
Abstract
We propose a multiple imputation method for estimating the incidence rate with interval censored data and time-dependent (and/or time-independent) covariates. The method has two stages. First, we use a semi-parametric G-transformation model to estimate the cumulative baseline hazard function and the effects of the time-dependent (and/or time-independent covariates) on the interval censored infection times. Second, we derive the participant's unique cumulative distribution function and impute infection times conditional on the covariate values. To assess performance, we simulated infection times from a Cox proportional hazards model and induced interval censoring by varying the testing rate, e.g., participants test 100%, 75%, 50% of the time, etc. We then compared the incidence rate estimates from our G-imputation approach with single random-point and mid-point imputation. By comparison, our G-imputation approach gave more accurate incidence rate estimates and appropriate standard errors for models with time-independent covariates only, time-dependent covariates only, and a mixture of time-dependent and time-independent covariates across various testing rates. We demonstrate, for the first time, a multiple imputation approach for incidence rate estimation with interval censored data and time-dependent (and/or time-independent) covariates.
Keywords
1 Introduction
The gold-standard for estimating the incidence rate is to periodically test a cohort of uninfected participants for new infection events. 1 One limitation of this approach, however, is that we rarely (if ever) observe the exact time of infection. Instead, we know only that the infection event occurs within an interval censored by the latest-negative and earliest-positive test times. Our uncertainty about the timing of the infection event will be proportional to the length of the censoring interval, which will increase if tests are missed or scheduled at lengthy time intervals (i.e., every 12 or 24 months), as is often the case in large, population-based HIV incidence cohorts.2,3 For example, in what year does the seroconversion event occur if a participant tests HIV-negative in June 2016, misses the scheduled test in July 2017, and tests HIV-positive in June 2018? Because the censoring interval extends across one or more years, we cannot identify the aggregating interval (i.e., the year) in which the infection event truly occurs. Extended interval censoring poses methodological challenges for accurately estimating the rate of new infections over time. 4
A common solution to the interval censoring problem is to impute an infection time. After right-censoring the data, the incidence rate can then be estimated using standard statistical methods.5–9 However, popular deterministic approaches, which impute an infection time at the mid-point or end-point of the censoring interval, can lead to artefactual trends in the incidence rates. 4 A better approach is to multiply impute a single infection time from a uniform distribution, which gives estimates close enough to the true incidence rate and accounts for variation across the imputed values. 4 Nevertheless, the single random-point method assumes that the hazard of infection is constant across the censored interval, thus discarding potentially useful information about the timing of the infection event. For example, in sub-Saharan Africa, we know that the time to HIV acquisition is shorter for younger women (aged 19–25 years) when compared with their demographic counterparts.10–13 Use of covariate data could reduce uncertainty about the infection time and improve the accuracy of our incidence rate estimates.
In recent years, several methods have been developed to infer the effects of covariates on interval censored infection times.9,14 Hsu et al. 15 proposed a Cox proportional hazards model with time-independent covariates to identify the nearest neighbors of infection. They then derived a non-parametric distribution (analogous to a Kaplan-Meier estimator) from this neighborhood and imputed the infection times. Pan 16 also developed a multiple imputation approach for failure times using a Cox proportional hazards model with time-independent covariates, similar to Chen and Sun. 17 In these model-based approaches, the aim was to estimate the regression parameters for interval censored data, with empirical demonstrations limited to the case of one or more time-independent covariates. To date, these models have not been extended to estimate the incidence rate with interval censored data and time-dependent covariates.
To estimate the incidence rate with interval censored data, we propose a multiple imputation approach that is a function of the participant's time-dependent and/or time-independent covariates. Our imputation approach has two stages. For stage 1, we use a semi-parametric G-transformation model to estimate the cumulative baseline hazard function and the effects of covariates on the interval censored infection times. The G-transformation model was recently developed by Zeng et al.18,19 and advances existing proportional hazard methods by accommodating interval censored data and time-dependent covariates. For stage 2, we derive the participant's unique cumulative distribution function and impute the infection times conditional on the covariate values, which is the main contribution of our study. We undertook a simulation study to evaluate the performance of our G-imputation model for incidence rate estimation under various testing rates. For our empirical demonstration, we used interval censored data from one of sub-Saharan Africa's largest and longest-running HIV surveillance systems to estimate the annual incidence rate conditional on time-independent (sex) and time-dependent (age, marital status, and community HIV prevalence) covariates.
