
Abstract
Background and objective
This study aims to assess the effectiveness of combining radiomics features (RFs) with deep learning features (DFs) for classifying brain tumors—specifically Glioma, Meningioma, and Pituitary Tumor—using MRI scans and advanced ensemble learning techniques.
Methods
A total of 3064 T1-weighted contrast-enhanced brain MRI scans were analyzed. RFs were extracted using Pyradiomics, while DFs were obtained from a 3D convolutional neural network (CNN). These features were used both individually and together to train a range of machine learning models, including Support Vector Machines (SVM), Decision Trees (DT), Random Forests (RF), AdaBoost, Bagging, k-Nearest Neighbors (KNN), and Multi-Layer Perceptrons (MLP). To enhance the accuracy of these models, ensemble approaches such as Stacking, Voting, and Boosting were employed. LASSO feature selection and five-fold cross-validation were utilized to ensure the models’ robustness.
Results
The results demonstrated that combining RFs and DFs significantly improved the model's performance compared to using either feature set alone. The best performance was achieved using the combined RF + DF approach with ensemble methods, particularly Boosting, which resulted in an accuracy of 95.0%, an AUC of 0.92, a sensitivity of 88%, and a specificity of 90%. Conversely, models utilizing only RFs or DFs showed lower performance, with RFs reaching an AUC of 0.82 and DFs achieving an AUC of 0.85.
Conclusion
The integration of RFs and DFs, along with advanced ensemble methods, significantly improves the accuracy and reliability of brain tumor classification using MRI. This approach shows strong clinical potential, with opportunities for further enhancing generalizability and precision through additional MRI sequences and advanced machine learning techniques.
Introduction
According to the World Health Organization (WHO), a brain tumor is an abnormal growth that affects the central nervous system (CNS). 1 Brain tumors are generally characterized by the abnormal proliferation of brain cells, which can compress nearby tissues and disrupt neural pathways, impairing normal brain functions. There are two main categories of brain tumors: non-cancerous (benign) and cancerous (malignant). Common types of brain tumors include glioma, meningioma, and pituitary tumors, each exhibiting different degrees of malignancy. 2
Glioma is a type of brain tumor that forms in the glial tissue of the brain and spinal cord, while meningioma arises from the membrane surrounding the brain and spinal cord. Pituitary tumors develop in the pituitary gland. 2 The initial assessment of brain tumors is usually conducted by oncologists using imaging modalities like magnetic resonance imaging (MRI) and computed tomography (CT) scans. 2 However, if more information about the tumor type is needed, a surgical biopsy of the affected tissue is required for a definitive diagnosis.
Recent advancements in brain tissue imaging have significantly improved both image contrast and resolution, enabling radiologists to detect even small lesions and thereby enhancing diagnostic accuracy.3,4 Additionally, progress in engineering and artificial intelligence (AI) has led to the development of computer-aided diagnosis (CAD) systems. These systems integrate AI with imaging tools, assisting physicians in improving the early detection of cancer. Various AI techniques, such as artificial neural networks (ANN) and convolutional neural networks (CNN), have been employed to classify and identify brain tumors.3,5–10 These advancements in imaging and AI are anticipated to further enhance the precision of brain tumor detection moving forward.
Machine learning (ML) applications for brain tumor classification are typically divided into two main categories: identifying brain MR images as either normal or abnormal, and classifying abnormal MR images into various types of brain cancer. 6 Convolutional Neural Networks (CNNs) have gained significant attention in disease detection and classification, particularly for their strong performance in brain tumor classification. 11 This improvement in tumor grading accuracy aids physicians in selecting the most effective treatment strategies, ultimately enhancing patient recovery rates. Studies have demonstrated that CNNs can significantly improve diagnostic accuracy and treatment outcomes in brain tumor classification.12–15
In recent years, ML has been used to identify patterns in data by leveraging features linked to specific outcomes. Radiomics applies mathematical techniques to analyze spatial characteristics of medical images, such as tissue shape and texture, offering important clinical insights.16,17 While traditional radiomics features (RFs)—such as intensity, morphology, and texture—extract valuable information from images, the process is often time-consuming and sensitive to small variations. In contrast, deep learning methods automatically learn relevant features directly from the images, making the analysis more efficient and robust.18,19
In this study, we combined RFs and deep learning features (DFs) extracted from MR images using Pyradiomics and an autoencoder to assess their individual and combined effectiveness in brain tumor classification. Additionally, we applied a CNN directly to MR images to evaluate its performance as a standalone classifier. Various machine learning algorithms were also employed, utilizing LASSO for feature selection, alongside different classifiers to identify the most accurate approach for tumor classification. The primary goal was to determine whether combining DFs with RFs would enhance classification accuracy and reliability compared to using each feature set individually.
Material and methods
Our research utilized several methods to analyze and classify brain tumors from MR images. These included extracting relevant features with Pyradiomics software and deep learning algorithms, applying feature selection and classification techniques using machine learning (ML), and conducting further analysis by directly applying a CNN to the MR images. Study flowchart is shown in Figure 1.
