
Abstract
This article extends multivariate generalizability theory (MGT) to tests with different random-effects designs for each level of a fixed facet. There are numerous situations in which the design of a test and the resulting data structure are not definable by a single design. One example is mixed-format tests that are composed of multiple-choice and free-response items, with the latter involving variability attributable to both items and raters. In this case, two distinct designs are needed to fully characterize the design and capture potential sources of error associated with each item format. Another example involves tests containing both testlets and one or more stand-alone sets of items. Testlet effects need to be taken into account for the testlet-based items, but not the stand-alone sets of items. This article presents an extension of MGT that faithfully models such complex test designs, along with two real-data examples. Among other things, these examples illustrate that estimates of error variance, error–tolerance ratios, and reliability-like coefficients can be biased if there is a mismatch between the user-specified universe of generalization and the complex nature of the test.
Keywords
The conceptual framework for generalizability (G) theory, including multivariate generalizability theory (MGT), was introduced and discussed extensively five decades ago by Cronbach et al. (1972). Two decades later, Shavelson and Webb (1991) provided an abbreviated, highly readable treatment of G theory, including a brief consideration of MGT. A decade later, Brennan (2001a) provided a lengthy, integrated treatment of G theory, including four chapters on MGT (see Brennan, 2022, for a history of G theory).
MGT, as discussed in the above references, is exceptionally powerful and flexible. Still, both Brennan (2001a) and Cronbach et al. (1972) are somewhat limited in that they provide little integrated treatment of some kinds of complex design/data structures that are often encountered in educational measurement contexts. Two examples are considered in this article: (a) mixed-format tests that involve both multiple-choice (MC) and free-response (FR) items; and (b) tests that involve one or more sets of stand-alone items as well as testlets (or passages) with associated items. These are examples of complex test designs, which we model here using an extension of traditional MGT.
One distinguishing feature of such designs is that they cannot be described verbally or symbolically as a “single” multivariate design, in the usual sense of that term in MGT. In the notation of Brennan (2001a), the
It is not uncommon to encounter complex designs. For example, many large-scale testing programs administer mixed-format tests such as the Advanced Placement (AP) examinations (College Board, 2019), the National Assessment of Educational Progress (National Center for Education Statistics, 2019), the Graduate Record Examinations (GRE), and many K–12 tests.
Despite their popularity, very little G theory research exists for complex designs. One attempt to combine two distinct designs was made by Moses and Kim (2015) who proposed an extended version of an existing multivariate design that can be used for mixed-format tests. However, some limitations were acknowledged by the authors. For example, although double scoring was used for each FR item, raters were not assigned in a manner that conformed with an actual crossed or nested rater effects design.
The primary purpose of the present study is to illustrate how MGT can be extended to complex designs like those typically associated with mixed-format tests and tests involving testlets. In doing so, both G study and D study matters are considered, many of which involve challenging issues that often arise with real data. Before considering these complex MGT designs, we provide a brief overview of G theory and MGT using the notation and conventions in Brennan (2001a).
An Overview of G Theory and MGT
The conceptual framework of G theory (both univariate and multivariate) involves a universe of admissible observations (UAO) that is associated with a G study, and a universe of generalization (UG) that is associated with a D study. Next, we consider a simple univariate design and then a simple multivariate design.
Simple Univariate Example
Suppose the UAO consists of a large number of passages,
Conceptually, the typical UG for this situation is a set of randomly parallel forms, each of which consists of
Simple Multivariate Example
Conceptually, any application of MGT also involves a UAO and a G study, as well as a UG and D study. The primary distinctions between univariate G theory and MGT are as follows: (a) MGT involves explicit and detailed consideration of random-effects designs for each level (or category) of a fixed facet and (b) MGT typically involves at least one facet (usually persons) that “crosses” the fixed facet—that is, the crossed facet contributes data to all levels of the fixed facet. (Strictly speaking, there can be multiple fixed facets in MGT, but we do not consider this possibility here.)
Probably the simplest MGT example is the so-called “table of specifications” (TOS) model discussed initially by Jarjoura and Brennan (1982, 1983) and subsequently by Brennan (2001a). In this model, each of the
For the TOS model, there is only one so-called “linked” (or crossed) facet—namely, the objects of measurement facet
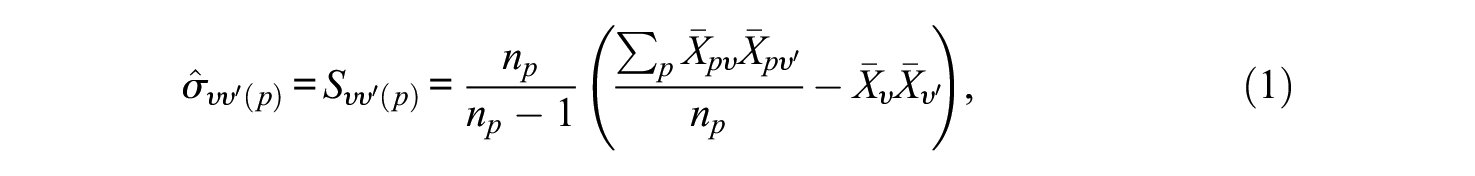
where
Once the variance and covariance components are estimated from the G study, the estimated D study variance and covariance components can be obtained in a straightforward manner by dividing each component by a user-specified D study sample size (or product of sample sizes). In general, letting
Estimates of these matrices are designated
No matter how simple or complicated the design may be, these matrices provide the universe score variance and covariance components for universe scores, relative errors, and absolute errors. For the two designs specifically considered subsequently in this article,
Composite Scores in MGT
One advantage of using MGT over univariate G theory is that MGT allows for separate estimates of variance and covariance components for each level of the fixed facet. This permits addressing numerous issues including those associated with composite scores.
