
Abstract
In this study, we present new approximation methods for the network revenue management problem with customer choice behavior. Our methods are sampling‐based and so can handle fairly general customer choice models. The starting point for our methods is a dynamic program that allows randomization. An attractive feature of this dynamic program is that the size of its action space is linear in the number of itineraries, as opposed to exponential. It turns out that this dynamic program has a structure that is similar to the dynamic program for the network revenue management problem under the so called independent demand setting. Our approximation methods exploit this similarity and build on ideas developed for the independent demand setting. We present two approximation methods. The first one is based on relaxing the flight leg capacity constraints using Lagrange multipliers, whereas the second method involves solving a perfect hindsight relaxation problem. We show that both methods yield upper bounds on the optimal expected total revenue. Computational experiments demonstrate the tractability of our methods and indicate that they can generate tighter upper bounds and higher expected revenues when compared with the standard deterministic linear program that appears in the literature.
Introduction
Network revenue management with customer choice behavior is well‐studied and has many applications in the airline, hotel, and car rental industries. In the context of airlines, a representative example, it involves controlling the sale of itineraries over a flight network. Customers arrive over the booking period to purchase itineraries. The airline has to decide which itineraries to make available for sale at each point in time taking into account the remaining capacities on the flight legs. This is a crucial decision to make since the customer's purchasing decision is influenced by the set of itineraries that are offered. Depending on the offer set, the customer may purchase one of the offered itineraries, or may not purchase anything and simply leave. The airline's goal is to determine the set of itineraries to offer at each point in time that maximizes the expected total revenues over the booking period. The airline's decision problem can be formulated as a dynamic program. However, computing the value functions and the optimal policy quickly become intractable and one has to resort to approximation methods.
Many of the approximation methods for the network revenue management problem with customer choice build on methods developed for network revenue management under the assumption that the customer's purchasing decision is not influenced by the set of offered itineraries. This is the so called independent demand setting, where we assume that customers arrive with the intention of purchasing a fixed itinerary. If the itinerary is available, they make the purchase. Otherwise, they leave without making any purchase. Even with the independent demand assumption, the dynamic programming formulation of the network revenue management problem becomes intractable as the size of its state space increases exponentially with the number of flight legs. Consequently, the approximation methods for the network revenue management problem with independent demand have mainly been concerned with reducing the dimensionality of the state space. Incorporating customer choice behavior adds another layer of complexity since the size of the action space also increases exponentially with the number of itineraries. This is because of the combinatorial nature of the problem of deciding which subset of itineraries to offer for sale from the set of all possible itineraries. So, while many of the approximation methods for the network revenue management problem with customer choice are able to handle the dimensionality of the state space quite well, they are less effective in dealing with the complexity of the action space. As a result, the tractability of many of the existing methods depends on the underlying model of customer choice. Much of the existing literature assumes that the customer choices are governed by the multinomial logit model and that the consideration sets, the sets of itineraries of interest to the different customer segments, are disjoint (e.g., Kunnumkal and Topaloglu 2010b, Liu and van Ryzin 2008, Zhang 2011, Zhang and Adelman 2009).
In this study, we propose new approximation methods that remain tractable for the class of random utility choice models. This class of choice models includes many of the commonly used customer choice models in the literature such as multinomial logit, nested logit, Markovian second choice, universal backup, and Lancaster demand (see Farias et al. 2013, Mahajan and van Ryzin 2001). We assume that a customer's choice decision is governed by a simple utility maximization principle. That is, a customer has a utility for purchasing each of the itineraries and to not purchasing anything. Of the available alternatives, the customer chooses the one with the highest utility. We note that this is equivalent to assuming that each customer has a ranked list of preferences and chooses the highest ranked option that is available. The starting point for our methods is a dynamic program that allows randomization. We generate a sample path of customer arrivals along with their utilities for the different itineraries and formulate a dynamic program in order to compute the optimal offer sets. We show that it is possible to reformulate this problem as a dynamic program where the number of decision variables is linear in the number of itineraries. As a result, the size of the action space becomes manageable. In fact, the resulting formulation is similar to the dynamic programming formulation of the network revenue management problem with independent demand. Consequently, we use ideas from the independent demand setting to reduce the size of the state space. We particularly focus on two approximation methods. One is based on the Lagrangian relaxation idea developed in Kunnumkal and Topaloglu (2010a) and the second is based on the randomized linear programming approach developed in Talluri and van Ryzin (1999).
