
Abstract
A treatment for a complicated disease might be helpful for some but not all patients, which makes predicting the treatment effect for new patients important yet challenging. Here we develop a method for predicting the treatment effect based on patient characteristics and use it for predicting the effect of the only drug (Riluzole) approved for treating amyotrophic lateral sclerosis. Our proposed method of model-based random forests detects similarities in the treatment effect among patients and on this basis computes personalised models for new patients. The entire procedure focuses on a base model, which usually contains the treatment indicator as a single covariate and takes the survival time or a health or treatment success measurement as primary outcome. This base model is used both to grow the model-based trees within the forest, in which the patient characteristics that interact with the treatment are split variables, and to compute the personalised models, in which the similarity measurements enter as weights. We applied the personalised models using data from several clinical trials for amyotrophic lateral sclerosis from the Pooled Resource Open–Access Clinical Trials database. Our results indicate that some amyotrophic lateral sclerosis patients benefit more from the drug Riluzole than others. Our method allows gradually shifting from stratified medicine to personalised medicine and can also be used in assessing the treatment effect for other diseases studied in a clinical trial.
Keywords
1 Introduction
Amyotrophic lateral sclerosis (ALS) is a deadly disease that affects motor neurons in the brain and spinal cord, i.e. the neurons responsible for voluntary muscle control. Riluzole (Rilutek) is the only approved drug for this disease to date. According to the European Medicines Agency, 1 Riluzole prolongs the median survival of ALS patients, depending on the dose, by a few months. Several side effects, such as sickness, weakness or increased liver enzyme levels are mentioned. 1 Knowledge how Riluzole works on the nervous system of ALS patients is limited. The Pooled Resource Open–Access Clinical Trials (PRO-ACT) database 2 is the largest database containing clinical trial data of ALS patients available and was initiated to retrieve more information on the disease. It contains data from 17 ALS studies conducted between 1990 and 2010. Using these data, we aimed at finding out more about the effect of Riluzole on the health and survival of patients.
Before statistical analyses and p-values entered into medical progress 70 years ago, doctors treated patients individually based on their experiences and knowledge. 3 Since the beginning of the ‘golden age of randomised clinical trials’, however, medication became more and more standardised. Nowadays, much knowledge about the effect of drugs has accumulated, cornerstone drugs such as antibiotics have been used for decades and many diseases can be treated successfully; however, providing new drugs for the general public becomes more difficult. Diseases such as ALS are too complex to treat all patients in the same way. Therefore, there is a need to return to more individualised treatments, but this time with the use of statistical concepts.
In the past years, there has been an immense effort towards personalised medicine in the analysis of randomised controlled trials. The goal is to identify predictive factors, i.e. factors that interact with the treatment, 4 such as biomarkers, other treatments and environmental circumstances. In the following, we will refer to these factors as patient characteristics. Prognostic factors, i.e. factors that directly affect the patient’s outcome, are only of secondary interest, but should not be neglected, because they not only change the general level of the outcome – showing in the individual intercept – but might also be predictive and prognostic. 5 Note that we use the terms predictive and prognostic as in the medical literature, 4 but in a statistical sense both groups of variables are useful predictors. For drugs for which the biological mode of action is unknown, predictive and prognostic factors should first be identified in a data-driven way. New hypotheses can then be generated and new trials can be planned based on these hypotheses. In this first step, we ask whether a certain patient characteristic is relevant and not why.
Many new statistical methods in the field of stratified medicine, i.e. subgroup analysis, have been developed. Subgroup analyses aim at finding groups of patients that have differential treatment effects. Most of the methods are based on recursive partitioning (trees) and/or interaction models.6–12 The tree-based methods for subgroup analyses have specialised splitting procedures for partitioning the patients into groups with higher and lower treatment effect. Interaction models evaluate the interaction between the treatment and given patient characteristics. The idea behind methods of subgroup analyses in general is to obtain a treatment effect

However, the assumption that the treatment effect is a step function may be too restrictive, and
2 Methods
Seibold et al., 2016
5
introduced a means of conducting subgroup analysis for randomised controlled trials using model-based recursive partitioning. One first defines a model
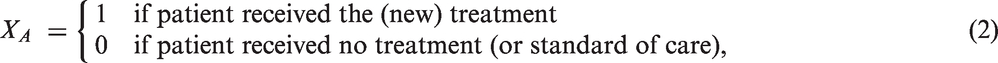


In most applications, the model contains only an intercept α and a treatment effect β, i.e.
Conceptually, the partitioned model parameters
The most intuitive step from a tree structure to a more complex structure is to use a random forest instead of a single tree. Hence, we propose a strategy in which a model-based random forest is used to measure how similar patients are with respect to the treatment effect and the treatment effect of each patient is predicted on this basis using personalised models.
2.1 Random forest
Random forests
13
compute an ensemble of T trees. The proposed algorithm draws subsamples
This section focuses on the estimation of the trees, and the following section features the computation of the similarity measure and how the forest can be used to estimate personalised treatment effects.
2.2 Split procedure
The special feature of our method is the split procedure, which is based on the empirical estimating function
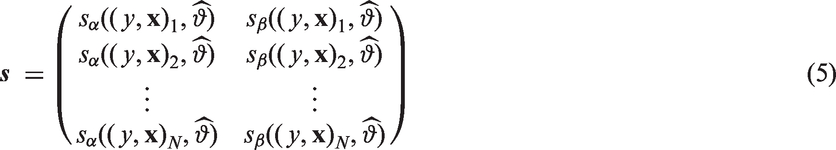
To obtain a split in model-based recursive partitioning for this setup, the following steps have to be performed:
Estimate the parameters in the prespecified model Compute the associated score matrix Perform tests of independence between the score contributions and the partitioning variables:
If any p-value is lower than the significance level, select the partitioning variable that has the highest association (lowest p-value) to any of the relevant residuals for the split. Search for the optimal split point in the selected partitioning variable using a suitable criterion, such that the models in the resulting daughter nodes have as little association between the partitioning variable and the residuals as possible.
