
Abstract
Underwater ROVs (Remotely Operated Vehicles) are indispensable for subsea exploration and task execution, yet typical teleoperation engines based on egocentric (first-person) video feeds restrict human operators’ field-of-view and limit precise maneuvering in complex, unstructured underwater environments. To address this, we first propose EgoExo, a geometry-driven solution integrated into a visual SLAM pipeline that synthesizes on-demand exocentric (third-person) views from egocentric camera feeds. We further propose EgoExo++, which extends beyond 2D exocentric view synthesis (EgoExo) to augment a piecewise-planar 2.5D ground surface estimation on-the-fly. Its anchor-free aerial viewpoint supports ground-relative reasoning, such as clearance and terrain-based navigation marker following. The computations involved are closed-form and rely solely on egocentric views and monocular SLAM estimates, which makes it portable across existing teleoperation engines and robust to varying waterbody characteristics. We validate the geometric accuracy of our approach through extensive experiments of 2-DOF indoor navigation and 6-DOF underwater cave exploration in challenging low-light conditions. To assess operational benefits, we conduct two user studies with simulation and real-world data, each involving 15 participants, comparing baseline egocentric teleoperation and EgoExo++. Results indicate improved system usability (SUS), reduced perceived workload (NASA-TLX), and significant gains in objective teleoperation performance, including 16% faster missions, 5-fold reduction in path deviation ratio, and fewer collision events (2 vs 5 across trials). Furthermore, we highlight the role of EgoExo++ augmented visuals in supporting shared autonomy, operator training, and embodied teleoperation. This new interactive approach to ROV teleoperation presents promising opportunities for future research in subsea telerobotics. The source packages for EgoExo++ are available at: https://github.com/uf-robopi/EgoExo.
1. Introduction
Unmanned submersible vehicles such as ROVs (Remotely Operated Vehicles) play a crucial role in subsea inspection, remote surveillance, and underwater cave exploration (Rumson, 2021; Siegel et al., 2023; Wishnak, 2022). They are particularly useful in inspecting deep-water structures and surveying confined spaces that are beyond the reach of human scuba divers (Buzzacott et al., 2009; Joshi et al., 2022). In a typical mission, ROVs are controlled by human operators from a surface vessel, who are responsible for the safe and efficient maneuvering of the vehicle (Kennedy et al., 2019; Konoplin et al., 2019). The control consoles for teleoperation typically offer real-time data such as the egocentric video feed, pose, velocity, depth, etc. State-of-the-art (SOTA) ROVs can also include autonomous features for atomic tasks such as hovering (Jin et al., 2022), following navigation guidelines inside underwater caves and overhead structures (Abdullah et al., 2024a; Mohammadi et al., 2023; Yu et al., 2023a), object manipulation (Chen et al., 2025; Manjunatha et al., 2018), trajectory estimation, etc.
While the subsea industries and agencies such as NOAA and naval defense teams deploy underwater ROVs with high-end cameras, sonars, and IMUs (Elor et al., 2021; Wishnak, 2022)—safe and efficient teleoperation remains a challenge in adverse visibility conditions and around complex or sensitive structures. The typical first-person feeds from an ROV camera provide very limited information in landmark-deprived underwater scenes. The operators on the surface can only see the egocentric view, often without global or peripheral semantic information around the ROV (Lensgraf et al., 2023; Thatipelli et al., 2025). Although ROVs can use artificial lights to enhance visibility in low-light scenes, their bright lights get reflected and back-scattered by suspended particles directly at the front camera (Yu et al., 2023a), creating glare and large blind spots for the operator. Additionally, the autonomous and semi-autonomous features of ROVs become erroneous without peripheral positioning in such noisy sensing conditions.
In this paper, we address these issues by introducing an AR (augmented reality) inspired ROV teleoperation interface that generates third-person (exocentric) perspectives as well as provides interactive control choices for viewpoint selection. As shown in Figure 1, the proposed console can generate multiple exocentric views from past egocentric images, with a virtual ROV model projected on the images as if it were taken by a third person following the robot. Our early work introduced the idea of The proposed teleoperation interface is demonstrated for an underwater cave exploration scenario with an ROV. The traditional console interfaces are based on egocentric views (top left), which are limiting and disorienting to a surface operator in noisy low-light conditions. Our EgoExo solution (Abdullah et al., 2024c) offers on-demand exocentric views from a fixed EOB (eye on the back) viewpoint, that is, third-person views from behind the ROV (bottom left). In 
Specifically, we introduce an efficient framework for generating egocentric to exocentric visual perspectives integrated into a visual SLAM system for underwater ROV teleoperation. The base EgoExo algorithm keeps track of the ROV camera poses and exploits a buffer of egocentric views for exocentric view synthesis. We then transform and project a pre-sampled 3D model of the ROV, in the form of a point cloud, into those views to generate realistic augmented visuals with more peripheral information. In parallel, the EgoExo++ pipeline utilizes SLAM-generated feature points to identify ground regions and fuses them into a piecewise-planar ground surface where pixel colors are transferred from corresponding image regions. This 2.5D ground reconstruction is particularly meaningful in seabed/structure inspection tasks as well as underwater cave missions where navigation cues such as caveline, arrows, and cookies (Abdullah et al., 2024a) are located on or near the floor. In our implementation, we employ a temporal fuse and stack strategy to preserve the historical ground evidence, while the 3D ROV model is projected on the same spatial context. The resulting 2.5D perspective enables operators to interact with the scene using dynamic viewpoints in real-time. As illustrated in Figure 1, these views provide operators with a globally informed and semantically rich snapshot of the surrounding environment. In addition to supporting interactive viewpoint control, the SLAM backend delivers real-time updates on camera pose and environmental mapping to better assist with atomic tasks such as obstacle avoidance, object following, next-best-view planning, object manipulation, etc (Cai et al., 2020; Chen et al., 2025; Palomeras et al., 2019).
We validate the proposed method through a series of analytical, simulation-based, and real-world experiments conducted in both terrestrial and underwater settings. In the base EgoExo system, we first quantify the geometric accuracy of view augmentation with a TurtleBot4 ground robot through reprojection error analysis of known reference points in indoor scenes. Then we conduct underwater cave trials with a BlueROV2 at various geographical locations, which pose unique challenges such as low visibility, turbid water conditions, and moving shadow effects. In such challenging operation scenarios, 15 human subjects rate the utility of EgoExo visuals using the System Usability Scale (SUS) (Brooke, 1996); it achieves an average SUS score of 77.5, indicating the class of Good usability. We further discuss various challenging cases of caveline detection and following in noisy low-light conditions inside multiple underwater caves. These findings establish EgoExo’s trailing views as a useful teleoperation aid, and also highlight the critical role of maintaining altitude clearance and detecting on-ground navigation markers, motivating the semantic ground representation of EgoExo++.
