
Abstract
The Gaussian Filter (GF) is one of the most widely used filtering algorithms; instances are the Extended Kalman Filter, the Unscented Kalman Filter and the Divided Difference Filter. The GF represents the belief of the current state by a Gaussian distribution, whose mean is an affine function of the measurement. We show that this representation can be too restrictive to accurately capture the dependences in systems with nonlinear observation models, and we investigate how the GF can be generalized to alleviate this problem. To this end, we view the GF as the solution to a constrained optimization problem. From this new perspective, the GF is seen as a special case of a much broader class of filters, obtained by relaxing the constraint on the form of the approximate posterior. On this basis, we outline some conditions which potential generalizations have to satisfy in order to maintain the computational efficiency of the GF. We propose one concrete generalization which corresponds to the standard GF using a pseudo measurement instead of the actual measurement. Extending an existing GF implementation in this manner is trivial. Nevertheless, we show that this small change can have a major impact on the estimation accuracy.
1. Introduction
Decision making requires knowledge of some variables of interest. In the vast majority of real-world problems, these variables are latent; that is, they cannot be observed directly and must be inferred from available measurements. To maintain an up-to-date belief over the latent variables, past measurements have to be fused continuously with incoming measurements. This process is called filtering and its applications range from robotics to estimating a communication signal using noisy measurements (Anderson and Moore, 1979).
1.1. Dynamical systems modeling
Dynamical systems are typically modeled in a state–space representation, which means that the state is chosen such that the following two statements hold. First, the current observation depends only on the current state. Second, the next state of the system depends only on the current state. These assumptions can be visualized by the belief network shown in Figure 1.
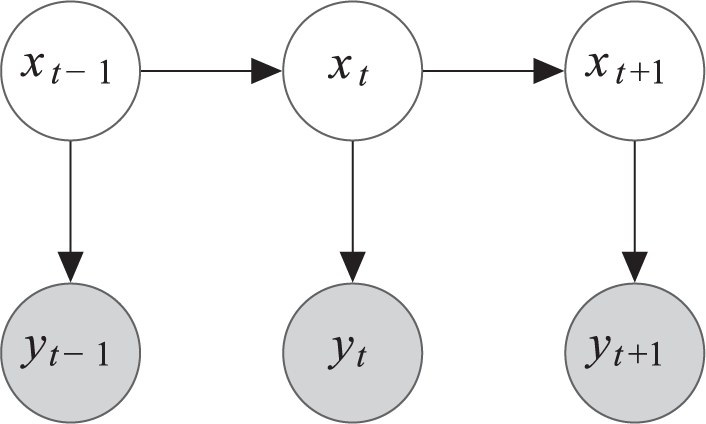
The belief network which characterizes the evolution of the state
A stationary system can be characterized by two functions. The process model

describes the evolution of the state
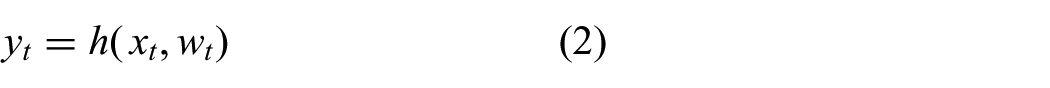
describes how a measurement is produced from the current state. Following the same reasoning as above, we assume the noise
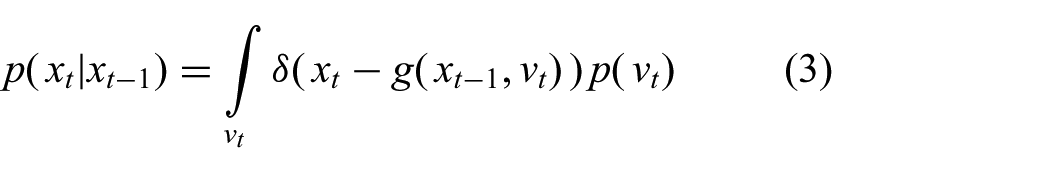
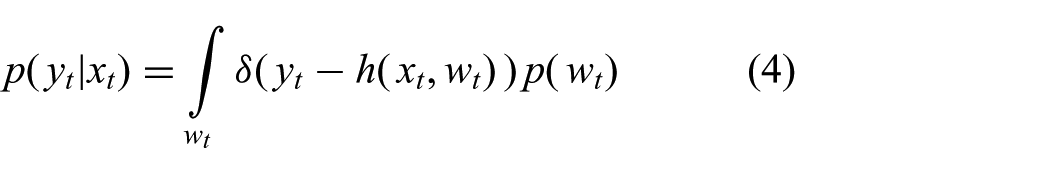
where
1.2. Exact filtering
The desired posterior distribution over the current state
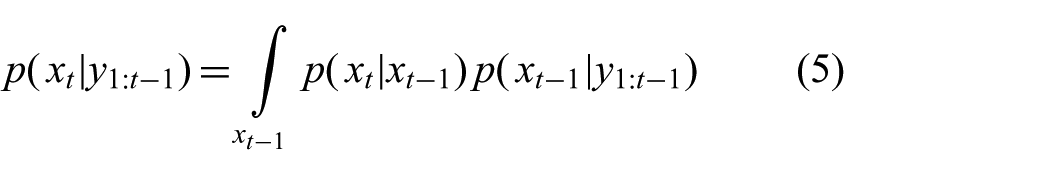
and an update step
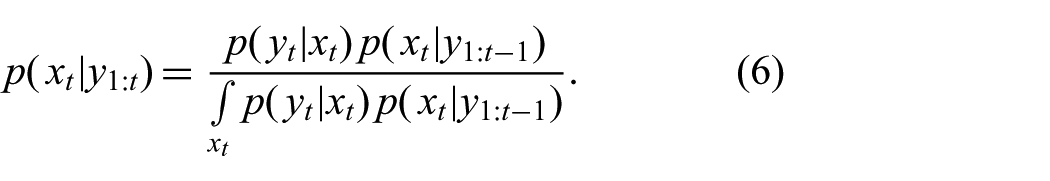
Kalman (1960) found the solution to these equations for linear process and observation models with additive Gaussian noise. However, filtering in nonlinear systems remains an important area of research. Exact solutions (Beneš, 1981; Daum, 1986) have been found for only a very restricted class of process and observation models. For more general dynamical systems, it is well known that the exact posterior distribution cannot be represented by a finite number of parameters (Kushner, 1967). Therefore, the need for approximations is evident.
1.3. Approximate filtering
Approximate filtering methods are typically divided into deterministic, parametric methods, such as the Unscented Kalman Filter (UKF) (Julier and Uhlmann, 1997) and the Extended Kalman Filter (EKF) (Sorenson, 1960), and stochastic, nonparametric methods such as the particle filter (Gordon et al., 1993). In this paper, we argue that there is a more fundamental division between filtering methods.
To the best of our knowledge, all existing filtering algorithms either compute expectations with respect to the conditional distribution
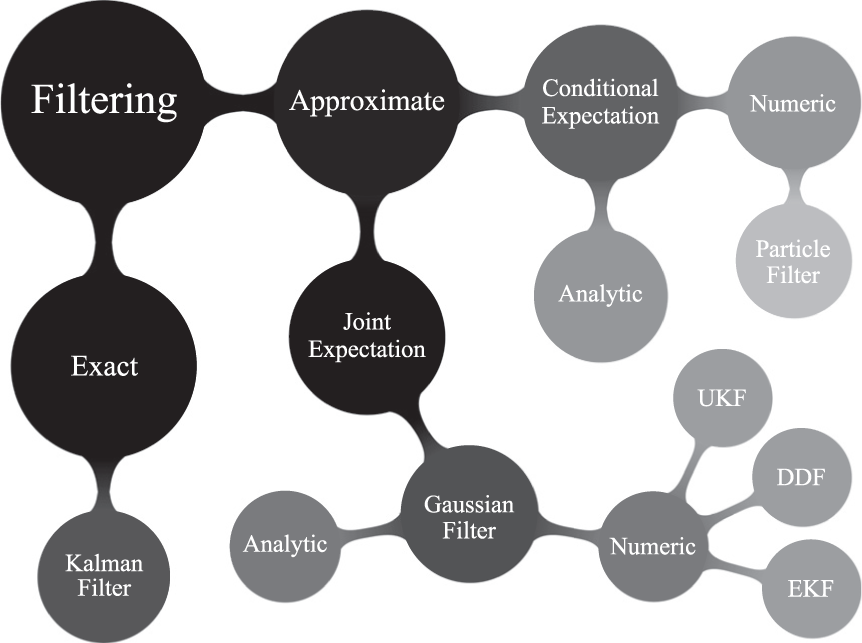
A taxonomy of filtering algorithms.
Since conditional expectation methods suffer from the curse of dimensionality, we focus on joint expectation methods in this paper. To the best of our knowledge, all such methods approximate the true joint distribution
1.4. Contributions
The first contribution of this article is to provide a new perspective on the theory underlying Gaussian filtering. From this new perspective, the posterior belief obtained by the GF is seen as the solution of a constrained optimization problem. The objective of this optimization measures how well the approximate belief fits the exact posterior, and the constraint restricts the posterior belief to being Gaussian with the mean being an affine function of the measurement. This new perspective provides insights into the limitations and possible extensions of the GF. We show that the constraint on the form of the belief can lead to poor approximations of the exact posterior. This indicates that more accurate filters can be obtained by relaxing this constraint.
An analysis of how the constraint can be relaxed while maintaining the computational efficiency of the GF is the second main contribution of this article. This analysis provides the basis for generalizations of the GF. We provide one such generalization, but hope that this analysis will also stimulate further research in this direction.
The third contribution is one particular generalization of the GF, which amounts to using a pseudo measurement, that is, a nonlinear feature of the original measurement. This extension is straightforward and can readily be applied in standard GF implementations. We provide simulation examples indicating that this simple change can improve filtering performance significantly. These examples are chosen to highlight specific properties of the method, to illustrate the theoretical insights and to provide intuition on how the proposed technique can be applied to practical filtering problems.
While no full-scale robotic filtering example is presented herein, the results of this paper have already given rise to practical applications. In Wüthrich et al. (2016), a method for robustifying GFs against outliers using a pseudo measurement is presented, which is applied to three-dimensional (3D) object tracking using a depth sensor in Issac et al. (2016).
The present paper is an extension of preliminary results published in Wüthrich et al. (2015). The theoretical analysis has been significantly extended and is now contained in Sections 6, 7 and 8. Furthermore, two additional simulation experiments have been added in Sections 9.3 and 9.4 to further illustrate the practical relevance of the proposed method.
1.5. Outline
In Sections 2–4, we first review existing filtering methods, in particular the GF. Then, in Section 6, we view the GF as the solution to a constrained optimization problem. From this perspective, the GF is seen as a special case of a potentially much broader class of filters. In Section 7, we analyze how the GF could be generalized. Finally, in Section 8, we propose one possible extension of the GF and show that this generalization coincides with the GF using a pseudo measurement. Numerical simulations in Section 9 illustrate why using such pseudo measurements instead of the actual measurement can improve estimation accuracy significantly.
2. Approximate prediction
We start out with the distribution