Let the composite score be denoted
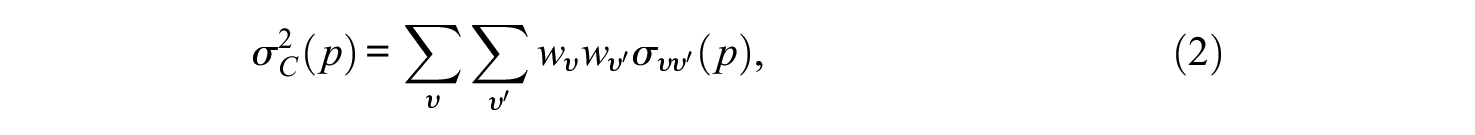
where
Assuming the estimator of the composite universe score is
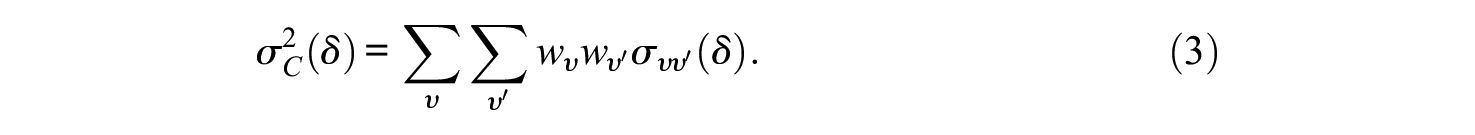
Similarly, absolute error variance for the composite is,
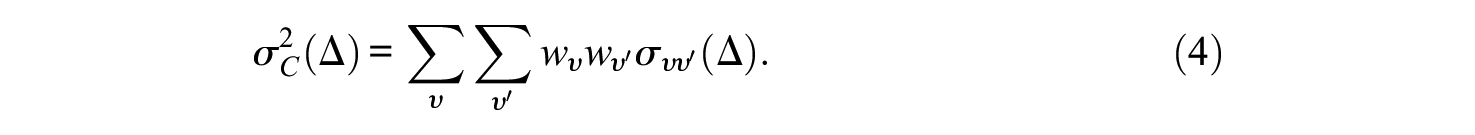
Kane’s (1996) error–tolerance

which provides an indicator of the extent to which the absolute standard error of measurement (SEM) is large relative to the standard deviation of universe scores, where universe scores are what we would like to know about examinees. Similarly, an error–tolerance ratio for

The error–tolerance ratios in Equations 5 and 6 have corresponding reliability-like coefficients, called an index of dependability

and
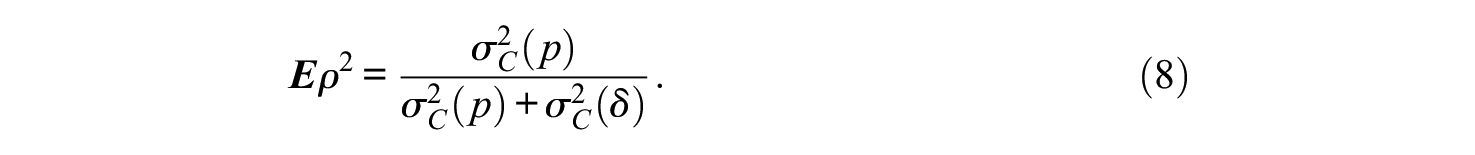
It is easy to show that
Example I: Mixed-Format Tests
Mixed-format tests are usually defined as having both MC and FR items, with examinee responses to the FR items evaluated by raters. Estimating error variances for mixed-format tests is relatively complicated compared with single-format tests. Primarily, this complexity arises because the use of different item formats introduces multiple different sources of error. As discussed next, this complexity can be addressed in a principled way through an expanded use of MGT.
AP German Language Exam
This example uses data from the AP German Language exam administered in 2013. This exam is a mixed-format test that consists of MC and FR items. The exam has 65 MC items scored 0 or 1, and 4 FR items scored 0 through 5. For the German exam, a composite score is defined as a weighted sum of the MC and FR section scores with a set of pre-specified section weights.
The section weights are established a priori by the College Board to achieve an intended proportion of points for each section. We use the term “relative weights” to refer to the proportional contributions to the composite score, in keeping with the terminology used by Powers and Brennan (2009). For AP German Language, the pre-specified relative weights were 0.5 for both MC and FR sections. That is, the test developers’ intent was that each section contributes 50% to the composite score, which ranges from 0 to 130. In other words, the College Board wants 65 points associated with each of the two sections. Note that the AP data used in this article are for illustrative purposes, only.