(1) EgoExo++ transforms the semantically empty world representation of EgoExo into a 2.5D ground-referenced altitude map. It leverages the already available sparse SLAM features to identify and reconstruct locally observable ground patches from each local view, which are then temporally fused in the global frame. (2) It advances the visualization from a trajectory-anchored, EOB perspective to an anchor-free aerial viewpoint, allowing operators to view the ROV from arbitrary vantage points above the reconstructed ground surface and to reason more effectively about altitude clearance and navigation cues.
Notably, EgoExo++ reduces perceived workload while achieving approximately 16% faster mission completion, 5× lower Path Deviation Ratio (PDR), and fewer collisions compared to the baseline (egocentric only) teleoperation system. Together, these additional evaluations demonstrate both technical soundness and operational relevance of the proposed framework. Finally, we discuss the broader potential of the EgoExo++ paradigm for shared autonomy and digital twin-based training, as well as its dependency on SLAM and the practical limitations that arise in challenging underwater environments.
2. Background and Related Work
2.1. Third-person views for ROV teleoperation
A common issue reported by ROV operators is that using a remote vision platform for teleoperation is like looking through a “soda straw” (Islam, 2024; Woods et al., 2004). This is because the typical ROV controller interfaces are based on egocentric first person camera views—which provide no peripheral vision, resulting in significantly reduced situational awareness (Casper and Murphy, 2003; Zollmann et al., 2014). Researchers have explored both fixed (Ferland et al., 2009; Lager et al., 2018) and dynamic (Nguyen et al., 2001; Okura et al., 2013) viewpoint augmentation methods in contemporary human-machine interface study (Abdullah et al., 2024b; Xia et al., 2022).
Two primary approaches are used for generating exocentric views in unmanned ground and aerial vehicles. The first leverages external cameras to capture the vehicle’s motion from a distance; examples include fixed ground cameras (Jangir et al., 2022), UAV-mounted overhead views (Erat et al., 2018; Gawel et al., 2018; Inoue et al., 2023; Saakes et al., 2013), elevated on-robot mounts (Shiroma et al., 2004), camera-equipped follower ROVs (Nagatani et al., 2011), and fisheye lenses for top-down perspectives (Hing et al., 2010; Sato et al., 2013). The second method utilizes additional onboard sensors, such as LiDAR (Light Detection and Ranging), to generate a point cloud of the surrounding environment (Ferland et al., 2009; Lager et al., 2018) and use it to create an augmented/virtual reality for interfacing and teleoperation (Hing et al., 2010; Livatino et al., 2021; Thomason et al., 2019; Xia et al., 2023b).
Adapting the aforementioned methods from terrestrial or aerial domains to underwater environments presents inherent challenges. Firstly, sending diver-robot teams (Islam et al., 2021) is not always an option in complex deep-water missions—which are the majority of use cases for ROVs. Secondly, UGVs that utilize past egocentric views (Ito et al., 2008; Murata et al., 2014) primarily rely on GPS-based localization that does not apply to GPS-denied underwater environments. Unlike underwater ROVs, ground vehicles generally operate on a 2D plane with limited pitch and roll variations over rough terrain (Yoon et al., 2025). Thirdly, installing an external visual system requires significant hardware modifications, for example, they need to be rugged and pressure-sealed, recalibrated for buoyancy and motion dynamics, and additional tether integration for high-speed exocentric data transfer. Even with all the structural modifications, an external camera will provide a single additional third-person perspective.
A range of AR/VR-based teleoperation systems have been developed to enhance operator immersion and augment visual feedback for subsea tasks such as object grasping and manipulation (Bruno et al., 2018; Chen et al., 2025; Girbes-Juan et al., 2020; Xia et al., 2022), inspection (Blow et al., 2025; Zhou et al., 2023), and navigation (Xia et al., 2023c). These systems commonly support third-person perspectives by embedding the operator within an XR (extended reality) environment that incorporates a digital twin of the ROV (Xia et al., 2023a) and reconstructs the surrounding scene using 3D models. While such immersive interfaces improve situational awareness and control, they often require extensive sensory augmentation (e.g., visual, auditory, haptic) at both the ROV and operator ends (Chen et al., 2025; Xia et al., 2023b; Zhou et al., 2023), which increases hardware demands and complicates real-time deployment.
2.2. 2.5D exocentric view generation
Generating 2.5D/3D third-person views from front-facing camera is critical for scene understanding, both for human teleoperators and for autonomous vehicles. The challenges lie in extreme viewpoint shift and lack of direct depth cues from monocular inputs. Recent efforts for 2.5D view synthesis can be categorized into two main areas: homography-based geometric projections (Abbas and Zisserman, 2019; Wang et al., 2019) and generative models using encoder-decoder, adversarial, or transformer-based learning (Li et al., 2024; Luo et al., 2024).
The geometry-guided CNN proposed by (Abbas and Zisserman, 2019) warps frontal images to the top view using a fitted homography matrix. While efficient for structured environments, their approach is limited to the flat-ground assumption and struggles with non-planar surfaces. Zhu et al. (Zhu et al., 2018) introduce an intermediate homography view from generative adversarial network (GAN) to reduce the difficulty of pure geometric transformation. Transformer models such as BEVFormer (Li et al., 2024) and BEVDepth (Li et al., 2023) integrate temporal or multi-view cues to improve realism in synthesized views at a cost of high computation. Other learning-based approaches fuse multiple camera views or additional sensors (e.g., LiDAR) to generate semantic aerial views (Reiher et al., 2020; Samani et al., 2023), diverging from monocular egocentric setups. Unlike these data-driven approaches, we propose a lightweight geometric solution, integrated into a visual SLAM pipeline that offers real-time, interactive third-person perspectives without relying on multi-modal sensory augmentation or additional hardware.
