
Abstract
BACKGROUND:
It is often difficult to automatically segment lung tumors due to the large tumor size variation ranging from less than 1 cm to greater than 7 cm depending on the T-stage.
OBJECTIVE:
This study aims to accurately segment lung tumors of various sizes using a consistency learning-based multi-scale dual-attention network (CL-MSDA-Net).
METHODS:
To avoid under- and over-segmentation caused by different ratios of lung tumors and surrounding structures in the input patch according to the size of the lung tumor, a size-invariant patch is generated by normalizing the ratio to the average size of the lung tumors used for the training. Two input patches, a size-invariant patch and size-variant patch are trained on a consistency learning-based network consisting of dual branches that share weights to generate a similar output for each branch with consistency loss. The network of each branch has a multi-scale dual-attention module that learns image features of different scales and uses channel and spatial attention to enhance the scale-attention ability to segment lung tumors of different sizes.
RESULTS:
In experiments with hospital datasets, CL-MSDA-Net showed an F1-score of 80.49%, recall of 79.06%, and precision of 86.78%. This resulted in 3.91%, 3.38%, and 2.95% higher F1-scores than the results of U-Net, U-Net with a multi-scale module, and U-Net with a multi-scale dual-attention module, respectively. In experiments with the NSCLC-Radiomics datasets, CL-MSDA-Net showed an F1-score of 71.7%, recall of 68.24%, and precision of 79.33%. This resulted in 3.66%, 3.38%, and 3.13% higher F1-scores than the results of U-Net, U-Net with a multi-scale module, and U-Net with a multi-scale dual-attention module, respectively.
CONCLUSIONS:
CL-MSDA-Net improves the segmentation performance on average for tumors of all sizes with significant improvements especially for small sized tumors.
Introduction
Lung cancer is the most common malignant tumor and leading cause of cancer deaths worldwide [1]. To evaluate treatment response and disease progression, it is essential to measure tumor response, such as changes in tumor size, on chest CT images. The RECIST (Response Evaluation Criteria in Solid Tumors) 1.1 criteria for tumor response evaluation is a one-dimensional measure of tumor diameter based on the assumption that tumors are spherical and that there is a proportional change in tumor volume and a parallel change in tumor diameter [2]. However, there are limitations in evaluating the response to treatment in lung cancer patients with large, irregularly shaped lesions, in which volumetric measurements are required [3, 4]. In addition, automated segmentation of lung tumors from chest CT images is essential for reproducible volumetric measurements.
Recently, convolutional neural networks (CNN) based on deep learning have been widely used for image segmentation and have shown remarkable performance. However, CNNs are limited by perceived local information, making it difficult to capture structural dissimilarities and spatial dependencies due to inter-patient variability. To solve this problem, several studies on lung tumor segmentation have proposed multi-scale strategies and attention mechanism. Jiang et al. [5] proposed a multi-scale framework that simultaneously combines features across multiple image resolutions and feature levels through residual connection. Yang et al. [6] proposed a multi-level and multi-scale deep supervision framework that adjusts the weights of the layers by generating multiple predictions from multiple layers and monitoring the local depth of the learned features. Chen et al. [7] proposed a multi-attention framework incorporating multiple attention mechanisms for modeling spatial and channel-dimensional semantic interdependencies from global and local perspectives. Banu et al. [8] proposed a multi-attention framework that improves the ability to discriminate between nodular and non-nodular feature representations. Zhang et al. [9] proposed a multi-scale and multi-attention framework to effectively integrate channel attention modules and the U-Nets to segment malignant lung areas from surrounding chest areas. However, despite the application of multi-scale and attention, it is difficult to accurately segment small-sized tumors due to the lack of semantic information inside lung tumors. Several studies have tried to differentiate lung tumors from surrounding structures by generating patches with different window settings. Byun et al. [10] proposed a dual-coupling net with a shape-focused prior based on lung and mediastinal window images to accurately extract shape information from lung tumors. Lee et al. [11] proposed a dual-window capsule network that learns the relative spatial relationship between lung tumors and surrounding structures based on ensemble learning. However, these studies using dual-window patches have limitations such as requiring manual labeling for each patch and still showing poor segmentation performance in small-sized tumors.
Despite several recent lung tumor segmentation techniques, as shown in Fig. 1, lung tumors vary in size making it difficult to consistently segment lung tumors on chest CT images. This is because of the characteristics of lung tumors, in which small lung tumors less than 1 cm and large lung tumors greater than 7 cm are distributed according to the T stage [12]. In this paper, we propose a consistency learning-based multi-scale dual-attention lung tumor segmentation method to accurately segment lung tumors of various sizes on chest CT images. The main contributions of this paper can be summarized as follows. First, we propose a size-invariant patch generated by normalizing the tumor in the training data to the ratio of the average tumor size to avoid under- and over-segmentation caused by different ratios of lung tumors and surrounding structures in the input patch. Second, we integrate a multi-scale module and dual-attention module to learn image features at different scales and enhances the scale-attention ability to segment lung tumors of different sizes. Third, we propose a consistency loss that trains a network branch using size-variant patches and a network branch using size-invariant patches to have similar predictions. Fourth, we evaluate the efficacy of our framework on the publicly available NSCLC-Radiomics dataset and the Veterans Health Service Medical Center-approved chest CT dataset through ablation studies.
