
Abstract
The study of the predictive ability of a marker is mainly based on the accuracy measures provided by the so-called confusion matrix. Besides, the area under the receiver operating characteristic curve has become a popular index for summarizing the overall accuracy of a marker. However, the nature of the relationship between the marker and the outcome, and the role that potential confounders play in this relationship could be fundamental in order to extrapolate the observed results. Directed acyclic graphs commonly used in epidemiology and in causality, could provide good feedback for learning the possibilities and limits of this extrapolation applied to the binary classification problem. Both the covariate-specific and the covariate-adjusted receiver operating characteristic curves are valuable tools, which can help to a better understanding of the real classification abilities of a marker. Since they are strongly related with the conditional distributions of the marker on the positive (subjects with the studied characteristic) and negative (subjects without the studied characteristic) populations, the use of proportional hazard regression models arises in a very natural way. We explore the use of flexible proportional hazard Cox regression models for estimating the covariate-specific and the covariate-adjusted receiver operating characteristic curves. We study their large- and finite-sample properties and apply the proposed estimators to a real-world problem. The developed code (in R language) is provided on Supplemental Material.
Keywords
Introduction
The receiver operating characteristic (ROC) curve
1
is routinely used for evaluating the performance of a continuous marker as diagnostic or prognostic tool. Conventionally, the (pooled) ROC curve depicts, for each potential threshold,
When we measure the marker performance, the emphasis is often placed on accuracy, and we are not worried about the nature of the relationship between the marker and the outcome, or the potential interference that covariates could have on this relationship. However, this can be a crucial component in the correct practical implementation of the obtained results. For instance, Yala et al. 4 considered different mammography-based breast cancer risk models. On a cohort including 8751 examinations and 269 cancers (at 5 years), the Tyrer-Cuzick (TC) model 5 reported an AUC of 0.62 (95% confidence interval of 0.57–0.66). Considering the 3157 patients who were white (7107 examinations; 233 cancers) the AUC was essentially the same, 0.62 (0.57–0.67). However, on the 202 patients who were African-American (424 examinations; 11 cancers) the AUC was only 0.45 (0.21–0.66). In this case, the modest classification capacity reported by the TC model, mostly computed in white women, totally disappears when we apply the model to African-American women. Besides, the overall (pooled) AUC does not reflect the correct weighted average of those AUCs (0.61), and the poor behavior of the procedure in this small subpopulation is totally diluted. In this context, the covariate-specific and the covariate-adjusted ROC curves arise as valuable tools for depicting the real diagnostic accuracy of a marker taking into account the relevant information provided by the covariates.
Recall that the pooled ROC curve describes the performance of classification rules based on the same thresholds for each subject. That is, the thresholds are independent of the covariate value of each particular subject. As we saw previously, the consequence of this classification is that, when the covariate is associated with both the marker and the binary outcome, the marker should be calibrated to account for this covariate (see, Janes and Pepe
6
for a deeper discussion about the need of adjusting for covariates in studies of diagnostic, screening, or prognostic markers). The covariate-specific ROC curve is the standard ROC curve conditioned on a specific covariate value. That is, it describes the diagnostic accuracy of the studied marker in the subpopulation determined by each covariate value. It describes the accuracy of the marker when covariate-specific thresholds are used for selecting the classification rules. Mathematically, let

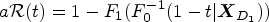

There is a number of proposals for estimating both the covariate-specific and the covariate-adjusted ROC curves. Early proposals, such as the ones by Pepe,8,9 or Faraggi 10 rely on parametric or semiparametric regression models. Fully nonparametric estimators based on nonparametric estimators of the involved conditional distribution and quantile functions were proposed by López-de-Ullibarri et al. 11 Pardo-Fernández et al. 12 reviewed the existing methods including covariates in the ROC analysis focusing on those employing nonparametric regression models. They classified those procedures in two categories: those modeling directly the covariate-specific ROC curve as the response of a generalized regression model (see, for instance, the proposal by Rodríguez-Alvarez et al., 13 where generalized additive models are considered) and those based on induced-regression methodology (e.g. the proposals by González-Manteiga et al. 14 and Rodríguez-Álvarez et al., 15 where nonparametric location-scale models are employed). After the publication of this review, new estimators have been proposed in the specialized literature. For instance, Inácio de Carvalho and Rodríguez-Álvarez16,17 proposed a highly robust model based on a combination of B-splines, dependent Dirichlet process mixture models, and the Bayesian bootstrap for the covariate-adjusted ROC curve. Recently, Bianco et al.18,19 also focused on the robust aspects of the covariate-specific ROC curve estimation, and considered regression-induced procedures with complex covariate structures.
In this piece of research, we aim the direct estimation of the involved conditional CDFs. With this goal, we assume that the relationship between the marker on both the positive and the negative populations and the covariates follows the proportional hazard regression model proposed by Cox. 20 In this context, this model implies that the effect of the covariate vector is proportional along all the potential values of the marker. The already traditional strategy of using the Breslow estimator and the maximization of the partial likelihood function involving the marginal distributions of the ranks of the observed marker values 21 is used for estimating the unknown CDFs. In order to gain flexibility in the final estimator, we let different effects and models on the two involved populations, and an adaptive regression splines function is used in order to modulate the impact of the covariate on the CDFs.
The rest of the article is organized as follows. In Section 2, both the proposed model and its semiparametric estimator are exposed. In Section 3, we explore the asymptotic properties of the resulting covariate-specific and covariate-adjusted ROC curve estimators. Finite-sample behavior of these estimators are studied via Monte Carlo simulations in Section 4, while a real-world example illustrates their practical use in Section 5. Finally, in Section 6, we present our main conclusions. Some technical issues are relegated to the Appendix. As Supplemental Material, we provide the R code used for implementing the proposed procedure and additional Monte Carlo results.
The model
Let
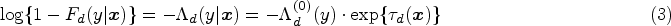
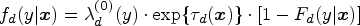
In this context, the proportional hazards model implies that the marker has a baseline behavior, determined by the so-called baseline cumulative risk function,
As usual, parametric and semi-parametric models are restrictive. The required assumptions could result unrealistic for particular practical situations. Fortunately, the literature is plenty of goodness of fit (GoF) procedures. In the context of PH Cox regression, Lin and Wei 22 , Grønnesby and Borgan, 23 or Parzen and Lipstsitz, 24 among others, have proposed specific GoF tests for the model at hand. Software implementations of some of these procedures, including several R packages, are available.