The methods that we propose have a number of appealing features. Since they are sampling‐based, they can handle many of the commonly used customer choice models in the literature. In particular, we do not require the assumption that customer choices come from a multinomial logit choice model with disjoint consideration sets. Our methods yield upper bounds on the optimal expected revenue and estimates of the expected marginal values of capacity on the flight legs. The marginal value of capacity on a flight leg, referred to as its bid price, is useful in constructing control policies. On the other hand, upper bounds are useful when assessing the suboptimality of heuristic control policies. Another useful feature of our approach is that the randomized dynamic program we propose has a similar structure to the dynamic program for the network revenue management problem with independent demand. This allows us to draw upon the rich literature around the network revenue management problem with independent demand. The two approximation methods that we propose require solving only linear programs, which most commercial optimization packages are capable of. Moreover, since the linear programs we solve have only a polynomial number of variables and constraints, it minimizes the need for customized coding in the way of column generation techniques. This may enhance the practical appeal of our methods. Finally, our methods yield bid prices, which are compatible with the infrastructure of current revenue management systems that use bid price control policies.
Literature Review
Our work builds on previous research. Liu and van Ryzin (2008) propose a deterministic linear program for the network revenue management problem with customer choice. Zhang and Adelman (2009), Meissner and Strauss (2012b), and Zhang (2011) use the linear programming approach to approximate dynamic programming to come up with different value function approximations, where as Kunnumkal and Topaloglu (2010b) use Lagrangian relaxation ideas. All of the above mentioned methods provide upper bounds on the optimal expected revenue. However, their tractability depends on the assumptions that the customers' choices are governed by the multinomial logit model and that the consideration sets of the different customer segments are disjoint. Bront et al. (2009) analyze the case where the consideration sets overlap and show that even the column generation subproblem in the deterministic linear program of Liu and van Ryzin (2008) is NP‐hard. So even solving the deterministic linear program to get an upper bound on the optimal expected revenue becomes intractable in general.
Bront et al. (2009) and Meissner and Strauss (2011) propose heuristic methods for column generation. On the other hand, Mendez‐Diaz et al. (2011) propose a branch‐and‐cut algorithm to solve the column generation subproblem. Talluri (2011) proposes a concave program for general choice models and describes a way to randomize it. Meissner et al. (2013) build on this concave program and show how it can be strengthened by adding additional constraints. The above mentioned solution methods yield upper bounds on the optimal expected revenue as well as bid prices. There are other ways to obtain bid prices that do not necessarily yield upper bounds. Chaneton and Vulcano (2011) use stochastic approximation to compute bid prices, while Meissner and Strauss (2012a) propose a heuristic method to iteratively improve upon an initial set of bid prices.
Given a set of bid prices, they can be used in different ways to decide which set of itineraries to make available for sale at each point in time. Certain control policies involve solving a combinatorial optimization problem that has the same structure as the column generation subproblem of the deterministic linear program (e.g., Kunnumkal and Topaloglu 2010b, Zhang and Adelman 2009). As a result, they tend to be intractable in general. Other control policies tend to be easier to implement. For example, bid prices can be used in a traditional manner where an itinerary is made available for sale only if its revenue exceeds the sum of the bid prices on the flight legs that it uses (e.g., Chaneton and Vulcano 2011).
The utility maximization criterion to model customer choice behavior has appeared previously in the literature. For example, van Ryzin and Vulcano (2008) and Chaneton and Vulcano (2011) use it to model customer choice in network revenue management while Mahajan and van Ryzin (2001) use it in the context of optimizing retail assortments. The above mentioned papers assume that the random utilities (or equivalently the ranked preference lists) are available as inputs to the optimization model.
Papers concerned with estimating the parameters of the choice model include Farias et al. (2013) and van Ryzin and Vulcano (2011). Farias et al. (2013) consider a choice model where each customer is endowed with a ranked list of preferences among the products and chooses the most preferred product from the offered products. They estimate this choice model under limited data and use a robust approach to predict the revenue generated by offering a given assortment. van Ryzin and Vulcano (2011) use the Expectation‐maximization method to obtain maximum likelihood estimates of the arrival rates of customers and their ranked list of preferences.
As mentioned, our work relies on approximation methods for the network revenue management problem with independent demand. We refer the reader to Talluri and van Ryzin (2004) for a comprehensive review of the revenue management literature. The papers closest to ours are Kunnumkal and Topaloglu (2010a) and Talluri and van Ryzin (1999). Both methods yield upper bounds and bid prices for the independent demand setting. We build on these works to obtain tractable upper bounds and bid prices for the choice network revenue management problem.
In terms of choice models, the paper closest to ours is Chaneton and Vulcano (2011). Chaneton and Vulcano (2011) compute bid prices using stochastic approximation, while we use linear programming. In addition, our methods yield upper bounds on the optimal expected revenues.
Our methods involve computing expected values of functions of high dimensional random variables. As it gets intractable to obtain closed form expressions for the expected values, we resort to Monte Carlo simulation. We generate a sample of the random variables, solve optimization problems over the sample, and approximate the expected value using the sample average. Our methods thus have connections to the sample average approximation (SAA) method for solving stochastic optimization problems (e.g., Kleywegt et al. 2002).
