
Abstract
Oil price forecasts have traditionally attracted the interest of both the empirical literature and policy makers, although research efforts have been intensified in the last 15 years. The present study investigates the forecasting characteristics that have the greatest impact on the accuracy level of such forecasts. To achieve this, we employ a meta-analysis approach of more than 6,000 observations of relative root mean squared errors (RRMSEs) which are pooled within a Bayesian Model Averaging (BMA) method. The findings indicate that forecasting frameworks such as MIDAS and combined forecasts tend to report significantly lower forecast errors. In addition, the choice of the oil price benchmark is an important factor, with the Brent price to offer lower forecast errors. Furthermore, the short-run horizons tend to produce more accurate forecasts and the same holds for the real, instead of the nominal oil prices. A number of robustness tests confirms the validity of these results. Overall, the findings of this study serve as a guide for future oil price forecasting exercises.
1. Introduction
Since the regime change in oil price fluctuations in the early 2000’s, which is characterised by the unprecedented levels of oil prices and their severe volatility, the extant literature (Knetsch, 2007; Alquist et al., 2013; Degiannakis and Filis, 2018) and policy documents (Bernanke, 2005; ECB, 2015) have highlighted the need for more accurate oil price forecasts. Figure 1 depicts the regime change in oil prices in the post-2003 period, when we observe a series of episodes with huge price swings. For instance, the WTI crude oil price reached its peak at almost $140 in July 2008, which was then followed by a rapid and sharp decline at about $40 in January 2009. In addition, in June 2014, oil reached once again a price above $100, and then a fall below $50 seven months later (February 2015). More recently, due to Covid-19 pandemic, oil prices lost about 65% of their value (from $60 in December 2019 to almost $20 in April 2020). We should also highlight that for the first time we experienced negative oil prices, when the WTI dropped at -$37 on the 20th April 2020 (not shown in Figure 1 as it was constructed using monthly data).
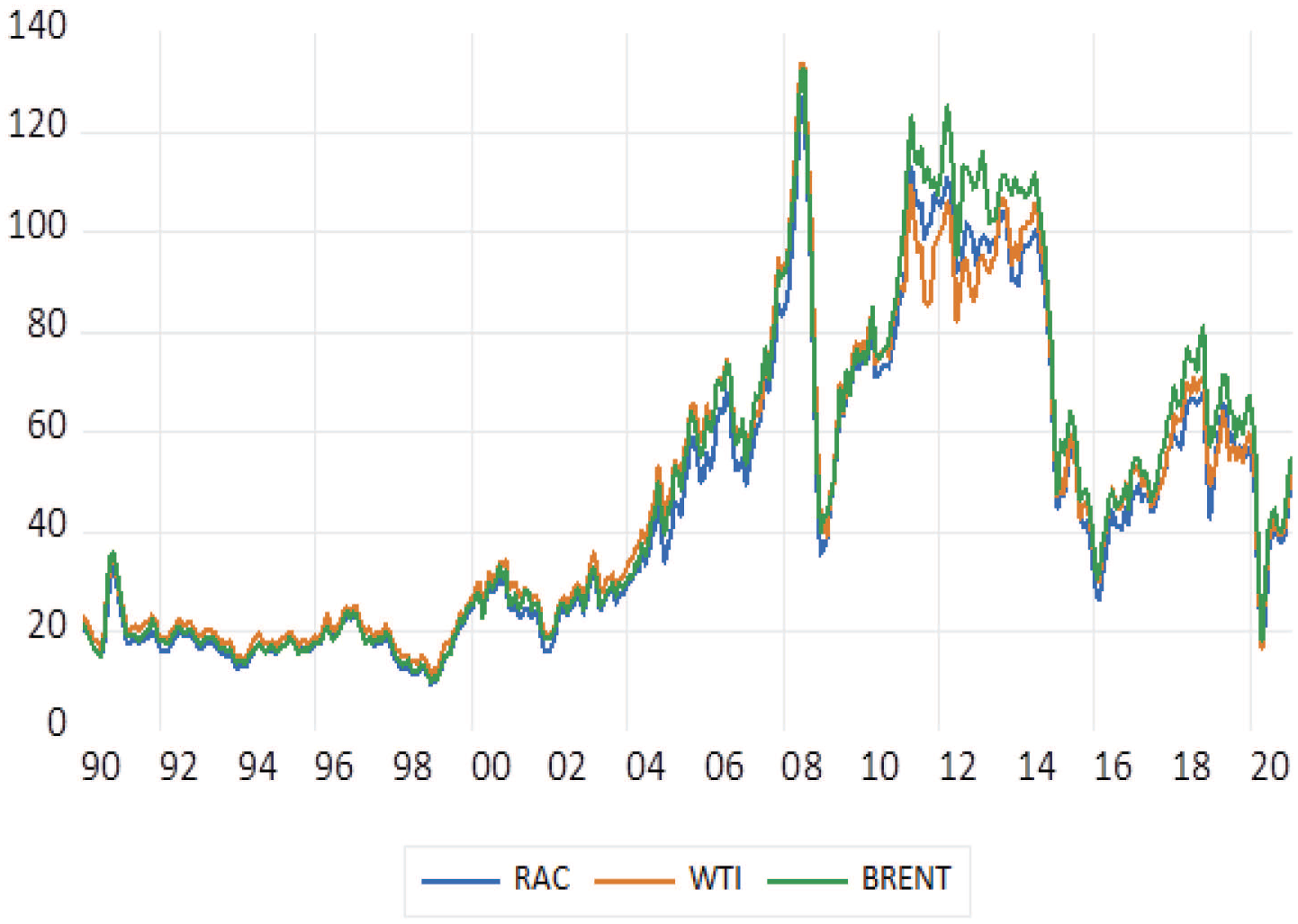
Nominal (spot) oil price
The need for accurate oil price forecasts, given the aforementioned abrupt changes, stems from the fact that they form important decision-making inputs for a number of stakeholders, including private businesses, central banks and the national governments. For instance, Alquist et al. (2013) provide evidence that oil price forecasts help industrial sector companies to forecast their product prices. Moreover, they indicate that investment decisions regarding climate change and carbon emissions predictions, as well as, formulation of regulatory policies in the energy sector may significantly be influenced by oil price forecasts. In addition, Baumeister (2014) shows that oil price forecasting is an important tool for monetary authorities given that it conveys information about predictions in inflation and economic activity. Finally, Baumeister et al. (2018) highlight the importance of oil price forecasts for national governments of both oil-exporters and oil-importers in devising their investment strategies and budget plans. It is also important to highlight that central banks are interested in forecasting real oil prices in domestic currency units, which captures the real cost of oil for domestic consumption (Baumeister and Kilian, 2014). In turn, this further increases the complexity of oil price forecasts as their accuracy further depends of how future exchange rates are estimated.
Moreover, since oil is a physical commodity, it is intuitively expected that its price should be primarily affected by oil market fundamentals, namely unexpected oil supply disruptions, unanticipated changes in global demand for crude oil and unexpected changes in inventory demand (see, for instance, Kilian, 2009; Kilian, 2010; Kilian and Murphy, 2014). However, the more recent literature highlights the significant effect of financial markets as drivers of oil price movements. This is known as the financialisation of the oil market and is primarily related to speculative activity in this market. In this regard, Fratzscher et al. (2014) explain that oil acts as a financial asset due to the fact that it reacts rapidly to information associated with other financial assets such as stock prices or exchange rates. More recently, Degiannakis and Filis (2018) show that apart from the oil market fundamentals, information stemming from the financial markets could improve oil price forecasts.
