
Abstract
Covariance Based – Structural Equation Modelling (CB-SEM) is often used to investigate moderation and latent interaction effects. This study illustrates and compares the application of constrained, unconstrained and orthogonalized CB-SEM approaches to latent variable interaction analysis using AMOS. Although all three techniques provided similar parameter estimates, the orthogonalized approach provided reduced standard errors resulting in identifying a significant latent interaction, suggesting the orthogonalized approach may be better suited for exploratory research.
The illustrated example demonstrates three CB-SEM techniques, and the simplicity of the three approaches to test for interaction effects. The three approaches can be comfortably implemented in available software programs. Guidelines and recommendations for the use of the three approaches are identified with a step-wise process of assessing the latent interaction effect in CB-SEM.
As far as we are aware this is the first investigation comparing and recommending specific CB-SEM latent variable moderation analysis techniques in marketing research.
Keywords
Introduction
To estimate complex heterogeneity effects, Covariance Based – Structural Equation Modelling (CB-SEM) is often used to investigate moderation and latent interaction effects (e.g., Nunkoo, Ramkissoon, & Gursoy, 2013). Moderation analysis generally takes the form of multi-group analysis for categorical data, (e.g., gender) or creating and analysing subgroups from continuous moderator variables (e.g., level of knowledge) (Baron & Kenny, 1986; Nuzzo, 2019). When the moderating variable is continuous, the assessment and interpretation of moderation using multi-group analysis may be undermined by problems which researchers may not recognize or understand (Dwyer, Gill, & Seetaram, 2012; Okazaki, Li, & Hirose, 2009). Many researchers using CB-SEM follow a common (yet suboptimal) practice of artificially categorizing continuous moderating variables into subgroups, such as ‘‘high’’ and ‘‘low’’ based on whether the cases fall above or below the median of the moderators (Luo, Song, Marnburg, & Øgaard, 2014; Tang & Jang, 2014). This practice results in a loss of information; compromises the interpretation and reduces the variance of the moderators causing the estimated moderating effects to be downward biased and inevitably results in Type I and Type II errors (Aguinis, Edwards, & Bradley, 2017; Dawson, 2014; MacCallum, Zhang, Preacher, & Rucker, 2002). However, when a categorical variable is used as a moderator, then multi-group analysis would be appropriate.
As an alternative, structural equation modelling (SEM) measures latent constructs at the observation level (measurement model), simultaneously testing hypothesized relationships between constructs within a single framework (structural model) and identifies measurement error when estimating the moderator effect (Dwyer et al., 2012; Hair, Black, Babin, & Andersen, 2010; Hair, Sarstedt, Ringle, & Mena, 2012). This approach multiplies the indicators of the latent variables (independent variables) to create moderator variable indicators which measures the interaction term in the path model (Kenny & Judd, 1984). This provides a strong basis for evaluating the underlying factor structure relating multiple indicators to their factors, controlling measurement error, increasing statistical power, testing the implicit factor structure used to create scale scores, and ultimately providing a more defensible interpretation of the interaction effects (Marsh, Wen, & Hau, 2006).
There are three well-documented approaches to latent interaction modelling in CB-SEM, the constrained approach (Algina & Moulder, 2001; Jöreskog & Yang, 1996), the unconstrained approach (Marsh, Hau, & Wen, 2004; Marsh et al., 2006), and the orthogonalized approach (Little, Bovaird, & Widaman, 2006).
Although other studies compare and discuss advantages and disadvantages of different approaches to latent interactions, the purpose and unique contribution of this paper is: 1) Illustrate and compare the application of the constrained, unconstrained and orthogonalized approaches to CB-SEM moderation analysis techniques in recent marketing literature, 2) demonstrate the step by step process to undertake the different approaches, and 3) provide clear guidelines and recommendations for the use and analysis of latent interaction effects. A marketing study using the Theory Planned Behavior (TPB) is used as an illustrative example comparing the constrained, unconstrained and orthogonalized approaches. The unique contribution of the paper are the recommendations and guidelines for the selection of appropriate estimation methods included in the final section to help researchers identify, based on their research goals, an appropriate CB-SEM latent interaction analysis approach.
Background and review of estimation methods for latent variable interaction
Systematic literature review, sources and search strategy
To examine how SEM methods have been applied to research methodology in marketing a systematic literature review covering the years 2009 to 2019 was conducted using the Web of Science (WoS) data bases.
The Preferred Reporting Items for Systematic Reviews (PRISMA) guidelines were used to identify, select, and critically appraise the relevant research search (see Appendix A) (Moher, Liberati, Tetzlaff, & Altman, 2009). The review was restricted to Business research articles published in English, with non-academic publications (i.e., conference papers, book chapters, and book series) excluded. The search criteria included the terms; factor-based SEM OR factor based SEM OR covariance-based SEM OR covariance based SEM OR SEM OR CB-SEM OR latent interaction approach OR latent interaction OR moderator.
Systematic literature review results
The initial search extracted 2,563 articles from the WoS databases. From this initial extraction 1,817 non-marketing articles were excluded. The remaining 746 articles were examined to ensure they met the criteria (reported using CB-SEM methodology). As a result, 394 articles were excluded for not using CB-SEM, and 352 CB-SEM articles remained for analysis. Of the 352 articles 183 articles were considered tutorial/guideline articles that did not disclose details of moderator assessment and were excluded. The list of journals from which the 169 remaining articles were extracted and used in the analysis are presented in Appendix B.
Despite being an established statistical technique in marketing studies, the execution of latent interaction analysis using CB-SEM is rarely reported by researchers. An analysis of the 169 marketing articles reported using CB-SEM identified 82 articles using multi-group analysis, 14 using CB-SEM and Hayes PROCESS and 73 reporting latent interactions techniques. Twenty-two articles reporting a latent interaction approach were not explained in enough detail to establish the specific analysis technique, implying that a mean-centred computed latent variable score was not considered against an indicator level mean centre approach for the interaction term. Fifty-one articles mentioned the details of the latent interaction approach, the majority reported using the constrained (n = 26) approach, 23 using the unconstrained approach and 2 reported using the orthogonal approach.
Background and review of latent variable interaction estimation methods
Utilizing the computed latent variable interaction term in CB-SEM may result in factor indeterminacy (Grice, 2001). Factor indeterminacy produces more than one solution that is mathematically sound without providing a means to determine which of the several solutions corresponds to the hypothesis being tested. Therefore, using an interaction term in a computed latent variable score in CB-SEM tends to increase the influence of factor indeterminacy, or random variance, weakening the relationship with the external criterion and explanatory accuracy (Diamantopoulos, Sarstedt, Fuchs, Wilczynski, & Kaiser, 2012). This is not a concern if the mean-centre approach is taken at the indicator level of the interaction term and used in the parameter estimation of the structural relationships.
The SEM approach provides superior results when investigating latent variable interaction with continuous measured moderators, regardless of differences in procedures or techniques (Arminger & Muthén, 1998; Coenders, Lubbers, Scheepers, & Verkuyten, 2008; Klein & Moosbrugger, 2000; Yang-Wallentin & Jöreskog, 2001). Notwithstanding the superiority of the latent interaction approach when using CB-SEM, the number of articles published in marketing journals using this approach suggest that researchers would benefit from a review of the constrained, unconstrained, and orthogonalized approaches.
Although the constrained approach is the most widely used method for latent variable interactions analysis it involves nonlinear constraint requirements used to specify the factor loadings and variances associated with the interaction term (Algina & Moulder, 2001). In particular, some parameters are constrained to have fixed constant values (e.g., 0), whereas others are freely estimated in the SEM analysis. Constraints determine which parameters of the measurement model of the product latent variable (e.g., loadings of the indicators and error (co)variances) are not freely estimated but expressed in terms of the parameters of the measurement models of the first-order effect variables. Importantly, these constraints are typically based on the assumption that latent variables must achieve normal distribution.
Hayduk (1987) implemented Kenny and Judd's (1984) suggested classical constrained technique using LISREL, but the complicated model specification was ambiguous and impractical to use by most researchers. A decade later, Jöreskog and Yang (1996) provided a general model for the specification of constraints, which relied on uncentered indicators – indicators were used in their original format and the mean of the latent interaction were not centred at zero. The inclusion of the constant intercept term in their model considered additional derived nonlinear constraints under the assumption of multivariate normality. Specifically, these constraints are;
Factor loadings of the product indicators on latent interaction term, for example; λx1x4 = λx1λx4 Mean of latent interaction term, for example; E (ξ1ξ2) = Cov (ξ1ξ2) Variance of latent interaction term, for example; Var (ξ1ξ2) = Var (ξ1)Var (ξ2) + Cov2(ξ1, ξ2) Covariance of individual latent factors with latent interaction term, for example; Cov (ξ1, ξ1ξ2) = Cov (ξ2, ξ1ξ2) = 0 Variance of the unique factors of the product indicators, for example;
Zero covariances between the unique factors of exogenous indicators and those of product indicators (assuming zero covariances among the unique factors of exogenous indicators) Covariances between unique factors of product indicators that share the same exogenous indicators (assuming zero covariances among the unique factors of exogenous indicators), for example;
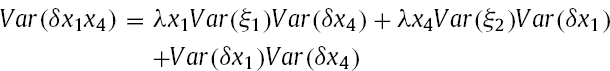
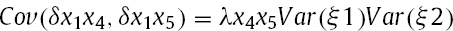
Algina and Moulder (2001) revised and simplified the Jöreskog-Yang model by mean-centring the indicators, which allows the researchers to ignore the intercepts and latent means (at least of the first-order effect variables) to improve the interpretability of the estimates. The coefficient value for a mean-centred predictor would be more practically meaningful than the same coefficient for the same predictor with an arbitrary zero point (i.e., interpreting the relative size of change in Y for a one-unit m change in X at a given level of Z may be easier if the zero point of Z is the average value of Z rather than an arbitrary and non-meaningful scale value). The interpretation may also be improved by plotting the predicted relation between X and Y over a range of plausible z scores (e.g., Aiken & West, 1991; Cohen, Cohen, West, & Aikken, 2003; Mossholder, Kemery, & Bedeian, 1990). In addition, the use of mean-centring eases the ill conditioning of the correlation matrix among the predictors that results from nonessential multicollinearity among the first-order predictors (ξ1 and ξ2) and their latent product variable interaction term (ξ1*ξ2) (Marquardt, 1980). Notably, mean-centring helps to avoid the instability of regression path estimates by producing stable and robust standard error (SE) results and overcomes the issue of interpreting non-meaningful zero-points within the range of the variables (Dalal & Zickar, 2012).
The Algina and Moulder (2001) approach yields better convergence rates, less bias, lower Type I error rates, and greater power. Fig. 1 depicts a constrained approach interaction model with two first-order effect variables (ξ1 and ξ2) and a latent product variable (ξ1*ξ2). The list of constraints are shown in Fig. 1 so that readers can compare the pioneering studies by Algina and Moulder (2001), Kenny and Judd (1984), and Jöreskog and Yang (1996) against the two straightforward approaches proposed in the current study.
