
Abstract
Background
Studies report higher diagnostic accuracy using the collective intelligence (CI) of multiple clinicians compared with individual clinicians. However, the diagnostic process is iterative, and unexplored is the value of CI in improving clinical recommendations leading to a final diagnosis.
Methods
To compare the appropriateness of diagnostic recommendations advised by individual physicians versus the CI of physicians, we entered actual consultation requests sent by primary care physicians to specialists onto a web-based CI platform capable of collecting diagnostic recommendations (next steps for care) from multiple physicians. We solicited responses to 35 cases (12 endocrinology, 13 gynecology, 10 neurology) from ≥3 physicians of any specialty through the CI platform, which aggregated responses into a CI output. The primary outcome was the appropriateness of individual physician recommendations versus the CI output recommendations, using recommendations agreed upon by 2 specialists in the same specialty as a gold standard. The secondary outcome was the recommendations’ potential for harm.
Results
A total of 177 physicians responded. Cases had a median of 7 respondents (interquartile range: 5–10). Diagnostic recommendations in the CI output achieved higher levels of appropriateness (69%) than recommendations from individual physicians (45%; χ2 = 5.95, P = 0.015). Of the CI recommendations, 54% were potentially harmful, as compared with 41% of individuals’ recommendations (χ2 = 2.49, P = 0.11).
Limitations
Cases were from a single institution. CI was solicited using a single algorithm/platform.
Conclusions
When seeking specialist guidance, diagnostic recommendations from the CI of multiple physicians are more appropriate than recommendations from most individual physicians, measured against specialist recommendations. Although CI provides useful recommendations, some have potential for harm. Future research should explore how to use CI to improve diagnosis while limiting harm from inappropriate tests/therapies.
Diagnostic errors, defined by the National Academy of Medicine as “the failure to establish an accurate and timely explanation of a patient’s health problem or communicate that explanation to the patient,” 1 are frequent and have a significant impact on patient morbidity and mortality.2–7 Prior studies have shown that 5% of US adults who seek outpatient care annually experience a diagnostic error 5 and that diagnostic errors may contribute to approximately 10% of patient deaths.8,9 Less is known about diagnostic error than other areas of patient safety.10–12 To advance the field, in 2015, the National Academy of Medicine published Improving Diagnosis in Health Care. 13 This report provided 8 key suggestions to improve diagnosis and reduce diagnostic errors, including the recommendation to facilitate more effective teamwork among health care professionals.
This recommendation has driven patient safety advocates to explore collective intelligence (CI) tools to address diagnostic error and delay. CI is a shared intelligence that emerges from a group of individuals acting independently or collectively on the same task. It leverages the fact that a group is likely to outperform an individual in cognitive tasks across a variety of fields.14,15 Within medicine, CI has shown promise in areas of visual diagnosis (radiology, dermatology),16,17 where CI has reliably outperformed individual physicians in detecting malignancies. Few studies have explored the benefit of CI for general medical diagnosis, and prior studies in general diagnosis have focused on simulated cases. 18 A study of medical students’ abilities to accurately diagnose simulated emergency medicine cases found that the CI outperformed individual students. 19 Another recent study found that the CI of multiple physicians had greater diagnostic accuracy than individual physicians in 1500+ simulated cases written for general practitioners. 20
The development of digital tools that facilitate collaboration and communication among physicians21–23 provides new opportunities to investigate and leverage the potential of CI, particularly for physicians who practice in isolated settings. A CI platform open to all health care practitioners is the Human Diagnosis Project (Human Dx), a multinational effort in which physicians and medical students both submit and solve clinical cases, and was the platform used in a prior CI study. 20
Although CI has shown promise for improving diagnostic accuracy, there is limited literature assessing whether the CI of multiple physicians has utility in the diagnostic process, prior to reaching a definitive final diagnosis. Most literature has focused on diagnostic accuracy and diagnosis as if clinicians reach a diagnosis in a 1-step process. However, as noted by the National Academy of Medicine, 1 the diagnostic process is complex and iterative. It involves a repeating cycle of information gathering, information integration and interpretation, and a working diagnosis until the diagnosis is communicated to the patient. Reducing diagnostic errors will require interventions at each stage of the diagnostic process.
In recognition of the multistep, iterative nature of the diagnostic process in real clinical care, we sought to determine if CI would provide value during earlier stages of the process. Specifically, when a clinician refers a patient to a specialist, the referring clinician is often seeking guidance on next steps for evaluation and care (rather than an immediate diagnosis), a stage during which feedback can most impact diagnostic accuracy. 24 Ideally, all general practitioners would have adequate access to specialty expertise when making decisions outside their clinical expertise, but specialty access is limited in many settings due to time, cost, or availability. Accordingly, our study aimed to 1) assess the appropriateness of diagnostic steps advised by the CI of multiple physicians versus individual physicians collected on a digital CI platform at an earlier stage of the diagnostic process when cases were referred to a specialist and 2) describe the potential harm of inaccurate recommendations from the CI output and individual physicians. We hypothesized that the CI output from multiple physicians would provide more appropriate diagnostic recommendations than individual physicians measured against specialist recommendations as the gold standard.