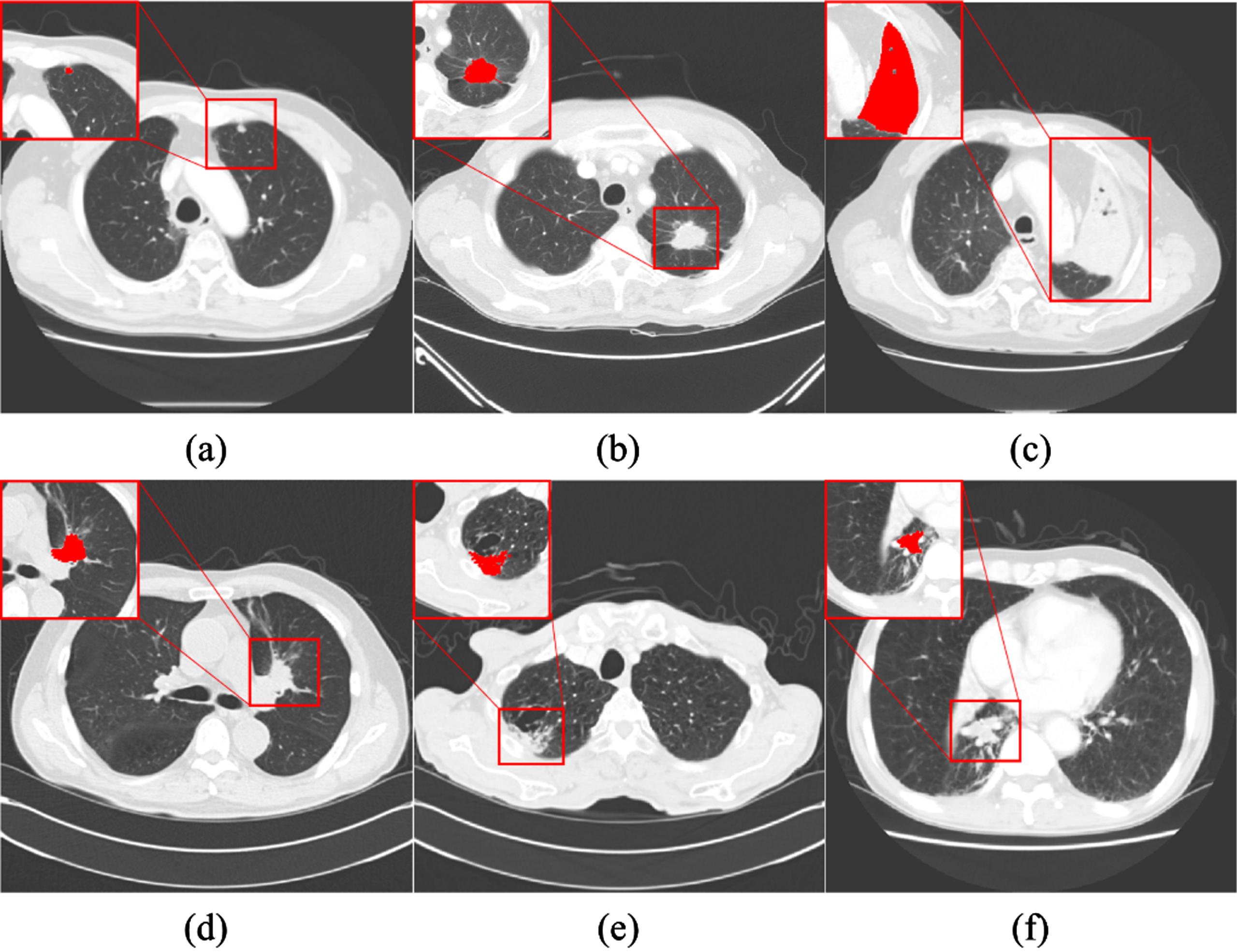
Examples of lung tumors of various types, as well as size, location, and shape on chest CT images: (a) small-sized lung tumor (b) medium-sized lung tumor (c) large-sized lung tumor (d) mediastinum-attached tumor (e) chest wall-attached tumor (f) vessel-attached tumor. (red area indicates lung tumor).
Materials
In this study, we used two datasets, the hospital dataset from the Veterans Health Service Medical Center (VHSMC) and the NSCLC-Radiomics public dataset from The Cancer Imaging Archive (TCIA) [13]. The patient characteristics for each dataset used in this study are shown in Table 1, and the study using the hospital dataset was approved by the Institutional Review Board of the Veterans Health Service Medical Center (IRB File Number: BOHUN 2018-07-009-005).
Patient characteristics for each dataset used in this study
Patient characteristics for each dataset used in this study
The VHSMC dataset obtained from 259 NSCLC patients who underwent curative surgical resection consisted of 148 lung adenocarcinomas (LUADs) and 111 lung squamous cell carcinomas (LUSCs). The tumor size was measured by measuring the longest diameter in the representative image slice with the largest tumor, and the distribution of the tumor sizes ranged from 0.76 to 14.33 cm with an average size of 4.6 cm and a standard deviation of 2.66 cm. The CT images were acquired from July 11, 2003 to June 29, 2015 from four different CT scanner manufacturers: BrightSpeed S, Discovery CT750 HD, LightSpeed Plus, LightSpeed Pro 16, LightSpeed Ultra, LightSpeed VCT, LightSpeed 16, ProSpeed Advantage (GE Healthcare), Brilliance 64, GEMINI TF 16, Ingenuity (Philips), SOMATOM Definition AS+, SOMATOM Emotion, SOMATOM Emotion 6, SOMATOM Sensation 16, SOMATOM Sensation 64, SOMATOM Definition AS+, SOMATOM Spirit, Biograph 6 (Siemens Healthineers) Aquilion, and Asteion (TOSHIBA). Each image slice had a matrix size of 512x512 pixels with an in-plane resolution ranging from 0.52 to 1.17 mm. The slice thickness ranged from 2.5 mm to 10 mm, and a dose protocol of 100 to 130 kVp at 60∼583 mAs was used. The CT images consisted of 245 contrast-enhanced images and 14 non-contrast-enhanced images. The lung tumor areas were semi-automatically segmented by one board-certified radiologist using in-house software [14], and the segmented areas were manually corrected by the radiologist as needed.
The NSCLC-Radiomics dataset obtained from 422 NSCLC patients consisted of 51 LUADs, 152 LUSCs, 114 large cell lung carcinomas, 63 not otherwise specified, and 42 not applicable, of which 39 LUADs and 115 LUSCs were selectively used. The distribution of the tumor sizes ranged from 1.36 to 14.63 cm with an average size of 5.58 cm and a standard deviation of 2.69 cm. The CT images were acquired from September 27, 2004 to January 1, 2014 from two different CT scanner manufacturers: Biograph 40, SOMATOM Sensation 10, SOMATOM Sensation 16, SOMATOM Sensation Open (Siemens Healthineers) and XiO (CMS Imaging, Inc). Each image slice had a matrix size of 512x512 pixels with an in-plane resolution of 0.97 mm. The slice thickness was 3 mm and a dose protocol of 120 to 140 kVp at 40∼491 mAs was used.