We make the following research contributions in this study. (i) We present a new dynamic programming approximation for the network revenue management problem with customer choice behavior. This dynamic programming formulation is attractive because it allows randomization and the size of its action space is linear in the number of itineraries. (ii) We further build on this randomized dynamic program to obtain tractable approximation methods. As our methods are sampling‐based, we are not constrained by the underlying customer choice model. We are able to handle a variety of choice models; all we require is the ability to generate samples of the customers' utilities for the different alternatives. (iii) We show that our approximation methods generate upper bounds on the optimal expected revenues. Upper bounds are useful when assessing the suboptimality of heuristic control policies. We also show how our methods can be used to obtain bid prices. (iv) Computational experiments indicate that our methods can yield significantly tighter upper bounds and higher revenues than the standard deterministic linear program. Moreover, our methods are fast, easy to implement and scale well with problem size.
The rest of the article is organized as follows. Section 3 describes the network revenue management problem with customer choice behavior and formulates it as a dynamic program. In section 4, we describe the linear program proposed by Liu and van Ryzin (2008). In section 5, we present the randomized dynamic program and in section 6 we describe two tractable approximation methods based on it. The first method is based on relaxing the flight leg capacity constraints whereas the second method solves a perfect hindsight relaxation (PH). Our approximation methods are sampling‐based. We generate samples of the customers' utilities for the different alternatives and solve linear programming problems to decide on the itineraries to offer at each time period on each sample path. We use sample averages to estimate upper bounds and to obtain bid prices. Section 7 presents our computational experiments. The proofs of all the propositions and lemmas are deferred to Appendix S1 in the online Supporting Information.
Problem Formulation
We have an airline network consisting of a set of flight legs that we can use to serve the customers that arrive over time with the intention of purchasing itineraries. We use
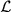
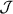
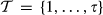
We assume that customer choice is governed by a simple utility maximization principle. That is, the customer's utilities for the different alternatives are random variables and the customer chooses the alternative with the highest utility. We note that the utility maximization principle is essentially equivalent to a choice model where customers have an ordered list of preferences and pick the most preferred alternative from the ones available. We let U
jt
be the random variable which denotes the utility for purchasing itinerary j at time period t and let U
ϕt
be the random variable which denotes the utility for not purchasing any itinerary at time period t. We let
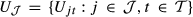
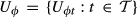
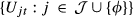
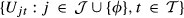
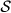
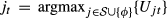
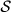
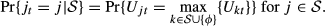
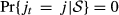
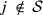
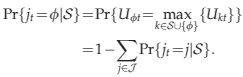
At each time period, we have to decide which itineraries to make available for sale taking into account the state of the remaining leg capacities. Using x
it
to denote the remaining capacity on flight leg i at time period t,
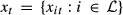
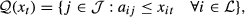
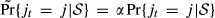
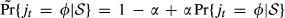
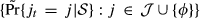
Solving the above dynamic program for practical problem instances becomes difficult for two reasons. One is that the size of the state space increases exponentially with the number of flight legs in the airline network. For, if we let
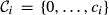
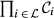
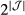
The choice‐based deterministic linear program (CDLP), proposed by Liu and van Ryzin (2008), is an approximation that replaces all random quantities by their expected values. If set
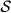
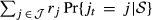
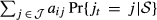
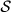
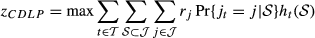
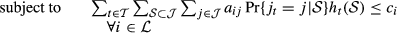
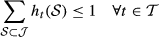
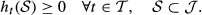
In the above linear program, the decision variable
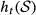
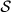
There are two main uses of CDLP. First, Liu and van Ryzin (2008) show that its optimal objective value gives an upper bound on the optimal expected total revenue. That is, we have V
1(c) ≤ z
CDLP
. Second, we can use the dual solution of the CDLP to construct heuristic control policies. Let
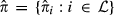
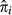
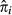
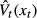
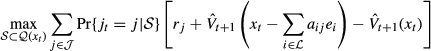
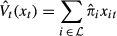
In this section, we present a randomized dynamic program for the network revenue management problem with customer choice behavior. Letting
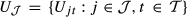
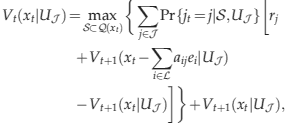
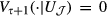
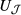
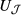
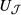
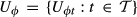
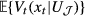
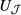
We have
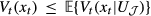
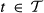
Note that Proposition 1 implies that
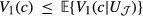
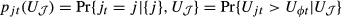
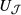
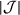
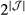
Consider the optimization problem
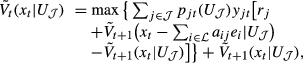
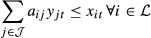
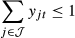
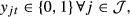
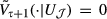
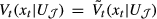
In dynamic program (12)–(15), the decision variable y jt indicates if itinerary j is offered at time period t. More generally, we can interpret y jt as the fraction of time itinerary j is offered at time period t. The first set of constraints ensure that the total capacity consumed on each flight leg does not exceed its available capacity. The second set of constraints ensure that we offer at most one itinerary at each time period. Although the number of decision variables in problem (12)–(15) is manageable, the size of the state space is still exponential in the capacities of the flight legs. On the other hand, noting that the decision variables in problem (12)–(15) are only over the itineraries, this problem has a similar structure to the network revenue management problem with independent demand. This allows us to use approximation ideas developed for the independent demand setting to reduce the complexity of the state space. We present two approximation methods in the following section.