Methods
CI Platform and Cases
The Human Dx platform is a mobile application that allows individuals with any level of medical training (medical student, resident/fellow, attending physician) to both 1) submit their own clinical case to elicit feedback on the diagnosis and plan and 2) contribute feedback on diagnoses and plans for any case submitted by other Human Dx users. For this study, Human Dx users responded by using free text to submit a ranked list of differential diagnoses and suggested next steps for the plan of care. Submitted cases include a 1-line summary of the case, a clinical question, and relevant history, physical examination, and diagnostic tests (e.g., laboratory or imaging results; see Supplementary Appendix 1: Example Case). This study was approved by our institution’s institutional review board.
At the time of this study, Human Dx used a 1/n proportionally weighted algorithm based on individual user responses to produce a CI for the case, as previously described 20 (see Supplementary Appendix 2: Collective Intelligence Rule). In brief, for a submitted case, the Human Dx algorithm creates a CI output composed of respondents’ ranked list of diagnoses (collective differential) and recommendations or next steps (collective plan; see Supplementary Appendix 3: Sample Collective Intelligence Output). This CI output reflects both how frequently a diagnosis or plan appears among all responses and its ranking on each respondent’s ordered list (e.g., top diagnosis versus fifth diagnosis), but this automated process does not account for alternative spellings of the same recommendation (e.g., “blood pressure measurement” or “BP measurement”).
To acquire a sample of diverse real-life cases to submit to the Human Dx platform, an investigator (E.C.K.) reviewed actual specialist consultation requests in endocrinology, gynecology, and neurology cases submitted by clinicians at an integrated health care system from 2015 to 2017, using the health care system’s existing electronic consultation platform (e-consult).25,26 These 3 specialties were chosen because they are areas in which primary care clinicians have some knowledge, and within this health care system, a specialist is required to review e-consult requests prior to scheduling an in-person specialty clinic appointment. As a result, the specialist consultants often provide recommendations to the referring clinician to advance patient care prior to scheduling a patient for an appointment. For each of the 3 specialties, an investigator (E.C.K.) selected ∼15 to 20 cases for which there were clear diagnostic steps recommended by the e-consult specialist. Most cases were early in the diagnostic process, and no diagnosis was provided through the e-consult communication. We focused on cases in which recommendations were provided about next steps for evaluation of the patient (i.e., the plan) rather than diagnosis. Cases were selected to ensure no chief complaint was represented more than twice.
Identification of Specialist-Consensus Recommendations
Few cases had guideline-recommended approaches for working up the patient’s complaint. Therefore, to assess the appropriateness of the recommended approach in the study cases, the study team used agreement between 2 specialist physicians as indicative of a reasonable standard of care and the basis for comparison (i.e., specialist-consensus recommendations), per an established approach drawn from the patient safety literature27,28 (Figure 1). The first specialist (specialist A in Figure 1, step 1) was the initial specialist within the integrated health care system who responded to the e-consult. To acquire the recommendations of a second specialist, an investigator (E.C.K.) entered case information onto the Human Dx platform from August 2017 to March 2018. From board-certified specialist users on Human Dx, the study team recruited an endocrinologist, neurologist, and gynecologist to respond to the study cases entered on Human Dx in their specialty (specialist B in Figure 1, step 2); each of these specialists responded to the case by submitting a differential diagnosis and planned next steps from September 2017 to April 2018. The Human Dx specialists had access to the exact same information as the other Human Dx users who later responded to the case (Figure 1, step 4). If the e-consult specialist and Human Dx specialist agreed on at least 1 recommended next step in a submitted case, we included that case in this analysis (N = 35). The 2 specialists reached agreement on at least 1 recommendation in 12 of 14 (86%) endocrinology, 13 of 19 (68%) gynecology, and 10 of 19 (53%) neurology cases. We designated recommendations that both specialists agreed upon as “specialist-consensus recommendations” and established this as the gold standard against which to assess our outcomes. Each of the 35 cases had 1 to 6 specialist-consensus recommendations. Supplementary Appendix 4 contains 1-line summaries of cases included in this study with their specialist-consensus recommendations.