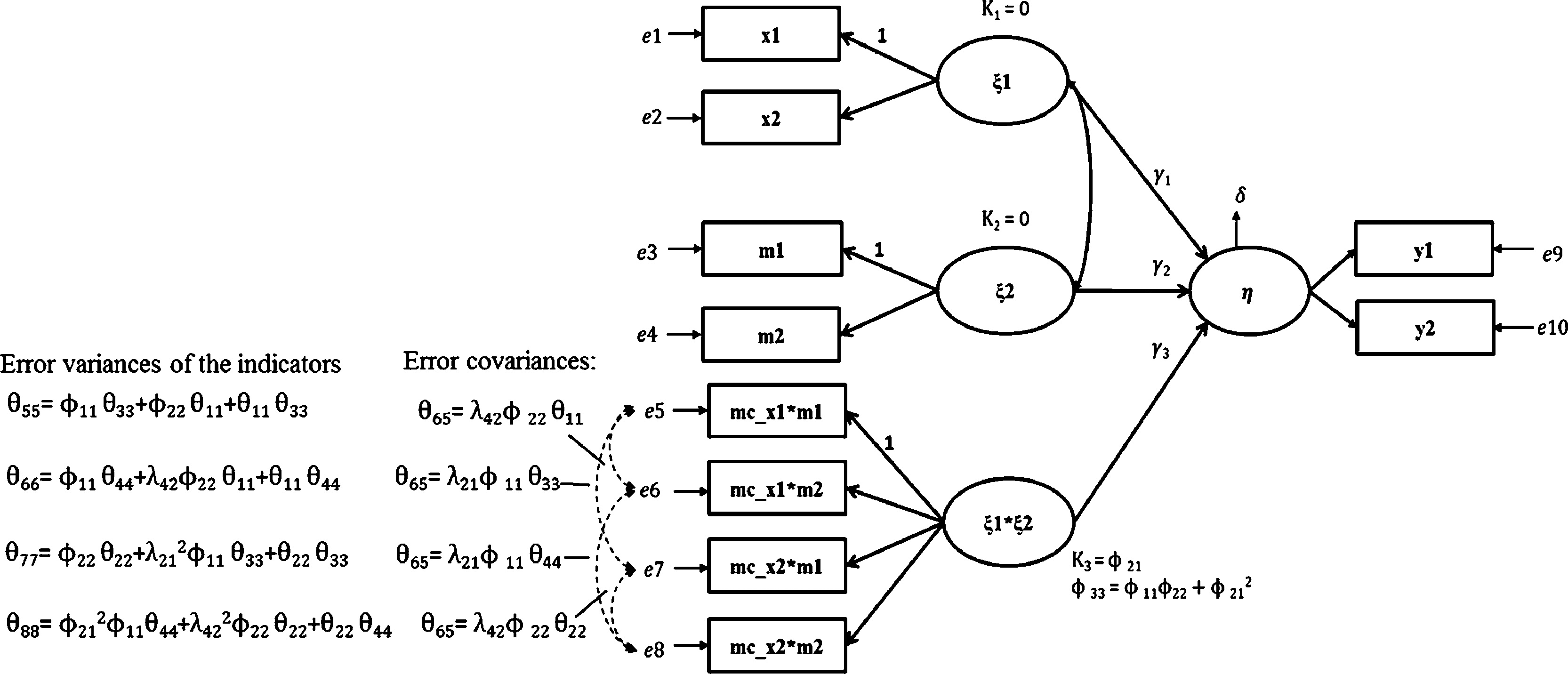
Constraints implied by the constrained approach.
The revised Jöreskog and Yang (1996) approach has not captured the attention of researchers, since specifying and implementing these constraints requires multivariate normal distribution, a situation rarely achieved in behavioural studies. Even when the first-order effect variables (ξ1 and ξ2) are normally distributed, the product of two normally distributed variables (ξ1*ξ2) produce a leptokurtic distribution (Hayes, 2014; Marsh, Hau, et al., 2004).
Consequently, Marsh, et al., (2004; 2007) proposed an Unconstrained Approach omitting complicated constraints, relying on centred indicator variables and the product of centred indicators to define the latent interaction term indicators.
The latent first-order effect variable means are fixed to zero (e.g., κ1= κ2= 0) and the latent product variable mean is equal to the covariance of the two first-order effect variables (e.g., κ3 = ϕ21), see Fig. 1. This constraint is not be necessary if the double-mean-centring strategy is used in the unconstrained approach (Lin, Wen, Marsh, & Lin, 2010). That is, all the observed indicators are mean-centred before creating the product terms, and the product terms are then mean-centred before fitting the model with the latent interaction factor. The critical advantage of this unconstrained approach compared to the constrained approach is the ease of use for applied researchers, the estimation is slightly less biased, and the solutions are more likely to converge when the indicators are normally distributed and the sample size is small (Marsh et al., 2007). Therefore, the unconstrained approach is fundamentally different and impressively simple to implement compared to the original Kenny and Judd (1984) approach.
Although the unconstrained approach has substantial advantages over the constrained approach, it still requires the analyses to be based on a mean-centred structure, thus making the analyses understandably tedious for applied researchers. This approach contains some degree of correlation between the interaction term and the original first-order variables which can influence the partial path coefficients result. In this case collinearity in the path model may exist, which will inflate the standard errors or bias the path coefficient estimates. This issue prompted Little et al. (2006) to employ the orthogonalized approach (also known as the residual centring approach) to measure the latent interaction effect (Lance, 1988). The orthogonalized approach avoids statistical dependency between first-order effect indicators and the latent product variable by using residuals to form indicators for the product variable. This approach reduces or eliminates correlations among first-order (ξ1 and ξ2) and interaction (product) factors (ξ1*ξ2), and associated multicollinearity.
The orthogonalized approach consists of a two-step procedure. In the first step, two respective uncentered indicators of the first-order effect variables (ξ1 and ξ2) are multiplied and the resulting product is then regressed on all first order effect indicators (see Fig. 1), creating product indicators: x1*m1, x1*m2, x2*m1, and x2*m2. Next, each product indicator is regressed on all indicators of the exogenous variable and the moderator variable. For the example in Fig. 1, the following four regression models are established and estimated:
x1*m1 =b1,11*x1+b2,11*x2+b3,11*m1+b4,11*m2+e11 x1*m2=b1,12*x1+b2,12*x2+b3,12*m1+b4,12*m2+e12 x2*m1 =b1,21*x1+b2,21*x2+b3,21*m1+b4,21*m2+e13 x2*m2 =b1,22*x1+b2,22*x2+b3,22*m1+b4,22*m2+e14
In the second step, the residuals of these regression analyses are saved in the data set and used as indicators of the product variable in the latent interaction model. The advantage of this approach is the ease of implementation. The residuals can be computed using simple regression analyses and conventional statistical software packages, such as SPSS or Stata. Importantly, the variance of this orthogonalized interaction term contains unique variance that fully represents the interaction effect, independent of the first-order effect variance (as well as general error) (Little et al., 2006). Thus, the indicators of the interaction term do not share any variance with any of the indicators of the exogenous variable or the moderator variable. The interaction term is orthogonal to the other two constructs (ξ1 and ξ2), precluding any collinearity issues among the constructs. Another consequence of orthogonality is that the path coefficient estimates in the model, without the interaction term, are identical to those with the interaction term. This approach avoids changes in the standardized beta coefficient results when including the interaction variable. Hence, the Little et al. (2006) approach has a correlated error structure that provides unbiased estimates, and indirectly increases and facilitates the interpretability of the moderation analysis.
Both the unconstrained approach and the orthogonalized approach are valuable alternatives to the traditional constrained approaches. Simulation studies have shown that the orthogonalized approach performs well, similar to a mean-centring approach when the unconstrained approach is used, and demonstrates reasonable model fit and standard errors (Little et al., 2006; Steinmetz, Davidov, & Schmidt, 2011). The next section demonstrates and assesses the approaches using data collected from a marketing study.
The Theory of Planned Behavior (TPB) has been successfully used to explain human motivation, behaviour and intention in various contexts and domains (Ajzen & Fishbein, 1980, 2008; Fishbein & Ajzen, 2010) including predicting dishonest actions (Beck & Ajzen, 1991), intention to adopt permission-based location-aware mobile advertising (Richard & Meuli, 2013), adoption of internet banking (Shih & Fang, 2004), sports involvement (Armitage & Conner, 2001), as well as Internet and online purchasing actions (George, 2004). Three predictors of behavioural intention which form the core of TPB include; attitude towards the behaviour (ATB), subjective norms (SN), and perceived behavioural control (PBC) (Sparks & Pan, 2009). Attitude towards a behaviour is an individual's overall favourable evaluation of a particular behaviour; subjective norm are beliefs accompanying the behaviour based on pressures from society, friends or families, perceived behavioural control is the individual's perception of the ease or difficulty of performing the specific task (Conner, Warren, Close, & Sparks, 1999).
TPB postulates that the stronger the ATB, SN and PBC, the more likely consumers exhibit positive intention (Ajzen, 1991; Jalilvand, Samiei, Dini, & Yaghoubi Manzari, 2012; Lee, 2009). Despite the growing body of research on the positive association of ATB, SN, and PBC on intention, key questions remain as to which specific predictor enhance or diminish behavioural intention when a moderator is included in the behaviour intention model (Kidwell & Jewell, 2007). Oullette and Wood (1998) found that although TPB predicts behavioural intention, when past behaviour is added, variance in behavioural intention increases. According to Armitage and Conner's (2001) meta-analysis, SN is a weak predictor, and produces inconsistent behavioural intentions results. However, when type of measure (e.g., self-report or objective) is included as a moderator, SN demonstrated heterogeneity and inconsistent results explaining intention behaviour, suggesting SN requires further empirical investigation. The current study focuses on moderation effects between SN and behaviour intention.
Tourism marketing studies have consistently found that ATB and PBC are determinants of travelling or re-visit intention (Bigné, Sanz, Ruiz, & Aldás, 2010; Morosan & Jeong, 2006, 2008). However, empirical evidence for the influence of SN is contradictory. Li and Buhalis (2006) found that referents’ opinions (one form of SN) does not have an impact on travellers’ intention to visit, however past experience may act as a moderator (Amaro & Duarte, 2013). Previous experience travelling to a specific place increases one's intention to revisit (Mazursky, 1989; Perdue, 1985). Sönmez and Graefe (1998) found that once an individual visited a destination, they perceived that destination as a safe destination, and were more willing to visit again.
Past experience (PE) reduces risk of an unsatisfactory experience and is a good predictor of travellers’ intention to choose a destination (Gitelson & Crompton, 1984). The inclusion of PE in a model should increase the predictive capability of the original TPB (Kidwell & Jewell, 2007; Lam & Hsu, 2006; Smith et al., 2008). PE will likely influence people's deliberation and heuristic information processing with respect to SN and behavioural intention (Wood, Tam, & Witt, 2005). For instance, travellers with little travel experience may be more motivated to (re)visit a specific destination because they feel safe, want to investigate new aspects of the destination, or enrich the destination experience. In contrast, those with extensive travel experience may be less motivated to (re)visit a destination because based on their past experiences (and heuristics) there is less to uncover or experience at the destination. The inclusion of PE into TPB theory suggests SN will have a strong positive effect on behavioural intention when PE is low. Alternatively, when PE is high, SN may display a strong negative effect on behavioural intention. Therefore, the purpose of study one is to test the predicted moderating effects of PE on SN and Intention to Revisit (ITR). The proposed model and interaction (SN*PE) are displayed in Fig. 2.