Based on the aforementioned developments in the oil market, as well as, the complexity of its price forecasts, the literature has developed an array of different forecasting frameworks and has employed a series of different predictors in search of improved accuracy. For instance, early studies that focus on the use of Vector Error Correction models (Coppola, 2008; Murat and Tokat, 2009) or futures-based forecasts (Knetsch, 2007; Alquist and Kilian, 2010) attempt to show whether these forecasts can outperform the random-walk. Other studies, such as those by Baumeister and Kilian (2012), Baumeister and Kilian (2014) and Naser (2016) employ Vector Autoregressive-type (VAR) forecasting frameworks (e.g., structural VARs, time-varying parameter VARs), whereas Baumeister et al. (2014) and Baumeister and Kilian (2014, 2015) assess the predictive accuracy of combined forecasts. Baumeister et al. (2015) and, more recently, Degiannakis and Filis (2018) exploit the advantages of the mixed-data sampling (MIDAS) forecasting framework.
In terms of predictors, the existing studies have more commonly used the oil market fundamentals such as world oil production, global economic activity index, US crude oil inventories among others (see, for example, Baumeister and Kilian, 2012; Baumeister et al., 2015; Rubaszek, 2021). It should be noted also that it is not uncommon for studies to use futures prices (see Coppola, 2008; Alquist and Kilian, 2010; Baumeister et al., 2014; Pak, 2018) and product spreads (see Baumeister et al., 2018) as potential predictors. Furthermore, recent studies, such as those by Baumeister et al. (2015), Degiannakis and Filis (2018) and Zhang and Wang (2019), assess the predictive information of financial data in oil price forecasts. Turning to the data frequency, we note that for most studies data are collected and reported monthly, although quarterly frequencies are also reported (see Baumeister et al., 2014). In addition, the use of financial data allows to assess whether higher frequency data (daily or weekly) could improve the forecasting accuracy of oil prices.
The choice of the crude oil price benchmark is another interesting distinction among the existing studies. There are three main variables, namely, the US refiners’ acquisition cost (RAC), the West Texas Intermediate (WTI) and the Brent crude oil (Brent), which are used extensively in the forecasting exercises. Pertaining to the readily available information, empirical studies that forecast both WTI and RAC include Alquist et al. (2013), Baumeister et al. (2015), Baumeister and Kilian (2015), Wang et al. (2017) and Baumeister et al. (2018). In addition, authors such as Coppola (2008), Alquist and Kilian (2010), Naser (2016) and Rubaszek (2021) focus on the WTI price forecasts, whereas other studies such as Knetsch (2007), and Degiannakis and Filis (2018) concentrate solely on the Brent crude oil prices. Finally, authors who develop forecasting frameworks for both WTI and Brent benchmarks include Chen (2014), Funk (2018), and Zhang and Wang (2019).
We should emphasise that the aim of this study is not to provide a thorough review of the related literature. Rather, with the aforementioned considerations in mind, we perform a meta-analysis approach, which has been proven to be a useful methodical tool for integrating the empirical findings of numerous existing studies. Each oil price forecasting study presents different results given the use of different modelling frameworks, data frequencies, forecast horizons, and sample periods, among others. However, when these empirical results are systematically combined and reviewed, we are able to identify and interpret the various factors that contribute the most to higher forecast accuracy. Therefore, the meta-analysis technique is important in order to provide meaningful interpretations regarding differences in forecasting accuracy from one study to another.
Hence, given the increasing interest in this line of research and the numerous papers that have been published, especially in the last 15 years, our study makes an important contribution by providing a quantitative navigation that will allow to explore those factors that systematically provide more accurate oil price forecasts. In this regard, this is the first meta-analysis attempt in this line of research. For this purpose, we employ a Bayesian Model Averaging (BMA) model, which facilitates the investigation of the factors leading to more accurate forecasts across the different studies.
Our findings can be succinctly summarised as follows. First, MIDAS and combined forecasting frameworks, among other forecasting techniques, exhibit significantly higher forecasting accuracy. Second, the use of Brent crude oil price generates better predictions in comparison with other crude oil benchmarks. Finally, the short-run forecasting horizons and the use of real oil price also contribute to lower forecast errors.
The remaining of the paper is structured as follows. Section 2 describes the data collection process. Section 3 presents the empirical method, while Section 4 discusses the main results along with robustness checks. Finally, Section 5 concludes the study.
2. Forecasts errors across literature
2.1 Data collection
A significant part of the forecasting literature uses the random walk (RW) without a drift, (also known as the no-change forecast), as the benchmark forecasting framework Its h-month ahead forecast error at any time point is shown as

where t =1…T denotes the out-of-sample forecasting observations. Furthermore, h shows the h-month ahead forecast horizon that takes values from 1 up to N months ahead. For instance,

where the superscript m denotes a forecasting model other than the random walk, while hl indicates the h-month ahead horizon from study l. When the ratios are lower than one then the competing model is able to outperform the benchmark model. The main variable of interest in our study is the relative RMSE (RRMSE, thereafter).
1
We use the terms
We perform a Google scholar search using the key combinations ‘oil price predictability’, ‘oil price forecasts’, ‘oil price forecasting’ and ‘oil price modelling’. In order to impose a certain quality threshold, we only focus on published papers. The inclusion of working papers, many of which produce large horse-races of forecasts, would make the total amount of observations intractable. This search was carried out between July and September 2021.
The next step is to impose a number of criteria according to which a study can be included in our sample. Our first criterion requires for a study to report at least one RMSE or RRMSE, which is the metric that we focus on. Therefore, the papers that report on alternative evaluation metrics for the relative forecasting performance (such as the direction of change statistic) are excluded.
The second criterion is associated with the great number of combinations of forecasting techniques and the corresponding RMSEs or RRMSEs, and thus, we only collect on the reported RMSEs or RRMSEs that use random walk as the benchmark forecasting framework. 2 Therefore, the reported RMSEs or RRMSEs that are based on different benchmark are not included in our meta-sample. Our third criterion is related to the use of non-standard machine learning strategies (such as random forests and artificial neural networks) from a number of papers the last years. As a result, we focus on traditional econometric models and thus we excluded those studies. In this way, we ensure the comparability of the collected RRMSEs across studies. 3
Overall, the total sample consists of 6,089 observations collected from 21 papers. Table 1 presents the summary of the selected studies, together with the descriptive statistics of their RRMSEs. Figure 2 presents the histogram of the selected RRMSEs, which exhibits fat tails, showing a wide range of forecast errors. The selection process is summarised in a PRISMA chart in Appendix 1, while the full list of studies is provided in Appendix 2.