The survival literature is rich in proportional hazards (PH) models. The exponential distribution is the most well-known family. Distributions satisfying
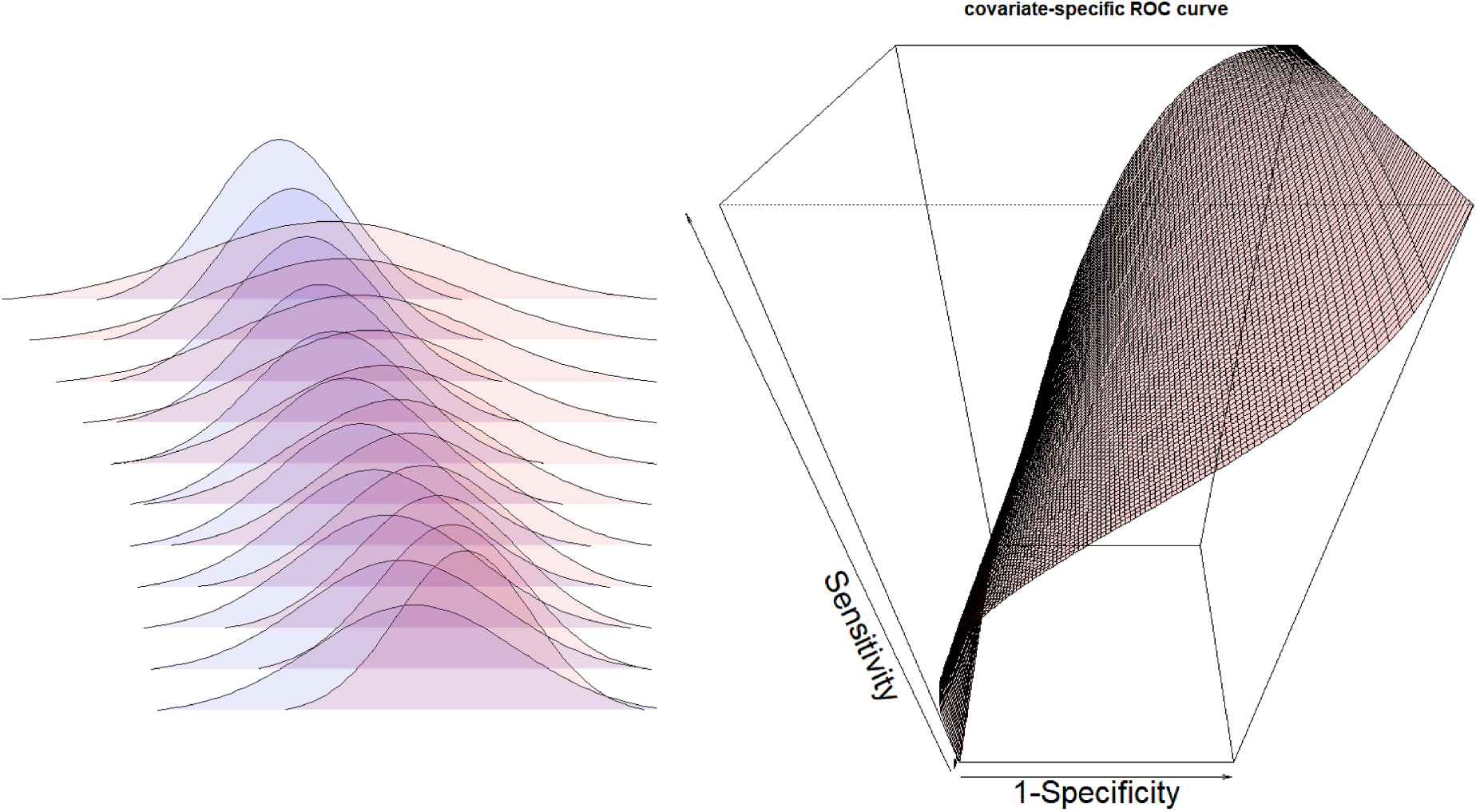
Covariate-specific receiver operating characteristic (ROC) curve. At left, density functions for the negative (following a distribution
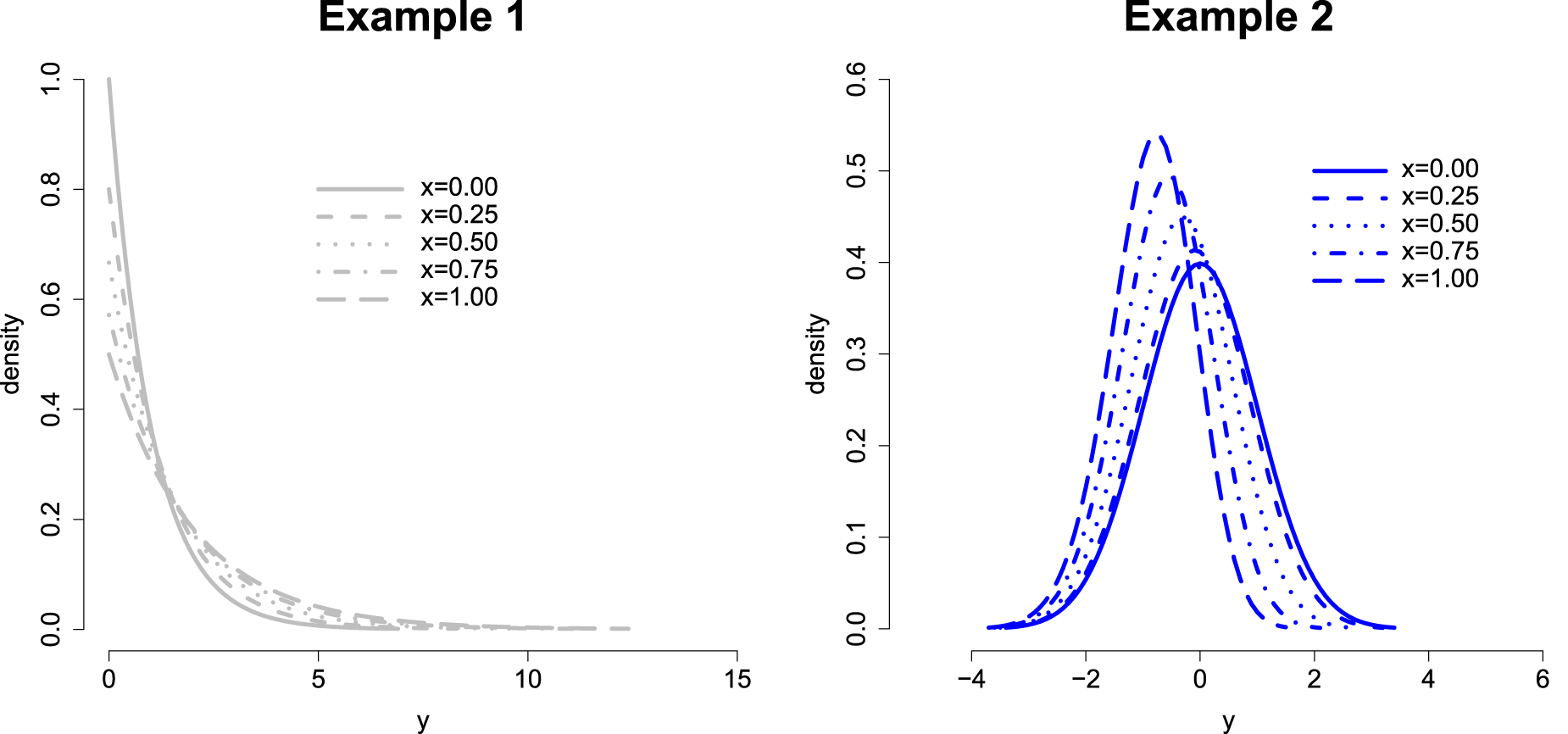
Proportional hazard (PH) examples. Example 1: Exponential density functions
From the standard covariate-specific ROC curve definition, under the functional restrictions of the considered model given in equation (3), we directly obtain the following alternative characterization for the covariate-specific ROC curve in terms of the involved cumulative risk functions,
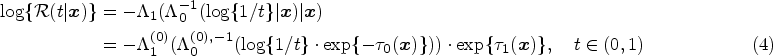
For
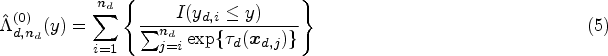
where

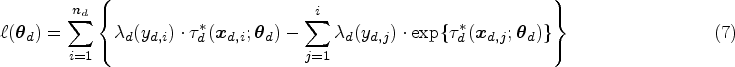
As it is well-known, both the number and location of the knots characterizing the B-splines basis functions have the potential to impact inferences, more so for the former than the latter. In practice, we will use the penalized cubic spline function,
29
pspline, implemented in the package survival
30
in the software R. In this sense, the basis would change in the positive (
Once computed the risk function estimates for both the positive and the negative populations (
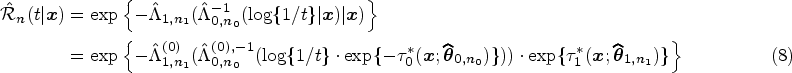

First thing to note is that, despite the asymptotic properties of the considered estimator, in general, our target would approximate the function
then
We also want to note that there is a gap between the theoretical results here considered and the practical implementation of the procedures. While in the theoretical results we consider fixed base and knots for the spline construction, in the practical implementation, as we have already commented, we use a penalized splines algorithm.
Assuming all the functions involved in the model (3) are smooth enough (for

From this result and the properties of the empirical CDF estimator, the convergence of the PH version for the adjusted ROC curve estimator introduced in (9) is immediate.