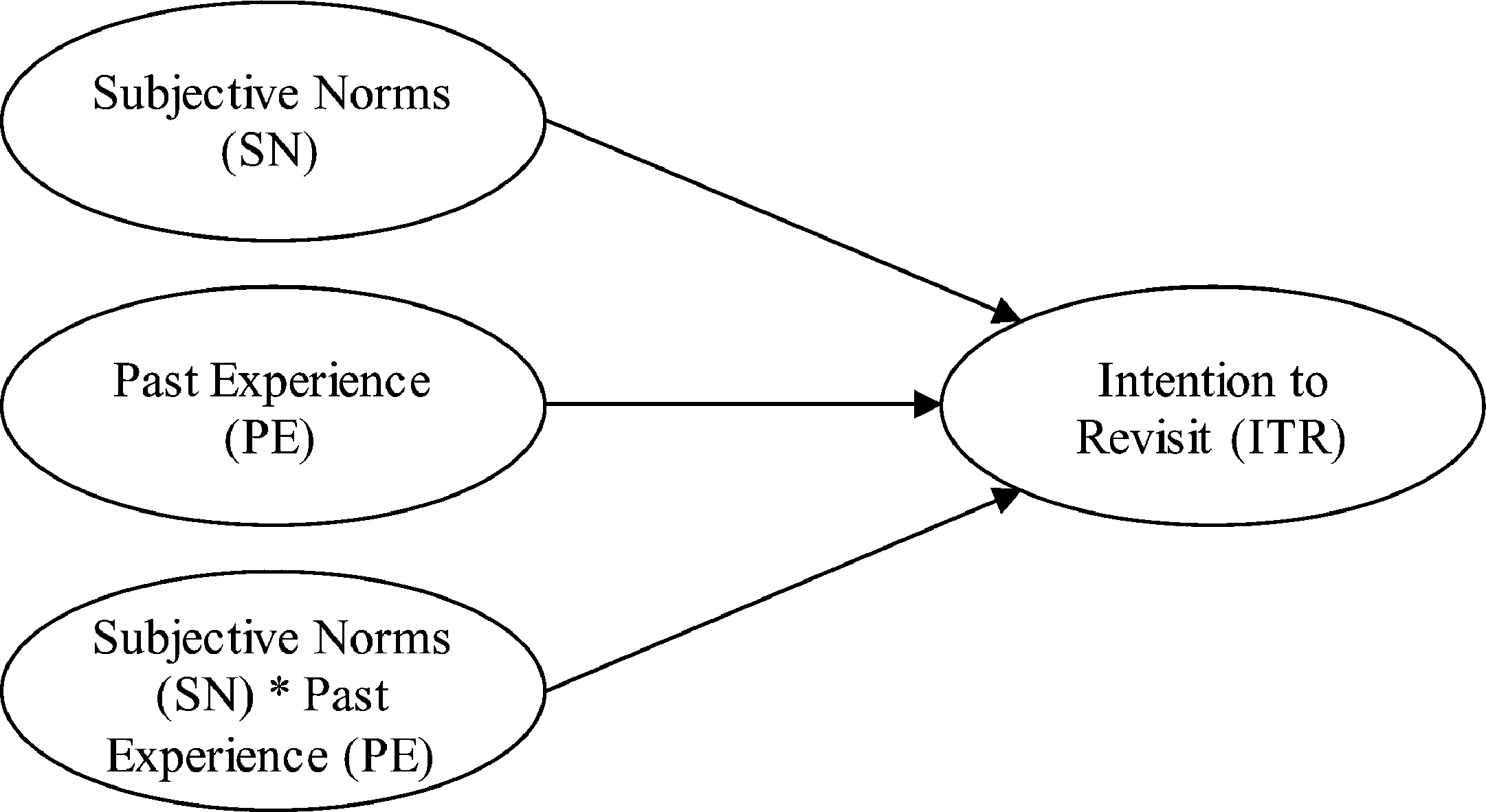
Research model: Direct and Interaction Effects.
The study collected data through an intercept survey from 350 international tourists who visited Malaysia within the last year. After cleaning the data, the sample final size was 338; comprised of 205 females (60.7%) and 133 males, between 18 and 25 years of age (see Appendix D for additional detail). Twelve observations were discarded due to non-response and straight-lining (e.g., giving identical answers to items in a response scale) (Hair, Hult, Ringle, & Sarstedt, 2017; Kim, Dykema, Stevenson, Black, & Moberg, 2019).
Measurement
Each SN, PE, and ITR latent variable was measured with three indicators, adapted from previous studies (e.g., Huang & Hsu, 2009; Lam & Hsu, 2006; Mokhtaran, Fakharyan, Jalilvand, & Mohebi, 2015). The relative simplicity of the model adequately illustrates and demonstrate the three latent interaction analysis approaches. Regardless of the number of items used to measure the constructs in a model, the same procedures apply.
Table 1 reports acceptable result of reliability (both Cronbach's Alpha and Composite Reliability), construct convergent, and discriminant validity (Fornell & Larcker, 1981). In all cases the respondents’ level of agreement or disagreement was measured using 7-point Likert-type scales, anchored with 1 = Strongly Disagree to 7 = Strongly Agree.
Item loadings, Cronbach's Alpha (CA), Composite Reliability (CR), Average Variance Explained (AVE), and Discriminant Validity.

Item loadings, Cronbach's Alpha (CA), Composite Reliability (CR), Average Variance Explained (AVE), and Discriminant Validity.
Note: Loadings meet or exceed the minimum criteria (0.60), CA and CR exceed the minimum criteria (0.70), AVE exceed the minimum criteria (0.50) (Hair et al., 2010). Numbers on diagonal are the square root of the AVEs and off-diagonal numbers are inter-constructs correlations. All construct intercorrelations are less than the corresponding square root of the AVEs.
Subjective Norm (SN): The three item scale was adapted from Lam and Hsu (2006) to measure tourists SN.
Past Experience (PE): PE was measured using three items adapted from Huang and Hsu (2009).
Intention to Revisit (ITR): Mokhtaran et al.'s (2015) three item scale was used to measure tourists’ intention to revisit Malaysia.
Constrained approach
The constrained approach was conducted based on the Algina and Moulder (2001) reformulation of the Jöreskog and Yang (1996) approach described earlier. Centred items were used to calculate the SN and PE product indicators. Since there were three items for both SN and PE, the latent interaction variable of SN_PE ended up with nine (three times three) product indicators. The item measuring intention was kept in its original scale. The SN and PE latent variables means were fixed to zero, and the mean of the SN_PE latent product term was constrained to be equal to the covariance of the latent variables SN and PE. In addition, the exogenous variables (SN, PE, and SN_PE) were allowed to correlate. The intercepts of the exogenous variable indicators were fixed to zero, but the intercept of the ITR items were estimated. Eighteen error covariances were estimated between product indicators which have a common component:
the error of ‘MC_SN1_PE1’ covaried with the error of ‘MC_SN1_PE2’, the error of ‘MC_SN1_PE2’ covaried with the error of ‘MC_SN1_PE3’, the error of ‘MC_SN1_PE1’ covaried with the error of ‘MC_SN1_PE3’, the error of ‘MC_SN2_PE1’ covaried with the error of ‘MC_SN2_PE2’, the error of ‘MC_SN2_PE2’ covaried with the error of ‘MC_SN2_PE3’, the error of ‘MC_SN2_PE1’ covaried with the error of ‘MC_SN2_PE3’, the error of ‘MC_SN3_PE1’ covaried with the error of ‘MC_SN3_PE2’, the error of ‘MC_SN3_PE2’ covaried with the error of ‘MC_SN3_PE3’, the error of ‘MC_SN3_PE1’ covaried with the error of ‘MC_SN3_PE3’, the error of ‘MC_SN1_PE1’ covaried with the error of ‘MC_SN2_PE1’, the error of ‘MC_SN2_PE1’ covaried with the error of ‘MC_SN3_PE1’, the error of ‘MC_SN1_PE1’ covaried with the error of ‘MC_SN3_PE1’, the error of ‘MC_SN1_PE2’ covaried with the error of ‘MC_SN2_PE2’, the error of ‘MC_SN2_PE2’ covaried with the error of ‘MC_SN3_PE2’, the error of ‘MC_SN1_PE2’ covaried with the error of ‘MC_SN3_PE2’ the error of ‘MC_SN1_PE3’ covaried with the error of ‘MC_SN2_PE3’, the error of ‘MC_SN2_PE3’ covaried with the error of ‘MC_SN3_PE3’, the error of ‘MC_SN1_PE3’ covaried with the error of ‘MC_SN3_PE3’,
Lastly, the non-covariances between error terms were fixed to zero because these product indicators had no common component (Fig. 3).
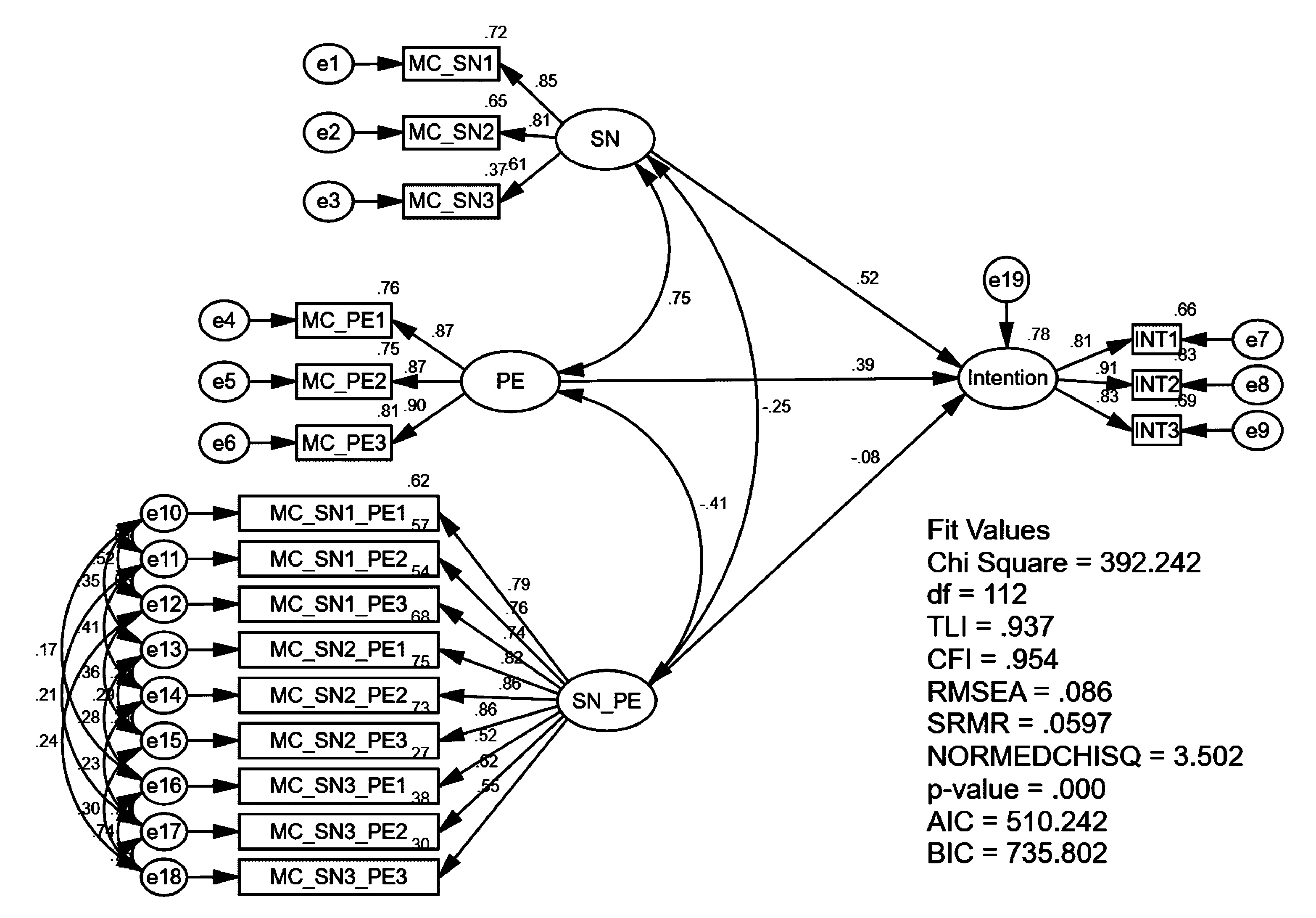
A latent variable interaction using constrained approach.