For instance with
We substitute (5) in (7) in order to write this expectation in terms of the last belief and the process model
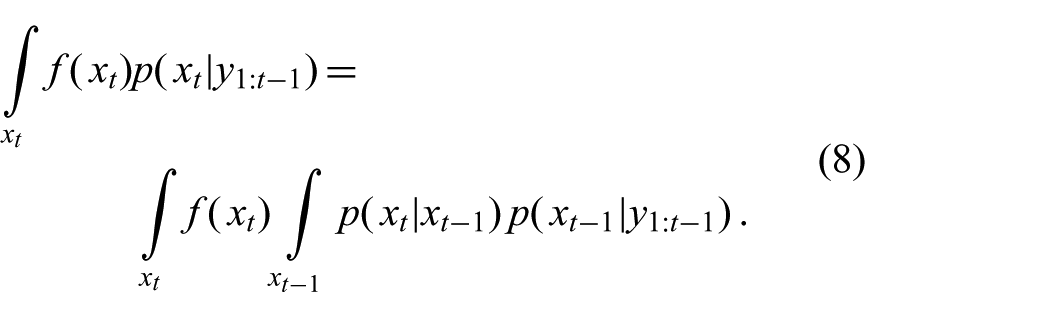
Substituting the distributional process model (3) and solving the integral over
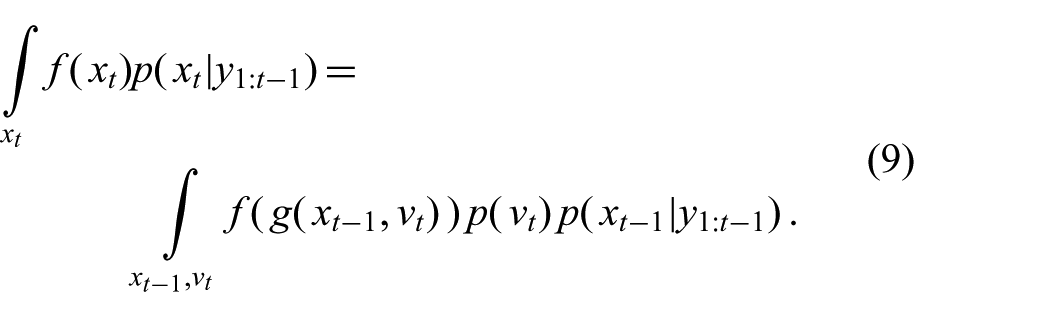
For certain process models
Both types of methods approximate (9) by evaluating the integrand at different points and summing them up
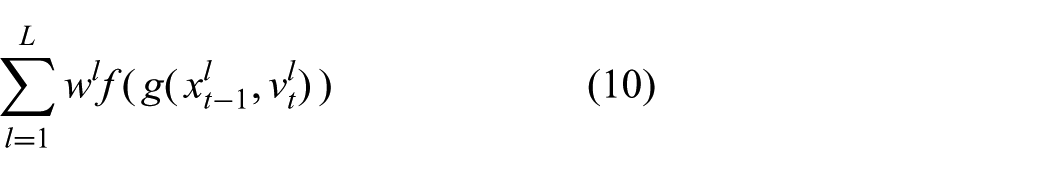
where L is the number of evaluations. The evaluation points
2.1. Monte Carlo integration
In Monte Carlo integration,
2.2. Gaussian quadrature
Another possibility is to use deterministic numerical integration algorithms, such as Gaussian quadrature methods. In such methods, the weights
2.3. Conclusion
Which particular numeric integration method is used to compute the approximate expectations is inconsequential for the results presented in this paper. What is important here is that the numeric computation of expectations of the type (7) is tractable; that is, it does not suffer from the curse of dimensionality. As we will see shortly, this is unfortunately not the case in the update step.
3. Approximate update
The goal of the update step is to obtain an approximation of the posterior
3.1. Computation of conditional expectations
As for the prediction, when there is no exact solution to (6), we compute expectations with respect to the posterior
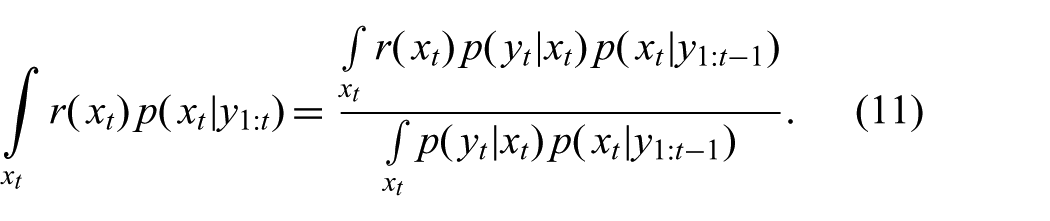
Both the numerator and the denominator can be written as
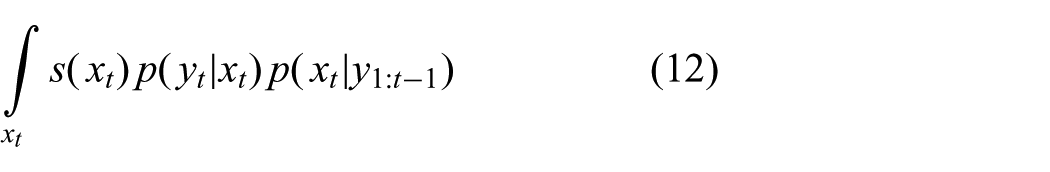
with
As in the prediction step, we can approximate this expectation either by sampling, which is used in Sequential Monte Carlo (Cappé et al., 2007; Gordon et al., 1993), or by applying deterministic methods such as Gaussian quadrature (Kushner and Budhiraja, 2000).
There is, however, a very important difference from the prediction step. We now need to compute the expectation of a function weighted with
Unfortunately, this effect becomes worse with increasing dimensionality. To see this, consider a simple example with a predictive distribution
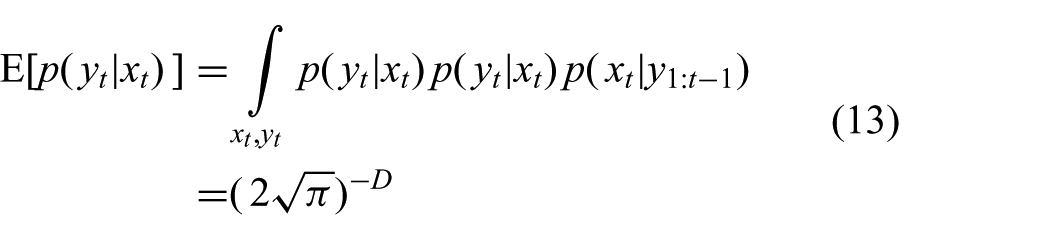
where
3.2. Computation of joint expectations
There are a number of approaches which avoid computing such expectations with respect to the conditional distribution
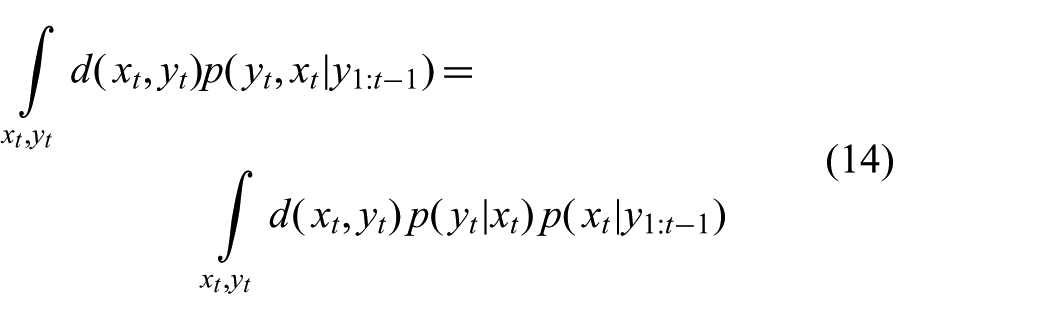
where
Inserting the observation model from (4) into the joint expectation above and solving the integral over
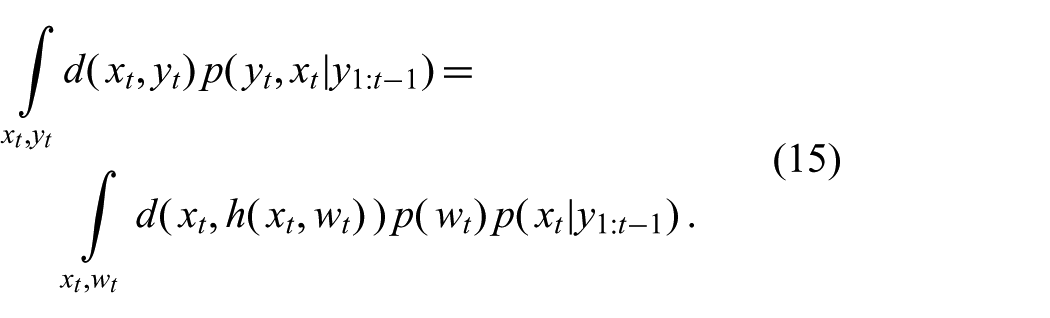
This term has the same form as the expectation in the prediction step (9). It is an integral of some function with respect to probability densities from which we can sample. This allows us to approximate this expectation efficiently, even for high-dimensional states.
3.3. Conclusion
The insight of this section is that numeric computation of expectations with respect to the conditional distribution
Note that expectations with respect to the marginals
3.4. Notation
In the following theoretical Sections 4–8, we only consider a single update step. For ease of notation, we will not explicitly write the dependence on all previous observations
It is important to keep in mind that the parameters computed in the following sections are also time varying; all computations described in the following are carried out at each time step.
4. The Gaussian Filter
The advantage in terms of computational complexity of joint expectation filters over conditional expectation filters comes at a price: the approximate posterior
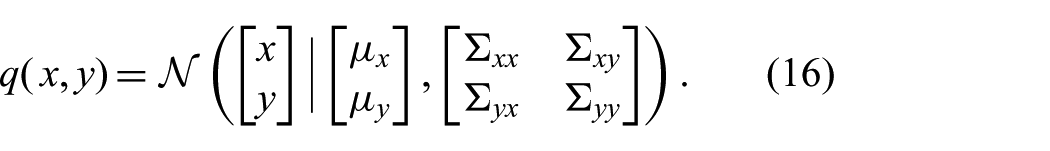
The parameters of this approximation are readily obtained by moment matching; that is, the moments of the Gaussian are set to the moments of the exact distribution


