
Abstract
This study compared explicit and behavioural measures of source credibility judgements based on two factors: a source's past record of accuracy and its production of predictions that participants would like to believe. The former is considered to be a rational factor for judging credibility, while the latter is considered nonrational (i.e., it does not predict actual credibility). In Experiments 1 and 2, participants saw an equal number of predictions from two sources, one of which was either highly or slightly more accurate/desirable than the other. In Experiment 3, either one source was high accuracy and the other high desirability, or one source was higher on both measures. For all experiments, participants then saw new accurate and inaccurate predictions and said which source they thought was most likely to produce each (behavioural task). Participants then gave a percentage rating for each source's perceived accuracy (explicit judgement task). Participants showed sensitivity to past accuracy differences using both tasks, but not to the size of the differences. Desirability influenced performance only on the behavioural task. However, when the two factors conflicted, participants responded solely using past accuracy information. Behaviours reflect source credibility judgements based on both rational and irrational factors, but participants appear to be both more strongly influenced by the rational factor and more aware of that influence.
The citizens of modern technological societies are often said to be overwhelmed by a flood of information. Certainly, we live in an information-rich environment, and we are often called on to evaluate that information. Whether one is determining the safety of a neighbourhood before deciding to move, or seeking online information about possible medical treatments, these judgements can have long-term consequences. Sometimes messages are in a familiar knowledge domain and can be evaluated on their own merits. However, frequently we must evaluate messages when we have little relevant expertise and few clear guidelines.
This process is often complicated by multiple messages, from many quarters, containing conflicting information. Under these circumstances, one common heuristic is to judge the message based on the credibility of the source that produces it: A credible source is more likely than a noncredible one to produce trustworthy messages (e.g., Halperin, Snyder, Shenkel, & Houston, 1976; Ziegler, Diehl, & Ruther, 2002). First, however, one must judge the credibility of the source itself. As a simple example, suppose the weather forecasters on two news channels predict different conditions for the next day. How do people decide which one to trust? One might use the frequency with which each forecaster has been correct in the past. One might also judge credibility based on the frequency with which each forecaster predicts sunshine—or on their relative training and credentials, or on the charisma and energy with which they gesture at their map.
The study of credibility judgement has a long history. Early studies identified several factors contributing to these judgements, including expertise, dynamism, perceived bias, and how entertaining a source is (e.g., Berlo, Lemert, & Mertz, 1969; Eagly, Wood, & Chaiken, 1978; Markham, 1968). These studies measured judgement in the most straightforward and explicit way possible: They asked participants to say how much they trusted a source, generally using a rating scale. Others gathered changes in ratings for the message rather than the source itself (Slater & Rouner, 1996; Weiner & Mowen, 1986). Later research using similar methods has expanded the list of factors that can influence these explicit judgements, as well as creating a more complex picture of the judgement process. Sources that are willing to describe the limitations of their arguments (as scientific articles often do) are better trusted than those that present their side entirely in a positive light (Bohner, Einwiller, Erb, & Siebler, 2003). Surface features of utterances, such as tone of voice, can also influence credibility judgement (Ozuro & Hirst, 2006). Multiple factors can also interact, sometimes in unfortunate ways. For example, explicit judgements of credibility reflect a source's accuracy levels when the source is an in-group member, but not when the source is an obvious out-group member (Lindholm, 2008).
However, explicit measures of credibility judgement have serious limitations. Conscious awareness of judgement and decision-making processes is limited (Nisbett & Wilson, 1977). Particularly with a multifactorial and emotionally involving process like credibility judgement, explicit reports may not reflect the complete picture. Some factors, such as expertise and past record of accuracy, intuitively seem likely to produce accurate judgements, and people may be particularly willing to acknowledge their use of these factors. On the other hand, in-group membership, and the frequency with which a source says things that one wishes to believe, are more problematic, and people may prefer not to acknowledge these contributions, to themselves or to others, if they can avoid it. We refer to these general categories, somewhat simplistically, as rational and nonrational factors that may influence credibility judgement.