For the unconstrained approach, the double-mean-centring strategy was used in the unconstrained approach (Lin et al., 2010)(Fig. 4). Since both first-order effects, SN and PE are measured with three indicators each, the latent interaction variable SN_PE consisted of nine (three times three) product indicators. Guided by Lin et al. (2010), the indicators of both SN and PE were first mean-centred before calculating the product indicators. Then, the mean-centred of SN and PE were multiplied together to form the nine product indicators. These nine product indicators of SN_PE were mean-centred again before calculating the latent interaction result. By using the double-mean-centring strategy, the researcher does not need to constrain the mean of the interaction latent factor equal to the covariance between the two main latent factors. Moreover, the items measuring Intention (ITR) were not mean-centred. In addition, the exogenous variables (SN, PE, and SN_PE) were allowed to correlate. Eighteen error covariances were estimated between product indicators which have a common component:
the error of ‘DMC_SN1_PE1’ covaried with the error of ‘DMC_SN1_PE2’, the error of ‘DMC_SN1_PE2’ covaried with the error of ‘DMC_SN1_PE3’, the error of ‘DMC_SN1_PE1’ covaried with the error of ‘DMC_SN1_PE3’, the error of ‘DMC_SN2_PE1’ covaried with the error of ‘DMC_SN2_PE2’, the error of ‘DMC_SN2_PE2’ covaried with the error of ‘DMC_SN2_PE3’, the error of ‘DMC_SN2_PE1’ covaried with the error of ‘DMC_SN2_PE3’, the error of ‘DMC_SN3_PE1’ covaried with the error of ‘DMC_SN3_PE2’, the error of ‘DMC_SN3_PE2’ covaried with the error of ‘DMC_SN3_PE3’, the error of ‘DMC_SN3_PE1’ covaried with the error of ‘DMC_SN3_PE3’, the error of ‘DMC_SN1_PE1’ covaried with the error of ‘DMC_SN2_PE1’, the error of ‘DMC_SN2_PE1’ covaried with the error of ‘DMC_SN3_PE1’, the error of ‘DMC_SN1_PE1’ covaried with the error of ‘DMC_SN3_PE1’, the error of ‘DMC_SN1_PE2’ covaried with the error of ‘DMC_SN2_PE2’, the error of ‘DMC_SN2_PE2’ covaried with the error of ‘DMC_SN3_PE2’, the error of ‘DMC_SN1_PE2’ covaried with the error of ‘DMC_SN3_PE2’ the error of ‘DMC_SN1_PE3’ covaried with the error of ‘DMC_SN2_PE3’, the error of ‘DMC_SN2_PE3’ covaried with the error of ‘DMC_SN3_PE3’, the error of ‘DMC_SN1_PE3’ covaried with the error of ‘DMC_SN3_PE3’,
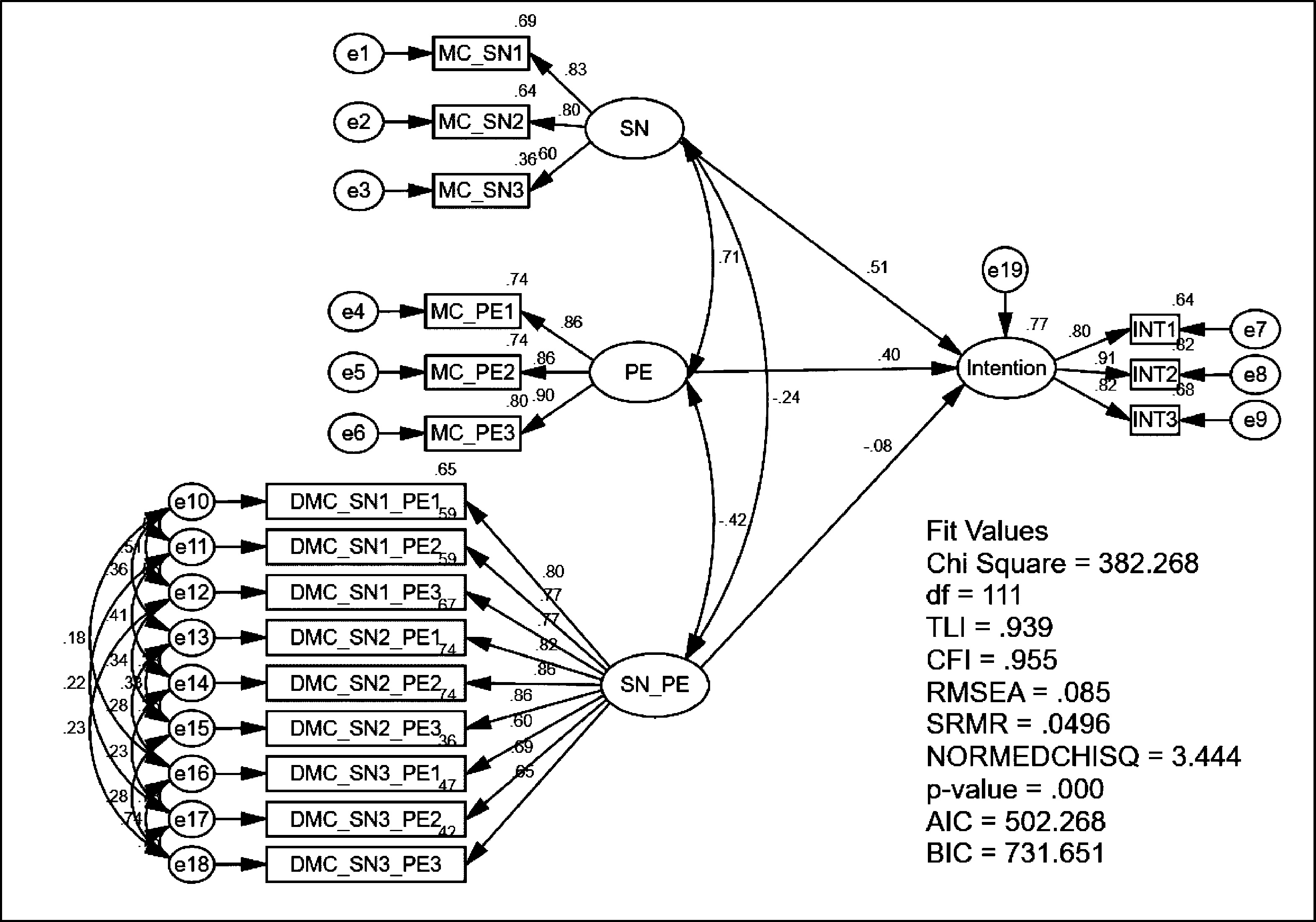
A latent variable interaction using unconstrained approach.
Lastly, the non-covariances between error terms were fixed to zero because these product indicators had no common component (Fig. 4).
The orthogonalized approach was computed in two steps (Little et al., 2006). In step 1 the uncentered SN indicator was multiplied with the uncentered PE indicator. This resulted in nine indicators for the interaction variable (SN_PE): SN1*PE1, SN1*PE2, SN1*PE3, SN2*PE1, SN2*PE2, SN2*PE3, SN3*PE1, SN3*PE2, and SN3*PE3 (see Fig. 5).
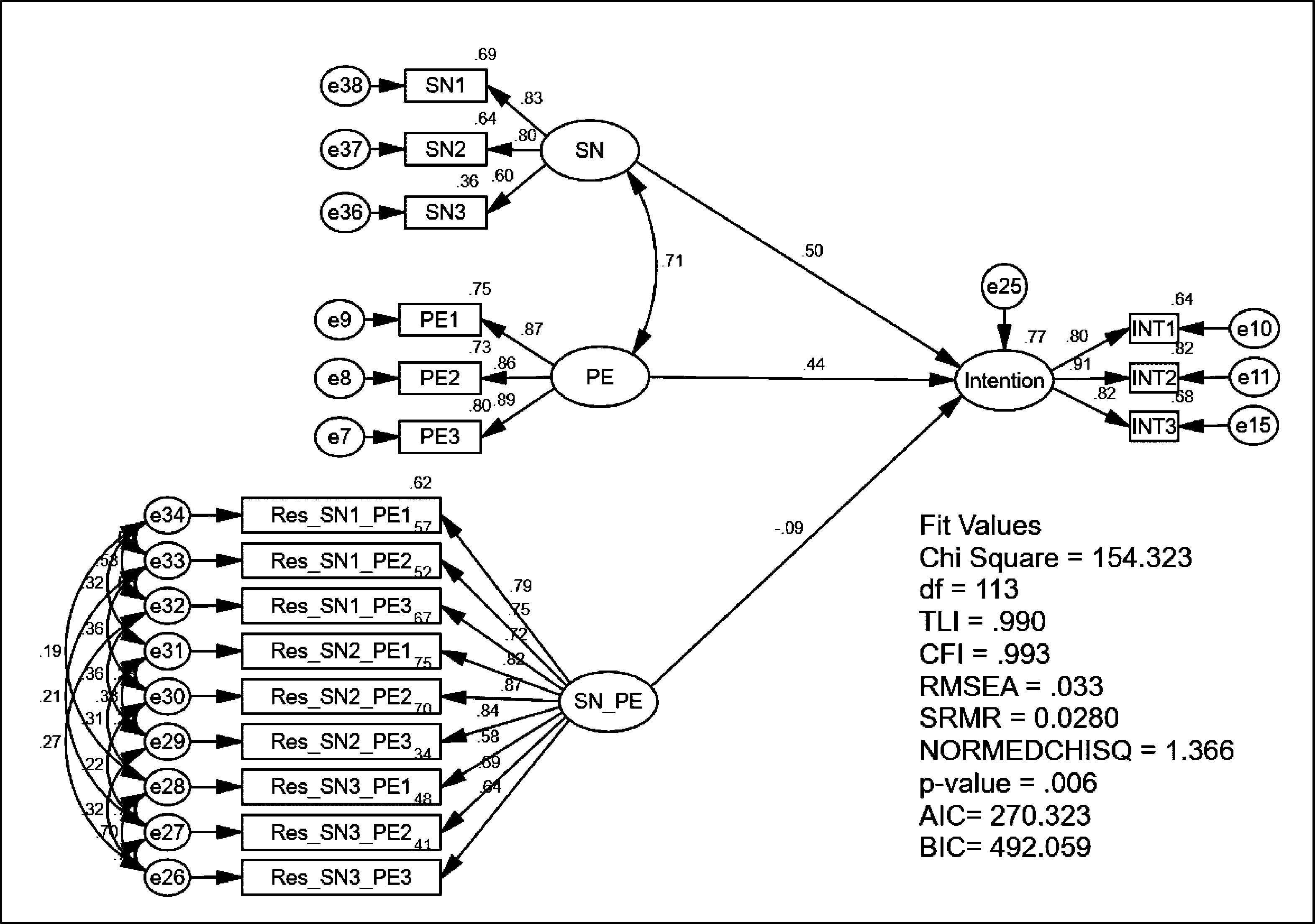
A latent variable interaction using orthogonalized approach.
