
Abstract
Background:
To compare the readability of patient education materials (PEMs) on rhinologic conditions and procedures from the American Rhinologic Society (ARS) with those generated by large language models (LLMs).
Methods:
Forty-one PEMs from the ARS were retrieved. Readability was assessed through the Flesch Kincaid Reading Ease (FKRE) and Flesch Kincaid Grade Level (FKGL), in which higher FKRE and lower FKGL scores indicate better readability. Three LLMs—ChatGPT 4.o, Google Gemini, and Microsoft Copilot—were then used to translate each ARS PEM to the recommended sixth-grade reading level. Readability scores were calculated and compared for each translated PEM.
Results:
A total of 164 PEMs were evaluated, including 123 generated by LLMs. The original ARS PEMs had a mean FKGL of 10.28, while AI-generated PEMs demonstrated significantly better readability, with a mean FKGL of 8.6 (P < .0001). Among the AI platforms, Gemini was the most easily readable, reaching a mean FKGL of 7.5 and FKRE of 65.5.
Conclusion:
LLMs improved the readability of PEMs, potentially enhancing accessibility to medical information for diverse populations. Despite these findings, healthcare providers and patients should cautiously appraise LLM-generated content, particularly for rhinology conditions and procedures.
Level of Evidence: N/A.
Keywords
Introduction
Artificial intelligence (AI) platforms are reshaping several aspects of healthcare, with generative large language models (LLM) emerging as influential new tools. Generative LLMs such as ChatGPT (Open AI, San Francisco, CA, USA), Google Gemini (formerly known as Bard; Google, Mountain View, CA, USA), and Microsoft Copilot (Microsoft, Redmond, WA, USA), can interact with users in life-like conversations and have vast applications in healthcare. Notably, the ability of LLMs to respond to common patient questions, succeed on resident exams, and generate post-operative instructions is being explored with encouraging results.1 -4 New possibilities for AI platforms to aid providers in creating patient education materials (PEMs) are developing, especially in specialized areas of medicine such as otolaryngology.
According to the Healthy People 2030 campaign, health literacy (HL) refers to the extent to which people can find, interpret, and utilize information to guide their healthcare-related decisions. 5 Hence, appropriate HL is crucial for empowering patients in their healthcare decisions and optimizing surgical outcomes.6,7 Yet, in the United States, nearly 47% of adults have limited literacy skills, which correlates with increased hospitalizations, higher healthcare costs, and poorer ability to comprehend labels.8 -10 Rhinology, a subspecialty encompassing a range of complex pathology and treatments, requires PEMs that are comprehensible and concise. From understanding complicated conditions to managing potential complications, patients need clear guidance about what to expect in their treatment course to effectively participate in their care. While the use of PEMs can lead to better understanding, compliance, and patient outcomes, traditional PEMs often exceed the recommended readability levels, posing challenges for many patients.11 -13
LLMs appear to be a promising solution to this challenge. Emerging evidence suggests that these tools can effectively translate complex medical information into clear, accessible language while maintaining accuracy. This can, in effect, transform patient education and help providers empower their patients. 14 Despite the growing use of AI in otolaryngology, there is limited data regarding its effectiveness in creating specialized PEMs for rhinology. Swisher et al 15 demonstrated that the understandability and actionability of patient rhinology handouts can be improved using ChatGPT-4. However, there are no comparative analyses of multiple AI platforms in creating PEMs for both rhinologic procedures and conditions. We aimed to eliminate this gap in the literature and compare PEMs from the American Rhinologic Society (ARS) against PEMs generated by LLMs ChatGPT 4.o, Copilot, and Gemini.
Materials and Methods
Native Patient Education Materials
PEMs on rhinology were identified by accessing the ARS website. Forty-one PEMS were retrieved, across the following categories: Basics (Anatomy, Physiology, and Endoscopy), Nasal Disorders, Sinusitis and Related Disorders, Medical Treatments, Nasal Surgery, Sinus Surgery, and Disorders and Surgery Relating to the Eye. A portable document format (PDF) of each PEM was exported.
Artificial Intelligence Generated Patient Educational Materials
Three major AI platforms, ChatGPT 4.o, Gemini, and Copilot, were accessed (October 2024). The PDFs of all PEMs were then pasted into each AI platform after the prompt, “translate to a sixth-grade reading level.”
