
Abstract
Even as vaccination for severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) expands in the United States, cases will linger among unvaccinated individuals for at least the next year, allowing the spread of the coronavirus to continue in communities across the country. Detecting these infections, particularly asymptomatic ones, is critical to stemming further transmission of the virus in the months ahead. This will require active surveillance efforts in which these undetected cases are proactively sought out rather than waiting for individuals to present to testing sites for diagnosis. However, finding these pockets of asymptomatic cases (i.e., hotspots) is akin to searching for needles in a haystack as choosing where and when to test within communities is hampered by a lack of epidemiological information to guide decision makers’ allocation of these resources. Making sequential decisions with partial information is a classic problem in decision science, the explore v. exploit dilemma. Using methods—bandit algorithms—similar to those used to search for other kinds of lost or hidden objects, from downed aircraft or underground oil deposits, we can address the explore v. exploit tradeoff facing active surveillance efforts and optimize the deployment of mobile testing resources to maximize the yield of new SARS-CoV-2 diagnoses. These bandit algorithms can be implemented easily as a guide to active case finding for SARS-CoV-2. A simple Thompson sampling algorithm and an extension of it to integrate spatial correlation in the data are now embedded in a fully functional prototype of a web app to allow policymakers to use either of these algorithms to target SARS-CoV-2 testing. In this instance, potential testing locations were identified by using mobility data from UberMedia to target high-frequency venues in Columbus, Ohio, as part of a planned feasibility study of the algorithms in the field. However, it is easily adaptable to other jurisdictions, requiring only a set of candidate test locations with point-to-point distances between all locations, whether or not mobility data are integrated into decision making in choosing places to test.
Even as vaccinations against severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) roll out in the United States, new infections continue to mount across the country. 1 However, while new infections will decrease as more people are immunized, lingering cases of the coronavirus will still exist in communities across the United States, frustrating attempts to fully suppress transmission and end the pandemic. 2 Even though multiple sites for testing for SARS-COV-2 are available in many communities, tracking down and detecting many cases of the virus will require active surveillance, in which public health workers seek out infections rather than waiting for individuals to present for diagnosis. 3
While active surveillance efforts, particularly tied to contact tracing, were stymied by the scale of the epidemic in 2020 in the United States, other countries, particularly, China, South Korea, Hong Kong, Singapore, Taiwan, Australia, Vietnam, and New Zealand, achieved low community transmission levels through robust control measures that include extensive surveillance efforts.4,5 In fact, relying on presentation to health care facilities for diagnosis cannot contain the pandemic, and community-based surveillance and contact tracing are vital to early detection of new cases and prevention of the resurgence of the disease.5,6
Community-based surveillance efforts in the United States are now widespread and have taken SARS-CoV-2 testing out of the health care setting. There are different types of off-site testing designs, retrofitting existing structures (e.g., a sporting venue) and using tents for pop-up clinics and vans to take SARS-CoV-2 testing fully mobile. 7 Our efforts are directed toward the last two design choices, in which SARS-CoV-2 testing does not depend on individuals seeking out a fixed site but can be moved to seek out places in the community at higher risk for transmission than others and reach vulnerable populations that may not be able to reach other venues at a distance from their homes (e.g., the elderly, those without transport).