G theory analyses are usually conducted using the mean score metric. Let
Universe of Admissible Observations and Associated G Studies
Let
G Study Designs
For the AP German Language exam, each FR item is scored by a single rater, which makes it impossible to disentangle the variability attributable to raters and items. This is an example of the so-called “problem of one” discussed by Brennan (2016b). Even though the rater and item facets are both conceptualized as being random and crossed in the UAO, the G study design, using single ratings of FR items for the operational data, fails to reflect the structure of the UAO.
Unfortunately, the usual way of addressing this complexity is to pretend that it does not exist (or does not matter) and simply conduct an MGT analysis using the
Design
For the G study
Example I: G Study
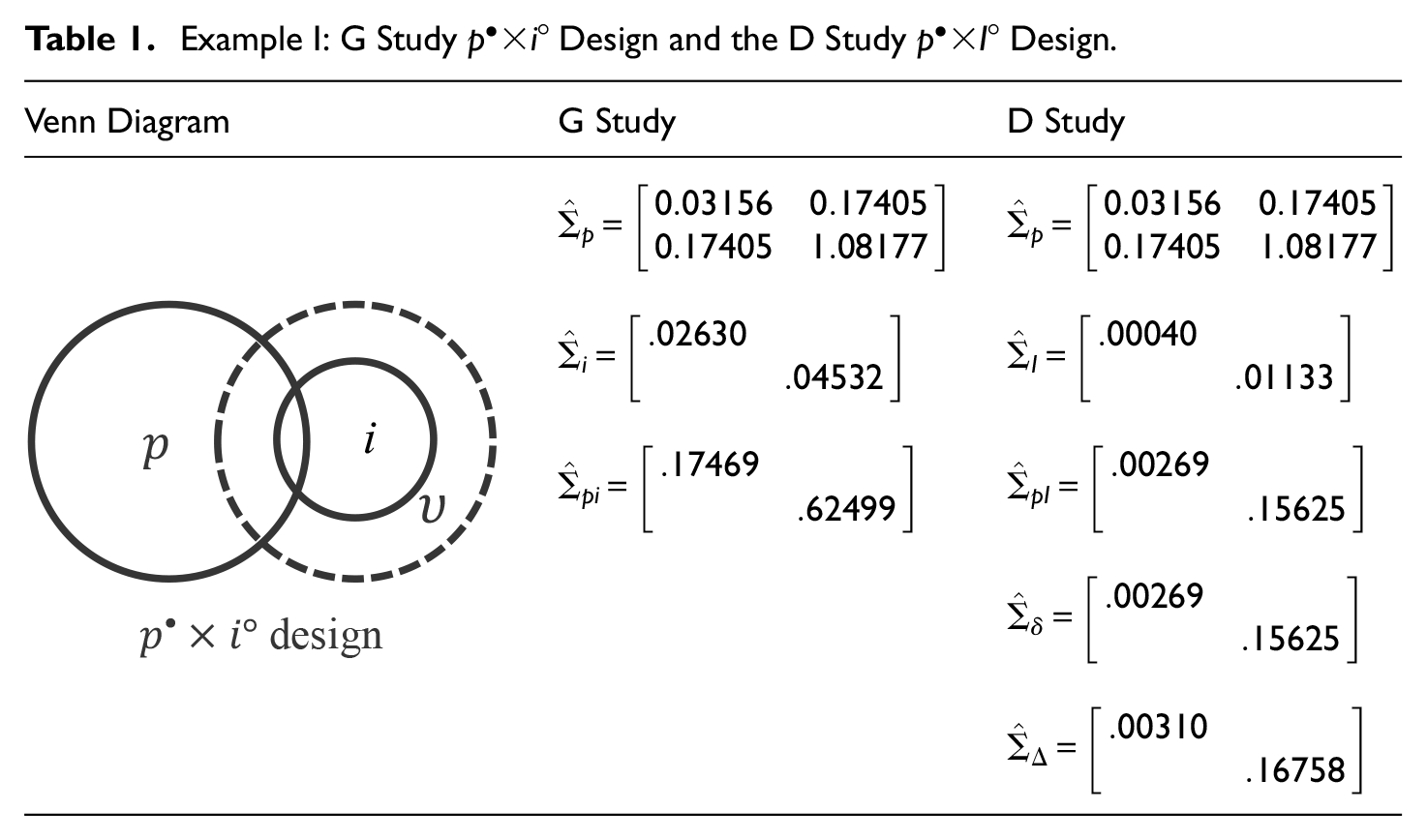
For the German Exam considered here, we can denote this G study design more explicitly as
For example, if the same rater actually rated all FR items for all examinees, then the rater facet would be both hidden and fixed, as far as the G study is concerned. If a single different rater rated all FR items for all examinees, then the rater facet would be hidden and random. In any case, for a G study
Design
Table 2 considers the
Example I: G Study
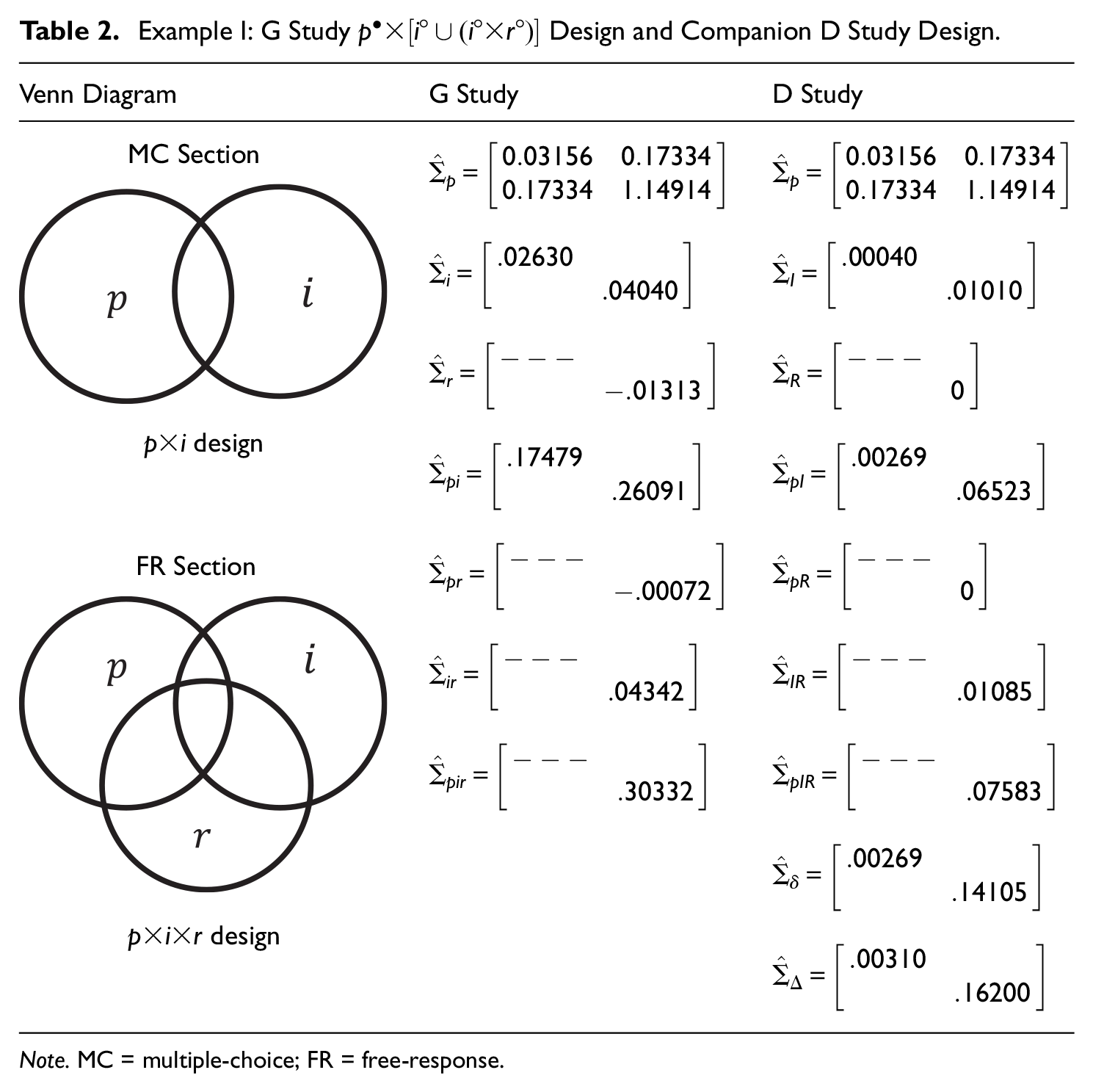
Note. MC = multiple-choice; FR = free-response.
This second MGT design is rarely seen in the literature, although it is quite similar to that discussed by Moses and Kim (2015). Specifically, they suggested an MGT design for mixed-format tests, which they denoted
Design
This third design is different from the second design in that raters are nested within items as opposed to being crossed. It follows that some variance components in the crossed UAO are confounded in estimated variance components for this nested design. As illustrated later, this confounding typically leads to smaller error variances than for the crossed design (see, also, Brennan, 2001a). Venn diagrams pertaining to the
Example I: G Study
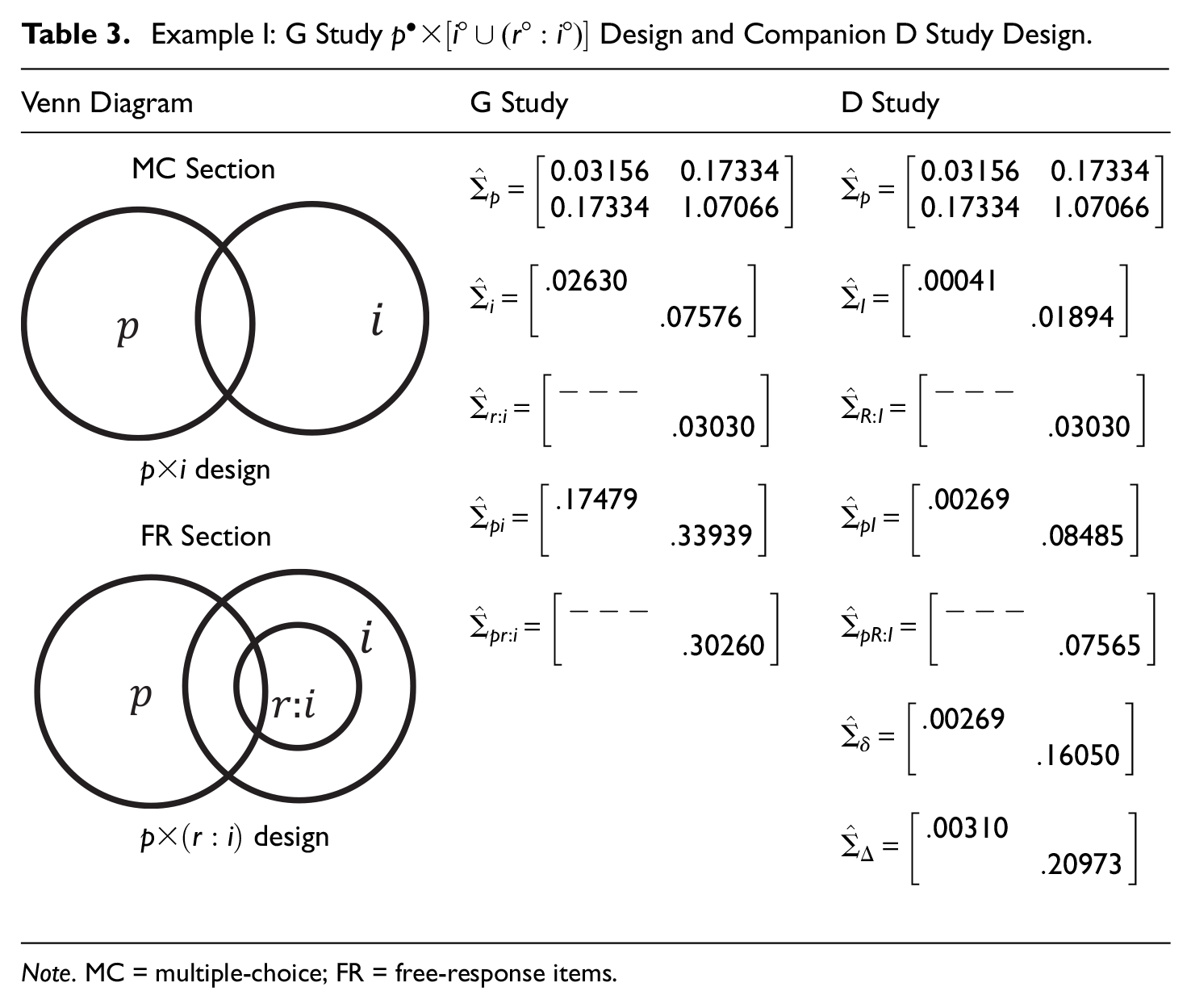
Note. MC = multiple-choice; FR = free-response items.