Readability Assessment
According to the American Medical Association (AMA) and National Institutes of Health (NIH), PEMs should be written at or below the sixth-grade reading level.16,17 In this study, readability was determined with 2 well-validated readability measures, the Flesch Kincaid Grade Level (FKGL) and Flesch Kincaid Reading Ease (FKRE). FKRE is a measure of readability graded on a scale from 0 to 100, where 0 is considered unreadable and 100 is very easy to read. 18 FKRE is based on the average number of syllables per word and the average number of words per sentence. 19 A FKRE score of 80 has been deemed acceptable in prior studies. 20 Similarly, FKGL represents the average United States grade level that a person should have completed to comprehend the text and is measured by the total number of words, sentences, and syllables. 21 FKGL ranges from 0 to 18, with 18 being the most difficult level. An FKGL at the sixth-grade reading level correlates to a score of 6 to 6.9. 22 The FKGL and FKRE of each PEM (Original and AI-generated) were measured using an online readability tool, WebFx and recorded in a shared Microsoft Excel document. 23
Statistical Analysis
The mean FKRE and FKGL scores for ARS, the combined AI platforms, and the individual AI-platforms were calculated. The difference in means was compared using a 2-sample t-test. All analysis was conducted at the 95% confidence level with P-values less than .05 considered statistically significant. All statistical analysis was performed using IBM SPSS.
Results
A total of 164 PEMs, of which 123 were generated by AI platforms (41 from each platform), were evaluated for FKRE and FKGL. Table 1 displays sample responses from each AI platform for the topic, “Endoscopic Sinus Surgery.” Overall the AI platforms were able to significantly reduce the FKRE and FKGL of the ARS documents, indicating that they are more easily readable. The mean FKGL of the ARS PEMs was significantly higher than that of the AI translations (10.28 ± 1.38 vs 8.61 ± 1.77 (Mean Difference = 1.67, P < .0001), signifying that they are more difficult to understand. Similarly, the mean FKRE of the ARS PEMs was significantly lower than that of the AI-translations, reiterating that they are more difficult to understand (48.22 ± 8.91 vs 59.82 ± 11.18 (Mean Difference = 11.6, P < .0001). These values reflect that AI simplified the readability of the resources from a high school to a middle school level.
Sample Responses From Each Artificial Intelligence Platform for the Topic, Endoscopic Sinus Surgery.

When analyzing each AI platform individually, the mean FKGL of ChatGPT, Gemini, and Copilot was 9.10 ± 1.34, 7.48 ± 1.86, and 9.24 ± 1.68, respectively. ChatGPT had a significantly higher (less readable) FKGL than Gemini (Mean Difference = 1.63, P < .0001). Similarly, Copilot had a significantly higher FKGL than Gemini (Mean Difference = 1.76 [0.98-2.54], P < .0001). There was no significant difference in FKGL between ChatGPT and Copilot (Mean Difference = 0.14, P = .68). Overall, Gemini produced responses with a significantly lower FKGL than both ChatGPT and Copilot, correlating to easier comprehension and overall more patient-friendly resources.
