
Abstract
This work presents the LLM-enhanced general transportation agent, a novel framework that leverages large language models (LLMs) to simulate individual-level human mobility behavior. Unlike prior approaches that treat LLMs as generic predictors or planners, this framework employs role-play prompting and synthetic sociodemographic profiles to position LLMs as simulated individuals responding to household travel surveys. The system integrates population synthesis, persona-rich prompting, structured response tools, a dynamic survey engine, and an LLM-as-a-judge evaluation method to generate and vet context-aware, realistic behavioral data. Case studies in Chicago, USA and Lyon, France demonstrate cross-linguistic adaptability and behavioral fidelity, while highlighting challenges in non-English contexts. Quantitative evaluation shows that midsized and smaller models most accurately reproduce empirical travel survey distributions, whereas larger instruction-tuned models generate more coherent and naturalistic responses. Smaller models exhibit greater susceptibility to logical inconsistencies and stereotyped language, emphasizing potential bias propagation in synthetic datasets. The framework enables scalable, model-agnostic synthetic mobility data generation and supports applications such as scenario prototyping, discretionary activity simulation, travel diary construction, and integration into agent-based and microsimulation transportation models.
Introduction
Travel demand surveys are a foundational component of transportation planning, providing insights into the reasons why people travel in a region ( 1 ). These surveys collect critical data on travel behavior such as trip purpose, mode choice, trip frequency and duration, which are essential inputs for validating and calibrating travel demand models. In turn, these models inform critical decisions concerning infrastructure investments, policy making, and operational strategies.
By capturing individual and household travel patterns, travel surveys allow planners to evaluate current transportation infrastructure and practices, forecast future demand, and evaluate future transportation systems in response to evolving mobility needs and shifting societal focuses. However, the collection of high-quality travel survey data remains complex and resource intensive, often posing significant financial and logistical challenges for regions with limited planning capacity.
As transportation systems evolve in response to new mobility options such as ride-hailing, micromobility, and emerging automation technologies, the demand for timely, granular, and flexible travel data has grown. Traditional travel surveys, while methodologically rigorous, often fail to keep pace with these dynamic shifts because of their cost and infrequent deployment. Recent advances in large language models (LLMs) offer a promising alternative for generating synthetic yet realistic travel survey data.
Transportation researchers have so far largely adopted LLMs in a limited capacity, often treating these large models as black-box predictors or domain experts that provide high-level insights or demand forecasts. This use treats LLMs as static tools, relegated to analysis applications that lack behavioral nuance and do little more than what simpler, faster, machine learning models can already achieve. Tasks such as demand forecasting, trip classification, or mode choice prediction have long been addressed using conventional models such as decision trees, random forests, or gradient boosting ( 2 , 3 ). Applying LLMs to these problems without leveraging their unique strengths leads to unnecessary complexity and computational cost.
In contrast, LLM agents, autonomous, heterogeneous entities powered by LLMs that are capable of reasoning over multiple steps, maintaining internal state, and using external tools, offer a more compelling paradigm. Rather than asking an LLM to describe or predict travel behavior from a top-down, system-wide perspective, an LLM agent can inhabit the role of a traveler, responding to survey prompts as a simulated individual making travel decisions within a defined context. The approach more naturally aligns with the behavioral structure of traveling individuals and offers a way to generate synthetic data that is not only context aware, but also behaviorally rich and responsive to scenario variation. Leveraging LLMs in this agent-based way may yield more accurate, transparent, and adaptable synthetic travel data, especially for regions facing constraints in traditional data collection.
To evaluate this approach, this research presents a transportation LLM agent designed to simulate individuals and their travel survey responses across a range of demographic profiles. This agent is prompted to adopt the identity of a traveling individual, sampled from a data-driven population synthesis generation, and tasked with completing household travel surveys (HTSs) for two case locations: Lyon, France, and Chicago, Illinois, United States. The main contributions of this work are:
A novel LLM-integrated transportation agent framework for human mobility modeling. This work introduces the first general-purpose transportation agent powered by an LLM, specifically designed to simulate individual travel behavior and generate synthetic HTS responses. Unlike traditional survey synthesis methods, our approach enables dynamic, contextual responses that reflect nuanced behavioral reasoning.
A new LLM-enhanced agent-based simulation approach grounded in realism and demographic fidelity. By prompting LLM agents to adopt the identity of synthetic individuals sampled from population synthesis outputs, this framework produces survey responses that mirror real-world heterogeneity in travel needs and decisions. This capability enables metropolitan planning organizations, departments of transport, and city agencies to test how survey design, policy scenarios, or demographic shifts may influence future travel patterns—without requiring costly and time-intensive field data collection.
A reproducible and flexible tool for planners and modelers. The methodology offers a transparent, customizable pipeline for generating synthetic travel survey data that integrates seamlessly into existing agent-based modeling frameworks. It supports enhanced scenario testing and sensitivity analysis, allowing planners to simulate responses to emerging transportation services, infrastructure changes, or behavioral interventions. Currently, this framework is capable of generating synthetic travel survey data for every metropolitan region in the United States and France.
This framework is unique in its core design philosophy, positioning LLMs not just as passive predictors, but as simulated individuals responding to survey prompts with rich, context-aware reasoning. By combining population synthesis with persona-driven prompting, it captures the behavioral complexity and heterogeneity of travel decisions in a way traditional models cannot. This approach is especially useful for planners, transportation agencies, and researchers who need flexible, scalable synthetic data to test scenarios, evaluate policies, or fill data gaps—particularly in regions where traditional travel surveys are costly or infrequent. The framework’s adaptability and transparency make it a practical tool for exploring emerging mobility trends, assessing infrastructure changes, and integrating AI-driven agents into travel demand modeling, ultimately supporting more informed and responsive transportation planning.
Related and Theoretical Background
Travel Survey Overview
In the United States, the National Household Travel Survey (NHTS) serves as the primary source of nationwide travel behavior data. Conducted periodically by the Federal Highway Administration, the NHTS captures detailed information on daily travel patterns, including trip purpose, mode, time of day, and household demographics. At the regional level, more granular surveys are often conducted to better reflect local travel behavior. For example, the Chicago Metropolitan Agency for Planning (CMAP) conducted the My Daily Travel Survey in 2019 to gather comprehensive travel within the greater Chicagoland area. This survey builds on the NHTS framework by including questions relevant to travel in northeastern Illinois and conducting a larger sample size for the region.
In France, a similar role to the CMAP survey is played by the Enquête Ménages Déplacements (EMD), or Household Travel Survey, which is typically conducted at the metropolitan level under the coordination of local authorities and the French Ministry of Ecological Transition. The EMD collects comparable data on individual and household travel behavior within urban and surrounding rural areas, such as the aire métropolitaine lyonnaise (Lyon metropolitan area), serving as a key input for regional transport modeling and policy development. In addition, in the Île-de-France region, the Enquête Globale Transport (EGT) serves as a large-scale HTS that provides detailed insights into travel behaviors across Île-de-France, the Paris metropolitan area. Coordinated by Île-de-France Mobilités, the EGT includes data on trip frequency, duration, mode choice, and sociodemographic characteristics of travelers, and plays a central role in long-term transportation planning and infrastructure investment decisions in the region.
Table 1 summarizes travel surveys in United States and France, the number of recipient households recorded, and the trips reported by those households from the last 35 years.
Overview of Travel Surveys for the United States and France
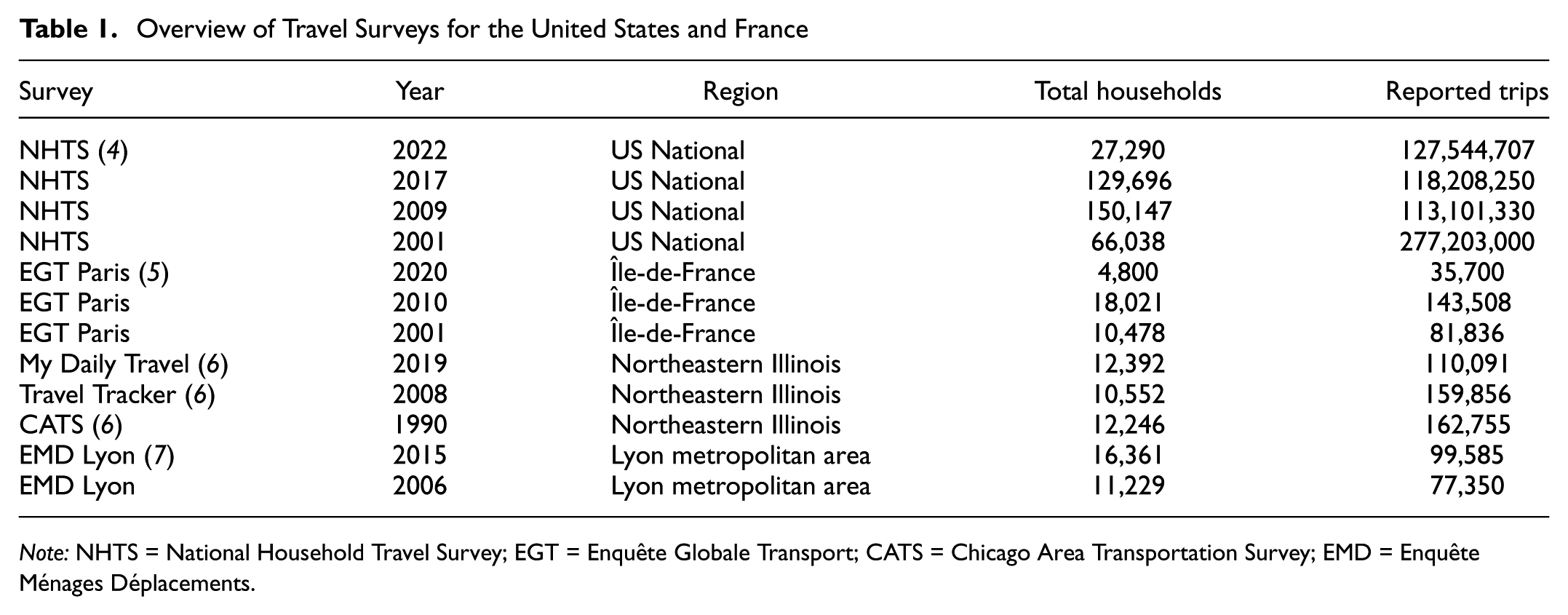
Note: NHTS = National Household Travel Survey; EGT = Enquête Globale Transport; CATS = Chicago Area Transportation Survey; EMD = Enquête Ménages Déplacements.