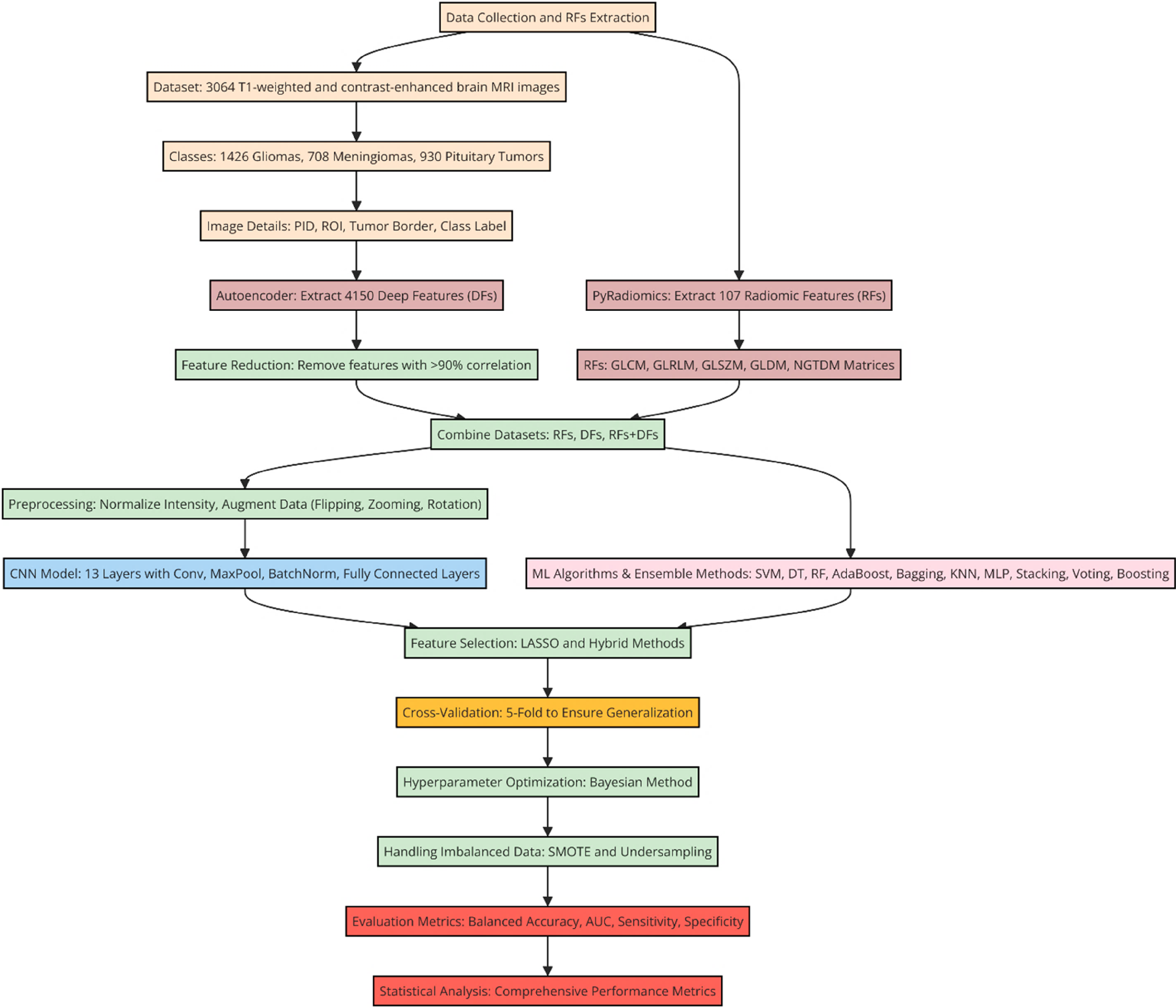
Study flowchart: feature extraction, machine learning, and evaluation.
Dataset and feature extraction
In this study, we analyzed a dataset comprising 3064 T1-weighted contrast-enhanced brain MRI scans. The dataset included three types of brain tumors: 1426 gliomas, 708 meningiomas, and 930 pituitary tumors. Each image was meticulously annotated with detailed information, such as patient identification (PID), the tumor region of interest (ROI), tumor boundary, and class label.
We initially employed an Autoencoder model to extract 4150 features, referred to as “DFs,” from the original images. To enhance the model's efficiency, we applied correlation-based techniques to remove features with minimal predictive value, discarding those with a correlation above 90%. The remaining features, deemed most informative, were utilized in subsequent analyses. Additionally, we employed Pyradiomics software to extract RFs from the image masks. For each ROI, 107 RFs were extracted, facilitating deeper insights into the relationship between imaging data and brain tumor classification. These RFs included Hounsfield Unit (HU) intensities and texture properties derived from five key matrices: the gray-level co-occurrence matrix (GLCM), the gray-level run-length matrix (GLRLM), the gray-level size zone matrix (GLSZM), the gray-level dependence matrix (GLDM), and the neighborhood gray-tone difference matrix (NGTDM). These matrices are standard tools in radiomics, used to quantitatively assess the texture and structure of medical images. In this study, the Pyradiomics settings were carefully optimized to improve the extraction of useful features from MRI images. The images were first resampled to a consistent voxel size, and their intensity values were normalized to reduce unwanted variations. Key radiomic features, such as intensity-based and texture features (including GLCM and GLRLM), were extracted from the segmented tumor regions. Intensity discretization was applied to capture sufficient detail while keeping the analysis efficient. Gaussian smoothing was used to clean up the segmentation masks, ensuring that small irregularities didn’t affect the results. LASSO feature selection helped to focus on the most predictive features, reducing the complexity of the model. These adjustments, combined with ensemble methods like boosting, played a crucial role in enhancing the overall performance of the classification model when using both radiomics and deep learning features. Lastly, we combined these datasets to create new datasets, including RFs only, DFs only, and DFs + RFs. Employing multiple feature extraction techniques alongside data integration provides a thorough approach to understanding and assessing the grading of participants, potentially contributing to more accurate diagnosis and treatment of brain tumors.
Autoencoder to extract DFs
In this study, we propose an Autoencoder-based feature extractor for DF learning in computer vision tasks. Feature learning can be categorized into supervised and unsupervised approaches. Autoencoders, which fall under unsupervised neural networks, have demonstrated their effectiveness in extracting DFs from unlabelled data. The Autoencoder architecture is composed of two components: the encoder and the decoder. The encoder compresses the input data into a lower-dimensional representation, while the decoder reconstructs the input from this compressed data. The input to the Autoencoder is represented as x ∈ RN, where N denotes the dimensionality of the input data.
