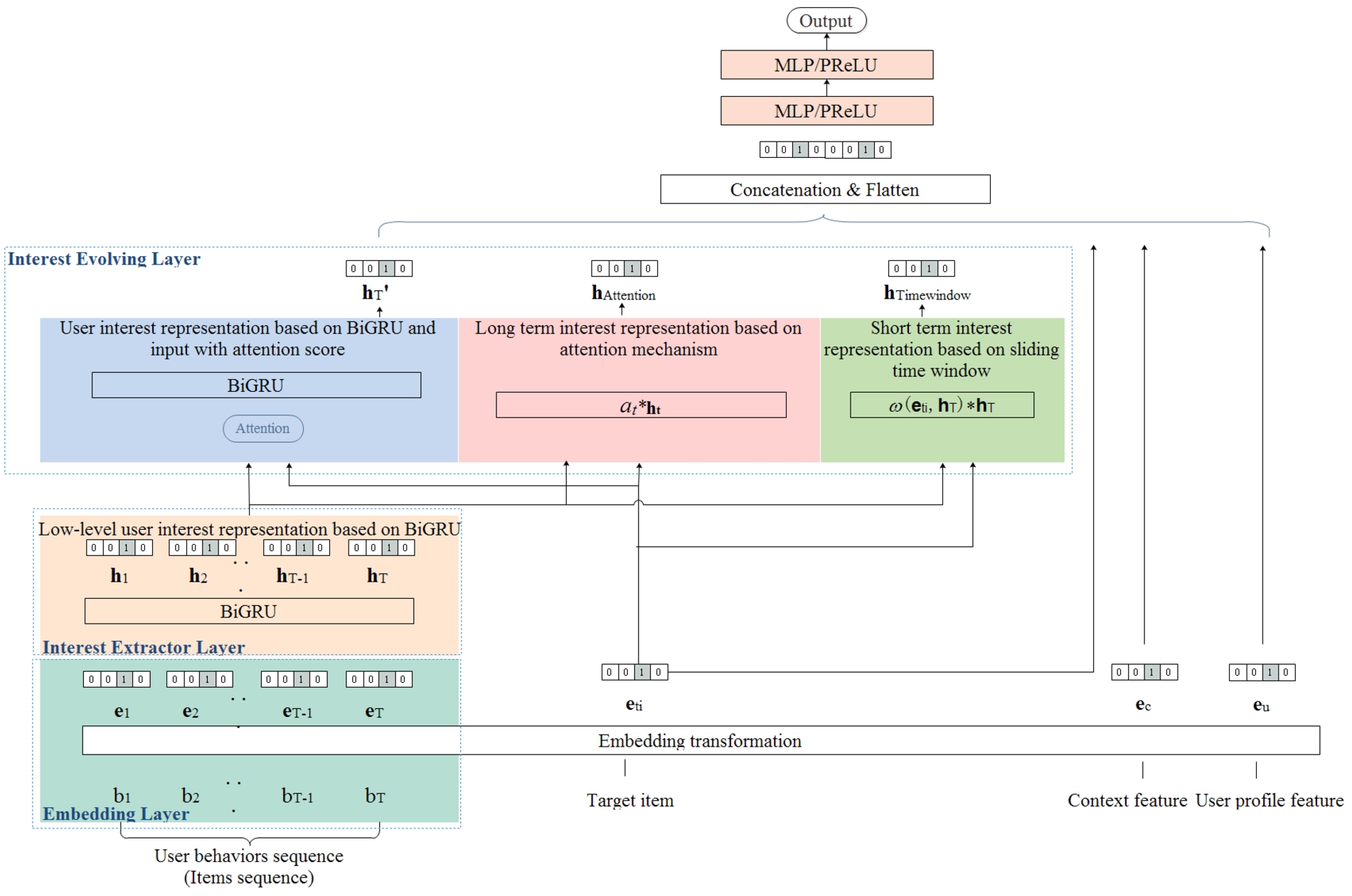
MLIM model architecture.
Figure 1 shows that the proposed model is a stacked structure composed of the embedding layer, the user interest representation module, the MLP network and the full connection layer. The role of each module in CTR prediction modeling is as follows:
(1) Embedding layer: corresponds to the olive green part at the bottom of Fig. 1, which is used to transform input various ad data features into low-dimensional dense vectors, as detailed in Section 3.2.
(2) User interest representation module: contains the interest extraction layer and interest evolution layer, corresponding to the dark yellow part in the middle left part of Fig. 1 and the blue, pink and grass green parts in the middle part respectively, which are used to mine user preferences from behavioral data and obtain interest representation. See Section 3.3 and 3.4 for detailed descriptions.
(3) MLP network: corresponding to the dark pink part in the upper part of Fig. 1, it is a deep neural network composed of multiple perceptrons [35], which is used to implicitly learn feature interactions and obtain high-order abstract features containing complex information. See Section 3.5 for details.
(4) Full connection layer: corresponding to the white part at the top of Fig. 1, it is the full connection layer with an output node, which is used to calculate the predicted click through rate. See Section 3.6 for details.
