
Abstract
We consider a context‐based dynamic pricing problem of online products, which have low sales. Sales data from Alibaba, a major global online retailer, illustrate the prevalence of low‐sale products. For these products, existing single‐product dynamic pricing algorithms do not work well due to insufficient data samples. To address this challenge, we propose pricing policies that concurrently perform clustering over product demand and set individual pricing decisions on the fly. By clustering data and identifying products that have similar demand patterns, we utilize sales data from products within the same cluster to improve demand estimation for better pricing decisions. We evaluate the algorithms using regret, and the result shows that when product demand functions come from multiple clusters, our algorithms significantly outperform traditional single‐product pricing policies. Numerical experiments using a real data set from Alibaba demonstrate that the proposed policies, compared with several benchmark policies, increase the revenue. The results show that online clustering is an effective approach to tackling dynamic pricing problems associated with low‐sale products.
INTRODUCTION
Over the past several decades, dynamic pricing has been widely adopted by industries, such as retail, airlines, and hotels, with great success (see, e.g., Cross, 1995; Smith et al., 1992). Dynamic pricing has been recognized as an important lever not only for balancing supply and demand, but also for increasing revenue and profit. Recent advances in online retailing and increased availability of online sales data have created opportunities for firms to better use customer information to make pricing decisions, see, for example, the survey paper by den Boer (2015). Indeed, the advances in information technology have made the sales data easily accessible, facilitating the estimation of demand and the adjustment of price in real time. Increasing availability of demand data allows for more knowledge to be gained about the market and customers, as well as the use of advanced analytics tools to make better pricing decisions.
However, in practice, there are often products with low sales amount or user views. For these products, few available data points exist. For example, Tmall Supermarket, a business division of Alibaba, is a large‐scale online store. In contrast to a typical consumer‐to‐consumer (C2C) platform (e.g., Taobao under Alibaba) that has millions of products available, Tmall Supermarket is designed to provide carefully selected high‐quality products to customers. We reviewed the sales data from May to July of 2018 on Tmall Supermarket with nearly 75,000 products offered during this period of time, and they show that more than 16,000 products (21.6% of all products) have a daily average number of unique visitors (UVs) 1 less than 10, and more than 10,000 products (14.3% of all products) have a daily average number of UVs at most 1. Although each low‐sale product alone may have little impact on the company's revenue, the combined sales of all low‐sale products are significant.
Pricing low‐sale products is often challenging due to the limited sales records available for demand estimation. In fast‐evolving markets (e.g., fashion or online advertising), demand data from the distant past may not be useful for predicting customers' purchasing behavior in the near future. Classical statistical estimation theory has shown that data insufficiency leads to large estimation error of the underlying demand, which results in suboptimal pricing decisions. To overcome the issue of data insufficiency, some literature in other applications such as customer segmentation cluster the objects (i.e., customers) using their feature data (see, e.g., Su & Chen, 2015). However, clustering low‐sale products by their features may not always work well. For the following two reasons, in this paper we choose to define clusters based on demand patterns rather than features for low‐sale products: (i) Some products with very similar features may have very different demand, for example, two bags with same/similar appearance may have totally different demand because one belongs to a famous brand and the other is a copycat (only difference is the feature of product brand). (ii) Some (seemingly) completely unrelated products may exhibit same or similar demand pattern. In fact, the research on dynamic pricing of products with little sales data remains relatively unexplored. To the best of our knowledge, there exists no dynamic pricing policy in the literature for low‐sale products that admits theoretical performance guarantee. This paper fills the gap by developing adaptive context‐based dynamic pricing learning algorithms for low‐sale products, and our results show that the algorithms perform well both theoretically and numerically.
Contributions of this paper
Although each low‐sale product only has a few sales records, the total number of low‐sale products is usually quite large. In this paper, we address the challenge of pricing low‐sale products using an important idea from machine learning—clustering. Our starting point is that there are some set of products out there, though we do not know which ones, that share similar underlying demand patterns. For these products, information can be extracted from their collective sales data to improve the estimation of their demand function. The problem is formulated as developing adaptive learning algorithms that identify the products exhibiting similar demand patterns, and extract the hidden information from sales data of seemingly unrelated products to improve the pricing decisions of low‐sale products and increase revenue. As we mentioned earlier in the introduction, our method of clustering is based on similar demand patterns instead of similar product features. The reason is that products with similar features may have different demand.
We consider a generalized linear demand model with arbitrary contextual covariate information about products and develop a learning algorithm that integrates product clustering with pricing decisions. Our policy consists of two phases. The first phase constructs confidence bounds on the distance between clusters, which enables dynamic clustering without any prior knowledge of the cluster structure. The second phase carefully controls the price variation based on the estimated clusters, striking a proper balance between price exploration and revenue maximization by exploiting the cluster structure. Since the pricing part of the algorithm is inspired by semimyopic policy proposed by Keskin and Zeevi (2014), we refer to our algorithm as the Clustered Semi‐Myopic Pricing (CSMP) policy. We first establish the theoretical regret bound of the proposed policy. Specifically, when the demand functions of the products belong to m clusters, where m is smaller than the total number of products (denoted by n), the performance of our algorithm is better than that of existing dynamic pricing policies that treat each product separately. Let T denote the length of the selling season; we show in Theorem 1 that our algorithm achieves the regret of