The nature of interaction plot for all three approaches.
Nine new residual-based indicators were created from the residuals of the regression of all exogenous indicators (e.g., SN1…PE3) on each of the nine new interactive variable indicators 1 . Computing the regression for all nine interactive indicator variables (e.g., SN1*PE1, SN1*PE2,…, SN3*PE3) produces nine regression residuals (Res_ SN1PE1, Res_ SN1PE2,… Res_ SN3PE3). The nine regression residuals were used as measures of the latent variable interaction.
Detailed instructions how to save residuals using SPSS ver 25 can be found in Appendix C.
In the second step, the latent interaction model was specified; three SN items as indicators of the SN variable, three PE items as indicators of the PE variable, and nine regression residuals as indicators of the latent SN_PE variable interaction. For each latent variable (SN, PE, and the latent variable interaction SN_PE), one factor loading was fixed in order to provide a scale for the respective latent variables (i.e., fix the factor loading of the first indicator to 1). Finally, eighteen error covariances between nine pairs of the SN_PE residual product indicators were specified:
error of ‘Res_SN1_PE1’ covaried with the error of ‘Res_SN1_PE2’, error of ‘Res_SN1_PE2’ covaried with the error of ‘Res_SN1_PE3’, error of ‘Res_SN1_PE1’ covaried with the error of ‘Res_SN1_PE3’, error of ‘Res_SN2_PE1’ covaried with the error of ‘Res_SN2_PE2’, error of ‘Res_SN2_PE2’ covaried with the error of ‘Res_SN2_PE3’, error of ‘Res_SN2_PE1’ covaried with the error of ‘Res_SN2_PE3’, error of ‘Res_SN3_PE1’ covaried with the error of ‘Res_SN3_PE2’, error of ‘Res_SN3_PE2’ covaried with the error of ‘Res_SN3_PE3’, error of ‘Res_SN3_PE1’ covaried with the error of ‘Res_SN3_PE3’, error of ‘Res_SN1_PE1’ covaried with the error of ‘Res_SN2_PE1’, error of ‘Res_SN2_PE1’ covaried with the error of ‘Res_SN3_PE1’, error of ‘Res_SN1_PE1’ covaried with the error of ‘Res_SN3_PE1’, error of ‘Res_SN1_PE2’ covaried with the error of ‘Res_SN2_PE2’, error of ‘Res_SN2_PE2’ covaried with the error of ‘Res_SN3_PE2’, error of ‘Res_SN1_PE2’ covaried with the error of ‘Res_SN3_PE2’, error of ‘Res_SN1_PE3’ covaried with the error of ‘Res_SN2_PE3’, error of ‘Res_SN2_PE3’ covaried with the error of ‘Res_SN3_PE3’, error of ‘Res_SN1_PE3’ covaried with the error of ‘Res_SN3_PE3’,
This procedure freed the error correlation of the residual product indicators from the multiplication of the same first-order effect items (SN and PE), thereby ensuring the residual product indicators had no common component with the first-order effect items. By covarying the residuals (see 1-18), the analysis ensures that the indicators of the interaction term do not share any variance with the indicators of the exogenous construct and the moderator, that is, the interaction term is orthogonal to the other two constructs, precluding any collinearity issues among the constructs.
Analyses were conducted using AMOS 25.0 Bootstrap Maximum Likelihood (BML) since the latent product variable is not normally distributed (Arbuckle, 2017). The BML procedure produces appropriate standard errors adjusting for lack of multivariate normality (Byrne, 2016; Hoyle, 2012). As recommended by Hair et al. (2010) 5,000 bootstrap subsamples were performed.
Descriptive statistics
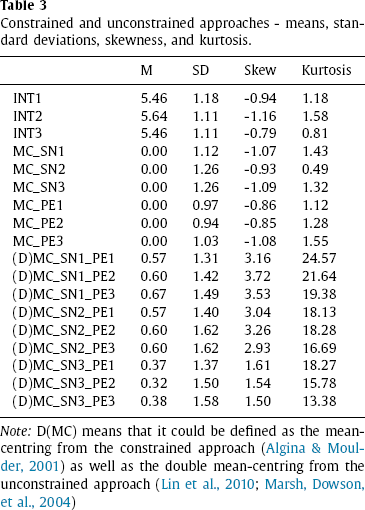
Although the first-order effect indicators (SN and PE) correlate significantly with the latent product indicator terms under the Constrained Approach and Unconstrained Approach (see Table 2), due to mean-centring and double mean-centring, multicollinearity is not an issue (Algina & Moulder, 2001; Lin et al., 2010). The mean-centred indicators for SN and PE and the latent product interaction are shown in Table 3. The latent product indicator data exhibits positive skewness and kurtosis, while SN, PE, and INT (ITR) indicator data exhibit slight skewness, but are within acceptable limits for analysis (Lei & Lomax, 2005) 2 .
The significance correlations occurring in the constrained and unconstrained approaches between the first-order effect indicators and the product indicators result partly from the severe level of nonnormality of the predictor variables in our study. Nonnormality is a typical problem in a model that includes interaction terms and is especially evident when Likert scales are used (Flora & Curran, 2004)
Constrained and unconstrained approaches item correlations.
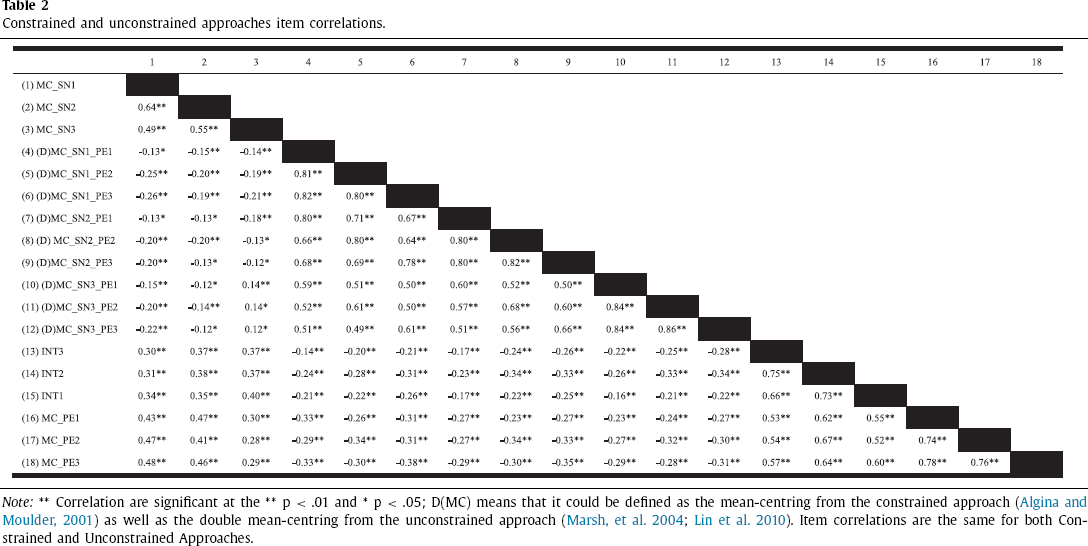
Constrained and unconstrained approaches - means, standard deviations, skewness, and kurtosis.
Note: D(MC) means that it could be defined as the mean-centring from the constrained approach (Algina & Moulder, 2001) as well as the double mean-centring from the unconstrained approach (Lin et al., 2010; Marsh, Dowson, et al., 2004)
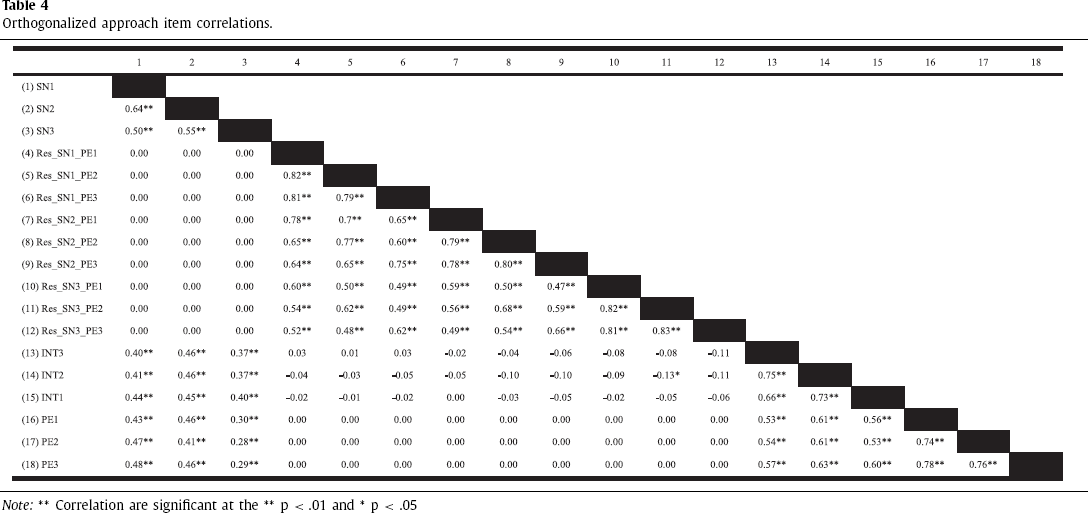
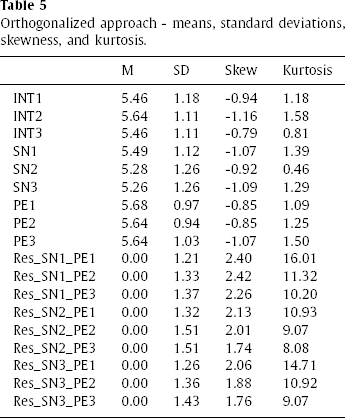
As expected from the Orthogonalized Approach using residual centring (refer to Table 4), the first-order effect indicators (SN and PE) show zero correlation with those of the latent product indicator terms (Little et al., 2006; Steinmetz et al., 2011). Using residuals as indicators for the latent product interaction items, results in residuals being purged from the common variance between the SN and PE first-order effect indicators and the latent product indicators. Table 5 reports the means, standard deviations, skewness, and kurtosis of the residual centring model approach. The latent product indicator data exhibits positive skewness and kurtosis, while SN, PE, and INT (ITR) indicator data exhibit slight skewness but are within acceptable limits.