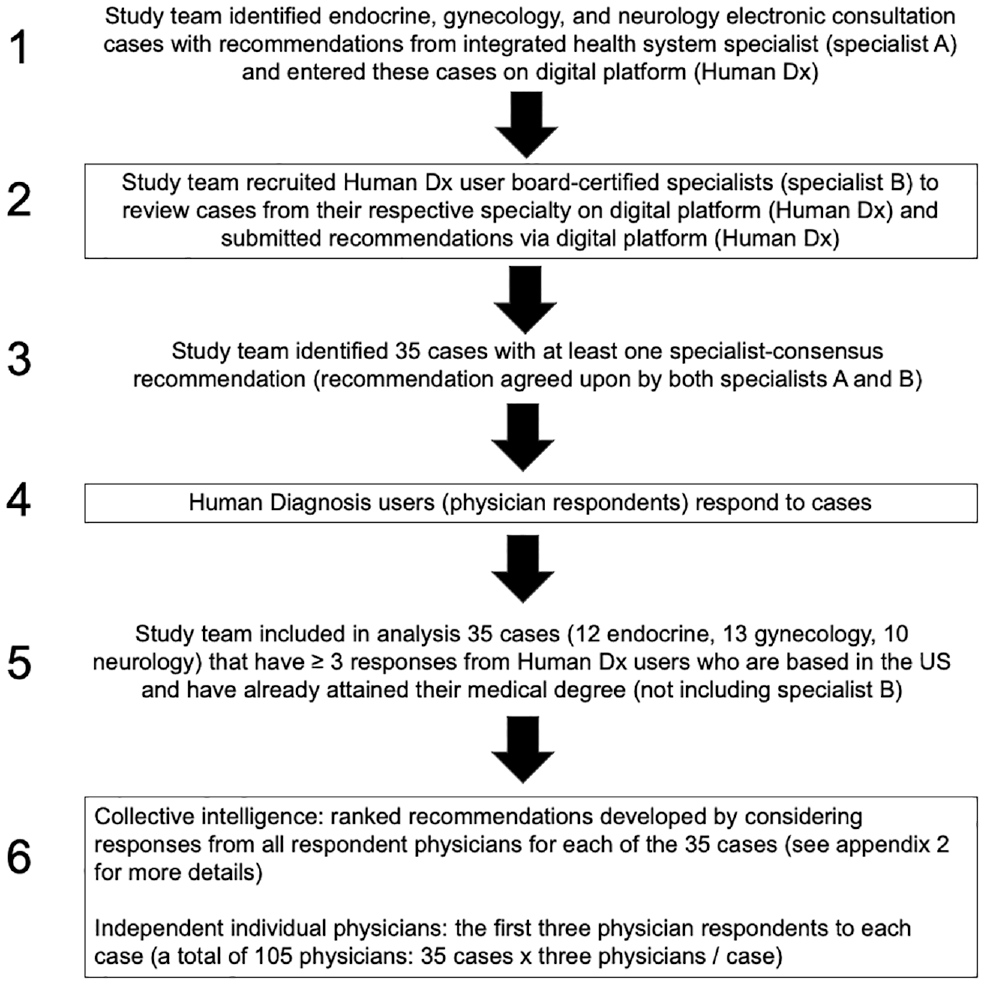
Study workflow. Specialist A was 1 of 2 specialists from each specialty who responded to the integrated health system e-consult. Specialist B was the same clinician for all cases within his or her specialty and responded to the case on Human Dx.
Data Collection
CI output
We solicited responses to the 35 cases with specialist-consensus recommendations from Human Dx users from August 2017 to November 2018 until we had a minimum of 3 respondents, which is the number after which the accuracy of CI plateaus. 20 We included only respondents with medical degrees who practiced within the United States (due to differences in practice patterns and available resources among countries). The physician respondents could be trained in any specialty, including endocrinology, gynecology, or neurology. The CI output for each case was derived from the responses of all physician respondents within the United States (excluding the designated specialist B for each case).
Independent individual physician respondents
We designated the first 3 US-based physician respondents to each case (who could be trained in any specialty) to serve as our comparison cohort of “independent individual physicians” (Figure 1, step 6). Designating these physicians and their individual recommendations was meant to serve as a proxy for a clinician practicing independently in the community without specialty access. The responses from these 3 respondents were also included in the CI output. There were variable numbers of respondents to each case, and we wished to avoid any 1 case from contributing more than any other case in comparing independent individual physician respondents’ recommendations against the CI output. Accordingly, by capping at 3 those included in the “independent individual physician” cohort, we ensured that each case had an equal contribution to the outcome.
Participant characteristics
We collected respondents’ level of training, location, and specialty based on self-reported information provided when individuals registered on the Human Dx platform.
Outcomes
Primary outcome
Our primary outcome was the appropriateness of recommended diagnostic next steps, based on agreement with specialist-consensus recommendations. We report this outcome separately for 1) the CI output and 2) the first 3 individual physician respondents (the independent individual physician cohort), which is consistent with the approach used in a prior CI study on the same platform. 20 We defined appropriateness at four different levels (from most to least appropriate):
Strict appropriateness: all specialist-consensus recommendations, regardless of the number of recommendations, appear at the top of the ranked list from the CI output or an individual. (If there were 5 specialist-consensus recommendations, the top 5 recommendations in the CI output or provided by an individual were the 5 specialist-consensus recommendations.)