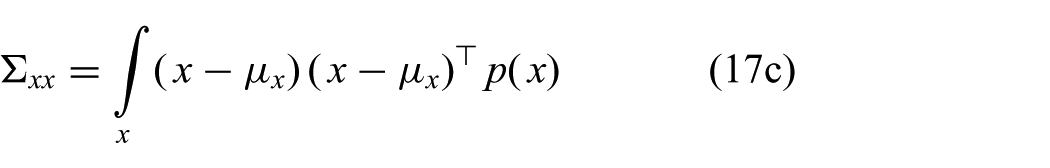
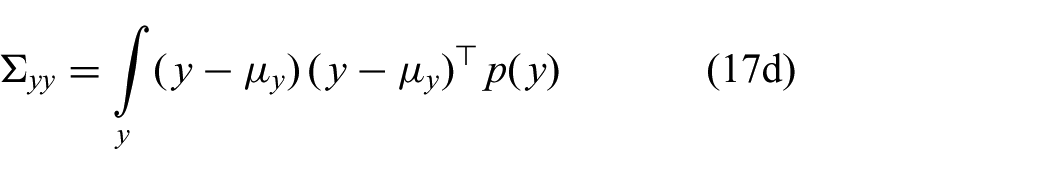
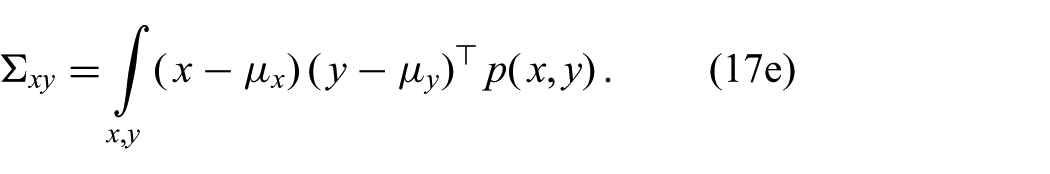
All of these expectations can be computed efficiently for reasons explained in the previous section.
After the moment matching step, we condition on y to obtain the desired posterior, which is a simple operation since the approximation is Gaussian
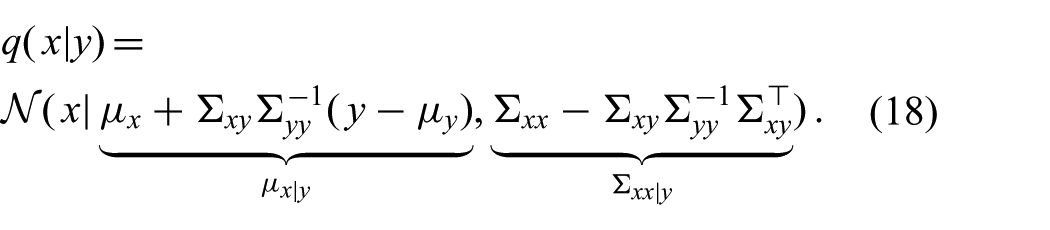
This approach is called the GF. Widely used filters such as the EKF (Sorenson, 1960) and the UKF (Julier and Uhlmann, 1997) can be seen as instances of the GF, differing only in the numeric integration method used for computing the expectations in (17). We refer the interested reader toWu et al. (2006), Särkkä (2013) and Ito and Xiong (2000) for more details on this point of view on Gaussian filtering.
4.1. Rank-deficient covariance matrix
Equation (18) involves a matrix inverse, which does not exist if
4.2. Approximate integration schemes
The EKF solves the integrals (17) by linearizing the measurement function and then performing analytic integration. This approximation does not take the uncertainty in the estimate into account, which can lead to large errors and sometimes even divergence of the filter (Ito and Xiong, 2000; van der Merwe and Wan, 2003).
Therefore, approximations based on numeric integration methods are preferable in most cases (van der Merwe and Wan, 2003). Deterministic Gaussian integration schemes have been investigated thoroughly, resulting in filters such as the UKF (Julier and Uhlmann, 1997), the DDF (Nørgaard et al., 2000) and the Cubature Kalman Filter (Arasaratnam and Haykin, 2009). Alternatively, numeric integration can also be performed using Monte Carlo methods.
5. Problem statement and assumptions
While much effort has been devoted to finding accurate numeric integration schemes for GFs, there seems to be no joint expectation method using a non-Gaussian joint approximation
This holds true even if we can compute the integrals accurately. The problem of a too restrictive parametric form of the belief is hence separate from the problem of numeric integration. In this article, we focus on the first problem and, to simplify analysis, we will assume that all numeric integrals with respect to the joint distribution can be computed with high precision. Nevertheless, the extensions proposed in this article are compatible with any of the numeric integration methods used in the standard GF. However, we do not analyze the impact of the integration inaccuracies on the proposed method.
6. A new perspective of the Gaussian Filter
In this section, we investigate whether it is possible to find a more general form of the approximate posterior
6.1. Objective for the approximate joint distribution
In the GF, the parameters of the Gaussian belief (16) are found by moment matching. For a Gaussian approximation
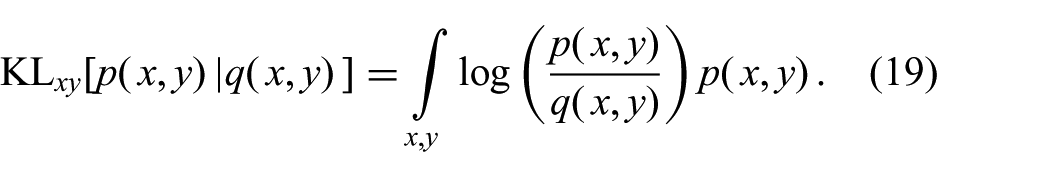
Hence, the GF can be understood as minimizing (19), subject to the constraint that
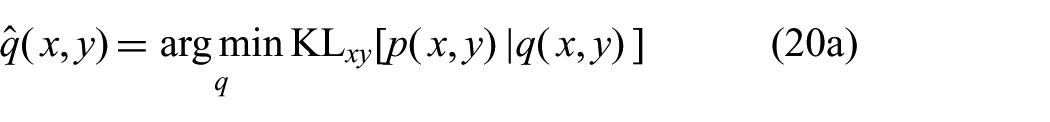
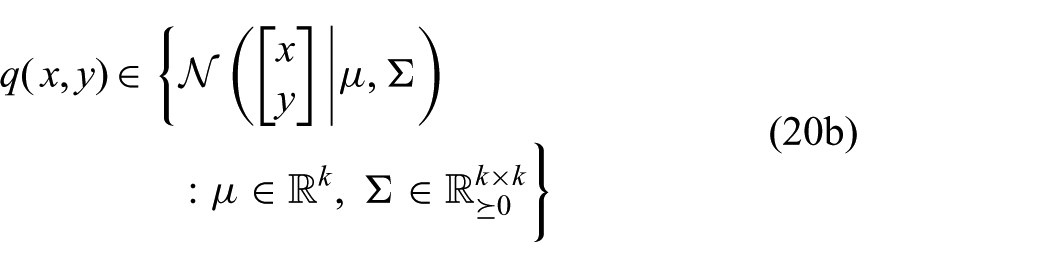

where k is the sum of the dimensions of x and y, and
6.2. Objective for the approximate posterior distribution
The goal is therefore to rewrite the constrained optimization with subsequent conditioning (20) as a constrained optimization directly yielding the same posterior
Any joint Gaussian distribution
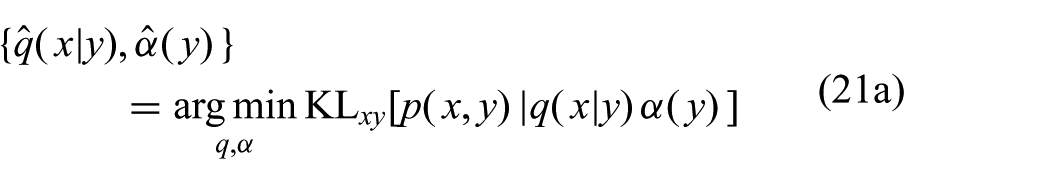
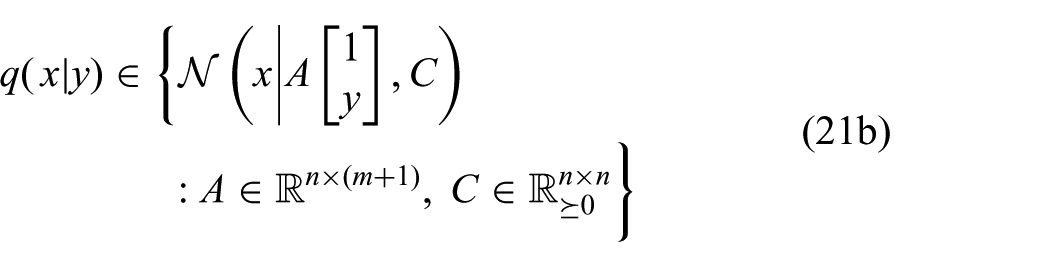
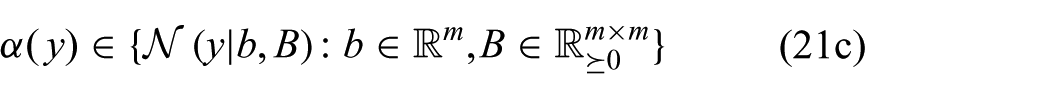
where n is the dimension of x and m is the dimension of y. The new constraints (21b) and (21c) ensure that the joint distribution
The posterior
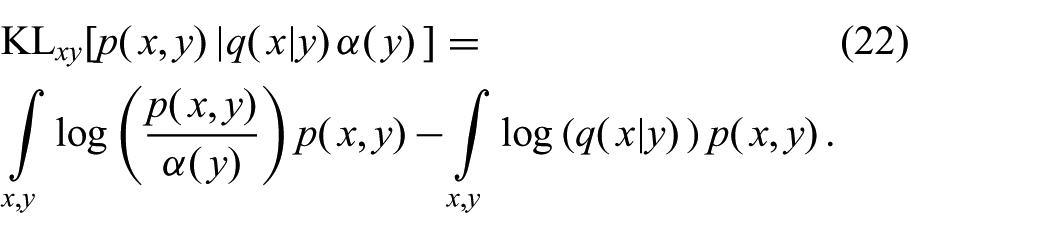
Only the second term depends on the posterior
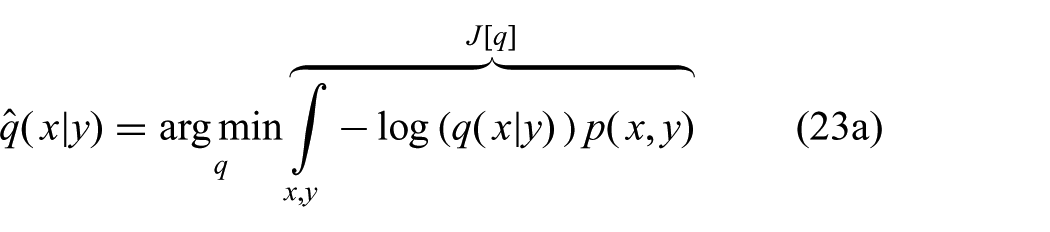
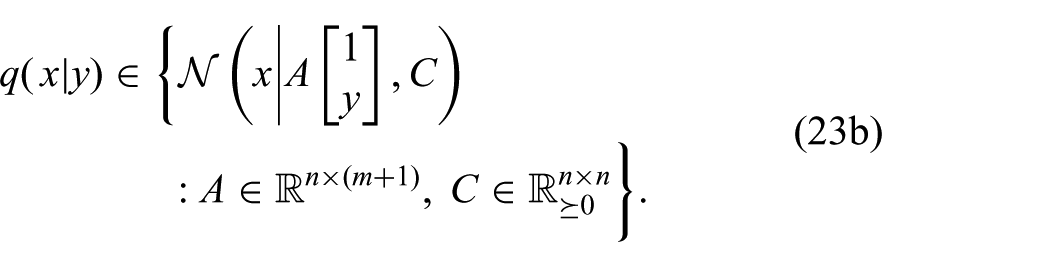
We have thus found a constrained optimization problem which yields the GF equations (17) and (18) as the solution. This point of view will serve as the basis for generalizations of the GF by relaxing (23b) in Section 7. First, we will look at the new objective (23a) in some more detail and make connections to alternative objective functions commonly used in filtering. We emphasize, however, that using (23a) as an objective is mainly justified by the fact that it yields the GF equations, and not by the following interpretations.
6.3. Connection to assumed density filtering
Above we showed that the GF minimizes the KL-divergence (19) between the exact joint distribution
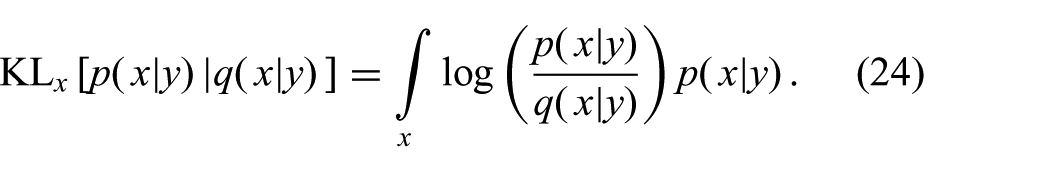
This objective is used in assumed density filtering (ADF) (Maybeck, 1979; Murphy, 2012) and expectation propagation (Minka, 2001). A drawback of such methods is their restriction to models where (24) can be optimized analytically. Approximating the integral (24) numerically is intractable in general since it requires the computation of expectations of the form of (11). Despite their differences in computational requirements, we shall make the connection here between the new objective (23a) and the commonly used objective (24).
By adding and subtracting
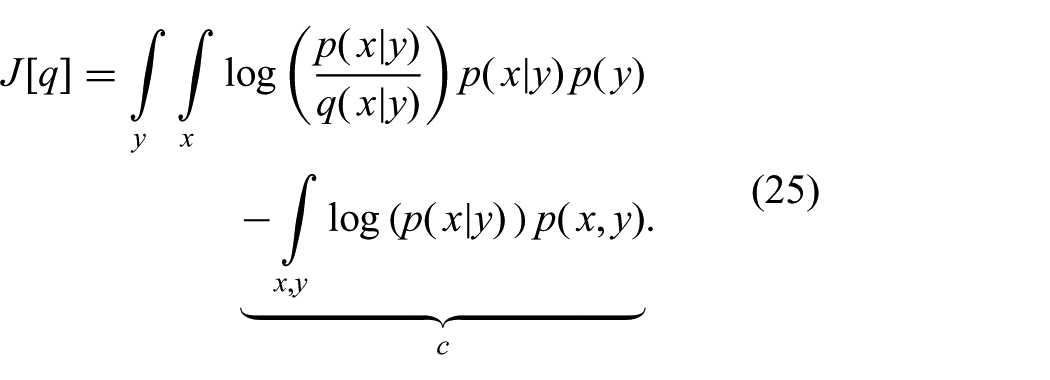
Using the definition of the KL-divergence (24), we can hence write the objective as
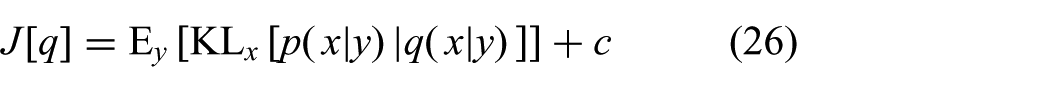
where
This means that the GF avoids computing the intractable conditional expectations in (24) by taking the expectation with respect to y. This leads to the objective (23a), where only expectations with respect to the joint distribution
6.4. Information theoretic interpretation
The Shannon information content of an outcome z is defined as

