
Abstract
Causal effect estimates for the association of obesity with health care costs can be biased by reversed causation and omitted variables. In this study, we use genetic variants as instrumental variables to overcome these limitations, a method that is often called Mendelian randomization (MR). We describe the assumptions, available methods, and potential pitfalls of using genetic information and how to address them. We estimate the effect of body mass index (BMI) on total health care costs using data from a German observational study and from published large-scale data. In a meta-analysis of several MR approaches, we find that models using genetic instruments identify additional annual costs of €280 for a 1-unit increase in BMI. This is more than 3 times higher than estimates from linear regression without instrumental variables (€75). We found little evidence of a nonlinear relationship between BMI and health care costs. Our results suggest that the use of genetic instruments can be a powerful tool for estimating causal effects in health economic evaluation that might be superior to other types of instruments where there is a strong association with a modifiable risk factor.
Overweight and obesity are global public health concerns in terms of economic costs and effects on health.
1
The projected global prevalence of obesity will reach 18% in men and surpass 21% in women in 2025.
2
Higher body mass index (BMI), expressed in units of kg/m2, is a risk factor for type 2 diabetes mellitus, cardiovascular diseases, and certain types of cancer, resulting in shortened life expectancy.
3
According to the World Health Organization,
4
individuals are classified as obese with a BMI
Accurate estimates of health care costs are crucial to judge the tradeoffs between medical possibilities, their financial viability, and quality and fairness in any health care system. Because of practical and ethical issues, many health risk conditions (e.g., obesity) cannot be assessed in randomized controlled trials (RCTs), and cost data collected in RCTs often have limited generalizability. 7 On the other hand, observational studies can estimate the relation between health care costs and health conditions but generally cannot identify causal effects. 8 Many previous studies that estimated the association of obesity with health care costs arise from observational studies (e.g., Finkelstein et al., 9 Trasande et al. 10 ) that are unable to fully account for unmeasured confounders. For example, factors such as social deprivation or bias from self-reported height and weight measures are often not accounted for. In addition, the direction of the omitted variable bias is usually unclear. Cawley and Meyerhoefer 8 discussed how some people became obese after suffering an injury or chronic depression and have higher medical costs because of the injury or depression. Carreras-Torres et al. 11 found that higher BMI increased the risk of being a smoker, but smoking itself lowers BMI. 12
The presence of reverse causation and omitted variables motivated the use of instrumental variable (IV) analysis. The aim of the IV method is to exclude a correlation between the explanatory variables and the error term in a regression analysis. This is done by replacing the explanatory variables with other variables that are closely related to them but do not correlate with the error term.
For example, in the case of health care costs of obesity, Cawley and Meyerhoefer 8 used the BMI of a biological relative as an IV. Compared with a standard ordinary least squares (OLS) model, the authors found a 4-fold increase in the marginal costs of obesity and a 3-fold increase in the marginal costs of 1 unit of BMI. Studies by Black et al. 13 and Kinge and Morris 14 found similar differences between OLS and IV models. They both used the BMI of a biological relative as an IV.
However, a potential concern with this approach is that unobserved characteristics may be correlated with both a person’s own BMI and his or her relative’s BMI, for example, when they live in the same household. 15
In this article, we use an IV approach called Mendelian randomization (MR). MR is originally a concept from genetic epidemiology that uses genetic variants as IVs to overcome some limitations in cases where genetic polymorphisms have a well-known effect on modifiable risk factors such as BMI. 16 If the IV assumptions hold, genetic variants can be used to estimate the effect of BMI on health care costs. Because genotypes are assigned randomly when passed from parents to offspring, the population genotype distribution is assumed to be unrelated to confounders and can therefore serve as a valid instrument. This random segregation of alleles, according to Mendel’s law of independent assortment, mimics a natural experiment in which individuals are randomly assigned to groups based on their exposure. 17
Recent literature has suggested that MR can be a powerful tool for economic evaluation 18 ; however, we only identified few studies that used it.15,19–24
In this study, we use Mendelian randomization to estimate the effect of BMI on total annual health care costs and compare the results with a simple OLS model using data from a German population-based cohort study and published summary data.
Materials and Methods
Data
Study population
We use data from the KORA (Cooperative Health Research in the Augsburg Region) F4 study (2006–2010,
We also use summary-level data for individuals of European ancestry (
Confounders
All models adjust for age, sex, and education. Education was classified into 3 groups: basic education (≤ 9 years of schooling), medium education, and higher education (≥ 12 years of schooling, required to enter university). We also included the 10 first genetic principal components as covariates to control for residual population structure (allele frequency differences between cases and controls due to systematic ancestry differences) when estimating the BMI–health care costs summary-level effects from the KORA data. 27 Genetic associations should not be adjusted for large numbers of confounders, particularly if they may be on the causal pathway between the risk factor and the outcome. 28
Outcomes
The calculation of health care costs included outpatient services, hospital care, rehabilitation, and medication. Resource utilization of those services was assessed with an established questionnaire
29
and followed the standard way of how costs were calculated in previous KORA studies.
30
The time horizons for the assessment of used services varied from 7 days for medication, 3 months for outpatient physician contacts, and 12 months for inpatient and outpatient stays (hospital and rehabilitation). We extrapolated all measures to 12 months, under the assumption that the data were representative of the entire year, and then valued resource utilization by unit costs as provided by Bock et al.