As can be seen from the above, due to the introduction of user interest representation module, MLIM model can obtain accurate user interest representation describing the evolution law from user behavior. At the same time, by using the strong nonlinear fitting ability of MLP, it can learn the potential relationship in complex data, and improve the accuracy of CTR prediction to a certain extent. In the following Sections, we will introduce each submodule and its role in the CTR prediction modeling.
In this study, the main features used are: user profile, user behavior, advertisement and context. Each of these four types of features contains multiple fields. For example, the fields of user profile include gender, age, etc; The field of user behavior contains the list of user access goods IDs; The field of context includes time, etc; The fields of the advertisement include ad ID, store ID, etc; It is worth noting that advertisement is also regarded as a goods or item.
We use an embedding layer to transform the above four types of features into embedding vectors that are convenient for deep learning model processing. As shown in Fig. 2, the input of embedding layer is the above four types of features composed of one-hot coding of categorical fields and numerical fields. The output is the obtained user behavior sequence items embedding vectors, user profile embedding vector, advertisement embedding vector and context embedding vector.
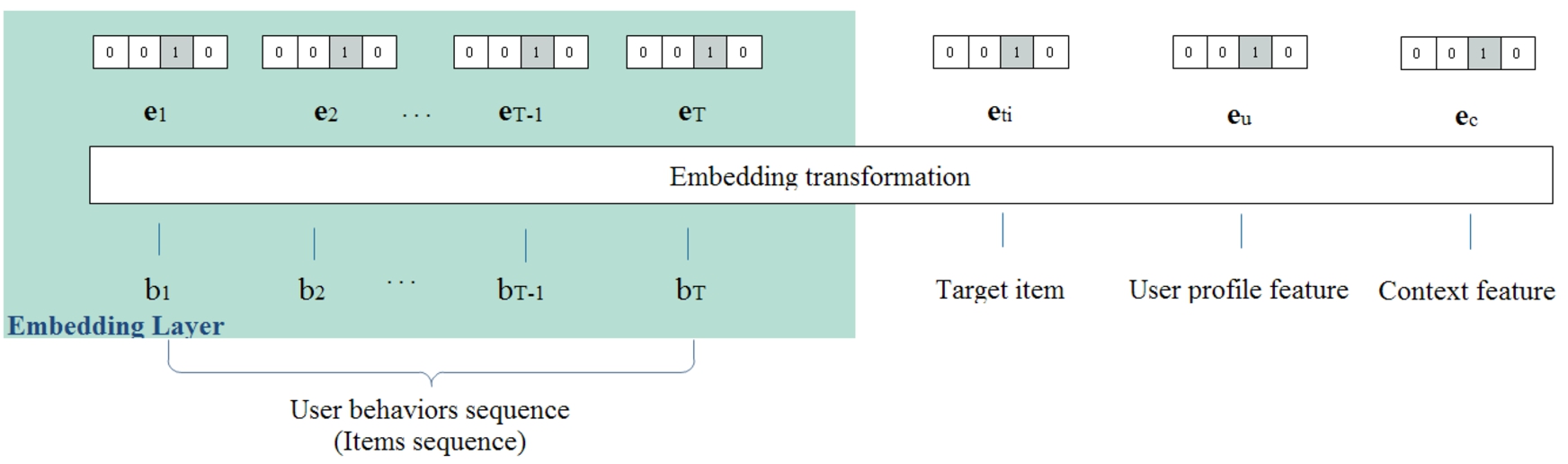
Embedding layer architecture.
Each categorical field feature can be encoded into a one-hot vector, for example, the “female” feature in the user profile is encoded as
In the embedding layer, we adopt look_up table embedding mapping network to map the high-dimensional one-hot vector to the low-dimensional space
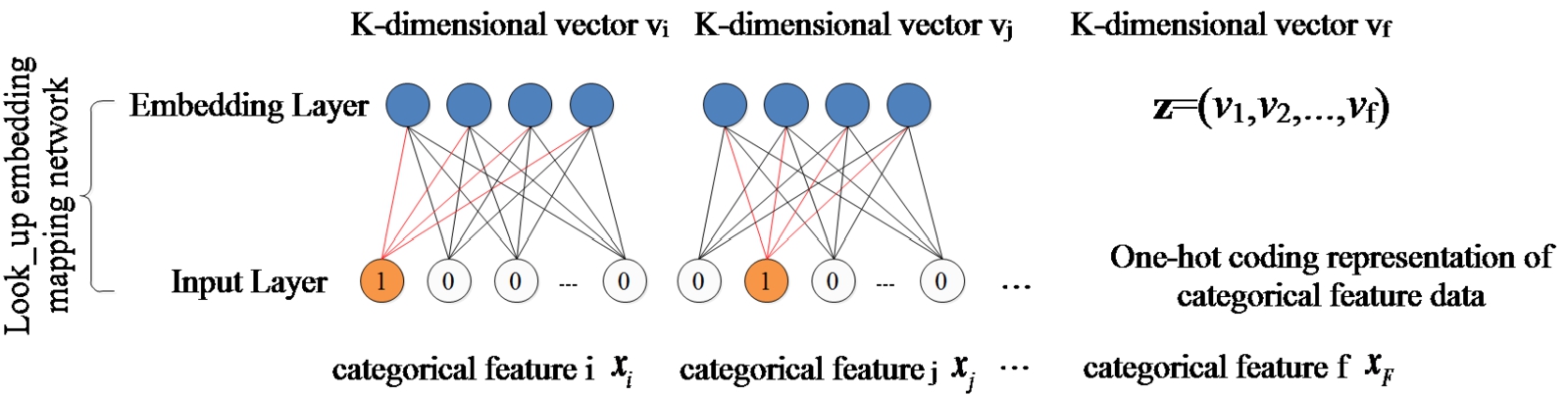
Look_up table embedding mapping network.