3. EgoExo++: Problem Formulation
We formulate the EgoExo++ problem as a 3D geometric algorithm that involves generating an on-demand EOB view, reconstructing the ground surface, and then projecting the ROV model both on 2D and 2.5D context for augmented rendering of the scene; see Figure 2. The proposed method has the following computational components. The computational pipeline is shown. From historical egocentric views and SLAM-derived poses, EgoExo computes a 2D exocentric image by applying pose geometry to project the ROV model; a sparse map of the environment is also constructed using SLAM-derived feature points. EgoExo++ reuses the feature points to fit a ground plane via RANSAC, then generates a textured 2.5D ground surface, and augments the ROV mesh to produce interactive exocentric views.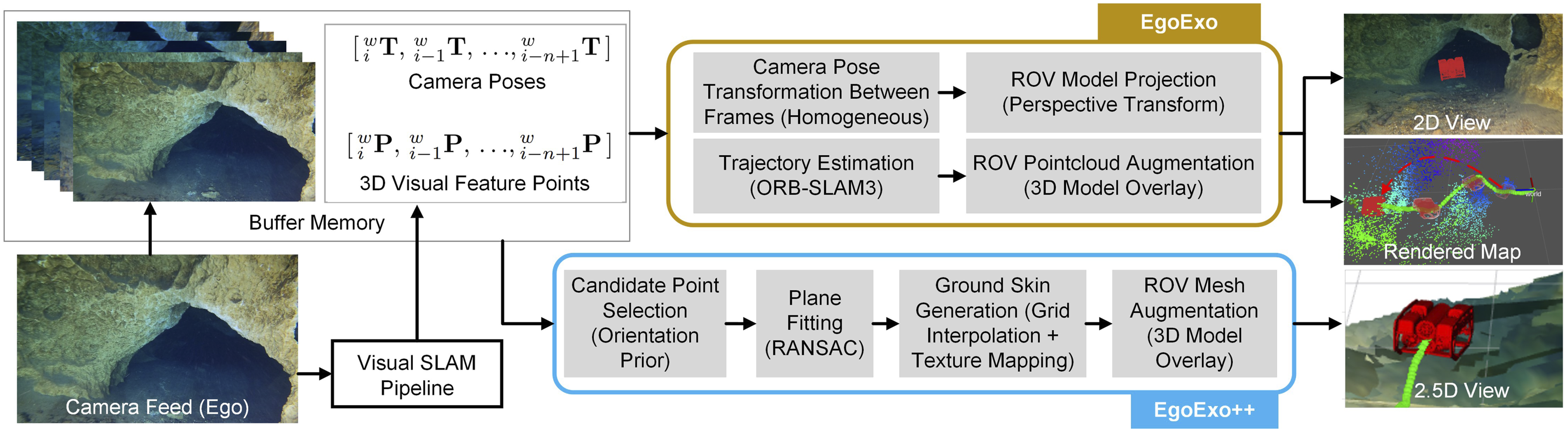
3.1. Curating ROV pose and image buffer
A monocular SLAM algorithm such as ORB-SLAM3 (Campos et al., 2021) provides a continuous solution for estimating and tracking camera poses from a sequence of monocular images. We use an ORB-SLAM3-based framework to obtain camera poses of each keyframe location to eventually construct the trajectory map of the teleoperated robot. In our implementation, the SLAM pipeline initiates the trajectory estimation process by building a pose buffer of length n:
3.2. Generating 2D Exo image
Given the pose memory
We use the ROV point cloud model
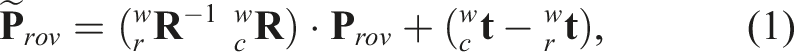
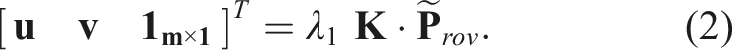
3.3. Generating 2.5D Exo views
In EgoExo++, we reuse the SLAM-generated visual features to estimate the ground surface and synthesize a lightweight terrain-aware 2.5D perspective. We focus on reconstructing only the ground surface rather than the full volumetric scene since the ground structure provides altitude awareness and a stable spatial anchor for teleoperation. Moreover, navigation markers in underwater caves, such as cavelines and arrows, are typically located on the ground, making ground reconstruction more relevant for guided navigation. The process involves four stages: (i) selecting candidate feature points for the ground surface, (ii) fitting the ground plane, (iii) translating texture from image pixels to the estimated surface, and (iv) fusing multiple frames over time for real-time visualization.
Due to the lack of horizon line in open water settings and the uneven geometry of confined underwater spaces (e.g., caves), we incorporate geometric priors based on the camera orientation to initialize the ground region estimation. In the nominal case with zero pitch and roll, the ground remains within the bottom half of the image, separated by a horizontal line at v = H/2 (where H is the image height). As the camera pitches downward, this line shifts upward, since a larger portion of the ground comes within the camera’s FOV, and vice versa. A camera roll rotates this dividing line on the image plane accordingly. By computing this orientation-adjusted imaginary horizon from the known camera pose, we restrict candidates to points that fall within the “ground side” of the image. This prior ensures that no 3D point projecting above the horizon (e.g., from cave walls and ceiling) is selected as ground.
Let
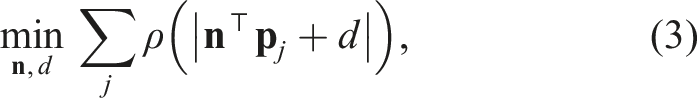
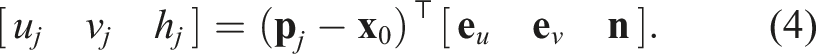
A rectangular grid (ξ, η) is constructed on the ground plane, and the sparse heights {h
j
} are interpolated to obtain a smooth elevation field h(ξ, η). Each grid vertex
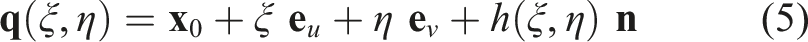
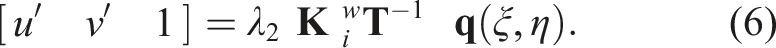
Image colors
3.4. ROV model rendering and scene update
While the SLAM system constructs a sparse map of the surroundings, the proposed algorithm simultaneously renders the 3D ROV point cloud (or mesh for EgoExo++) on the same spatial context. The ROV points
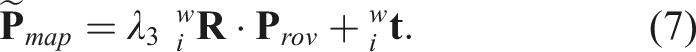
4. Implementation & Evaluation
4.1. Implementation details
The framework is implemented using ROS Noetic in an Ubuntu 20.04 environment, running on an Intel Core i9 processor with 16 GB of RAM. A ROS node for ORB-SLAM3 is integrated as the monocular SLAM backbone. Note that we adopt the North-East-Down (NED) frame convention used by (Manderson et al., 2016), which is local to the SLAM origin (not aligned with Earth’s North/East). The scaling parameters λ1, λ2, and λ3 are empirically tuned once for each test sequence according to the scale of the map and the approximate physical dimensions of the ROV to ensure visually realistic projections. Once chosen, the scale parameters remain fixed throughout the mission and do not require retuning during operation.