2 Methods
We propose a method for estimating trends in the incidence rate with interval censored data and time-dependent and/or time-independent covariates. Consider an incidence cohort study with
We use a two-stage approach to impute a value for T conditional on the participant's covariate data. For the first stage, we estimate the cumulative baseline hazard function and the effects of the covariates on the infection risk. Previously, from a proportional hazards framework, this could only be done for interval censored data with time-independent covariates.
18
Zeng et al.
19
have proposed nonparametric maximum likelihood estimation of a broad class of semiparametric models that allow for one or more possibly time-dependent covariates. Under the semiparametric transformation model, the cumulative hazard function for T conditional on

For the second stage, we use β and
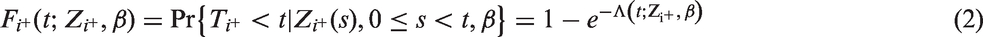
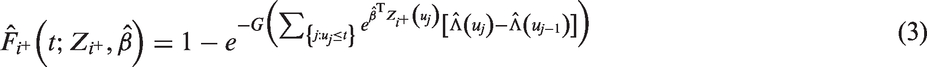
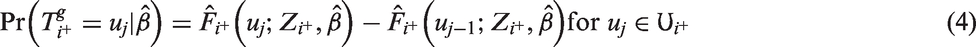
Thus, the probability of sampling an infection time,
2.1 Simulation study
We undertook a simulation analysis to evaluate the performance of our G-imputation model. Using the methods of Austin
20
and Bender et al.,
21
we generated infection times from three Cox proportional hazards models. Model (1) with two time-independent covariates:
To simulate a closed incidence cohort, we set
In the real-world, participants miss their scheduled test dates. Thus, we induced interval censoring on the infection times by varying the probability p (
We next imputed the infection times, denoted by
We undertook the simulation as follows: Step 1: Generate the infection times T and the full dataset,
2.2 Empirical study
To empirically demonstrate our G-imputation model, we used interval censored data from the Africa Health Research Institute (AHRI), located in the KwaZulu-Natal province of South Africa. Since 2004, field-workers have visited households every 12 months to identify eligible participants for HIV testing. Prior to 2007, women aged 15–49 years and men aged 15–54 years were included in the HIV survey, after which eligibility was extended to cover all residents aged >15 years of age. Approximately 80% of participants agreed to at least one HIV test between 2005 and 2015. Details of the surveillance system and the open HIV incidence cohort are provided elsewhere. 22
We selected sex as a time-independent covariate, and four time-dependent covariates: age (mean-centered), age-squared (mean-centered), marital status, and the HIV prevalence of the participant's surrounding community. We constructed the time-varying community HIV prevalence measure using a geospatial method from previous work.