To reduce the differences in intensity and pixel spacing among the CT images, intensity rescaling and spacing normalization are performed on the entire set of the CT images. For intensity rescaling, the intensity values of the CT images with lung window settings (WW: 1500, WL: –600) are rescaled to gray-scale intensities ranging from 0 to 255 [15]. For spacing normalization, all CT images are resampled to the minimum pixel spacing value. For data augmentation, we performed random rotation (–20° to 20°), random translation (–20 pixel to 20 pixel) and random scaling (0.8 to 1.2 times), increasing the amount of training data by 5 times.
Input patch generation
Lung tumors have various size distributions from small lung tumors of less than 1 cm to large lung tumors greater than 7 cm in size. Generating an input patch with a size that encompasses all the various sizes suffers from class imbalance problems, with small tumors having a small tumor relative to their background, and large tumors having a small background relative to their tumor area. Therefore, to compensate for the degradation of the small tumor segmentation performance caused by such a class imbalance problem, we propose a size-invariant patch that is used simultaneously with a size-variant patch that contains various original size information.
To generate size-variant patches, input images are cropped to 256 × 256 pixels based on the center coordinates of the tumor slice with the largest area. To generate size-invariant patches, the size-normalization ratio calculates the average tumor size over the current tumor size. The average tumor size is determined by calculating the average of tumor sizes within the training set, and each tumor is normalized to the average tumor size. The size-invariant patches are cropped to the same size as the size-variant patches.
When the size-invariant patches are extracted, as shown in Fig. 2, small lung tumors expand into average-sized lung tumors and decrease the ratio of the surrounding structures, whereas large lung tumors shrink into average-sized lung tumors and expand the ratio of the surrounding structures. Therefore, size-invariant patches have the same scale retaining similar proportions of the tumor and background, while size-variant patches have variable scales by preserving the original size information.
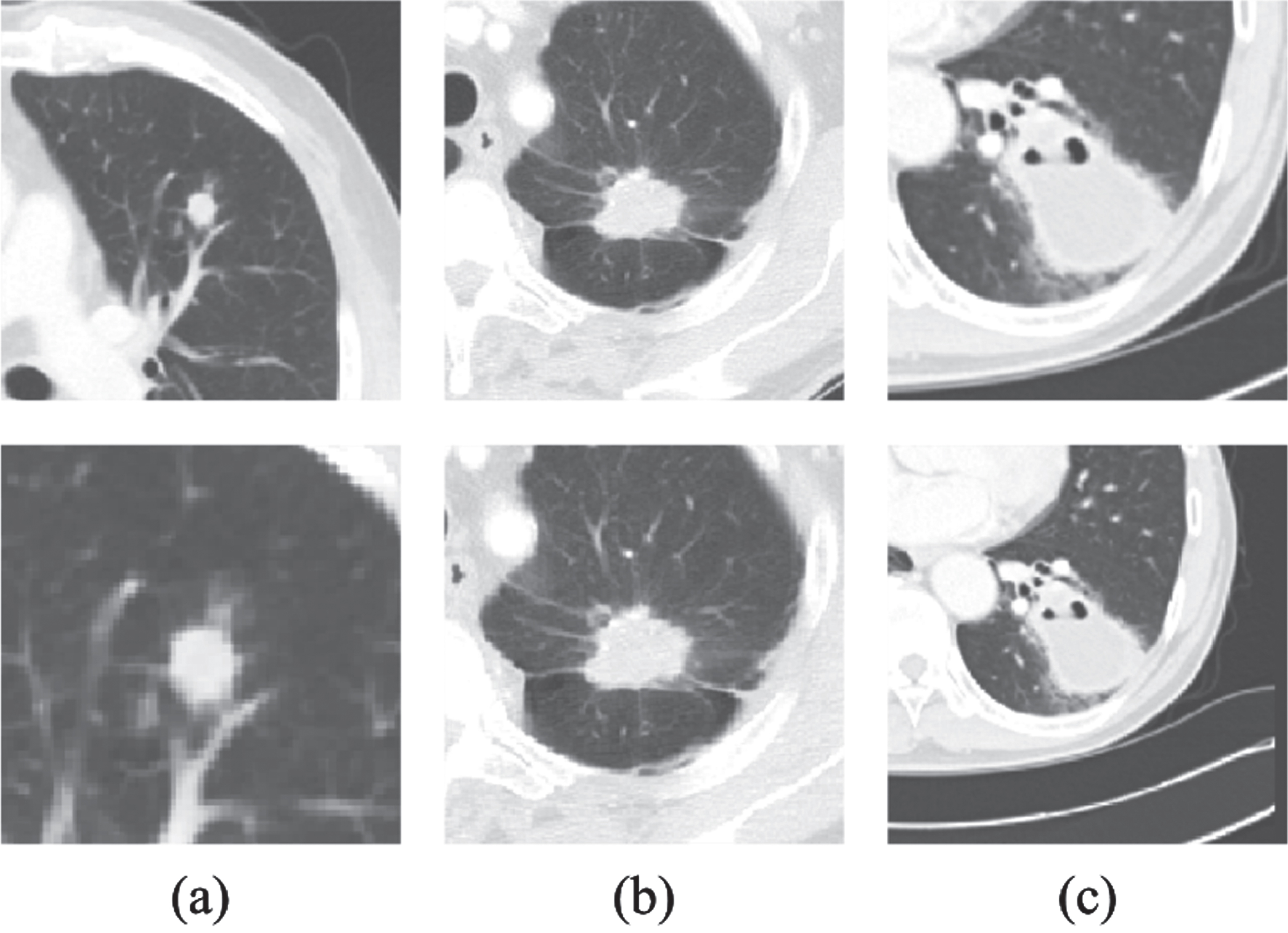
Examples of size-variant patches (first row) and their size-invariant patches (second row): (a) small-sized lung tumor with 0.76 cm (b) medium-sized lung tumor with 3.91 cm (c) large-sized lung tumor with 6.70 cm.