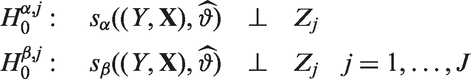
This split procedure is repeated until a stopping criterion is met. This can be, for example, when no p-values are lower than the significance level or if subgroups become too small. For detailed information on stopping criteria, see Hothorn et al., 2015.
17
In the end, a tree is obtained with disjoint subgroups

Accordingly in a random forest of T trees, each tree defines disjoint subgroups

The independence tests can be performed using permutation tests18,19 or, for reasonably large samples, using M-fluctuation tests.14,20 Unbiased recursive partitioning methods commonly use tests with node-wise null hypotheses of ‘no further split needed’, as we do here.14,16,19 Since one test is computed per patient characteristic eligible in the given node, multiplicity adjustment such as Bonferroni correction is recommended. More details on the algorithm and the test procedures used are documented in Appendix 2.
2.3 Personalised models
In personalised medicine, the goal is to learn how much a person will profit from a given treatment and what would happen if the standard of care or no treatment is given. For any patient, it is possible to compute a personalised model based on the similarity of this observation to the observations in the training data. In general, any measure of similarity
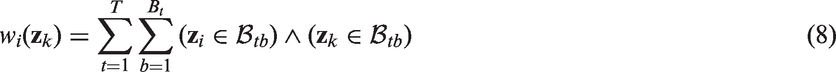
To obtain the personalised model
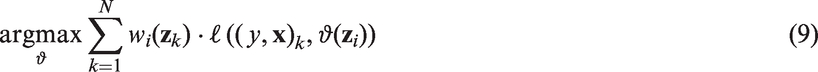
In other words, every patient k from the training set is included
Using the personalised models, it is possible to obtain a log-likelihood. From the personalised model for patient i, the log-likelihood contribution

2.4 Improvement through personalised models
To check whether the personalised models actually lead to an improvement of the base model, one tests the hypothesis


This strict null hypothesis is to be rejected if any of the patient characteristics contain information on the outcome or the treatment effect. To conduct the test, one can proceed as follows:
Compute the forest log-likelihood and the log-likelihood of the base model and calculate their difference. This difference is a measure of how much better the personalised models are compared to the base model. Draw parametric bootstrap samples from the base model. Compute the forest log-likelihood and the log-likelihood of the base model in the bootstrap samples and again compute the differences. The distribution of these values represents the distribution under the null hypothesis. The p-value is then the proportion of bootstrap samples in which the difference in log-likelihoods exceeds the observed difference in the original data. Note, that this p-value will be very low or even 0 when the patient characteristics contain information on the outcome or the treatment effect.
In practice, one may be interested in just
2.5 Dependence plots
A partial dependence plot describes the dependence of a function (in our case the treatment effect
2.6 Variable importance
The variable importance for the random forest is computed based on the tree log-likelihoods. For a given forest computed with T trees, the log-likelihood is computed as follows:
Select the out-of-bag data Compute the log-likelihood contribution of each observation Compute the out-of-bag log-likelihood as the sum of the contributions
To obtain the variable importance of a given variable


If the variable importance is high, the variable is an important predictive and/or prognostic factor. Note that due to the signed differences, the variable importances might become negative signalling that the log-likelihood merely improved by chance and that the variable is not important. As the size of the negative values conveys information on the overall importance variability, we do not collapse to 0 which would otherwise be a sensible restriction. It is possible to compute also conditional variable importances 26 to account for correlation between patient characteristics. In the following, we focus on unconditional variable importances.
3 Results
3.1 PRO-ACT data
The PRO-ACT (https://nctu.partners.org/ProACT) database contains longitudinal data of ALS patients that participated in one of 16 phase II and III trials and one observational study. It is a project initiated by the non-profit organisation Prize4Life (http://www.prize4life.org/) to enhance knowledge about ALS. It contains information on a broad variety of patient characteristics, such as vital signs, the patient’s and family’s history, and treatment information. Identification criteria, such as study centres, are not included in the database. Also collected are the survival time and the ALS functional rating scale (ALSFRS), which is a score measuring the patients’ ability of living a normal life.
27
The ALSFRS is a sum-score of 10 items, each of which ranges between 0 and 4, where 0 represents complete inability and 4 represents normal ability. The items are speech, salivation, swallowing, hand-writing, cutting food and handling utensils, dressing and hygiene, turning in bed and adjusting bed clothes, walking, climbing stairs and breathing. As outcomes in the study, we used both the survival time (denoted by survival) and the ALSFRS 6 months after treatment start (denoted by
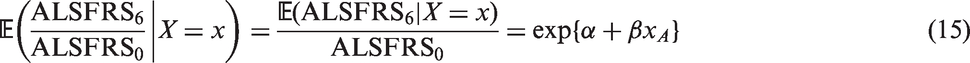
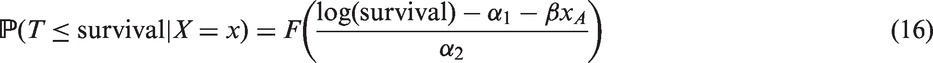
ALSFRS base model (Gaussian generalised linear model with log-link and offset).

Given are the parameter estimates, their standard error and the Wald confidence interval.
Survival time base model (Weibull model).

Given are the parameter estimates, their standard error and the Wald confidence interval.