23
Previous research has shown that the five covariates are strongly associated with the risk of HIV acquisition in our study area.12,13,24–26 We obtained estimates of β and
3 Results
3.1 Simulation analysis
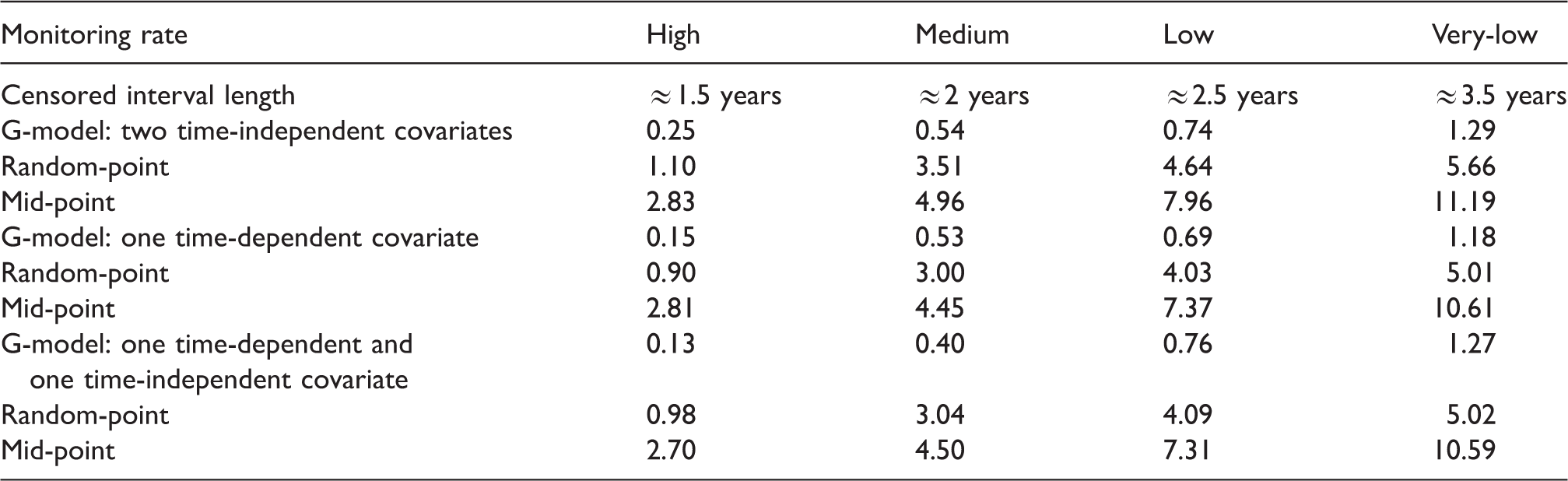
Table 1 shows the simulation MSE results for the single random-point and mid-point imputation methods. The MSE results are compared with estimates from a G-imputation model with two time-independent covariates (Figure S1), one time-dependent covariate (Figure S2), and one time-dependent and time-independent covariate (Figure 1). Results show that the G-imputation model was more accurate for a high, medium, low, and very-low testing rate, and produced smaller MSEs when compared with the single random-point and mid-point methods (see Figure 1 and Table S1 of the Supplement). The empirical average and empirical standard deviation of the estimates and the empirical average of the standard errors (of the standard error estimators) are shown in Table S1 of the Supplement.
Simulation study results showing the estimated number of new infections from our G-imputation model with one time-independent and time-dependent covariate. Results are compared with the single random-point and mid-point imputation approaches under a high (80–100%), medium (60–80%), low (40–60%), and very-low (25–40%) testing rate. IC is the average length