The encoder output is represented by yencoded = σ1(W1 x + b1), where W1 represents the input layers to the bottleneck layer multiplication, b1 is the corresponding bias term, and σ1 is the activation function. On the other hand, the overall network's output is ydecoded = σ2(W2yencoded + b2), where W2 represents the bottleneck to output hidden layers multiplication, b2 is the bias term, and σ2 is the activation function. The learning process starts by minimizing the objective function as follows:
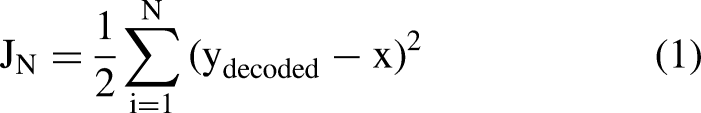
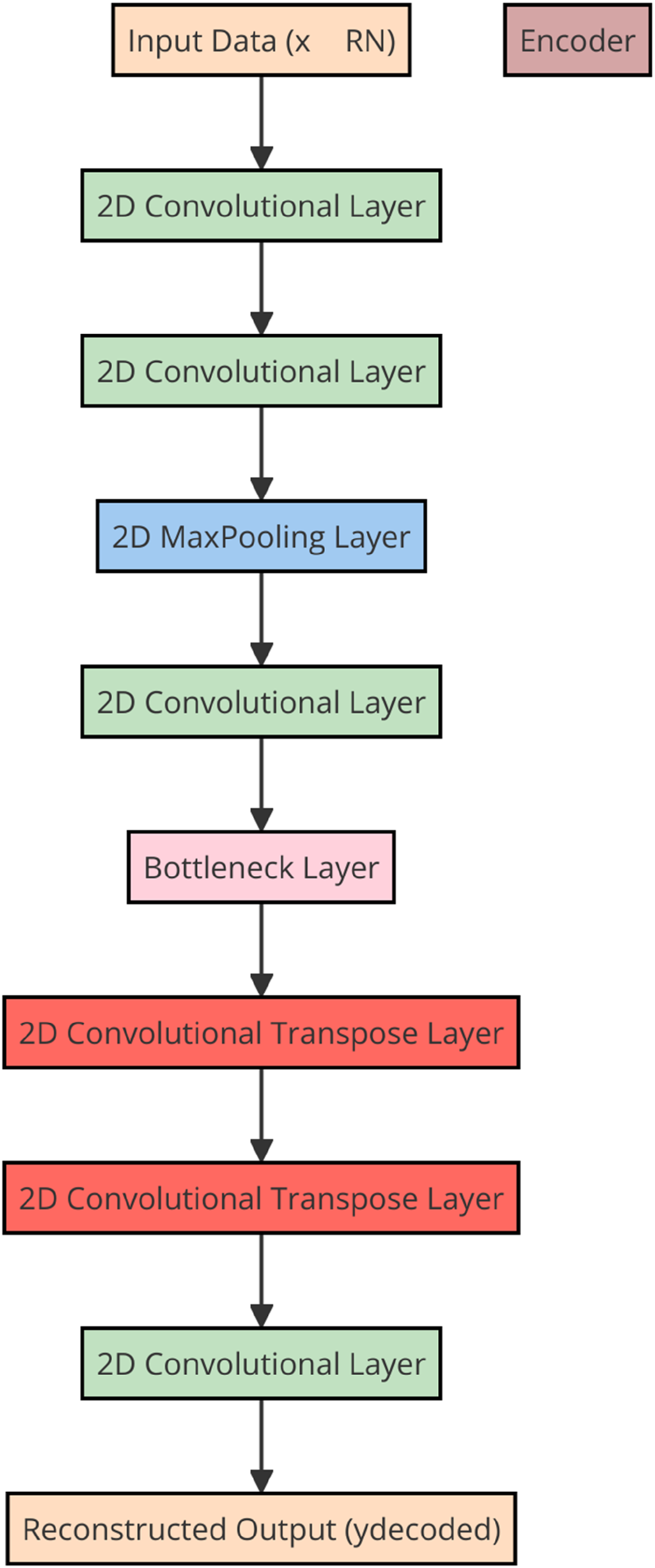
Architecture of autoencoder model used in this study.
In our study, several image augmentation techniques were applied to enhance the model's performance by increasing data variability and reducing overfitting, with horizontal flipping, rotation, and zooming proving to be the most effective. Horizontal flipping allowed the model to generalize better by exposing it to different orientations of tumors that can naturally vary in location. Rotation at small angles helped the model become more robust to positional variations during MRI scans, simulating real-world differences in how patients are positioned during imaging. Zooming in and out provided the model with the ability to detect tumors at varying scales, ensuring it could accurately classify tumors regardless of minor differences in image focus. These augmentations increased the diversity of the training set without altering the key structural details of the brain tumors, leading to improved generalization and robustness in performance across the dataset.. These augmented images were then fed into a 13-layer CNN, consisting of three 2D convolutional layers with 32, 64, 128, and 256 filters, each using a kernel size of 3 × 3 × 3. Each convolutional layer was followed by a max-pooling layer with a stride of 2, a ReLU activation function, and a batch normalization layer. The feature extraction block comprised three Conv-Maxpool-Bn modules. The output from these layers was flattened and passed through a fully connected layer with 256 neurons and a dropout rate of 30%. Finally, the output was passed through a dense layer with three neurons and a softmax activation function to address the classification task. We intentionally designed the network to be relatively simple in order to minimize the risk of overfitting. Figure 3 provides a schematic representation of the CNN model employed in this study.
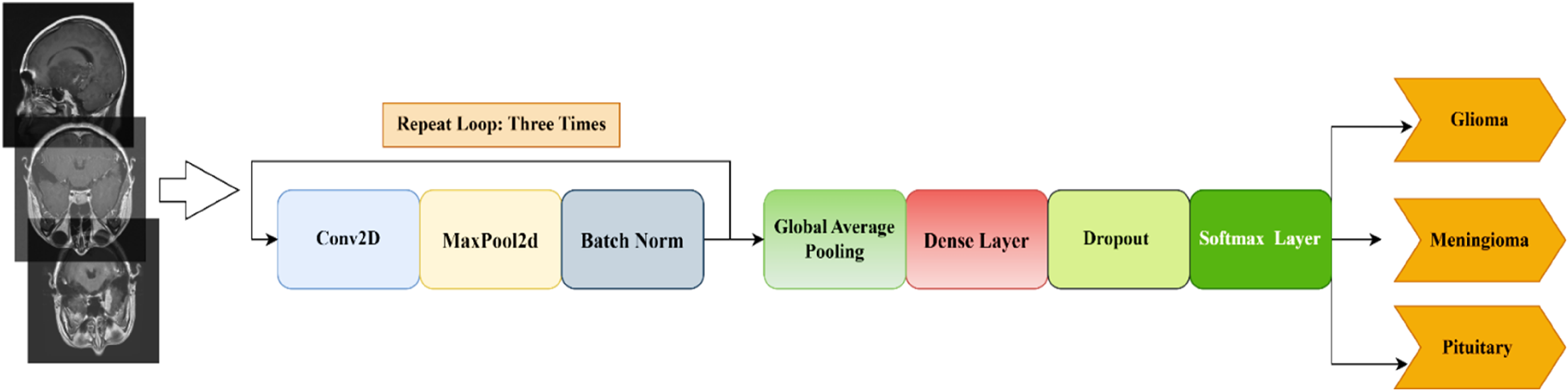
Schematic diagram of the proposed CNN model consisting of 13 layers.