31
The costs of prescription medication were estimated using pharmacy retail prices, based on patient information on medication name and national drug codes. For details on the costing of resource utilization, please compare appendix Table A1. Table 1 presents an overview of the data set. Observations with missing (assumed at random) or implausible information were also removed, resulting in a sample size of
Summary Statistics for the KORA F4 Data Set a
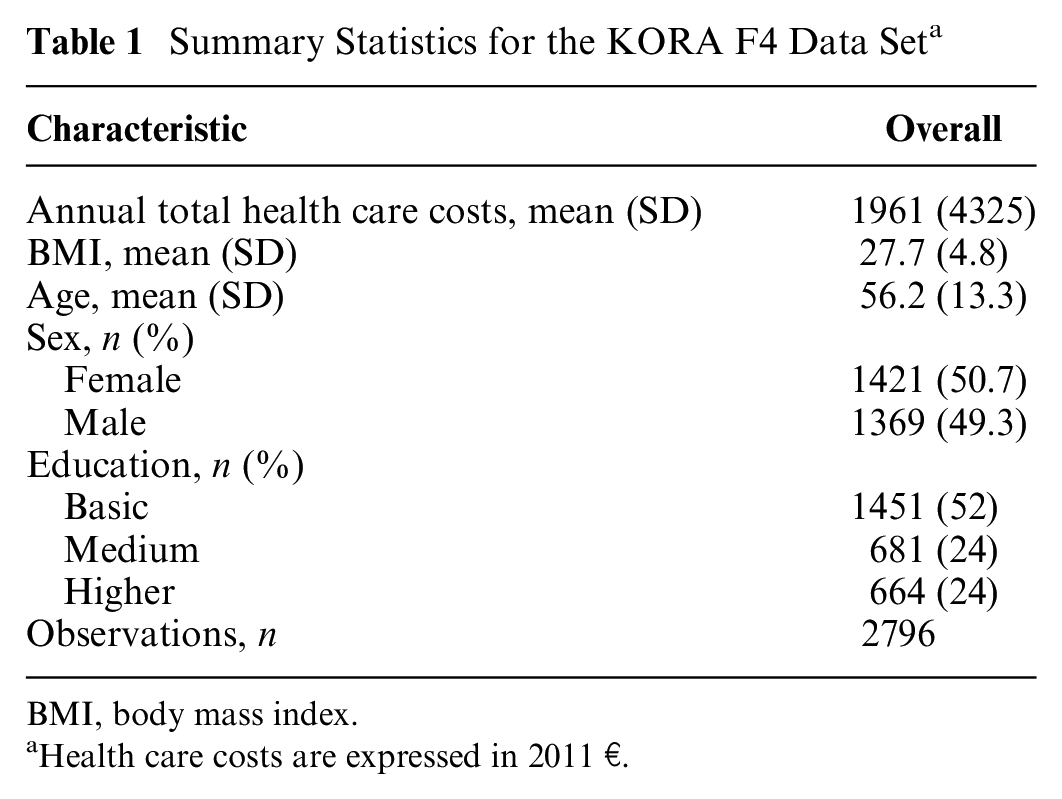
BMI, body mass index.
Health care costs are expressed in 2011 €.
Genetic instruments
We selected the 77 single-nucleotide polymorphisms (SNPs), out of the 97 reported (the remaining 20 SNPs are relevant for non-Europeans only), that are highly associated (
Mendelian Randomization
The IV method is used to estimate causal relationships when controlled experiments are not feasible or to infer causality in the presence of unmeasured confounding. An instrument is a variable that predicts the risk factor but, conditional on the risk factor, shows no independent association with the outcome. The random assignment in trials is an example of what would be an ideal instrument, but instruments can also be found in observational settings with a naturally varying phenomenon. For example, suppose a researcher wishes to estimate the causal effect of smoking on general health. 37 It is difficult to imply that smoking causes poor health because other variables, such as depression, can affect both health and smoking. An individual may start smoking because of depression, and simultaneously depression may influence health status. In addition, it is difficult to conduct controlled experiments on smoking status in the general population. In this case, the tax rate for tobacco products is a reasonable choice for an instrument for smoking, because higher prices tend to keep people from smoking. Moreover, tax rates for tobacco products are supposed to be unrelated to depression. If the researcher then finds an association between tobacco taxes and health status, this may be viewed as evidence that smoking causes changes in health.
Mendelian randomization is a type of IV analysis that uses genetic variants as instruments. The random allocation of genetic variants at conception means that these variants are less likely to violate some of the assumptions of IV analysis than nongenetic instruments, even describing it as nature’s randomized controlled trial. 38 A disease or trait does not alter the inherited alleles, and therefore these do not change over time. The SNP alleles’ random inheritance makes the genotype distribution largely independent of socioeconomic and lifestyle factors. Valid genetic instrumental variables are defined by 3 key assumptions (see Figure 1):
The genetic variant is associated with the risk factor of interest (the relevance assumption).
The genetic variant shares no common cause with the outcome (the independence assumption).
The genetic variants do not affect the outcome except through the risk factor (the exclusion restriction assumption).
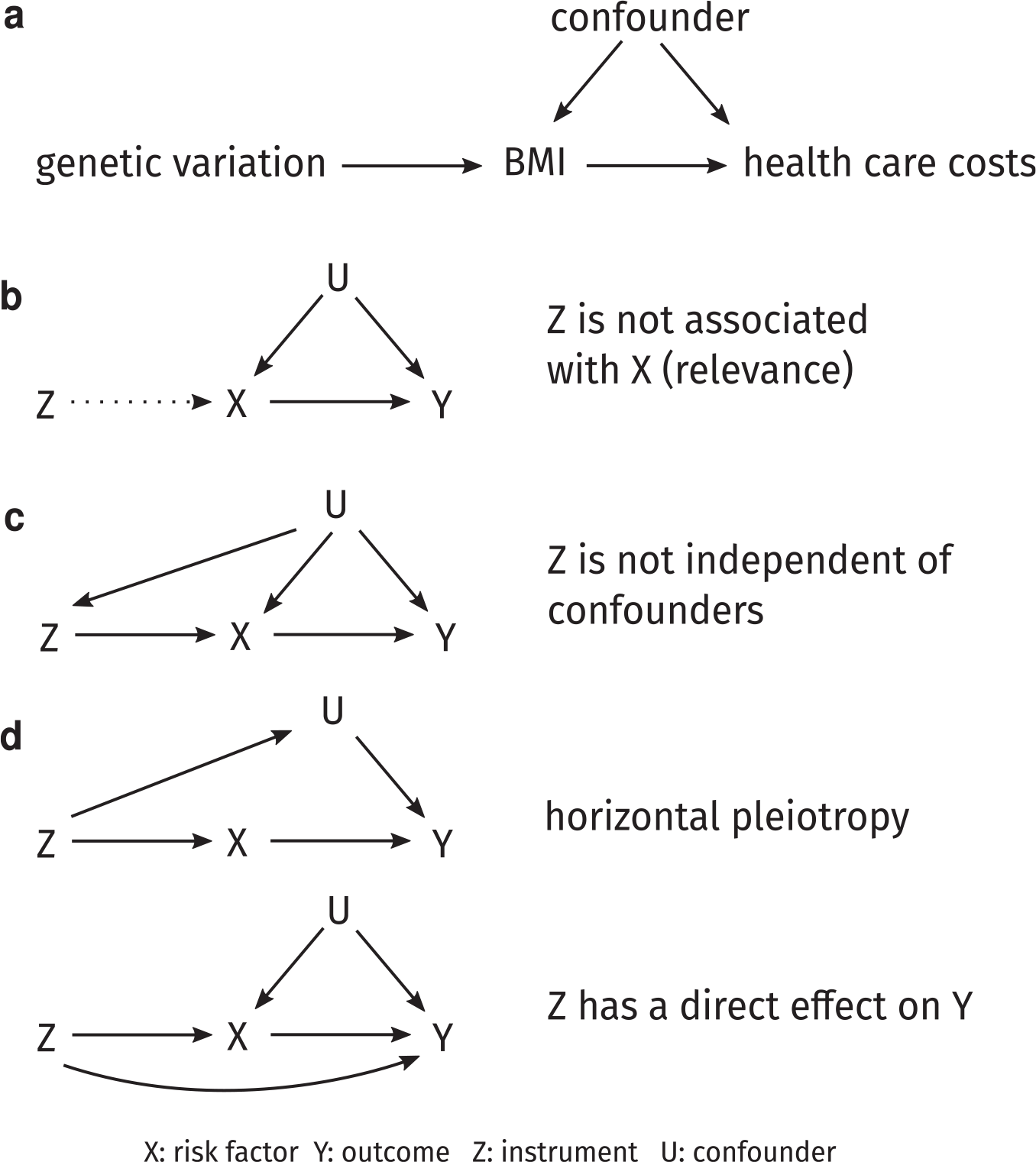
(a) A simplified causal diagram depicting our study. The instrumental variable (IV) assumptions are that the genetic variants are associated with risk factor body mass index (BMI), that they have no other influence on the outcome health care costs, except through BMI, and that there are no confounders of the genetic variants–outcome association. (b) An example of violation of the relevance condition: the instrument is not associated with the risk factor. (c) If, for example, variants associated with BMI had different frequencies in different ethnic groups, then the independence assumption would be violated. (d) The exclusion restriction assumption is violated in the presence of horizontal pleiotropy, in which genetic variants associated with the risk factor also affect a confounder. This assumption is also violated when the instrument has a direct effect on the outcome.
