
Abstract
A time–space diagram (TSD) is an efficient tool for traffic analysis and visualization, representing the macroscopic traffic state as a set of cells. However, its application is often hampered by data sparsity, which obscures high-resolution traffic dynamics. This study proposes a modified K-nearest neighbors method, characterized by an adaptive iterative process, to impute missing TSD data. To support the method’s design, analytical bounds on error propagation motivated by Green’s function-based theory are established, and a practical empirical formula for the optimal K parameter is derived. The framework’s performance was rigorously validated on diverse data sets from China (Ubiquitous Traffic Eyes), the US (Next Generation Simulation), and Germany (HighD) across 30 distinct experimental conditions. Compared against four baseline models, the proposed model demonstrates a compelling balance between high imputation accuracy and exceptional computational efficiency. Further analyses confirm the influence of neighborhood order and the systematic performance bias. The model’s potential for knowledge transfer is also demonstrated via a cross-data set imputation scheme.
Keywords
Introduction
The time–space diagram (TSD) is a fundamental tool in transportation research, offering a visual representation of macroscopic changes in traffic flow across spatial and temporal dimensions ( 1 ). By illustrating congestion patterns, peak periods, and overall traffic trends, TSDs enable engineers and managers to analyze the dynamic characteristics of road traffic. Consequently, they are extensively applied in the study of traffic flow theory, vehicle behavior, and traffic wave propagation, advancing traffic science ( 2 – 5 ). The data populating a TSD, which represent traffic states within discrete cells, are typically sourced from fixed detectors or probe vehicles ( 6 ). However, both sources present significant limitations. Fixed detectors incur high installation and maintenance costs, resulting in low deployment density. In contrast, probe vehicles, often limited to specific fleets such as taxis, exhibit low penetration rates ( 7 ). These constraints collectively lead to data sparsity, yielding TSDs that are often insufficient to accurately represent the underlying traffic dynamics.
Existing methods mainly fall into two categories: (1) interpolation and (2) prediction ( 7 ). Interpolation techniques leverage temporal proximity or pattern similarity to estimate missing values as the average or a weighted average of adjacent data points ( 8 ). A conventional method, for instance, imputes a missing value using historical data from the same detector at a corresponding time ( 9 ). However, the efficacy of these methods hinges on the assumption of similarity between neighboring traffic states, rendering them unreliable in scenarios with contiguous missing data, a condition known as high sparsity ( 10 ). This limitation has spurred a more direct focus on the TSD problem, which moves beyond simple interpolation by attempting to model the underlying spatiotemporal relationships to reconstruct a complete, high-resolution TSD from the inputs of low-resolution TSDs. This refinement task is distinct from pure prediction because it can utilize data from all available dimensions, including temporally future data, to inform the imputation of a missing cell. A recent and important example of this approach is the work by He ( 4 ), who proposed a simple yet effective multivariate linear regression (MLR) model that leverages local spatiotemporal features to enhance the TSD resolution, establishing an important methodological baseline specifically for this refinement task.
Alongside these model-based refinement techniques, other data-driven approaches, often adapted from the broader field of traffic state estimation (TSE), have gained prominence ( 7 ). These include statistical models and, more recently, deep learning (DL). The DL techniques excel at modeling the intricate, nonlinear dependencies inherent in large-scale data sets ( 4 , 11 , 12 ). For instance, Zhang et al. ( 7 ) utilized a traffic state reconstruction generative adversarial network (TSR-GAN) to reconstruct spatiotemporal traffic states, and Xu et al. ( 13 ) proposed a multi-directional recurrent graph convolutional network to reconstruct TSDs from sparse data. These advanced DL models can achieve high imputation accuracy; however, their practical application faces significant challenges. Crucially, the TSD imputation task differs fundamentally from traditional TSE ( 14 ) because imputation can leverage future traffic states as input to enhance quality, a feature typically unavailable in real time TSEs ( 4 ). Therefore, models trained on fixed-dimension historical data may be ill-suited for the dynamic nature of TSD imputation. Furthermore, the high computational cost, extensive parameter counts, and limited transferability of complex DL models hinder their practical application in many real time intelligent transportation systems (ITS) ( 15 ).
This landscape creates a pressing need for a method capable of directly imputing TSD data that balances imputation accuracy with computational efficiency, requires minimal training data, and offers robust performance, particularly under high data sparsity. The K-nearest neighbors (KNN) algorithm presents a compelling alternative for traffic data imputation. It operates by identifying temporal or spatial neighbors based on a defined distance metric to impute missing values ( 16 – 19 ). The simplicity and efficiency of KNNs have led to their widespread application in traffic prediction and imputation ( 20 ). Notable adaptations include the Linearly Sewing Principle Component (KNN-LSPC) algorithm ( 16 ), a data-driven car-following model ( 21 ), a kernel-based KNN ( 22 ), and a hybrid model fusing KNN with support vector regression ( 17 ). A significant advantage of KNNs over more complex data-driven models is their parsimonious nature, often relying on a single parameter K. This facilitates direct deployment in an ITS for handling high-resolution TSDs. However, conventional KNN applications face challenges. The highly nonlinear dynamics of traffic flow can lead to significant errors when simply using adjacent spatiotemporal points ( 23 ). In addition, the algorithm’s performance degrades substantially at high data sparsity, as sufficient neighboring points may be unavailable for reliable imputation.
Leveraging the inherent spatiotemporal correlations in traffic flow ( 22 , 24 , 25 ), this study introduces an efficient and robust imputation framework to accurately reconstruct high-resolution TSDs from sparse data. The proposed framework is centered on a modified KNN algorithm, distinguished by an adaptive iterative process designed to overcome high sparsity. It begins by extracting spatiotemporal features using first-order spatial neighborhood weights ( 26 ). A key aspect of this study is establishing analytical bounds on error propagation, motivated by Green’s function-based theory, to provide theoretical insight into the method’s stability. In addition, an empirical formula is derived for determining the optimal model parameter. The model’s performance, robustness, and transferability are rigorously validated using diverse data sets from China, the US, and Germany.
The primary contributions of this study are as follows.
An algorithm with an adaptive iterative process is proposed, which ensures imputation feasibility even at high sparsity levels using a single parameter.
A theoretical analysis providing motivational analytical bounds for error propagation dynamics, integrating principles from traffic flow theory with computational analysis.
The competitive performance and practical efficiency of this model are demonstrated against a comprehensive set of baseline methods, including MLR, SoftImpute, Kalman Filter (KF), and TSR-GAN, across 30 distinct scenarios of data sparsity and resolution, validated through cross-data set testing.
A practical formula is derived to determine the optimal model parameter by analyzing its correlation with imputation error, sparsity, and data set size.
Methodology
Model Description
The KNN method is a nonparametric, instance-based learning approach renowned for its simplicity and high efficiency ( 27 , 28 ). Its fundamental assumption is that the data set exhibits self-similarity: if two samples are close in their feature space, their corresponding target values will also be similar ( 21 ), which is highly applicable to traffic data because TSDs inherently possess strong spatiotemporal correlations. It is reasonable to assume that similar spatiotemporal traffic conditions will produce similar traffic states. This periodic phenomenon has been well-validated in numerous traffic flow studies ( 29 – 32 ). Therefore, this study adopts the KNN algorithm as the foundation for a concise and efficient data-driven framework to address the TSD imputation problem, which offers a low-complexity, flexible alternative to parameter-heavy DL models, making it highly suitable for practical ITS deployment.
Given a sample
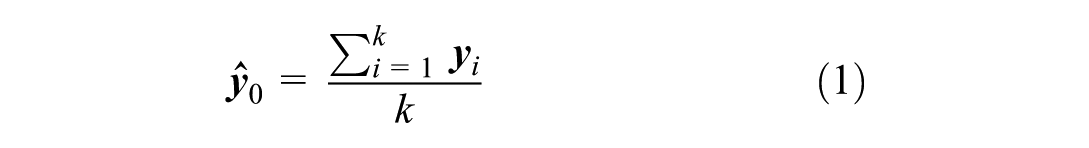
where xi represents the similar sample’s feature to x0, the similarity is measured by Euclidean distance, and yi represents the corresponding observed value of xi.
To apply this framework, the feature vector is defined first. As shown in Figure 1, for any target cell yi (representing speed) in the TSD, its feature vector xi is constructed from the observations of the eight adjacent cells (the first-order spatial neighborhood). This method abstracts the complex local spatiotemporal context into a simple yet effective mapping relationship. In addition, a standard KNN treats all K neighbors equally, regardless of their proximity to the target. Given the strong evidence that traffic states exhibit significant spatiotemporal correlations, neighbors that are spatiotemporally closer to the target cell should intuitively have a greater influence on the imputation. Therefore, a weighting coefficient α is introduced based on the spatiotemporal distance to refine the model. The resulting modified KNN formula is as follows:
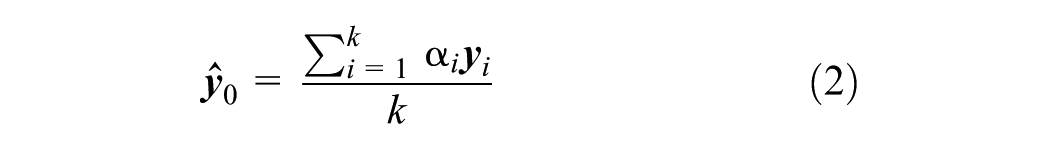
where the weighted coefficient αi is positively correlated with the inverse of the spatiotemporal distance between yi and y0, and all coefficients are normalized.
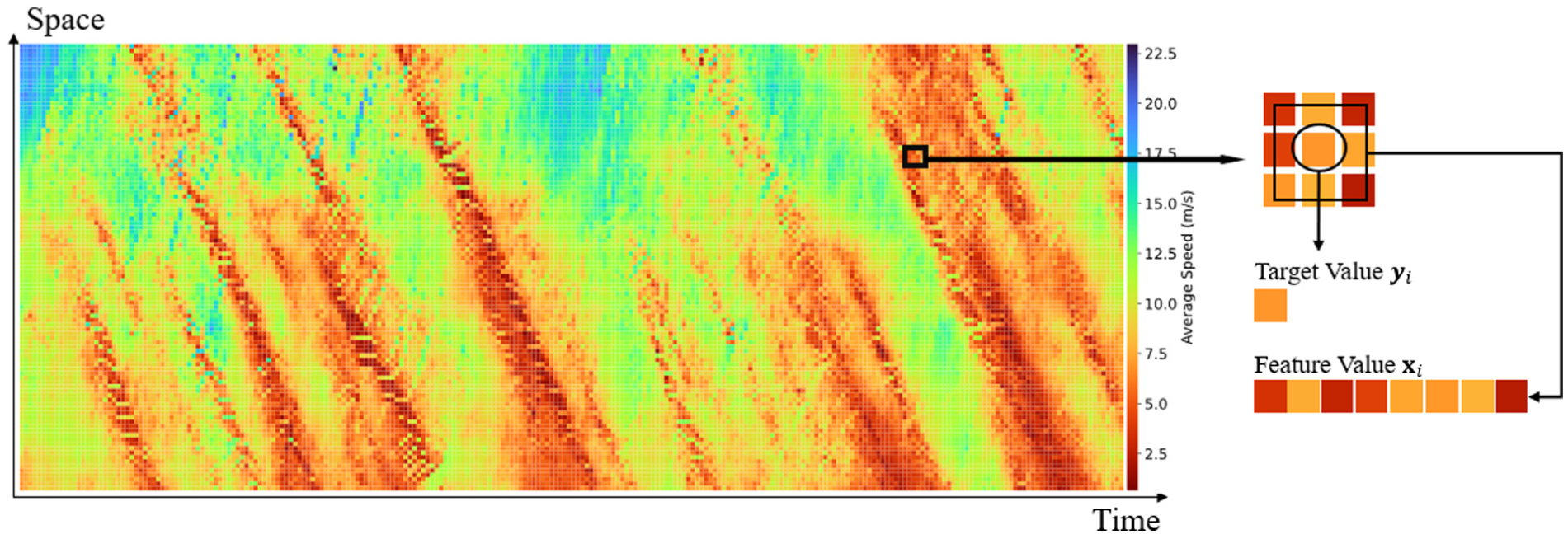
Feature and target value mapping in time–space diagram.