Data
For this study, three sets of data were obtained: one from the operational administration and the other two from a special study conducted by the College Board. As noted previously, operationally, an examinee’s response to each of the four FR items is evaluated by a single rater. Consequently, the unconfounded effect of rater variability cannot be studied using the operational data, alone. For this reason, a special study was conducted to obtain additional ratings for each FR item for a subset of the examinees. Doing so facilitated examining rater effects—in particular, their impact on estimated error variances and related statistics.
Figure 1 depicts the structure of the operational data (first column) and the two subsets of data for the special study (two lower-right cells). The operational MC data are labeled ①, the operational FR ratings are labeled ②, and the special study FR ratings are labeled ③ and ④.
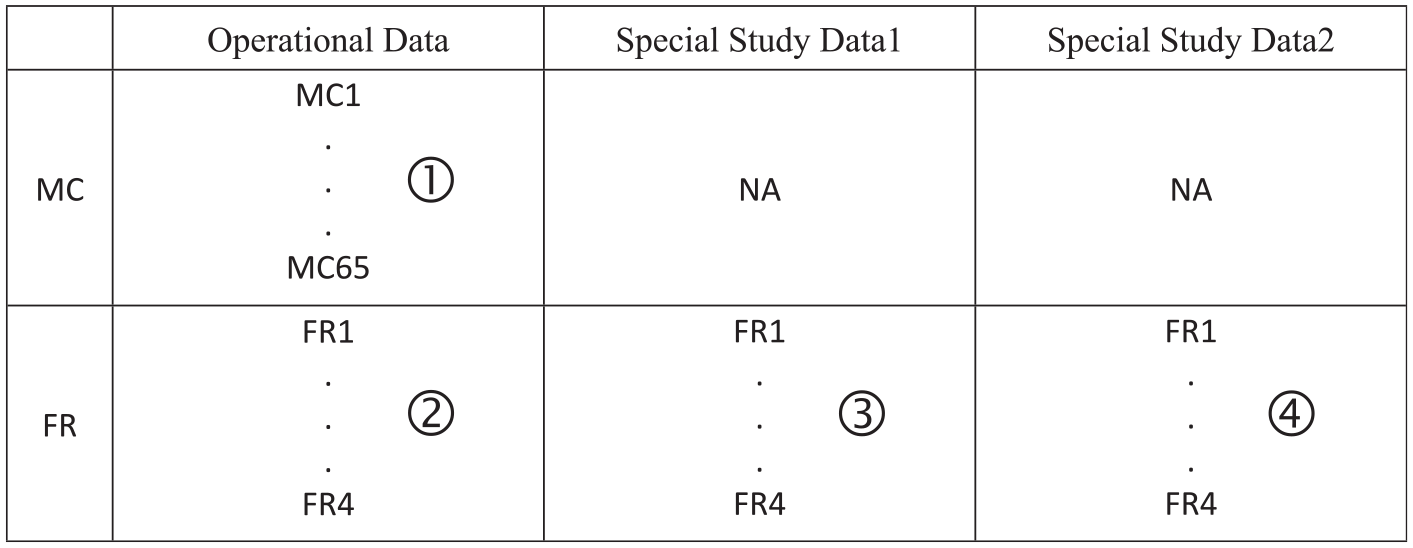
Data Structure for the Three Datasets in Example I.
For the special study, FR answer books for 109 examinees were selected from the operational administration. To make the rating task manageable, these 109 examinees were split into approximately equal subsets (denoted P1–P55 and P56–P109). For each person, each FR item was scored by two additional raters in the manner indicated in Figure 2. (Note that the identifiers R1 to R8 in Figure 2 designate different raters, not simply different ratings.) In short, the word “Folder” in Figure 2 is a designator for a set of data associated with a set of persons, a pair of raters, and a single FR item.
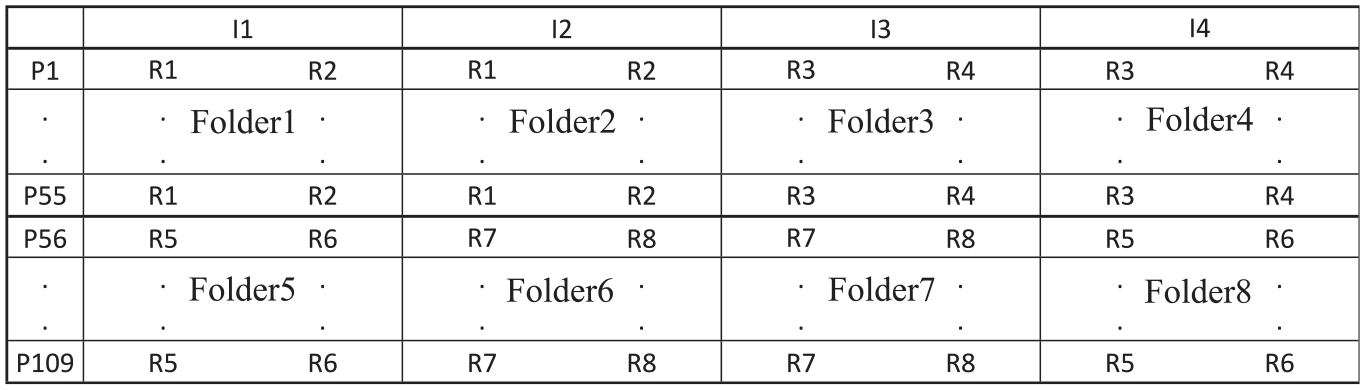
Venn Diagrams for G Study
Clearly, the special study does not conform to a fully crossed or fully nested design, but carefully selected subsets of the data do conform to a crossed or nested design. Specifically, four pairs of folders provide data for persons crossed with raters crossed with items—specifically, Folders 1 and 2, 3 and 4, 5 and 8, and 6 and 7. By contrast, four different pairs of folders provide data for persons crossed with raters nested within items—specifically, Folders 1 and 3, 2 and 4, 5 and 6, and 7 and 8. Consequently, as discussed below, it was possible to examine three G theory designs: one that conforms with the operational administration and two that provide different perspectives on rater effects.