The first assumption is required because the risk factor will be estimated using the allele distribution of the genetic instruments. This assumption can be tested using the weak instruments test based on the first-stage F statistic. 39 The second and third assumptions are harder to validate because of potential pleiotropic effects of SNPs or SNPs in linkage disequilibrium (nonrandom association of alleles at different loci) correlated with genes that have effects on the outcome independently of the risk factor (see Figure 1c). 40 Another violation would happen if the sample consists of a population substructure with distinct distributions of alleles that is also linked with the outcome. In this situation, the substructure would be a prevalent cause of both SNP and outcome, opening up a path from SNP to nonexposure-mediated outcome (see Figure 1d). See Glymour et al. 41 for examples violating the independence and exclusion restriction assumptions.
If the biological mechanism connecting the genetic variant to the risk factor is well understood, a single variant could plausibly fulfill these circumstances. In many cases, however, MR studies include multiple genetic variants. Then, for each of the genetic variants, the 3 main assumptions must hold.
In our study, we perform both one-sample MR using individual-level data and two-sample MR using summarized data. The one-sample analysis is based on the KORA data only, whereas the two-sample analysis uses the GIANT data for the SNP–BMI association and the KORA data for the SNP–health care costs association. We then meta-analyzed the MR estimates from each genetic instrument (SNP) from these analyses and report point estimates for the MR analyses together with standard errors (SEs) and 95% confidence intervals (CIs).
In the following, we explain both one-sample and two-sample approaches in more detail.
One-sample Mendelian randomization and 2-stage least squares
To estimate the impact of BMI on medical spending, we first used a 2-stage least squares (2SLS) model. In the first step of the 2SLS approach, the endogenous regressor of interest (BMI) is regressed on all valid instruments. As the instruments are assumed to be exogenous, this approximation of the endogenous variables will not correlate with the error term.
In the second step, the outcome (total annual health care costs) is regressed on the fitted values of BMI from the first stage.
Stage 1: Regress independent variable X (BMI) on instruments Z (genetic loci):

Stage 2: Regress
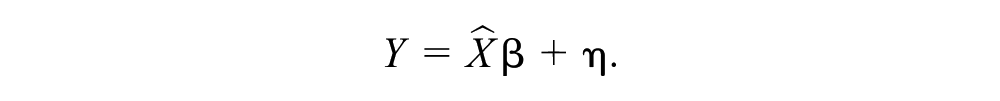
The 2SLS estimates are then
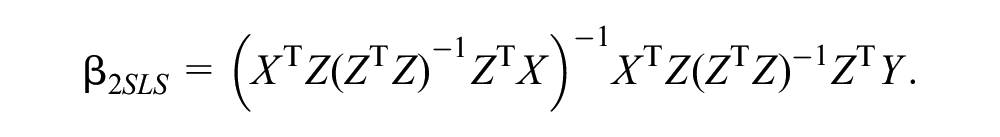
All 2SLS models control for age, sex, and education. This approach, using individual-level data in a single data set, is called one-sample MR. For comparison, we compute linear OLS non-IV models that regress health care costs on BMI and again adjust for the same covariates as before. We use the Durbin–Wu–Hausman endogeneity test 42 to evaluate whether there is any evidence that the instrumental variable estimate differs from the OLS estimate. In this test, a significant result indicates disagreement between OLS and IV estimates.
Two-sample Mendelian randomization using summary data
Another popular MR method combines (publicly) available summary data on SNP–risk factor and SNP–outcome associations from 2 separate studies for large numbers of uncorrelated variants. These can be obtained from the published literature, typically from summary results provided by consortia of GWAS, or estimated directly from individual-level participant data. This is referred to as two-sample MR using summary data. The main advantage of two-sample MR is increased statistical power, but the quality of the pooled results is dependent on that of the individual studies. See Lawlor 43 for a detailed comparison of one-sample and two-sample MR.
Two-sample MR takes advantage of the fact that the risk factor–outcome association
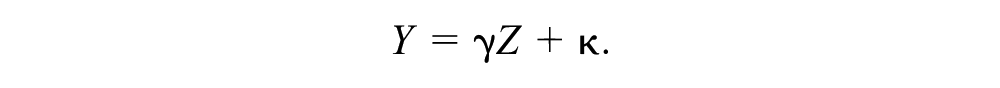
Then the causal effect can be calculated using the Wald estimate 44 :
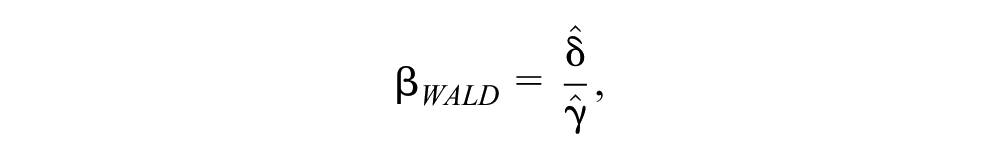
where the estimate
In our study, we use the reported SNP–risk factor associations from the GIANT consortium and the SNP–outcome associations from the KORA data. Recently, a variety of different methods that go beyond the simple Wald estimate have been developed. We consider the 4 most common methods to calculate the causal effect of a two-sample MR study: the inverse variance weighted (IVW) method, the simple and weighted median, and MR Egger regression. The IVW meta-analysis of each Wald ratio is the easiest way to obtain an MR estimate using multiple SNPs. Using random effects allows each SNP to have different mean effects (e.g., due to horizontal pleiotropy), returning an unbiased estimate if the horizontal pleiotropy is balanced.