Moderate appropriateness: did not meet strict level criteria, but all of the specialist-consensus recommendations were ranked highly within the CI output or the individual’s recommendations. Specifically, if there were X number of specialist-consensus recommendations, all of them appeared within the top 10 or the top 3 ×X number of recommendations (whichever was lower). We used 2 measurement criteria because the number of recommendations varied across cases from 1 to 6. If a case had only 2 specialist-consensus recommendations, then both recommendations would need to appear in the top 6 CI output recommendations or an individual’s recommendations (3 × 2). Alternatively, if a case had 5 recommendations, we looked only at the top 10, rather than the top 15 (3 × 5) recommendations.
Lenient appropriateness: at least 1 but not all specialist-consensus recommendations appeared within the top 10 or top 3 ×X recommendations from the CI output or an individual.
Not appropriate: none of the specialist-consensus recommendations appeared within the top 10 or 3 ×X recommendations from the CI output or an individual.
Secondary outcome
The secondary outcome was the potential harm of the recommendations. We assessed the potential for meaningful harm based on a scale previously used to classify the harm of errors.7,29 For each recommendation, we used a binary outcome that focused on the potential for at least moderate meaningful harm, which included initiation or cessation of medications without indication or with contraindications, invasive testing, exposure to unnecessary radiation beyond a plain radiograph, and any other actions determined by 2 physician investigators (E.C.K., S.S.N.) to have potential to result in at least moderate harm. We assessed harm only for recommendations that were not specialist-consultant recommendations. For both the CI output recommendations and the independent individual physician cohort recommendations, we report recommendations that were identified as having the potential for at least moderate harm that appeared among the top 10 or top 3 ×X recommendations (whichever was lower, as per the primary outcome).
Analyses
Two investigators (E.C.K., S.S.N.) independently assessed the primary and secondary outcomes and manually eliminated duplicate recommendations (e.g., a list of 8 recommendations with 1 set of duplicates [“EKG” and “ECG” each appeared] would be treated as a list of 7 recommendations), then reached agreement on appropriateness or harm of all recommendations in all cases. We used descriptive statistics to report the characteristics of respondents and all outcomes. We used chi-squared testing to determine differences in the appropriateness and harm of the CI output versus the individual physician cohort. For the CI output, we report both outcomes at a case level (of 35 total cases). For the independent individual physician cohort, we report the outcomes at the individual level; therefore, the overall assessment of individual physicians is out of 105 physicians (35 cases × 3 physician respondents per case). Our funding source had no role in this study.
Results
Respondent Characteristics
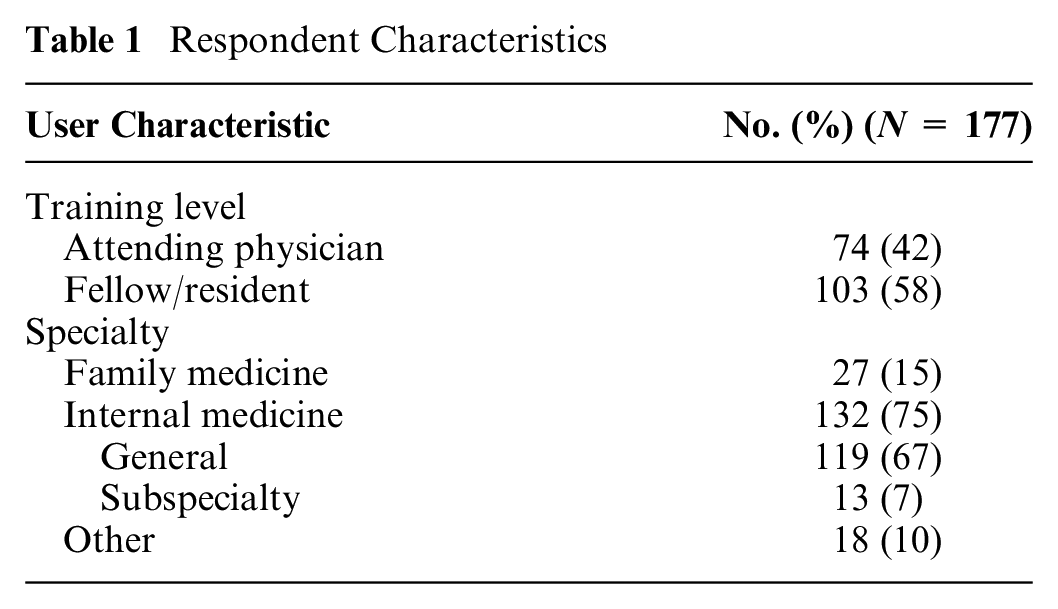
A total of 177 physicians responded to the 35 cases (12 endocrinology, 13 gynecology, 10 neurology) on Human Dx. A median of 7 physicians (interquartile range [IQR]: 5–10) responded to each case. Table 1 shows the characteristics of respondents.