3.2 Personalised models
We computed personalised models for all observations in the respective training data, which were used to obtain the random forest. The distribution of parameter estimates in the personalised models is given in Figure 1 for the ALSFRS and in Figure 2 for the survival time. Figure 1 shows that all patients are predicted to have a positive Riluzole effect, i.e. for all patients taking Riluzole, a higher ALSFRS is achieved compared to those not taking Riluzole. However, there is a variability in the treatment effects, and the distribution of the treatment effect is bimodal (as is the distribution of the intercept). The treatment effect estimated from the base model is between the two modes. The lowest treatment effect a person in this data set is predicted to have is 0.0027.
Kernel density estimates of the personalised parameter estimates for the ALSFRS. Distribution of the personalised parameter estimates for the survival time. The baseline hazard functions are given in the left panel; the kernel density estimate of the treatment effect estimate is given in the right panel.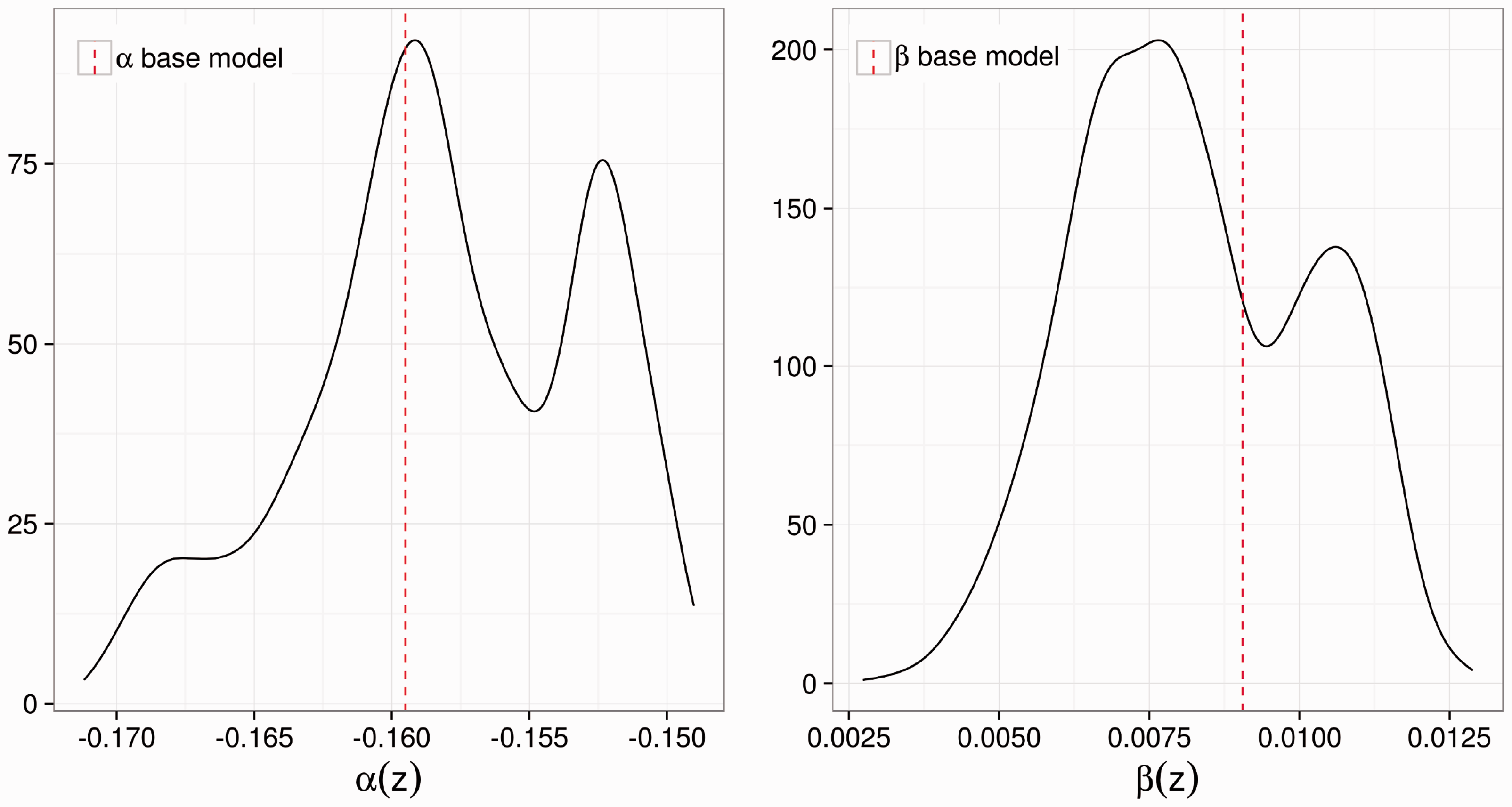
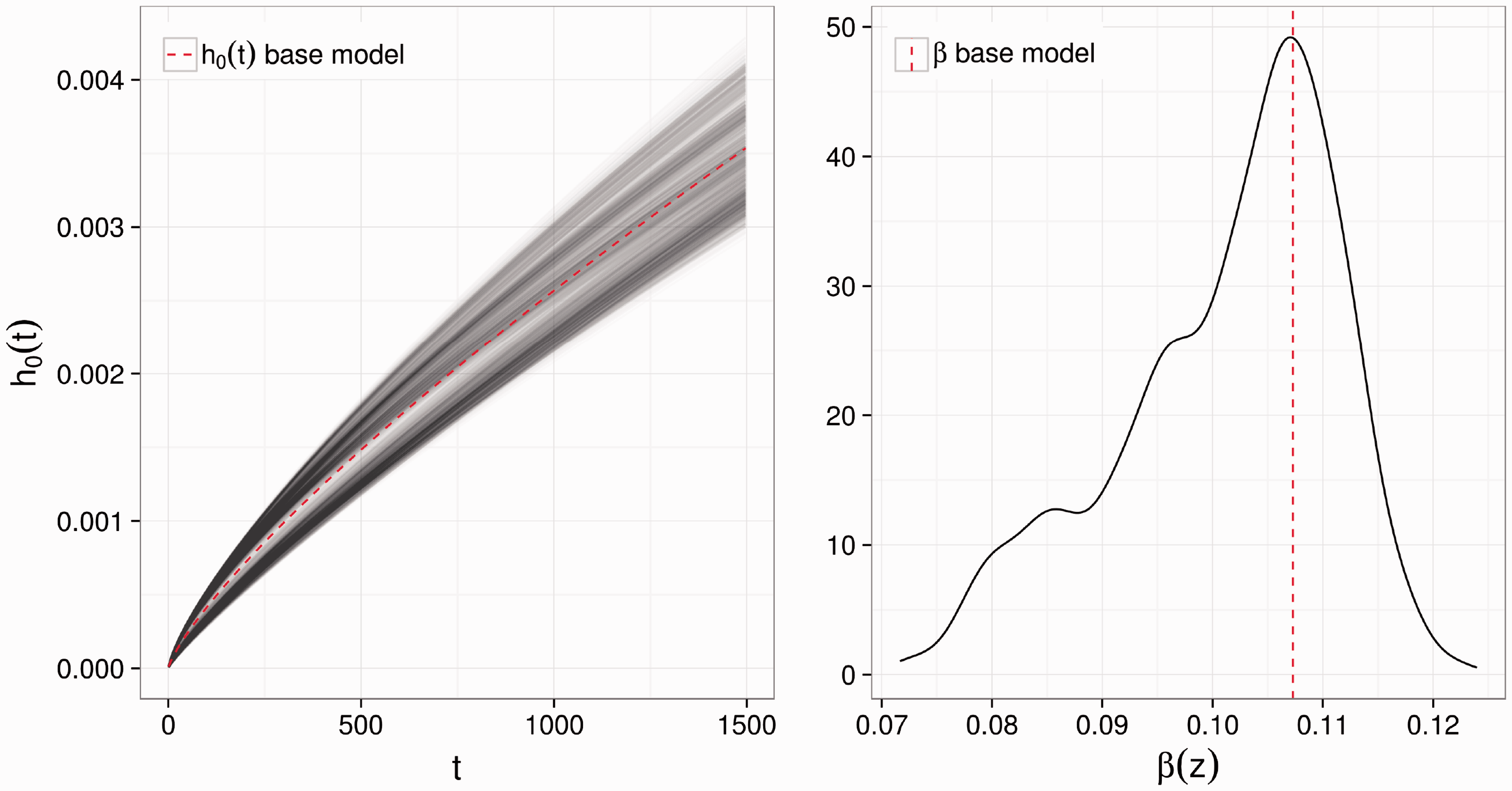
For the survival time, the lowest predicted treatment effect is 0.0717. However, the value of the treatment effect in the personalised survival models cannot be interpreted in isolation; its meaning depends on the shape of the baseline hazard, i.e. on α1 and α2. Instead of depicting the densities of the two baseline