Forecast errors’ descriptive statistics of the selected studies
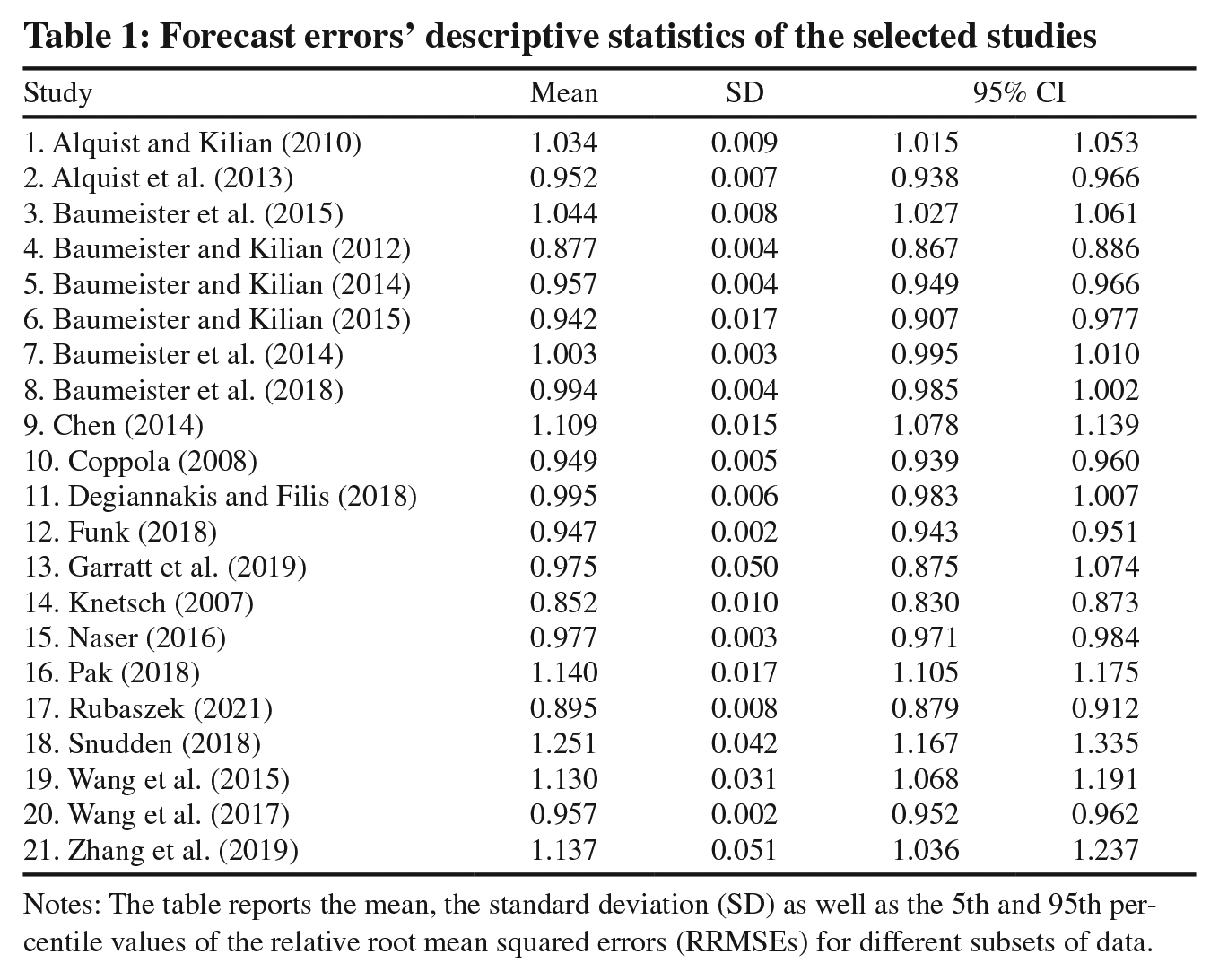
Notes: The table reports the mean, the standard deviation (SD) as well as the 5th and 95th percentile values of the relative root mean squared errors (RRMSEs) for different subsets of data.
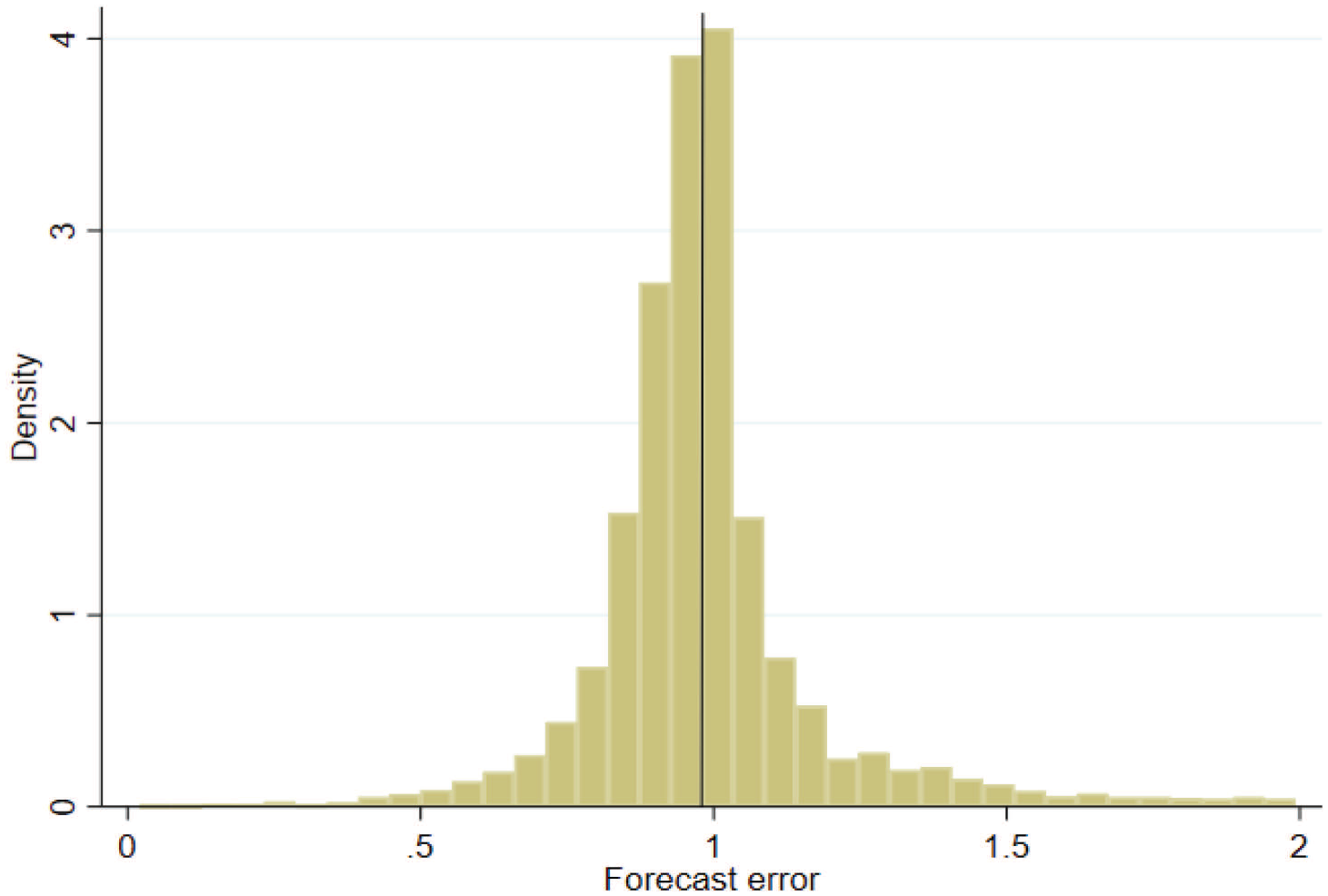
Histogram of RRMSEs
2.2 Heterogeneity of forecasts errors
In order to examine the heterogeneity of the reported RRMSEs across the literature, we look into three categories. From each category we identify factors that may systematically influence the reported RRMSEs. We describe this process in the following paragraphs.

Second, we create the moderator variable ‘structural’ that takes 1 when the RRMSE comes from a structural framework, either a structural VAR or a DSGE. Third, we create the dummy variable ‘midas’ where a value of 1 is assigned when a MIDAS framework is used. In a similar fashion, we use the same type of moderator dummy variables for frameworks using regression-based forecasts (‘regression’), combined forecasts (‘combined’) and finally, frameworks that use futures prices (‘future’) and product spreads (‘product’). 4
The second characteristic is the forecasting period. More precisely, we take into account the date of the end-of-sample, as the forecast errors are reported for the end of the sample period. In this way, we examine whether there is a trend in the reported results.
The third characteristic is associated with the use of real-time forecasts which are introduced by Baumeister and Kilian (2012) and followed by other authors in the literature of this particular area of research. We additionally take this characteristic into account by including the variable ‘real-time’ that takes 1 when real-time forecasts are reported.
Table 2 presents a reflection of the three forecasting groups and the variables under consideration, while Figure 3 provides a graphical illustration of the heterogeneity of the reported estimates across the three different categories.