Design
As there were three FR scores available for each FR item based on the operational administration and special study (i.e., ②,③, and ④ in Figure 1), three separate
Design
For the second G study design,
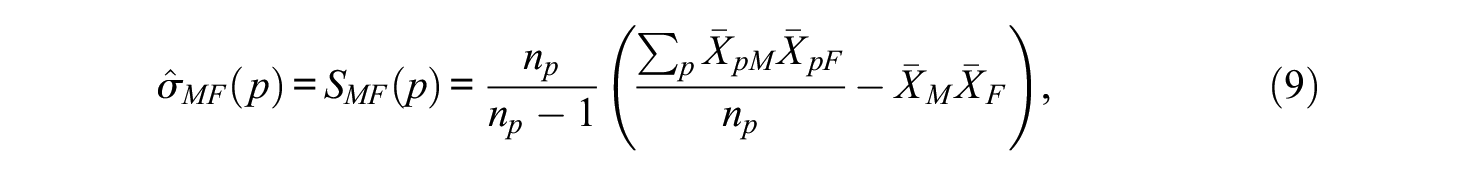
where
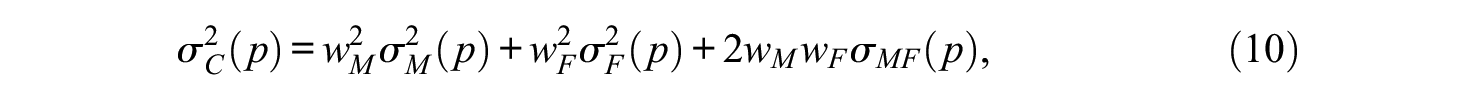
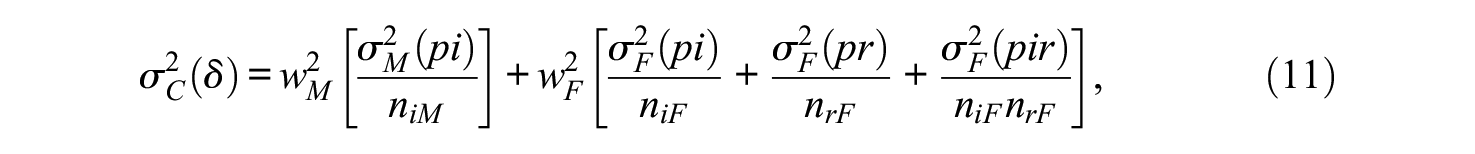
and
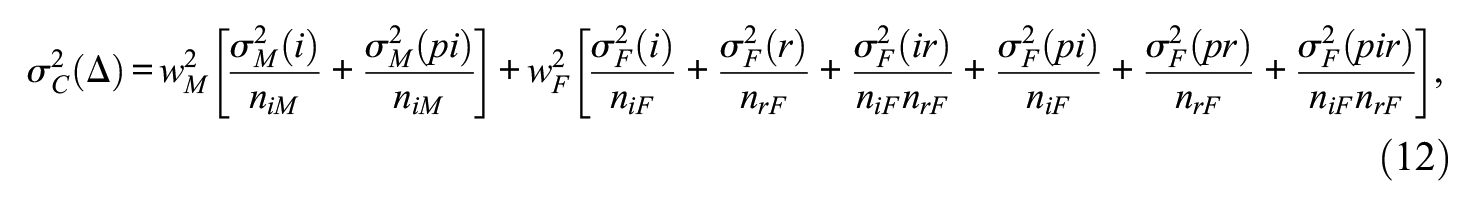
where
Recall that, for the special study, four pairs of folders provide data for persons crossed with raters crossed with items—specifically, Folders 1 and 2, 3 and 4, 5 and 8, and 6 and 7. For each of these pairs of folders, the design is
D study statistics were computed using the average of the estimated variance components for these four replications or subsets, with the expectation that these averages would serve as more accurate estimates than estimates from a single subset. (The MC estimated variance components are the same as those in Table 1). The operational responses to the FR items (② in Figure 1) could not be used in this analysis because rater information was not available. Negative variance component estimates were retained for the pseudo-replications, but average variance components (over replications) that were negative were set to zero.
Design
For this design, the same basic approach was used as for the crossed design. The only difference is that the pairs of folders for the FR part of the
Estimated G and D Study Variance and Covariance Components
The estimated G study and D study variance–covariance components based on the
The middle and right parts of Table 2 show the estimated G study and D study variance–covariance matrices for the
The focus of Example I is on rater effects. To simplify design notation here, let the
Composite Summary Statistics
It is important to note that the estimated variance and covariance components in Tables 1 to 3 are for single persons, single items, and single raters. That is one reason why the numbers are very small in absolute magnitude. Obviously, our ultimate interest is in the 0 to 130 composite-score metric discussed previously. The first three rows in Table 4 provide relevant statistics for this metric. Specifically, these rows provide estimated standard deviations of person universe scores, absolute errors, and relative errors. The next two rows provide estimated error–tolerance ratios, and the last two rows provide estimated coefficients. Both coefficients necessarily range from 0 to 1. Both error–tolerance ratios usually have the same range, although they have substantially different interpretations, as discussed previously.
Example I: D Study Composite-Score Statistics.