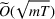
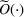
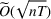
We carry out a thorough numerical experiment using both synthetic data and a real data set from Alibaba consisting of a large number of low‐sale products. Several benchmarks, one treats each product separately, one puts all products into a single cluster, and the other one applies a classical clustering method (K‐means method for illustration), are compared with our algorithms under various scenarios. The numerical results show that our algorithms are effective and their performances are consistent in different scenarios (e.g., with almost static covariates, model misspecification).
It is well known that providing a performance guarantee for a clustering method is challenging due to the nonconvexity of the loss function (e.g., in K‐means), which is why there exists no clustering and pricing policy with theoretical guarantees in the existing literature. This is the first paper to establish the regret bound for a dynamic clustering and pricing policy. Instead of adopting an existing clustering algorithm from the machine learning literature (e.g., K‐means), which usually requires the number of clusters as an input, our algorithms dynamically update the clusters based on the gathered information about customers' purchase behavior. In addition to significantly improving the theoretical performance as compared to classical dynamic pricing algorithms without clustering, our algorithms demonstrate excellent performance in our simulation study.
Literature review
In this subsection, we review some related research from both the revenue management and machine learning literature.
Related literature in dynamic pricing
Due to increasing popularity of online retailing, dynamic pricing has become an active research area in revenue management in the past decade. We only briefly review a few of the most related works and refer the interested readers to den Boer (2015) and Kumar et al. (2018) for comprehensive literature surveys. Earlier work and review of dynamic pricing include Bitran and Caldentey (2003), Elmaghraby and Keskinocak (2003), Gallego and Van Ryzin (1994), and Gallego and Van Ryzin (1997). These papers assume that demand information is known to the retailer a priori and either characterize or compute the optimal pricing decisions. In some retailing industries, such as fast fashion, this assumption may not hold due to the quickly changing market environment. As a result, with the recent development of information technology, combining dynamic pricing with demand learning has attracted much interest in research. Depending on the structure of the underlying demand functions, these works can be roughly divided into two categories: parametric demand models (see, e.g., Bertsimas & Perakis, 2006; Besbes & Zeevi, 2009; Broder & Rusmevichientong, 2012; Carvalho & Puterman, 2005; Chen, Simchi‐Levi, et al., 2022; den Boer & Zwart, 2013; Farias & Van Roy, 2010; Harrison et al., 2012; Keskin & Zeevi, 2014; Wang et al., 2021) and nonparametric demand models (see, e.g., Araman & Caldentey, 2009; Besbes & Zeevi, 2015; Chen et al., 2015, 2021; Chen & Shi, 2019; Chen & Wang, 2022; Cheung et al., 2017; Cohen et al., 2018; Lei et al., 2014; Wang et al., 2014). The aforementioned papers assume that the price is continuous. Other works consider a discrete set of prices, see, for example, Ferreira et al. (2018), and recent studies examine pricing problems with strategic customers (e.g., Chen, Gao, et al., 2022) or in dynamically changing environments (e.g., Besbes et al., 2015; Keskin & Zeevi, 2016)
Dynamic pricing and learning with demand covariates (or contextual information) have received increasing attention in recent years because of their flexibility and clarity in modeling customers and market environment. Research involving this information include, among others, Ban and Keskin (2021), Chen, Owen, et al. (2022), Chen and Gallego (2021), Javanmard and Nazerzadeh (2019), Lobel et al. (2018), Nambiar et al. (2019), and Qiang and Bayati (2016). In many online‐retailing applications, sellers have access to rich covariate information reflecting the current market situation. Moreover, the covariate information is not static but usually evolves over time. Our paper incorporates time‐evolving covariate information into the demand model. In particular, given the observable covariate information of a product, we assume that the customer decision depends on both the selling price and covariates. Although covariates provide richer information for accurate demand estimation, a demand model that incorporates covariate information involves more parameters to be estimated. Therefore, it requires more data for estimation with the presence of covariates, which poses an additional challenge for low‐sale products.
Related literature in clustering for pricing
In the literature, there are some interesting two‐stage methods that first use historical data to determine the cluster structure of demand functions in an offline manner, and then dynamically make pricing decisions for another product by learning which cluster it demand belongs to. Ferreira et al. (2015) study a pricing problem with flash sales on the Rue La La platform. Using historical information and offline optimization, the authors classify the demand of all products into multiple groups, and use demand information for products that did not experience lost sales to estimate demand for products that had lost sales. They construct “demand curves” on the percentage of total sales with respect to the number of hours after the sales event starts, then classify these curves into four clusters. For a sold‐out product, they check which one of the four curves is the closest to its sales behavior and use that to estimate the lost sales. Cheung et al. (2017) consider the single‐product pricing problem, where the demand of the product is assumed to be from one of the K demand functions (called demand hypothesis in that paper). Those K demand functions are assumed to be known, and the decision is to choose which of those functions is the true demand curve of the product. In their field experiment with Groupon, they applied K‐means clustering to historical demand data to generate those K demand functions offline. That is, clustering is conducted offline first using historical data, then dynamic pricing decisions are made in an online fashion for a new product, assuming that its demand is one of the K demand functions. Very recently, Keskin et al. (2020) studied personalized pricing in retail electricity market, where they applied a spectral clustering approach to decide customer types based on customers' features. In this paper, as we discussed earlier, instead of using observable features, we cluster products based on estimated demand patterns.