hazard parameters, in Figure 2, we show the baseline hazard curves. The baseline hazard varies for different patients, and there is a gap in the middle. The baseline hazard estimated from the base model lies close to that gap.
From the personalised models, we obtained the ‘forest log-likelihoods’ for both outcomes. For the Gaussian GLM with log-link and offset, the log-likelihood contribution for observation i is defined as

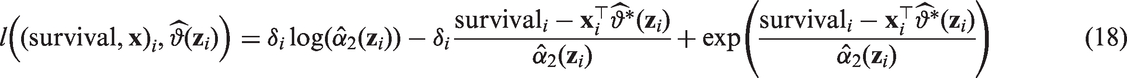
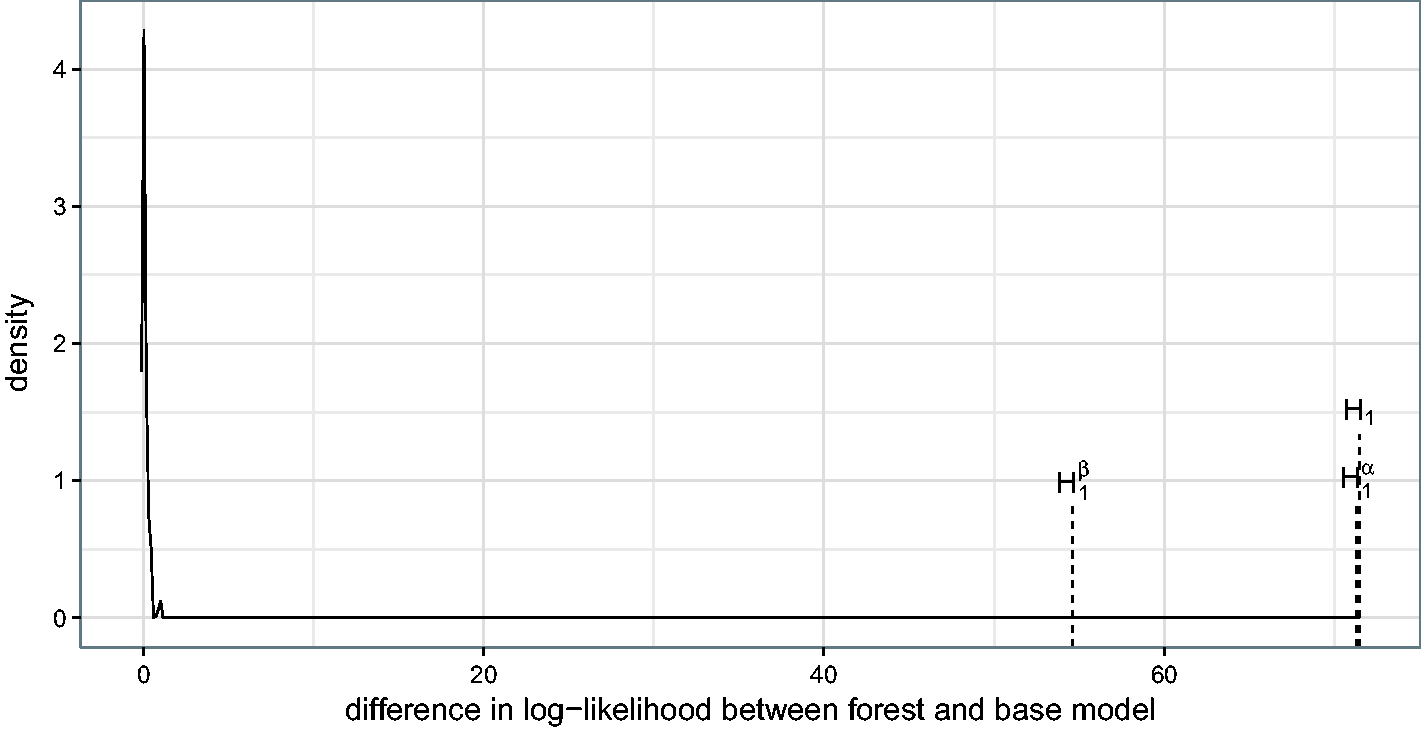
As can be seen in Figures 3 and 4, the forest log-likelihoods are higher than the log-likelihoods of the base models for both the ALSFRS and the survival time. The figures show the difference in log-likelihood between the forest and the corresponding base model. To show that this difference is not due to overfitting, we drew 50 samples from the base models, i.e. 50 parametric bootstrap samples for which the assumption holds that the intercept (or baseline hazard) and treatment effect are the same for all patients. ALSFRS values are drawn from a normal distribution truncated at 0 to assure positivity. (The effect of truncation is virtually negligible; only two observations had a truncation probability of more than 1%.) The survival times are drawn from a Weibull distribution censored at the originally observed censoring times (if exceeded). The differences in log-likelihoods for both ALSFRS and survival time are distributed close to 0, with a slight shift to the right, for the