In this section, we describe two tractable relaxations of problem (12)–(15). The first method is based on relaxing the flight leg capacity constraints using Lagrange multipliers. This yields an upper bound on the value function of the randomized dynamic program. We find the set of Lagrange multipliers which yields the tightest upper bound by solving a linear program. This idea is similar to that pursued in Kunnumkal and Topaloglu (2010a) . The second method we propose is based on solving a PH, where we have access to the customers' utilities for not purchasing anything also. This method is similar to the randomized linear programming method of Talluri and van Ryzin (1999). We note that other approximation methods developed for the network revenue management problem with independent demand can also be applied to problem (12)–(15). In this study, we particularly focus on the above‐mentioned two methods because they involve solving linear programs, which can be done quickly and efficiently. Speed is an important factor since we have to resolve the problems for many different samples.
Capacity Relaxation
Letting
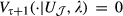
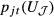
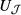
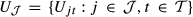
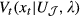
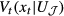
If
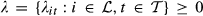
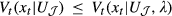
Note that Propositions 1 and 2 together imply that as long as the Lagrange multipliers are nonnegative, we have
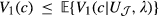
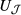
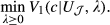
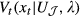
We have
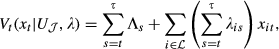
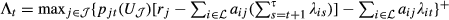
Using the result in Lemma 2, we have that the problem
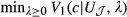
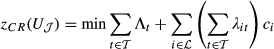
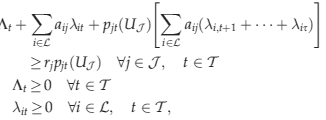
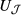
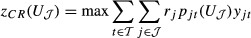
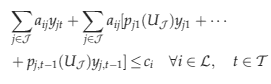
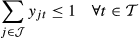
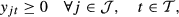
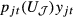
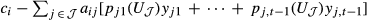
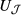
Letting
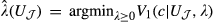
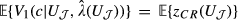
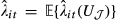
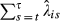
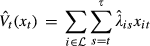
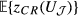
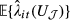
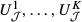
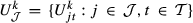
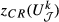
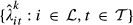
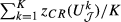
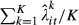
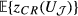
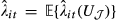
We consider another relaxation of problem (10) where we allow access to the customers' utilities for not purchasing anything as well. In particular, letting
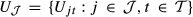
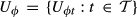
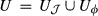
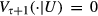
We have
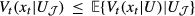
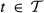
Proposition 3 together with Proposition 1 imply that
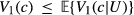
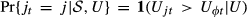
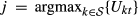
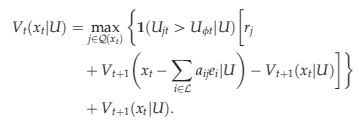
It follows that we can solve problem (22) as the following linear binary integer program:
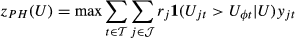
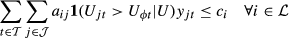
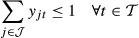
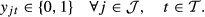
We use
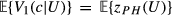
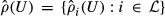
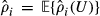
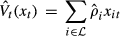
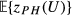
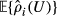
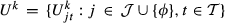
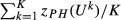
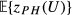
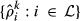
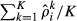
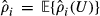
We close this section with a comment on the upper bounds obtained by problems (4)–(7), (17)–(20), and (23)–(26). It turns out that none of the upper bounds uniformly dominates the other. In Appendix S2 of online Supporting Information, we give examples to illustrate this. Intuitively, if there are no capacity constraints on the flight legs, then the CDLP obtains the optimal expected revenue and is therefore tighter than the other two solution methods. On the other hand, comparing the capacity relaxation (CR) and the PH, we expect the CR method to obtain a tighter bound when there is ample capacity on the flight legs and the utilities for purchasing the itineraries
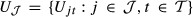
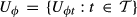
In this section, we numerically compare the upper bounds and expected revenues obtained by four benchmark solution methods. We first describe the benchmark solution methods. After that we present our experimental setup and the results of the numerical study.
