
Abstract
In a landscape of accelerated approvals and a less mature evidence base, constrained health systems make reimbursement decisions based on uncertain evidence about the expected clinical and economic value of a health technology. Uncertain decisions require expert judgments, and there has recently been a drive to improve the accountability and transparency in the way these judgments are collected and reported. Structured expert elicitation (SEE) refers to formal methods to quantify experts’ judgments. Protocols for conducting SEE exist; however, the time and resource requirements of SEE and the lack of simple tools for its implementation are potential deterrents to its implementation. This article describes the development of Structured Expert Elicitation Resources (STEER), a collection of open access resources based on a published protocol for SEE specific to the health care decision-making (HCDM) setting. The resources cover the entire SEE process from design to reporting. The resources include an overview and a practical guide for conducting SEE in this setting, adaptable tools for building bespoke SEE exercises, training materials for experts taking part in SEE, resources used in previous SEE exercises, and examples of published SEE in HCDM. The materials cover practical considerations such as timelines team skills requirements, and administrative requirements such as contracting. The use of off-the-shelf resources can streamline the SEE process in HCDM while maintaining robustness.
Highlights
There is a drive to improve accountability and transparency in the way expert judgments are used in health care decision making; however, the time and resource requirements of SEE and the lack of simple tools for its implementation are potential deterrents to its implementation.
Structured Expert Elicitation Resources (STEER) is a collection of open access resources for conducting SEE in health care decision making, based on a published methods protocol for SEE specific to this setting.
The use of off-the-shelf resources can streamline the SEE process in health care decision making while maintaining robustness.
Keywords
Background
Constrained health systems make reimbursement decisions based on evidence of clinical and economic value in relation to existing relevant alternatives. This process relies on various sources of evidence typically assembled using cost-effectiveness models. The evidence used in cost-effectiveness models is inherently uncertain. Any uncertainty in the evidence base can be reflected in estimates of the expected clinical and economic value of a health technology in the form of parametric and structural uncertainty and subsequently in the decisions that are made using this evidence.
Where there is uncertainty, decisions require judgments, for example, by comparing different scenarios and assessing which is more plausible. In a landscape of accelerated approvals and a less mature evidence base, obtaining judgments from clinical experts is becoming increasingly important to inform health care decision making (HCDM). A recent review of 25 company submissions to the National Institute for Health and Care Excellence (NICE), England, found that 23 of the 25 appraisals used expert judgment in some form. 1
Recent guidance from HTA organizations has increased the incentive to improve the accountability in the way these judgments are collected, to make them more explicit and to incorporate these transparently into the decision-making process. For example, the NICE manual for health technology evaluation expresses preference for “structured methods” for eliciting experts’ beliefs when empirical evidence is not available. 2 Infarmed, Portugal’s health technology assessment (HTA) agency, states that in absence of empirical evidence, opinions of experts can be elicited and that “gathering experts’ opinions should be based on a structured and explicit process.” 3 Canada’s Drug and Health Technology Agency (CADTH) methods guide recommends expert elicitation “as a potential source of data for filling in gaps in the available information.” 4
Formal methods to quantify experts’ judgments exist and are termed structured expert elicitation (SEE). SEE can be used to quantify uncertainty in judgments by capturing experts’ beliefs in the terms of probability distributions that can subsequently feed into probabilistic sensitivity analysis and value-of-information analysis. 5 The use of structured processes supports experts to consider all available evidence carefully, to minimize common biases, and to capture experts’ beliefs accurately.
To do so, SEE requires careful planning and resourcing. Decisions need to be made regarding whose judgments to seek (i.e., who is an expert), which quantities to elicit experts’ beliefs on, how to phrase questions, training of experts to express their beliefs in the required format, and how to record experts’ beliefs. The Medical Research Council (MRC) funded the development of reference case methods for SEE in HCDM (the MRC protocol) 6 taking into consideration published information on the strengths and weaknesses of the different methods available and the evidence requirements for decision making and practical constraints in this setting.
The time and resource requirements of SEE, and the lack of simple tools for its implementation, are potentially a deterrent to its implementation in HCDM. An SEE exercise is a stand-alone research study that requires careful planning to ensure that the elicited quantities accurately represent beliefs of experts with limited quantitative training on often abstract quantities.
Resources such as SHELF, the MATCH front end to SHELF, Excel examples such as EXPLICIT, and the numerous examples outside of the HCDM all provide options for execution (and in some cases design) of an elicitation session.7–10 However, when it comes to planning an SEE, identifying relevant resources and using them to design a novel SEE study can be challenging. First, generic SEE guidance may not be suitable in the HCDM setting. 6 For example, the elicitation of complex quantities such as correlation or regression coefficients and the use of more complex methods (e.g., equivalent prior sample, 11 in which the expert expresses uncertainty by providing the sample size on which they are basing their estimate) may not be appropriate when subject knowledge expertise does not ensure required quantitative skills and training needed to teach those skills is unfeasible given the resource and time constraints typical for the HCDM setting. Second, none of the execution tools can easily be adapted to develop bespoke elicitation tools that allow independent completion by experts using different elicitation methods while providing automated personalized feedback interpreting the probability distributions provided by experts. Third, none of the available resources provide guidance specific to the HCDM setting on key practical issues such as timelines, team skills requirements, and administrative requirements such as contracting when health professionals are engaged as private consultants and advisor. Finally, there are no databases of applied SEE exercises in the HCDM setting, from which investigators can draw from past experiences.
This article describes Structured Expert Elicitation Resources (STEER; available at https://www.york.ac.uk/che/economic-evaluation/steer/), a collection of open access resources for conducting SEE in HCDM. The resources were designed to streamline the process while maintaining robustness. STEER includes the following:
an overview of SEE in HCDM and a practical guide for conducting SEE based on the MRC protocol, 6 tailored to a HCDM context;
adaptable tools for building easy-to-complete, bespoke apps for conducting SEE, in Excel and R;
training materials for experts taking part in SEE, using terminology and practice examples tailored to the HCDM context;
resources used in previous SEE exercises, and;
examples of published SEE in HCDM.
This article describes each of these components in turn and provides an applied example demonstrating the use of the materials. The contents of STEER are based on the methods in the MRC protocol, 6 developed based on a systematic review of elicitation methods and the practical challenges of implementing them in an HCDM setting.