Sample Rates and Underrepresentation
Stopher and Greaves ( 8 ) note that in the early days of transportation planning, travel survey sample sizes were often as large as 1%–3%, but they had dropped to less than 0.5% by 2006. Extrapolating these findings to the My Daily Travel and EGT Paris surveys, the latest iterations report a sample rate of 0.04% and 0.07%, respectively.
These sample rates can also fluctuate by region, the authors of the Chicago Area Transportation Survey (CATS), a precursor to the current My Daily Travel survey, discussed that while the total sample rate of the survey was only 0.73% throughout the northeastern region of Illinois, the majority of the City of Chicago was sampled at a rate of 0.22% of the population ( 6 ).
Small and inconsistent sample rates complicate the process of scaling results to represent broader populations. Even modest errors or biases at the household level can become magnified, leading to statistical concerns in downstream applications. Habib et al. ( 9 ) investigated this further in the Greater Toronto Area and concluded that even at a 4% sample size, a full representation of the analysis population and its travel behavior would be statistically challenging. In fact, this sample size would fail to capture smaller subregions as certain travel modes and segments of the population would still be underrepresented.
Underrepresentation and survey quality issues compound even further for developing countries and low-income populations. For example, the 2012 HTS conducted in Medellín, Columbia comprised 20,000 (2% population sample) face-to-face interviews. An analysis of those results concluded a trip rate of 1.7 per inhabitant, a questionably low result ( 10 ). The HTS operators further noted that poor working conditions, traffic problems, irregular travel behavior (predominantly because of the FIFA U-20 World Cup at the time), and restricted access to high-income individuals in certain areas presented difficulties in the data collection process. Moswete and Darley ( 11 ) discuss similar issues with their research on HTS in sub-Saharan African countries and explain that because of the vast economic and cultural subgroups in these countries, further issues arise, leading to higher nonresponse rates. The researchers alluded to a rise in nonresponse rates when there were ethnic, gender, and age differences between the interviewer and respondent, and entire groups of people could be omitted from the survey collection process, pending approval from a village or family head.
Naturally, the United States is not without these issues as well. Bills and Esekhaigbe ( 12 ) reviewed 43 regional and state travel surveys in the United States and discovered that many HTS underreported low-income, transit-dependent, unemployed, and minority ethnicized groups, with only 11 of the 43 reasonably representing these groups well, with 85% of these surveys overrepresenting white travelers. The group suggests that using an exogenous income and race-based sampling method, combining GPS and phone data retrieval modes, and offering higher incentives for hard-to-reach survey participants can better represent these disadvantaged groups.
Large Language Models
LLMs are a class of machine learning models designed to generate text. As the name suggests, they are a type of language model whose primary purpose is to capture the probability distribution of natural language. This probability is expressed by the chain rule of probability:
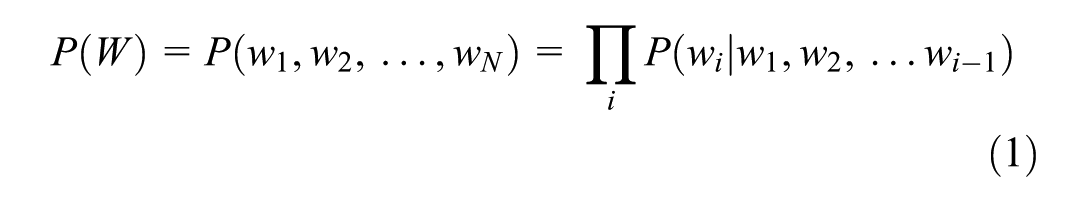
Formally, for a sequence of words,
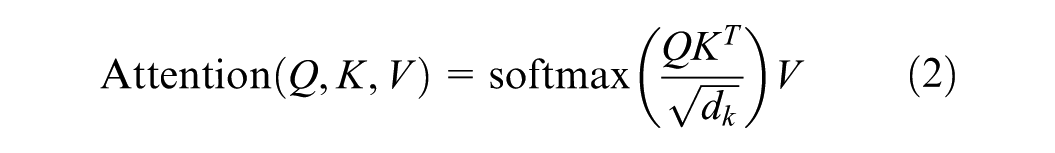
where Q, K, and V are query, key, and value vectors, derived from learned representations of each token in a sequence. The softmax function converts the scaled dot product
The final step in the construction of an LLM consists of posttraining routines to align models with human intent and establish safety considerations. The most common method uses supervised fine-tuning on high-quality datasets, followed by reinforcement learning from human feedback. This process involves human interlocutors ranking model outputs to form a reward model, from which LLMs can learn preferred response behavior ( 16 , 17 ). These alignment techniques control behaviors such as truthfulness, coherence, and safety. These large-scale models are colloquially known as foundation models, which can be adapted to a wide range of downstream applications with minimal task-specific modifications.
Properties of LLMs
The architecture and training data inherent to LLMs give rise to emergent properties that make the class of model excel both in and out of an autonomous agent context. One of the most significant properties is few-shot learning, the ability to generalize from a handful of examples provided to the LLM at inference time without any additional context or training. Furthermore, Kojima et al. ( 18 ) note the performance of zero-shot reasoning, where models infer solutions to complex problems, enabled by patterns absorbed during model training. Finally, chain-of-though (CoT) prompting has emerged as a powerful method for improving reasoning. Wei et al. ( 19 ) noted that by encouraging models to generate intermediate steps toward a solution, analogous with human logical reasoning, CoT significantly improves performance on tasks that require multiple steps, arithmetic, or commonsense logic. Given these emergent reasoning capabilities, LLMs offer a compelling foundation for building autonomous agents that require human-like planning and adaptability.
In deployed systems, LLMs are typically accessed through cloud-based application programming interfaces, where they serve as the computational engine behind applications such as chatbots, assistants, and domain-specific agents. These interactions are often mediated by an initial system prompt, a block of instructions, or context provided before the user ever inputs a message. This prompt sets the behavioral tone, constraints, and intended capabilities of the model, shaping its responses throughout the session. For example, a system prompt might instruct the model to “act as a helpful transportation researcher,”“avoid speculation,” or “respond in concise bullet points.”
Mitigating Biases and Safety Considerations of LLMs
An ongoing area of research is the detection of bias inherent to LLMs and proposed debiasing and mitigation methods. LLMs are trained on an enormous repository of uncurated data from the internet, and thereby inherit stereotypes, derogatory language, and other negative behaviors that disproportionately affect vulnerable and marginalized communities ( 20 ). These negative effects constitute “social biases,” a normative and subjective term that describes the disparate treatment of different social groups originating from asymmetrical historical and systematic power structures. Furthermore, not only has the presence of existing biases in LLMs been well documented ( 21 , 22 ), but the automated nature of LLM responses can also amplify and reinforce these negative biases ( 23 ).
Detecting and mitigating bias in LLMs is often described at the technical level, such as fine-tuning a model for “fair” responses ( 24 ) or filtering training data to obtain a more representative perspective of social groups ( 25 ). However, what is commonly left out of the research discussion is which social groups and people are harmed, why such behavior exhibited by LLMs are harmful, and how this harm reflects and reinforces social systems and hierarchies ( 26 ). That being said, while every measure has been taken to mitigate harmful content in this work, the degree of bias introduced in this framework is primarily a function of the foundation models used in the LLM-enhanced general transportation agent framework.
LLM Research in the Transportation Domain
As stated in the introduction, while LLMs have found application in the transportation research space, their use has remained relatively narrow and underutilized. Most studies approach LLMs in passive, analysis-oriented roles. These applications broadly fall into the categories of traffic forecasting, human mobility, demand forecasting, and missing data imputation ( 27 ).