Ultimately, credibility judgement is interesting primarily because it influences eventual decisions. Returning to our initial example, suppose that the weather forecaster on Channel 2, who is usually accurate, predicts that it will rain tomorrow, while the less consistently accurate forecaster on Channel 3 says it will be sunny. If you claim to trust the Channel 2 forecaster, but you spend the morning packing bathing suits and head for a lake an hour's drive away, then your behaviour reflects confidence in the Channel 3 forecaster's judgement—and conflicts with your explicit claims about your internal processes. This conflict, between behaviour and explicit claims of trust, is the focus of the current article.
A number of studies have used behavioural measures of credibility judgement to examine the ways we respond to messages from varying sources. In general, these studies focus on judgements within specific real-world contexts and do not require participants to be aware of the ways that credibility influences their decisions. Studies in courtroom contexts, for example, present testimony from eyewitnesses who vary on particular axes and measure the weight given to each using the participant's guilty/not-guilty verdict (e.g., Johnson, Bush, & Mitchell, 1998; G. Kaufmann, Drevland, Wessel, Overskeid, & Magnussen, 2003). Studies of consumer decision making measure the credibility of advertisers using final purchase decisions (e.g., Jain & Posovac, 2001).
These behavioural studies have some advantages over those that rely entirely on explicit participant ratings, in that they do not depend on participants' introspective insight in order to demonstrate the existence of a credibility judgement. However, they too have their limitations. How people weight different features changes considerably when they have reason to be suspicious of a speaker (Johnson et al., 1998). For example, stakes are high in a criminal trial, and some witnesses may have strong incentive to be biased in their memory or testimony. Thus, a factor that leads to high credibility estimates in a courtroom context may lead to low estimates in another context. Too, participants may be primed by courtroom stimuli to attend more carefully to some types of information than they might in less fraught settings. Information from court eyewitnesses may therefore be treated very differently from information from everyday sources. Likewise, people may judge advertisements using another set of nongeneralizable heuristics. Another problem is that guilty/not guilty verdicts, or purchase/no purchase decisions, can only be used as measures in particular settings, increasing the difficulty of generalizing findings based on them—that is, the purchase/no-purchase paradigm cannot be precisely translated for use in judging eyewitness credibility or the trustworthiness of politicians. Overall, these behavioural measures have high environmental validity, but for very specific environments. Therefore, a gap exists in the research: We need to evaluate judgements of source credibility, using both explicit and behavioural measures, in a relatively non-context-specific manner—a paradigm that can, at least hypothetically, be used across multiple situations.
People generally attribute accurate statements to sources perceived as credible, and inaccurate statements to sources perceived as noncredible (Fragale & Heath, 2004). This phenomenon could hypothetically be used as a behavioural measure of credibility judgement in many different contexts. Although we use a pair of fictional psychics, taking advantage of the freedom to have them make statements in a wide variety of domains, one could as easily ask participants to attribute accurate and inaccurate statements to weather forecasters, newspapers, or eyewitnesses in a court case (the latter two contexts, in fact, are those used in Fragale & Heath's original study).
Since participants have the option of attributing any number of accurate or inaccurate statements to the same source, this method may also be somewhat more nuanced than the one-choice-per-study measures (e.g., purchase/no purchase) described above. Whereas previous studies have generally shown that a source either is trusted enough to push decision-makers over a particular threshold (e.g., to purchase a product), or is not trusted sufficiently, the current task can measure varying degrees of trust. While a participant might trust two sources at a sufficient level to purchase a product, they might attribute accurate statements to one source 75% of the time and to another 90% of the time.
The current set of studies compares estimates of accuracy rate (explicit judgement) and attributions of accurate and inaccurate statements (behavioural judgement) for one rational and one nonrational factor. Experiment 1 examines judgements based on past record of accuracy (a rational factor). Experiment 2 examines judgements based on production of desirable statements (a nonrational factor). Experiment 3 places these two factors in conflict, measuring judgements when one source is frequently accurate, while another frequently produces desirable statements.
Experiment 1
People making credibility judgements are sensitive to a variety of accuracy-related factors, including a source's expertise (Birnbaum & Stegner, 1979), reputation (D. Q. Kaufmann, Stasson, & Hart, 1999), and memory for peripheral details of a target event (Wells & Leippe, 1981). In this experiment, we examined judgements based on the most straightforward indication of a source's future accuracy—its past accuracy. Participants encountered a pair of sources that differed to either a large or a small extent in their accuracy, and they made both behavioural and explicit judgements of future credibility. Since this factor is not only a rational one to use in making credibility judgements, but a fairly easy one to detect, we expected that both tasks would reflect a judgement that the high-accuracy source was the most credible. This seemed particularly likely in the high-difference condition, where the distinction between the sources was particularly obvious.