To simultaneously train pairs of two input patches, the size-variant patch and size-invariant patch, we propose a consistency learning-based multi-scale dual-attention network (CL-MSDA-Net). As shown in Fig. 3, the proposed network consists of dual-branch networks, each receiving different input patches. One network is for feature extraction and tumor segmentation using the size-variant patches, and the other network is for feature extraction and tumor segmentation using the size-invariant patches. A consistency learning framework enables training to obtain common feature representations without the need to compute optimized hyperparameter values, allowing different input patches to be considered simultaneously.
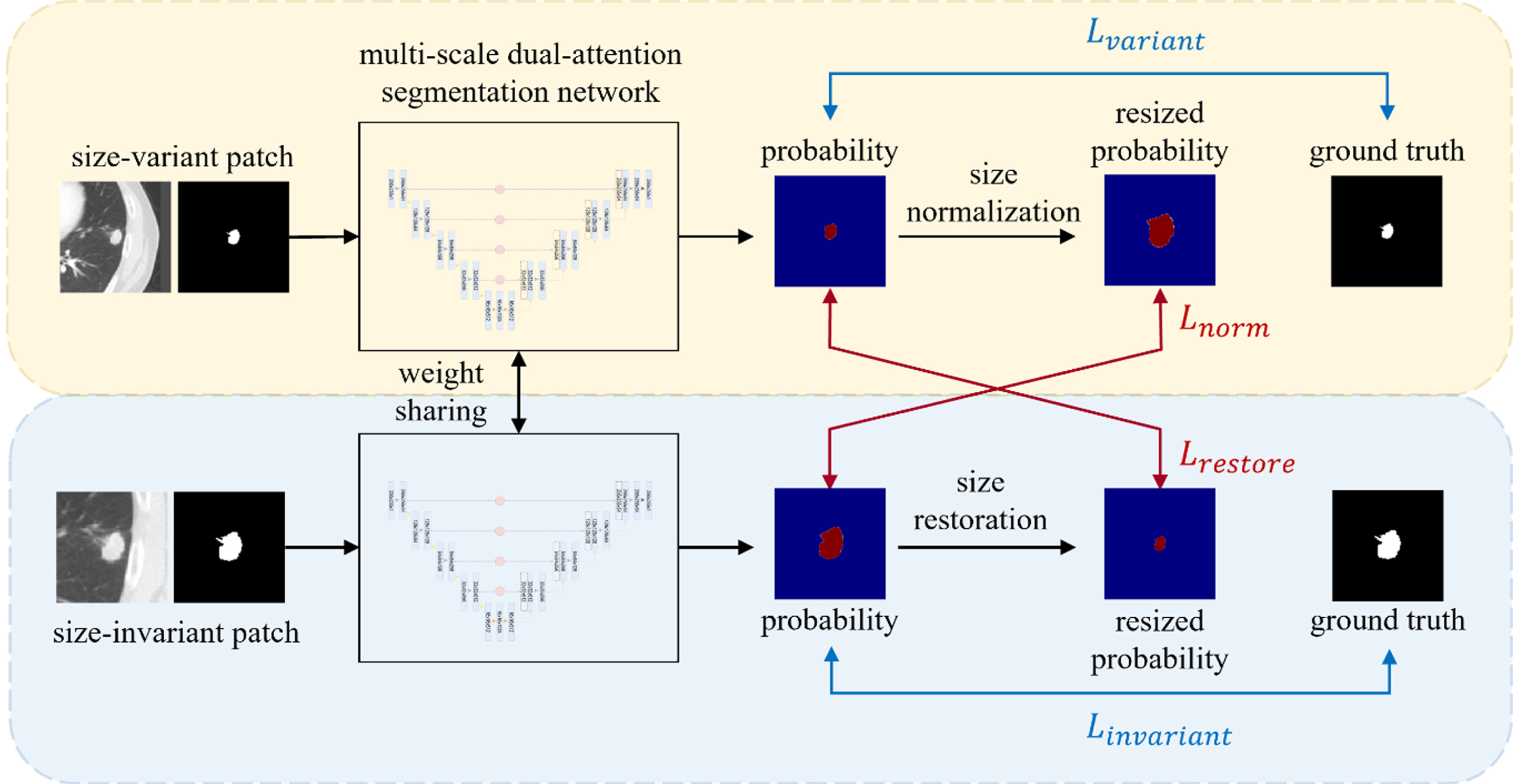
An illustration of CL-MSDA-Net architecture for lung tumor segmentation.
As shown in Fig. 4, each branch network consists of a contracting path and an expansive path based on 2D U-Net [16] consists shared weights to learn the common features of each input patch. The contracting patch consists of two 3×3 convolution operations followed by a batch normalization and a rectified linear unit (ReLU) activation function, and a 2×2 max pooling with stride 2 for down-sampling. The expansive path concatenates the same level output feature maps of the layer in the contracting path via skip connections and then performs two 3×3 convolution operations followed by a batch normalization, ReLU activation function, and 2×2 up-sampling with bilinear interpolation. The number of feature channels is doubled after the convolution operation in the contrastive patch, and the feature size is halved after the down-sampling. In contrast, the number of feature channels is halved after the convolution operation in the expansive path, and the feature size is doubled after the up-sampling. Bilinear interpolation up-sampling in the decoder is used to restore the original image size for pixel level prediction but has the problem of not considering the correlation between each pixel label [17]. To obtain multi-scale features and improve the scale-attention ability considering the channel and spatial correlation, a multi-scale dual-attention (MSDA) module is proposed. Inspired by SA-Net [18], we use a multi-scale module consisting of convolutional blocks to have hierarchical residual connections to enlarge the receptive field range. The multi-scale module consists of three 3×3 convolution operations that generate multiscale hierarchical feature maps to generate larger receptive fields. In addition, the dual-attention module consisting of channel-attention and spatial-attention [19] was applied to each scale extracted using the multi-scale module to focus only on the tumor area. The spatial attention module aggregates tumor information from different locations to enhance the feature representation at locations, and the channel attention module aggregates tumor information from different channels to obtain a correlation between any two channel feature maps. The dual-attention module can segment lung tumors of various sizes by considering both channel attention and spatial attention to generate weighted maps that highlight the spatial and channel information of lung tumors. The detailed structure of the MSDA module is shown in Fig. 5.