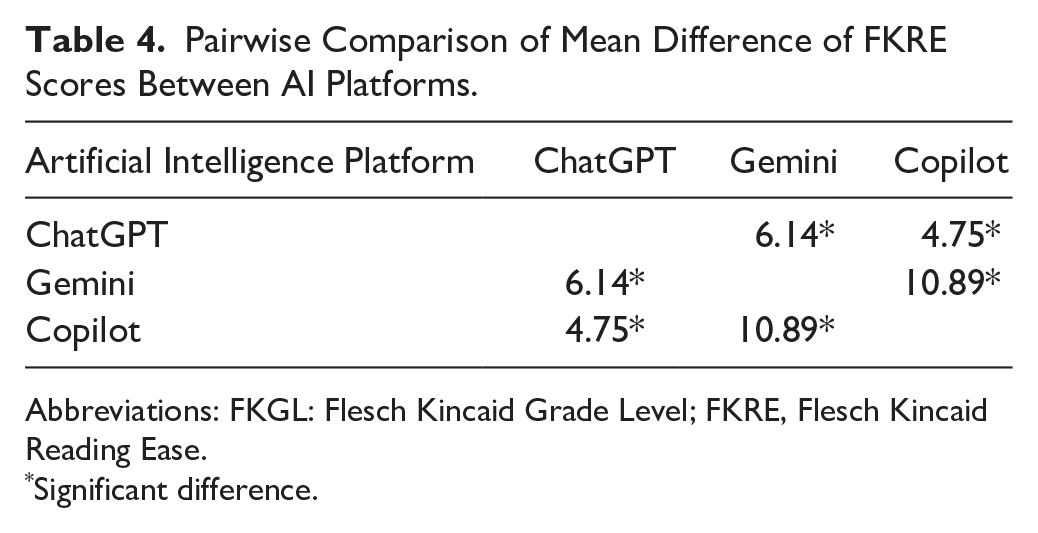
ChatGPT, Gemini, and Copilot had a mean FKRE of 59.36 ± 7.74, 65.50 ± 11.99, 54.61 ± 10.78, respectively. Gemini had a significantly higher (more easily readable) FKRE than ChatGPT (Mean Difference = 6.14, P = .007). Sub-analysis of ChatGPT and Copilot showed that the FKRE score of Copilot was significantly higher than that of ChatGPT (Mean Difference = 4.75, P = .02). Gemini had a significantly higher FKRE (more readable) than Copilot (Mean Difference = 10.89, P < .0001). Overall, Gemini produced responses with a significantly higher FKRE than both ChatGPT and Copilot. A summary of FKGL and FKRE results is shown in Figure 1.
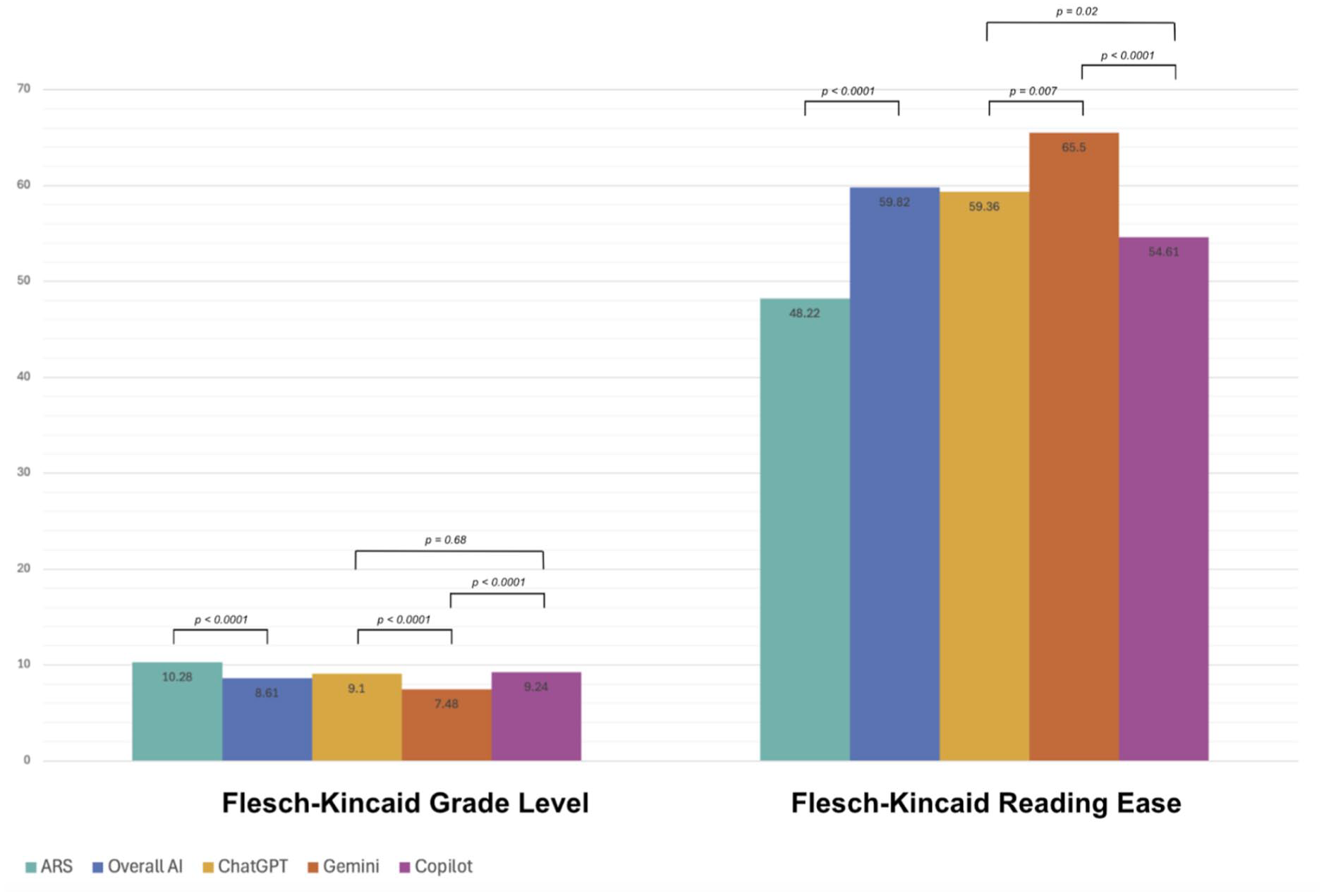