Choice‐based deterministic linear program (CDLP): This is the solution method that we describe in Section 4. In our practical implementation, we divide the booking horizon into five equal segments. At the beginning of each segment, we solve problem (4)–(7) after replacing the right‐hand side of Equation 5 with the remaining capacities on the flight legs and the set of time periods
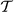
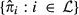
Capacity Relaxation (CR): This is the solution method that we describe in section 6.1. In our practical implementation, we divide the booking horizon into five equal segments. At the beginning of each segment, we solve problem (17)–(20) after replacing the right‐hand side of Equation 18 with the remaining capacities on the flight legs and the set of time periods
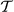
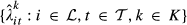
Perfect hindsight relaxation (PH): This is the solution method that we describe in section 6.2. As with CDLP and CR, in our practical implementation, we divide the booking horizon into five equal segments. At the start of each segment, we refresh our bid prices by solving the linear programming relaxation of problem (23)–(26) after replacing the right‐hand side of Equation 24 with the remaining capacities on the flight legs and the set of time periods
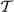
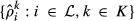
Sample average approximation (SAA): This solution method is similar to PH, but instead of solving a separate optimization problem for each sample path, we link the decisions across the different sample paths by introducing nonanticipativity constraints and solve a single optimization problem across all sample paths. SAA is based on the SAA method for stochastic programs (e.g., Kleywegt et al. 2002). The main motivation is to tighten the upper bounds obtained by, and improve the revenue performance of, PH. SAA generates K samples of the utilities {U
1,…,U
K
} and solves
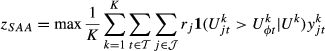
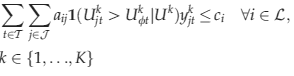
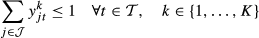
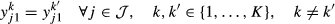
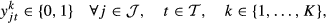
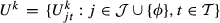
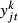
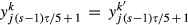
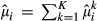
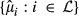
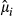
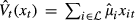
Note that the CDLP, CR, PH, and SAA control policies involve solving problem (8), which is intractable in general. In Appendix S3 of online Supporting Information, we explore simpler alternatives: We consider a traditional bid price control policy which makes an itinerary available for sale provided its revenue exceeds the sum of the bid prices on the flight legs that it uses. We also consider primal policies, which use the primal solutions to the different optimization problems to decide on the offer set. We also note that all the benchmark methods obtain bid prices that are capacity‐independent, in that they do not naturally change with the capacities on the flight legs. It is possible to obtain capacity‐dependent bid prices by using the optimal dual values obtained by the benchmark methods in a dynamic programming decomposition scheme as suggested by Liu and van Ryzin (2008) or Zhang (2011). We test the performance of the dynamic programming decomposition approaches in Appendix S3 of online Supporting Information.
We evaluate the performance of the benchmark solution methods on three groups of test problems. Customer choice is governed by the multinomial logit model in all cases. The first group involves an airline network with a single hub serving multiple spokes and is based on the test problems in Kunnumkal and Topaloglu (2010b). In these test problems, the consideration sets of the different customer segments are disjoint. The second group of test problems also involves an airline network with a single hub serving multiple spokes. However there is some level of overlap in the consideration sets of the different customer segments. The third group of test problems involves parallel flights that operate between the same origin destination pair. The consideration sets of the different customer segments overlap. These test problems are drawn from Bront et al. (2009).
We consider an airline network with a single hub that serves N spokes. Half of the spokes have two flights to the hub, while the remaining half have two flights from the hub. The total number of flights is 2N. Figure 1 shows the structure of the airline network with N = 8. There are four itineraries between each spoke‐to‐hub and hub‐to‐spoke origin destination pair. On the other hand, we have eight itineraries between each spoke‐to‐spoke origin destination pair, so that the total number of itineraries is 2N(N + 2). Half of these itineraries are high fare itineraries while the other half are low fare itineraries. We let γ denote the ratio between the high fare and the low fare.