As can be seen from Fig. 3, each field feature in the mapping network corresponds to a trainable look_up table matrix
After each categorical field feature is transformed by the above mapping network, a K-dimensional embedding vector is generated, and the embedding vectors corresponding to all F categorical features are concatenated into a
In the embedding layer, we have obtained the ordered items embedding vector of user behavior. In the following interest extraction layer, we extract the low-level user interest representation from the items embedding vector. The architecture of the interest extraction layer is shown in Fig. 4. The input of this layer is the ordered items embedding vector
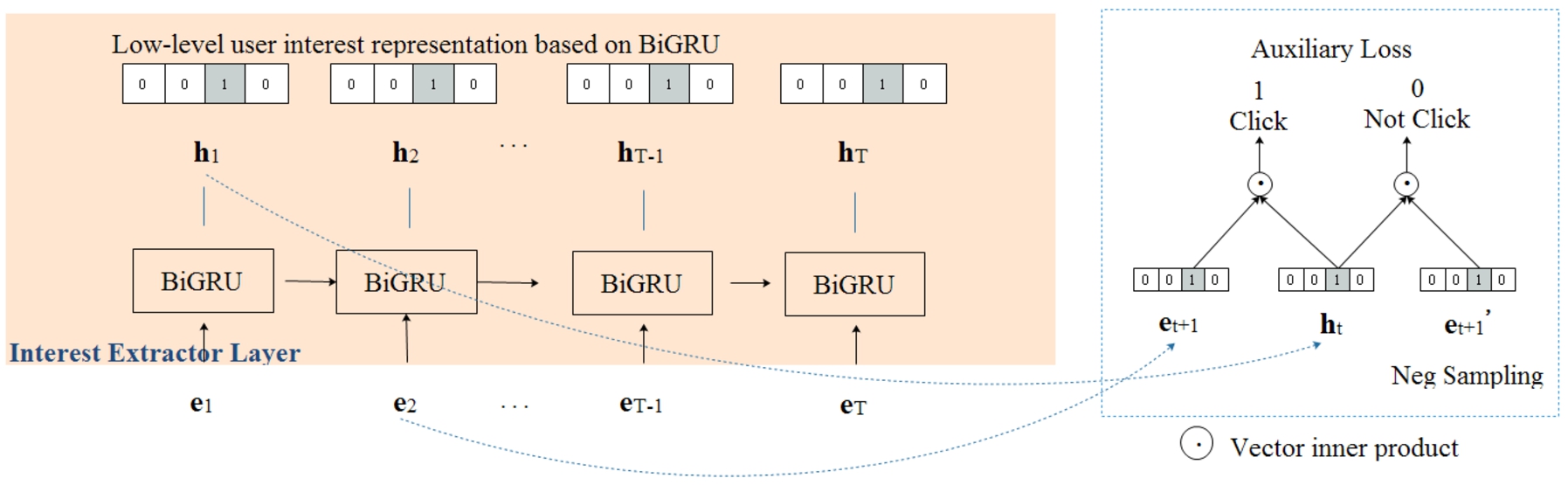
Interest extraction layer architecture.
Because the user behavior sequence has the characteristics of gradual change over time, RNN can just model the change process and state of sequence data. As a variant of RNN, GRU (Gate Recurrent Unit) overcomes the defect of gradient disappearance and has the advantage of faster training speed. Therefore, in the interest extraction layer, we adopt GRU to extract low-level user interest representation. The structure of GRU network is shown in Fig. 5.