Flesch-Kincaid grade level and Flesch-Kincaid reading ease of materials from the ARS and artificial intelligence platforms.
Figure 2 displays the FKGL and FKRE for the original ARS sheets and from the AI-generated sheets in each PEM category. For FKGL, there was a significant difference between the original ARS sheets and the AI-generated sheets only in the “Nasal Disorders” category. Of all the ARS sheets, the “Disorders and Surgery Related to the Eye” category had the lowest (most easily readable) FKGL. Of all the AI-generated sheets, the Basics category had the lowest (most easily readable) FKGL.
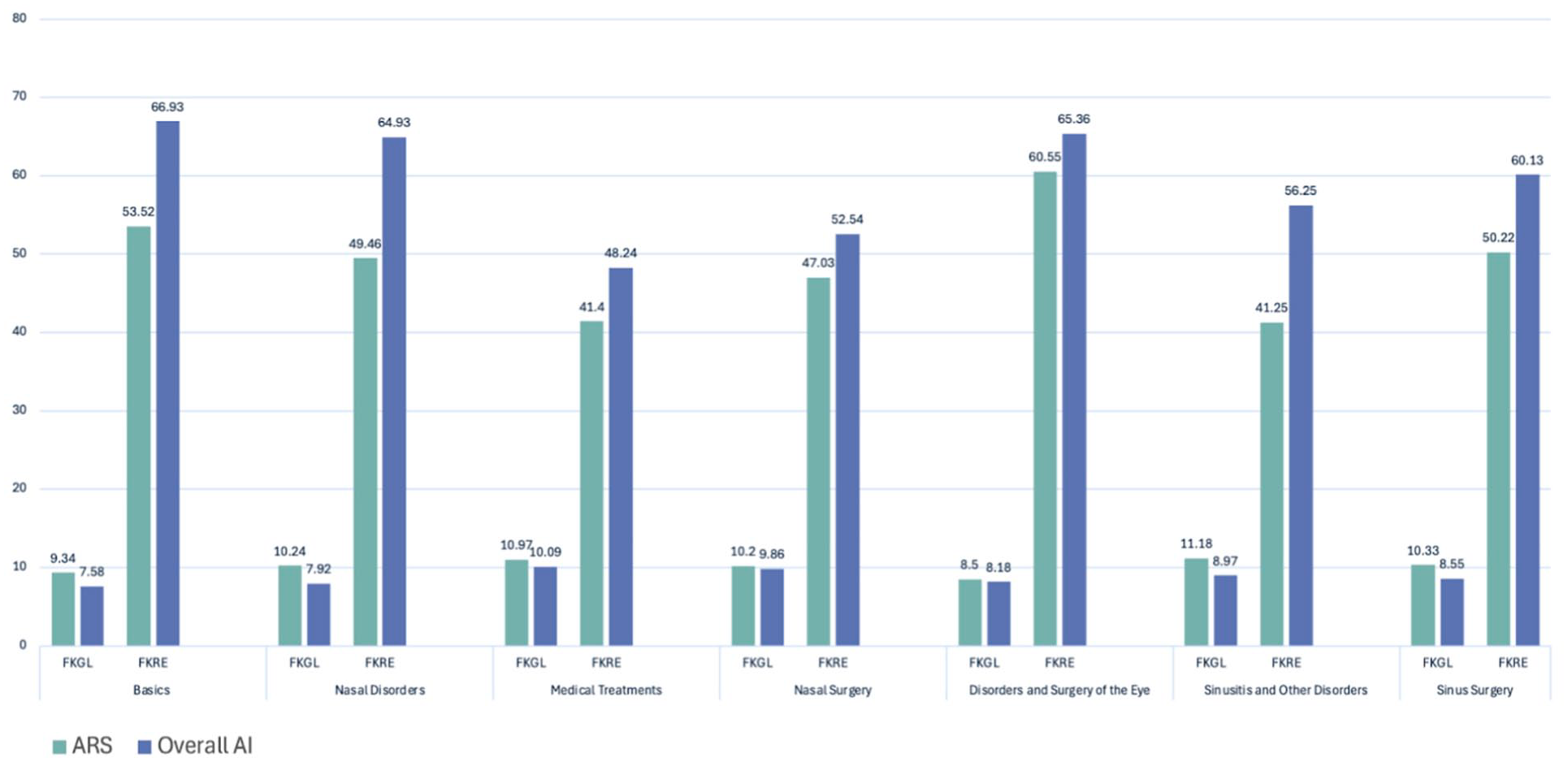