We then express these inliers in a local plane frame and rasterize them onto a regular 2D grid with cell size 0.01 unit. Heights on this grid are obtained with a LinearNDInterpolator over the inlier samples, with a NearestNDInterpolator used to fill holes where the linear interpolation is undefined. The resulting dense 3D surface is triangulated as a regular mesh (two triangles per grid cell) provided that all three vertices back-project to valid image pixels inside the convex hull of the ground inliers; for efficiency and decimation, we cap the number of triangles per frame at 20000.
4.2. Proof of concept: 2D indoor navigation
We conduct 2D indoor navigation experiments with a TurtleBot4 to validate the geometric accuracy of our algorithm. (a) The TurtleBot4 trajectory during teleoperation is shown; here, the f numbers indicate the EOB distance from current to reference frame used for the generated EgoExo views. (b) Reprojection errors for reference points (checkerboard corners) are evaluated for different EOB distances (f). The estimated ground surface is shown as a convex hull of inlier points; the surface normal is overlaid for better visualization.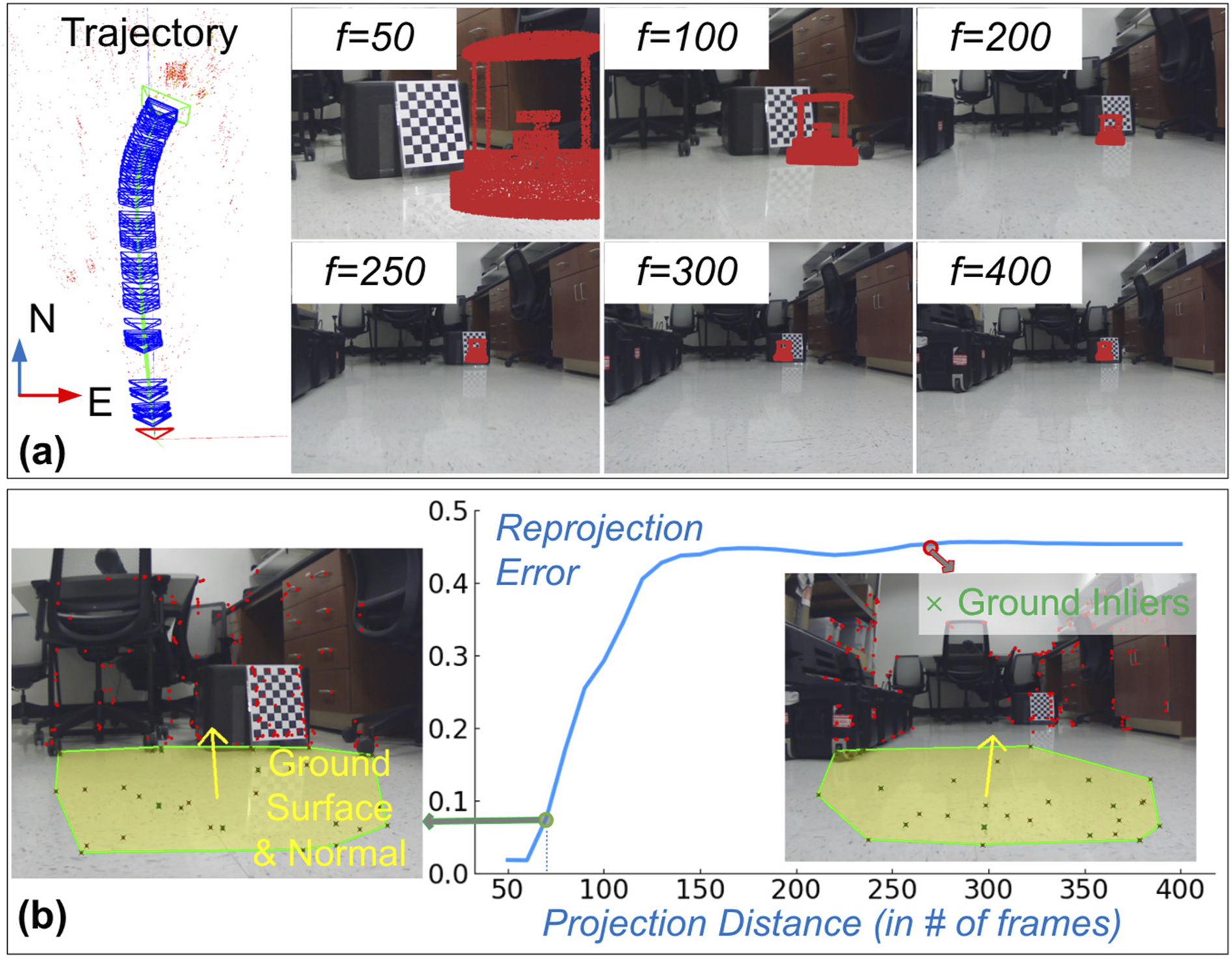
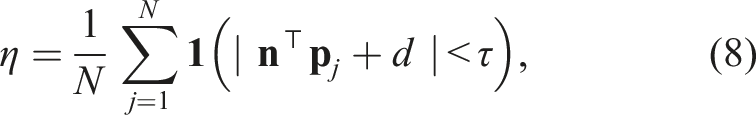
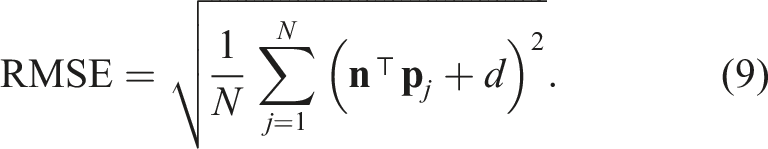
A lower RMSE reflects a tighter fit around the estimated plane. Next, to assess temporal consistency, we compute the angular difference between consecutive plane normals:
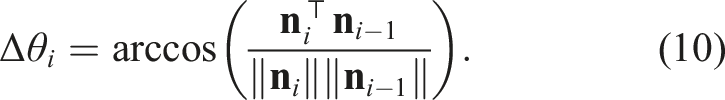
The mean angular drift across frames is reported, where low values indicate temporal stability. Finally, the altitude at instance i is computed as the vertical distance of the camera center

In the absence of true measurement, the computed (scaled) altitude is not meaningful; however, a low deviation across frames indicates that the synthesized 2.5D ground remains consistent for visualization.