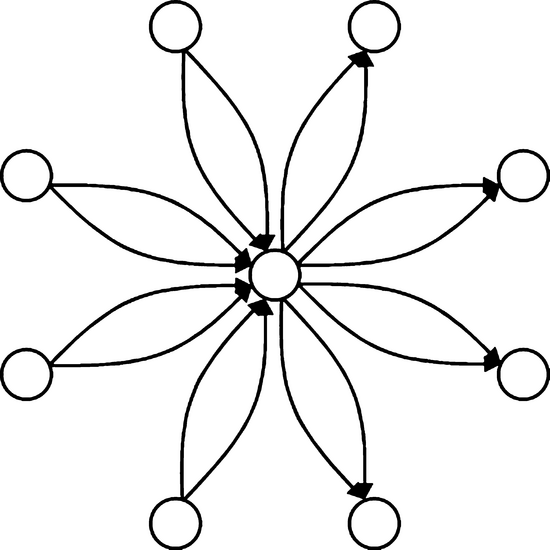
Structure of the Airline Network with a Single Hub and Eight Spokes
Each origin destination pair is associated with a customer segment. We let
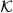
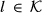
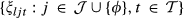
We measure the tightness of the leg capacities in the same manner as Zhang and Adelman (2009). Letting
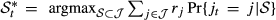
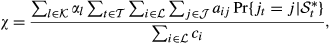
Table 1 compares the upper bounds obtained by CR, PH, SAA, and CDLP. The first column in this table gives the characteristics of the problem by using (N,γ,χ). The second, third, fourth, and fifth columns, respectively, give the upper bounds obtained by CR, PH, SAA, and CDLP. The sixth column gives the percentage gap between the upper bounds obtained by PH and CR, while the last two columns give the percentage gap between the upper bounds obtained by SAA and CR, and CDLP and CR, respectively. CR performs consistently well in our computational experiments and we use CR as a benchmark. In the last three columns, a “✓ ” indicates that the gap is significant at the 95% level, while a “⊙” indicates that the gap is not significant at the 95% level. We observe that CR generates significantly tighter upper bounds than PH, SAA, and CDLP. SAA provides a small but consistent improvement over PH. On average, the upper bounds obtained by CR are about 3% tighter than PH, 2% tighter than SAA, and 9% tighter than CDLP.
Comparison of the Upper Bounds on the Optimal Expected Total Revenue for Test Problems on an Airline Network with a Single Hub and Disjoint Consideration Sets
CR, capacity relaxation; PH, perfect hindsight relaxation; SAA, sample average approximation; CDLP, choice‐based deterministic linear program.
Table 2 compares the total expected revenues obtained by CR, PH, SAA, and CDLP. We evaluate the expected revenues by simulation and use common random numbers in our simulations. The columns have a similar interpretation as in Table 1 except that they give the expected revenues obtained by the four methods. The last three columns include a “✓” if CR does better than the respective solution method at the 95% level, a “×” otherwise, and a “⊙” if there does not exist a statistically significant difference between the two. The average gap between the total expected revenues obtained by CR and CDLP is around 3%. The performance gaps are statistically significant in 10 of the 12 test problems. The performance gap between CR and CDLP seems to increase with the fare ratio and the tightness of the leg capacities. The performance gaps between CR and PH are small in most cases, although we observe one instance where PH performs about 1% better than CR. PH performs significantly better than CDLP. The average gap between the total expected revenues obtained by PH and CDLP is around 3%. The performance of SAA is comparable to that of PH in most cases.
Comparison of the Expected Total Revenues for the Test Problems on an Airline Network with a Single Hub and Disjoint Consideration Sets
CR, capacity relaxation; PH, perfect hindsight relaxation; SAA, sample average approximation; CDLP, choice‐based deterministic linear program.
Figure 2 shows how the upper bounds obtained by CR and PH change with the number of samples K for a representative test problem. We see that both CR and PH are fairly robust to the number of samples. For K ≥ 100, the widths of the confidence intervals are small enough that the differences in the upper bounds are statistically significant at the 95% level.
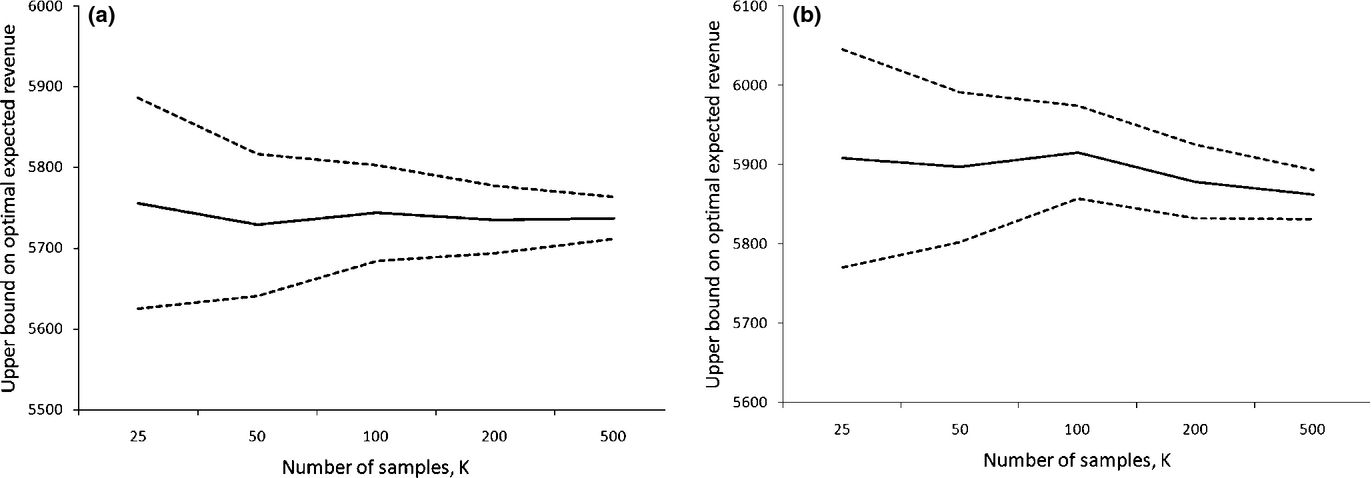
Sensitivity of the Upper Bounds Obtained by Capacity Relaxation (CR) and Perfect Hindsight Relaxation (PH) to the Number of Samples. The Plot on the Left Corresponds to CR, Whereas the Plot on the Right Corresponds to PH. The Solid line Represents the Sample Mean, While the Dashed Lines Represent the 95% Confidence Interval. The Plots are for the Test Problem on an Airline Network with a Single Hub and Disjoint Consideration Segments with Parameters (8, 3, 1.3)