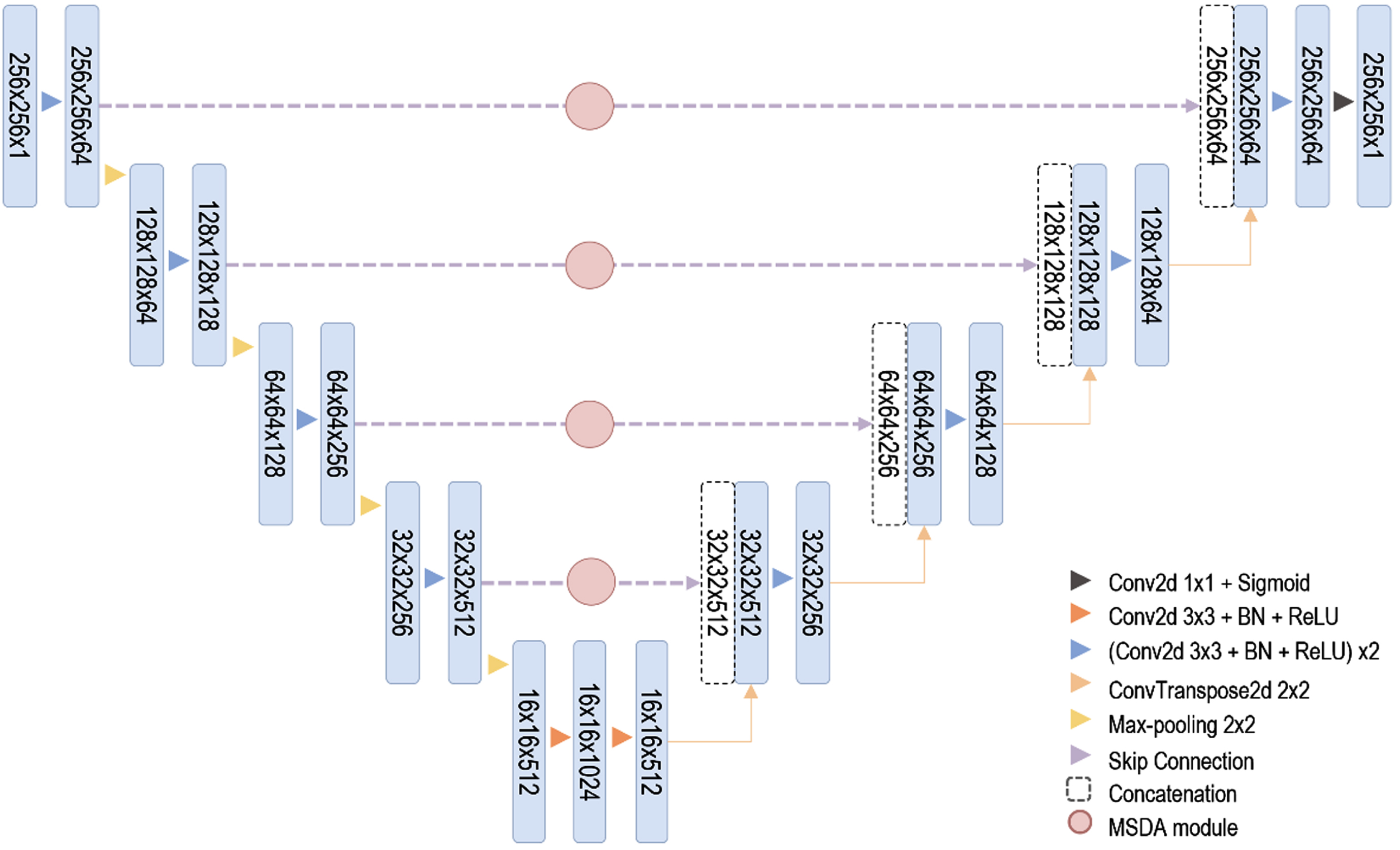
An Illustration of MSDA-Net architecture.
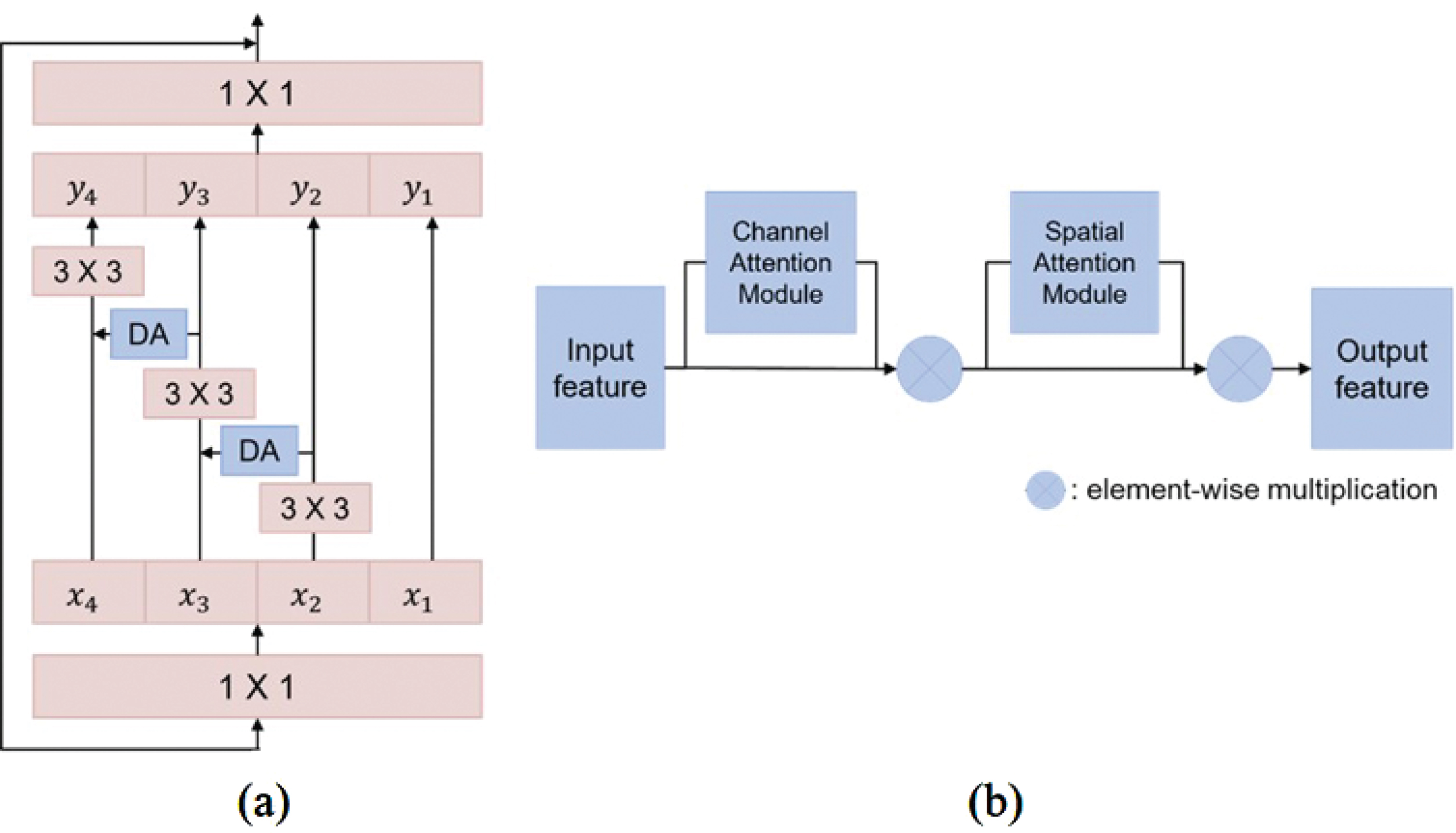
An illustration of the proposed module structure: (a) MSDA module (b) Dual-attention module.