Ml alghoritms
In our study, we employed a comprehensive ML approach to analyze a dataset containing both RFs and DFs. To enhance predictive performance and ensure generalizability while reducing the risk of overfitting, we applied a combination of ensemble learning and feature selection techniques, followed by thorough cross-validation and parameter tuning. Initially, we used the Least Absolute Shrinkage and Selection Operator (LASSO) for feature selection, identifying the most relevant features. We then evaluated the performance of seven classifiers: Support Vector Machines (SVM), Decision Trees (DT), Random Forest (RF), AdaBoost, Bagging, K-Nearest Neighbors (KNN), and Multi-Layer Perceptron (MLP), chosen for their demonstrated effectiveness in handling complex, high-dimensional data. Each classifier was trained and tested using individual feature sets (RFs and DFs) as well as the combined feature set (RFs + DFs).
To further optimize model performance, we implemented three ensemble methods: Stacking, Voting, and Boosting. Stacking integrates predictions from multiple base models to form a meta-model, improving accuracy by leveraging the strengths of each base model. Voting combines predictions from several models—either through majority voting (hard voting) or probability averaging (soft voting)—to increase robustness and stability. Boosting trains models sequentially, focusing on correcting errors from prior models, thereby enhancing the overall accuracy and power of the ensemble.
Model evaluation and validation
To ensure a robust evaluation of our models, we employed 5-fold cross-validation. The dataset was randomly split into five subsets, with each subset serving as the test set once, while the others were used for training. This process was repeated five times, ensuring that every data point was used for both training and validation. This method provided a comprehensive assessment of model performance while reducing the risk of overfitting.
Hyperparameter optimization
To optimize the hyperparameters of each classifier, we applied Bayesian optimization, a refined method that iteratively searches for optimal hyperparameters by modeling the distribution of the unknown objective function. This technique allowed us to efficiently explore the hyperparameter space, identifying the best configurations for each classifier and enhancing their predictive performance. Our overall methodology—integrating diverse feature sets, utilizing multiple classifiers, employing ensemble learning, performing cross-validation, and applying Bayesian optimization—enabled the development of robust and accurate machine learning models. By combining various feature types and leveraging ensemble techniques, we achieved superior performance metrics across all models, highlighting the effectiveness of our comprehensive ML pipeline in medical image analysis. The computational resources required for training the ensemble models were substantial due to the complexity of integrating both radiomic features (RFs) and deep learning features (DFs). The models were trained on high-performance GPUs, such as NVIDIA Tesla V100, with a minimum of 16GB of VRAM, which was essential for efficient deep learning computations, particularly for the 3D CNN. Additionally, the system utilized at least 64GB of RAM to manage the large MRI dataset and the high-dimensional feature sets. Training times for the ensemble models varied depending on the specific approach (e.g., boosting, stacking) and the feature sets used, with the process taking several hours to days. GPU acceleration and parallelization were critical in optimizing the computational workload and ensuring efficient model training.
Statistical analysis
In this study, we assessed the performance of machine learning models using five-fold cross-validation, which ensures that models are evaluated on multiple independent test sets, providing a reliable estimate of their ability to generalize to unseen data. Given the challenge of working with imbalanced datasets—where class distributions are uneven—we implemented several strategies to reduce potential biases. The dataset exhibited class imbalance, with certain classes having significantly more samples than others. To address this, we applied the Synthetic Minority Over-sampling Technique (SMOTE) to increase the representation of minority classes by generating synthetic samples through interpolation between existing ones, thereby achieving a more balanced class distribution. This oversampling was complemented by undersampling the majority class to further prevent bias towards the more dominant class. 20 Overfitting during CNN training was monitored and mitigated using several techniques. A validation set was used to track the model's performance at each epoch, with the validation accuracy and loss providing key indicators of overfitting. If the validation loss increased while the training accuracy continued to improve, this was a sign of overfitting. To address this, early stopping was implemented, which halted training if the validation loss did not improve after a set number of epochs. Additionally, dropout layers were incorporated into the CNN architecture to randomly deactivate neurons during training, reducing the risk of the model relying too heavily on specific neurons and improving generalization to unseen data. The stopping criteria for CNN training were carefully designed to prevent overfitting and ensure optimal model performance. The model was initially trained for a maximum of 100 epochs, with early stopping employed as a key measure to terminate training if the model began to overfit. Specifically, early stopping was triggered if the validation loss did not improve for 10 consecutive epochs. This patience value of 10 allowed the model sufficient time to converge while avoiding unnecessary overtraining. Additionally, the model weights were saved at the epoch with the lowest validation loss, ensuring that the best-performing version of the model was preserved for final evaluation. These criteria helped balance thorough training with overfitting prevention, leading to improved generalization on unseen data.
For model evaluation, we utilized multiple metrics to provide a more comprehensive assessment, as relying solely on accuracy can be misleading when working with imbalanced datasets.
In particular, we focused on Balanced Accuracy, which is the average of sensitivity (true positive rate) and specificity (true negative rate). This metric evaluates the model's ability to correctly classify both positive and negative classes, offering a more equitable performance measure in scenarios with uneven class distributions.
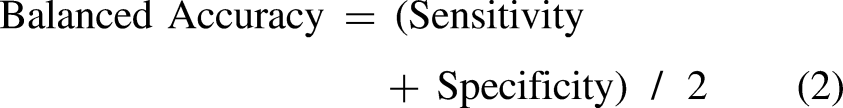
Sensitivity and Specificity: Sensitivity refers to the proportion of true positives that the model correctly identifies, while specificity measures the proportion of true negatives accurately detected. These metrics are critical when evaluating models in situations where the cost of misclassification varies significantly between classes. They are defined as follows:
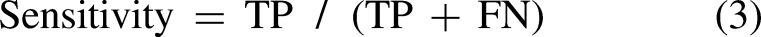
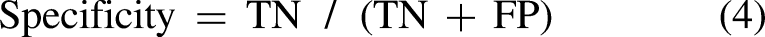
By utilizing these metrics, our study provides a comprehensive evaluation of the models, considering both their accuracy and their ability to manage imbalanced datasets. The combination of balanced accuracy and AUC offers a more detailed perspective on the models’ strengths and weaknesses, ensuring that our findings are robust and applicable in various clinical settings. This approach ensures that the models not only achieve high overall accuracy but also maintain strong discriminative power and reliability in accurately identifying both positive and negative cases within an imbalanced dataset.