Related literature in other operations management problems
The method of clustering is quite popular for many operations management problems such as demand forecast for new products and customer segmentation. In the following, we give a brief review of some recent papers on these two topics that are based on data clustering approach.
Demand forecasting for new products is a prevalent yet challenging problem. Since new products at launch have no historical sales data, a commonly used approach is to borrow data from “similar old products” for demand forecasting. To connect the new product with old products, current literature typically use product features. For instance, Baardman et al. (2018) assume a demand function, which is a weighted sum of unknown functions (each representing a cluster) of product features. While in Ban et al. (2018), similar products are predefined such that common demand parameters are estimated using sales data of old products. Hu et al. (2018) investigate the effectiveness of clustering based on product category, features, or time series of demand, respectively.
Customer segmentation is another application of clustering. Jagabathula et al. (2018) assume a general parametric model for customers' features with unknown parameters, and use K‐means clustering to segment customers. Bernstein et al. (2018) consider the dynamic personalized assortment optimization using clustering of customers. They develop a hierarchical Bayesian model for mapping from customer profiles to segments.
Compared with these literature, besides a totally different problem setting, our paper is also different in the approach. First, we consider an online clustering approach with provable performance instead of an offline setting as in Baardman et al. (2018), Ban et al. (2018), Hu et al. (2018), and Jagabathula et al. (2018). Second, we know neither the number of clusters (in contrast to Baardman et al., 2018; Bernstein et al., 2018, that assume known number of clusters), nor the set of products in each cluster (as compared with Ban et al., 2018, who assume known products in each cluster). Finally, we do not assume any specific probabilistic structure on the demand model and clusters (in contrast with Bernstein et al., 2018, who assign and update the probability for a product to belong to some cluster), but define clusters using product neighborhood based on their estimated demand parameters.
Related literature in multiarm bandit problem
A successful dynamic pricing algorithm requires a careful balancing between exploration (i.e., learning the underlying demand function) and exploitation (i.e., making the optimal pricing strategy based on the learned information so far). The exploration–exploitation trade‐off has been extensively investigated in the multi‐armed bandit (MAB) literature; see Bubeck et al. (2012) for a comprehensive literature review. Among the vast MAB literature, there is a line of research on bandit clustering that addresses a different but related problem (see, e.g., Cesa‐Bianchi et al., 2013; Gentile et al., 2014, 2017; Nguyen & Lauw, 2014). The setting is that there is a finite number of arms, which belong to several unknown clusters, where unknown reward functions of arms in each cluster are the same. Under this assumption, the MAB algorithms aim to cluster different arms and learn the reward function for each cluster. The setting of the bandit‐clustering problem is quite different from ours. In the bandit clustering problem, the arms belong to different clusters and the decision for each period is which arm to play. In our setting, the products belong to different clusters and the decision for each period is what prices to charge for all products, and we have a continuum set of prices to choose from for each product. In addition, in contrast to the linear reward in bandit‐clustering problem, the demand functions in our setting follow a generalized linear model (GLM). As will be seen in Section 3, we design a price perturbation strategy based on the estimated cluster, which is very different from the algorithms in bandit‐clustering literature.
Related literature in clustering
We end this section by giving a brief overview of clustering methods in the machine learning literature. To save space, we only discuss several popular clustering methods, and refer the interested reader to Saxena et al. (2017) for a recent literature review on the topic. The first one is called hierarchical clustering (Murtagh, 1983), which iteratively clusters objects (either bottom‐up, from a single object to several big clusters; or top‐down, from a big cluster to single product). Comparable with hierarchical clustering, another class of clustering method is partitional clustering, in which the objects do not have any hierarchical structure, but rather are grouped into different clusters horizontally. Among these clustering methods, K‐means clustering is probably the most well‐known and most widely applied method (see, e.g., MacQueen et al., 1967). Several extensions and modifications of K‐means clustering method have been proposed in the literature, for example, K‐means++ (Arthur & Vassilvitskii, 2007) and fuzzy c‐means clustering (Dunn, 1973). Another important class of clustering method is based on graph theory. For instance, the spectral clustering uses graph Laplacian to help determine clusters (Shi & Malik, 2000; Von Luxburg, 2007). Beside these general methods for clustering, there are many clustering methods for specific problems such as decision tree, neural network, etc. It should be noted that nearly all the clustering methods in the literature are based on offline data. This paper, however, integrates clustering into online learning and decision‐making process.
Organization of the paper
The remainder of this paper is organized as follows. In Section 2, we present the problem formulation. Our main algorithm is presented in Section 3 together with the theoretical results for the algorithm performance. In Section 4, we report the results of several numerical experiments based on both synthetic data and a real data set. We conclude the paper with a discussion about future research in Section 5. Finally, all the technical proofs are presented in the Supporting Information.
PROBLEM FORMULATION
We consider a retailer that sells n products, labeled by
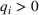