Overview and Practical Guide for SEE in HCDM
Two documents were developed to support and guide researchers who wish to conduct an SEE study. A brief overview document was developed with the aim of introducing the core concepts and challenges of SEE in an HCDM setting to a naïve audience. This provides a definition for SEE (Figure 1), a rationale for its use in HCDM, the key principles outlined by Bojke et al., 6 the methodology in brief, and a checklist of things to consider. A more detailed practical guide was developed that was aimed at researchers seeking guidance on how to implement an SEE exercise and follows the framework laid out by Bojke et al. 6 As such, rather than outlining a list of instructions, the guide offers several methodological choices that are supported by the existing literature and key considerations on how to select the most appropriate methods based on context, evidence, and experience. Most importantly, the practical guide specifies that judgments should first be elicited individually before they are aggregated and provides 3 methodological choices for individual elicitation and 2 for aggregation. For individual elicitation, options include individual interviews, group discussion (with experts providing individual judgments), or online surveys. For aggregation, a consensus workshop or mathematical aggregation via linear opinion pooling may be preferable. The following should be considered when deciding on an approach:
Budget and timelines: Smaller budgets and shorter timelines favor the use of fewer experts or online surveys and mathematical aggregation, as this minimizes the number of touchpoints with the experts.
Number of experts: Workshops are not suitable for large numbers of experts, so mathematical aggregation is advised if the expert pool is large.6,8
Number of quantities of interest: Interviews and workshops are not well-suited to large numbers of quantities of interest.
Value of qualitative nuance: For quantities of interest for which the empirical evidence is severely lacking despite being critical for decision making, the qualitative discussion surrounding experts’ judgments can be highly valuable as this can inform the narrative that supports the model and demonstrates the value of a product. Group interaction may also be valuable in bringing together the clinical community and provides an opportunity to discuss wider aspects of a HTA submission with clinicians. This benefit needs balancing with the need for an experienced facilitator to avoid the introduction of bias.
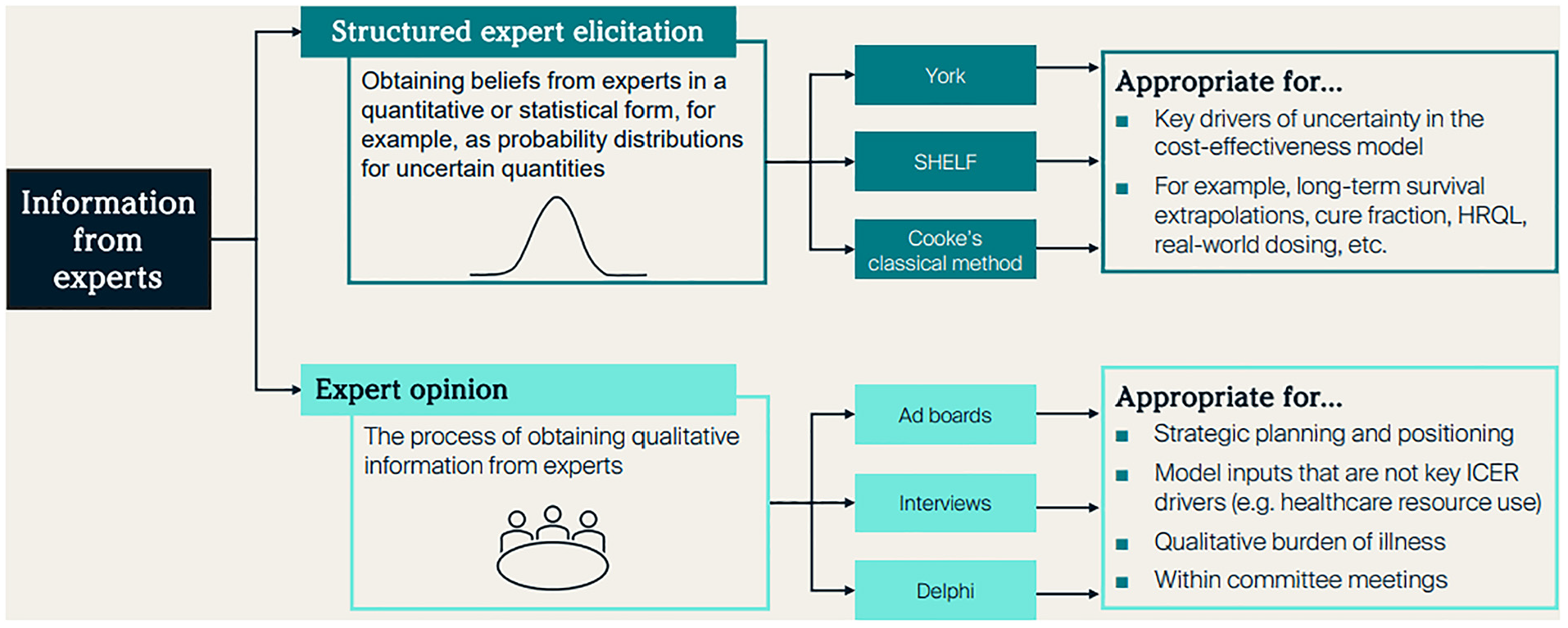
Comparison of structured expert elicitation with other methods to gather expert opinion.
Example approaches to elicitation are shown in Figure 2. The overview and practical guide are designed to be used alongside the generic tools provided as part of STEER, which are outlined below.