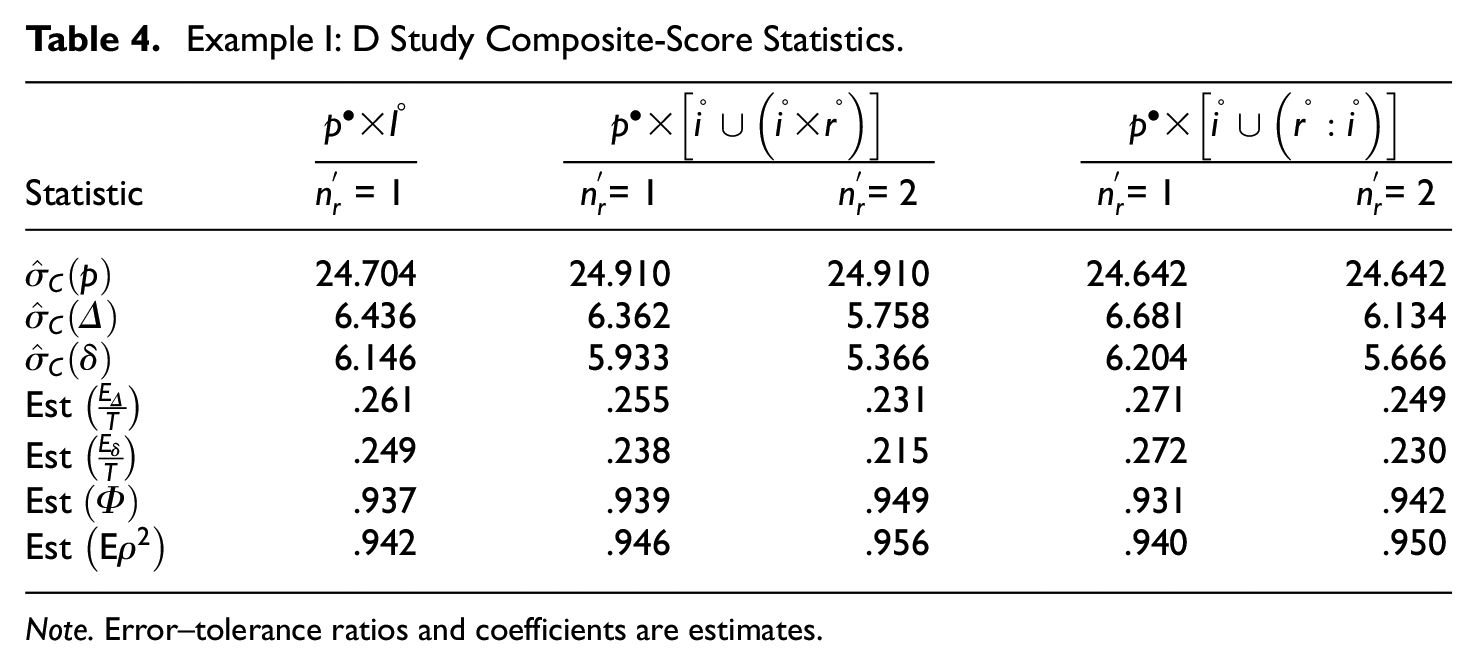
Note. Error–tolerance ratios and coefficients are estimates.
Results are reported for all three designs. The second column provides results for the D0 operational design. DC and DN results are provided for D study sample sizes of both
There are at least two principal results in Table 4. First, as the number of raters increases, both
The data sets for the three designs in Table 4 overlap, but, as discussed previously, the data were manipulated differently to conform with the different designs. Consequently, the results for one design are not entirely predictable from the results for any other design.
2
Furthermore, estimates of variance components (and functions of them) are themselves subject to sampling variability (see Brennan, 2001a), which can distort results somewhat. These facts are associated with some anomalies in the Table 4 results. For example, for any particular
For the operational D0 design and the more complicated DN design, the MC items are the same, and they do not involve any ratings. Therefore, for present purposes, we can focus exclusively on the four-item FR section for these two designs. Under the D0 design, for each person, there is a single rating for each item. The total number of raters involved is typically knowable, but the actual process of assigning raters to person and items is likely to be vague.
Strictly speaking, for the DN design with
Example II: Tests With Testlets
Items involving a common stimulus are usually bundled together. For such items, logic and research suggest that dependencies can exist. Consequently, it has been suggested that testlet effects be taken into consideration in measurement analyses to avoid possible underestimation of error variance and overestimation of reliability (Lee, 2000a, 2000b; Lee & Frisbie, 1999; Sireci et al., 1991).
Exam and Dataset
The second example uses the same exam as the first example, but with a different dataset. Unlike the previous example that examined rater effects, investigating testlet effects does not necessarily require a special study to collect data from multiple raters. Thus, data from a single administration to a large group were used in this example with a total sample size of 4,111.
The AP German Language exam was designed to measure four distinct skills: reading (R), listening (L), writing (W), and speaking (S). The R and L sections are composed of testlet-based items, only, while the W and S sections each consists of a separate stand-alone set of items. There are four testlets associated with R with 5, 7, 11, and 7 MC items in each testlet. Five testlets are used for L with 10, 7, 5, 5, and 8 MC items within each testlet. For each testlet, a common stimulus provides the basis for answering the items that belong to the testlet. For both W and S, there are two independent FR items scored 0 to 5. Note that there is only one rating per item, which means that FR items and ratings are completely confounded in the data.