An alternative approach is to take the median effect of all available SNPs. 48 This has the advantage that only half the SNPs need to be valid instruments (i.e., robust association with the exposure, exhibiting no horizontal pleiotropy, no association with confounders) for unbiased estimation of causal effects. The weighted median can be obtained by weighting the contribution of each SNP by the inverse variance of its association with the outcome, so stronger SNPs contribute more to the estimate.
MR Egger regression 49 adapts the IVW linear regression analysis by allowing a nonzero intercept, so the net-horizontal pleiotropic effect (i.e., effects of the SNPs on the outcome not mediated by the exposure) across all SNPs can be unbalanced, or directional. The method returns an unbiased causal effect even if the horizontal pleiotropic effects are not correlated with the SNP–exposure effects (known as the InSIDE assumption). See Hemani et al. 50 for more details on all methods.
Invalid Instruments
As the number of biomarker-associated variants is constantly increasing through GWAS, selection of the most appropriate instruments is an important issue 51 for one-sample MR. Using too many genetic variants as instruments can lead to spurious estimates and increased type I error rates. This implies that, even if a set of multiple instruments is valid (i.e., they are not associated with confounding factors, have no direct effect on the outcome, and are at least weakly associated with the exposure), the 2SLS estimator can still be biased toward the conventional regression estimate.52,53 A weak instrument explains only a small proportion of the variation in the risk factor. Using many weak instruments can still result in weak instrument bias.53,54 To address the weak instrument problem in the one-sample 2SLS models, we consider both least absolute shrinkage and selection operator (LASSO) variable selection and combining the genetic variants into a single risk score.
LASSO selection
LASSO selection suggests selecting optimal instruments in the first-stage regression by variable selection. 55 A similar approach with explicit application to MR was proposed by Kang et al. 56 Additional work by Windmeijer et al. 57 recommends using the adaptive LASSO to retain the oracle properties. 58 In the adaptive LASSO for the first stage, the goal is to minimize
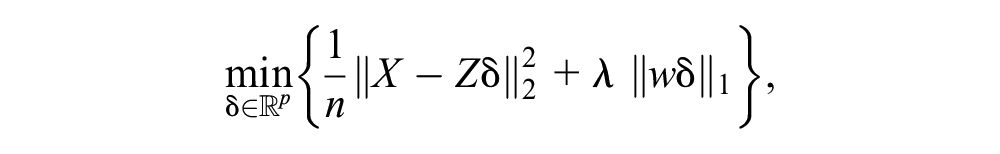
where
Genetic risk score
An individual’s genetic risk score (GRS) is equal to the number of alleles he or she has that are associated with an elevated risk factor; each person has zero, 1, or 2 alleles for each of the relevant SNPs, so a high score means a higher risk. 24 In our study, the 77 genetic variants from the Locke et al. 26 study result in a maximum possible GRS of 154.
The GRS has 2 benefits: first, it is stronger (explains more weight variation) than any of the SNPs separately, and second, it may be more valid as it decreases the likelihood that any alternative biological pathway (pleiotropy) in any single SNP will bias the IV outcomes. 59
However, Palmer et al. 60 showed that an unweighted score has lower power than adding multiple IVs into the 2SLS, and using an appropriately weighted allele score performs similarly to adding each valid SNP as an instrument.
Meta-analysis
We meta-analyzed the MR estimates from each genetic instrument (SNP) from the 6 individual analyses (one-sample 2SLS with GRS, one-sample 2SLS with LASSO, two-sample simple median, two-sample weighted median, two-sample IVW, two-sample MR Egger), assuming an inverse variance-weighted random-effects model to avoid overprecision and to allow for heterogeneity in the causal estimates. 61
Pleiotropy
A common problem in MR analyses is the presence of pleiotropic effects (i.e., a genetic variant has associations with more than 1 risk factor on different causal pathways). 62 This can be especially problematic for polygenic risk factors such as BMI, where the influence of genetic variants is less specific. 63 To test violations of the IV assumptions, we used 3 approaches. First, we checked, in the Phenoscanner database, 64 whether genes related to BMI are also significantly associated with other determinants of health care costs. In a second check, we used the MR Egger intercept test 49 for pleiotropy. In MR Egger regression, the intercept is left unconstrained to test for evidence of bias-generating pleiotropy, with a null hypothesis of no pleiotropic effects. As a third test for pleiotropy, we conducted Sargan’s test for overidentification. 65 This test is only available for one-sample MR with multiple instruments (i.e., the 2SLS analysis with LASSO selection). The null hypothesis in this test is that all exogenous instruments are in fact exogenous and uncorrelated with the model residuals, and all overidentifying restrictions are therefore valid.
Nonlinearity
Previous research found evidence of a nonlinear relationship between BMI and health care costs,8,66 and MR is often unable to detect such nonlinearities because genetic variants usually explain only a small percentage of the variance in the risk factor.
67
We used the method of Staley and Burgess,
67
which assesses nonlinear exposure–outcome relationships using IV analysis in the context of MR. To test for nonlinear effects of BMI on health care costs in our sample, we fitted both a fractional polynomial model and a piecewise linear model and performed the Cochran Q test, quadratic test, and fractional polynomial test. The heterogeneity test using Cochran’s Q statistic is used to assess whether the localized average causal effect (LACE) estimates differ more than would be expected by chance. The second is a trend test where the LACE estimates are meta-regressed against the mean value of the exposure in each stratum, equivalent to fitting a quadratic exposure–outcome model. The third test is a more flexible variant that compares twice the difference in the log-likelihood between the linear model and the best-fitting fractional polynomial of degree 1 with a
Results
One-Sample MR
Table 2 presents the results of the association between BMI and health care costs, according to the one-sample analysis. The OLS model finds an effect of €75.8 (SE 14.6) for a 1-unit increase in BMI. In contrast, the 2SLS model using the GRS estimates an effect of €129.0 (SE 241.2) for a 1-unit increase in BMI. The 2SLS LASSO model selects 64 valid genetic instruments for BMI and finds an effect of 146.1€ (SE 190.8). Other significant cost drivers or savers in the OLS models are age and higher education for the BMI model, but all associations lose significance at the 0.05 level when moving from OLS to 2SLS analysis.