Under conditions in Theorem 1, and the variance of the marker on both the positive and the negative populations is bounded, then

Under conditions in Theorem 1, we have that
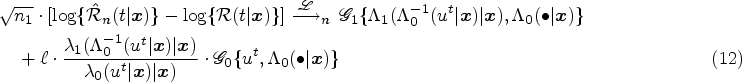
Because the conditional cumulative hazard functions,
For the asymptotic distribution of the PH covariate-adjusted ROC curve estimator, a similar result to Theorem 2 can be used on the first summand of the equality,
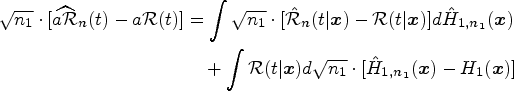
We report the results of the Monte Carlo simulation study performed to evaluate the finite-sample behavior of the proposed PH covariate-specific and covariate-adjusted ROC curve estimators. We consider here (additional models are provided in the Supplemental Material) the combination of different covariate-specific ROC curves, and two different configurations for the covariate distributions. In Scenario I, we have a bi-normal model and the covariate does not affect the outcome (the pooled ROC curve would be the most appropriate estimator). In Scenario II, both the positive and negative populations follow the exponential distributions with the covariate impacting linearly on the parameter. Scenario III and VI mix exponential (for the negative) and normal (for the positive) population; the covariate impacts on means and standard deviations of both the positive and the negative populations in linear and non-linear fashions, and the different covariate-specific ROC curves cover a wide range of shapes (see Figures 3 and 4). Scenario IV considers Weibull distributed populations with the covariate impacting linearly (negative) and non-linearly (positive) on the shape parameter. Scenario V is a bi-normal model with the covariate only impacting linearly on the means of both positive and negative populations. Finally, Scenarios VII and VIII consider exponential distributions on both the positive and the negative populations, with the covariate impacting in non-linear, the first, and non-smoothing, the former, ways on the parameter. Explicitly, we have the following eight scenarios:
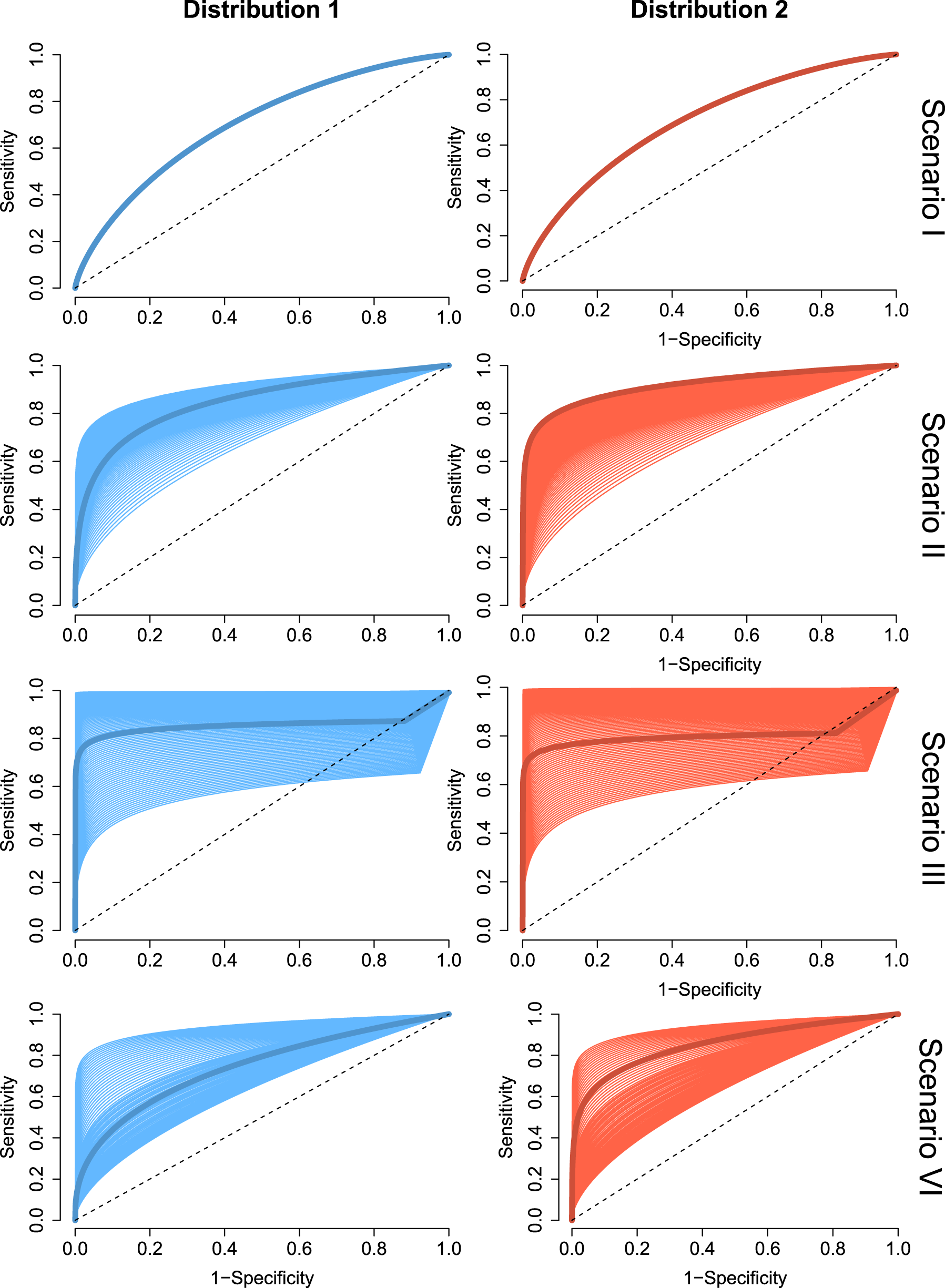
Models I to IV (covariate-specific receiver operating characteristic (ROC) curves). Pooled (thick line) and covariate-specific ROC curves (colored area) for Scenarios I to IV, and the two covariate distributions considered in the Monte Carlo simulations.
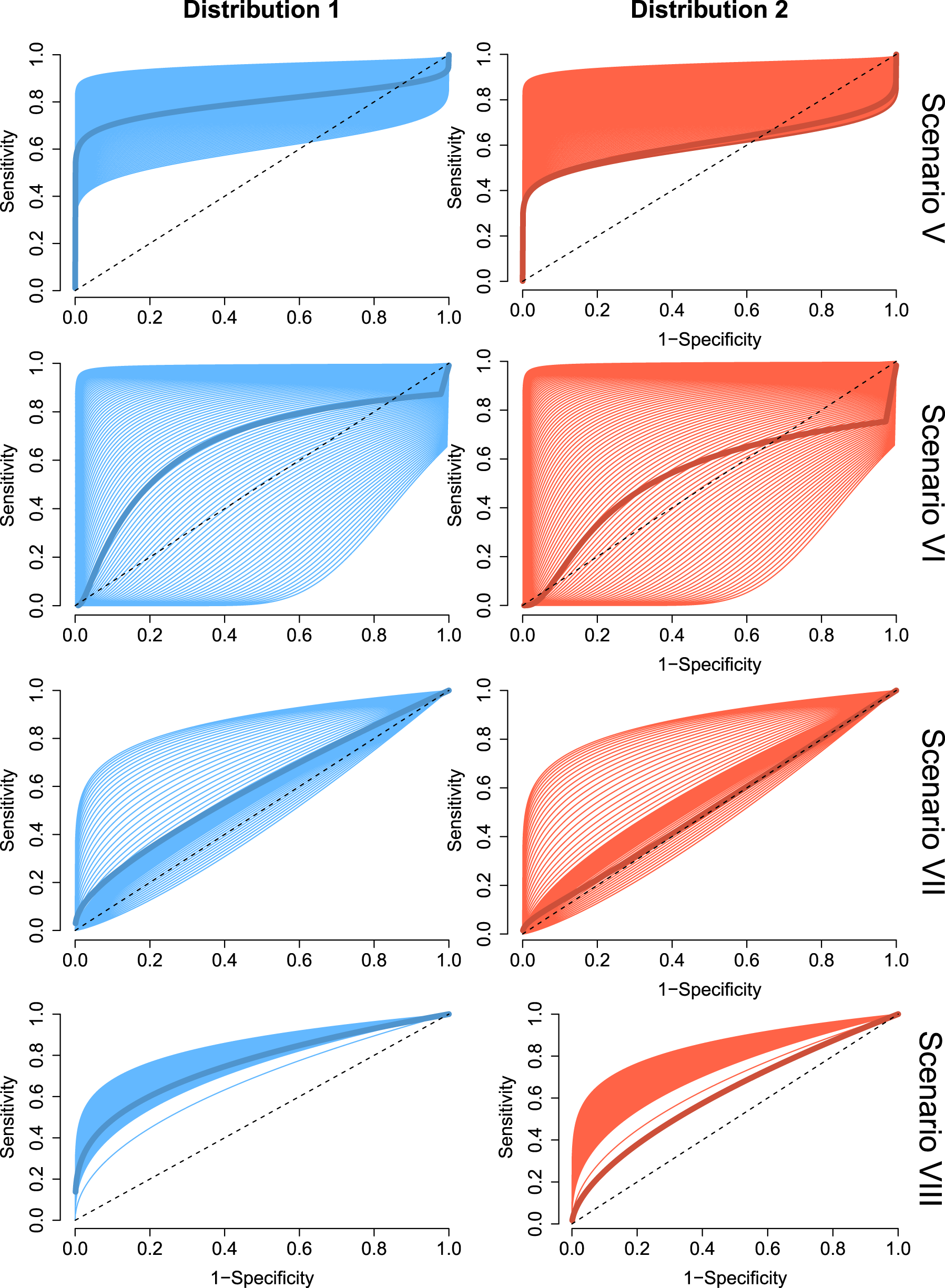
Models V to VIII (covariate-specific receiver operating characteristic (ROC) curves). Pooled (thick line) and covariate-specific ROC curves (colored area) for Scenarios V to VIII, and the two covariate distributions considered in the Monte Carlo simulations.