which is identical to (23a).
6.5. Properties of the objective
Further arguments why
First of all, if the approximate distribution
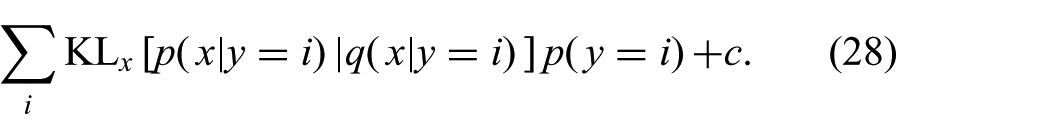
If there is no constraint linking
If we remove the constraints in x as well, then the unconstrained minimum of (24) can be attained, which is at
7. Conditions for generalizations of the Gaussian Filter
We have seen that the more we relax the constraint (23b), the closer we get to the solution of ADF (24) and to the exact posterior
Unfortunately, this is a very difficult problem. In this section, we merely outline a few conditions that such a parametric family of distributions would have to fulfill. In Section 8, we shall then give one concrete example leading to a straightforward generalization of the GF.
7.1. General conditions
First of all, for the objective (23a) to be well defined, we require that

with
Secondly,

where
7.2. Conditions for efficiency
The question we will address in the following is what
The first condition for efficiency is that the objective function (23a) has to be convex in the parameters
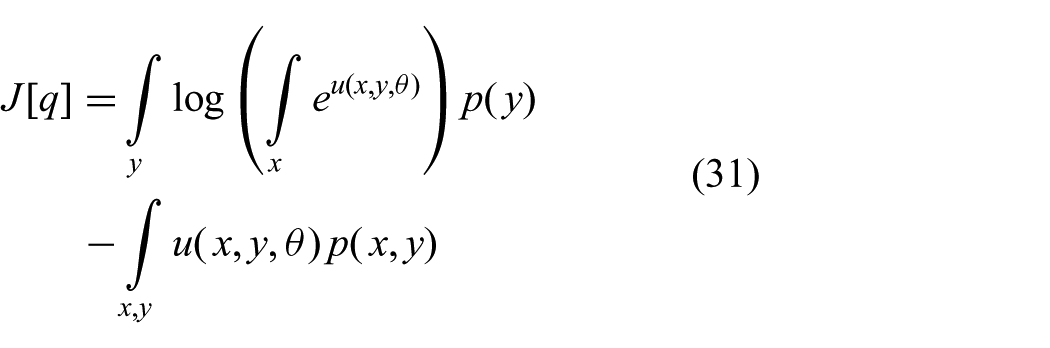
which is convex in
Given that (31) is convex, we can in principle find the optimal parameters by setting its derivative to zero and solving for
Setting the derivative of (31) with respect to

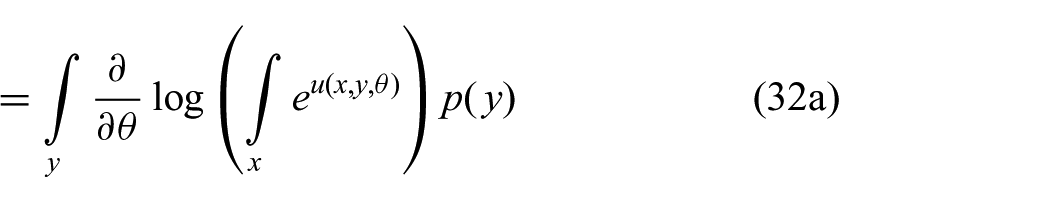
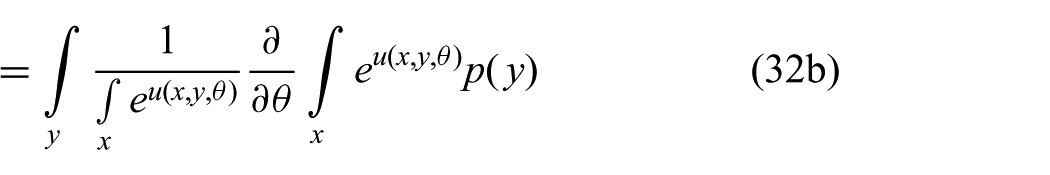
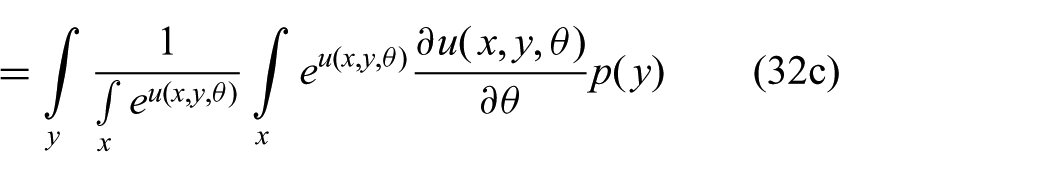
where we applied the chain rule in the step from (32a) to (32b) and from (32b) to (32c).
The left-most term in (32c) can be moved inside the integral, and by comparison with (30), we finally obtain
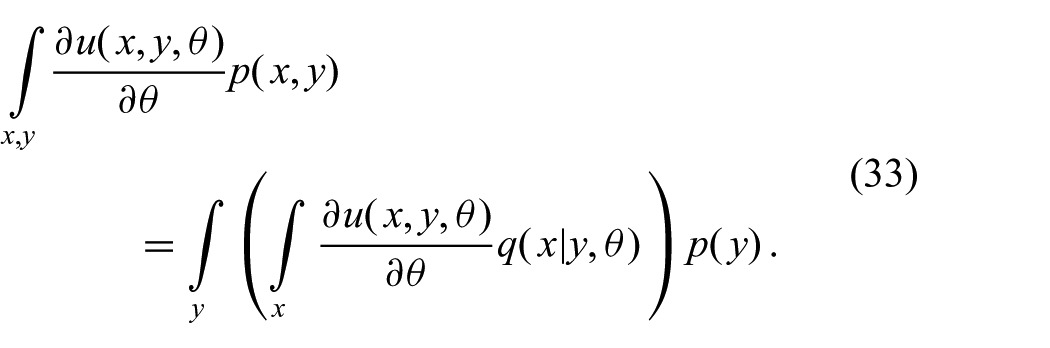
Before this system of equations can be solved, all integrals have to be computed. The integral over x on the right-hand side of (33) is an expectation with respect to the parametric approximation. Since the integrand depends on unknown parameters, this inner integral cannot be approximated numerically. Therefore,
In general, the outer integral over y cannot be solved in closed form since
Numeric integration is only possible if the integrand depends on no other variable than the ones we integrate out. Therefore, we require
On the left-hand side of (33), we evaluate an expectation with respect to
Finally, after computing the integrals, we have to solve the system of equations (33) in order to find the optimal
It is not clear how the most general
8. The Feature Gaussian Filter
We have seen that any approximate distribution with some required properties can be written in the form of (30). The objective is now to find a function
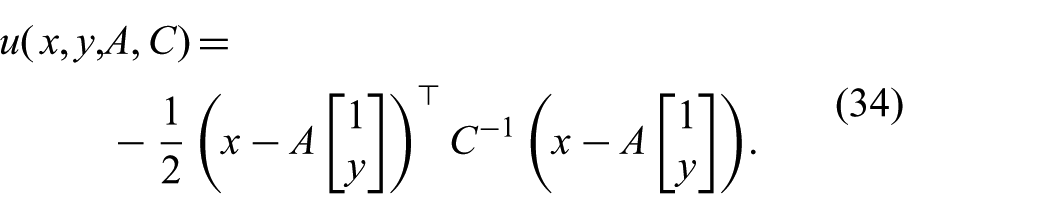
Next, we generalize this function without violating any of the conditions outlined in Section 7.2. While different ways are conceivable, we propose a straightforward generalization by allowing for nonlinear features in the measurement
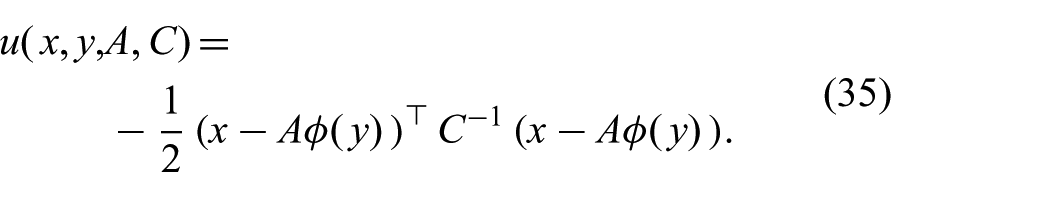
This generalization is mathematically very similar to the generalization of linear regression using features (Bishop, 2006).
Inserting (35) into (30) leads to an approximate distribution which is Gaussian in x, but can have nonlinear dependences on y
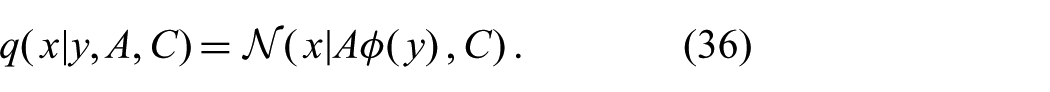
Because this approximation complies with the desiderata from Section 7.2, as we show next, the parameters can be optimized efficiently. We refer to the resulting filtering algorithm as the Feature Gaussian Filter (FGF).
8.1. Solving for A
The derivative of
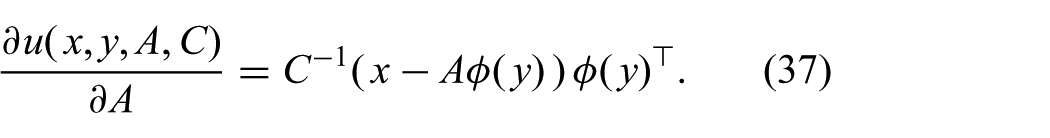
As required, the inner integral in (33) can be solved in closed form since the approximate distribution is Gaussian in x
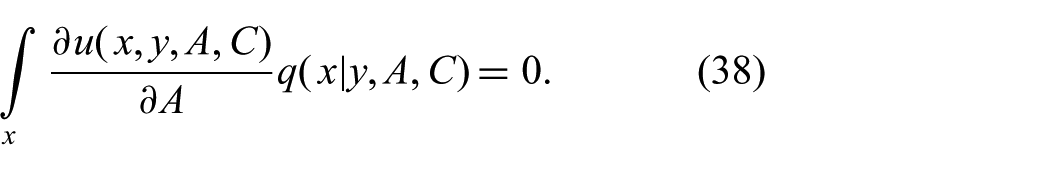
Inserting these results into (33), we can solve for A