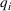
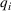
Customers arrive sequentially at time In time t, the retailer observes the covariates Customer searches for product The customer decides whether or not to purchase product
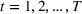
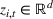
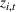
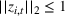
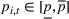
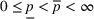
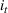
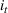
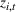

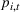


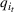
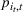
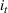
The customer's purchasing decision follows a GLM (see, e.g., McCullagh & Nelder, 1989). That is, given price The commonly used linear and logistic models are special cases of GLM with link function
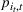
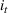
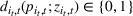
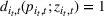
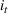
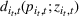
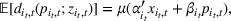
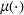
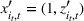
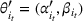
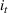
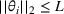

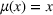
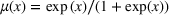
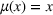
For convenience and with a slight abuse of notation, we write
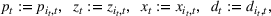
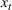
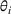
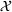
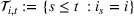
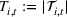
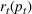
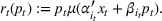
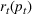
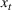
The firm's optimization problem and regret
The firm's goal is to decide the price For consistency with the online pricing literature, see, for example, Ban and Keskin (2021), Chen, Owen, et al. (2022), Javanmard and Nazerzadeh (2019), and Qiang and Bayati (2016), in this paper we use expected revenue as the objective to maximize. However, we point out that all our analyses and results carry over to the objective of profit maximization. That is, if
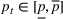
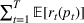
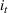

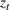

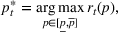
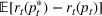
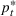
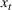
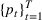
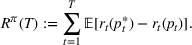
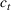
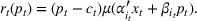
Cluster of products
Two products i1 and i2 are said to be “similar” if they have similar underlying demand functions, that is,
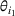
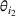
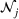
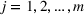
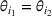
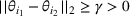
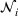
It is important to note that the number of clusters m and each cluster
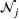
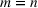
It is also worthwhile to note that our clustering is based on demand parameters/patterns and not on product categories or features, since it is the demand of the products that we want to learn. The clustering approach based on demand is prevalent in the literature (besides Cheung et al., 2017; Ferreira et al., 2015, and the references therein, we also refer to Van Kampen et al., 2012, for a comprehensive review). Clustering based on category/feature similarity is useful in some problems (see, e.g., Su & Chen, 2015, investigate customer segmentation using features of clicking data), but it does not apply to our setting because, for instance, products with similar feature for different brands may have very different demand (see our earlier discussion in the introduction). Moreover, in our model, motivated by Alibaba's business the product feature For its application to the online pricing problem, the contextual information in our model is about the product. That is, at the beginning of each period, the firm observes the contextual information about each product, then determines the pricing decision for the product, and then the arriving customer makes a purchasing decision. We point out that our algorithm and result apply equally to personalized pricing in which the contextual information is about the customer. That is, a customer arrives (e.g., logging on the website) and reveals his/her contextual information, and then the firm makes a pricing decision based on that information. The objective is to make personalized pricing decisions to maximize total revenue (see, e.g., Ban & Keskin, 2021).
PRICING POLICY AND MAIN RESULTS
In this section, we discuss the specifics of the learning algorithm, its theoretical performance, and a sketch of its proof. Specifically, we describe the policy procedure and discuss its intuitions in Section 3.1 before presenting its regret and outlining the proof in Section 3.2.
Description of the pricing policy
Our policy consists of two phases for each period



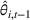
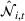
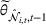
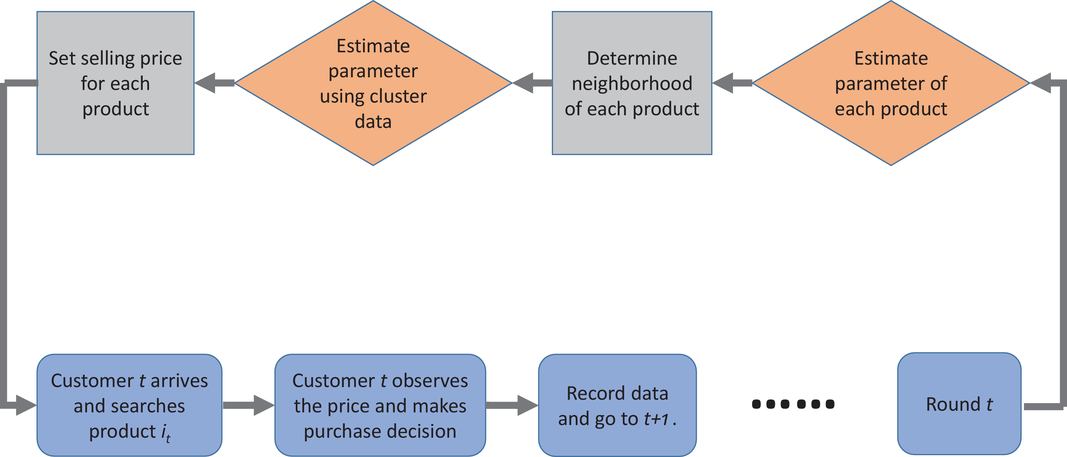
Flow chart of the algorithm
The CSMP Algorithm
In the following, we discuss the parameter estimation of GLM demand functions and the construction of a neighborhood in detail.
Parameter estimation of GLM
As shown in Figure 1, the parameter estimation is an important part of our policy construction. We adopt the classical maximum likelihood estimation (MLE) method for parameter estimation (see McCullagh & Nelder, 1989). For completeness, we briefly describe the MLE method here. Let 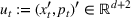
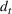
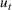
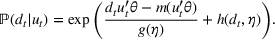
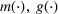
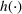
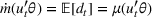
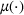
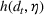
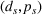
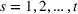
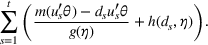

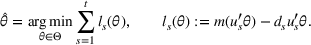
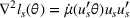
Determining the neighborhood of each product
The first phase of our policy determines which products to include in the neighborhood of each product 
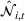
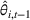

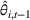
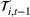

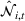
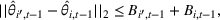
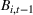
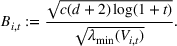
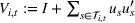

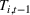
Setting the price of each product
Once we define the (estimated) neighborhood 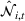

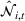
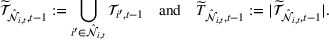
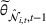
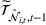
To decide on the price, we first compute 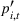
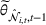
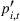
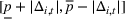
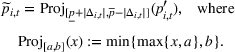
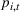
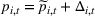
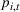
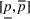
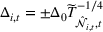
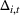
We note that this pricing scheme belongs to the class of semimyopic pricing (SMP) policies defined in Keskin and Zeevi (2014). Since our policy combines clustering with SMP, we refer to it as the CSMP algorithm.
We briefly discuss each step of the algorithm and the intuition behind the theoretical performance. For Steps 1 and 2, the main purpose is to identify the correct neighborhood of the product searched in period t; that is, 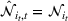
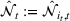
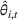
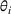

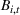
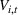
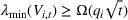
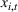
Following the discussion above, when 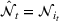
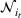
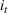
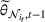
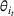
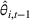
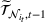
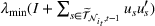
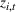
The design of the CSMP algorithm depends critically on two things. First, by taking an appropriate price perturbation in Step 4, we balance the exploration and exploitation. If the perturbation is too much, even though it helps to achieve good parameter estimation, it may lead to loss of revenue (due to purposely charging the wrong price). Second, the sequence of demand covariates 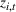
Theoretical performance of the CSMP algorithm
This section presents the regret of the CSMP pricing policy. Before proceeding to the main result, we first make some technical assumptions that will be needed for the theorem.
The expected revenue function There exist some constants
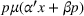
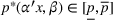
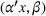
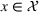
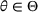
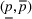
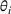

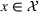
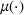
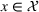
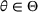
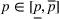
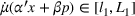
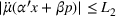
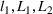
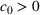
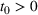