Evaluation of ground plane estimation is presented for indoor UGV operation.

Figure 3(b) illustrates two representative examples from an office scene: one for f = 70 with a low reprojection error, and another for f = 260 with a high error. As seen, the estimated ground plane normal validates the geometric accuracy for the f = 70 case. On the other hand, a misaligned plane normal for the f = 260 case demonstrates the underlying error in pose estimation as well as in the reprojection process. Essentially, the geometric accuracy of our proposed algorithm depends on the pose estimation performance of the SLAM system.
Memory requirement of the proposed framework for different buffer lengths.

End-to-end computational speed of the proposed framework; the rows report: (

4.3. Field deployment: 3D underwater caves
EgoExo and EgoExo++ views are shown for field trials conducted in the Peacock Springs cave system, Florida. (a) The EgoExo pipeline generates 2D exocentric imagery from directly behind the ROV, along with a sparse 3D map of the environment. Pop-ups show: (i-ii) Ego and Exo views with rendered ROV pose; and (iii-iv) updated camera poses and Exo view of the 3D map. (b) The EgoExo++ extends it by reconstructing the ground surface and offering full 360° exocentric viewpoints. Pop-ups show operator-selected viewpoints above the ground surface: (i) back, (ii) front, (iii) top, and (iv) side.
A snapshot from our cave exploration scenario: (a) egocentric view with detected reference points; and (b) synthesized EgoExo view with projected ROV point cloud. We use a sample logo for homographic projection on the reference surface to demonstrate the accuracy in pose estimation.
Evaluation of ground plane estimation is presented for field trials conducted in two distinct cave systems in FL, USA.
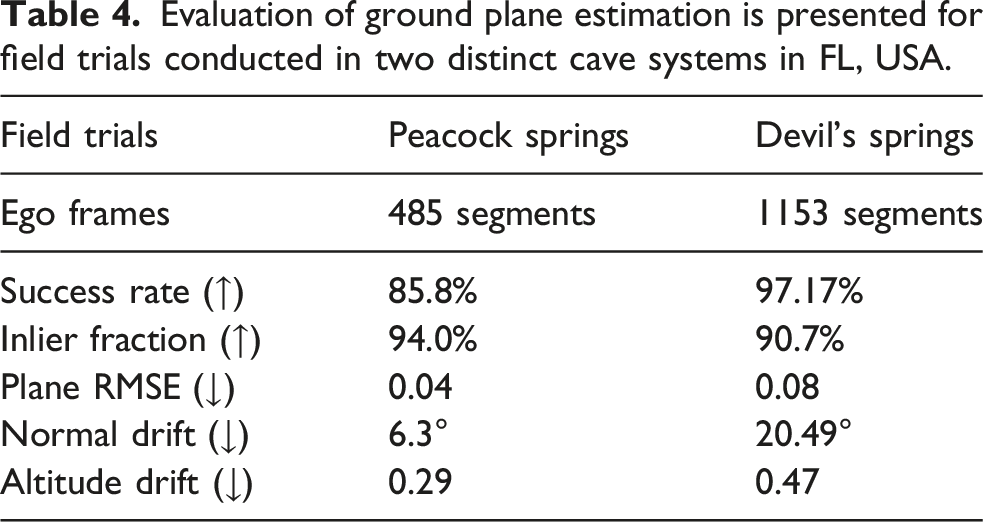
The results in Table 4 show that although trials in Devil’s Springs cave systems have a higher success rate in detecting the ground plane, the plane quality from Peacock Springs cave systems is consistently better. This difference can be attributed to the more complex cave structure and the challenging ROV trajectory executed in the latter case. In Devil’s Springs, several obstacles (e.g., large rocks) appeared directly in front of the ROV, forcing the operator to ascend and maneuver around. The terrain itself had high altitude variations, composed of rocks, boulders, and scattered pebbles, in contrast to the relatively smooth sedimentary floor observed in Peacock Springs. The reconstructed ground map from Peacock Springs shows consistent elevation and orientation (see Figure 4 (b)), supporting the quantitative results. More snapshots from the two sites are provided in Figure 8. As seen, the rocky terrain in Devil’s Springs and the resulting jerky vehicle motion led to larger errors in ground plane estimation, greater deviations in the fitted normal, and higher variability in estimated altitude.
4.4. User study #1: SUS
The goal of this user study is to assess interface-level usability using real mission data. Hence, the study is conducted with multiple underwater cave exploration data collected during our field trials. A BlueROV2 recorded egocentric video feeds inside the caves at up to 100-m penetrations. Later on, the playback sessions are presented to 15 human participants, between the ages of 21-32, with little/no prior teleoperation experiences. They evaluate the ease of operation with our developed EgoExo console and compare it to traditional consoles. Their feedback is recorded using the System Usability Scale (SUS) (Brooke, 1996), with our interface achieving an average SUS score of 77.5. We also formulate an independent set of questions on the teleoperator’s preference for the novel features of our method. The individual questions and corresponding scores are presented in Table 5. Some key observations from this study are listed below. (1) The obtained SUS score is fairly above median (score: 68) and is considered Good for user experience; it is slightly below the Excellent (score: 80.3) category. (2) Post-operation feedback from our ROV operators suggests that the exocentric views are more useful for safe ROV maneuvers. (3) The synthesized 3D map provides a better sense of the ROV’s global location and improves spatial awareness of the teleoperators. (4) The operators report a significantly lower workload (perceived cognitive load) in conducting complex tasks such as object following and structure mapping. In our study, 15 human participants provide their feedback to the following two sets of questions: (i) The first 10 questions are from SUS (Brooke, 1996); and (ii) The remaining three questions are custom-designed. Response to each question is scaled from 1 (strongly disagree) to 5 (strongly agree).