8.2. Solving for C
The matrix C is constrained to be positive definite, such that the approximate distribution (36) is Gaussian. As it turns out, the unconstrained optimization yields a positive definite matrix. Thus, there is no need to take this constraint into account explicitly.
The derivative with respect to
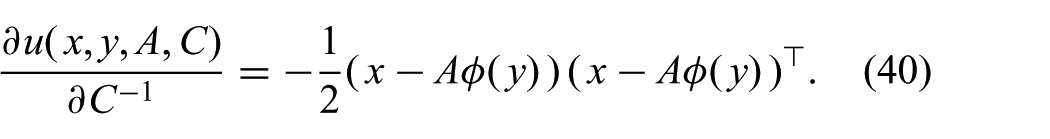
As before, the inner integral in (33) can be solved in closed form since the approximate distribution is Gaussian in x
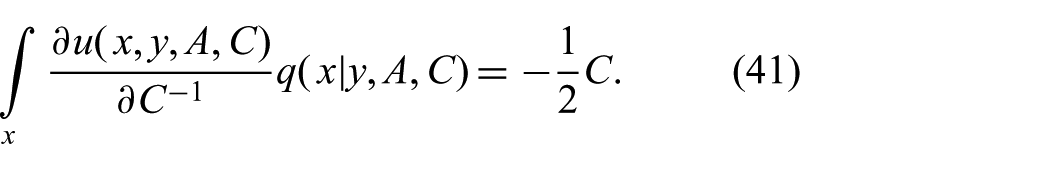
Inserting these results into (33), we can solve for C
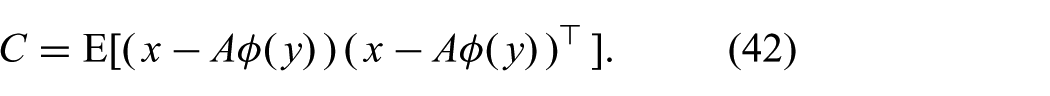
8.3. Connection to the Gaussian Filter
For a feature of the form

we can see by comparing (35) to (34) that the FGF is equivalent to the GF using a pseudo measurement
To show how the FGF equations (39) and (42) reduce to the GF equations (17) and (18), we insert
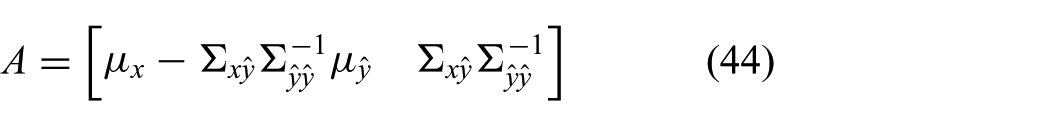
with the parameters
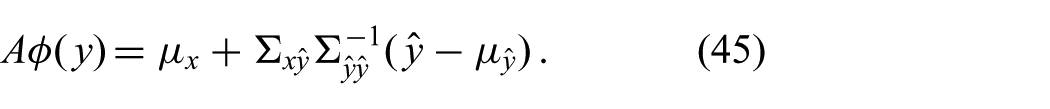
Inserting this result into (42), we obtain the covariance

Clearly, these equations correspond to the GF equations (18). In particular, with a feature
8.4. Implementation
The FGF could be implemented by computing A as in (39) and C as in (42). In general, the expectations would have to be computed using some numeric integration method, as for the standard GF. Alternatively, an existing implementation of the standard GF can be adapted to implement a FGF with only minor changes.
Implementing a GF requires the specification of a process model (1) and a measurement model (2). The GF’s prediction and update steps are fully determined by those models, and are then applied to the current belief and measurement to compute a new belief at each time step, see Algorithm 1.

As shown in Section 8.3, the FGF is equivalent to the standard GF using a pseudo measurement

In Section 9, we illustrate how this simple change in implementation can have major effects on the estimation accuracy of the filtering algorithm. We also provide code for a GF that uses Monte Carlo integration and the corresponding FGF. 1
8.5. Related approaches
Applying nonlinear transformations to the physical sensor measurements before feeding them into a GF is not uncommon in robotics and other applications (Daum and Fitzgerald, 1983; Durrant-Whyte, 1996; Rotella et al., 2014; Vaganay et al., 1993). While these transformations are often motivated from physical insight or introduced heuristically, we provide a different interpretation. We see using a measurement feature
8.6. The more features the better?
The analysis above suggests that adding features will never decrease filtering accuracy.
8.6.1. Redundant features
At first sight, it might be somewhat surprising that there is no problem with using several features containing the same information, that is, which are a function of the same measurement. One might be tempted to think that by doing so, one biases the filter towards this measurement. This is, however, not the case. The more features that are in the feature vector, the more expressive the belief (36) and the better the fit (23a) to the exact posterior
To illustrate that the FGF is capable of using redundant features, consider the very simple case of a feature that creates a copy of the measurement

In this case, the FGF will yield precisely the same result as if there were no duplicate of the measurement in the feature.
In the following, we perform the FGF calculations by hand to provide some intuition why this happens. The posterior mean is given by (45). As explained in Section 4.1, in an actual implementation, matrix inverses are not computed explicitly. The right-most product of (45) can be written as the solution of the system
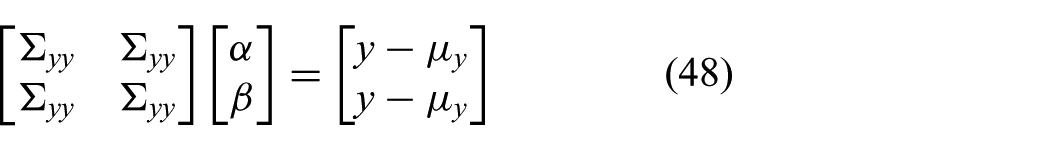
which yields the constraint

Solving for the FGF mean (45), we obtain
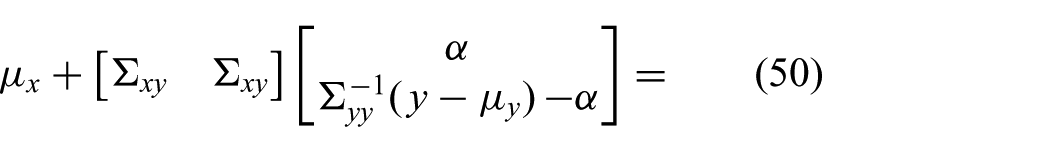

which is the same as we would get with only one copy of the original measurement y. We could reason the same way about the covariance. Hence, adding a copy of a measurement or of a measurement feature does not affect the filtering result. Please note that the above calculation is just for illustration, it will be performed automatically by the filter.
8.6.2. Overfitting
An important question is whether the FGF suffers from overfitting in the same way linear regression suffers from overfitting when too many features are used (Bishop, 2006). In linear regression, the objective is to fit a function to a finite set of points. It is not desirable to fit the points perfectly since this would lead to poor generalization of the function. Here, the situation is fundamentally different. The objective is to fit an approximate distribution
In practice, however, the numeric integration methods in the filter use of course a finite number of samples. Hence, when the number of features is too large with respect to the number of samples used in the numeric integration, then the FGF can suffer from overfitting. Fortunately, we can always generate more samples to offset overfitting, while in linear regression the size of the dataset is fixed.
8.7. Feature selection
There are two ways of selecting features. We can use some generic features in y, such as monomials, without looking at the structure of the problem in detail. If we require even better accuracy, we can hand design a feature for the specific problem at hand. Ideally, one would choose a feature which maps the measurement to a representation which relates to the state linearly.
In Section 9, we give examples of both types of features. We show that the filtering accuracy can be improved significantly by using an appropriate feature.
9. Simulation examples illustrating the benefit of measurement features
As the previous analysis suggests, it is beneficial to augment the measurement with nonlinear features since this gives the approximation more flexibility to fit the exact distribution. In this section, we illustrate this effect in four examples, which are abstractions of relevant filtering problems in robotics. We opt to present small examples to provide insight into specific important aspects of the proposed method, and to give some intuition on how it can be applied to practical filtering problems. A full-scale experimental application is presented in Issac et al. (2016), where a particular type of FGF is used for 3D object tracking using a depth camera.
We implemented the GF using Monte Carlo for the required integrals and the FGF as in Algorithm 2. The code for all the simulations is publicly available, see endnote 1. In the two first examples, it is possible to solve the integrals analytically, so we present here the exact results rather than the approximate ones.
The first two examples use monomials as features and illustrate why using such features can have a major impact on the estimation accuracy. The last two examples illustrate how features can be designed for specific systems. Another example of a designed feature is given in Wüthrich et al. (2016), where the authors derive a feature in order to handle fat-tailed measurement models.
9.1. Estimation of sensor noise magnitude
The measurement process (2) of a dynamical system can often be represented by a nonlinear observation model with additive noise

where
We define an augmented state
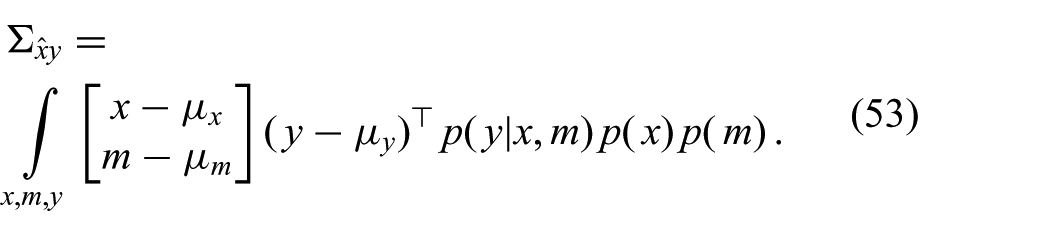
The integral over y can be solved easily since
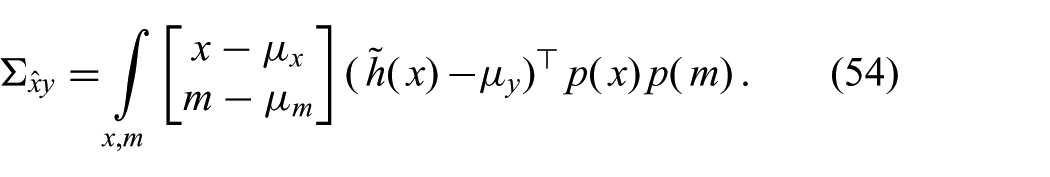
Interestingly, the second factor does not depend on m. Therefore, the integral over m is solved easily and yields
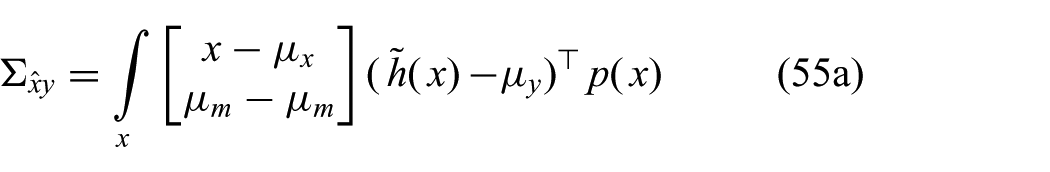