Flesch-Kincaid Grade Level and Flesch-Kincaid Reading Ease for patient education materials from the ARS and AI across categories.
Regarding FKRE, there was a significant difference between the original ARS sheets and the AI-generated sheets from the “Basics and Nasal Disorders” categories. Of all the ARS sheets, the “Disorders and Surgery Related to the Eye” category was most easily readable. Of all the AI-generated sheets, the “Basics” category was most easily readable. An overall summary of the results from this study is presented in Tables 2 to 4.
Average FKRE and FKGL Scores.
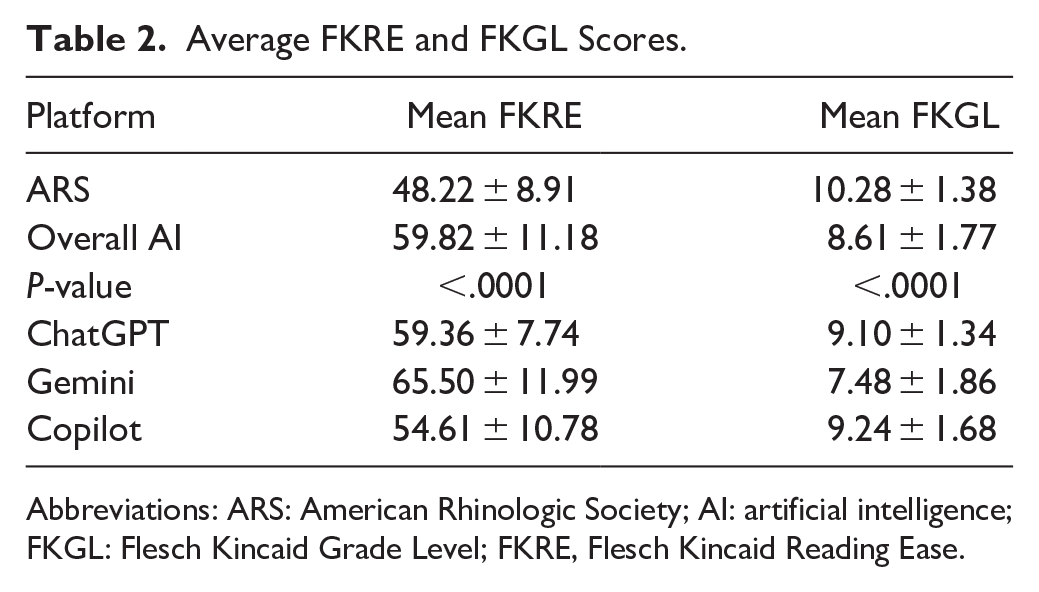
Abbreviations: ARS: American Rhinologic Society; AI: artificial intelligence; FKGL: Flesch Kincaid Grade Level; FKRE, Flesch Kincaid Reading Ease.