Method
Participants
Participants were undergraduate students from the Illinois Institute of Technology who participated in the study for course credit. There were 19 participants in the high-difference condition and 18 in the low-difference condition, for a total of 37 participants. All participants were fluent in English.
Materials and design
An introductory paragraph, seen by all participants, described a small psychic hotline with a staff of 2: Anna Ashland and Candy Carson. We chose to use “psychics” as they could predict a wide variety of topics with equal a priori trustworthiness (or lack thereof). Both sources were the same gender and were not associated with physical representations, so any participant biases prior to stimulus exposure should apply equally to both.
Twenty study scenarios were created, consisting of predictions about a variety of situations (see Appendix A for examples). Each scenario had two versions: one accurate (prediction is described as coming true) and one inaccurate (prediction is described as not coming true). Scenarios were normed by 51 additional participants (each of whom saw only one version of each scenario) who rated likelihood and desirability for each prediction. We then created two stimulus sets each for two conditions. In the high-difference condition, Anna was accurate 80% of the time, and Candy was accurate 20% of the time, while in the low-difference condition, accuracy was 60% and 40%, respectively. For all stimulus sets, sources were matched on the likelihood and desirability of their predictions.
Fourteen test scenarios were created, normed to have neutral desirability. For these scenarios, a sourceless prediction was followed by a description of the scenario's outcome. Each scenario had two versions, one accurate and one inaccurate. All participants saw seven accurate and seven inaccurate scenarios. Accuracy of particular scenarios was counterbalanced across participants.
All stimuli were presented using Superlab Pro experimental design software on a Windows 2000 computer.
Procedure
At the beginning of the experiment, participants saw the introductory paragraph, followed by the 20 study scenarios. They were instructed to read the stories carefully; they were not given any information as to the purpose of the study or specifically told to attend to any particular aspect of the text. Order of scenario presentation was randomized. Participants read at their own pace. Participants were assigned to either the high-difference condition or the low-difference condition.
Participants next read the 14 test predictions, with outcomes, and were instructed to judge which source they believed was the more likely origin (behavioural judgement task). After completing this task, participants were asked what percentage of the time they thought each source would be accurate overall (explicit judgement task). They were also asked to describe any strategy they used when attributing predictions to the sources.
Results and discussion
The purpose of this study was to examine behavioural and explicit judgements of source credibility based on sources' past record of accuracy. For the behavioural task, participants attributed accurate and inaccurate predictions to whichever of the two sources they considered most likely to have made them. Two questions were of interest with regard to this task: First, were accurate predictions more likely to be attributed to the high-accuracy source, and inaccurate predictions to the low-accuracy source? Second, were participants sensitive to the degree of difference between the sources; that is, did difference condition have an effect on attributions? For the first question, attribution of accurate versus inaccurate predictions could be compared either for the high-accuracy source or for the low-accuracy source, since the two sets were complimentary. We arbitrarily chose to make the comparison using the high-accuracy source. A two-way analysis of variance (ANOVA; condition: high difference vs. low difference; prediction type: accurate vs. inaccurate) revealed no significant interaction between those two variables, F(1, 35) = 0.25, p = .62, MSE = 195.09. There was no main effect of condition, F(1, 35) = 0.15, p = .70, MSE = 13.20. There was a significant overall main effect of prediction type, F(1, 35) = 19.93, p < .001, MSE = 15,337.79. A post hoc t test on prediction type, further exploring this main effect, revealed that the high-accuracy source was more likely to have accurate than inaccurate predictions attributed to it, across conditions, t(36) = 4.53, MSE = 6.38, p < .001. Participants' behaviour reflected sensitivity to the presence of an accuracy difference between sources, but not to the size of that accuracy. Means and standard deviations for the attribution task are shown in Table 1. (Note that the numbers listed here are the percentage of accurate and inaccurate predictions attributed to the accurate source. Participants could attribute all of both types of predictions to a single source if they wished; they are independent and do not sum to 100%.)