The first considered configuration for the distribution of the covariate assumes it is uniformly distributed in both the positive and the negative populations, while the second configuration considers Beta distributions with different parameters for the two populations. Particularly,
Figures 3 and 4 show the pooled ROC curve for the eight scenarios and the two covariate distributions and the different covariate-specific ROC curves when the covariate takes the values
In order to gain clarity analyzing Figures 3 and 4, we want to highlight that the pooled (overall) ROC curve is not the average of the covariate-specific ROC curves, but the ROC curve associated with the overall distribution functions.
Figures 5 and 6 show the violin plots for the error measure
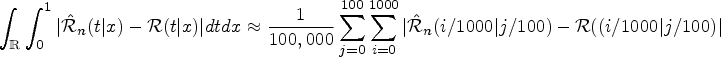
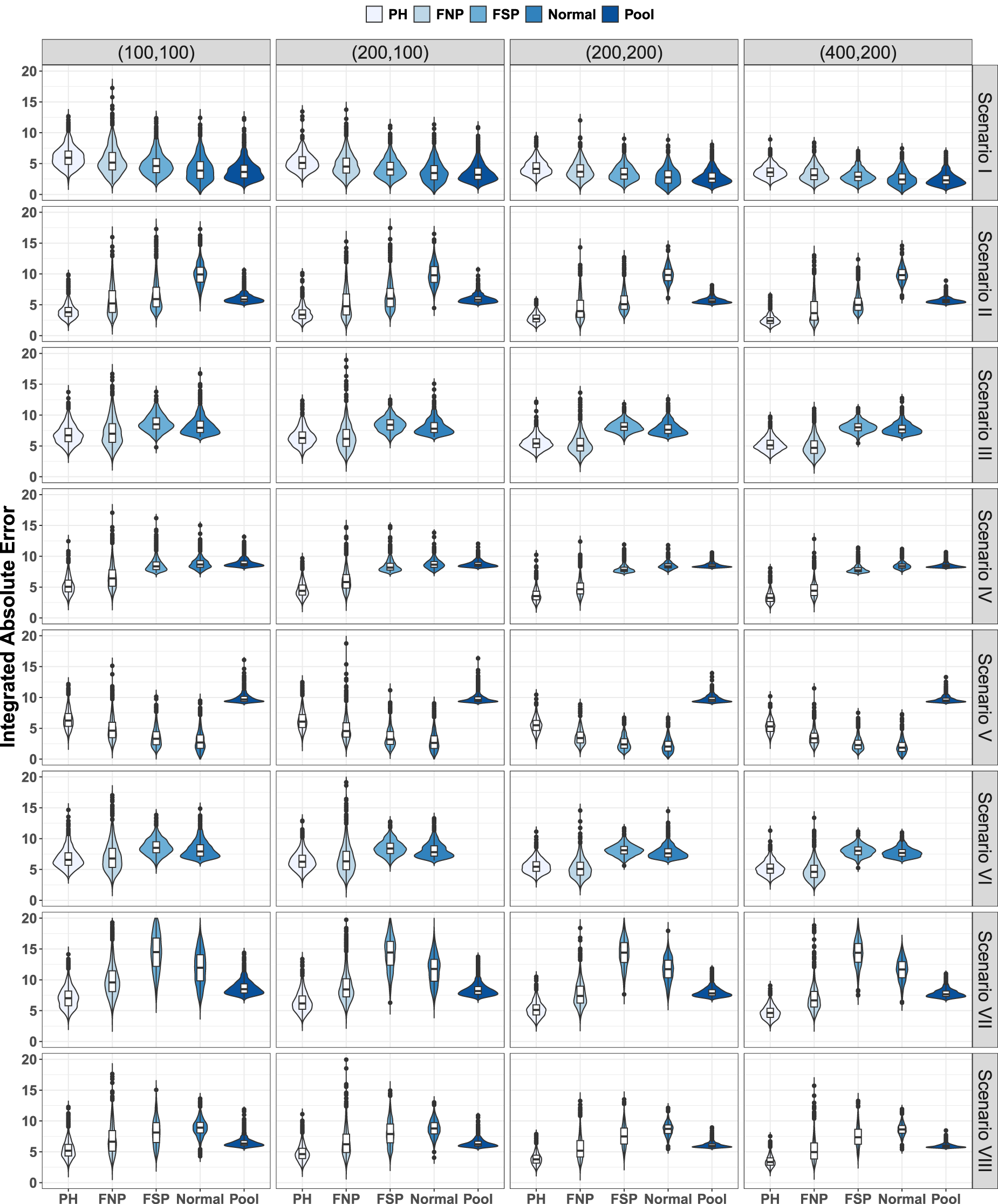
Covariate-specific receiver operating characteristic (ROC) curve. Distribution 1. Violin plots for
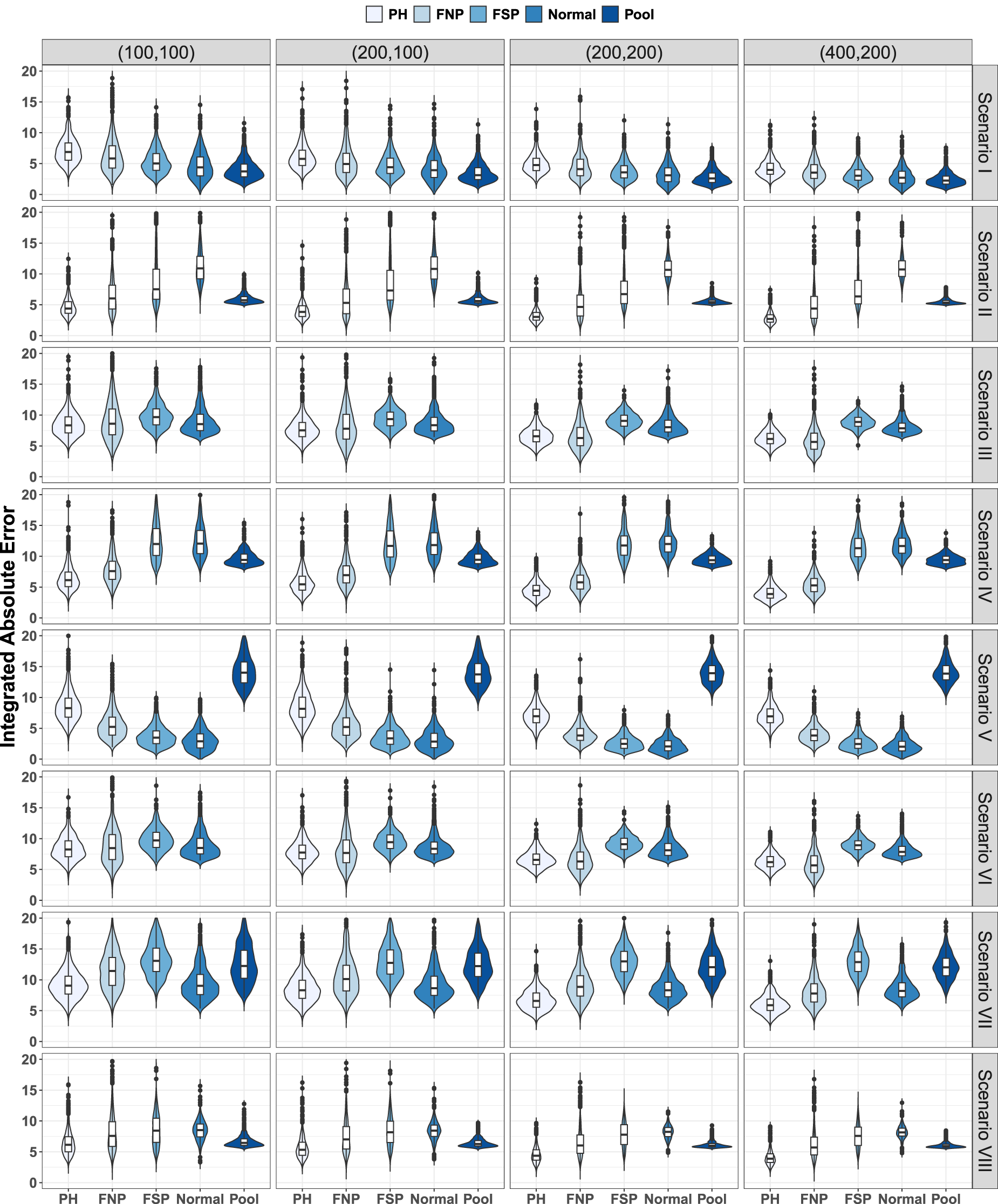
Covariate-specific receiver operating characteristic (ROC) curve. Distribution 2. Violin plots for
We realize that the used error measure could not be finite for covariates with non bounded dominium. Here, we consider
Under Distribution 1 (Figure 5), PH and FNP seem to be more affected by noise than FSP and Normal (Scenario I). Under the PH assumption (Scenarios II, IV, VII, and VIII), PH is the clear winner. Spline implementation suffers more with complex functional shapes (Scenarios VII and VIII), although the errors adequately reduce when sample size increases. Despite the pooled estimator (Pool) presents bias in these scenarios, its overall behavior is not worse (even better in some of the configurations) than FSP and Normal. Pool performs better than Normal in Scenario II, and better than FSP and Normal in Scenarios IV and VIII. The behavior of PH and FNP was similar in Scenarios III and VI; FNP was superior to