These kinds of mobile testing opportunities have been successful in increasing uptake of human immunodeficiency virus (HIV) testing in the United States and abroad, particularly targeting high-risk populations that otherwise may not come forward for screening.8–10 This targeted testing among high-risk communities is now also happening in the context of coronavirus disease 2019 (COVID-19). 11 Combining these types of testing interventions with geospatial and phylogenetic data, information on social and sexual networks has also been proposed as a way to home in on hotspots of HIV, increasing the yield of testing. 12 However, even with these kinds of efforts, approximately 14% of Americans living with HIV remain unaware of their HIV serostatus, leaving the detection of undiagnosed infections as the “holy grail” of HIV control efforts, indicating additional approaches are necessary to reach these individuals. 13 A similar situation may persist with SARS-CoV-2 in the United States, with many undiagnosed infections still undetected across the country. 14
As happened with HIV infection, new platforms for SARS-CoV-2 testing are emerging quickly, from at-home tests to rapid antigen assays to supplement standard laboratory-based polymerase chain reaction (PCR) diagnostics, with saliva-based alternatives to invasive nasopharyngeal swabs for the comfort and convenience of patients. 15 But these technologies cannot address the simple question that underlies active surveillance efforts: where can we find lingering cases of SARS-COV-2? Identifying most, if not all, infections in the United States through active case finding, contact tracing, isolation of infected individuals, and quarantine of their contacts is the ideal route to containing SARS-CoV-2.16–18 Universal testing, contact tracing, and isolation strategies for SARS-CoV-2 deployed in places like Wuhan, China, and akin to the universal test-and-treat efforts for HIV in some countries are expensive, are resource intensive, and, in the context of SARS-CoV-2 control in Wuhan, have raised human rights concerns.19,20 If universal testing, contact tracing, and isolation are infeasible for the United States, how can we maximize the yield of new cases detected? While we might target pop-up or mobile testing to places where we believe the prevalence of undetected infection to be very high (e.g., apartment buildings, nursing homes, police stations) in many cities and towns, choosing between these venues may be difficult both in terms of their epidemiological value (i.e., the underlying prevalence at a site) and the willingness of people passing through these locations to volunteer for testing.
The elements of the predicament for screening for SARS-CoV-2 in the United States are clear: many people remain undiagnosed with SARS-CoV-2, and the prospects of universal testing of entire communities are slim. Thus, we want to maximize the number of cases detected with the limited resources we do have while cognizant that we also have imperfect information about where these undetected infections are to be found. Policymakers have choices about how to address this problem. In deciding where to deploy their testing resources, policymakers must choose between making the best possible choice based on their current understanding of the evidence and investing in improving their understanding of the evidence in the hope that it will lead to even better choices in subsequent periods. That is, policymakers can go with what they know and target testing at places they assume are high risk (e.g., nursing homes), but the kinds and numbers of high-risk venues, which might yield the most cases, may be large and diverse and shift over time. 21 In addition, SARS-CoV-2 is an overdispersed pathogen tending to spread in clusters with heterogeneity and stochasticity in transmission, and targeting locations based on simple assumptions about risk environments may turn up to be dead-ends. 22 Beyond universal testing, the alternative is to test randomly across a community, with the hopes of finding “hotspots” but facing the prospect that the number of positive diagnoses may wane at promising locations as testing uncovers most of the undiagnosed cases there or the epidemic moves on to new places in a community. Both of these choices open to policymakers present an iterative series of questions: where do we test today, how long do we stay in that location, when do we move on, and where do we go next? How can policymakers best make these complicated decisions between the choices open to them for venues to test for SARS-CoV-2 on an ongoing basis and in an evidence-based fashion? Here we describe how a set of tools we have modified and adapted from the sequential decision making field—namely, bandit algorithms—may help solve the conundrum of SARS-CoV-2 testing in the context of limited resources.
The Explore v. Exploit Dilemma and Bandit Algorithms
The “explore v. exploit dilemma” is a classic problem, where a limited resource must be deployed across alternative targets in a way that maximizes overall gain, when the critical attribute of each target is only partially known at the time of deployment but may become better understood as a result of the deployment decision. This is a problem that has been studied in depth in the fields of operations research and decision science. How do you mine your best current prospects (“exploit”) while keeping your eye open to better opportunities (“explore”)? The tools that are used to address this dilemma are called bandit algorithms. 23 They are widely used to guide sequential decisions under uncertainty in a range of settings, from commercial applications (e.g., oil exploration) to military efforts (e.g., searching for downed airplanes). 24
We have previously studied the use of bandit algorithms for HIV testing—to identify undiagnosed HIV infection using mobile testing units—for several years.24,25 Using model-based simulation studies, we have shown that bandit algorithms outperform more traditional approaches for deploying HIV testing resources, including going this year where you found the most HIV cases last year or sampling a large number of candidate locations before settling down on the best place to test.24,25 The basic bandit algorithm—known as Thompson sampling—outperforms these other methods. 26 Thompson sampling is an adaptive Bayesian approach. First, it makes an inventory of all possible target settings. Second, a policymaker offers an initial assessment of the prevalence of undetected infection in each target setting. This takes the form of a probability distribution and is, by design, a subjective exercise that permits the policymaker to be as definitive or tentative as their prior information directs them to be. These prior probability distributions are updated as new information arrives. Third, the decision to deploy testing resources on the first day is made via a random selection from the various prior distributions assigned to each candidate setting. Fourth, on each day, a record is maintained in every active testing setting of the total tests performed and the number of positive cases detected. This information is used to update the prior distribution for that site. Then, the decision to deploy testing resources on the next day is repeated via a random selection using the updated priors (i.e., posteriors) and the process repeats.