Results
The results of this study demonstrate the effectiveness of various ML models and ensemble methods when applied to RFs, DFs, and their combination (RFs + DFs). The evaluation was conducted using four key performance metrics: accuracy, AUC, sensitivity, and specificity. The findings presented below highlight the comparative performance of the models and illustrate the impact of feature selection and ensemble methods on their outcomes.
Model performance with individual feature sets
Models trained using RFs alone exhibited moderate performance across all metrics. The average accuracy of these models ranged from 59.0% to 65.0% (Figure 4). AUC values varied between 0.70 and 0.76, indicating a reasonable discriminative ability but with room for improvement (Figure 5). Sensitivity and specificity also showed moderate values, suggesting that while the RF feature set provides some predictive power, it is not optimal when used in isolation (Figures 6 and 7). In contrast, models trained solely on DFs demonstrated a slight improvement over RFs, with accuracy values ranging from 61.0% to 67.0%. AUC values for DF models were generally higher, ranging from 0.73 to 0.79, indicating better class distinction. Sensitivity and specificity also showed a more balanced performance compared to RFs, making DFs a marginally better option when using individual feature sets.
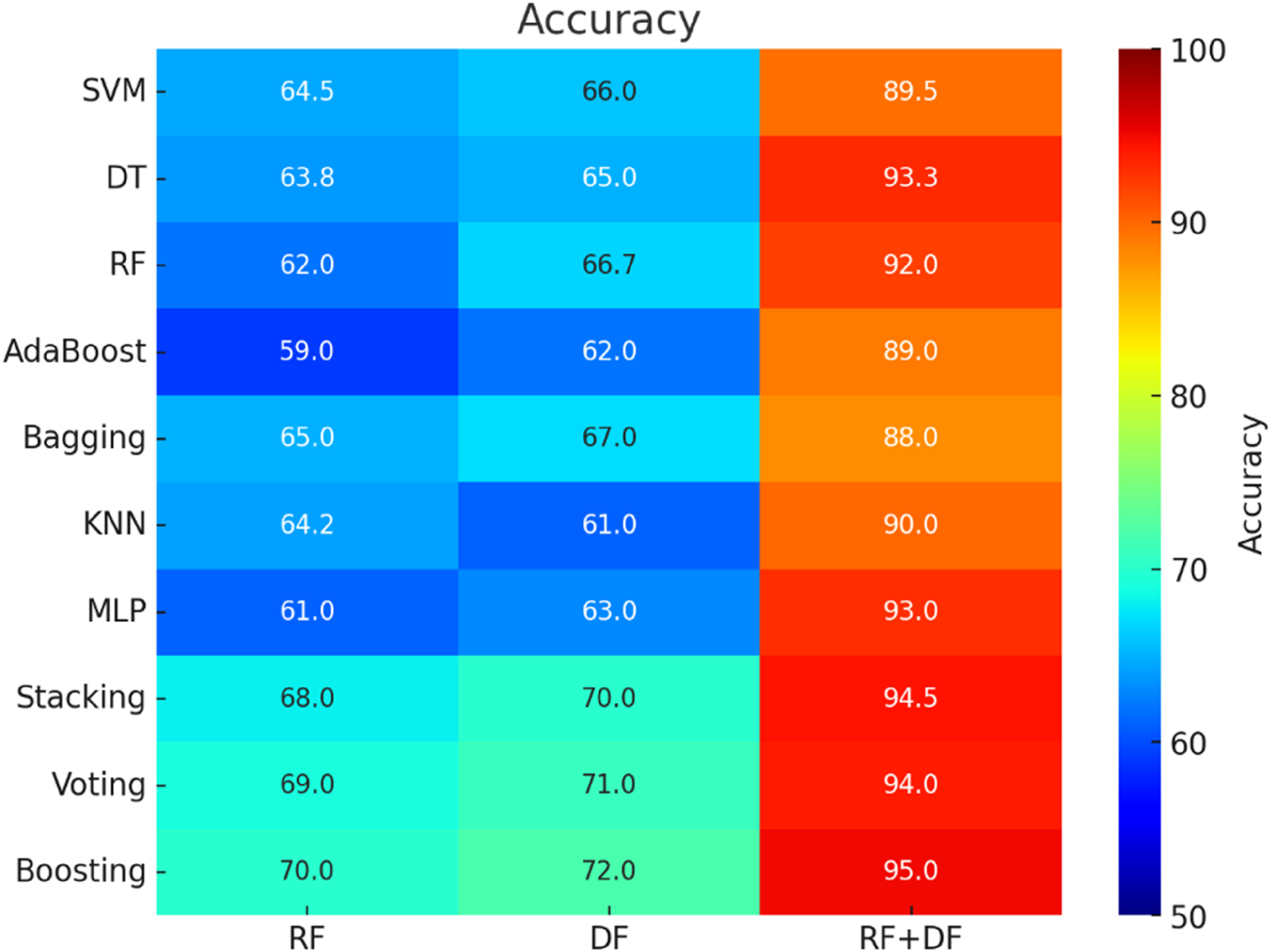
Heatmap and mean 5-fold cross-validation accuracy for brain tumor classification.