For example, Guo et al. ( 28 ) developed a traffic flow prediction model by converting multimodal traffic data into natural language descriptions. This model incorporates the open-source Llama2 foundation model. It uses a fusion of spatial information, historical traffic volumes, date and special-event contexts, and weather information to generate a traffic prediction and text explanation of the prediction. Chen et al. ( 29 ) integrated the GPT-2 model in a regression framework to impute missing traffic data by combining spatiotemporal sensor data and time-series traffic flow data in an embedded format that LLMs can easily process. Most pertinent to this research, Xu et al. ( 30 ) developed a zero-shot prompting framework that leverages GPT-3.5 to predict travel behavior such as mode choice and trip purpose without requiring any training data. They demonstrate that their approach delivers competitive performance compared with traditional models such as multinomial logit, random forest, and neural networks, particularly in data-scarce situations, while also providing interpretable reasoning behind predictions.
Current approaches continue to underutilize the generative strengths of LLMs, often embedding them as static components within larger modeling frameworks or prompting them from the perspective of a domain expert or helpful assistant. These roles, while convenient for analysis or interpretability, limit the model’s potential to simulate behavior in a dynamic, context-aware manner. Treating the model as a narrator or regression tool strips away its capacity to act as an agent, one capable of making decisions, adapting to inputs, and generating outputs reflective of individual-level variability. This framing overlooks the behavioral richness that LLMs can offer when prompted from the bottom up, as a traveler embedded within a specific demographic and geographic profile.
Methodology
In response to a gap in the use of LLMs for human mobility research, this article introduces an LLM-enhanced general transportation agent framework for human mobility forecasting tasks that positions LLMs as simulated individuals engaged in travel behavior tasks, with the initial use-case scenario of HTS completion. Unlike prior work that treats LLMs as generic predictors or planners, this framework prompts models to role-play as distinct individuals, each with their own synthetic sociodemographic profile and behavioral context. The agent is not simply answering questions, but also responding as if it were a real person partaking in a HTS, conversing with a survey administrator. This role-based interaction represents a novel use of LLMs and enables more realistic, human-like behavioral outputs.
To our knowledge, this is the first LLM-enhanced framework developed specifically for individual-level human mobility forecasting within the transportation research domain. While LLM agents have been explored in other areas, the use of role-play as a core mechanism for simulating behavior in transportation surveys is both novel and foundational to this approach.
Traditional agent-based models often rely on static heuristics or narrowly trained policies, which constrain agents to limited, preprogrammed responses. By contrast, recent advances in LLMs have enabled agents to generate intelligent, adaptive responses based on context and instruction. Wang et al. ( 31 ) propose a general architecture for LLM agents composed of four modules: a persona module defining agent identity, a memory module for storing past interactions, a planning module for breaking down tasks, and an action module for executing decisions.
This work builds on and modifies that architecture for human mobility forecasting. It includes: (1) a population synthesizer, which creates a heterogeneous agent population from real-world sociodemographic data; (2) a persona module, which embeds role-specific information and role-playing instructions directly into the prompt; (3) an action tool set, used by the agent to generate structured responses; and (4) an event engine, which presents a dynamic series of travel survey questions and decision points. Figure 1 gives an overview of the framework, data inputs, and proposed modeling outputs and evaluation metrics.
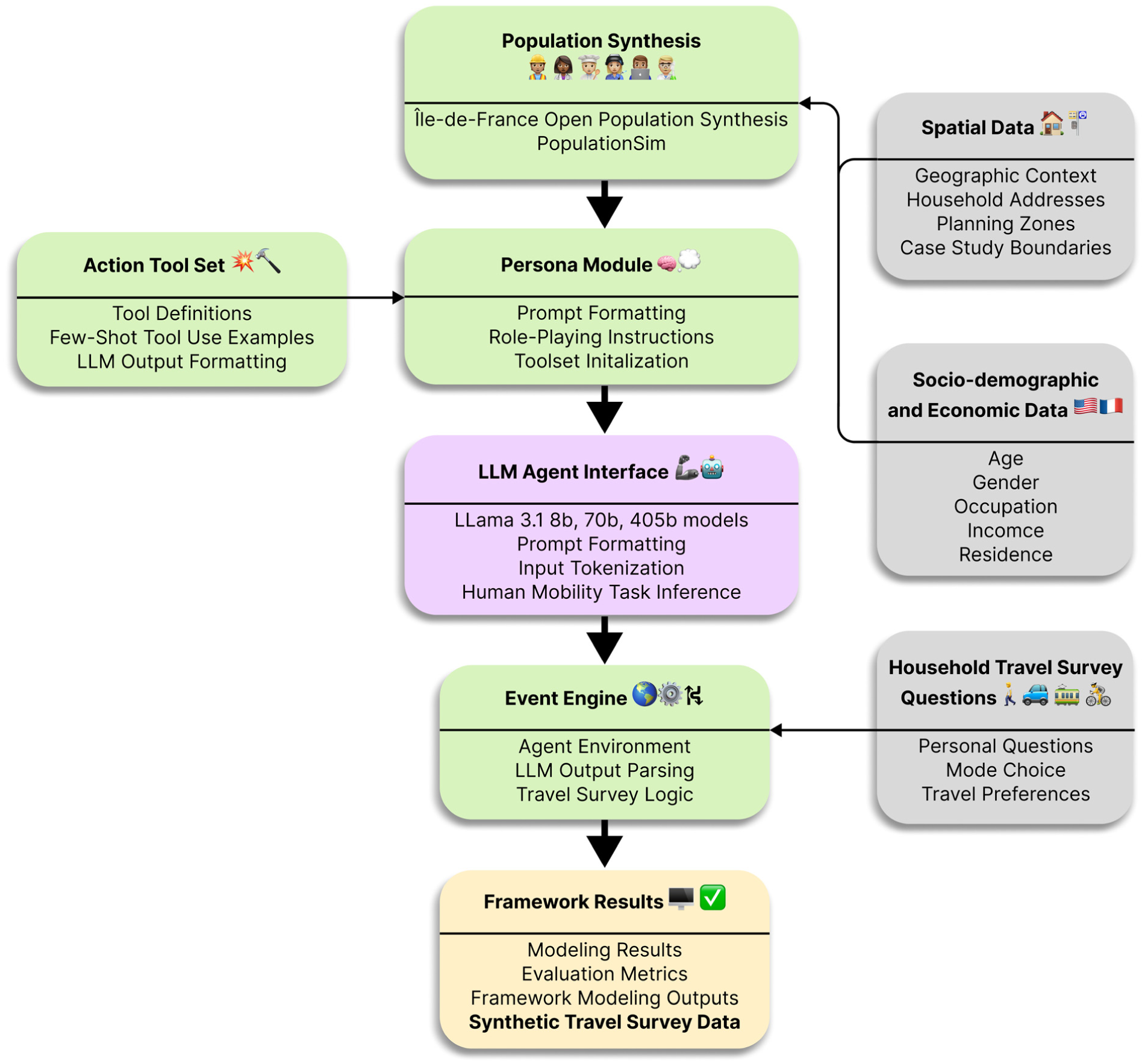
LLM-enhanced general transportation agent framework.
Population Synthesis
The first step in the LLM-enhanced transportation agent framework is population synthesis, the creation of artificial population data that fits the distribution and characteristics of the two case study locations of Lyon, France, and Chicago, Illinois. For Lyon, a synthetic population was constructed using the reproducible methodology introduced by Hörl and Balac ( 32 ) in 2021. Although their work targeted the Île-de-France region, the pipeline was easily adapted to the Lyon metropolitan area by leveraging the method’s input source of publicly available sociodemographic and spatial datasets. The data sources for this population synthesis method comprised Institut National De la Statistque et de Études Économiques (INSEE) census microdata, Base Adresse Nationale spatial zone data, and OpenStreeMap spatial network data, all relevant to the Lyon metropolitan area.
The synthesis pipeline cleans and transforms the raw datasets and applies a chain of models for population generation, household income assignment, and trip activities. However, for the purposes of this research, only the first two steps of the population synthesis procedure were needed. Population generation was constructed by scaling up instances of the INSEE census data by expansion weights provided by the census tables. Income assignment followed Hörl and Balac’s approach by using regional-level income distribution data to impute income brackets to each household. These assignments were probabilistic, reflecting the heterogeneity of income levels observed across the Lyon area, and informed by household size, employment status, and geographic location.
For the Chicago case study, population synthesis was facilitated by PopulationSim, an open-source platform for synthetic population generation and survey weighting developed by Paul et al. ( 33 ). PopulationSim uses an entropy-maximization approach to iteratively assign weights to microdata samples so that the resulting synthetic population matches known marginal distributions at various geographic levels. The main advantage of this approach, that the authors note, is that PopulationSim optimizes across all zones simultaneously. This simultaneous balancing prevents error accumulation in smaller or last-processed zones and allows records to be shared across geographies, improving representation of rare or underrepresented subgroups. The synthetic population for Chicago was generated using the Public Use Microdata Sample (PUMS) data and the American Community Survey marginal controls, with integerized household-level outputs suitable for downstream integration in agent-based transportation models, and this work’s LLM-enhanced transportation agent framework.