Table 3 gives the CPU seconds required by the four solution methods for different numbers of spokes in the airline network and different numbers of time periods in the booking horizon. All the computational experiments are carried out on a Pentium Core 2 Duo desktop with 3‐GHz CPU and 4‐GB RAM. We use CPLEX 11.2 to solve all the linear programs. We note that since the choice probabilities come from the multinomial logit model and since the consideration sets of the different customer segments are disjoint, we do not require column generation to solve CDLP. Instead, we use the compact formulation of CDLP given in Gallego et al. (2011). The running times of PH, SAA, and CDLP are comparable and is of the order of seconds. On the other hand, the running time of CR is in minutes. We observe that the running time of PH and to some extent CR, is not very sensitive to the number of spokes in the airline network. The reason is that on each sample path, problems (23)–(26) and (17)–(20) require decision variables only for the itineraries in the consideration set of the customer segment that arrives at each time period. For example, if customer segment l t arrives at time period t on a sample path, then we require the decision variables y jt only for the itineraries in the consideration set of segment l t . Since a customer segment is only interested in the set of itineraries connecting the origin destination pair that it is associated with, the sizes of the consideration sets do not increase as we increase the number of spokes in the airline network. As a result, the running times of PH and CR do not change very much.
CPU seconds for CR, PH, SAA, and CDLP as a Function of the Number of Spokes in the Airline Network and the Number of Time Periods in the Booking Horizon
The CPU times are for an airline network with a single hub and disjoint consideration sets. For the part table under section ‘No. of spokes’, the number of time periods is 200. For the part table under section ‘No. of time periods’, the number of spokes is six.
CR, capacity relaxation; PH, perfect hindsight relaxation; SAA, sample average approximation; CDLP, choice‐based deterministic linear program.
We consider the same airline network as in section 7 except that each origin destination pair is now associated with two customer segments. The first segment is interested only in the low fare itineraries, while the second segment considers both the high fare and low fare itineraries connecting the origin destination pair. Within each segment, customer choice is governed by the multinomial logit model. We label our test problems by the triplet (N,γ,χ) ∈ {2,4,6}×{1.5,3}×{1.3,1.6}, which gives us a total of 12 test problems.
Table 4 compares the upper bounds obtained by the four solution methods. CR continues to obtain the tightest upper bound. The upper bound obtained by CR is on average 6% tighter than PH and SAA, and 7% tighter than CDLP. The upper bounds obtained by PH and SAA are comparable, and are about 1% tighter than CDLP on average. There are two test problems where CDLP does about 2% better than PH and SAA. However, PH and SAA obtain tighter upper bounds than CDLP in the remaining test problems and the improvements can be as high as 9%. Table 5 compares the total expected revenues obtained by the four solution methods. The results display the same trends as before. CR, PH, and SAA perform similarly on average and generate significantly higher revenues than CDLP. The average gaps between the total expected revenues obtained by CR and PH, CR and SAA, and CR and CDLP are −0.2%, −0.2%, and 3%, respectively. The tightness of the leg capacities and the size of the network as measured by the number of spokes appear to be two factors which contribute to increasing the performance gaps between CDLP and the remaining solution methods.
Comparison of the Upper Bounds on the Optimal Expected Total Revenue for the Test Problems on an Airline Network with a Single Hub and Overlapping Consideration Sets
CR, capacity relaxation; PH, perfect hindsight relaxation; SAA, sample average approximation; CDLP, choice‐based deterministic linear program.
Comparison of the Expected Total Revenues for the Test Problems on an Airline Network with a Single Hub and Overlapping Consideration Sets
CR, Capacity relaxation; PH, perfect hindsight relaxation; SAA, sample average approximation; CDLP, choice‐based deterministic linear program.