Respondent Characteristics
Appropriateness
As shown in Figure 2 and detailed in Supplementary Appendix 5, when combining all levels of appropriateness, the CI output performed better than the independent individual physicians, respectively, in each specialty and overall: endocrinology (7/12) 58% versus (12/36) 33%, gynecology (10/13) 77% versus (18/39) 46%, neurology (7/10) 70% versus (17/30) 57%, and overall (24/35) 69% versus (47/105) 45%. These differences in appropriateness were statistically different for the cases overall (69% vs 45%, χ2 = 5.95, P = 0.015) but not within any specialty.
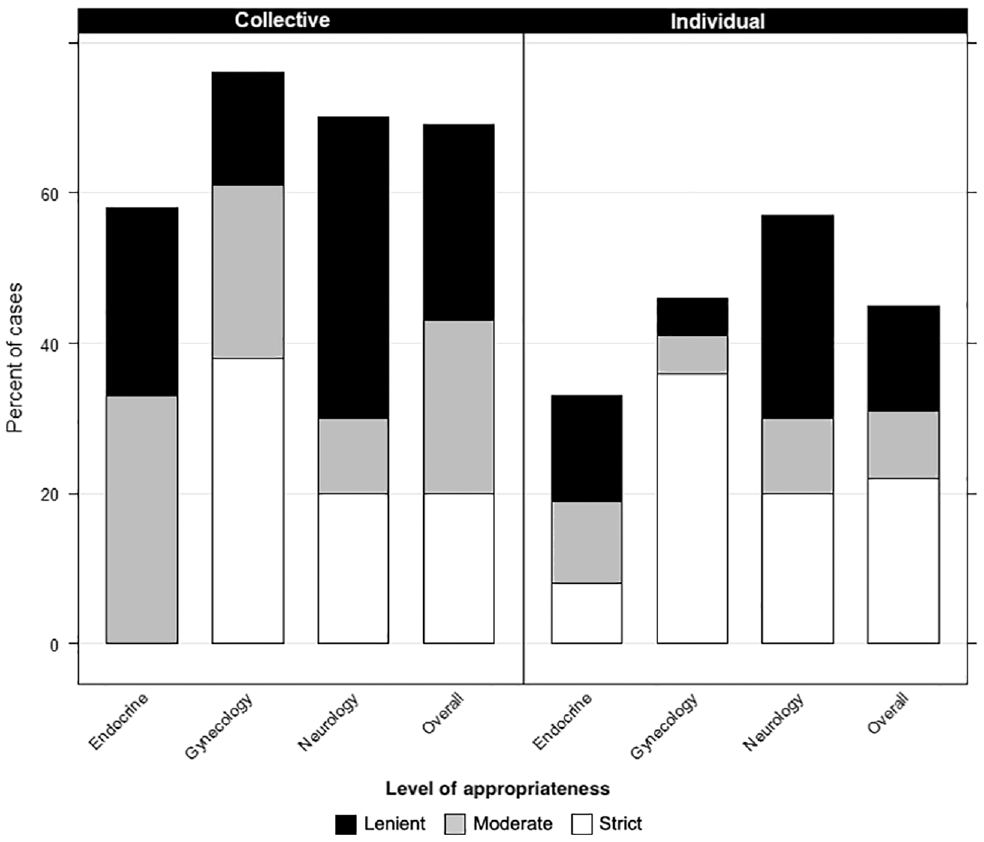
Appropriateness of recommendations from collective intelligence of multiple physicians versus individual physicians by specialty and in all cases.
Figure 2 displays the level of appropriateness (strict, moderate, or lenient) of the CI output recommendations compared with the independent individual physicians. (Data also shown in Supplementary Appendix 5.) Unlike the results for any level of appropriateness, the CI output did not consistently perform better than individual physicians when considering only strict appropriateness. CI achieved strict appropriateness for 7 cases (20%) overall and for none of the endocrinology cases. In contrast, individual physicians achieved strict appropriateness in 22% of cases overall, and at least 1 of 3 individual physicians achieved strict appropriateness in each of the three specialties. Among all cases, strict appropriateness was the most common level of appropriateness that individuals achieved (22%) versus moderate (9%) or lenient (14%) appropriateness, whereas the CI achieved higher rates of moderate (23%) and lenient (26%) appropriateness. Some individual physicians achieved strict appropriateness in cases in which the CI did not. Specifically, 3 physicians provided strictly appropriate recommendations for an endocrinology case, whereas the CI did not provide strictly appropriate recommendations for any endocrinology cases.