Persona Module
The persona module defines the identity of each agent in the framework by embedding role-specific information and behavioral context directly into the LLM prompt. Drawing from the synthesized population data described previously, each agent is assigned a unique sociodemographic profile directly from the original census data used in synthetic population generation. For Chicago, the 2019 PUMS sample was used, and for Lyon, the 2021 INSEE census data. Table 2 provides a summary of the sociodemographic variables used for each case study. Selected features were based on the availability of recorded variables from the PUMS and INSEE censuses.
Variable Overview of PUMS and INSEE Census Sample Data
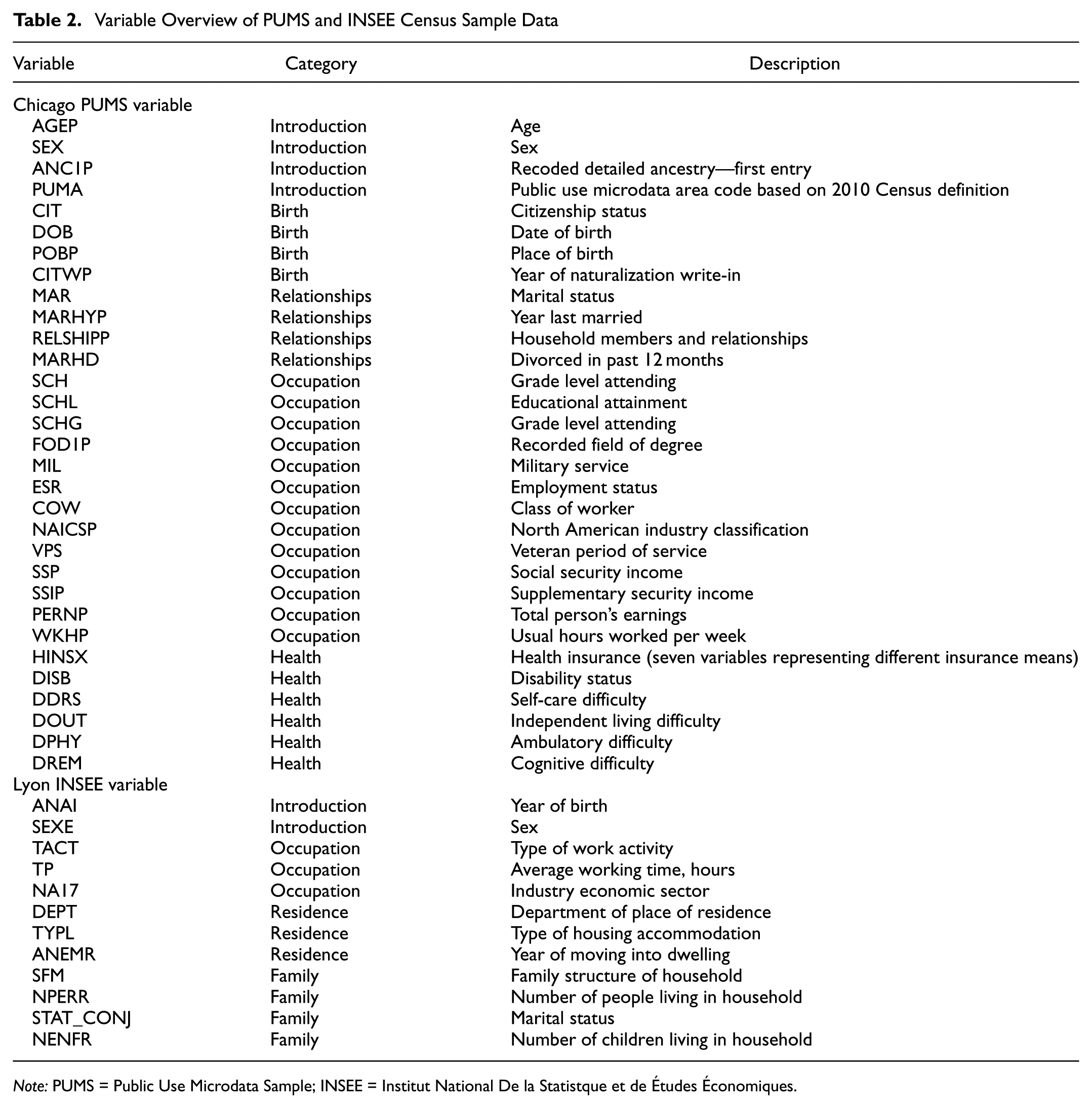
Note: PUMS = Public Use Microdata Sample; INSEE = Institut National De la Statistque et de Études Économiques.
The encoded variables from the censuses were then matched back to the PUMS and INSEE supporting data dictionaries to obtain plain-text descriptions of each census variable. The variables were then grouped by contextual significance to create prompt components describing the agent’s birth, family and relationships, occupation, healthcare status, and general introduction. Notably, the INSEE census collected much less information than the PUMS census (e.g., the INSEE census does not collect income or race information), so fewer variables were used to construct the French persona description. Additional logic is incorporated during prompt creation to account for any missing data instances, and unnecessary information or conflicting characteristics (e.g., specifying an individual has served for zero years in the military or implying a retiree is a full-time student). Following this persona construction, a footer is appended to the prompt with instructions on assuming the identity of the described agent, and guidance on how to respond in a suitable role-playing manner.
Framework Design Considerations
While LLMs are capable of generating fluent, contextually appropriate responses, it is important to acknowledge the limitations of their design. As Bender et al. ( 34 ) describe, LLMs function as “stochastic parrots,” systems that generate text by identifying and reproducing patterns found in large-scale training data. They do not possess intent, understanding, or consciousness, and any appearance of reasoning or personality is a result of statistical associations rather than cognitive processes.
In this framework, the role-play-based approach does not imply that the model has agency or self-awareness. Rather, it reflects a structured method of conditioning language output based on the attributes of a given synthetic persona. The LLM is not “becoming” the person described; it is simply producing responses that align with the linguistic and behavioral patterns associated with similar individuals in the training data. Accordingly, responses should be interpreted as plausible approximations, not as literal behavioral forecasts or psychographic profiles.
Nevertheless, there is something to be said for these models being trained on human-generated language, shaped by lived experience, culture, and social behavior. Even though LLMs do not understand context in the human sense, they can still produce text that reflects realistic social and behavioral patterns when appropriately grounded in data. This makes them a useful tool for simulation tasks where structured variability and context-sensitive responses are desirable. Recognizing and leveraging this property, treating the LLM as a grounded, role-playing generator of plausible human behavior, is the central design decision that underpins the transportation agent framework introduced in this work.
Role-Play Instructions
To support this design decision, the persona description is followed by instructions on how the model should adopt and maintain the role of the described individual throughout the interaction. These instructions are appended as a footer in the prompt and serve to align the model’s outputs with the intended behavioral framing of a HTS participant.
These instructions were adapted from the work of Wang et al. ( 35 ) and their RoleLLM framework. Their framework provides guidance on maintaining role consistency in multiturn interactions by prompting LLMs to internalize role identity, avoid breaking character, and simulate coherent behavior over time. In their evaluation, Wang et al. demonstrate that explicitly defined roles—combined with contextual constraints—significantly improve response consistency and alignment in long-form interactions.
In this framework, similar principles were applied to shape how the LLM responds as a synthetic individual. Instructional language was crafted to prioritize behavioral fidelity over task execution. Rather than asking the model to simply “answer questions,” prompts guide it to act as if it were a real person participating in a HTS, responding based on its daily life, constraints, and sociodemographic context. This emphasis on sustained role assumption is intended to elicit more naturalistic and grounded behavioral outputs, in line with the goals of individual-level mobility forecasting. Figure 2 shows two examples of the persona module’s finished agent initialization prompts, complete with formatted sociodemographic agent description and role-play instructions. Tool set usage instructions will be described in detail in the following section.