List of Moderator Variables
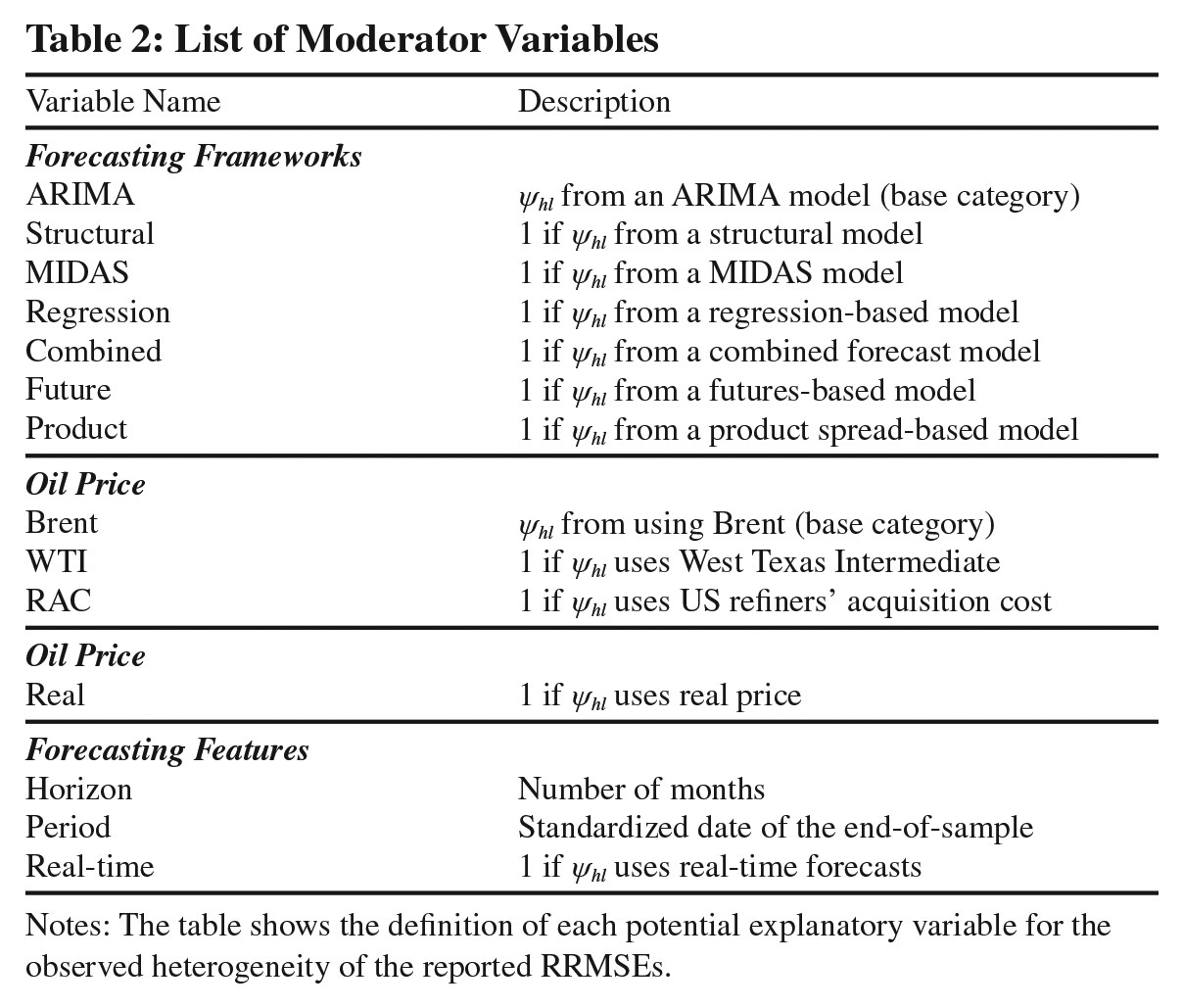
Notes: The table shows the definition of each potential explanatory variable for the observed heterogeneity of the reported RRMSEs.
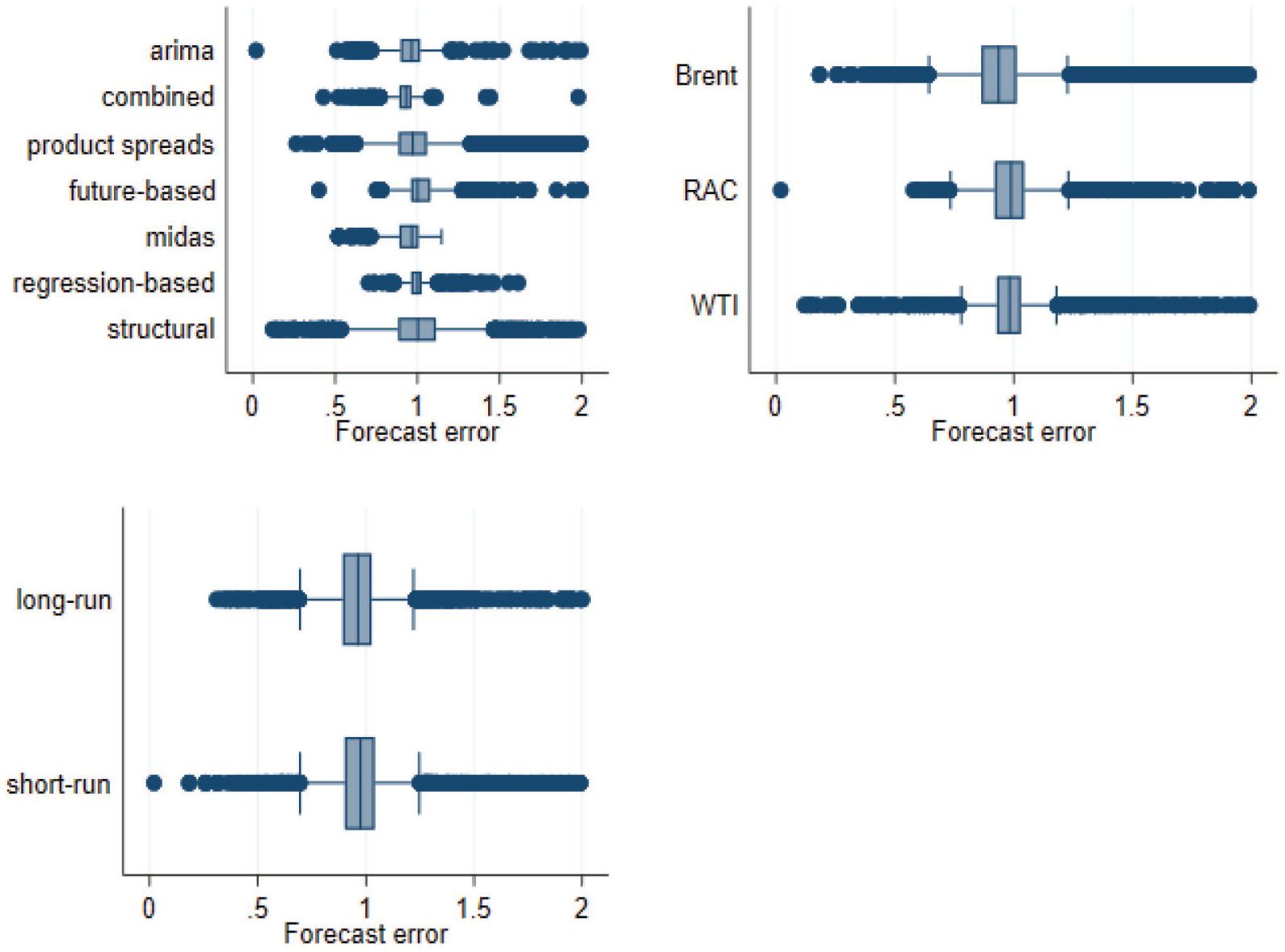
Heterogeneity of RRMSEs across different forecasting frameworks, prices and horizons
3. Methodology
This section presents the method according to which the factors that systematically affect the reported estimates can be identified. The benchmark method is the Bayesian Model Averaging (BMA) that belongs to the family of models that deal with big data (Koop, 2017). The usefulness of this technique is properly revealed when the number of regressors is quite large. Overall, BMA remains an increasingly popular method of identifying the significant drivers of a specific variable (here the RRMSE). Our meta-regression model can be written as:

where ψhl is the h-month ahead horizon’s relative forecast error from study l, Z depicts the moderator variables described in Section 2.2, γs are the coefficients of each moderator and the subscript S is the indicator of each moderator. In total, we have 12 moderator variables, and therefore S ∈ [1,12]. As usual, the error term, ε, is normally distributed; ε ~ N(0,σ). The superscript ξ indicates that the equation (4) is valid under model Mξ of the BMA exercise. In our case, the use of 12 regressors results in 4,096(=212) different models to choose from. This means that the model space consists of M1,…,Mξ models, where ξ ∈ [1,…,4096]. Due to the moderate number of explanatory variables, it is computationally feasible to evaluate and average all model specifications. At the same time, the analytical solution can also be derived. We estimate the posterior model density as well as the posterior inclusion probabilities both analytically and computationally. The results from both approaches are identical.