of the censored interval. (a). High testing rate, IC ≈ 1.5 years. (b) Medium testing rate, IC ≈ 2.0 years. (c) Low testing rate, IC ≈ 2.5 years. (d) Very-low testing rate, IC ≈ 3.5 years. Mean-squared errors for the simulation study, which compares our G-imputation model with the single random-point and mid-point imputation approaches under a high (80–100%), medium (60–80%), low (40–60%), and very-low (25–40%) testing rate.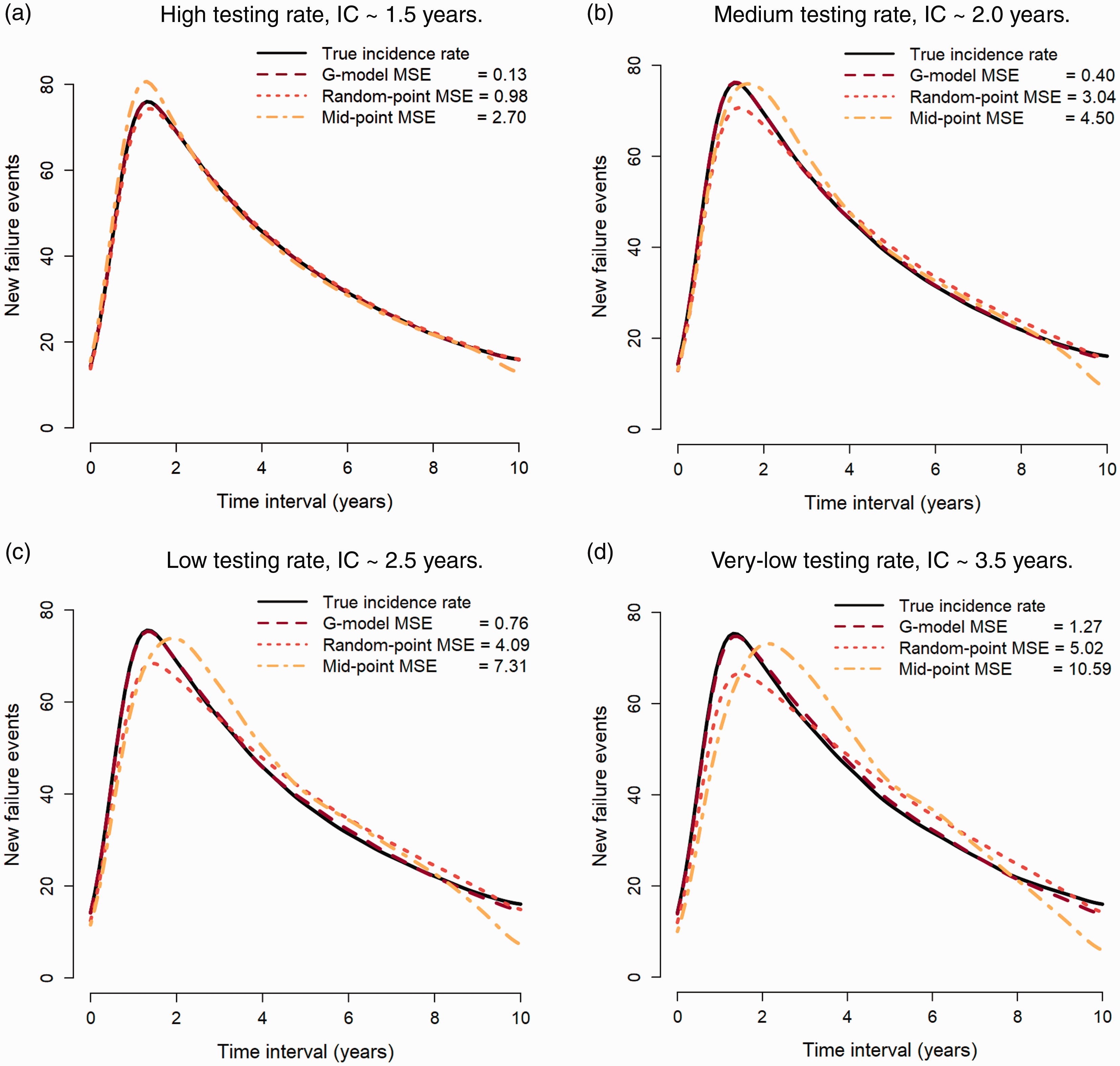
3.2 Empirical analysis
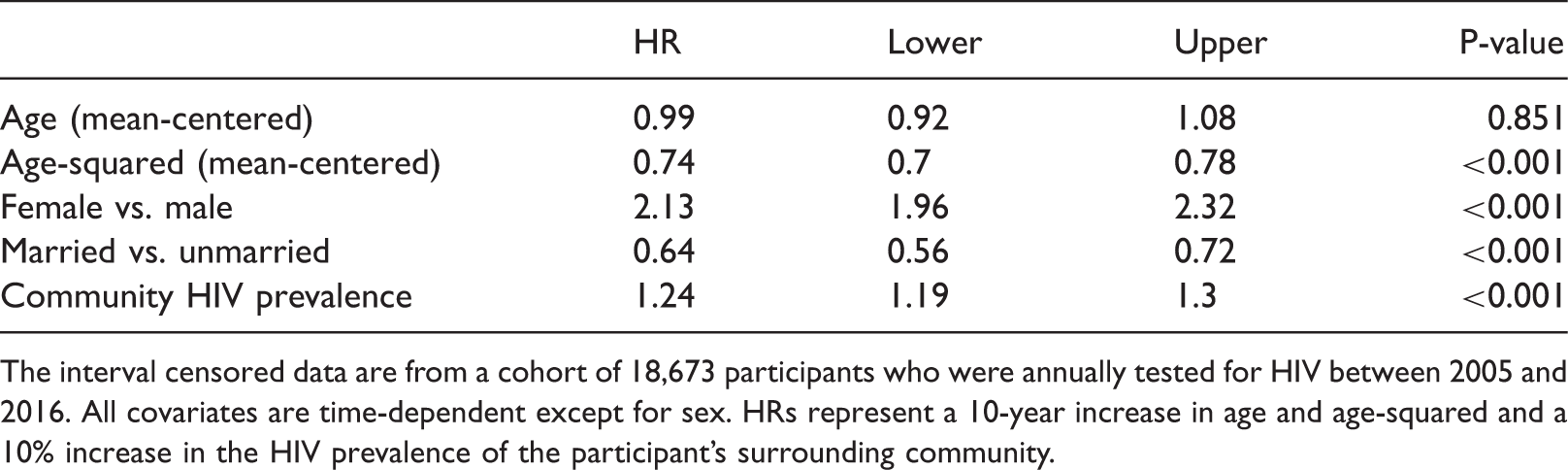
An empirical analysis of the AHRI data shows that there were 2898 (15.5%) seroconversion events for the 18,670 repeat-testers between 2005 and 2016. The observation time was 4.46 (standard deviation [SD]: 3.24) years and the median length of the censored interval was 2.78 (interquartile range (IQR): 1.27–5.04) years. Results for the semi-parametric G-transformation model are shown in Table 2: all covariates except mean-centered age were statistically associated with the time to infection (at the 0.001 level). Figure 2 and Table S2 shows the incidence rate estimates, standard errors, and 95% confidence intervals for the G-imputation model, single random-point, and mid-point imputation methods. The G-imputation model results show that the annual HIV incidence rate increased from 2.62 events per 100 person-years in 2005 to 3.92 events per 