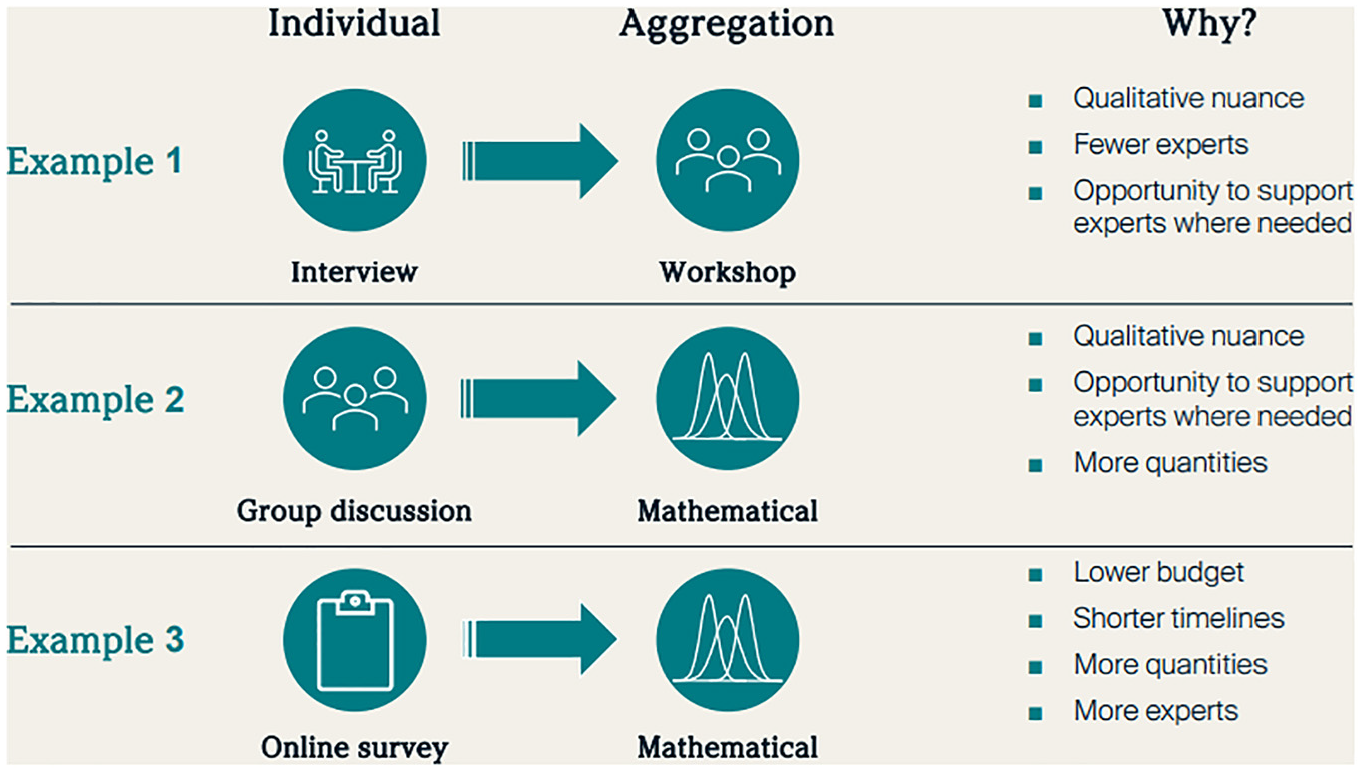
Example approaches to elicitation.
Generic Tools for Conducting SEE
R Code for Building Bespoke Web Apps for Conducting SEE
The code (downloadable from https://github.com/jankovicd/code_for_elicitation_apps) produces a Shiny app 13 for a generic elicitation exercise with 4 hypothetical parameters, as shown in Figure 3.
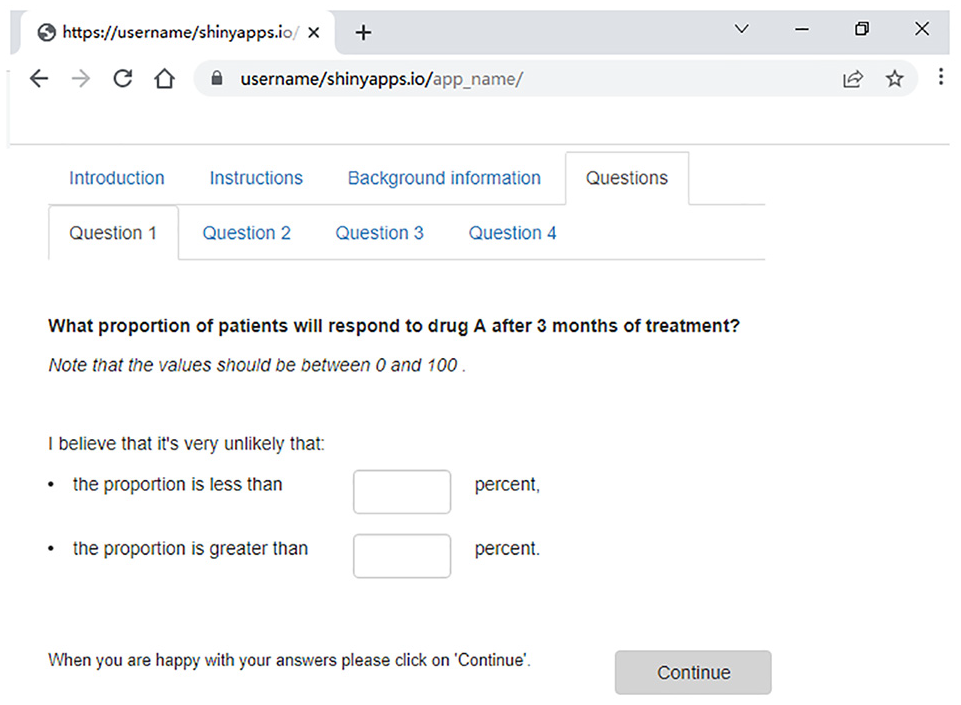
STEER Shiny app setup.
The code can be customized to produce bespoke apps for conducting SEE that can be deployed to a Web page and disseminated by sending the relevant link and a unique ID to each expert. Experts’ answers are saved on their device in a single file that can be sent back to the investigator.
Elicitation methods in the app
The resulting apps can use 3 elicitation methods: chips and bins (also known as roulette or the histogram method), tertiles, or quartiles (also referred to as bisection). 14 Tertiles and quartiles are 2 different types of variable interval methods. The 3 methods are the most widely used in HCDM. 15 There is no evidence that either of the methods leads to more accurate priors, although chips and bins have been suggested to be more intuitive for experts not trained in probabilities and statistics. 6
All elicitation methods first elicit the plausible range. If using chips and bins, experts are then presented with a plot in which they can express their uncertainty. The range on the x-axis of the plot is always slightly wider than the expert’s range, unless this is prevented by the limits of the parameter being elicited (e.g., if an expert’s lower limit is 0%, then the lower limit of the plot is also 0%). The bin width on the plot (i.e., the range of intervals on the histogram) can take value of 1, 2, or 5 or their multiple of 10, 100, or 1,000. The exact bin width is derived to make the total number of bins as close to 10 as possible. The total number of chips provided to experts is twice the number of bins, allowing flexibility in the shape of experts’ priors while maintaining consistency across plots given that the number of bins is not always the same across plots. Experts are encouraged to think of chips in terms of relative probabilities across bins (i.e., the values in the range a–b are twice as likely as values in the range b–c), rather than absolute probabilities (e.g., 5% per chip).