Percentage attribution of predictions to high-accuracy source for Experiment 1: Behavioural task
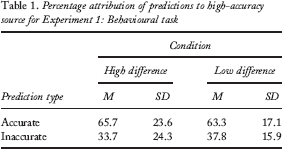
The same pattern of judgement was reflected by the explicit task. A two-way ANOVA (condition: high difference vs. low difference; predictor: accurate vs. inaccurate) revealed no significant interaction between those two variables, F(1, 35) = 0.15, p = .70, MSE = 52.94. There was no main effect of condition, F(1, 35) = 0.01, p = .93, MSE = 2.68. There was a significant overall main effect of predictor, F(1, 35) = 28.91, p < .001, MSE = 10,110.95. A post hoc t test on predictors revealed that the high-accuracy source was judged by participants to be significantly more accurate than the low-accuracy source, t(36) = 5.45, MSE = 4.30, p < .001. Means and standard deviations for the explicit task are shown in Table 2.
Judged accuracy percentage for Experiment 1: Explicit task
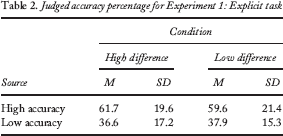
Participants do appear to judge a source's credibility based on its past record of accuracy—a rational piece of information to use in making such a judgement. The same judgement is apparent using both an explicit task and a behavioural one. In both cases, participants were sensitive to the existence of a difference in accuracy between sources, but not to the size of that difference. While people are good at determining whether or not a source has been accurate in the past, they do not appear as skilled at determining how accurate or inaccurate it has been: a dichotomous judgement rather than a continuous one.
Experiment 2
Experiment 1 examined the use of rational information in judging a source's credibility. However, judgements are often affected by desire-based as well as rational factors. Past literature shows that the desirability of a source's message does interact with judgements of a source's credibility, frequently in ways that have little to do with actual credibility. Czapinski and Lewicka (1979) showed that credibility and the content of a message, positive or negative, combined to influence the interpretation of that message. When a low-credibility source presented information, negative messages were rejected significantly more often than positive ones. In high-credibility conditions, negative information was received more readily than positive information.
Jones, Sinclair, and Courneya (2003) found that when messages promoting exercise were framed in a positive manner (i.e., potential gains), rather than negative (potential losses), they received different responses from the participants. The participants were more likely to say they intended to exercise and to actually report that they exercised over a two-week period after hearing the positive message than after hearing the negative message—suggesting that the source may have appeared more credible with positive messages. In all of these studies, the desirability of the message should not affect credibility judgement (speaking prescriptively), but appears to have an influence nevertheless.
While explicit and behavioural measures gave similar results for Experiment 1, it seems possible that a nonrational factor would show a dissociation. Participants might be influenced behaviourally by such a factor yet remain consciously unaware of it—or they might be influenced in their explicit judgements while basing riskier behavioural changes only on more rational factors.
Method
Participants
Participants were undergraduate students from the Illinois Institute of Technology who participated in the study for course credit. There were 14 participants in the high-difference condition and 17 in the low-difference condition, for a total of 31 participants. All participants were fluent in English.
Materials and design
The introductory paragraph was identical to that described in Experiment 1. Twenty study scenarios were created, consisting of predictions about a variety of situations. No outcomes were given for these scenarios. We created two versions of each scenario: one where the prediction was desirable and the other where the prediction was undesirable (see Appendix B for examples). For each scenario pair, the final prediction was identical across versions, but the set-up was changed to make that prediction desirable or undesirable. For example, a prediction of a person winning a contest might seem desirable if that person was made to seem likable, but undesirable if they were made to seem unpleasant. Scenarios were normed for perceived likelihood and desirability by 31 additional participants, each of whom saw only one version of each prediction. We then created two stimulus sets each for both conditions. In the high-difference condition, Anna's predictions were desirable 80% of the time, and Candy's predictions were desirable only 20% of the time, while in the low-difference condition, desirability was 60% and 40%, respectively. The two sources were matched on the perceived likelihood of the predictions they made.