Harm
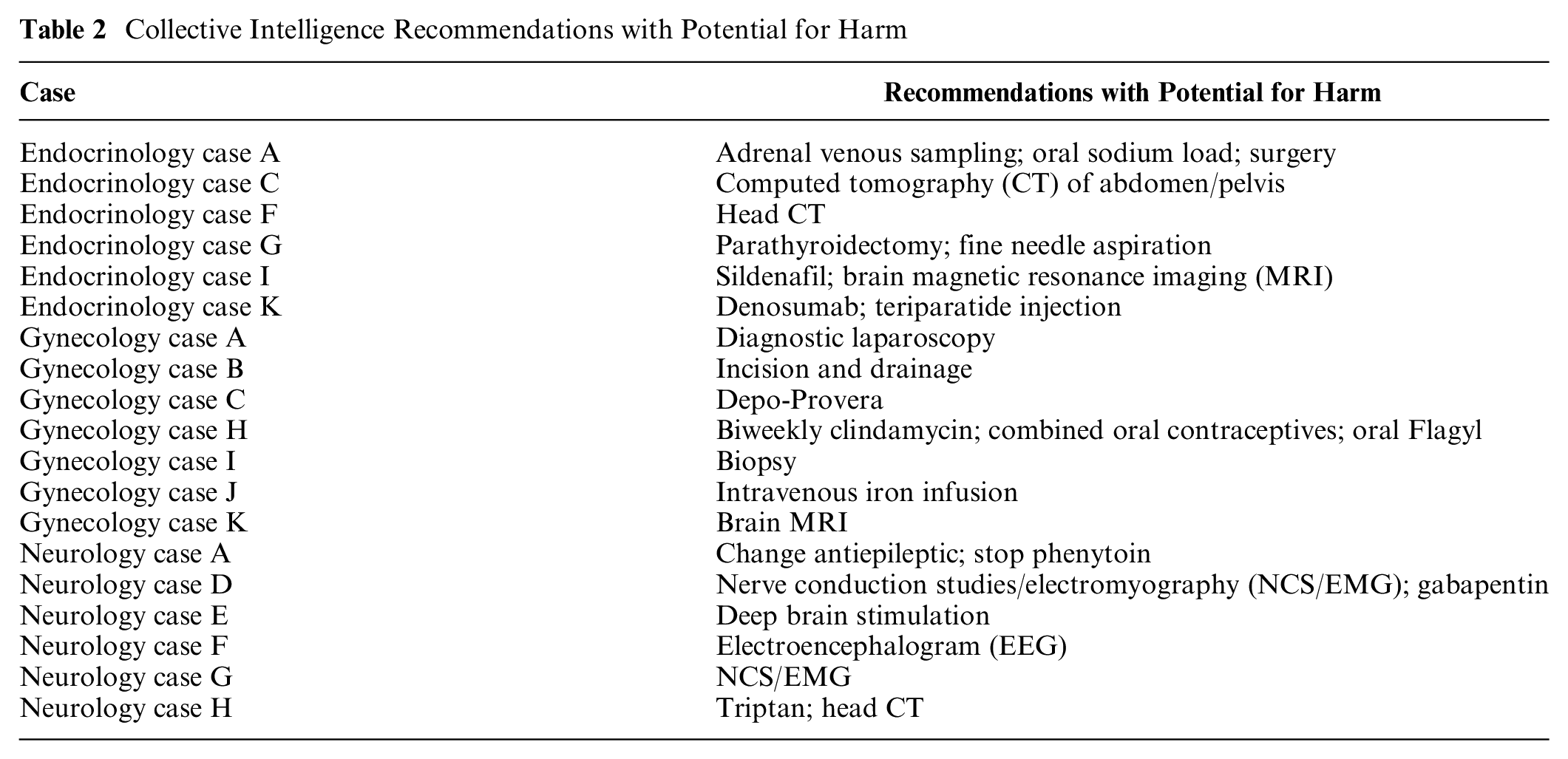
When evaluating the top 10 or top 3 ×X recommendations, 1 or more recommendations from the CI output for 19 (54%) of the cases (6 endocrinology, 7 gynecology, and 6 neurology, or 54%) had potential for meaningful harm (Table 2). In most cases, 1 or fewer recommendations in the CI output had potential for harm: endocrinology (median 0.5, interquartile range [IQR] 0–2), gynecology (median 1, IQR 0–1), and neurology (median 1, IQR 0–2).
Collective Intelligence Recommendations with Potential for Harm
Among the individual independent physician cohort, 41% of 105 respondents (43 total: 13 endocrinology, 16 gynecology, 14 neurology) also submitted at least 1 recommendation with potential for meaningful harm. Of the 105 individuals, most provided recommendations with no potential for moderate harm (median 0, IQR 0–1). There were no differences in the number of harmful recommendations recommended by the individual physician cohort when comparing specialties (median 0, IQR 0–1 for all 3 specialties). These recommendations with potential for harm suggested by 43 individual physicians were distributed across 80% of the cases (n = 28; 8 endocrinology, 11 gynecology, and 9 neurology).