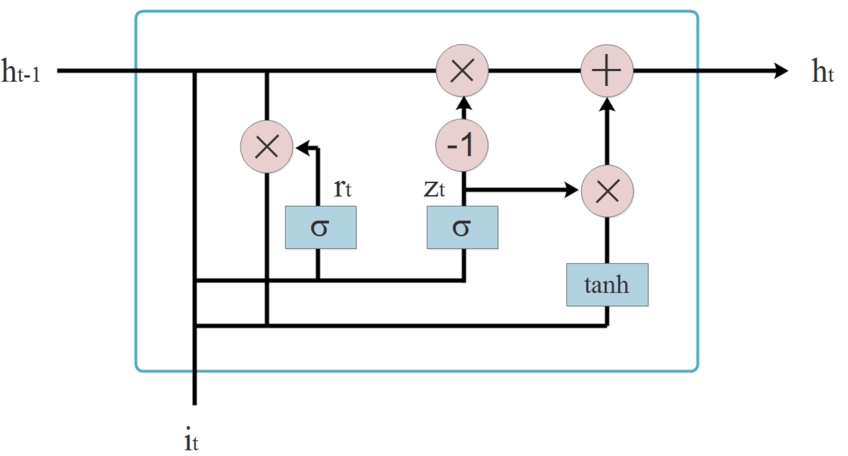
GRU structure.
GRU network can be formally described as follows,
Because of the forgetfulness of recurrent neural network, the information contained in the last state is lossy. We use BiGRU to overcome this defect, as shown in Fig. 6, BiGRU contains two subnetworks that deal with left and right behavior sequences respectively, corresponding to forward and backward transmission. Using element-wise sum to combine the forward and backward outputs, and the output of BiGRU neural network is shown in Eq. (6),
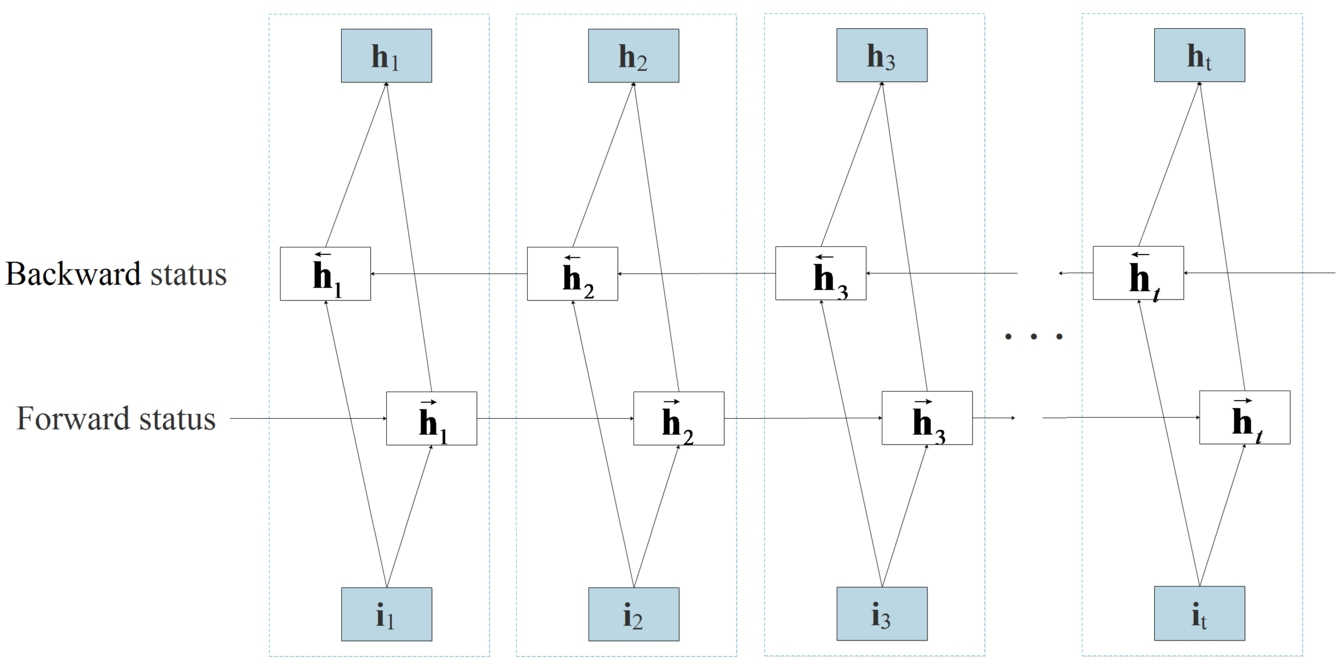
BiGRU network.