Orthogonalized approach item correlations.
Orthogonalized approach - means, standard deviations, skewness, and kurtosis.
Reviewing the Goodness of Fit (GoF) criteria (see Table 6), to help identify which model best fits the data, the orthogonalized residual centring approach appears to outperform the constrained and unconstrained approach across the GoF dimensions; NORMEDCHISQ = 1.366 vs 3.444 vs 3.502, TLI = 0.990 vs 0.939 vs 0.937, CFI = 0.993 vs 0.955 vs 0.954, RMSEA = 0.033 vs 0.085 vs 0.086, SRMR = 0.028 vs 0.049 vs 0.060 (Bagozzi & Yi, 2012).
The Akaike's Information Criterion (AIC) and Bayesian Information Criterion (BIC) are information indexes used to determine which model best approximates the data (Vrieze, 2012). When comparing non-nested models, smaller values indicate better models both in terms of model fit, model parsimony and minimizing information loss.
Considering AIC and BIC, the orthogonalized approach (AIC = 270.32, BIC = 492.06) is preferable to the unconstrained approach (AIC = 502.268, BIC = 731.651) and constrained approach (AIC = 510.24, BIC = 735.80). All three approaches result in comparable latent parameter first-order estimates (or main effect model), indicating that ITR is positively and significantly influenced by SN and PE. The interaction effect was negative in all three cases. The orthogonalized approach revealed a better significant SN*PE interaction effect (β = -0.087, t = -2.175, p < 0.05) than the unconstrained approach (β = -0.082, t = -2.050, p < 0.05), while the constrained approach reported a non-significant SN*PE interaction effect (β = -0.075, t = -1.471, p > 0.05), refer to the lower half of Table 6.
Comparison of results from the three latent variable interaction approaches.
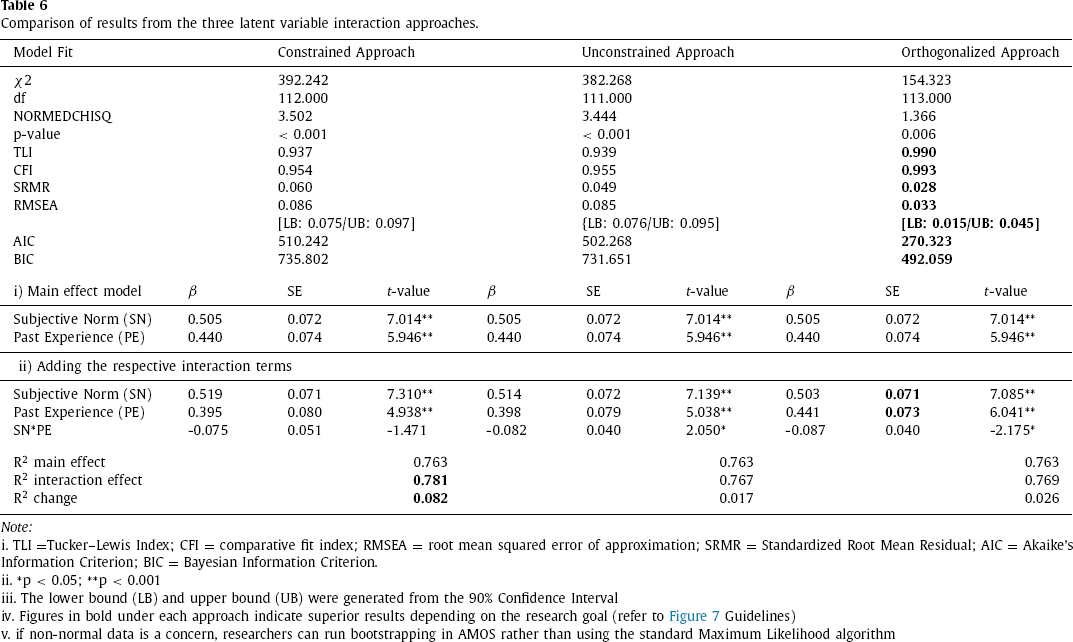
Comparison of results from the three latent variable interaction approaches.
Note: i. TLI =Tucker–Lewis Index; CFI = comparative fit index; RMSEA = root mean squared error of approximation; SRMR = Standardized Root Mean Residual; AIC = Akaike's Information Criterion; BIC = Bayesian Information Criterion.
ii. *p < 0.05; **p < 0.001
iii. The lower bound (LB) and upper bound (UB) were generated from the 90% Confidence Interval
iv. Figures in bold under each approach indicate superior results depending on the research goal (refer to Figure 7 Guidelines)
v. if non-normal data is a concern, researchers can run bootstrapping in AMOS rather than using the standard Maximum Likelihood algorithm
The incremental R2 change between the main effect results and adding the interaction effect for the constrained approach R2 was 0.082; the inclusion of the interaction term increased the explanation power by 8.2%, representing a small effect, f 2 = .089 (Carte & Russell, 2003; Cohen, 1988). For the orthogonalized approach, the incremental R2 was 0.026 indicating an increase in explanation power by 2.6%, which also signifies a small effect, f 2 = .027. On the other hand, the unconstrained approach exhibits the smallest incremental R2 value of .017 indicating an increase in explanatory power by 1.7%, representing a small effect, f 2 = .017. In this study, the small incremental interaction effect from both the unconstrained and orthogonalized approaches can be interpreted as meaningful since the resulting beta change is significant (Chin, Marcolin, & Newsted, 2003).
There are several interesting findings that can be observed from the comparison of approaches. The results indicate that the constrained approach has slightly better explanatory power compared to both the unconstrained and orthogonalized approaches. One of the reasons is that the constrained interaction contains both the unique and shared variance that fully represents the interaction effect. In contrast, the variance of both the unconstrained orthogonalized interaction term contains only the unique variance (from double mean-centring and residual value for interaction), the unique variance of each indicator is counted only once in the variance of the latent interaction effect (the multiplying of pair indicators) while shared variance is counted three times — once within the variance term of the latent interaction effect and twice among the covariances. Therefore, the constrained approach maximizes the explained variance of the endogenous latent variable compared to the unconstrained and orthogonalized approaches because the indicators of the interaction term of the indicators do share variance with indicators of the exogenous latent variable (SN) and the moderator (PE).
The constrained approach exhibits the highest explanatory power of interaction effects. This effect comes at a cost, namely the downward biased estimation of the single or main effects. Similarly, such result also occurs on the unconstrained approach. Table 6 indicates that the path coefficient estimates (β) without the interaction term in the two models are identical. The result of the interaction term was consistent with Little et al. (2006) finding, who found that the orthogonalized approach prevents changes in the standardized beta coefficient result of independent variable when running the interaction. Therefore, correlated error structure provides unbiased estimates, which indirectly increases the interpretability of the overall results of the moderator analysis. The characteristics of the orthogonalized approach facilitates interpretation of the moderating effect strength compared to both constrained and unconstrained approach.
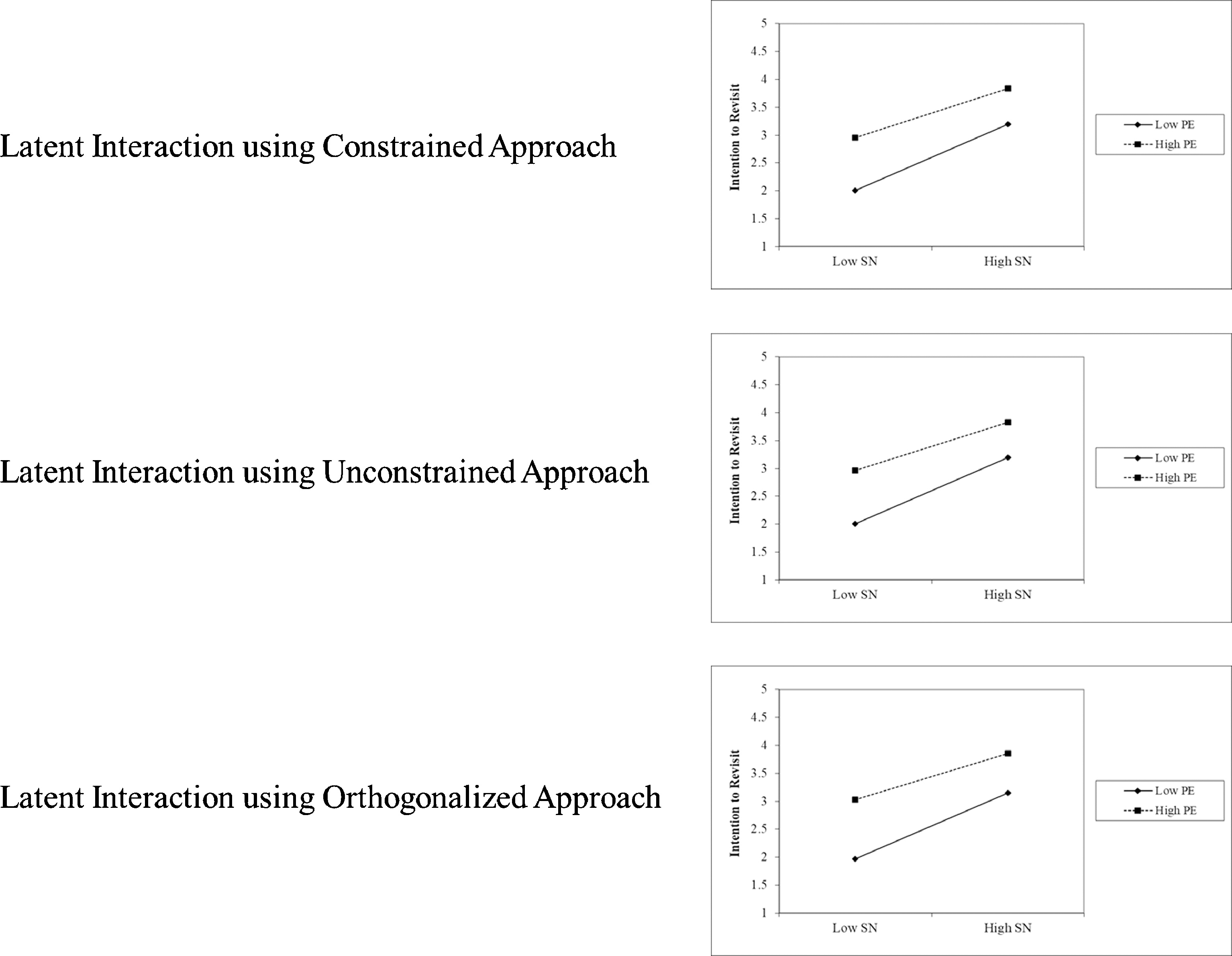
Fig. 5 illustrates the nature of the SN*PE interaction for all three approaches - constrained, unconstrained and orthogonal approach. Both the unconstrained and orthogonal approaches indicate a statistically significant effect of past experience (PE) on intention to revisit (ITR) dependent on subjective norm (SN) (see Table 6).