A significant challenge for the direct application of Equation 2 arises under high data sparsity. When a target cell’s spatiotemporal neighbors are missing, a reliable distance calculation and weighted average become impossible. This prevents the standard KNN algorithm from functioning. To address this critical limitation, this study introduces an adaptive iterative mechanism, as shown in Figure 2. The core principle of this framework is to progressively populate the TSD by prioritizing imputations based on data availability. The algorithm operates in iterations, and in each iteration N, it strategically identifies all missing cells for which a complete or sufficient eight-neighbor feature vector can be constructed from the currently available observed and previously imputed data. The modified KNN is then applied to these “high-confidence” cells, and their values are updated within the TSD. This newly imputed data is immediately incorporated into the data set, effectively expanding the pool of available information (i.e., refining the feature set) for the subsequent iteration, N + 1. This self-adaptive process repeats, leveraging newly imputed values to solve progressively more difficult gaps, until all missing values have been imputed or the process converges to a stable state. This iterative approach ensures the imputation process remains robust and effective, even when a significant proportion of the data is randomly missing, by intelligently using high-confidence estimations to unlock subsequent, more challenging imputations.
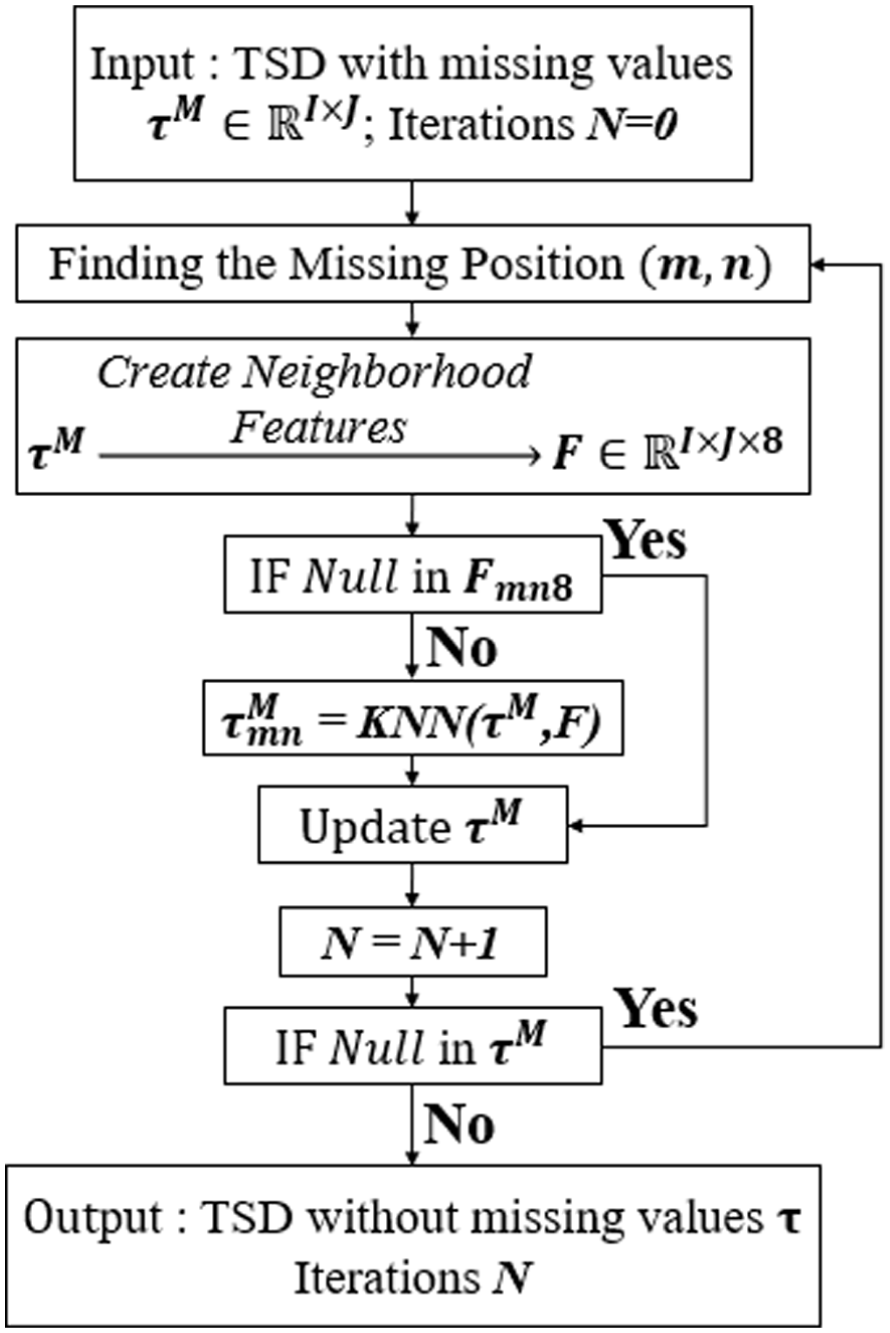
Modified K-nearest neighbor (KNN) algorithm for time–space diagram (TSD) imputation.
A notable characteristic of the KNN algorithm is that it does not involve an explicit training phase; as a nonparametric method, its training complexity is effective o(1). The computational burden is concentrated in the imputation (prediction) phase. The proposed modified KNN framework is iterative, as described in the previous section. This iterative design, which is essential for handling high sparsity, defines its practical computational cost. The total imputation complexity of this framework is approximately o(T·Nm·No·D), where T represents the number of iterations required for convergence, Nm represents the number of missing points,
Although DL can learn nonlinear feature representations, its numerous hidden layers and neurons make it significantly more complex, requiring extensive, computationally expensive offline training and managing many parameters. In sharp contrast, this modified KNN algorithm remains nonparametric, which drastically simplifies model tuning and enhances implementation stability. Therefore, this framework’s balance of zero training cost and predictable, manageable imputation complexity could efficiently meet engineering requirements, rapidly providing reliable initial solutions for sophisticated traffic management analyses.
Theoretical Foundation and Convergence Analysis
The modified KNN framework is a nonparametric, data-driven method. To provide a theoretical justification for its design, particularly the use of a weighted average of spatiotemporal neighbors, this section develops an analytical framework to explore the fundamental error propagation dynamics in TSD imputation. This framework is built on the classic Lighthill–Whitham–Richards (LWR) traffic flow model. It should be emphasized that the purpose of this analysis is to offer theoretical motivation and to demonstrate that under idealized conditions, the error of a local weighted estimation process is bounded and convergent. This provides a foundational rationale for this algorithm’s stability and effectiveness, rather than serving as a direct mathematical proof of the KNN algorithm.
Given the one-dimensional (1D) traffic flow conservation law based on the LWR traffic flow model ( 33 , 34 ).
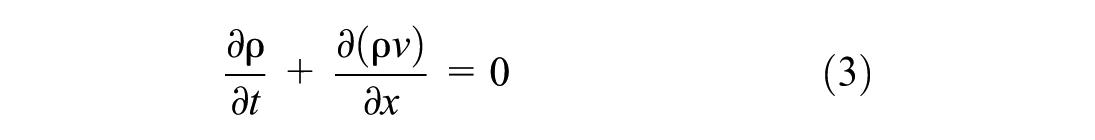
where
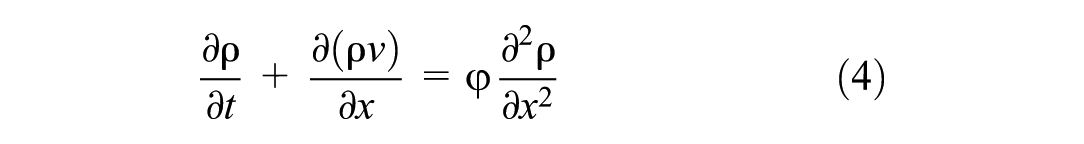
where φ controls spatial diffusion intensity ( 35 ).
The Green’s function
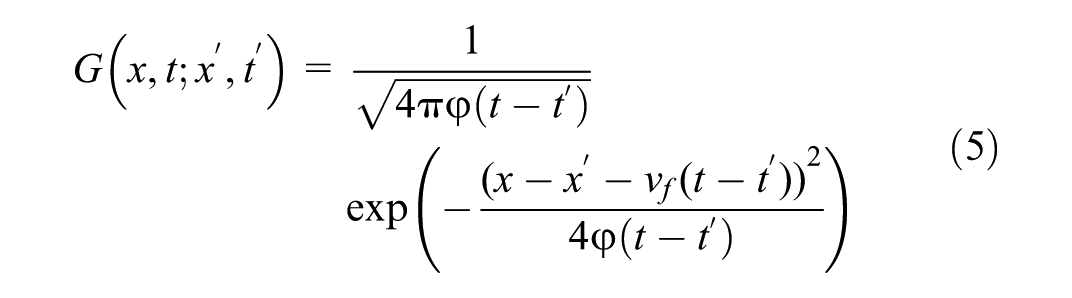
encoding convective transport vf and diffusive smoothing φ. The weight matrix
W is constructed via temporal integration of G.
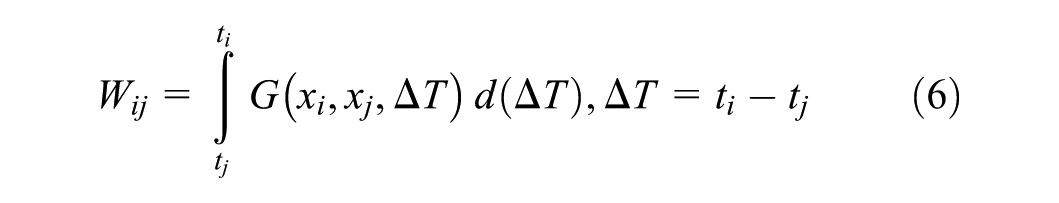
with diagonal elements quantifying historical self-influence.
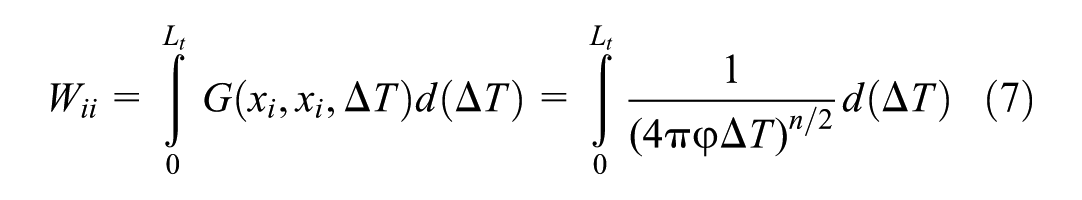
and off-diagonal elements.
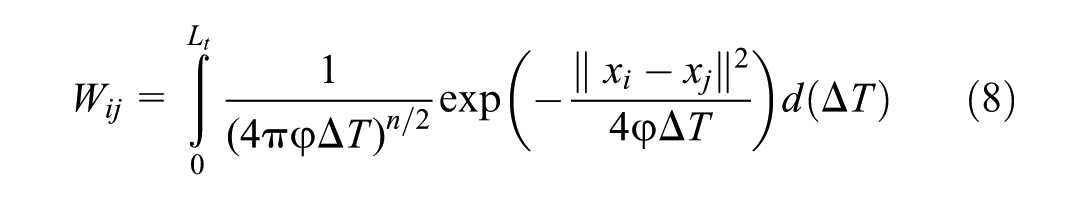
For missing values
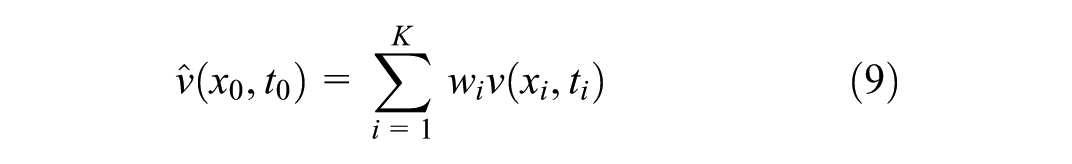
where wi represents the Green’s function-derived weight . This physical model serves as the theoretical analog for the practical, data-driven weighted KNN approach. Based on this theoretical framework, the total error evolution ϵ across K iterations can be expressed as,
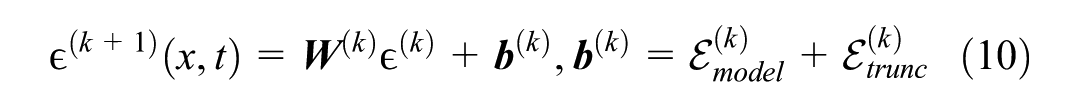
where
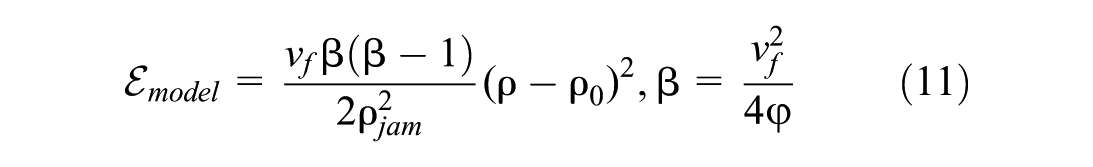
bounded by
As the number of iterations increases, missing points are supplemented with weighted values, resulting in a more concentrated distribution of traffic flow density and a decrease in
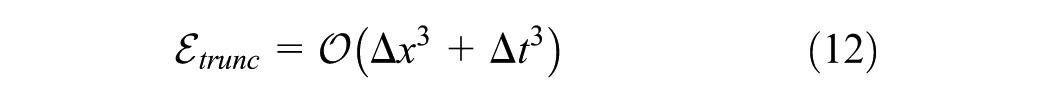
After expanding the neighborhood samples, the truncation error can be limited to.