At the outset, this strategy assigns greatest priority to settings based entirely on the policymaker’s initial assessment, which is based on the data available at the moment. But as the testing campaign proceeds, this strategy provides new information about the probability of finding a case among the available locations by using the daily test results (positive and negative) at each site selected to refine the understanding of the prevalence at each location. Over time, this continuous process of “learning while doing” homes in on the places with highest potential yield of finding new cases faster than other strategies. In addition, if the situation changes—for instance, if one has saturated a given location and depleted the number of undetected cases in that location—the posterior distribution associated with that location will reflect those shifts as well, making it less likely that the site will be chosen in the future. The algorithm is flexible in its accommodation of the time-value of information. If, for example, there is reason to believe that information acquired in previous rounds should have diminishing influence over time (e.g., the site has not been visited in a month) or some exogenous factor has changed the underlying environment (e.g., emergence of new viral strains or variants), one can apply a “discount factor” that assigns less and less weight to prior observations as time goes by. Alternatively, if there is reason to privilege initial assumptions and to make decisions increasingly resistant to new observations, one can apply a different discount factor that assigns decreasing weight to newer data. 27 In practical terms, this strategy is meant on an ongoing basis to guide and draw those performing testing in the field to the sites where more people are willing to test and with a premium on locations with a higher prevalence of undetected infection. That is, the goal is to maximize yield of positive cases, not to estimate local prevalence of disease. The details of the Thompson sampling strategy are described in Table 1.
Thompson Sampling Strategy for Identifying Testing Sites for Severe Acute Respiratory Syndrome Coronavirus 2.

We have also developed a variation on Thompson sampling to account for spatial correlation in the prevalence of undetected infections between adjacent geographical areas using a hierarchical Bayesian spatial modeling framework employing an intrinsic conditional autoregressive (ICAR) prior distribution for the spatial random effects and exchangeable, normally distributed random effects to account for nonspatial heterogeneity.25,28 The details of the spatial algorithm are shown in Table 2.
Hierarchical Bayesian Spatial Strategy for Identifying Testing Sites for SARS-CoV-2.

Adapting the Bandit Algorithm to SARS-CoV-2
Bandit algorithms, including Thompson sampling and those that model spatial correlation, can be implemented easily as a guide to active case finding and screening for SARS-CoV-2. To provide priors to initialize the algorithms for use with SARS-CoV-2, we defined a set of highly trafficked candidate locations for daily testing. For Columbus, Ohio, we used raw data from the UberMedia COVID-19 recovery data set (https://covid19.ubermedia.com/covid-19-recovery-insights/), which contains pairs of individual smart devices within 5 meters of