parametric bootstrap samples. The large difference in the ALS data supports the assumption that the base models are not ideal and personalised models are meaningful (the respective p-values are both 0). To approximately check the sub-hypotheses given in equations (11) and (12), we also computed log-likelihoods of the two forests that split only with respect to one of the partial score functions – either intercept (or baseline hazard) or treatment effect. For the ALSFRS, both the forest under Difference in log-likelihoods between forest and base model using the original data (dashed lines; H1, the usual forest; Difference in log-likelihoods between forest and base model using the original data (dashed lines; H1, the usual forest; 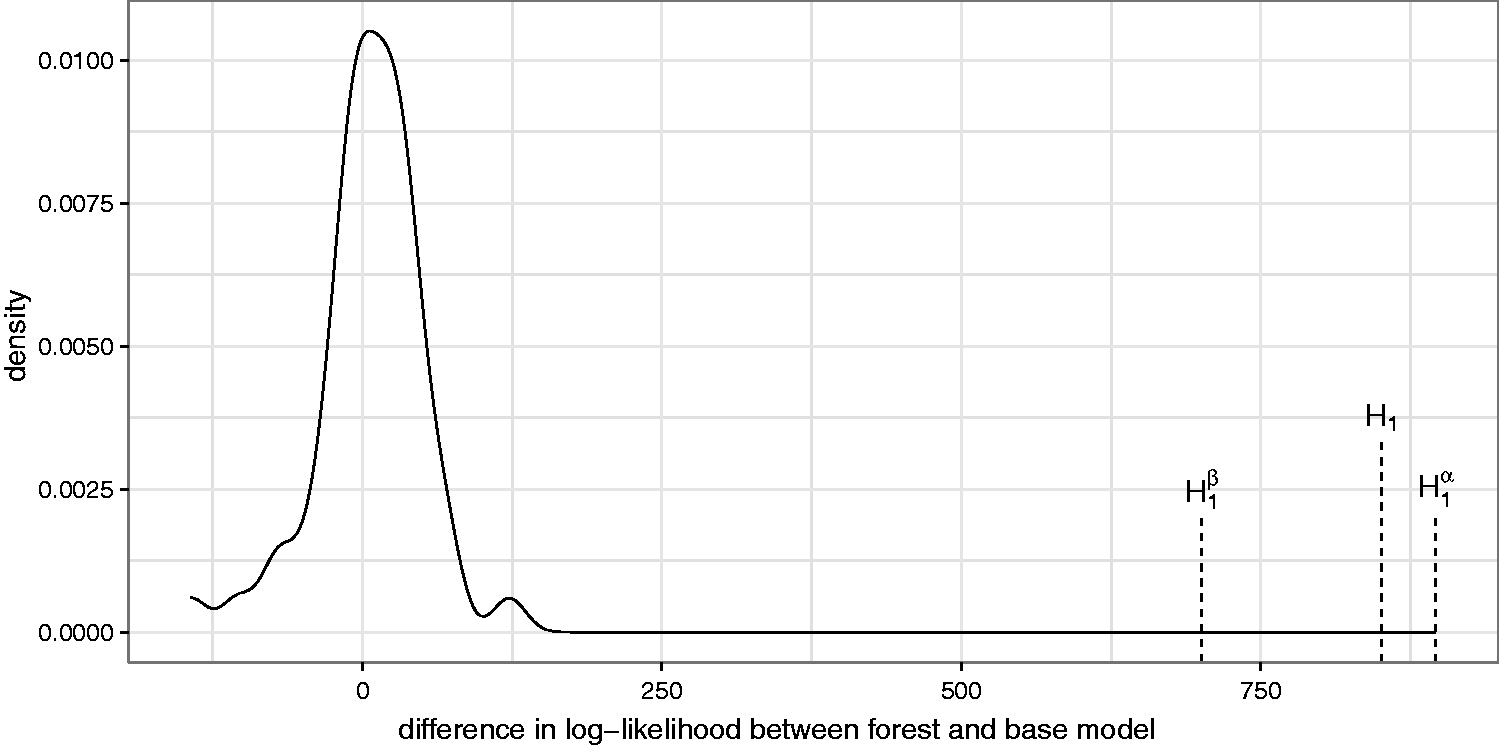
3.3 Dependence plots
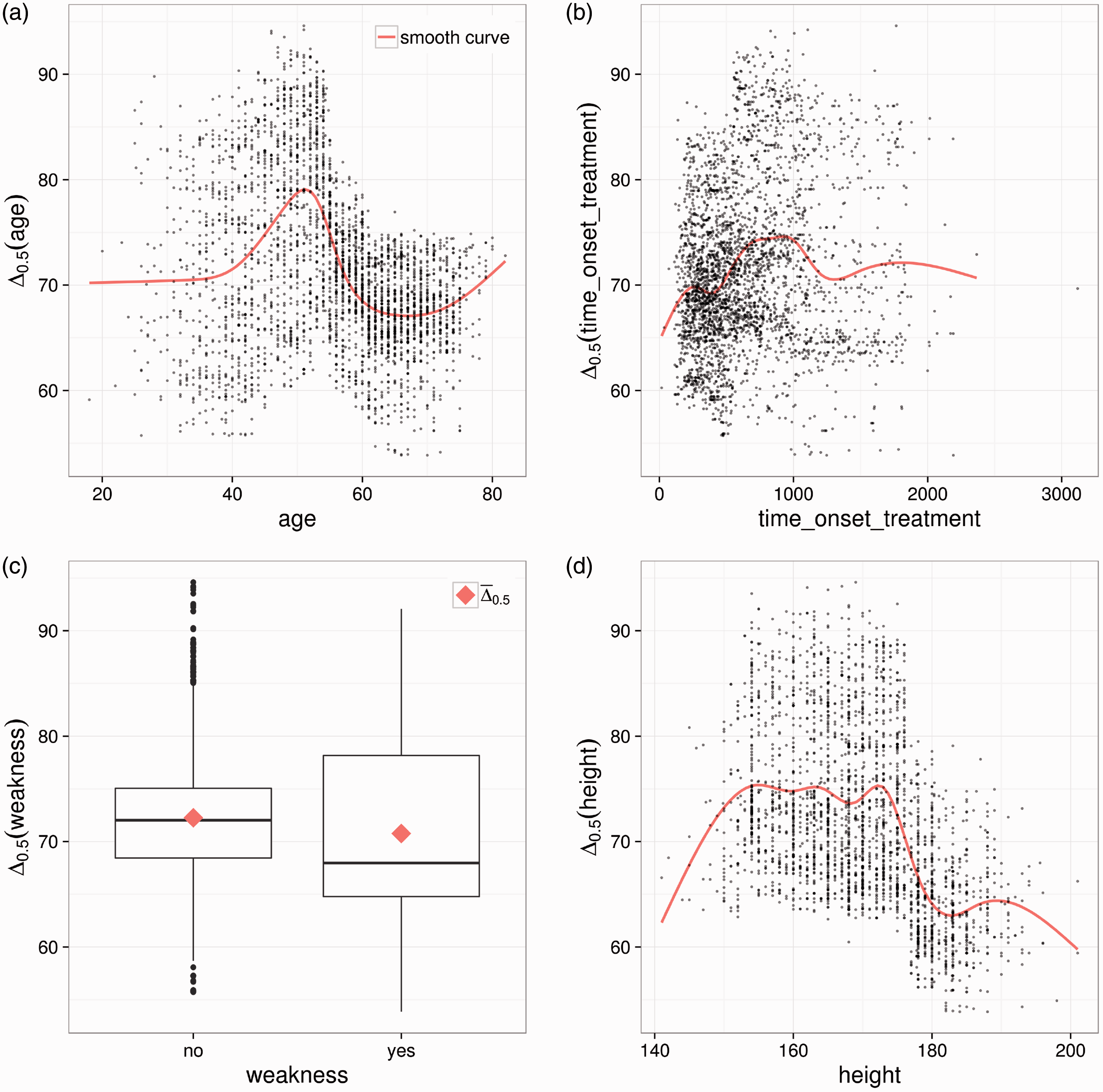
The dependence plots as shown in Figures 5 and 6 can be obtained for any partitioning variable. Here we show the dependence plots for the four variables with the highest variable importance (see Section 3.4). For continuous variables, such as age, we show a scatter plot, as before. For categorical variables, such as the variable weakness, which indicates whether a patient suffers from muscle weakness (yes/no), boxplots giving the variation of Dependence plots for the four patient characteristics with the highest variable importance from the ALSFRS forest. (a) Dependence plot for the time in days between disease onset and treatment start. (b) Dependence plot