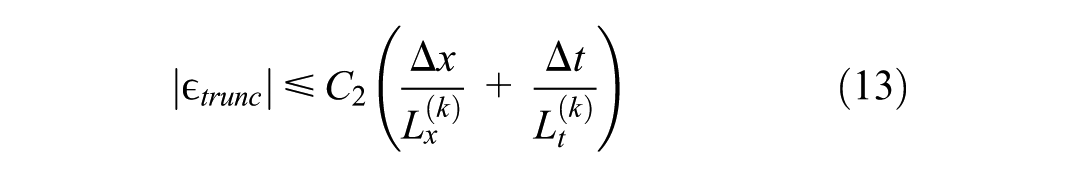
where C2 depends on φ and vf; with fixed
For Equation 10, if the spectral radius of the weight matrix W is less than one, the error bound converges according to a geometric series,
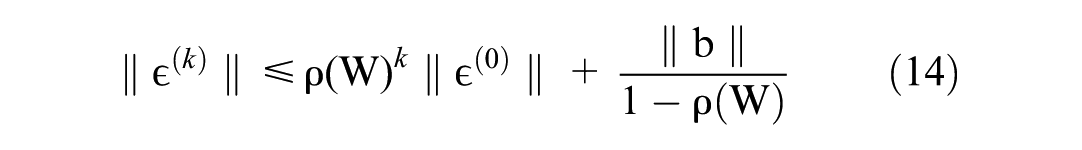
According to the Gershgorin circle theorem (
37
), the center of the Gershgorin disk for each row i is Wii, with the radius
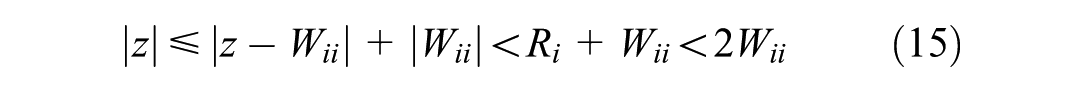
In reality,
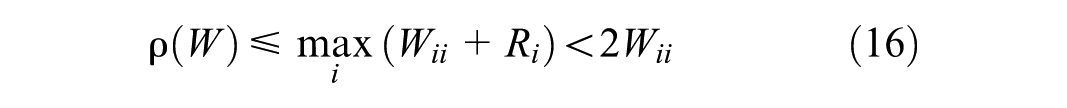
In practical settings, compared with the scale of the TSDs, Lx and Lt are sufficiently small to ensure that
To validate this theoretical convergence, the numerical simulation results are shown in Figure 3. It is crucial to clarify that this is a theoretical simulation designed to test the convergence of the derived framework. The parameters analyzed, free-flow velocity vf, jam density
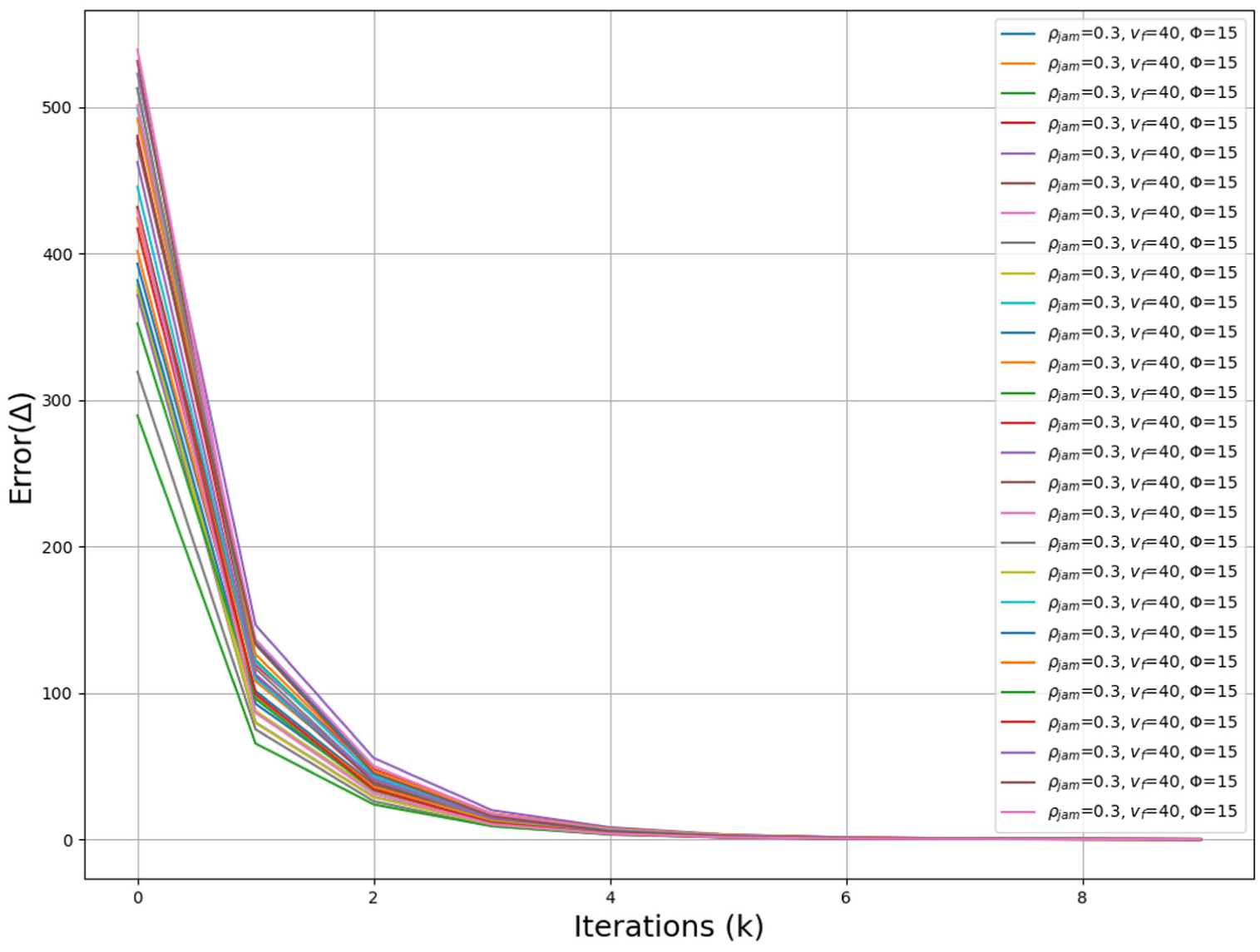
Sensitivity analysis results under 10% missing rate.
Note that Error(Δ) denotes the cumulative error between the imputed results and the original data on the TSD.
Experiments and Discussions
Data Set Description
To ensure a fair evaluation of the modified KNN algorithm’s effectiveness in TSD imputation, three representative trajectory data sets were selected from diverse traffic environments, which have different traffic flow and road conditions.
Next Generation Simulation (NGSIM) ( 38 ): Highway section US-101 in Los Angeles, US, capturing complex weaving traffic flows.
HighD ( 39 ): German highway naturalistic trajectories from RWTH Aachen University, reflecting free-flow conditions.
Ubiquitous Traffic Eyes (UTE) ( 40 ): RML-7 highway section in Nanjing, China, representing mixed traffic operations.
Detailed information on the three data sets is provided in Table 1.
Description of Detailed Information in Three Data Sets
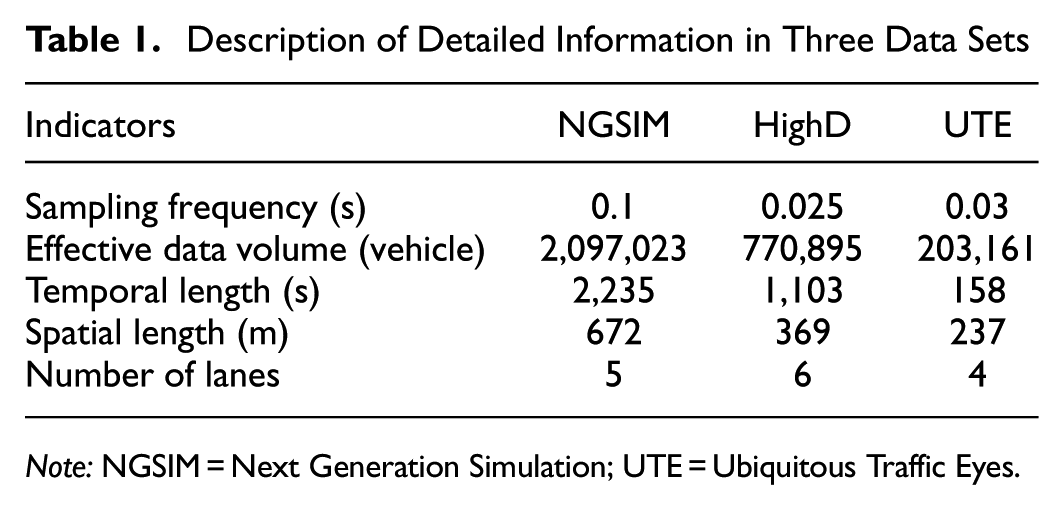
Note: NGSIM = Next Generation Simulation; UTE = Ubiquitous Traffic Eyes.
The trajectory data from aerial video sources introduces inherent perspective distortions, causing spatiotemporal positioning errors in road boundary and entry/exit zone detection ( 41 ). The TSD reliability is enhanced by systematically excluding terminal zones during preprocessing. The experimental framework establishes two spatiotemporal resolutions.
Fine-grained TSD (10 m × 1 s): Minimum spatial resolution of 10 m (encompassing ≥ 2 typical vehicles) with 1-s temporal granularity, achieving sub-vehicle-level traffic state characterization.
Benchmark TSD (20 m × 5 s): Coarser-resolution baseline for comparative analysis.
To simulate the various levels of data corruption found in real-world scenarios, missing values were introduced into the processed TSDs. This study focuses on the missing completely at random pattern, which was implemented by randomly selecting and removing a specific percentage of individual cells from the TSD matrix, independent of their spatiotemporal location or underlying speed value. The severity of data corruption was adjusted by controlling this random missing ratio across five levels: 10%, 20%, 30%, 40%, and 50% ( 42 ).
Baseline Models and Experimental Indicators
To comprehensively evaluate the performance of the proposed modified KNN algorithm, its effectiveness is benchmarked against a diverse set of established and advanced methods for TSD imputation. Recognizing the need to position this computationally efficient approach within the broader landscape of imputation techniques, baselines were included from classic statistical models to contemporary DL architectures. Advanced DL methods often achieve high accuracy by modeling complex nonlinear dependencies; their significant computational demands, large parameter counts, and requirements for extensive training data can limit practical deployment in a real time ITS. Therefore, this comparison includes computationally intensive and lightweight models to provide a holistic assessment of the accuracy–efficiency trade-off. The selected baseline models for comparison in this study are as follows.
Multivariate Linear Regression
Inspired by the approach proposed in the literature ( 4 ), this model utilizes the spatiotemporal features derived from the eight adjacent cells (first-order spatial neighborhood) to predict the value of a target cell. The MLR model was implemented noniteratively: it was trained once on all available data points in the sparse TSD to fit a single linear model, which was then used to predict all missing values simultaneously.
Alternating Least Squares With SoftImpute
This method is an efficient algorithm for matrix completion using nuclear norm regularization. It approximates the underlying low-rank structure of the TSD matrix via fast alternating least squares. The implementation utilizes a rank approximation and iterates until convergence or a maximum of iterations. The corresponding software package, SoftImpute, is designed for matrix imputation ( 43 ).