4.5. User study #2: NASA-TLX
Unlike the SUS study, this experiment involves active teleoperation, enabling objective assessment of performance metrics such as mission completion time, path deviation ratio, and collision count. Such metrics are difficult to measure in real cave environments due to the lack of reliable ground-truth localization and trajectory data. Hence, this user study is conducted in a Gazebo-simulated environment of a 60 m deep, 25 m × 15 m underwater industrial facility containing pipelines, subsea pods (Abdullah et al., 2025a; Blow et al., 2025), and visual fiducial markers (see Figure 6). Participants are tasked with teleoperating the NemeSys robot in ROV mode (Abdullah et al., 2025b) in a lawnmower pattern along the three green pipelines and visually detecting the front/back-faced markers attached to the pod with the ROV’s front-facing camera. The autopilot assists in maintaining the intended depth, so the operator primarily controls surge and yaw motion in the horizontal plane; however, depth and roll control remain available for collision avoidance if needed. The participant pool consists of 15 individuals (aged 25–36), including 4 females and 11 males, with prior teleoperation experience distributed as 3 experts (significant ROV teleoperation experience), 4 intermediate users, and 8 novices (no teleoperation experience). Each participant performs the same mission twice: first using only egocentric camera views and then using the proposed EgoExo++ system. A Gazebo-simulated underwater facility with five subsea pods is used to evaluate teleoperation performance. Participants drive the ROV by following the green pipelines and visually identify fiducial markers mounted on the pods. Each operator repeats the mission twice—first using the egocentric camera feed and then using the proposed EgoExo++ interface.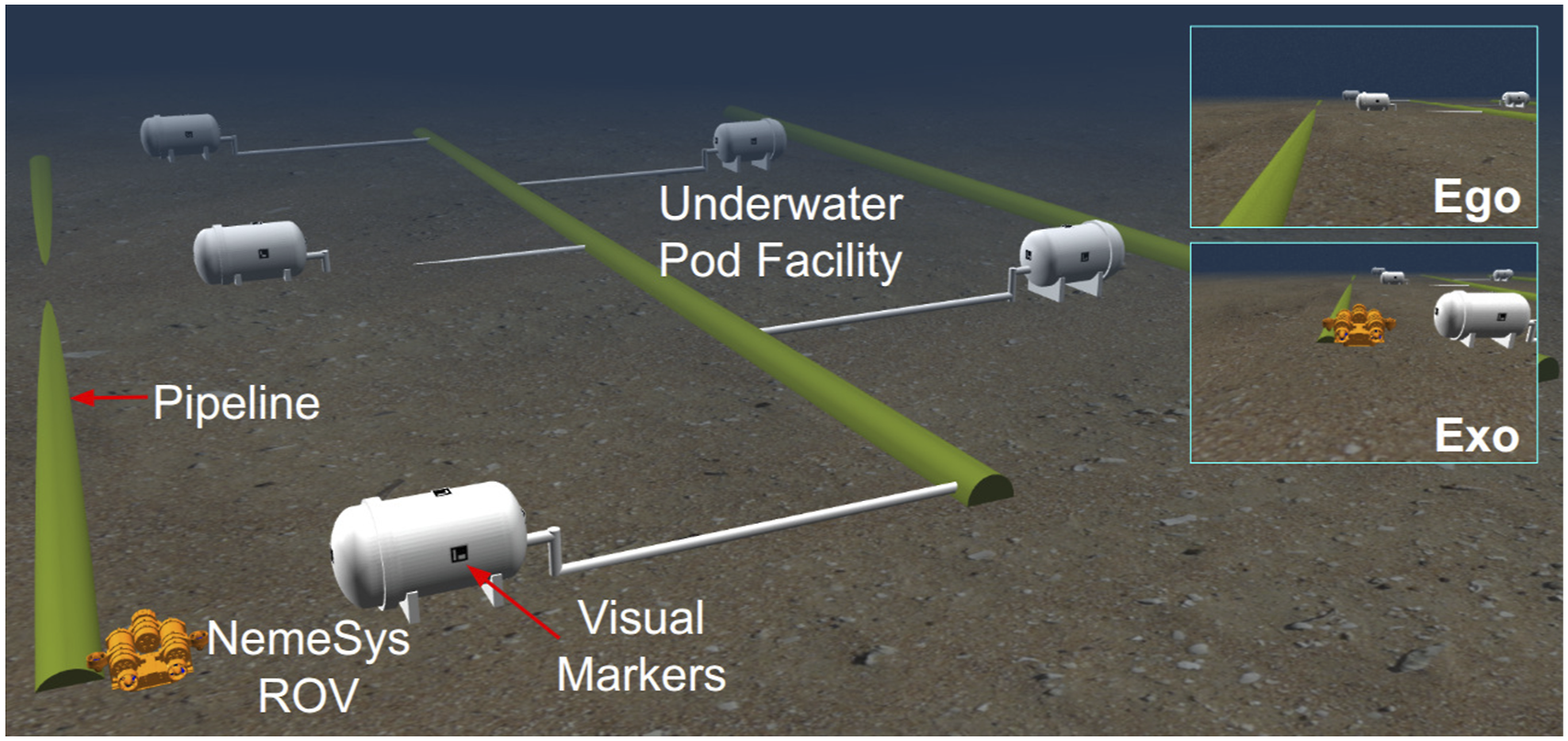
NASA-TLX subjective workload is compared between egocentric-only teleoperation and EgoExo++. Scores are collected from 15 participants on the standard unweighted 0 (very low) to 20 (very high) scale;

Task performance for 15 users is compared between the traditional egocentric teleoperation interface and EgoExo++. Scores for mean and standard deviation are reported for the first two metrics, while the final row reports the total collision count across all participants.

Essentially, PDR = 0 indicates perfect adherence to the intended trajectory, while positive values represent proportionally higher deviation. Collision is counted as the number of physical contacts with the seabed, pipelines, or pod structures. Compared to egocentric-only teleoperation, EgoExo++ achieves 16% faster mission completion and 5× lower PDR. The relatively large standard deviation in PDR reflects variability in operator expertise, particularly among novice participants who made wide turns at the sharp corners. Additionally, only 2 collisions were observed under EgoExo++ compared to 5 under egocentric-only teleoperation, indicating safer and more confident navigation behavior of the ROV.