The main characteristic of the model averaging techniques is that they assign a weight to each model and then, average across these models. Therefore, the inference is not based on individual models, but instead on weighted averages. Even with a small number of regressors, the model space consists of many potential combinations. In the remaining part of this Section, we present the basic concepts of the BMA. Appendix 3 provides a more detailed technical discussion. Based on the Bayes’ rule, the posterior density of γ is written as:
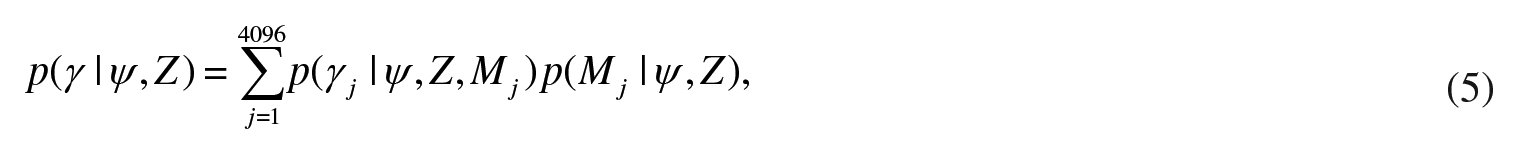
where p(γj | ψ, Z, Mj) is the posterior distribution under model Mj and p(Mj |ψ, Z) is the posterior model probability. 6 The above equation shows that the posterior model probabilities are used as weights. More precisely, the posterior density of γ for each model Mj is weighted by the posterior model probability of each model Mj. The point estimates for the posterior mean can be derived by taking expectations:
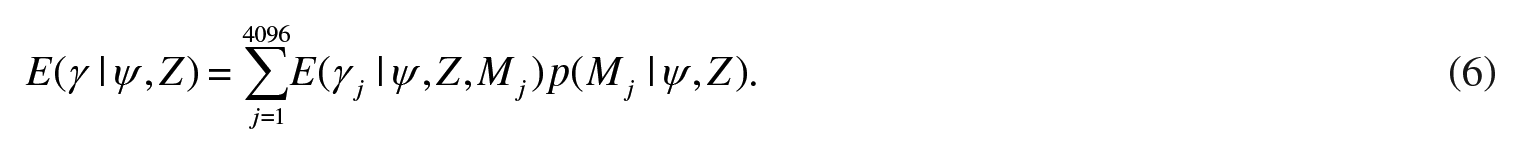
The posterior variance is proved to be:
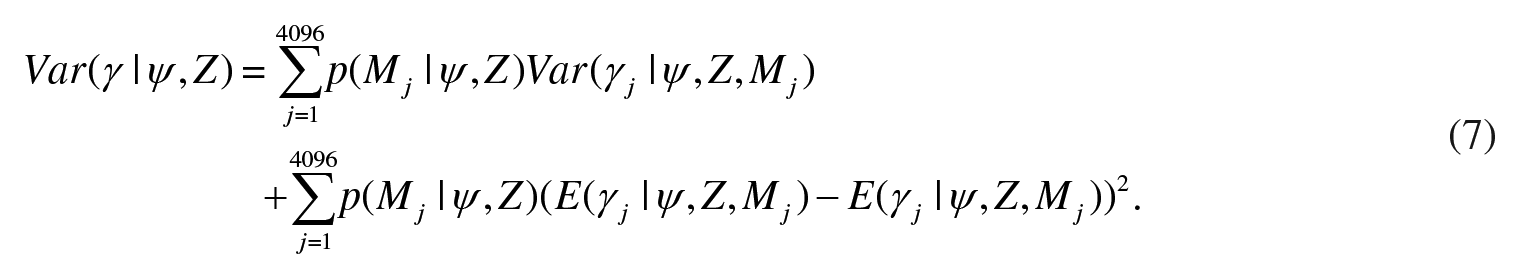
To help better understand our benchmark model, it is instructive at this point to consider the posterior inclusion probability (PIP) metric which is defined as the sum of posterior model probabilities of all models that include the specific regressor and takes the following form:

with i ∈ [1,12] indicating that each regressor has a specific inclusion probability. Therefore, the PIP shows how frequently a regressor appears in the alternative Mj models. In this way, the level of PIP determines whether a regressor can be considered as a robust determinant. The value of the PIP ranges between zero and one, where a value close to one for a particular regressor denotes larger explanatory power. In other words, the variable with the highest estimated PIP is this variable that is present in almost all alternative model specifications and therefore, a robust driver that explains the heterogeneity of the reported estimates.
As far as the parameters priors are concerned, we choose the following options. As there is no prior knowledge, we use non-informative priors for the intercept and the variance; p(c) ∝1 and p(σ) ∝ σ−1. Regarding the γ parameters, we assume that they are centered at zero and the variance is proportional to

In this study, we employ two different choices regarding g. Firstly, we set g = N, which is the unit information prior (UIP), where N is the sample size. Secondly, we set the hyper-g prior as suggested by Liang et al. (2008). For the case of model priors, we also use two alternative choices. Firstly, we use the uniform model prior that assumes equal probability to all models. Secondly, we relax this assumption by setting a beta-binomial prior. The approximation of the posterior distribution is simulated by a MCMC sampler algorithm.
4. Results
4.1 Main evidence
Table 3 shows the first round of results. Following Kass and Raftery (1995), we categorise the effect of a variable as weak, positive, strong, and decisive if its PIP lies between 0.5–0.75, 0.75–0.95, 0.95–0.99 and 0.99–1, respectively. We begin our analysis with the evaluation of the relative performance of the different forecasting frameworks. The results suggest that the MIDAS frameworks, as well as, the combined forecasts tend to generate significantly lower forecast errors. Such forecasting frameworks have the ability to outperform the ARIMA framework, given the negative and significant coefficients. By contrast, the use of structural-based, regression-based, futures-based, as well as, forecasts based on product spreads, does not seem to significantly outperform the forecasting accuracy of the ARIMA framework.