We also use auxiliary loss to supervise the learning of interest state
Although the low-level user interest representation sequence is obtained in the interest extraction layer, each interest point in the sequence has the same influence on the final output. And low-level user interest representation cannot fully reflect the diversity, concentration and periodicity of interest. Therefore, in the interest evolution layer, we innovatively adopt attention mechanism, BiGRU and sliding time window to continue modeling, as shown in Fig. 7. The input of this layer is T interest points
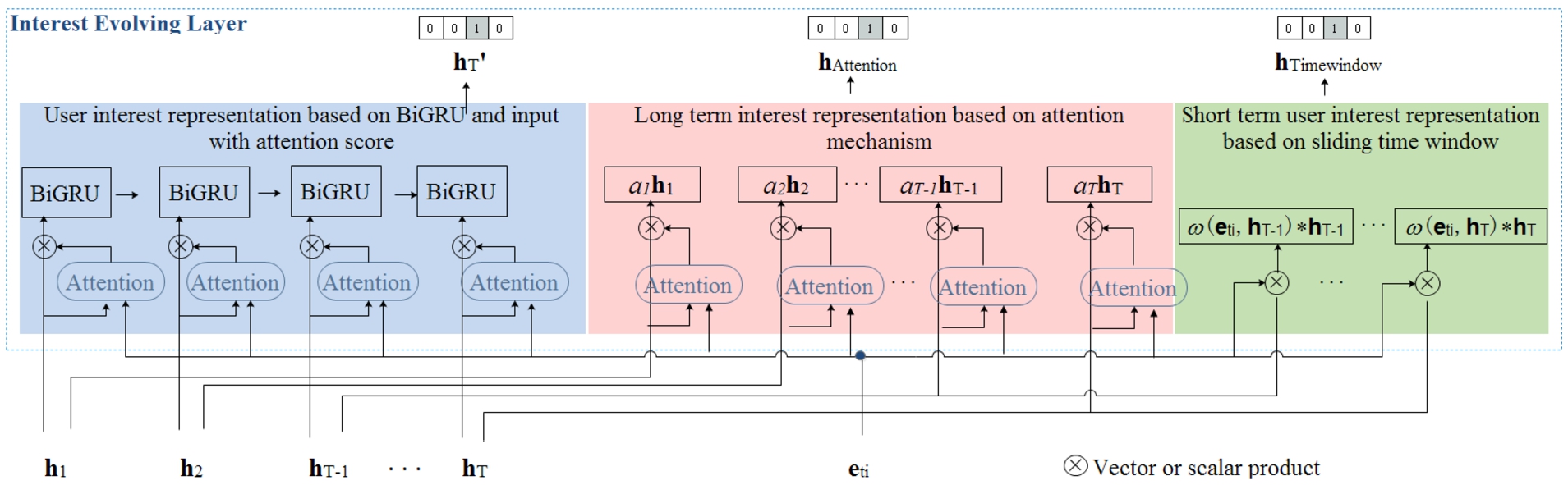
Interest evolution layer architecture.
∙ Long term interest representation based on attention mechanism
Firstly, in order to model the influence of different interest points on CTR prediction results, we use attention mechanism to learn the correlation between the current target item and each user interest point to obtain the long-term user interest representation
The attention function used is as follows:
Long-term user interest representation
∙ User interest representation based on BiGRU and input with attention score
Secondly, we continue to use BiGRU to model the potential correlation between different interest points and further mine the dependency relationship in user interest. We take the long-term user interest representation with attention score
In this process, the local activation of each input step can strengthen the interest related to the target advertisement, weaken the interference caused by interest drift, and also describe the influence of each interest point on the final result to a certain extent.
∙ Short term interest representation based on sliding time window
And then, in order to capture the concentration and periodicity of user interest reflected in the process of changing over time, we model user short-term interest in different periods based on sliding time window, as shown in Eq. (10):
∙ Multi-level user interest representation
Finally, we concatenate interest representation
MLP has strong nonlinear fitting ability and can implicitly learn the potential association relationship between features. We concatenate multi-level user interest representation
The forward propagation process of MLP network is formally described as follows:
After the combination learning of MLP, high-order abstract feature
Objective function
When the high-order abstract feature
In the interest extraction layer (Section 3.3), in order to make up for the deficiency of the traditional negative logarithm likelihood function, we once introduced the auxiliary loss function
Experiments
In the section, we introduce the experiments in detail, including the datasets, evaluation metrics, baseline methods, experimental parameters settings, results analysis, and ablation study.
Datasets and task description
Amazon product dataset1
Amazon product dataset.[EB/OL]. http://jmcauley.ucsd.edu/data/amazon/.
∙ Books dataset
Review data in the Books dataset contains the “reviewerID”, “asin”, “reviewerName”, “helpful”, “reviewText”, “overall”, “summary”, “unixReviewTime”, “reviewTime” fields; Metadata contains the “asin”, “title”, “price”, “imUrl”, “related”, “salesRank”, “brand”, and “categories” fields.
∙ Electronics dataset
Review data and Metadata in the Electronics dataset contain the same fields as the Books Dataset.
The statistics of the above datasets is shown in Table 1.
Statistics of datasets used in this paper
∙ Task description
We treat reviews as behaviors and sort a user’s reviews by time. Suppose that all the behaviors of a user u are
We use AUC (area under the receiver operating characteristic curve) [36] as the main evaluation metric of current prediction task. The larger the AUC value is, the better the discrimination ability of the model is, and the higher the accuracy of CTR prediction is. In addition, we also use RMSE (root mean squared error) [37] as an auxiliary evaluation metric, which measures the deviation between the predicted value and the real value. The smaller the value, the better.
Baseline methods
Since the contributions and innovations of the proposed model lie in modeling user behavior and deep mining user preferences, we mainly compare the mainstream CTR models that include user behavior analysis or that can model user behavior.