If using either of the variable interval methods, experts are then asked to provide their quartiles or tertiles.
Once experts have expressed their uncertainty using the relevant method, they are presented with feedback on their quantities. With chips and bins, the feedback includes the probability placed on an expert’s mode interval and the probability on either side of the mode, as shown in Figure 4. For unimodal distributions, the feedback states the 98% probability interval and compares 2 sections of the distribution, as close to the median as possible.
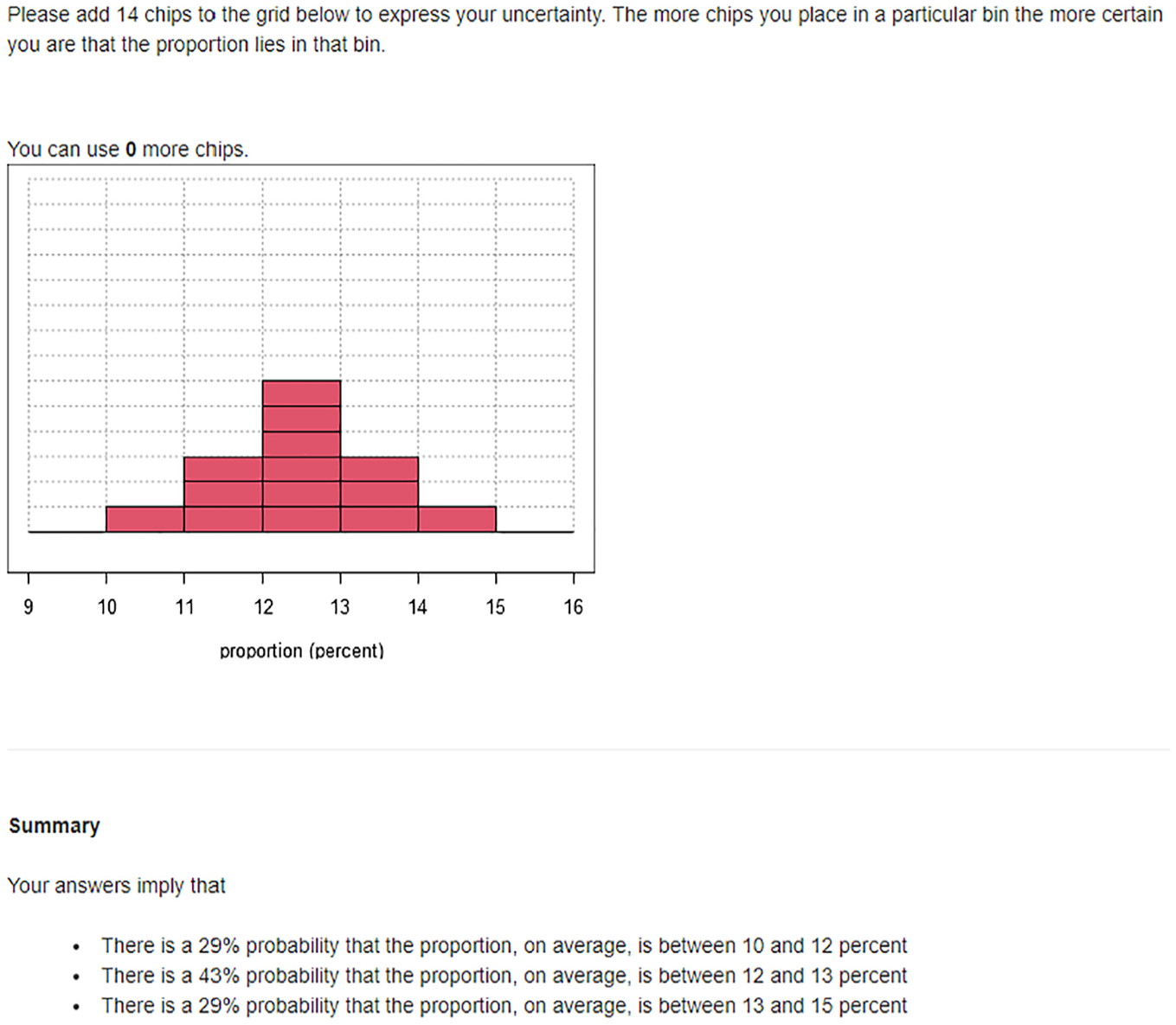
Chips and bins feedback in STEER Shiny app.
With the variable interval methods, the feedback includes comparison of different parameter ranges (e.g., the proportion is equally likely to be between 20% and 40% as it is to be outside this range).
Experts are then asked to provide a rationale for their answers in free-text boxes and save them. Experts can also edit and resave their answers at any point in the exercise.
The app includes instructions for experts, based on the training materials used in previous SEE exercises at the University of York. They explain the difference between uncertainty and variability and provide instructions for how to complete the exercise. The instructions are specific to the elicitation method selected by the user (chips and bins, tertiles, or quartiles) and can be further edited, as described in the section “Customizable Elements of the App.”
Customizable elements of the app
The code has 3 customizable elements:
The “manual_inputs.R” file is an R script in which the investigator can use predefined objects to indicate whether to include a consent form and questions about experts (e.g., role, professional experience), to set the elicitation method (chips and bins, quartiles, or tertiles), and to define elicitation questions (wording, quantities being elicited, and parameter units and limits).
The “www” folder contains 4 htm files containing text presented on the home page, the consent form, elicitation instructions for experts, and project-specific background information. These files can be edited in basic text-editing programs (e.g., MS Word).
The “about_you.R” file containing questions about experts, if these are included in the exercise (if about_you <- TRUE in the maual_inputs.R file). The questions about experts are added using standard Shiny widgets. 16 The STEER code includes 2 examples.
Detailed instructions for using the STEER Shiny code are provided on the STEER Web site.