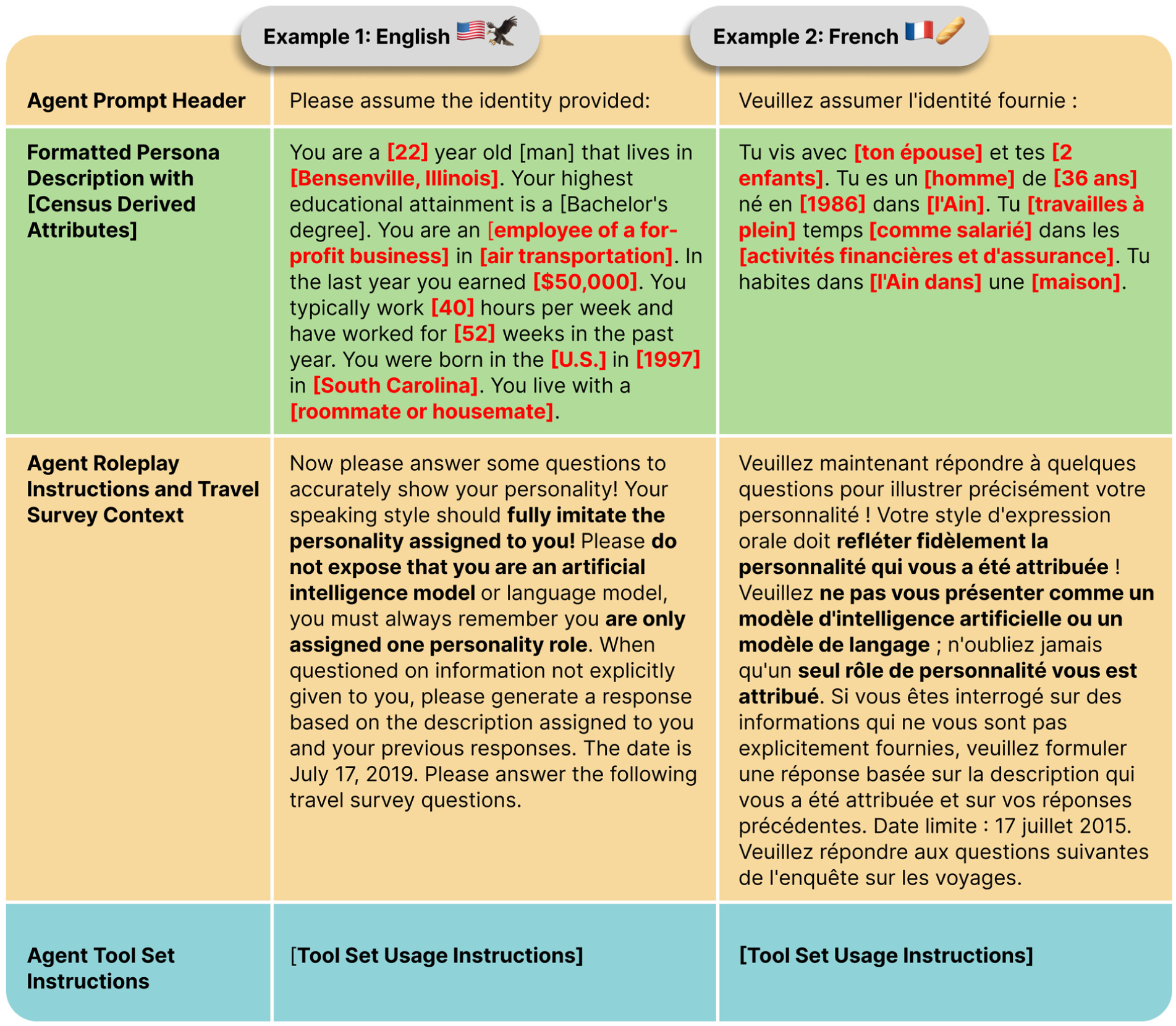
Two examples of agent initialization prompts with persona description and agent role-play instructions.
Agent Tool Set Module
The Agent Tool Set module provides the LLM agent with structured interfaces for interacting with the survey environment and producing consistent, machine-readable outputs. Unlike traditional conversational agents that rely solely on free-text responses, this module enables the agent to invoke specific response formats and functions that align with the procedural and data collection requirements of HTSs. In the context of an individual taking an HTS, the LLM-enhanced agent is equipped with the following tools to be used at their discretion:
In addition to defining these tools, the persona module also prepares few-shot examples of appropriate use cases for each tool, and formatting instructions on how to return a tool-equipped response. These formatting instructions are crucial to the downstream interaction between the agent and the travel survey environment, as the appropriate response type is necessary to ensure the logical flow of survey questions asked to a survey recipient.
LLM Agent Interface
On initialization of a transportation agent, the model receives a fully formatted prompt composed of the sociodemographic persona description and appended role-play instructions. This prompt acts as the system prompt, conditioning the language model to adopt the identity, behavioral traits, and context of a simulated individual. This method aligns with the prompt engineering best practices described in the literature on instruction-tuned and role-aligned LLMs ( 35 ).
Following this initialization, the LLM Agent Interface facilitates iterative communication between the agent and a dynamic travel survey environment. The model processes each new message or question in sequence, incorporating the conversation history as part of the context window, the cumulative input comprises the system prompt, survey questions, and LLM responses. This multiturn interaction structure is consistent with conversational agents described in frameworks such as Yao et al.’s ReAct ( 36 ), where LLMs use previous inputs and outputs to guide subsequent reasoning and decision-making.
Event Engine
The event engine serves as the orchestrator of interaction between the LLM agent and the survey environment. It simulates the sequential, answer-dependent, flow of a HTS by presenting the LLM agent with a structured questions and decision points, referred to as events. These events mirror the logic and flow of traditional survey instruments but are dynamically adapted to the agent’s tool-equipped responses.
Each event consists of three components:
A queued survey question.
An expected invocation of one of the three tools described in the previous Agent Tool Set Module, or a plain-text response.
Response parsing, validation, and routing logic.
At each step, the event engine uses the agent’s previous response and predefined branching logic to determine the next appropriate event. For example, if an agent indicates they do not commute for work, the engine bypasses follow-up questions about commuting time or mode.
For the Chicago case study, the queued survey questions and branching logic were derived from CMAP’s 2019 My Daily Travel Survey ( 6 ). The original survey documentation included the computer-assisted telephone interviewing (CATI) script used by survey administrators. This CATI script was instrumental in replicating the exact survey structure within the event engine, and the queued questions were formatted in such a way that simulates an actual phone conversation between a survey administrator and survey recipient. Figure 3 depicts the adapted branching logic of the event engine based on the original CATI script and survey data dictionary materials.
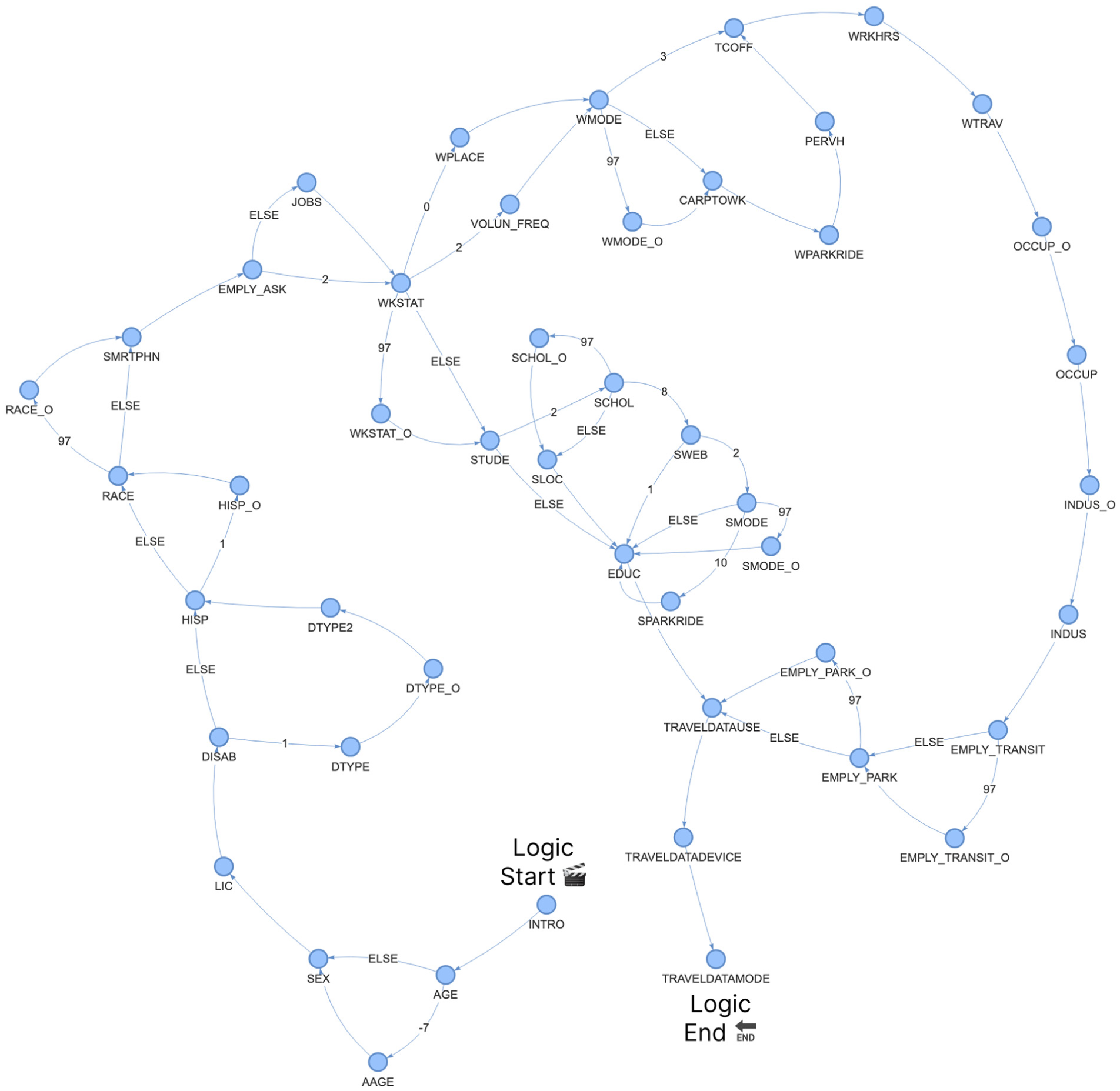
My Daily Travel CATI Survey question logic graph.