The potential for harm was not statistically significantly different when comparing the CI output in the 35 cases to the recommendations submitted by the 105 physicians in the independent individual physician cohort: 54% (19/35) versus 41% (41/105, χ2 = 2.49, P = 0.11).
Discussion
Key Findings
In this study, we assessed the performance of the CI of multiple physicians versus individual physicians in providing appropriate diagnostic steps for a plan of care across 3 specialties. Although the CI recommendations matched the gold standard specialist recommendations more frequently than most independent individual physicians, the CI recommendations aligned with specialist recommendations only ∼70% of the time. Moreover, at least 1 of the recommendations advised by the CI had potential for at least moderate harm in approximately half of the cases.
Performance of CI in the Literature
Our findings are consistent with prior studies demonstrating that CI outperforms individual physicians in diagnostic accuracy16,17,19,20 and at a rate of ∼30% improvement in accuracy.19,20 However, our study expands the literature in an important way. By focusing on actual cases for which a clinician consulted specialists for advice, we provide evidence that CI provides value early in the diagnostic process (such as during the information gathering stage) prior to reaching a definitive final diagnosis. Feedback may be particularly important during these earlier steps in the diagnostic process.24,30 Specifically, the CI recommendations suggest paths forward in the diagnostic process that may not be explored by a clinician practicing independently. These findings also suggest that CI tools may be beneficial in more complex clinical scenarios, beyond straightforward cases with a known diagnosis.
Despite the potential benefits of a CI tool for these types of e-consult cases, we found that there were instances in which individual physicians performed better than the collective. Prior studies have had conflicting results as to whether the CI is better than the best individual physician with comparable training 16 or just better than the average physician with comparable training.19,20 Absent a methodology to reliably predict whether a specific individual is going to perform better than the CI, clinicians may rely on their own perceptions for when to ignore the wisdom of the crowd. Studies have shown that clinicians are overconfident in their diagnostic ability; in particular, clinicians do a poor job of calibrating their diagnostic accuracy in cases with high uncertainty.31,32 Since cases referred to a specialist are more likely to have higher diagnostic uncertainty, clinicians’ overconfidence in these situations may pose a barrier to adoption of CI tools.
Potential Harm of CI
Although our findings support the potential for CI to improve the diagnostic workup in cases in which clinicians may request advice from a specialist, we did find potential for harm in more than half of cases. However, there was a wide range in the type of harm: from inappropriate initiation of prescription medications, to radiation exposure from unnecessary imaging, to invasive diagnostic testing. The harm of an invasive diagnostic test (e.g., diagnostic laparoscopy) is higher than initiating an inappropriate prescription medication (e.g., gabapentin). Our prior studies suggest that clinicians would not blindly follow all recommendations of the CI output. 33 In particular, we previously identified trust in the source of the recommendation as an important consideration that factored into how clinicians would behave after receiving information from a clinical decision support tool. 33
It is important to also note that even if a CI recommendation seems relatively benign (additional unnecessary laboratory test), studies increasingly show that overtesting is not only wasteful but can also result in patient harm.34–37 Thus, although CI helps address some of the most common causes of diagnostic errors, such as failure in hypothesis generation or failure to order a necessary test,2,38,39 this must be weighed against the harm of pursuing unnecessary tests. Of note, potential harm was also present in nearly half of individuals’ recommendations as well, suggesting that the potential harm of CI recommendations may be similar to harm from an inappropriate/inaccurate individual physician care recommendation. Although there was no statistically significant difference in harm between the CI output and independent individual physicians, this issue warrants further exploration in a larger study.
Study Limitations
Our study has several important limitations. We used a single CI platform and algorithm. However, prior studies comparing different algorithms used to generate a CI output have demonstrated that algorithmic differences have a limited impact on the benefit of CI and that the results of CI collected from 1 platform are likely generalizable.16,19,20 The users of Human Dx may not be representative of all physicians, but by removing medical students and international practitioners from our analysis, it is more likely these findings are generalizable to practicing primary care clinicians in the United States. We collected our real-world patient cases from a single health care system and prioritized cases in which specialists provided a clear recommendation. This may result in a selection of less complex cases and skew specialist-consensus recommendations to be compatible with local practice patterns, but by requiring that 2 specialists agree on a recommendation, we increased the likelihood that recommendations would be considered appropriate in multiple settings. Nonetheless, the use of specialist-consensus recommendations as the gold standard has its limitations, because there will also be disagreement among specialists. Despite these limitations, our study adds to the literature by demonstrating the potential for CI to assist primary care clinicians in identifying appropriate evaluative steps during the diagnostic process, not just for determination of a diagnosis.