Effect of BMI on Annual Total Health Care Costs Using an OLS Model and Two One-Sample 2SLS Models with Genetic Variants as Instrumental Variables a
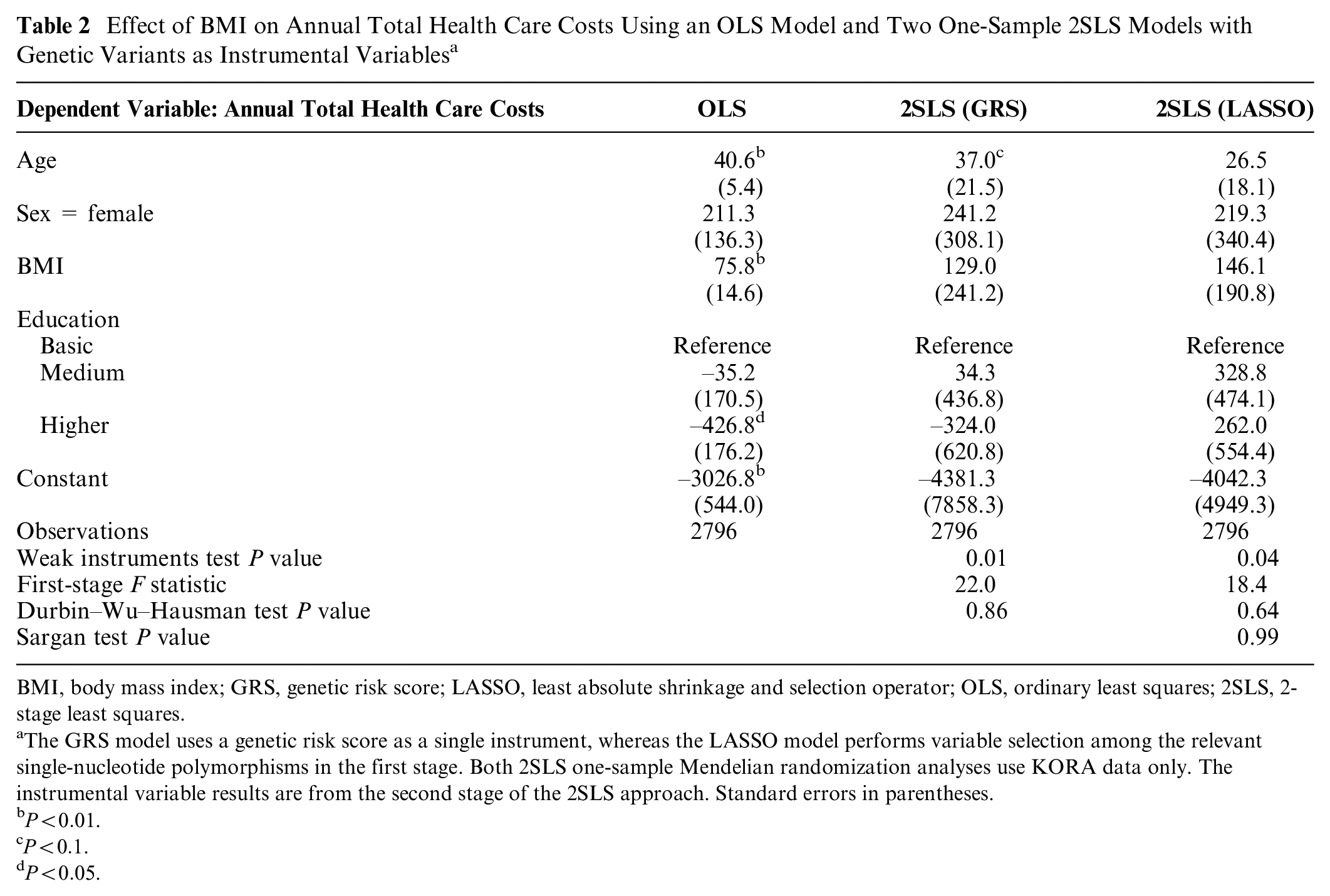
BMI, body mass index; GRS, genetic risk score; LASSO, least absolute shrinkage and selection operator; OLS, ordinary least squares; 2SLS, 2-stage least squares.
The GRS model uses a genetic risk score as a single instrument, whereas the LASSO model performs variable selection among the relevant single-nucleotide polymorphisms in the first stage. Both 2SLS one-sample Mendelian randomization analyses use KORA data only. The instrumental variable results are from the second stage of the 2SLS approach. Standard errors in parentheses.
In both 2SLS analyses, we find little evidence of weak instruments, because the weak instruments test P value is <0.05 in both cases and the F statistics are above the traditional threshold of 10. 39 The Durbin–Wu–Hausman test, however, suggests no strong evidence of differences between the OLS and IV estimates.
Two-Sample MR
In Figure 2 and Table 3, we present the effect estimates from the two-sample MR analyses. All 4 methods find a higher causal effect than the 2SLS approaches. For example, the MR Egger method estimates a causal effect of €397.7 (95% CI, –795 to 1590) for a 1-unit increase in BMI. These effects increase from €405.1 (95% CI, –87 to 898) for the IVW method, to €428.3 (95% CI, –295 to 1152) for the weighted median, to €540.8 (95% CI, –192 to 1273) for the simple median method. However, all 95% confidence intervals are very wide, and the results cannot be considered statistically significant. The absence of pleiotropic effects is supported by the MR Egger intercept test (P = 0.99).
Effect of BMI on Annual Total Health Care Costs Estimated by Two-Sample MR Using Simple Median, Weighted Median, IVW, and MR Egger Methods a
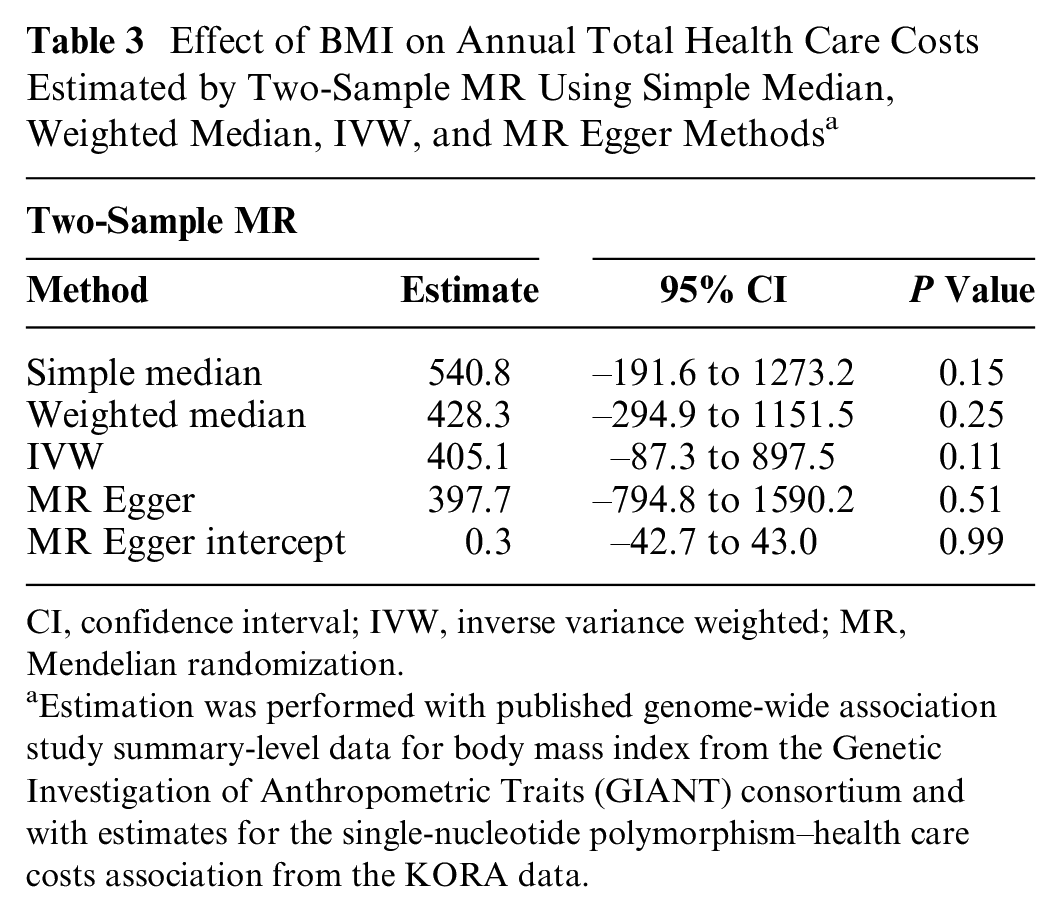
CI, confidence interval; IVW, inverse variance weighted; MR, Mendelian randomization.