Experimental parameters settings and sensitivity analysis
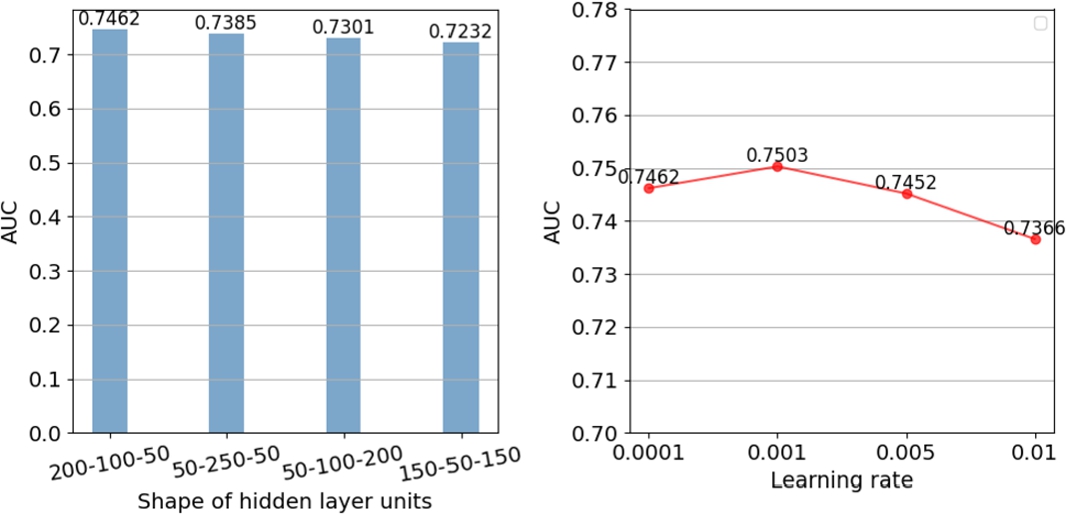
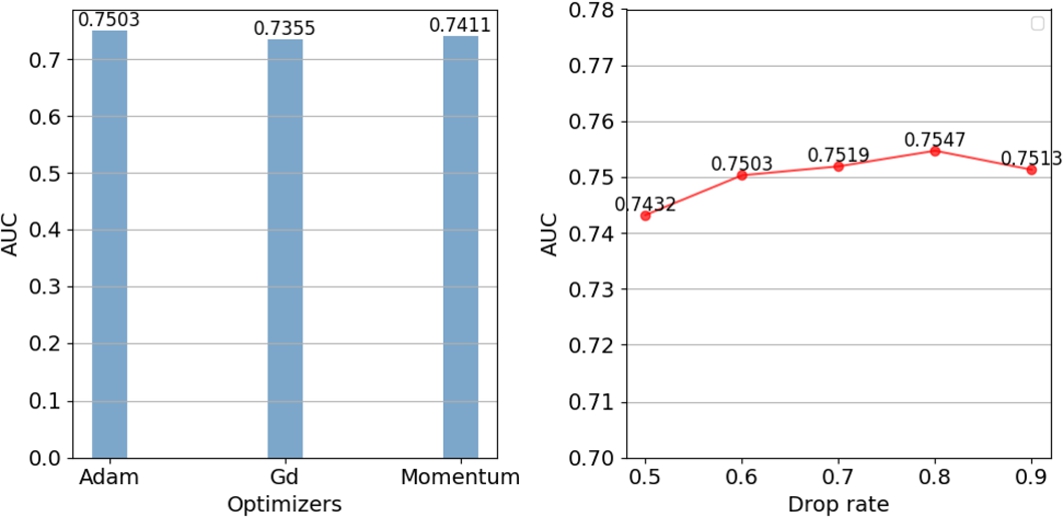
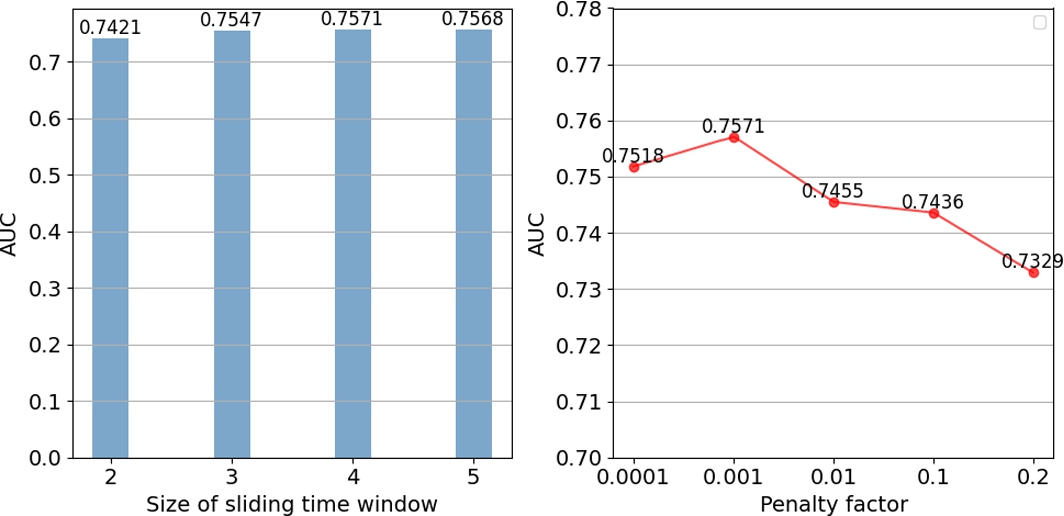
We adopt TensorFlow to implement the proposed model. In order to determine the hyperparameters of MLIM model, we first fix other parameters and change the parameter to be determined for optimization. For MLIM model that are trained from scratch, we randomly initialize model parameters with a Gaussian distribution (with a mean of 0 and standard deviation of 0.01). According to experience, we set the number of hidden layers of MLP as 3, and take PReLU as the activation function to conduct experiments on hidden layer units with different shapes. As shown in Fig. 8, we find that the relatively optimal result is obtained when the hidden layer units are [200–100–50] on Books dataset, which may be that this shape is more suitable for the current dataset. For the learning rate, the test is conducted in the range of
Hyperparameters settings and sensitivity analysis I.