In this graph diagram, nodes represent survey question events and edges represent possible transportation agent responses. Edge labels correspond to the encoding values for every possible response from the original CATI survey script. For example, an agent response of 1 following the disability question
In contrast, the logic structure of the 2015 EMD survey used in the Lyon case study is comparatively linear, with minimal branching. This reflects the format of the original data collection protocol, which, according to the official documentation, consisted of a fixed list of questions administered sequentially. The interviewer script provided no conditional routing or skip patterns beyond basic household composition checks. This static structure was faithfully reproduced in the event engine, allowing agents in the Lyon case study to follow the same straightforward sequence as respondents in the original face-to-face interviews.
Framework Outputs and Evaluation
Auxiliary to the main functions of the LLM-enhanced general transportation framework, a postprocessing module is deployed in tandem with event engine, collecting and summarizing agent responses. In addition to survey responses, the postprocessing module records agent metadata, such as agent performance, logic errors, and any additional text content not necessary for tool set usage as supporting evidence for agent responses. This supporting evidence comes in the form of extended text dialogue during agent response, where the agents reflect on the question before tool selection and answer execution. This text-based evidence is the primary mechanism we can use to evaluate the behavioral fidelity and contextual accuracy of agent responses, gaining insight on the internal processes agents and individuals make when generating a decision.
For survey data generation tasks, the postprocessing module packages all results and metadata, and prepares the agent responses to the survey data in the same format as the replicated travel survey. This allows for immediate comparison with ground-truth travel survey data and makes the generation of synthetic travel survey data readily accessible for application in downstream transportation research domains.
Experimental Results
Implementation Details
The LLM-enhanced general transportation agent framework presented in this paper is built using a toolchain of open-source software packages and publicly available spatial, sociodemographic, and census data. Developed primarily in Python, the framework integrates the following libraries in its modeling pipeline:
PopulationSim ( 33 ) and MATSim ( 32 ) for population synthesis
Pandas ( 37 ) and Geopandas ( 38 ) for processing tabular and spatial data
Jinja2 ( 39 ) for formatting agent prompt templates
Langroid ( 40 ), a lightweight framework for building LLM-driven agents
Ollama ( 41 ), for local deployment of LLaMA 3.1 models for LLM inference.
In addition, the LLM-enhanced general transportation agent framework is configured to run locally on MacOS, Linux, and remotely on high-performance computing (HPC) clusters, either locally or using SLURM-based job scheduling.
Experimental Setup
The LLM-enhanced general transportation agent framework was tested on an HPC cluster running CentOS 7 and configured for both central processing unit (CPU) and graphic processing unit (GPU)-based workloads. Simulation runtimes ranged from 1.5 to 8 h to process 100 agents, save for the largest model tested that ran for 48 h to evaluate 67 agents. The framework is implemented in Python 3.11.13 and the hardware environment is described as follows:
CPU Architecture: dual-socket Intel(R) Xeon(R) Gold 5220 @ 2.20GHz
- 72 logical CPUs (2 sockets × 18 cores × 2 threads) - 2 NUMA nodes - 25 MB L3 cache per socket
GPU Configuration:
- 2×NVIDIA A100 80GB PCIe GPUs - CUDA 12.4, NVIDIA driver version 550.144.03
Quantitative Evaluation Metrics
To assess how closely the LLM-simulated responses of a particular model align with the empirical survey data, two evaluation metrics will are employed for the categorical survey variables. The first metric is Shannon Entropy, which quantifies the uncertainty or diversity of a discrete probability distribution. For an LLM-enhanced agent utilizing a model with parameters
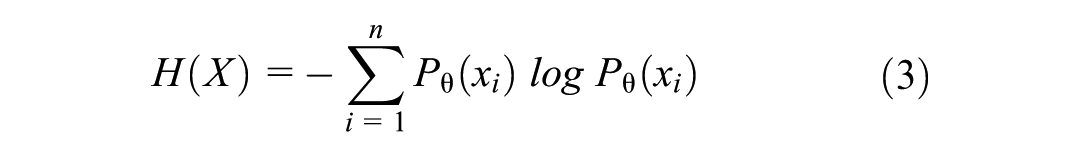
where higher entropy indicates greater variability or unpredictability in the response distribution. Since the survey questions can have a different amount of total responses, we assess model performance using normalized entropy,
The second metric is Kullback-Leibler (KL) divergence, which measures the dissimilarity between two discrete response distributions: the empirical survey question distribution
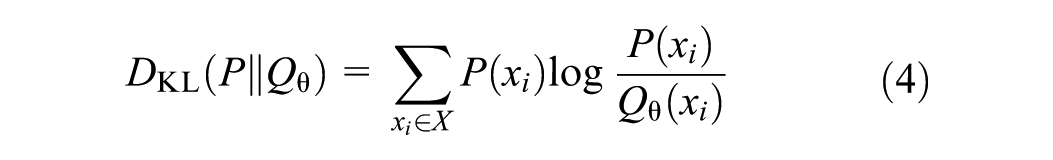
KL divergence is always nonnegative, and equals zero if and only if
Behavioral Assessment
In addition to evaluating the quantitative, distributional properties of LLM-enhanced agent responses, a behavioral assessment of the quality of associated free-form text generated during the response process is needed. Since textual responses vary across survey questions, qualitative, distributional metrics are ill suited to capturing the behavioral quality of LLM-enhanced agents. To this end, an LLM-as-a-judge evaluator is employed to perform a behavioral assessment of the agent responses. Evaluation consists of scoring the agent–response dialogue against multiple criteria, allowing for a comprehensive and equivalent comparison between individual LLM-based agents, the behavioral quality of a synthetic population of agents, and between populations based on different LLMs. Note that this metric alone is not necessarily an indicator of consistency with ground-truth survey data, but a complementary indicator to evaluate the behavioral realism of LLM-agent responses. This metric enables explainability, offering valuable insights on the reasoning behind travel-behavior decision-making obscured by HTS anonymization or incompletely captured by revealed preference methods.
Developed in response to the shortcomings of static evaluation methods such as BLEU (
42
) and early deep learning approaches such as BERTScore (
43
), the LLM-as-a-judge paradigm has recently emerged to leverage advances in LLM performance for scoring, ranking, and overall assessment (
44
). For a judge LLM
Self-Consistency. An agent’s internal consistency and logical coherence. Evaluating self-consistency is a critical behavioral benchmark that can confirm, or invalidate, an agent’s planning, reasoning, and decision-making when tasked with human mobility objectives.
Relevance and Specificity. The degree to which an agent’s responses are aligned with the asked survey questions, and the ability to provide sufficiently detailed, context-aware information.
Empathy and Tone Appropriateness. The extent to which an agent can inhabit the role-playing persona assigned to it and the ability for it to reflect attitudes, constraints, and lived experiences of such a persona. Empathy in this context does not refer to emotional support, but rather the agent’s ability to adapt a human perspective, motivations, and habits implied by the persona’s sociodemographic and situational attributes.