Kalman Filter
A KF is a classic, widely used method for time series state estimation and smoothing. For TSD imputation, it was adapted by treating each spatial row of the TSD as an independent 1D time series. A 1D Kalman smoother is applied row-wise, assuming a simple constant velocity model. The KF smoother efficiently imputes missing values based on temporal correlations within each spatial slice, with a computational cost primarily dependent on the TSD dimensions rather than the missing rate ( 44 ).
Traffic State Reconstruction Generative Adversarial Network
This model employs a GAN architecture specifically designed to reconstruct spatiotemporal traffic states. This implementation follows a typical GAN training strategy involving a generator and a discriminator. The training includes a pretraining phase using pixel-wise and scale distribution losses, followed by adversarial fine-tuning for each specific missing rate using a relativistic least squares GAN loss combined with the pretraining losses ( 7 ).
The mean absolute percentage error (MAPE) is employed as the evaluation metric. The formula for MAPE is as follows:
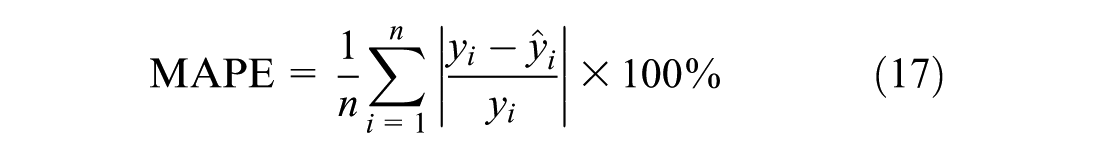
where yi represents the actual speed values in the ith cell of TSD and
In addition, the total computational time required by each model to complete the TSD imputation task is recorded as a key indicator of computational efficiency and practical deployability. This metric is defined as the sum of two components: (1) training time; and (2) imputation time, providing a comprehensive measure of the overall computational overhead associated with using each method for a given imputation task (the specific CPU configuration for completing the experiment is Intel (R) Core (TM) i9-10940X CPU @ 3.30 GHz (28 CPUs), ∼ 3.3 GHz).
Parameters of the Modified KNN Model
A key advantage of the proposed modified KNN algorithm is its parsimony, relying primarily on a single parameter: the number of nearest neighbors K. This section details the investigation into the model’s sensitivity to K and presents a practical empirical formula for estimating an optimal value, enhancing the model’s usability in real-world applications.
To understand the effect of K on imputation performance, the optimal value was determined by systematically traversing K values of 2–10 across all 30 experimental conditions. The relationship between K and the resulting MAPE is shown in Figure 4. The results reveal a consistent trend in most scenarios (e.g., Figure 4, a, b, d, e, f): the error typically exhibits a U-shaped relationship with K. Initially, as K increases from a small value, the error decreases. This is probably because incorporating more neighbors helps to average out noise and capture the underlying traffic state more reliably. However, beyond a certain optimal point (often found between K = 3 and K = 8 in these tests, see Appendix C for optimal values), further increasing K leads to a rise in error. Selecting too many neighbors, especially those spatiotemporally distant, can introduce irrelevant information or patterns from dissimilar traffic conditions, increasing the risk of mismatch and degrading imputation accuracy, which reflects the classic bias-variance trade-off inherent in KNN models. A notable exception is observed in the high-resolution NGSIM data set (Figure 4c), where the error consistently decreases as K increases within the tested range [2, 10]. This does not necessarily contradict the general U-shaped trend but suggests that for large-scale, complex data sets with potentially richer patterns, the optimal K might lie beyond the traversed range. The flattening of the error curve at larger K values in Figure 4c supports this speculation. While exploring K > 10 could be beneficial for such specific cases, the range [2, 10] provided effective results across the majority of conditions in this study. This analysis underscores that the optimal choice of K is influenced by factors such as data set size, traffic complexity, and data sparsity.
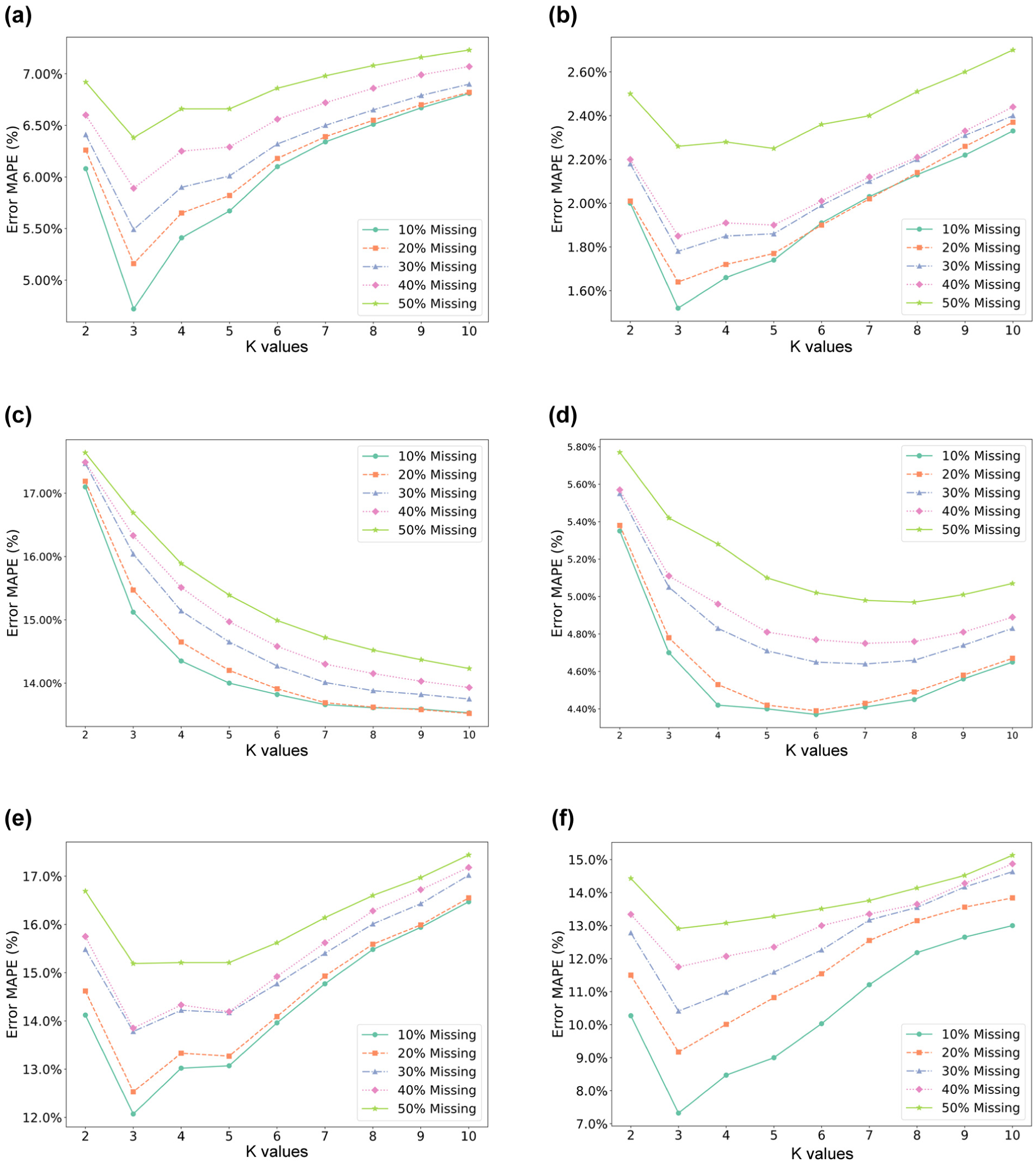
Modified K-nearest neighbor (KNN) model errors for different values of K in different cases: (a) HighD 1 s × 10 m; (b) HighD 5 s × 20 m; (c) NGSIM 1 s × 10 m; (d) NGSIM 5 s × 20 m; (e) UTE 1 s × 10 m; and (f) UTE 5 s × 20 m.
Given the observed relationship between K, MAPE, missing rate (MR), and data set size N, defined as the number of available spatiotemporal data points in the TSD, and motivated by the need for a practical method to select K without extensive traversal, an empirical formula is proposed. Based on the analysis shown in Figure 4, the imputation error is modeled using a quadratic polynomial that incorporates K, MR, and N, including linear, quadratic, and interaction terms.
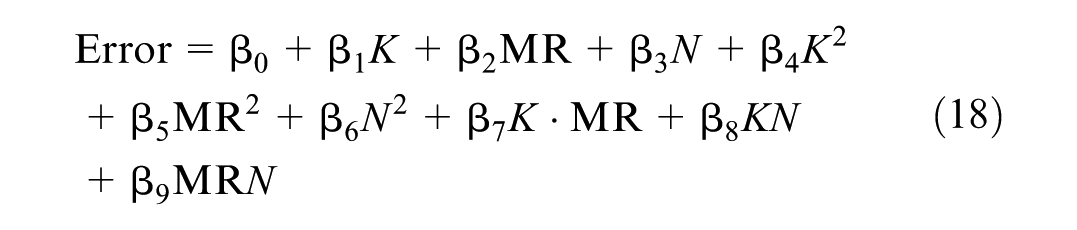
An ordinary least squares regression is employed to derive the coefficients. The regression was fitted using data points (K, MR, N, and Error) pooled from all 30 experimental conditions across the three data sets. Before fitting, MAPE values across all conditions were normalized to ensure comparability and allow for integrated analysis. The resulting coefficients are presented in Table 2. The goodness-of-fit for this empirical formula is shown in Figure 5, where the high coefficient of determination R2 values (from 0.78 to 0.97) across the diverse data sets and resolutions confirm that the quadratic model effectively captures the underlying relationship between K and imputation error, substantiating the modeling hypothesis.
Coefficient Table of Empirical Formula
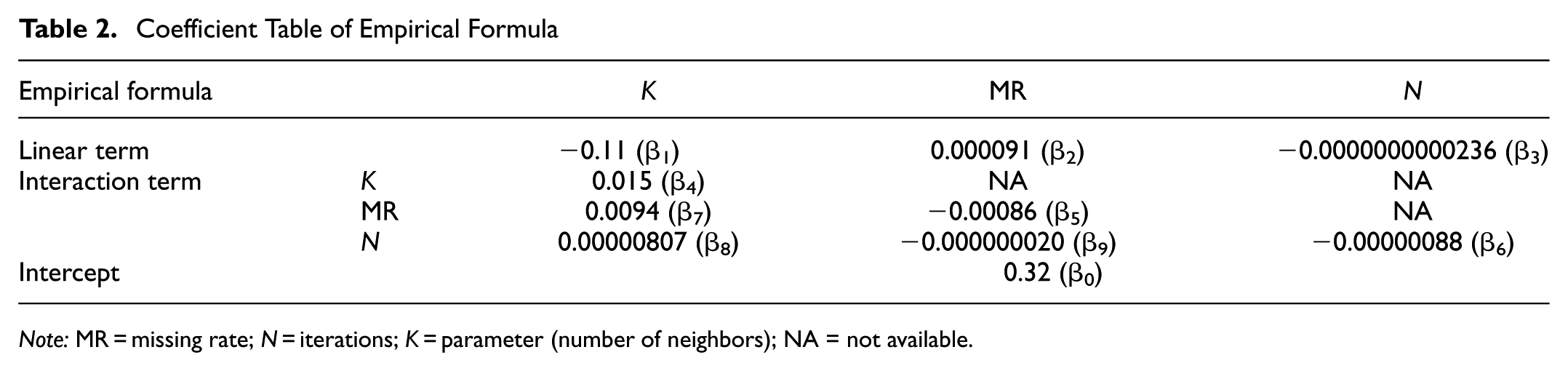
Note: MR = missing rate; N = iterations; K = parameter (number of neighbors); NA = not available.