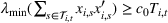
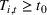
The first assumption A‐1 is a standard regularity condition on expected revenue, which is prevalent in the pricing literature (see, e.g., Broder & Rusmevichientong, 2012). The second assumption A‐2 states that the purchasing probability will increase if and only if the utility 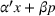
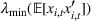
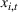
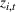
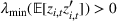
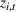
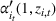
Under Assumption A, we have the following theoretical result on the regret of the CSMP algorithm. Let input parameter 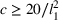
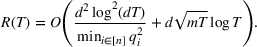
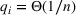

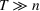
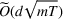
Here, we briefly discuss the very high‐level ideas of proving Theorem 1, with the technical details deferred to the Supporting Information. One key step of proving the main part of the regret 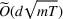
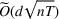
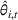
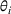
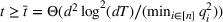
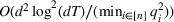
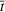
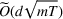
Although the key ideas are quite simple, the proofs are technical and involved, which differ from the existing literature. For instance, compared with the bandit with clustering literature (see, e.g., Cesa‐Bianchi et al., 2013; Gentile et al., 2014, 2017; Nguyen & Lauw, 2014), our action set (prices) is continuous instead of finite and we have to exploit unique structure of revenue function (e.g., Assumption A) by using price perturbation techniques. Moreover, we do not assume stochasticity of context 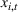
We have a number of remarks about the CSMP algorithm and the result on regret, following in order. Our pricing policy achieves the regret 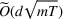
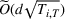

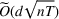
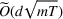
To obtain a lower bound for the regret of our problem, we consider a special case of our model in which the decision maker knows the underlying true clusters Lower bound of regret
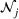
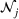
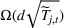
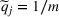

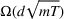
When n is large, the first term in our regret bound Improving the regret for large n
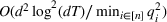
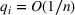

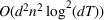
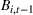
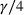
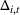
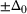
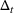
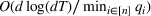
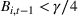
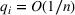

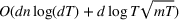
Our theoretical development assumes that products within the same cluster have exactly the same parameters One relevant stream of literature to this setting is the so‐called bandit with model mis‐specification, which assumes that the reward function is mis‐specified with error ε (see, e.g., Crammer & Gentile, 2013; Foster & Rakhlin, 2020; Foster et al., 2020; Ghosh et al., 2017; Lattimore et al., 2020), and they show that the part of regret related to ε has to be Relaxing the cluster assumption
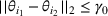
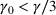
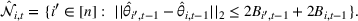
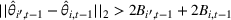
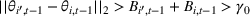
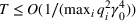
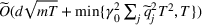
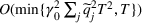
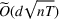
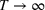
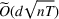
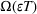
SIMULATION RESULTS WITH SYNTHETIC AND REAL DATA
This section provides the simulation experiment results for algorithm CSMP. First, we conduct a simulation study using synthetic data in Section 4.1 to illustrate the effectiveness and robustness of our algorithms against several benchmark approaches. Second, the simulation results using a real data set from Alibaba are provided in Section 4.2. Finally, we summarize all numerical experiment results in Section 4.3.
Simulation using synthetic data
In this section, we demonstrate the effectiveness of our algorithms using some synthetic data simulation. We first show the performance of CSMP against several benchmark algorithms. Then, several robustness tests are conducted for CSMP. The first test is for the case when clustering assumption is violated (i.e., parameters within the same cluster are slightly different). The second test is when the demand covariates 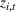
We shall compare the performance of our algorithms with the following benchmarks: The SMP algorithm, which treats each product independently (IND), and we refer to it as SMP‐IND. The SMP algorithm, which treats all products as one (ONE) single cluster, and we refer to the algorithm as SMP‐ONE. The CSMP with K‐means Clustering (CSMP‐KMeans), which uses K‐means clustering for product clustering in Step 2 of CSMP.
The first two benchmarks are natural special cases of our algorithm. Algorithm SMP‐IND skips the clustering step in our algorithm and always sets the neighborhood as 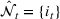
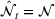

Logistic demand with clusters
For illustration of a GLM demand, we simulate using a logistic function. We set the time horizon 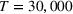
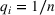