Fourteen test scenarios were created, using the same norming data. For these scenarios, a sourceless prediction was followed by a description of the scenario's outcome. All scenarios were of neutral desirability and had both an accurate and inaccurate version. All participants saw seven accurate and seven inaccurate scenarios. Accuracy of particular scenarios was counterbalanced across participants.
Procedure
The procedure was identical to that from Experiment 1, with the addition of an explicit desirability rating task following the explicit credibility judgement task. This was intended to determine whether participants were consciously aware of the difference between the two sources. Participants rated the overall desirability of each source's predictions on a scale from 1–5.
Results and discussion
For this experiment, attribution of accurate versus inaccurate predictions could be compared either for the high-desirability source or for the low-desirability source, since the two sets were complimentary. We arbitrarily chose to make the comparison using the high-desirability source. A two-way ANOVA (condition: high difference vs. low difference; prediction type: accurate vs. inaccurate) revealed a significant interaction between these two variables, F(1, 29) = 5.73, p = .02, MSE = 0.71. There was no main effect of either condition or prediction type, F(1, 29) = 1.45, p = .24, MSE = 0.04, and F(1, 29) = 0.64, p = .43, MSE = 0.08, respectively. Further exploring the interaction, we found that in the high-difference condition, accurate predictions were more likely than inaccurate predictions to be attributed to the high-desirability source (and conversely, inaccurate predictions were more likely than accurate conditions to be attributed to the low-desirability source), t(13) = 2.12, MSE < 0.001, p = .05. In the low-difference condition, no such effect appeared, t(16) = –1.20, MSE = 0.12, p = .25. Means and standard deviations for these attributions appear in Table 3. A record of desirable or undesirable predictions thus appeared to influence behavioural credibility judgement only when that record was clear and strong.
Percentage attribution of predictions to high-desirability source for Experiment 2: Behavioural task
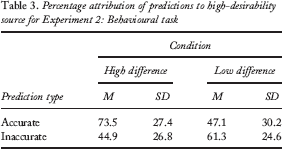
This behavioural difference was not reflected in explicit accuracy judgements. A two-way ANOVA (condition: high difference vs. low difference; predictor: desirable vs. undesirable) revealed no significant interaction, F(1, 29) = 0.30, p = .59, MSE = 309.20. There was no significant main effect of either condition or predictor on accuracy judgements, F(1, 29) = 0.16, p = .70, MSE = 24.72, and F(1, 29) = 1.38, p = .25, MSE = 1,424.04, respectively. Means and standard deviations for explicit accuracy judgements appear in Table 4. Explicit ratings of credibility thus showed no effect of past desirability on judgements, in spite of the presence of just such an effect in the behavioural data.
Judged accuracy percentage for Experiment 2: Explicit task
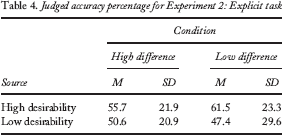
In examining desirability ratings, a two-way ANOVA (condition: high difference vs. low difference; predictor: high desirability vs. low desirability) showed no significant interaction between the two variables, F(1, 29) = 0.54, p = .47, MSE = 2.54. There was no main effect of either condition or predictor, F(1, 29) = 0.04, p = .85, MSE = 0.02, and F(1, 29) = 1.60, p = .22, MSE = 7.54, respectively. Means and standard deviations for desirability ratings appear in Table 5. Although the norming study showed differences in desirability between the predictions used for the two sources, this rating task did not show significant explicit awareness of that pattern. That is, participants were not consciously keeping track of sources' desirability records. The differences in desirability between the two sources were reflected only in the behavioural judgement task.
Explicit desirability ratings for Experiment 2
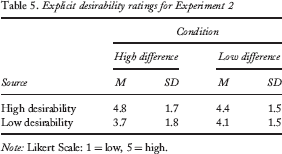
Note: Likert Scale: 1 = low, 5 = high.
Participant behaviour was affected by the desirability of statements produced by the two sources in the high-difference condition only. Explicit ratings did not reflect this effect. People appear to be vulnerable to an influence of desire-based factors on their credibility judgements, but they remain unaware of that influence.