Bayesian Model Averaging results
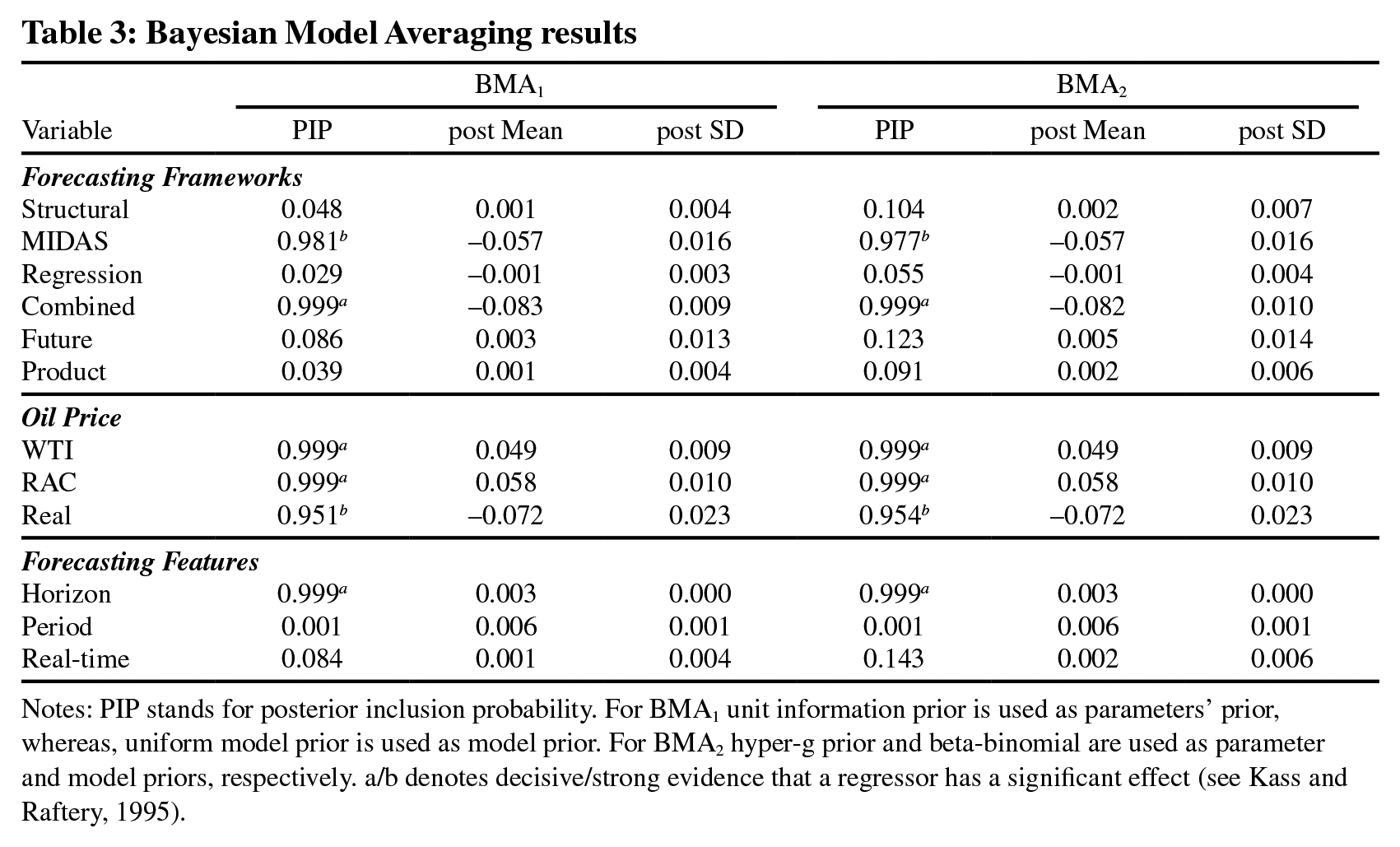
Notes: PIP stands for posterior inclusion probability. For BMA1 unit information prior is used as parameters’ prior, whereas, uniform model prior is used as model prior. For BMA2 hyper-g prior and beta-binomial are used as parameter and model priors, respectively. a/b denotes decisive/strong evidence that a regressor has a significant effect (see Kass and Raftery, 1995).
The fact that MIDAS models tend to produce lower forecast errors can be interpreted as follows. The related literature has shown that oil price forecasts are impacted by the fundamental factors of the oil market (i.e., unanticipated changes in oil supply, oil demand, and inventory levels). However, recent research efforts (Degiannakis and Filis, 2018) have also shown that the oil market has become more financialised, meaning that it has become more interconnected with other global financial markets (such as the stock markets, or foreign exchange, among others). Considering that these asset markets convey information to the oil market at a much higher frequency, relatively to the oil market fundamentals, our finding suggests that the use of such higher-frequency financial data, tends to improve oil price forecasts at lower frequencies. This is a feature only available to the MIDAS framework.
With reference to the improved predictive accuracy of combined forecasts frameworks, we maintain that such forecast combinations act as insurance against the poorer forecasting performance of the individual frameworks. Hence, when combining forecasts the weak performance of an individual forecasting framework can be counterbalanced by the better performance of another framework, leading to an overall improvement in the forecast accuracy. This argument is also evident in the work of Baumeister and Kilian (2015) who employ forecast (pooled) combinations. Furthermore, different forecasting strategies exhibit superior forecasting performance at different horizons. Consequently, their combination improves the overall forecasting performance. Therefore, we note that information derived from combined forecasts helps to provide significant predictive gains.
Turning our attention to the choice of the oil price benchmark, our results suggest that the forecasting exercises that use either the US refiners’ acquisition cost (RAC) or the WTI crude oil price tend to report higher RRMSEs compared to those studies that use the Brent crude oil price, given the positive and significant coefficients. Alquist et al. (2013) argue that although the RAC can be used to approximate global oil price movements, it cannot be viewed as the indicative proxy for the price that US refineries paid for crude oil. In this regard, Baumeister et al. (2014) are supportive in favour of the WTI spot price. According to them, the WTI is not subject to revisions and it is also available without delays, which is not the case when the RAC is considered. This could justify the higher forecast error of the RAC compared to the Brent price.
Furthermore, the WTI is considered to be more volatile than the Brent, which makes it harder to be accurately predicted. Possible reasons can be found in the geographical area that they are produced and the transportation costs. Brent is extracted at sea and transferred by ships, which makes it to be less dependent on abrupt changes in transportation costs. By contrast, the WTI is drilled in landlocked regions and thus, its price is affected by both higher transportation costs as well as pipeline bottlenecks and higher storage constraints (Baumeister and Kilian, 2015). Overall, our arguments help to clarify the reasons why the use of Brent appears to provide better forecasting performance. Such findings are also in accordance with Manescu and Van Robays (2014) and Degiannakis and Filis (2018) who propose the importance to use the Brent spot price.
Even more, the WTI crude oil market has attracted the attention of the non-commercial investors, via its futures contracts. Indeed, the WTI has the most liquid and actively traded futures contracts in the crude oil market compared with Brent (Buyuksahin et al., 2013). This explains why the WTI is regarded as a valuable financial asset by energy traders. Such trading activity results in higher volatility for the WTI, which could further explain the lower forecasting accuracy for this crude oil benchmark. Such finding has important implications for end-users of oil price forecasts. Let us assume that there is a Permian Basin operator who is interested in forecasting the price of oil to help guide current production decisions. It is apparent that the appropriate oil price measure to forecast is the price of WTI. In this case, the operator should be aware that her forecasting framework should be improved so as to accommodate the fact that the WTI is harder to predict.
As far as the difference between real and nominal oil prices is concerned, our evidence shows a negative and significant coefficient, which indicates lower forecast errors for the real oil price. This suggests that forecasts of the real price tend to be better than forecasts of the nominal one. A plausible explanation for this finding can be traced at the effect of inflation. More specifically, the higher forecast errors of the nominal oil prices could be explained by the fact that they have an inflation component, which adds uncertainty to the future path of oil prices. Put differently, nominal oil price forecasts make also implicit assumptions about the future inflation, hence they are harder to predict.