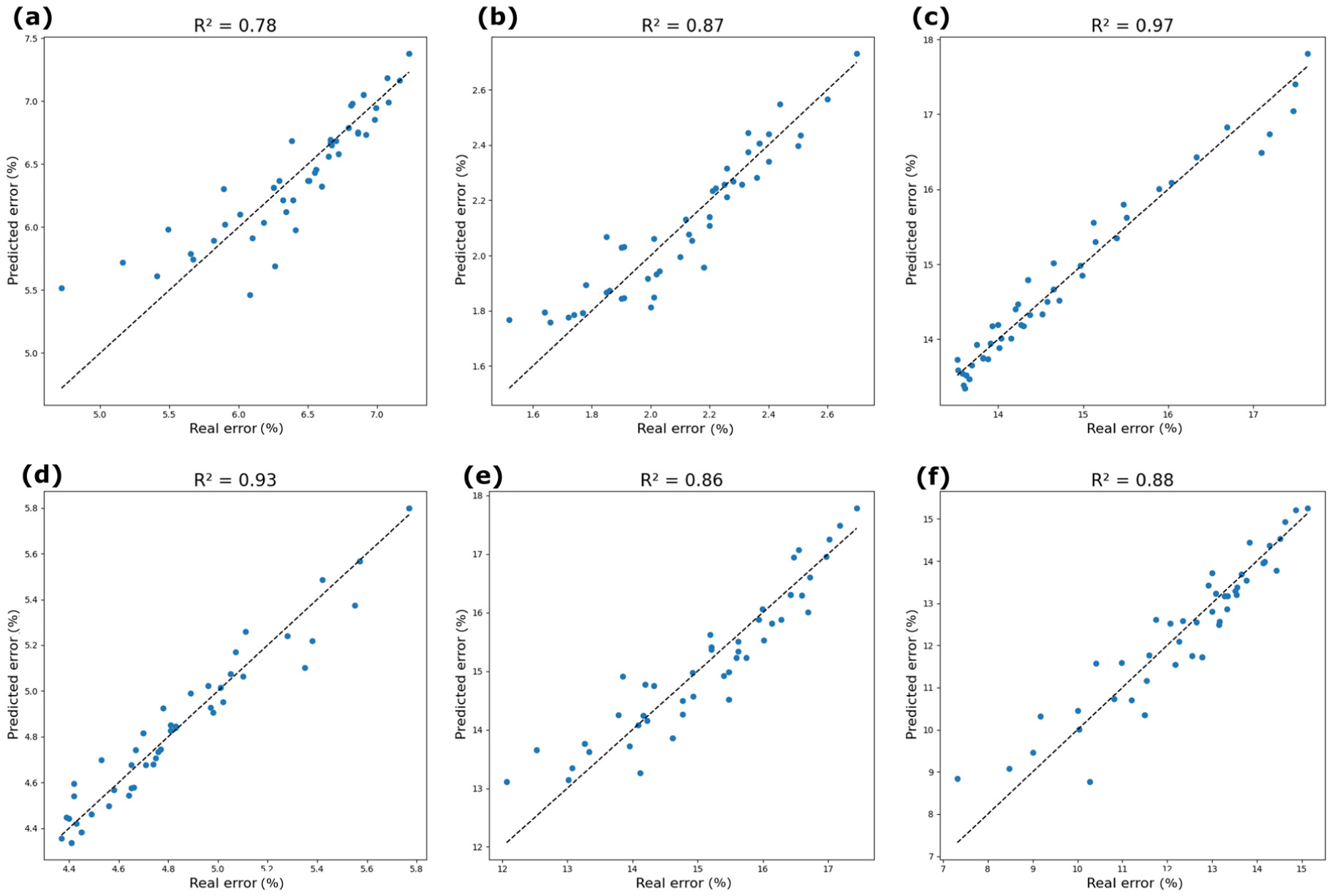
Fitting effect of correlation between K values and errors: (a) HighD 1 s × 10 m; (b) HighD 5 s × 20 m; (c) NGSIM 1 s × 10 m; (d) NGSIM 5 s × 20 m; (e) UTE 1 s × 10 m; and (f) UTE 5 s × 20 m.
The coefficients presented in Table 2 provide insights into how each factor influences the imputation error. The intercept (β0 = 0.32) serves as a baseline normalized error under theoretical zero conditions. Linear terms, such as the negative coefficient for K (β1 = –0.11), reflects the initial error reduction observed as K increases from small values (consistent with Figure 4). Quadratic terms, such as the positive coefficient for K2 (β4 = 0.015), capture the characteristic U-shaped curve, ensuring the error eventually increases as K becomes excessively large. Furthermore, interaction terms model the interplay between factors; for example, the positive
Because this empirical formula was derived from pooled data encompassing diverse traffic conditions and experimental settings (sparsity, resolution), it is expected to possess reasonable transferability for estimating a near-optimal K value in similar highway TSD imputation tasks. Data set-specific fine-tuning might yield marginal improvements; this formula offers a valuable and computationally inexpensive starting point. In practice, when encountering a new TSD, the MR and N can be determined, and the formula can be applied. The optimal integer value for K can be estimated by finding the value of K where the partial derivative of Equation 18 for K is zero, for instance, by solving
Effect Analysis of Imputation
Using the imputation process of the NGSIM data set with a cell size of 1 s× 10 m and an MR of 50% as an example to show the modified KNN’s mechanism. With the optimal K value obtained through traversal, the model required only three iterations to fill in all the missing values. The imputation process is shown in Figure 6.
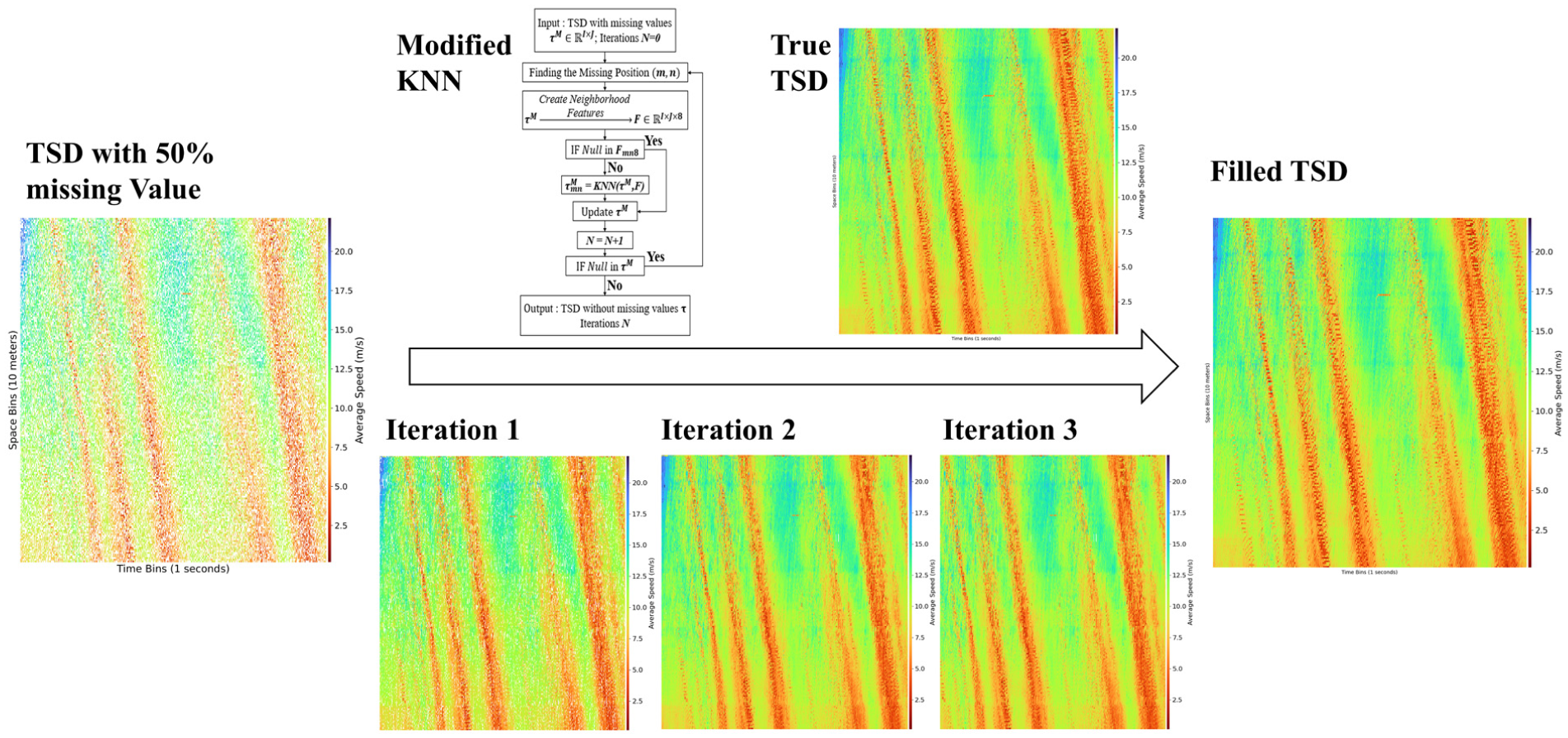
Example of imputation process.
Comparative results for imputation accuracy, shown in Figure 7, reveal nuanced performance characteristics across the models. The DL approach, TSR-GAN, frequently achieved the lowest MAPE, particularly at lower resolutions and intermediate MRs at high resolution; its advantage was not universal, especially considering its computational overhead. The proposed modified KNN demonstrated remarkably strong and consistent performance, often yielding MAPE values very close to, and in several instances exceeding, those of TSR-GAN. The modified KNN consistently outperformed MLR, SoftImpute, and KF across nearly all scenarios, showcasing superior accuracy and robustness, especially as data sparsity increased. For example, on the challenging NGSIM 1 s × 10 m data set with 50% missing data, the modified KNN’s MAPE was substantially better than MLR, SoftImpute, and KF. The SoftImpute model showed notable strength on the UTE 1 s × 10 m data set, achieving the best accuracy among non-DL methods at higher missing rates (e.g., 12.04% MAPE at 50% missingness), aligning with observations about potential data set-specific suitability. However, its performance on NGSIM was less competitive. The MLR generally exhibited higher errors than the modified KNN, particularly at high missing rates, reinforcing concerns about its stability. The KF, while computationally stable, typically yielded moderate accuracy, often falling behind the modified KNN and TSR-GAN.
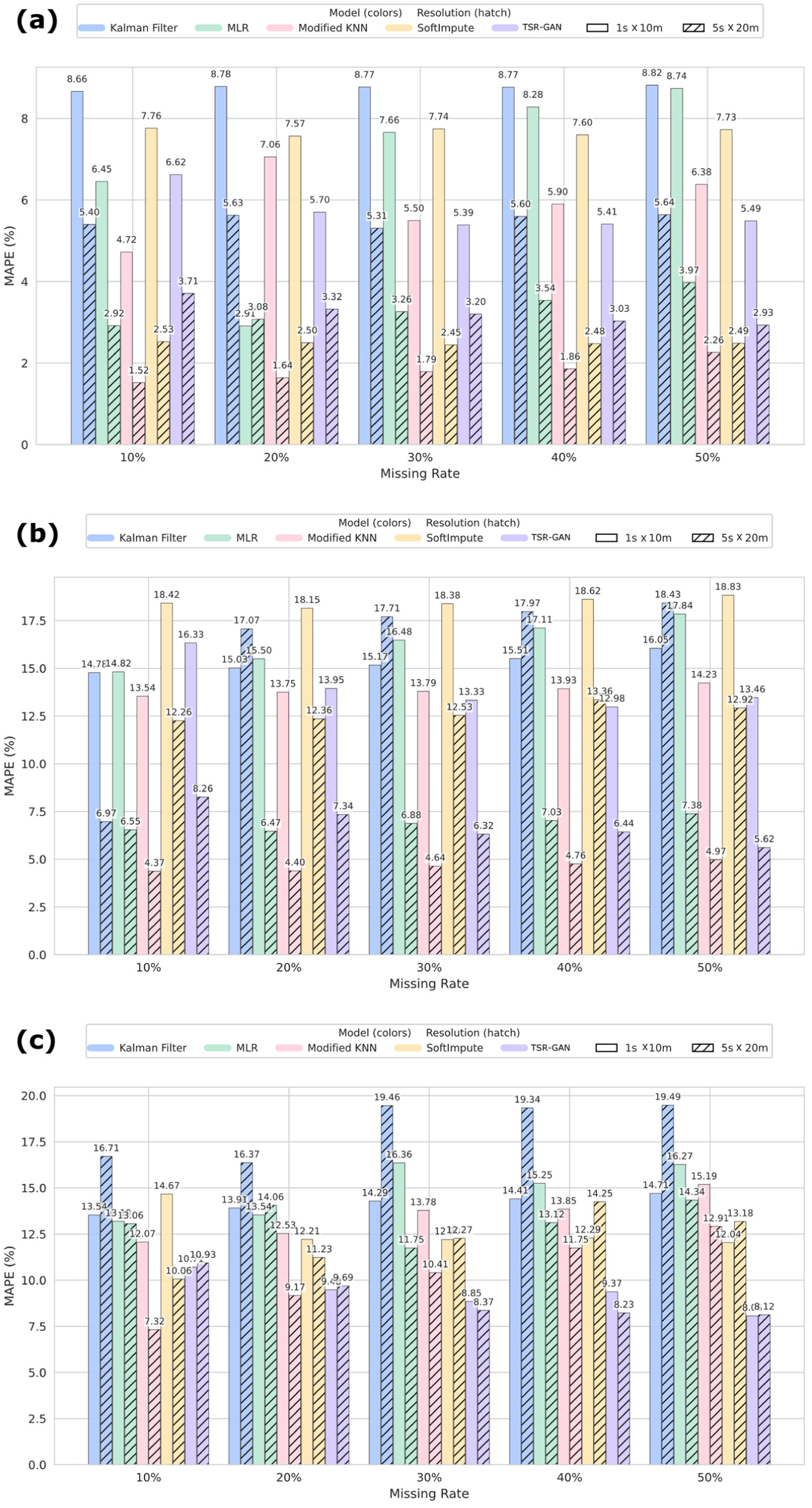
Comparison of model’s MAPE under different conditions: (a) HighD, (b) NGSIM, and (c) UTE.