Analysis code
The code analyzes the priors elicited using the STEER generic tools described above. The code accepts the file format generated by the R tool, avoiding the need to manually enter each elicited quantity or carry out any additional formatting of the files. The analysis code fits distributions of choice (normal, log normal, beta, or gamma) to experts’ priors using the SHELF fitdist function 17 and produces aggregate distributions with equal weighting, given the lack of evidence for differential weighting in HCDM. 6 The code saves tables of experts’ individual and pooled distribution parameters as well as plots comparing fitted distributions with experts’ quantiles (example shown in Figure 5a) and plots comparing individual with aggregate probability distributions for each elicitation question (Figure 5b).
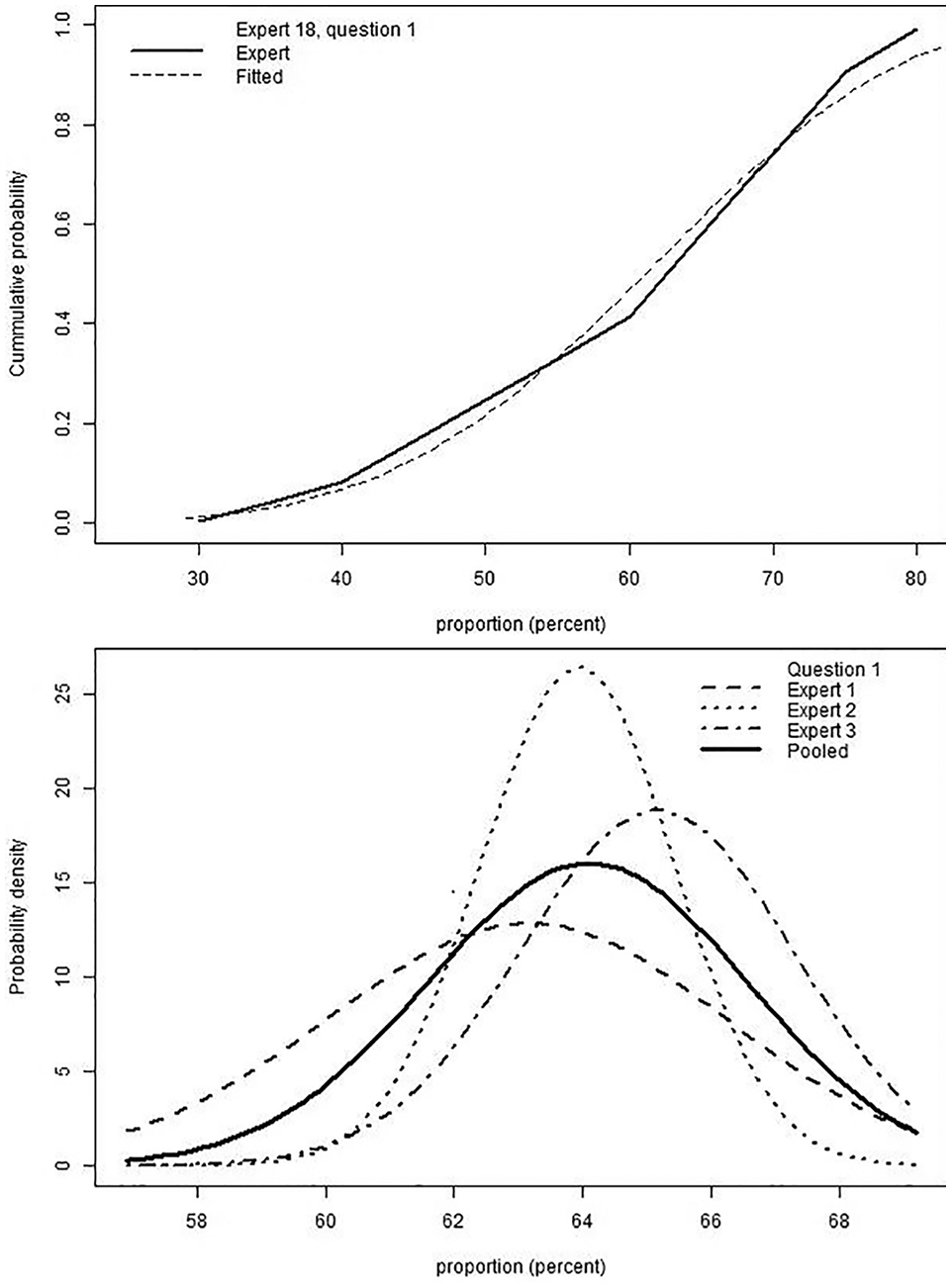
Example outputs of the R tool analysis code: (a) cumulative probability density curve for an expert’s histogram and the fitted beta distribution and (b) probability distribution for distributions fitted to experts’ individual priors and the aggregate prior.
The code is open source and can be edited to add further options (such as multiple distributions per elicitation question, differential weighting, or fitting additional parametric distributions).
Excel Template for Developing Bespoke SEE Exercises
Three excel templates are available for a generic elicitation exercise: one each for the chips and bins method, quartiles method, and tertiles method. The design of the Excel tools and the underlying code and assumptions match the R tool as closely as possible.
Each Excel tool contains 4 worksheets:
Introduction: basic information on the purpose of structured expert elicitation and STEER.
Instructions: an example exercise for experts matching the R tool.
Background information: left blank for the user to input the information for their exercise.
Question template: The user should copy this sheet to produce the required number of questions. The user should then input their question, quantity of interest, unit and parameter upper and lower limits. As in the R tool, the expert is first asked to provide the 98% probability interval. Following this, the expert creates the figure for their desired input method using the button provided (this requires macros to be enabled) and can then either input their chips into the bins shown or input their quartiles or tertiles (example shown in Figure 6). Feedback is provided for the expert to cross-check their answers against along with a comment box for them to input the rationale for their answers.