Interestingly enough, we do not find evidence that the real-time forecasts are superior. Real-time forecasts are based on datasets that take into consideration delays in reporting relevant information or potential revisions in data series (for instance, this is particular relevant for oil production information). According to Alquist et al. (2013) and Baumeister et al. (2014), forecasters who ignore such constraints in the data series, tend to produce better forecasts. Nevertheless, our findings do not lend support to this claim.
Furthermore, ‘horizon’ appears to have a positive and significant coefficient. This means that longer forecasting horizons produce higher RRMSEs, indicating a lower forecast performance. 7 This is a plausible finding given that at longer horizons we expect the autoregressive and moving-average components of oil prices to prevail relatively to the fundamentals of the oil market or the financial information. By contrast, we do not find any significant influence on the quality of forecasts from the forecasting period moderator, suggesting that either the more recent or the earlier forecasts in our dataset do not seem to exhibit different levels of predictive accuracy. Such finding could potentially suggest that the oil market maintains a certain level of unpredictability even under the use of the more recently developed forecasting frameworks and data availability (e.g., MIDAS framework and intra-day data). This could be explained by the fact that since 2003 there is a regime change in the behaviour of oil prices, as already mentioned in Section 1. More specifically, prices have become more volatile, adding extra difficulty to the forecaster to generate significantly improved forecasts in the more recent years, relatively to the earlier period. Therefore, it is not entirely unexpected that this variable is not found statistically significant.
4.2 Robustness tests
Having analysed the first round results, it is important to use an array of robustness tests so as to verify the stability of our findings. The first test is to replace the Bayesian setting (BMA) with a frequentist one (FMA) which allows us to maintain the basic rational of model averaging techniques. In this respect, the main difference between frequentist and Bayesian averaging is the construction of weights. Instead of using posterior model probabilities, the new weights are replaced with information criteria. In our exercise, we follow the approach proposed by Magnus et al. (2010) and extended by Amini and Parmeter (2012) who select the weights by minimising the Mallows criterion (Hansen, 2007). The main benefit is that this version of FMA is based on the orthogonalisation of the covariate space that leads to the significant reduction of the models that need to be estimated. In our case, the model space is not an issue due to the moderate number of regressors, as explained in the previous Sections.
The second test is to apply a pure frequentist least squares exercise without using any weighting scheme. Table 4 shows the results for both FMA and OLS with clustered standard errors at study level. Applying both types of frequentist analysis leads to results that are quantitatively and qualitatively similar to the BMA.
Frequentist Model Averaging and Least Squares
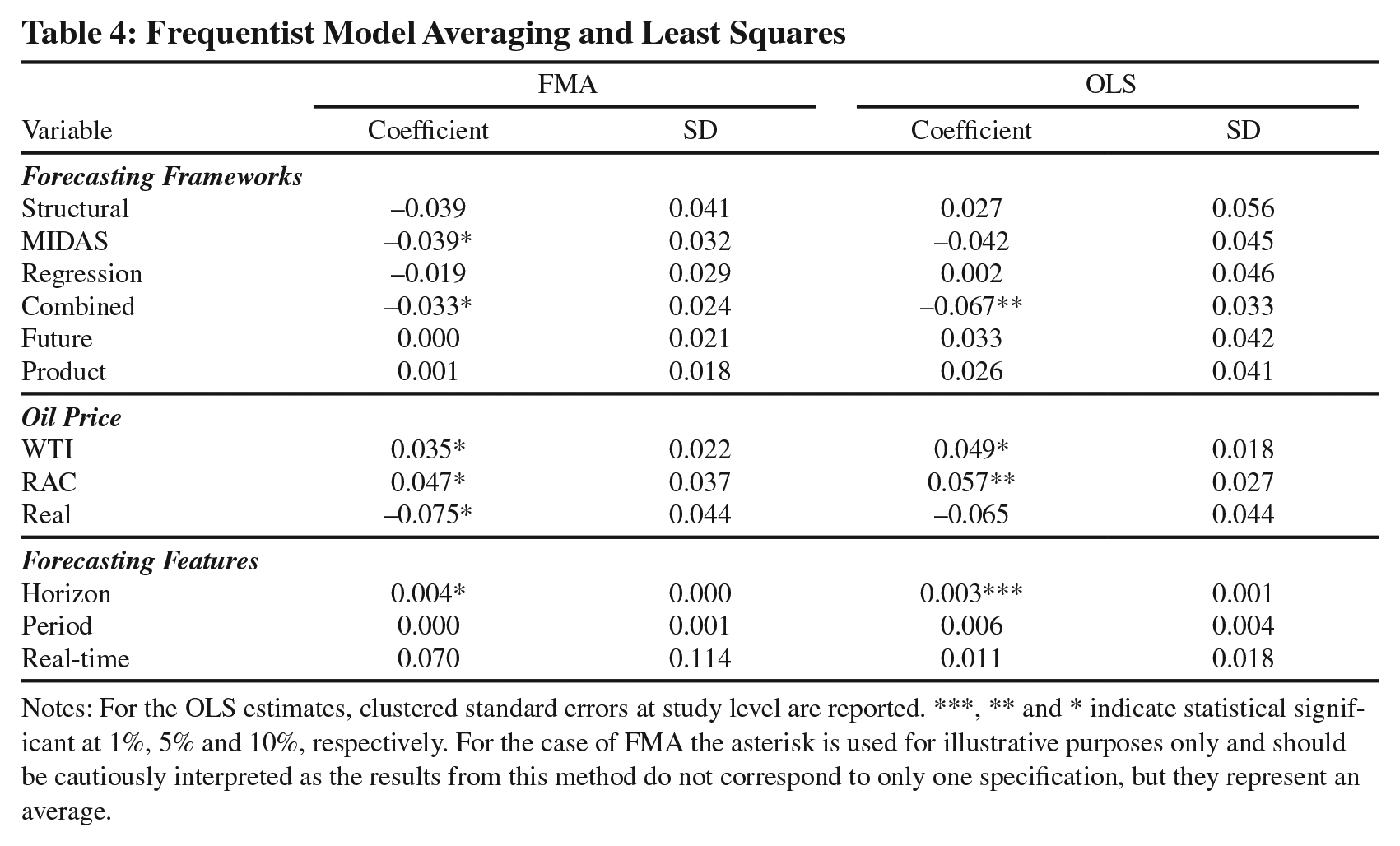
Notes: For the OLS estimates, clustered standard errors at study level are reported. ***, ** and * indicate statistical significant at 1%, 5% and 10%, respectively. For the case of FMA the asterisk is used for illustrative purposes only and should be cautiously interpreted as the results from this method do not correspond to only one specification, but they represent an average.
Overall, the moderator variables that were found to be robust drivers of the observed heterogeneity of the forecast errors remain the same; MIDAS and combined forecasts frameworks tend to have a better performance. The opposite is true when the forecasting exercises are based on the WTI and RAC oil price benchmarks. The horizon does continue to play a role, with longer horizons resulting in worse forecasts. Finally, when the focus is on real prices, then these forecasts are superior compared to those based on nominal prices.