The analysis of computational efficiency, shown in Figure 8, highlights stark differences in resource requirements. The TSR-GAN consistently demanded the highest computational time, often requiring 10 s or even over 100 s per run, reflecting the intensive nature of the DL model training and inference. In contrast, MLR and SoftImpute consistently demonstrate low computational overheads. The computational time for the modified KNN and KF is data set-dependent but remains significantly lower than that of TSR-GAN. Their execution times showed only marginal increases with rising missing rates, positioning them as computationally lightweight options. The KF occupied an intermediate position; its execution time was significantly higher than the MLR, modified KNN, and SoftImpute, but substantially lower than TSR-GAN, and notably stable across different missing rates because of its noniterative, row-wise processing structure.
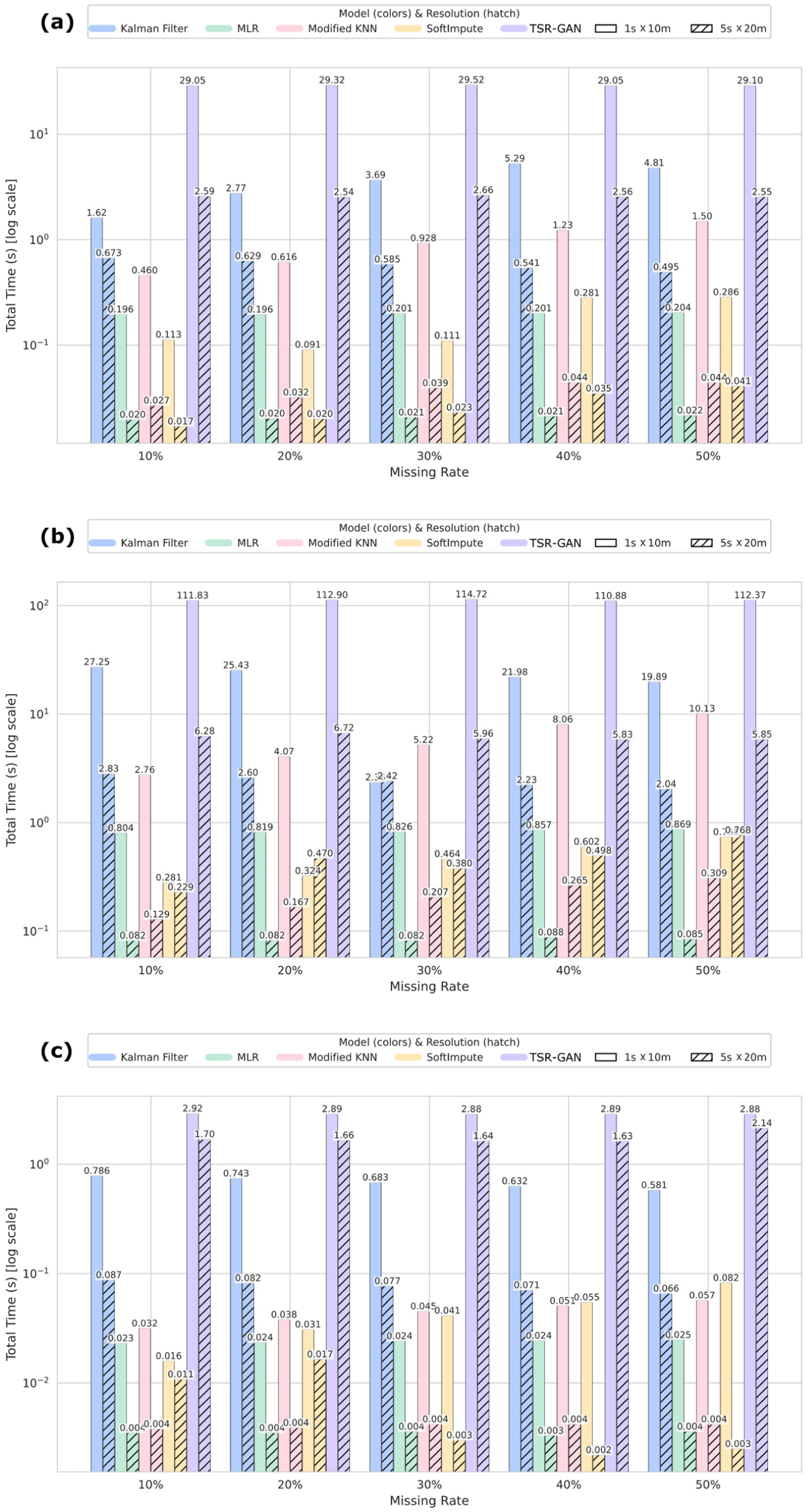
Comparison of model’s computational efficiency under different conditions: (a) HighD; (b) NGSIM; and (c) UTE.
Synthesizing these findings, Figure 9 shows a distinct accuracy–efficiency landscape. TSR-GAN occupies the high accuracy, high-cost corner. In addition, MLR and SoftImpute are low-cost options but often compromise on accuracy or consistency. The KF offers stable, moderate performance and efficiency. The proposed modified KNN algorithm distinguishes itself by occupying a highly advantageous position in this landscape. It delivers accuracy that is consistently among the best, frequently rivaling or exceeding the state-of-the-art DL model, especially at lower resolutions, while maintaining exceptional computational efficiency comparable with the simplest baseline methods. This compelling combination of high accuracy, robustness against data sparsity, and minimal computational overhead makes the modified KNN algorithm a highly practical and effective solution for TSD imputation. Its consistent performance across diverse international data sets further supports its strong transferability and generalizability, rendering it suitable for objective benchmarking and deployment in various ITS contexts where balancing accuracy and efficiency is paramount.
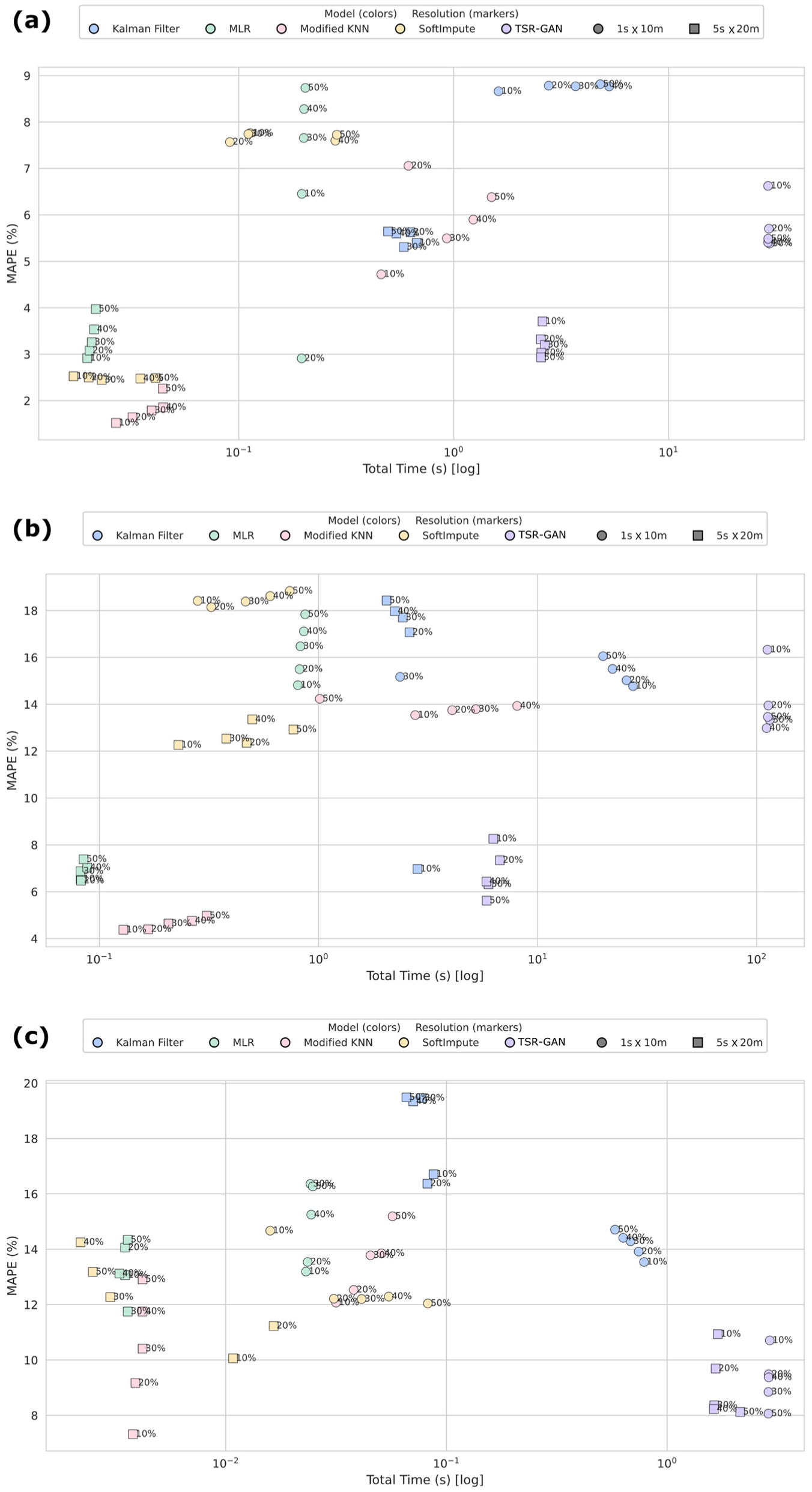
Accuracy–efficiency trade-off of time–space diagram (TSD) imputation models under different conditions: (a) HighD; (b) NGSIM; and (c) UTE.
Influence of Neighborhood Order on Imputation Performance
Selecting appropriate features is crucial to the performance of KNN algorithms. In spatiotemporal data such as TSDs, the neighborhood used to extract features defines the model’s receptive field and influences its ability to capture relevant local traffic dynamics. To systematically investigate the effect of this receptive field size on imputation accuracy, a comprehensive set of experiments was conducted. The “Neighborhood Order” is defined based on the spatial and temporal adjacency layers around a target cell within the TSD grid. Order 1 corresponds precisely to the first-order spatial neighborhood used throughout this study, encompassing the immediate eight neighboring cells surrounding the target cell. Order 2 expands this to include the 24 cells forming the next layer outward (a 5 × 5 grid excluding the central 3 × 3 grid). Similarly, Order 3 includes the subsequent layer of 48 cells (a 7 × 7 grid excluding the central 5 × 5 grid). For each order, the observed values (speeds) within the corresponding neighborhood cells were used as the feature vector for the KNN model. Imputation performance was evaluated across three neighborhood orders across all experimental conditions: three distinct data sets, two spatiotemporal resolutions, and five random missing data rates. The optimal K value determined previously for the first-order neighborhood was used for all orders within each condition for consistency.