Table 6 gives the CPU seconds required by the four solution methods for different numbers of spokes in the airline network and different numbers of time periods in the booking horizon. Unlike the case with disjoint consideration sets, CDLP now has an exponential number of decision variables and has to be solved using column generation. The column generation subproblem can be formulated as a linear mixed‐integer program (see Bront et al. 2009). We terminate the column generation procedure when the sum of the maximum reduced profits over the time periods is within 5% of the objective value of the restricted problem (see Zhang and Adelman 2009). In contrast, the solution procedure for CR, PH, and SAA remains unchanged. As a result, the running times of CR, PH, and SAA are similar to the case with disjoint consideration sets. On the other hand, the running time of CDLP increases substantially and it can take significantly longer to solve CDLP compared to the other solution methods.
CPU Seconds for CR, PH, SAA, and CDLP as a Function of the Number of Spokes in the Airline Network and the Number of Time Periods in the Booking Horizon
The CPU times are for an airline network with a single hub and overlapping consideration sets. For the part table under section ‘No. of spokes’, the number of time periods is 200. For the part table under section ‘No. of time periods’, the number of spokes is six.
CR, capacity relaxation; PH, perfect hindsight relaxation; SAA, sample average approximation; CDLP, choice‐based deterministic linear program.
Parallel Flights and Overlapping Consideration Sets
We have three parallel flights that operate between the same origin destination pair. The initial capacities on the flights are 30, 50, and 40, respectively. There is a high fare and a low fare itinerary on each flight, so that the total number of itineraries is six. The revenues associated with the three low fare itineraries are 400, 500, and 300, respectively. The high fare itinerary on each flight is twice as expensive as the corresponding low fare itinerary. We have 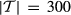
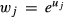
Table 7 compares the upper bounds obtained by CR, PH, SAA, and CDLP. The first column gives the characteristics of the problem by using 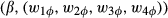
Comparison of the Upper Bounds on the Optimal Expected Total Revenue for the Test Problems on a Parallel Flight Network and Overlapping Consideration Sets
CR, capacity relaxation; PH, perfect hindsight relaxation; SAA, sample average approximation; CDLP, choice‐based deterministic linear program.
Table 8 compares the total expected revenues obtained by CR, PH, SAA, and CDLP. The columns have the same interpretation as in Table 7 except that they give the expected revenues obtained by the four methods. On average, CR and PH perform comparably and generate higher revenues than CDLP. The average gap between the total expected revenues obtained by CR and PH is around 0.5%, while that between CR and CDLP is around 3%. We observe two instances where SAA obtains the highest revenue among the four methods. However, on average it does not perform as well as CR and the average gap between the total expected revenues obtained by CR and SAA is around 1.5%.
Comparison of the Expected Total Revenues for the Test Problems on a Parallel Flight Network and Overlapping Consideration Sets
CR, capacity relaxation; PH, perfect hindsight relaxation; SAA, sample average approximation; CDLP, choice‐based deterministic linear program.
Conclusions
We presented new methods to obtain upper bounds and bid prices for the network revenue management problem with customer choice behavior. The starting point for our methods is a dynamic programming approximation that we solve for a sample of the customers' utilities for the different itineraries. An attractive feature of this randomized dynamic program is that the number of decision variables is linear in the number of itineraries. As a result, we are able to reduce the complexity of the action space. We build on this randomized dynamic program to obtain two tractable approximation methods. The first method that we propose involves relaxing the flight leg capacity constraints using Lagrange multipliers. The second method involves solving a PH. We showed that both methods give upper bounds on the optimal expected total revenue.
Our methods may also be appealing from a practical standpoint as they involve solving only linear programs. Computational experiments indicate that our methods are computationally efficient, and can significantly improve upon the upper bounds and expected revenues obtained by the CDLP. Broadly, we find that our methods are more advantageous for relatively larger test problems with tight leg capacities and large fare ratios. Problems with these characteristics typically tend to be more difficult to solve, because the consequences of offering the “wrong” set of itineraries tend to be more severe. It is therefore encouraging that the CR and PH methods provide good performance for such test problems.
Although the CR method tends to obtain tighter upper bounds than the PH method, it also tends to be more computationally intensive. On the other hand, the revenues obtained by the two methods are mostly comparable. Therefore, the CR method may be more suitable for obtaining tight upper bounds on the optimal expected total revenues, which can be done through an overnight run. On the other hand, the PH method may be more attractive to obtain control policies, where the controls need to be recomputed frequently.
One direction for future research would be to reduce the computational burden of the CR method by building on the dynamic disaggregation ideas described in Vossen and Zhang (2013). Another interesting direction would be to further strengthen the CR and PH using SAA techniques. The SAA method we presented is a first step in that direction. We find that it improves upon the upper bounds and expected revenues at a modest increase in computational time. It would be worth exploring the application of SAA ideas for multi‐stage stochastic optimization problems to the two relaxations and studying the trade‐off in solution quality with computational cost.
Footnotes
Acknowledgments
The author thanks the two anonymous referees, the senior editor, and the department editor whose comments helped substantially improve the paper. The author gratefully acknowledges the financial support of Indian School of Business.