both FSP and Normal. In these two scenarios, the error values for the Pool estimator were out of the considered scale, and the corresponding violin plots are not visible in the figure. Special mention deserves Scenario V. This is probably the most adverse scenario among the considered for the proposed PH estimator; the covariate only impacts on the mean values of the distributions. Since the model is bi-normal and the covariate impact is linear, not surprisingly, FSP and Normal reach the best results. Besides, FNP adapts better than PH to the considered situation, which improves results of Pool, specially, when the sample size increases.
Under Distribution 2 (Figure 6), comparative results among the five considered procedures were similar. However, it is fair to highlight that, in all of them and for the eight considered scenarios and four considered sample size configurations, the level of observed error was much larger than those observed under Distribution 1. Both bias and standard error were much higher for Distribution 2.
We also consider the same eight models, the same two covariate distributions, and the four sample size configurations for studying the behavior of the proposed PH covariate-adjusted ROC curve estimator. Covariate-adjusted versions of the non-parametric induced location-scale regression model (FNP), the Pepe’s frequentist semi-parametric 32 (FSP), the Faraggi’s parametric approach 10 (Normal), and the standard pooled non-parametric ROC curve estimators (Pool) are included as reference. R package ROCnReg was used for computing FNP, FSP, and Normal. Figure 7 shows the covariate-adjusted ROC curves for the eight scenarios and the two covariate distributions.
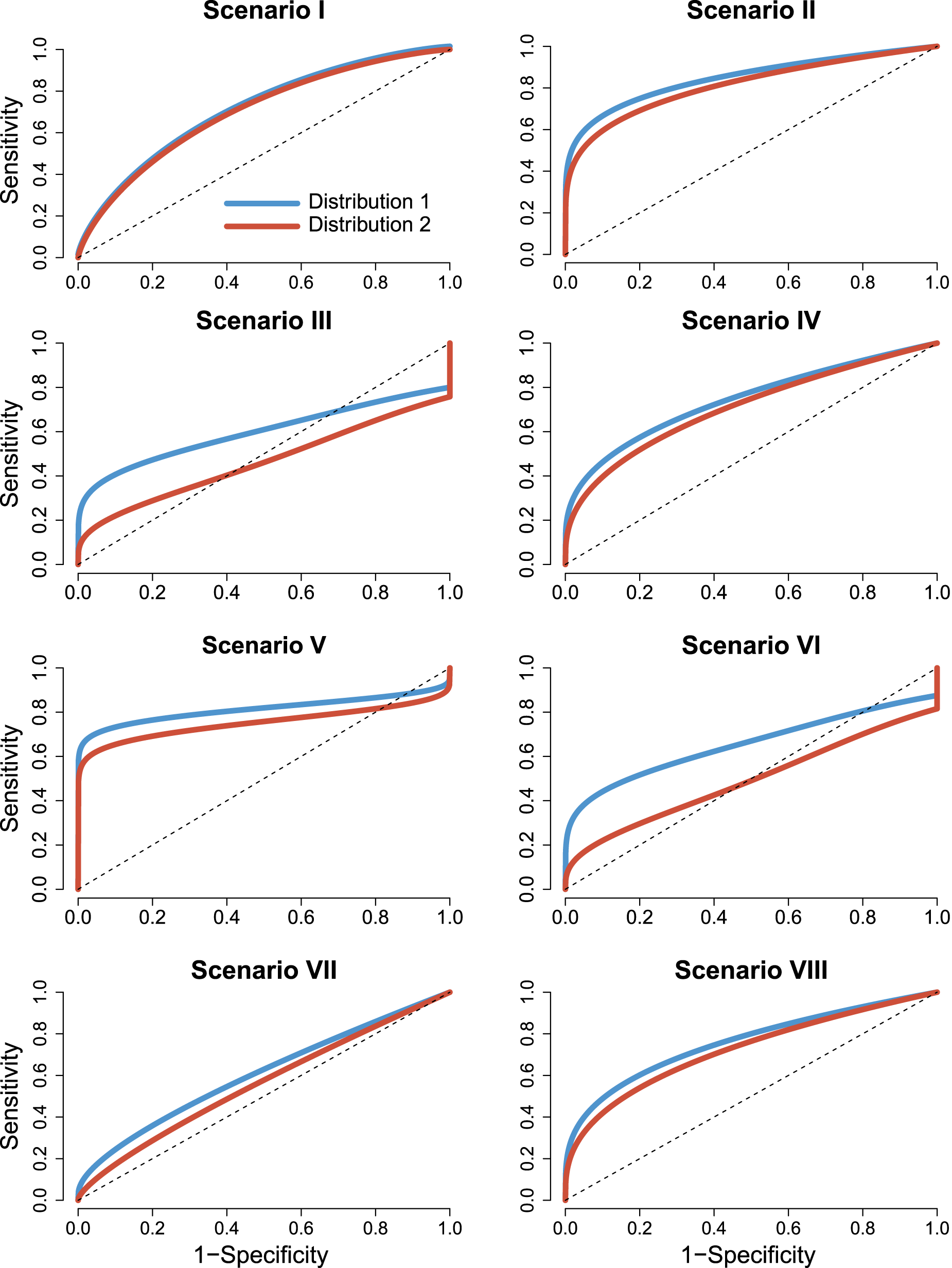
Models (covariate-adjusted receiver operating characteristic (ROC) curves). Covariate-adjusted ROC curves for the eight scenarios considered in the Monte Carlo simulations.