for the creatinine level in mmol/L. (c) Dependence plot for the phosphorus level in mmol/L. (d) Dependence plot for the forced vital capacity (volume of air in litres that can forcibly be blown out after full inspiration). Dependence plots for the four patient characteristics with the highest variable importance from the survival time forest. (a) Dependence plot for the age. (b) Dependence plot for the time in days between disease onset and treatment start. Outlier has been omitted in the estimation of the smooth curve. (c) Dependence plot for the weakness indicator. (d) Dependence plot for the height.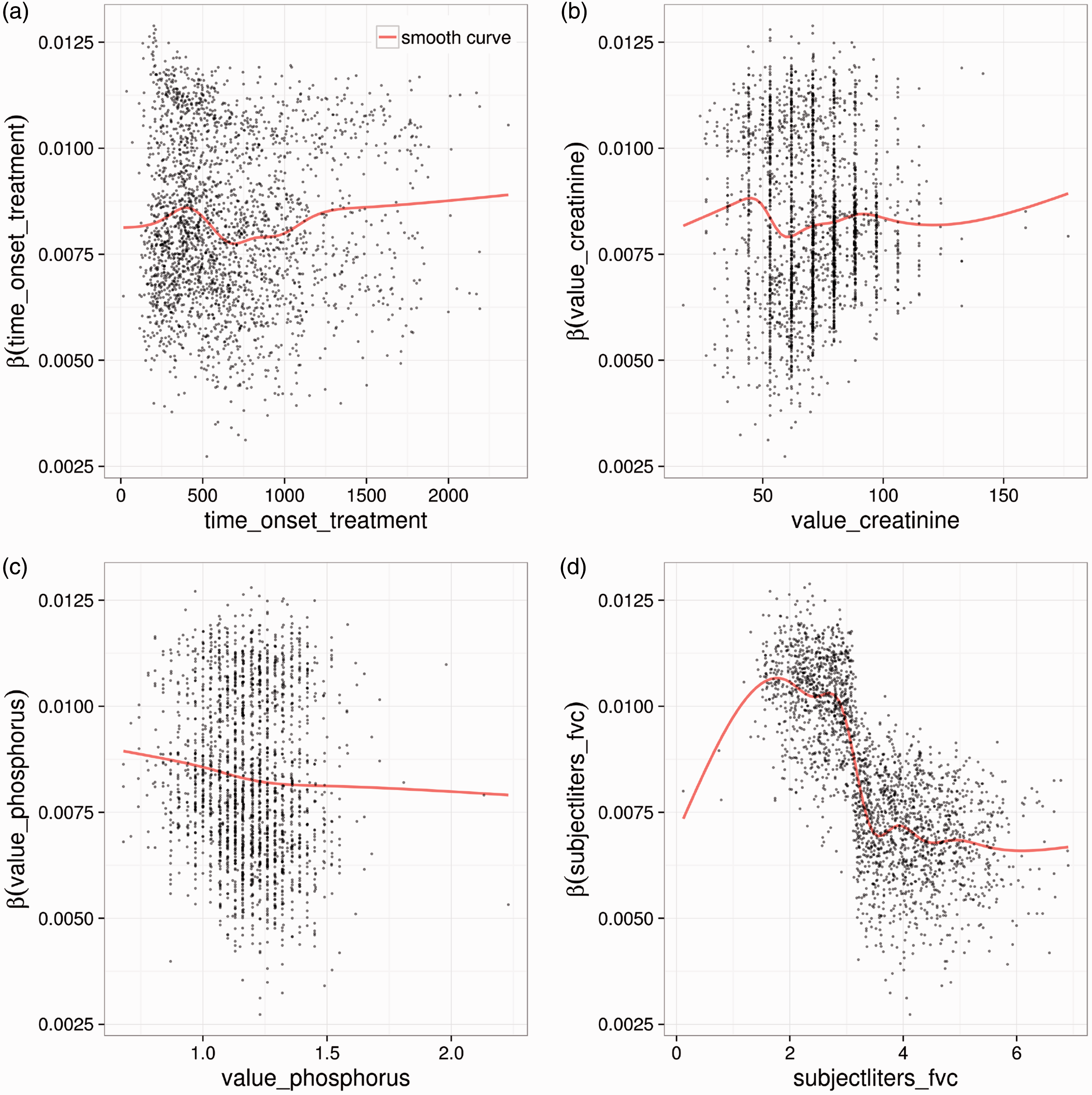
The most obvious pattern of the four graphs in Figure 5 is shown in Figure 5(d), in which the personalised treatment effects are plotted against the forced vital capacity (FVC). Patients with a low lung function (low FVC) are predicted to have a higher treatment effect than those with better lung function. The graph shows a relatively clear cut at approximately 3 L. This indicates that FVC is a predictive factor. For the time between disease onset and treatment start, the pattern is less clear. Patients with a short as well as those with a long time between disease onset and treatment start seem to benefit most. Also for the creatinine value, which indicates kidney function, only weak patterns are observed. The phosphorus balance is slightly negatively associated with the treatment effect.
For the survival time, plotting only the treatment effect against a variable is not meaningful since the interpretation of the treatment effect depends on the shape of the baseline hazard. Therefore, we took a different approach in this case and show on the y-axis the difference in median survival between treatment and control intake. For example, a value of 70 means that based on the personalised model of this patient, the median survival is prolonged by 70 days if the patient takes Riluzole. The difference in median survival is denoted by
3.4 Variable importance
Figures 7 and 8 show the variable importance of each split variable. Figure 7 suggests that the time between disease onset and start of treatment plays the most important role for the personalised models. The time between disease onset and start of treatment, the FVC, and the phosphorus balance have been shown to be the most important variables for stratified models,
5
which is underlined by this analysis. The time between disease onset and start of treatment contains information on the state of disease progression for patients in the trial. If the disease onset and the start of treatment are far apart, the patient is likely to have a slow progression.
28
Also Riluzole has been shown to not be effective when the disease is already far progressed.
1
Thus, it is not surprising that this variable is selected as an important variable.
Variable importances of all split variables used for the ALSFRS forest. Variable importances of all split variables used for the survival time forest.