each other within a 5-minute window. These data were cleaned for obvious geolocation errors and to remove contacts on roadways using the Census Tiger Lines. These data were then spatially joined with Loveland Landgrid (https://landgrid.com/) parcel data. We produced indices of contacts and unique contacts per parcel, and we also rarified the window of the contact definition. These various indices generally produced consistent rankings. We chose highly trafficked locations as these venues create more opportunities for casual encounters for testing but also because these bandit algorithms are sensitive to testing volume, and a low number of volunteers could hamper the effectiveness of this approach. In fact, in our studies of bandit algorithms in the context of HIV infection, at fewer than 10 tests per day, bandit algorithms performed poorly. 24 Before deploying these algorithms in field testing, establishing a floor for daily testing volume at potential locations through simulation using best estimates of local epidemiology of SARS-CoV-2 will be an important operational consideration, and performing more tests at fewer sites may be a tradeoff to weigh for those using these algorithms in practice. We supplemented this list of highly trafficked locations with residential settings (e.g., apartment buildings), where close contacts are numerous and frequent and where adherence to social distancing and other infection control measures may be more difficult. These are likely to be potential hotspots for disease transmission and could be important places to search for new cases, particularly in census tracts with no public locations for testing. Because we are assessing the yield of testing at point locations rather than areal zones, we use the Euclidean distance between locations rather than map adjacencies when defining spatial proximity. However, distances between locations can be defined in other ways given topographical considerations and local contexts. We set prior distributions for the prevalences in these locations with a Beta(0.50,0.50) distribution (i.e., Jeffreys prior), indicating our lack of knowledge of SARS-CoV-2 prevalence in any of these areas in Columbus. With more data on the epidemiology of SARS-CoV-2, these prior distributions could be crafted to reflect more knowledge of local epidemics. Potential testing sites can also be determined in other ways beyond the use of cell phone and epidemiological data. For instance, targeting industries that are low-work-from-home and demand high physical proximity for workplace testing could be considered potential targeting sites where social gatherings regularly still take place even in the context of the pandemic (e.g., houses of worship).29,30
We have now set up a fully functional prototype of a web app to allow policymakers in Columbus to use Thompson sampling to target SARS-CoV-2 testing in the city (Figure 1).
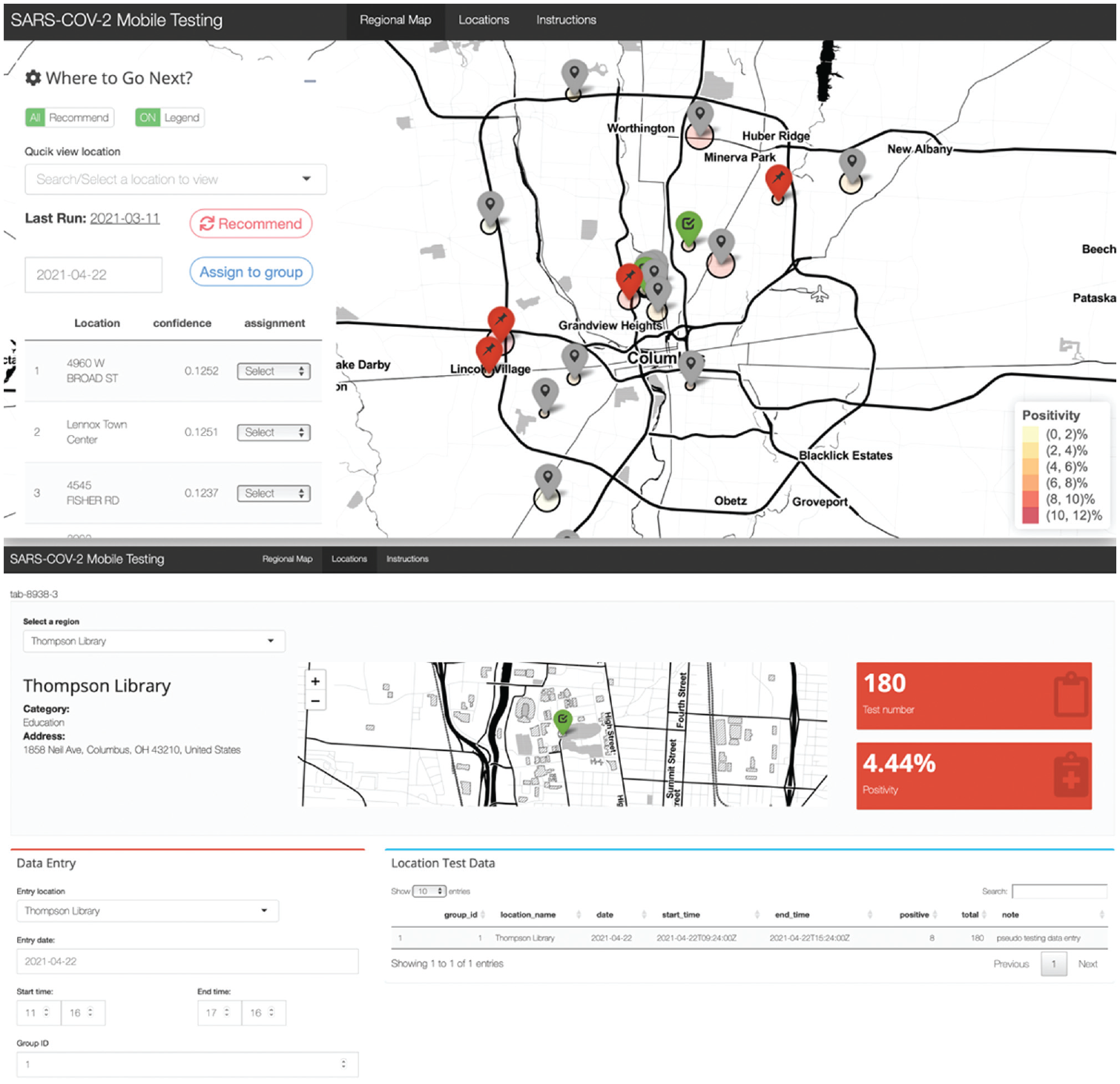
Home page of the web app for targeting severe acute respiratory syndrome coronavirus 2 testing with mobile units (https://netzissou.shinyapps.io/BanditDemo/).