Figures 8 and 9 show the violin plots for the error measure
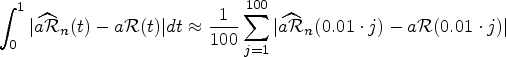
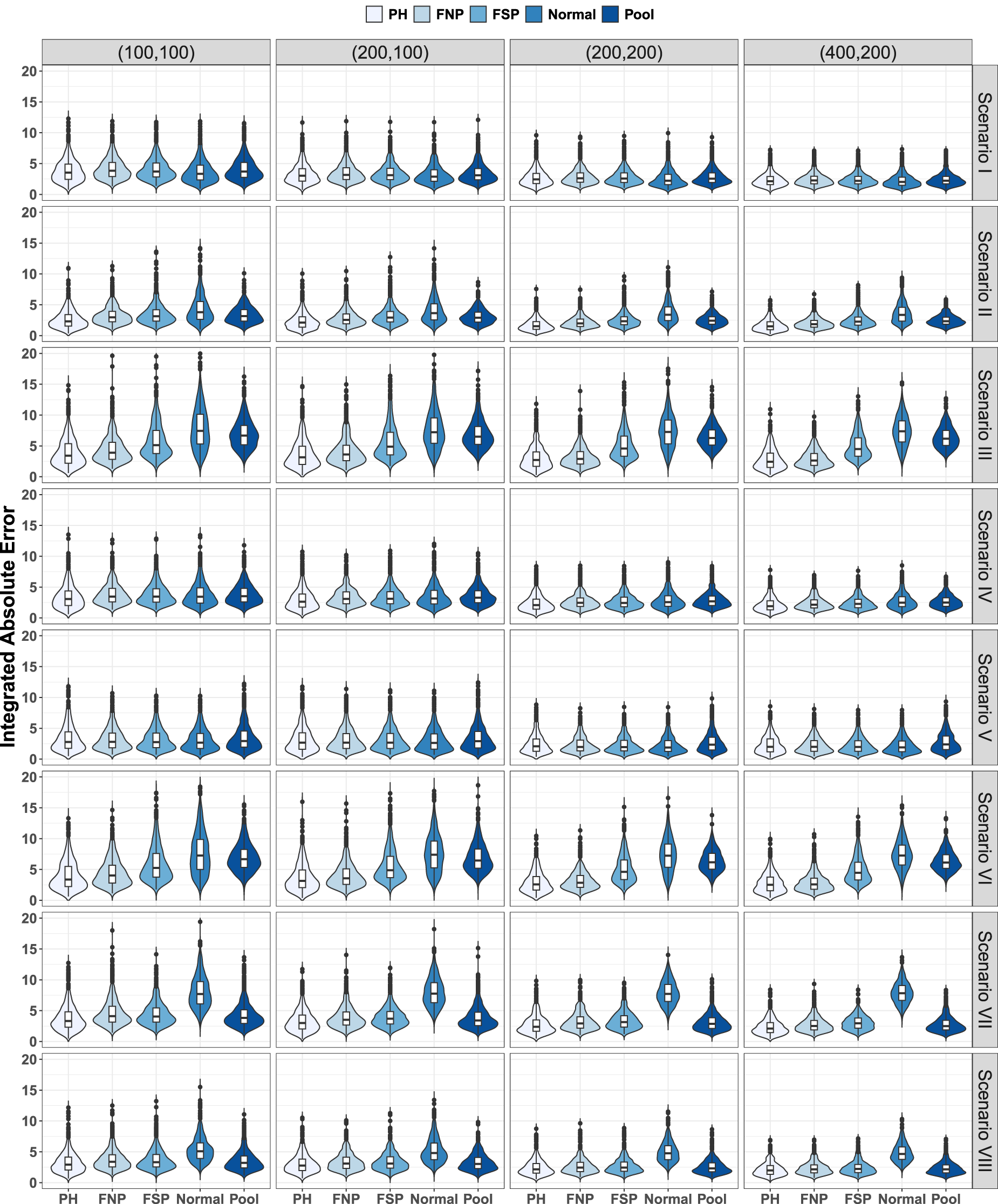
Covariate-adjusted receiver operating characteristic (ROC) curve. Distribution 1. Violin plots for
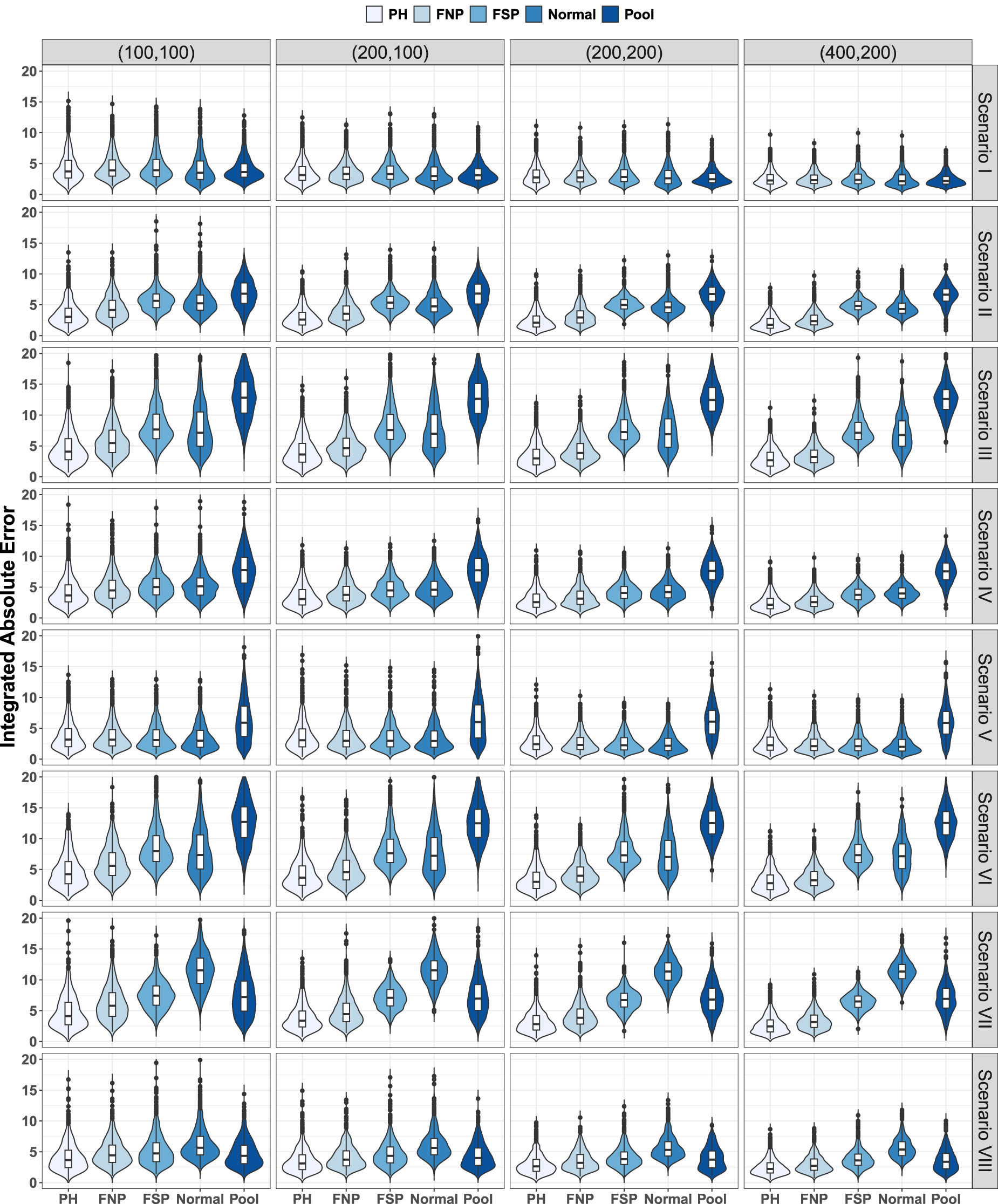
Covariate-adjusted receiver operating characteristic (ROC) curve. Distribution 2. Violin plots for
In general, the observed differences among the five considered estimators were smaller for the covariate-adjusted than for the covariate-specific ROC curves. Under Distribution 1 (Figure 8), PH obtained clear better results in Scenarios II, III, VI, and VII. FNP was the second classified in Scenarios II, III, and VI. In Scenarios I, IV, and V, the five estimators behave in a very similar way. We can see slightly better results for PH in Scenarios IV and VIII. However, while in Scenario IV, the remaining four estimators behave similarly, in Scenario VIII, Pool was the second classified and Normal clearly obtained the worst results. Highlight that the problems of PH with Scenario V for the covariate-specific ROC curve estimation are diluted for the covariate-adjusted ROC curve. Besides, not surprisingly, Normal procedure did not work on Scenarios VI and VII, and performed poorly in Scenario VIII. Distribution 2 exacerbates, in general, the differences among the estimators and the pooled estimators behaves worse in most of the considered configurations. In Scenario I, the pooled estimator, Pool, was the best, especially for the smallest sample size. In Scenario V, Pool estimator obtained clearly the worst results, while the difference among the remaining four estimators was almost negligible. In Scenarios II, III, IV, VI, VII, and VIII, the proposed PH is again the clear winner, with FNP in the second position. It is worth mentioning that, under Scenarios III, VI, and VIII, PH and FNP clearly outperformed the other three. In Scenarios III and VI, the Pool estimator failed, and part of its errors were out of the considered scale. Finally, we want to highlight the good general performance of FNP, which reached very competitive results in the eight considered scenarios, even in those under the PH assumptions (Scenarios II, IV, VIII, and VIII).