Experiment 3
In Experiment 1, participants showed sensitivity to differences in accuracy on both an explicit and a behavioural level, in both the high-difference and the low-difference condition. In Experiment 2, high differences in prediction desirability led to differences in behavioural credibility judgement only. In Experiment 3, these two factors were placed in conflict. This more complex set-up better reflects real-world situations, in which one information source rarely shows clear superiority on all axes. It would be a more adaptive strategy if, given the option, people's behaviour reflected rational rather than nonrational evidence for trustworthiness. The previous two experiments provide some support for this idea: Even small differences in past accuracy produce large behavioural effects, suggesting a particular sensitivity to this factor. On the other hand, when faced with sources that differ in their production of desirable statements, people seem to lack explicit awareness of the resulting behavioural changes. This might make people vulnerable to desire-based reasoning, even in the presence of useful accuracy-relevant data.
Method
Participants
Participants were undergraduate students from the Illinois Institute of Technology who participated in the study for course credit. There were 20 participants in the conflicting condition and 18 in the compatible condition, for a total of 38 participants. All participants were fluent in English.
Materials and design
Twenty study scenarios were created based on previous norming (see Appendix C for examples). Each scenario set-up varied to create a desirable and undesirable version of the prediction, and each scenario outcome varied to create an accurate and inaccurate version. These scenarios were used to construct two different conditions, conflicting and compatible, each with four counterbalancing versions of the experiment. In the conflicting conditions, Anna gave desirable predictions 80% of the time, but was accurate only 20% of the time. Candy's predictions were desirable 20% of the time and accurate 80% of the time. In the compatible conditions, Anna's predictions were desirable 80% of the time and accurate 80% of the time. Candy's predictions were desirable 20% of the time and accurate 20% of the time.
The 14 test scenarios were identical to those from Experiment 2.
Procedure
The procedure was identical to that of Experiment 2.
Results and discussion
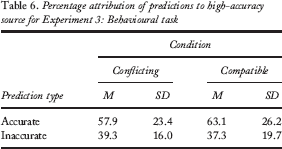
For Experiment 3, we analysed attributions of accurate and inaccurate predictions to the accurate source. Since this source was also high desirability in the compatible condition, but low desirability in the incompatible condition, we would expect either use of both factors or use of the desire-based factor alone to be reflected in an effect of condition and/or an interaction between condition and prediction type. If only the accuracy-based factor is used to make attributions, there should be no effect of condition and no interaction, but only an effect of prediction type. This latter pattern is precisely what we found. A two-way ANOVA (condition: conflicting factors vs. compatible factors; prediction type: accurate vs. inaccurate) revealed no significant interaction, F(1, 36) = 0.31, p = .58, MSE = 0.025. There was also no significant main effect of condition, F(1, 36) = 0.35, p = .56, MSE = 0.005. There was, however, a significant main effect of prediction type, such that accurate predictions were significantly more likely to be attributed to the high-accuracy source, regardless of that source's desirability status, F(1, 36) = 11.84, p = .001, MSE = 0.93. Means and standard deviations for these attributions appear in Table 6.
Percentage attribution of predictions to high-accuracy source for Experiment 3: Behavioural task
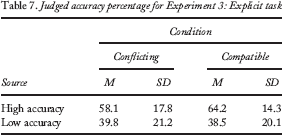
For the explicit judgement task, a two-way ANOVA (condition: conflicting vs. compatible; predictor: accurate vs. inaccurate) revealed no significant interaction, F(1, 36) = 0.49, p = .49, MSE = 262.52. There was no significant main effect of condition, F(1, 36) = 0.69, p = .41, MSE = 108.63. There was, however, a significant main effect of predictor, such that the accurate predictor received significantly higher accuracy ratings than the nonaccurate predictor, independent of desirability status, F(1, 36) = 17.13, p < .001, MSE = 9,147.38. Means and standard deviations for explicit judgements appear in Table 7.
Judged accuracy percentage for Experiment 3: Explicit task
For desirability ratings, a two-way ANOVA (condition: conflicting vs. compatible; predictor: high desirability vs. low desirability) revealed no significant interaction, F(1, 36) = 2.53, p = .12, MSE = 8.01. There was no significant main effect of either condition or predictor, F(1, 36) = 1.80, p = .19, MSE = 2.55, and F(1, 36) = 0.14, p = .72, MSE = 0.43, respectively. Means and standard deviations for desirability judgements appear in Table 8. As in Experiment 2, participants were not consciously aware of the overall patterns of desirability difference between the sources. Unlike Experiment 2, those differences did not significantly influence behaviour. This suggests that conscious awareness of accuracy differences may be one of the advantages that factor has over desirability when the two conflict.