Hyperparameters settings and sensitivity analysis II.
Hyperparameters settings and sensitivity analysis III.
In order to be fair, we adopt a consistent experimental environment for the baseline models. When the baseline models include deep neural network, the same embedding dimension, hidden layer shape (number of layers and units per layer), learning rate, drop rate and penaly factor as the proposed model are used.
Table 2 shows the results of each model on Books dataset and Electronics dataset. It can be seen that all deep structure models are significantly better than LR model with simple structure and limited expression ability, and it also proves the effectiveness of the deep neural network in nonlinear transformation and feature extraction. It is found that the performance of Wide & Deep model with manual design features is not good, while PNN is better than Wide & Deep model thanks to the low-order feature interaction in the dot product layer, which indicates that multi-level feature interactions are helpful to improve the accuracy of CTR prediction.
In deep learning based baselines, PNN and Wide & Deep perform poorly, which verifies the importance of extracting user interest from user behaviors. Generally, users don’t show their interest clearly, whereas DIN model designs a local activation unit structure, strengthening the relevant user interest by soft searching some user behaviors related to candidate advertisement, and obtaining the adaptive change representation of user interest. Compared with PNN and Wide & Deep, this structure greatly improves the expression ability of model. Although DIN activates some user behaviors related to candidate ad, it ignores the sequential information in user behaviors. DIEN uses a two-layer GRU structure to capture the evolution of user interest, and achieves slightly better performance than DIN.
Results of all models on both datasets
Results of all models on both datasets
DIN and DIEN obtain user interest representation through modeling user behavior, and achieve good effect in improving the accuracy of CTR prediction. On the basis of DIEN, the proposed model further mines the evolution law of interest. Specifically, on the one hand, we improve the two-layer GRU, and use HBiGRU to mine the relevance of interest. On the other hand, we use attention mechanism and sliding time window to model the diversity, concentration and periodicity of interest, so as to obtain the final user interest representation with richer information. Compared to the baseline models, the optimal results are obtained on current datasets with rich user behavior.
In this section, we explore the influence of using single GRU, BiGRU-attm, HBiGRU, AI-HBiGRU, HBiGRU-AM, and HBiGRU-AMTW, auxiliary loss in the user interest modeling part of the proposed model on prediction performance, respectively.
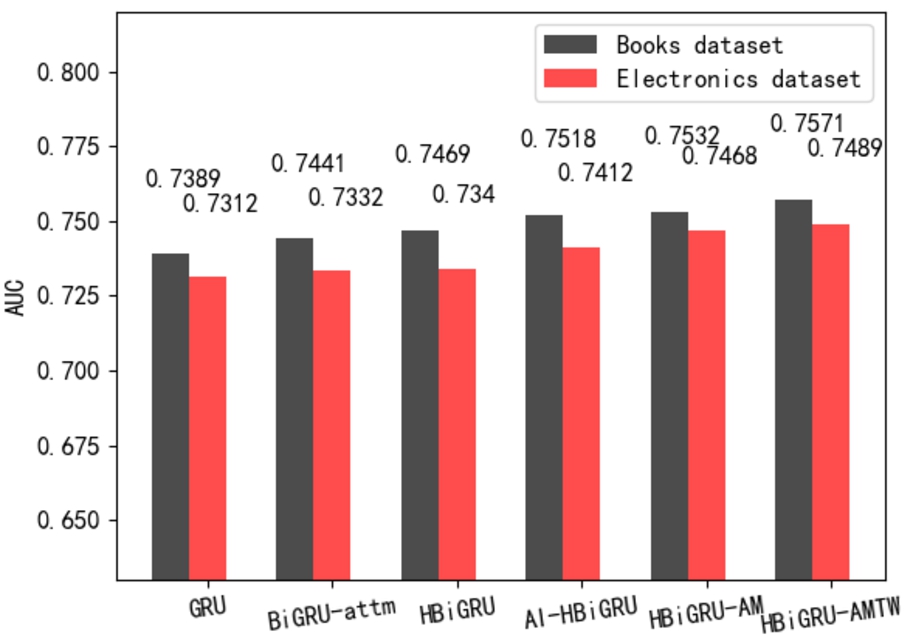
AUC values obtained by different interest modeling modules in MLIM model.