Universe of Admissible Observations
The UAO is the conjunction of universes for R, L, W, and S. Letting
Strictly speaking, the UAO is within square brackets, with the population of persons crossed with the UAO. The superscript closed circle associated with
G Study
Design
Clearly, the G study design that mirrors the UAO is
Example II: Results for G Study
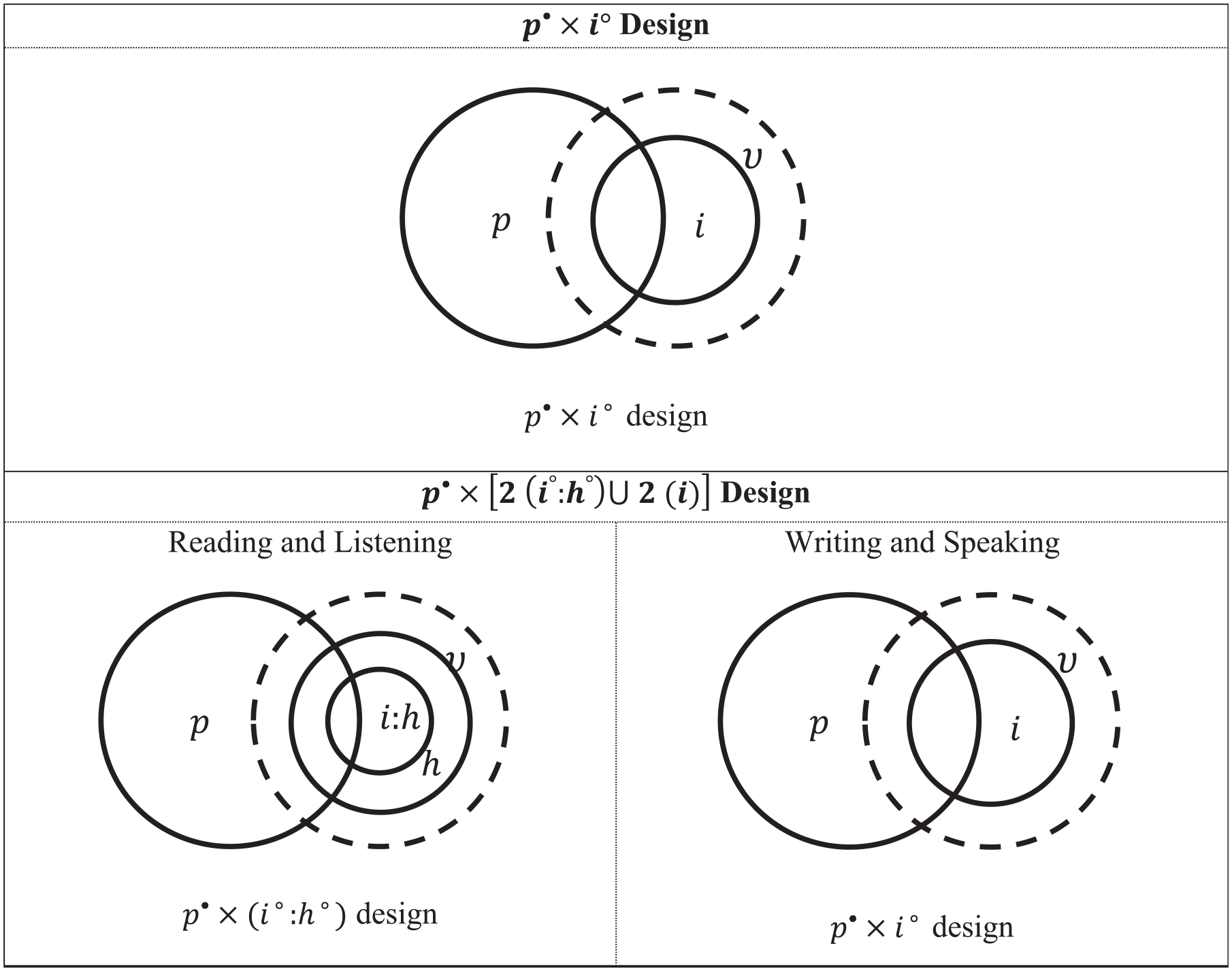
Venn Diagrams for G Study
G Study
Design
The G study
This two sub-designs perspective implies that the following steps can be used to estimate variance components and covariance components for the “full”
Example II: Results for G Study

The covariance components in (iii) can also be obtained directly from the G study results for the
D Study Results for Sections
For the simple (in a sense, “simplistic“) D Study
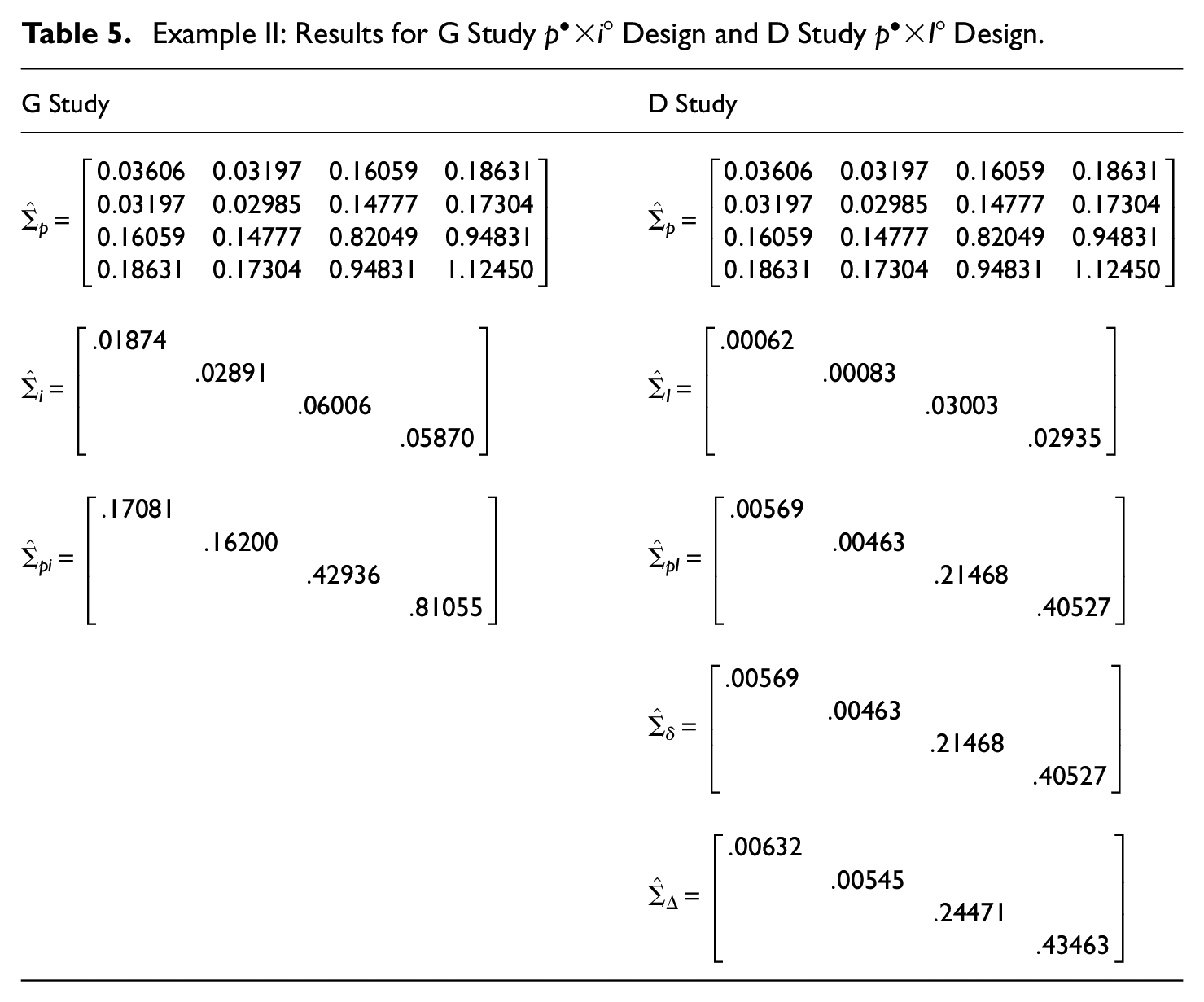
As shown in Table 5, the variance components associated with W and S are always larger than those for R and L. This is attributable to the fact that the maximum possible score for FR items in W and S is 5 times larger than that for the MC items in R and L. Also, variability attributable solely to items is relatively small regardless of the section, while variability attributable to person–item interactions is relatively large.
Table 6 provides corresponding results for the D study
A comparison of the section results for the “simple” design in Table 5 and the “actual” design in Table 6 reveals that estimated error variances for the simple design are smaller than for the actual design. This does not mean that the simple design is preferable; rather, as discussed below, the explanation is that the simple design confounds certain effects in the actual design, which in turn almost always leads to underestimates of error variance.
For example, for both R and L,
D Study Results for Composite
General formulas for composite universe score variance, error variances, error–tolerance ratios, and coefficients are provided by Equations 2 to 8. As discussed earlier, letting
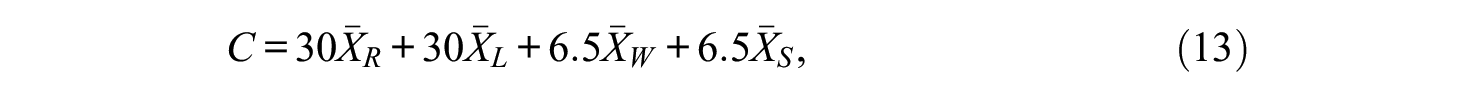
where MC items are scored (0,1) and FR items are scored (0–5).
Table 7 provides estimates of composite standard deviations for universe scores, absolute errors, and relative errors, followed by error–tolerance ratios and coefficients. Results are provided for both the simplified
Example II: D Study Composite-Score Statistics.