For illustrating the practical behavior of the proposed PH estimators in a real-world setting, we consider the synthetic dataset endosyn, publicly available in the R package ROCnReg. The data mimics endocrine data from a cross-sectional study carried out by the Galician Endocrinology and Nutrition Foundation. Detailed information about the original study can be found by Tomé Martínez de Rituerto et al. 35
The original study focused in determining the role of the BMI (body mass index) in cardiovascular disease (CVD) risk. With this goal, the 2840 enrolled subjects were classified as positive (691, 24.3%), if they had two or more CVD risk factors (considered risk factors included raised triglycerides, reduced HD-cholesterol, raised blood pressure, and raised fasting plasma glucose), and as negative (2149, 75.7%) otherwise. Here, we want to analyze the capacity of BMI for predicting CVD risk, and also to consider the potential role that demographic factors such as age and gender can play in order to interpret the results. Table 1 describes the variables involved in the study by CVD risk group. Figure 10 contains the directed acyclic graph (DAG) 36 showing the potential pathway.
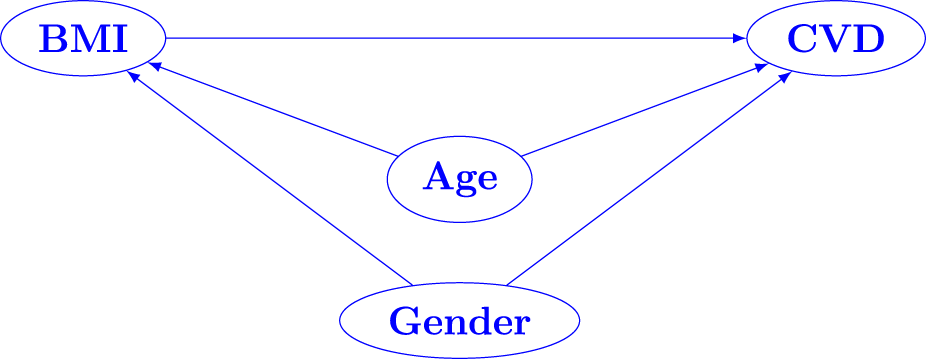
DAG for the endosyn dataset. BMI is affecting CVD, while Age and Gender could affect both BMI and CVD. DAG: directed acyclic graph; BMI: body mass index; CVD: cardiovascular disease.
Descriptive. Basic description for the variables involved in the study by CVD group (with CVD or positive vs. without CVD or negative).
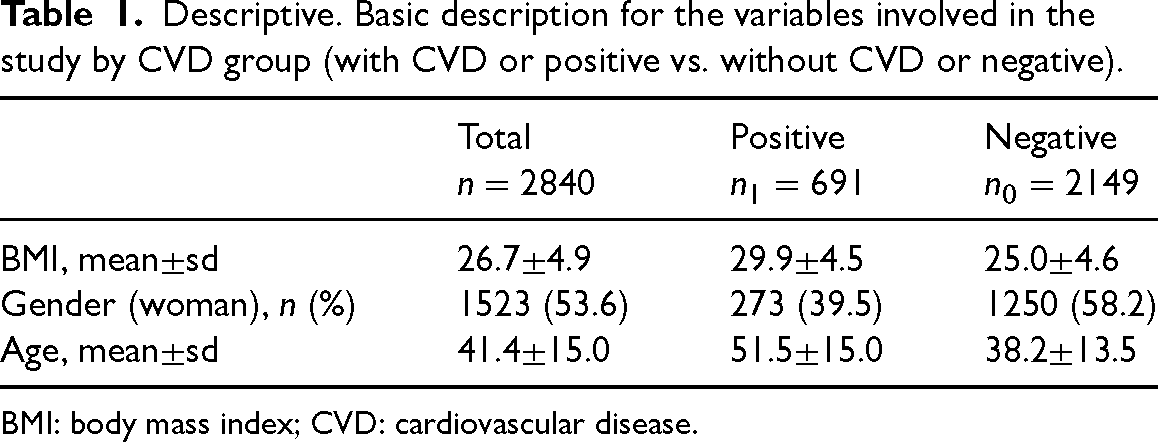
BMI: body mass index; CVD: cardiovascular disease.
The age ranged between 18.3 and 84.7 years old. Individuals in the positive group were, on average, 13.3 years older, had 4.4 kg/m
The overall (pooled) AUC, approximated through the empirical estimator, was 0.76 (with a 95% confidence interval based on 5000 bootstrap replications of 0.74–0.78). When we stratified by sex, we have AUCs of 0.72 (0.69–0.75), and 0.80 (0.77–0.83) for men and women, respectively. The covariate-adjusted AUC (aAUC) was, therefore, 0.76 (0.74–0.78). That is, it seems that BMI is more related to CVD in women than in men. Figure 11 (top-left) shows the pooled ROC curve with a 95% confidence band (R package nsROC 37 was used in this plot), and covariate-specific (csROC) and covariate-adjusted ROC (aROC) curves by gender (top-right). We checked the GoF of the proposed model through the Grønnesby and Borgan test, 23 which reported p-values of 0.484 and 0.364 in the models associated with the positive and the negative populations in men, respectively, and p-values of 0.244 and 0.318 in the model associated with the positive and the negative populations in women, respectively.