Pairwise Comparison of Mean Difference of FKGL Scores Between AI Platforms.
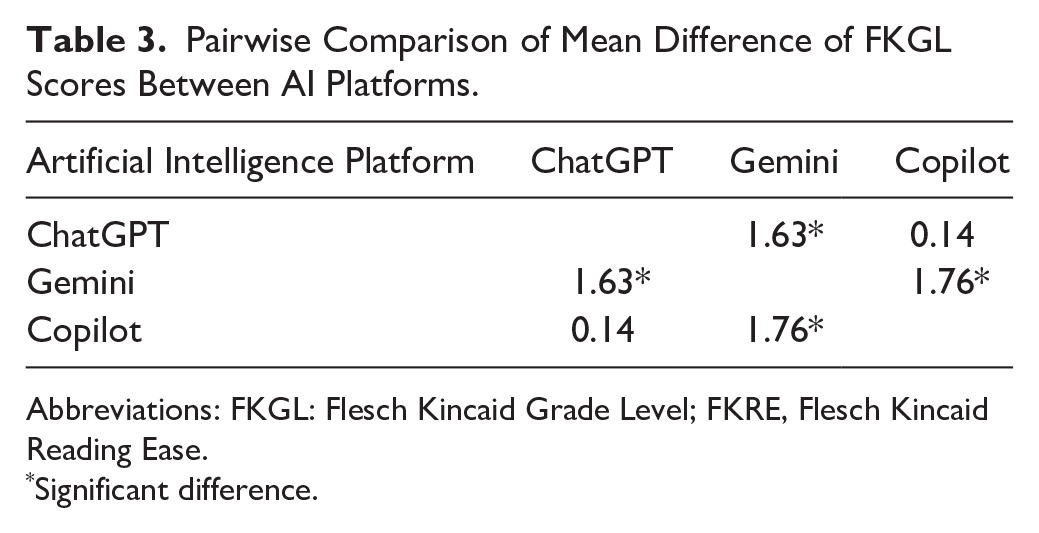
Abbreviations: FKGL: Flesch Kincaid Grade Level; FKRE, Flesch Kincaid Reading Ease.
Significant difference.
Pairwise Comparison of Mean Difference of FKRE Scores Between AI Platforms.
Abbreviations: FKGL: Flesch Kincaid Grade Level; FKRE, Flesch Kincaid Reading Ease.
Significant difference.
Despite these promising results, AI platforms often struggled to generate resources at the nationally recommended reading level, even when prompted to generate resources at the sixth-grade level. Out of the pooled data between the 3 AI platforms, only 21% and 6% percent of AI-generated materials were at the recommended FKGL and FKRE, respectively. More specifically, 4.88% of ChatGPT 4.o responses, 41.46% of Gemini responses, and 4.88% of Copilot responses, were written at the correct FKGL, and 0% of ChatGPT 4.o responses, 6% of Gemini responses, and 2% of Copilot responses were written at the correct FKRE.
Discussion
In this study, we compared the ability of several AI platforms to enhance the readability of educational materials in rhinology. We found that, although each AI platform significantly improved readability (from a high school to a middle school reading level), the platforms still struggled to consistently achieve the recommended sixth-grade reading level. Of the models tested, Gemini was the most effective, generally yielding the highest readability improvements. These findings demonstrate the feasibility of using AI to improve PEMs for patients of diverse literacy levels and simultaneously highlight its limitations.
The Internet allows for instant access to a breadth of knowledge, and studies have shown that up to 70% of patients use the Internet for health-related information. 24 According to the American Medical Association and National Institutes of Health, PEMs should be written at or below the sixth-grade reading level. 16 However, a recent study that assessed the readability of online patient resources in rhinology found that the minimum education level to adequately comprehend the current resources was college attendance, far beyond the sixth-grade level. 24 An additional study concluded that most educational materials in pediatric otolaryngology exceed the recommended reading level for adequate comprehension of information. 25 AI chatbots such as ChatGPT, Copilot, and Gemini can therefore serve as a powerful tool for patients, as they can potentially provide accurate patient education materials with improved readability.