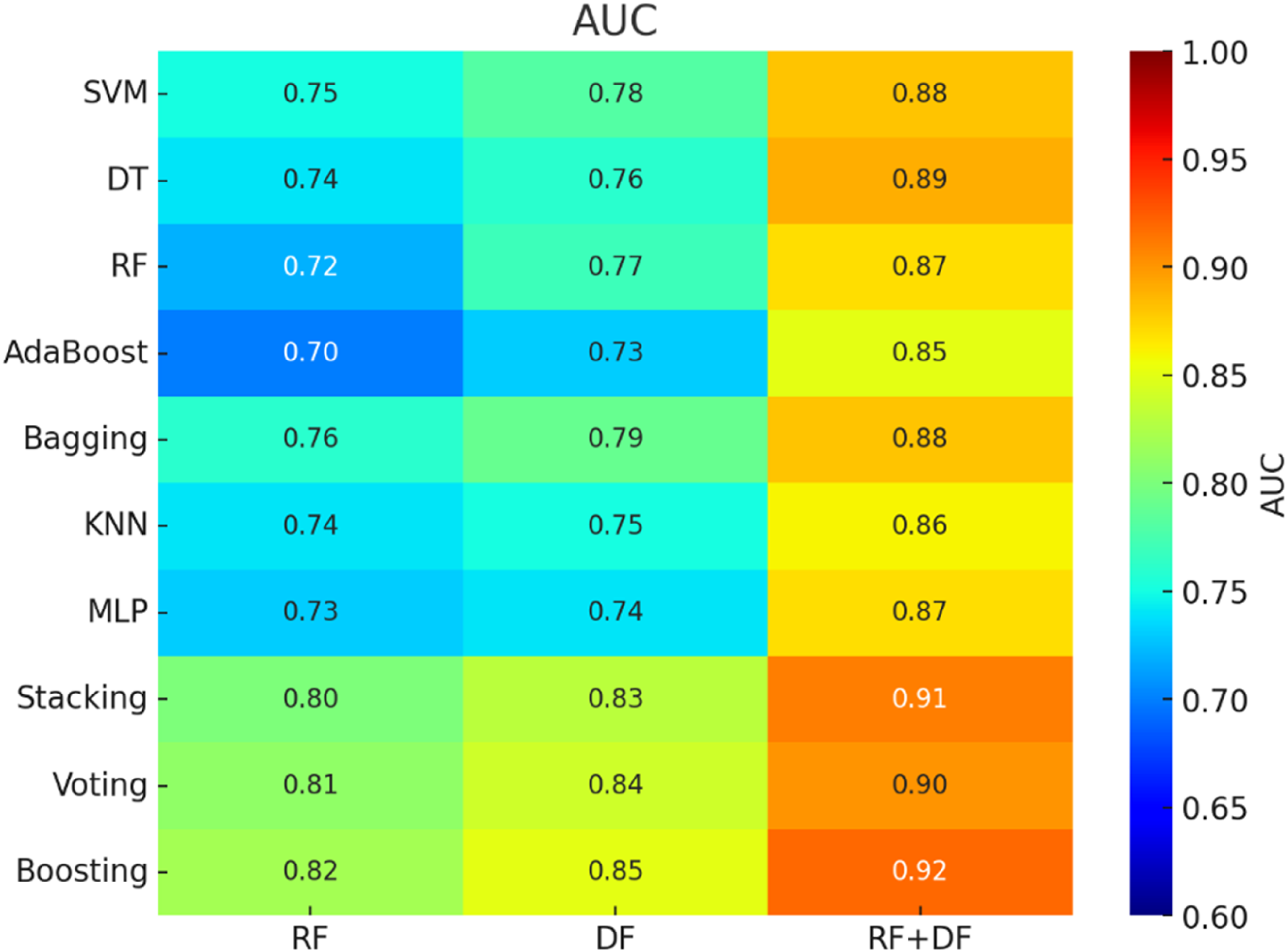
Heatmap and mean 5-fold cross-validation AUC for brain tumor classification.
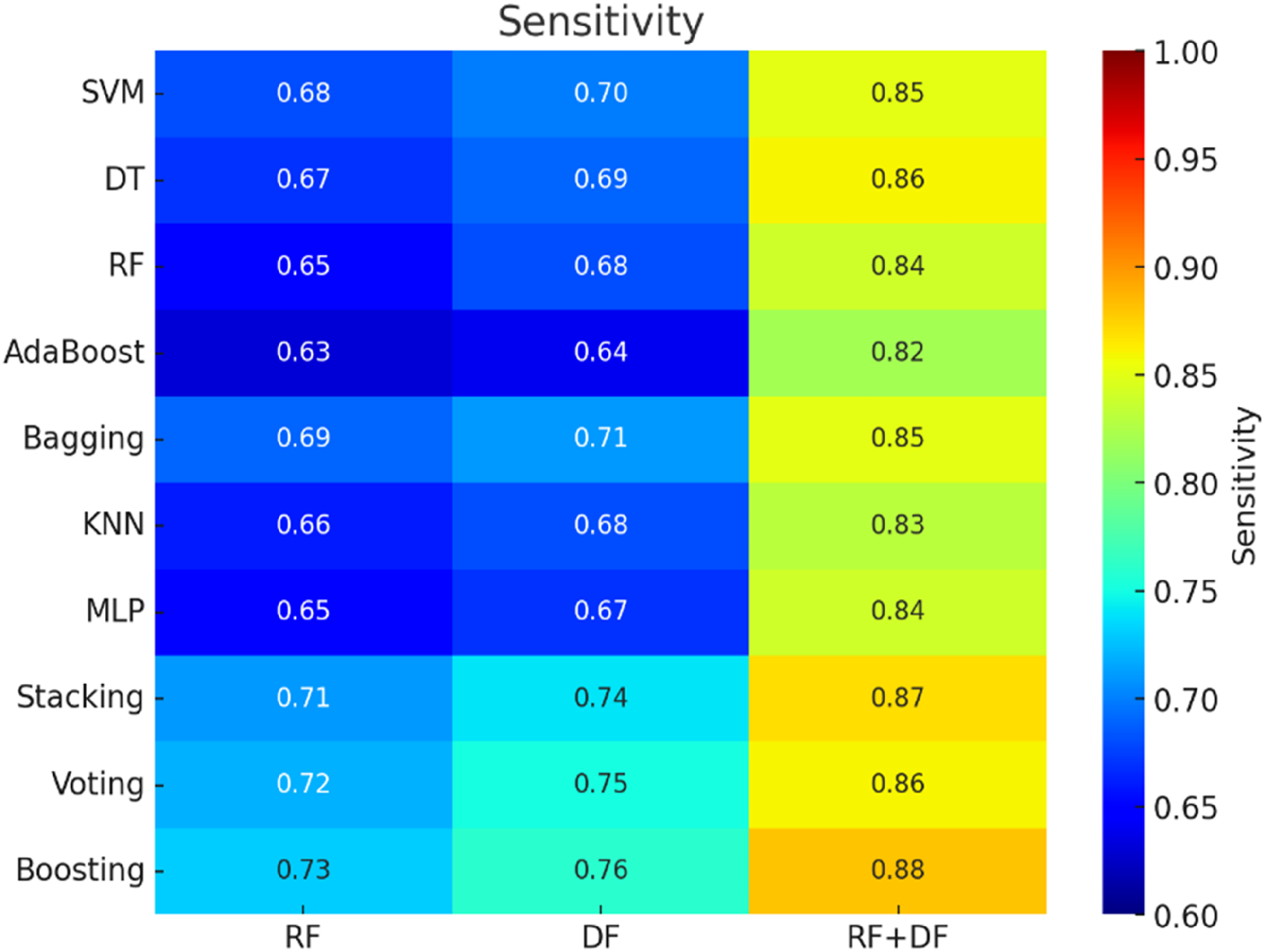
Heatmap and mean 5-fold cross-validation sensitivity for brain tumor classification.