100 person-years in 2010, which remained stable at around 4 events per 100 person-years from 2011 to 2016. Estimates from the single random-point method are close to the G-model estimates from 2005 to 2013, with a slight decline in the incidence rate in the last three years of the observation period. The mid-point method concentrates the imputed infection events at the middle of the observation period and therefore shows an increase and then decrease in the incidence rate over time.
4
Annual HIV incidence rate (2005–2016) estimates from (a) our G-imputation model, (b) single random-point imputation, and (c) mid-point imputation using interval censored data from the AHRI surveillance area. The solid line represents the smoothed incidence rate estimates with 95% confidence intervals and the crosses are the estimated incidence rates at each year. (a) G-model imputation. (b) Single random-point imputation. (c) Mid-point imputation. G-transformation model results for the empirical analysis. Exponentiated proportional hazards ratios (HR) and 95% confidence intervals for the risk of HIV acquisition conditional on age, sex, marital status, and community HIV prevalence. The interval censored data are from a cohort of 18,673 participants who were annually tested for HIV between 2005 and 2016. All covariates are time-dependent except for sex. HRs represent a 10-year increase in age and age-squared and a 10% increase in the HIV prevalence of the participant's surrounding community.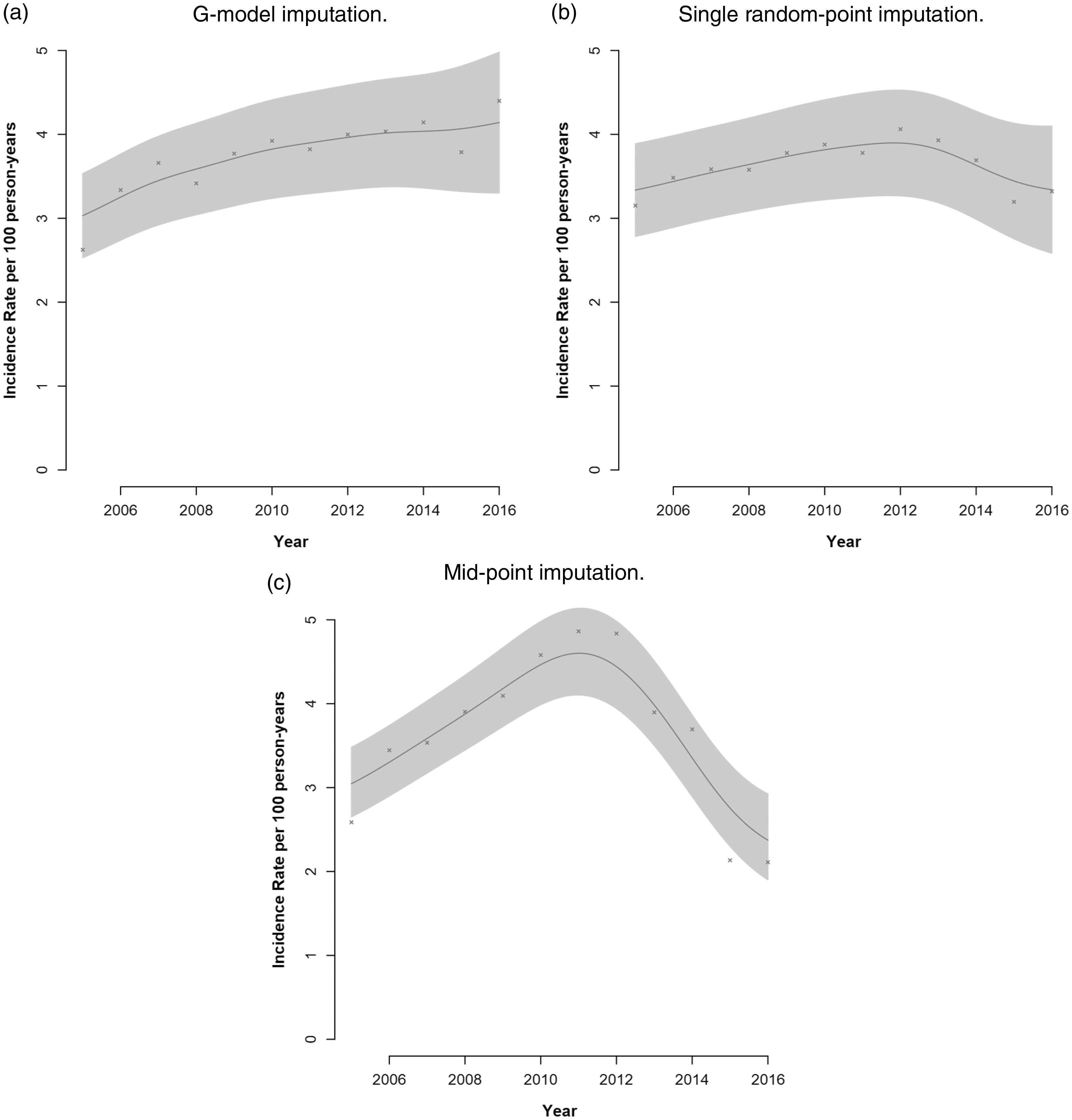
4 Discussion
We have described a multiple imputation approach for estimating the incidence rate with interval censored data and time-dependent covariates. Interval censoring arises when the infection event is known only to occur between the latest-negative and earliest-positive test times, which is an unavoidable problem in incidence cohorts with periodic testing. Previous research has shown that ad hoc methods for imputing the infection time can lead to artefactual trends in the incidence rate once the censoring interval extends across one or more aggregating intervals. 4 To reduce bias, we propose a two-stage multiple imputation approach: First, we estimate the effects of covariates (time-dependent and/or time-dependent) on the interval censored infection times using a semi-parametric G-transformation model proposed by Zeng et al. 18 Second, we use the estimated regression parameters and the estimated cumulative baseline hazard to derive a unique cumulative distribution function from the participant's covariate values, from which we multiply impute the infection times. As far as we know, our G-imputation model is the first to use one or more time-dependent covariates to estimate trends in the incidence rate.