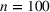
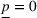
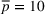
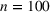
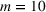
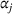
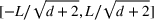
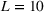
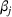
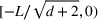
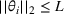
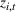
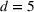
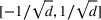
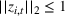
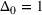
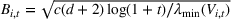
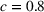
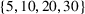
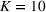
To evaluate the performance of algorithms, we adopt both the cumulative regret in (6) and the percentage revenue loss defined by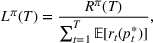
For each experiment, we conduct 30 independent runs and take their average as the output. We also output the standard deviation of percentage revenue loss for all policies in Table 1. It can be seen that our policy CSMP has quite small standard deviation, so we will neglect standard deviation results in other experiments.
Standard deviation (%) of percentage revenue loss corresponding to different time periods for logistic demand with 10 clusters
We recognize that a more appropriate measure for evaluating an algorithm is the regret (and percentage of loss) of expected total profit (instead of expected total revenue). We choose the latter for the following reasons. First, it is consistent with the objective of this paper, which is the choice of the existing literature. Second, it is revenue, not profit, that is being evaluated at our industry partner, Alibaba. Third, even if we wish to measure it using profit, the cost data of products are not available to us, since the true costs depend on such critical things as terms of contracts with suppliers, that are confidential information.
The results are shown in Figure 2. According to this figure, our algorithm CSMP outperforms all the benchmarks except for CSMP‐KMeans when 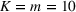
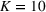
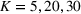
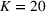
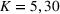
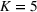
Mean and standard deviation (%) of percentage revenue loss of CSMP (logistic demand with 10 clusters) with different parameters c
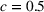
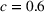
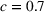
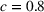
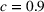
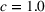
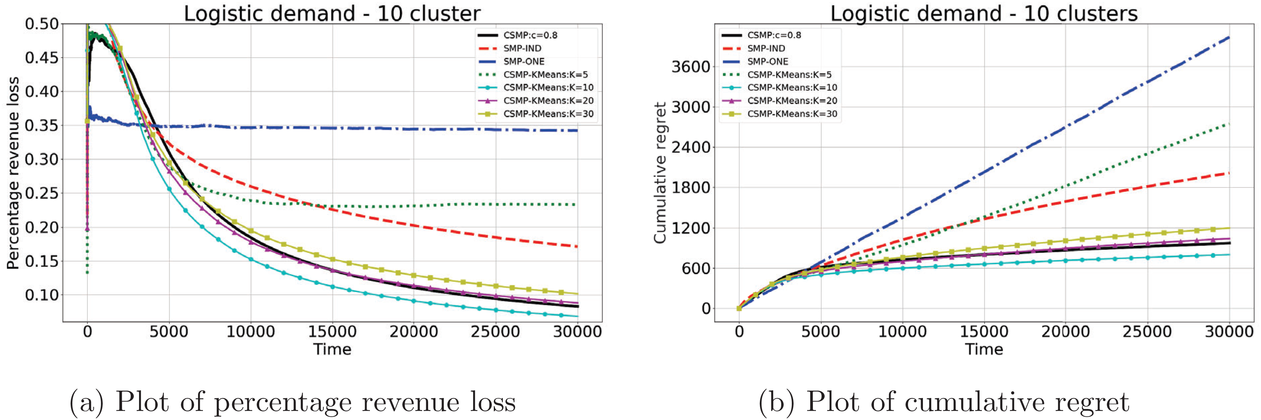
Performance of different policies for logistic demand with 10 clusters. The graph on the left‐hand side shows the percentage revenue loss of all algorithms, and the graph on the right‐hand side shows the cumulative regrets for each algorithm
Logistic demand with relaxed clusters
As we discussed in Section 3.2, strict clustering assumption might not hold and sometimes products within the same cluster are slightly different. This experiment tests the robustness of CSMP when parameters of products in the same cluster are slightly different. To this end, after we generate the 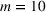
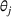
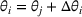
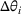
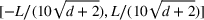
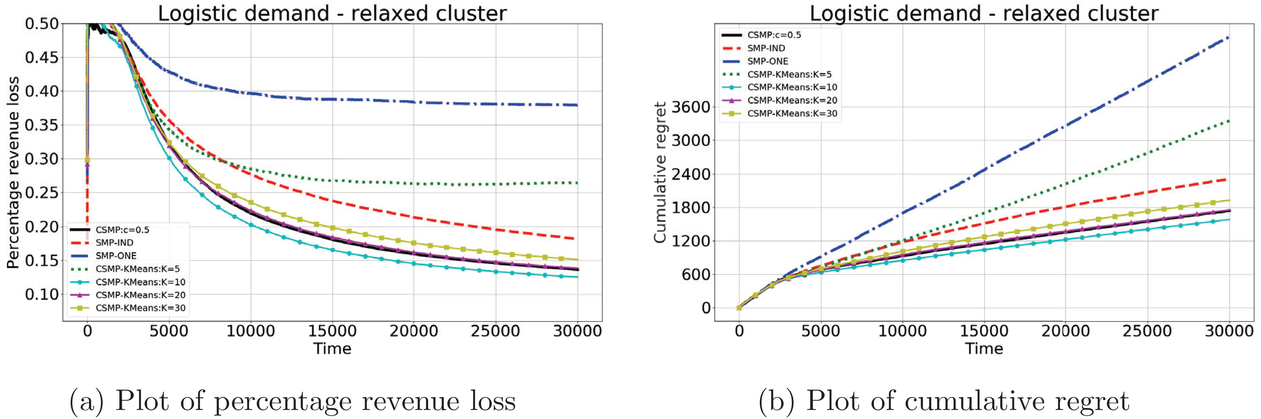
Performance of different policies for logistic demand with relaxed clusters
Logistic demand with almost static features
As we discussed after Assumption A‐3, in some applications there might be features that have little variations (nearly static). We next test the robustness of our algorithm CSMP when the feature variations are small. To this end, we assume that one feature in 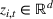