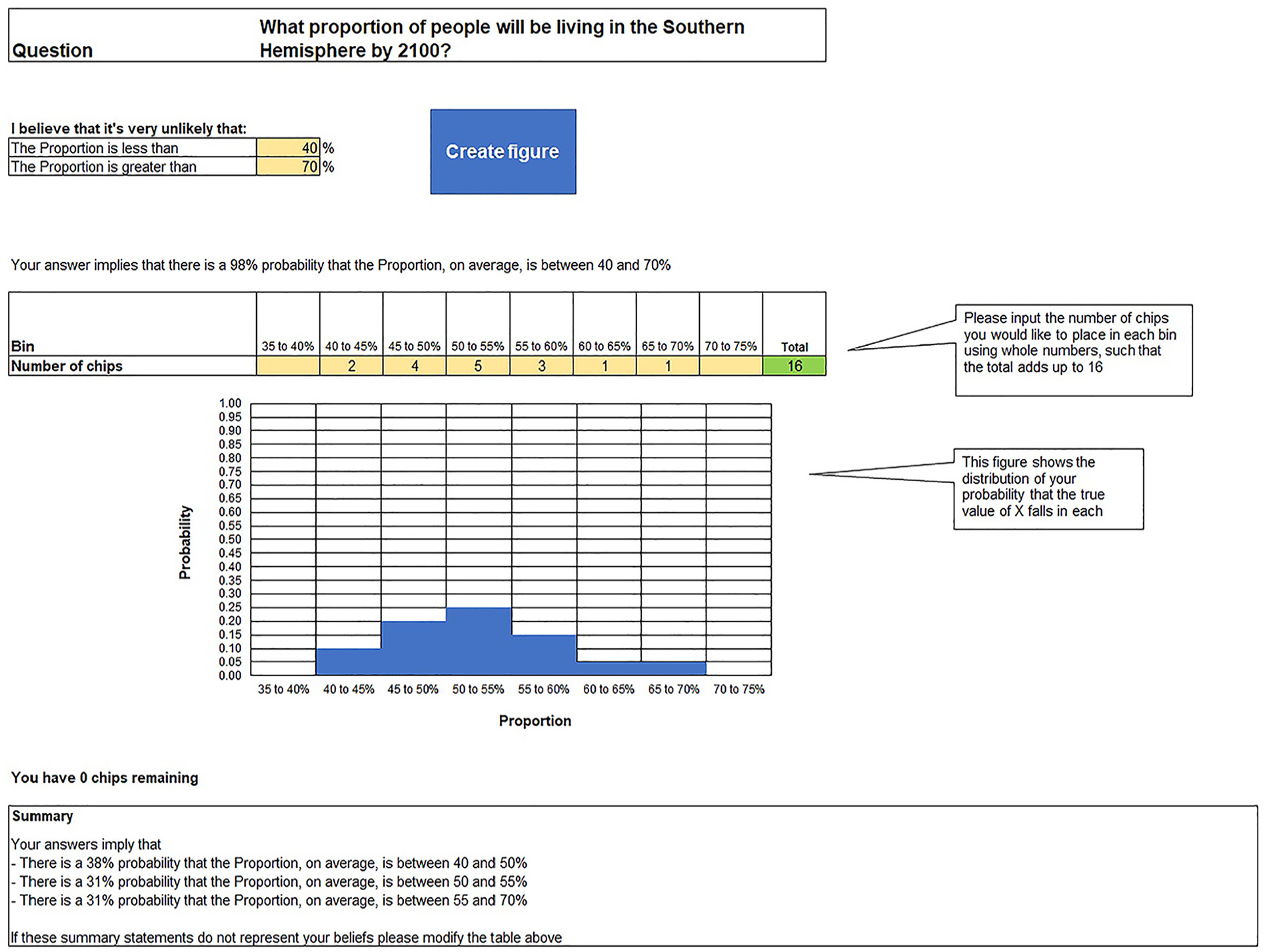
Chips and bins input in the Excel tool.
Training Materials for Experts Taking Part in SEE
Although the evidence is limited, there are some suggestions from the literature that training can reduce biases such as anchoring, confirmation bias, and overconfidence and may help with expert motivation.18–20 Therefore, expert training has been identified as a key component of SEE for HCDM. 6
As part of the STEER resources, a template training slide deck (Microsoft PowerPoint®) has been included to provide the basis for expert training. This includes the following key components:
Outline of objectives and purpose
Description of how the results will be used
Description of what is required from experts
Outline of process
Common biases and heuristics
Example and practice questions
Description of the quantities of interest and discussion/resolution of any ambiguity
Description of how dependence between quantities of interest will be handled
Assumptions and definitions used
This can be adapted based on the specific requirements of the SEE exercise, and further content can be added based on the context of the exercise.
The training slide deck has been tailored to experts typically encountered in the HCDM setting. Namely, the generic examples provided represent the quantities most commonly elicited in this setting (proportions and positive continuous variables), 15 while the wording is tailored to experts with limited probabilistic training.
Open Access Resources from Previous SEE
STEER provides elicitation resources used in previous SEE exercises conducted by the Centre for Health Economics, University of York.6,21–25 These include SEE protocols, training materials, and tools for conducting SEE that can be adapted to new examples.
Examples of Previous SEE Applied in Health Care Decision Modeling
A downloadable Excel sheet lists examples of published SEE exercises applied in the context of health care decision modeling. The publications were extracted from 2 recent reviews of SEE for decision modeling in health care.15,26 Additional publications were identified by directly contacting authors known to have published in the field. The spreadsheet includes information about the key methodological choices in each study. Users are able to search through the references by filtering specific methodological choices of interest. The sheet will continue to be updated in a nonsystematic manner, with significant examples, such as elicitations successfully used in decision making, added as they become available.
Applied Example
An applied example is provided, which was motivated by the NICE pathways pilot in renal cell carcinoma (RCC).27,28 In this appraisal, we sought to gain expert input from 5 to 10 experienced oncologists to inform expectations of long-term outcomes for a large number of treatments used at different lines for advanced RCC. We focus our example on the steps we took to adapt the STEER materials to our example and the judgments made as part of this. The SEE protocol is provided in the Supplementary Materials. The full exercise and its results will be published separately.
Protocol Design
The template protocol provided within the STEER repository was adapted for the RCC quantities of interest. During protocol design, the repository was reviewed to identify similar exercises that sought to elicit information on survival or progression-free survival (PFS) in oncology. One particularly relevant publication 29 was identified that was used for inspiration when writing the protocol.