(1) The EgoExo trailing view helps operators anticipate turning points and align the ROV efficiently to identify pod markers with that peripheral information; and (2) The 2.5D EgoExo++ map offers a global situational context, allowing operators to maintain a clear sense of “where am I?”, particularly during U-turns where no pipeline is visible. ROV trajectories for egocentric and EgoExo++ teleoperation are visually compared. Egocentric-only missions (red) exhibit wider turning radii and more lateral deviation (shaded red regions). In contrast, EgoExo++ trajectories (blue) are more compact and aligned with the ideal pipeline route.
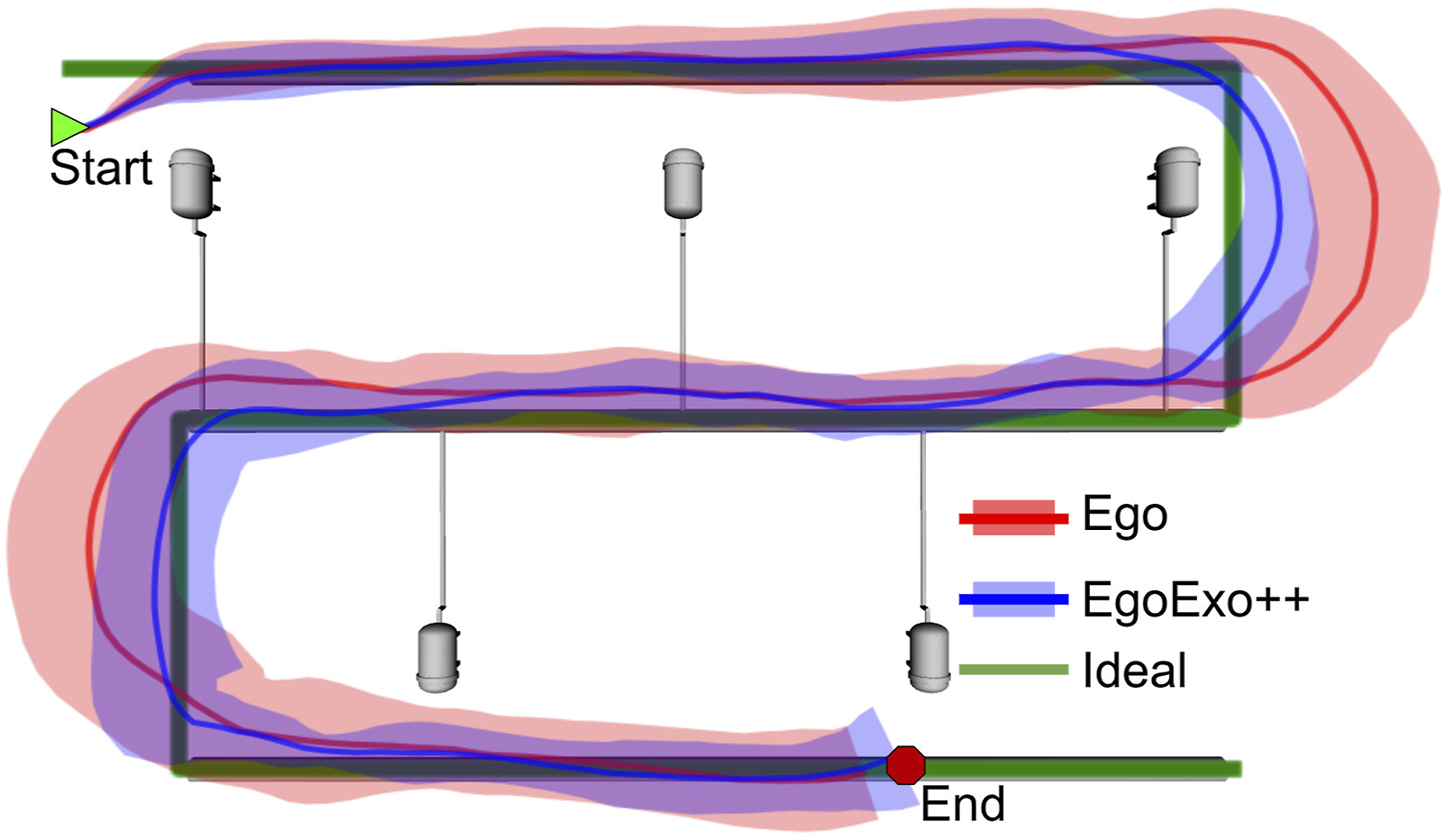
Nevertheless, a commonly reported limitation of our system is perceptual disorientation caused by occasional latency in the augmented view. Aside from this effect, the operators preferred EgoExo++ for more confident ROV teleoperation.
5. Improved Underwater ROV Teleoperation: Strengths, Challenges, and Limitations
EgoExo and EgoExo++ views are shown from field trials at two different cave systems. In EgoExo, the operator slides across the EOB distance f to find the preferred Exo view, for example, f = 100 for the first case. EgoExo++ further enables free 360° viewpoint control, allowing the ROV to be visualized from arbitrary perspectives such as top, back, front, and side views. A video demonstration is provided in the supplementary files; it can also be seen here: https://youtu.be/xpvnzIJ_YbM.
Three challenging scenarios are shown for ROV teleoperation inside underwater caves: (i) caveline is not visible, that is, blended with the background; (ii) caveline is not in the FOV; and (iii) front camera-light interactions with suspended particles are causing hazy egocentric views. In all cases, our augmented visuals are clearer and more informative to a surface operator.
Challenges in estimating uneven ground surface in unstructured environments: terrain complexities, such as elevation changes, narrow passages, and misleading planar obstacles, hinder the accurate ground surface reconstruction.
However, successful relocalization remains the responsibility of the operator and the SLAM system; EgoExo++ only supports this process passively through improved situational awareness. It operates as a lightweight visualization layer that deterministically consumes SLAM pose and sparse map without modeling or propagating uncertainty. This design choice prioritizes real-time operation and simplicity of integration with existing teleoperation engines.