Explicit desirability ratings for Experiment 3
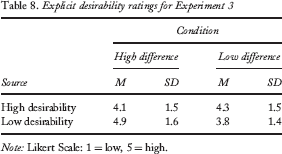
Note: Likert Scale: 1 = low, 5 = high.
General Discussion
Past research has shown that people consciously identify many factors that influence their source credibility judgements, including past accuracy, expertise, and charisma. However, conscious descriptions of judgement often fail to reflect the full set of underlying processes, and most research on behavioural measures of judgement has been limited by specific contexts. For example, guilty/not-guilty verdicts are a good way to measure the judged credibility of eyewitnesses, but are less relevant to the credibility of politicians or gossip columnists. In the current study, we created a more generalizable behavioural measure of credibility judgement and compared it with an explicit measure of the same judgements.
Our first experiment examined the use of a source's past record of accuracy for judging that source's credibility. This is a rational factor to use in such judgements, probably resulting in a relatively accurate understanding of a source's trustworthiness. Participants were sensitive to the relative accuracy of the two sources, but not to the degree of the better source's advantage. This sensitivity was similar for both the explicit and behavioural judgement tasks—in this case, conscious claims appeared to reflect actual underlying processes.
However, we then looked at a less rational contribution to credibility judgements and found a very different pattern. A source's past record of desirability—the frequency with which it produces information that one wants to believe—is not actually related to that source's trustworthiness. However, when the difference in desirability between two sources was high, behaviour changed to reflect an underlying judgement that the more desirable source was also the more credible. This change was not reflected in the explicit task. Participants appeared unaware that this less rational factor had any influence on their credibility judgements. This vulnerability could be maladaptive, since people have more difficulty changing a process that they are unaware of.
However, the limits of that vulnerability were demonstrated in the final experiment. When a source's past accuracy and desirability were placed in conflict, both behavioural and explicit judgements reflected primarily accuracy information. A wide body of literature shows that judgements and decisions are often influenced by nonrational, desire-based factors (Kunda, 1990). However, few studies have specifically looked at how these factors influence cognition when more useful data are also present. At least in the present study, we see that the less useful information is used only when nothing else is available. Like the random number used as the basis for guessing an otherwise entirely unknown quantity (Tversky & Kahneman, 1974), it comes into play only because nothing better is available.
Taken together, our findings support two notable claims. First, people are sometimes, but not always, consciously aware of which factors they are using to judge source credibility. At least within the bounds of the types of judgement studied here, people are most likely to be aware of the influence of rational factors—the information most likely to result in accurate credibility judgements—and less likely to be aware of the influence of nonrational, desire-based factors. This runs the risk of causing people to overestimate the accuracy of their own judgement processes, while undermining them with irrelevant data.
That risk, however, is minimized by the second notable finding. When more useful data are available to credibility judgement processes, those data are what people tend to use. It is possible, in fact, that the greater conscious awareness of rational factors is what permits them to override the nonrational ones. This would suggest that credibility judgements are largely deliberately directed and that it is only when that direction is lacking that less conscious processes lead to errors. Another possibility, however, is that both types of judgement are largely nonconscious, but that we allow ourselves to become aware only of the ones that support a positive self-image—which make us look like good judges.
The current study demonstrates a dissociation between explicit and behavioural credibility judgement under limited circumstances. However, it does permit some speculation as to what other conditions might lead to such a dissociation. One possibility is that nonrational factors of all types could influence behaviour without affecting explicit judgement. A source's similarity to the self, and a source's attractiveness, might be two such factors. The latter, in particular, is known to affect judgements of a source's unrelated characteristics, under circumstances where someone might be reluctant to admit the effect to themselves or others (Freeman, 1988).