The CL-MSDA-Net is a consistency learning framework that contains two differently networks fseg1 and fseg2, both of which are trained with the two input patches generated by the input patch generation step. The CL-MSDA-Net is optimized using two supervised losses, L
variant
and L
invariant
, and two consistency losses, L
norm
and L
restore
. The total loss for CL-MSDA-Net is as follows:
The CL-MSDA-Net is trained with a supervised loss defined as a combination of Binary Cross-Entropy loss and Dice loss to penalize false-negative and false-positive predictions. The supervised loss function is formulated as follows:
The consistency loss simultaneously supervises each prediction from networks fseg1 and fseg2, respectively. The consistency loss computes the similarity between pairs of predictions to jointly learn common features. They are scaled by equal ratios to calculate the consistency of the predicted probability across input patches of different ratios. The prediction fseg1 (X
i
) is normalized by multiplying the size-normalization ratio, which is calculated as the average tumor size over the current tumor size, and the prediction
Our network was implemented with Python 3.7 and the PyTorch framework and trained with four NVIDIA GeForce RTX 3090 GPUs. We trained with the initial learning rate using the Adam optimizer, and the learning rate was reduced by a factor of 0.95 per epoch using the LambdaLR scheduler. The maximum number of epochs was set to 100, and training was stopped early if the performance did not improve after 25 epochs. The hyperparameters used in the experiments are summarized in Table 2.
Hyperparameter settings for experiment: The same hyperparameter settings were set except for the loss function of the proposed method, and each dataset used a different initial learning rate for optimization
Hyperparameter settings for experiment: The same hyperparameter settings were set except for the loss function of the proposed method, and each dataset used a different initial learning rate for optimization
We evaluated the ablation studies for the effects of a multi-scale module, a multi-scale dual-attention module, and a consistency learning-based multi-scale dual-attention module using U-Net on two experimental datasets. The VHSCMC and NSCLC-Radiomics datasets were analyzed with a 5-fold cross validation and hold-out validation, respectively. The configurations of the train, validation and test set of each dataset are shown in Table 3. As an experimental plan, we analyzed the segmentation results according to the performance of the entire tumor group and tumor size groups, and the performance of the proposed method and other modules was evaluated by three evaluation criteria: F1-score, recall, and precision. The tumor size groups were established according to the clinical T-stage and categorized into three groups. Size group 1 represents tumors measuring≤3 cm (T1), size group 2 represents tumors measuring > 3 cm and≤5 cm (T2), and size group 3 represents tumors measuring > 5 cm (T3/T4).
Patient characteristics for training, validation, and test of each dataset. The amount of data is provided for whole and for each group, and minimum and maximum tumor sizes are given in parentheses. The VHSCMC dataset and NSCLC-Radiomics were performed with 5-fold cross validation and hold-out validation, respectively. In the VHSCMC dataset, each fold has the same configuration
Tables 4 and 5 show the performance evaluation results for each method on the entire VHSMC dataset, as well as on tumor size groups within the dataset. The proposed method improved the segmentation performance compared to the other methods, and the proposed method showed the best results with an F1-score of 80.49%, and in particular, the precision improved the most with a score of 86.78% compared to the other methods. In the case of Group 1, the F1-score, recall, and precision of the proposed method were 81.53%, 80.49%, and 86.75%, respectively, which were significantly improved by 5.09%, 2.42%, and 5.92%, compared to U-Net using the multi-scale dual-attention module. When using the multi-scale dual-attention module, Group 1 showed lower performance. This was because the ratio to tumor area was very small and provided little semantic information, although it considered the relative spatial relationship with surrounding structures. However, the largest performance improvement was seen through size normalization and consistency learning, in which small tumors were expanded to average-sized tumors, and the proportion of the surrounding structures was decreased. Group 2 showed a smaller increase than Group 1 but still showed performance improvements of 4.43%, 2.7%, and 4.57%, respectively, compared to U-Net using multi-scale dual-attention module. Group 3 showed the best performance in terms of precision, but had a slightly decreased F1 score and recall by 0.95% and 2.84%, respectively, compared to the method without consistency learning. In Group 3 with the VHSMC dataset, the effect of size normalization seems difficult to ascertain because the variations in tumor size are variable and low in number.