As a result, there is no linear correlation between the measurement y and the parameters m. Inserting this result into (18) shows that the innovation corresponding to m is zero. The corresponding part of the covariance matrix does not change either. Hence, the measurement has no effect on the estimate of m. It will behave as if no observation had been made. This illustrates the failure of the GF to capture certain dependences in nonlinear dynamical systems.
In contrast, if a nonlinear feature in the measurement y is used, the integral over y in (53) will not yield
In the remainder of the paper, we are considering several time steps again, and will thus reintroduce the time indices, which we dropped earlier.
9.1.1. Numerical example
For the purpose of illustrating the theoretical argument above, we use a small toy example. We consider a single sensor, where all quantities in (52), including the standard deviation

Choosing a simple process model
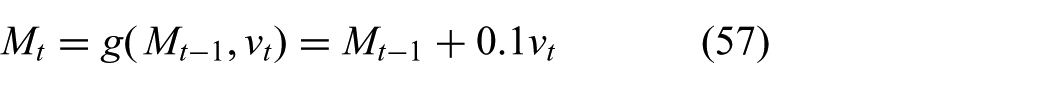
the dynamical system (1), (2) is fully defined. Recall that we defined the noise
This example captures the fundamental properties of the FGF as pertaining to the estimation of sensor noise intensity
In Figure 3, we show the simulation result of a single update step. The true density in grayscale was computed numerically for the purpose of comparison. It would, of course, be too expensive to use in a filtering algorithm.
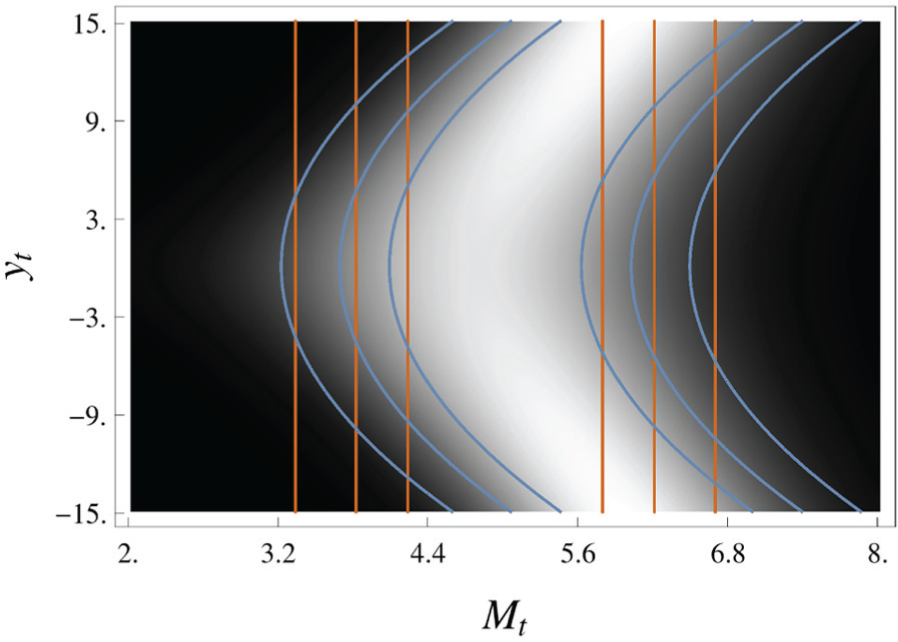
Simulation of a single update step with prior
The overlaid orange contour lines show the approximate conditional distribution
The true conditional distribution
As explained in Section 8.3, the standard GF is the special case of the FGF with the feature
To analyze actual filtering performance, we simulate the dynamical system and the two filters for 1000 time steps. The results are shown in Figure 4.
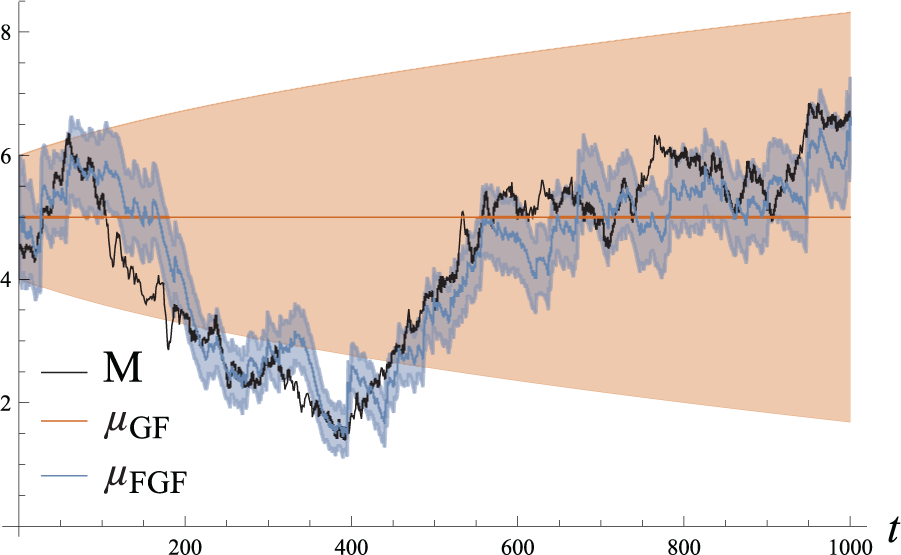
Simulation of the system (56), (57) for 1000 time steps. The simulated noise parameter
As expected, the standard GF does not react in any way to the incoming measurements. The FGF, on the other hand, is capable of inferring the state
9.1.2. Insights
While it was convenient to simulate a very simple system for illustration purposes, it is important to note that the theoretical argument given above applies to realistic, nonlinear and multivariate systems. We showed that it is not possible to infer the sensor noise magnitude using a standard GF, a problem which can be solved by using a nonlinear measurement feature. This result could be useful for any filtering problem where the sensor accuracy is not precisely known or varies over time.
9.2. Nonlinear observation model
In this section, we investigate how the theoretical benefit of adding nonlinear features translates into improved filtering performance for systems with nonlinear observation models. To clearly illustrate the difference of GF and FGF, we choose a simple system with a strong nonlinearity (step function).
The process model and the observation model are given by

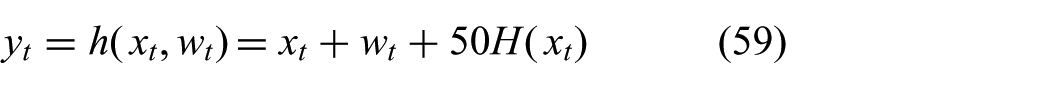
where
In Figure 5, we plot the true conditional density
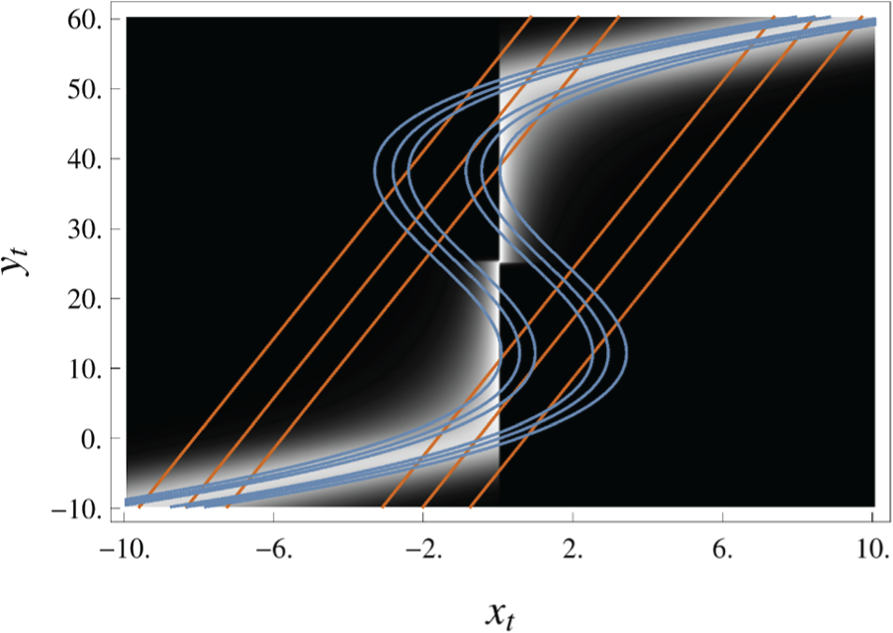
Simulation of a single update step with prior
The contour lines reflect the restrictions on the posterior of the GF (23b). The mean of the approximate density
The approximate density
Figure 6 shows how this difference translates to filtering performance. When
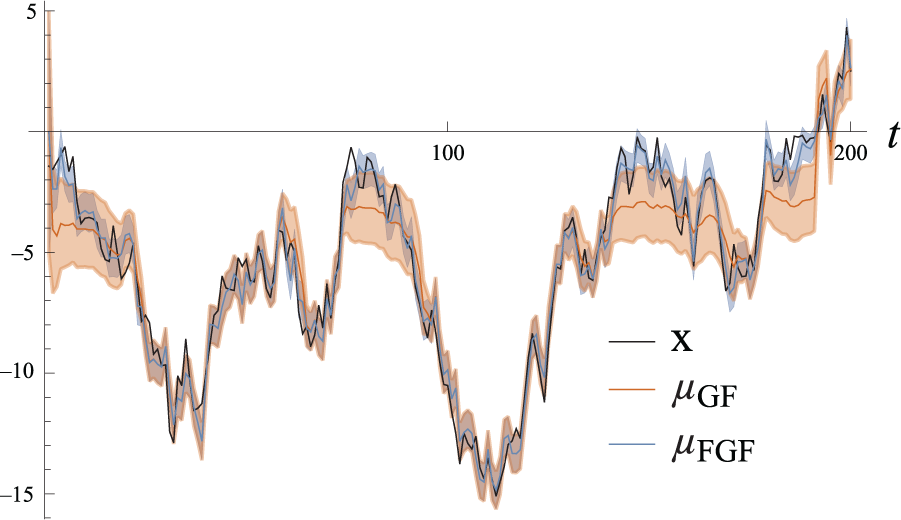
Simulation of the system (58), (59) for 200 time steps. The simulated state
9.2.1. Insights
This simulation shows that using a measurement feature can greatly improve filtering performance. Based on the theoretical analysis and this example, we believe that it is plausible that using measurement features can also significantly improve accuracy for systems with more realistic nonlinearities.
9.3. Measurement in polar coordinates
Suppose we want to estimate the two-dimensional position
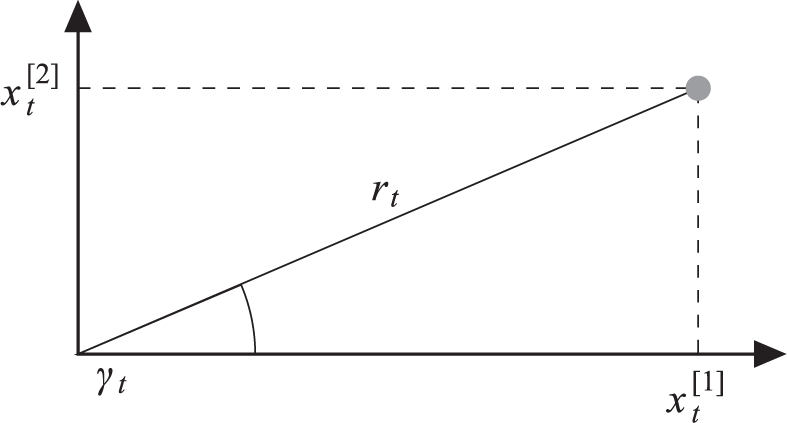
We want to estimate the state
Such measurements are for example generated by sonar and radar sensors (Durrant-Whyte, 1996; Julier and Uhlmann, 1997; Karlgaard and Schaub, 2006).
We define the process model to be linear Gaussian in Cartesian coordinates