Of particular interest is the finding that the constrained (mean-centred) approach produces high kurtosis (platykurtic) in the interaction latent variable (SN*PE) (Table 3), which also manifests in larger standard error (SE) (cf. Fan & Wang, 1998; Finch, West, & MacKinnon, 1997). The orthogonal approach does not produce the same level of kurtosis in the interaction latent variable (SN*PE) (Table 5), which manifests in smaller standard error. This difference in standard error produces significantly different results. On the other hand, the result produced from the unconstrained approach was exceptional because the double mean-centring helps to reduce the standard error during the estimation of the structural model. This result implies that the constrained (mean-centred) approach may provide a more conservative biased result compared to both the unconstrained and orthogonal approach. Contrary to the Lei and Lomax (2005) findings, the results from our current study demonstrate the potential effect of SE bias on the interaction results depending on the latent interaction modelling approach.
Although High PE indicates an overall stronger propensity to revisit, the line labelled Low PE has a steeper gradient. This indicates that SN has a stronger effect on ITR when PE is lower. This interaction indicates that travellers with little past experience may be more motivated to (re)visit a destination based on SN in order to enhance their destination experiences (Wood et al., 2005).
The results indicate that both the unconstrained and orthogonalized approaches result in nearly identical parameter estimates to the constrained approach. However, only the constrained approach interaction effect is not significant, the reduced standard error from the unconstrained and orthogonalized approaches detect a significant interaction effect between SN and PE as expected by the TPB model (Anastasopoulos, 1992; Kidwell & Jewell, 2007; Smith et al., 2008).
The estimation of interaction effects between latent variables with CB-SEM requires sophisticated analysis methods when the latent variables are measured with multiple indicators, since a number of complex constraints should be imposed on the model. Due to these constraint requirements few researchers include an empirical test of latent variables interaction effect used CB-SEM (Grissemann & Stokburger-Sauer, 2012; Yeh & Ku, 2017). This is unfortunate since CB-SEM methods control for measurement error and possess more power than conventional regression analysis to detect interaction effects.
The objectives of this paper are threefold. First, the paper outlines the implications of the constrained, unconstrained, and orthogonalized approaches to represent latent variable interactions in CB-SEM (e.g., AMOS). Second, using TPB as a foundation the study analyses a theoretically postulated interaction effect between SN and PE in the marketing domain and highlights several merits of the constrained, unconstrained, and orthogonalized approaches. Third, the paper provides guidelines for creating CB-SEM latent interaction terms for analysis.
The latent interaction effect for both the unconstrained and orthogonalized approach perform similarly with respect to the path coefficient estimates as well as effect size (Little et al., 2006; Steinmetz et al., 2011). The interaction between SN and PE hypothesized by TPB were similar using both approaches, however only the results from the unconstrained and orthogonalized approach were statistically significant. The study found both the constrained and unconstrained approaches generated better explanatory power than the orthogonalized approach due to the effect of both unique and shared variance from the observed covariation pattern among all possible indicators of the interaction.
The analysis demonstrated that the orthogonalized approach results in better model fit, with intercorrelations among the indicators reduced to zero and no multicollinearity concerns. Another consequence of the orthogonalized approach is that the path coefficient estimates in the model without the interaction term are identical to those with the interaction term. This characteristic greatly facilitates the interpretation of the moderating effects’ strength compared with both the constrained and the unconstrained approaches.
Scholars should consider either the unconstrained or the orthogonalized approach to better identify, analyse and interpret latent interaction effects. First and foremost, information loss is substantially reduced, both latent variable interaction approaches are derived from the observed covariation pattern among all possible indicators of the interaction. Second, there are no complicated constraints that need to be calculated for either approach. Third, no recalculations of parameters are required for either approach. Finally, both procedures can be performed using standard structural model software (e.g., AMOS, LISREL, SEPATH, EQS, Ωnyx, lavvan, and Mplus).
Recommendation
To aid researchers to achieve satisfactory results when assessing the latent interaction effects and provide guidelines for the use of the three approaches, a step-wise process of assessing the latent interaction effect in CB-SEM is presented in Fig. 7.
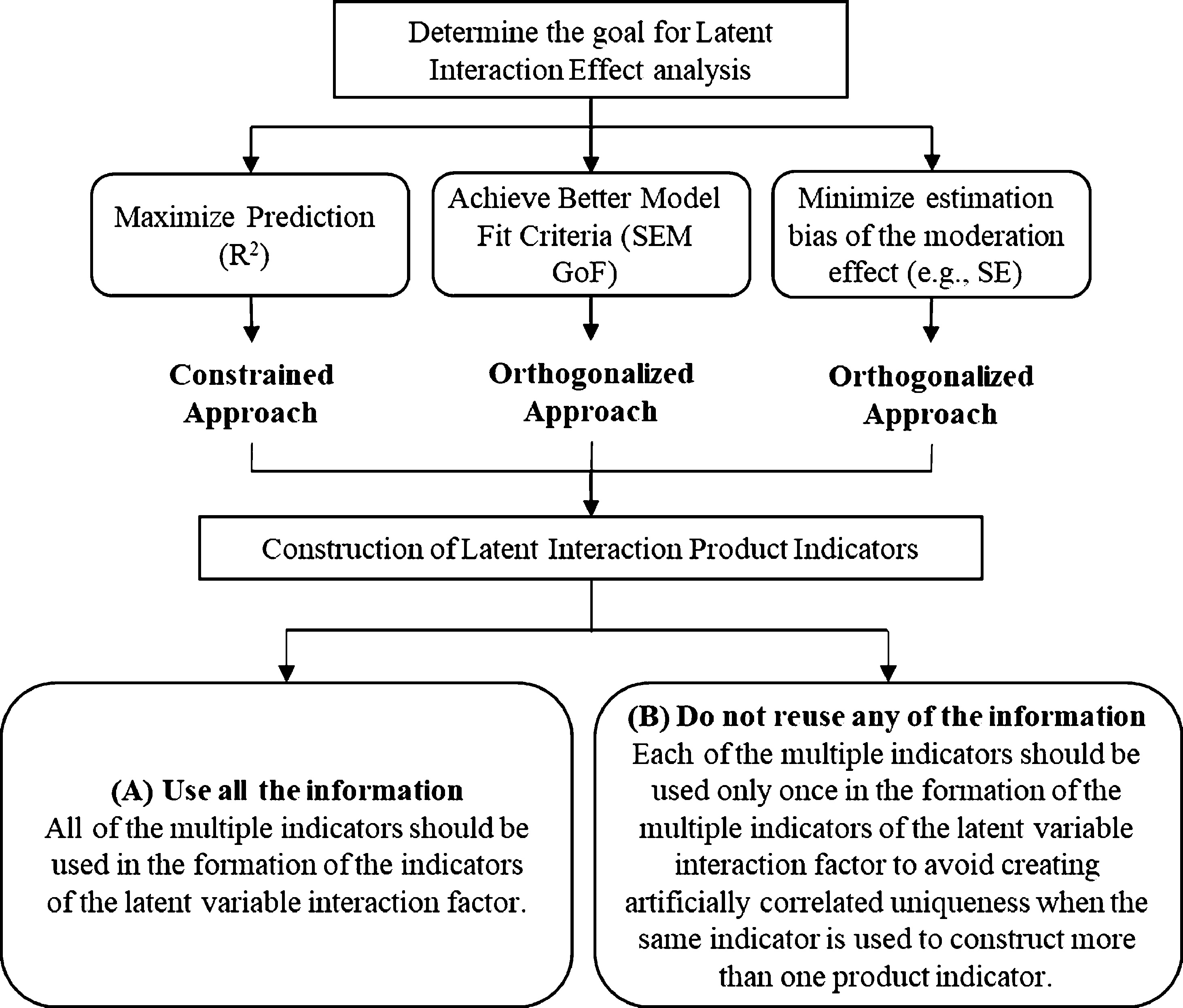
Guidelines for Creating the Latent Interaction Term in CB-SEM. Note: (A) is suitable to used when the number of matched-pair strategy to constructing interaction indicators is small (9 and below or use when sample size is large); (B) is suitable to used when the number of matched-pair strategy to constructing interaction indicators is large (9 and above or use when sample size is small) ( Marsh et al., 2004 ; 2006 ).
Firstly, researchers must consider the goal of the analysis for the latent interaction effects in CB-SEM. Goal analysis can be divided into three aspects: 1) Maximize prediction, 2) achieve better model fit, and 3) minimize estimate bias of the moderating effect. If satisfactory model fit and multicollinearity are not an issue the unconstrained approach is recommended. However, if the researcher faces both issues (unsatisfactory model fit and collinearity), the orthogonalized approach is recommended as it produces better model fit results and reduces collinearity issues. Importantly, our comparison study of the three approaches does not encourage researchers to estimate the latent interaction effect using the constrained approach because the constrained approach does not produce satisfactory path coefficient results or model fit.
Secondly, researchers should consider the construction of latent interaction indicators within the model. There are two key recommendations (Marsh & Craven, 2006; Marsh, Hau, et al., 2004):
use all the available information. All first-order multiple indicators should be used in the formation of the latent variable interaction indicators. This is especially important when the number of constructed latent interaction indicators is small (9 and below), and/or when the sample size is large (n ≥ 200), and do not reuse information (multiple indicators should be used only once), especially when the number of constructed latent interaction indicators is large (9 and above) or when sample size is small (n ≤ 200).
In the construction of the product indicators for the latent interaction variable (e.g., ξ1*ξ2 items), some situations may have natural matching that should be used to form product indicators (e.g., when ξ1 and ξ2 items have parallel wording) or more generally, when the two first-order effect factors, ξ1 and ξ2, have the same number of indicators. In other circumstances it may be better to match the ξ1 and ξ2 indicators in terms of the highest loadings of the indicators; the best item from the first factor with the best item from the second factor, etc. (Marsh, Hau, et al., 2004; Saris, Batista-Foguet, & Coenders, 2007).
When the number of indicators differs for the two first-order effect factors, then a simple matching strategy does not work. For example, when there are five indicators for the first factor and ten for the second factor. One approach is to use the ten items from the second factor to form five (item-pair) parcels by taking the average of the first two items to form the first item parcel, the average of the second two items to form the second parcel, and so forth. Consequently, the first factor would be defined in terms of five (single-indicator) indicators, the second factor would be defined by five (item-pair parcel) indicators, and the latent interaction factor would be defined in terms of five matched-product indicators. Little, Cunningham, Shahar, and Widaman (2002) provide additional detail and explanation regarding the parcelling procedure.
For exploratory research the orthogonalized approach is recommended since it is less likely to have factor score indeterminacy issues, and more likely to produce smaller SE (i.e., less conservative) results.
As with most research this study has a number of limitations. Although three indicators per latent variable, and three single indicators for the intention to revisit, is not necessarily representative, the small number of items per variable enables a clear and understandable presentation of the two methodology approaches. Future research should estimate and compare the constrained, unconstrained, and orthogonalization approaches using more than three indicators per construct.
This study is limited to the use of a 7-point Likert scale in assessing the latent interaction effect in CB-SEM. To provide a better comparison test between constrained, unconstrained and orthogonalized approaches, future research could compare the result of Likert-type scales with 5-point, 7-point or 10-point format. Using different scale formats (anchors) may affect the data in terms of assessing the latent interaction effect when looking into the results of path-coefficient, explanatory power, and model fit.
The empirical example in this study relies on using all multiple indicators in the construction of the latent interaction variable. This limits the generalizability under a matched-pair strategy condition when constructing interaction indicators with a large number of indicators. The recommendation for future researchers is to implement the matched pair strategies when constructing the indicators to identify which condition works best for the constrained, unconstrained, and orthogonalized approach.