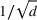
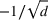
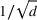
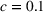
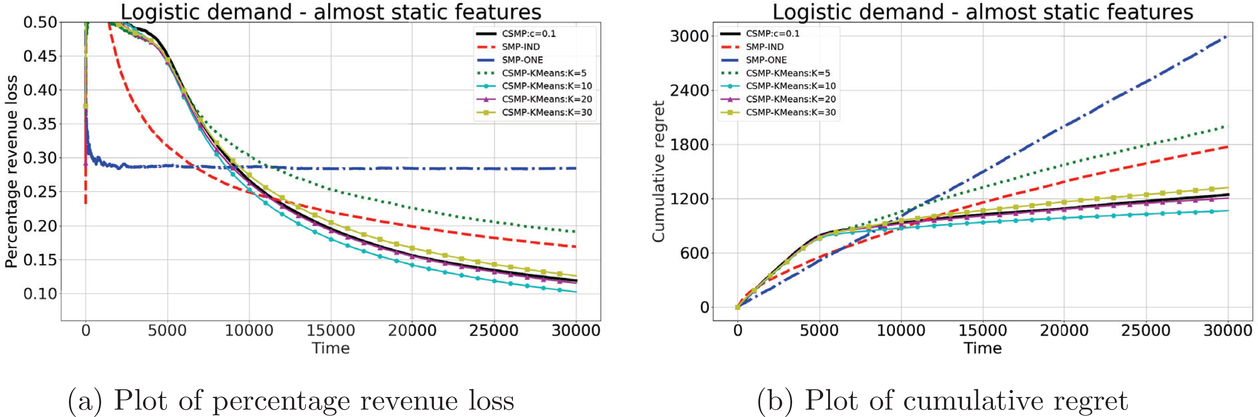
Performance of different policies for logistic demand with 10 clusters and almost static features
Logistic demand with model misspecification
In real applications, it may happen that the demand model is misspecified. In this experiment, we consider a misspecified logistic demand model. Specifically, we let the expected demand of product i be 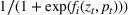
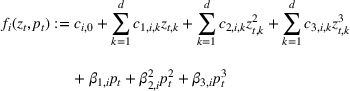
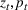
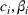
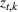
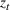
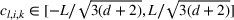
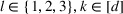
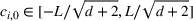
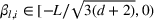
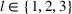
To test the robustness of the misspecified CSMP, it is compared with CSMP, which correctly specifies the demand model. We call the benchmark the CSMP‐Oracle. The numerical results are summarized in Figure 5. As seen, when compared with the oracle, the misspecified CSMP has slightly worse performance as expected. But the overall difference in percentage revenue loss is only 3.48%, showing that our algorithm CSMP is rather robust with such a model misspecification.
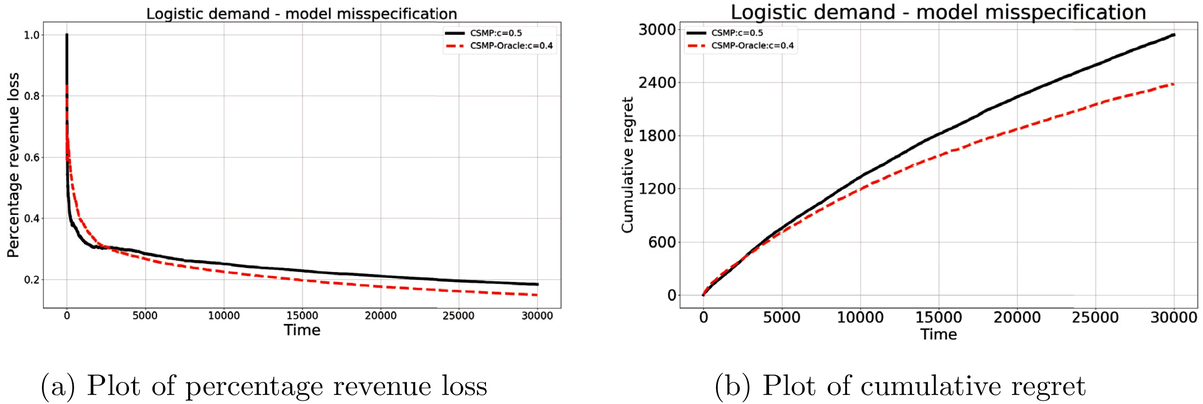
Performance of CSMP with (misspecified) logistic demand versus the oracle
Simulation using real data from Alibaba
This section presents the results of our algorithms (for illustration, we use CSMP with logistic demand) and other benchmarks using a real data set provided by Alibaba. To better simulate the real demand process, we fit the demand data to create a sophisticated ground truth model (hence our algorithm CSMP may have a model misspecification). Before presenting the results, we introduce the data set and preprocessing of the data.
The data set
To motivate our study of pricing for low‐sale products, we extract sales data from May 29, 2018, to July 28, 2018. During this period, nearly 75,000 products were offered by Tmall Supermarket. There are more than 21.6% (i.e., 16,000) products with average numbers of daily unique visits less than 10. Among all these low‐sale products, Alibaba provided us with a test data set comprising 100 products that have at least one sale during the 61‐day period, and at least two prices charged with each price offered to more than 10% of all customers. Because these selected products have relatively sufficient variation of prices and different observations of customers' purchases, demand parameters can be estimated quite accurately using the sales data in the data set. As the focus of this paper is on single‐product pricing where the demand of each product depends on its own price, this numerical study using the real data set is also conducted under this setting. In Section EC.3 in the Supporting Information, we conduct a data analysis to show that this assumption is indeed reasonable for this data set.
For the features of products, we are provided by Alibaba with five features (hence average gross merchandise volume (GMV, i.e., product revenue) in past 30 days, average demand in past 30 days, average number of unique buyers (UBs, i.e., unique IP, which makes the purchase) in past 30 days, average number of UVs in past 30 days, and average number of independent product views (IPVs, i.e., total number of views on the product, including repetitive views from the same user) in past 30 days.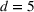
These features are selected by Alibaba's feature engineering team 2 (via a recursive feature elimination approach from a raw set of features). Note that these features are not exogenous, since features in the future can be affected by current pricing decision. Such endogenous features are often used in the demand forecasting literature. For instance, a time‐series model uses past demand to predict future demand (see, e.g., Brown, 1959); an artificial neural network (ANN) model uses historical demand data of composite products as features for demand prediction (Chang et al., 2005). In the pricing literature, some endogenous features have also been used. For example, in Ban and Keskin (2021) and Bastani et al. (2022), their model features include auto loan data, for example, competitors' rate, that are affected by the rate offered by the decision maker (the auto loan company). Incorporating the impact of pricing decisions on features leads to challenging dynamic programming problem with partial information. Hence, features are considered as given and we only optimize for current period (i.e., ignoring the long‐run effect of the current pricing decision).
To understand the data and features better, we provide a summary statistics on the data and feature. First, we calculated the number of prices charged during the time horizon, average demand per day, average UV per day, and average IPV per day, for each one of the selected 100 products. Table 3 summarizes the mean and standard deviation of each of the data. Then, to understand the variation of features, we calculated the standard deviation of each of the five features of every product. In Table 4 we summarize the mean and standard deviation of feature variations of all products.
Summary statistics of average data of the 100 products
Summary statistics of feature variation of the 100 products