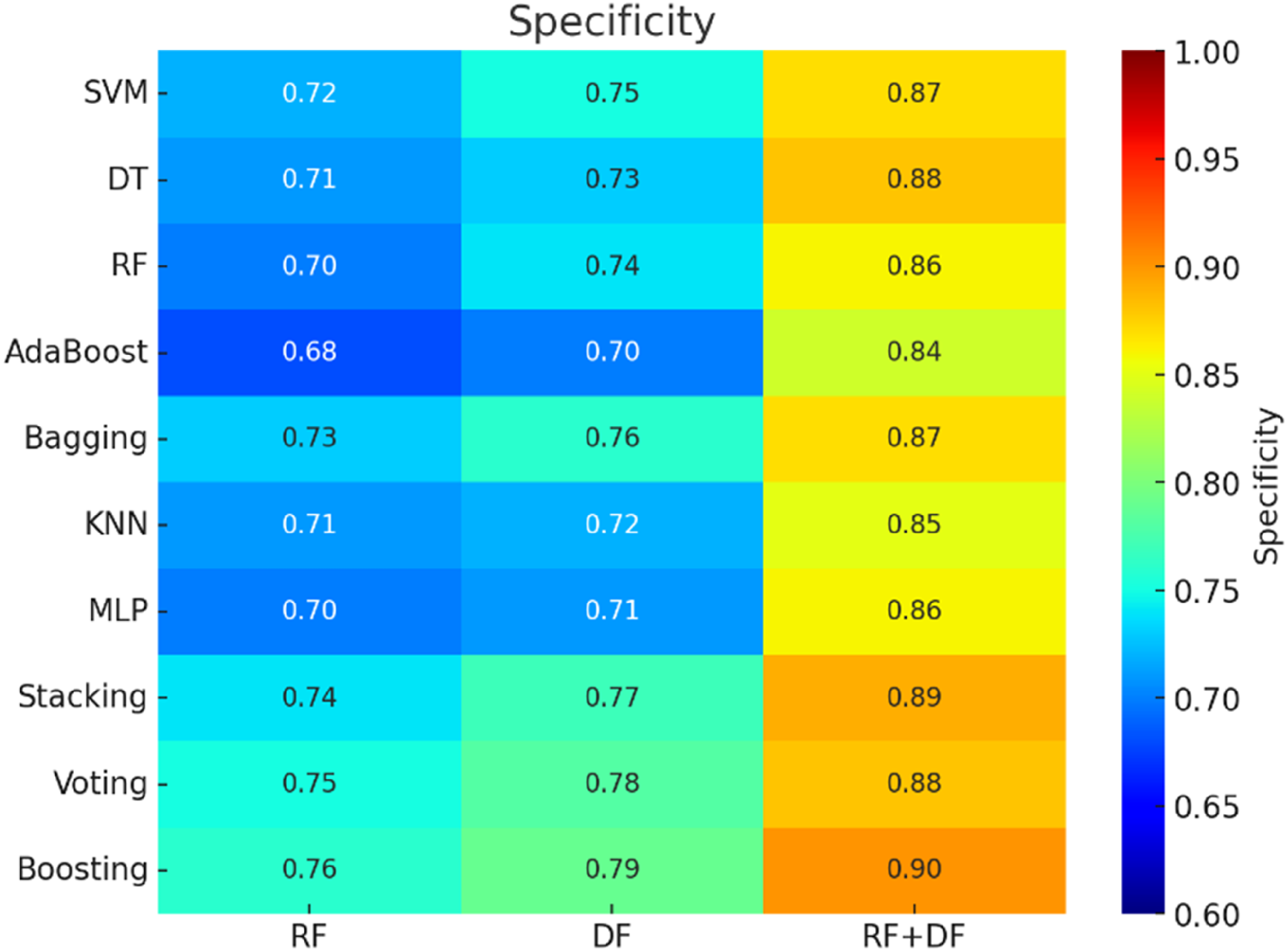
Heatmap and mean 5-fold cross-validation specificity for brain tumor classification.
Enhanced performance with combined feature set (RF + DF)
The integration of both feature sets significantly improved performance across all metrics. The accuracy of models utilizing the combined RFs + DFs feature set ranged from 88.0% to 95.0%, marking a substantial improvement compared to models using either RFs or DFs alone. This enhancement was particularly evident in the AUC scores, which ranged from 0.85 to 0.92, indicating a strong ability to discriminate between classes. Sensitivity and specificity also showed considerable improvement, demonstrating that the combined feature sets was more effective at identifying underlying patterns in the data, leading to reduced false positive and false negative rates.
Impact of ensemble methods
The stacking method consistently outperformed individual models across all metrics. When applied to the RFs + DFs feature set, stacking achieved an accuracy of up to 94.5% and an AUC of 0.91. These results demonstrate that stacking effectively leverages the strengths of various base models, leading to more precise and reliable predictions.
The voting ensemble method also improved model performance, though to a lesser extent than stacking. Accuracy for voting ranged from 90.0% to 94.0%, with AUC scores reaching up to 0.90. This moderate improvement suggests that while voting reduces prediction errors by averaging the outputs of individual models, it may not be as powerful as stacking in boosting overall performance.
Among all ensemble methods, boosting exhibited the most significant improvements, particularly when applied to the RFs + DFs feature set. With an accuracy of up to 95.0% and an AUC of 0.92, boosting demonstrated its ability to sequentially correct errors, leading to substantial performance gains. Additionally, sensitivity and specificity were highest with boosting, highlighting its effectiveness in addressing class imbalances and improving both true positive and true negative rates.