Results of the performance evaluation of lung tumor segmentation on the entire VMHSC dataset: Mean and standard values of the proposed and comparative methods in terms of F1-score, recall and precision are provided
Results of the performance evaluation of lung tumor segmentation on the VMHSC dataset based on the tumor size groups: Mean and standard values of the proposed and comparative methods in terms of F1-score, recall and precision are provided
Table 6 shows the performance evaluation results for each method on the NSCLC-Radiomics dataset. The proposed method showed the best performance compared to the other methods with an F1-score of 71.70%, recall of 68.24%, and precision of 79.33%. In Group 1 with a small tumor size and Group 2 with a medium tumor size, the same trend as in the VHSMC dataset was observed. In Group 3, the proposed method showed the best results with an F1 score, recall, and precision of 72.52%, 68.43%, and 79.89%, respectively. This means that the NSCLC-Radiomics dataset has a relatively large amount of data for Group 3 compared to the VHSMC dataset, and the large-sized tumor distributions also has a small number of variations ranging from 6 to 11 cm.
Results of the performance evaluation of lung tumor segmentation on NSCLC-Radiomics dataset: Mean and standard values of the proposed and comparative methods in terms of F1-score, recall and precision are provided
Figure 6 qualitatively evaluated the performance of each segmentation method compared to the ground truth on the VHSMC dataset. In U-Net and U-Net using the multi-scale module, under-segmentation occurred in most of the tumors, and outliers occurred in other structures similar in shape to the tumors, such as the mediastinum. U-Net using the multi-scale dual-attention module showed better results than U-Net and U-Net using the multi-scale module, but under-segmentation still occurred in Groups 1 and 3. The proposed method showed the most similar segmentation results to the ground truth in all groups with various tumor sizes.
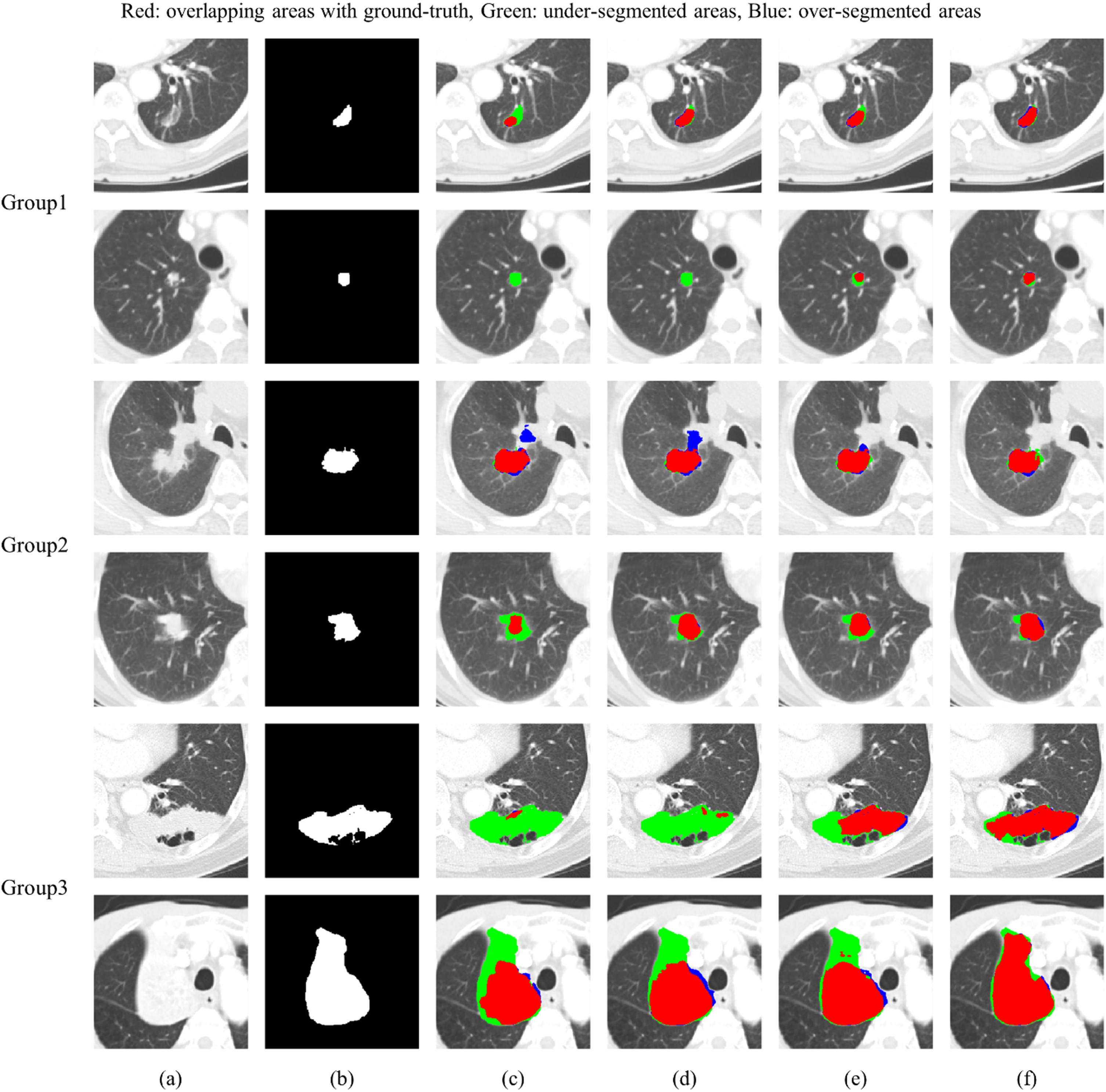
Results of the qualitative evaluation of lung tumor segmentations on VHSMC dataset: (a) Original CT image, (b) Ground truth, (c) Lung tumor segmentation using U-Net (d) Lung tumor segmentation using U-Net with multi-scale module, (e) Lung tumor segmentation using U-Net with multi-scale dual-attention module and (f) Lung tumor segmentation using proposed method.
Figure 7 qualitatively evaluated the performance of each segmentation method compared to the ground truth on the NSCLC-Radiomics dataset. In U-Net, U-Net using the multi-scale module and U-Net using the multi-scale dual-attention, more severe under-segmentation occurred in most tumors than in the segmentation results of the VHSMC dataset. The proposed method showed the best segmentation results in all groups with various tumor sizes.