Estimation was performed with published genome-wide association study summary-level data for body mass index from the Genetic Investigation of Anthropometric Traits (GIANT) consortium and with estimates for the single-nucleotide polymorphism–health care costs association from the KORA data.
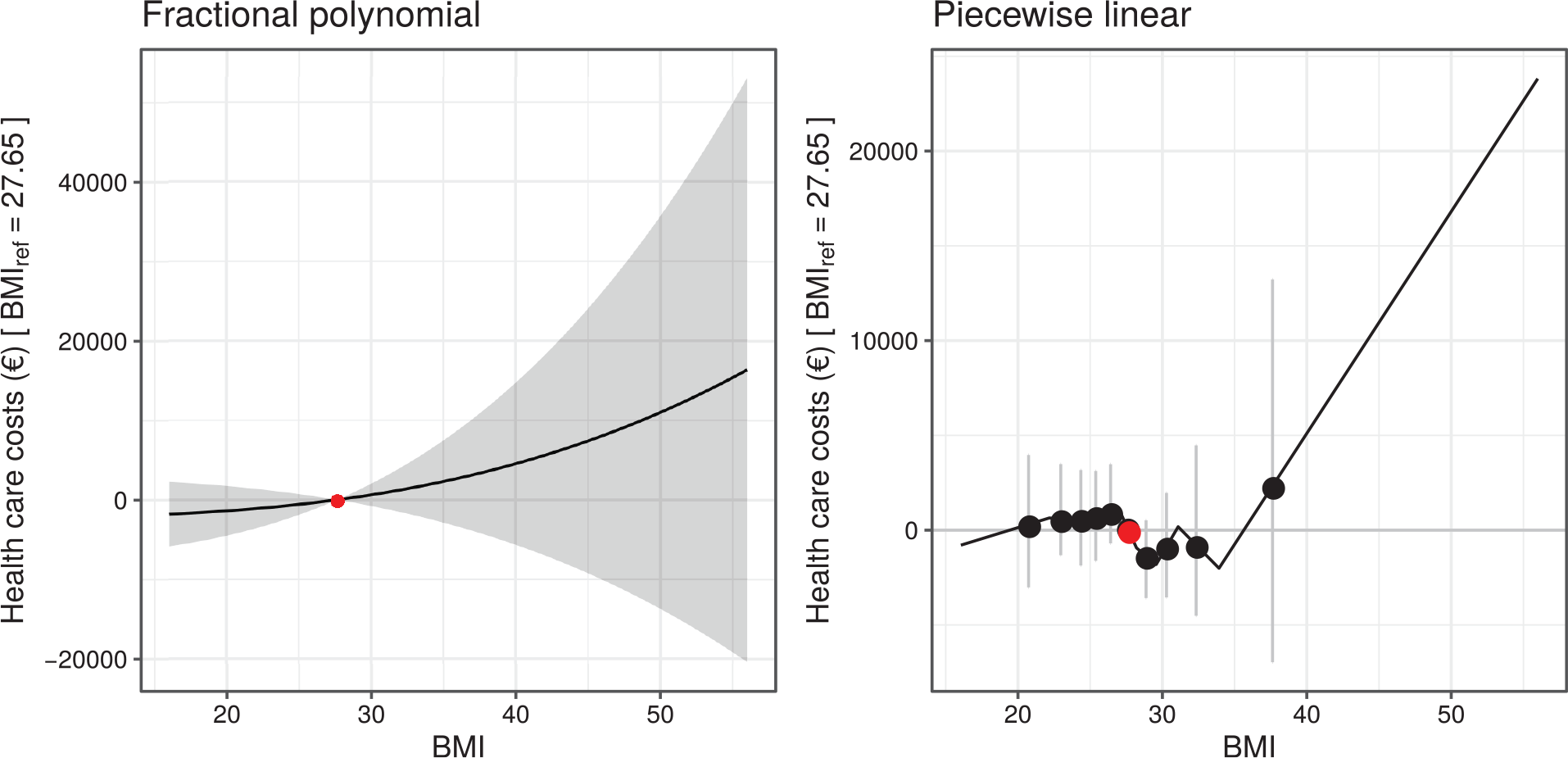
Plot of the gene–outcome v. gene–exposure regression coefficients for body mass index across different two-sample Mendelian randomization methods. Each point represents a single-nucleotide polymorphism. Some outliers are not shown.
Meta-Analysis
The meta-analysis of the 6 individual analyses (one-sample 2SLS with GRS, one-sample 2SLS with LASSO, two-sample simple median, two-sample weighted median, two-sample IVW, two-sample MR Egger) estimates a total causal effect of €279.8 for a 1-unit increase in BMI on annual total health care costs (see Figure 3). The 95% confidence interval for this effect is 47.3 to 512.3, and the complete prediction interval is –49.5 to 609.2. Most weight is assigned to the 2SLS LASSO (38.7%) and IVW (22.3%) methods.