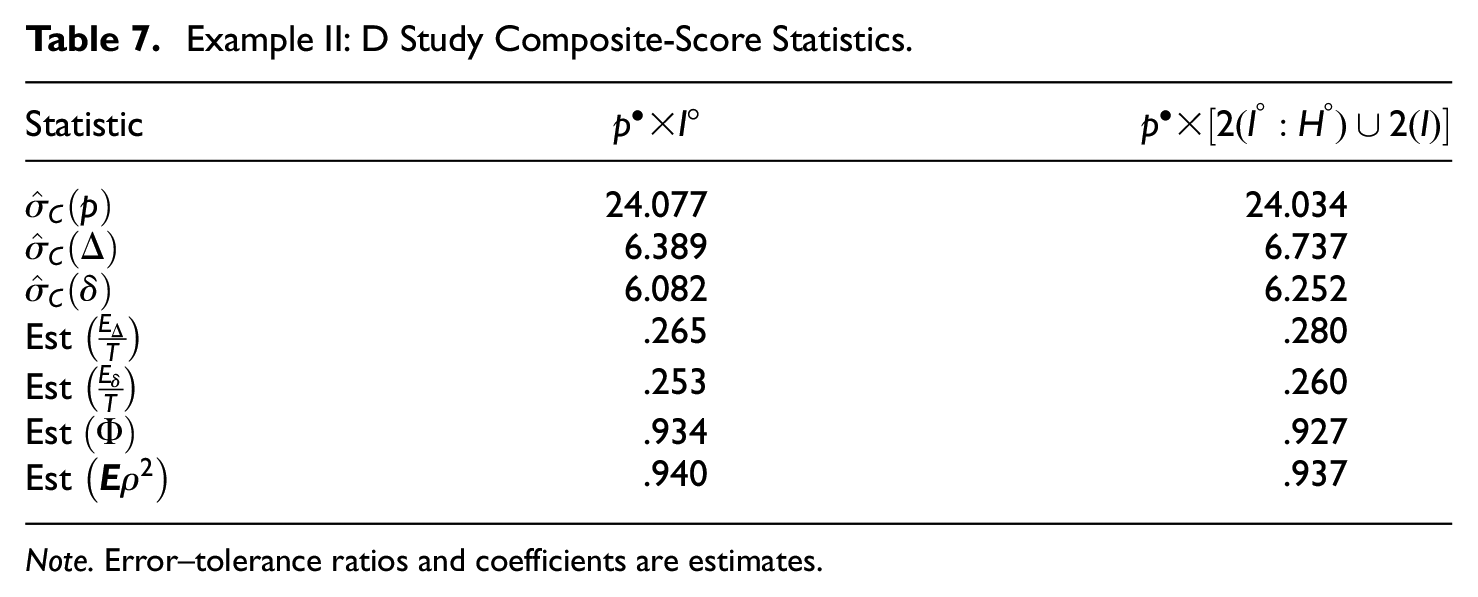
Note. Error–tolerance ratios and coefficients are estimates.
As expected, for both designs, relative error variance is consistently smaller than absolute error variance. Consequently, for both designs,
Basically, error–tolerance ratios quantify the magnitude of the SEM relative to the standard deviation of universe scores. As such, error–tolerance ratios are highly recommended because they are easy to interpret and they focus on SEMs, which are almost always the most important results of a D study analysis. By contrast, it is easy to exaggerate the meaningfulness of seemingly large coefficients. For example, for the actual Coefficients are a crude device that do not bring to the surface many subtleties implied by variance components. In particular, the interpretations being made in current assessments are best evaluated through use of a standard error of measurement. (p. 394)
It is reasonable to question whether
At first glance, results for the
Summary and Discussion
Univariate G theory can accommodate one or more fixed facets in certain restricted senses, but MGT does so in a much more elegant and flexible manner. Furthermore, estimation of variance components is often more complicated for a typical univariate G theory mixed model than for its MGT counterpart. In short, univariate G theory with a fixed facet is considerably more restrictive than MGT, especially the extension of MGT discussed in this article.
Brennan (2010) stated that “multivariate G theory is the whole of G theory, with univariate G theory simply being a special case” (p. 15). Still, virtually all prior MGT literature is limited in that it uses the same design structure for each level of a fixed facet. By contrast, this article has extended MGT largely through the explicit introduction of different designs for different levels of the fixed facet. Doing so permits a much more faithful analysis of the actual design structure of many tests, as illustrated by the mixed-format and testlets examples. This article also illustrates the use of error–tolerance ratios and advocates their use over coefficients, arguing that the former are much more easily and meaningfully interpreted than the latter.
The two examples in this article are particularly instructive in illustrating that (a) real-data applications are often much more complicated than is typically reflected by simplified analyses in much of the extant literature, (b) extended MGT is a viable alternative for such complex real-world measurement situations, (c) simplified analyses that do not capture real-data complexities often overstate measurement precision (see the testlets example), and (d) simplified analyses often hide important considerations about confounded facets (see the discussion of item-rater confounding in the mixed-format example).
It is recognized, of course, that real-world datasets may be limited in such a way that the types of analyses discussed in this article are not viable, and/or other practical circumstances may preclude performing the types of complex MGT analyses discussed here. Even so, it is almost always possible to describe a complex measurement procedure at a sufficient level of detail such that reported analyses can be qualified in a reasonable manner. Unfortunately, that is often not done. A particularly egregious example is the too frequent unqualified use of coefficient alpha as a presumably “adequate” reliability analysis. As Cronbach (2004) stated in his last published paper,
I no longer regard the alpha formula as the most appropriate way to examine most data. Over the years, my associates and I developed the complex generalizability (G) theory. (p. 403)
Some limitations of the present study should be noted. First, sample sizes (especially, numbers of raters) were small for Example I, which occasionally led to negative estimates of variance components, which were simply set to zero. This is not a practical problem in most large-scale testing programs in which raters are well-trained and, therefore, usually do not contribute much to the variability in observed scores (Brennan, 2000; Brennan & Johnson, 1995). Of course, analyses with larger number of raters would give improved estimates.
Second, the same single AP exam was used for both examples. Although the two examples were conducted with different sets of data, the use of the same exam might weaken the generalizability of the findings to other large-scale assessments that employ a format similar to AP German. Future research could be conducted using different tests to examine how generalizable results are to other similarly structured large-scale exams.
Third, the D studies reported here could be conducted with varying numbers of conditions. For example, the numbers of testlets and/or items could be manipulated for Example II to investigate the likely psychometric properties of a shortened or lengthened test.
Fourth, the 0 to 130 composite scores considered here for the two examples are indeed actual scores used with AP German. However, the scores reported to examinees are 1 to 5 integers. In principle, composite-score analyses could be conducted for the 1 to 5 scale. If that were done, additional analyses involving decision consistency likely would be appropriate, as well.
Finally, GENOVA and mGENOVA (which were used for the analyses in this article) employ the analogous ANOVA procedure to obtain estimated variance components. Alternatively, maximum likelihood and/or Bayesian procedures might be employed. In recent years, restricted maximum likelihood (REML) has become quite popular (see, for example, Jiang, 2018) especially as it precludes the possibility of obtaining negative estimates. Bayesian procedures are an even more flexible alternative (see, for example, Jiang & Skorupski, 2018; LoPilato et al., 2015). It should be recognized, however, that maximum likelihood and Bayesian procedures are computationally intensive and make normality assumptions that may be problematic.
Footnotes
Acknowledgements
The authors thank the College Board for making available the Advanced Placement data used in this paper.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.