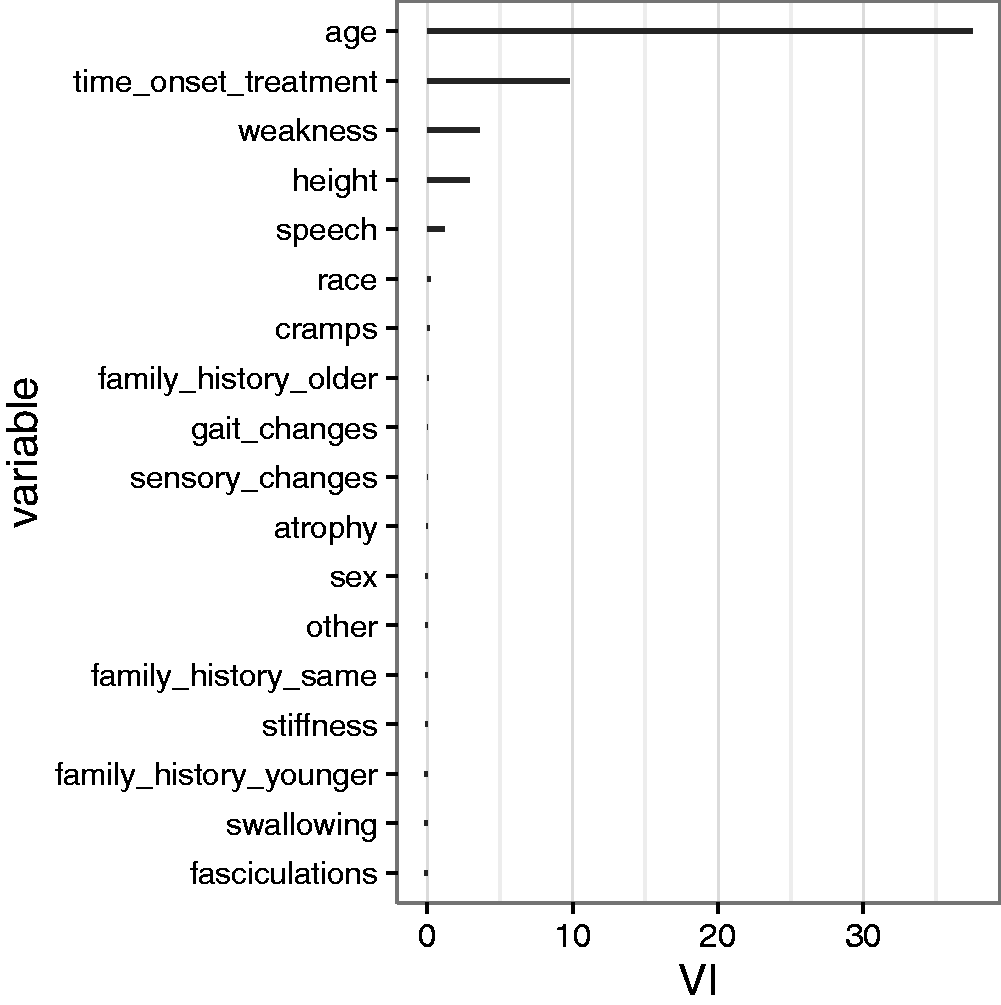
For the Riluzole effect on the survival time, the patient’s age and again the time between onset and treatment start play a role. Both variables have been identified before 5 as important factors for survival time.
4 Discussion
Model-based forests can find important predictive and prognostic patient characteristics and – more importantly – via the personalised models provide the possibility to predict the counterfactual individual treatment effect of a future patient. The personalised models allow a shift from standardised medicine back to personalised medicine, but this time in a controlled way by using statistical principles. Through analysis of the PRO-ACT data and simulations (see Appendix 3), we showed that personalised models can perform better than the standard global model if there are differences in treatment effect between patients. If there is no difference, the performance of the methods is about the same. In our performance checks, we focused on the fit of the model to the data based on the log-likelihood. Performance of the method for new patients was studied using simulations.
The proposed method is applicable to clinical trial data where treatment is randomised. In our analysis of the PRO-ACT data, we included several clinical trials for which we have no knowledge about inclusion criteria or any other details of the study protocol as this information is not given out in order to anonymise data. This could possibly lead to confounding issues. As there is interest in methodology for when treatment is not randomised, we included a small simulation study on this topic in Appendix 4. The results seem promising in the case where the patient characteristic that impacts the treatment assignment is not the predictive factor. However, there is a bias when a patient characteristic is predictive and also impacts treatment assignment. Further work in the area of observational trials is needed where, e.g. adjustment methods such as propensity scoring 29 could be of use.
The presented methods are based on tree-based subgroup analyses but go a step further. Not only are subgroups identified and the treatment effect within each group estimated, but many slightly varying trees are used to retrieve a measure of similarity between patients. On this basis, a model is computed in which more similar patients are weighted higher. The personalised models provide point estimates for the treatment effect. When the individual treatment effects are plotted against patient characteristics, researchers can determine whether the patient characteristics are predictive factors and in what way the patient characteristics and the treatment interact. For ALS patients, the FVC value was predictive for the ALSFRS, and the patient’s age and height were predictive for survival. The next step would be to generate hypotheses from these findings and plan a study to test these. Our method offers a promising means of providing individual treatment effect predictions and can be applied to any clinical trial data where baseline patient characteristics are available.
All results were obtained solely using open-source implementation software (see Section 5), which provides easy access to the methods.
5 Computational details
The code for data preprocessing of the PRO-ACT data is available in the TH.data package. 30 The source code for the full analyses is available on https://github.com/HeidiSeibold/personalised_medicine. Implementation of all methods discussed in this article is based on the R partykit package (version 1.0-2). 31 Other R packages used were sandwich (2.3-3),32,33 survival (2.38-1), 34 eha (2.4-2) 35 and ggplot2 (2.0.0). 36 All computations were conducted in the R system for statistical computing (version 3.2.0). 37
Footnotes
Acknowledgements
We thank Karen A. Brune for improving the language.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Heidi Seibold and Torsten Hothorn were financially supported by the Swiss National Science Foundation (Grant 205321_163456).