To run simulation using the real data set, we first create a ground truth model for the demand. We consider two ground truth models in this simulation study. The first one is the commonly used logistic demand function (hence no model misspecification for our algorithm CSMP), and the second is a random forest model (as used in simulation study of Nambiar et al., 2019, hence there is model misspecification for CSMP). We use the demand data of each product to fit these two demand models, and then apply them to simulate the demand process. To test the accuracy of these two demand models, we calculated the average receiver operating characteristic area under the curve (ROC‐AUC) score (among the selected products) of the logistic and random forest model, respectively. The results show that the ROC‐AUC score of the random forest model is 11.7% higher than that of the logistic model (thus the random forest model fits the reality better).
We want to generate customer's arrival at each time t, that is, the product 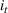
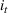
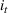
Numerical results for the algorithms
We first provide the specifications of the parameters in the CSMP algorithm in Algorithm 1. The confidence bound The price lower bound of each product is 50% lower than its lowest price during the 61‐day period, and the price upper bound is 50% higher than its highest price during this period of time. The basic price perturbation parameter Δ0 of each product is set as the length of price range divided by 4, that is,
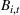
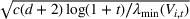
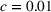
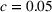
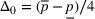
For benchmark algorithms, they are the same as those in the previous subsection, with CSMP‐KMeans have 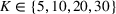
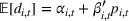
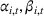
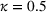
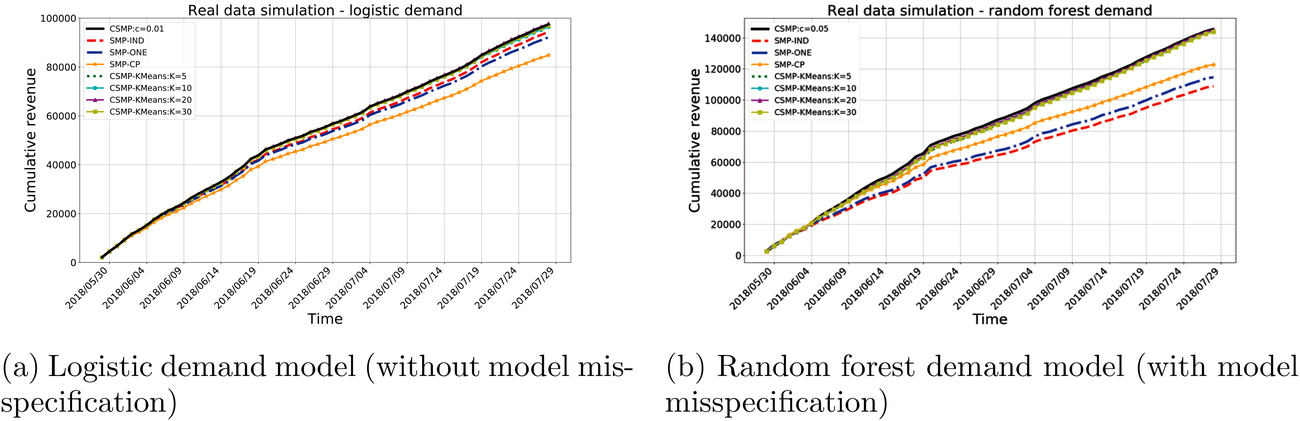
Plot of cumulative revenue over different dates for two demand models
It can be seen that all the methods using clustering have better performance, and their performances are comparable. It is interesting to note that for clustering using K‐means method, their performances with different value of K are actually quite close. Finally, it is observed that the advantage of using clustering with random forest model (i.e., misspecified model) is more than that with logistic model.
Summary of numerical experiments
In this section we first present the simulation results using synthetic data under various scenarios to test the effectiveness and robustness of our algorithms, then we present the simulation results with real data from Alibaba using a more sophisticated ground truth demand model (for a more realistic simulation and robustness test under model misspecification). The main findings from the numerical study are summarized as follows. In all the numerical results, pricing with clustering (either using our method in CSMP or classical K‐means clustering with appropriate choice of K) outperforms the benchmarks of applying single‐product pricing algorithm on each product or naively putting all products into a single cluster. Dynamic pricing with K‐means clustering method sometimes works as effectively as (and at times even better than) our algorithm CSMP. But its performance depends on the choice of the number of clusters K, which is unknown to the decision maker. The CSMP algorithm is quite robust under different scenarios: slightly different demand parameters within the same cluster, near static or slowly changing features, and misspecified ground truth demand model.
CONCLUSION
With the rapid development of e‐commerce, data‐driven dynamic pricing is becoming increasingly important due to the dynamic market environment and easy access to online sales data. While there is abundant literature on dynamic pricing of normal products, the pricing of products with low sales received little attention. The data from Alibaba Group show that the number of such low‐sale products is large, and that even though the demand for each low‐sale product is small, the total revenue for all the low‐sale products is quite significant. In this paper, we present data clustering and dynamic pricing algorithms to address this challenging problem. We believe that this paper is the first to integrate online clustering learning in dynamic pricing of low‐sale products.
A learning algorithm is proposed in this paper, which learns the demand and decides product clustering simultaneously on the fly. We have established the regret bound for this under mild technical conditions. Moreover, we test our algorithms on a real data set from Alibaba Group by simulating the demand function. Numerical results show that our algorithm outperforms the benchmarks, where one either considers all products separately, or treats all products as a single cluster.
There are several possible future research directions. The first one is an in‐depth study of the method for product clustering (e.g., Gentile et al., 2014; Nguyen & Lauw, 2014). Second, to highlight the benefit of clustering techniques for low‐sale products, in this paper we study a dynamic pricing problem with sufficient inventory. One extension is to apply the clustering method for the revenue management problem with inventory constraint. Third, we believe that it will be interesting to include substitutability/complementarity of products and even assortment decisions.
Footnotes
ACKNOWLEDGMENTS
We thank the department editor, senior editor, and anonymous referees for their detailed and constructive comments that have helped to considerably improve the exposition of this paper.
1
A terminology used within Alibaba to represent a unique user login identification.
2
We requested to include some other features, such as number/score of customer ratings and competitor's price on similar product, but were unable to obtain such data due to technical reasons.