Across more than 1500 mission segments collected from our field trials in three different cave systems, SLAM tracking loss occurred in less than 5% of the segments, with successful relocalization achieved in roughly half of these events. The major causes are abrupt vehicle motion or collisions that drive the ROV too close to an obstacle, producing feature-deprived imagery and disrupting tracking; an example is illustrated in Figure 11. Across datasets, the terrain estimation method achieves an average success rate of approximately 92% (see Table 4), implying that 8% of segments are rejected due to insufficient visual support. In such cases, EgoExo++ omits unreliable ground patches and leaves a hole in the reconstructed scene rather than rendering incorrect geometry. An example of SLAM failure during aggressive pitch maneuvering is illustrated. A “nose-down” dive drives the ROV too close to the cave floor, causing the scene to become feature-deprived and leading to a SLAM tracking loss.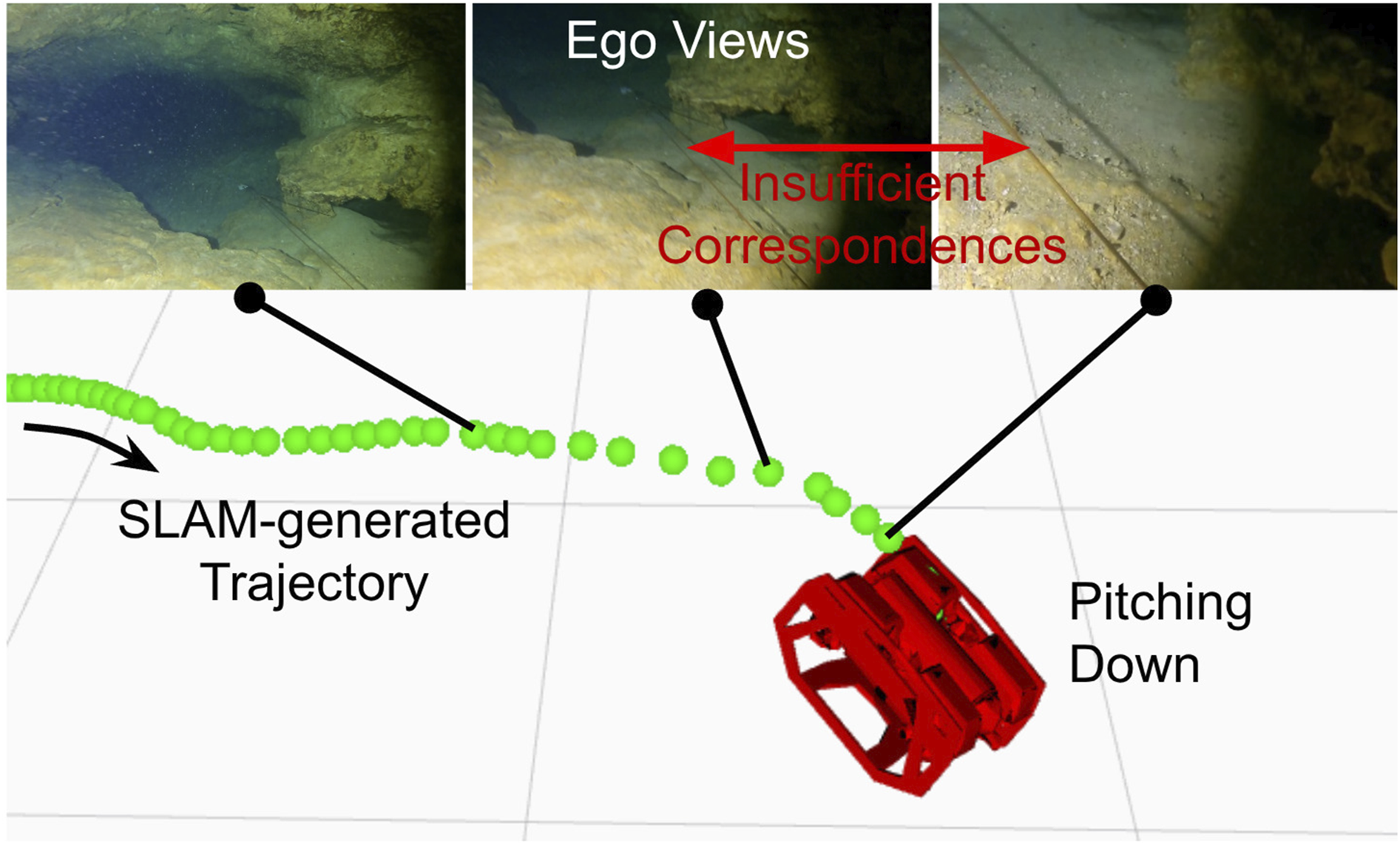
6. Conclusion and Future Work
This work presents an AR-based framework to synthesize exocentric camera views from egocentric feed in real-time for improved underwater ROV teleoperation. A pose geometry-based closed-form solution is formulated for the proposed EgoExo++ problem and then integrated into a visual SLAM backbone. The end-to-end pipeline only requires a sequence of past egocentric views to generate 2D/2.5D exocentric views with the accurate ROV model projected onto them. The proof-of-concept is validated by ground plane estimation and reprojection error analyses in a series of 2D indoor navigation experiments. Subsequent field experiments are conducted to demonstrate the effectiveness of 2.5D scene rendering in unstructured underwater cave scenarios. We validate the system through two subjective studies: one in simulation and one using real underwater datasets. These studies demonstrate improved system usability (SUS), reduced perceived workload (NASA-TLX), and quantitative gains in teleoperation performance, including more efficient paths and faster mission completion compared to egocentric-only baselines. We are currently exploring more comprehensive multi-sensor fusion-based underwater SLAM backbones, such as the SVIn2 (Rahman et al., 2022), for more accurate and robust estimation. We will further extend our simulation platform with interactive tools to enable advanced teleoperation studies such as confined-space navigation, SLAM-recovery behavior, close-up inspection, complex maneuvering around structures, etc.
Supplemental Material
Footnotes
Acknowledgments
The authors would like to acknowledge the help from Woodville Karst Plain Project (WKPP), El Centro Investigador del Sistema Acuífero de Quintana Roo A.C. (CINDAQ), Global Underwater Explorers (GUE), Ricardo Constantino, and Project Baseline in providing access to challenging underwater caves. The authors are also grateful for equipment support by Halcyon Dive Systems, Teledyne FLIR LLC, and KELDAN GmbH lights. We appreciate the participants of our user study for their time and valuable feedback during the evaluation process. Finally, we thank the anonymous reviewers for their insightful suggestions, which significantly improved this paper.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported in part by the NSF grants 2330416, 2534503, and 2545370.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online. The source packages are available at: https://github.com/uf-robopi/EgoExo. The demo video can be seen here: ![]() .
.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.