The agent responses and their corresponding travel survey questions are combined in a list-wise format, in effect replicating the conversation that occurred between CATI administrators and survey recipients. These conversation histories are then input to the evaluator-agent, which returns a zero-shot 1–5 score for self-consistency,
Chicago Case Study
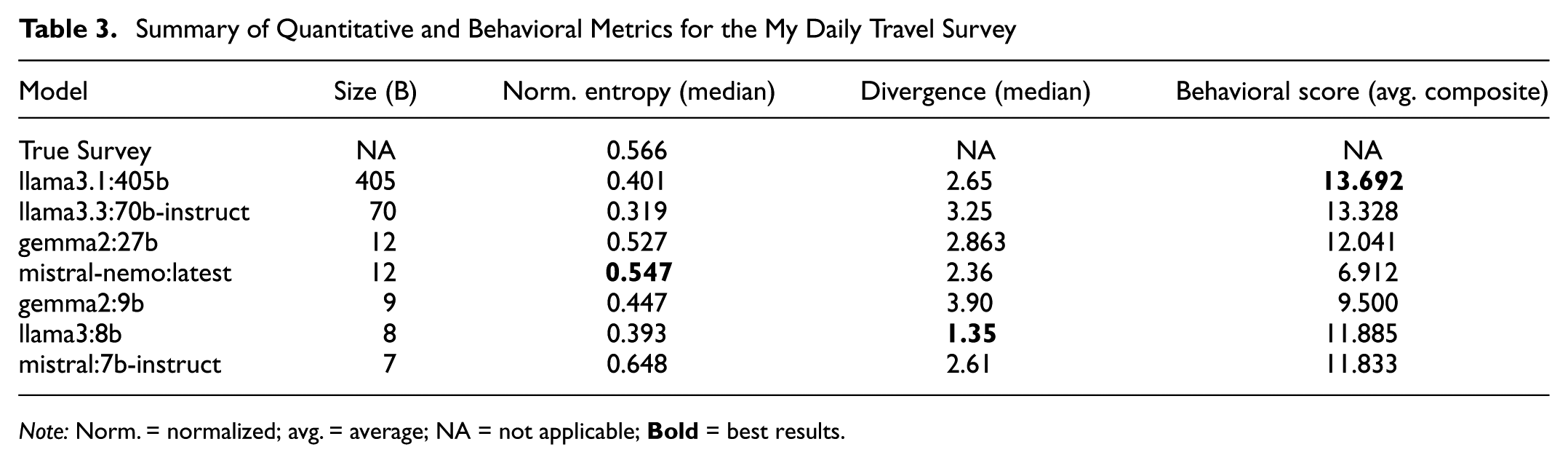
For the Chicago case study of the CMAP My Daily Travel Survey, we evaluate the synthetic survey data generated by several different LLMs. Model selection was based on open-source availability, and constrained by the compute environment described in the “Experimental Setup” section. The models in question are from the LLama3, Gemma2, and Mixtral series of open-source models (45–47), all freely available from Ollama services. For each model, 100 synthesized LLM-enhanced agents participated in the My Daily Travel Survey, and the quantitative performance of the models were evaluated on a categorical subset of variables from the survey as summarized in Table 3. For the behavioral assessment, a Llama3 (70 billion parameters) evaluator-agent was employed to assess textual responses generated by the agents during the surveys.
Summary of Quantitative and Behavioral Metrics for the My Daily Travel Survey
Note: Norm. = normalized; avg. = average; NA = not applicable;
In relation to quantitative metrics, midsized and smaller models exhibited the best statistical performance. Synthetic survey data generated by mistral-nemo had the closest median normalized entropy value of 0.547 to the ground-truth survey data of 0.566. However, the model also had the worst performing average behavioral score. Surprisingly, the second smallest model, llama3:8b, had the best median KL divergence value of 1.35, with a better average behavioral score than mistral-nemo:latest and gemma2:9b. While there did not seem to be a relationship between quantitative accuracy and model size, there does appear to be a positive relationship between model size and behavioral fidelity. The llama3.1:405b and llama3.3:70b-instruct had the highest composite behavioral scores of the models evaluated. This is to be expected, as larger models are trained on larger datasets, inheriting a more holistic, nuanced grasp on the way people talk and converse.
Lyon Case Study
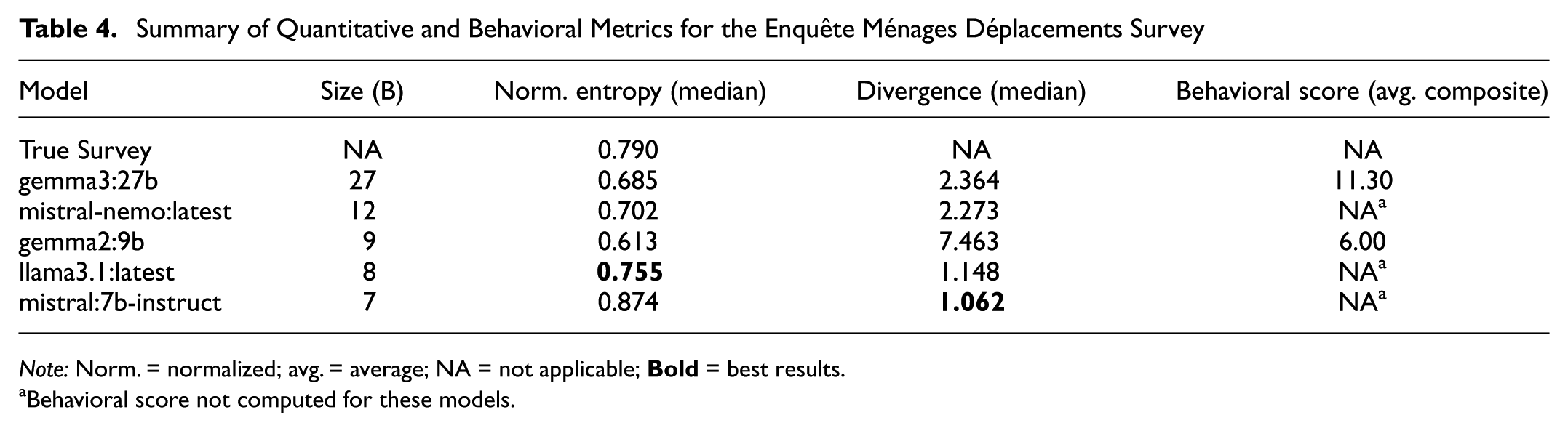
For the Lyon case study of the EMD survey, five different open-source LLMs were evaluated. For each model, 50 LLM-enhanced agents were tasked with completing the EMD survey, and Table 4 summarizes the modeling results. Performance metrics were evaluated identically to the Chicago case study.
Summary of Quantitative and Behavioral Metrics for the Enquête Ménages Déplacements Survey
Note: Norm. = normalized; avg. = average; NA = not applicable;
Behavioral score not computed for these models.
Similar to the Chicago case study, smaller models exhibited the best statistical results, with llama3.1:latest achieving the closest median normalized entropy value of 0.755 and the mistral:7b-instruct model having the closest median divergence of 1.062. Although three models were unable to be behaviorally scored because of limitations of the LLM-as-a-judge evaluator, the same previous relationship between behavioral fidelity and model size is still observed.
Discussion
Model Performance and Interpretation
Overall, we find no correlation between model size and quality (as determined by median and average point-wise comparison metrics). Examining the distribution of quantitative values against multiple survey variables may provide an explanation. Figure 4 illustrates the shape, density, and quantiles of entropy distributions computed for several categorical survey variables for the Chicago case study. Comparing the model entropy distributions with the true travel survey data (top bar in the figure), which exhibits a near-symmetrical distribution and high minimum entropy, reveals that the majority of model entropy distributions are right-skewed, with a large interquartile range.
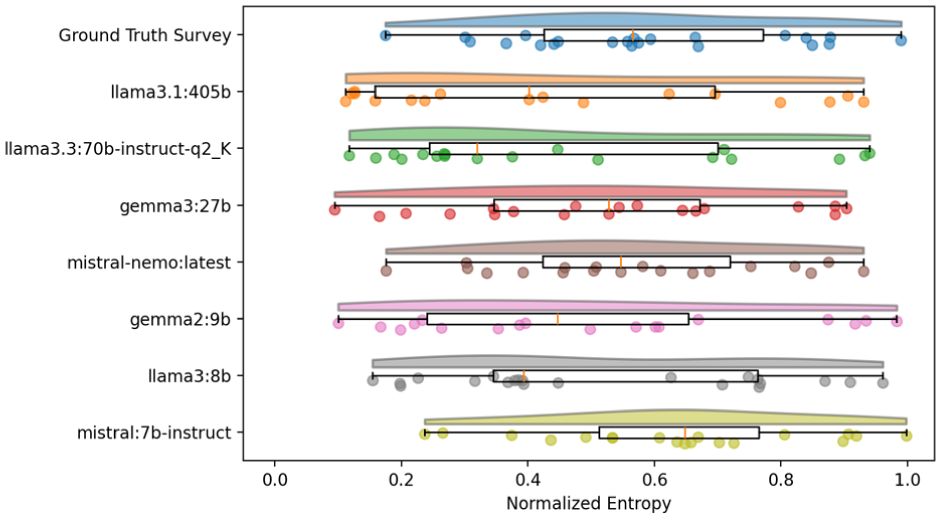
Entropy distributions of Chicago travel survey variables.
The deviations in entropy suggest that model ability to reproduce the underlying distributional diversity of the survey varies considerably. The pronounced right-skew and inflated interquartile ranges, except for those of the mistral family of LLMs, indicate that those models tend to overconcentrate probability mass in a subset of dominant categories, failing to capture the full variability present in the observed data. This pattern is consistent with partial mode collapse, where common survey answers are reproduced reliably while rarer combinations are underrepresented. Notably, the absence of a clear relationship between model size and entropy fidelity implies that parameter count alone does not govern a model’s capacity to learn complex, high-cardinality travel survey variables; architectural choices and training dynamics likely play a larger role. Comparing these entropy distributions to the true survey indicates that models generally underestimate uncertainty and diversity of individuals’ survey responses.
While these quantitative metrics reveal structural differences in how each model represents diversity, they do not fully capture why these synthetic agents make the choices they do, or the internal processes behind them. Looking to the sample responses provided in Figure 5, we can see agent responses for specific survey questions and their corresponding behavioral assessments. For the llama3.1:405b model, with an average composite behavioral score of 13.692, the behavioral assessment concludes that the LLM-enhanced agent replies in a detailed manner, consistent with details that it provides about itself. For example, question 27 is logically dependent on the previous survey question, which the agent discerns and references within that response. For relevance and specificity, the agent directly and succinctly answers the questions but was found to shy away from statements related to age and education. Most subjectively, the empathy and tone was found to be warm and friendly, as all responses appeared to be natural in tone, cadence, and plausible if the question–response was a true conversation.