It is straightforward to adapt the algorithm to other jurisdictions, requiring only a set of candidate test locations with point-to-point distances between all locations. Finally, the only inputs required for these bandit algorithms between testing forays are the number of tests performed on a given day in each location and the number of positive tests obtained on that day in that location. This makes the algorithm easy to use by local public health departments. The algorithm is simple enough that it can make virtually instantaneous use of new data to inform the deployment of testing units for the next day’s effort. This would make this approach best suited for rapid diagnostic tests, particularly rapid lateral-flow antigen-based assays, which, although with lower sensitivity than standard PCR, are well positioned to detect individuals with high titers of SARS-CoV-2 and most likely to transmit in a given settings. 7 In fact, while a pilot in Columbus, Ohio, is still in the planning stage, we intend to use the BinaxNOW COVID-19 Ag Card provided through our collaboration with the Ohio Department of Health. 31 However, even with standard PCR-based assays and the delays in reporting of SARS-CoV-2 results in practice, these tools can be useful. In this case, the updating of prior distributions for testing locations will be lagged, so the allocation of new testing assignments will only benefit from additional information about potential yield of new diagnoses among locations as testing results from previous days become available. Furthermore, bandit algorithms complement test pooling strategies and can help to concentrate positives within pools to minimize the number of second-round tests needed. Finally, although these algorithms are simple to set up and run, the practical considerations of deploying testing teams to multiple locations, often shifting teams at least initially from day to day, require the support and engagement of local public health officials, the resources to mount and maintain a mobile testing program over time, and a seamless integration of the algorithms into the normal workflow of testing sites. In the context of SARS-CoV-2, ensuring safety of those getting tested as well as staff at a given testing location is also paramount. 7
Bandit algorithms could provide a useful, simple tool to find needles in a haystack—the tens of thousands of undiagnosed infections from coast to coast—when one cannot test everyone, everywhere. As discussed above, bandit algorithms are widely used to successfully address the explore v. exploit dilemma in several other fields. Deployment of bandit algorithms for SARS-CoV-2 may provide useful answers, enable more cost-effective testing, and offer a lifeline to policymakers trying to figure out where to test next for SARS-CoV-2.
Footnotes
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Financial support for this study was provided entirely by grants from the National Institute on Drug Abuse DP2 (DA049282 to GSG), R37 (DA15612 to GSG and ADP), the National Institute of Allergy and Infectious Diseases R01 (AI137093 to JLW), the National Science Foundation Northeast Big Data Innovation Hub Subaward 4 (GG01486-02) PTE Federal Award (No. OAC-19165850) (EPF), Yale-AWS Enterprise Agreement (EPF), and the Tobin Center for Economic Policy at Yale University (EPF). The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report.
Research Data
All code and data associated with the web app are available at https://github.com/NetZissou/Bandit. The web app itself is available at ![]() .
.