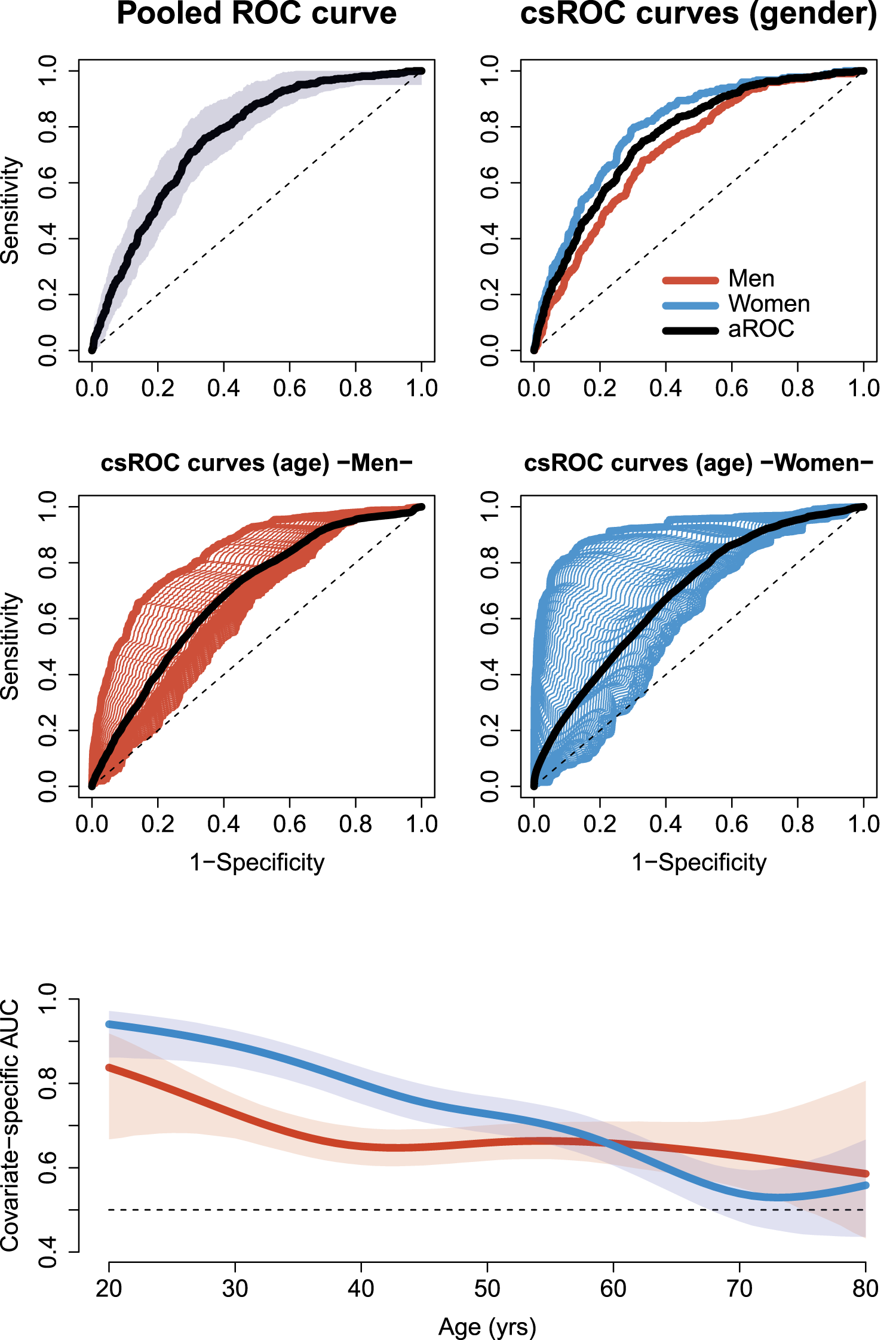
Endosyn data. Pooled ROC curve with 95% confidence bands (top-left). csROC curves by gender and aROC curve (top-right). In the middle, PH csROC curves for different values of ages (ranged between 20 and 80 years old) stratified by gender, and PH aROC curves (in black). Evolution of the csAUC with the age by gender (bottom). ROC: receiver operating characteristic; csROC: covariate-specific receiver operating characteristic; aROC: adjusted receiver operating characteristic; PH: proportional hazard; csAUC: covariate-specific area under the receiver operating characteristic curve.
The PH conditional ROC curves show that age has a great impact on the BMI prediction capacity, specially, in women (Figure 11, middle). In men, the covariate-specific AUCs (csAUCs) oscillated between 0.84 (0.67–0.92) at 20 years, and 0.59 (0.43–0.81) at 80 years; while in women, they oscillated between 0.94 (0.86–0.97) at 20 years, and 0.53 (0.45–0.60) at 73 years (Figure 11, bottom).
The so-called “nosological paradigm” 38 commonly underlies the statistical approach to the binary classification problem. However, the sensitivity and specificity can be affected for a number of external factors. Thinking about the real pathway between the studied marker, the disease under consideration, and the potential confounders can help to do a better use of the observed results, considering the potential difference between the population used for testing our marker, and the population or subjects particularities on which we are applying our results. This could help us to understand the real accuracy of the marker we are using on a population with particular characteristics, and to customize the threshold we should use in the decision making process. The covariate-specific, or conditional, and the covariate-adjusted ROC curves are valuable tools for addressing the problem. They are based on the conditional distribution functions of the marker on the positive and negative populations. Of course, a variety of estimation procedures have already been proposed in the specialized literature (see Pardo-Fernández et al. 12 for a review of some of these methods).
In this piece of research, we consider the PH Cox regression model for approximating the involved CDFs and, through a direct plug-in procedure, we propose an estimator for the covariate-specific ROC curve. Integrating the resulting estimator with respect to the empirical CDF of the covariate on the positive population provides a PH estimator for the covariate-adjusted ROC curve. In order to gain flexibility in our approximations, a spline procedure is included in the involved Cox regressions.
The huge quantity of papers and books dealing with the theoretical properties of the PH regression models, and other related problems were really helpful in order to develop the asymptotic properties of the estimators here proposed. Although this theory includes both the survival and the hazard functions, being the former more related to our purpose than the latter, we do prefer to present our results in terms of hazard functions, since these function are which actually characterize the problem. Despite theoretically there are no restrictions in order to approximate a multivariate spline function, in practice, dealing with more than one dimension turns the estimation complex, imprecise, and unstable. In these situations, simplifying the problem by using for example additive models would be advisable.
Not surprisingly, Monte Carlo simulations show that the new proposal outperforms its competitors when the underlying model satisfies the required assumptions. The used spline approximation adequately deals with the approximation of non-linear effects. Besides, the PH estimates showed competitive results when some deviations of the original model were introduced. The estimators, however, fail in situations where the impact of the covariate strongly affects the location parameter and does not affect (or affects in an “non controllable” way) the shape of the distributions. We provide results from twelve simulation scenarios (eight in the main article and four in the Supplemental Material).
In the considered real-world problem, we can clearly see how these tools help to have a better understanding of the reality. Both the age and gender strongly affect the capacity of BMI for predicting CVD risk. While the overall AUC was 0.76, it oscillated between 0.94 for women in their 20 s and 0.53 for women in her 70 s. That is, the BMI is a good predictive marker for CVD risk in young women (also in young men; the AUC in this group was 0.84), although it loses its accuracy for women in their 70 s. In this problem, results provided by the PH estimators are slightly smoother than those provided by the Bayesian non-parametric approach 39 and presented by Rodríguez-Álvarez and Inácio de Carvalho. 34 Remarkable that, based on the GoF tests performed, the model proposed in equation (3) is perfectly compatible with the considered data structure.
In short, the proposed estimators are promising tools for approximating both the conditional and the covariate-adjusted ROC curves, which are helpful in order to understand not only the predictive accuracy of the marker of interest, but also the conditions for extrapolating this accuracy, and the way it should be applied on different populations, for example to decide the threshold to be used depending on the population characteristics. Besides, given the number of studies related with PH Cox regressions, the considered methodology could be easily extended to problems in which the marker has measurement restrictions, for instance, limit of detection. Another advantage is the existence of a number of R packages implementing PH Cox regression models, including routines for spline regression, which facilitates the practical computation of the PH ROC curve estimates. As the Supplemental Material, we provide the R code used in the Monte Carlo simulation study (Section 5), and an additional set of simulations.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802241311458 - Supplemental material for Semiparametric estimator for the covariate-specific receiver operating characteristic curve
Supplemental material, sj-pdf-1-smm-10.1177_09622802241311458 for Semiparametric estimator for the covariate-specific receiver operating characteristic curve by Pablo Martínez-Camblor and Juan Carlos Pardo-Fernández in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The authors are grateful to María Xosé Rodríguez-Álvarez for her helpful insight on the topics considered in this article. They also want to acknowledge to the anonymous reviewers and to the AE for their helpful suggestions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported from the Grants GRUPIN AYUD/2021/50897 from the Asturies Government and PID2020-118101GB-I00 and PID2023-148811NB-I00 from Agencia Estatal de Investigación (Ministerio de Ciencia, Innovación y Universidades, Spanish Government).
Data availability
Data used are publicly available in the R package ROCnReg (>data(endosyn)).
Supplemental material
Supplemental material for this article is available online. As Supplemental Material, we provide: the R code used in Section 4, and a document containing additional Monte Carlo simulations.
Proofs of the theorems
We want to highlight that, in the proofs of the theorems, we are assuming that parameters of the involved spline function are fixed. This introduces a gap between the considered practical implementation, in which we used penalized splines, and the theoretical results. To consider an adaptative solution for the smooth function could imply to lose the convergence ratio, since the convergence rate of the spline function would not be We are proving the equivalent result
with Similarly to Lemma 6.1 by Tsiatis,
42
for
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.