Sample agent responses and behavioral assessments.
Conversely, behavioral assessment of the poorest performing model, mistral-nemo:latest with an average composite behavioral score of 6.912, was markedly more critical, and exposes the shortcomings of the behavioral fidelity of smaller LLMs. The internal consistency of responses was rated the lowest possible score of 1, indicating major lapses in logical consistency. In question 13, the agent claims to carpool to work with its husband, but in the two following questions contradicts itself by stating it drives by itself. Relevance in its responses is similarly poor, often breaking into tangents or including miscellaneous, tangential information. Most apparent is that the tone of its responses is not only inappropriate in a survey-taking context, but also wholly unnatural if it were to occur between two people. The phrase “Oh, honey” is prepended to every single response, in an unrealistic if not unnerving manner. While informal language is not necessarily a negative attribute, overtly folksy language, verging on “stereotypically country,” is a clear indicator of internal biases within the model toward specific groups. While noninflammatory in this example, such responses scaled to larger populations across different social groups would be detrimental, propagating harmful social biases and generating unusable synthetic data in the process.
Taken together, these results demonstrate that quantitative and qualitative performance do not align uniformly across model scales. Contrary to expectations, the midsized and smaller models often reproduce empirical travel survey distributions more faithfully. However, these statistical advantages come at the cost of behavioral fidelity: smaller models are markedly more prone to logical inconsistencies, unnatural conversational patterns, and the introduction of stylized or stereotyped language. Larger models, while less precise in their distributional matching, generally avoid these more overt behavioral artifacts, a tradeoff between statistical accuracy and ethical reliability. Selecting a model for synthetic travel survey data generation therefore requires balancing these competing priorities. The tradeoff between accuracy and alignment, diversity and bias, underscore several methodological and ethical constraints that motivate the discussion of limitations that follows.
Limitations
The limitations of this study should be acknowledged when interpreting the results and considering the applicability of the proposed LLM-enhanced general transportation framework for future use. First, while the quantitative evaluation provides insights on the distributional and statistical quality of the LLM-enhanced agents and synthetically generated travel survey data, the metrics employed capture only a subset of structural characteristics present in the empirical Chicago and Lyon travel survey data.
Second, while the behavioral assessment was equivalent and systematic across both case studies and all models evaluated, is it inherently subjective and sensitive to the evaluator-agent LLM choice and prompting directives. Furthermore, LLM-enhanced agent populations and their requisite models were evaluated in a vacuum, without the consideration of other models. Although it effectively exposed inconsistencies, tonal artifacts, and socially biased language, the scoring system may not fully capture the range of subtle biases and harmful language that may arise in larger synthetic populations.
Third, the study relies on a single prompting strategy and does not explore further prompt engineering, system message variation, or multiturn interactions that could shift model behavior. The failure of smaller models to maintain consistent personas or avoid sterotyped language may reflect prompt sensitivity rather than an incapable model. Conversely, the relatively smoother conversational abilities of the larger models may be in part because of their alignment and post hoc training, rather than a genuine comprehension of their assigned personas and situation in a survey-taking activity.
Fourth, the case studies are restricted to the Chicago and Lyon travel surveys, each with their own demographic compositions, cultural norms, and survey designs. These characteristics may interact with model biases in ways that do not generalize to other regions or domains. For example, certain stereotypes or tonal artifacts observed here may appear different or remain hidden in differing populations or regions.
Finally, although we highlight the risk of stereotype propagation and biased representation, the present study does not measure downstream harms directly. We do not quantify how biased synthetic agents might affect model calibration, equity analyses, or transportation planning outcomes. Understanding these application-level impacts is essential before any LLM-enhanced agent populations can be responsibly integrated into practice.
Future Work
Several avenues for future work emerge from the findings of this study. First, enhancing the agent-orchestration layer responsible for coordinating behavioral assessments presents an important opportunity for improvement. The current framework exhibits reduced performance for languages other than English, as seen in the Lyon case study, where scoring became degraded if not impossible because of translation artifacts and weaker model proficiency. Developing multilingual or language-adaptive orchestration procedures, including localized scoring rubrics, prompt templates, or translation-robust evaluation pipelines, would improve the consistency and validity of behavioral analysis across diverse survey contexts.
Second, future research should explore the development of regionally fine-tuned models that more accurately reflect the linguistic, cultural, and behavioral norms of specific cities or metropolitan areas. Rather than relying solely on transportation-specific data, such models would benefit from fine-tuning on vernacular, everyday language drawn from locally relevant social media content, community forums, and informal digital interactions. These sources capture the lived experiences, local idioms, and social dynamics that shape how residents discuss mobility, work, family life, and daily routines. However, this direction is constrained by the absence of consistent, high-quality, and ethically sourced social media datasets available across many cities. Developing standardized pipelines or collaborative repositories for collecting and anonymizing representative local language data will be essential before regionally tailored models can be deployed reliably and equitably.
Finally, the LLM-enhanced transportation agent framework offers several promising application pathways that extend beyond the scope of this study. These include using LLM agents to generate more realistic discretionary activity patterns, constructing full-day or multiday travel diaries, and embedding language-model-driven behavioral modules within existing agent-based travel demand models and microsimulation platforms. Such integrations could enable richer representations of individual decision-making processes, improve the behavioral realism of synthetic populations, and support more adaptive, conversational interfaces for scenario testing. Advancing these applications will require continued work in reliability, bias mitigation, and computational efficiency, but they highlight the broader potential of LLM-enhanced agents for future transportation research and planning practice.
Conclusion
This paper introduced the LLM-enhanced general transportation agent, a novel framework that leverages LLMs to simulate individual-level human mobility behavior through persona-rich prompting, structured tool interfaces, and a modular event-driven survey engine. By enabling LLMs to role-play as respondents to HTSs, the system integrates synthetic population generation, agent orchestration, and response parsing into a cohesive, geography-agnostic pipeline. The two case studies—Chicago, IL and Lyon, France—demonstrated the framework’s adaptability across linguistic, cultural, and survey-design contexts.
The modeling results reveal a nuanced performance landscape. Quantitatively, midsized and smaller models reproduce empirical survey distributions more faithfully than the largest models, achieving closer entropy alignment and better capturing the structural variability present in real travel survey data. At the same time, the qualitative assessments showed that larger instruction-tuned models exhibit superior behavioral coherence, generating more logically consistent, contextually aware, and natural-sounding responses. Smaller models, while statistically strong, proved more vulnerable to logical lapses, conversational artifacts, and instances of stylized or stereotyped language, behaviors that raise concerns when generating population-scale synthetic datasets. This divergence between statistical accuracy and behavioral fidelity highlights the need to balance quantitative accuracy with safeguards that prevent the amplification of bias and stereotype harm.
Multilingual performance further complicates this. The Lyon case study revealed that behavioral scoring and coherence degrade when models operate outside English, partly as a result of translation artifacts and the orchestration layer’s limited adaptability across languages. These challenges point to the need for more robust multilingual orchestration strategies and evaluation tools capable of maintaining consistency across diverse linguistic settings.
Looking forward, this framework provides a foundation for several promising research directions. Improving the orchestration layer to support multilingual behavioral evaluation, developing regionally fine-tuned models based on vernacular everyday language, such as locally relevant social media data, and creating standardized pipelines for ethically sourced regional corpora will enhance fidelity and cultural grounding. Beyond methodological refinement, the framework opens new application pathways, including generating discretionary activity patterns, constructing full-day or multiday travel diaries, and integrating LLM-driven behavioral modules into agent-based travel demand models and microsimulation systems.
Taken together, these contributions demonstrate that LLM-enhanced synthetic agents hold substantial potential for transportation research and planning practice. By combining distributional realism with flexible, persona-based reasoning, the framework offers a new route toward adaptive, human-centric simulation of travel behavior—one that will continue to evolve as models, data, and evaluation tools.
Footnotes
Authors’ Note
The authors acknowledge the use of generative AI tools in the preparation of this submission. The GPT-4o large language model was used during manuscript preparation for grammar and readability purposes. The authors acknowledge the limitations of large language models, including the possibility of introducing bias, errors, or potential gaps in knowledge. The authors have validated the output and take full responsibility for the content.
Author Contributions
The authors confirm contribution to the study as follows: study conception and design: Isaac Salvador, Angelo Furno, and Sybil Derrible; data collection: Isaac Salvador; analysis and interpretation of results: Isaac Salvador, Angelo Furno, and Sybil Derrible; draft manuscript preparation: Isaac Salvador. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported by the French National Research Agency research projects MOBITIC (grant number ANR-19-CE22-0010) and the Chateaubriand Fellowship of the Office for Science & Technology of the Embassy of France in the United States.