The Path Forward
Our findings suggest several areas for further exploration. For clinicians without adequate or timely access to specialty advice, these findings suggest that access to the CI of multiple clinicians can provide useful recommendations to advance the diagnostic process. This is consistent with prior recommendations that feedback improves diagnosis.1,24,40,41 Although the CI tools currently available do not replace the need for timely access to specialty care, they may help improve the diagnostic process in settings with inadequate specialty access.
Given the high rate of inappropriate recommendations, clinicians must be judicious in their acceptance of recommendations. For CI tools, providing users with quality assurance data on those providing feedback (e.g., information about expertise, clinical training) is crucial to their acceptance of recommendations. 33 Developers and users of CI tools should collaboratively explore how to increase the benefits of CI tools (e.g., ensuring necessary diagnostic tests are ordered, expanding the differential diagnosis) while mitigating or providing transparency on how to evaluate the risks from potentially harmful recommendations. Methodologies to help differentiate high-quality recommendations from inappropriate recommendations and more highly skilled from less expert contributors may increase the value and uptake of CI tools in actual clinical practice. This is particularly true when considering the growth and improvement in other clinical decision support tools. 42
This work also provides a pathway toward operationalizing the provision of feedback to clinicians. Feedback has been identified as a necessary step to increase diagnostic calibration, a concept that describes when clinicians’ confidence in their diagnostic decision making aligns with their actual diagnostic accuracy. Well-calibrated clinicians are better able to identify the correct balance between undertesting (failing to explore a broad enough array of potential diagnoses) and overtesting (exposing patients to the costs and harm of unnecessary tests).30,32,40,41,43 Tools like the one tested in this study provide an approach for clinicians to acquire real-time feedback on their clinical decision making, which may help facilitate diagnostic improvement. Adoption could be incentivized by providing continuous medical education credits for using these feedback tools.
Conclusions
The CI of multiple physicians provides more appropriate recommendations than individual physicians when using board-certified specialist recommendations as a gold standard for next steps in the diagnostic process. This suggests that a CI tool may provide useful evaluation recommendations even before a specialist weighs in, thereby improving timely and accurate diagnoses in settings where access to specialty care might be nonexistent, sparse, or delayed. Recommendations provided by a CI tool should not be blindly followed, as some have potential for meaningful harm. Moreover, clinicians should be wary of higher-risk diagnostic tests/therapies suggested by the CI. Future work is needed to explore how best to leverage CI (and digital tools to facilitate collaboration) to address gaps in the diagnostic process without exposing patients to additional unnecessary harm. There is also promise in evaluating the use of CI tools to facilitate more timely feedback to clinicians on their medical decision making.
Supplemental Material
sj-docx-1-mdm-10.1177_0272989X211031209 – Supplemental material for Comparison of Diagnostic Recommendations from Individual Physicians versus the Collective Intelligence of Multiple Physicians in Ambulatory Cases Referred for Specialist Consultation
Supplemental material, sj-docx-1-mdm-10.1177_0272989X211031209 for Comparison of Diagnostic Recommendations from Individual Physicians versus the Collective Intelligence of Multiple Physicians in Ambulatory Cases Referred for Specialist Consultation by Elaine C. Khoong, Sarah S. Nouri, Delphine S. Tuot, Shantanu Nundy, Valy Fontil and Urmimala Sarkar in Medical Decision Making
Footnotes
Acknowledgements
We would like to acknowledge our Human Dx collaborators who provided us the data for this project as well as the Human Dx users for contributing responses. We would like to also thank our specialist collaborators for contributing a second recommendation on these cases. We would like to thank our collaborators at the Center for Innovation in Access and Quality for providing us with electronic consultation cases. Lastly, we acknowledge Natalie Rivadeneira, MPH, for creating the graphs for this report and Amy J. Markowitz, JD, for assisting with manuscript revisions.
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Dr. Nundy was previously employed by Human Dx. The remaining authors declare that there is no conflict of interest.
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Financial support for this study was provided in part by grants from the following government agencies and foundations. The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report: Moore Foundation (Urmimala Sarkar, Valy Fontil); the National Heart Lung and Blood Institute of the National Institutes of Health (NIH; award No. K12HL138046; the content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH; Elaine C. Khoong); National Center for Advancing Translational Sciences of the NIH (award No. KL2TR001870; the content is solely the responsibility of the authors and do not necessarily represent the official views of the NIH; Elaine C. Khoong); National Institute for Health’s National Research Service Award (grant T32HP19025; Elaine C. Khoong and Sarah S. Nouri); Blue Shield of California Foundation (Delphine S. Tuot); and National Cancer Institute (grant K24CA212294; Urmimala Sarkar).
Prior Meeting Presentations
Preliminary results were presented at the Society of General Internal Medicine meeting in May 2019.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.