Figure 11 shows the prediction results using different modules in modeling user interest representation on two datasets. It can be seen that on the two datasets, BiGRU-attm obtains better performance than single GRU, because the accuracy of interest representation is improved to some extent by increasing the attention score on the basis of each interest point. HBiGRU also achieves slightly better results than BiGRU-attm, which illustrates the necessity of using hierarchical BiGRU to learn the correlation between user interest points. Because the attention score is used to influence the input of each step in the second BiGRU, AI-HBiGRU achieves better results than BiGRU-attm and HBiGRU.
Although AI-HBiGRU has made progress, there is still a certain degree of information loss in the process of interest evolution. Therefore, we continue to explore the influence of increasing long-term user interest representation based on attention mechanism and short-term user interest representation based on sliding time window on prediction performance. It is found that increasing long-term user interest representation results in a certain degree of performance improvement on Electronics dataset. Continuing to increase short-term user interest representation has a significant performance improvement on Books dataset, but a limited performance improvement on Electronics dataset. This may be because the user interest of Books dataset is more concentrated and phased, while the user interest of Electronics dataset tends to be more stable. A consistent rule can be found on both datasets: by increasing long-term user interest representation module and short-term user interest representation module, a multi-level interest representation with richer information can be obtained, which improves the accuracy of CTR prediction to different degrees.
We further explore the influence of auxiliary loss, in which the negative examples used are generated by random sampling. It can be observed from Fig. 12 that the global loss L and auxiliary loss
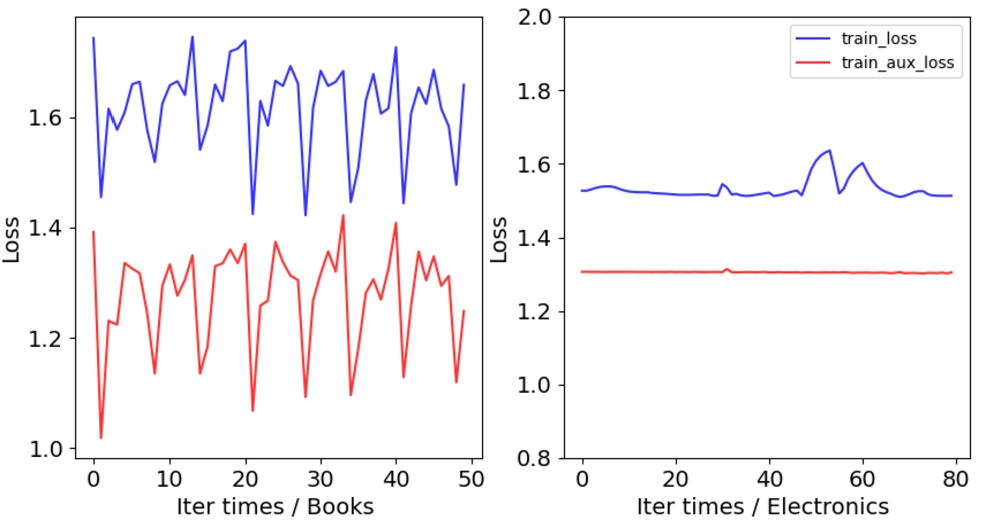
Change curve of loss and auxiliary loss during training.
Main conclusions
This work mainly studies CTR prediction modeling in web advertising or recommendation scenarios with rich user behavior data. In the previous content based deep CTR model, user interest preference information is generally not fully mined. This study proposes a deep CTR prediction model called MLIM, which focuses on modeling the evolution law of user interest. Specifically, we design an interest extraction layer to capture low-level interest sequence, and use auxiliary loss to supervise the interest states. On this basis, we design an interest evolution layer to obtain multi-level user interest representation that reflects diversity, relevance, concentration and periodicity. Comprehensive experiments show that our proposed model is helpful to improve the prediction performance to a certain extent.
Managerial insights
This study has some managerial implications as well. Precision marketing can help advertisers spend their advertising expenses in the right place, and is an important weight for enterprises to improve their performance. Mining user preferences is an effective way for precision marketing. The method proposed in this paper can predict the future and guide users to a certain extent by describing the evolution law of user interest in CTR modeling, and enrich the data-driven marketing decisions. However, users’ needs change over time, and precision marketing can only be relatively accurate.
Future work
Given the conclusions and insights of this study, our work can be extended as follows. Future research could 1) mine more side information to obtain more accurate user interest representation, 2)study more feature combination learning methods.
Footnotes
Acknowledgements
This work is supported by the Scientific Research Project of Guizhou University of Finance and Economics (NO.2020XYB08) and Scientific Research Initiation Project for Introduction Talents of Guizhou University of Finance and Economics (NO.2021YJ049).