Other approaches attempt to provide simple and more accessible methods to test interactions have been developed in recent years. This study focuses only on the three CB-SEM approaches that appear complex but are relatively easy to implement.
Conclusion
The illustrated example in this study shows the ease of use of the three approaches (i.e., constrained, unconstrained, and orthogonalized) to test for interaction effects in the marketing context. Furthermore, the two approaches can be comfortably implemented in many available software programs (e.g., AMOS, LISREL, SEPATH, EQS, Ωnyx, lavvan, and Mplus). Using these three approaches outlined in this study can help marketing scholars detect interaction effects formulated in their theories which may otherwise not be detected using multi-group analysis, or a continuous moderator. We hope that readers interested in testing for interaction effects using CB-SEM will find the didactic approach taken in presenting this material to be helpful in fulfilling their endeavours.
Footnotes
Study selection PRISMA Flowchart. preferred reporting items for systematic reviews;moderator assessment in CB-SEM
Results from PRISMA;Marketing Journal Publications Using CB-SEM
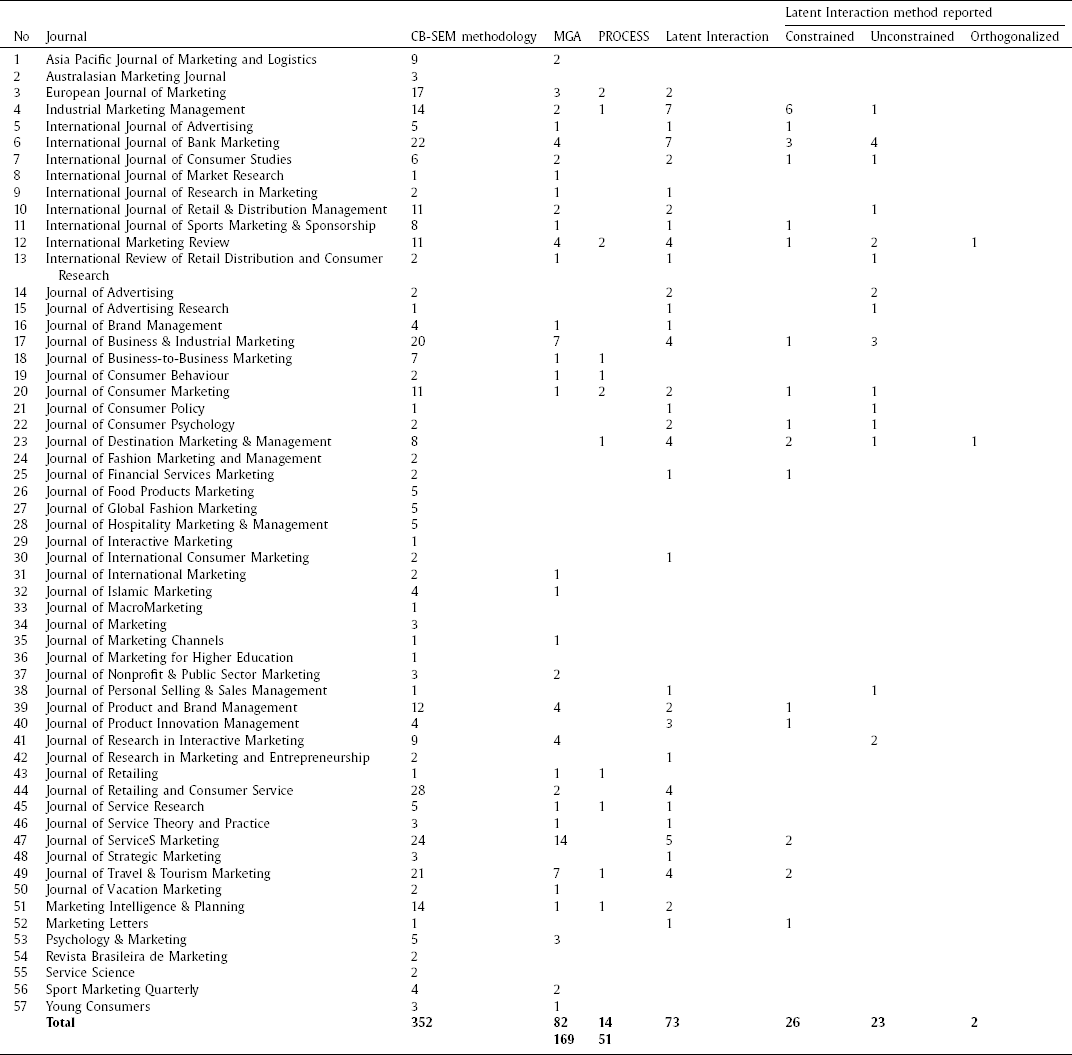
| Latent Interaction method reported | ||||||||
|---|---|---|---|---|---|---|---|---|
| No | Journal | CB-SEM methodology | MGA | PROCESS | Latent Interaction | Constrained | Unconstrained | Orthogonalized |
| 1 | Asia Pacific Journal of Marketing and Logistics | 9 | 2 | |||||
| 2 | Australasian Marketing Journal | 3 | ||||||
| 3 | European Journal of Marketing | 17 | 3 | 2 | 2 | |||
| 4 | Industrial Marketing Management | 14 | 2 | 1 | 7 | 6 | 1 | |
| 5 | International Journal of Advertising | 5 | 1 | 1 | 1 | |||
| 6 | International Journal of Bank Marketing | 22 | 4 | 7 | 3 | 4 | ||
| 7 | International Journal of Consumer Studies | 6 | 2 | 2 | 1 | 1 | ||
| 8 | International Journal of Market Research | 1 | 1 | |||||
| 9 | International Journal of Research in Marketing | 2 | 1 | 1 | ||||
| 10 | International Journal of Retail & Distribution Management | 11 | 2 | 2 | 1 | |||
| 11 | International Journal of Sports Marketing & Sponsorship | 8 | 1 | 1 | 1 | |||
| 12 | International Marketing Review | 11 | 4 | 2 | 4 | 1 | 2 | 1 |
| 13 | International Review of Retail Distribution and Consumer Research | 2 | 1 | 1 | 1 | |||
| 14 | Journal of Advertising | 2 | 2 | 2 | ||||
| 15 | Journal of Advertising Research | 1 | 1 | 1 | ||||
| 16 | Journal of Brand Management | 4 | 1 | 1 | ||||
| 17 | Journal of Business & Industrial Marketing | 20 | 7 | 4 | 1 | 3 | ||
| 18 | Journal of Business-to-Business Marketing | 7 | 1 | 1 | ||||
| 19 | Journal of Consumer Behaviour | 2 | 1 | 1 | ||||
| 20 | Journal of Consumer Marketing | 11 | 1 | 2 | 2 | 1 | 1 | |
| 21 | Journal of Consumer Policy | 1 | 1 | 1 | ||||
| 22 | Journal of Consumer Psychology | 2 | 2 | 1 | 1 | |||
| 23 | Journal of Destination Marketing & Management | 8 | 1 | 4 | 2 | 1 | 1 | |
| 24 | Journal of Fashion Marketing and Management | 2 | ||||||
| 25 | Journal of Financial Services Marketing | 2 | 1 | 1 | ||||
| 26 | Journal of Food Products Marketing | 5 | ||||||
| 27 | Journal of Global Fashion Marketing | 5 | ||||||
| 28 | Journal of Hospitality Marketing & Management | 5 | ||||||
| 29 | Journal of Interactive Marketing | 1 | ||||||
| 30 | Journal of International Consumer Marketing | 2 | 1 | |||||
| 31 | Journal of International Marketing | 2 | 1 | |||||
| 32 | Journal of Islamic Marketing | 4 | 1 | |||||
| 33 | Journal of MacroMarketing | 1 | ||||||
| 34 | Journal of Marketing | 3 | ||||||
| 35 | Journal of Marketing Channels | 1 | 1 | |||||
| 36 | Journal of Marketing for Higher Education | 1 | ||||||
| 37 | Journal of Nonprofit & Public Sector Marketing | 3 | 2 | |||||
| 38 | Journal of Personal Selling & Sales Management | 1 | 1 | 1 | ||||
| 39 | Journal of Product and Brand Management | 12 | 4 | 2 | 1 | |||
| 40 | Journal of Product Innovation Management | 4 | 3 | 1 | ||||
| 41 | Journal of Research in Interactive Marketing | 9 | 4 | 2 | ||||
| 42 | Journal of Research in Marketing and Entrepreneurship | 2 | 1 | |||||
| 43 | Journal of Retailing | 1 | 1 | 1 | ||||
| 44 | Journal of Retailing and Consumer Service | 28 | 2 | 4 | ||||
| 45 | Journal of Service Research | 5 | 1 | 1 | 1 | |||
| 46 | Journal of Service Theory and Practice | 3 | 1 | 1 | ||||
| 47 | Journal of ServiceS Marketing | 24 | 14 | 5 | 2 | |||
| 48 | Journal of Strategic Marketing | 3 | 1 | |||||
| 49 | Journal of Travel & Tourism Marketing | 21 | 7 | 1 | 4 | 2 | ||
| 50 | Journal of Vacation Marketing | 2 | 1 | |||||
| 51 | Marketing Intelligence & Planning | 14 | 1 | 1 | 2 | |||
| 52 | Marketing Letters | 1 | 1 | 1 | ||||
| 53 | Psychology & Marketing | 5 | 3 | |||||
| 54 | Revista Brasileira de Marketing | 2 | ||||||
| 55 | Service Science | 2 | ||||||
| 56 | Sport Marketing Quarterly | 4 | 2 | |||||
| 57 | Young Consumers | 3 | 1 | |||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
SPSS Instructions to Compute Orthogonal Approach
For example, the first regression is one in which all IV indicators (e.g., SN1, SN2, SN3, PE1, PE2, and PE3) are the predictors and SN1*PE1 is the dependent variable. The residual of this regression is saved in a data file. In SPSS under Linear Regression, the residuals can be saved by choosing: SAVE: Residuals “unstandardized”. When the regression analysis is run a new variable (the residual of the SN1*PE1 regression), titled RES_1, is saved and appears in the immediate right column of the variables in the SPSS Data View. Rename RES_1 as Res_SN1_PE1 and continue with the next set of residuals SN1_PE2, etc. saving each new RES_x as Res_SNx_PEy.
Respondent Profile
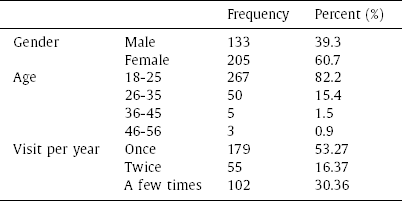
| Frequency | Percent (%) | ||
|---|---|---|---|
| Gender | Male | 133 | 39.3 |
| Female | 205 | 60.7 | |
| Age | 18-25 | 267 | 82.2 |
| 26-35 | 50 | 15.4 | |
| 36-45 | 5 | 1.5 | |
| 46-56 | 3 | 0.9 | |
| Visit per year | Once | 179 | 53.27 |
| Twice | 55 | 16.37 | |
| A few times | 102 | 30.36 |