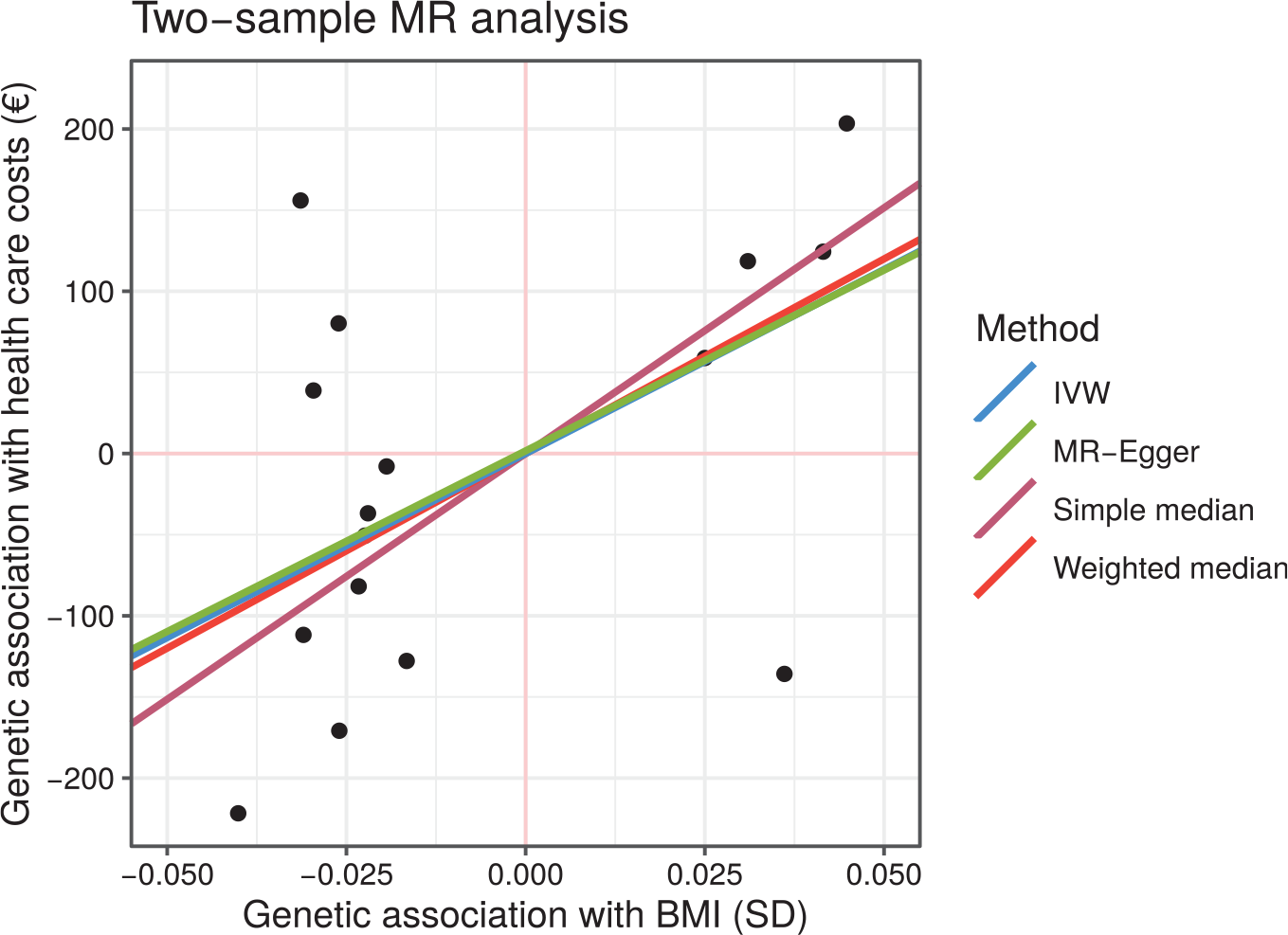
Meta-analysis of one-sample and two-sample Mendelian randomization (MR) causal estimates using individual single-nucleotide polymorphisms (SNPs) as instrumental variables. One-sample MR using both a genetic risk score (GRS) and least absolute shrinkage and selection operator (LASSO) variable selection was performed using the KORA data only. Two-sample MR using 4 different methods was performed with published genome-wide association study summary-level data for body mass index from the Genetic Investigation of Anthropometric Traits (GIANT) consortium and with estimates for the SNP–health care costs association from the KORA data.
Pleiotropy
In the PhenoScanner database, we found that some SNPs are relevant to obesity-related illnesses such as type 2 diabetes and high blood pressure. As in Böckerman et al., 15 we assume that the associations with obesity-related conditions occur because of the SNPs’ association with high BMI, but we cannot definitely rule out other pathways. The Sargan test does not provide evidence of pleiotropic effects in the 2SLS LASSO model (see P values in Table 2). In addition, the absence of pleiotropic effects is supported by the MR Egger intercept test (P = 0.99; see Table 3).
Nonlinearity
There was no strong evidence that the association between BMI and health care costs was nonlinear (see Figure 4), with the quadratic test yielding a P value of 0.52 (fractional polynomial test P = 0.59, Cochran Q test P = 0.62). The best-fitting fractional polynomial of degree 1 for the relationship between BMI and health care costs had power 3, and there was no evidence to suggest a fractional polynomial of degree 2 fitted the data better (P = 0.87).
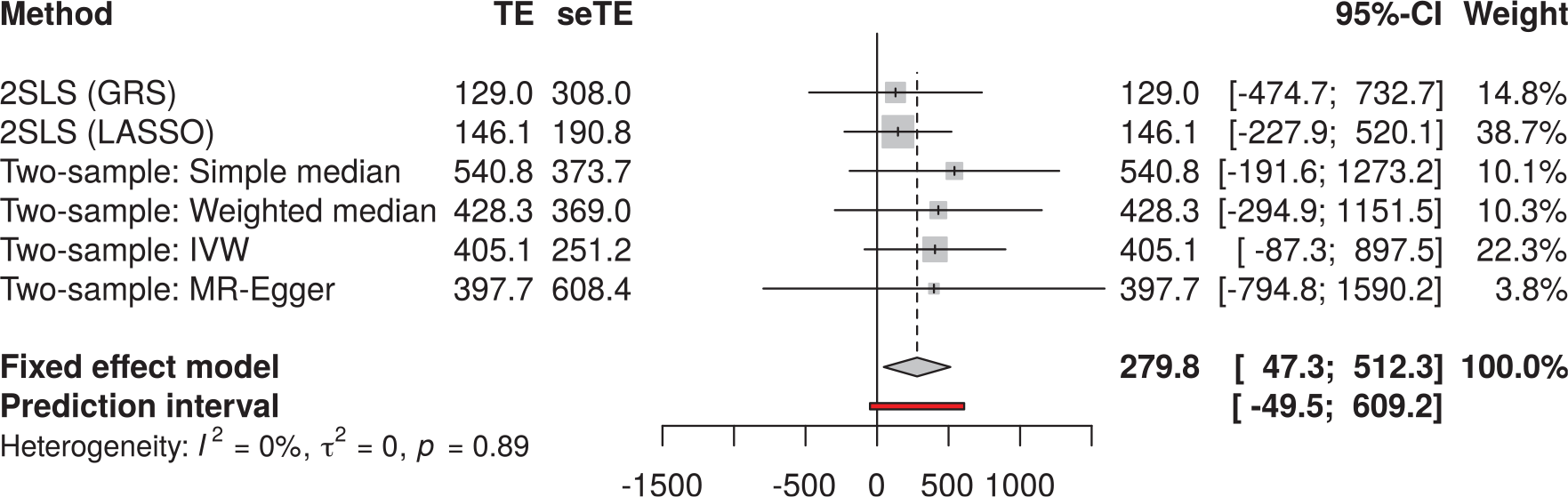
Exposure–outcome relationships for body mass index (BMI) with health care costs estimated using the fractional polynomial and piecewise linear methods. The red points represent the reference point of BMI of 27.65 kg/m2. Gray areas and lines represent the 95% confidence intervals.