and the observation model is given by
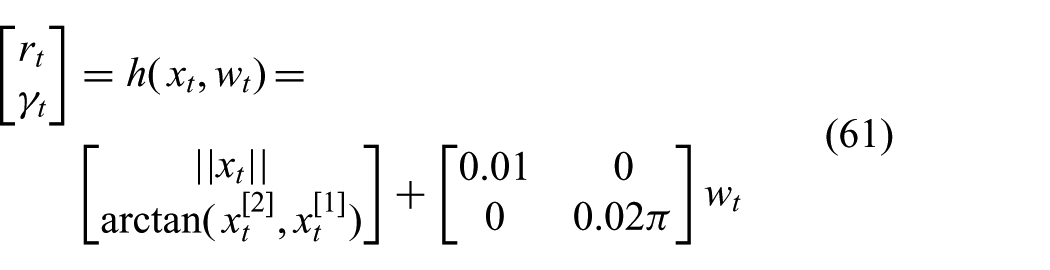
where the superscripts index the vector elements. The nonlinear function applied to
It is not uncommon in the filtering literature to transform measurements of this type back to Cartesian coordinates before filtering, see, for example, Durrant-Whyte (1996). This corresponds to using the measurement feature

Intuitively, this makes the task of the filter easier since the relation between the transformed measurement and the state is simpler. We show that this technique can indeed improve performance significantly for parts of the state space by allowing the approximate posterior to fit the exact posterior more accurately.
Furthermore, the analysis in this paper suggests that it is not necessary to choose between one measurement representation or the other. We can simply stack both of them, and the filter will automatically weight them.
Figure 8 shows that using the measurement feature (62) (we refer to this filter as Cartesian-FGF) can significantly improve filtering accuracy. The gain in accuracy is the greatest when the object is close to zero in at least one of the axes. This is because the measurement function (61) is highly nonlinear in this area.
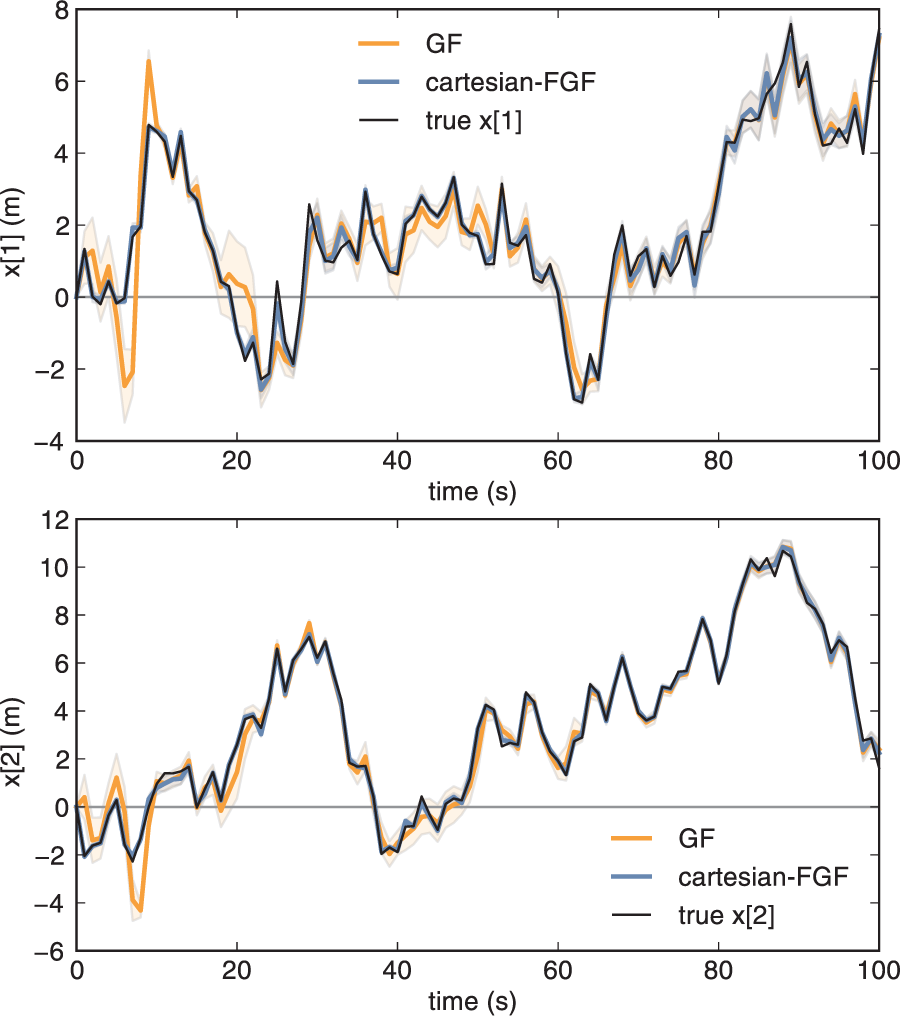
Simulation of the system (60), (61) for 100 time steps. The simulated state
To understand this difference in estimation accuracy, we show the relationship between the state dimension
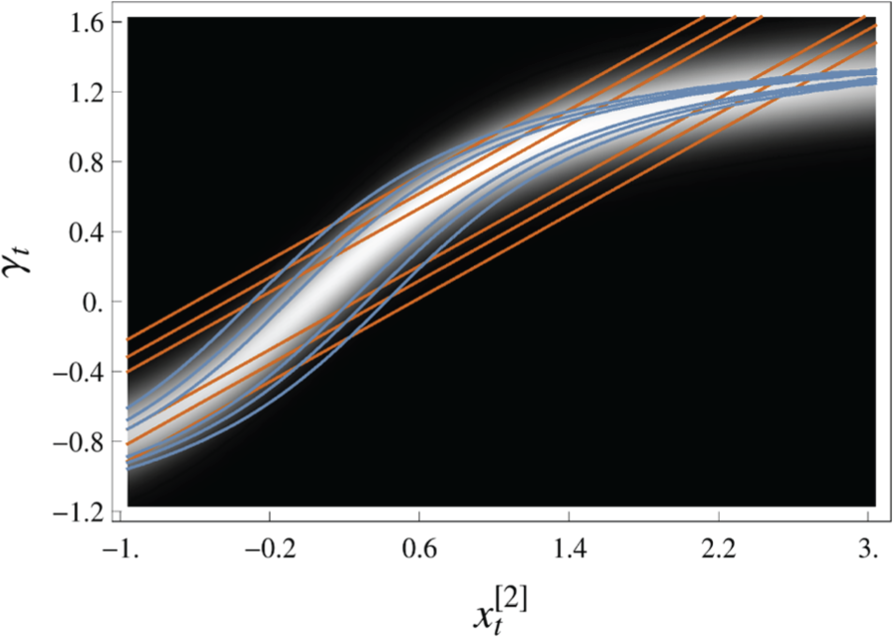
A visualization of the dependence between
9.3.1. Insights
We have shown that using the measurement feature (62) can improve the estimation accuracy when the object is close to zero. However, when the object is further away from zero, the improvement vanishes. More generally, the benefits of a particular feature depend on the parameters of the problem at hand, and on the state the system is currently in. While using a particular feature might improve estimation accuracy for one particular configuration, it could potentially worsen accuracy in a different configuration. Hence, the question arises which feature mapping should be used for a particular problem.
Fortunately, we can just stack all the features and the original measurements, and the filter will weight them automatically. The filter will autonomously pick the features which allow it to best represent the posterior belief in the particular configuration it is in. As discussed in Section 8.6.2, as long as the numeric integration method is accurate enough, there will be no overfitting.
We illustrate this effect in Figure 10, where we compare the Cartesian-FGF to an FGF using monomials as features. We see that using monomials of degree 2 only seems to improve the filtering accuracy slightly. In this case, the best measurement representation is clearly (62). The filter which combines all features and the original measurement (all-FGF) performs equally well since it automatically picks the best representation.
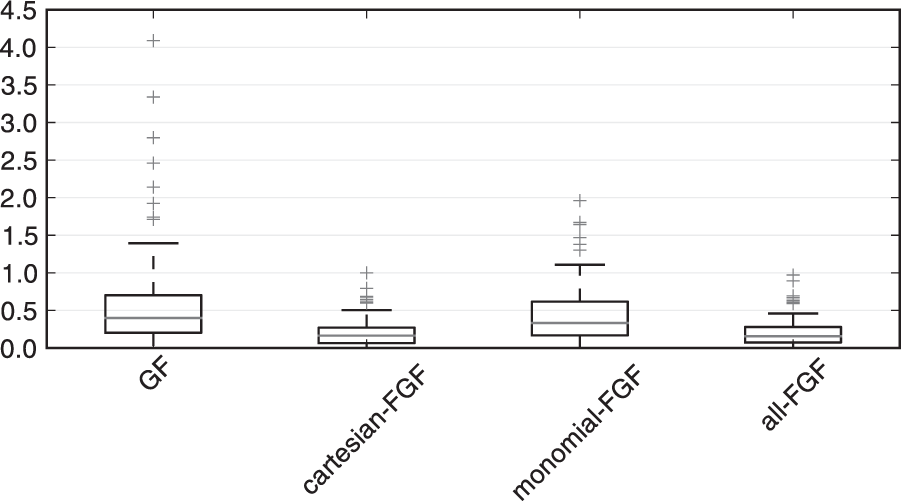
The boxplots represent the distribution of the tracking error. Each data point is the error at one time step of the simulation of the system (60), (61). The GF uses the plain observation
9.4. 2-link planar robot
In this simulation, we look at the problem of estimating the joint angles of a robot given information about the end-effector pose. This problem is practically relevant, because the joint readings can be unreliable due to noisy sensors, drift, cable stretch or poor calibration. We therefore seek to obtain a more accurate estimate of the joint angles by incorporating a sensor which yields measurements of the end-effector pose. This sensor might be a camera on the robot, which performs simultaneous localization and mapping (SLAM); it might be an external camera, which detects the position of the end-effector, or it could be an inertial measurement unit (IMU), which is mounted on the end-effector. For instance, we might want to estimate the configuration of the neck of a humanoid robot using the joint sensors as well as the head-mounted camera.
The relation between end-effector pose and joint angles is highly nonlinear, which means that the GF is not able to exploit all the available information. To illustrate this problem, we simulate the two-link robot in Figure 11. The state
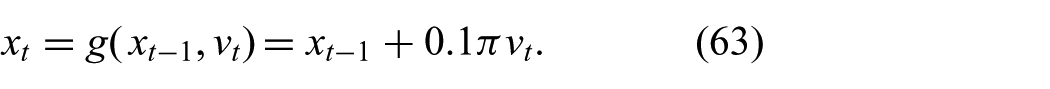
We receive noisy measurements of the joint angles