Comprehensive evaluation
The analysis confirms that combining RFs and DFs features with advanced ensemble methods leads to superior model performance across all metrics. Ensemble techniques, particularly stacking and boosting, significantly enhance predictive accuracy, AUC, sensitivity, and specificity. These results highlight the importance of integrating diverse feature sets and employing powerful ensemble approaches to improve the generalizability and reliability of machine learning models in medical image analysis.
Discussion
This study aimed to investigate the potential of combining RFs and DFs for brain tumor classification. Our analysis revealed that the integrated model, utilizing both RFs and DFs, outperformed models based on radiomics or deep learning alone. Furthermore, the model's sensitivity and specificity were comparable to those of clinical radiologists, indicating its potential utility in glioma grading.5,18,21–23 Previous research in this area has primarily focused on the use of either radiomics or deep learning techniques for the quantitative analysis of glioma grading.5,7,13,17,19
This study employs a range of ML algorithms and advanced ensemble techniques to analyze and predict outcomes using RFs, DFs, and their combination (RFs + DFs). Rather than relying solely on LASSO for feature selection, a hybrid approach was implemented to efficiently identify the most relevant features from both RFs and DFs. Several classifiers were applied, including SVM, Decision Trees, Random Forest, KNN, MLP, Bagging, and AdaBoost. These classifiers were tested on various RF and DF combinations to determine the most effective model for outcome prediction. Ensemble methods, such as Stacking, Voting, and Boosting, were also employed to further optimize performance.
The results indicated that the Boosting method, when combined with RFs and DFs, provided the best performance, achieving a mean accuracy of 95.0%, an AUC of 0.92, sensitivity of 88%, and specificity of 90%. These metrics significantly exceeded the performance of models using only RFs or DFs, which reached a maximum accuracy of around 67%. The findings demonstrate that incorporating DFs alongside RFs, enhanced by ensemble techniques like Boosting, significantly improves predictive performance. This approach surpasses conventional feature selection and classification methods, highlighting the importance of combining diverse imaging features and employing ensemble strategies for optimal brain tumor grade prediction.
The study by Xiao et al. 24 introduces a non-invasive method for glioma grading, a critical factor in determining clinical prognosis and survival prediction. This method combines RFs and DFs to provide a more comprehensive representation of the images. Radiomic features were extracted from the region of interest, while a VGG-16 model pre-trained on ImageNet was fine-tuned to extract DFs. Feature selection was then applied to obtain optimal subsets of both RFs and DFs, as well as a combined set. These feature subsets were used to train classifiers such as logistic regression, support vector machines, and linear discriminant analysis for glioma grade prediction. The proposed approach was tested on the BraTS 2018 dataset, which includes 285 subjects from various institutions. The results demonstrated that the combined method achieved the highest AUC of 94.4%, outperforming the use of RFs or DFs individually. Similarly, our findings show that integrating both RFs and DFs, especially when enhanced by advanced ensemble methods like Boosting, significantly improves predictive accuracy and discriminative power, achieving an AUC of 92%. These results underscore the effectiveness of combining multiple feature types for glioma grading and suggest that such integrative methods could be pivotal for clinical decision-making.
The study by Ning et al. 25 explored the feasibility of combining global RFs and local DFs from multi-modal magnetic resonance imaging (MRI) to develop a non-invasive glioma grading model. The results demonstrated that the combined model outperformed those based solely on either RFs or DFs, achieving an area under the receiver operating characteristic curve (AUC) of 0.94 for the validation cohort and 0.88 for the independent testing cohort from a local hospital. The model also achieved a sensitivity of 86% and specificity of 92% in the validation cohort, and a sensitivity of 88% and specificity of 81% in the independent testing cohort.
Similar to the findings of Ning et al., 25 this study highlights the significant advantages of combining RFs with DFs to enhance predictive accuracy and model robustness for early brain tumor detection. By integrating detailed quantitative imaging biomarkers from radiomics with data-driven insights from deep learning, we achieve a more comprehensive analysis of tumor characteristics. This combined approach not only improves sensitivity and specificity but also significantly enhances the model's diagnostic performance. The results emphasize the potential of this integrative method in advancing early diagnostic techniques in neuro-oncology, enabling more precise and reliable clinical assessments.
Similar to the study by Çinarer et al. 26 which developed a deep learning-based classification method for glioma grading by combining RFs with a deep neural network (DNN) and discrete wavelet transform (DWT), achieving a high accuracy of 96.15%, our study highlights the strength of integrating diverse feature sets for brain tumor classification.
While Çinarer et al. 26 focused on combining RFs with DWT-enhanced DNNs, our approach utilized both RFs and DFs alongside various machine learning algorithms and ensemble methods. In our study, the highest performance was achieved using a boosted ensemble model with the combined RF + DF feature set, resulting in an accuracy of 95.0%, an AUC of 0.92, a sensitivity of 88%, and a specificity of 90%. This highlights the significant impact of incorporating diverse imaging features and applying ensemble methods to enhance diagnostic performance. Similar to the findings of Çinarer et al., our results confirm that a multifaceted approach—integrating diverse features with optimized machine learning algorithms—is crucial for improving the accuracy and reliability of brain tumor grading. These advanced models show great potential in supporting clinicians during the diagnostic process, as evidenced by comparable successes in related studies.
While the advantages of combining RFs and DFs have received limited attention, our findings demonstrate that this integration significantly improves brain tumor classification performance. However, the study's limitations include a small sample size, which may affect the generalizability of the results, and the reliance on a single feature selection algorithm, which might not have been the most suitable for this dataset. Additionally, other feature extraction methods, such as Principal Component Analysis (PCA), were not explored, potentially limiting further insights. Future research should explore various feature selection and extraction techniques and validate these findings on larger cohorts to enhance the robustness of the models.
Conclusion
This study investigated the combination of RFs and DFs for brain tumor classification based on MRI scans. A dataset of 3064 brain MRI images was used, with RFs extracted using Pyradiomics and DFs obtained through an autoencoder. Various machine learning algorithms, including ensemble methods like Boosting, were applied. The results showed that combining RFs and DFs, particularly with Boosting, achieved the highest predictive accuracy of 95% and an AUC of 0.92. These findings underscore the importance of integrating diverse imaging features and advanced machine learning techniques for improving brain tumor classification.
Footnotes
Acknowledgements
We pay sincere thanks to all cited researchers.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.