Discussion
This study is one of the first that uses an MR approach to estimate the marginal health care costs of a prevalent clinical condition. MR offers new opportunities for reliable causal inference in health economic research within the framework of observational research designs. The recent advent of affordable GWASs provides an exciting opportunity to understand with far greater precision the genetic factors that influence variation in psychological, social, and health-related traits. Even an incomplete understanding of the genetic architecture of a trait could be a boon for social scientists; the presence of genetic variants can be detected with high reliability, thus allowing to identify or clarify the actual biological mechanisms that underlie social and health behaviors. 68
Using MR, our findings indicate that a 1-unit increase in BMI increases total medical spending by €279.8, based on the meta-analysis of several MR methods. The OLS model, which does not use instrumental variables, only finds additional spending of €75.8. This demonstrates that an MR study with genetic instruments may detect more hidden bias than a non-IV analysis, leading to higher estimated effects. It is important to note that OLS estimates average treatment effects, whereas IV estimates local average treatment effects. This may partially account for the differences in the effect estimates. 69 Our study results are in a similar direction to those of Cawley and Meyerhoefer, 8 Black et al., 13 and Kinge and Morris, 14 which imply much higher costs of obesity in the IV analysis compared with the non-IV analysis. These studies use the BMI of the respondent’s oldest child as instrument and report that the IV estimate for the association between BMI and health care costs is between 2 and 4 times higher than in the non-IV approach, about the same magnitude that we find. However, as it is likely that, because of shared environmental exposures, a child’s BMI is correlated with relevant covariates, 70 the use of such non- or quasi-genetic IVs is found to be controversial and might lead to biased estimates as well.
Another advantage of our data is that the height and weight measurements of individuals in the KORA sample were performed by trained staff. This is more accurate than self-reported measurements where people tend to underestimate their weight and overestimate their height, resulting in an underestimation in BMI. 71
Because participants in our study were asked to self-report their health service usage over the past 3 to 12 months, recall bias cannot be excluded, and it is expected that total utilization and costs are underestimated. Health care utilization was priced using average reference value; therefore, actual costs might deviate. However, this should not influence the validity of the study results because its effect on relative excess cost estimates is expected to be rather small. 72 In addition, we were unable to consider cost categories such as presenteeism, premature death, or out-of-pocket payments for medication. In total, these limitations led to an underestimation of total health care costs that might also lead to an underestimation of marginal costs—which of course applies for both the OLS and one-sample/two-sample MR.
Other studies found similar results. Within the BMI range of 25 to 45 kg/m2, a study in the United States by Wang et al. 73 described an increase in medical and pharmaceutical costs of $202.3 per BMI unit. A review of 75 international studies by Kent et al. 74 reported a median increase in mean total annual health care costs of 36% for obese individuals compared with individuals of healthy weight. However, all these studies rely on traditional non-IV estimations and might underestimate the true effect.
A major limitation of our study is the low statistical power of the one-sample approach. Making anticonservative assumptions (i.e., that the true causal effect is the MR effect reported in the study, with an observational estimate as per the OLS estimate), power is 0.44. 75 This low power is mainly because of the small sample size, large variance in health care costs, and the weak SNP–BMI association. The differing effect size of covariates and larger confidence intervals between OLS and 2SLS models may also be attributable to low power. To reach a power level of 0.8, the sample size would need to be at least 12,000.
Having weak or invalid instruments can be a problem in MR analysis. This is a common problem in MR because behavioral traits are mainly affected by numerous genes with small effects. 68 Davies et al. 52 show that 2SLS is especially vulnerable to weak instrument bias in MR and propose the limited information maximum likelihood and the continuously updating estimator as unbiased alternatives to 2SLS. However, these methods are difficult to implement and interpret. For this reason, we used the GRS and adaptive LASSO variable selection in the first state of 2SLS to rule out invalid and weak instruments. The SNPs we used have been discovered in GWAS and should be well founded, but it is also possible that there might be some direct effect that does not operate through a high BMI because some SNPs are linked to obesity-related illnesses.
The Durbin–Wu–Hausman test P value suggests no significant difference between OLS and IV estimates for the one-sample methods. However, the effects being estimated by the 2 methods may not be the same—the MR estimate reflects the effects of lifelong perturbations in the risk factor, whereas OLS regression results may reflect more acute effects. 76 According to Burgess and Thompson, 77 it would be fallacious to assume that a nonsignificant result means the OLS estimate is unconfounded. MR estimates are almost always less precise and have wider confidence intervals than OLS regression, so tests for difference often have low statistical power.
It must also be noted that the KORA F4 study was part of the GWAS consortium that discovered the relevant SNPs for BMI in the study by Locke et al. 26 Because the same data were used at the GWAS discovery stage and in our analysis, it is possible that chance correlation between SNPs and confounders can lead to overestimation of the SNP–trait effect. 78 This is the so-called winner’s curse or Beavis effect. 79 However, the KORA F4 study was only a small fraction of the more than 300,000 individuals in this GWAS, so it should not strongly bias our analysis. Furthermore, this problem almost exclusively affects the one-sample analysis.
Burgess et al. 80 note that instrumental variable estimates using a linear model may not reflect causal effects for large changes in the exposure. In our case, we find the relationship between BMI and costs approximately linear, and therefore the linear model is justified.
In the 2SLS estimator, we assume normal distribution of cost data, which is not present because of skewness, positivity, and heavy tails. This can also affect the validity of the standard errors and confidence intervals.81,82 Still, the use of a linear model is justified because the skewness and tail distribution are not extreme, and the large sample size guarantees near-normality of sample means because of the central limit theorem. 83
In conclusion, we have shown that MR can be a viable tool in health economic analyses. We found more than 3 times higher costs for a 1-unit BMI unit increase in our IV model than in the OLS model. Because the association of genetic variants with BMI is still weak, and the sample size of our one-sample analysis is very low, the results have to be interpreted carefully.
Footnotes
Acknowledgements
We thank Konstantin Strauch, Thomas Meitinger, Harald Grallert, Christine Meisinger, and Annette Peters for providing the data.
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
The author(s) received no financial support for the research, authorship, and/or publication of this article.