We undertook a simulation analysis to assess the performance of our G-imputation model. To do this, we generated infection times from covariate data with a 100% testing rate (the gold-standard). We reduced the testing rate to create interval censored data and then imputed the infection times using three G-models with two time-independent covariates, one time-dependent covariate, and one time-dependent and time-independent covariate. For comparison, we imputed mid-point and single random-point infection times and estimated the incidence rates for the three methods. Simulation results show that G-imputation model was accurate for either time-dependent and/or time-independent covariates under a high, medium, low, and very-low testing rate. G-model imputation also produced smaller MSEs than the mid-point and single random-point imputation approaches. The mid-point approach performs poorly when tests are missed; and while single random-point imputation is comparatively more accurate, 4 it assumes that the hazard of infection is independent of covariates. Previously, Hsu et al., 15 Pan, 16 and Chen and Sun 17 used a proportional hazards approach to infer the effects of time-independent covariates on the interval censored failure times. Using the recent work of Zeng et al,18,19 we extend this approach to infer the infection times as a function of time-dependent covariates.
Our G-imputation model treats the unobserved infection time, T, as a missing data point for which a value is imputed conditional on the participant's time-dependent and/or time-independent covariate values, Z. However, from the perspective of the G-transformation model proposed by Zeng et al.,
18
missing data assumptions are not required for T. The G-transformation model assumes that the number of test times, denoted by K, is random and that there exists a random sequence of test times,
For our G-imputation approach, we assume that the tests
Our G-imputation approach requires that covariate values exist at L and R, where (L, R] is the smallest interval that brackets T. If L and R exist, then the G-transformation method proposed by Zeng et al.
18
has several options for extrapolating the time-dependent covariate values across the interval (L, R]. For our analyses, we chose the default extrapolation setting, which is to use the participant's covariate value nearest to
Missing data on
Our G-imputation approach has some limitations. First, covariate data are required, which may be unavailable or too costly to collect. In this case, single random-point imputation is a suitable candidate for estimating trends in the incidence rate. 4 Second, the baseline cumulative distribution function could have large jumps due to data sparseness, which is most likely to occur at the end of the observation period where there is attrition or testing fatigue. As proposed by Hsu et al., 15 a smoothing function could be fit to the cumulative density function to reduce the jump sizes. Third, our imputation approach depends on assumptions that are relevant to the proportional hazards framework, since the semi-parametric G-transformation model of Zeng et al. (2016) is used to estimate the effects of the covariates on the interval censored infection times. A key assumption is that the model is correctly specified. We advise the careful selection of covariates based on existing knowledge of the study sample or from other study findings undertaken in comparative contexts. In our empirical example, we selected covariates based on previous studies in the AHRI surveillance area showing that age and sex,12,13,23,25 marital status,10,25,40 and community HIV prevalence 23 are significantly associated with the time to HIV acquisition (see Table 2).
We acknowledge that several interval censoring methods have been developed within the proportional hazards framework.41–47 However, there is no clear guidance on how these methods can be used to estimate the incidence rate, and in which situations they should be applied. 48 We are aware of one method for incidence rate estimation with interval censored data, however, covariate data was not used. 49 In this study, we have proposed a method for inferring the time to infection conditional on one or more time-dependent covariates. Our G-imputation model therefore contributes to an emerging methodological framework for estimating the incidence rate with interval censored data.
Supplemental Material
Supplemental material for Estimating trends in the incidence rate with interval censored data and time-dependent covariates
Supplemental Material for Estimating trends in the incidence rate with interval censored data and time-dependent covariates by Alain Vandormael, Frank Tanser, Diego Cuadros and Adrian Dobra in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by NIH grants (R01HD084233 and R01AI124389) from the National Institute of Child Health and Human Development (NICHD). Funding for the Demographic Surveillance Information System and Population-based HIV Survey was received from the Wellcome Trust, UK. FT and AV were supported by South African MRC Flagship (MRC-RFA-UFSP-01–2013/UKZN HIVEPI). FT was supported by a UK Academy of Medical Sciences Newton Advanced Fellowship (NA1501061).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.