Within the protocol, we followed the guidance on expert recruitment in that we aimed to recruit at least 5 experts with relevant substantive expertise (defined in our case as at least 5 y of experience treating advanced RCC and practicing at the consultant level). We sought diversity in center geography as we understood that treatment practice varied across the country. Experts were identified by hand searching RCC publications and NHS Web sites. Given the timing of the exercise, during the junior doctors and nurses strikes, we aimed to contact 40 experts to ensure sufficient recruitment. Experts were required to declare any potential conflicts using standard NICE forms.
Quantities elicited took some thought for this applied example as the quantities must be simple and observable and dependence must be captured. We sought to understand the expected outcomes for people receiving different initial and subsequent therapies in UK practice. There were 2 potential methods to elicit the required information, either
landmark survival estimates for each treatment sequence or
landmark estimates of either PFS or time to next treatment per line of therapy.
Based on expert input, the latter was expected to be more intuitive and avoid issues with treatment effect being highly dependent on subsequent therapies. Treatments to include were selected based on UK best and current practice, as described in the relevant guidelines and confirmed by the participants in the elicitation exercise during training and numerical data on subsequent treatment use from the trial for the primary intervention being appraised.
Other key considerations in the choice of the quantities of interest were the following:
What time points to select: we based this on historical data and expert expectations of the time points at which a reasonable proportion might still be expected to remain in PFS for at least 1 of the treatments of interest. We handled dependency by eliciting conditional survival probabilities for the latter 2 of the 3 landmark time points.
Which population to elicit for: the relevant UK population (aligned with the decision problem) or the population in the key trial for the intervention being appraised—we decided to elicit for the former to align with the appraisal decision problem.
The practical guide to SEE notes that the approach to elicitation should be decided based on the following:
Budget and timelines
Number of experts
Number of quantities of interest
Value of qualitative nuance
In our example, the timelines for the exercise were tight (less than 6 wk from initiation of protocol development to input of the results into the economic model), and no additional budget was provided to conduct the exercise. We sought to recruit between 5 and 10 experts to have enough for a valid exercise. Recruitment was complicated due to NHS strikes that were occurring during the time period, requiring 38 experts to be contacted to recruit 9 despite high levels of interest. Contracting was completed using standard contracts for the provision of expert advice to a NICE External Assessment Group; a number of experts presented details of conflicts for some of therapies involved, which had to be clarified to determine their level of potential conflict. We had 22 quantities of interest at 3 time points: to make this manageable for experts, we limited the number of quantities an individual expert was asked to estimate to 10 and assigned more experts to the treatments of most interest to the decision problem. Focus was given when assigning experts to each treatment to the intervention that will be first appraised using the pathways pilot model (cabozantinib + nivolumab) and the key comparators for that treatment. In our example, additional consultation was conducted to provide qualitative input to the appraisal that this exercise sought to inform, meaning that this exercise was not being relied on to provide this type of input.
These considerations meant that we decided that an initial short pilot, followed by training with groups of experts over Microsoft Teams, then an online survey followed by mathematical aggregation and a call with a clinical expert to provide context to results, was the most feasible approach while retaining robust methods. The rationale for how experts made their judgments was collected as part of the online survey.
We chose the chips and bins method as it is viewed as less complex and easier to complete by health care professionals, and given that surveys were being sent out online for completion within a relatively short period of time, the ease of completion was considered to be of high importance.
Following the example in the practical guide, we carefully considered the wording of the questions for the quantities of interest to ensure the questions were written in neutral, unambiguous, comprehensible language. We piloted the questions with clinical experts before launching the survey. Key elements included in the questions were the patient population, landmark time point, treatment being evaluated, and details regarding whether or not the patient had had prior adjuvant treatment.
For each treatment, we asked the experts the following questions:
“What proportion of patients will be both alive and progression free at
“
Preparation
We produced an evidence brief based on the systematic review conducted for the NICE appraisal. We kept the text in this light to enable experts to quickly review the available information. A copy of this can be found in the supplementary Materials, Section J.1.4.
We adapted the training slides provided in the STEER repository for use in training meetings with experts. A summary of the slides used is provided in the Supplementary Materials, Section J.2. In addition to the practice question in the slide deck, we would recommend that experts are allowed to practice with 1 question relevant to the quantities of interest. We used the training exercise as a second opportunity to pilot question the wording and to ensure the evidence brief contained all of the relevant materials and was formatted in a way that experts were quickly able to review.
Individual Elicitation
We elicited individual judgments using the STEER R tool from 9 oncologists. With regard to the application of the R code, the code was first downloaded in a ZIP file from GitHub using the link provided and then unzipped. The R project was then opened. The manual inputs file was altered as follows (full code for the about_you.R and manual_inputs.R scripts is provided in Supplementary Materials, Section J.3):
Line 3: Expert IDs were input for each of the 9 experts.
Line 16: include_about_you was set to TRUE to allow questions about experts to be input.
Line 18: n_about_you was set to 4.
Line 22: Elicitationmethod was kept as chips and bins.
Line 31: Quantity was amended to: c("proportion", "proportion", …..); because there were 10 quantities at 3 time points, the proportion was repeated 30 times.
Line 42: Units was amended to c("%", "%" ….) as above % was repeated 30 times.
Line 49: Quant_limit_lower was amended to c(0, 0, ….) as above repeated 30 times.
Line 50: Quant_limit_upper was amended to c(100, 100, …..) as above repeated 30 times.
Line 55: Eli_que_text was amended to include all 30 questions. As an example, the first question was, “What proportion of patients will be both alive and progression free at 3 years for the advanced RCC patient population in England if they received cabozantinib plus nivolumab at 1st line in the int/poor risk group and had not had previous treatment with adjuvant pembrolizumab?”
Amends were made to the standard questions in about_you; we included 4 questions that would allow us to categorize our respondents according to their expertise and diversity.
dummy_app was set to FALSE in apps.R.
The app was then published by first installing the package rsconnect, then loading the rsconnect library, then creating a token in Shinyapps.io and pasting the token and secret into the R console and then using the command deployApp().
The deployed app can be found using the following link: https://nice-rcc-clinician-survey.shinyapps.io/rcc_r_code_clinician_1/ and can be accessed by entering dummy unique identifier 0000.