Another possibility is that a source's record of producing desirable statements was a relatively nonsalient characteristic, an idea supported by the fact that it only had an influence on credibility judgement when intersource differences were large. In this case, dissociations like the one shown here might appear when source characteristics are most difficult to detect. This could be due to the nature of the characteristic, or due to a distracting context during initial source exposure. While the idea that the same characteristic could lead to either task congruence or dissociation, depending on circumstances, is intriguing, the current Experiment 3 can be taken as at least mild evidence against it. Here, a more salient source characteristic was used in place of the weaker and less useful one, across tasks—there was no dissociation associated with the weaker one.
Although our participants were generally good at identifying the existence of differences in accuracy between sources (when those differences existed), they did not appear to be sensitive to the size of those differences. Studies on probability matching have often found that people are capable of accurately identifying the base rate of events (e.g., Gaissmaier & Schooler, 2008; White & Koehler, 2007). However, these studies differ from the current study in two ways. First, participants are generally aware during study that this accuracy rate will be useful to track. Second, they receive explicit feedback during the test process. During the current experiment, participants were not encouraged to pay more attention to the source's accuracy rates than to any other aspect of the study scenarios.
This is also true of real-world credibility judgements, for which source accuracy information is usually present, but not highlighted. Under these circumstances, participants are likely to form general impressions of relative accuracy, which then translate into rough estimates for both judgement tasks. Given the minimal salience of accuracy information, it is not surprising that people are better at simply comparing the two sources than at precisely identifying their accuracy rates.
Limitations and future directions
The primary limitation of these studies is that we only examined two potential factors influencing credibility judgement. These were chosen for simplicity of design, because both could be manipulated through slight changes in phrasing of scenarios and because they could be manipulated in parallel. Factors such as charisma or expertise, which do not lend themselves to this type of manipulation, may be processed differently. Source characteristics that are dichotomous rather than continuous (e.g., gender) may also be treated differently. Future work should examine the relationship between explicit and behavioural judgements of these other types of factor. Such work could also confirm that the differences found here are related to how useful a factor actually is in judging credibility and not to some other distinction between a source's past accuracy and past desirability.
One key difference between this paradigm and many real-world credibility attributions is the lack of consequences for inaccurate judgement. Participants who mistakenly treat the more desire-friendly source as more accurate will neither purchase a defective product nor send an innocent to jail. Desire-based credibility judgement does appear to be a fragile phenomenon, and future research should examine whether accuracy-based contingency manipulation has an influence over the use of this type of information—and, in general, whether and how manipulation of consequences in the lab changes the credibility judgement process overall. Such research might draw on tasks from the game theory literature: for example, by having participants place bets on predicted outcomes (see Sanfey, 2007, for a review of how these methods are used in other social decision-making contexts). It does seem likely that some form of desire-based reasoning will persist even in the presence of more salience consequences, particularly when no alternative strategies are available. In general, person modelling is a robust process, and people prefer to act on dubious data rather than on no data at all (Nowak & Sigmund, 1998).
Another area for exploration is the question of what happens when the array of potential informational sources is more complex than those presented here. In the experiments described above, participants must keep track of only two sources, with a mean accuracy rate (when known) of 50%. If five sources get, respectively, 40%, 50%, 60%, 70%, and 80% of their predictions right, how are those sources judged? Is a source treated as credible if it is accurate more often than not? If it surpasses the mean? The current work suggests that trustworthiness is often judged as a dichotomy, but more complex situations may lead to more nuanced judgements.
Other future research might examine the interaction between multiple source characteristics that are all rational or nonrational, or situations where a characteristic's utility is less clear. For example, a source that is an expert in one particular area (e.g., cognitive psychology) may or may not be more credible in related areas (e.g., social psychology) or unrelated areas (e.g., physics). How do people judge credibility when it may differ across situations? Like desirability, expertise in an unrelated area might be used to judge credibility only when little other information is available—or might simply be given less weight in the final decision.
Conclusions
Source credibility judgement is a vital component of decision-making processes. Particularly in areas outside our own expertise, we need to know how well we can trust sources of new information. The credibility of a source informs the credibility of the information from that source, changing the weight we give it when forming a more complete model of the world and when acting on that model. However, our conscious judgements of credibility do not always match the underlying processes that inform those actions. This may, ultimately, be to our advantage—those processes that we are most aware of are not only the most adaptive, but the most influential and the ones over which we have the greatest control.