Our results both align with and challenge existing literature. AI platforms have been shown to produce accurate responses to surgical inquiries and create high-quality patient education materials in several fields.26 -28 Yet many of these studies assessed the accuracy of AI chatbots in response to medical questions and not the AI chatbots’ ability to create PEMs—thus the readability of AI-generated PEMs is an active area of interest. For instance, studies that focused on AI-generated PEMs for procedures generally found the information to be difficult to read without prompting.29,30 Eid et al 31 prompted ChatGPT and Gemini to create PEMs for 16 common ophthalmic plastic and reconstructive surgery topics at the sixth-grade reading level, yet both platforms created PEMs at an eighth- to ninth-grade level (FKGL 7.8 and 8.5). Similarly, Garg et al 26 prompted ChatGPT to reduce responses regarding aesthetic facial plastic surgery to an eighth-grade level without compromising accuracy, yet the responses were found to be between a 10th- and 12th-grade level. These discrepancies underscore that further refinements of AI platforms are necessary to properly bridge literacy gaps, particularly for complex topics relating to rhinologic conditions and management.
The variety in the readability of information generated by LLMs may lie in differences in their underlying architecture and access to up-to-date information. Likewise, it is possible that there is not enough AI data available on surgical procedures in rhinology for the LLMs to update and translate to an appropriate middle school level. For instance, ChatGPT 4.o completed its training in October 2023 and runs based on a Generative Pre-Trained Transformer system.26,32 Therefore, GPT has restricted knowledge of the world and events after 2022 and users without premium subscriptions will not have unlimited web browsing capability. While ChatGPT-4 and Copilot rely on a Generative Pre-Trained transformer architecture, Gemini utilizes a Pathways Language Model (PaLM 2), which surveys the internet in real-time to generate information.33,34 Despite the differences in the systems that power these LLMs, all 3 platforms were able to simplify the PEMs to a middle school level, albeit not reaching the precise level recommended by the AMA. These gaps highlight areas that the technology can improve on in the future and the technical complexity inherent in the descriptions of rhinologic procedures and conditions.
There are several limitations to our study. We did not assess the consistency of responses longitudinally, which could reveal that the readability of responses changes over time. We also prompted the AI platforms to generate PEMs based on a selection of topics curated by the ARS, which could limit the generalizability of the responses. Finally, we utilized standardized readability formulas, which are calculated based on metrics such as word count and sentence length, which may not truly reflect the ease of comprehension of a text. 35
Despite these limitations, to our knowledge, we present the largest comparative study of several major AI platforms in the generation of PEMs in rhinology. Future studies should explore the accuracy of AI-revised PEMs, whether AI-revised PEMs are preferred by patients, and the consistency of AI chatbots in accuracy and readability, even when accessed from different accounts or at different times. Other chatbots should be tested as well. Eventually assessing the responses of LLMs in languages other than English could prove useful in assessing the usefulness of these technologies in diverse patient populations.
PEMs empower patients with knowledge regarding their surgeries or medical conditions, allowing them to make informed decisions about their healthcare and giving them greater autonomy. Especially within the context of the medical and surgical management of complex rhinologic disease, patient education is essential to positive outcomes. Those with lower HL are 3 times more likely to experience poor outcomes and have been associated with worse scores on patient-reported rhinologic symptom outcomes scales. 36 Patient education is especially important in rhinology due to the complexity of care, and postsurgical management often requires frequent follow-up. 37 In addition, the PEMs provided by the ARS in 2012 were written between a ninth-grade and graduate reading level, far beyond what is appropriate for the average patient. 38 Ensuring that online health education materials are both reliable and readable can help improve clinical outcomes by enhancing patient engagement and HL. Our results emphasize that, in a specialized field such as rhinology, it is critical to have appropriate resources for patients and that new AI LLMs have the potential to bridge gaps in HL.
Conclusion
AI platforms simplified PEMs in the field of rhinology to a more appropriate reading level. While these tools show significant promise, further refinement in AI-generated materials is necessary to ensure they are inclusive to patients of all literacy levels and to meet the needs of diverse patient populations.
Footnotes
Author Contributions
ALS: conception, data collection, manuscript writing, and manuscript editing. RAH: manuscript writing and manuscript editing. AX: data collection and manuscript writing. DP: statistics and manuscript writing. LB: manuscript writing and manuscript editing. WDH: Supervision and manuscript editing.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.