The experimental results, shown in Figure 10, reveal a clear and consistent trend across all tested scenarios. The KNN model utilizing the first-order neighborhood consistently achieves the lowest MAPE, indicating the highest imputation accuracy. As the neighborhood order increases from first to second, and then to third, the model’s performance exhibits a persistent and significant degradation, manifested as a marked increase in imputation error. This seemingly counterintuitive outcome, where incorporating more spatiotemporal information leads to poorer results, highlights a fundamental aspect of applying instance-based learning methods such as KNN to traffic flow data. The first-order neighborhood appears to capture the most relevant and highly correlated contextual information necessary for accurately estimating the state of the target cell; this immediate vicinity constitutes the core predictive signal. In contrast, expanding the receptive field to second and third orders introduces information from a broader spatial-temporal region; the correlation between these more distant neighbors and the target cell diminishes rapidly. These distant cells are more likely influenced by different traffic dynamics or perturbations (e.g., upstream bottlenecks or downstream spillbacks occurring further away in time or space), which predominantly act as irrelevant noise or confounding factors within the feature vector. An abundance of such low-correlation features impairs the algorithm’s ability to identify genuinely similar spatiotemporal patterns based on the distance metric, leading to suboptimal neighbor selection and less accurate imputation. In addition, the consistency of this finding across three data sets reflecting diverse traffic characteristics and driving behaviors strongly suggests that for the task of local TSD imputation, the most critical predictive information is invariably contained in the immediate spatiotemporal vicinity. This reinforces the suitability of the first-order spatial neighborhood as the feature extraction method for the proposed modified KNN algorithm and underscores the importance of leveraging local correlations in TSD data imputation.
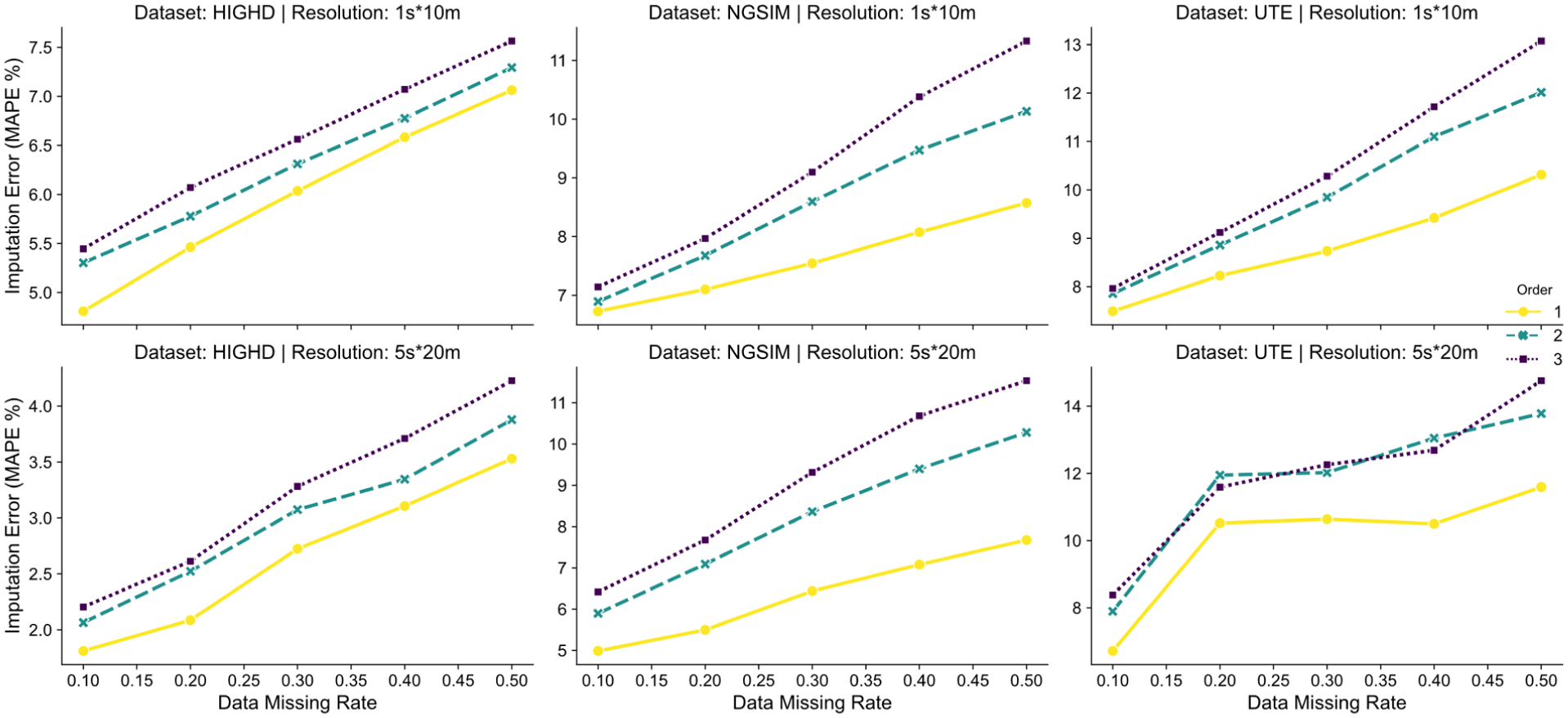
Influence of neighborhood order on imputation performance.
Analysis of Imputation Error Distribution Across Traffic Regimes
To investigate potential biases and assess the robustness of the modified KNN model under varying traffic states, a detailed analysis of the conditional distribution of imputation errors across distinct speed regimes was conducted. For each data set, the free-flow speed was estimated as the 90th percentile of all observed speeds pertaining to that segment. This 90th percentile threshold is utilized as a robust estimator, effectively approximating the unconstrained vehicular speed while remaining insensitive to anomalous low-speed observations. Subsequently, each 5-min interval was classified based on the ratio of its interval mean speed to the estimated free-flow speed. An interval was classified as “Congested-Flow” if the ratio was below 0.6 (
45
). The MAPE for each imputation was classified into four bins: 0%–5%, 5%–10%, 10%–20%, and > 20%. Then, the conditional probability distributions were computed, representing the proportion of errors in each speed regime falling into each error category. To statistically assess whether the observed differences in these conditional distributions were significant, indicating a dependence between error magnitude and speed regime, Pearson’s chi-squared
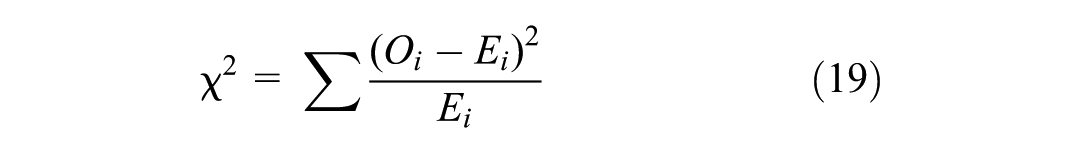
where Oi represents the observed frequency in cell i of the contingency table and Ei represents the expected frequency in cell i under the null hypothesis of independence between speed regime and error bin. The resulting p-values were compared against a significance level of α = 0.05.
The test results shown in Figure 11 revealed statistically significant evidence (p < 0.05) of dependence between the error distribution and speed regime in the vast majority of tested conditions, particularly as the MR increased beyond 10% or 20% across all data sets and resolutions. The consistently significant p-values, often below 0.001, strongly suggest the presence of a systematic bias effect in the modified KNN model’s performance relative to the prevailing traffic state. Although warnings for low expected frequencies occasionally arose, primarily at the 10% MR or in the high accuracy HighD (20 m × 5 s) case, the persistent significance across numerous conditions lends confidence to the overall finding of dependence. In addition, the congested-flow regime consistently exhibits a markedly higher proportion of large errors (> 20%) compared with the free-flow regime. This disparity generally widens as the missing data rate increases. In contrast, the free-flow regime consistently demonstrates a significantly higher proportion of very small errors (0%–5%) compared with the congested-flow regime in almost all conditions where bias was statistically detected.
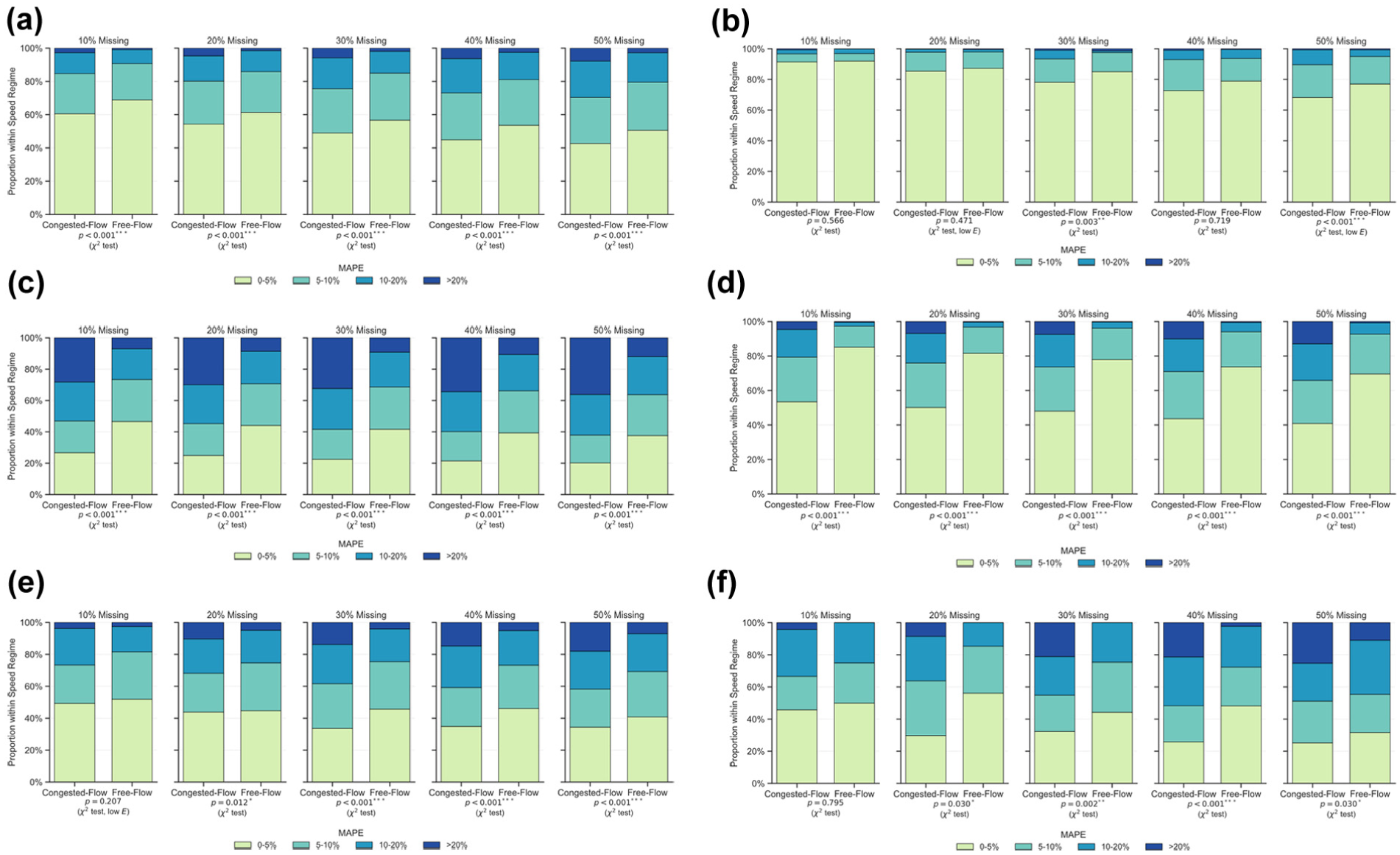
Conditional distribution of modified KNN imputation errors by speed regime and MR: (a) HighD (10 m × 1 s); (b) HighD (20 m × 5 s); (c) NGSIM (10 m × 1 s); (d) NGSIM (20 m × 5 s); (e) UTE (10 m × 1 s); and (f) UTE (20 m × 5 s).
These findings suggest that the modified KNN model’s reliability is contingent on the traffic state being imputed. It appears less robust when estimating speeds during congested conditions compared with free-flow conditions. The inherent increase in speed variability and potentially more complex spatiotemporal dynamics characteristic of congestion probably challenge the KNN algorithm’s core assumption of local similarity, making it harder to find truly representative neighbors and increasing the likelihood of large percentage errors. The model demonstrates strong performance in smoother, high-speed traffic, characterized by a higher concentration of low-magnitude errors; its tendency toward larger deviations in congested regimes represents a notable bias.
Cross-Filling Across Data Sets
The fundamental dynamic characteristics of traffic flow, influenced by human behavior and infrastructure design, exhibit a certain degree of universality. For instance, congestion patterns during peak hours tend to follow similar rules across different areas ( 46 ). When dealing with data sets with high MRs, transferring knowledge from other data sets for imputation is currently an effective solution ( 18 , 47 ). The modified KNN model for imputing missing values in TSDs relies on finding similar spatiotemporal neighborhood features. This simple framework allows the model’s knowledge transfer capabilities to be explored across different data sets. To investigate cross-filling across data sets, a straightforward cross-dataset imputation scheme is designed. It is inferred that dimensional consistency is necessary for a simple model, such as a KNN, to effectively match different data sets. After normalization, differences in dimensions and ranges of data sets are eliminated, enhancing the comparability of traffic characteristics between different data sets. Therefore, the speed data from the three data sets need to be normalized. The normalization results are shown in Figure 12.