Finally, we apply a variant of the least absolute shrinkage and selection operator (LASSO). This method combines the concept of minimising the least squares along with a shrinkage process that removes the drivers that are not important. The minimisation process can be written as:
LASSO estimates
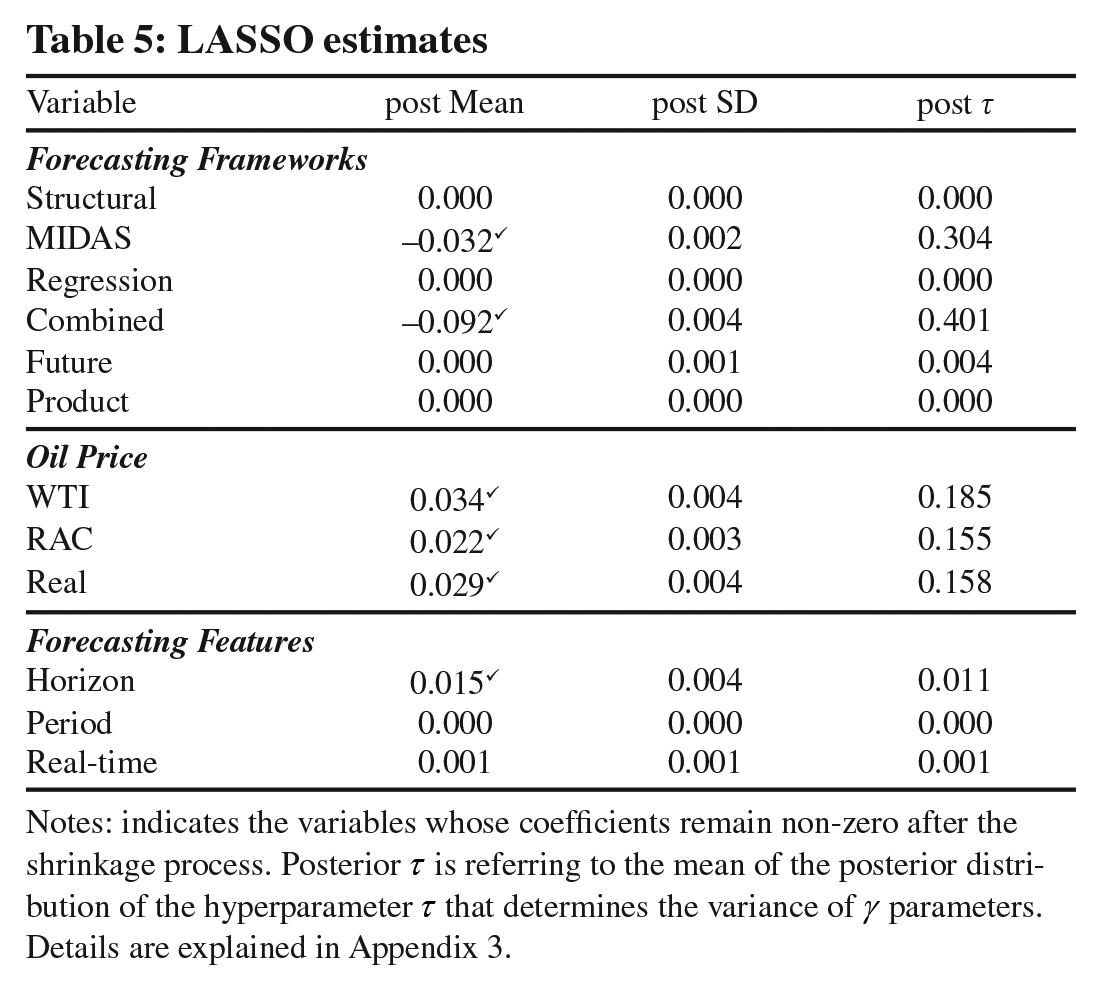
Notes: indicates the variables whose coefficients remain non-zero after the shrinkage process. Posterior τ is referring to the mean of the posterior distribution of the hyperparameter τ that determines the variance of γ parameters. Details are explained in Appendix 3.
5. Conclusions
The aim of this paper is to provide a comprehensive assessment of the factors that contribute to improve oil price forecasts, by conducting a meta-analysis. The period of time of the paper stems from the fact that since the early 2000’s and the regime change in oil price fluctuations, there is an ever-increasing interest in oil price forecasts. However, despite the numerous efforts, there is no empirical evidence to summarise the different findings from different studies and identify the key factors that contribute to the accuracy of such forecasts. Thus, our quantitative survey on forecasting characteristics contributes to the practice of oil price forecasting. To the best of our knowledge, this is the first study that attempts to detect the factors that play an important role in oil price prediction by focusing on the relative root mean squared error (RRMSE) metric. We employ a Bayesian Model Averaging (BMA) method which is used to combine information from various forecasting characteristics in order to produce an accurate predictive performance.
Using a dataset that covers a large range of different forecasting frameworks, datasets, horizons and oil price benchmarks, we attempt to identify the most importance drivers of the forecasting accuracy. Based on the RRMSE metric, we summarise our findings as follows. First, the choice of the forecasting framework plays an important role. MIDAS and combined forecasts provide systematically better predictions than other forecasting strategies. Second, the price benchmark is also an important factor. Our evidence indicates that the forecasting ability is improved when the Brent price is used, whereas the opposite holds when the WTI or the RAC are employed. Finally, shorter forecasting horizons, as well as the use of real prices generate forecasts of greater accuracy. By contrast, the forecasting period and the real-time datasets are not important factors of the forecasting ability. Our findings remain unchanged under a set of different robustness tests.
The results of the present study have important implications for various stakeholders. Forecasting characteristics contain information that help financial market participants (traders and energy investors), policy makers, multinational corporations, and the oil industry, among other stakeholders, to improve oil price forecasts. Considering financial market participants, accurate oil price forecasts convey information regarding future oil price returns. Given that oil is also regarded as a financial asset, energy investors and traders should pay attention to superior forecasts in order to make better decisions regarding allocation of funds or portfolio risk estimation, among others. Similarly, policy makers benefit from accurate oil price forecasts in order to develop macroeconomic policies that help to prevent economic recessions, tackle inflationary pressures or boost industrial production. Furthermore, accurate oil price forecasts offer important information to the oil industry companies in terms of their financing, investment and managerial decisions related to their capital expenditure, market share, earnings expectations and stock price performance, among others. Additionally, multinational corporations are significantly benefited by accurate oil price forecasts and thus corporate decision making managers could be able to create strategies to mitigate the impact of higher oil price for example, in order to reduce the effect of rising costs on production.
For the purposes of the current meta-analysis, we make use of the RRMSE which is the most frequently used metric of forecasting performance. Therefore, a potential venue for future research in this field of study could be the consideration of alternative forecasting accuracy metrics, such as the directional accuracy. The extent to which alternative measures behave differently within the context of this type of empirical analysis may trigger attempts for more accurate oil price forecasts and thus such attempts are expected to intensify in the future.
Supplemental Material
sj-pdf-1-enj-10.5547_01956574.45.2.mfil – Supplemental material for Evaluating Oil Price Forecasts: A Meta-analysis
Supplemental material, sj-pdf-1-enj-10.5547_01956574.45.2.mfil for Evaluating Oil Price Forecasts: A Meta-analysis by Michail Filippidis, George Filis and Georgios Magkonis in The Energy Journal
Footnotes
Appendices
Acknowledgements
We would like to thank the handling editor (Prof. David C. Broadstock) and three anonymous referees for their constructive comments on a previous version of the paper. In addition, we would also like to thank the participants of the 2022 International Symposium on Environmental and Energy Finance Issues (ISEFI) Conference and the 2022 International Research Meeting in Business and Management (IRMBAM), for their helpful suggestions. The usual disclaimer applies.
2.
![]() argue that the conventional random walk forecast is uninformative in terms of forecast accuracy and should not be used for forecasting comparisons of aggregated data. However, our decision to employ the random walk based on the fact that this benchmark is widely used in the literature on forecasting oil prices.
argue that the conventional random walk forecast is uninformative in terms of forecast accuracy and should not be used for forecasting comparisons of aggregated data. However, our decision to employ the random walk based on the fact that this benchmark is widely used in the literature on forecasting oil prices.
3.
For simplicity, we use the term RRMSE to the remainder of the paper.
5.
The VIF statistics do not support the existence of multicollinearity. The values are available upon request.
6.
To avoid unnecessary confusion, we will use ψ instead of
7.
This result remains the same when we use a dummy variable for measuring the horizon assigning 1 for shorter forecasts (up to 12 months) and 0 otherwise.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.