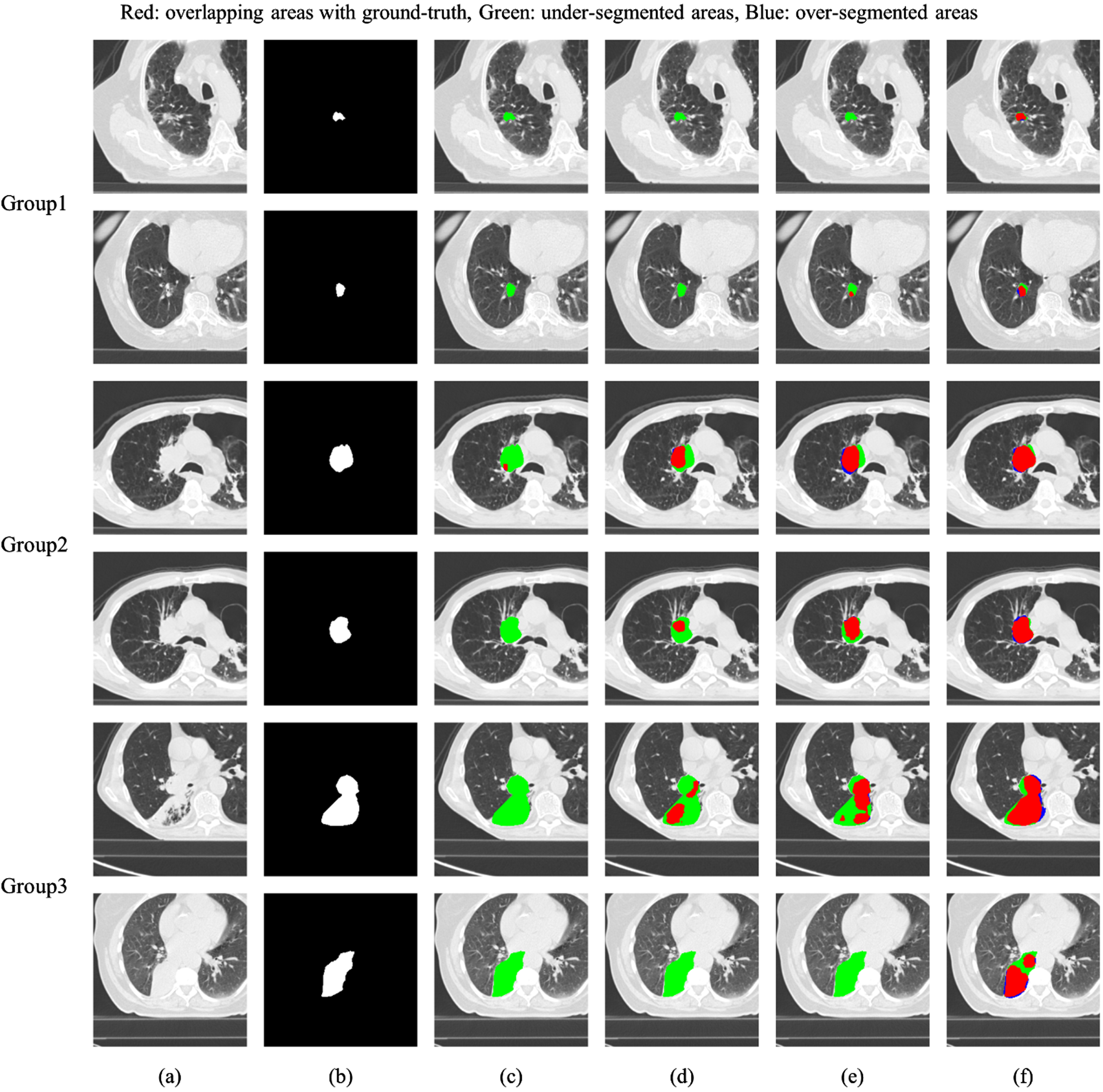
Results of the qualitative evaluation of lung tumor segmentations on NSCLC-Radiomics dataset: (a) Original CT image, (b) Ground truth, (c) Lung tumor segmentation using U-Net (d) Lung tumor segmentation using U-Net with multi-scale module, (e) Lung tumor segmentation using U-Net with multi-scale dual-attention module and (f) Lung tumor segmentation using proposed method.
In this paper, we proposed a CL-MSDA-Net that can accurately segment lung tumors of various sizes on chest CT images. The proposed method uses not only the size-variant patch that preserve original size information, but also the size-invariant patch normalized to the average size of tumors while maintaining a similar tumor-to-background ratio. Through this method, small-sized tumors can learn semantic information within the tumor, and large-sized tumors can learn the surrounding information together. In addition, a pair of features were simultaneously learned through consistency learning to increase the learning stability between the networks in each branch, resulting in consistent segmentation results in lung tumors of different sizes. Finally, a multi-scale dual-attention module focused on the tumor area rather than surrounding structures to distinguish important areas at multiple scales.
The CL-MSDA-Net model showed the best segmentation performance on both the VHSMC and NSCLC-Radiomics datasets and showed an F1 score of 80.49%, recall of 79.06%, and precision of 86.78% on the VHSMC dataset, respectively, and showed an F1 score of 71.7%, recall of 68.24%, and precision of 79.33% on the NSCLC-Radiomics dataset, respectively. The VHSMC dataset has a wide distribution with a small amount of data in a large-sized tumor group, while the NSCLC-Radiomics has a constant size with a large amount of data in a large-sized tumor group. Although the dataset distributions are different, the proposed method showed the best performance in both datasets. In particular, small-sized lung tumors in the VHSMC dataset showed significant performance improvements, and large-sized lung tumors in the NSCLC-Radiomics dataset showed significant performance improvements by applying consistency learning.
Despite the overall good performance on both datasets, our study has several limitations. Because our method processes data in 2D slices, it is difficult to consider spatial continuity information in lung tumors. For lung tumors attached to the mediastinum, vessels, or chest wall, spatial continuity information can also be an important factor in segmentation. In addition, the proposed method could not be compared with other SOTA methods because the experimental configuration was different from the public datasets. In the future, these limitations are complemented, and it is expected that the tumor volume can be measured to evaluate the treatment response which is useful for predicting the prognosis.
Footnotes
Acknowledgments
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. RS-2023-00207947) and a sabbatical year (2022) and research grant (2023) from Seoul Women’s University.