and relatively accurate measurements of the end-effector position
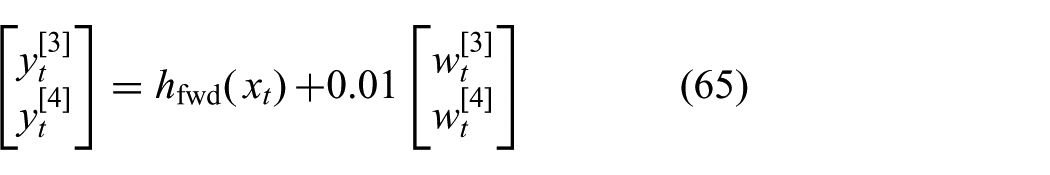
where
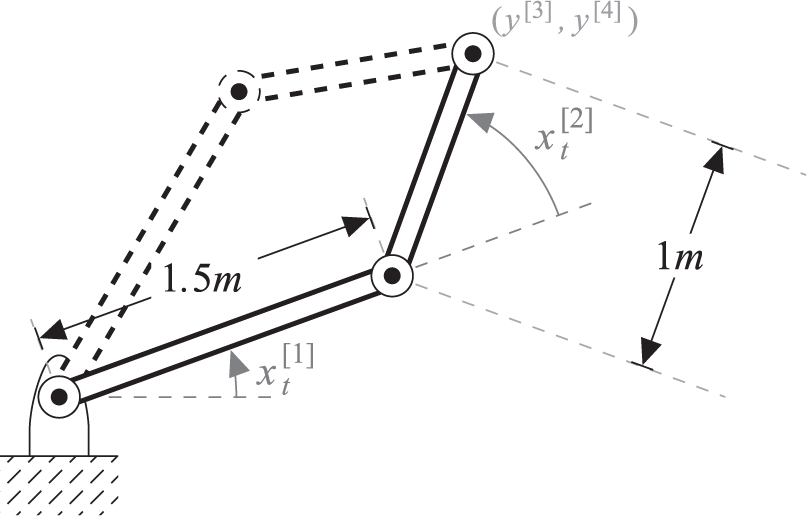
Kinematics of a two link manipulator. The state
An obvious candidate for a feature is the inverse kinematics. There are however two solutions, as shown in Figure 11. We will denote the solution with the elbow on the left side by
In Figure 12, we show the filtering performance using the two features. Not surprisingly, the filter using
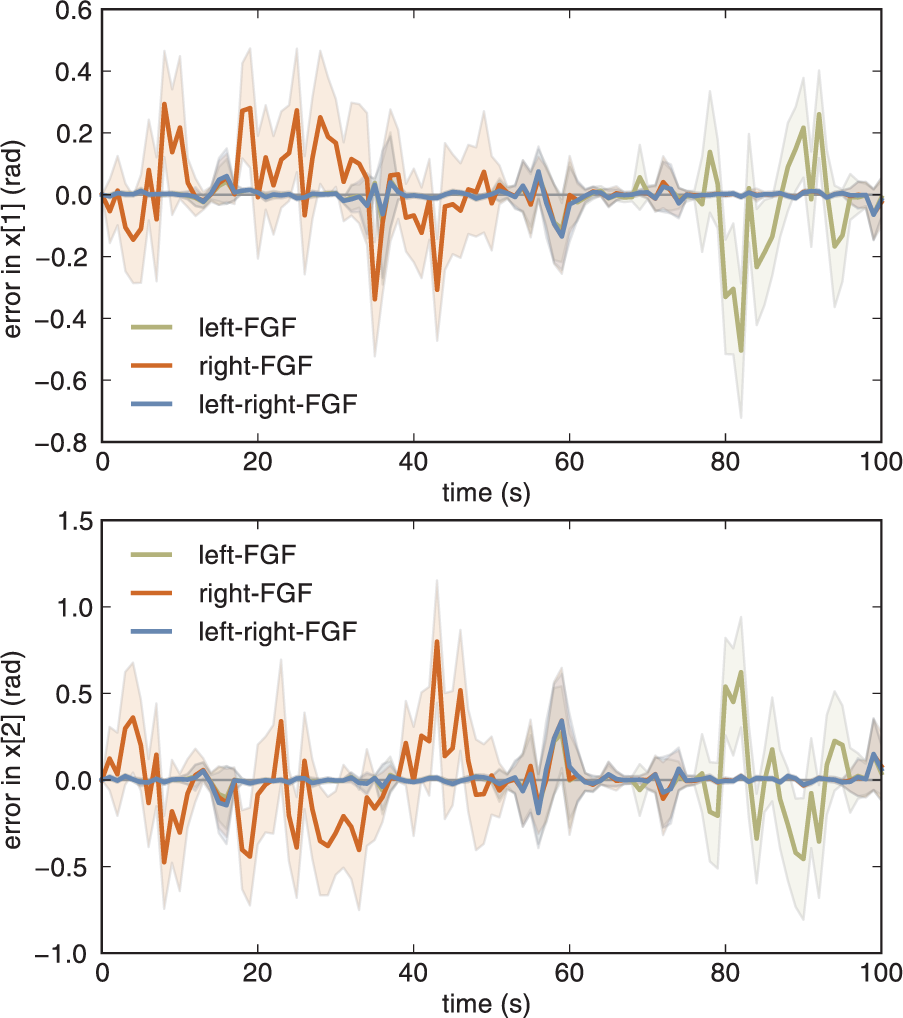
Simulation of the system (63), (64), (65) for 100 time steps. We plot the mean errors and standard deviations of the estimates obtained using
In Figure 13, we compare the estimation accuracy using different features. In this example, using monomials of degree 2 already improves estimation accuracy significantly. A further improvement can be obtained using the problem-specific features, that is, the inverse kinematics. As in the previous example, using all features at once yields an estimation accuracy which is at least as good as the filters using the individual features.
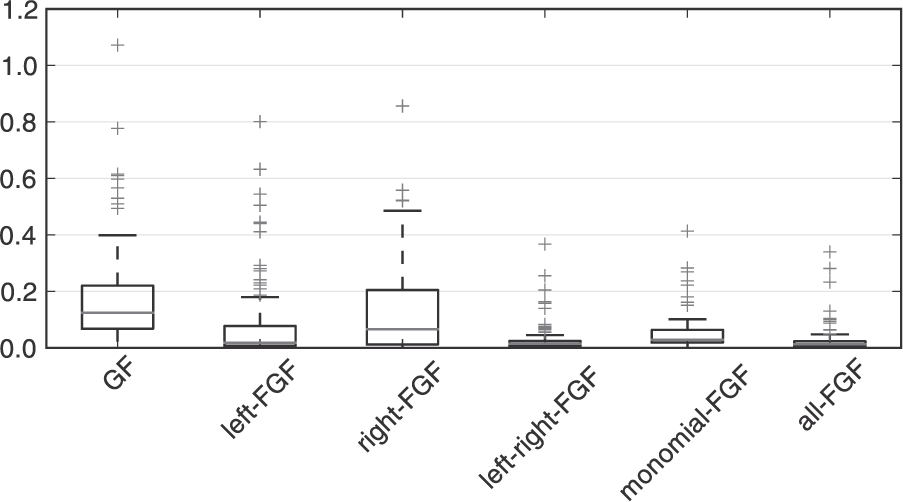
The boxplots represent the distribution of the tracking error. Each data point is the error at one time step of the simulation of the system (63), (64), (65). The GF uses the plain observation
9.4.1. Insights
This example provides some intuition into how the insights from this paper can be applied to larger, more realistic problems. It shows that using generic measurement features, here monomials, can improve estimation accuracy significantly. By using problem-specific features which approximately cancel the nonlinearity in the observation model, we can typically further improve accuracy. This example also shows that it is possible to combine different features which are complementary. The filter will automatically assign weight to the features necessary for approximating the exact posterior well.
10. Discussion
The key insight in this article is that the GF can be understood as the solution to a constrained optimization problem. From this new perspective, the GF is seen as a special case of a much broader class of filters obtained by relaxing the constraint on the form of the approximate posterior.
On this basis, we outlined some conditions which potential generalizations have to satisfy in order to maintain the properties which make the GF computationally efficient.
We proposed one particular, straightforward generalization which corresponds to filtering with a pseudo measurement. Extending an existing GF implementation in this manner is trivial. Nevertheless, we showed that this small change can have a major impact on the estimation accuracy.
The simulations provided in this article are abstractions of realistic problems, they serve to illustrate the theoretical concepts and to provide intuition on how these could be applied to practical filtering problems. The ideas in this paper are not intended to solve one concrete filtering problem, but rather to provide a theoretical basis for future research. In fact, these insights have already given rise to practical filtering algorithms in Wüthrich et al. (2016) and Issac et al. (2016). The first reference proposes using a measurement feature for robustifying GFs against outliers. The second one applies this idea to 3D object tracking using a depth sensor, which provides measurements contaminated with outliers.
10.1. Directions
One interesting direction of future work is to attempt to further relax the constraint on the form of the approximation, without violating the conditions which ensure computational efficiency. For instance, could we allow for an approximate belief where not just the mean, but also the covariance depends on the measurement?
Explicitly taking the inaccuracy of the numerical integration method into account is another interesting direction for future work. Doing so would be necessary to guarantee that our belief in fact approximates the exact posterior well, even when the numeric approximation is not perfect. An analysis based on learning theory (Vapnik, 1995) might make sense. We would expect a trade-off between the number of samples in the numeric integration and the complexity of the form of the belief. For the FGF, this would mean that the more samples we use in the numeric integration, the more features we can use simultaneously without overfitting.
Footnotes
Appendix 1. Posterior mean and covariance as solutions of a linear system
Recall the GF posterior
The posterior mean can be formulated as the solution of the linear system
where we have introduced an auxiliary vector a of the same size as y. Similarly, we can find the posterior covariance by solving
where we have introduced the auxiliary matrix A of appropriate dimensions.
These systems can be passed to any linear solver, since there exists a unique solution for
Declaration of conflicting interests
The authors declare that there is no conflict of interest.
Funding
This research was supported in part by the Max Planck ETH Center for Learning Systems, the Max Planck Society, National Science Foundation grants IIS-1205249, IIS-1017134, EECS-0926052, the Office of Naval Research and the Okawa Foundation. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the funding organizations.