Experts were provided with the opportunity to provide feedback in the tool. All of the experts provided commentary in the boxes provided (this was stressed as important during training). In addition to this, experts were provided with an e-mail address to contact with any queries. Two experts contacted to clarify how to return results. The analysts conducting the exercise reviewed expert responses once received, and in instances of suspected errors in data input or missing values, they contacted the relevant experts to provide further guidance. This was required in 3 cases, with the most common misunderstanding being interpretation of conditional survival.
Aggregation
As noted above, we used mathematical aggregation as we considered this to be the most suitable option given the guidance in the MRC protocol, timelines, and lack of need for qualitative input. First, a probability distribution was fitted to each expert’s beliefs from the histogram. The statistical best fit distribution was selected from the normal, gamma, log normal, and beta distributions. These were then pooled, assuming that each expert contributed equally to the group overall distribution. The MRC protocol advises the use of linear pooling with equal weights for mathematical aggregation for simplicity and due to a lack of research on how to generate appropriate weights.
Modeling/Analysis and Reporting
The results from the expert elicitation were applied in 3 ways to guide the decision model. First, we used these results to help select baseline risk curves for PFS and postprogression survival in best supportive care. Due to the availability of a relatively mature real-world evidence dataset for extrapolations, the outputs were used qualitatively rather than quantitatively. Second, we used the results to guide the selection of the fractional polynomial network meta-analysis for determining the expected difference between treatments for PFS.
Validation of the results from the expert elicitation was undertaken with 1 clinical expert, who was identified at the start of the relevant appraisal as a key expert in the area and had already provided advice on other topics related to the appraisal, via a phone call during which results were presented and discussed and context given for interpretation.
Reporting of the exercise can be found in NICE TA964 27 ; publication is ongoing. The style of reporting was loosely based on the example provided in Cope et al. 29 with adaptations made to address the specific decision problem for RCC and the requirements of the NICE External Assessment Group template.
Discussion
This article describes STEER open access resources for conducting SEE, including an overview of the process and a practical guide for conducting SEE in this setting, adaptable tools for building bespoke SEE exercises, training materials for experts taking part in SEE, resources used in previous SEE exercises, and examples of published SEE in HCDM.
Unlike existing software for conducting SEE,7–10 STEER provides end-to-end resources for the entire SEE process, from guidance on key practical issues such as timelines, team skills requirements and a checklist, to training materials, adaptable tools for creating bespoke SEE exercises, and analysis code compatible with the tools. Furthermore, its alignment with the MRC protocol for SEE, 6 which has been explicitly cited by decision makers such as NICE 2 and Inframed 3 as an SEE protocol suitable for HTA submissions, means the materials are tailored to an HCDM context, taking into considerations practical challenges encountered in this setting.
The scope of STEER is limited by uncertainties that exist regarding SEE methodology. The MRC protocol 6 highlighted that optimum methodological choices in SEE are not always clear and are dependent on the context of the planned use. The design of each SEE exercise requires prioritization of quantities for elicitation based on how likely they are to be important to decision making and the feasibility of eliciting these quantities. This requires consideration of, for example, how the results will be used, types of quantities being elicited, the number of quantities, and available resources. The MRC protocol 6 provides guiding principles for choosing between available methods, while the STEER practical guide summarizes the types of choices that need to be made to help guide the planning process. It should be noted, however, that although a formal process aims to reduce bias (and tools such as STEER can facilitate the implementation of formal elicitation processes), beliefs are inherently personal, and this needs to be considered by decision makers using this information.
Overall, STEER provides support for investigators conducting SEE to use within HCDM. The use of such off-the-shelf resources can help streamline the SEE process while maintaining methodological robustness.
Supplemental Material
sj-docx-1-mdm-10.1177_0272989X251343013 – Supplemental material for STEER: Open Access Resources for Conducting Structured Expert Elicitation for Health Care Decision Making
Supplemental material, sj-docx-1-mdm-10.1177_0272989X251343013 for STEER: Open Access Resources for Conducting Structured Expert Elicitation for Health Care Decision Making by Dina Jankovic, James Horscroft, Dawn Lee, Laura Bojke and Marta Soares in Medical Decision Making
Footnotes
Acknowledgements
We are grateful for support from Rose Hart, Lumanity, who validated the STEER R code and advised on code accessibility. Furthermore, we thank Jaime Peters and Ed Wilson, University of Exeter; Matthew Stevenson, University of Sheffield; and Mario Ouwens and Bartholomeus Willigers, AstraZeneca, for piloting the resources. We are grateful for the technical support from Gill Forder and Kirtsy Adegboro, University of York, who built the STEER Web site and Ashley Bowman and Victoria Palmer, Lumanity, who helped with the design of the STEER overview and practical guide and who organized the final dissemination Webinar.
Presented at:
• STEER: Structured Expert Elicitation Resources for Healthcare Decision-Making, dissemination Webinar, November 2022
• SEE sense: Tools for Conducting Structured Expert Elicitation to Support Healthcare Decision Making, virtual workshop at ISPOR, May 2022
• R Shiny for expert elicitation: Easily-Adaptable Code for Building Bespoke Web Applications, R for HTA annual workshop, May 2022
• ISPOR short course: Structured Expert Elicitation for Healthcare Decision Making Confirmation, delivered online, December 2023
• STEER short course: Structured Expert Elicitation for Healthcare Decision Making Confirmation, delivered online, November 2024.
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article. The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Financial support for this study was provided in part by a grant from the University of York, match funded by Lumanity. The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report. The following authors are employed by the University of York: Dina Jankovic, Laura Bojke, Marta Soares. James Horscroft was employed by Lumanity for the duration for the project. Dawn Lee was employed by Lumanity and PenTAG, University of Exeter, for the duration of the project. Dina Jankovic, James Horscroft, Dawn Lee, and Laura Bojke have received funding for teaching a private short course (STEER short course above), for which teaching materials included the resources described in this article. Dina Jankovic, James Horscroft, Dawn Lee, Laura Bojke, and Marta Soares have received funding for teaching ISPOR short courses for which the teaching materials included the resources described in this article.
Ethical Considerations
Not applicable; the publication does not involve research on humans or animals.
Consent to Participate
Not applicable; the publication does not include any data collected from subjects.
Patient Consent
Not applicable; the publication does not include a study of patients.
Consent for Publication
Not applicable; the publication does not contain any data from an individual person.
Data Availability
All resources described in the article are open source; no additional data are involved.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.