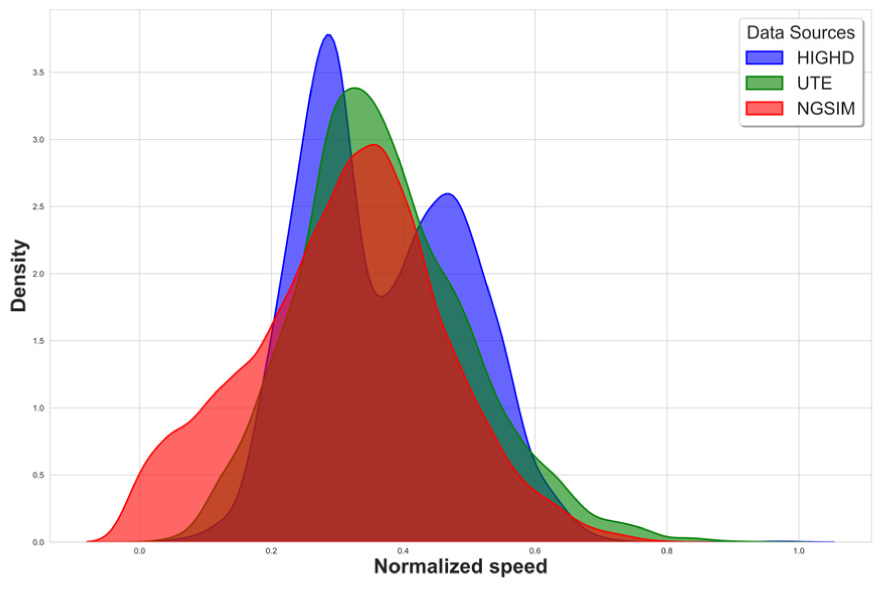
Normalized distribution of three data sets.
Define the sample library for different data sets as Yj, with the corresponding spatiotemporal neighborhood features as Xj. For a specific sample
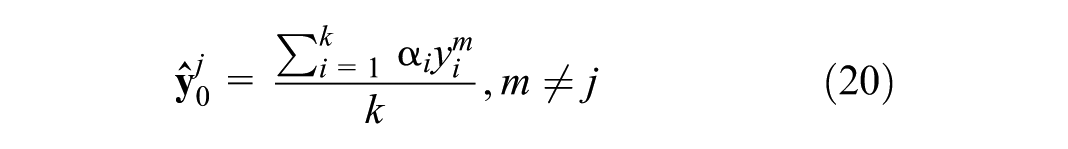
where
To simplify the experiment, the spatiotemporal cell scale was fixed at 5 s×20 m, the number of neighbors was five, and the MR at 10%, using MAPE as the error metric. Jensen–Shannon divergence (JS divergence) was used to measure the similarity between the distributions of the two data sets.
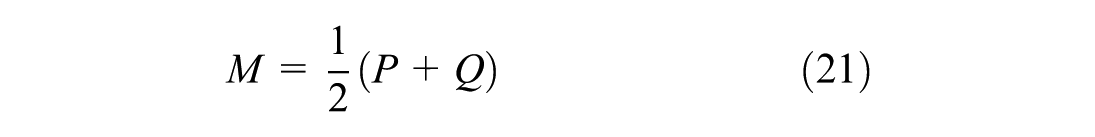
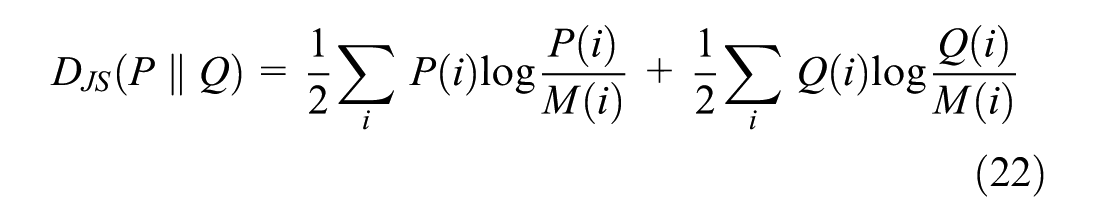
where P and Q represent two different distributions, where lower JS values indicate higher distribution similarity. Table 3 highlights that the accuracy of the cross-data set imputation scheme based on the modified KNN model is basically maintained at a high level. Paired data sets with lower JS divergence values exhibit better imputation performance, indicating that distribution similarity significantly affects the imputation outcome. In cases with higher JS divergence values, multisource imputation performs significantly better than single-source imputation. For example, using both HighD and UTE data sources to impute the UTE data set yields better results than using a single data source. In addition, the imputation effectiveness depends on distribution similarity and the quality and richness of the data sets. Although cross-imputation did not achieve the same level of accuracy as self-imputation within the same data set, it still maintained a high degree of accuracy. This result may be attributed to the high acquisition accuracy and quality of the selected datasets. Therefore, for lower-quality data sets or those lacking sufficient spatiotemporal neighborhood features, self-imputation methods are impractical. In these cases, the value of cross-data set imputation methods becomes more apparent. Designing a reasonable transfer learning framework based on modified KNN methods for cross-data set traffic flow imputation is a direction for future work.
Cross-Data Set Imputation Results
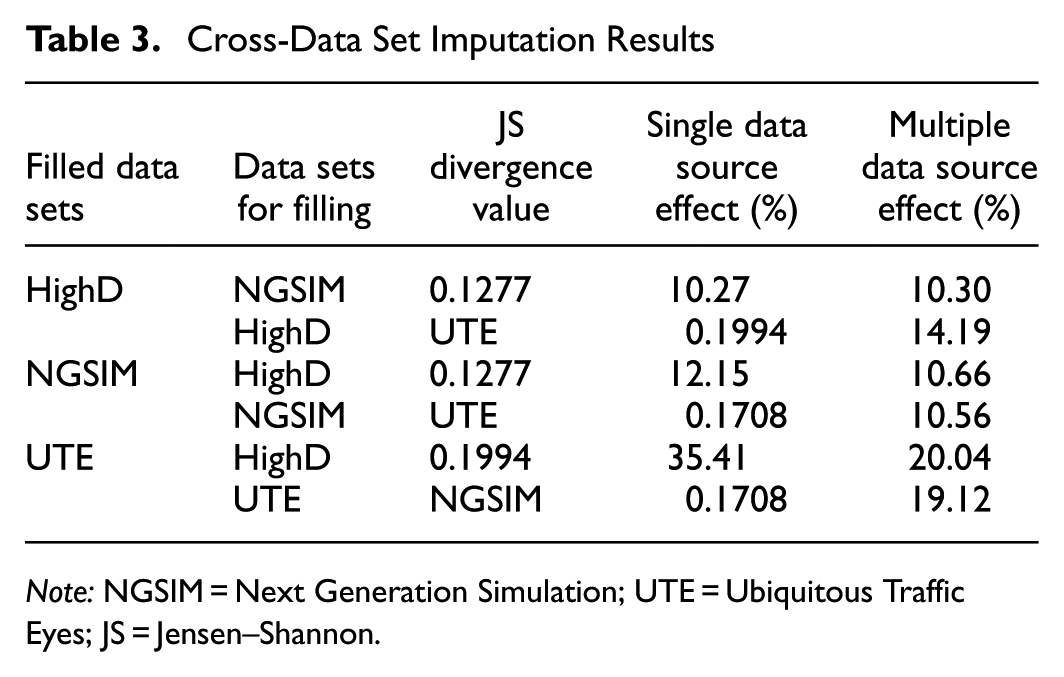
Note: NGSIM = Next Generation Simulation; UTE = Ubiquitous Traffic Eyes; JS = Jensen–Shannon.
Conclusion
The traffic TSD remains a fundamental and efficient tool for visualizing traffic flow dynamics in transportation research and practice. However, data sparsity, stemming from limitations in sensing infrastructure, often hinders the construction and utility of high-resolution TSDs, obscuring crucial details of traffic dynamics. While advanced DL frameworks have demonstrated high precision in imputation tasks, their substantial computational demands, significant parameter counts, and reliance on extensive training data often limit their practical applicability, particularly in resource-constrained or real time ITS environments.
To address these limitations by balancing accuracy and efficiency, this study proposed and evaluated a modified KNN framework incorporating spatiotemporal weighting and an adaptive iterative process for imputing missing data in high-resolution TSDs. Furthermore, theoretical motivation on the stability and convergence of these local weighted averaging methods was provided using analysis inspired by Green’s function within an idealized traffic flow model context, supported by numerical simulations. The adaptive iterative mechanism proved crucial for handling high missing rates effectively, enabling robust imputation while maintaining the model’s inherent simplicity, relying primarily on a single key parameter, K. Rigorous validation was performed using diverse trajectory datasets from the United States (NGSIM), Germany (HighD), and China (UTE) under 30 distinct experimental conditions encompassing two spatiotemporal resolutions and five levels of random data sparsity ranging from 10% to 50%. Compared against a comprehensive suite of baseline models, including MLR, SoftImpute with Alternating Least Squares (SoftImpute-ALS), KF, and TSR-GAN, the proposed modified KNN framework demonstrated a compelling balance between high imputation accuracy and exceptional computational efficiency. It consistently achieved accuracy competitive with, and occasionally surpassing, the computationally intensive TSR-GAN, while significantly outperforming the other baseline methods, particularly showcasing strong robustness under high data sparsity conditions. A practical empirical formula relating the optimal parameter K to data sparsity and data set size was derived via polynomial fitting on pooled data, offering an efficient method for parameter estimation in practice and significantly reducing the need for computationally expensive parameter searches. Further analysis confirmed the effectiveness of using the immediate first-order neighborhood for feature extraction, demonstrating that incorporating higher-order neighbors tended to degrade performance by introducing noise. In addition, a preliminary investigation into cross-data set imputation highlighted the model’s potential for knowledge transfer, particularly when leveraging multiple source data sets or data sets with similar underlying traffic flow distributions.
Given the importance and widespread use of TSDs, the proposed modified KNN imputation framework offers a significant contribution by providing a practical, robust, and computationally efficient tool to enhance the resolution and completeness of traffic state data. However, certain limitations should be acknowledged. The reliance on immediate spatiotemporal neighbors and Euclidean distance in feature space, while effective and computationally simple, may not fully capture all complex real-world traffic correlations. Furthermore, the analysis of error distribution revealed a tendency for the KNN model to exhibit larger percentage errors under congested conditions compared with free-flow states, indicating a potential performance bias relative to the traffic regime. Future research should be directed toward addressing these limitations. Enhancements to imputation accuracy could be pursued by exploring more sophisticated feature engineering or non-Euclidean distance metrics to better encapsulate traffic dynamics and mitigate the observed performance bias under congestion. To address scalability for large-scale TSDs, optimizations, such as KD-Tree indexing for accelerated neighbor retrieval or parallelization of the iterative process, require systematic investigation. The cross-data set imputation framework could also be enhanced by incorporating formal transfer learning techniques to improve performance in cases of extreme data sparsity. Finally, evaluating the proposed method’s performance specifically against structured missing data patterns remains an important avenue for future work.
Supplemental Material
sj-docx-1-trr-10.1177_03611981261419011 – Supplemental material for A Simple Yet Efficient K-Nearest Neighbor-Based Method for High-Resolution Traffic Time–Space Diagram Imputation
Supplemental material, sj-docx-1-trr-10.1177_03611981261419011 for A Simple Yet Efficient K-Nearest Neighbor-Based Method for High-Resolution Traffic Time–Space Diagram Imputation by Junjie Hu, Jaeyoung Jay Lee, Jun Bai and Suyi Mao in Transportation Research Record
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Junjie Hu, Jun Bai; data collection: Junjie Hu; analysis and interpretation of results: Junjie Hu, Jaeyoung Jay Lee; draft manuscript preparation: Junjie Hu, Jaeyoung Jay Lee, Jun Bai, Suyi Mao. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Jaeyoung Jay Lee is on the Transportation Research Record’s Editorial Board. His role is a handling editor. This potential conflict of interest has been acknowledged by all authors, and no part of the editorial decision-making process was influenced by his involvement.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the Natural Science Foundation of China under Grant No. 72471249, the Natural Science Foundation of Changsha under Grant No. kq2402221, and the Changsha Major Science and Technology Project (No. kh2401002).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.